
Abstract
Team Formation (TF) problems represent one of the most significant areas in computer science and optimization. The challenge lies in forming the best team of experts capable of completing a specific task at the lowest cost, which is a highly complex problem. Furthermore, the TF problem involves multiple attributes, each of which can be treated as a distinct objective that needs to be optimized. The problem solution varies according to the specified objectives. In this study, the TF problem is formulated as a bi-objective optimization problem, and a novel algorithm, Chaotic Jellyfish Search with Enhanced Swap Operator (CJSESOS), is proposed. This method is based on the Jellyfish Search Optimizer (JSO), a recent swarm intelligence algorithm known for its superior performance in various optimization tasks. CJSESOS introduces two major enhancements: (1) a chaotic sequence generated via a logistic map to improve solution diversity and exploration (CJSO), and (2) an enhanced swap sequence operator that increases the algorithm’s ability to escape local optima. The CJSESOS algorithm was adapted to enhance its exploration capabilities during the search for Pareto-optimal solutions. The effectiveness of the proposed bi-objective Chaotic Jellyfish search optimizer (Bi-CJSESOS) was evaluated using a different dataset with different skill numbers, in addition to twelve benchmark functions. Experimental results showed that, for the same fault discovery rate, the Bi-CJSESOS can find an optimal team and satisfy the two objectives more than the other comparative algorithms.
Similar content being viewed by others


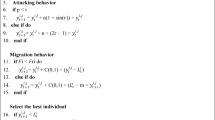
Introduction
A team formation problem is defined as creating the most effective team of experts in a social network to carry out a task at the lowest possible cost. It is also considered one of the most significant problems in computer science and optimization. Many real-world applications are based on their objective, such as task assignment, vehicle routing, nurse scheduling, resource allocation, airline crew scheduling, and many other applications. The TF problem has different attributes on which it depends, and every attribute can be considered as a problem objective that needs to be achieved in an optimal way. These attributes include communication cost, personal cost, workload balancing, unique expertise, and team reliability. The problem solution varies according to the specified objectives. Numerous studies have explored this problem using various optimization algorithms, and we will briefly discuss the most significant ones later. While many optimization algorithms have been developed and continuously refined to address real-world challenges, questions remain about whether these enhanced methods can consistently solve all real-world problems or if they sometimes fall short. According to the No Free Lunch (NFL) Theorem for optimization1 there is no guarantee that an improved algorithm will be universally effective for all optimization problems. However, in this study, we aimed to tackle some of the gaps of the original algorithm by incorporating proposed strategies. The results demonstrated the success of these strategies in addressing those gaps, enhancing the algorithm’s ability to discover innovative solutions, and improving its capability to escape local minimum by diversifying the search outcomes.
Motivations and contributions
The main aim of this paper is to propose a swarm intelligent method to solve the bi-objective TF problem. The proposed method is based on the Jellyfish Search Optimizer (JSO)2 that simulates the behaviour of jellyfish in the ocean1. The proposed method is named the Chaotic Jellyfish Search with enhanced swap operator (CJSESOS). The CJSESOS method is suggested to enhance one or more jellyfish search performance characteristics. To evaluate the CJSO method it was compared to well-known optimization algorithms such as the Particle Swarm Optimization (PSO)3 Genetic Algorithm (GA)4 Heap-based optimizer (HBO)5 the standard Jellyfish search optimizer (JSO), and the Chaotic Jellyfish search optimizer6 (CJSO). These algorithms were chosen for comparison due to their proven effectiveness in solving diverse optimization problems. PSO is widely recognized for its simplicity and fast convergence, while GA excels in exploring complex search spaces through crossover and mutation operations. HBO offers a unique approach inspired by heap data structures, which enhances exploration and exploitation balance. JSO, as a nature-inspired algorithm, demonstrates strong performance in escaping local minima and achieving robust optimization. To evaluate the proposed method against both well-established and innovative techniques, we first employ a set of mathematical benchmark functions. This initial evaluation provides a foundational performance comparison. Subsequently, we address the Team Formation (TF) problem using a real-world dataset from the Internet Movie Database (IMDB)7allowing us to assess the method’s practical effectiveness. Our contributions to accomplishing the above-mentioned aim can be summarized as follows:
The Jellyfish Search (JSO) optimizer has garnered significant attention from experts and scholars seeking to refine and implement it. JSO optimizer proved superior to other evolutionary algorithms in different contexts6. However, the JSO occasionally fails to discover the global best solution for some functions; in addition, the JSO is used for solving single-objective optimization problems. So, we proposed modifications to the JSO by two modifications to the original JSO algorithm, the first is the chaotic sequence generated by iterating a logistic map7 which is named CJSO. This enhancement discovers a creative solution by directing particles to different locations of the search space, the second is enhanced swap sequence operator which increased the CJSO algorithm’s ability to escape from local minimum by diversifying the results. The new method suggested is named CJSESOS. This enhancement discovers a creative solution by directing particles to different locations of the search space and increases the JSO algorithm’s ability to escape from the local minimum by diversifying the results. It utilizes CJSESOS to solve the bi-objective team formation problem. Most previous research treats team formation problems as a single objective problem and focuses on minimizing the problem cost while ignoring the workload of team members. This research proposed the CJSESOS method for solving a bi-objective team formation problem. Apply a set of experiments to evaluate the suggested method. The analysis of the experimental results shows that the introduced method outperforms all compared algorithms on the parameters of efficiency and accuracy. The suggested algorithm creates teams that always possess the necessary skills, provides approximation guarantees on team communication costs, and is competitive in load balancing.
Paper organization
The remainder of the paper is laid out as follows. The related work and contribution are illustrated in Sect. 2. The description of the team formation problem is illustrated in Sect. 3. Section 4 describes the suggested method used for solving the problem. The experimental results are shown in Sect. 5. Finally, Sect. 6 brings the work to a close and identifies areas for potential research.
Related work
The first to have thought about the problem of teams forming for a single task are Lappas et al.8 who introduced TF as a network of experts and considered the minimum collaborative cost between these experts. but they ignored the workload balancing attribute.
On the other hand, Anagnostopoulos et al.9 thoughts about balancing the workload goal but disregarded the communication costs. Concentrating just on one of these goals leads to an unfair and poorly communicated team.
The strategy for locating the group of experts, whether they have a leader or not, has been offered by Kargar et al. at10 since they discuss the problem differently. They considered several cost models where the expert contributes various skills to complete a task.
Majumder et al. in11 concentrated on the workload factor. They aim to create an efficient team of users that meets the demands of a project and has chosen strong team members. They want to make sure that no user is overworked by the task and that no user is assigned responsibilities that are outside the scope of her or his abilities.
Anagnostopoulos again tried to solve the team formation problem, but this time considered the problem a multi-objective problem. The author used non-deterministic and approximate algorithms to explore the search space and come up with a good approximation of the common solution to such problems. The provided algorithms can create teams that have the necessary competencies and offer approximate guarantees for the required objectives12.
Also, swarm intelligence (SI) techniques proved their efficiency in solving the TF problem. Eichmann13 presents a solution for TF problem based on nature-inspired swarm intelligence, called Ant Colony Optimization (ACO). Gutiérrez et al. in14 attempted to address the problem of multiple teams forming using the variable neighborhood search algorithm; they found multiple different teams solving multiple tasks while considering each team’s minimal cost. Also, Basiri et al. In15 tried to present a solution for the TF problem by using the Brain Drain optimization algorithm. To evaluate the algorithm’s performance, it was compared with six different algorithms and tested using the Internet Movie Database (IMDB), Database Systems & Logic Programming (DBLP), and Association for Computing Machinery (ACM) dataset.
Since multi-objective optimization is an area of mathematics used in multiple-criterion decision-making, it deals with optimization issues involving two or more objective functions that must be optimized at the same time. This assumption makes the problem even more difficult16 Zhang et al.17 suggested multi-objective particle swarm optimizations (MOPSO) to form a convenient team of experts able to develop an effective product. Implemented a more advanced fuzzy analytical hierarchy procedure based on the fuzzy language preference relation, to confirm the precision and validity of a member’s skills. The experiment results showed that the MOPSO is an efficient model for TF. Also in18 the researchers deal with the TF problem, they aim to find an ideal team that can get the job done while keeping project management and personnel costs to a minimum.
Recently, different researchers focused on solving this problem using swarm intelligence techniques as they have proven their ability to reach the optimal solution, especially when solving real-world problems19. In20 2018, The African Buffalo (IABO) algorithm was modified by the author to address the problem with team formation. The IABO algorithm is paired with the crossover and switch operators, to create preferable teams with all the essential skills. In 2019, the author made another effort to resolve the TF problem utilizing PSO, and it has also been improved using swap operators21. Their objectives were to find an optimal team to complete a task while minimizing team communication costs. In 2020, Ashmawi once again attempted to use a modified Jaya optimization technique to address the problem of TF. An Improved Jaya algorithm with a modified swap operator (IJMSO) is the name of the suggested algorithm. To expedite the search, the author enhanced the Jaya algorithm by using a single-point crossover. To ensure that the skills and abilities needed to complete the task are consistent, they also utilize a new swap operator. In 202122, The author concentrated on a distinct idea, graph reduction, which condenses the massive data to just the experts and the required skills, enabling the quick extraction of experts for collaboration. In 2022 23, the Slap Swarm Algorithm (SSA), the Owl Search Algorithm (OSA), the Sooty Tern Optimization Algorithm (STOA), the Squirrel Search Algorithm (SqSA), and the Crow Search Algorithm (CSA) are five metaheuristic methods the author uses to tackle the team formation problem. The analysis takes into consideration the very minimum in terms of team costs and skills. The best results for the team formation issue reveal that the CSA is the more successful metaheuristic algorithm in terms of the overall efficacy of the solution and runtime. We can infer from this literature study that many problems can be framed as optimization issues and resolved to utilize optimization techniques24,25,26,27,28,29,30. Table 1 lists the most well-known and significant contributions to team formation (TF) in literature.
Team formation problem definition
The team formation problem is defined as how to obtain a team of experts that covers all the required skills and can perform the required task with the least communication cost.
Mathematical model of team formation problem
-
The problem can be expressed as a task S, where \(S= \{{s}_{1},{s}_{2},...{s}_{m}\}\) are a collection of skills that must be acquired, \(\:V=\{{v}_{1\:}{,v}_{2\:},...{v}_{n\:}\}\) are a group of experts, since any expert has a set of skills and potentially a price for each skill, each expert \(\:{v}_{i\:}\) is associated with a set of unique skills \(\:s\left({v}_{i\:}\right),\:s\left({v}_{\:j}\right) \epsilon\)S The set of experts that have the skill\(\:{\:S}_{k}\) is denoted as C(\(\:{\:S}_{k}\)), (i.e., C(\(\:{\:S}_{k}\)) \(\:\epsilon\) V. These experts are connected in a social network modeled as an undirected graph G = (V, E), where V is the set of experts and E is the set of edges representing communication links between them. The communication cost between two experts vi and vj is denoted by eij. The goal is to find the subset of experts X= {\(\:{v}_{i1\:}\), \(\:{v}_{i2\:},{v}_{i3\:}\)....,\(\:{v}_{ik\:}\)} that can effectively perform the task with the lowest possible communication cost CC(X). Where \(\:1\le\:\:ik\:\le\:\:r\:,\:scince\:\varvec{r}\:\text{i}\text{s}\:\text{u}\text{p}\text{p}\text{e}\text{r}\:\text{b}\text{o}\text{u}\text{n}\text{d}\:\text{f}\text{o}\text{r}\:\text{t}\text{h}\text{e}\text{s}\text{e}\:\text{i}\text{n}\text{d}\text{i}\text{c}\text{e}\text{s}.\:\)If there is a bound on the team size, where r is the maximum team size.
Therefore, this can be done by using optimization algorithms (e.g., swarm intelligent algorithms)19.
While the communication cost between any two experts (e.g., \(\:{v}_{i\:}\)and \(\:{v}_{j\:})\) is \(\:{e}_{ij}\) can be computed according to Eq. (1)
Optimization objectives
-
Objective one.
The objective of this study is to create teams that can complete the assigned task with the least communication cost (determined by Eq. (2)) and achieve a fair allocation of the overall workload among team members, which can be defined as a constraint.
Where:
-
\(\:\left|{v}_{ik}\right|\:\)is the cardinality of team (is the number of experts in the team).
-
e(ij) is the communication cost between expert vi and expert vj, as defined in Eq. (1).
-
This formulation ensures that all pairwise communication costs between members of the selected team are considered.
-
Objective Two.
Workload, an important constraint is the workload L(v) of an expert v, which is the quantity of tasks in which he participates. The challenge is to select the team that minimizing the maximum workload \(\:{W}_{l}\:\:\)across all the experts.
In this paper, the fitness function is composed of two objectives. The first objective is to minimize the communication cost between the team members. While the second objective is to select a team with the goal of achieving a fair allocation of the overall workload among team members. The two objectives are defined using Eqs. (2) and (3).
To formulate the fitness function, we used the weighted sum method, which is a simple and traditional method for bi-objective optimization. It produces a Pareto-optimal set of solutions by changing the weights among the objective functions. Yang et al.31 showed experimentally that the weighted sum method for combining the bi-objectives into a single objective is very efficient even with highly nonlinear problems, complex constraints, and diverse Pareto optimal sets. Moreover, Wang et al.32 showed that the random weighted-based GA (multi-objective GA based on the weighted sum method) is superior to some popular multi -objective algorithms. The fitness function used in this work is defined by Eqs. (6)–(8). The best solution is the one that minimize the fitness.
The fitness function used in this work is defined by Eqs. (6)–(8) using the pre-determined weights strategy, the best solution is the one that minimize the fitness.
where, \(\:{weight}_{1}\), and \(\:{weight}_{2}\:\)are the weights used to find the Pareto-optimal set of solutions, \(\:{weight}_{init}\:\)denotes the initial value of \(\:{weight}_{1}\), iter is the current iteration number, and n is a modulation index. With the increase in the iteration the value of \(\:{weight}_{1}\) increases from\(\:\:\:{weight}_{init}\:\:\)to 1, whereas \(\:{weight}_{2}\) decrease from (1 − \(\:{weight}_{init}\)) to 0. The values of \(\:{weight}_{1}\) and \(\:{weight}_{2}\) determine the importance of each objective to the fitness function. The different values of \(\:\:{weight}_{1}\) and \(\:{weight}_{2}\) produce different non-dominated solutions with sufficient diversity, so the Pareto front can be approximated correctly.
Pareto optimal concepts
When dealing with Bi-objective Optimization Problems, the aim is to achieve multiple goals which may conflict with each other. So, the optimality notation changes from producing one optimal solution to be set of optimal solutions33. Each of them has at least one objective which is better than its corresponding objective in other solutions. This definition leads us to find a set of solutions that is called the Pareto Front, whose corresponding elements are called nondominated. Thus, the Pareto front is a set of Pareto solutions which are not dominated by any other solution. Solution x = [x1, x2,...,xn] is said to dominate a solution y = [y1, y2,...,yn], if and only if is not better than for any objective i = 1, 2,.,n, and there exist at least one objective xi in x which is better than its corresponding objective yi in y11, better solution mean it has a minimum/maximum value when the problem is minimization/maximization. Figure 1 depicts the difference between dominated and non-dominated solutions (NDS) and represents the Pareto front. In Figure 1, the objective functions f1 and f2 are to be minimized. It is obvious that solution A dominates solution D because \(\:f1\)(A) < f1 (D) and f2(A) < f2(D). Moreover the solutions, A, B and C are non-dominated solutions because none of them is better than the others in both objectives; A as is the best for objective f1, whereas \(\:C\) is the best for \(\:f2\) objective, and \(\:B\) is better than \(\:A\) for objective 2 and better then \(\:C\) for the objective \(\:f1.\) The set of non-dominated solutions of the bi-objective optimization problem is called the Pareto optimal set, and its representation in the objective space is the Pareto front. This set satisfies two properties: (i) any solution found is dominated by at least one solution in the Pareto set, and (ii) every two solutions in the set are non-dominated to each other. Figure.1, is explain a sample representation of dominated non-dominated solutions and a Pareto front34.

Sample representation of dominated non-dominated and pareto front.
Proposed methods
A Jellyfish is a creature that has evolved to adapt to the harsh conditions of the ocean. Because they are poor swimmers, they have evolved a body form that allows them to navigate through the ocean currents. Tentacles are used to sting prey. The survival habit of jellyfish in the water inspired JSO. The search particles are dubbed jellyfish, and the following assumptions are made:
-
1.
Jellyfish switch between both forms of movement, which are governed by a time control system and allow jellyfish to follow the ocean current or move inside the swarm.
-
2.
Jellyfish move through the ocean in search of food, and they are more attracted to regions with a greater concentration of food. So, the quality of food available at a location is considered as the jellyfish objective function value.
The jellyfish is drawn to better locations when it is aware of the food quality at the locations of other jellyfish. The most important feature of the jellyfish is its ability to quickly update its positions in the direction of achieving the goal function.
The mathematical model of jellyfish optimizer (JSO)
Initialization
In the initialization phase, the Jellyfish Optimization Algorithm generates an initial population of candidate solutions randomly within the defined search space. Each candidate solution is represented by a set of variables, and the position of each variable is initialized uniformly at random between its lower and upper bounds.
This can be mathematically represented by:
Where:
-
\(\:{X}_{ij}\) is the value of the \(\:{j}^{th}\)variable for the \(\:{i}^{th}\)individual in the population.
-
\(\:{Ub}_{j}\) is upper bound and \(\:{Lb}_{j}\) is lower bound, for the \(\:{j}^{th}\:\)variable.
Update: During the iteration of the JSO algorithm, each individual in the population has the ability to update its position by migrating either within a jellyfish swarm or along the ocean current. There are two forms of swarm motion: active motion and passive motion.
Each jellyfish has a different sort of movement, which is controlled by a time control function called c(t), which is dependent on the number of iterations. And it can be calculated from Eq. (10).
since \(\:t\) is the iteration counter and \(\:{t}_{max}\) is maximum number of the iterations.
If \(\:c\left(t\right)\:\ge\:{C}_{0}\) the jellyfish update its position along the ocean current defined in Eq. (11).
Where\(\:\:\overrightarrow{TREND}\) signifies the movement away from the population’s mean (µ) in the direction of the global best \(\:{X}_{g}\).
where the size of population is defined as N and distribution coefficient defined as \(\:\beta\:\).
In case of c(t) < \(\:{C}_{0}\)the jellyfish updates its position using swarm motion. In swarm motion, if 1-c(t) < rand (0,1), the jellyfish displays (i) Active Motion, otherwise display (ii) Passive Motion.
-
i.
Active Motion.
Jellyfish are comparing their food quality with other jellyfish in the swarm and updating their position based on that comparison. A jellyfish named \(\:k\) is chosen at a random way to determine its active motion direction. If jellyfish \(\:k\)‘s food quality is superior to that of jellyfish \(\:i\), then jellyfish \(\:i\:\)swims toward \(\:k\), otherwise, it departs from \(\:k\). This movement for minimization problem this description can be formulated mathematically from Eq. (14)
-
ii.
Passive Motion.
Jellyfish search their own neighborhood for a better location this description denotes a passive motion, and it can be formulated mathematically from Eq. (15).
since \(\gamma\) is a motion coefficient constant. The degree of algorithm exploration and exploitation is managed by the time control function. In the beginning, exploration is caused by c(t) acquiring larger values. The search tends to be more exploitation oriented as the execution goes on. Exploration is targeted by ocean currents, whereas exploitation is targeted by swarm motion.
Oceans are located around the world. The earth is approximately spherical, so when a jellyfish moves outside the bounded search area, it will return to the opposite bound.
Out of bound jellyfish are modified in the other direction. If a jellyfish\(\:{X}_{j\:}\) (\(\:{X}_{j\:}\)is the location of the \(\:{j}^{th\:}\:\)jellyfish) trespass the upper bound \(\:{Ub}_{j\:}\)in dimension \(\:j\) by \(\:{\delta\:x}_{j\:}\) distance, then it is exchange by another jellyfish \(\:X^{\prime}\) (\(\:{X}_{j\:}^{{\prime\:}}\)is the updated location after checking boundary constraints) inside the lower bound \(\:{Lb}_{j\:}\) by the same \(\:{\delta\:x}_{j\:}\) distance. Similarly, if it trespasses the lower bound \(\:{Lb}_{k\:}\) in \(\:{k}^{th}\)dimension by a distance \(\:{\delta\:x}_{k\:}\), it is modified inside the same distance \(\:{\delta\:x}_{k\:}\) from the upper bound \(\:{Ub}_{k\:}\). This modification for out of bounds jellyfish can defined mathematically using (16) and (17).
Chaotic local search
Chaos optimization is considered one of the most popular search methods35,36. Although Jellyfish Search Optimizer Algorithms depend on randomness in the way they it built to search through the search space and increase the ability of exploration in the search process, it may occasionally fail to obtain the optimal solution to prevent this flaw. Recently, chaos-based randomization methods have been used, as shown in35,36. They help to discover new solutions in the search space by moving particles towards different regions in the search space. The main concept is to use chaos parameters and variables to form a solution space. The chaotic features are ergodicity, regularity, and stochastic qualities, which are used to find the global optimum, increase the convergence rate, and increase the algorithm’s ability to avoid trapping in local minima2. All these advantages can dramatically boost the performance of evolutionary algorithms. There are many chaotic maps used for enhancing meta-heuristic algorithms, such as logistic, singer, tent, piecewise, and sinusoidal. The chaotic map’s efficiency varies according to the problem. In this work, a logistic map is adopted to obtain chaotic sets, as it is the most well-known map. Logistic map is defined as follows.
where \(\:{\:C}_{n}\)ϵ [0, 1], that represents the ratio of existing population to the maximum possible population, and \(\:\mu\:\) is a parameter. A generated sequence of numbers by iterating a Logistic map, with \(\:\mu\:\) = 4 exhibits chaotic behavior
Enhanced swap operator sequence (ESOS)
Utilizing the swap operator (SO), as shown in37,38 there are two variables in the swap operator procedure \(\:SO\:(x,\:y)\). For example, suppose you have a sequence of odd numbers S= (1 − 3−5 − 7− 9), the applied swap operator is SO= (2, 3), and then, the obtained sequence will be S = S + SO (2,3) = (1-3-5-7-9) + SO (2,3) = (1-5-3-7-9).
In JSO algorithm, the enhanced swap operator sequence \(\:ESOS\:(x,y,z)\) which has three variable: variable \(\:x\) is the \(\:{\text{s}\text{k}\text{i}\text{l}\text{l}}_{id}\), and variables \(\:y\) and \(\:z\) are the current \(\:{expert}_{id}\:\)and the new \(\:{expert}_{id}\), which are selected randomly every iteration, and ensure that the values \(\:y\:and\:z\) are always different.
For example, \(\:ESOS\:(\text{1,4},5)\) means for \(\:{\text{s}\text{k}\text{i}\text{l}\text{l}}_{id}\) = 1 swap the \(\:{expert}_{id}\) = 4 with \(\:{expert}_{id}\) = 5.
Using ESOS can ensure the validity of the solution and prevent getting new solutions outside from search space during the updating process. ESOS plays a crucial role in solving discrete optimization problems such as the problem of team formation.
Jellyfish search optimizer algorithms with enhanced swap operator and chaotic sequence (CJSESO)
In this subsection, chaotic variables are utilized in lieu of the random variables that were previously used to update the JS position. This update in the JS position impacts the convergence rate and optimal solution. The combination of chaos and JSO is known as “CJSO”. Chaotic maps may be used in a variety of ways in JSO. In2many chaotic maps have previously been examined, and the logistic map produced the best results. The proposed algorithm in this work uses a logistic chaotic map. The performance and convergence rate of JSO may be considerably enhanced by this map. Equation (18) provides a description of the CJSO approach in combination with chaotic sequences. All three forms of motion in the algorithm—ocean current, active motion, and passive motion—can be replaced by chaos. The literature-based data is adequate to show that chaos may provide a more varied set of sequences than is required for updating the positions of particles in algorithms that are inspired by nature. The objective of the proposed algorithm is to suggest chaos in a way that influences positively on the old JSO algorithm. The time control function \(\:c\left(t\right),\) is a function of iteration count and used \(\:{t}_{max}\) and the constants \(\:{C}_{0}\). This means that determining the sort of movement a jellyfish will make simply requires comparing the random numbers produced during the computation of c(t) or by comparing them. The quantity of jellyfish executing a certain movement type in each iteration along with the growing value of the iteration count \(\:\left(t\right)\) for \(\:{C}_{0}=0.5\). It is evident from previous studies that during the algorithm execution, the number of jellyfish in an iteration performing ocean current movements is supported after the initialization of exploratory moves. And find that a limited number of jellyfish perform a passive motion throughout the execution process. Throughout the whole execution process, the predominant number of jellyfish is those that are actively moving in swarms. In addition, the number grows as the execution becomes more sophisticated. The effectiveness of the algorithm will thus be most sensitive to any improvements made to active motion, which encourages the use of chaos in active motion. The suggested algorithm substitutes the rand (0,1) function used in Eq. (14) with a chaotic map. The suggested study’s description of chaotic active swarm motion is presented in Eq. (19).
Update the solution using an enhanced swap operator. According to Eq. (20), which represents the main conversion from the continuous domain to the discrete domain via the use of the enhanced swap operator, each solution’s location in the population is updated.
Since the variable \(\:x\) is the \(\:{\text{s}\text{k}\text{i}\text{l}\text{l}}_{id}\), and variables \(\:y\) and \(\:z\) are the current \(\:{expert}_{id}\:\)and the best \(\:{expert}_{id}\), which are selected randomly every iteration. Figure.2 illustrates an example of a swap sequence between the current solution and the best one during the iteration loop.

Enhanced swap sequence operator.
The general Step of the proposed algorithm CJSESOS is illustrated in Algorithm 1.
The pseudo-code of Jellyfish algorithm (CJSESOS.

Jellyfish Search Optimizer Algorithms with Enhanced swap operator and chaotic sequence (CJSESOS).
Computational complexity of the proposed CJSESOS
The proposed algorithm begins by initializing a population of N individuals within a D-dimensional search space. A chaotic sequence is generated using a logistic map, involving straightforward iterative calculations for each individual. This initialization step has a computational complexity of \(\:O(N\cdot\:D)\) and represents the first of five primary operations contributing to the computational complexity of the CJSESOS algorithm.
The second operation is fitness evaluation, where each individual’s fitness is computed using the objective function. This step is the most computationally demanding, with a complexity of \(\:O(N\cdot\:{C}_{f})\), where \(\:{C}_{f}\:\)is the cost of evaluating the fitness function.
The third operation involves generating chaotic sequences for all particles, which requires \(\:O(N\cdot\:D)\), as each individual undergoes simple logistic map-based computations.
The fourth operation is the Enhanced Swap Sequence Operator (ESSO), which modifies selected particles to increase population diversity. This step has a complexity of \(\:O(K\cdot\:D)\), where\(\:\:K\le\:N\) is the number of individuals undergoing the ESSO operation.
The final operation is the selection process, where N individuals are sorted based on fitness. This step has a complexity of \(\:O(N\cdot\:\text{log}N)\).
These steps are repeated over T generations, resulting in a total computational complexity of:
\(\:O(G\cdot\:(N\cdot\:{C}_{f}+N\cdot\:D+K\cdot\:D+N\cdot\:\text{log}N\left)\right)\), where, N Population size, D Dimensionality of the problem, \(\:{C}_{f}\:\) Cost of fitness evaluation, T Number of generations, and K Number of individuals undergoing ESSO operations \(\:(K\le\:N\)).
The computational complexity of the Jellyfish Search (JS) algorithm over T iterations is summarized as:
\(\:O(G\cdot\:(N\cdot\:{C}_{f}+N\cdot\:D\left)\right)\). Additionally, Table 2 provides a comparison of the computational complexities of CJSESOS and JS methods.
Numerical experiments
Optimization algorithms must be capable of exploring the search space to discover favourable areas and exploiting these areas to obtain the best solution. The CJSESOS algorithm requires a balance between exploration and exploitation. In this section, we attempt to evaluate their behaviour and performance. The proposed method was experimented on a set of benchmark functions, a simple example model of the problem, and then tested using the IMDB dataset. The results of our experiment showed that the suggested method is an auspicious algorithm able to find the best solution at the lowest cost. Numerical experiments to perform wide exploration and deep exploration during the search process.
The CJSESOS method was programmed in MATLAB and Windows 10. The simulation tests were carried out on an Intel Core i7 computer with 8 GB of RAM. The results were compared against the following algorithms (PSO, GA, HBO, JSO, and CJSO) using a set benchmark function and different datasets. The general efficiency of our suggested method and its ability to converge to optimality are investigated using different experiments. But in the first summary, the setting parameters of the CJSESOS algorithm are as follows, since the compared algorithms’ parameters are taken from their original paper.
Parameter setting
The introduced algorithms parameters are outlined with their allocated values as shown in Table 3. These values are determined using several numerical experiments to stabilize them or based on a commonly used setting in the literature.
Benchmark function set and compared algorithms
To measure the performance of the CJSESOS suggested method, a collection of popular benchmark functions is used for testing. Both multimodal and unimodal functions are included in this collection of benchmark functions. The selected set of benchmark functions includes 7 unimodal functions (F1–F7). We have a single global optimal solution using this benchmark function that can be used to assess the local exploitation capability of our suggested algorithm. We are also using six multimodal functions (F8-F13), which have multiple local optimal solutions besides the global optimal solution. These functions are used to test the global exploration capability and local optimal avoidance capability of our suggested method. Table 4 reveals the mathematical formulas and characteristics of these functions. The benchmark functions are scalable in two different dimensions. 30 runs were performed for each function. The average (mean) and standard deviations (std) of function values over 30 independent runs for D = 30, 100 dimensions are reported in Table 5, and Table 6. The value of the function evaluation is used as the main termination criteria. The results of these experiments have shown that the proposed method has achieved the best results in terms of average (Mean), and standard deviation (Std), and they are returning a solution with a good fitness value within the prescribed number of iterations.
For example, in Table 5 at dimension (30), we notice that the CJSO method reaches optimal value in cases of (F8, F10, F13, F14). Furthermore, CJSESOS is very close to optimal value in most cases (F3, F4, F5, F6, F7, F9, F11, F12) and can observe that CJSESOS outperforms other compared algorithms. These Results can get better by increasing the number of iterations. From this experiment, it is clear that the suggested method is an effective algorithm and can produce promising solutions.
In Table 6 the benchmark functions are scalable at dimensions = 100. 30 runs were performed for each function. The average (mean) and standard deviations (std) of function values over 30 independent runs for dimension (D = 100) are reported in Table 6 respectively. The value of the function evaluation is used as the main termination criteria. The results of these experiments have shown that the proposed method has achieved the best results in terms of average (Mean), and standard deviation (Std), and they are returning a solution with a good fitness value within the prescribed number of iterations. In Table 6 at dimension (100), we notice that the CJSO algorithm reaches optimal value in cases of (F8, F10). Furthermore, CJSESOS is fairly near the optimal value in most cases (F3, F4, F5, F6, F7, F9, F11, F12) and can observe that CJSESOS outperforms other comparable algorithms, although it seems to have some issues with F1 and F2 optimization. By doing more iterations, this failure may be fixed. It is evident from this experiment that the recommended algorithm is efficient and capable of producing good results. Finally, it is evident that the proposed method is promising and can outperform other algorithms that were examined.
Data set and comparison algorithms
The suggested technique is evaluated on three datasets, namely ACM40 DBLP41 and IMDB42 to show its effectiveness. Using MATLAB software and Windows 10, the simulation tests were carried out on an Intel Core i7 computer with 8 GB of RAM.
The proposed CJSESOS method was compared with PSO, GA, GWO, HBO, AO, POA, JSO, and the enhanced algorithm CJSO. Communication-Cost is the chosen performance metric for TF. The optimal tuning settings are applied to all experiments. Table 3 lists all parameter settings for the introduced algorithms.
ACM dataset description
Association for Computing Machinery (ACM) dataset40 serves as a real-life dataset from which the connectivity and expertise data are extracted. The suggested method is tested on ACM dataset to mimic reality. which has been extracted from the ACM XML. ACM (Association for Computing Machinery) is an online database that compiles data from articles that were published between 2003 and 2010. The authors of the article are regarded as specialists, and each author’s expertise is reflected in the title of the paper, which has been reduced to its essential terms such as (game theory, agendas, multi agent systems, industrial applications, logistics, scheduling, auctions, multi object auctions, bidding strategies, equilibrium analysis). The dataset is available online.

Average communication cost comparison between CJSESOS, and other compared algorithms on the ACM dataset.
In this subsection, the convergence of the suggested algorithm is examined and compared with HBO, JSO, PSO, GA, and GWO. Using the ACM dataset and construct the collaborative social network from randomly selected 100 experts, and choose 3, 5 and 7 skills to perform tasks and standardized these chooses on all compared algorithms. The results at different numbers of skills (3,5,7) are shown in Fig. 3. which represents the average fitness (communication cost) of the proposed method compared with other algorithms, and it demonstrates that CJSESOS outperform the other algorithms. And we can observe that the fitness value increases with an increasing skill number. But, in all cases, the proposed algorithm outperforms the others. The performance of CJSESOS will be tested in different ways in the following sections.
DBLP dataset description
DBLP dataset is used as a real-life dataset41 to extract the connective and expertise data. The suggested method also tested on DBLP, which has been extracted from DBLP XML. DBLP (Database Systems & Logic Programming), which has many specialists in various fields such as (database, theory, data-mining, and artificial intelligence), among others. In the DBLP, each expert’s skills are based on the title of the paper they have written, deconstructed into understandable language. The dataset may be found online. Applying the proposed method and the other comparative algorithms to this dataset, the performance of the suggested method is evaluated in order to identify teams that can complete the task. Apply a set of experiments with a different number of skills. From the DBLP data set, construct the collaborative social network from randomly selected 100 experts, and choose 3, 5, 7, 10, and 15 skills to perform tasks and standardize this chooses on all compared algorithms. The experiment clarified that the suggested method CJSESOS can find teams with the lowest communication costs calculated.
Comparison between JSO, HBO, PSO, GA, GWO, CJSO and proposed CJSESOS on DBLP dataset
The convergence of the recommended method is evaluated in this subsection and compared with HBO, JSO, PSO, GA, AO, POA, CJSO, and GWO. Using the DBLP dataset at number of expert sets equals 100 with various skill numbers. The results at different numbers of skills (3,5,7,10,15) are display in Fig. 4, which represents the convergence curve for the nine algorithms, and it clarifies that CJSESOS outperforms the other algorithms.
Throughout the search process, the suggested method is successful in working in an equivalent manner in the exploration and exploitation processes, overall iteration number. It also outperformed all other algorithms in convergence in all experiments and obtained the best communication cost in most cases, as shown in Fig. 4. As a result, when CJSESOS convergence is compared to other algorithms, they found that while the number of iterations increases, the convergence rate becomes more rapid. Furthermore, as shown by the convergence curves in Fig. 4, the suggested method solves precocious convergence better than other algorithms by balancing exploration and exploitation as well as improving population diversity. The enhanced efficiency of the CJSESOS method is due to two modifications to the original JSO algorithm, one of which is the chaotic sequence generated by iterating a logistic map, named CJSO. This enhancement aided in the results’ diversification and the ability to find new solutions in search space by directing particles to different regions of the search space, the second is due to enhanced swap sequence operator which increased the CJSO algorithm’s ability to escape from the local minimum. Evaluate the effectiveness of the suggested method against the competing algorithms. Table 7 summarizes the results of 30 random runs, average (Mean) and standard deviation (Std) respectively. The best results are shown in bold font. In Table 7, the suggested method outperforms the others.
Additionally, the fitness values obtained by CJSESOS, as shown in Table 7 are in most cases is better than those obtained by other algorithms, demonstrating their ability to survive from a local optimum.

Comparison between CJSESOS, and other compared algorithms on DBLP dataset at skills numbers=5, 7, 10, 15.
According to Table 7; Fig. 4, the suggested method is more capable of exploring and exploiting search.
space than other optimization algorithms. This clears CJSESOS, superior abilities to achieve solution variety compared to the others. Finally, this result confirmed that the suggested method outperforms other algorithms in terms of discovery. We can also observe from the results that the CJSESOS method is auspicious, powerful, and it can find the best or near-best solution within an acceptable time frame.
Non-parametric test analysis (Wilcoxon signed ranks test)
A nonparametric Wilcoxon rank-sum test39 based on fitness function is run for DBLP datasets at each of the five different skills named DBLP_3, DBLP_5, DBLP_7, DBLP_10, and DBLP 15 to determine if there is a statistical difference between the CJSESOS results and the comparative algorithms results. The results of the Wilcoxon test are shown in Table 8 and its significance level is set at 0.05. No. R + is the positive ranking number in which CJSESOS.
outperforms the comparator algorithms. No. R- is the negative ranking number in which the CJSESOS falls short of outperforming the comparator algorithms.
The ties number is the number of times the CJSESOS and the other comparison algorithm had the same number of rankings. Sum R- and Sum R+, respectively, reflect the sum of the negative and positive rankings. According to Table 8, the No. R + in which CJSESOS outperforms PSO, GA, GWO, HBO, JSO, AO, POA and CJSO are 5 cases out of the 5 experiments. For instance, on the DBLP_5, the number of runs in which CJSESOS superior to PSO is 85 out of 100 runs and it fails to outrank PSO in 14 runs and presents a similar performance in one run, the number of runs in which CJSESOS superior to GA is 84 out of 100 runs and it fails to outrank PSO in 15 runs and presents a similar performance in one run, the number of runs in which CJSESOS outperforms HBO is 97 out of 100 runs and it fails to outrank HBO in 3. The number of runs in which CJSESOS superior to JSO is 95 out of 100 runs and it fails to outrank JSO in 4 runs and presents a similar performance in one run, the number of runs in which CJSESOS outperforms AO is 97 out of 100 runs and it fails to outrank AO in 3and the number of runs in which CJSESOS superior to GWO, POA, and CJSO is 99 out of 100 runs and presents a similar performance in one run. In DBLP_7, the number of runs in which CJSESOS superior to GA is 97out of 100 runs and it fails to outrank GA in 2 runs and presents a similar performance in one run, and the number of runs in which CJSESOS superior to PSO, GWO, HBO, JSO, POA, AO, CJSO is 99 out of 100 runs. Interestingly, CJSESOS has obtained the top performance in all 100 runs for DBLP_3, DBLP_10, DBLP_15. Evidently, Sum R + is greater than Sum R- for the dataset utilized in this test. If there is a significant difference between the suggested method and the compared algorithms, the p-values in Table 8 show it. The strength of the evidence increases as the p-value decreases. The p-value cut-off for statistical significance is less than 0.05. It means that the null hypothesis is strongly refuted by the evidence. Table 8 shows that CJSESOS outperformed the other methods in the DBLP dataset, where there is a substantial difference between all the trials in this dataset at various skills and employed in this test (p-value less than 0.05). Last but not least, the p-values demonstrate that the proposed method outcomes substantially vary from those of existing comparison approaches on the DBLP dataset.
IMDB dataset description
IMDb (Internet Movie Database)42 is an online database that includes cast, production crew, and personal biographies, story summaries, trivia, ratings, and critical criticism for films, television shows, home videos, video games, and streaming content online. In this section, using the data set to include actors and the characters or roles they played in different movies. We assume that the set of genres of the movies that a person has participated make the set of skills for that person. For example, Desmyter Stef has the skills (action, comedy, crime, drama, mystery, romance, sport) The dataset may be found online.
Comparison between JSO, HBO, PSO, GA, GWO, CJSO and proposed CJSESOS on IMDB dataset
In this subsection, the convergence of the suggested method is examined, compared with HBO, JSO, PSO, GA, AO, POA and GWO. Using the IMDB dataset at number of expert sets equals 100 with various skill numbers to perform tasks and standardized this chooses on all compared algorithms. The results at different numbers of skills (3,5,7,10,15) are clear at Fig. 5, which represents the convergence curve for the nine algorithms, and it clarifies that CJSESOS outperform the other algorithms due to two modifications to the original JSO algorithm. Also, can observe that the algorithms are auspicious and powerful, and can obtain the best solution within an acceptable time frame. Verify the efficiency of the proposed method with the compared algorithms on the IMDB dataset. Table 9 summarizes the results, of the 30 random runs’ average (Mean), and standard deviation (Std) respectively. The best results are shown in bold font. Results from Table 9 outperform the others. Furthermore, as shown in Table 9 the fitness values achieved by CJSESOS are consistently better than those acquired by other algorithms, demonstrating their ability to survive from local optima. In contrast, it is simple for other algorithms to get stuck in local optima.

Comparison between CJSESOS, and other compared algorithms on IMBD dataset at skills number = 5, 7, 10, 15.
Additionally, the nonparametric Wilcoxon rank-sum test is performed for IMDB datasets based on fitness function to see whether there is a significant difference between CJSESOS findings and those of the other comparison approaches. Appling the test in different skill number, named IMDB_3, IMDB_5, IMDB_7, IMDB_10, IMDB_15 for skills number 3, 5, 7, 10, 15 respectively. Table 10 summarizes the results, from results can observe that CJSESOS has achieved the best result in all 100 runs. For the dataset named IMBD_3, IMDB_5, IMDB_7, IMDB10, IMDB_15. Evidently, Sum R + is greater than Sum R-. for the dataset utilized in this test. The p-values in Table 10 show whether the suggested method and the compared algorithm vary significantly. The strength of the evidence increases as the p-value decreases. The p-value cut off for statistical significance is less than 0.05. It means that the null hypothesis is strongly refuted by the evidence. Table 10 shows that CJSESOS outperformed PSO, GA, GWO, HBO, JSO, and CJSO in the IMDB dataset, where there is a substantial difference between all the trials in this dataset at various skills and those employed in this test (p-value less than 0.05).
Finally, the p-values demonstrate that the proposed method’s outcomes substantially vary from those of existing comparison approaches on the IMDB dataset. From the set of experiments were applied to test the suggested algorithm’s performance we can conclude that, the suggested CJSESO algorithm enhanced the performance and effectiveness of the traditional JSO algorithm. Also, the ability of the proposed algorithm to select the best solution with the least communication cost outperformed all the compared algorithms.
Comparison between GA, PSO, HBO, JSO, CJSO, NSGAII and proposed CJSESOS on IMDB dataset
This experiment is evaluating the performance of the CJSESOS against each of the JSO, CJSO, the PSO, the HBO, GA, and the NSGAII in solving the bi-objective TF problem over five different skill levels using the IMBD dataset. Figure 6 illustrates the approximate Pareto front proposed by different algorithms. In general, overall skills numbers except (skill number = 10) the ((CJSESOS)), could approximate a large number of NDS located on/close to the reference front. While the (JSO), could approximate some solutions (not all) that are located on or close to the reference front overall skills. The (HBO), could approximate some solutions (not all) that are located on/close to the reference front overall skills numbers except (skill number = 3). The (PSO), could approximate one solution that is located close to the reference front overall skills numbers except (skill number = 3). On the other hand, GA has the worst approximated Pareto front among all the algorithms. The (NSGAII), could approximate some solutions (not all) that are located on/close to the reference front overall skills numbers except (skill number = 10). In the end, the ((CJSESOS)) could approximate the largest number of NDS overall skills number except (skill number = 10), most of those solutions located on/close to the reference front. The reference Pareto front at (skill number = 10) contains only four NDS, so the comparison between the algorithms will be on their capability to reach this global optimal solution. CJSO can approximate two global optima’s, JSO can also approximate two global optima’s, and HBO can approximate one global optimal. All of those solutions are located on the reference front. On the other hand, GA and PSO are approximately one global optimal and those solutions are located close to the reference front. From Fig. 6, (CJSESOS) is superior to other algorithms, which could find the global optimal solution.

The approximated non-dominated solutions set of bi-objective TF problem by different algorithms at skills number = 3,5,7,10,15.
Performance metrics
The following two metrics were applied: Determine the estimated solution’s cardinality with respect to the established Pareto-optimal front. using diversity to gauge diversity (spread and uniformity). Assume that R is presented as a reference Pareto front that contains all known NDS that A is an estimated Pareto front, that m is the present objective space’s dimension.
The metrics are described as follows:
-
(1)
Cardinality Ratio (CR): Presented as the number of NDS in a set A, and |A| is the cardinality of that set. A set’s cardinality ratio, or CR(A), is the ratio of |A| to the cardinality of R, or |R|, as determined by Eq. (21)
It is preferable to use Pareto fronts with a greater CR and a lower spread.
On the five various skill numbers, a series of experiments were carried out. As can be seen from Table 11, CJSESOS had the biggest CR among the five studies, indicating that it was able to find the most NDS. However, CR alone cannot demonstrate a heuristic algorithm’s superiority because it is important to assess the identified NDS’s quality and variety.
Conclusion and future work
The problem of team formation is known as one of the most popular and important data science problems. The TF problem has different attributes on which it depends, and every attribute can be considered as a problem objective that needs to be achieved in an optimal way. This research focused on two objectives, which are communication cost and workload, and suggested an algorithm to solve the bi-objective TF problem, called Chaotic Jellyfish Search with enhanced swap operator (CJSESOS). CJSESO suggested two modifications to the original JSO algorithm, one of which is the chaotic sequence generated by iterating a chaotic map, named CJSO. This improvement helped in diversifying the solutions, the second is enhanced swap sequence operator which increased the CJSO algorithm’s ability to avoid local minimum. A set of experiments were applied to test the suggested algorithm’s performance. Firstly, a group of benchmark functions were used to evaluate the suggested algorithm’s performance against a standard one and some well-known optimizers and then solve the single objective TF problem using the IMBD set to evaluate the proposed algorithm’s performance. Secondly, we solved the Bi-objective TF problem and adapted the CJSESO algorithm to enhance its exploration capabilities during the search for Pareto-optimal solutions. The effectiveness of the proposed bi-objective Chaotic Jellyfish search optimizer (MO-CJSO) was evaluated using an IMBD dataset with different skill numbers. The suggested algorithm is compared with the following algorithms, particle swarm algorithm (PSO), genetic algorithm (GA), heap-based optimizer (HBO), standard jellyfish optimizer (JSO), and the devolved jellyfish (CJSO). According to experimental results, the suggested CJSESO algorithm enhanced the performance and effectiveness of the traditional JSO algorithm. Also, the ability of the proposed method to find an optimal team and satisfy the problem’s objectives outperforms the comparison algorithms. In the future, a parallel version of the proposed method will be developed and applied to different real-world applications such as nurse scheduling problems and task assignment problems. Since the experimental methods are very expensive and time-consuming. By simplifications, all the previous problems can convert to optimization problem. Additionally, we can apply the adopted algorithm to solve the TF problem with respect to other objectives, since TF problem has different attributes and different objectives. Finally, we want to emphasize that development and innovation are ongoing processes without limits. They encourage us to explore new and captivating ideas continuously, expanding the horizons of our minds.
Data availability
The authors confirm that the data supporting the findings of this study are available within the article and its supplementary materials.
References
Wolpert, D. H. & Macready, W. G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1 (1), 67–82 (1997).
Chou, J. S. & Truong Dinh-Nhat,A novel metaheuristic optimizer inspired by behavior of jellyfish in ocean. Appl. Math. Comput. 389, 125535 (2021).
Rajpurohit, J., Sharma, T. K. Chaotic active swarm motion in jellyfish search optimizer. Int. J. Syst. Assur. Eng. Manag. 1 https://doi.org/10.1007/s13198-021-01561-6 (2022).
Kennedy, J. & Eberhart, R. Particle swarm optimization. In Proc. of ICNN’95-International Conference on Neural Networks, IEEE, vol. 4, pp. 1942–1948, (1995).
Askari, Q., Saeed, M. & Younas, I. Heap-based optimizer inspired by corporate rank hierarchy for global optimization. Expert Syst. Appl. 161, 1–27 (2020).
Rai, H. & Verma, H. K. Economic Load Dispatch Using Jellyfish Search Optimizer, in proc. of the 10th IEEE International Conference on Communication Systems and Network Technologies (CSNT), pp. 301–304, (2021).
Nageh, N., Elshamy, A., Hassan, A. W. S., Sami, M. & Salam, M. A. Enhanced Heap-Based optimizer algorithm for solving team formation problem. Comput. Mater. Continua 73(3), 5245–5268 (2022).
Lappas, T., Liu, K. & Terzi, E. Finding a team of experts in social networks, in Proc. of the 15th ACM SIGKDD Int. Conf. on Knowledge Discovery and Data Mining, Paris, France, pp. 467–476, (2009).
Anagnostopoulos, A., Becchetti, L., Castillo, C., Gionis, A. & Leonardi, S. Power in unity: Forming teams in large-scale community systems, in Proc. of the 19th ACM international conference on Information and knowledge management, Association for Computing Machinery, New York, NY, United States, pp. 599–608, (2010).
An, A. M.Kargar and TeamExp: Top-κ team formation in social networks in Proc—IEEE international conference Data Mining, ICDM, Vancouver, Canada, pp 1231–1234, (2011).
Majumder, A., Datta, S. & Naidu, K. Capacitated team formation problem on social networks, In Proceedings of the 18th ACM SIGKDD international conference on knowledge discovery and data mining, Beijing China, pp. 1005–1013, (2012).
Anagnostopoulos, A., Becchetti, L., Castillo, C., Gionis, A. & Leonardi, S. Online team formation in social networks, in Proc. of the 21st Int. Conf. on World Wide Web, New York, NY, USA, pp. 839–848, (2012).
Eichmann, C. & Mueller, C. Team formation based on Nature-Inspired swarm intelligence. J. Softw. 10 (3), 344–354 (2015).
Gutiérrez, J. H., Astudillo, C. A., Ballesteros-Pérez, P., Mora-Melia, D. & Candia-Vejer, A. The multiple team formation problem using sociometry. Comput. Oper. Res. 75, 150–162 (2016).
Basiri, J., Taghiyareh, F. & Ghorbani, A. Collaborative team formation using brain drain optimization: a practical and effective solution. World Wide Web. 20 (6), 1385–1407 (2017).
Wang, G. G., Gao, D. & Pedrycz, W. Solving multiobjective fuzzy job-shop scheduling problem by a hybrid adaptive differential evolution algorithm. IEEE Trans. Ind. Inf. 18(12), 8519–8528. https://doi.org/10.1109/TII.2022.3165636 (2022).
Zhang, X. J. C. & L.Zhang and Multi-objective team formation optimization for new product development. Comput. Ind. Eng. 64 (3), 804–811 (2013).
Kargar, M., An, A. & Zihayat, M. Efficient bi-objective team formation in social networks, in Joint European conference. on Machine Learning and Knowledge Discovery in Databases, Berlin, Heidelberg, Springer, pp. 483–498, (2012).
Sharma, A., Pandey, J. K. & Ram, M. Swarm Intelligence: Foundation, Principles, and Engineering Applications (CRC, 2022).
El-Ashmawi, W. H. & J.I.J.I.T.C.S. An improved African Buffalo optimization algorithm for collaborative team formation in social network. Intrnational J. Inform. Technol. Comput. Sci. 10, 16–29 (2018).
El-Ashmawi, W. H., Ali, A. F. & Tawhid, M. A. An improved particle swarm optimization with a new swap operator for team formation problem. J. Industrial Eng. Int. 15 (1), 53–71 (2019).
Rehman, M. Z. et al. A novel state space reduction algorithm for team formation in social networks. PloS One. 16 (12), 259786 (2021).
Kader, M. & Zamli, K. Z. Comparative study of five metaheuristic algorithms for team formation problem. in Human-centered Technology for a Better Tomorrow. Lecture Notes in Mechanical Engineering (ed Hassan, M. H. A., et al.) 133–143. https://doi.org/10.1007/978-981-16-4115-2_10 (Springer, Singapore, 2022).
Khan, S. & Shaheen, M. WisRule: First cognitive algorithm of wise association rule mining. J. Inf. Sci. 50(4), 874–893. https://doi.org/10.1177/01655515221108695 (2022).
Şahin, D. Ö. & Kılıç, E. Two new feature selection metrics for text classification, Automatika: časopis za automatiku, mjerenje, elektroniku, računarstvo i komunikacije, vol. 60, no. 2, pp.162–171, (2019).
Hu, G., Du, B., Wang, X. & Wei, G. An enhanced black widow optimization algorithm for feature selection. Knowl.-Based Syst. 235, 107638. https://doi.org/10.1016/j.knosys.2021.107638 (2022).
Hu, G., Zhong, J., Du, B. & Wei, G. An enhanced hybrid arithmetic optimization algorithm for engineering applications. Comput. Methods Appl. Mech. Eng. 394, 114901. https://doi.org/10.1016/j.cma.2022.114901 (2022).
Hu, G., Li, M. & Wang, X., Wei, G. & Chang, C. T. An enhanced manta ray foraging optimization algorithm for shape optimization of complex CCG-Ball curves. Knowl.-Based Syst. 240, 108071 (2022).
Ibrahim, S. et al. Wind speed ensemble forecasting based on deep learning using adaptive dynamic optimization algorithm, Institute of Electrical and Electronics Engineers Access (IEEE Access), vol. 9, no. 1, pp. 125787–125804,. (2021).
Salamai, E. S. M. & El-kenawy Dynamic voting classifier for risk identification in supply chain 4.0. Computers Mater. Continua. 69 (3), 3749–3766 (2021).
Yang, X. S. Bat algorithm for bi-objective optimisation. Int. J. Bio-Inspired Comput. 3 (5), 267–274 (2011).
Wang, S., Ali, S. & Gotlieb, A. Cost-effective test suite minimization in product lines using search techniques. J. Syst. Softw. 103, 370–391 (2015).
Ngatchou, P., Zarei, A. & El-Sharkawi, A. Pareto multi objective optimization, in Proc. of the 13th Int. Conf. on Intelligent Systems Application to Power Systems, Arlington, VA, USA, IEEE, pp. 84–91, (2005).
Reda, N., Hamdy, A. & Rashed, E. A. Bi-objective adapted binary Bat for test suite reduction. Intell. Autom. Soft Comput. 31 (2), 781–797 (2022).
Mirjalili, S. & Gandomi, A. H. Chaotic gravitational constants for the gravitational search algorithm. Appl. Soft Comput. 53, 407–419 (2017).
García-Ródenas, R., Jiménez Linares, L. López-Gómez, J. A. A Memetic Chaotic Gravitational Search Algorithm for unconstrained global optimization problems. Appl. Soft Comput. 79, 14–29. https://doi.org/10.1016/j.asoc.2019.03.011 (2019).
Wei, X., Jiang-wei, Z. & Hon-lin, Z. Enhanced self tentative particle swarm optimization algorithm for TSP. J. North. China Electr. Power Univ. 36 (6), 69–74 (2009).
Zhang, J. W. & Si, W. J. Improved enhanced self-tentative PSO algorithm for TSP. In Sixth International Conference on Natural Computation (ICNC), Vol. 5, pp 2638–2641.
Derrac, J., Garcıa, S., Molina, D. & Herrera, F. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms Swarm and Evolutionary Computation, Elsevier, vol. 1, no. 1, pp. 3–18, (2011).
Zamli, K. Z. ACM Dataset, (2020). Available: https://github.com/MAK660/Dataset/blob/master/ACM_DataSet.txt.
Zamli, K. Z. DBLP Dataset, (2020). Available: https://github.com/MAK660/Dataset/blob/master/DBLP_DataSet.txt.
Zamli, K. Z. IMDB dataset, (2020). Available: https://github.com/MAK660/Dataset/blob/master/IMDB_DataSet.txt.
Acknowledgements
The authors would like to thank the Deanship of Scientific Research, Prince Sattam bin Abdulaziz University, Al-Kharj, Saudi Arabia, for supporting this research via funding from Prince Sattam bin Abdulaziz University project number (PSAU/2024/R/1445).
Author information
Authors and Affiliations
Contributions
M.A.S and N.N conceived of the presented idea, developed the theory and performed the computations, verified the analytical methods. M.A revised the results. All authors discussed the results and contributed to the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Salam, M.A., Aldawsari, M. & Nageh, N. Bi-objective jellyfish algorithm for team formation problem. Sci Rep 15, 32417 (2025). https://doi.org/10.1038/s41598-025-11566-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-11566-x
