
Abstract
To address the challenges of low performance in vehicle image detection from UAV aerial imagery, difficulties in small target feature extraction, and the large parameter size of existing models, we propose the OSD-YOLOv10 algorithm, an enhanced version based on YOLOv10n. The proposed algorithm incorporates several key innovations: First, we employ online convolutional reparameterization to construct the OCRConv module and design a lightweight feature extraction structure, SPCC, to replace the conventional C2f module, thereby reducing computational load and parameter count. Second, we integrate an efficient dual-layer feed-forward hybrid attention module to enhance the model’s feature extraction capabilities. We also construct a dual small-target detection layer that combines shallow and ultra-shallow features to improve small-target detection. Finally, we introduce the DySample dynamic upsampling module to enhance feature fusion in the neck network from a point sampling perspective. Extensive experiments on the VisDrone-DET2019 and UAVDT datasets demonstrate that OSD-YOLOv10 achieves a 40.7% reduction in parameter count and a 3.6% decrease in floating-point operations, while improving accuracy and mean average precision by 1.3% and 1.6%, respectively. Compared to other YOLO series and lightweight models, OSD-YOLOv10 exhibits superior detection accuracy and lower computational complexity, achieving an optimal balance between high accuracy and low resource consumption. These advancements make it particularly suitable for deployment in UAV onboard hardware for vehicle target detection tasks. Code will be available online (https://github.com/Z76y/OSD-YOLO).
Similar content being viewed by others

Introduction
In recent years, unmanned aerial vehicles (UAVs) have been extensively deployed in agriculture1, traffic surveillance2,3, urban management4, and emergency response5 owing to their superior mobility, real-time data transmission capabilities, and efficient imaging performance. For road safety supervision, the integration of high-speed UAVs with object detection technology enables rapid vehicle identification and localization within road networks6,7, demonstrating significant application value for traffic flow statistics, safety monitoring, and vehicular positioning.Target detection in UAV aerial imagery is a core technological component, critically influencing both mission execution accuracy and the practical application’s efficacy. With advancements in deep learning, deep neural network-based object detection has emerged as the predominant solution for UAV vision systems. Current detection algorithms fall into two categories: Two-stage and one-stage detection algorithms. Two-stage detectors (e.g., R-CNN series8,9,10) excel in high-precision localization and small-object detection within complex scenarios through region proposal generation followed by refined classification and regression. However, their substantial computational demands and slow inference speeds hinder real-time deployment, particularly on embedded systems. Single-stage detectors (e.g., YOLO series11,12,13,14) reformulate detection as a regression problem, directly predicting object locations and categories from input images. This paradigm delivers marked speed advantages, making them ideal for the real-time processing of large-scale aerial imagery on embedded platforms15,16. They exhibit exceptional performance in intelligent transportation and disaster monitoring.
Nevertheless, fundamental limitations persist: Single-stage detectors exhibit severe accuracy degradation when processing small and densely clustered objects, particularly under long-range imaging or heavy occlusion in complex scenarios. More critically, UAV applications require extreme lightweight to accommodate the real-time processing of massive data streams on resource-constrained devices17. Consequently, ensuring high detection accuracy under stringent lightweight constraints has emerged as the core challenge constraining UAV object detection technology18,19. This irreconcilable accuracy-efficiency trade-off constitutes the primary research focus—where instantaneous scene interpretation and reliable information delivery directly determine mission outcomes in time-sensitive applications such as emergency response and environmental monitoring. Existing solutions remain incapable of simultaneously fulfilling the dual requirements for high timeliness and precision, significantly impairing mission-critical operations.
To address these challenges, researchers have focused on developing efficient and lightweight target detection networks. Recently, YOLOv1014 introduced an efficient architecture through innovations such as a lightweight classification head, spatial-channel decoupling downsampling, and rank-guided block design. Building on this, we propose OSD-YOLOv10, a lightweight UAV aerial target detection model based on YOLOv10. By significantly reducing the number of parameters and computational load, OSD-YOLOv10 achieves state-of-the-art detection speed while maintaining high accuracy, making it particularly suitable for vehicle target detection on UAVs with limited computational resources. The main contributions of this paper are as follows:
-
(1)
To address the issues of excessive parameter counts and computational load, we propose the OCRConv module and integrate it with a lightweight feature extraction structure, SPCC. Leveraging online convolutional reparameterization20 and partial convolution(PConv) operations21, this design achieves significant model lightweight without compromising performance.
-
(2)
To mitigate the problem of missed detections for small targets, we design an efficient spatial attention framework, Dual-Feed Mixed Attention (DFMA)Network, combined with a reconfigured dual-layer small-target detection network. This enhancement improves the model’s ability to recognize small targets in complex environments.
-
(3)
To address the loss of tiny target features during upsampling, we introduce DySample22, a dynamic upsampling module that enhances the feature fusion capability of the neck network from a point sampling perspective, ensuring better preservation of critical details.
Through these innovations, OSD-YOLOv10 achieves a balance between high accuracy and low resource consumption, making it a robust solution for real-time UAV-based vehicle target detection.
Related work
UAV object detection
Object detection is one of the core tasks in computer vision and serves as a crucial foundation for many advanced visual applications. With the increasing use of UAV (Unmanned Aerial Vehicle) technology in fields such as traffic monitoring23,24, disaster rescue25, and road planning26, object detection using UAV imagery has become a focal area of research. However, UAVs typically operate at altitudes ranging from tens to hundreds of meters, resulting in images where the targets are small in scale, low in resolution, and exhibit weak feature representation. These characteristics create significant technical challenges for effective object detection.
To solve the above problems, researchers have proposed various detection methods for UAV viewpoints.For instance, Song et al.27 based on the single-stage detection framework SSD, combined with the K-means + + clustering algorithm to optimize the anchor ratio, and introduced a low-pass filter to alleviate the aliasing effect caused by the pooling operation, thereby improving the recognition ability of small targets. Lu et al.28 designed a hybrid method of CNN and Transformer to achieve more effective UAV image detection by using multi-scale feature information.Hoanh et al.29 proposed a method of fusing the Transformer encoder-decoder and object focusing network to improve the performance of small object detection by optimizing the expression ability of multi-layer feature maps. Nguyen et al.30 designed a hybrid convolution-transformer architecture, which combined an adaptive attention mechanism and feature fusion module to strengthen fine-grained feature extraction and significantly enhance the robustness of small object recognition. Zhu et al.31 implemented TPH-YOLOv5, which replaces conventional prediction heads with Transformer-based structures and integrates channel-spatial attention mechanisms via CBAM modules, demonstrating superior performance in dense UAV scenarios. Zhang et al.32 proposed the PARE-YOLO algorithm, which involves the reconstruction of neck networks to enhance multi-scale feature extraction and fusion to improve the accuracy of UAV-based detection. Zhang et al.33 presented Drone-YOLO, which enhances YOLOv8’s detection capabilities for UAV imagery by utilizing RepVGG blocks as downsampling layers and integrating auxiliary feature branches within the neck network. In addition, Tahir et al.34 combined Swin Transformer and Soft-NMS mechanism to significantly improve the recognition ability of pedestrians and vehicles in occluded environments.
Although existing studies have achieved good performance in specific scenarios, they still have shortcomings in the balance between accuracy and computational efficiency, and more reasonable network design or optimization strategies are urgently needed to achieve better comprehensive performance.
Network lightweighting techniques
The widespread use of deep learning models for various visual tasks has posed deployment challenges due to their large number of parameters and high computational costs, especially on resource-constrained edge devices. Therefore, network lightweighting has become a popular research topic in recent years. Current lightweighting techniques include lightweight network structure optimization, quantization35, knowledge distillation36, and network pruning37. Quantization lowers the precision of weights to reduce storage overhead and computational burden. Knowledge distillation uses high-performance teacher models to guide the learning process of lightweight student models, enabling them to retain key semantic information while achieving higher efficiency. Pruning aims to remove redundant connections or channels to compress model size and improve inference speed. However, these methods may lead to information loss, causing a decline in model performance. In contrast, network structure optimization designs efficient architectures for specific tasks and scenarios to minimize model size while maintaining high accuracy under limited computational resources. This approach is currently the most active area of research.In recent years, several innovative architectures have been proposed to achieve model lightweighting. For instance, Cao et al.38 utilized MobileNetV3 as the backbone network and incorporated depthwise separable convolution to control the number of channels, thereby significantly reducing both model parameters and computational load. Xu et al.39, introduced reparameterization techniques to decrease inference computation while preserving model accuracy. Zhang et al.40 employed partial convolutions to reconstruct the backbone and neck networks, minimizing redundant memory accesses. Wang et al.41 integrated the lightweight MobileNetV2 backbone network into the YOLOv4 framework to effectively compress the model size. Additionally, Wang et al.42 adopted Ghost convolution to construct a lightweight backbone network and combined it with the GSConv module to enhance feature representation capabilities, thus reducing computational complexity and improving the efficiency of target learning.
These methods serve as critical references for this study and guide the development of effective solutions. However, existing methods still exhibit limitations in balancing performance and efficiency. Some approaches overly prioritize real-time performance, sacrificing the integrity of network architecture design and leading to inadequate performance in complex scenarios. Other methods excessively focus on accuracy, resulting in an initially excessive number of parameters. Even after lightweight processing, these models often fail to meet the requirements for embedded deployment. Improving accuracy and generalization capabilities while preserving the lightweight characteristics of the model remains a pivotal challenge in the field of lightweight UAV target detection.
Methodology
YOLOv10
The YOLOv10 model represents the most recent progress in the YOLO family of object detection algorithms and has gained widespread attention in the global research community. YOLOv1014 introduces a unified dual assignment strategy, eliminating the reliance on non-maximum suppression (NMS) during training, a first in the YOLO series. Additionally, YOLOv10 adopts a model design strategy driven by overall efficiency and accuracy, incorporating innovations such as lightweight classification heads, spatial-channel decoupled downsampling, and a rank-guided block design. These advancements enable YOLOv10 to achieve outstanding performance on the COCO dataset, maintaining high detection accuracy in complex backgrounds while remaining lightweight enough for deployment on embedded devices.
YOLOv10 offers six variants: YOLOv10n, YOLOv10s, YOLOv10m, YOLOv10b, YOLOv10l, and YOLOv10x. Given the stringent requirements of UAV applications for model efficiency and lightweight design, this paper selects YOLOv10n as the baseline model to evaluate its performance in vehicle and pedestrian detection for UAV aerial imagery. YOLOv10n comprises four main components: Input, Backbone, Neck, and Head.
Input: Handles image enhancement tasks, including HSV augmentation, image translation, scaling, flipping, and mosaic augmentation.
Backbone: Builds upon the C2f and SPPF structures from YOLOv8 and introduces three novel modules: SCDown, C2fCIB, and PSA. SCDown achieves spatial-channel decoupled downsampling by combining pointwise and depthwise convolutions. C2fCIB, the core module of YOLOv10, employs depthwise convolution for spatial mixing and pointwise convolution for efficient channel mixing within a compact inverted block structure. To address the high computational cost of self-attention mechanisms, YOLOv10 integrates a partial self-attention mechanism called Position-wise Spatial Attention (PSA), enhancing model performance.
Neck: Retains the FPN and PANet structures for effective multi-scale feature fusion.
Head: Utilizes lightweight One-to-one Head and One-to-many Head detection heads during training, with final detection results generated through the unified dual assignment strategy.
Through these innovative designs, YOLOv10 significantly improves computational efficiency while maintaining high detection accuracy, making it well-suited for deployment on edge devices in UAV applications.
OSD-YOLOv10
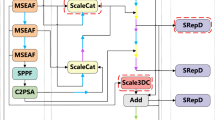
This paper proposes a novel and efficient lightweight vehicle target detection model, OSD-YOLOv10, designed for UAV applications, as illustrated in Fig. 1. The model incorporates several key innovations to enhance performance while maintaining computational efficiency. First, to reduce computational complexity, the original C2f module in YOLOv10 is replaced with an integrated lightweight SPCC network. This modification not only reduces model complexity but also enables more efficient multi-scale feature extraction and detection. Additionally, standard convolutions are partially replaced with the efficient OCRConv module, which enhances the model’s multi-scale feature extraction capabilities for UAV imagery while keeping computational costs low, thereby improving overall performance. Second, to address the challenge of small target detection, an efficient Dual-Feed Mixed Attention (DFMA)network mechanism is introduced at the neck of the network. This module enhances the model’s ability to learn global information from input feature maps, thereby improving the network’s expressive power. Furthermore, a dual small target detection layer is constructed in the head of the network. This layer combines a shallow small target detection layer, which fuses features from the P2 layer, with a small target detection layer that integrates the shallowest features from the P1 layer. This dual-layer design significantly enhances the model’s accuracy in detecting small targets. Finally, to minimize the loss of target features during upsampling, the DySample module is introduced. In dense scenes where target feature information is highly overlapping, DySample’s adaptive sampling position weight generation mechanism preserves more complete details across hierarchical feature maps, ensuring robust feature representation. The detailed design principles and implementation of each module in OSD-YOLOv10 are elaborated in the following sections.

Structure of OSD-YOLOv10(compared with YOLOv10, Conv is mainly replaced by OCRConv, C2f is replaced by SPCC designed in this paper, upsampling is replaced by Dysample, PSA is replaced by DFMA designed in this paper and combine reconstruct the small object layer). (The model diagram was created by our collaborator, Yang Zhang. All images displayed are from the publicly available VisDrone2019 dataset.)
OCRConv
A standard convolution module usually consists of a batch normalization layer, regular convolution layer, and activation function. This configuration usually results in a large number of similar feature maps, which results in high computational cost and memory consumption. OCRConv is a convolutional layer built by the Online Convolutional Reparameterization (OREPA) technique20, which aims to optimize memory usage and computational efficiency during model training to enhance the overall performance and resource utilization of convolutional neural networks. Therefore, we introduce the Online Convolutional Reparameterization (OREPA) technique into the convolution of the YOLOv10 network to reduce the model complexity while improving the training speed. The proposed technique mainly uses two key technical steps as shown in Fig. 2: Block Linearization and Block Squeezing. Firstly, in the Block Linearization stage, OREPA removes the nonlinear layers commonly used in the training process. Although these layers help to improve the expressive power of the model, they increase the computational complexity and memory consumption. Instead, a linear scaling layer is introduced, which is a key component of the OREPA technique. This layer scales feature maps using learnable vectors, enabling more efficient weight updates during training. By maintaining the diversity of optimization directions and feature expressiveness, this approach not only improves model performance but also reduces training costs and memory usage. Next, in the block-squeezing stage, OREPA merges the linearized blocks into a single convolutional layer. This means that the original complex architecture consisting of multiple convolutional layers and batch normalization layers will be simplified into a single convolutional layer, a process that greatly reduces the complexity and memory requirements at training time. Through block squeezing, OREPA reduces the computation and storage overhead of intermediate feature maps, thus improving the training efficiency. Specifically, block extrusion represents all linear layers in the parameter-heavy structure as convolutional layers with corresponding parameters, and compresses multiple layers and multiple branches into a single convolutional layer, which simplifies the model structure and reduces the consumption of computational resources.

An overview of the proposed Online Re-Parameterization (OREPA), a two-stage pipeline. In the first stage (Block Linearization), we remove all the non-linear components in the prototype re-param block. In the second stage (Block Squeezing), we merge the block to a single convolutional layer (OCRConv). Through the steps, we significantly reduce the training cost while keep the high performance.
SPCC
The C2f module makes it difficult to locate dense small targets under complex backgrounds. with the increasing depth of convolutional neural networks (CNNs), repeated convolution operations tend to induce feature redundancy and similarity across channels., which means there is a lot of repeated information in the deep feature map, resulting in information redundancy and excessive model parameters.
To address this bottleneck, partial convolution (PConv) introduced in the FasterNet framework21 achieves efficient feature extraction through structured sparsity: Given an input feature map h×w×c, PConv applies convolutional transformations exclusively to a selected channel subset \(h \times w \times c_{p}^{2}\). The processed feature tensor is subsequently concatenated with the original unprocessed channels along the channel dimension while preserving the output dimensionality. This design maintains complete channel information while reducing floating-point operations of conventional convolution, significantly enhancing computational efficiency.
For enhanced multi-scale feature discriminability, the Shuffle Attention43 (SA) mechanism partitions input feature channels into multiple mutually exclusive subgroups. Within each subgroup, dual-path attention modeling operates in parallel: the channel attention branch generates channel-wise weight vectors via global average pooling, while the spatial attention branch constructs spatial saliency maps through group normalization. Attention weights fused by element-wise multiplication are applied to corresponding sub-features, with cross-subgroup feature interaction achieved through differentiable channel shuffling. This architecture enables more efficient capture of complex patterns and structures within feature maps while circumventing redundant computations without compromising representational capacity.
Building upon these advances, we propose the SPCC_Bottleneck to reconfigure the C2f module in OSD-YOLO, This is shown in Fig. 3: Stage 1 harnesses PConv for selective feature extraction to capture fine-grained local details; Stage 2 executes cross-channel integration via 1 × 1 standard convolution; Stage 3 incorporates SA for dual-dimensional (channel-space) dynamic feature calibration. This tri-stage cascade synergistically reduces model complexity while enhancing backbone network functionality through multi-scale feature refinement, thereby establishing discriminative feature representations within constrained computational resources.

The structure of SPCC (mainly shows the SPCC_BottleNeck of the SPCC module designed in this paper).
DySample
The YOLOv10n model typically employs nearest-neighbor interpolation for its upsampling layer, a method that simply duplicates adjacent pixel values. However, this approach presents significant limitations: it ignores smooth transitions between pixels, uses only a few surrounding pixels for prediction, and focuses mainly on spatial information while ignoring the semantic information of the feature map; it is prone to blur and distortion when dealing with complex scenes or edge details, and performs especially poorly when dealing with small targets. In addition, the traditional kernel-based upsampling process requires a large amount of computation and parameter overhead, which is not conducive to the realization of lightweight network architectures. Therefore, the DySample22 module is introduced in the feature fusion step to replace the original upsampling module. DySample realizes content-aware upsampling by dynamically determining the optimal sampling position of each output pixel through a learning mechanism, which not only improves the quality and flexibility of upsampling but also recovers small targets and edge information more accurately. In addition, DySample reduces model complexity and computational cost while maintaining high performance by reducing the need for high-resolution feature inputs and optimizing the computational process. The DySample flowchart is shown in Fig. 4.

The DySample implementation diagram.The linear layer and pixel shuffle technique are combined with a fixed range factor to generate the offset (O), which is then added to the original grid position (G) to obtain the sampling set (S). The input features are resampled using the grid_sample function to obtain the upsampled features (X’).
Given an input feature map \({\text{X}}\) of size \(C \times H \times W\) and a point sampling set S of \(2g \times sH \times sW\), where \(2g\) denotes the X and y coordinates. DySample first generates offsets of size \(2g{{\text{s}}^2} \times H \times W\) through a 1 × 1 convolutional layer (linear projection layer) with input and output channels C and \(2g{s^2}\). Then, it is reshaped into an offset O of \(2g \times sH \times sW\) by the Pixel Shuffle operation, while the sampling set S is the sum of the offset O and the original sampling grid G. Finally, the grid_sample function resamples the input feature map X using the positions in the point sampling set S to produce a feature map \(X'\) of size \(C \times sH \times sW\). The specific implementation formula is as follows:
DFMA
The self-attention mechanism is extensively utilized in object detection due to its strong global modeling capability and ability to capture long-range dependencies. In wide-area images captured at high altitudes, small vehicle targets often occupy only a few pixels, making them challenging to detect. To place greater emphasis on small target regions within images during object detection, this study proposes an efficient DFMA attention mechanism.
The DualFeed-MixAttention Network (DFMA) is a novel spatial attention architecture that comprises two feed-forward neural networks (FFNs) and an innovative Mixed Local Channel-Spatial Attention (MLCA)44 module. The design aims to optimize semantic perception in complex scenes through multi-scale feature modeling and dynamic feature recalibration. As shown in Fig. 5, the input feature map is first decomposed into two parallel branches, a and b, by a 1 × 1 convolutional layer. Branch a retains the original semantic information to maintain the base feature flow, while branch b performs in-depth feature modulation by cascading a two-stage feed-forward neural network (FFN) and an MLCA module. The FFN enhances the model’s ability to capture complex patterns through nonlinear transformations, and the MLCA module integrates local and global information extraction units and channel-space fusion units. The former uses local average pooling (LAP) and global average pooling (GAP) to extract detail-sensitive features and global structural priors from the feature map, respectively. The latter models long-range dependencies between channels using 1D convolution (Conv1D) and combines it with deformable convolution to generate spatial attention masks. Ultimately, it realizes dynamic feature recalibration through weight fusion (critical feature enhancement and noncritical feature suppression). After the two-branch features are spliced together, a 1 × 1 convolutional layer accomplishes cross-channel information fusion, which further enhances the model’s characterization capability. The DFMA module is typically placed in the final layer of the backbone network, where the resolution is relatively low. This effectively alleviates quadratic computational complexity. After being integrated into detection frameworks such as YOLO with low computational cost, the proposed architecture significantly improves the identifiability of small target features and the robustness of detection in complex scenes.

The structure of DFMA(mainly showing the design of the joined MLCA module and the principle of DFMA implementation).
Double small target detection network
The YOLOv10 classification head uses a lightweight architecture of two 3 × 3 depthwise separable convolutional layers and one 1 × 1 convolutional layer. The original YOLOv10 detection head is designed based on multi-scale feature maps. When the input resolution is 640 × 640, the backbone network generates three-level feature maps of 80 × 80 (level P3), 40 × 40 (level P4), and 20 × 20 (level P5) through progressive downsampling with a step size of 2. These correspond to the construction of small, medium, and large detection heads, respectively. The P3-level, high-resolution feature map (80 × 80) covers an 8 × 8 pixel area of the original image. It focuses on capturing detailed information to detect small objects larger than 16 × 16 pixels. Conversely, the P5-level, low-resolution feature map (20 × 20) covers an area of 32 × 32 pixels per grid. It relies on global semantic information to detect large objects larger than 64 × 64 pixels. In the UAV image scene, however, targets are usually distributed at a very low pixel density. For example, targets are usually 4 × 4 pixels. This makes the P5-level feature map dilute small target features due to its large grid coverage (32 × 32 pixels). In contrast, the P3-level feature map can retain more detailed information due to the lack of high-level semantic association. Consequently, the missed detection rate of small targets increases.
To address the issue of bottlenecks, we propose a design that incorporates dual small object detection layers. Within the neck network, the first detection layer leverages the feature map from the P2 level to create an x-small detection head, which is responsible for detecting objects larger than 4 × 4 pixels. The second detection layer integrates the feature maps from both the P1 and P2 levels, utilizing cross-level feature enhancement to construct the xx-small detection head, specifically targeting ultra-small objects that are larger than 2 × 2 pixels. This design fully capitalizes on the benefits of shallow, high-resolution feature maps while mitigating information attenuation commonly caused by deeper convolutions, thanks to the complementary features between layers. This approach significantly enhances the model’s capability to represent small targets. To further optimize deployment efficiency, this paper reconstructs the detection network architecture, retaining only the xx-small, x-small, small, and medium detection heads. Consequently, the reconstructed dual small object detection network achieves a more balanced trade-off between model complexity and accuracy.
Experiments and results
Experimental environment and parameter configuration
The training and development of this experiment is based on Pytorch framework under Linux server, using Ubuntu system, the specific experimental environment is shown in Table 1.
The experiments were trained, validated, and tested in the same environment. All training was done from scratch, initialized with weights trained on the COCO dataset. Experimental hyperparameters: the input image was resized to 640 × 640 pixels; momentum was set to 0.937, batch size to 16, and weight decay to 0.0005; the number of epochs was 200.The optimizer was Stochastic Gradient Descent (SGD), with an initial learning rate of 0.01. and the rest of the hyperparameters were taken as defaults from YOLOv10.
Description of the datasets
To confirm the effectiveness of the improved OSD-YOLOv10 model, the public datasets VisDrone201945 and UAVDT46 are selected for experiments in this paper.
The VisDrone2019 dataset is a large UAV vision dataset open-sourced by Tianjin University. It contains 10,209 still images taken by UAVs from different angles, of which 6,471 are the training set, 548 are the validation set, and 1,610 are the test set, totaling about 2.6 million target instances covering 10 target categories such as pedestrians, cars, and trucks, and covering 14 urban and rural environments in China.
The UAVDT dataset consists of 50 videos and 38,327 images containing three object classes: cars, buses, and trucks. Among them, 23,258 images were used for training and 15,069 images were used for testing.
The target types in both datasets are diverse and predominantly small, and Fig. 6 shows the percentage of targets in each category.

(a) Each category and quantity of the VidroneDET-2019 dataset. (b) Each category and number of UAVDT datasets.
Evaluation criteria
The model was evaluated based on its detection performance and model size. Precision (P), Recall (R), Average Precision (AP), and Mean Average Precision (mAP) were used to measure the accuracy of all object categories. In addition, the computational complexity of the network was evaluated using the metric gigafloating point operations per second (GFLOPs). The size of the model was determined by the number of parameters, and the real-time processing speed of the model was measured in frames per second (FPS). mAP@0.5 and mAP@0.5:0.95 represent the mean AP for each class when the Intersection over Union (IoU) threshold is 0.5 and when IoU ranges from 0.5 to 0.95, respectively, where IoU is the overlap rate between the predicted bounding box and the true bounding box, i.e. the ratio of intersection and union, which is used to evaluate the accuracy of object detection.
True positives (TP) are cases where both the actual label and the prediction are positive. A false negative (FN) occurs when the label is positive but the prediction is falsely negative. A false positive (FP) occurs when the actual label is negative but the prediction is positive. True Negative (TN) indicates a situation where both the label and the prediction are negative.The formulas for P and R are given below:
AP is the area under the PR curve; the higher the AP, the higher the accuracy. mAP is the average of the APs of all categories; a higher mAP indicates better model performance. the formulas for AP and mAP are given below:
where n is the number of instances of a given category and AP(i) is the accuracy of detection of category i.
GFLOPs denotes the number of billion floating point operations per second, which is used to measure the computational complexity of the model.GFLOPs is calculated as follows:
The higher the GFLOPs, the higher the computation and hardware requirements.
FPS is an important indicator of the model’s image processing speed. The higher the FPS value, the more images the model processes per unit time, which means the faster the recognition speed. The calculation formula is as follows:
Where FrameNum is the total number of frames detected and ElapsedTime is the total time taken by the model to perform the detection.
Ablation experiment
To demonstrate the effectiveness of the proposed OSD-YOLOv10 network, we performed ablation experiments based on the baseline network on the VisDrone2019 dataset. Given the inherent randomness in deep learning experiments, all results reported in this study are averaged over multiple runs to ensure robustness and reliability. The experiments first evaluate the performance of each module individually within the baseline network. Subsequently, a stacking approach is employed to incrementally integrate modules into the baseline network, allowing for a comparative analysis of their effectiveness, as shown in Table 2.
A (OCRConv): The OCRConv module, constructed using the online convolutional reparameterization technique, replaces standard convolutions. By removing nonlinear layers and merging convolutional layers, this approach simplifies the model architecture and reduces computational resource consumption. Resulting in a 7.3% reduction in computational load compared to the original model.
B (SPCC): The lightweight SPCC structure improves the C2f module by incorporating partial convolution operations and the efficient Shuffle Attention mechanism. This design reduces information redundancy and model parameter counts without compromising performance. Results show an 11.1% reduction in computation and an 8.1% reduction in parameters while maintaining precision and recall rates.
C (Dual Small Target Detection Layer): The small target detection layer is reconstructed by combining the shallowest (P1) and shallow (P2) features, enhancing the model’s ability to detect small targets. This modification reduces the model’s parameter count by 18.5% while slightly improving accuracy.
D (DFMA): The original PSA module is replaced with the more efficient DFMA module, which utilizes a hybrid local-channel attention mechanism (MLCA). This lightweight and efficient module improves precision, recall, and mAP@0.5 by 1.2, 1.0, and 1.4% points, respectively, while keeping parameter counts and GFLOPs stable.
E (DySample): The dynamic upsampling module, DySample, enhances the neck network’s feature fusion capability. Compared to the original model, DySample improves precision, recall, and mAP@0.5 by 0.9, 0.6, and 1.1% points, respectively.
F (A + SPCC): Combining the OCRConv module (A) with the SPCC module (B) further reduces model complexity while slightly improving precision.
G (F + Small Target Detection Layer): Reconstructing the small target detection layer on top of Module F significantly reduces the model’s parameter count to only 40.7% of the original model, with a slight improvement in precision and recall.
H (G + DFMA): Adding the DFMA module to Module G improves precision, recall, and mAP@0.5 compared to using Module G alone, achieving better detection performance without increasing complexity.
I (H + DySample): Incorporating DySample into Module H further enhances precision, recall, and mAP@0.5 while maintaining lower computational complexity and parameter counts compared to the original model.
The final configuration (I) achieves an optimal balance between high accuracy and lightweight design, making it well-suited for scenarios requiring both high precision and real-time performance.
Comparative with multiple datasets
The use of different datasets for training and validation plays a key role in the performance and robustness of the model. It can significantly improve the generalization ability, performance, and robustness of object detection models, ensuring their effectiveness in a variety of practical applications. In this paper, the original model YOLOv10n and the improved model OSD-YOLOv10 are tested on two datasets, VisDrone2019 and UAVDT, respectively, and the experimental results are shown in Tables 3 and 4 below.
As shown in Table 3, the OSD-YOLOv10 model demonstrates enhanced detection performance with precision and mean average precision (mAP) improvements of 1.3% and 1.6%, respectively. Analyzing the accuracy performance of each category, we can see that the OSD-YOLOv10 model has better detection performance in detecting small targets such as people, bicycles, tricycles, and motors, which are increased by 0.7%, 0.9%, 0.7%, and 0.3% respectively compared to YOLOv10. The results demonstrate the architectural advantages of OSD-YOLOv10 in detecting small objects.
Comparison with Table 4 shows that the Mean Average Precision (mAP) of the OSD-YOLOv10 model is increased by 0.6% compared to the YOLOv10 model, and the accuracy of each category shows a small improvement. The results show that OSD-YOLOv10 also performs better than YOLOv10 on the UAVDT dataset.

Lightweight comparison of the OSD-YOLOv10 and YOLOv10 models in the VisDrone dataset and UAVDT dataset.
It is important to prioritize lightweighting the model while maintaining accuracy to facilitate model deployment on resource-constrained edge devices, thereby improving the detection speed at the edge and achieving real-time detection. As shown in Fig. 7, a comparison was made between OSD-YOLOv10 and YOLOv10 in terms of parameters and GFLOPs.The improved OSD-YOLOv10 model exhibited a reduction of 40.7% in the number of parameters and 3.6% in GFLOPs. In summary, the OSD-YOLOv10 model underwent further optimization while maintaining the high accuracy of the original model and achieved a significant reduction in model size, which is beneficial for subsequent deployment on the edge for real-time detection.
Comparative with different models
To evaluate OSD-YOLOv10’s superiority, we conducted a large number of comparative experiments for validation. Table 5 compares OSD-YOLOv10 and other models on the VisDrone2019 dataset. The selection criteria for the comparison algorithms were the number of parameters and computational complexity within a reasonable range.
We retained and emphasized the best performance results for each metric. As shown in Table 5, OSD-YOLOv10 has higher performance compared with the baseline model YOLOv10n, with 0.5% improvement in accuracy and 0.2% improvement in mAP@0.5. In addition, the number of parameters of OSD-YOLOv10 is reduced by about 1.1 M, and the computational complexity is reduced by 0.3GFLOPs. Compared with the typical lightweight models of the YOLO series, YOLOX-tiny, YOLOv5n, YOLOv7-tiny, and YOLOv8n, the accuracy is increased by 0.8%, 5.2%, 0.3%, and 1.1%, respectively, and is increased by 1.8%, 7.2%, 0.9%, and 1.3%, respectively, on mAP@0.5. Compared with YOLOX-tiny, YOLOv5n, YOLOv7-tiny, and YOLOv8n, the number of model parameters is reduced by 68%, 11.1%, 73.3%, and 46.7%, respectively. The computational complexity of the model is reduced by 48.3%, 40.2%, and 2.5%, respectively. Compared with recent research results, our model has better precision, recall, and mAP@0.5 than EfficientDet-D047, Gold-YOLO48, and FFCA-YOLO40. It also has a lower number of parameters and computational complexity.In addition, compared with the recently released YOLOv11n49the precision, recall, and mAP@0.5 are increased by 0.5%, 0.2%, and 0.5%, respectively, and the parameter count of OSD-YOLOv10 is reduced by 38.5%.
Figure 8 shows the model mAP@0.5 versus the number of parameters and the computational complexity. The model in the upper left corner of the scatter plot is better. OSD-YOLOv10 achieves a better balance between accuracy, number of parameters, and computational complexity. OSD-YOLOv10 achieves higher mAP@0.5 and lower parameter count and computational complexity compared to other models.

mAP50-Params (a) and mAP50-GFLOPs (b) scatter diagram of models on VisDrone2019 dataset.
Table 6 gives the processing speeds of OSD-YOLOv10 and the other three models with the highest detection accuracy. On the VisDrone2019 dataset, the FPS of OSD-YOLOv10 is 136. the processing speed is 27 frames per second slower compared to YOLOv11n. However, OSD-YOLOv10 has higher detection accuracy and a lower off-target rate. Additionally, OSD-YOLO outperforms Gold-YOLO and FFCA-YOLO by 24 and 47 frames per second, respectively. When detection accuracy is similar, OSD-YOLOv10 has a faster detection speed and requires fewer computations.
In summary, OSD-YOLOv10 achieves the highest mAP and lower computational complexity at a higher inference speed, representing the best configuration in terms of overall performance. This configuration illustrates the great potential and wide applicability of the scheme in practical applications to meet the requirements of high accuracy, low computational resources, and high real-time performance.
Visual comparative analysis
To intuitively and efficiently demonstrate the detection efficacy of our proposed model, we conducted comparative analyses of model performance through confusion matrices and inference result visualizations.

(a) Confusion matrix plot of YOLOv10; (b) Confusion matrix plot of OSD-YOLOv10.
To visualize the model’s capability in predicting target categories, we present the confusion matrices of YOLOv10 and our OSD-YOLOv10 in Fig. 9. The rows and columns represent the true and predicted categories, respectively. Values along the diagonal indicate the proportion of correctly predicted categories, while off-diagonal entries denote misclassification rates. As shown in Fig. 9, OSD-YOLOv10 exhibits darker diagonal coloration than YOLOv10, indicating enhanced prediction accuracy. However, for small objects (e.g., bicycles, tricycles, and motorcycles), a higher proportion of background misclassification persists, suggesting substantial missed detections. Although our improved model reduces the missed detection rate for these categories, their correct prediction ratios remain suboptimal. This limitation arises because bicycles—being compact transportation tools—typically appear in densely occluded formations, complicating reliable detection in complex backgrounds.

Visualization results between YOLOv10 (a) and OSD-YOLOv10 (b) on the VisDrone2019 dataset. (The experimental images are sourced from the VisDrone2019 dataset.).
To visually validate the detection performance, we performed inference experiments comparing YOLOv10 and OSD-YOLOv10 across multiple representative scenarios. These scenes contain diverse small objects well-suited for evaluation. Detection results are illustrated in Fig. 10, with key regions magnified for visual clarity. Comparative analysis reveals that our method achieves superior accuracy for distant targets within the field of view relative to YOLOv10. Furthermore, it effectively mitigates prevalent false positives and missed detections of small objects under UAV perspectives, thereby significantly enhancing overall detection performance.
Conclusions
In this paper, we propose OSD-YOLOv10, a lightweight and efficient vehicle target detection model tailored for UAV aerial photography, addressing the challenge of achieving efficient deployment on resource-constrained devices such as UAVs. To realize a lightweight architecture, we introduce the SPCC module to replace the C2f module in the original network.The SPCC_Bottleneck structure ensures robust feature extraction while significantly reducing model computation and parameter counts.Additionally, we employ the online convolutional reparameterization technique to eliminate nonlinear layers and merge convolutional layers, simplifying the model structure and minimizing computational resource consumption. However, lightweight operations may result in information loss. To mitigate this, we propose an efficient spatial attention mechanism, DFMA, which enhances the model’s ability to represent features of vehicles across varying scales. DFMA leverages a dual-layer feed-forward neural network and a hybrid local-channel attention module, combined with a reconfigured dual-layer small-target detection network, to improve recognition accuracy for small targets in complex environments. Furthermore, we introduce the DySample module, which achieves content-aware upsampling by dynamically determining the optimal sampling location for each output pixel. This approach enables more accurate recovery of small targets and edge details, reducing model complexity and computational costs while maintaining high performance. Finally, experiments on VisDrone2019 and UAVDT datasets validate the higher detection accuracy and lower computational complexity of OSD-YOLOv10 compared to other YOLO series models and lightweight models, proving that it achieves an optimal balance between high accuracy and low resource consumption, and is suitable to be deployed in UAV airborne hardware to carry out vehicle target detection.
Data availability
The datasets used and analysed during the current study available from the corresponding author on reasonable request.
References
Moradi, S., Bokani, A. & Hassan, J. UAV-based smart agriculture: A review of UAV sensing and applications[C]//2022 32nd International Telecommunication Networks and Applications Conference (ITNAC). IEEE, : 181–184. (2022).
Byun, S. et al. Road traffic monitoring from UAV images using deep learning networks[J]. Remote Sens. 13 (20), 4027 (2021).
Sun, W., Dai, L., Zhang, X. et al. RSOD: Real-time small object detection algorithm in UAV-based traffic monitoring. Appl Intell 52, 8448–8463 (2022).
Outay, F., Mengash, H. A. & Adnan, M. Applications of unmanned aerial vehicle (UAV) in road safety, traffic and highway infrastructure management: recent advances and challenges[J]. Transp. Res. Part. A: Policy Pract. 141, 116–129 (2020).
Jin, W. et al. Research on application and deployment of UAV in emergency response[C]//2020 IEEE 10th International Conference on Electronics Information and Emergency Communication (ICEIEC). IEEE, : 277–280. (2020).
Gomaa, A., Abdelwahab, M. M. & Abo-Zahhad, M. Efficient vehicle detection and tracking strategy in aerial videos by employing morphological operations and feature points motion analysis. Multimedia Tools Appl. 79 (35), 26023–26043 (2020).
Gomaa, A. & Abdelwahab, M. M. and Mohammed Abo-Zahhad. Real-time algorithm for simultaneous vehicle detection and tracking in aerial view videos. 2018 IEEE 61st International Midwest Symposium on Circuits and Systems (MWSCAS). IEEE, (2018).
Girshick, R. et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. : 580–587. (2014).
Girshick, R. Fast r-cnn[J]. arXiv preprint arXiv:1504.08083, (2015).
Ren, S. et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Trans. Pattern Anal. Mach. Intell. 39 (6), 1137–1149 (2016).
Wang, C. Y., Bochkovskiy, A. & Liao, H. Y. M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. : 7464–7475. (2023).
Jocher, G., Chaurasia, A., Qiu, J. & Ultralytics, Y. O. L. O. Version 8.0.0. Available online: (2023). https://github.com/ultralytics/ultralytics (accessed on 5 April 2024).
Wang, C. Y., Yeh, I. H. & Mark Liao, H. Y. Yolov9: Learning what you want to learn using programmable gradient information[C]//European Conference on Computer Vision. Springer, Cham, : 1–21. (2025).
Wang A, Chen H, Liu L, et al. Yolov10: Real-time end-to-end object detection[J]. Advances in Neural Information Processing Systems, 37: 107984–108011 (2024).
Gomaa, A. Advanced domain adaptation technique for object detection leveraging semi-automated dataset construction and enhanced yolov8. 2024 6th Novel Intelligent and Leading Emerging Sciences Conference (NILES). IEEE, (2024).
Gomaa, A. & Abdalrazik, A. Novel deep learning domain adaptation approach for object detection using semi-self building dataset and modified yolov4. World Electr. Veh. J. 15.6 : 255. (2024).
Wei, X., Li, Z. & Wang, Y. SED-YOLO based multi-scale attention for small object detection in remote sensing[J]. Sci. Rep. 15 (1), 3125 (2025).
Su, J. et al. MPE-YOLO: enhanced small target detection in aerial imaging[J]. Sci. Rep. 14 (1), 17799 (2024).
Xiao, Y. & Di, N. SOD-YOLO: A lightweight small object detection framework[J]. Sci. Rep. 14 (1), 25624 (2024).
Hu, M. et al. Online convolutional re-parameterization[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. : 568–577. (2022).
Chen, J. et al. Run, don’t walk: chasing higher FLOPS for faster neural networks[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. : 12021–12031. (2023).
Liu, W. et al. Learning to upsample by learning to sample[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. : 6027–6037. (2023).
Qiu, Z., Bai, H. & Chen, T. Special Vehicle Detection from UAV Perspective via YOLO-GNS Based Deep Learning Network. Drones 7, 117. (2023).
Chen, Z., Cao, L. & Wang, Q. YOLOv5-Based Vehicle Detection Method for High-Resolution UAV Images. Mob. Inf. Syst. 2022, 1828848. (2022).
Du, Y. & Multi -UAV Search and Rescue with Enhanced A∗ Algorithm Path Planning in 3D Environment. Int. J. Aerosp. Eng. 2023, 8614117. (2023).
Patel, T., Guo, B. H., van der Walt, J. D. & Zou, Y. Effective Motion Sensors and Deep Learning Techniques for Unmanned Ground Vehicle (UGV)-Based Automated Pavement Layer Change Detection in Road Construction135 (Buildings, 2022).
Song, S. Q., Li, X. & Zhu, X. F. Urban road vehicle detection method by aerial photography based on improved SSD. Transducer Microsyst. Technol. 40, 114–117 (2021).
Lu, W. et al. A CNN-transformer hybrid model based on Cswin transformer for UAV image object detection. IEEE J. Sel. Top. Appl. Earth Observ Remote Sens. 16, 1211–1231. https://doi.org/10.1109/JSTARS.2023.3234161 (2023).
Hoanh, N. & Pham, T. V. Focus-attention approach in optimizing Detr for object detection from high-resolution images[J]. Knowl. Based Syst. 296, 111939 (2024).
Nguyen, H. et al. Enhanced object recognition from remote sensing images based on hybrid Convolution and transformer structure[J]. Earth Sci. Inf. 18 (2), 1–15 (2025).
Zhu X, Lyu S, Wang X, et al. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2021: 2778–2788.
Zhang, H. et al. Fusion of multi-scale attention for aerial images small-target detection model based on PARE-YOLO[J]. Sci. Rep. 15 (1), 4753 (2025).
Zhang, Z. Drone-YOLO: An efficient neural network method for target detection in drone images. Drones, 7, no. 8, (2023).
Tahir, N. U. A., Long, Z., Zhang, Z., Asim, M. & ELAffendi, M. PVswin-YOLOv8s: UAV-based pedestrian and vehicle detection for traffic management in smart cities using improved YOLOv8. Drones 8, 84 (2024).
Liu, Y., Zhang, W. & Wang, J. Zero-shot adversarial quantization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June ; pp. 1512–1521. (2021).
Zhu, J. et al. Complementary relation contrastive distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June ; pp. 9260–9269. (2021).
Wimmer, P., Mehnert, J. & Condurache, A. Interspace pruning: Using adaptive filter representations to improve training of sparse cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June; pp. 12527–12537. (2022).
Cao, L. et al. An improved lightweight real-time detection algorithm based on the edge computing platform for UAV images[J]. Electronics 12 (10), 2274 (2023).
Qu, Yi, et al. Optimization algorithm for steel surface defect detection based on PP-YOLOE. Electronics 1219 (2023): 4161.
Zhang, Y. et al. FFCA-YOLO for Small Object Detection in Remote Sensing images[J] (IEEE Transactions on Geoscience and Remote Sensing, 2024).
Wang, S. et al. LUMF-YOLO: A lightweight object detection network integrating UAV motion features. Computing 107, 25 (2025).
Wang, H. et al. Lightweight aerial image object detection. IEEE Sens. J. 25, 9167–9184 (2025).
Zhang, Q. L. & Yang, Y. B. Sa-net: Shuffle attention for deep convolutional neural networks[C]//ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, : 2235–2239. (2021).
Wan, D. et al. Mixed local channel attention for object detection[J]. Eng. Appl. Artif. Intell. 123, 106442 (2023).
Du, D. et al. VisDrone-DET2019: The vision meets drone object detection in image challenge results[C]//Proceedings of the IEEE/CVF international conference on computer vision workshops. : 0–0. (2019).
Du, D. et al. The unmanned aerial vehicle benchmark: Object detection and tracking[C]//Proceedings of the European conference on computer vision (ECCV). : 370–386. (2018).
Tan, M., Pang, R. & Le, Q. V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 10781–10790). (2020).
Wang, C. et al. Gold-YOLO: efficient object detector via gather-and-distribute mechanism. Adv. Neural. Inf. Process. Syst. 36, 51094–51112 (2023).
Zhou, Sicheng, et al. Improved YOLO for long range detection of small drones. Scientific Reports 15.1 (2025): 12280.
Funding
This research was supported by the National Natural Science Foundation of China under grant No. 62341118.
Author information
Authors and Affiliations
Contributions
Y.Z.: Conceptualization, methodology, formal analysis, data curation, validation, writing—original draft, writing—review and editing, visualization. X.C.: Methodology, Funding acquisition, writing—review and editing, supervision. S.S.: Investigation, data curation, visualization. H.Y.: Visualization, data curation. Y.W.: validation, supervision, writing—review, and editing. J.L.:data curation, data curation. J.W.: Visualization, data curation. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhang, Y., Chen, X., Sun, S. et al. Vehicle detection in drone aerial views based on lightweight OSD-YOLOv10. Sci Rep 15, 25155 (2025). https://doi.org/10.1038/s41598-025-09825-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-09825-y
