
Abstract
Indoor activity monitoring methods ensure the well-being and security of elderly and visually impaired people living in their houses. These systems utilize numerous technologies and sensors to monitor day-to-day activities, including medication adherence, movement, and sleep patterns, providing a comprehensive view of the user’s overall health and daily life. The accuracy and adaptability of deep learning (DL) models make human activity recognition (HAR) a valuable tool for enhancing effectiveness, security, and personalized experiences in indoor environments. HAR, utilizing DL techniques, innovates indoor monitoring by enabling precise understanding and detection of human actions. Deep neural networks (DNNs) analyze data from multiple sensors, such as cameras or accelerometers, to distinguish between various action patterns. DL models mechanically remove and learn discriminating features, making them suitable for identifying intricate human activities in sensor data. Nevertheless, selecting the appropriate DL architectures and optimizing their parameters is crucial for achieving improved solutions. This study proposes an Improved Pelican Optimisation for Indoor Activity Recognition in Persons with Disabilities using the Recurrent Neural Network (IPOIAR-DPRNN) method. The primary aim of the IPOIAR-DPRNN method is to enhance indoor activity detection systems for individuals with disabilities. Initially, the image pre-processing stage applies adaptive bilateral filtering (ABF) to reduce unwanted distortions or artefacts in the image. Furthermore, the EfficientNetB7 method is employed for the feature extraction process. For the detection and classification of indoor activities, the bidirectional long short-term memory with multi-head self-attention (BiLSTM-MHSA) technique is used. Additionally, the improved pelican optimization algorithm (IPOA)-based hyperparameter tuning is performed to enhance the detection results of the BiLSTM-MHSA technique. The validation of the IPOIAR-DPRNN approach is examined using the Florence 3D Actions dataset, and the outcomes are measured against various metrics. The comparison study of the IPOIAR-DPRNN approach revealed a superior accuracy value of 97.11% compared to existing techniques.
Similar content being viewed by others
Introduction
People spend almost 90% of their indoor time and nearly 70% of that time at home1. The quicker improvement of wireless sensor systems and the Internet of Things (IoT) for identifying human activity enhances the likelihood of utilizing diverse sensor readings. For many applications, the sensor is held by consumers as wearable gadgets or embedded into household wares2. The readings from the sensor are then gathered and interpreted to recognize the probable activity. The primary goal of activity recognition is to enhance recognition by identifying sudden changes in metrics such as covariance and mean that indicate modifications in time series data within an indoor setting3. To enhance personalized medical care services for individuals with disabilities, automatic HAR methods are essential for monitoring the everyday activities of ageing people and enabling them to live independently and safely at home4. In an automatic HAR method, multiple sensors are utilized to collect video data or signals, providing continuous medical monitoring by detecting day-to-day life activities and generating an alert in case of an emergency the individual5. Monitoring human activities within indoor settings of everyday life is a vital way to explain the efficiency and medical status of humans6.
Thus, indoor activity recognition is a genuine component of personalized medical care and life-care methods, particularly for individuals with disabilities and the elderly within indoor settings7. HAR has been a very active investigation concept for the last two decades. Its applications span several domains, including remote monitoring, healthcare, surveillance and security, human-computer interaction, and gaming. Activity recognition can be defined as the ability to detect or recognize existing activities based on information acquired from various sensors8. These sensors may be wearable devices, cameras, or sensors integrated into everyday objects or settings. With the development of technology and the reduction in the cost of gadgets, logging everyday routines has become practical and very popular. People are logging their day-to-day activities, such as sleeping, preparing meals, eating, watching TV, or the number of steps taken9. To acquire these activities, various methods are utilized. These models can be broadly categorized into sensor-based and vision-based models. One of the innovative methods in this field is a vision-based approach, which uses a camera to acquire information about human activities10. By employing computer vision (CV) models on this captured data, dissimilar activities might be detected.
This study proposes an Improved Pelican Optimisation for Indoor Activity Recognition in Persons with Disabilities using the Recurrent Neural Network (IPOIAR-DPRNN) method. The primary aim of the IPOIAR-DPRNN method is to enhance indoor activity detection systems for individuals with disabilities. Initially, the image pre-processing stage applies adaptive bilateral filtering (ABF) to reduce unwanted distortions or artefacts in the image. Furthermore, the EfficientNetB7 method is employed for the feature extraction process. For the detection and classification of indoor activities, the bidirectional long short-term memory with multi-head self-attention (BiLSTM-MHSA) technique is used. Additionally, the improved pelican optimization algorithm (IPOA)-based hyperparameter tuning is performed to enhance the detection results of the BiLSTM-MHSA technique. The validation of the IPOIAR-DPRNN approach is examined using the Florence 3D Actions dataset, and the outcomes are measured against various metrics. The major contribution of the IPOIAR-DPRNN approach is listed below.
-
The IPOIAR-DPRNN model utilizes ABF to enhance image pre-processing, effectively mitigating noise while preserving essential edge details, thereby improving the quality of the input data for subsequent analysis. This step contributes to more accurate feature extraction and overall model performance. By maintaining edge integrity, ABF supports better detection and classification outcomes.
-
The IPOIAR-DPRNN method utilizes EfficientNetB7 to extract robust and high-quality features from pre-processed images, thereby enabling the model to capture intrinsic patterns effectively. This improves the overall accuracy and reliability of the detection process. Its efficient architecture also ensures faster computation and better scalability.
-
The IPOIAR-DPRNN approach utilizes the BiLSTM-MHSA model to accurately detect and classify indoor activities, effectively capturing temporal dependencies and contextual relationships. This approach enhances the technique’s ability to recognize intrinsic activity patterns. As a result, it improves the precision and robustness of the classification process.
-
The IPOIAR-DPRNN methodology utilizes the IPOA model to optimize hyperparameter tuning, thereby enhancing the learning efficiency and accuracy of the method. By refining the search process, IPOA prevents premature convergence and improves global exploration. This results in a more robust and well-tuned model performance.
-
The integration of ABF, EfficientNetB7, BiLSTM-MHSA, and the IPOA into a unified framework presents a novel and comprehensive approach. This integration leverages the strengths of each technique to enhance the accuracy and robustness of indoor activity recognition. The novelty of the IPOIAR-DPRNN technique lies in the fusion of advanced pre-processing, feature extraction, classification, and hyperparameter optimization, which outperforms existing methods. This integrated model provides a more reliable and precise solution for complex indoor activity monitoring tasks.
Related works
Khan et al.11 developed the transparent RFID Tag Wall (TRT-Wall). This new model employs a passive UHF-RFID tag array integrated with DL models for contactless human activities monitoring methods. Jin et al.12 presented an innovative structure intended for precisely detecting activities undertaken by stroke patients. This method employs a data fusion approach that utilizes various sensors to construct a fusion tensor and utilizes a bi-directional LSTM (Bi-LSTM) model enhanced with an attention mechanism. This system effectively acquires progressive designs and longer-term dependencies in the data, leading to improved implementation for wearable sensor-based activity categorization. Additionally, an improved loss function is developed to enhance the learning procedure. Rizk and Hashima13 proposed RISense, a DL-assisted method for HAR utilizing a reconfigurable intelligent surface (RIS). RISense developed innovative modules intended to create a human activity representational space that guarantees divisibility between activity modules, even in the presence of distorted and noisy channel state information (CSI) measurements. These representations are fed into an RNN, which learns the sequential modifications in aspects to evaluate user activity precisely. Bouazizi et al.14 developed a method to utilize a 2D-LIDAR positioned on a cleaning robot. The robot can continuously gather distance information. To attain goals, the sizes taken by moving LIDAR are interpolated, transformed, and compared with a surrounding reference condition.
Kao et al.15 discovered the use of drowning prevention technology in fixed methods, including surrounding settings, IoT, and AI, to reduce the possibility. The image identification capability of drowning prevention methods is improved through CV. Finally, the IoT enables drowning prevention methods with wide-ranging intelligence by connecting multiple gadgets and communication devices. Ye et al.16 developed an innovative DL structure that depends upon graph attention (GAT) networks and embedding technology, like the time-oriented and location-oriented graph attention (TLGAT) models. Subsequently, TLGAT delivered the sensor observation structure as a fully connected (FC) graph to the technique’s progressive correlation, along with the correlation between sensor positions within sensor observations. El Zein et al.17 introduced HAR-LightCNN, a CSI-based HAR solution. The key element of this solution is a deeper yet lightweight CNN technique, which is notable for its reduced computational demands. This work enhances the technique’s generalization capability by utilizing time series data augmentation (TSDA) models that address concerns related to small datasets and class imbalance. ZHANG et al.18 developed YGC-SLAM, a robust visual simultaneous localization and mapping (SLAM) methodology for indoor dynamic environments that integrates an improved you only look once version 5 (YOLOv5) with convolution block attention and enhanced EIOU loss for dynamic object detection, integrated with semantic and multi-view geometric constraints within the ORB-SLAM2 technique. Polo-Rodríguez et al.19 proposed an improved multi-occupant tracking system in real domestic environments by integrating ultra-wideband (UWB) wearable tags and ambient anchors with millimeter-wave (mmWave) radar. Various data autoencoder approaches, including long short-term memory (LSTM) networks, convolutional neural networks (CNNs), and transformers, were evaluated, with the convolutional LSTM (ConvLSTM) technique achieving the optimal performance.
Materials and methods
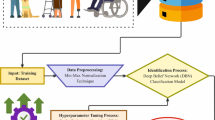
In this article, a novel IPOIAR-DPRNN method is proposed. The primary objective of the IPOIAR-DPRNN model is to improve indoor activity detection systems for individuals with disabilities. Figure 1 establishes the complete procedure of the IPOIAR-DPRNN model.

Overall process of the IPOIAR-DPRNN method.
Image pre-processing: ABF model
Initially, the image pre-processing stage applies ABF to minimize unwanted distortions or artefacts in the image20. This model is chosen for its superior capability in reducing noise while preserving crucial edge details, which is significant for accurate feature extraction in indoor activity recognition. Unlike standard filters that may blur edges or lose fine textures, ABF adapts to local image characteristics, maintaining sharp boundaries and improving image clarity. This makes it efficient in handling complex indoor scenes where object contours and motion details are vital. Compared to conventional filters, such as Gaussian or median filtering, ABF achieves a better balance between smoothing and edge preservation. Its adaptability also helps in dealing with the varying lighting conditions and noise levels often encountered in real-world environments. Overall, ABF improves the quality of input data, which directly contributes to more reliable downstream analysis and model performance.
ABF is a noise-reduction approach used to enhance the quality of sensor data for indoor activity recognition in individuals with disabilities. It works by preserving edges while smoothing out areas of uniform intensity, ensuring that significant activity-related features are retained. For individuals with disabilities, this filtration model enhances the precision of sensor readings, which are crucial for recognizing intelligent activities and movements. Minimizing noise and retaining related particulars allows for more accurate and consistent activity recognition.
Feature extractor: EfficientNetB7
Furthermore, the EfficientNetB7 method is employed for feature extraction21. This method is chosen for its superior performance in balancing accuracy and computational efficiency. A compound scaling method that uniformly scales depth, width, and resolution is employed, yielding superior feature representation compared to conventional CNNs, such as ResNet or VGG. This model is more appropriate for resource-constrained environments due to its higher accuracy with fewer parameters and lower computational cost. The model also captures rich and hierarchical features to recognize complex indoor activities accurately. Furthermore, EfficientNetB7 illustrates robust generalization across diverse image recognition tasks, ensuring better adaptability to varied indoor settings. This combination of efficiency and accuracy justifies its use over other heavier or less efficient architectures.
Due to the increased depth and width of the convolutional layers, the deep CNN (DCNN) structure is generally over-parameterized, making it computationally costly and compromising network performance. Deep networks are more widely used on testing datasets, and their efficiency regarding network parameters, inference speed, model dimensions, and floating-point operations per second (flops) improves. They presented a family of EfficientNet sequence models, namely EfficientNet B0-B7, as a backbone architecture that has surpassed numerous DCNN-based architectures, such as DenseNet, Inception-V2, Inception-V3, ResNet50, and ResNet for tasks including TL, ImageNet, and other problems. These challenges traditional scaling methods used by previous investigations, which consist of randomly improving the model’s resolution, depth, and width to increase generalizability. This compound scaling is based on balancing the network dimensions of resolution \(\:r\), depth \(\:d\), and width \(\:w\) by raising them to a power of infinity, as expressed in Eq. (1).
So that \(\:\alpha\:.\beta\:2.y2\approx\:2\) where \(\:\alpha\:\ge\:1,\beta\:\ge\:1,y\ge\:1.\alpha\:,\beta\:\) and \(\:y\) values are described by the grid searching model. A user-defined parameter is recognized when a rise in computing resources is noted. Flops of the convolutional network process are equal to \(\:r2,\:d,\) and\(\:\:w2\). Simultaneously, flops should be improved to 4 times after the width and resolution are doubled. The rise in flops is derived from the relations \(\:(\alpha\:.\beta\:2.y2){\varnothing}\) like complete flops are inflamed by \(\:2{\varnothing}\) for new value. The EffcientNet architecture contains stem blocks, which emulate the seven blocks and final layers. All blocks in EfficientNet have an adjustable volume of modules and a variety of modules from EfficientNet-B0 to B7. It comprises variable depth and parameters. EfficientNetB0 is the simpler form of EfficientNet, with 237 layers and 5.3 M parameters, while EfficientNet-B7 contains 813 layers and 66 M parameters. EffcientNet architecture uses MBConv layers, equivalent to MobileNet-V2 and MnasNet. In the meantime, a layer of normalization is already present in the stem layer. Thus, no other image standardization is required as a pre-processing phase. Hence, it captures an input image within the 0255 range. Now, five variations of the pre-trained EfficientNet, ranging from EfficientNet-B0 to B4, are available to assist with classification. The situations for selecting EfficientNet change are derived from various variables, including the dataset size, available resources for model estimation and training, batch size, network parameters, and model depth. EfficientNet-B5 is a significant improvement over EfficientNet-B7, with more parameters and a deeper network.
Indoor activities classification: BiLSTM-MHSA
For the detection and classification of indoor activities, the BiLSTM-MHSA technique is employed22. This technique is chosen for its ability to capture both past and future contextual information effectively, which is crucial for comprehending temporal dependencies in sequential data. Unlike standard LSTMs, the bidirectional structure enables the processing of input in both directions, thereby improving sequence modelling accuracy. The addition of MHSA enhances the model’s focus on significant features by learning relationships between diverse time steps, enabling it to weigh relevant information more effectively than conventional attention mechanisms. This integration results in superior performance in handling complex and varied indoor activity patterns. Compared to simpler classifiers or unidirectional models, BiLSTM-MHSA exhibits better generalization and robustness in recognizing complex temporal dynamics within activity sequences.
The LSTM model regulates information flow through gating mechanisms and memory units, thereby resolving the exploding and vanishing gradient issues in conventional RNNs and enhancing its capability to capture longer-term dependencies in sequences. This forget gate determines the amount of the state of the memory cell that needs to be maintained from the preceding time step and the amount that needs to be overlooked. The gate of the input determines the amount of input data from the current time step that needs to be included in the state of the memory cell. Its upgrade is derived from the forget gate output and an input gate to update the state of the memory cell at the current time step. The gate of the output establishes that a portion of the present state of the memory cell should be the output, and it incorporates the hidden layer (HL) to determine the output for the current time steps. The one-directional LSTM manages input in a time sequence and a forward direction, and the output of every time step relies solely on the present time step and the preceding time steps. It may be unable to capture the sequence symmetries and apply contextual information thoroughly; therefore, Bi-LSTM is proposed. Bi-LSTM is an expansion of LSTM. Handling the input sequence in either direction can improve the understanding and seizure of the symmetric information and dependencies within the sequence. This article utilizes a single-layer Bi-LSTM network unit to perform feature extraction and sequence modelling on the output of the embedding layer. Bi-LSTM comprises dual LSTM layers, one handling the forward sequence and the other handling the backward sequence.
The Bi-LSTM layer’s output is fed into the MHSA layer, which enhances the method’s performance by calculating numerous attention heads in parallel. All attention heads learn distinct information through various linear transformations, thereby capturing a range of diverse contextual relationships and dependencies within the sequence. During this study, there exist\(\:\:h\) attention heads. Initially, the sequence is linearly converted using different weight matrices to create value (\(\:V\)), key \(\:\left({K}_{i}\right)\), and query \(\:\left({Q}_{i}\right)\)Vectors. All attention heads contain an autonomous weighted matrix. The equation for computing the key, value, and query vectors is shown:
The \(\:i\) value ranges between 1 to \(\:h\), and \(\:{W}_{{Q}_{i}},\) \(\:{W}_{{K}_{i}}\), and \(\:{W}_{{V}_{i}}\) mean weighted matrices.
The SA mechanism is then performed on all attention heads to attain the output of every head, computed as shown:
Whereas \(\:{d}_{k}\) denotes the size of the primary vector applied for scaling the grades.
At last, the outputs of every attention head are connected to attain the output \(\:M,\) as exposed in Eq. (6).
Here, \(\:{W}_{O}\) represents the matrix of output linear transformation.
Regarding the above-mentioned equation and phases, the MHSA may handle the output sequence \(\:Y\) of the Bi-LSTM layer in parallel. All attention heads of the layer of MHSA learning attributes in various subsets, which allows the method to understand the relations within the input sequence from dissimilar viewpoints. By combining attention information from multiple heads, the technique considers various types of contextual information and comprehensively understands the dependencies within sequences.
Hyperparameter selection: IPOA
Additionally, the IPOA model-based hyperparameter tuning is performed to improve the recognition outcomes of the BiLSTM-MHSA model23. This model is chosen for its improved exploration and exploitation capabilities compared to conventional optimization methods. IPOA incorporates adaptive strategies and refined position updating mechanisms that prevent premature convergence and help avoid local optima, ensuring a more thorough search of the hyperparameter space. Its balance between global search and local refinement results in faster convergence and improved model performance. Compared to conventional algorithms like genetic algorithm (GA) or particle swarm optimization (PSO), IPOA presents better robustness and precision in optimizing intrinsic DL models. This makes it specifically effective for tuning hyperparameters in high-dimensional, nonlinear problems, such as indoor activity recognition. Overall, IPOA contributes to achieving superior accuracy and stability in the final model.
The pelican model is the stimulated optimizer model presented. It stimulates the pelican’s natural behaviours in searching, which mainly comprises dual phases: surface flight and exploration. Then, the optimizer procedure of the Pelican model should be presented. Initially, initializing the population of the pelican:
Here, \(\:{x}_{ij}\) refers to \(\:{the\:j}_{th}\) size location of the \(\:{i}_{th}\) pelican, \(\:n\) denotes the population size of pelicans, \(\:m\) refers to the problem size, \(\:rand\) signifies a randomly generated number in the interval [0, 1], \(\:{l}_{j}\) and \(\:{u}_{j}\) symbolize the lower and upper limits to solve the \(\:J\)-dimensionality difficulties, correspondingly.
Next, the initialization is finished, and the pelican arrives at an exploration phase, while the position of the prey is arbitrarily made in the joining area. The pelican looks for and ultimately defines the spatial coordinate of the prey within the exploration phase, then flies to the prey’s location. The pelican’s spatial location is upgraded as shown:
Here: \(\:{x}_{p,q}^{\left(1\right)}\) refers to \(\:{q}_{th}\) dimensional location of the \(\:{p}_{th}\) pelican in the initial phase; \(\:{f}_{q}\) denotes \(\:{the\:q}_{th}\) prey’s location; \(\:I\) signify randomly formed integer 1 or 2, \(\:{F}_{f}\) characteristics prey’s targeted function; and \(\:{F}_{p}\) stands for the\(\:\:{p}_{th}\) pelican objective function. During this initial stage, the pelican acknowledges a novel location when the targeted function of the \(\:{p}_{th}\) pelican is enhanced at the present location. The procedure is stated in the Eq. (9):
Now, \(\:{x}_{p}=[{x}_{p1}{x}_{p2}\dots\:{x}_{pq}]\) refers to the unique location of the \(\:{p}_{th}\) pelican, \(\:{x}_{{p}^{*}}\) stands for the novel area of the \(\:{p}_{th}\) pelican, and \(\:{F}_{p}^{*}\) denotes a targeted function of the \(\:{p}_{th}\) pelican in its novel. After exploration, the pelican updates its position at the water surface using Eq. (10).
Whereas \(\:{x}_{p,q}^{\left(2\right)}\) means \(\:{q}_{th}\) location dimension of the \(\:{p}_{th}\) pelican in the next phase, \(\:{f}_{q}\) refers to \(\:{q}_{th}\) location of the prey, and \(\:R\) \(\:(1-of\:nodes\:in\:the\:hiddent/T)\) denotes local searching region radius of all pelican. Similar to the initial phase, in the next phase, the targeted function of the \(\:{p}_{th}\) pelican is enhanced at the present location, and the pelican’s location is upgraded based on Eq. (10).
The IPOA enhances POA by incorporating a sine-cosine model and a linear weight \(\:\omega\:\) to prevent local optima, updating the location as in Eq. (11).
Whereas \(\:{x}_{p,q}^{t}\) stands for \(\:{q}_{th}\) location of the \(\:{p}_{th}\) pelican at the \(\:{t}_{th}\) iteration, \(\:{P}_{p}^{t}\) refers to a globally optimum solution, \(\:{R}_{2}\in\:\left(\text{0,2}\varPi\:\right),\) \(\:{R}_{3}\in\:\left(\text{0,2}\right)\), and \(\:\omega\:\)denotes iteration weight upgraded based on the Eq. (12):
Here, \(\:{T}_{\text{m}\text{a}\text{x}}\) means maximal iteration counts, \(\:t\) signifies present iteration counts, and \(\:{\omega\:}_{\text{m}\text{a}\text{x}}=0.9,\) \(\:{\omega\:}_{\text{m}\text{a}\text{x}}=0.2\).
The fitness selection is an excellent feature prompting the performance in IPOA. The hyperparameter choice procedure encompasses the solution encoding approach to evaluate the effectiveness of candidate solutions. Here, the IPOA considers accuracy as a key condition for intending the fitness function. Its formulation is given below:
Here, \(\:TP\) illustrates the positive value of true, and \(\:FP\) implies the positive value of false.
Experimental validation
The performance validation of the IPOIAR-DPRNN methodology is examined under the Florence 3D Actions dataset24. Table 1 describes the dataset.
Figure 2 presents the confusion matrix generated by the IPOIAR-DPRNN method for TRPH/TSPH ratios of 80:20 and 70:30. The confusion matrices highlight consistent and high classification accuracy across all phases. In the TRPH with 80% data, classes like C1 and C4 exhibit robust correct predictions with values of 175 and 193. Even with mitigated training data at 70%, performance remains stable with 137 correct predictions for C1 and 163 for C6. TSPH using 20% and 30% data also illustrate reliable results, such as 57 correct predictions for C6 and 70 for C3, reflecting the robust generalization and robustness of the model in recognizing multiple indoor activities.

Confusion matrix of (a-c) TRPH of 80% and 70% and (b-d) TSPH of 20% and 30%.
Table 2; Fig. 3 present the indoor activity detection results of the IPOIAR-DPRNN technique for TRPH/TSPH ratios of 80:20 and 70:30. The outcomes suggest that the IPOIAR-DPRNN technique correctly identified the samples. With 80%TRPH, the IPOIAR-DPRNN technique achieves an average \(\:acc{u}_{y}\) of 97.11%, \(\:pre{c}_{n}\) of 87.10%, \(\:rec{a}_{l}\) of 86.94%, \(\:{F}_{measure}\:\)of 86.98%, and \(\:MCC\) of 85.38%. Besides, with 20%TSPH, the IPOIAR-DPRNN approach reaches an average \(\:acc{u}_{y}\) of 96.74%, \(\:pre{c}_{n}\) of 85.43%, \(\:rec{a}_{l}\) of 86.14 \(\:{F}_{measure}\:\)of 85.60%, and \(\:MCC\) of 83.88%. Moreover, with 70%TRPH, the IPOIAR-DPRNN approach gains an average \(\:acc{u}_{y}\) of 96.01%, \(\:pre{c}_{n}\) of 82.06%, \(\:rec{a}_{l}\) of 82.02%, \(\:{F}_{measure}\:\)of 81.96%, and \(\:MCC\) of 79.77%. At last, with 30%TSPH, the IPOIAR-DPRNN approach attains an average \(\:acc{u}_{y}\) of 95.26%, \(\:pre{c}_{n}\) of 78.86%, \(\:rec{a}_{l}\) of 78.78%, \(\:{F}_{measure}\:\)of 78.63%, and \(\:MCC\) of 76.08%.

Average of IPOIAR-DPRNN approach under 80:20 and 70:30 of TRPH/TSPH.
In Fig. 4, the training (TRA) \(\:acc{u}_{y}\) and validation (VAL) \(\:acc{u}_{y}\) analysis of the IPOIAR-DPRNN methodology under 80%TRPH and 20%TSPH is illustrated. The \(\:acc{u}_{y}\:\)values are computed across an interval of 0–50 epochs. The figure highlights that the TRA and VAL \(\:acc{u}_{y}\) analysis exhibits an increasing trend, which alerts to the capacity of the IPOIAR-DPRNN methodology to achieve superior outcomes across multiple iterations. Simultaneously, the TRA and VAL \(\:acc{u}_{y}\) leftovers closer across the epochs, which identifies inferior overfitting and demonstrates the higher performance of the IPOIAR-DPRNN approach, assuring consistent prediction on hidden samples.

\(\:Acc{u}_{y}\) curve of IPOIAR-DPRNN model under 80%TRPH and 20%TSPH.
In Fig. 5, the TRA loss (TRALOS) and VAL loss (VALLOS) curve of the IPOIAR-DPRNN model under 80%TRPH and 20%TSPH is shown. The values of loss are computed within the range of 0 to 50 epochs. It is demonstrated that the TRALOS and VALLOS values exhibit a diminishing tendency, indicating the capacity of the IPOIAR-DPRNN model to strike a balance between simplification and data fitting. The constant reduction in loss values, alongside assurances of the maximum performance of the IPOIAR-DPRNN technique and the tuning of prediction results over time.

Loss graph of IPOIAR-DPRNN model under 80%TRPH and 20%TSPH.
Table 3; Fig. 6 exemplify the comparative results of the IPOIAR-DPRNN approach with existing models under dissimilar metrics18,19,25,26,27. The outcomes indicate that the proposed IPOIAR-DPRNN methodology has achieved maximum results with maximal \(\:acc{u}_{y}\), \(\:pre{c}_{n}\), \(\:rec{a}_{l},\) and \(\:{F}_{measure}\) of 97.11%, 87.10%, 86.94%, and 86.98%, respectively. Whereas the existing technique’s multi-part bag-of-poses, RF-PCA, HAR3DS-Lie Group, LMMML-Skelets, lie group + CNN, Skeletal BoW, HDS-SP, SJACHA-3DCNN, YOLOv5, CNN, and ConvLSTM models have gained worst performance.

Comparative analysis of IPOIAR-DPRNN model with existing methods.
Table 4; Fig. 7 present the computational time (CT) analysis of the IPOIAR-DPRNN technique in comparison to existing models. Among the methods listed, IPOIAR-DPRNN technique illustrates the fastest CT of 9.55 s, significantly outperforming others such as RF-PCA with 12.70 s and Lie group + CNN with 13.31 s. Multi-part bag-of-poses and ConvLSTM exhibit similar processing speeds with CTs of 14.77 s and 14.74 s, respectively, while YOLOv5 takes slightly longer at 15.72 s. CNN records a CT of 15.07 s and HDS-SP takes 16.20 s. The most time-consuming approaches are HAR3DS-Lie Group with 17.67 s and SJACHA-3DCNN with 19.53 s. These CT values help assess trade-offs between speed and performance metrics like accuracy of 93.5% or higher.

CT evaluation of IPOIAR-DPRNN technique with existing models.
Table 5; Fig. 8 present the error analysis of the IPOIAR-DPRNN approach in comparison to existing techniques. Multi-part bag-of-poses attains the highest \(\:acc{u}_{y}\) of 17.85% along with a \(\:pre{c}_{n}\) of 18.95%, 21.50% recall, and \(\:{F}_{measure}\) of 19.78%, suggesting a relatively balanced but modest performance. In contrast, the IPOIAR-DPRNN approach records the lowest \(\:acc{u}_{y}\) of 2.89%, with \(\:pre{c}_{n}\) of 12.90%, \(\:rec{a}_{l}\) of 13.06%, and \(\:{F}_{measure}\) of 13.02%, indicating limited effectiveness despite its fastest computation time of 9.55 s. RF-PCA exhibits stronger \(\:{F}_{measure}\) at 23.98% despite an \(\:acc{u}_{y}\) of 10.33%, implying better balance in its prediction outputs. HAR3DS-Lie Group and LMMML-Skelets presents higher \(\:{F}_{measure}\) at 20.57% and 23.49% respectively, even with lower \(\:acc{u}_{y}\) of 9.12% and 6.58%. Notably, HDS-SP achieves the highest \(\:pre{c}_{n}\) of 23.71% and robust \(\:rec{a}_{l}\) at 22.66%, but its \(\:acc{u}_{y}\) of 4.12% and low \(\:{F}_{measure}\) of 15.50% reflect inconsistent prediction performance. Overall, the results emphasize a trade-off between speed and predictive quality, with no single method dominating across all metrics.

Error analysis of IPOIAR-DPRNN approach with existing techniques.
Table 6 portrays the computational efficiency of the IPOIAR-DPRNN model28,29, highlighting its efficiency in mitigating both FLOPs and GPU memory usage, making it the most lightweight among all compared models. With just 0.91 FLOPs and GPU memory usage of 124 MB, the IPOIAR-DPRNN model is far more effectual than other methods such as ShuffleNetv2 with 5.51 FLOPs and 1284 MB or HFP with 5.44 FLOPs and 984 MB. Even typically optimized models like GhostNetv2 and MobileNetv2 require 3.99 FLOPs and 454 MB, and 2.90 FLOPs with 1223 MB respectively. The baseline model operates at 2.02 FLOPs and consumes 1060 MB of GPU, while Network Slimming attains 2.97 FLOPs and 1295 MB. Despite its ultra-low computational cost, the IPOIAR-DPRNN technique still maintains high-performance results such as accuracy of 97.11% and F-measure of 86.98%, making it an ideal choice for resource-constrained environments.
Table 7; Fig. 9 present the results of the analysis of the ablation study of the IPOIAR-DPRNN method. The ablation study depicts the progressive performance improvements achieved through diverse model architectures, with IPOIAR-DPRNN method illustrating the most promising results. EfficientNetB7 delivers robust baseline metrics with an \(\:acc{u}_{y}\) of 95.40%, \(\:pre{c}_{n}\) of 85.05%, \(\:rec{a}_{l}\) of 84.87%, and \(\:{F}_{measure}\) of 85.09%. IPOA builds on this with marginal gains, attaining an \(\:acc{u}_{y}\) of 95.95%, \(\:pre{c}_{n}\) of 85.61%, \(\:rec{a}_{l}\) of 85.48%, and \(\:{F}_{measure}\) of 85.76%. Further enhancement is observed in BiLSTM-MHSA, which achieves an \(\:acc{u}_{y}\) of 96.51%, \(\:pre{c}_{n}\) of 86.41%, \(\:rec{a}_{l}\) of 86.26%, and \(\:{F}_{measure}\) of 86.38%. The IPOIAR-DPRNN model outperforms with an \(\:acc{u}_{y}\) of 97.11%, \(\:pre{c}_{n}\) of 87.10%, \(\:rec{a}_{l}\) of 86.94%, and \(\:{F}_{measure}\) of 86.98%, confirming that the integration of advanced attention mechanisms or structural modifications contributes to notable gains across all evaluation metrics.

Comparative performance evaluation of the IPOIAR-DPRNN method through ablation study.
Conclusion
In this study, a novel IPOIAR-DPRNN method is proposed. The primary objective of the IPOIAR-DPRNN method is to improve indoor activity detection systems for individuals with disabilities. Initially, the image pre-processing stage applies ABF to minimize unwanted distortions or artefacts in the image. Furthermore, the EfficientNetB7 method is employed for the feature extraction process. For the detection and classification of indoor activities, the BiLSTM-MHSA technique is used. Additionally, the IPOA model-based hyperparameter is carried out to enhance the detection results of the BiLSTM-MHSA method. The validation of the IPOIAR-DPRNN approach is examined using the Florence 3D Actions dataset, and the outcomes are measured against various metrics. The comparison study of the IPOIAR-DPRNN approach revealed a superior accuracy value of 97.11% compared to existing techniques. The limitations of the IPOIAR-DPRNN approach comprise its reliance on a specific indoor activity dataset, which may restrict the generalizability of the results to more diverse environments or activities. The performance may be affected by discrepancies in sensor quality or placement, which were not extensively explored. Additionally, real-time implementation and computational efficiency on low-power devices remain to be addressed. Future work should focus on expanding the system to handle multi-modal sensor data and testing in more varied real-world settings. Incorporating transfer learning (TL) and adaptive learning strategies may improve adaptability to new activities. Moreover, exploring lightweight models for deployment on edge devices would improve practical usability. Finally, user-centric studies could provide valuable feedback to refine system usability and effectiveness.
Data availability
The data supporting this study’s findings are openly available at https://www.micc.unifi.it/resources/datasets/florence-3d-actions-dataset/, reference number [24].
References
Brik, B., Esseghir, M., Merghem-Boulahia, L. & Snoussi, H. An IoT-based deep learning approach to analyze indoor thermal comfort of disabled people. Build. Environ. 203, 108056 (2021).
Rakshanasri, S. L., Naren, J., Vithya, G., Akhil, S. & Kumar, D. A framework on health smart home using IoT and machine learning for disabled people. Int. J. Psychosocial Rehabilitation. 24 (2), 01–09 (2020).
Qi, J. et al. Examining sensor-based physical activity recognition and monitoring for healthcare using internet of things: A systematic review. J. Biomed. Inform. 87, 138–153 (2018).
Bibbò, L., Carotenuto, R. & Della Corte, F. An overview of indoor localization system for human activity recognition (HAR) in healthcare. Sensors 22 (21), 8119 (2022).
Perez, A. J., Siddiqui, F., Zeadally, S. & Lane, D. A review of IoT systems to enable independence for the elderly and disabled individuals. Internet of Things 21, 100653 (2023).
Das, R., Tuna, A., Demirel, S. & Yurdakul, M. K. A survey on the internet of things solutions for the elderly and disabled: applications, prospects, and challenges. Int. J. Comput. Networks Appl. 4 (3), 1–9 (2017).
Tegou, T. et al. A low-cost indoor activity monitoring system for detecting frailty in older adults. Sensors 19 (3), 452 (2019).
Vasco Lopes, N. Internet of things feasibility for disabled people. Trans. Emerg. Telecommunications Technol. 31 (12), e3906 (2020).
Sharma, A., Vats, A., Dash, S. S. & Kaur, S. Artificial Intelligence enabled virtual sixth sense application for the disabled. thought 4, 10 (2020).
Jubbori, T. A., Khaldi, A. & Zayood, K. Whale Optimization Algorithm with Deep Learning based Indoor Monitoring of Elderly and Disabled People. Int. J. Adv. Appl. Comput. Intell. 5(2), 24–33 (2024).
Khan, M. Z. et al. Transparent RFID tag wall enabled by artificial intelligence for assisted living. Sci. Rep. 14 (1), 18896 (2024).
Jin, F., Zou, M., Peng, X., Lei, H. & Ren, Y. Deep Learning-Enhanced internet of things for activity recognition in Post-Stroke rehabilitation. IEEE J. Biomed. Health Inform. (2023).
Rizk, H. & Hashima, S. June. RISense: 6G-Enhanced Human Activity Recognition System with RIS and Deep LDA. In 2024 25th IEEE International Conference on Mobile Data Management (MDM), 119–128 (IEEE, 2024).
Bouazizi, M., Mora, L. & Ohtsuki, T. A. and A 2D-Lidar-equipped unmanned robot-based approach for indoor human activity detection. Sensors 23 (5), 2534 (2023).
Kao, W. C., Fan, Y. L., Hsu, F. R., Shen, C. Y. & Liao, L. D. Next-Generation swimming pool drowning prevention strategy integrating AI and IoT technologies. Heliyon 10(18) (2024).
Ye, J., Jiang, H. & Zhong, J. A graph-attention-based method for single-resident daily activity recognition in smart homes. Sensors 23 (3), 1626. (2023).
El Zein, H., Mourad-Chehade, F. & Amoud, H. CSI-based Human Activity Recognition via Lightweight CNN Model and Data Augmentation. IEEE Sens. J. (2024).
ZHANG, J., Fuyang, K. E., Qinqin, T. A. N. G., Wenming, Y. U. & ZHANG, M. YGC-SLAM: A visual SLAM based on improved YOLOv5 and geometric constraints for dynamic indoor environments. Virtual Real. Intell. Hardw. 7 (1), 62–82 (2025).
Polo-Rodríguez, A., Anguita-Molina, M. Á., Rojas-Ruiz, I. & Medina-Quero, J. Multi-occupant tracking with radar and wearable devices for enhanced accuracy in indoor environments. Eng. Appl. Artif. Intell. 154, 110872. (2025).
Saradhi, M. V., Rao, P. V., Krishnan, V. G., Sathyamoorthy, K. & Vijayaraja, V. Prediction of alzheimer’s disease using LeNet-CNN model with optimal adaptive bilateral filtering. Int. J. Communication Networks Inform. Secur. 15 (1), 52–58 (2023).
Alkhalifa, A. K. et al. Prairie dog optimization algorithm with deep learning assisted based aerial image classification on UAV imagery. Heliyon 10(18) (2024).
Guo, S. et al. Research on the Lossless compression system of the argo buoy based on BiLSTM-MHSA-MLP. J. Mar. Sci. Eng. 12 (12), 2298 (2024).
Tian, J. et al. Temperature compensation method of TMR sensor based on IPOA-DBN for residual current monitoring in substations. J. Sens. 2024 (1), 7369859. (2024).
https://www.micc.unifi.it/resources/datasets/florence-3d-actions-dataset/
Sun, B. et al. Effective human action recognition using global and local offsets of skeleton joints. Multimedia Tools Appl. 78, 6329–6353 (2019).
Chen, J., Yang, W., Liu, C. & Yao, L. A data augmentation method for skeleton-based action recognition with relative features. Appl. Sci. 11 (23), 11481. (2021).
Rahayu, E. S., Yuniarno, E. M., Purnama, I. K. E. & Purnomo, M. H. A Combination Model of Shifting Joint Angle Changes With 3D-Deep Convolutional Neural Network to Recognize Human Activity. IEEE Trans. Neural Syst. Rehabil. Eng. (2024).
Jeon, J., Kim, J., Kang, J. K., Moon, S. & Kim, Y. Target capacity filter pruning method for optimized inference time based on YOLOv5 in embedded systems. IEEE Access. 10, 70840–70849 (2022).
Wen, S. et al. PcMNet: an efficient lightweight apple detection algorithm in natural orchards. Smart Agric. Technol. 9, 100623 (2024).
Acknowledgements
The authors extend their appreciation to the King Salman center For Disability Research for funding this work through Research Group no KSRG-2024- 426.
Author information
Authors and Affiliations
Contributions
Munya A. Arasi: Conceptualization, methodology, validation, investigation, writing—original draft preparation, fundingHanadi Alkhudhayr: Conceptualization, methodology, writing—original draft preparation, writing—review and editingAbdulwhab Alkharashi: methodology, validation, writing—original draft preparationAmani A Alneil: software, validation, data curation, writing—review and editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Arasi, M.A., Alkhudhayr, H., Alkharashi, A. et al. Enhancing indoor activity recognition for disabled persons using multi head self attention recurrent neural network with improved pelican algorithm. Sci Rep 15, 33164 (2025). https://doi.org/10.1038/s41598-025-14515-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-14515-w
