
Abstract
Effective sample design has a major role in the quality of parameter estimation in statistical parameter estimation issues. The ranking set sampling (RSS) strategy is effective and a less costly option than simple random sampling (SRS). A novel mixture continuous lifetime distribution that has been proposed recently is the power Chris-Jerry distribution (PC-JD). It is useful for modeling a number of real data sets. This paper investigates the RSS approach for estimating the PC-JD’s parameters. There are roughly sixteen different techniques of estimation that are used, such as the maximum likelihood method, the percentiles method, some methods based on minimum distance, the Kolmogorov method, and some methods based on minimum and maximum spacing distances. In comparison to a SRS, the simulation research assesses the performance of the suggested RSS-based estimates in terms of some measures of accuracy. To identify the optimal estimating strategy, the partial and overall ranks of many estimates are shown. According to numerical results, the maximum likelihood approach seems to be quite beneficial in evaluating the estimated quality of RSS and SRS. RSS is a more effective sampling approach than SRS owing to its better efficiency. Additionally, the different estimation techniques with survival data for both sampling techniques are examined.
Similar content being viewed by others

Introduction
Most environmental, biological, and ecological research includes circumstances in which rating a limited number of chosen units is comparatively simple and reliable, but conducting the actual measurement is expensive, time-consuming, and damaging. For example, determining the ages of animals may be necessary in research involving growth and animals, but this process is expensive and time-consuming. On the other hand, it is inexpensive and simple to gather the animal size characteristics that are strongly connected with age. Observational economy may be achieved in any of these scenarios by utilizing the ranked set sampling (RSS) approach.
McIntyre1 established RSS as a more efficient method for estimating the average pasture output than simple random sampling (SRS). The sample mean derived from an RSS is an unbiased estimator of the population mean, with less variation than the corresponding SRS estimator, as demonstrated by Takahasi and Wakimoto2. After that, Dell and Clutter3 confirmed that RSS offers more accurate population mean estimators than SRS, even when ranking errors are presented. The RSS approach may be summed up like this: From the population of interest, s random samples, each of size s, are chosen. Each sample’s units are rated using any low-cost technique, such as visual inspection, in relation to an interest variable. Next, for the actual measurement, the smallest and second-smallest units are chosen from the first and second samples.
Until the biggest unit from the sth sample is chosen for measurement, the process is repeated. This results in a total of s-measured units, each of which represents a single cycle. Until a sufficient sample of \(n = sw\) units is obtained, this procedure may be repeated w times. The RSS data are composed of these sw units. In fact, RSS is non-parametric in nature, as it was first established for the purpose of estimating the mean4 without assuming anything about the underlying model. A number of publications covering different facets of non-parametric inference have lately refined this non-parametric approach to RSS (Bohn5, Mahdizadeh and Arghami6, Mahdizadeh and Zamanzade7,8). However, parameter estimation for various distributions has received the majority of attention in studies based on RSS. Fei et al.9 examined the parameter estimators for the Weibull and extreme-value distributions, whereas the estimators of the half-logistic distribution were addressed by Adatia10. The maximum likelihood estimators (MLEs), under RSS, of the location-scale family’s parameters have been explored by Stokes11. The use of modified RSS for parameter estimation for the normal, exponential, and gamma distributions was investigated by Shaibu and Muttlak12. The MLEs of the parameters for the generalized Rayleigh and generalized logistic distributions were considered, respectively, by Refs.13,14. Under the frameworks of SRS, RSS, and maximum RSS with unequal size, the MLE and Bayesian estimation of the exponential-Poisson distribution were analyzed by15. Taconeli and Giolo16 provided the MLEs of the two extensions of the Lindley distribution. Using data from SRS, extreme RSS, and median RSS, Ref.17 examined and compared the effectiveness of a number of conventional estimators for the Pareto distribution. Reference18 analyzed the MLE of the exponentiated Pareto distribution. Sabry et al.19 discussed the estimation of Weibull distribution based on neoteric RSS.. MLEs of the log-logistic distribution have been investigated by Ref.20, whereas the MLEs of half-logistic xgamma distribution have been provided by Ref.21. The MLEs of the parameters for the inverted Topp-Leone and generalized exponential distributions were considered, respectively, by Refs.22,23. Reference24 examined the point and bootstrap interval estimators for the parameters of the discrete Weibull distribution. Using maximum RSS with unequal samples, Ref.25 examined Bayesian and non-Bayesian estimators for the inverted Kumaraswamy distribution. Aljohani26 discussed the estimators of the unit generalized Rayleigh distribution in the framework of the RSS. For more research on RSS-based reliability estimate27,28,29,30,31.
Further findings on RSS-based parametric estimation encompass several estimation techniques were studied by some authors. Reference32 investigated and compared the MLEs, modified moments estimators, maximum product of spacings (MPS) estimators, and Anderson-Darling (AD) estimators for the Birnbaum-Saunders distribution. For the inverse power Cauchy distribution, Ref.33 investigated a number of traditional estimation techniques, such as AD, MPS, ML, ordinary least squares (OLS), and Cramer-von Mises (CVM). The parameter estimators for the two-parameter xgamma distribution using weighted LS (WLS), OLS, CVM, ML, and MPS techniques were covered by Ref.34. Utilizing the right tail AD (RTAD), left tail AD (LTAD), MPS, OLS, percentiles, CVM, AD, WLS, minimum spacing (MS) absolute log distance (MSALD), and MS absolute distance (MSAD) methods, Ref.35 estimated the arctan uniform distribution on the basis of RSS and SRS. Reference36 focused on evaluating the AD, OLS, ML, MPS, WLS, and CVM estimators in the framework of SRS and RSS. The ML, CVM, AD, RTAD, MPS, percentiles, LTAD, OLS, WLS, MSALD, and MSAD were among the estimators that were compared for the generalized unit half-logistic geometric distribution in the framework of SRS and RSS methods in Ref37.
Probability distribution models are essential and widely utilized in many domains, including physics, medicine, business management, engineering, etc. They are ideal for forecasting and prediction when modeling real-world problems. Since it allows for a number of intriguing traits, the Lindley distribution38 has been extensively researched in the statistical literature. The Lindley distribution is a better fit for lifetime data analysis scenarios than the exponential distribution. In particular, it has been applied to predicting stress-strength reliability by analyzing large amounts of actual data. Using the similar idea of Lindley distribution, other probability distributions have been suggested, such as Akash distribution39, Sujatha distribution40, Aradhana distribution41, xgamma distribution42, Ishita distribution43, and Chris-Jerry distribution (C-JD)44, among others.
Ezeilo et al.45 proposed a new recent more flexible lifetime model with two-parameter, called the power C-JD (PC-JD). It is considered as a generalization of C-JD with extra shape parameter. Several statistical properties and parameter estimators using some different estimation methods based on SRS were provided by Ezeilo et al.46. The probability density function (PDF) of the PC-JD with shape parameter \(\alpha >0\) and scale parameter \(\beta >0\) is as follows:
The cumulative distribution function (CDF), survival function (SF), and hazard rate function (HRF) of the PC-JD are given, respectively, by:
and
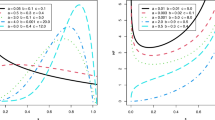
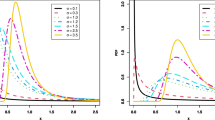
Fig. 1 displays the PDF and HRF plots for PC-JD. The PC-JD’s density function exhibits various asymmetric patterns and a reversed j-shaped pattern, as seen in Fig. 1. Furthermore, the PC-JD’s HRF displays rising, inverted j-shaped, and upside-down forms.

Plots of the PDF and HRF for the PC-JD.
In the statistical literature, different estimating techniques are often suggested since parameter estimation is important in real-world applications. This article’s goal is to investigate sixteen distinct estimation techniques for the PC-JD parameters based on RSS and SRS designs. We specifically compare OLS, WLS, MS square distance (MSSD), MSALD, MS Linex distance (MSLD), MS square log distance (MSSLD), MSAD, ML, MPS, the Kolmogorov method, AD, LTAD, CVM, RTAD, AD left tail second order (ADSO)), as well as the percentiles (PC) method. To evaluate and compare the performance of RSS-based estimates as well as SRS-based estimates for the parameters of the PC-JD, an extensive simulation study was carried out. The simulation study is performed in the case of perfect ranking. The partial and overall ranks of the mean square errors, mean absolute relative error, average absolute biases, average absolute difference, maximum absolute difference, and average squared absolute error of these estimates are presented to determine the best estimation approach. In light of the analysis of survival data, more conclusions have been drawn. The results of simulations and real-data applications showed that RSS-based estimators performed significantly better than their simple random sampling counterparts based on the same number of observed units.
The set-up of this article is as follows: In Sect. "Estimation methods for the PC-JD", a number of estimators with various estimating techniques are provided. Section "Real data analysis" compares the performance of the RSS-based estimators using Monte Carlo simulation. Additional information based on actual data is provided in Sect. "Summary and conclusion". A few closing thoughts are included in the last section.
Estimation methods for the PC-JD
Here, based on RSS design, sixteen estimation methods are considered to estimate the parameters \(\alpha\) and \(\beta\) of the PC-JD. In all methods, suppose that \({z_{({i_1}:s){i_2}}}\) be the \({i_1}\)th ranked observation (in this case, the \({i_1}\)th order statistic) in the \({i_1}\)th from the \({i_2}\)th cycle, where \({i_1}=1, 2,\ldots , s\) and \({i_2}=1,2,\ldots , w\), we take them to be the RSS data for Z with sample size \(n = sw\). In simplified form, the selected sample under the RSS design is represented by \({z_{{i_1}{i_2}}}.\)
Maximum likelihood estimation
Here, the MLEs of parameters \(\alpha\) and \(\beta\) of the PC-JD are obtained based on RSS. Let \({z_{{i_1}{i_2}}} = ({z_{{i_1}{i_2}}},\,\,{i_1} = 1,...,s,\,\,\,{i_2} = 1,2,...,w)\) are the observed RSS of size \(n = sw\) where s is the set size and w is the number of cycles, taken from the PC-JD. The likelihood function of \(\pmb T = (\alpha , \beta )\), based on RSS, is given by:
where
Then, by inserting PDF (5) in Eq. (4), the likelihood function of the observed samples takes the following form.
The log-likelihood function of Eq. (6) is as follows:
where \(\Xi ({z_{{i_1}{i_2}}},\pmb T) = {e^{ - \beta z_{{i_1}{i_2}}^\alpha }}\left( {\frac{{\beta z_{{i_1}{i_2}}^\alpha (\beta z_{{i_1}{i_2}}^\alpha + 2)}}{{\beta + 2}} + 1} \right) .\)
The MLEs \({\tilde{\alpha }_1}\) of \({ \alpha }\), and \({\tilde{\beta }_1}\) of \({ \beta }\) are obtained by partially differentiating the log-likelihood of Eq. (7) with respect to the unknown parameters \({ \alpha }\), and \({ \beta }\) and then equalizing them to zero, produces
and
where, \({\Xi '_\alpha }(z_{{i_1}{i_2}}^{},\pmb T) = \frac{\partial }{{\partial \alpha }}\Xi (z_{{i_1}{i_2}}^{},\pmb T) = -\frac{\beta ^2 z_{{i_1}{i_2}}^{\alpha } \log (z_{{i_1}{i_2}}) e^{\beta \left( -z_{{i_1}{i_2}}^{\alpha }\right) } \left( \beta z_{{i_1}{i_2}}^{2 \alpha }+1\right) }{\beta +2}\) and \({\Xi '_\beta }(z_{{i_1}{i_2}}^{},\pmb T) = \frac{\partial }{{\partial \beta }}\Xi (z_{{i_1}{i_2}}^{},\pmb T) = -\frac{\beta z_{{i_1}{i_2}}^{\alpha } e^{\beta \left( -z_{{i_1}{i_2}}^{\alpha }\right) } \left( \beta +\beta (\beta +2) z_{{i_1}{i_2}}^{2 \alpha }+\beta z_{{i_1}{i_2}}^{\alpha }+4\right) }{(\beta +2)^2}\).
Since \({\tilde{\alpha }_1}\) and \({\tilde{\beta }_1}\) lack closed-form equations, numerical calculations utilizing nonlinear optimization algorithms, like the Newton-Raphson iterative approach, should be employed.
Minimum distance estimation methods
Estimation techniques based on minimizing certain well-known goodness of fit statistics are helpful and produce good results in many situations. Five well-liked techniques are taken into consideration here, which minimize test statistics between the theoretical and empirical CDFs.
Anderson darling
Let \({z_{(1:n)}},{z_{(2:n)}},...,{z_{(n:n)}}\) be an ordered sample forming RSS of size \(n = sw\), with set size s and cycle number w, collected from the PC-JD. The AD estimates (ADEs) \({\tilde{\alpha }_{2}}\) of \(\alpha\) and \({\tilde{\beta }_{2}}\) of \(\beta\) are determined, respectively, by minimizing the following function:
where \(G\left( {.\left| \pmb T \right. } \right)\) and \(\bar{G}\left( {.\left| \pmb T \right. } \right)\) are the CDF and SF of the PC-JD given, respectively, in Eqs. (2) and (3). Rather than using (8), the following non-linear equations can be numerically solved to get \({\tilde{\alpha }_{2}}\) and \({\tilde{\beta }_{2}}\)
and
where
and
and \({\upsilon _1}\left( {{z_{({i_1} - 1:n)}}\left| \pmb T \right. } \right)\) and \({\upsilon _2}\left( {{z_{({i_1} - 1:n)}}\left| \pmb T \right. } \right)\) have the similar expressions with ordered sample \({z_{({i_1} - 1:n)}}\).
Right tail Anderson darling
Let \({z_{(1:n)}},{z_{(2:n)}},...,{z_{(n:n)}}\) be an ordered sample forming RSS of size \(n = sw\), with set size s and cycle number w, collected from the PC-JD. The RTAD estimates (RTADEs) \({\tilde{\alpha }_{3}}\) of \(\alpha\) and \({\tilde{\beta }_{3}}\) of \(\beta\) are produced, respectively, by minimizing the following function:
where \(G\left( {.\left| \pmb T \right. } \right)\) and \(\bar{G}\left( {.\left| \pmb T \right. } \right)\) are the CDF and SF of the PC-JD given, respectively, in Eqs. (2) and (3). Instead of using (11), the following non-linear equations can be numerically solved to obtain, \({\tilde{\alpha }_{3}}\) and \({\tilde{\beta }_{3}}\) respectively, as follows:
and
where, \({\upsilon _1}\left( {.\left| \pmb T \right. } \right)\) and \({\upsilon _2}\left( {.\left| \pmb T \right. } \right)\) are given in (9) and (10).
Left tail Anderson darling
Let \({z_{(1:n)}},{z_{(2:n)}},...,{z_{(n:n)}}\) be an ordered sample that was obtained from the PC-JD and formed an RSS of size \(n = sw\) with set size s and cycle number w. The LTAD estimates (LTADEs) \({\tilde{\alpha }_{4}}\) of \(\alpha\) and \({\tilde{\beta }_{4}}\) of \(\beta\) are determined, respectively, by minimizing the following function:
Note that \(G\left( {.\left| \pmb T \right. } \right)\) is the CDF of the PC-JD given in Eq. (2).The following non-linear equations can be quantitatively solved in place of (12) to get, \({\tilde{\alpha }_{4}}\) and \({\tilde{\beta }_{4}}\) respectively:
and
where, \({\upsilon _1}\left( {.\left| \pmb T \right. } \right)\) and \({\upsilon _2}\left( {.\left| \pmb T \right. } \right)\) are given in (9) and (10).
AD left tail second order
Let \({z_{(1:n)}},{z_{(2:n)}},...,{z_{(n:n)}}\) be an ordered sample constructed by the PC-JD with CDF (2), resulting in an RSS of size \(n = sw\) with set size s and cycle number w. One finds the ADSO estimate (ADSOE) \({\tilde{\alpha }_{5}}\) of \(\alpha\) and \({\tilde{\beta }_{5}}\) of \(\beta\) by minimizing the function below:
Instead of solving Eq. (13) quantitatively, one can solve the following non-linear equations to obtain \({\tilde{\alpha }_{5}}\) and \({\tilde{\beta }_{5}}\) respectively,
and
where, \({\upsilon _1}\left( {.\left| \pmb T \right. } \right)\) and \({\upsilon _2}\left( {.\left| \pmb T \right. } \right)\) are given in (9) and (10).
Cramér-von mises estimators
Let \({z_{(1:n)}},{z_{(2:n)}},...,{z_{(n:n)}}\) be an ordered sample created using the PC-JD with CDF (2), which yields an RSS of size \(n = sw\), where s is the set size and w is the cycle number. The CVM estimates (CVMEs) \({\tilde{\alpha }_{6}}\) of \(\alpha\) and \({\tilde{\beta }_{6}}\) of \(\beta\) may be obtained by minimizing the function that follows:
where \(G\left( {.\left| \pmb T \right. } \right)\) is the CDF of the PC-JD given in Eq. (2). As an alternative to solving (14), one could solve the following non-linear equations to obtain \({\tilde{\alpha }_{6}}\) and \({\tilde{\beta }_{6}}\)
and
where, \({\upsilon _1}\left( {.\left| \pmb T \right. } \right)\) and \({\upsilon _2}\left( {.\left| \pmb T \right. } \right)\) are given in (9) and (10).
Method of maximum and minimum spacing distance
The MPS approach was first presented by Cheng and Amin47,48. This approach depends on maximizing the geometric mean of the data’s spacings. For the most part, the MPS is reliable and effective.
Maximum product spacing distance
Suppose that \({z_{(1:n)}},{z_{(2:n)}},...,{z_{(n:n)}}\) be an ordered sample forming RSS of size \(n = sw\) gathered from the PC-JD with CDF (2). Afterward, the uniform spacing is determined by
Note that \(G\left( {{z_{(0:n)}}\pmb T} \right) = 0,\,\,\,\,G\left( {{z_{(n + 1:n)}}\left| \pmb T \right. } \right) = 1,\) and \(\sum \limits _{{i_1} = 1}^{n + 1} {{\Theta _{{i_1}}}} = 1.\)
The following function is maximized with respect to \(\alpha\) and \(\beta\) to provide the MPS estimates (MPSEs) \({\tilde{\alpha }_{7}}\) and \({\tilde{\beta }_{7}}\)
Instead of numericaly solving Eq. (15), the following equations can be numerically computed to produce the MPSEs \({\tilde{\alpha }_{7}}\) and \({\tilde{\beta }_{7}}\)
and
where, \({\upsilon _1}\left( {.\left| \pmb T \right. } \right)\) and \({\upsilon _2}\left( {.\left| \pmb T \right. } \right)\) are given in (9) and (10).
Minimum product spacing distance
Assume that \({z_{(1:n)}},{z_{(2:n)}},...,{z_{(n:n)}}\) an ordered sample obtained from the PC-JD, with cycle number w and set size s, forms an RSS of size \(n = sw\). By minimizing the subsequent functions, the MSAD estimates (MSADEs) \({\tilde{\alpha }_{8}}\) of \(\alpha\) and \({\tilde{\beta }_{8}}\) of \(\beta\) MSALD estimates (MSALDEs) \({\tilde{\alpha }_{9}}\) of \(\alpha\) and \({\tilde{\beta }_{9}}\) of \(\beta\) are found to be, respectively:
The following non-linear equations can possibly be solved in place of (16) to obtain \({\tilde{\alpha }_{8}}\) and \({\tilde{\beta }_{8}}\)
and
where, \({\upsilon _1}\left( {.\left| \pmb T \right. } \right)\) and \({\upsilon _2}\left( {.\left| \pmb T \right. } \right)\) are given in (9) and (10).
It may be possible to solve the following non-linear equations in lieu of Eq. (16) to obtain \({\tilde{\alpha }_{9}}\) and \({\tilde{\beta }_{9}}\)
and
where, \({\upsilon _1}\left( {.\left| \pmb T \right. } \right)\) and \({\upsilon _2}\left( {.\left| \pmb T \right. } \right)\) are given in (9) and (10).
Next, by minimizing the following functions, the MSSD estimates (MSSDEs) \({\tilde{\alpha }_{10}}\) of \(\alpha\) and \({\tilde{\beta }_{10}}\) of \(\beta\) and the MSSLD estimates (MSSLDEs) \({\tilde{\alpha }_{11}}\) of \(\alpha\) and \({\tilde{\beta }_{11}}\) of \(\beta\) are determined, respectively:
Instead of solving Eq. (17), the following non-linear equations could be solved to get \({\tilde{\alpha }_{10}}\) and \({\tilde{\beta }_{10}}\)
and
where, \({\upsilon _1}\left( {.\left| \pmb T \right. } \right)\) and \({\upsilon _2}\left( {.\left| \pmb T \right. } \right)\) are given in (9) and (10).
The following non-linear equations might be solved in place of Eq. (17), in order to obtain \({\tilde{\alpha }_{11}}\) and \({\tilde{\beta }_{11}}\)
and
where, \({\upsilon _1}\left( {.\left| \pmb T \right. } \right)\) and \({\upsilon _2}\left( {.\left| \pmb T \right. } \right)\) are given in (9) and (10).
Finally, MSLD estimates (MSLDE) \({\tilde{\alpha }_{12}}\) of \(\alpha\) and \({\tilde{\beta }_{12}}\) are yielded, respectively, by minimizing the following function:
The following non-linear equations might be solved in place of Eq. (18), in order to achieve \({\tilde{\alpha }_{12}}\) and \({\tilde{\beta }_{12}}\)
and
where, \({\upsilon _1}\left( {.\left| T \right. } \right)\) and \({\upsilon _2}\left( {.\left| T \right. } \right)\) are given in (9) and (10).
Methods of ordinary and weighted least squares
The OLS estimates (OLSE) and WLS estimates (WLAE) were introduced by Swain et al.49 to estimate the parameters of the beta distribution.
Assume that \({z_{(1:n)}},{z_{(2:n)}},...,{z_{(n:n)}}\) an ordered sample obtained from the PC-JD, with cycle number w and set size s, forms an RSS of size \(n = sw\). By minimizing the following function, the OLSEs \({\tilde{\alpha }_{13}}\) of \(\alpha\) and \({\tilde{\beta }_{13}}\) of \(\beta\) are found to be, respectively:
The following non-linear equations can also be solved in place of Eq. (19) to obtain \({\tilde{\alpha }_{13}}\) and \({\tilde{\beta }_{13}}\):
and
The WLSEs \({\tilde{\alpha }_{14}}\) of \(\alpha\) and \({\tilde{\beta }_{14}}\) of \(\beta\) are determined by minimizing the following function:
The following non-linear equations can also be solved in place of Eq. (20) to obtain \({\tilde{\alpha }_{14}}\) and \({\tilde{\beta }_{14}}\):
and
where, \({\upsilon _1}\left( {.\left| \pmb T \right. } \right)\) and \({\upsilon _2}\left( {.\left| \pmb T \right. } \right)\) are given in (9) and (10).
Kolmogorov method
Assume that \({z_{(1:n)}},{z_{(2:n)}},...,{z_{(n:n)}}\) an ordered sample obtained from the PC-JD, with cycle number w and set size s, forms an RSS of size \(n = sw\). In order to obtain the Kolmogorov estimates (KEs) \({\tilde{\alpha }_{15}}\) and \({\tilde{\beta }_{15}}\) the following function is minimized with regard to \({ \alpha }\) and \({ \beta }\)
Percentile method
We can estimate the unknown parameters \({ \alpha }\) and \({ \beta }\) of the PC-JD by equating the sample percentile points with the population percentile points. This technique is called the percentile approach50,51. The function \(P(\pmb T)\) can be minimized with regard to \({ \alpha }\) and \({ \beta }\) in order to produce the percentile estimators (PEs) \({\tilde{\alpha }_{16}}\), of \({ \alpha }\) and \({\tilde{\beta }_{16}}\) of \({ \beta }\) if \(p_i\) represents the estimate of \(G\left( {{z_{({i_1}:n)}}\left| \pmb T \right. } \right)\)
Numerical simulation
The effectiveness of several estimating techniques for the PC-JD is evaluated in this section. Synthetic datasets will be generated randomly and ranked, after which several methods will be applied to determine the most suitable. In addition, the datasets will be ranked, and the estimating techniques will be used to choose the best option. The following procedures will be used to carry out the simulation:
-
Using the PC-JD, create SRS of sizes \(n = 30, 80, 150, 300, 400,\) and \(500\).
-
The corresponding sample sizes \(n = sw\) are computed to construct an RSS from the PC-JD with a constant set size of \(s = 5\) and changing cycle numbers \(w = 6, 16, 30, 60, 80,\) and \(100\). The results are \(n = sw= 30, 80, 150, 300, 400,\) and \(500\).
-
For each of the two generating processes, get the PC-JD estimator \(\hat{\alpha }, \hat{\beta }\). The estimating techniques are assessed using six distinct metrics, which are outlined below:
-
1.
The average of absolute bias (BIAS), denoted by (\(\pmb K{_1}\)), computed by the formula: \(|\pmb K{_1}(\widehat{\pmb T})| = \frac{1}{M}\sum _{i=1}^{M}|\widehat{\pmb T}-\pmb T|\).
-
2.
The mean squared error, denoted by (\(\pmb K{_2}\)), and determined as follows: \(\pmb K{_2} = \frac{1}{M}\sum _{i=1}^{M}(\widehat{\pmb T}-\pmb T)^2\).
-
3.
The mean absolute relative error (MRE), denoted by (\(\pmb K{_3}\)), and evaluated using the expression: \(\pmb K{_3} = \frac{1}{M}\sum _{i=1}^{M}|\widehat{\pmb T}-\pmb T|/\pmb T\).
-
4.
The average absolute difference, denoted as \(\pmb K{_4}\), calculated by: \(\pmb K{_4} = \frac{1}{n H}\sum _{i=1}^{H}\sum _{j=1}^{n}|G(z_{ij}; \pmb T)-G(z_{ij};\widehat{ \pmb T})|\), where \(G(z;\pmb T)=G(z)\) and \(z_{ij}\) represents values obtained at the i-th iteration sample and j-th component of this sample.
-
5.
The maximum absolute difference, represented by \(\pmb K{_5}\), obtained from: \(\pmb K{_5} = \frac{1}{H}\sum _{i=1}^{H}\max \limits _{j=1,\ldots ,n} |F(z_{ij}; \pmb T)-F(z_{ij};\widehat{ \pmb T})|\).
-
6.
The average squared absolute error (ASAE), denoted by (\(\pmb K{_6}\)), and computed as: \(\pmb K{_6}= \frac{1}{H}\sum _{i=1}^{H}\frac{|z_{(i)}-\hat{z}_{(i)}|}{z_{(n)}-z_{(1)}}\), where \(z_{(i)}\) denotes the ascending ordered observations, \(\pmb T= (\alpha ,\beta )\).
-
1.
-
The results of the evaluation metric are shown in Tables 1 through 10, which provide a summary of the results and allow for comparison amongst estimating techniques.
-
Figures 2, 3, 4, 5, 6, 7, 8, 9, and 10 graphically illustrate the numerical data from Tables 1 and 2, illustrating Bias, MSE, MRE, \(D_{abs}, D_{max}\), and ASAE for various estimators as a function of sample size. In all instances, the metrics decrease as n grows, underscoring enhanced estimate precision with bigger samples. The use of black and red lines clearly distinguishes RSS and SRS methodologies, while the uniform arrangement across figures guarantees comparability. Subtle modifications in subplot spacing and legend placement may improve readability, but the visualizations effectively convey the performance patterns of the estimators (Tables 3, 4, 5, 6, 7, 8, 9).
-
Table 13 provides the \(\pmb K{_2}\) ratio of SRS to RSS, which makes it easier to evaluate how well the sampling techniques perform in comparison.
-
Tables 11 and 12 present the partial and total ranks of the estimates for SRS and RSS, respectively, and offer a comprehensive performance analysis.
After a careful examination of the rankings and results of the simulation, the following conclusions have been drawn:
-
Start of model estimates show consistency for both SRS and RSS datasets, indicating that as sample sizes increase, they will converge to true parameter values.
-
The MLE methodologies appear to be quite helpful in assessing the estimate quality of RSS and SRS.
-
RSS is a more effective sampling strategy with lower MSE and other metrics since its efficiency is higher than SRS’s.









Real data analysis
In order to validate the practicality of the proposed estimation strategies, we meticulously chose two real-world datasets and thoroughly presented our findings in this section. The aim was to showcase potential scenarios and applications where these estimation techniques could be employed using a comprehensive analysis of the actual data. This investigation sheds light on how these estimation methods can be utilized effectively, emphasizing their practical relevance for applied research endeavors and informed decision-making processes. The first data set is given in Table 12, which represents tensile strength measures in GPa of 69 carbon fibres available at52
The second data represent remission times (in months) of bladder cancer 128 patients, given in Table 13, discussed previously by53.

Graphical representation for the first real dataset.

Graphical representation for the second real dataset.
The data scrutiny in Table 14 encompasses a thorough examination of descriptive metrics and graphical depictions in Figs. 11 and 12. These visual representations, including violin plots, total time on test (TTT) plots, histograms, kernel density plots, quantile-quantile (Q-Q) plots, and box plots, offer valuable glimpses into the dataset’s attributes and distribution patterns.
Furthermore, a Kolmogorov-Smirnov (KS) test, denoted by \(K^*\), was administered to assess the dataset’s congruence with a PC-JD. The outcomes for the first dataset, with a KS distance of 0.0403 and a p-value of 0.9999, and for the second dataset, with a KS distance of 0.0540 and a p-value of 0.8481, signify the suitability of the chosen distribution for modeling the two real datasets. Figures 13 and 14 corroborate these results.

Graphical representation displaying the histogram overlaid with the estimated PDF, CDF, and survival function curves for the PC-JD using the first dataset.

Graphical representation displaying the histogram overlaid with the estimated PDF, CDF, and survival function curves for the PC-JD using the second dataset.
In light of the theoretical findings and discourse presented earlier, the datasets was subjected to analysis using two sampling methodologies: SRS and RSS. Tables 15,16,17 and 18 showcase the estimates derived from SRS and RSS applied to the PC-JD. These estimates span a range of sample sizes and estimation techniques, providing a comprehensive overview of the results achieved through different sampling methods and estimation procedures.
In order to accentuate the advantages of RSS compared to SRS across the various estimation techniques, we conducted an evaluation using the first dataset utilizing multiple goodness-of-fit statistics, including the AD test (\(A^*\)), CVM test (\(C^*\)), and \(K^*\). These statistical tests were employed to evaluate how well the data aligns with the model, offering insights into how effectively RSS captures the underlying distribution compared to SRS. Table 19 presents a comparative analysis of the goodness-of-fit values between the SRS and RSS designs.
The comparative analysis between the two designs, utilizing goodness-of-fit values, facilitates the assessment of their relative effectiveness in fitting the dataset to the proposed model. The focus of this comparison is to identify which sampling design and estimation techniques yield superior goodness-of-fit results. The model’s fit to the dataset is visualized in Figs. 15 and 16. It is noteworthy that the RSS design exhibits better performance compared to the SRS design in terms of efficiency, as evidenced by the smaller goodness-of-fit values obtained. This superiority of RSS over SRS is consistently observed across all estimates. These findings highlight the advantages of utilizing RSS over SRS for fitting the dataset to the model and obtaining more efficient estimates.

Plots of the estimated PDFs of the PC-JD with histogram for the two sampling methods at n=10.

Plots of the estimated CDFs of the PC-JD for the two sampling methods at n=10.
Summary and conclusion
The creation of economical, well-thought-out, and effective sampling techniques that might aid in the achievement of observational economy is a primary emphasis in much research pertaining to agriculture, biology, the environment, and ecology. One of those efficient sampling techniques that can assist us in achieving these goals at a reasonable cost is the RSS approach. This work explores the RSS method for parameter estimation of the PC-JD. The ML approach, the percentiles method, certain minimum distance-based methods, the Kolmogorov method, and some methods based on minimum and maximum spacing distances are only a few of the sixteen distinct estimation strategies that are employed. The simulation research evaluates the effectiveness of the proposed RSS-based estimates with respect to certain accuracy metrics compared to an SRS. The partial and total ranks of several estimates are displayed to help you choose the best estimating approach. Numerical findings indicate that the maximum likelihood technique appears to be quite helpful in assessing the estimated quality of SRS and RSS. RSS is more efficient than SRS, and it is a more effective sampling method. Also, the various methods of estimating using survival data for the two sampling strategies are studied. Future work could focus on Bayesian estimation in imperfect ranking of PC-JD through advanced RSS methods.
Data availability
The data that supports the findings of this study are available within the article.
References
McIntyre, G. A. A method of unbiased selective sampling, using ranked sets. Aust. J. Agric. Res. 3, 385–390 (1952).
Takahasi, K. & Wakimoto, K. On unbiased estimates of the population mean based on the sample stratified by means of ordering. Ann. Inst. Stat. Math. 20, 1–31 (1968).
Dell, T. R. & Clutter, J. L. Ranked set sampling theory with order statistic background. Biometrics 28, 545–555 (1972).
Patil, G. P., Sinha, A. K. & Taillie, C. Ranked set sampling. In Handbook of Statistics Vol. 12 (eds Patil, G. P. & Rao, C. R.) 167–200 (North-Holland, 1994).
Bohn, L. L. A review of non-parametric ranked-set sampling methodology. Commun. Stat. A-Theory Meth. 25, 2675–2685 (1996).
Mahdizadeh, M. & Arghami, N. Quantile estimation using ranked set samples from a population with known mean. Commun. Stat. Simul. Comput. 41, 1872–1881 (2012).
Mahdizadeh, M. & Zamanzade, E. Confidence intervals for quantiles in ranked set sampling. Iran J. Sci. Technol. Trans. Sci. 43, 3017–3028 (2019).
Mahdizadeh, M. & Zamanzade, E. New estimator for the variances of strata in ranked set sampling. Soft. Comput. 25(13), 8007–8013. https://doi.org/10.1007/s00500-021-05787-1 (2021).
Fei, H., Sinha, B. K. & Wu, Z. Estimation of parameters in two-parameter Weibull and extreme-value distributions using a ranked set sample. J. Stat. Res. 28, 149–161 (1994).
Adatia, A. Estimation of parameters of the half-logistic distribution using generalized ranked set sampling. Comput. Stat. Data Anal. 33, 1–13 (2000).
Stokes, S. L. Parametric ranked set sampling. Ann. Inst. Stat. Math. 47, 465–482 (1995).
Shaibu, A. B. & Muttlak, H. A. Estimating the parameters of the normal, exponential and gamma distributions using median and extreme ranked set samples. Statistica (Bologna) 64(1), 75–98 (2004).
Esemen, M. & Gurler, S. Parameter estimation of generalized Rayleigh distribution based on ranked set sample. J. Stat. Comput. Simul. 88(4), 615–628 (2017).
Khamnei, H. J. & Abusaleh, S. Estimation of parameters in the generalized logistic distribution based on ranked set sampling. Int. J. Nonlinear Sci. 24(3), 154–160 (2017).
Joukar, A., Ramezani, M. & MirMostafaee, S. M. T. K. Parameter estimation for the exponential-Poisson distribution based on ranked set samples. Commun. Stat. Theory Methods 50(3), 560–581. https://doi.org/10.1080/03610926.2019.1639745 (2019).
Taconeli, C. A. & Giolo, S. R. Maximum likelihood estimation based on ranked set sampling designs for two extensions of the Lindley distribution with uncensored and right-censored data. Comput. Stat. 35, 1827–1851. https://doi.org/10.1007/s00180-020-00984-2 (2020).
Qian, W., Chen, W. & He, X. Parameter estimation for the Pareto distribution based on ranked set sampling. Stat. Pap. 62, 395–417. https://doi.org/10.1007/s00362-019-01102-1 (2021).
Khamnei, H. J., Meidute-Kavaliauskiene, I., Fathi, M., Valackiene, A. & Ghorbani, S. Parameter Estimation of the Exponentiated Pareto Distribution Using Ranked Set Sampling and Simple Random Sampling. Axioms 11, 293. https://doi.org/10.3390/axioms11060293 (2022).
Sabry, M., Amin, E. & Gira, A. Parameter estimation based on neoteric ranked set samples with applications to Weibull distribution. Egypt. Stat. J. 68(2), 15–23. https://doi.org/10.21608/esju.2024.291355.1035 (2024).
He, X., Chen, W. & Qian, W. Maximum likelihood estimators of the parameters of the log-logistic distribution. Stat. Pap. 61(5), 1875–1892 (2018).
Bantan, R., Hassan, A. S., Elsehetry, M. & Kibria, Golam. Half-logistic Xgamma distribution: Properties and estimation under censored samples. Discret. Dyn. Nat. Soc. https://doi.org/10.1155/2020/9136513 (2020).
Bantan, R. et al. A two-parameter model: Properties and estimation under ranked sampling. Mathematics 9(11), 1214 (2021).
Hassan, A. S., Elshaarawy, R. S. & Nagy, H. F. Parameter estimation of exponentiated exponential distribution under selective ranked set sampling. Stat. Trans. New Ser. 23(4), 37–58 (2022).
Taconeli, C. A. & Rodrigues de Lara, I. A. Discrete Weibull distribution: Different estimation methods under ranked set sampling and simple random sampling. J. Stat. Comput. Simul. 92(8), 1740–1762. https://doi.org/10.1080/00949655.2021.2005597 (2022).
Hassan, A. S. & Atia, S. A. Statistical inference and data analysis for inverted Kumaraswamy distribution based on maximum ranked set sampling with unequal samples. Sci. Rep. 14, 25450. https://doi.org/10.1038/s41598-024-74468-4 (2024).
Aljohani, H. M. Statistical inference for a novel distribution using ranked set sampling with applications. Heliyon 10(2024), e26893 (2024).
Akgul, F. G., AcitaS, S. & Senoglu, B. Inferences on stress-strength reliability based on ranked set sampling data in case of Lindley distribution. J. Stat. Comput. Simul. 88(15), 3018–3032 (2018).
Hassan, A. S., Almanjahie, I. M., Al-Omari, A. I., Alzoubi, L. & Nagy, H. F. Stress-strength modeling using median-ranked set sampling: Estimation. Simul. Appl. Math. 11, 318. https://doi.org/10.3390/math11020318 (2023).
Hassan, A. S. & Nagy, H. F. Reliability estimation in multicomponent stress strength for generalized inverted exponential distribution based on ranked set sampling. Gazi Univ. J. Sci. 35(1), 314–331. https://doi.org/10.35378/gujs.760469 (2022).
Yousef, M. M., Hassan, A. S., Al-Nefaie, A. H., Almetwally, E. M. & Almongy, H. M. Bayesian estimation using MCMC method of system reliability for inverted Topp-Leone distribution based on ranked set sampling. Mathematics 10, 3122. https://doi.org/10.3390/math1017312 (2022).
Hassan, A. S., Elshaarawy, R. S. & Nagy, H. F. Estimation study of multi-component stress-strength reliability using advanced sampling approach. Gazi Univ. J. Sci. https://doi.org/10.35378/gujs.1132770 (2024).
Pedroso, V. C., Taconeli, C. A. & Giolo, S. R. Estimation based on ranked set sampling for the two-parameter Birnbaum–Saunders distribution. J. Stat. Comput. Simul. 91(2), 316–333. https://doi.org/10.1080/00949655.2020.1814287 (2021).
Hassan, A. S., Alsadat, N., Elgarhy, M., Chesneau, C. & Elmorsy, R. M. Different classical estimation methods using ranked set sampling and data analysis for the inverse power Cauchy distribution. J. Radiat. Res. Appl. Sci. 16(4), 100685. https://doi.org/10.1016/j.jrras.2023.100685 (2023).
Al-Omari, A. I., Benchiha, S. & Almanjahie, I. M. Efficient estimation of two-parameter xgamma distribution parameters using ranked set sampling design. Mathematics 10, 3170. https://doi.org/10.3390/math1017317 (2022).
Alyami, S. A. et al. Estimation methods based on ranked set sampling for the arctan uniform distribution with application. AIMS Math. 9(4), 10304–10332 (2024).
Nagy, H. F., Al-Omari, A. I., Hassan, A. S. & Alomani, G. A. Improved estimation of the inverted Kumaraswamy distribution parameters based on ranked set sampling with an application to real data. Mathematics 10, 4102. https://doi.org/10.3390/math10214102 (2022).
Alsadat, N., Hassan, A. S., Gemeay, A. M., Chesneau, C. & Elgarhy, M. Different estimation methods for the generalized unit half-logistic geometric distribution: Using ranked set sampling. AIP Adv. 13, 085230. https://doi.org/10.1063/5.0169140 (2023).
Lindley, D. V. Fiducial distribution and Bayes’ theorem. J. R. Stat. Soc. 20(1), 102–107 (1958).
Shanker, R. Akash distribution and its applications. Int. J. Prob. Stat. 4(3), 65–75. https://doi.org/10.5923/j.ijps.20150403.01 (2015).
Shanker, R. Sujatha distribution and its applications. Stat. Trans. New Ser. 17, 391–410. https://doi.org/10.21307/stattrans2016-029 (2016).
Shanker, R. Aradhana distribution and applications. Int. J. Stat. Appl. 6(1), 23–34. https://doi.org/10.5923/j.statistics.20160601.04 (2016).
Sen, S., Maiti, S. & Chandra, N. The Xgamma distribution: Statistical properties and application. J. Mod. Appl. Stat. Methods 15(1), 774–788. https://doi.org/10.22237/jmasm/146207742 (2016).
Shanker, R. & Shukla, K. K. Ishita distribution and its application. Biometric Biostat. Int. J. 5(2), 39–46. https://doi.org/10.15406/bbij.2017.05.00126 (2017).
Onyekwere, C. K. & Obulezi, O. J. Chris-Jerry distribution and its applications. Asian J. Probab. Stat., 20, 16–30 (2022). Ezeilo, C.I., Sidney, O. I., Umeh, E. U. and Onyekwere, C. K. (2023).
Ezeilo, C. I., Sidney, O. I., Umeh, E. U. & Onyekwere, C. K. On Power Chris-Jerry distribution: Properties and parameter estimation methods. Asian J. Probab. Stat. 25(3), 29–44 (2023).
Ezeilo, C. I., Umeh, E. U., Osuagwu, D. C. & Onyekwere, C. K. Exploring the impact of factors affecting the lifespan of HIVs/AIDS patient’s survival: An investigation using advanced statistical techniques. Open J. Stat. 13, 595–610 (2023).
Cheng, R. C. H., & Amin, N. A. K. Maximum product of spacings estimation with application to the lognormal distribution. Tech. rep. (1979).
Cheng, R. C. H. & Amin, N. A. K. Estimating parameters in continuous univariate distributions with a shifted origin. J. R. Stat. Soc. Ser. B (Methodol.) 45(3), 394–403 (1983).
Swain, J. J., Venkatraman, S. & Wilson, J. R. Least-squares estimation of distribution functions in Johnson’s translation system. J. Stat. Comput. Simul. 29(4), 271–297 (1988).
Kao, J. H. K. Computer methods for estimating Weibull parameters in reliability studies. IRE Trans. Reliab. Qual. Control PGRQC-13, 15–22 (1958).
Kao, J. H. K. A graphical estimation of mixed Weibull parameters in life-testing of electron tubes. Technometrics 1(4), 389–407 (1959).
Bader, M. G., & Priest, A. M. Statistical aspects of fibre and bundle strength in hybrid composites. Prog. Sci. Eng. Compos. 1129-1136 (1982).
Lee, E. T., & Wang, J. Statistical Methods for Survival Data Analysis (Vol. 476). Wiley (2003).
Funding
This work was supported and funded by the Deanship of Scientific Research at Imam Mohammad Ibn Saud Islamic University (IMSIU) (grant number IMSIU-DDRSP2503).
Author information
Authors and Affiliations
Contributions
The authors have worked equally to write and review the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
El-Saeed, A.R., Hassan, A.S., Elgarhy, M. et al. Optimal estimation of power Chris-Jerry distribution parameters using ranked set sampling design with application. Sci Rep 15, 32321 (2025). https://doi.org/10.1038/s41598-025-11152-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-11152-1
