
Abstract
Aerial images can cover a wide area and capture rich scene information. These images are often taken from a high altitude and contain many small objects. It is difficult to detect small objects accurately because their features are not obvious and are susceptible to background interference. The CPDD-YOLOv8 is proposed to improve the performance of small object detection. Firstly, we propose the C2fGAM structure, which integrates the Global Attention Mechanism (GAM) into the C2f structure of the backbone so that the model can better understand the overall semantics of the images. Secondly, a detection layer named P2 is added to extract the shallow features. Thirdly, a new DSC2f structure is proposed, which uses Dynamic Snake Convolution (DSConv) to take the place of the first standard Conv of Bottleneck in the C2f structure, so that the model can adapt to different inputs more effectively. Finally, the Dynamic Head (DyHead), which integrates multiple attention mechanisms, is used in the head to assign different weights to different feature layers. To prove the effectiveness of the CPDD-YOLOv8, we carry out ablation and comparison experiments on the VisDrone2019 dataset. Ablation experiments show that all the improved and added modules in CPDD-YOLOv8 are effective. Comparative experiments suggest that the mAP of CPDD-YOLOv8 is higher than the other seven comparison models. The mAP@0.5 of this model reaches 41%, which is 6.9% higher than that of YOLOv8. The CPDD-YOLOv8’s small object detection rate is improved by 13.1%. The generalizability of the CPDD-YOLOv8 model is verified on the WiderPerson, VOC_MASK and SHWD datasets.
Similar content being viewed by others
Introduction
Due to the gradual reduction of the cost of manufacturing drones, coupled with their easy operation and small size, their use has become common in daily life. The drone can be equipped with high-definition aerial camera to capture high-quality photos and videos. Due to its higher flexibility and wider field of view than fixed cameras, aerial images have been widely used in many fields1,2,3. Aerial images can help people complete tasks in harsh environments, with difficult operations and certain dangers. When natural and man-made disasters occur, aerial images can help rescuers quickly understand the disaster situations, guide rescue activities, and improve rescue efficiency4,5; Military departments can use aerial images for intelligence-gathering to help formulate optimal military command strategies6,7. Aerial images can also be used to monitor traffic, abnormal human activities, agricultural data collection8, migration of wild animals, and dynamic tracking of sports events. Detecting aerial images can realize the automatic acquisition and analysis of surface information and provide data support for various industries and fields9,10. It is of great importance to detect aerial images.
With the continuous development of artificial intelligence, small object detection algorithms increasingly apply to various fields. By using object detection technology, a lot of human resource consumption can be reduced. As aerial images are taken at a high altitude, an abundance of small objects can be observed in these images. There are also problems such as complex object backgrounds and mutual occlusion of objects11,12. Aerial images are often taken in different weather and lighting conditions, which can cause the appearance and lighting of the object to change, increasing the difficulty of object detection. Small objects are often sparsely distributed in the image and may mix with the background, making them more difficult to distinguish and locate. This requires a model that can effectively handle contrast and visual feature differences between objects and complex backgrounds13. In the actual scene, there are many small objects, including persons, traffic signs, animals, etc. Studying and researching small object detection algorithms is helpful to develop the object detection technology in complex scenes. The object types in aerial images are diverse, covering all kinds of object types from vehicles to buildings, human activities and natural environment, which require the model to have good generalization ability and adaptability. We focus on images taken at a high altitude through cameras on drones, aiming to analyze and process these high-altitude images to explore their potential applications in areas. Through the in-depth study of these images, we hope to improve the performance of image processing algorithms, and then promote the development of drone technology in practical applications. In this paper, we aim to improve the accuracy of the model to meet the needs of specific application scenarios, such as suspect identification and vehicle plate recognition, which require accurate detection. Although our approach is somewhat slower in computation speed, the trade-off is to achieve greater accuracy. We propose the CPDD-YOLOv8, which improves the traditional model’s ability to detect small objects. The contributions are as follows:
-
1.
We propose a new C2fGAM structure after integrating GAM into the Concat of C2f structures, we use this structure in the backbone of YOLOv8. This structure enhances the traditional backbone network by integrating GAM, making the network understand the overall semantics of the images, thus improving the small object detection capability of the model.
-
2.
This paper introduces the P2 detection layer to recognize and locate small objects more accurately and pay more attention to their details to reduce false detection. Different from the traditional small object detection layer, our small object detection layer uses DyHead as the detection head, which effectively improves the performance of small object detection.
-
3.
A new DSC2f structure is proposed, replacing the first Conv in a Bottleneck structure with DSConv. This structure further enhances the ability of the model to capture complex objects, enhancing its robustness and generalization ability.
-
4.
The head part uses the DyHead to optimize the network’s performance across various object types. The structure is simultaneously embedded with scale, spatial, and task awareness attention mechanisms so that the model can dynamically select different detection heads according to the attributes and locations of objects.
In this paper, we improve the original YOLOv8 model by integrating the C2f structure of GAM attention mechanism, introducing P2 detection layer, replacing the convolutional C2f structure and head. The experimental results show that these improvements significantly improve the detection ability of small objects.
Related work
Object detection algorithms mainly contain object location and object classification. According to the number of stages, the object detection algorithms are classified into two-stage and one-stage. The former consists of two steps: generating the candidate box, classifying and locating the candidate box, mainly including R-CNN series algorithms14. The latter can directly classify and locate the image without excessive computational resources15, including YOLO series algorithms16 and SSD algorithm17.
In recent years, many scientific achievements have been made in the object detection field. Huang et al.18 enhanced YOLOv3 by adjusting the input image’s resolution from the standard size to 608 × 608, changing the prediction scale from 2 to 4, and adding a feature mapping layer to extract richer details. However, increasing the image’s resolution will inevitably prolong the model’s prediction time. Yan et al.19 proposed a new object definition method considering that the current object detection is mainly used to identify single objects, which leads to large model parameters and slow detection efficiency. By establishing the concept of group objects, they provided a new perspective for dealing with dense and obscured scenes and proposed a group object detection method. The results show that this method can accurately detect weak objects in complex environments with fewer parameters and higher detection speeds. Gu et al.20 constructed a new dataset and proposed a two-tower transformer network. The network replaces the traditional attention mechanism with a Fast attention module, thus reducing the model’s training time and memory consumption. At the same time, a pre-Fusion vision module was introduced to process unstructured information in the input data. In addition, the authors proposed a two-layer learnable gate structure, which enables the neural network to independently select the weight ratio of different information sources. Ye et al.21 proposed a cross-layer non-local module for fine-grained image recognition. The module enables the model to learn more discriminant features and adaptively focus on the multi-scale image portion, thus achieving optimal results while reducing computational costs. Khan et al.22 proposed a two-stage framework to solve the problem of vulnerability to background interference in high-resolution satellite images. The first part is to generate multi-scale object schemes, and the second part is to classify each scheme. In addition, they verified the effectiveness of the framework with other reference models. Zhao et al.23 introduced MobileNetv3 into YOLOv5, designed a depthwise separable information module, used CARAFE upsampling to improve the model’s feature extraction ability, and used dynamic head to make the model lightweight. However, the mAP decreases after the model is lightweight. Zhou et al.24 introduced the lightweight convolution module RepGhost structure into the backbone of YOLOv7, used the decoupled head in YOLOX instead of the original head, and added EMA attention in different positions. These improvements improve the detection accuracy of dragon fruit. However, after decoupling, the head will learn more parameter information, which increases the model’s calculating parameter amount. Zhao et al.25 proposed a visualization converter in YOLOv8, added an additional layer to merge different layers’ information, and replaced the traditional convolution with a GSConv module, improving the accuracy and speed in YOLOv8. However, this model’s detection is relatively single. Zhang et al.26 added CBAM module to the YOLOv8, enhanced the adaptability of multi-scale object changes by using WIoU. However, the model’s parameters become larger, and the image processing speed becomes slower. Chen et al.27 fused the C2f structure with ResNet in YOLOv8, proposed the C2f_Res2block module, and added MHSA and EAM attention. The accuracy of the dataset for detecting student classroom behavior is improved. However, improving the mAP of the model will increase the model’s parameters. Fan et al.28 built a remote sensing dataset in complex environments aiming at the imbalance of remote sensing data classes and the problems of missing detection and false detection in existing object detection algorithms. Based on YOLOv7, they proposed an innovative CSDP module to enhance the feature extraction capability of the model and introduced the MPDIoU loss function to solve the imbalance between the object and the background. The ability of the model to detect small ship objects is improved. Li et al.29 Improved the neck of YOLOv8, realized more advanced feature fusion, adopted GhostblockV2 module to replace C2f structure, and used WiseIoU loss function, thus improving the performance of small object detection. These deep learning models show relatively good performance in a variety of tasks and can achieve satisfactory results. However, they still have some limitations. When the scenario is relatively simple, the potential of the model is not fully utilized; In the case of large or single number of objects to be detected, the effect of the model may be limited. These factors can cause the robustness of the model to decline in real-world applications, especially in the face of complex backgrounds or small objects, where performance may not meet expectations. Therefore, it is necessary to further study and improve these limitations. Our model has the ability to accurately detect small objects in complex scenes, thus significantly improving the detection performance of small objects. This enhanced detection capability not only improves identification accuracy, but also better meets the needs of various practical applications and promotes the development of areas such as intelligent monitoring and autonomous driving.
Models
YOLOv8
The structure of YOLOv8 comprises three main components: backbone, neck, and head. C2f structure is used in the backbone, which is more abundant than the C3 structure of YOLOv5, and adjusts different channel numbers for different scale models. Neck part used the E-ELAN in YOLOv7 to enhance the network’s feature fusion ability. Head part comprises three standard convolution detectors and the Decoupled-Head. At the same time, the prior method is Anchor-Free. When training data, turning off Mosiac enhancement in the last ten epochs in YOLOX is introduced. YOLOv8 can detect, classify, and segment. According to the model’s depth and width, YOLOv8 has five types: YOLOv8n, YOLOv8s, YOLOv8m, YOLOv8l, and YOLOv8x. YOLOv8n has the smallest parameters and computational complexity but the lowest precision. YOLOv8x has the largest parameters and computational complexity but the highest precision. Considering the model’s size and accuracy, we choose the YOLOv8s as the benchmark.
CPDD-YOLOv8
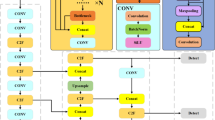
YOLOv8 is based on the previous YOLO version to select the advantages of the respective version of the improvement and achieve a higher object detection accuracy. However, YOLOv8 still needs to improve its detection accuracy. To solve this problem, we propose the CPDD-YOLOv8 small object detection model. This model proposes a new C2fGAM structure which can amplify global dimensional feature interactions while minimizing diffuse information; The P2 layer is introduced, and the shallow branch is added. The model can receive more shallow information and transmit more detailed information so that more small object features can be extracted; A new DSC2f structure is proposed, which replaces the first Conv of Bottleneck in backbone C2f structure with DSConv. This improvement enables the model to extract the features of complex objects; Finally, DyHead is used in the head part to dynamically select the suitable detection head based on features of the object, to improve the model’s small object detection ability. The Fig. 1 shows the structure of CPDD-YOLOv8, where the modules are newly added or replaced in the dotted boxes.

CPDD-YOLOv8 structure. We used “Visio” to make it, and all the elements in the picture were made by ourselves.
C2fGAM
Traditional attention mechanisms usually sum information from different locations, which may cause some information to be ignored or lost in the weighting process. GAM can consider all location information globally30,31. The GAM is a new attention module after the CBAM, which also combines channel attention and spatial attention to extract interactive information from different dimensions of space and channels32,33. Figures 2 and 3 show the structures of the channel attention and spatial mechanisms, and Fig. 4 shows the GAM mechanism structure.

Channel attention mechanism. We used “Visio” to make it, and all the elements in the picture were made by ourselves.

Mechanism of spatial attention. We used “Visio” to make it, and all the elements in the picture were made by ourselves.

GAM attention mechanism. We used “Visio” to make it, and all the elements in the picture were made by ourselves.
The process is expressed as the follows: firstly, the channel attention module retains the three-dimensional information \({F_2}\) of the input feature \({F_1}\). Then, feature \({F_2}\) is further input to the spatial attention module to fuse the spatial information and get the final output feature \({F_3}\). In the channel attention submodule, \({F_1}\) first performs feature channel replacement through three-dimensional permutations, which converts the input feature map from C×W×H to W×H×C. Then amplifies the cross-dimensional channel correlation by MLP, and then converts it into the dimensions before three-dimensional permutations C×W×H by reversing permutations34. Finally, the feature \({F_2}\) is derived by activating the function. In the spatial attention submodule, the input feature \({F_2}\) passes through two 7 × 7 convolution layers. The former decreases channels to reduce the computational amount and the dimension is converted from C × W × H to C/r × W × H, and the latter increases channels to the origin dimension35. Finally, the activation function further fuses the spatial information to obtain the output features \({F_3}\)36,37.
Equation (1) is the channel attention mechanism, and Eq. (2) is the spatial attention mechanism.
Where \({F_1}\) is the input feature, \({F_2}\) is the intermediate state, \({F_3}\) is the output feature, \({M_C}\) is the channel attention coefficient, \({M_S}\) is the spatial attention coefficient, and \(\otimes\) is the element-by-element multiplication.
C2f is a key module in the backbone of the YOLOv8. It is composed of a series of convolutions. Split is used for feature layering, and Concat fuses high and low layer features. This module can maintain light weight while providing richer gradient flow information to obtain rich spatial and semantic information. Unlike the C2fGAM structure in reference 28, our C2fGAM structure integrates GAM after the Concat of the C2f structure and is used to replace part of the C2f structure in the backbone. The method described in reference 28 is to integrate GAM after the Concat of C2f, while the original Concat is still connected to the Conv, and C2fGAM is used to replace the C2f structure in the neck. The original C2f and C2fGAM structures are shown in Fig. 5 (a) and (b). C2fGAM improves the sensitivity of the model to small objects by adaptively adjusting the importance of each feature map. This mechanism can more accurately capture the details of small objects in complex scenes, thereby improving detection accuracy and reducing missed detection rates.

C2f and C2fGAM structures. We used “Visio” to make it, and all the elements in the picture were made by ourselves.
P2 small object detection layer
After the input image passes through multiple convolution layers, the different feature maps will be obtained according to different convolution depths. The deep network’s feature maps have a limited resolution, but contain rich semantic information. The feature maps output by the shallow network has high resolution, but it has much detailed information, such as position and texture. The output of the YOLOv8 detection model consists of three output layers: P3, P4, and P5. The P3 detection layer has a feature map size of 80 × 80, detecting objects with a size of 8 × 8 or more. The P4 detection layer has a feature map size of 40 × 40, used for objects with a size of 16 × 16 or more. Finally, the P5 detection layer’s feature map size is 20 × 20, targeting objects with a size of 32 × 32 or more. Many small objects are in aerial images, and YOLOv8 has a deep sampling depth, so accurately detecting small objects is difficult. After deep convolution and multiple pooling, the feature map will lose much important information. This may cause the features of large objects to cover up those of small objects, leading to false and missed detection. The existing model can not play a maximum role for images containing many small objects, and the original three-scale feature map is difficult to effectively detect small objects. The P2 detection layer has a feature map size of 160 × 160, detecting objects with a size of 4 × 4 or more. Figure 6 shows the detection layer after introducing the P2 detection layer. Compared with the traditional small object detection layer, our small object detection layer uses DyHead as the detection head, which significantly improves the performance of small object detection. By dynamically adjusting the processing of feature maps, DyHead can better capture the details of small objects, thus improving the detection accuracy. Adding small object detection layer can significantly improve the detection ability of the model on multi-scale and multi-resolution images. This is because the small object detection layer is specifically designed to capture and identify smaller objects in an image, allowing the model to better handle input images of different sizes and resolutions.

Feature extraction network with P2 detection layer added. We used “Visio” to make it, and all the elements in the picture were made by ourselves.
DSC2f
The traditional convolution kernel always has the fixed weight, so the receptive field is the same when processing different image regions. If the central coordinate of the standard two-dimensional convolution kernel is \({R_i}=\left( {{x_i},{y_i}} \right)\) and the expansion rate is 1. Equation (3) expresses the convolution kernel of 3 × 3.
Objects with various scales or deformation exist in different positions in the images, so traditional convolution operation may suffer information loss when processing the image. To solve this problem, the Deformable Convolution Network (DCN) enables the network to learn geometric changes freely. DSConv is designed based on DCN to make the convolution kernel more flexible and focus on key features. DSConv can effectively capture the characteristics of complex, slender, and weak objects when the objects are occluded or overlapping. The deformation offset \(\Delta\) is introduced to make the convolution kernel adapt to the characteristics of small object. However, if the model randomly learns the offset, object’s receptive field may stray outside the object. DSConv adopts an iterative strategy to match each object to an observable position in turn, which ensures continuous attention to object features. In DSConv, a 9 × 9 convolution kernel K is used, and for the x-axis direction, the location of each grid in K is \({K_{i \pm c}}\), as shown in Eq. (4), where c = {0, 1, 2, 3, 4}, representing the horizontal distance from the central grid. Selecting the location of \({K_{i \pm c}}\) in K is an iterative process. Starting at the central location, the location of each subsequent from the central grid depends on the location of the former grid, \({K_{i+1}}\) adds an offset \(\Delta =\left\{ {\delta |\delta \in \left[ { - 1,1} \right]} \right\}\) based on \({K_i}\), and the offset is required to accumulate.
For the y-axis direction, the location of each grid in K is \({K_{{\text{j}} \pm c}}\), as shown in Eq. (5).
Since \(\Delta\) is usually a fraction, but coordinates are usually integers, a bilinear interpolation is used to calculate the coordinate value of DSConv. The bilinear interpolation calculation process is shown in Eq. (6).
Where K represents the fraction’s position in Eq. (4) and Eq. (5), \(K^{\prime }\) enumerates all integral space positions. B is a bilinear interpolation kernel, which can be divided into two one-dimensional interpolation kernels. The implementation process is as shown in Eq. (7).
Where b is a single linear interpolation kernel, \({K_x}\) represents the x-axis position in Eq. (4), \(K_{x}^{\prime }\) represents the integral space position in Eq. (4), \({K_y}\) represents the y-axis position in Eq. (5), and \(K_{y}^{\prime }\) represents the integral space position in Eq. (5).
By dynamically adjusting the focus area of feature maps, DSConv can better capture details of small objects and improve the localization and classification performance of objects. DSC2f is the improvement of C2f replacing the first Conv in the C2f Bottleneck with DSConv, which enhances the model’s detection capacity. DSC2f can adaptively adjust the channel weights of feature maps, thereby enhancing the ability to express features of small objects and improving the ability to capture information.
DyHead
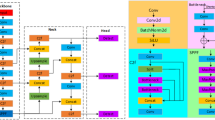
DyHead can dynamically select the appropriate detection head for object detection based on the object’s performance at different scales. This can effectively deal with the objects appearing in different scales. The dynamic head module consists of scale, spatial, and task awareness attention in order38. The structure of DyHead is shown in Fig. 7.
The following is the DyHead implementation process. Given a specific tensor \(F \in {R^{L \times S \times C}}\), the self-attention equation is Eq. (8).
\(\pi \left( \cdot \right)\) is an attention function that is implemented through the fully connected layer. It is a high computation cost to learn self-attention function on all dimensions directly. The function is decomposed into three attentions, the equation is expressed as Eq. (9).
\({\pi _L}\), \({\pi _S}\), and \({\pi _C}\) are functions employed to scale, spatial, and task awareness. Firstly, scale awareness attention is introduced which fusing features of different scales based on their semantic importance. First, the average pooling (avg pool) of the feature map is carried out, and then the features are extracted by 1 × 1 convolution (conv 1 × 1) and relu function. Finally, the output result is obtained by dot multiplication between the calculated results through hard sigmoid activation function and the input features. The equation of scale awareness is expressed as Eq. (10).
\(f\left( \cdot \right)\) is a linear function approximated by a 1 × 1 convolution layer, and the \(\sigma \left( x \right)\) is a sigmoid function.

DyHead. We used “Visio” to make it, and all the elements in the picture were made by ourselves.
Due to the high dimensionality of S, this module contains two steps: First, the attentional learning is sparse by using DCN. Second, the features are aggregated across layers in the same spatial position. First, the feature map is obtained by index, and then the feature is processed by 3 × 3 convolution (conv 3 × 3) to obtain the offset of the feature and the weight of the offset, and then the result is obtained by sigmoid activation function. Finally, the obtained features are aggregated across layers. The equation for spatial awareness is Eq. (11).
Where K is the sparse sampling positions’ number, \({p_k}+\Delta {p_k}\) represents the spatial offset of self-learning, and \(\Delta {p_k}\) focuses on different regions. \(\Delta {m_k}\) is an important scalar for self-learning at \({p_k}\) .
In the task awareness module, the model can adjust parameters according to different input features by dynamically adjusting activation function. The input features are first globally pooled (avg pool), then through a full connection layer (fc) and relu activation function, then through a full connection layer (fc) and normalize, and the parameters are obtained in the process. The parameter is normalized to [-1,1] and then summed with the default value [1,0,0,0] to get the final result. The equation for task awareness is Eq. (12).
Where \({\left[ {{\alpha ^1},{\beta ^1},{\alpha ^2},{\beta ^2}} \right]^T}=\theta \left( \cdot \right)\) is a hyper function of the learning control activation threshold. \({F_{\text{c}}}\) is the feature slice of the c-th channel. DyHead can better handle the details of small objects by introducing a dynamic feature map enhancement mechanism. This mechanism can extract the features of small objects more effectively and adapt to objects of different scales better. By dynamically adjusting the weight of the feature map, DyHead can enhance the feature extraction ability of small objects, thereby improving the detection accuracy of small objects.
Experiment
Experiment environment
Ablation, comparative, and generalization experiments are carried out to prove the CPDD-YOLOv8 model’s effectiveness. All experiments are carried out on a computer with a Windows 10 operating system, Intel(R) Core(TM) i9-10900X CPU @ 3.70 GHz, NVIDIA GeForce RTX 3080 graphics card, and 10GB video memory. The software environments are Python3.8.0, cuda11.6, and pytorch12.1.1. The epoch is 200, the initial learning rate (lr0) is 0.01, the final learning rate (lrf) is 0.01, the momentum is 0.937, and the seed is 0, with other parameters retaining their default values. And all experiments employ pretraining weights. In order to ensure the reliability of the experimental results, each experiment is independently repeated three times with the same setup, and the results of each experiment are averaged as the final result.
Experimental dataset
The experiments are based on the VisDrone2019 dataset39. The dataset is captured under different conditions, including rural and urban scenes in 14 regions in China from south to north. It consists of 10 categories, namely pedestrian, people, car, van, bus, truck, motor, bicycle, awning-tricycle, and tricycle. 6471 images, 548 images and 1610 images in this dataset are used for training, verification and testing, respectively. VisDrone2019 is a publicly available dataset, the dataset can be downloaded at https://github.com/VisDrone.
Evaluation index
In this paper, Precision, Recall, F1, mAP @ 0.5, mAP @ 0.5: 0.95, Parameters, FPS and GFLOPs are used as the evaluation indexes of the experiment. The Precision formula is shown in Eq. (13).
Where TP is the number of detected positive instances and actual positive instances. FP is the number of detected positive instances and actual negative instances. Recall refers to the proportion of correctly detected objects to all existing objects, and the formula is shown in Eq. (14).
Where FN is the number of detected negative instances and actual positive instances.
The AP is the area enclosed by the precision and recall curves and coordinate axes of each category, as expressed in Eq. (15).
mAP is the average of AP values for all categories. Where n represents the number of categories of summary detection objects in the dataset, and the formula is as shown in Eq. (16).
mAP @ 0.5 represents the accurate detected rate of the case where the IoU of the detected box and the real box is greater than or equal to 0.5, and mAP @ 0.5: 0.95 represents the case where the IoU of the detected box and the real box is between 0.5 and 0.95. Parameters indicates the total number of experiment parameters of the model, The model’s parameters mainly include the parameter of Convolutional Layers, the parameter of Fully connected layers, the parameter of Batch Normalization layers, the parameter of Pooling layers, and the parameter of the detection head. FPS indicates how many frames a system or device can process per second. The GFLOPs refers to the computational complexity of the model. The GFLOPs mainly include each layer’s GFLOPs of Convolutional Layers, Fully connected layers, Batch Normalization layers, Pooling layers, and the detection head.
During the experiment process, we use the model.parameters() method in the PyTorch framework to calculate the number of parameters of the model. In addition, we use a third-party library ‘thop’ to compute the GFLOPs of the model.
Ablation experiment
In order to verify the influence of DSConv position on the detection accuracy of small objects, we conduct the following ablation experiments. In the experiment, DSC2f1 indicates that only the first Conv in a Bottleneck is replaced, DSC2f2 indicates that only the second Conv in a Bottleneck is replaced, and DSC2f3 indicates that both Conv in a Bottleneck are replaced by DSConv. The experimental results are shown in Table 1.
According to the experimental results, YOLOv8s-DSC2f1 has the best performance in Precision, Recall, F1, mAP@0.5 and mAP@0.5:0.95, so the structure of YOLOv8s-DSC2f1 is chosen in this paper.
Eight sets of ablation experiments are set up to clarify the impact of each module on the network’s performance. In the part, C2fGAM, P2 small object detection layer, DSC2f, and DyHead structure are used, each based on YOLOv8. Table 2 shows the results of the ablation experiment.
According to the data from groups 1 to 5 in Table 2, the detection effects of C2fGAM, P2 small object detection layer, DSC2f, and DyHead module, Precision, Recall, mAP@0.5, mAP@0.5:0.95, are improved compared with the original model YOLOv8, which verify the effectiveness of each module. Experimental results from groups 6 to 8 show that, based on the original YOLOv8 model, mAP@0.5 and mAP@0.5:0.95 are improved with each additional module. This suggests that the structures proposed can enhance the object detection’s average accuracy. The mAP@0.5 of YOLOv8s-C2fGAM-P2-DSC2f-DyHead (CPDD-YOLOv8) is 5.9% higher than that of the YOLOv8s, and the mAP@0.5:0.95 is 4.1% higher, effectively improving the YOLOv8 model’s detection accuracy. It can be seen from the data in the Table 2 that the number of parameters in the improved model increases and the detection speed decreases because these improved strategies increase the complexity of reasoning. This increase in complexity is to improve precision and accuracy in the detection task, sacrificing some speed in exchange for better detection performance. In summary, although the improved model has an increased number of parameters and a decreased FPS, its improved mAP and detection performance may significantly increase the usefulness and application range of the model, especially in tasks requiring high-precision detection.
Table 3 shows the number and detection rate of small object detected by each ablation experiment, as well as the number and detection rate of correctly detected small object. In Table 3, Number1 represents the total number of small objects detected. Rate1 represents the small object’s detection rate, which is Number1 divided by the total number of small objects in this test set. Number2 represents the total number of small objects correctly detected. Rate2 represents the small object’s correct detection rate, which is Number2 divided by the total number of small objects in this test set.
A total of 56,281 small objects are labeled in this test set. In Table 3, the small object’s detection rate of YOLOv8s-C2fGAM-P2-DSC2f-DyHead (CPDD-YOLOv8) is 13.1% higher than that of the YOLOv8s, and the small object’s correct detection rate is 9.6% higher. The small object’s detection performance is effectively improved. The data in the Table 3 shows that on the basis of the original model, with each addition of an improvement module, the number of small objects that can be detected keeps increasing, and the correct detection rate of small objects also increases. This shows that each module can effectively improve the detection effect of small objects.

The mAP@0.5 and mAP@0.5:0.95 in ablation experiments. We used “Origin” to make it, and all the elements in the picture were made by ourselves.
Figure 8 compares the mAP @ 0.5 and mAP @ 0.5: 0.95 results of the ablation experiment.
Comparative experiment
To prove the performance of CPDD-YOLOv8, it is evaluated with the current mainstream algorithms. The results are shown in the Table 4.
Table 4 shows that YOLOv10 has the highest FPS. However, compared to CPDD-YOLOv8, YOLOv10 performs poorly in Precision, Recall, F1, mAP @ 0.5 and mAP @ 0.5: 0.95. In Table 4, the mAP @ 0.5 and mAP @0.5:0.95 of the CPDD-YOLOv8 are higher than those of other models. CPDD-YOLOv8 focuses on improving detection accuracy, so it is acceptable to sacrifice the performance of parameters, FPS, and GFLOPs. Figure 9 compares the mAP @ 0.5 and mAP @ 0.5: 0.95 results from different model experiments.

The mAP @ 0.5 and mAP @ 0.5: 0.95 for different models. We used “Origin” to make it, and all the elements in the picture were made by ourselves.
Visualization
To verify the validity of the CPDD-YOLOv8 model, we compared the two-stage algorithm Faster R-CNN, one-stage algorithm YOLOv8 and CPDD-YOLOv8. Figure 10 shows the detection effects of these three models in the same scenario.

Faster R-CNN, YOLOv8 and CPDD-YOLOv8 visualizations. The photographs originate from the VisDrone2019.
In Fig. 10, lines 1 to 3 show the visualization effects of the two-stage classical algorithm Faster R-CNN, YOLOv8, CPDD-YOLOv8, respectively. In the first column, both Faster R-CNN and YOLOv8 have more missed detection phenomena in small object detection, while CPDD-YOLOv8 performs better. The second column shows that Faster R-CNN and CPDD-YOLOv8 are able to successfully detect the obscured vehicle below the image, while YOLOv8 fails to identify this object. Although the Faster R-CNN can also detect this vehicle, the number of missed detections is still relatively high. In the third column, YOLOv8 is unable to detect vehicle obscured by trees, while the Faster R-CNN is able to identify it, but also experiences false detection. CPDD-YOLOv8 detects occlusion with a low false detection rate. It can be seen that CPDD-YOLOv8 performs well in small object detection and shows good robustness. It is worth noting that although CPDD-YOLOv8 is able to detect more small objects, the model also shows some false detection phenomena. This can be caused by the object being too small, blurry, obscured, or the objects being too dense.
Generalization experiment
The WiderPerson dataset contains 13,382 images, but only 9000 of them provide labels. The original dataset is labelled in VOC format, so we first convert the labels to YOLO format. During the conversion process, the two categories of “humanoid object” and “dense crowd” are removed from the data set, and the three categories of “pedestrian,” “cyclist,” and “occlusion person” are unified into “pedestrian.” One image is found to be incorrectly labelled during the conversion process, so the dataset used in the experiment includes 8999 images. These images are divided into a training, a verification, and a test set, containing 7199, 899, and 901 images, respectively. To prove the effectiveness of CPDD-YOLOv8, it is compared with the current mainstream models on the WiderPerson dataset. WiderPerson is a publicly available dataset, the dataset can be downloaded at http://www.cbsr.ia.ac.cn/users/sfzhang/WiderPerson/. Table 5 shows the results.
The VOC_MASK dataset contains 7952 images, which are divided into training sets (6361 images), validation sets (795 images), and test sets (796 images) in an 8:1:1 ratio. VOC_MASK is a publicly available dataset, the dataset can be downloaded at https://aistudio.baidu.com/datasetdetail/112619. CPDD-YOLOv8 is compared with the current mainstream models, and the experimental results are shown in Table 6.
The SHWD dataset consists of 6064 training images, 758 validation images, and 759 test images. This dataset contains not only a large number of large objects, but also some small objects. Comparison experiments conduct on this dataset are shown in Table 7. SHWD is a publicly available dataset, the dataset can be downloaded at https://github.com/njvisionpower/Safety-Helmet-Wearing-Dataset.
According to the results, the mAP @ 0.5 and mAP @ 0.5: 0.95 of CPDD-YOLOv8 are completely higher than those of other models, which proves the model’s effectiveness proposed in this paper and its generalization ability.
Discussion
We verify the contribution of each module to the overall model performance through a series of ablation experiments, clearly demonstrating the effectiveness of each module. We also conduct comparative experiments to comprehensively compare our model with current mainstream methods, and the results show that our model shows obvious superiority on several key indicators, demonstrating its advancement in performance. Finally, the generalization experiment further proves that our model shows strong robustness when facing different datasets and tasks, and can maintain good performance in a variety of environments. Overall, these experimental results collectively support the validity, innovation, and broad applicability of our method.
According to the experimental results, it can be observed that the improved model is better than other existing models in terms of mAP. Compared with the traditional model, the improved model shows significantly enhanced in the small object detection. The mAP of CPDD-YOLOv8 is improved for the following reasons:
-
1.
The introduction of C2fGAM module in YOLOv8 model significantly improves the attention to information-intensive areas in images and effectively reduces background misrecognition, which lays a foundation for improving the detection accuracy of the model in complex scenes. Specifically, by directing attention to key areas, C2fGAM not only mitigates the impact of background interference, but also enhances the ability to capture detail, thereby improving overall detection performance. These improvements ensure the accuracy and reliability of CPDD-YOLOv8 when processing images, especially in situations with complex backgrounds or small object sizes.
-
2.
The introduction of P2 small object detection layer in YOLOv8 significantly enhances the model’s ability to identify small-size objects, thus solving the problem of insufficient detection performance of small and medium-sized objects in the previous YOLO version. Specifically, the P2 layer provides richer detail by using higher-resolution feature maps, which allows the model to capture and locate small objects more accurately. Our small object detection layer uses DyHead as the detection head, an innovation that significantly improves the performance of small object detection. DyHead improves detection accuracy by dynamically adjusting the processing of feature maps.
-
3.
The introduction of DSC2f makes up for the shortcomings of traditional convolution in capturing object boundary information. The traditional convolution operation is limited by the feature extraction of fixed shape and size, and it is difficult to adapt to the object changes of different scale and shape in the image. As a result, the accuracy of feature extraction is affected when the object boundary is fuzzy or the scale is small. DSC2f dynamically adjusts the shape of the convolution kernel so that it can better adapt to objects of different scales and shapes. Specifically, the method dynamically adjusts the convolution kernel according to the features of the input image to capture the shape information of the object more effectively. This dynamically adjusted convolution kernel can describe the boundary of the object more accurately and improve the performance of the object detection model in dealing with complex scenes.
-
4.
The use of DyHead can make up for the shortcomings of the YOLOv8 when dealing with objects of different scales. Traditional object detection models usually adopt a fixed-size detection head, which leads to performance degradation when dealing with objects with large scale changes. The introduction of DyHead allows the model to dynamically select appropriate detection heads at different levels to handle objects at different scales.
Conclusions
We propose the CPDD-YOLOv8 with higher detection accuracy to improve the difficult problem of object recognition and location. The model is based on YOLOv8 and has been improved upon. Information loss is reduced by incorporating GAM attention mechanisms into the C2f structure. The P2 layer is added to extract small objects’ information from the shallow layer. DSConv is used to take place of the Conv of Bottleneck in the C2f structure, which enhances the network’s ability to detect small objects. Using the DyHead detection head, different objects can dynamically select detection heads in different situations. The experimental results show that the CPDD-YOLOv8 can improve object detection accuracy. In these scenarios, it is necessary to identify the objects from high altitudes or complex environments when detecting small objects, such as small object detection by drone from high altitudes and small object detection in complex environments. In practical scenarios, small objects have applications in safety monitoring, autonomous driving, and industrial inspection. The high-precision small object detection model can significantly improve the overall performance of the system and reduce the rate of missed detection, thereby improving safety and efficiency. In addition, this development can also promote research in related fields and the development of object detection technology in more complex scenarios.
Although the model has improved the network’s ability of small object, some shortcomings need to be further enhanced. The main research work in the future is as follows:
-
1.
Lighten model. The model isn’t easy to deploy because of the large number of parameters. Despite the FPS reduction, this improvement shows a trade-off between accuracy and speed. Optimizing a model is an ongoing process, and future work can be devoted to further optimization to improve inference efficiency while maintaining high accuracy. Model pruning, lightweight network design, and other methods are planned to address this.
-
2.
Improve the detection speed. The model’s response speed is related to the application’s practicability. We plan to optimize the candidate region generation algorithm and use more efficient activation functions so that the model can improve the speed of object detection while maintaining accuracy.
Data availability
The datasets used during the current study available from the corresponding author on reasonable request.
References
Lau, W. J., Lim, J. M., Chong, C. Y., Ho, N. S. & Ooi, T. W. M. General outage probability model for UAV-to-UAV links in multi-UAV networks. Comput. Netw. 229, 109752 (2023).
Rudys, S. et al. Hostile UAV detection and neutralization using a UAV system. Drones 6, 250 (2022).
Liao, Y. H. & Juang, J. G. Real-time UAV Trash Monitoring System. Appl. Sci. 12, 1838 (2022).
Alladi, T., Naren, Bansal, G., Vinay, C., Mohsen, G. & SecAuthUAV A novel authentication scheme for UAV-Ground station and UAV-UAV communication. IEEE T Veh. Technol. 69, 15068–15077 (2020).
Hadiwardoyo, S. A. et al. Three dimensional UAV positioning for dynamic UAV-to-Car communications. Sensors-Basel 20, 356 (2020).
Kim, K. et al. UAV chasing based on YOLOv3 and object tracker for counter UAV system. IEEE Access. 11, 34659–34673 (2023).
Ye, J., Zhang, C., Lei, H. J., Pan, G. F. & Ding, Z. G. Secure UAV-to-UAV systems with spatially random UAVs. IEEE Wirel. Commun. Le. 8, 564–567 (2018).
Li, F., Luo, J., Qiao, Y. & Li, Y. Joint UAV deployment and task offloading scheme for Multi-UAV-Assisted edge computing. Drones. 7, 284 (2023).
Ye, Z., Hu, H., Li, F. Y., Huang, K. Z. & F. & Disentangling semantic-to-visual confusion for zero-shot learning. IEEE T Multimedia. 24, 2828–2840 (2021).
Ye, Z. H. et al. SR-GAN: semantic rectifying generative adversarial network for zero-shot learning. IEEE ICME 85–90 (2019).
Liao, L. et al. Eagle-YOLO: An Eagle-Inspired YOLO for object detection in unmanned aerial vehicles scenarios. Mathematics-basel. 11, 2093 (2023).
Li, J., Ye, D. H., Kolsch, M., Wachs, J. P. & Bouman, C. A. Fast and robust UAV to UAV detection and tracking from video. IEEE T Emerg. Top. Com. 10, 1519–1531 (2021).
Ye, Z. H., Yang, G. Y., Jin, X. B., Liu, Y. F. & Huang, K. Z. Rebalanced zero-shot learning. IEEE T Image Process. (2023).
Girshick, R., Donahue, J., Darrell, T. & Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv:1311.2524, 2013. (2014). https://arxiv.org/abs/1311
Shi, T., Ding, Y. & Zhu, W. X. YOLOv5s_2E: improved YOLOv5s for aerial small target detection. IEEE Access. 11, 80479–80490 (2023).
Redmon, J., Divvala, S., Girshick, R. & Farhadi, A. You only look once: Unified, Real-Time object detection. arXiv:1506.02640v5, 2015. (2016). https://arxiv.org/abs/1506.02640
Liu, W. et al. SSD: Single shot multiBox detector. arXiv:1512.02325, (2015). https://arxiv.org/abs/1512.02325 (2016).
Huang, J. H., Zhang, H. Y., Wang, L., Zhang, Z. L. & Zhao, C. M. Improved YOLOv3 model for miniature camera detection. Opt. Laser Technol. 142, 107133 (2021).
Yan, P. et al. Clustered remote sensing target distribution detection aided by density-based spatial analysis. Int. J. Appl. Earth Obs. 132, 104019 (2024).
Gu, Y., Hu, Z., Zhao, Y., Liao, J. & Zhang, W. M. F. G. T. N. A multi-modal fast gated transformer for identifying single trawl marine fishing vessel. Ocean Eng. 303, 117711 (2024).
Ye, Z. H. et al. V associating multi-scale receptive fields for fine-grained recognition. IEEE ICIP 1851–1855 (2020).
Khan, S. D., Alarabi, L. & Basalamah, S. A unified deep learning framework of multi-scale detectors for geo-spatial object detection in high-resolution satellite images. Arab. J. Sci. Eng. 47, 9489–9504 (2022).
Zhao, K. H., Xie, B. X., Miao, X. A. & Xia, J. Q. LPO-YOLOv5s: a lightweight pouring robot object detection algorithm. Sensors-basel 23, 6399 (2023).
Zhou, J., Zhang, Y. & Wang, J. RDE-YOLOv7: an improved model based on YOLOv7 for better performance in detecting dragon fruits. Agronomy-basel 13, 1042 (2023).
Zhao, X. M. & Song, Y. L. Improved ship detection with YOLOv8 enhanced with mobileViT and GSConv. Electronics-Switz. 12, 4666 (2023).
Zhang, W. L., Li, Y. N. & Liu, A. RCDAM-Net: a foreign object detection algorithm for transmission tower lines based on RevCol network. Appl. Sci-basel. 14, 1152 (2024).
Chen, H. W., Zhou, G. H. & Jiang, H. X. Student behavior detection in the classroom based on improved YOLOv8. Sensors-basel. 23, 8385 (2023).
Fan, X. Y. et al. A small ship object detection method for satellite remote sensing data. IEEE J-STARS (2024).
Li, Y. T., Fan, Q. S., Huang, H. S., Han, Z. G. & Gu, Q. A modified YOLOv8 detection network for UAV aerial image recognition. Drone 7, 304 (2023).
Liu, Y. C., Shao, Z. R. & Hoffmann, N. Global attention mechanism: Retain information to enhance channel-spatial interactions. arXiv:2112.05561v1 (2021).
Jiang, B. et al. ROD-YOLO: improved YOLOv8 semantic segmentation of obstacles in complex road scenes based on swin transformer. ISCAIS 13210, 561–566 (2024).
Wang, Z. Y., Yuan, G. W., Zhou, H., Ma, Y. & Ma, Y. T. Foreign-object detection in high-voltage transmission line based on improved YOLOv8m. Appl. Sci-basel. 13, 12775 (2023).
Shi, J. Y., Bai, Y. H., Zhou, J. & Zhang, B. H. Multi-crop navigation line extraction based on improved YOLO-v8 and threshold-DBSCAN under complex agricultural environments. Agriculture 14, (2024).
Li, S., Tao, T., Zhang, Y., Li, M. Y. & Qu, H. Y. YOLO v7-CS: a YOLO v7-Based model for lightweight bayberry target detection count. Agronomy-basel 13, 2952 (2023).
Bai, T. B., Lv, B. L., Wang, Y., Gao, J. L. & Wang, J. Crack Detection of track slab based on RSG-YOLO. IEEE Access. 11, 124004–124013 (2023).
Zhang, Q., Zhang, J. N., Li, Y., Zhu, C. F. & Wang, G. F. IL-YOLO: an efficient detection algorithm for insulator defects in complex backgrounds of transmission lines. IEEE Access. 12, 14532–14546 (2024).
Wang, C. Q. et al. Mask detection method based on YOLO-GBC network. Electronics-Switz 12, 408 (2023).
Qin, Y., Miao, W. Q. & Qian, C. A High-Precision fall detection model based on dynamic convolution in complex scenes. Electronics-Switz 13, 1141 (2024).
Zhu, P. F. et al. Detection and tracking meet drones challenge. IEEE T Pattern Anal. 44, 7380–7399 (2022).
Acknowledgements
This research was funded by the Defense Industrial Technology Development Program under Grant JCKYS2022DC10, and the Foundation of Science and Technology Research Project of Colleges and Universities in Hebei Province under Grant QN2023140.
Author information
Authors and Affiliations
Contributions
J. W.(Methodology, Validation, Writing-original draft preparation, Funding acquisition); J. G.(Software, Investigation, Project administration, Writing-original draft Preparation, Data curation, Visualization, Formal analysis); B. Z.( Conceptualization, Methodology, Validation, Resources, Supervision, Writing-review and editing, Funding acquisition). All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wang, J., Gao, J. & Zhang, B. A small object detection model in aerial images based on CPDD-YOLOv8. Sci Rep 15, 770 (2025). https://doi.org/10.1038/s41598-024-84938-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-84938-4
Keywords
This article is cited by
-
YOLO-based deep learning framework for real-time multi-class plant health monitoring in precision agriculture
Scientific Reports (2026)
-
AWD-YOLO enhancing autonomous driving perception reliability in adverse weather
Scientific Reports (2026)
-
UAVs detect hazards with multi-directional Mamba on overhead transmission lines
Scientific Reports (2025)
-
LRDS-YOLO enhances small object detection in UAV aerial images with a lightweight and efficient design
Scientific Reports (2025)
-
Enhancing wind turbine blade damage detection with YOLO-Wind
Scientific Reports (2025)
