
Abstract
The growth of the internet and big data has spurred the demand for more extensive information hoarding to store and distribute information. In today’s digital era, ensuring the security of data transmission is paramount. Advancements in digital technology have facilitated the proliferation of high-resolution graphics over the Internet, raising security concerns and enabling unauthorized access to sensitive data. Researchers have increasingly explored steganography as a reliable method for secure communication because it plays a crucial role in concealing and safeguarding sensitive information. This study introduces a novel and comprehensive steganography framework using the discrete cosine transform (DCT) and the deep learning algorithm, generative adversarial network. By leveraging deep learning techniques in both spatial and frequency domains, the proposed hybrid architecture offers a robust solution for applications requiring high levels of data integrity and security. While conventional steganography methods are typically classified into spatial and transform domains, extensive research and analysis demonstrate that the hybrid approach surpasses individual techniques in performance. The experimental results validate the effectiveness of the proposed steganography approach, showcasing superior visual image quality with a mean square error (MSE) of 93.30%, peak signal-to-noise ratio (PSNR) of 58.27%, root mean squared error (RMSE) of 96.10%, and structural similarity index measure (SSIM) of 94.20%, in comparison to existing leading methodologies. The proposed model achieved reconstruction accuracies of 96.2% using Xu Net and 95.7% with SR Net. By combining DCT with deep learning algorithms, the proposed approach overcomes the limitations of spatial domain methods, offering a more flexible and effective steganography solution. Furthermore, simulation results confirm that the proposed technique outperforms state-of-the-art methods across key performance metrics, including MSE, PSNR, SSIM, and RMSE.
Similar content being viewed by others
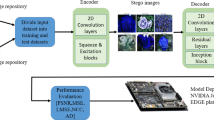
Introduction
The modern world would not survive without computers and other electronic communication devices. Sensitive digital data in large numbers is delivered and received for various purposes, ranging from straightforward data sharing to intricate preparations for streamlining organizational and industrial operations. An eavesdropper attempts to prevent the exchange of information during a conversation over an open channel. Thus, data security becomes essential. Researchers have been studying the secure transfer of sensitive data over public networks for a long time1. This process is becoming more and more difficult. For centuries, people have used cryptography as a security measure to muddle sensitive data into unintelligible signals. Essential content is transformed into a scribbled, encrypted version using encryption techniques2. Different new techniques have been created recently to protect data from unauthorized access, keep data safe, and hide data. These include cryptography3, watermarking4, and steganography5.
Third parties cannot decipher encrypted data, making it ideal for transmission6. The primary issue with cryptography, however, is that encrypted signals have no purpose and are, therefore, accessible to adversaries and easily manipulated or decoded using sophisticated cryptanalysis methods. Steganography is the process of encrypting digital media with a secure message hidden inside. The true point of dispute with this strategy is maintaining the power and imperceptibility of the image while hiding important information beneath a cover. Images are frequently employed as cover media in steganography systems, even though numerous different steganography algorithms have been given in the literature for various payload messages and covers (such as music, video, and images)7. Because it yields better results and prevents anyone from being able to tell the distinction between the cover image and the steganographic objects, steganography is, therefore, crucial in today’s advanced technology, where people use the internet and various image communication methods at high speeds8. Text messages, images, audio files, and video files are just a few of the sources from which secret information can be concealed using steganography,9. Numerous applications of steganography can enhance security for online voting, mobile banking, and secret communication between two communicators10. The medical, military, multimedia and industrial sectors are among the main users of private communications that can be used for both internal and external security requirements. The need for secure communication and data security in the digital age has led to the development of sophisticated techniques for information hiding. Image steganography is an essential method for preventing unauthorized access to sensitive data. It’s a technique for concealing information from digital images. Traditional steganographic techniques have mostly operated in the spatial or transform domains, each having advantages and disadvantages of its own.
Most used structural analysis model, the spatial rich model11 and its many variations12,13, are not as good at finding patterns as models based on deep learning, like those in14,15,16,17,18. It poses a risk to steganography algorithms’ security. Furthermore, to prevent steganography model identification, some steganography algorithms overemphasize steganography security. But this also drastically lowers the viability of these kinds of methods. Its capacity is only 0.1 bpp or less, yet it can successfully defy steganalysis’s detection to safeguard steganography, similar to the research of19. Finally, we can assess the accuracy of the extraction by comparing the extracted secret information with the original confidential data. It provides a definite measure of a steganographic model’s effectiveness. Other Least Significant Bit (LSB)-based approaches include pixel intensity value decomposition20 and bit-plane index manipulation21. In transform domain methods, transform coefficients have an embedded hidden message. Since space domain strategies are more powerful and complex than transform domain strategies, it will be more difficult to recognize them22. Since images are so large, compression is generally necessary. The irreversible method and the secret message may lose their integrity as a result of this issue. To address this issue, a compression technique implements the concealed notice. One of the most crucial transformations that embed data during a compression procedure like JPEG is the discrete cosine transform (DCT). DCT approaches are crucial among all transform domain methods since digital cameras and scanners generate images in this format more often than any other23,24.
The spatial domain steganography algorithms can hide more information, are easier to use, and don’t hurt the quality of the hidden images as much25,26. They work by directly substituting the secret information for cover image pixels. These methods are less resistant to attacks on image processing, though. Therefore, we advise against using them in real-time security applications. Furthermore, frequency domain techniques are more resilient and less susceptible to many forms of attacks. The discrete Fourier transform (DFT)27, the discrete-wavelet transform (DWT)28, the DCT29, the contourlet transform30, and other forms of these basic transforms are some of the most used methods in this field. All other steganography techniques work flawlessly with the least amount of image quality degradation due to DCT’s powerful “Energy Com” action “property, which enables the alteration or removal of less significant high-frequency components from an image while concentrating the most sensitive information on low-frequency components31. In this study, a new way of hiding images is introduced by using a hybrid method that combines spatial and DCT domains with the creative use of Generative Adversarial Networks (GANs). To raise the imperceptibility and safety of the implanted data, GANs, which are well-known for their ability to generate realistic and perceptually convincing content, are used. When compared to other SOTA methods, this type of intelligent data concealing provides higher embedding capacity.
A study32 describes a new way to make predictions called the Deep Convolutional Residual Network with Temporal Attention and Transformer (DTTR). This model uses a deep convolutional network for temporal attention to make a multimodal fusion “encoding-decoding” architecture. Another study,33, employed deep learning models for flood flow prediction, proposing a versatile two-dimensional hidden layer (Td) architecture. When compared to single hidden layer architectures, this design specifically takes into account the spatiotemporal features of hydrological data. The TdRNN, TdLSTM, TdBiLSTM, and TdCNN models are created to see how the new structure affects the basic models. This is done by adding a TD structure to the recurrent neural network (RNN), the long short-term memory (LSTM), the bidirectional long short-term memory (BiLSTM), and the convolutional neural network (CNN).
GANs34 are crucial for image imperceptibility and robustness in the steganography process. In this study, GANs were used to make fake cover images so that the GAN algorithm could be tested for its ability to embed information in real images. We used the patchwork technique to select patches from a pool of synthetic images generated by GANs. Generating fake images with GANs improved the hybrid model’s ability to generalize, strengthening it against advanced threats that it hadn’t seen before35. This study used GANs to improve the embedding process by learning where each patch is and how strong it is. This made the cover image less distorted and identification harder. This study used another benefit of GANs to train the model on created steganographic images. The technique made the model more resistant to modern attacks and made it harder for attackers to get the encoded information. This study uses GANs to improve stego images, which makes the images look better and reduces the noise that comes from embedding. This makes the steganography technology harder to find and more durable36.
Problem statement
Even with recent advances in image steganography, it is still very difficult to achieve both outstanding resilience (resistance to common image processing procedures) and high imperceptibility (minimum visual distortion). Current methods frequently compromise on one component in favor of another, which restricts their usefulness. The necessity for more potent image steganography techniques that overcome these drawbacks is what spurs this research. By combining patchwork and transformation domain methodologies into a single, cohesive framework, this study hopes to accomplish this.
Motivation
The inherent trade-offs in conventional steganographic techniques are the driving force for this research. To increase payload capacity, spatial domain approaches-for example, LSB embedding-sometimes compromise visual quality. Transform domain approaches, on the other hand, get excellent at being undetectable but might not be as resistant to attacks, especially those that use DCT. The proposed hybrid steganography method uses GANs to overcome these limitations. This study aims to improve the spatial and transform domain embedding processes by using GANs’ ability to generate. This work will add a new level of complexity to the hidden data while keeping its robustness and perceptual accuracy.
-
How does GAN integration affect spatial domain embedding’s imperceptibility?
-
What are the benefits of integrating GANs over traditional DCT-based steganographic methods?
-
How much perceptual quality does the proposed hybrid steganography technology maintain through multiple extractions and embedding iterations?
-
How does the hybrid approach introduce computational challenges given the increased processing requirements associated with GANs?
Contribution
Combining GANs with spatial and DCT domain embedding in the proposed hybrid method makes image steganography much better in many ways. These advancements address significant issues with conventional steganographic techniques, paving the path for the concealment of more secure and imperceptible data in digital images.
-
The imperceptibility is greatly increased when GANs are used in spatial and DCT domain embedding techniques.
-
The suggested hybrid steganography method outperforms SOTA approaches.
-
The paper looks at the computational problems that the hybrid approach causes while also accounting for the extra processing needs that come with GANs. By understanding the trade-offs in computational complexity, the proposed strategy aims to strike a balance between processing power and performance.
The hybrid approach proposed here represents a major advance in image steganography by addressing fundamental problems and providing novel solutions. The study’s results add to the number of safe, undetectable ways to hide data and provide a flexible framework that can be used in many real-world situations.
Organization
The following outlines how this research is arranged: the related work is presented in section “Related work”. The detailed work and methodology of the hybrid technique are explained in section “Hybrid model”. The experimental results of a hybrid model are presented in section “Experimental results”. The performance evaluation metrics are presented in section “Performance evaluation metrics”. The discussion of the results and comparison with existing techniques is given in section “Discussion”. This study is concluded in section “Conclusion and future work” with a discussion of future work.
Related work
The classification could be based on the number of target applications, the type of cover image, the retrieval method, and the embedding method, as explained by the authors in37. Above all, the foundation of the steganographic technique is the embedding process, which conceals important information. Two primary categories may be used to group the different embedding-process-based steganography methods: spatial1 and frequency domain steganography38. LSB techniques use the intensity values of the cover image pixels to directly encode the secret message bits. Due to its increased susceptibility to steganalysis, LSB’s primary flaw is that it is insecure39. Successful data-hiding techniques reduce the system’s observability in an insecure medium, boost system security, and maintain the quality of the stego image.
The literature has suggested several methods for hiding data. Typically, the message bits are swapped directly into cover LSBs to alter the LSB planes. It is the most popular, simplest, and quickest method for hiding data in an image. RGB color versions are considered in most spatial domain steganography techniques, ranging from simple LSB replacement39,40 to intricate detection strategies based on saliency and edge41. Muhammad et al.1 showed a safe image steganography system that uses stego key-directed adaptive LSB replacement and multi-level cryptography. Comparing their approach to earlier SOTA approaches, they get it safer and more computationally efficient. However, there are constraints on its capacity to include hidden information. A unique approach to building S-boxes is presented in42, based on the nonlinear properties of quantum walks. We achieved strong security by employing these S-boxes to carry out LSB-based substitution. However, using two bits instead of one for each pixel in the cover image significantly reduces the image quality. A quantum walk-based chaotic system based on particle swarm optimization is built in43 to hide medical data. The position sequence in the model is used to identify the carrier image position that will be utilized to store secret data, and the generated velocity sequences are used to replace the secret bits.
Despite providing strong security, this quantum walk-based method is vulnerable to image processing-based assaults. In44, the LSB and XOR encryption techniques were presented. Because encryption and concealed phases have two layers, security is enhanced. A portion of the image that is less susceptible to cropping and compression can include this concealed information.45 investigates deep learning techniques, specifically on CNNs, for real-time image steganalysis. They do not seem to assess the effectiveness or performance of other deep learning models, such as GANs and RNNs.46 uses pre-trained CNN models, namely AlexNet, to boost the efficacy of image steganalysis. Despite being incredibly accurate, they only pay attention to one pre-trained model, leaving room for the investigation of other models. To build a deep residual network for steganalysis, use the Neural Architecture Search (NAS) algorithm. They give promising results; however, they don’t evaluate NAS’s efficacy in comparison to other automatic model optimization methods.
This paper47 introduces a unique hybrid method, CNN-DCT Steganography, which integrates CNNs with DCT for effective and safe data concealment in images stored in the cloud. The suggested method uses CNNs’ strong feature extraction skills and DCT’s spatial frequency domain transformation to achieve embedding that can’t be seen and better data hiding. The suggested CNN-DCT steganography method involves a two-step procedure for the cover image. At first, using a deep CNN to extract features makes it easier to find good places to embed data, which reduces visual distortions. The chosen areas go through the DCT-based steganography method, which hides private information in images so well that they can’t be told apart from the originals. The authors of a study48 highlight that information confidentiality is essential for advancing sustainable smart cities. Traditional image steganography frequently employs cover images to securely obscure concealed information or images. This research presents a novel image steganography algorithm based on an autoencoder (AE) neural network. The model utilizes the LSB Replacement approach to incorporate a secondary image within the LSB of the pixel values of the cover image. During the extraction step, the decoder uses the learned features to reconstruct both the original cover image and the stego secondary image. This makes it possible to sneakily add a whole image to the AE framework.
After reviewing a large number of pertinent works in each category of steganography methods, This study discovered that certain solutions lack sufficient decryption algorithms while others have low visual quality. Some are insecure and open to unauthorized attacks, while others have limited secret data embedding constraints. Through the creative use of GANs in conjunction with spatial and DCT domain embedding, this work introduces a new paradigm in image steganography. Because they combine the best aspects of spatial and frequency domain techniques, GANs, which are well known for their ability to produce realistic and perceptually enticing material, improve the imperceptibility and security of implanted information. This also improves visual image quality, robustness, security, and embedding capacity to achieve optimal visual image quality and embedding capacity, numerous researchers have endeavored to enhance both simultaneously49.
Hybrid model
This study initially highlights the fundamental prerequisites for the methodologies employed in the proposed work.
Least significant bit (LSB)
The most fundamental, easy-to-use, quick, and popular technique in the steganography and watermarking fields is called LSB. However, LSB techniques are susceptible to statistical attacks with minimal changes made to the stego image. As a result, numerous improved LSB-based image steganography techniques are being created to increase security, resilience, and efficiency. The most important ones are optimized LSB substitution based on learning approaches50, LSB matching algorithms51, and adaptive LSB embedding based on image attributes such as intensity and edge pixel nature52.
Discrete cosine transform (DCT)
DCT uses the summation of sinusoids with different frequencies and magnitudes to approximate an image. DCT has the benefit of being expressed without the need for complex numbers. DCT blocks \(8 \times 8\) of the basic functions are shown in Fig. 153, with the high-frequency DCT coefficients located on the lower right side and the low-frequency DCT coefficients in the upper left corner54. The DCT has the advantage of eliminating the less relevant redundant data without significantly lowering the quality of the image because an individual’s vision is not capable of perceiving the high-frequency component distortions in the image. On the other hand, low-frequency components are retained for decompression and reconstruction31. The cover image is split into \(8 \times 8\) blocks for the 2-D DCT transformation, and Eq. (1) is used to transform each block. In the frequency domain, this equation yields a block of the same dimensions.
It processes pixel values by multiplying them with weighted cosine functions and subsequently summing them to obtain a frequency representation of the image. The DCT enables the decomposition of an image into its frequency components, facilitating compression by eliminating less significant high-frequency details.
-
DT(l, k): This calculates a single DCT coefficient at position (l, k) in the transformed image. These coefficients represent the “amount” of different frequency components in the original image.
-
\(\frac{1}{\sqrt{2M}}\): A normalization factor.
-
C(l) and C(k): Scaling factors that adjust the DC component (average value) differently.
-
\(\sum\) (double summations): Sums over all pixels (xl, yl) in the original image.
-
p(xl, yl): The pixel value at position (xl, yl).
-
cos(...) terms: Cosine functions that represent the basis frequencies. They decompose the image into a sum of these frequencies.
Equation (2) can be used to derive the inverse of the 2-D DCT transformation.
The IDCT utilizes the frequency representation (DCT coefficients), applies weighted cosine functions, and aggregates the results to recreate the original pixel values. It constitutes the “decoder” component of the DCT encoding/decoding procedure employed in picture compression and various other applications.
-
iDT(xl, yl): This calculates the pixel value at position (xl, yl) in the reconstructed image.
-
\(\frac{1}{\sqrt{2M}}\): A normalization factor, similar to the DCT.
-
\(\sum\) (double summations): Sums overall DCT coefficients (l, k).
-
C(l) and C(k): Scaling factors, identical to those in the DCT, that adjust the DC component.
-
DT(l, k): The DCT coefficient at position (l, k)—these are the inputs to the IDCT.
-
cos(...) terms: Cosine functions, identical to those in the DCT, used to reconstruct the image from the frequency components.

DCT basic function.
Proposed hybrid model
The proposed image steganographic system is designed to fulfill security and imperceptibility while encoding as much secret information as possible. In this study, GAN was used as the basis for our suggested hybrid approach to meet these needs. The proposed model made different modules to reach different goals. This model is divided into two sections: first, a GAN with an encoder, decoder, and discriminator architecture is used to further strengthen the embedding of information more securely to achieve dual-domain steganography. The information is first hidden in the cover image using a DCT. This study provided a detailed introduction to the suggested GAN steganography method, focusing on two key areas: the network design and the loss function.
First stage of proposed hybrid model
The suggested steganographic technique first inserts hidden bits into high-frequency DCT coefficients of the cover image that are chosen at random. Subsequently, the chosen higher frequency coefficients are substituted with disordered values within the same DCT coefficient range of less than 1, hence contributing to the preservation of the cover image’s imperceptibility.
Performing DCT
Figure 2 displays the process to embed. As part of the flow, spatial-domain coefficients are changed into frequency domains, private data is split up at random, and encrypted data is added by giving DCT component values. First, we must convert the cover image (S) into the frequency domain using 2D DCT to fully utilize its features and minimize distortion. DCT separates the cover image into low- and high-frequency components, as shown in Fig. 3. Because of their superior energy compaction quality, the low-frequency DCT coefficients hold the majority of the essential information in the cover image. In that regard, altering these numbers will impact the image quality; however, changing higher values has not had a major effect on the imperceptibility of the cover image. We used the energy compaction property of DCT to add the secret data to the high-frequency DCT coefficients. This had little effect on the stego image’s invisibility. This effectively addresses our research question regarding the impact of employing a hybrid technique on the image’s imperceptibility.

Block diagram illustrating the steps involved in the secret data embedding process using DCT and chaotic sequence generation.

Illustration of the Zig-Zag pattern used for traversing DCT coefficients.
DCT coefficients selection
The key element influencing the STEGO image’s image quality and offering security against brute force attacks is the choice of the best places to include the secret data based on the DCT coefficients. This study suggests a hybrid image steganography method to pick any DCT site that can be used as a significant area for adding the hidden data from the high-frequency DCT components. The DCT components of the cover image do not contain the delicate low-frequency components of the window’s size as shown in Fig. 3. This means that Eqs. (3) and (4) tell us how to set the high-frequency DCT parameters and how many chunks \(NT_{b}\) to use for incorporating.
where M is the number of columns in the cover image (S) and \(k_{1}\) is the proportion of Dhf that is deemed significant. Two chaotic maps (\(C_{1}\) and \(C_{2}\)) are sorted using various initial and control parameters (\(x_{r1}\) = 2.768,\(x_{r2}\) = 2.987, \(\alpha\) = 0.941, \(\alpha\)2 = 0.9345) to produce the random locations Q1 and Q2.
DCT coefficients substitution
As shown in Table 1, the first stage is generating a \(2_{n}-1\) CCM sequence \(E_{1}, E_{2}, E_{{2_{n}}}-1\) having unique beginning and controlling length variables (1 = \(NT_{b}\)) and transposing these upward to generate an arr \(E^z_{x}\). This technique substitutes values for DCT coefficients and embeds secret data. The \(z^th\) number is made from the n-bit combination of the secret bits; if the value of the secret bits is not zero, the value \(E^z_{x}\) is chosen and put into the randomly chosen DCT components; if it is not zero, the DCT coefficient stays the same. The secret bits \(b_{s}\) are now incorporated in the \(D_{HF}\) area. Z starts at 1 and is changed by \(Zi_{x +1}\) every time the \(xi^th\) row is chosen, for any value of x. Because the DCT components change randomly, the model has greater durability and remains undetected.
Second stage of proposed hybrid model
This study carried out information concealment on the cover image in the second stage. The authors applied DCT on the cover image, which was the identical image that was utilized in the stego image of the first phase. In this stage, a GAN is used in conjunction with a deep learning algorithm to further improve security and image quality.
GAN network
The GAN network, comprising the discriminator, decoder, and encoder sub-networks, is shown in Fig. 4. This study used the hiding-extraction network as a generator to reveal hidden images with minimal color distortion and superior visual quality and to create steganographic images. The discriminator then receives the stego images generated by the aforementioned sub-network. Adversarial training increases the steganographic image’s security. During the training phase, the steganography model’s weights can be made better by using its ability to hide from steganography models and its ability to change the steganographic image and the reconstructed hidden image.

Illustration of the encoder–decoder GAN network for secret image embedding.
Encoder module
Figure 5 depicts the encoder network’s structure. To incorporate both shallow and deep characteristics into the different phases of convolution, ResNet has a lot of skip connections. A great deal of low-level, effective information about the image’s color and contour is included in the shallow feature, which is particularly helpful for creating steganographic images. As is widely known, the extreme instability of GAN during adversarial training is mostly caused by its structure, and gradient disappearance and other related phenomena frequently coexist with this instability, which impedes the network’s fast convergence. Nine leftover blocks must thus be added to the encoder network. In addition to learning richer feature information, our Resnet-based encoder network may also lessen the gradients’ disappearance as adversarial training progresses. Figure 5 also shows the specifics of the suggested network that makes use of a pre-trained ResNet GAN network. Included are a residual block, two convolutional layers with batch normalization (BN) and ReLU activation functions, and a skip connection. Cover image C and secret image S have the following measurements: \(Dc \times Wi \times He 3 \times 256 \times 256\), here Dc is the channel of the image and \(Wi \times He\) is its width-height.

Hybrid steganography approach utilizing DCT and GANs.
A 6-dim tensor of \(6 \times 256 \times 256\), which is produced by concatenating the cover image C with the secret image S, is received as input by the encoder network. During the downsampling stage, there are two \(3 \times 3\) convolutional layers with stride 2 and padding 1 and an \(8 \times 8\) convolutional layer with stride 1. Each convolutional layer is followed by the BN procedure and the ReLU activation function. The continuous residual layers get \(64 \times 64\) feature maps as input from the third convolutional layer. Nine continuous residual blocks are present in the intermediate residual layers, which help to learn more complex low- and high-dimensional characteristics. In between the two convolutional layers is the dropout layer. Each residual block undergoes two convolution procedures, following which its \(64 \times 64\) feature map is added to its output. The BN operation and the ReLU activation function come after the deconvolutional layers. In particular, the output of the tanh activation function of the \(256 \times 256\) steganographic image C comes after the final convolutional layer.
Decoder module
The 6-layer complete convolutional network is used by the decoder network to distinguish between steganographic images \({\bar{C}}\) and secret color images \({\bar{S}}\). The generators of the suggested hybrid model are the encoder and decoder networks from the preceding section. Previous research has demonstrated that the decoder network’s architecture is capable of successfully reconstructing both three-channel color secret images and single-channel grey scale secret images. Following stride 1 and padding 1 \(3 \times 3\) convolutional layers, BN procedures and ReLU activation functions are applied. But following the last convolutional layers was the sigmoid activation function. At last, the secret image \({\bar{S}}\) is revealed by the decoder network.
Discriminator module
As is common knowledge, one of the most crucial metrics for assessing the caliber of steganography models is security55. However, because the carrier image contains an excessive amount of information, this kind of steganography model has low security56. In light of the aforementioned issue, an enhanced steganography model was suggested in the literature57, This covered up the hidden greyscale image in the color carrier image’s Y channel. As a result, the discriminator in our model is the advanced stochastic model XuNet. To make the first layer of XuNet suitable for color image detection, This study transposes the KV kernel to produce a 3-channel matrix of \(5 \times 5\). The configuration of the last five convolutional layers is the same. With the sigmoid activation function, which has a range of values from 0 to 1, the detection probability in the final fully connected layers is output.
Loss function module
It is commonly recognized that unstable convergency and training instability are frequent issues for GANs. For the suggested technique to be reliably trained, loss functions should be carefully specified. WGAN was proposed in58 to enhance the convergence efficiency of GAN and stabilize the training process. Because of WGAN’s advantages, In this work, the authors use its discriminator loss function as our principal loss function and its generator loss function as part of the encoder–decoder composite loss function. The cross-entropy between the original and recovered secret information, the generator loss of WGAN, and the mean square error (MSE) loss \(L_{MSE}\) between the cover and stego image make up the encoder–decoder’s loss function. The definition of the total loss function \(L_{all}\) is given in Eq. (5):
where \(I_{co}\) and \(M_{in}\) denote the cover image and secret information, respectively. Use \(\alpha , \beta , and \gamma\) to modify the fraction of \(L_{mse}\), \(L_{e}\), and \(L_{inf}\) in \(L_{all}\). This study used \(\alpha = 0.3, \beta = 15, \gamma = 0.03\) in this investigation. The training objective is to reduce \(L_{all}\). The MSE loss between the cover and stego image is found using Eq. (6):
where the shape of an image is indicated by \(c \times h \times w\). The cross-entropy between the original and recovered secret information is computed using Eq. (7).
Equation (8) is used to calculate the score of the stego image, followed by its negative value.
Equation (9) calculates the difference between the two scores of the cover and stego image.
Reducing \(L_{c}\) is the aim of training to improve the module’s ability to discriminate between the stego image and cover.
Experimental results
This section presents data gained from experiments with various parameters, followed by a performance evaluation.
Experimental settings
The experiments were performed utilizing the parameters stated, where the specifics of the experimental configuration are presented in Table 2. This study employed a grid search method to ascertain the best hyperparameter configuration. Through thorough exploration of various hyperparameter combinations, the current study identified the best parameter configurations as given in Table 3.
Impact of DCT, GAN and encoder–decoder architecture in steganography
This study employed GANs, an encoder–decoder architecture, and DCT embedding59,60 to enhance imperceptibility and robustness, with each component complementing the others. The DCT converts the image into frequency coefficients, with the majority of information concentrated in the low-frequency components. The DCT embedding procedure incorporates information by altering the LSBs. The encoder–decoder architecture61 acquires representations in which the encoder identifies the most significant characteristics to compress the input image into latent space, subsequently employed by the decoder module to recover the original image. GAN comprises two components: the generator, which produces images, and the discriminator, which differentiates between produced and authentic images. GANs generate high-quality images, thereby improving their imperceptibility. This work utilized a hybrid method in which GANs, encoder–decoder architectures, and DCT embedding synergistically enhance one another. The encoder–decoder module offers an efficient representation, enabling the network to learn a dense representation of the image that facilitates more effective embedding within DCT coefficients. This embedding approach offers enhanced embedding capacity to attain image imperceptibility62.
In this study, GAN was used to improve the embedding process. The generator module was taught to create images that make the embedded information look like real images, which made the hidden information harder to spot. The integration of an encoder–decoder module with GAN-based training, which eliminates noise and distortions before refinement, enhances the model’s resilience to prevalent attacks. The authors assert that the encoder–decoder framework offers an effective representation of images, while DCT embedding presents a proficient technique for embedding secure messages within the frequency domain of images. Furthermore, the generator and discriminator components of GAN enhance the embedding process to ensure imperceptibility and resilience. The GAN component enhances the embedding process, guaranteeing that the resultant image is visually indistinguishable from the original, hence improving imperceptibility and resilience, which significantly complicates the extraction of concealed information.
Dataset
This study utilized the ImageNet2012 dataset to implement the proposed hybrid model, which provides security, hides information in the cover image, and maintains image quality. The training, validation, and test sets for this study are the validation sets of ImageNet 201263, which comprise 50k images across 1k categories. As the training set, this study chose at random 40k images to produce 20k pairs of covert images. Out of the 10k images, the proposed model selected 5k at random to make the 2500 pieces of cover secret image graphs for the validation set and an additional 5k images to make the 2500 pieces for the test set. The dual-domain hybrid steganography paradigm is implemented in all experiments as described in Tables 2 and 3.
Preprocessing techniques applied to the dataset
When you do data analysis or machine learning, you need to do preprocessing because the quality and usefulness of the data have a big impact on the results and how well the models work. Images of license plates frequently display noise due to substandard quality, requiring pre-processing. In a study64, the authors specified that the objectives during the preprocessing phase include image stabilization and the minimization and refinement of noise reduction. The authors pointed out that various studies have not extensively examined the impact of image processing, particularly encryption and steganography, on classification accuracy. Getting around these problems is important for making secret information embedding and extraction systems that work well and can be used in real life. We outline the preprocessing methods applied to the dataset below:
-
Resizing: The current study utilized a resizing approach to modify the proportions of the input image, maintaining consistency among all input images.
-
We utilized the Contrast Enhancement technique to enhance the contrast of the input images, thereby ensuring feature visibility and boosting performance.
-
Noise reduction: Various factors affect image quality. This study utilized a noise reduction method to remove superfluous noise from the input image.
-
Normalization: To enhance model convergence and mitigate numerical instability, this study implemented normalization to scale the input images within the range [0-1].
-
Color Space Conversion: This research utilized a color space conversion method to convert input images to grayscale, thereby augmenting processing efficiency and streamlining the learning process, which in turn enhances performance.
Training generator
The generator and the discriminator are taught in turn during the conventional GAN training procedure. The weight of the other network is fixed and won’t change after one of them has been trained. The generator is trained after the discriminator in the training sequence. Typically, the discriminator weights are updated five times, followed by a single update to the generator weights, to expedite the model’s convergence. Consequently, this study employed the steganalysis model as a discriminator and the encoder–decoder network as a generator. Due to the excessive amount of embedded information in our carrier image, Euclidean distance is high. Thus, it is simple for the stochastic model XuNet to converge. This study changed the weights of the generator four times a year and the discriminator weights once a year to achieve a balance between the performance of the discriminator and the encoder–decoder network. In total, 100 training epochs will be used. \(10^{-3}\) is the initial learning rate used to train the encoder and decoder networks. The Adam optimization technique is used to automatically change the encoder and decoder network’s parameters. The SGD optimization technique was used to update the discriminator’s parameters after its initial learning rate of \(10^{-3}\) was established.
Performance evaluation metrics
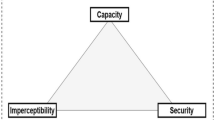
Three factors often evaluate steganography methods: extraction accuracy, security, and capacity. First of all, capacity is a measure of how many secret bits of information can be reconstituted after being encoded in the carrier image. Second, security means that secret images are invisible and that steganographic images are true and have minimal distortion, in addition to being able to withstand steganalysis model detection. Ultimately, the efficacy of steganographic models greatly depends on the precision of the extraction process. The entire steganography process is useless if confidential data cannot be precisely and fully recovered from the carrier image, regardless of how much of it is hidden there. As of right now, all deep learning-based steganography techniques struggle with extraction accuracy, making it impossible for them to completely recreate the hidden data. Still, one special benefit of the image-hiding technique known as steganography is that the secret image can fully recover without the need for a decoder network. Despite the inability to fully recreate the hidden image, the receiver still understands its entire semantic content.
The image quality assessment factors are the variables that determine the image’s quality. Another word for the parameters that show different aspects of image quality is Key performance indicators or KPIs. Among these KPIs are distortion, homogeneity, dynamic range, noise, sharpness, and color correctness. The following is a discussion of the key measurements that are typically employed in the steganography field:
Peak signal-to-noise ratio (PSNR)
The PSNR is determined by applying the subsequent formula, 10:
According to Table 4, the average PSNR attained in our suggested scheme is 58.27, indicating a noteworthy enhancement in contrast to other similar SOTA techniques.
Structural smilarity index measure (SSIM)
A useful method for assessing signal quality is SSIM. Although it can quickly compensate for non-structural aberrations, anomalies in structure can affect our system of vision. Emulation of this feature is the main function of the SSIM66. Moreover, SSIM values range from 0 to 1, with two remarkably comparable images having values that are very near to 1. Table 4 presents a comparison between our suggested method’s average SSIM value and that of the other SOTA techniques. Equation (11) yielded an SSIM value of 0.942 in our proposed scheme, which is likewise very close to 1, showing that the cover art and the stego have a lot in common.
where \(\sigma\) and \(\mu\) stand for variance and mean, respectively, and Co and Se are the Cover Image and Stego Image, respectively. \(C_{1}\) and \(C_{2}\) are constants.
Mean-squared-error
Higher image quality requires a low MSE, indicating a low error9. The MSE calculation formula is shown in Eq. (12):
where C and S are the covers and stego images, respectively, and m and n are the image’s dimensions.
Root mean squared error (RMSE)
The quantity of variance per pixel brought on by processing is measured by RMSE. Pixel variations decrease with decreasing RMSE values. In terms of RMSE, a value less than 1 is seen as favorable.
where m and n are the image’s dimensions, and C and S are the cover and stego images, respectively. The average RMSE value of our proposed scheme is shown versus the various SOTA techniques in Table 4. Equation (13) yielded an RMSE value of 0.961 for our suggested scheme, which is good since it is less than 1 and captures the tiny pixel changes for the suggested embedding process.
Correlation coefficient (CC)
The CC is utilized to evaluate the robustness of the derived results. In Eq. (14), cover and stego images are denoted by x and y. The average of the stego image is \({\bar{y}}\), while the average of the cover image is \({\bar{x}}\).
Results obtained using CC and BER metrics
This work employed the ImageNet 2012 dataset to enhance the viability of the suggested steganography system. The training dataset significantly influences the model’s performance. The training dataset comprises original images, images embedded with a secret image sized \(16 \times 16\), images embedded with a secret image sized \(32 \times 32\), and images embedded with a secret image sized \(64 \times 64\). We randomly select fifteen test images to determine the optimal image dataset for our studies. As starting points for comparison, this study chose three typical evaluation indicators: CC and bit error rate (BER), as well as PSNR and SSIM. PSNR and SSIM measure how similar the original stego images and the reconstructed stego images are to our eyes. BER, on the other hand, measures how the image dataset affects the extraction of secret information. The test results for SSIM, PSNR, and BER using different training datasets and the suggested steganography are shown in Table 5.
The experimental results indicate that when the secret image size is \(16 \times 16\), the BER of the reconstructed secret image is 0.1006. As the dimensions of the concealed image expand to \(32 \times 32\), the BER diminishes to 0.0686. Nevertheless, when the dimensions of the concealed image are expanded to \(64 \times 64\), the BER attains its peak value of 0.15. We can infer that as the secret image’s size increases, the BER first decreases and then increases. The smaller the secret image, the lesser the influence of its embedding procedure on the appearance and dispersion of the stego image. Thus, the complete extraction of the secret image is contingent upon the accurate reconstruction of the stego image’s comprehensive information. This also means that the best embedding capacity can find a balance between getting the hidden image out and making the stego image look good again.
Quantitative comparison of extraction accuracy with other methods
The precision of extraction is crucial for the efficacy of steganographic models. The steganography method is useless if the secret information hidden in the carrier image can’t be fully and accurately extracted, no matter how much of it there is. Currently, all deep learning-based steganography systems struggle with extraction accuracy, particularly in their inability to accurately recreate the concealed information. Still, the steganography method for hiding pictures has a big advantage: it doesn’t need a decoder network to get the hidden image right. Even if the recipient does not reconstruct the secret image flawlessly, they can still understand all the semantic information embedded in it.
A study44 employs pre-trained CNN models, particularly AlexNet, to enhance the efficacy of image steganalysis. The authors attain a significant degree of precision, although they concentrate predominantly on a singular pre-trained model, allowing for the potential investigation of alternative models. A separate study16 introduced an alternative CNN architecture that attained an error rate of 31.2%. Although the concept of learning hierarchical representations from raw images is attractive, it did not significantly enhance detection accuracy. The authors of the study76 incorporate an innovative secret block into StyleGAN77 and implement a mutual information mechanism to improve extraction accuracy. A study78 employs stable structural features to obscure secret signals by decomposing images into texture and structural components. However, these techniques entail intrinsic training expenses and frequently require modifications to the original generation model, leading to a reduction in image and visual quality. Figures 6 and 7 provide a visual depiction of the accuracy and loss numbers, respectively, for the initial 100 epochs of the model’s training phase. Seeing these graphs makes it easier to understand and analyze how the proposed model learned and how well it did during the first training phases.

Accuracy curve depicting the learning trend of the model.

Training loss curve of the proposed model.
The sections that came before looked at the proposed method’s performance from different angles, comparing it with both well-known and new embedding methods in DCT coefficients with the same embedding levels. Since the suggested method works in the frequency domain, several other frequency-domain methods with various transformations that have similar embedding level ranges to the suggested method have been tested. Their accuracy ranges are shown in Table 7. The suggested technique is adaptive, resulting in varying maximum embedding capacities for different images, with the average maximum hiding capacity detailed in Table 7. An analysis of these results indicates that the proposed strategy is unequivocally superior to all alternatives. However, the70 method, a recent embedding technique utilizing stable diffusion, possesses a little greater embedding capacity than the proposed method; however, the stego images produced by our method exhibit superior quality. Our proposed method is more practical than70 due to the presence of robust steganalysis techniques and sensitivity to elevated embedding levels.
Comparison of proposed model with recent studies
This study evaluated the outcomes of various performance evaluation metrics: PSNR, SSIM, BER, and CC, with contemporary research findings. Table 5 illustrates that the suggested model had outstanding performance across several metrics. This study achieved a PSNR of 59.90 and an SSIM of 0.98, demonstrating the suggested model’s higher performance compared to current state-of-the-art studies. The results show that this study does a better job of preserving image quality and structural similarity. However, compared to more recent studies on CC, this study’s value of 0.91 is a little lower. The results in Table 5 indicate that this study attained a lower BER of 0.15, suggesting that the suggested model demonstrates resilience to errors. This study demonstrated great robustness and a reduced embedding capacity of 0.039 when evaluated for payload and embedding capacity, indicating its potential for diverse image and video processing applications. The findings of this study indicate that the proposed model provides an impressive amalgamation of superior image quality, enhanced robustness, and minimal capacity, positioning it as a formidable candidate in the realms of encryption and steganography for various contemporary applications. The proposed method averages 0.017845 seconds for computation. Table 6 illustrates the computation time of the suggested technique across several cover images. The dimensions of the cover image are \(N \times N\). The computational complexity of the proposed DCT-GAN hybrid approach for medical images demonstrates superior performance compared to recent studies (Table 7).
Discussion
The ImageNet 2012 dataset was used to retrain the deep-learning steganography models that were needed for this study. These models hide color images to control the variables. Before any comparison experiments start, a retrained comparison model is made for each one, and the evaluation set is used to see how well these models work. It included one thousand pairs of exposed secret images and one thousand pairs of cover Stego images.
The stego images’ look and the rebuilt concealed images produced by our model and other comparative models are displayed in Table 8. Because of the improved visual quality, there is less of a distinction between the original carrier image and the carrier image containing sensitive information. Table 9 provides the overall performance measure of our steganography technique. The authors were able to get an average PSNR value of 58.27 by adding \(156 \times 156 \times 8\) = 1,64,541 bits to the \(256 \times 256\) colored cover image. This is because \(256 \times 256 \times 3\) channels equals 1,93,837 RGB elements, which means the payload can hold 1 bpp.
To easily reach 1 bpp payload capacity, the suggested technique only uses two color channels; the third color channel was left unattended to add an extra layer of protection. Nevertheless, there exist other plans like1 and42. The PSNR comparison of various benchmark steganography techniques in the literature with our proposed approach is displayed in Table 4 when embedding a 1 bpp payload capacity. There are several reasons why the PSNR values of other schemes lag. Furthermore, the proposed methodology only tests a limited number of datasets. The suggested technique places greater emphasis on replacing two bits in higher-frequency DCT components, whereas for DCT components with lower frequencies, just a single bit is changed. This leads to a reduction in overall pixel variance and a notable improvement in PSNR (i.e., 58.27). Table 4 shows the RMSE and SSIM performance metrics of our suggested steganography technique as well. Achieving both values extremely close to 1 reveals the higher stego image quality. Moreover, our stego images’ PSNR and SSIM values performed better than those of the other cutting-edge techniques.
The reconstructed secret image SSIM value is 2% lower than56, but the steganographic image SSIM value is still 1% lower than56. Tables 4 and 9 present the simulation results that support our second research question. The steganography technique proposed in our research can be readily implemented with low technological requirements, in contrast to other state-of-the-art technologies that need extensive processing. This indicates that our method would be more computationally efficient, which answers our third research question.
Computational complexity and its impact on practical applications
This study created a strong and effective hybrid model for protecting data sent over the internet. This model can also be used in other real-life situations, such as in education, by intelligence agencies, in the military, for secure communication, data protection, copyright management, intelligence gathering, digital watermarking, medical imaging, and by law enforcement. All of these situations need secure data protection. This paper thoroughly examines the computational complexity of the hybrid model and its implications for practical applications, particularly its viability in resource-limited settings. To illustrate the benefits of the proposed method, the authors compare its computational complexity with other GAN-based steganography techniques, focusing primarily on the number of floating point operations (FLOPs) and the number of parameters \(\#Param\). Specifically, FLOPs quantify the floating-point operations executed by the network, with a higher FLOP count signifying increased computational demands; \(\#Param\) denotes the number of parameters within the model that require training, with a greater \(\#Param\) indicating a more intricate model as given in Table 10.
The DCT-GAN steganography used in this work improved security and made it harder to figure out. However, it is harder to program than other methods. The DCT transformation, while efficient, adds to the total computational expense, particularly for images with a high resolution, where its complexity is \(O(N^2 log N)\), with N representing the number of pixels in the image. Moreover, the central component of the system, the GAN’s generator within the hybrid model, incurs significant computational overhead, as both forward and backward passes necessitate a complexity of O[N], along with supplementary expenses associated with backpropagation. Steganography with an encoder–decoder design improves security and imperceptibility, albeit at the expense of heightened computing complexity. The training of GANs is fundamentally iterative and frequently unstable, necessitating multiple iterations to optimize hyperparameters, which also escalates computational expenses. This, together with the necessity for comprehensive hyperparameter optimization, considerably elevates the computing demand. The incorporation of an encoder–decoder design significantly increases the computational complexity, especially in deep neural networks. These variables impose considerable constraints in resource-limited situations, such as mobile phones and embedded devices, where the processing requirements of DCT-GAN steganography escalate. In resource-constrained contexts, low processing power, memory, and energy resources can impede the actual implementation of such systems. Resource limits can be alleviated by utilizing advanced methodologies like TPUs or FPGAs for computational acceleration, employing sophisticated libraries for efficient DCT implementation, adopting lightweight GAN designs like MobileGAN or GhostNet, and implementing optimized training procedures.
Advantages of DCT-GAN compared to existing technologies to secure big data
This research attained improved security via a hybrid strategy utilizing DCT and GAN in conjunction. Adopting DCT, allows our research to embed data in the frequency domain which makes it less susceptible to basic statistical attacks compared to spatial domain methods. The use of GAN enables our research to produce stego-images that are statistically indistinguishable from the original images. Furthermore, the adversarial training process of GAN in our study enhanced the resilience of stego-images against sophisticated steganalysis methods, particularly those utilizing machine learning, as demonstrated by the data presented in Table 4. This research achieved an increased data payload with the utilization of GAN while maintaining little deterioration of the cover image. This study employed a hybrid approach combining DCT and GAN, integrating frequency domain analysis with machine learning to provide a synergistic impact, hence enhancing security beyond the capabilities of either method independently. This study employs DCT-GAN-based steganography, utilizing initial embedding through DCT, while the GAN refines the stego-image to improve its imperceptibility and detection resistance, as presented in Table 9. This research examined computational complexity and its influence on actual applications, as illustrated in Table 10, and how the framework enhances processing time, particularly in a big data scenario where efficiency is critical. This study compares traditional steganography methods with contemporary state-of-the-art approaches, emphasizing its advantages in security and robustness as given in Table 7. This study effectively demonstrated the distinct advantages and distinctive contributions of the proposed hybrid steganography framework for secure data exchange in the era of big data, utilizing DCT-GAN-based steganography approaches.
DCT-GAN steganography training and loss parameters for attack mitigation
The experiments were conducted using the specified parameters, with the details of the experimental configuration outlined in Table 2. This study utilized a grid search technique to determine the optimal hyperparameter configuration. The current study revealed the optimal hyperparameter configurations through a comprehensive analysis of numerous combinations, as presented in Table 3. This study utilized 100 epochs for training with a batch size of 32. We employed the SGD optimizer, initially configuring the learning rate at \(1 \times 10^{-2}\), which was subsequently optimized to \(1 \times 10^{-3}\). We utilized the Loss Function Module, which is formally delineated through Eqs. (5)–(9). This study utilized GANs, an encoder–decoder architecture, and DCT embedding59 to improve imperceptibility and resilience, with one element augmenting the others. The DCT transforms the image into frequency coefficients, predominantly concentrating information in the low-frequency components. The DCT embedding process integrates information by modifying the LSB. The encoder–decoder architecture. generates representations where the encoder discerns the most salient features to compress the input image into latent space, which is then utilized by the decoder module to reconstruct the original image. This study employed a hybrid approach wherein GANs, encoder–decoder designs, and DCT embedding mutually reinforce each other. The encoder–decoder module provides an efficient representation, allowing the network to acquire a dense image representation that enhances embedding within DCT coefficients. This embedding method provides increased embedding capacity to achieve visual imperceptibility62. This research investigated various hyperparameters to enhance the model’s performance against diverse attack types. The discussion section enumerates several potential assaults.
Experiments and performance evaluation using DCE-MRI medical dataset
The suggested approach employed a DCE-MRI medical images dataset sourced from the Cancer Imaging Archive (TCIA). The dimensions of the images are \(256 \times 256\) pixels. For the investigation, 450 DCE-MRI slices from 50 female patients are utilized. The suggested model was trained on 300 MR images and evaluated on 150 MR images. The breast-lesioned areas are the regions of interest (ROIs), whereas the remaining areas are the non-regions of interest (NROIs). A series of experiments was conducted to assess the efficacy of the hybrid strategy, including image quality evaluation, security evaluation, data loss attack assessment, and capacity assessment. This study utilized the DCE-MRI dataset to improve the efficacy of the proposed steganography system. The training dataset profoundly impacts the model’s performance. The training dataset consists of original images, images containing a concealed image of size \(16 \times 16\), images containing a concealed image of size \(32 \times 32\), and images containing a concealed image of size \(64 \times 64\). We randomly select fifteen test images to ascertain the appropriate image dataset for our research. This study selected three standard assessment metrics for comparison: CC, BER, and both PSNR and SSIM. PSNR and SSIM assess the visual similarity between the initial stego images and the recreated stego images. BER, conversely, assesses the impact of the image dataset on the extraction of confidential information. Table 11 presents the test results for SSIM, PSNR, and BER utilizing various training datasets and the proposed steganography method.
The experimental findings demonstrate that for a secret image size of \(16 \times 16\), the BER of the reconstructed secret image is 0.16. As the dimensions of the disguised image increase to \(32 \times 32\), the BER decreases to 0.43. However, when the dimensions of the hidden image are increased to \(64 \times 64\), the BER reaches its maximum value of 0.11. It can be deduced that when the size of the secret image rises, the BER initially lowers and, thereafter, climbs. The smaller the hidden image, the lesser the impact of its embedding process on the appearance and distribution of the stego image. The full extraction of the secret image depends on the precise reconstruction of the stego image’s complete information. This implies that optimal embedding capacity can achieve a balance between extracting the concealed image and maintaining the aesthetic quality of the stego image.
Potential attacks and their impacts on model performance
This research employed DCT, encoder–decoder, and GAN architectures to conceal hidden data within cover images. This study has multiple advantages; however, it is essential to comprehend the potential attacks that may impede the model’s performance in these situations.
-
Steganalysts can look at the stego image’s statistical features to find differences from how natural images are usually distributed. It entails analyzing pixel intensity measurements, histograms, or DCT coefficients.
-
Cybercriminals can conceal malware within benign files, such as images published to websites or email attachments. Upon opening, these files compromise the victim’s device surreptitiously.
-
Encoded messages or harmful links may be concealed within images or videos that are disseminated on social media, deceiving users into downloading or clicking on them and, therefore, initiating the infection of their devices.
-
Commonplace files like Word documents or PDF files may conceal financial information, personal data, or trade secrets and transmit them to unauthorized individuals.
-
Malicious entities can employ steganography to extract confidential information regarding competitors by penetrating internal files or eavesdropping on communications.
-
Steganography makes it easier to hide bad messages or illegal data transfers in normal network traffic, so security systems can’t find them.
-
Artificial intelligence techniques, such as CNNs, can be trained to differentiate between cover images and stego-images by analyzing tiny statistical or visual discrepancies.
-
If too much data is embedded that the steganography technology cannot handle, it could cause noticeable artifacts or distortions in the stego-image, making it easier to find.
-
Steganalysts might try to determine how much data they can conceal without compromising image quality or increasing the chance of discovery.
Analysis of potential attacks
Image processing assaults in steganography aim to identify and interfere with concealed messages hidden inside images. These assaults capitalize on the statistical and structural alterations.
-
Statistical Analysis Attacks: These attacks examine the statistical characteristics of an image to identify anomalies indicative of concealed data. Chi-square analysis, RS analysis, histogram analysis, and pixel value differencing (PVD) analysis. These attacks aim to ascertain whether the image’s statistics are excessively ideal or exhibit patterns that deviate from those of real images.
-
Attacks on Image Processing: It encompasses attacks that visually scrutinize the image for nuanced alterations, particularly following manipulations such as zooming or contrast adjustment. They are less perilous, yet they may expose basic concealment methods.
-
Deep Learning-Based Steganalysis: These assaults employ deep learning techniques. Some common deep learning attacks include CNNs and GANs.
-
Man in the Middle: The proposed methodology utilizes an advanced security approach to counteract threats efficiently. This is accomplished by encrypting pixel values through color modifications and modular arithmetic before splitting them into numerous units. Importantly, only segments of these units are integrated into cover images during dissemination, guaranteeing that no individual image encompasses all of the information required to rebuild the original image. This targeted incorporation substantially reduces the likelihood of illegal reconstruction, as merely eavesdropping on the images does not yield the whole data required.
-
Brute-Force Attack: In the context of a brute force attack, the difficulty of accurately estimating the pixel values is practically unfeasible. The increasing difficulty of attacks due to image size and unpredictability makes it uncommon for people who aren’t supposed to be there to get to information and computers. These problems make sure that the proposed architecture not only keeps data safe while it’s being sent but also consistently stops decryption attempts that aren’t legal. This creates a strong framework for sending sensitive images.
-
Prevention of Unintentional Assaults: We engineer the suggested approach to be robust against both intentional attacks and inadvertent noise or interference that could cause mistakes in image transmission. The suggested model additionally considers incidental noise or interference that may induce mistakes during transmission. Its attributes render it resilient to external attacks and internal threats from authorized users seeking to influence the transmission process. Consequently, the suggested approach demonstrates resilience against attacks and is a crucial element of data secrecy and cybersecurity.
-
Chosen Plaintext Attack: The formidable chosen plaintext attack significantly compromises a linear cryptographic system. This study extracts the secret keys of the proposed image encryption technique from the hash value of the plaintext images, making the suggested image encryption and decryption scheme resistant to chosen plaintext attacks.
This study presented a hybrid model utilizing DCT and GAN to counter potential attacks, offering robust embedding while minimizing statistical alterations resistant to standard image processing processes. In the initial step, we utilized the DCT approach to implement adaptive steganography, embedding data in less conspicuous regions of the image. This work employed a hybrid strategy for embedding that is more resilient to statistical and image processing challenges. This work implemented encryption before embedding it within the image. In this instance, even if the steganography is identified, the assailant cannot interpret the message without the encryption key. Given that deep learning is swiftly transforming the field of steganalysis, and optimal defenses will probably incorporate adversarial training along with other sophisticated machine learning methodologies, we have implemented a hybrid approach utilizing DCT and GAN to mitigate the dangers associated with steganalysis. This study uses the following metrics to judge how well a DCT-GAN-Encoder–Decoder steganography model works in the event of an attack: The study examines the optimal quantity of data that can be concealed without substantially compromising image quality or elevating the likelihood of discovery. This study examines the advantages of steganography systems in generating stego-images that are visually indistinguishable from authentic images. The focus of this study is on privacy, authenticity, and honesty to make the steganography system stronger against steganography attacks and protect the integrity of hidden data. DCT-GAN-Encoder–Decoder steganography is a viable method for secure data concealment. It is crucial to recognize potential threats and assess the model’s performance meticulously. Researchers can make more progress in the field of steganography and make sure that sensitive information is sent safely by understanding the pros and cons of this technology and putting in place the right countermeasures.
Accuracy of reconstruction
Because of things like batch normalization and pooling that happen during the network’s training phase, no steganography model can fully get back the hidden data based on the encoder–decoder network. Because of the steganography techniques used to hide the binary bit stream, even a small error in the extraction process could lead to the final secret information being reconstructed, which is very different from the original secret information. However, with the steganography techniques employed to conceal the hidden images, the aforementioned scenario is rare. However, this study continued to gauge the reconstruction’s correctness using numerical data.
The total of the variations in the relevant pixel values between the original secret image and the reconstructed secret image is represented by the pixel error determined by MSE. The extraction accuracy decreases as the pixel error values increase. Figure 8’s right side displays the error histogram for both the cover and the rebuilt stego. Table 12 displays the accuracy of the suggested hybrid model in comparison to other techniques.

Histogram demonstrating the pixel differences between cover and stego images.
Comparison with recent deep learning-based steganography methods
This work compared the suggested hybrid approach against contemporary deep learning techniques for PSNR, SSIM, CC, BER, and their benefits and capacity, measured in bits per pixel (bpp), as presented in Table 13. The suggested model exhibits improvements in PSNR (62.29) and SSIM (98.95), signifying improved image quality post-processing. It attains the greatest CC (0.905), indicating a robust connection between the initial and modified images. The suggested approach exhibits the lowest BER (0.12), indicating a reduction in retrieving information errors. Nonetheless, its capacity (0.079 bpp) is inferior to the high concealment method of79 (2.340 bpp), yet it outperforms other techniques emphasizing robustness and security. The suggested model’s advantage is its superior combination of robustness and security, surpassing the individual strengths of existing models, including strong concealment (79), high security (47,80), and high robustness (81,82,83).
Limitations and future work for dual DCT-GAN-based steganography
This study achieved outstanding performance relative to current state-of-the-art research based on evaluation metrics PSNR, SSIM, BER, and CC; yet, it identifies several weaknesses that it intends to address in future work. The following are several limitations of this study:
-
This paper proposed a DCT-GAN-based steganography that considered computational costs. It complicates the architecture. We conducted the studies on a modern hardware platform, but as the payload increases, the computational complexity of the model escalates. The performance of the model also degrades when this study employs a GAN network on a larger dataset for testing.
-
This study utilized the ImageNet 2012 dataset, which consisted of diverse general images across many categories. When the suggested model was tested with medical images, it didn’t work as well because the GAN’s generator takes into account the structure of those images.
-
The model’s performance deteriorates as the generator produces a limited number of outputs due to the diversity of the input image datasets throughout experimentation.
-
The preliminary investigation encountered problems when attempting to insert information in a specific area within the image.
-
This study successfully implemented an encryption approach; however, more advanced methods could be employed to enhance the security of information transmitted across the communication medium.
-
This paper proposed a novel notion of DCT-GAN-based steganography; however, more sophisticated approaches can still discover some information during the embedding process.
This research seeks to mitigate the constraints of the present study and to conduct experiments on subsequent endeavors.
-
Different architectures, like variational autoencoders and GANs that have been made better by genetic algorithms, will be looked at in this study to find ones that are more resilient and hard to spot.
-
This research aims to experiment with larger medical datasets to enhance the performance of the steganography method in a varied context.
-
This work intends to investigate video-based embedding techniques utilizing GANs in the future.
-
The study’s goal is to fix the model’s flaws by adding adversarial training methods, like quantization, to make it more resistant to different kinds of attacks, lower the cost of computation, and speed up inference.
-
The current study aims to improve security and resilience by combining GAN-based steganography with other methods, such as perceptual hashing and watermarking.
Optimizing computational efficiency in DCT-GAN hybrid steganography
This study evaluated the potential computational constraints in the hybrid model DCT-GAN, emphasizing lightweight network design and hardware acceleration to mitigate computational complexity. We discovered that the DCT is not intrinsically computationally demanding, yet its repeated application to huge images can be computationally intensive. GANs are notoriously demanding in terms of resources, particularly during the training phase. In this scenario, the generator network produces the steganographic image, while the discriminator network assesses it. Both entail multiple convolutional layers, which are resource-intensive. In the future, this study seeks to mitigate computational complexity by introducing Lightweight Network Designs, i.e. GANs, to decrease network depth. This research will develop a network with a reduced number of convolutional layers and a diminished quantity of filters per layer. This directly decreases the number of parameters and computations. In the future, we will evaluate MobileNet-style topologies or ShuffleNet, which are optimized for efficiency. We will employ depth-dependent separable convolutions to diminish computing expenses relative to ordinary convolutions while preserving acceptable accuracy. This study seeks to utilize efficient activation functions to substitute computationally intensive ones with more rapid equivalents. This study intends to optimize DCT block size reduction by employing smaller DCT block sizes to diminish computational effort. This study intends to employ GPUs, which are highly parallel processors, to enhance the acceleration of convolutional operations in GANs and matrix operations in DCT. We will employ Google’s TPUs, which are primarily engineered for machine learning tasks, particularly deep learning. They provide substantial performance improvements for GAN training and inference. This study seeks to diminish the computational complexity of the hybrid steganography framework, enhancing its practicality for real-world applications through the implementation of optimization approaches.
Conclusion and future work
The first step of the suggested hybrid model presents an efficient image steganography technique to conceal a secret image inside a cover image. The cover image’s two separate channels have the secret image smartly inserted into the LSB of DCT coefficients after it has been divided into discrete bits. The proposed method is particularly safe and resistant to image processing attacks while simultaneously guaranteeing the stego image’s high level of visual quality. We propose a GAN model in the second stage that is based on deep learning. It has three sub-networks: the discriminator network, the decoder network, and the encoder network. It might encrypt the hidden image into a similar-sized image using the encoder network, which consists of nine residual blocks, to create steganographic images with outstanding visual quality. The improved imperceptibility and security of our suggested system were verified by the simulation results measured on a variety of image quality factors. Empirical findings are provided to show that the recommended approach performs satisfactorily. The experiments indicate that our suggested steganography approach exhibits superior visual image quality, with an MSE of 93.30%, PSNR of 58.27%, RMSE of 96.10%, and SSIM of 94.20%, in comparison to existing leading methodologies. The proposed model achieved an reconstruction accuracy of 96.2% using Xu Net and 95.7% for SR Net. Specifically, it is demonstrated that the suggested approach has good imperceptibility based on four similarity metrics: MSE, SSIM, RMSE, and PSNR. Therefore, when applied independently on comparable images, the suggested method performs better than the existing LSB replacement and DCT algorithms. The experimental results show that stego images produced by the hybrid model have improved steganography security and imperceptibility, along with less color distortion. Moreover, this study aims to enhance resilience against potential attacks, improve the robustness of embedded data against various noise types, and investigate methods to increase the volume of data that can be embedded without significantly compromising image quality or heightening detection risk. In the future, more spatial and transform techniques may be deployed to increase the security and imperceptibility of information transmitted through images for the commercial, industrial, and healthcare sectors and to reduce computational power and memory usage.
Data availability
The ImageNet2012 dataset is publicly available and can be accessed at https://www.image-net.org/challenges/LSVRC/2012/ and DCE-MRI medical images dataset sourced from the Cancer Imaging Archive (TCIA) at https://www.cancerimagingarchive.net/collection/tcga-brca/.
References
Muhammad, K., Ahmad, J., Rehman, N. U., Jan, Z. & Sajjad, M. Cisska-lsb: Color image steganography using stego key-directed adaptive lsb substitution method. Multimed. Tools Appl. 76, 8597–8626 (2017).
Hassaballah, M., Hameed, M. A., Awad, A. I. & Muhammad, K. A novel image steganography method for industrial internet of things security. IEEE Trans. Ind. Inf. 17(11), 7743–7751 (2021).
Akhavan, A., Samsudin, A. & Akhshani, A. Cryptanalysis of an image encryption algorithm based on dna encoding. Opt. Laser Technol. 95, 94–99 (2017).
Bhatti, U. A. et al. Hybrid watermarking algorithm using Clifford algebra with Arnold scrambling and chaotic encryption. IEEE Access 8, 76386–76398 (2020).
Bhatti, U. A., Yu, Z., Yuan, L., Nawaz, S. A., Aamir, M. & Bhatti, M. A. A robust remote sensing image watermarking algorithm based on region-specific surf. In Proceedings of International Conference on Information Technology and Applications: ICITA 2021 75–85 (Springer, 2022).
Kadhim, I. J., Premaratne, P., Vial, P. J. & Halloran, B. Comprehensive survey of image steganography: Techniques, evaluations, and trends in future research. Neurocomputing 335, 299–326 (2019).
Hashim, M. M., Rahim, M., Johi, F. A., Taha, M. S. & Hamad, H. S. Performance evaluation measurement of image steganography techniques with analysis of lsb based on variation image formats. Int. J. Eng. Technol. 7(4), 3505–3514 (2018).
Sahu, M., Padhy, N., Gantayat, S. S. & Sahu, A. K. Local binary pattern-based reversible data hiding. CAAI Trans. Intell. Technol. 7(4), 695–709 (2022).
Subramanian, N., Elharrouss, O., Al-Maadeed, S. & Bouridane, A. Image steganography: A review of the recent advances. IEEE Access 9, 23409–23423 (2021).
Lingamallu, N. S. & Veeramani, V. Secure and covert communication using steganography by wavelet transform. Optik 242, 167167 (2021).
Fridrich, J. & Kodovsky, J. Rich models for steganalysis of digital images. IEEE Trans. Inf. Forensics Secur. 7(3), 868–882 (2012).
Zhangjie, F., Wang, F. & Xu, C. The secure steganography for hiding images via gan. EURASIP J. Image Video Process. 2020(1), 66 (2020).
Yang, Y., Chen, Y., Chen, Y. & Bi, W. A novel universal steganalysis algorithm based on the iqm and the srm. Comput. Mater. Contin. 56(2), 66 (2018).
Qian, Y., Dong, J., Wang, W. & Tan, T. Deep learning for steganalysis via convolutional neural networks. In: Media Watermarking, Security, and Forensics 2015, vol. 9409 171–180 (SPIE, 2015).
Xu, G., Wu, H.-Z. & Shi, Y.-Q. Structural design of convolutional neural networks for steganalysis. IEEE Signal Process. Lett. 23(5), 708–712 (2016).
Ye, J., Ni, J. & Yi, Y. Deep learning hierarchical representations for image steganalysis. IEEE Trans. Inf. Forensics Secur. 12(11), 2545–2557 (2017).
Boroumand, M., Chen, M. & Fridrich, J. Deep residual network for steganalysis of digital images. IEEE Trans. Inf. Forensics Secur. 14(5), 1181–1193 (2018).
Sajid, M. et al. Leveraging two-dimensional pre-trained vision transformers for three-dimensional model generation via masked autoencoders. Sci. Rep. 15(1), 3164 (2025).
Duan, X., Song, H., Qin, C. & Khurram Khan, M. Coverless steganography for digital images based on a generative model. Comput. Mater. Contin. 55(3), 66 (2018).
Abdulla, A. A., Sellahewa, H. & Jassim, S. A. Steganography based on pixel intensity value decomposition. In: Mobile Multimedia/Image Processing, Security, and Applications 2014, vol. 9120 19–27 (SPIE, 2014).
Abdulla, A. A., Jassim, S. A. & Sellahewa, H. Secure steganography technique based on bitplane indexes. In: 2013 IEEE International Symposium on Multimedia 287–291 (IEEE, 2013).
Baziyad, M., Rabie, T. & Kamel, I. Toward stronger energy compaction for high capacity dct-based steganography: A region-growing approach. Multimed. Tools Appl. 80, 8611–8637 (2021).
Bhattacharyya, S., Khan, A. & Sanyal, G. Dct difference modulation (dctdm) image steganography. Int. J. Inf. Netw. Secur. 3(1), 40–63 (2014).
Taj, R. A reversible-zero watermarking scheme for medical images. Sci. Rep. 14, 17320 (2024).
Sheidaee, A. & Farzinvash, L. A novel image steganography method based on dct and lsb. In: 2017 9th International Conference on Information and Knowledge Technology (IKT) 116–123 (IEEE, 2017).
Nguyen, T. D., Arch-Int, S. & Arch-Int, N. An adaptive multi bit-plane image steganography using block data-hiding. Multimed. Tools Appl. 75, 8319–8345 (2016).
Maurya, S. et al. A discrete cosine transform-based intelligent image steganography scheme using quantum substitution box. Quantum Inf. Process. 22(5), 206 (2023).
Sharafi, J., Khedmati, Y. & Shabani, M. Image steganography based on a new hybrid chaos map and discrete transforms. Optik 226, 165492 (2021).
Kaur, R. & Singh, B. A novel approach for data hiding based on combined application of discrete cosine transform and coupled chaotic map. Multimed. Tools Appl. 80, 14665–14691 (2021).
Reshma, V., Vinod Kumar, R., Shahi, D. & Shyjith, M. Optimized support vector neural network and contourlet transform for image steganography. Evol. Intell. 66, 1–17 (2020).
Siddeq, M. M. & Rodrigues, M. A. Dct and dst based image compression for 3d reconstruction. 3D Res. 8, 1–19 (2017).
Wang, W.-C. et al. Dttr: Encoding and decoding monthly runoff prediction model based on deep temporal attention convolution and multimodal fusion. J. Hydrol. 643, 131996 (2024).
Wang, Y.-Y., Wang, W.-C., Xu, D.-M., Zhao, Y.-W. & Zang, H.-F. A novel strategy for flood flow prediction: Integrating spatio-temporal information through a two-dimensional hidden layer structure. J. Hydrol. 66, 131482 (2024).
He, X. Enhancing image steganography through generative adversarial networks: Applications and innovations. Appl. Comput. Eng. 110, 122–128 (2024).
Meng, L., Jiang, X. & Sun, T. A review of coverless steganography. Neurocomputing 566, 126945 (2024).
Chakraborty, T., KS, U. R., Naik, S. M., Panja, M. & Manvitha, B. Ten years of generative adversarial nets (gans): A survey of the state-of-the-art. Mach. Learn. Sci. Technol. 5, 011001 (2024).
Punia, R. & Malik, A. Image interpolation-based steganographic techniques under spatial domain: A survey. In: International Conference on Computing, Communications, and Cyber-Security 671–685 (Springer, 2022).
Jung, D., Bae, H., Choi, H.-S. & Yoon, S. Pixelsteganalysis: Pixel-wise hidden information removal with low visual degradation. IEEE Trans. Dependable Secure Comput. 6, 66 (2021).
Wang, Y., Tang, M. & Wang, Z. High-capacity adaptive steganography based on lsb and hamming code. Optik 213, 164685 (2020).
Yahi, A., Bekkouche, T., Daachi, M. & Diffellah, N. A color image encryption scheme based on 1d cubic map. Optik 249, 168290 (2022).
Abd EL-Latif, A.A., Abd-El-Atty, B. & Venegas-Andraca, S.E. A novel image steganography technique based on quantum substitution boxes. Opt. Laser Technol. 116, 92–102 (2019).
Abd-El-Atty, B. A robust medical image steganography approach based on particle swarm optimization algorithm and quantum walks. Neural Comput. Appl. 35(1), 773–785 (2023).
Ahmed, A. & Ahmed, A. A secure image steganography using lsb and double xor operations. Int. J. Comput. Sci. Netw. Secur. 20(5), 139–144 (2020).
Ahmed, I.T., Hammad, B.T. & Jamil, N. Image steganalysis based on pretrained convolutional neural networks. In: 2022 IEEE 18th International Colloquium on Signal Processing & Applications (CSPA) 283–286 (IEEE, 2022).
Ruan, F. et al. Deep learning for real-time image steganalysis: A survey. J. Real-Time Image Proc. 17, 149–160 (2020).
Wang, H., Pan, X., Fan, L. & Zhao, S. Steganalysis of convolutional neural network based on neural architecture search. Multimed. Syst. 27, 379–387 (2021).
Ahmad, S. et al. Enhanced cnn-dct steganography: Deep learning-based image steganography over cloud. SN Comput. Sci. 5, 408 (2024).
Ibrahim, M., Elhafiz, R. & Okasha, H. Autoencoder-based image steganography with least significant bit replacement. In: 2024 16th International Conference on Electronics, Computers and Artificial Intelligence (ECAI) 1–6 (IEEE, 2024).
Sharma, R. P. & Malik, A. A comparative review on image interpolation-based reversible data hiding. In: International Conference on Computing, Communications, and Cyber-Security 687–699 (Springer, 2022).
Dadgostar, H. & Afsari, F. Image steganography based on interval-valued intuitionistic fuzzy edge detection and modified lsb. J. Inf. Secur. Appl. 30, 94–104 (2016).
Fateh, M., Rezvani, M. & Irani, Y. A new method of coding for steganography based on lsb matching revisited. Secur. Commun. Netw. 2021, 1–15 (2021).
Chakraborty, S., Jalal, A. S. & Bhatnagar, C. Lsb based non blind predictive edge adaptive image steganography. Multimed. Tools Appl. 76, 7973–7987 (2017).
Arya, V. & Singh, J. Robust image compression using two dimensional discrete cosine transform. Int. J. Electr. Electron. Res 4(2), 187–192 (2016).
Rao, K., Yip, P. & Britanak, V. Discrete Cosine Transform: Algorithms, Advantages, Applications (Academic Press, 2007).
Schütt, K., Kindermans, P., Sauceda, H., Chmiela, S., Tkatchenko, A., Müller, K., Guyon, I., Luxburg, U., Bengio, S. & Wallach, H., et al. Advances in neural information processing systems 30. Guyon, I., Luxburg, UV, Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds. 991–1001 (2017).
Duan, X. et al. Reversible image steganography scheme based on a u-net structure. IEEE Access 7, 9314–9323 (2019).
Zhang, R., Dong, S. & Liu, J. Invisible steganography via generative adversarial networks. Multimed. Tools Appl. 78, 8559–8575 (2019).
Arjovsky, M., Chintala, S. & Bottou, L. Wasserstein generative adversarial networks. In: International Conference on Machine Learning 214–223 (PMLR, 2017).
Baziyad, M., Kamel, I., Rabie, T. & Kabatyansky, G. A robust dct-based scheme for watermarking deep neural networks. Procedia Comput. Sci. 231, 397–402 (2024).
Dong, Y., Yan, R. & Yin, C. An adaptive robust watermarking scheme based on chaotic mapping. Sci. Rep. 14, 24735 (2024).
Li, X. & Wang, Z. Vaccine for digital images against steganography. Sci. Rep. 14, 21340 (2024).
Nasr, M.A., El-Shafai, W., El-Rabaie, E.-S.M., El-Fishawy, A.S., El-Hoseny, H.M., Abd El-Samie, F.E. & Abdel-Salam, N. A robust audio steganography technique based on image encryption using different chaotic maps. Sci. Rep. 14, 22054 (2024).
Fu, Z., Wang, F. & Cheng, X. The secure steganography for hiding images via gan. EURASIP J. Image Video Process. 2020(1), 46 (2020).
Sajid, M. et al. Enhancing melanoma diagnostic: Harnessing the synergy of ai and cnns for groundbreaking advances in early melanoma detection and treatment strategies. Int. J. Imaging Syst. Technol. 35(1), 70016 (2025).
Susanto, A., Sari, C.A. & Rachmawanto, E.H. et al. Hybrid method using hwt-dct for image watermarking. In: 2017 5th International Conference on Cyber and IT Service Management (CITSM) 1–5 (IEEE, 2017).
Jiang, N., Zhao, N. & Wang, L. Lsb based quantum image steganography algorithm. Int. J. Theor. Phys. 55(1), 107–123 (2016).
Pramanik, S. An adaptive image steganography approach depending on integer wavelet transform and genetic algorithm. Multimed. Tools Appl. 82, 34287–34319 (2023).
Li, Q. et al. Robust image steganography via color conversion. IEEE Trans. Circuits Syst. Video Technol. 6, 66 (2024).
Yao, Y., Wang, J., Chang, Q., Ren, Y. & Meng, W. High invisibility image steganography with wavelet transform and generative adversarial network. Expert Syst. Appl. 249, 123540 (2024).
Hu, X. et al. Establishing robust generative image steganography via popular stable diffusion. IEEE Trans. Inf. Forensics Secur. 6, 66 (2024).
Kumar, S. et al. Entropy based adaptive color image watermarking technique in yc b c r color space. Multimed. Tools Appl. 83, 13725–13751 (2024).
Singh, O. P. et al. Hidemarks: Hiding multiple marks for robust medical data sharing using iwt-lsb. Multimed. Tools Appl. 83, 24919–24937 (2024).
Khalifa, A. & Guzman, A. Imperceptible image steganography using symmetry-adapted deep learning techniques. Symmetry 14, 1325 (2022).
Su, W., Ni, J. & Sun, Y. Stegastylegan: Towards generic and practical generative image steganography. In: Proceedings of the AAAI Conference on Artificial Intelligence vol. 38 240–248 (2024).
Singh, O. P., Singh, K. N., Singh, A. K., Agrawal, A. K. & Zhou, H. An improved robust algorithm for optimisation-based colour medical image watermarking. Comput. Electr. Eng. 117, 109278 (2024).
Wei, P., Li, S., Zhang, X., Luo, G., Qian, Z. & Zhou, Q. Generative steganography network. In: Proceedings of the 30th ACM International Conference on Multimedia 1621–1629 (2022).
Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J. & Aila, T. Analyzing and improving the image quality of stylegan. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 8110–8119 (2020).
Liu, X., Ma, Z., Ma, J., Zhang, J., Schaefer, G. & Fang, H. Image disentanglement autoencoder for steganography without embedding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2303–2312 (2022).
Sanjalawe, Y., Al-E’mari, S., Fraihat, S., Abualhaj, M. & Alzubi, E. A deep learning-driven multi-layered steganographic approach for enhanced data security. Sci. Rep. 15(1), 4761 (2025).
Kuznetsov, A., Luhanko, N., Frontoni, E., Romeo, L. & Rosati, R. Image steganalysis using deep learning models. Multimed. Tools Appl. 83(16), 48607–48630 (2024).
Huo, Y., Qiao, Y. & Liu, Y. A deep learning-based steganography method for high dynamic range images. Vis. Comput. 40(11), 7887–7903 (2024).
Rehman, W. A novel approach to image steganography using generative adversarial networks. arXiv preprint arXiv:2412.00094 (2024).
Song, B., Wei, P., Wu, S., Lin, Y. & Zhou, W. A survey on deep-learning-based image steganography. Expert Syst. Appl. 66, 124390 (2024).
Acknowledgements
The authors extend their appreciation to the Deanship of Scientific Research at King Saud University for funding through the Vice Deanship of Scientific Research Chairs: Chair of Cyber Security.
Author information
Authors and Affiliations
Contributions
Kaleem Razzaq Malik: Conceptualization; Data curation; Formal analysis; Methodology; Writing - original draft; Software. Muhammad Sajid: Conceptualization; Data curation; Formal analysis; Methodology; Writing - original draft; Software. Ahmad Almogren: Investigation; Methodology; Writing - original draft; Writing - review & editing. Tauqeer Safdar Malik: Validation; Investigation; Writing - review & editing. Ali Haider Khan: Visualization; Validation; Writing - review & editing. Ayman Altameem: Validation; Investigation; Writing - review & editing. Ateeq Ur Rehman: Writing - review & editing; Methodology; Conceptualization. Seada Hussen: Writing - review & editing; Software; Resources; Methodology.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Malik, K.R., Sajid, M., Almogren, A. et al. A hybrid steganography framework using DCT and GAN for secure data communication in the big data era. Sci Rep 15, 19630 (2025). https://doi.org/10.1038/s41598-025-01054-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-01054-7
Keywords
This article is cited by
-
Integration of artificial intelligence with information security: a systematic literature review
Knowledge and Information Systems (2026)
-
Secure edge-guided adaptive image steganography using HED-based attention maps and CNN
Scientific Reports (2025)
-
Advanced multilayer security framework: integrating AES and LSB for enhanced data protection
The Journal of Supercomputing (2025)
