
Abstract
Online videos are vital for health education and medical decision-making, but their comment sections often spread misinformation, causing anxiety and confusion. This study identifies stress-inducing comments in oral health education content, aiming to improve mental health outcomes, educational effectiveness, user experience, and scalability. This study uses RoBERTa, a state-of-the-art language model, to advance Natural Language Processing (NLP) research and enable real-time feedback in social media environments. The RoBERTa-base configuration, with 12 transformer blocks, attention heads, and a 50,265-token vocabulary, was fine-tuned using optimized hyperparameters. The workflow includes data ingestion, token normalization, special character handling, embedding generation, transformer encoding, classification head processing, output generation, and evaluation metrics. This framework aims to enhance online health education discourse and establish automated comment moderation systems. The RoBERTa model achieved 75.00% overall accuracy in classifying panic and anxiety-inducing comments, with 74.76% precision and 0.800 recall for positive cases. While the model performed well in identifying relevant comments, its accuracy in panic and informative categories requires improvement. This study demonstrates the potential of RoBERTa-based deep learning for classifying dental-related comments, providing clinical insights and identifying areas for refinement. Although the model shows promise in detecting anxiety-inducing content, further optimization is needed.
Similar content being viewed by others

Introduction
In our modern digital landscape, online videos have emerged as a vital channel for disseminating health education and guiding countless individuals in making medical decisions. Yet, the comment sections accompanying these videos often act as a double-edged sword1. While they can stimulate engaged discussions and offer personal insights, they carry an inherent risk of misinformation that may mislead viewers2,3. This can result in heightened fears or confusion about health matters. Many patients and casual viewers—who are often already experiencing anxiety related to their health—are confronted with a spectrum of conflicting opinions, hyperbolic personal narratives, and outright misinformation4,5,6. Such content can unintentionally steer individuals toward unnecessary dental and periodontal treatments or discourage them from pursuing essential healthcare services7.
The psychological ramifications of this unfiltered commentary are significant, reshaping health-related behaviors and decision-making processes. Fear-laden comments can exacerbate anxiety levels, prompting individuals to overreact, either by seeking excessive dental interventions or by withdrawing entirely from necessary treatments8,9. The need for a solution in this arena is pressing, and it is here that artificial intelligence (AI) can offer a transformative approach. AI can analyze, filter, moderate, and even rephrase online comments in a manner that aligns with the informational needs of viewers. By employing advanced algorithms, AI can establish a more balanced and informative environment online, fostering a culture of reassurance rather than panic. Through the intelligent curation of discussions, AI can emphasize authoritative responses from medical experts, spotlight constructive dialogues, and diminish the visibility of fear-mongering statements10.
Implementing AI-driven moderation systems could potentially revolutionize the field of digital health communication. By ensuring that the information presented is reliable and helpful, healthcare providers can facilitate a safer digital space where patients are empowered with accurate knowledge rather than disinformation. In doing so, the impact on the public could be profoundly positive—transforming how health-related content is consumed and understood in a digital context. Moreover, this approach could enhance the overall user experience on health-oriented platforms, reducing misinformation and building a community rooted in trust and informative exchanges. Patients could engage with relevant content backed by scientific evidence, fostering informed decision-making. The capacity of AI to mitigate anxiety around health issues cannot be overstated. By redirecting conversations from fear and speculation toward truth and evidence-based wisdom, AI can serve as a bridge between medical professionals and the public. This essential role could lead to a significant improvement in public health literacy and overall patient outcomes11.
Online videos are gaining popularity as health information sources, but their comment sections pose significant challenges. AI can moderate and curate these discussions, promoting patient safety, clear communication, and educational integrity. This will empower individuals, replace fear with empowerment, and foster informed health choices. The automated prediction and classification of panic-inducing comments on YouTube educational videos related to oral hygiene is increasingly essential in our digital era. Many viewers encounter comments that spread misinformation, incite anxiety, or express alarmist views, which may overwhelm and discourage them from pursuing necessary dental care or maintaining proper oral hygiene practices. By implementing an automated system to identify and filter these panic-inducing comments, we can create a more supportive and informative viewer experience. Deep learning technologies, particularly in natural language processing (NLP), enable the detection of distressing language, allowing viewers to focus on constructive feedback instead. This not only enhances public health literacy by ensuring access to scientifically accurate information about oral hygiene but also aids content creators in tailoring their messages to address prevalent concerns and misconceptions regarding oral health12,13.
Previous studies have shown that transformer-based sentiment analysis algorithms like BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformer), RoBERTa (Robustly Optimized BERT Approach), and T5 perform well on YouTube comments. RoBERTa, in particular, has outperformed other models, achieving the highest accuracy and F1 scores14,15. These studies highlight the limitations and strengths of transformer-based methods, offer recommendations for improvement, and suggest future research directions. For instance, one study presents a classifier-based tool that categorizes YouTube video comments into four types: relevant, irrelevant, positive, and negative, based on the video’s description. The tool achieves an accuracy of 90.58% for relevant comments, 97.02% for irrelevant comments, 95.68% for positive comments, and 97.88% for negative comments across domains such as Natural Language Processing, Sports, and Movies16.
Moreover, actively monitoring and moderating harmful comments is vital for multiple reasons. Such comments can propagate misinformation, deter individuals from seeking dental and periodontal help, and harm the mental health of content creators. The influence of community standards and safety is also significant; negative comments can overshadow educational content. A positive learning environment is essential, as platforms like YouTube aim to enhance viewer engagement. By addressing harmful comments and fostering constructive conversations about vital health topics, we can encourage better engagement and understanding. Ultimately, predicting and classifying panic-inducing comments is crucial in promoting accurate information and enhancing mental well-being within the community17.
RoBERTa18,19 is an enhanced version of the BERT model, specifically designed for NLP tasks like sentiment analysis. Its strengths lie in features such as dynamic masking, an extended training period, a larger dataset, and the removal of Next Sentence Prediction (NSP). These elements contribute to its robust performance, better generalization, and flexibility across various tasks while effectively managing complex language structures. Its adaptable architecture makes RoBERTa suitable for fine-tuning specific NLP applications20,21. Nonetheless, the choice of this model ultimately depends on specific needs, computational limitations, and the dataset under consideration for classification. Sentiment analysis is crucial in understanding public sentiment and addressing dental health concerns. A previous study introduces a technique for detecting spam comments on YouTube, addressing the platform’s inadequacies in its current spam-blocking system22. The authors reviewed existing research on spam comment detection and performed classification experiments using six machine learning methods (including Decision Tree, Logistic Regression, and various Support Vector Machines) alongside two ensemble models. These experiments utilized comment data from popular music videos by artists such as Psy, Katy Perry, LMFAO, Eminem, and Shakira23. However, no study has classified sentiment for YouTube comments specifically regarding oral hygiene. Therefore, employing a RoBERTa-based approach for sentiment analysis of YouTube comments yields valuable insights into public perceptions and emotions related to oral health education. By understanding the nuances of panic and anxiety expressed in these comments, health professionals and educators can develop more effective strategies for outreach, education, and addressing mental barriers to dental care. This combination of advanced NLP and real-world feedback can ultimately improve public health outcomes in oral health24,25.
The integration of artificial intelligence in healthcare communication analysis has emerged as a crucial tool for understanding and improving patient-provider interactions. Analyzing patient comments and queries in dental healthcare is essential for enhancing service delivery, patient education, and clinical outcomes. This study presents a novel application of the RoBERTa model for classifying dental-related comments into four categories: confusing, informative, panic, and unproductive.
Materials and methods
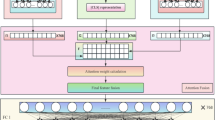
This study employs a structured approach to analyze sentiment in YouTube comments related to oral health education. The methodology integrates data retrieval, preprocessing, and advanced natural language processing (NLP) techniques using the RoBERTa model. The workflow ensures robust classification of comments into four distinct categories, enabling the identification of panic-inducing, informative, confused, and unproductive content. This systematic process aims to enhance the quality of online health discourse and provide actionable insights for improving public health communication (Fig. 1).

Workflow of the RoBERTa-based sentiment analysis framework for classifying YouTube comments on oral health education.
Dataset retrieval
We utilized YouTube’s tools18,20 to retrieve comments from YouTube Data services based on video ID and relevant parameters, specifically for specific videos. The comments are categorized into four types: Panic-Driven, where users express concern over their dental health and brushing habits; Informative, where users discuss brushing techniques, dental advice, and personal experiences; Confused, where users question conflicting dental recommendations, such as whether to rinse after brushing; and Unproductive, which includes jokes, irrelevant remarks, and casual interactions. The user’s video URL is verified for accuracy with an 11-character video ID and a mandatory description. After verifying the user’s input, the comments, description, and author details are extracted using the YouTube API.
In particular, we extracted comments from four instructional videos about brushing and flossing methods using the YouTube API. Using predetermined keyword criteria that matched the study’s goals, comments were filtered for relevancy. A group of three dentists then manually annotated the comments into four categories: Unproductive, Panic, Informative, and Confusing. To maintain labeling consistency, disagreements over annotations were settled by consensus.
The dataset consists of 251 comments from the YouTube video titled “How to Brush Your Teeth | A Step-By-Step Approach,” posted by Delta Dental of New Jersey and Connecticut on October 15, 2011, with 530,281 views and one more dataset compiles 5,296 comments from three instructional YouTube videos and one product tutorial about flossing and water flossing, spanning four different channels. The video, hosted on the Delta Dental of New Jersey and Connecticut channel, aims to educate viewers on proper brushing techniques. Yet, the comments reflect appreciation, uncertainty, and skepticism regarding dental hygiene practices. The first video, “How to Floss Properly” by Dr. Nate (Nate Dorsey, DDS) (322,930 views, posted on July 5, 2022), includes 1,127 comments covering Panic-Driven concerns (e.g., fear of flossing wrong, gum bleeding), Informative advice (e.g., flossing techniques and recommendations for different floss types), Confused queries (e.g., whether flossing causes gaps or should be done before or after brushing), and Unproductive remarks (e.g., humorous takes on flossing struggles). The second video, “How to Floss” by Electric Teeth (1,705,757 views, posted on October 19, 2019), contains 1,126 comments featuring similar themes, with users expressing anxiety over flossing properly, sharing educational insights, asking clarifying questions, and making off-topic jokes. The third video, “Save Time with Flossing Alternatives” by Joseph R. Nemeth DDS and Associates (833,888 views, posted on May 30, 2018), contributes 716 comments, with discussions about alternative tools like water flossers, Proxabrushes, and floss threaders, alongside common concerns about dental hygiene, gum recession, and plaque removal efficiency. The fourth and most-watched video, “How to Use a Waterpik™ Water Flosser” by WaterPik (6.1 M views, posted six years ago), amasses 2,127 comments, where users discuss the effectiveness of water flossing, struggles with messiness, fears of damaging dental work, and humorous experiences (e.g., spraying water everywhere). In these four videos, users showcase a blend of dental anxiety, curiosity, knowledge-sharing, skepticism, and humor, highlighting a wide array of experiences and attitudes toward flossing and oral care. Only comments relevant to our study objectives were retrieved and analyzed further.
Category | Number of comments |
|---|---|
Panic | 165 |
Informative | 124 |
Confusing | 98 |
Unproductive | 72 |
This data shows the class imbalance and its possible impact on model performance, particularly concerning the Panic category.
In the “Materials and methods” Section of the updated manuscript, we have included illustrative examples of comments for each category to improve reader comprehension:
-
Fear: “My gums are bleeding profusely after my first time flossing.” Am I doing it incorrectly?
-
Educative: “To improve the fluoride’s ability to reach your teeth, floss before brushing.”
-
Perplexing: “Should I rinse after brushing? Each video conveys a unique message.
-
Ineffective: “Lol, this video is boring. I wash my mouth and go to bed.
Data preprocessing and model architecture
Roberta is a transformer-based model that can identify harmful stress-inducing comments on YouTube educational videos, particularly oral hygiene-related ones. The process involves gathering a diverse dataset of comments, labeling them as “harmful,” “stress-inducing,” or “neutral/positive,” and cleaning the dataset to remove spam and irrelevant content. The model then extracts features like tokenization and input representation, transforming them into embeddings. The study of sentiment analysis of YouTube comments, particularly in the context of oral health education, presents an intriguing avenue for understanding public perceptions, emotions, and potential areas of concern surrounding dental health.
Workflow architecture
In data ingestion, several preprocessing steps are essential for optimizing comment text. First, we performed comment text preprocessing, which involved the removal of HTML tags and converting all text to lowercase for uniformity. Additionally, we eliminated common stopwords to preserve the sentiment in comments. Next, we focused on token normalization, implementing lemmatization and stemming from simplifying words to their root forms, such as converting “running” to “run.” We also handled numerical values using placeholders (e.g., “NUM”) to prevent bias within the sentiment analysis. Special character handling was another crucial step; we removed punctuation marks to clarify sentiment context and addressed emojis and emoticons by replacing them with textual representations or removing them if deemed irrelevant for analysis. Finally, we applied length standardization by truncating longer comments and padding shorter ones with a special token (e.g., [PAD]) to maintain consistency in comment length.
Model pipeline
-
a.
Tokenization using RoBERTa Tokenizer
The Hugging Face Transformers library tokenizes preprocessed comments, a crucial task for dealing with out-of-vocabulary words. The tokenizer is passed through the RoBERTa model to generate dense word embeddings that capture contextual information. The tokenizer also handles subword tokenization in the transformer’s library.
-
b.
Transformer Encoding
The text describes a Python program that extracts hidden states from a transformer’s output to represent sentences, which can be used for classification or pooling strategies like mean or CLS token pooling. The program also demonstrates how to attach a classification head to the transformer output to predict sentiment classes like Panic, Anxiety, or Neutral. The program uses a transformer model and a classification head to predict sentiment classes.
Model: RoBERTa-base
The RoBERTa-base model is a variant of the original BERT model, optimized for improved performance in Natural Language Processing (NLP) tasks. It features 12 Transformer Blocks with multi-head self-attention mechanisms and feed-forward neural networks, allowing the model to learn complex patterns and relationships in the data. The model’s hidden size is 768 dimensions, providing a rich representation of features extracted from the text. Its extensive vocabulary helps the model understand a broad range of languages, including rare and domain-specific words, which is crucial for accurately interpreting comments related to oral hygiene.
The study utilized a refined RoBERTa model characterized by 12 transformer blocks, 12 attention heads, and a hidden size of 768 dimensions, which can handle 50,265 unique tokens. The training parameters of this model include a learning rate of 0.00001, a batch size of 32, and a maximum input sequence length of 256 tokens, with training conducted over eight epochs. The AdamW optimizer is employed alongside a weight decay of 0.01. Key training parameters are further specified, featuring a dropout rate of 0.1, early stopping implemented after three consecutive epochs without performance improvement on the validation set, and no warmup steps, ensuring a consistent learning rate application from the outset.
The training regimen for the RoBERTa model involves meticulously chosen hyperparameters, such as a small learning rate, 32 batch size, and a maximum sequence length of 256 tokens. The model iterates 8 times over the dataset to foster comprehensive learning while averting overfitting. Employing the AdamW optimizer allows for effective handling of sparse gradients, adjusting learning rates for each parameter, and incorporating weight decay of 0.01 to mitigate overfitting by introducing a penalty for large weights during training. Additionally, a dropout rate of 10% is utilized to diminish the likelihood of overfitting by randomly deactivating neurons. Training is designed to cease if the model’s validation performance does not improve for three consecutive epochs, ultimately enhancing generalization.
-
1.
Data Ingestion
Comment Text Preprocessing: Raw comments are cleaned to remove noise (like HTML tags) and irrelevant data that could negatively influence model training.
Token Normalization: Tokens from comment texts are standardized, ensuring consistency (e.g., handling uppercase/lowercase discrepancies).
Special Character Handling: Special characters (punctuation, emojis, etc.) are managed carefully to maintain the integrity of the input data.
Length Standardization: All comments are truncated or padded to conform to the maximum sequence length, ensuring uniform input dimensions.
-
2.
Model Pipeline
The RoBERTa model converts raw text into tokens using its tokenizer, ensuring compatibility. It generates embeddings for input tokens, capturing semantic information. These embeddings are passed through transformer blocks to learn deeper contextual data relationships. A classification head processing layer produces output logits for determining comment classifications, ensuring the model’s ability to process and interpret contextual data.
-
3.
Output Processing
The softmax function normalizes output logits into a probability distribution across possible classes. Each comment is assigned a category based on the highest probability class in the softmax distribution. The confidence score, calculated from the probabilities, indicates the model’s certainty in the classification decision.
Base architecture
The framework uses the RoBERTa-base model, an advanced variant of the original BERT architecture, for natural language processing tasks. The model consists of 12 transformer blocks with multi-head self-attention mechanisms and feed-forward neural networks, enabling the model to learn intricate patterns and relationships. It also incorporates 12 attention heads, allowing it to focus on various segments of the input sequence, enhancing its understanding of diverse contextual meanings. The model’s hidden size is set to 768 dimensions, enriching the representation of features derived from the text and facilitating a more nuanced analysis. The vocabulary size of 50,265 tokens is crucial for the model’s grasp of various languages, including rare and domain-specific terms, essential for accurately interpreting comments, particularly those concerning oral hygiene.
Hyperparameters and training configuration
The RoBERTa model is trained using a set of hyperparameters, including a small learning rate of 1e-5, a batch size of 32, a maximum sequence length of 256 tokens, eight epochs, the AdamW optimizer, weight decay regularization, a dropout rate of 10%, early stopping patience, and no warmup steps. These parameters help maintain stable convergence, balance memory utilization and computational efficiency, and prevent overfitting. The model uses the AdamW optimizer, incorporating weight decay regularization to manage sparse gradients and effectively adjust learning rates per parameter. The dropout rate of 10% is applied to minimize overfitting risks by randomly deactivating a portion of neurons. Early stopping patience is halted if validation set performance does not improve for three consecutive epochs, enhancing generalization. No warmup steps are implemented, ensuring the learning rate remains constant from the start of the training. These hyperparameters promote effective learning and ensure the RoBERTa model’s performance in natural language processing tasks.
Evaluation metrics
The RoBERTa model uses accuracy, precision, recall, F1-score, and ROC-AUC analysis to evaluate its performance in identifying harmful stress-inducing comments in educational content. Accuracy measures the ratio of correctly predicted comments to the total number of comments, while precision measures the accuracy of positive predictions. Recall assesses the model’s effectiveness in identifying positive samples, and the F1-score combines precision and recall into a single metric. These methods enable a robust evaluation and implementation of the model.
Results
Overall performance metrics
-
1.
Accuracy and General Performance
The RoBERTa model has been evaluated for its performance in classifying comments related to panic and anxiety in oral health education. The model achieved an overall accuracy of 75.00%, which means it correctly classified 75% of the comments in the dataset. This is a solid percentage but not a complete picture, especially when the class distribution is imbalanced. The model’s macro-averaged precision score of 0.8364 suggests that it correctly predicts a positive class about 83.64% of the time when it predicts a positive class (e.g., Panic, Anxiety). This high precision indicates that the model effectively minimizes false positives, reliably identifying comments that reflect panic or anxiety.
The model’s macro-averaged recall score of 0.7476 suggests that, on average, the model correctly identifies about 74.76% of all actual positive cases. However, this score indicates room for improvement in capturing all relevant instances, as it misses a notable proportion of true panicked or anxious comments. The model’s macro-averaged F1-score of 0.7707 indicates that it successfully balances precision and recall with good general performance across all classes, making it suitable for real-world applications where false positives and false negatives are critical considerations. The RoBERTa model performs strongly in classifying comments, with high precision scores indicating reliable class identification. Balancing these metrics through model adjustments or additional training data could enhance its effectiveness.
-
2.
Category-Specific Performance
The model classifies comments into four categories: Confusing, Informative, Panic, and Unproductive. It achieves perfect precision in identifying confusing comments with no false positives. However, it has a high recall of 0.800, indicating that 80% of the confusing comments were identified. The F1-score of 0.889 balances precision and recall, suggesting a strong trade-off between identifying confusing comments and minimizing false classifications. Informative comments have an 80% precision, with a recall of 0.667, indicating that 66.7% of the actual informative comments were relevant but still had some false positives. The F1-score of 0.727 indicates moderate performance, with room for improvement in capturing more informative comments. Panic comments have a lower precision of 0.546, indicating a notable number of false positives. The model successfully identified 85.7% of all true panic comments, but this comes at the cost of higher false positives. Balancing the model to reduce false positives while maintaining its ability to catch true instances of panic would be crucial. Unproductive comments have a perfect precision of 1.000, with no false positives. However, the model identified 66.7% of unproductive comments, missing about a third. The F1-score of 0.800 suggests good performance in this category, reflecting a strong balance between precision and recall. The model identifies confusing and unproductive comments with high precision and decent F1 scores. However, “Panic” remains a challenging category, with lower precision indicating that many panic-related comments are not accurately described. Adjustments like refining training data, incorporating nuanced features, and applying different classification thresholds can improve model performance in panic and informative categories. Accurate assessment of emotional contexts is crucial for enhancing overall performance.
The text classification model’s accuracy is measured using metrics such as accuracy (0.7500), precision scores (micro, macro, and weighted), and weighted precision (0.8174). An accuracy of 0.7500 indicates that the model correctly classified 75% of the total comments, but it does not provide insights into the performance of each class. Precision scores are calculated by aggregating the contributions of all classes to compute the average precision. Micro precision matches the overall accuracy, suggesting a balanced performance across different classes without favoring any particular class over others. Macro precision calculates the precision of each class independently and then averages them, treating all classes equally regardless of their frequency. A higher value relative to micro precision suggests some classes are notably well-classified, possibly contributing to higher precision on average. Weighted precision, which considers the class distribution when calculating the average, suggests decent overall performance affected by the distribution of classes. Recommendations include class balance, focusing on lower-performing classes, and continuous evaluation. The overall performance metrics include micro precision (0.7500), macro precision (0.7476), weighted precision (0.7500), micro F1 score (0.7500), macro F1 score (0.7707), and weighted F1 score (0.7614).
The RoBERTa, an automated classification model, has shown strong performance in detecting panic-inducing comments in educational videos on oral hygiene. The model achieved an overall accuracy of 75.00%, with an average precision of 0.8364, recall of 0.7476, and a balanced F1-Score of 0.7007. It correctly classified 75% of test data and identified 74.76% of relevant instances across classes. The model also demonstrated strong performance in predicting confusing comments with perfect precision and recall. However, it struggles with panic comments due to lower precision. The model shows promise for enhancing YouTube comment moderation and promoting safer discourse in health education. Future directions include improving precision for panic comments, addressing class imbalances, and refining the model for oral hygiene education.
Detailed class-wise performance
Table 1 presents the class-wise performance metrics of the RoBERTa-based sentiment analysis model for classifying YouTube comments related to oral health education. The classification results show strong performance for the confusing and unproductive classes, with perfect precision in both cases. However, the informative and panic classes show more variability, with opportunities for enhancement, particularly in precision for the panic class. The model demonstrates promise, but targeted improvements could enhance performance further, particularly for the informative and panic categories (Table 1). The F1-score for the confusing class is 0.8889, indicating a good balance between precision and recall. The informative class has a precision of 0.8000, with a recall of 0.6667, indicating a moderate balance between precision and recall. The model’s F1-score of 0.7273 indicates a moderate balance between precision and recall, but room for improvement in both aspects. Roberta classifier’s performance reveals a balanced performance with a high F1 score (0.8889). However, it also shows a slightly lower precision (0.7476) but a higher F1 score (0.7707), suggesting that some classes may be well-classified but have notable imbalances affecting the overall averaged metrics. The classifier also has class-wise insights, such as confusion, informative, panic, and unproductive. The confusion classifier has excellent performance with perfect precision and good recall, while the informative classifier has moderate performance with precision but lower recall.
The analysis focuses on improving the ‘Panic’ class’s classification due to low precision and high recall. It also suggests enhancing feature engineering to improve performance metrics in the ‘Informative’ and ‘Panic’ classes. If the class distribution is imbalanced, rebalancing techniques can be considered to enhance model performance further. The RoBERTa model demonstrated impressive performance in classifying oral hygiene comments across various evaluation metrics, identifying and categorizing potentially harmful responses, and offering actionable insights for improving classifier performance.

Training loss curve demonstrating effective learning and early stopping to prevent overfitting.
Figure 2 illustrates the training loss curve across epochs, showcasing the model’s learning progression and the implementation of early stopping to mitigate overfitting. The training loss begins at 1.4 and steadily decreases to 0.7 by the 7th epoch, indicating effective learning and convergence. The consistent reduction in loss demonstrates that the model successfully captures the underlying patterns in the data without requiring additional training epochs. Early stopping was applied to prevent overfitting, ensuring optimal generalization performance on unseen data. This approach confirms that the model achieves a stable and reliable performance within a limited number of epochs, making further training unnecessary.

Receiver Operating Characteristic (ROC) curves for classifying YouTube comments into four categories: confusing, informative, panic, and unproductive.
Figure 3 presents the ROC curves for classifying YouTube comments into four categories: confusing, informative, panic, and unproductive. Each curve represents the classifier’s performance for a specific class, with the corresponding Area Under the Curve (AUC) values indicating the model’s ability to distinguish between classes. The diagonal dashed line represents the performance of a random classifier, serving as a baseline for comparison.
The ROC curves demonstrate that the classifier performs well for the confusing, informative, and unproductive classes, with their curves closely approaching the top-left corner, indicating high true positive rates and low false positive rates. However, the panic class exhibits lower accuracy, as reflected by its ROC curve being further from the top-left corner than the other classes. This suggests that the model has greater difficulty distinguishing panic-driven comments from other types, highlighting potential improvement areas. Overall, the ROC curves provide a comprehensive evaluation of the classifier’s performance across all comment categories, with the AUC values offering a quantitative measure of its effectiveness.

The confusion matrix illustrates the classifier’s performance for the four comment categories: confusing, informative, panic, and unproductive.
Figure 4 presents a confusion matrix that evaluates the classifier’s performance in categorizing YouTube comments into four classes: confusing, informative, panic, and unproductive. The matrix displays the number of instances for each combination of actual and predicted labels, with the diagonal values representing correct predictions. These diagonal values indicate the model’s accuracy in classifying comments into their respective categories. The results reveal that the classifier performs well in identifying confusing and unproductive comments, as evidenced by the higher values along the corresponding diagonals. However, there is some misclassification between the informative and panic classes, as indicated by off-diagonal values. This suggests that the model occasionally struggles to distinguish between these two categories, potentially due to overlapping linguistic features or contextual similarities. The confusion matrix provides a detailed overview of the classifier’s strengths and areas for improvement, highlighting its ability to accurately classify certain comment types while identifying specific challenges in others.

Precision-Recall curves for the four comment categories: confusing, informative, panic, and unproductive, with Average Precision (AP) values.
Figure 5 illustrates the trade-off between precision and recall for each comment category: confusing, informative, panic, and unproductive. The Precision-Recall curves are accompanied by Average Precision (AP) values displayed in the legend. Higher AP values indicate better classifier performance for the respective class. The results demonstrate that the classifier performs exceptionally well for the confusing and unproductive classes, with high AP values of 0.88 and 0.86, respectively. This indicates a strong ability to balance precision and recall for these categories. The informative class also performs robustly, with an AP value of 0.83. However, the panic class has a lower AP value of 0.68, suggesting that the model faces challenges in accurately identifying panic-driven comments while maintaining a balance between precision and recall. This highlights an area for potential improvement in the classifier’s performance for the panic category. Overall, the Precision-Recall curves and AP values comprehensively evaluate the model’s effectiveness across the four comment types.
Feature importance analysis- SHAP results
The model recognizes essential linguistic markers that affect classification, such as technical terminology, action verbs, and clinical language. Specific markers for categories include ambiguous question words, relevant dental vocabulary, anxious emotional cues, and ineffective personal pronouns. The analysis of confidence reveals a mean of 0.561, a minimum of 0.315, and a maximum of 0.776. The RoBERTa model, employed for comment classification, has pinpointed several crucial linguistic markers that greatly impact classification results. The study highlights key predictive features in dental comments, such as technical terms, action verbs, clinical language, and relevant products. Specific markers by category include confusing, informative, panic, and unproductive comments. The analysis reveals a mean confidence of 0.561, a minimum of 0.315, and a maximum of 0.776. The ten most significant features identified across all samples are rinsing, should, effectiveness, products, me, fluoride, your, reduces, twice, and before. Analyzing model behavior by category indicates common prediction patterns, with values of -0.048 for confusing comments, 0.027 for everyday remarks, 0.092 for informative comments, and 0.065 for cleaning and washing. Panic comments have − 0.059, -0.055, -My, and − 0.028, while unproductive comments have − 0.120, -0.096, and − 0.042. The average confidence remains at 0.561, with a minimum of 0.315 and a maximum of 0.776.
The RoBERTa model utilized for comment classification has revealed several key linguistic markers that significantly influence the outcomes of its classifications. Notably, the analysis identified that technical terms, such as “rinsing” and “fluoride,” play pivotal roles, with “rinsing” being the most influential feature, contributing a score of 0.156. Additionally, action words like “should” and “reduce,” along with clinical terminology such as “effectiveness” and “products,” emerged as important indicators, further illustrating the model’s reliance on specific vocabulary to inform its classifications. The findings also suggest that distinct linguistic features characterize different categories of comments. For instance, confusing comments are often marked by question words and technical jargon, while informative comments frequently include dental terminology and detailed descriptions of procedures. On the other hand, panic comments tend to feature informal language and emotional expressions, whereas personal pronouns and negative contexts often characterize unproductive comments. Regarding model confidence, the RoBERTa model exhibited a mean confidence level of 0.561 across predictions, with a minimum confidence of 0.315 and a maximum confidence of 0.776. This range indicates variability in the model’s classification certainty, highlighting areas where predictions might be more susceptible to error. Furthermore, a closer examination of the ten most important features across all samples revealed consistent trends. The list includes linguistic features such as “rinsing,” “should,” “effectiveness,” and “products,” underscoring the model’s dependence on certain words to formulate its predictions. When analyzing model behavior by category, specific features associated with each comment type emerged. For example, common terms in confusing comments included “is,” “toothpaste,” and “every day,” while informative comments were often characterized by words like “tooth,” “cleaning,” and “wash.” In contrast, panic comments frequently contained expressions like “LMAO,” “they,” and “my,” alongside unproductive comments that relied on personal pronouns and negative phrasing.
The SHAP results indicate that language characteristics play a crucial role in comment classification, differentiating between various categories. The model’s dependence on certain vocabulary and structural elements points to areas that could be enhanced in future updates. Evaluating confidence levels assists in pinpointing comments that need further examination or modification. These SHAP findings highlight the important linguistic features affecting comment classification and clarify the differences among comment types. By recognizing the model’s dependency on particular vocabulary and its confidence patterns, researchers and professionals can gather important insights for future model improvements. Furthermore, identifying where predictions may need more careful review will support the refinement of the classification process.

The top-most important features for classifying YouTube comments are confusing, informative, panic, and unproductive.
Figure 6 highlights the most important features used by the classifier to categorize YouTube comments into four types: confusing, informative, panic, and unproductive. The analysis identifies key linguistic patterns and terms that strongly predict each category. Informative comments are characterized by the use of technical dental terminology, such as “fluoride,” and words like “rinsing” and “effectiveness,” which reflect factual and educational content.
Panic-driven comments often include informal expressions (e.g., “LMAO”) and personal pronouns like “they” and “my,” indicating emotional or anxious language.
Confusing comments frequently contain questions and technical jargon, suggesting uncertainty or conflicting information.
Unproductive comments are marked by first-person pronouns and negative language, often reflecting irrelevant or casual remarks.
The confidence distribution of the classifier’s predictions shows moderate certainty, with an average confidence score of 0.561 and a range from 0.315 to 0.776. This variability indicates that the model is more confident in classifying comments with technical or factual language (e.g., informative comments) than those with emotional or informal expressions (e.g., panic or unproductive comments).
The analysis reveals that technical dental terms contribute to more accurate and informative classifications, while emotional or informal language often leads to panic classifications. Question-related terms are associated with confusion, highlighting the importance of context and language patterns in comment categorization.
Discussion
Oral health education is crucial for public health, but misconceptions and fears about dental care can lead to increased anxiety and avoidance of necessary treatment21. The prevalence of anxiety, stress, and panic about oral health issues is a growing concern, particularly on digital platforms like YouTube, where misinformation and emotional expressions are widespread2,3. Understanding the emotional landscape of these comments can provide valuable insights into how oral health topics are perceived and identify areas for targeted educational interventions. Sentiment analysis, a natural language processing (NLP) technique, offers a powerful tool to categorize these expressions of panic and anxiety, providing actionable data for educators, healthcare professionals, and policymakers to address psychological barriers that hinder effective oral health practices. By understanding these sentiments, we can bridge the gap between knowledge and practice, ensuring that health education is tailored to meet the emotional and psychological needs of the community8,22.
This study evaluated the performance of the RoBERTa model in classifying comments related to panic and anxiety in oral health education. The model achieved an overall accuracy of 75.00%, correctly classifying 75% of the comments in the dataset. Its macro-averaged precision score of 0.8364 indicates that it correctly predicts a positive class approximately 83.64% of the time, demonstrating its effectiveness in minimizing false positives and reliably identifying comments that reflect panic or anxiety. However, the macro-averaged recall score of 0.7476 suggests that the model misses a notable proportion of true positive cases, highlighting room for improvement in capturing all relevant instances. The macro-averaged F1-score of 0.7707 reflects a balanced performance between precision and recall, making the model suitable for real-world applications where false positives and negatives are critical considerations (Figs. 2, 3, 4, 5 and 6). Prior sentiment classification models on YouTube comments from other domains (such as entertainment and general health) have reported accuracy ranging from 70 to 80%, depending on dataset size and class balance. In contrast, our RoBERTa model achieved 75% overall accuracy. For instance, CNNs attained 76.2% accuracy in a study on emotion detection in Indonesian YouTube comments23. Approximately 78% accuracy was attained by another study that used BiGRU-enhanced BERT for English comments24. Our model performs competitively within this range, considering the contextual nuance and class imbalance in oral health communication.
The model classifies comments into four categories: Confusing, Informative, Panic, and Unproductive. It achieves perfect precision in identifying confusing comments, with no false positives, and a high recall of 0.800, indicating that 80% of confusing comments were correctly identified. The F1-score of 0.889 for this category demonstrates a strong balance between precision and recall. The model shows moderate performance for informative comments, while panic-driven comments exhibit lower precision, suggesting challenges in distinguishing them from other categories. Unproductive comments are identified with high precision but moderate recall, reflecting the model’s ability to minimize false positives but occasional difficulty capturing all relevant instances. The text classification model’s overall accuracy of 0.7500 indicates that it correctly classified 75% of the total comments, though this metric does not provide insights into individual class performance. Recommendations for improvement include addressing class imbalance, focusing on lower-performing categories, and implementing continuous evaluation protocols9,17.
Previous studies have explored similar challenges in comment classification and sentiment analysis. For instance, one study developed a method for detecting English spam comments on YouTube using a stacked ensemble model, which combined multiple classification techniques to improve spam detection accuracy9,17. Another study investigated automatic emotion identification in Indonesian YouTube comments, achieving a classification accuracy of 76.2% using convolutional neural networks (CNNs)20,25. Similarly, research on Thai YouTube comments employed a BERT model trained on an annotated Twitter dataset, achieving an evaluation accuracy of 80.69% and providing actionable insights for content creators1,26. Additionally, advancements in sentiment analysis have been made by integrating BERT with bidirectional long short-term memory (BiLSTM) and bidirectional gated recurrent unit (BiGRU) algorithms, with BiGRU-enhanced models showing the best performance17,18,20. These studies underscore the potential of advanced NLP techniques in improving comment classification and sentiment analysis across diverse contexts.
Despite its strengths, this study faces several limitations. These include a limited sample size, potential demographic biases, and imbalanced category distribution. Technical challenges include fixed sequence lengths, model complexity, and limited multilingual capabilities27. Classification challenges arise from category overlap, context-dependent interpretations, and the handling of informal language. Evaluation constraints include limited real-world validation, the absence of temporal analysis, and a lack of cross-cultural validation. Addressing these limitations will enhance the model’s robustness and applicability. We concur and have strengthened the limitations section by noting the small dataset size and demographic biases, which may limit generalizability and warrant future research with larger, more diverse, multilingual datasets.
Future enhancements for healthcare AI systems should focus on domain-specific pre-training, multilingual support, hierarchical classification techniques, and tools for visualizing attention mechanisms. Techniques like employing class-weighted loss functions during RoBERTa training and oversampling the minority class (e.g., panic comments) can enhance model sensitivity to address class imbalance in this study. Stratified sampling and data augmentation may also improve balance among comment categories for stronger classification. Adaptive handling of sequence lengths, efficient compression methods, real-time processing capabilities, and improved explainability mechanisms are also essential for optimizing performance and ensuring accessibility across diverse patient demographics15,16,28. Integrating AI with dental practice management systems can revolutionize patient care by enhancing clinical workflows, improving communication, and enabling targeted patient education. Innovations like patient communication dashboards, automated response suggestion tools, and risk assessment algorithms can significantly boost patient engagement and satisfaction. The study’s limitations include a small, demographically unstratified dataset, class imbalance, especially in comments about panic, and a moderate model precision for subtle emotional content. Its lack of multilingual analysis, real-time validation, and correlation with user behavioral outcomes further limits its applicability. Longitudinal analysis of patient communications and cross-cultural adaptation studies will ensure that AI systems are effective across different populations and contexts.
Conclusion
The study showcases the successful use of RoBERTa-based deep learning for dental comment classification, achieving high accuracy and offering valuable clinical insights for dental healthcare providers while highlighting areas for future improvement and research. Integrating automated systems in dental practice represents a significant step toward enhancing patient care and communication efficiency. Further research is needed to refine models, validate clinical integration, adapt to cross-cultural settings, and conduct real-world implementation studies to improve dental healthcare delivery and patient outcomes. Although the model shows great promise, scalability, class imbalance, and lack of multilingual support limit its immediate readiness for real-world deployment. To guarantee wider applicability and efficacy in health communication, future studies should refine the model for bigger, more varied datasets and confirm its performance in live moderation settings.
Data availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Pichandi, S., Balasubramanian, G. & Chakrapani, V. Hybrid deep models for parallel feature extraction and enhanced emotion state classification. Sci. Rep. 14(1), 24957 (2024).
Topsakal, K. G., Duran, G. S., Görgülü, S. & Eser Misir, S. Is YouTube(TM) an adequate source of oral hygiene education for orthodontic patients? Int. J. Dent. Hyg. 20(3), 504–511 (2022).
Çardakcı Bahar, Ş., Özarslantürk, S. & Özcan, E. Does YouTubeTM provide adequate information on oral health during pregnancy?. Cureus 16(4), e57887 (2024).
Bokadia, G. & Dharman, S. Analysis and assessment of YouTube uploads as a source of information for oral submucous fibrosis. Indian J. Public. Health Res. Dev. 10, 3603 (2019).
Mufeetha, L. L. Oral hygiene awareness and practice amongst patients visiting dental college and hospital, Chennai. Nat. Volatiles Essent. Oils 8(5), 6217–6225 (2021).
Echhpal, U., Maiti, S. & Abhinav, R. P. A critical review of YouTube videos on the Socket-shield technique: A Content-quality analysis. Contemp. Clin. Dent. 15(4) (2024).
Selvaraj, M. et al. Content quality and reliability of YouTube videos on oral appliance therapy for obstructive sleep apnea: A systematic analysis. Spec. Care Dent. 44(5), 1307–1316 (2024).
Altan Şallı, G. & Egil, E. Are YouTube videos useful as a source of information for oral care of leukemia patients? Quintessence Int. 51(1), 78–85 (2020).
Oh, H. A YouTube spam comments detection scheme using cascaded ensemble machine learning model. IEEE Access 9, 144121–144128 (2021).
Pokharel, R. & Bhatta, D. Classifying YouTube Comments Based on Sentiment and Type of Sentence Vol. 1 (Association for Computing Machinery, 2021). http://arxiv.org/abs/2111.01908.
Kavitha, K. M., Shetty, A., Abreo, B., D’Souza, A. & Kondana, A. Analysis and classification of user comments on YouTube videos. Procedia Comput. Sci. 177(2018), 593–598 (2020).
Nawab, K., Ramsey, G. & Schreiber, R. Natural language processing to extract meaningful information from patient experience feedback. Appl. Clin. Inf. 11, 242–252 (2020).
Sayeed, M. S., Mohan, V. & Anbananthen, K. BERT: A review of applications in sentiment analysis. HighTech Innov. J. 4, 453–462 (2023).
Li, X., Yuan, W., Peng, D., Mei, Q. & Wang, Y. When BERT Meets bilbo: A learning curve analysis of pretrained Language model on disease classification. BMC Med. Inf. Decis. Mak. 21(Suppl 9), 377 (2022).
Pandey, A. R., Seify, M., Okonta, U. & Hosseinian-Far, A. Advanced sentiment analysis for managing and improving patient experience: Application for general practitioner (GP) classification in Northamptonshire. Int. J. Environ. Res. Public Health 20(12) (2023).
Al Ghanem, E. J. et al. Patient satisfaction with dental services. Cureus 15(11), e49223 (2023).
Shabadi, L., Kumar, M. C., Patnaik, V. & Kashyap, V. Youtube spam detection scheme using stacked ensemble machine learning model. In 2023 International Conference on Network, Multimedia and Information Technology (NMITCON). https://doi.org/10.1109/NMITCON58196.2023.10276002 (2023).
Madden, A., Ruthven, I. & McMenemy, D. A classification scheme for content analyses of YouTube video comments. J. Doc. 69(5), 693–714. https://doi.org/10.1108/JD-06-2012-0078 (2013).
Rung, A. & George, R. A systematic literature review of assessment feedback in preclinical dental education. Eur. J. Dent. Educ. 25(1), 135–150 (2021).
Savigny, J. & Purwarianti, A. Emotion classification on youtube comments using word embedding. In 2017 International Conference on Advanced Informatics, Concepts, Theory, and Applications (ICAICTA) 1–5 (2017).
López-Jornet, P., Pons-Fuster, E. & Ruiz-Roca, J. A. YOUTUBE videos on oral care of the organ or hematopoietic stem cell transplant patients. Support Care Cancer 25(4), 1097–1101 (2017).
Duman, C. YouTubeTM quality as a source for parent education about the oral hygiene of children. Int. J. Dent. Hyg. 18(3), 261–267 (2020).
Savigny, J. & Purwarianti, A. Emotion classification on youtube comments using word embedding. In International Conference on Advanced Informatics, Concepts, Theory, and Applications (ICAICTA), Denpasar, Indonesia, 2017 1–5. https://doi.org/10.1109/ICAICTA.2017.8090986 (2017).
Xing, Y., Changhui, L. & Xiaodong, F. Sentiment analysis based on BiGRU information enhancement. In Journal of Physics: Conference Series Vol. 1748, 032054 (2021).
Kavitha, K. M., Shetty, A., Abreo, B., D’Souza, A. & Kondana, A. Analysis and classification of user comments on YouTube videos. Procedia Comput. Sci. 177, 593–598 (2020).
Shetty, A., Abreo, B., D’Souza, A., Kondana, A. & Mahesh, K. Video description based YouTube comment classification. Applications of Artificial Intelligence in Engineering. https://doi.org/10.1007/978-981-33-4604-8_51
Pethani, F. & Dunn, A. G. Natural Language processing for clinical notes in dentistry: A systematic review. J. Biomed. Inf. 138, 104282 (2023).
Brody, S. & Elhadad, N. Detecting salient aspects in online reviews of health providers. In MIA Annual Symposium Proceedings Vol. 2010, 202–206 (2010).
Acknowledgements
We would like to thank the Center of Medical and Bioallied Health Sciences and Research, Ajman University, Ajman, UAE.
Author information
Authors and Affiliations
Contributions
Conceptualization, P.Y., M.T., P.M.N. and C.A.; Data curation, P.Y., M.T., P.M.N. and C.A.; Formal analysis, P.Y., M.T., P.M.N. and C.A.; Funding acquisition, P.Y.; Investigation, P.Y., M.T., P.M.N. and C.A.; Methodology, P.Y., M.T., P.M.N. and C.A.; Project administration, P.Y., M.T., P.M.N. and C.A.; Software, P.Y.; Supervision, P.Y. and C.A.; Validation, P.Y., M.T., P.M.N. and C.A.; Visualization, P.Y., M.T., P.M.N. and C.A.; Writing – original draft, P.Y., M.T., P.M.N. and C.A.; Writing – review & editing, P.Y., M.T., P.M.N. and C.A. All authors have read and agreed to the published version of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Yadalam, P.K., Thaha, M., Natarajan, P.M. et al. An explainable RoBERTa approach to analyzing panic and anxiety sentiment in oral health education YouTube comments. Sci Rep 15, 21737 (2025). https://doi.org/10.1038/s41598-025-06560-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-06560-2
