
Abstract
Alzheimer’s disease is a progressive neurological disorder that profoundly affects cognitive functions and daily activities. Rapid and precise identification is essential for effective intervention and improved patient outcomes. This research introduces an innovative hybrid filtering approach with a deep transfer learning model for detecting Alzheimer’s disease utilizing brain imaging data. The hybrid filtering method integrates the Adaptive Non-Local Means filter with a Sharpening filter for image preprocessing. Furthermore, the deep learning model used in this study is constructed on the EfficientNetV2B3 architecture, augmented with additional layers and fine-tuning to guarantee effective classification among four categories: Mild, moderate, very mild, and non-demented. The work employs Grad-CAM++ to enhance interpretability by localizing disease-relevant characteristics in brain images. The experimental assessment, performed on a publicly accessible dataset, illustrates the ability of the model to achieve an accuracy of 99.45%. These findings underscore the capability of sophisticated deep learning methodologies to aid clinicians in accurately identifying Alzheimer’s disease.
Similar content being viewed by others
Introduction
As the global population ages, the prevalence of Alzheimer’s disease (AD), an irreversible, relentless neurodegenerative disorder, continues to obliterate memory and cognitive function, presenting a grave peril that could ultimately lead to death1. Early Alzheimer’s disease diagnosis pertains to identifying the condition during its nascent phases, before the onset of substantial cognitive deterioration, to implement medical interventions that can extend daily functioning2. According to3, AD currently impacts an estimated 36.6 million individuals; this figure is projected to double within the following two decades.4 mention that AD has a global impact, affecting an estimated 46 million individuals; however, precise figures regarding the exact number of those affected remain unavailable. Nevertheless, in previous times, diagnostic techniques, which frequently depended on subjective clinical evaluations, encountered constraints regarding precision and effectiveness. Additionally, the overall expense and effort incurred by patients and their families are escalating substantially5,6.
Recent advancements in deep learning (DL) models have shown great promise in improving the accuracy and efficiency of Alzheimer’s disease detection. These models leverage large datasets, including medical imaging and clinical data, to identify subtle patterns and biomarkers associated with the disease at its earliest stages. By automating and enhancing diagnostic processes, DL-based approaches offer a potential solution to the limitations of traditional methods. However, in recent years, the performance of image-based Alzheimer’s disease detection using pre-trained convolutional neural network models has been superior to existing methods7. Numerous advantages underscore the potential of deep learning as a promising instrument for disease diagnosis and medical image analysis, with the capacity to fundamentally transform the domain of Alzheimer’s detection8. This study evaluates and proposes an innovative deep-learning approach for the early detection of Alzheimer’s disease to address this critical issue. Scholars are in quest of a straightforward and precise method to diagnose Alzheimer’s disease before the onset of symptoms. Early Alzheimer’s detection identifies symptoms before the disease progresses to the risk stage9. Conventional diagnostic approaches are laborious and subjective and might overlook subtle subtleties that are suggestive of Alzheimer’s pathology in its early stages. As a result, sophisticated diagnostic instruments that can improve the precision and effectiveness of detection are urgently required. As a result, the significance of non-invasive biomarkers and the transformative potential of artificial intelligence and deep learning in early AD detection continues to grow10. Deep learning, classified as a subset of artificial intelligence, can significantly alter medical imaging by focusing on its effects on segmentation, object detection, and image classification11,12 across multiple medical domains. In particular, deep convolutional neural networks (CNNs) demonstrate exceptional proficiency in deriving intricate features and patterns from complex datasets. Deep hypercomplex-inspired CNNs enhance feature extraction for image classification by allowing weight sharing across input channels13. Researchers have developed efficient deep-learning models that can accurately detect features from sizeable medical image datasets without using deeper layers to detect Alzheimer’s disease in its early stages14,15.
The study aims to address current diagnostic challenges related to Alzheimer’s disease (AD) and enhance diagnostic accuracy through deep learning capabilities. A powerful tool will be provided to clinicians to enable earlier interventions and ultimately improve the quality of patient care. Moreover, this research not only makes a valuable contribution to the progression of AI-powered healthcare but also has the potential to assist physicians in the early detection of Alzheimer’s disease, thereby ultimately enhancing the well-being of those afflicted.
Contribution of the proposed study
Here is a summary of the primary contributions:
-
i.
A novel Hybrid Filtering approach was developed to pre-process the image data to facilitate accurate and efficient analysis by our proposed deep transfer learning framework.
-
ii.
An advanced deep transfer learning model was designed based on EfficientNetV2B3. The model involves attaching layers with fine-tuning to enable rapid and precise identification and diagnosis of Alzheimer’s disease cases.
-
iii.
An explainable AI technique was explored and employed, utilizing Grad-CAM++ for discriminative localization to mark the most reliable classification results of Alzheimer’s disease patients using MRI image datasets and improving the model transparency and interpretability.
Research questions
-
How well does the proposed hybrid filtering method enhance Magnetic Resonance Imaging (MRI) image preprocessing to strengthen model robustness and improve accuracy?
-
How does the proposed model perform relative to other state-of-the-art methods regarding accuracy, precision, recall, and specificity for multi-class Alzheimer’s disease diagnosis?
-
How do advanced explainable AI techniques, such as Grad-CAM++, enhance clinicians’ ability to interpret and trust AI-based diagnostic approaches?
The following sections of this article are organized in the following manner: section "Literature review" offers a thorough summary of the research conducted in the study area. Section "Proposed methodology" outlines the methodology of the proposed work. Section "Result analysis" presents experimental results and describes the dataset. Section "Discussion" discusses the suggested study. Section "Conclusions" contains our results and recommendations for future development efforts.
Literature review
Alzheimer’s disease is a progressive neurological condition caused by the deterioration of nerve cells in different brain areas16. It poses significant physical and psychological challenges to both patients and their families. Individuals experience behavioral, emotional, and physical declines as the disease advances. Although the complete cure is a concerning issue, early detection is crucial for managing the condition effectively. In recent years, learning-based methods like deep and machine learning have significantly advanced the early detection of various diseases, including heart, eye, lung, and breast cancer17,18,19,20. These techniques have also been extensively applied to the preliminary diagnosis of Alzheimer’s disease, enhancing early identification and intervention strategies.
Limitations of existing diagnostic methods
Despite progress in the comprehension of Alzheimer’s disease, numerous limitations remain in existing diagnostic methods. Conventional approaches typically diagnose Alzheimer’s disease only after the onset of substantial symptoms and considerable brain damage, thereby restricting the efficacy of interventions21. These methods frequently depend on cognitive assessments and patient history, demonstrating limited predictive capability concerning disease progression21. Although biomarkers in cerebrospinal fluid (CSF) and amyloid PET scans can enhance diagnostic accuracy, these techniques are intrusive, expensive, and not readily available22. Ziyad et al.23 highlight the importance of AI in detecting Alzheimer’s, achieving 97% accuracy in classifying patients using CNNs on MRI scans. This approach aims to enhance prognosis through early detection.24 have embraced a more comprehensive viewpoint, contending that early detection of Alzheimer’s disease through the utilization of MRI images in conjunction with support vector machine (SVM) and transfer learning technologies yields an improved accuracy rate of 94.44%. This hybrid architecture integrates the LSTM and Deep Maxout neural networks. The study by25 offered probably the most comprehensive empirical analysis of a machine learning model that comprised GaussianNB, Decision Tree, Random Forest, XGBoost, Voting Classifier, and GradientBoost to predict Alzheimer’s disease. With a validation accuracy 96% for the AD dataset, the model is trained utilizing the open access series of imaging studies (OASIS) dataset. As they pertain to AD detection, deep learning and machine learning were examined in the article by26. Utilizing Group Grey Wolf Optimization (GGWO) techniques enhanced the efficacy of CNN, KNN, and decision tree classifiers, achieving 96.23% accuracy in Alzheimer’s detection compared to other methods. Employing convolutional and recurrent neural networks,27 put forth a classification system designed to address Alzheimer’s disease. Because of this, we need non-invasive, rapid, affordable, and accurate ways to diagnose AD right away.
Deep learning models for enhanced Alzheimer’s disease detection
The subject of Alzheimer’s disease analysis has been dramatically enhanced by recent developments in interpretable deep-learning models. For example,28 explores contemporary perspectives on machine learning in the context of precision psychiatry, highlighting the significance of model interpretability and personalized predictions. These findings emphasize the crucial requirement for creating models that attain high precision and provide insight into the fundamental mechanisms of Alzheimer’s disease. By integrating interpretability-focused approaches, the clinical applicability of deep learning models can be significantly enhanced, guaranteeing that they offer healthcare providers practical and valuable insights.
Table1 presents some recent state-of-art works on Alzeimir’s disease detection. Hazarika et al.29 introduced a hybrid model that merges LeNet and AlexNet, applied to the ADNI dataset, and achieved an accuracy of 93.58%, noting that many models struggle to surpass 90% in classification tasks. Meanwhile, Mawra et al.30 developed a CNN architecture with the OASIS dataset, reaching 99.68% accuracy, but pointed out challenges related to generalizability and interpretability. Chethana et al.31 used a combination of CNN and RNN on the ADNI dataset, achieving 98.45% accuracy, with a primary concern being the potential for overfitting due to model complexity. Suchitra et al.32 employed the EfficientNetB7 model on the ADNI dataset, achieving 98.2% accuracy in Alzheimer’s disease classification. However, the study’s limitations include a lack of interpretability due to the model’s complexity. Valoor and Gangadharan33 utilized a hybrid U-net and GAN model to analyze data from the ADNI dataset, achieving an accuracy of 95%. Their approach demonstrated promising results in medical imaging applications but faced scalability challenges when applied to multi-modal data. Similarly, Kina34 proposed an attention-based deep learning model, analyzing data from Kaggle with an accuracy of 95.19%. However, the model exhibited suboptimal performance in handling specific subsets of the dataset, indicating room for improvement in generalization. Both studies underscore the effectiveness of advanced DL architectures while highlighting the need to address challenges like scalability and dataset-specific limitations for broader applicability.
The role of explainable AI (XAI)
Explainable AI (XAI) techniques are essential for addressing this gap, offering insights into the decision-making processes of AI models and improving transparency35. Some investigations used explainable AI (XAI) to analyze MRI images of Alzheimer’s disease cases visually. ÖZBAY, F. A et al.36 proposed NCA-based CNN models to detect Alzheimer’s disease, where for the discriminative visualization they used Grad-CAM (Gradient-weighted Class Activation Mapping). Chethana, S. et al.31 suggested an approach employing Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN) on MRI scans to classify AD stages. Additionally, Explainable AI (XAI) via Grad-CAM is utilized to identify affected brain regions, addressing diagnostic delays. Mahmud et al.37 utilized ensemble deep learning models on the Kaggle dataset, achieving accuracies up to 96%. Their approach incorporated explainable AI techniques (saliency maps and grad-CAM) to enhance the model’s interpretability and provide insights into the diagnostic process. A limitation noted was the potential for biases within the datasets used.
Problem statement and research gap
Most studies mentioned above utilized a relatively small number of Alzheimer’s disease cases to train different machine-learning models. Small datasets are prone to causing overfitting in a convolutional neural network (CNN) framework. The model would not accurately reflect classification performance on datasets not included in the training data. Moreover, several current techniques are trained and evaluated using raw images without preliminary processing or augmentation. Therefore, the network’s generalization error rises while the training benefits are reduced. Furthermore, most studies have utilized pre-trained models and trained their frameworks with either three or two classes. Some studies used conventional explainable AI techniques for discriminative localization.
To address these challenges, we constructed a substantial and reliable dataset. We then conducted thorough novel pre-processing and augmentation procedures on the gathered images rather than utilizing them in their original state. Our study enhanced a classic deep transfer learning model by fine-tuning and optimizing hyperparameters to increase model robustness. The study was improved by combining multi-class image class comparisons using four-class categories. We explored and utilized an advanced explainable AI called Grad-CAM++ for the discriminative localization of the resulting images to increase the model interpretability and generability.
Proposed methodology
This section delineates the processes of data preprocessing, data augmentation, the CNN model, and the implemented architecture that were carried out before conducting trials for performance evaluation. Figure 1 visually represents the proposed methodology. The proposed Alzheimer’s Disease detection system utilizes MRI scans of the human brain as input in this block diagram. Subsequently, the gathered images undergo preprocessing by applying resizing and denoising methods. Subsequently, the image data undergoes augmentation. Ultimately, the model performed training and testing using the clinical datasets. The proposed model was constructed using the foundational deep learning model termed EfficientNetV2B3. This study involved the development of the model by incorporating additional layers into its underlying network. The layers experienced modifications through regularization, kernel initialization, and reliable fine-tuning techniques to enhance the experiment’s robustness and efficiency. Furthermore, this model can precisely categorize images into four distinct classes with the maximum level of accuracy. Again, the pseudocode of AD classification from MRI scans is illustrated in Algorithm 1.

Proposed workflow diagram of Alzheimer’s disease classification.

Pseudocode of Alzheimer’s Disease Classification from MRI Images
Preprocessing of images
Preprocessing the images from the dataset is essential to optimizing the learning module’s performance and ensuring accuracy. This preprocessing phase consists of effective resizing with hybrid filtering (adaptive nonlocal means denoising and sharpening filter) operations on the image data.
Resizing of images
The inputs’ dimensions over the models pre-trained on ImageNet will be either smaller or equal to 224*224. For transfer learning, it is necessary to ensure that the inputs are compatible with the pre-trained model. To ensure uniform dimensions for all collected images, we resized individuals to a resolution of 224*224 pixels.
Denoising of images
Denoising an image involves the restoration of a signal from images that contain noise. Denoising is eliminating undesirable noise from an image to enhance its analysis. One effective method for image denoising is the Non-Local Means (NLM) technique. Non-Local Means (NLM) denoising is a widely used method for reducing noise in images41. It operates on the principle that patches in an image with comparable characteristics also have identical pixel values. NLM denoising is a technique that averages pixel values of similar patches in an image to reduce noise while preserving underlying structures, using a weighted average based on similarity between the reference patch and neighborhood patches.
We may now mathematically represent this process. Let’s consider I as the image affected by noise, where u denotes the pixel values in the noisy image, and v represents the pixel values after the denoising process.
The Equation1 for NLM denoising is expressed as :
where x denotes the position of a pixel within the image, while y represents the pixel’s position in the neighboring region \(\Omega\) centered around x. The function w(x, y) assigns a weight to the pixel at location y, which is determined by the similarity of the patches surrounding pixels x and y. C(x) serves as a normalization factor, ensuring that the weights assigned to pixels around x sum up to 1, maintaining the integrity of the weighted averaging process. The weight function w(x, y) can be defined by utilizing a Gaussian kernel in Equation2:
where the patch located at point x is denoted as P(x). The decay of weights can be controlled using the parameter h. The normalization coefficient Z(x) ensures that all the weights add up to 1. The NLM denoising approach entails traversing all pixels in the image and implementing the weighted averaging procedure to efficiently remove noise from the image.
Reducing noise in MRI images is essential for enhancing diagnostic precision and minimizing artifacts that could hinder interpretation. Traditional methods like Non-Local Means (NLM) filtering can be slow and may not adapt well to images’ diverse noise characteristics and intensity variations. We employed the Adaptive Non-Local Means (NLM) filter approach in our investigations to address this. This technique dynamically adjusts filtering strength based on local image properties, guaranteeing optimal noise reduction across various intensities.
In particular, the method initially computes the mean intensity of the input image. This means intensity is then used to adjust the filtering parameter h in the cv2.fastNlMeansDenoising function from the OpenCV library. The adjustment is based on the following relationship as shown in Equation3.
where base \(\_h\) is a predetermined baseline value, and in our study, the baseline value 10 was used in this case. When the mean intensity is high, h increases, enhancing filtering to manage higher noise in brighter areas. In contrast, darker regions undergo milder filtering to retain details that uniform filtering might obscure. The fastNlMeansDenoising function uses templateWindowSize set to 7 and searchWindowSize set to 21, determining the local neighborhood sizes for filtering. Before filtering, the input image is normalized to a [0, 255] range and then scaled back to its original range. This adaptive technique effectively reduces noise while preserving fine details. Figure 2 shows the preprocessing results of using the Adaptive NLM filter.

Sample preprocessing results based on Adaptive NLM Filter and Sharpening Filter: (a) Mild_demented case (b) Moderate_demented case.
Sharpening of images
Following the noise reduction procedure, a sharpening filter is incorporated in this study to enhance the collected MRI image details and improve edge definition. The non-local means (NLM) filtering inherent in the denoising process can cause blurring, potentially obscuring fine details and softening edges. A subsequent sharpening filter mitigates this blurring, enhancing the visibility of subtle features and improving the overall image sharpness. This sharpening step is beneficial for tasks such as feature extraction, where precise edge definition is crucial.
The concept of the sharpening filter is based on Laplacian filters, which emphasize areas of rapid intensity change and represent a second-order derivative enhancement system42. Typically, this is derived as shown in Eq. 4.
Here,
Equation 4 leads to the derivation of the discrete Laplacian:
From Eq. 7, a mask is generated as presented in Fig. 3a. Additionally, the literature43 indicates that various other types of Laplacian masks and filters are available. This study employs a modified Laplacian filter, the kernel shown in Fig. 3b. Hence, the intensity value in the given Laplacian filter is calculated by adding the center point of the mask to the sum of the surrounding points. This can be expressed as:\(C5 + (C1 + C2 + C3 + C4 + C6 + C7 + C8 + C9)\). In this case, the intensity value of “0” is obtained by summing the center value with the surrounding values in the mask. When the original image is processed using this mask, the result is a darker image that highlights only the edges, where the intensity value is 0. The original image can be reconstructed using the rules specified in Eqs. 8 and 9.

An illustration of various filters is presented: (a) the generated mask, (b) a modified Laplacian filter, and (c) a sharpening filter.
In this context, g(x, y) denotes the filtered output after applying the desired operation. If the center value of the Laplacian filter is negative, the process follows Eqs. 8 and 9; otherwise. Let us define f(x, y) as C5, with \(C1,C2,\ldots ,C9\) representing the other surrounding points. Based on the corresponding Laplacian mask, Eq. 10 can be derived from Eq. 9. From Eq. 10, the resulting mask or filter is shown in Fig. 3c.
This filter, known as the sharpening filter, is designed to enhance image details and emphasize edges. The sharpening filter process is implemented using OpenCV’s filter2D function. In addition, it helps make transitions between features more distinct and noticeable, in contrast to smooth, noisy, or blurred images. Figure 2 depicts the preprocessing results of using the Sharpening filter.
Augmentation of images
Image augmentation44 is a widely used technique in deep learning that artificially enhances the training dataset’s variety through various modifications to the source images. This contributes to the improvement and resilience of deep learning models. Augmentation techniques commonly encompass operations that involve rotation, mirroring, scaling, cropping, adjustments in the brightness and contrast and other geometrical or color alterations can be operated by using ImageDataGenrator45. So, applying image augmentation procedures in our study, we can mitigate overfitting and enhance the model’s capacity to handle diverse real-world situations, resulting in a more efficient and dependable model for our proposed deep learning model. The augmentation approaches employed in our investigation are presented in Table 2 and the description of these augmentation criteria is given as follows:
-
Rotation: Applied random rotations across a range of \({\pm }7\) degrees to achieve model invariance to varying orientations of brain scans.
-
Width and Height Shifting: Horizontal and vertical transformations of up to 5% of the image sizes were employed to replicate positional variation in MRI images.
-
Zooming: A zoom range of 10% was utilized to simulate variations in the field of view.
-
Rescaling: All pixel values were normalized into the interval [0, 1] by dividing by 255, enhancing convergence during training.
-
Shearing: A shear transformation with a magnitude of 5% was used to induce affine distortions, hence improving the model’s generalization capacity.
-
Brightness Adjustment: Random brightness fluctuations within the interval [0.1, 1.5] were implemented to accommodate variations in image contrast and lighting circumstances.
-
Flipping: Horizontal and vertical flips were utilized to emulate various views, hence diminishing bias towards particular orientations.
Proposed transfer learning model
The proposed model methodology relies on a sophisticated deep transfer learning (DTL) architecture. Scholars have recently shown a growing interest in employing transfer learning-based convolutional neural network (CNN) models to address diverse computer vision challenges. These models have gained extensive application in medical disease diagnostics11,19 over the past few decades. In this study, we developed and implemented a transfer learning architecture based on CNNs to classify Alzheimer’s disease from MRI images. In our experiment, we train a DTL pre-trained CNN model termed EfficientNetV2B3 using the preprocessed image data. The DTL algorithm that was adopted in our experiment is explained below:
-
EfficientNetV2B3 : EfficientNetV2B3 is a deep neural network architecture introduced as an extension of the EfficientNet family46. The EfficientNetV2B3 model is designed to optimize computational efficiency and model performance across various tasks, particularly image classification. It incorporates improvements over its predecessors, including enhanced feature extraction capabilities and a well-balanced trade-off between model size and accuracy. This architecture is based on compound scaling, which uniformly scales the network dimensions (depth, width, and resolution) to achieve better performance. EfficientNetV2B3 is pre-trained on large-scale datasets, making it effective for transfer learning tasks. Its architecture allows for efficient utilization of computational resources while maintaining competitive accuracy levels.
Therefore, we choose EfficientNetV2B3 rather than EfficientNetV2B0, B1, and B2 because EfficientNetV2B3 is anticipated to possess a more extensive architecture when compared to EfficientNetV2B0, B1, and B2. The heightened depth is expected to enhance the model’s capacity for capturing intricate features, potentially leading to improved capabilities in representation learning. Additionally, EfficientNetV2B3 is projected to have an increased width, leading to a more expansive capacity for feature extraction. Furthermore, EfficientNetV2B3 will likely feature an elevated resolution compared to its forerunners. This heightened resolution has the potential to augment the model’s capability to capture intricate details in images, enhancing its overall performance.
Design and modification of the model’s structure
The proposed study used EfficientNetV2B3 as the foundational model. The base network was constructed and developed using techniques including layer attachment, regularization, kernel initializer, and hyper-parameter tuning.
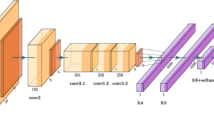
The model takes a pre-processed dataset of images with dimensions of 224*224 pixels as input. Figure 4 depicts the block-wise internal details of the EfficientNetV2B3 pre-trained network. The feature extraction unit of EfficientNetV2B3 has six blocks that incorporate essential operations, including convolution, depth-wise convolution, batch normalization, activation, dropout, and global-average pooling. Block 1, block 2, block 3, block 4, block 5 and block 6 have two, three, three, five, seven and twelve sub-blocks with out-shape (112, 112, 16), (56, 56, 40), (28, 28, 56), (14, 14, 112), (14, 14, 136) and (7, 7, 232) respectively. Block 1a contains a total of 5760 parameters. Upon completing six blocks, Block 6l generates 322944 parameters respectively.
After the EfficientNetV2B3 model completes its six blocks, which progressively reduce spatial dimensions and increase the number of channels, the final feature extractor layer outputs a \(7 \times 7 \times\) 2048 feature map. This map is then processed by a global average pooling layer, which reduces the spatial dimensions to a \(1 \times 1\) grid. This pooling layer averages all values within each feature map, simplifying the model and enhancing robustness by reducing the risk of overfitting. Subsequently, dense layers with the ELU activation function and GlorotNormal kernel initializer are added, along with dropout layers to prevent overfitting. The model concludes with a fully connected layer using the SoftMax activation function for multiclass classification. This configuration enables the model to utilize the detailed feature representations from the EfficientNetV2B3 backbone while maintaining a straightforward and efficient classification mechanism.

The proposed transfer learning architecture, consisting of: Feature Extraction unit (including Block-wise operations, parameters, output-shape) and Modified Unit (including layers modification, regularization, kernel initialization, hyper-parameter tuning, parameters and output-shape).
Model development process
-
Layer Modification and Fine-tuning: Following the final activation layer of the pre-trained network, we incorporated global average pooling, dense layers with the eLU activation function, and “GlorotNormal” kernel initializer, dropout layers and the modification was ended with a fc (fully connected) layer named SoftMax for multiclass categorization. We used fine-tuning to make it easier for the pre-trained models to adapt to our particular task. The following points give more details of our model development:
-
i.
GA Pooling Layer: The Global Average Pooling (GAP) layer is integral to convolutional neural networks (CNNs) for image classification. Unlike traditional fully connected layers, GAP operates on the entire spatial dimensions of the input feature map. Computing the average of all values within each feature map condenses information, resulting in a single value per feature map and effectively reducing spatial dimensions to a 1x1 grid. While GAP can partially provide translation invariance by limiting the spatial dimensions of the feature map to a single value per feature map, it does not entirely ensure translation invariance. The main objective of incorporating GAP (Global Average Pooling) into our architecture is to reduce the number of model parameters and mitigate the risk of overfitting. This, in turn, can improve our system’s resilience to slight spatial translations.
-
ii.
Dropout Layer: The Dropout layer is a regularization technique employed in neural networks to mitigate overfitting. During training, it randomly deactivates a specified fraction of neurons, preventing co-dependency and encouraging the network to learn more robust features. This dropout of neurons simulates training multiple diverse networks and improves the model’s generalization capabilities. Randomly excluding neurons using a Dropout layer in our study reduces the risk of overfitting, enhancing the proposed model’s ability to adapt to various inputs and improving its overall performance on unseen data. The proposed study incorporates two dropout layers, each having a dropout rate of 0.2 and 0.3, respectively.
-
iii.
Dense Layer: Dense layer also known as a fully connected layer, is a fundamental component in neural networks. It connects every neuron from one layer to every neuron in the subsequent layer, creating a dense interconnection pattern. Each connection is associated with a weight and the layer typically includes a bias term. The Dense layer plays a pivotal role in our study for learning complex patterns and relationships within the data. Our study structures the dense layer with the ’eLu’ activation function and the ’GlorotNormal’ kernel initializer.
The “Glorot Normal” kernel initializer, sometimes referred to as Xavier normal initialization, aims to mitigate the problems of vanishing or exploding gradients by sampling weights from a normal distribution with a mean of 0 and a variance that depends on the number of input and output units. This method guarantees that the weights are evenly distributed, enhancing the workout’s stability and effectiveness. Although the tanh activation function is often linked to it, its usefulness extends beyond just tanh. The initializer is effective with the eLU activation function since it may ensure a consistent and steady flow of gradients.
The eLU activation function mitigates the vanishing gradient problem, a prevalent challenge in deep networks, and permits negative inputs, hence minimizing the occurrence of dead neurons. The smooth gradient of the training process is enhanced by the “Glorot Normal” initializer, resulting in stable and efficient training. The effectiveness of this combination was confirmed by empirical validation in our experiments, exhibiting enhanced performance and stability during the training process.
The objective is to utilize the “Glorot Normal” initializer and the eLU activation function to improve our model’s learning capacity and stability.
-
iv.
SoftMax Activation Layer(Output Classification): We utilized an output layer activated with softmax for the classification task. This layer assigns probabilities to diverse classes, enabling the efficient categorization of MRI images into their respective relevant groups.
-
v.
Random Seed: Employing a constant random seed is crucial for guaranteeing the replicability of our studies. By specifying the seed as 45, we ensure that every execution of our model will yield consistent outcomes. Reproducibility is crucial in scientific study, enabling us to compare our findings with other investigations.
-
vi.
Adamax Optimizer: Adamax, an extension of the Adam optimizer for deep learning, employs adaptive learning rates, dynamically adjusting them during training. It utilizes the infinity norm for stable parameter updates and is characterized by two key parameters, beta1 and beta2, controlling moment estimate decay rates. Adamax excels in handling sparse gradients, demonstrating robust performance across various neural network architectures. To ensure numerical stability in the parameter update step, a small positive constant, epsilon \(\epsilon\), is added to the denominator, preventing division by zero. This feature enhances the reliability and efficiency of our research optimization processes, so Adamax is a popular choice in our proposed deep neural network training. In our investigation, we employed a learning rate of 1e-03 and a decay rate having two parameters: beta1=0.91 and beta2=0.9994. We also set the epsilon value to 1e-08.
-
i.
Result analysis
Dataset description
The dataset employed for the investigation was obtained from a publicly accessible source. The collection comprises 6400 MRI images of Alzheimer’s disease in total. These images were obtained from Kaggle’s “Alzheimer’s Dataset (4 classes of Images)” by Yasir Hussein Shakir47. We chose this dataset because it is publicly available, sufficiently sized for deep learning, and includes multi-class categorization of Alzheimer’s stages, allowing for a detailed investigation of disease progression. While acknowledging the class imbalance, especially in the Moderate Demented group, we used data augmentation and regularization strategies to reduce its influence and strengthen the model.
Figure 5 illustrates the sample MRI images of four distinct cases. 80% of the total dataset samples were allocated for training, while the remaining 20% were used for testing. Table 3 shows the dataset distribution used in this study. Moreover, Table 4 compares this dataset and other widely used datasets in this field. Some sample images are shown in Fig. 5.

Sample MRI Images of Alzheimer’s disease based on four different cases: Mild-demented, Moderate-demented, Non-demented and Very-mild-demented.
However, current research, such as48 and49, emphasizes subject-level data splitting to avoid overlap between training and testing datasets. These studies provide reproducible evaluation pathways for determining the robustness of Alzheimer’s disease categorization models.
Multiple safeguards were taken to avoid leaking data between the training and testing sets. To ensure similar outcomes across model executions, a constant random seed (seed=45) was utilized for repeatable data splits and model training. Data augmentation methods were only used on the training data, including resizing, denoising, zooming, shifting, rescaling, rotating, shearing, and flipping. The test set was kept separate and undisturbed until it was evaluated. The test set was entirely segregated from the training process, with no utilization of test data during training, validation, or hyperparameter tuning. This ensures that the stated performance metrics precisely represent the model’s ability to generalize to new data. In addition, K-Fold cross-validation was used on the training set to optimize hyperparameters and accurately evaluate model performance, reducing bias caused by random data splitting. These measures combined guaranteed the accuracy and trustworthiness of the data and the dependability of the performance metrics given in this study.
Experimental setup and runtime
The suggested architecture was executed using Keras, utilizing the TensorFlow GPU support. The experiment, including both training and testing, was conducted in the Google Colaboratory environment with Python (python3) programming language, equipped with a processor Intel Core i3-7100U CPU @ 2.4GHz, Tesla T4 graphics card, 12.67GB of RAM, and 78.19GB of disk space. Throughout the experimental procedure, the image dataset was partitioned into two separate categories: training and testing, with proportions of 80% and 20% respectively. The proposed approach is designed to classify Alzheimer’s disease into four categories: Mild-demented, Moderate-demented, Non-demented and Very-Mild-demented utilizing MRI images of the human brain.
The proposed DL architecture used Adamax optimizer, an enhancement of the Adam optimizer for deep learning, and utilizes adaptive learning rates that are adjusted dynamically throughout the training process. It employs the infinity norm for stable parameter updates and is defined by two principal parameters, beta1 and beta2, which regulate the decay rates of moment estimates. Adamax proficiently manages sparse gradients, exhibiting strong performance across many neural network structures. To maintain numerical stability throughout the parameter update phase, a small positive constant, epsilon \(\epsilon\), is incorporated into the denominator to avert division by zero. This characteristic improves the reliability and efficiency of our research optimization methods, making Adamax a preferred option in our suggested deep neural network training. Our study utilized a learning rate 1e-03 and a decay rate characterized by two parameters: beta1=0.91 and beta2=0.9994. The epsilon value is also established at 1e−08. The batch size was configured at 32. The hyperparameter settings were established through experimentation, emphasizing those often utilized in similar deep learning tasks and fine-tuning according to the validation performance throughout the K-fold cross-validation procedure.
The average duration for each training epoch in this study’s extensive dataset was roughly 59 seconds, and the overall training procedure took approximately 30 minutes to reach convergence. The inference time, a crucial factor for real-time applications, was quantified to be approximately 368 milliseconds per MRI image on the NVIDIA Tesla T4 GPU. The model’s rapid inference time indicates that it is appropriate for real-time diagnostic applications, as long as sufficient processing resources exist. Again, scalability is essential when deploying in various clinical settings, including well-equipped research facilities and resource-constrained clinics. The design of the suggested model, EfficientNetV2B3, is renowned for its optimal combination of accuracy and efficiency. The model’s scalability is further improved through the fine-tuning and hyperparameter optimization conducted in this work. To assess the scalability of the model, we performed additional tests on different hardware configurations, which encompassed: The mid-range GPU option is the NVIDIA GeForce GTX 1080, while the integrated GPU option is the Intel Iris Xe Graphics. The model exhibited consistent performance across these configurations, with inference durations of 846 milliseconds on the GTX 1080 and around 51,520 milliseconds on the Intel Iris Xe. Although the model may not be optimal for real-time applications, it proves that it may nevertheless operate efficiently in less resource-intensive contexts.
Performance metrics
The evaluation of the Alzheimer’s disease detection approach firmly depends on utilizing the confusion matrix. This indispensable tool provides a thorough overview of anticipated and observed class labels, simplifying the assessment of true-positive (TP), true-negative (TN), false positives (FP) and false negatives (FN). Presented in Table 5, this graphical depiction provides valuable information about a model’s accuracy, precision, sensitivity, f1-score and specificity which are crucial for evaluating its effectiveness across several categories. The confusion matrix facilitates model perfection and decision-making in Alzheimer’s disease detection by visually representing categorization outcomes.
Several essential performance metrics are utilized to assess the efficacy of deep learning models, each providing a unique purpose. The Eqs. 11, 12, 13, 14, 15, 16 give the mathematical formulae of these metrics including Accuracy, Precision, Sensitivity, F1-Score, Specificity and Matthewscorrelationcoefficient(MCC).
In addition, this study used the loss function to evaluate the predicted model’s performance. A sparse categorical cross-entropy loss was employed to train the model. In addition to reducing the cost of the model’s parameters, the loss function was also used. Adding more epochs will lower the loss function. In terms of mathematical information, the loss function is defined by Eq. 17.
Here, Y = True label, \(\hat{Y}\) = Predicted Labels; and L(Y,\(\hat{Y}\)) is loss function.
Evaluation of the model
K-fold validation
K-fold coss-validation52 is a methodology employed to evaluate the effectiveness of a machine learning model by partitioning the dataset into multiple subsets. This study employed a five-fold cross-validation approach where 80% of the data was used for training and the rest of the 20% for validation. Specifically, in 5-fold cross-validation, the dataset is divided into five equally sized folds. The model undergoes training and assessment five times, each utilizing a distinct fold as the validation set and the remaining folds for training purposes. This iterative process ensures a comprehensive evaluation across different subsets of the data, contributing to a more robust assessment of the model’s performance.
Performance results
A five-fold cross-validation method was employed to assess the performance results across four class categories on the Alzheimer’s disease MRI image dataset. The evaluation was conducted using the performance metrics specified in section "Performance metrics". The aggregate performance was calculated by averaging the values of each fold, as illustrated in Table 6. From Table 6, it is observed that the highest average precision, sensitivity, f1-score, and specificity are 0.9975, 0.9975, 0.995, and 0.9976, respectively, as well as the lowest average precision, sensitivity, f1-score, and specificity observed at 0.995, 0.995, 0.995, and 0.9965, respectively. Furthermore, fold-wise average accuracy results are presented in Fig. 6. The outcomes of the fold-2 classification performance using the 4-class categories including moderate demented, non demented, mild demented and very mild demented are illustrated in Fig. 7. Figure 8 depicts accuracy and loss curve results over 30 epochs on fold-2. Additionally, its confusion matrix and ROC curves are presented in Figs. 9 and 10 respectively.
The Receiver Operating Characteristic (ROC) curve is a graphical representation used to assess the performance of a classification model across different discrimination thresholds. In the context of a 4-class image classification problem for this study, the ROC curve extends its utility to multiple classes by considering each class as a separate binary classification problem against the rest. For each class, the ROC curve plots the True Positive Rate (Sensitivity) against the False Positive Rate (1 - Specificity) at various decision thresholds. The ideal scenario is represented by a curve that reaches the top-left corner, indicating perfect discrimination with a sensitivity of 1 and specificity of 1. In this specific case, where the Area Under the Curve (AUC) value for each class is reported as 1.00, it signifies a model with impeccable performance for all classes. An AUC of 1.00 implies the model achieves perfect separation between positive and negative instances, resulting in an ideal ROC curve for each class (Table 7).

Fold-wise accuracy of the proposed model on four class categories including, Mild-demented, Moderate-demented, Non-demented and Very-mild-demented cases.

Graphical representation of performance results based on Precision, Sensitivity, F1-score, Specificity, MCC and AUC on fold-2.

Accuracy and loss curve of the proposed model on fold-2.

Confusion matrix of the proposed model on fold-2.

ROC curve of the proposed model using four class categories on fold-2.
Discriminative localization by Proposed Model Using Grad-Cam++
Grad-CAM++ (Gradient-weighted Class Activation Mapping++) is an extension of the Grad-CAM technique used in computer vision for visualizing and understanding convolutional neural networks (CNNs)53. Our proposed model incorporates Gradient-based class activation mapping++ (Grad-CAM++) to provide class activation mapping for identifying the particular region of the MRI images that mostly influenced the decision, as illustrated in Fig. 11. After processing through the final layer, a preliminary localization map is created to identify the key areas within the image for prediction. It helps interpret the decision-making process of deep learning models by highlighting the regions of input images that contribute the most to the model’s predictions. Unlike the original Grad-CAM, Grad-CAM++ considers both positive and negative gradients to localize essential features in the input image better. This enhanced technique provides more accurate and precise visual explanations, aiding researchers and practitioners in gaining insights into the inner workings of CNNs and improving model transparency and interpretability.

Procedure of gradient weighted class activation mapping++ (Grad-CAM++) as follows: The final feature map’s gradient of the target output class is utilized to localize significant portions coarsely.
The primary enhancement of Grad-CAM++ is in its methodology for computing the significance weights assigned to each feature map. Below is an elaborate elucidation of the equations employed in Grad-CAM++:
-
i.
Compute the Grad-CAM++ weights: Given a feature map \(A^k\) (where \(k\) denotes the index of the feature map) and the gradient of the score for a sample class \(c\) (represented as \(y^c\)) with respect to the feature map \(A^k\), the weight \(\alpha _{ij}^k\) is calculated as follows in Eq. 18.
$$\begin{aligned} \alpha _{ij}^k = \frac{\frac{\partial ^2 y^c}{\partial (A_{ij}^k)^2}}{2 \frac{\partial ^2 y^c}{\partial (A_{ij}^k)^2} + \sum _a \sum _b A_{ab}^k \cdot \frac{\partial ^3 y^c}{\partial (A_{ij}^k)^3}} \end{aligned}$$(18)Where, The terms \(\frac{\partial ^2 y^c}{\partial (A_{ij}^k)^2}\) and \(\frac{\partial ^3 y^c}{\partial (A_{ij}^k)^3}\) represents the second-order and third-order partial derivative of the class score \(y^c\) with respect to the activation \(A_{ij}^k\) at the spatial location \((i, j)\) in the feature map \(k\) respectively.
-
ii.
Compute the Grad-CAM++ maps: The Grad-CAM++ map \(L_{\text {Grad-CAM++}}^c\) is subsequently derived by integrating the feature maps with the calculated weights is represented in Eq. 19.
$$\begin{aligned} L_{\text {Grad-CAM++}}^c = \sum _{k} \alpha ^k \cdot \text {ReLU} \left( \sum _{i} \sum _{j} \alpha _{ij}^k \cdot \frac{\partial y^c}{\partial A_{ij}^k} \right) \end{aligned}$$(19)where, The weights \(\alpha _k\) are obtained by summing over \(\alpha _{ij}^k\) for all \(i\) and \(j\) for the feature map \(k\), represented as: \(\alpha _k = \sum _{i} \sum _{j} \alpha _{ij}^k\). Additionally, the ReLU(\(\cdot\)) function, which stands for Rectified Linear Unit, guarantees that only positive values contribute to the map. These weights generate a heatmap identifying the crucial areas in the input image that the model considers significant for its decision-making for a particular class. Some of these localizations are explored further by overlaying the heatmap on the input MRI images to assess the network’s learning from a clinical perspective. Figure 12 shows some MRI images with imposed localization. The intense blue color indicates the most critical region (processed attributes) from which the network has made the classification decision. Here are a few key findings:
-
Non-demented MRI images of the brain offer valuable insights into the brain’s structural integrity and normal functioning. According to the study54 they found age-related changes in various brain regions, including white matter maturation and cortical thickness, highlighting the importance of non-demented MRI data in understanding typical brain development. From Fig. 12a we found no substantial zone is localized.
-
Upon analyzing the heatmaps for cases of mild dementia from Fig. 12b, it is evident that our suggested model has identified and highlighted the specific regions associated with the hippocampus and entorhinal cortex55,56.
-
Moderate dementia, a stage of neurodegenerative diseases like Alzheimer’s, is associated with significant structural changes in the brain that can be visualized through MRI (Magnetic Resonance Imaging). Upon examining the heatmap depicted in Fig. 12c, it is apparent particularly in regions implicated in memory and cognition, such as the hippocampus, entorhinal cortex, and frontal lobes57.
-
Very mild dementia, presents a crucial aspect in understanding the early stages of neurodegenerative diseases such as Alzheimer’s. By analyzing the heatmap from Fig. 12d, it is observed that there may be subtle alterations in the volume and integrity of specific brain regions associated with memory and cognitive function, such as the hippocampus and cortical areas58.

Key sections of the MRI images (before and after scenario) that drive the decision are identified by applying the class activation heatmap (Grad-CAM++) generated by the proposed model: (a) non demented (b) mild demented (c) moderate demented and (d) very mild demented.
As the proposed model is incorporated with Grad-CAM++ and we also compare the model with other previous pretrained models based on various aspects, as shown in Table 8. Furthermore, Fig. 13 presents the outcome of different models with grad-cam++ and the proposed model with grad-cam++ by considering a sample image of a moderate dementia case.
According to Fig. 13, the heatmap and superimposed images generated by the proposed model are more refined and precise than others.

Grad-CAM++ generated images of different pretrained models and the proposed model on a sample image of Moderate Dementia case.
Discussion
This section critically evaluates our findings, compares them with prior research, and examines the implications and constraints of our suggested model.
Critical analysis of findings
This section assesses the performance of our proposed model, highlighting its significance accuracy (99.45%), precision (99.75%), specificity (99.76%), recall (99.5%), MCC (99.92%) and AUC (100%) in classifying Alzheimer’s disease into four categories: mild, moderate, very mild, and non-demented and integrates it with the distinct hybrid filtering method and the enhanced EfficientNetV2B3 architecture. Additionally, it examines the Grad-CAM++ outcomes and their clinical significance. Thus, the study shows how the hybrid filtering strategy and modified EfficientNetV2B3 architecture strengthened the model and improved classification performance.
Comparison with previous studies
The findings of this study were compared to those of other recent state-of-the-art works in this field and other pre-trained models. Initially, the suggested model was contrasted with several prior trained models. In this case, four different classes were considered for comparisons-with and without prepossessing on image data. Table 9 shows the comparisons between the suggested and the other pre-trained models. Therefore, it is observed from Table 9 that models trained without utilizing preprocessed data exhibit lower accuracy, precision, sensitivity, f1-score, and specificity values in comparison to models trained with preprocessed data. In contrast, the suggested model demonstrated a remarkable accuracy of 99.45%. In addition, the proposed model produced substantial scores for precision, sensitivity, f1-score and specificity as shown in Table 9. Therefore, the suggested architecture may significantly enhance its effectiveness and robustness by implementing efficient preprocessing techniques on image data and utilizing the pre-trained “EfficientNetV2B3” model. Again, the proposed model exhibits a remarkable accuracy of 97.67% without preprocessing, in contrast to a pretrained model like VGG16’s 92.41% with preprocessing (Table 9); nevertheless, the unique properties of the Kaggle dataset may have impacted these outcomes. The dataset’s intrinsic quality, structure, and distribution may partially exaggerate the model’s performance. To ascertain the robustness and generalizability of the suggested methodology, subsequent research should entail testing on varied datasets, including ADNI and OASIS. An ablation research examining the influence of preprocessing approaches on model performance will elucidate their effects.
To statistically validate the performance of the proposed model, confidence intervals (CI) provide a reliable metric to assess its accuracy compared to baseline methods. The computed 95% confidence interval (CI = [99.05%, 99.86%]) suggests that the model exhibits consistently high accuracy, demonstrating its robustness and reliability. This narrow interval signifies a low variability in classification results, reinforcing the model’s consistency.
The evaluation outcomes of the suggested investigation were also contrasted with prior examples of comparable recent studies by considering their architecture, number of classes and subjects. As shown in Table 10, the proposed research achieved 99.45% accuracy for four class categories consisting of mildly demented, moderately demented, non-demented, and very mildly demented cases. Agarwal et al.59 introduced a novel approach, combining end-to-end and transfer learning, utilizing the EfficientNet-b0 convolutional neural network (CNN). By analyzing 245 T1W MRI scans of cognitively normal (CN) subjects, 229 AD subjects, and 229 subjects with stable mild cognitive impairment (sMCI), the study achieved promising results in classification tasks.
Shankar et al.60 employed a thorough methodology for detecting Alzheimer’s disease, which included preprocessing images and extracting features using texture scale invariants, transforms, and histograms. They augmented the performance of classifiers such as CNN, KNN, and decision trees by applying Group Grey Wolf Optimization (GGWO) techniques. This approach yielded a remarkable accuracy of 96.23% in Alzheimer’s detection, surpassing the effectiveness of alternative methods. The above study did not utilize additional patient data and only considered three class categories. Nevertheless, our proposed model included a substantial quantity of patient data consisting of MRI images, categorized into four classes for the experiment. As demonstrated in Table 10, we achieved accuracy beyond the results reported in these investigations. Although Yang et al.61 and Pradhan et al.62 examined four different case types for the detection of Alzheimer’s disease, their collected dataset and accuracy were considerably lower than those of our proposed study, as indicated in Table 10. Additionally, they only considered traditional deep learning pretrained models, whereas we utilized a substantial number of MRI images and developed an advanced pretrained model. Zaabi et al.63 proposed a two-step approach: first, extracting regions of interest (e.g., the hippocampus) from brain images, followed by classification using deep learning techniques like Convolutional Neural Networks (CNN) and Transfer Learning. Evaluation on the Oasis dataset demonstrates Transfer Learning’s superior performance, achieving a classification rate of 92%.
Razavi et al.64 proposed a novel two-stage method integrating unsupervised feature learning with SoftMax regression for intelligent diagnosis. Evaluation on Alzheimer’s Brain image datasets offered automation and adaptability for efficient big data processing, as evidenced by experiments on ADNI data. The aforementioned study did not perform any sort of data preprocessing or augmentation on their raw data. Also, the dataset they chose was significantly less than the one we used in this study. The suggested model in this research used both preprocessing and augmentation methods on the raw images, which improved the outcomes as shown in Table 10, because this improves and reinforces the deep learning model.
Furthermore, we also compared our model with recently published works on several datasets as shown in Table 11. The suggested model, utilizing the modified EfficientNetV2B3 architecture, surpasses existing models regarding accuracy, precision, specificity, and recall. These findings indicate that the proposed modifications and the selection of EfficientNetV2B3 are highly successful in accomplishing the classification tasks on the Kaggle/DUBEY (2020) dataset. The comparative analysis highlights the proposed model’s strength and effectiveness compared to recent cutting-edge models as shown in Table 11. Although Suchitra et al.32 attained 98.2% accuracy utilizing EfficientNetB7, our suggested model employing the improved EfficientNetV2B3 architecture obtained 99.45% accuracy. The enhancement is due to EfficientNetV2B3’s optimized training methodology, superior regularization techniques, and advanced feature extraction capabilities, enabling it to identify more pertinent patterns in MRI images. Moreover, EfficientNetV2B3 possesses fewer parameters than EfficientNetB7, resulting in diminished computational expenses.
The proposed model attains an accuracy of 99.45%; nevertheless, employing EfficientNetV2B3 with additional layers escalates the model’s complexity and poses a risk of overfitting. To limit this risk, we utilized various strategies, including data augmentation (rotation, shifting, zooming, and flipping), dropout layers (with rates of 0.2 and 0.3), and K-fold cross-validation. Examining the training and validation curves (Fig. 8) indicates that the curves are closely aligned, implying that the model is generalizing effectively and not exhibiting overfitting.
Moreover, for discriminative visualization of our findings on this MRI image dataset we used an advanced explainable AI technique named Grad-CAM++.Furthermore, we compared our model and both Grad-CAM++ and the baseline model (Grad-CAM).
Significantly, Grad-CAM++ improves upon Grad-CAM by incorporating additional information from deeper neural network layers, resulting in more precise localization of important regions within an image.

Grad-CAM and Grad-CAM++ generated images of the proposed model on a sample image of Mild Dementia case.
-
Differences: The main difference between the two images as presented in Fig. 14 lies in the precision and localization of the heatmaps generated by Grad-CAM and Grad-CAM++ with our proposed model.
-
i.
Grad-CAM generated Image Fig. 14a: The heatmap highlights a broader area, indicating that a larger region of the original image influences the model’s prediction. This suggests the model might consider a more general pattern or feature within the image.
-
ii.
Grad-CAM++ generated Image Fig. 14b: The heatmap is more focused and precise, highlighting a smaller, more specific region of the image. This indicates the model relies on a more localized feature or detail within the image to predict.
-
i.
The proposed model utilizing Grad-CAM++ for localization demonstrates several superiorities over the models discussed in the following selected articles. Firstly, compared to36, who used an NCA-based hybrid CNN model with Grad-CAM, our model provides more precise localization of Alzheimer’s disease-related regions in brain MRI images. This precision is evident from the more focused and detailed heatmaps produced by Grad-CAM++, as shown in Fig. 14b- superimposed image. Secondly, in contrast to the approach by31, which integrates XAI with Grad-CAM, our model’s use of Grad-CAM++ offers enhanced interpretability and finer granularity in highlighting significant areas, aiding clinicians in making more accurate diagnoses. Additionally, Raju et al.65 employed a deep learning-based multilevel classification system; however, our model’s improved localization capabilities can potentially lead to higher classification accuracy by focusing on the most relevant features.
In essence, Grad-CAM++ provides a more fine-grained and accurate localization of the important regions in the image, making it easier to understand which parts of the image are driving the model’s decision. This makes our model a more effective tool for early disease progression detection and monitoring.
Significance of the model
Evaluation of research queries
-
RQ1: How well does the proposed hybrid filtering method enhance MRI image preprocessing to strengthen model robustness and improve accuracy?
Evaluation: The proposed hybrid filtering method enhances MRI image preprocessing by combining adaptive non-local means denoising and sharpening filters to effectively reduce noise while preserving fine details and improving edge definition. This preprocessing approach strengthens model robustness by optimizing image quality, leading to improved feature extraction and achieving a high classification accuracy of 99.45% as shown in Table9.
-
RQ2: How does the proposed model perform relative to other state-of-the-art methods in terms of accuracy, precision, recall, and specificity for multi-class Alzheimer’s disease diagnosis?
Evaluation: The proposed model, leveraging a modified EfficientNetV2B3 architecture, achieves a high accuracy of 99.45% for four-class Alzheimer’s disease diagnosis, outperforming existing models like VGG19 and ResNet152V2. It also demonstrates superior precision (99.75%), recall (99.5%), and specificity (99.76%) compared to other state-of-the-art methods shown in Table 9, 10 and 11 indicating its effectiveness in accurately classifying different stages of Alzheimer’s disease from MRI images. This performance is attributed to the model’s efficient feature extraction, fine-tuning techniques, and preprocessed image data.
-
RQ3: How do advanced explainable AI techniques, such as Grad-CAM++, enhance clinicians’ ability to interpret and trust AI-based diagnostic approaches?
Evaluation: Advanced explainable AI techniques, such as Grad-CAM++, enhance clinicians’ ability to interpret and trust AI-based diagnostic approaches by providing detailed visual explanations of the specific regions in medical images that influence the model’s predictions. As demonstrated in the study, this improved localization and precision allow clinicians to validate AI decisions against clinical knowledge, increasing transparency and confidence in the diagnostic process.
Clinical implementation considerations
The proposed study significantly impacts healthcare by improving early Alzheimer’s detection through a deep transfer learning model, allowing for timely interventions and better patient outcomes. Its high accuracy of 99.45% ensures reliable diagnostics, offering a trustworthy tool for healthcare professionals. Utilizing publicly available MRI datasets and transfer learning enhances resource efficiency, making it accessible for under-resourced settings. The inclusion of Grad-CAM++ facilitates explainable AI, helping clinicians understand and trust the diagnostic process. The methodology’s adaptability to other neurodegenerative diseases also broadens its potential impact across medical diagnostics.
Limitations and future directions
Although the proposed approach has shown remarkable success in classifying Alzheimer’s disease using MRI images, it is crucial to recognize the constraints of the dataset employed in this investigation. The dataset utilized in this study demonstrates a class imbalance, characterized by a limited number of samples in the Moderate Demented group (64 samples). This imbalance may bias the model towards the majority classes, impairing its capacity to categorize Moderate Demented cases reliably. To address this issue, we will investigate advanced data augmentation approaches. Future research will investigate GAN-based approaches to mitigate class imbalance further and enhance classification accuracy for the Moderate Demented category. Additionally, the dataset may lack complete representativeness of the worldwide population due to its acquisition from publicly accessible archives and the incomplete/imbalanced disclosure of demographic information on the participants. This could potentially add bias and impact the generalizability of the model. Furthermore, the variability in image quality of MRI scans from different sources can influence the model’s performance. To overcome these constraints, future research may involve collecting a broader and more diverse dataset, encompassing comprehensive demographic data and maintaining constant image quality and balancing. In addition, conducting a more extensive assessment of the model’s effectiveness across various demographics and environments would be beneficial.
The model’s efficient architecture and rapid inference times on high-performance GPUs highlight its potential for real-time clinical applications. Future efforts will aim to integrate the model with existing clinical workflows and imaging software, ensuring user-friendly interfaces and broad adoption in medical diagnostics.
Overall, the positive and hopeful outcomes of our suggested model in detecting Alzheimer’s disease from MRI images indicate that deep transfer learning could significantly impact fighting the ongoing threat in the coming years.
Conclusions
In this study, we proposed a deep transfer learning model that presents a promising solution for the timely identification of Alzheimer’s disease (AD) through the analysis of brain MRI images. The model, leveraging EfficientNetV2B3 architecture and fine-tuning with additional layers, demonstrates a high accuracy rate of 99.45% in classifying cases of Mild demented, normal, Moderate demented, and Very Mild demented. By incorporating Grad-CAM++ for discriminative localization, the model accurately identifies AD pathology and provides interpretable insights into radiological anomalies associated with the disease. These findings underscore the potential of sophisticated transfer learning techniques in augmenting AD diagnosis, particularly in resource-constrained settings. Ultimately, the proposed model holds promise for assisting healthcare providers in prompt identification and intervention, thereby improving patient outcomes in this pressing global health concern.
Limitation: Despite this study’s promising results, certain limitations remain. First, the research focuses on deep transfer learning; other machine learning techniques were not explored. Second, attention mechanisms, such as self-attention or transformer-based models, were not incorporated. Third, the model has not been integrated within a clinical device, which restricts its immediate applicability in practical healthcare settings.
Future work: Building upon the limitations identified in this study, future work will focus on addressing the following key aspects. Firstly, other machine learning techniques, including conventional and hybrid approaches. Secondly, attention mechanisms, such as self-attention and transformer-based architectures, will enhance the model’s ability to capture intricate relationships and dependencies within MRI image data. Finally, efforts will be made to integrate the proposed model within clinical devices and real-world workflows. This step will involve rigorous testing in clinical environments to assess its usability, reliability, and overall impact on patient outcomes.
Data availability
The Dataset is collected from Kaggle: Alzheimer’s Dataset: https://www.kaggle.com/datasets/yasserhessein/dataset-alzheimer
References
Hill, A. M. Alzheimer disease and the evolving treatment landscape. Am. J. Manag. Care 28(10 Suppl), 179–187 (2022).
Göker, H. Detection of alzheimer’s disease from electroencephalography (eeg) signals using multitaper and ensemble learning methods. Uludağ Üniversitesi Mühendislik Fakültesi Dergisi 28(1), 141–152 (2023).
Huma, T., Nawaz, R., Li, X. & Willden, A. Alzheimer’s disease (ad): Risks, treatments, prevention, and future implementations. Adv. Alzheimer’s Dis. 11(02), 11–21 (2022).
Jeremic, D., Jimenez-Diaz, L. & Navarro-López, J. D. A systematic review of therapeutic strategies against amyloid-\(\beta\) peptides in Alzheimer’s disease: Past, present, and future. Alzheimer’s Dementia 19, 060438 (2023).
Mujahid, M. et al. An efficient ensemble approach for Alzheimer’s disease detection using an adaptive synthetic technique and deep learning. Diagnostics 13(15), 2489 (2023).
Asaduzzaman, M., Alom, M. K. & Karim, M. E. Alzenet: Deep learning-based early prediction of Alzheimer’s disease through magnetic resonance imaging analysis. Telematics and Informatics Reports, 100189 (2025).
Janghel, R. & Rathore, Y. Deep convolution neural network based system for early diagnosis of Alzheimer’s disease. Irbm 42(4), 258–267 (2021).
Saimon, S. I. et al. Advancing neurological disease prediction through machine learning techniques. J. Comput. Sci. Technol. Stud. 7(1), 139–156 (2025).
Veitch, D. P. et al. Using the Alzheimer’s disease neuroimaging initiative to improve early detection, diagnosis, and treatment of Alzheimer’s disease. Alzheimer’s Dementia 18(4), 824–857 (2022).
Yin, Y., Wang, H., Liu, S., Sun, J., Jing, P., Liu, Y. Internet of things for diagnosis of alzheimer’s disease: A multimodal machine learning approach based on eye movement features. IEEE Internet Things J. (2023).
Ahamed, K. U. et al. A deep learning approach using effective preprocessing techniques to detect covid-19 from chest ct-scan and x-ray images. Comput. Biol. Med. 139, 105014 (2021).
Chen, J. et al. Multimodal mixing convolutional neural network and transformer for Alzheimer’s disease recognition. Expert Syst. Appl. 259, 125321 (2025).
Shahadat, N. & Maida, A. S. Deep separable hypercomplex networks. In The International FLAIRS Conference Proceedings, vol. 36 (2023).
El-Latif, A. A. A., Chelloug, S. A., Alabdulhafith, M. & Hammad, M. Accurate detection of Alzheimer’s disease using lightweight deep learning model on MRI data. Diagnostics 13(7), 1216 (2023).
Shastry, K. A., Shastry, S., Shastry, A. & Bhat, S. M. A multi-stage efficientnet based framework for Alzheimer’s and Parkinson’s diseases prediction on magnetic resonance imaging. Multimedia Tools and Applications, pp. 1–38 (2025).
Association, A. Alzheimer’s disease facts and figures. https://alz-journals.onlinelibrary.wiley.com/doi/10.1016/j.jalz.2019.01.010. Accessed: 01 June 2024 (2019).
Rath, A., Mishra, D., Panda, G. & Satapathy, S. C. Heart disease detection using deep learning methods from imbalanced ECG samples. Biomed. Signal Process. Control 68, 102820 (2021).
Nazir, T. et al. Retinal image analysis for diabetes-based eye disease detection using deep learning. Appl. Sci. 10(18), 6185 (2020).
Ahamed, M. K. U. et al. Dtlcx: An improved resnet architecture to classify normal and conventional pneumonia cases from covid-19 instances with grad-cam-based superimposed visualization utilizing chest x-ray images. Diagnostics 13(3), 551 (2023).
Das, A. et al. Breast cancer detection using an ensemble deep learning method. Biomed. Signal Process. Control 70, 103009 (2021).
Dickerson, B. C. et al. The Alzheimer’s association clinical practice guideline for the diagnostic evaluation, testing, counseling, and disclosure of suspected Alzheimer’s disease and related disorders (detecd-adrd): Executive summary of recommendations for specialty care. Alzheimer’s Dementia 21(1), 14337 (2025).
Leuzy, A. et al. Considerations in the clinical use of amyloid pet and csf biomarkers for Alzheimer’s disease. Alzheimer’s Dementia 21(3), 14528 (2025).
Ziyad, S.R., Alharbi, M. & Altulyan, M. Artificial intelligence model for Alzheimer’s disease detection with convolution neural network for magnetic resonance images. J. Alzheimer’s Dis. (Preprint), pp. 1–11 (2023).
Rabeh, A.B., Benzarti, F. & Amiri, H. Cnn-svm for prediction Alzheimer disease in early step. In: 2023 International Conference on Control, Automation and Diagnosis (ICCAD), pp. 1–6 (2023). IEEE.
Uddin, K.M.M., Alam, M.J., Uddin, M.A. & Aryal, S. A novel approach utilizing machine learning for the early diagnosis of Alzheimer’s disease. Biomed. Mater. Dev., pp. 1–17 (2023).
Thayumanasamy, I. & Ramamurthy, K. Performance analysis of machine learning and deep learning models for classification of Alzheimer’s disease from brain MRI. Traitement du Signal 39(6), 1961 (2022).
Cui, R. et al. Rnn-based longitudinal analysis for diagnosis of Alzheimer’s disease. Comput. Med. Imaging Graph. 73, 1–10 (2019).
Chen, Z. S., Galatzer-Levy, I. R., Bigio, B., Nasca, C., Zhang, Y., et al. Modern views of machine learning for precision psychiatry. Patterns 3(11) (2022).
Hazarika, R. A. et al. An approach for classification of Alzheimer’s disease using deep neural network and brain magnetic resonance imaging (MRI). Electronics 12(3), 676 (2023).
Marwa, E.-G., Moustafa, H.E.-D., Khalifa, F., Khater, H. & AbdElhalim, E. An MRI-based deep learning approach for accurate detection of Alzheimer’s disease. Alex. Eng. J. 63, 211–221 (2023).
Chethana, S., Charan, S. S., Srihitha, V., Palaniswamy, S. & Pati, P. B. A novel approach for Alzheimer’s disease detection using Xai and grad-cam. In: 2023 4th IEEE Global Conference for Advancement in Technology (GCAT), pp. 1–6 (2023). IEEE.
Suchitra, S., Krishnasamy, L. & Poovaraghan, R. A deep learning-based early alzheimer’s disease detection using magnetic resonance images. Multimedia Tools and Applications, 1–22 (2024).
Valoor, A. & Gangadharan, G. Unveiling the decision making process in Alzheimer’s disease diagnosis: A case-based counterfactual methodology for explainable deep learning. J. Neurosci. Methods 413, 110318 (2025).
Kina, E. Tleablcnn: Brain and Alzheimer’s disease detection using attention based explainable deep learning and smote using imbalanced brain MRI. IEEE Access (2025).
Taiyeb Khosroshahi, M. et al. Explainable artificial intelligence in neuroimaging of Alzheimer’s disease. Diagnostics 15(5), 612 (2025).
Özbay, F. A. & Özbay, E. An nca-based hybrid cnn model for classification of Alzheimer’s disease on grad-cam-enhanced brain MRI images. Turkish J. Sci. Technol. 18(1), 139–155 (2023).
Mahmud, T. et al. An explainable ai paradigm for Alzheimer’s diagnosis using deep transfer learning. Diagnostics 14(3), 345 (2024).
Balaji, P., Chaurasia, M. A., Bilfaqih, S. M., Muniasamy, A. & Alsid, L. E. G. Hybridized deep learning approach for detecting Alzheimer’s disease. Biomedicines 11(1), 149 (2023).
Hu, Z., Wang, Z., Jin, Y. & Hou, W. Vgg-tswinformer: Transformer-based deep learning model for early Alzheimer’s disease prediction. Comput. Methods Programs Biomed. 229, 107291 (2023).
Sethuraman, S. K. et al. Predicting Alzheimer’s disease using deep neuro-functional networks with resting-state fmRI. Electronics 12(4), 1031 (2023).
Heo, Y.-C., Kim, K. & Lee, Y. Image denoising using non-local means (nlm) approach in magnetic resonance (mr) imaging: A systematic review. Appl. Sci. 10(20), 7028 (2020).
Bhairannawar, S. S. Efficient medical image enhancement technique using transform hsv space and adaptive histogram equalization. In: Soft Computing Based Medical Image Analysis, pp. 51–60. Elsevier (2018).
Woods, J. Chapter 7-image enhancement and analysis. Multidimensional Signal, Image, and Video Processing and Coding, second ed., Academic Press, Boston, 223–256 (2012).
Shorten, C. & Khoshgoftaar, T. M. A survey on image data augmentation for deep learning. J. Big Data 6(1), 1–48 (2019).
Chollet, F. Building powerful image classification models using very little data. Keras Blog 5, 90–95 (2016).
Tan, M. & Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In: International Conference on Machine Learning, pp. 6105–6114 (2019).
Shakir, Y. H. Alzheimer Dataset. Accessed: 07 April 2025 (2021). https://www.kaggle.com/datasets/yasserhessein/dataset-alzheimer.
Wen, J. et al. Convolutional neural networks for classification of Alzheimer’s disease: Overview and reproducible evaluation. Med. Image Anal. 63, 101694 (2020).
Zhao, Z. et al. Conventional machine learning and deep learning in Alzheimer’s disease diagnosis using neuroimaging: A review. Front. Comput. Neurosci. 17, 1038636 (2023).
Kurdi, B., Lozano, S. & Banaji, M. R. Introducing the open affective standardized image set (oasis). Behav. Res. Methods 49, 457–470 (2017).
Gamberger, D., Ženko, B., Mitelpunkt, A., Shachar, N. & Lavrač, N. Clusters of male and female Alzheimer’s disease patients in the Alzheimer’s disease neuroimaging initiative (adni) database. Brain Inform. 3, 169–179 (2016).
Anguita, D. et al. The’k’in k-fold cross validation. In: ESANN 102, 441–446 (2012).
Chattopadhay, A., Sarkar, A., Howlader, P. & Balasubramanian, V. N. Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks. In: 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), pp. 839–847 (2018). IEEE.
Lebel, C. & Beaulieu, C. Longitudinal development of human brain wiring continues from childhood into adulthood. J. Neurosci. 31(30), 10937–10947 (2011).
Dickerson, B. C. & Sperling, R. A. Functional abnormalities of the medial temporal lobe memory system in mild cognitive impairment and Alzheimer’s disease: insights from functional mri studies. Neuropsychologia 46(6), 1624–1635 (2008).
Scheltens, P. et al. Atrophy of medial temporal lobes on mri in“ probable’’ Alzheimer’s disease and normal ageing: diagnostic value and neuropsychological correlates. J. Neurol. Neurosurg. Psychiatry 55(10), 967 (1992).
Boublay, N., Schott, A. & Krolak-Salmon, P. Neuroimaging correlates of neuropsychiatric symptoms in Alzheimer’s disease: A review of 20 years of research. Eur. J. Neurol. 23(10), 1500–1509 (2016).
Sun, Y. et al. A nationwide survey of mild cognitive impairment and dementia, including very mild dementia, in taiwan. PLoS ONE 9(6), 100303 (2014).
Agarwal, D. et al. Automated medical diagnosis of Alzheimer’ s disease using an efficient net convolutional neural network. J. Med. Syst. 47(1), 57 (2023).
Shankar, K. et al. Alzheimer detection using group grey wolf optimization based features with convolutional classifier. Comput. Electr. Eng. 77, 230–243 (2019).
Yang, K., Mohammed, E. A. & Far, B. H. Detection of Alzheimer’s disease using graph-regularized convolutional neural network based on structural similarity learning of brain magnetic resonance images. In: 2021 IEEE 22nd International Conference on Information Reuse and Integration for Data Science (IRI), pp. 326–333 (2021). IEEE.
Pradhan, A., Gige, J. & Eliazer, M. Detection of Alzheimer’s disease (ad) in MRI images using deep learning. Int. J. Eng. Res. Technol 10(3) (2021).
Zaabi, M., Smaoui, N., Derbel, H. & Hariri, W. Alzheimer’s disease detection using convolutional neural networks and transfer learning based methods. In: 2020 17th International Multi-Conference on Systems, Signals & Devices (SSD), pp. 939–943 (2020). IEEE.
Razavi, F., Tarokh, M. J. & Alborzi, M. An intelligent Alzheimer’s disease diagnosis method using unsupervised feature learning. J. Big Data 6, 1–16 (2019).
Raju, M., Thirupalani, M., Vidhyabharathi, S. & Thilagavathi, S. Deep learning based multilevel classification of Alzheimer’s disease using mri scans. In: IOP Conference Series: Materials Science and Engineering, vol. 1084, p. 012017 (2021). IOP Publishing.
Acknowledgements
The authors would like to extend their sincere appreciation to the Ongoing Research Funding program (ORF-2025-301), King Saud University, Riyadh, Saudi Arabia.
Author information
Authors and Affiliations
Contributions
Md. Khabir Uddin Ahamed: Conceptualization, Data curation, Methodology, Software, Resource, Visualization, Formal Analysis, Writing-original draft and review & editing. Rakib Hossen, Bikash Kumar Paul, Mohammad Hasan: Methodology, Software, Resource, Visualization, Formal Analysis. Waled Hussein Al-Arashi, Mohsin Kazi and Md. Alamin Talukder: Formal Analysis, Visualization, Validation, Supervision, Investigation, writing-review & editing.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
See Table 12.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ahamed, M.K.U., Hossen, R., Paul, B.K. et al. A hybrid filtering and deep learning approach for early Alzheimer’s disease identification. Sci Rep 15, 27694 (2025). https://doi.org/10.1038/s41598-025-03472-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-03472-z
