
Abstract
Pharmacogenomics (PGx) testing improves medication safety and efficacy by identifying genetic variants that affect drug response. However, current technologies often fail to resolve complex loci, detect structural variants, or phase alleles accurately. Here, we present an end-to-end PGx workflow based on Targeted Adaptive Sampling-Long Read Sequencing (TAS-LRS), integrating a streamlined laboratory protocol with a bioinformatics pipeline that includes a novel CYP2D6 caller. Using 1,000 ng of DNA and three-sample multiplexing on a single PromethION flow cell, the assay achieves consistent on-target (25x) and off-target (3x) coverage, enabling accurate, haplotype-resolved testing of 35 pharmacogenes alongside genome-wide genotyping from off-target reads. We further developed the workflow into a clinically ready service and validated its performance across 17 reference and clinical samples. The assay demonstrated high concordance for small variants (99.9%) and structural variants (> 95%), with phased diplotypes and metabolizer phenotypes reaching 97.7% and 98.0% concordance, respectively. Improved calls were observed in 12 genes due to enhanced genotyping, phasing, or novel allele detection. In addition, off-target reads supported accurate genome-wide imputation, comparable to short-read sequencing and superior to microarrays. These results establish the feasibility of long-read sequencing for clinical PGx testing and position TAS-LRS as a scalable solution combining both targeted and genome-wide utility.
Similar content being viewed by others

Introduction
Pharmacogenomics (PGx) is a branch of medicine focused on understanding how an individual’s genetic profile impacts their response to medications1. It examines the role of genetic variations in drug metabolism, effectiveness, and safety, aiding in understanding and predicting individual responses to specific drugs. PGx variants differ from those in other medical conditions in their high penetrance, widespread prevalence, and actionable potential. Although Adverse Drug Reactions (ADRs) are multifactorial in origin, a substantial subset, estimated at approximately one-third of serious cases, involve medications with known pharmacogenetic associations2,3. ADRs can manifest as allergic reactions or diminished drug efficacy, which can lead to negative outcomes or toxicity. For example, severe reactions such as Stevens-Johnson syndrome are associated to specific HLA-B alleles (HLA-B*58:01 and HLA-B*15:02) in patients taking Allopurinol and Carbamazepine, respectively4. In terms of efficacy, certain CYP2C19 alleles (*2 and *3) impair the metabolism of drugs like Clopidogrel, increasing the risk of cardiovascular events5. Similarly, individuals with extra copies of the CYP2D6 gene metabolize codeine into morphine at an accelerated rate, enhancing pain relief but also heightening the risk of serious side effects, such as respiratory depression or, in extreme cases, overdose and death6. PGx variants are also highly prevalent, with over 90% of the general population estimated to carry at least one variant that could significantly affect drug therapy1,7,8,9. For example, an NGS-based pilot study at the Mayo Clinic found that 99% of 1013 participants carried at least one actionable variant across five clinically important pharmacogenes (CYP2D6, CYP2C19, CYP2C9, VKORC1, and SLCO1B1)10. Lastly, and most importantly for clinical implementation, PGx variants are actionable. Consortia such as the Clinical Pharmacogenetics Implementation Consortium (CPIC) and the Dutch Pharmacogenetics Working Group (DPWG) have developed guidelines for over 100 gene-drug pairs widely available in the market11,12, which provide a robust and evidence-based framework for integrating PGx into clinical practice. These guidelines demonstrate that many ADRs can be mitigated through personalized approaches, such as dose adjustments or alternative therapies, highlighting the potential to improve effectiveness and safety without necessarily raising treatment costs. Indeed, several pilot studies have shown that pre-emptive PGx testing is feasible and can lead to reductions in emergency department visits, hospitalizations, and healthcare costs13,14,15,16. Among these, the PREPARE study - the largest prospective clinical trial to date conducted across seven European countries - reported a 30% decrease in ADRs in a diverse cohort of 6,944 patients14.
A range of technologies have been employed to characterize variation in PGx genes, including PCR, microarrays, and short-read sequencing17. More recently, long-read sequencing has emerged as a promising method for improving accuracy of genomic analysis18. Its ability to perform haplotype phasing without requiring parental data has the potential to aid in the interpretation of PGx variants19, for example, by enabling the differentiation of genotypes such as TPMT*3B/*3C (where the *3B allele contains rs1800460 and *3 C contains rs1142345) from TPMT*1/*3A (where *3A includes both rs1800460 and rs1142345). Long-read sequencing also offers higher resolution in complex genomic regions, such as structural variants and hybrid rearrangements, which are common in pharmacogenes like CYP2D6, UGT1A1, and HLA genes. For instance, the CYP2D6 *36+*10 haplotype, a common variant in East Asians characterized by a hybrid tandem duplication, is difficult to detect with standard microarray chips20 and may also be missed by short-read sequencing approaches21,22,23,24. Lastly, long-read sequencing is not limited by prior knowledge of specific variants, making it capable of identifying rare and novel alleles - a common limitation of targeted methods such as PCR, microarrays, and sequencing panels.
While historically more costly, the introduction of Targeted Adaptive Sampling-Long Read Sequencing (TAS-LRS) by Oxford Nanopore Technologies (ONT) has made long-read sequencing more accessible25,26,27. TAS-LRS leverages the real-time base-calling capabilities of nanopore sequencing to enrich for DNA fragments that map to a set of pre-defined genomic regions. The process begins by sequencing an initial stretch of each DNA molecule that enters the pore (approximately 400–800 bp). Basecalling and alignment are performed in real time to determine whether this short sequence matches the specified target regions. If a match is found, sequencing continues to generate a long read; if not, the fragment is ejected, allowing the next fragment to enter the pore. As a targeted method, TAS-LRS supports multiplexing, which reduces sequencing costs. Combined with the lower burden of instrument investment, this makes the technology more accessible to research and clinical laboratories. In addition, unlike conventional targeted assays that preselect DNA fragments during library preparation, TAS-LRS enriches target regions while also producing low-depth off-target data, enabling potential genome-wide analysis.
Here we introduce an end-to-end pharmacogenomics testing workflow based on TAS-LRS. We describe the experimental protocol and bioinformatics reporting pipeline, which integrates external tools with in-house algorithms, including a novel CYP2D6 caller. We also outline the development of this workflow into a clinically ready service, presenting analytical and clinical validation results assessing the assay’s Limit of Detection (LOD), accuracy, precision, and specificity. In addition, we demonstrate the utility of off-target signals generated during adaptive sampling for genome-wide genotyping, highlighting the broader research potential of this approach. Altogether, our workflow enables, for the first time, the clinical implementation of PGx testing using long-read sequencing.
Results
TAS-LRS workflow and validation study design
The implementation of PGx into clinical practice requires an end-to-end workflow that ensures analytical validity, clinical utility, and operational feasibility. Here we present a clinical workflow for pre-emptive PGx testing based on TAS-LRS), designed to balance comprehensive variant detection with cost-efficiency and scalability. The workflow consists of four key phases: (i) pre-test consultation (optional), (ii) sample preparation and sequencing, (iii) bioinformatics analysis and reporting, and (iv) post-test consultation, with multiple Quality Control (QC) steps applied throughout (Fig. 1a and "Methods"). The reporting workflow covers 35 pharmacogenes (Supplementary Table 1), including all Very Important Pharmacogenes (VIPs) from Pharmacogenomics Knowledgebase (PharmGKB) (N = 34) along with HLA-A, which is routinely tested in our laboratory. Additionally, genome-wide imputation from off-target reads is used for broader genotyping, supporting downstream research applications. Beyond genetic variation, the workflow also captures base modification signals, including 5mC, 5hmC, 6 mA, and 4mC, leveraging ONT’s native DNA sequencing capabilities. While not analyzed in this study, these epigenetic features offer potential insights into gene regulation and drug response for future research.

Overview of the TAS-LRS clinical workflow and validation framework. (a) Schematic of the end-to-end pharmacogenomics testing workflow based on Targeted Adaptive Sampling–Long Read Sequencing (TAS-LRS), comprising four main phases: optional pre-test consultation and sample collection; wet lab processing (DNA extraction, shearing, and Oxford Nanopore sequencing); bioinformatics analysis (including alignment, variant and star-allele calling, HLA typing, and genome-wide imputation); and post-test clinical consultation. Adaptive sampling enriches for 35 target pharmacogenes, including all PharmGKB Very Important Pharmacogenes (VIPs) and HLA-A, while generating low-depth off-target data for broader genome-wide applications. Blue, green, orange, and red indicate distinct workflow stages. (b) Validation framework for the TAS-LRS workflow, consisting of four core studies: (1) Limit of Detection (LOD), evaluating variant calling performance (SNVs, indels, and SVs) across different DNA input amounts (800 ng vs. 1000 ng) and basecalling models (High-accuracy (HAC) vs. Super-accuracy (SUP)); (2) Accuracy, assessed by diplotype and phenotype concordance across reference cell lines (GIAB, GeT-RM, 1KGP), external quality assessment (CAP EQA), and clinical samples from Tan Tock Seng Hospital (TTSH); (3) Precision, evaluated via reproducibility across sequencing runs and repeatability across independent bioinformatics analyses; and (4) Specificity, assessed through interference testing using triglyceride-spiked blood samples and cross-contamination testing using VerifyBamID2.
To evaluate the analytical performance of this workflow, we designed a validation framework based on recommendations from regulatory guidelines, including those from the Food and Drug Administration (FDA), College of American Pathologists/Clinical and Laboratory Standards Institute (CAP/CLSI), Clinical Laboratory Improvement Amendments (CLIA), and In Vitro Diagnostic Regulation (IVDR)28. The framework consists of four studies assessing key performance metrics: LOD, accuracy against established truth sets, precision (reproducibility and repeatability) and specificity (interference and cross-contamination) (Fig. 1b). The validation study included 17 unique samples across 10 sequencing runs (Supplementary Table 2), incorporating cell lines, CAP External Quality Assessment (EQA) samples, and real patient specimens to ensure clinically relevant testing. Cell lines were selected to represent a range of pharmacogenomic variants, including small variants (SNPs and indels) and structural variants (SVs). CAP EQA and patient samples were used to validate performance against orthogonal methods, including clinically validated workflows.
Across all validation runs, and when combining both the 1-hour Whole Genome Sequencing (WGS) and adaptive sampling stages, we obtained a mean sequencing yield of 37.09 Gbases per run, with a mean base quality score of 21.65. As expected, run yield positively correlated with the number of available starting pores on the flow cell (R2 = 0.67, p = 0.0036 for total bases; R2 = 0.66, p = 0.0043 for passed bases; Supplementary Fig. 1). De-multiplexing efficiency for the adaptive sampling runs using reads with Q-score > 10 was greater than 95%, resulting in an average of 10.38 Gbases of usable output per sample with our 3-plex strategy. On-target regions (N = 326) achieved a mean coverage of 25.2x, while off-target regions had an average coverage of 3.0x, indicating a mean fold enrichment of 8.5 (Supplementary Tables 3 and Supplementary Fig. 2). N50 values were as expected, with an average of 7,889 bp in on-target regions and 641 bp in off-target regions, confirming that adaptive sampling successfully enriched sequencing depth for the desired loci. Closer inspection of on-target coverage across the 35 pharmacogenes revealed a mean coverage of 21.9x (Supplementary Fig. 3). Only two genes, G6PD and SLC19A1, consistently showed lower coverage. For G6PD, the reduced coverage can be attributed to its X-linked location, which results in sex-dependent coverage differences. Indeed, female samples, which are expected to have approximately double the copy number of males, achieved an average depth of 17x, while male samples reached only 10x. In the case of SLC19A1, the lower coverage may be due to a low-complexity region in the flanking sequence of the target region (Supplementary Fig. 4), and could potentially be handled by further optimising padding in the target BED file.
To assess the impact of reduced sequencing depth on variant calling accuracy, we performed a depth of coverage analysis by randomly down-sampling reads from HG005, a male reference benchmark sample, to simulate depths ranging from 10x to 40x in on-target regions (Supplementary Table 4). In SNPs of interest evaluated above, the mean callability exceeded 99% at depths ≥ 15x, the mean genotype concordance was greater than 99.5% from 10x and the mean sensitivity, specificity and precision were above 98% in samples with at least 15x. However, for SLC19A1, the mean genotype concordance was only 92% in samples where the depth of coverage for all on-target regions was 30x indicating the lower performance for this region. A 100% concordance rate was achieved with the 40x sample. In G6PD, 100% callability was achieved from 25x onwards. However, HG005 does not include any variants in this region and thus the sensitivity and precision could not be evaluated.
Variant calling performance – Limit of detection (LOD) study
To evaluate the LOD of the TAS-LRS-based PGx workflow, we first assessed the accuracy of genotype calls using reference cell lines, focusing on raw genotype accuracy rather than diplotype interpretation. Given the potential impact of DNA input on long-read sequencing performance, we compared runs using 800 ng and 1000 ng of library input. Three runs were performed at 800 ng, while four runs were conducted at 1000 ng, including one sample (HG01190) sequenced under both conditions to enable direct comparison. Additionally, basecalling performance was evaluated using High-accuracy (HAC) and Super-accuracy (SUP) models.
For small variants, analysis included 1142 variants (1,103 SNPs and 39 indels) across 31 PGx genes, excluding CYP2D6, CYP2A6, HLA-A and HLA-B due to their complex structural variation that impacts the accuracy of calls returned by Clair3 (see "Methods"). Across all conditions, and with SUP basecalling, callability averaged 99.49% and genotype concordance averaged 99.90%. No significant differences in performance were observed between DNA input conditions; however, basecalling with SUP instead of HAC resulted in improved performance, most notably for callability, which increased by 1.41% (Table 1).
For SVs, including deletions, duplications, and hybrid alleles, evaluations were performed at the individual event level, generating aggregate performance metrics across all samples (Table 2). Our analyses focused on CYP2D6 and CYP2A6, as these were the only genes with SVs in our reference dataset of 17 unique samples. For duplications, performance remained consistent across DNA inputs and basecalling modes. For deletions, all expected events were also recovered, except for a missed CYP2D6 *5 deletion in sample NA18861 when using 800 ng of input and HAC mode, which was likely due to the lower sequencing depth in this sample (18.22x), and which was successfully recovered when using SUP calling mode. Hybrid alleles presented a greater challenge, with performance differences observed between 800 ng and 1000 ng of DNA input. Specifically, an increased number of false negatives was detected at 1000 ng, consistently for HAC and SUP; however, further inspection suggested that sequencing depth, rather than DNA input alone, was the primary factor influencing this trend (27.4x mean depth in samples from 800 ng input runs vs. 24.2x in samples from 1000 ng input runs). Lastly, it is worth noting that the pipeline did not return any false positives, with specificity and precision consistently maintained at 100%.
These results highlight the strong influence of sequencing depth on SV detection, particularly for hybrid alleles. When performing a follow up analysis at a per-locus depth of 25x in CYP2D6 and CYP2A6, genotype concordance reached 100%, indicating reliable detection across all SV types (Supplementary Table 5). The above findings also inform the choice of basecalling mode, with SUP demonstrating significant improvements in detecting both small variants and SVs. As a result, SUP was adopted as the default basecalling mode, and all subsequent validation studies were conducted using this approach.
PGx star allele diplotype and phenotype concordance – Accuracy study
While individual variant calling accuracy is critical for evaluating performance of genetic testing assays, pharmacogenomic workflows often require variant calls to be phased and interpreted into haplotypes, which are subsequently translated into metabolizer profiles. To address this, we expanded the performance assessment to evaluate the accuracy of diplotype and phenotype calling in pharmacogenes with complex alleles (i.e. star-alleles or similar; N = 20). A significant challenge in this analysis lies in the extensive number of star-alleles associated with many pharmacogenes, exemplified by CYP2D6, which has over 100 known star-alleles catalogued in PharmGKB29. This diversity complicates the availability of reference materials, particularly for rare or population-specific haplotypes. To address these limitations, we selected samples representing a broad range of star-alleles, with particular focus on CYP2D6, one of the most highly variable pharmacogenes, and prioritized frequent haplotypes observed in Southeast Asian populations, such as *36+*10 hybrids (Supplementary Table 2). Cell lines from National Institute of Standards and Technology (NIST) and Coriell (N = 11) were selected to include samples with truth data obtained either from Genetic Testing Reference Materials (GeT-RM), or orthogonal methods, such as 30x whole-genome short-read sequencing in the 1000 Genomes Project (1KGP). EQA samples were also included (N = 3), with known expected results provided by previous CAP EQA outcomes. Finally, we also evaluated patient samples that had been previously tested using orthogonal methods (N = 3), namely microarrays validated under a clinical workflow.
For each pharmacogene in each sample, diplotype calls generated by the TAS-LRS workflow were compared against truth data obtained from GeT-RM or orthogonal methods, including 30x whole-genome sequencing from 1KGP and clinically validated microarrays (see "Methods"). Diplotype concordance results were classified into four categories: concordant, where the call matched the truth set; discordant, where the call differed from the truth set; improved, where TAS-LRS calls were deemed correct upon manual review of both truth and test data; and no-calls, where the algorithm did not return a result due to quality control filters (see "Methods"). Overall, across 519 total diplotype calls evaluated, spanning 20 genes and 17 samples, we observed 446 concordant calls (85.93%), 2 discordant calls (0.39%), 61 improved calls (11.75%), and 10 no-calls (1.92%) (Fig. 2). Aside from concordant calls, the next most frequent category was improved calls. We identified improvements in 12 out of 20 genes (60.00%), including CYP2A6, CYP2B6, CYP2C9, CYP2D6, CYP4F2, DPYD, GSTP1, HLA-B, NAT2, NUDT15, SLCO1B1, and UGT1A1. These improvements were primarily driven by an expanded reportable range (N = 32), more accurate genotyping (N = 16), phasing (N = 9) and SV detection (N = 1), and identification of novel alleles due to enhanced phasing (N = 3). Notably, improved calls remained consistent across replicates, further supporting their validity. For example, NAT2 in sample NA19174 was ambiguously reported in the GeT-RM truth set as *4/*5 or *5/*6. This ambiguity persisted across short-read sequencing datasets analyzed with different tools, except for StellarPGx, which reported another set of potential star alleles (*16/*34). With TAS-LRS, the diplotype was fully resolved to *5.002/*6.002, with phasing supported by underlying read alignments in Integrative Genomics Viewer (IGV) (Fig. 3a). Clinically, distinguishing *5/*6 (slow acetylator) from *4/*5 (intermediate acetylator) is critical, as NAT2 encodes N-acetyltransferase 2, an enzyme involved in metabolizing drugs such as isoniazid, hydralazine, and sulfasalazine, and slow acetylators are at increased risk of drug-induced toxicities, including isoniazid-associated hepatotoxicity. Similarly, for CYP2B6 in sample NA19926, both GeT-RM and orthogonal microarray and short-read datasets consistently returned a *18/*20 call, while PyPGx on short-read data suggested a possible novel allele that was not fully resolved. TAS-LRS phased the four variants involved in *18 and *20 into a novel configuration, assigning two variants to *6 in haplotype 1 and two variants to a novel allele in haplotype 2. These phasing patterns were clearly supported by IGV read alignments (Fig. 3b). This reconfiguration has potential clinical implications, as CYP2B6 alleles such as *6 and *18 are associated with reduced enzymatic activity, impacting the metabolism of drugs including efavirenz, bupropion, and methadone. In another similar case, TAS-LRS identified a novel DPYD haplotype in sample NA19226 that was not supported by short-read data or reflected in the GeT-RM truth set (Supplementary Fig. 5a). While GeT-RM reported a *1/*9A diplotype based on the presence of c.85T > C (rs61622928), TAS-LRS revealed that c.1218G > A (rs1801265) co-occurred on the same haplotype. In this case, the ability to phase multiple functional variants on the same allele has important implications for fluoropyrimidine dosing, drugs that are used to treat colorectal and breast cancers and are primarily inactivated by DPYD. Both c.85T > C and c.1218G > A are missense variants associated with reduced DPYD enzyme activity in functional studies, and, when phased together on the same allele, their combined effect may further compromise enzyme function compared to either variant alone. As a final example, TAS-LRS resolved a complex UGT1A1 diplotype in a clinical sample previously reported as *1/*28 based on microarray genotyping. Phased long-read data showed that the *28 allele co-occurred with *80 (rs887829) and *27 (rs35350960), yielding a corrected diplotype of *1/*80+*28+*27 (Supplementary Fig. 5b). These additional variants, particularly *27, contribute to further reduced gene expression beyond the effect of *28 and misclassifying this diplotype as *1/*28 may therefore underestimate the risk of irinotecan-induced toxicity or hyperbilirubinemia.

Diplotype concordance for pharmacogenes with complex alleles. Results of the TAS-LRS workflow for (a) reference cell lines (n = 11), (b) clinical research samples (n = 3) and (c) external quality assessment (EQA) samples (n = 3) were compared against reference truth sets. GeT-RM calls were used as the truth set for HG001, HG01190, NA18861, NA18966, NA19174, and NA19226 unless otherwise specified. Diplotype calls for HG00337, HG005, HG01097, HG01572, and HG03259 were compared to PyPGx diplotypes from 30x short-read data. For all samples, ABCB1, G6PD, NUDT15, and UGT1A1 calls were compared to PyPGx outputs, and HLA-A and HLA-B calls were evaluated against optitype v1.3.5. Calls matching the truth set were labelled as concordant, while mismatched calls were considered improved based on IGV read support or consensus across orthogonal methods.

Examples of improved pharmacogene calls enabled by enhanced phasing, novel allele detection, and expanded haplotype coverage. (a) Phasing and haplotype resolution for NAT2 in NA19174. (b) Improved phasing and detection of a novel allele in CYP2B6 for NA19226. TAS-LRS resolved a partial call (*6/*18 + rs36056539) as the correct genotype.
In contrast to the improved calls, two discordant calls were observed in ABCB1 and CYP4F2. For ABCB1 in sample HG01572, Clair3 reported a TT genotype for the star-defining SNP rs2032582, which PyPGx interpreted as *2/*2, whereas short-read data supported a heterozygous alternate TC genotype, interpreted as *1/*2. IGV pileups showed evidence for the TC allele in TAS-LRS, but the C allele had insufficient support to be confidently called (Fig. 4a). This suggests that increased sequencing depth at this locus would likely have resulted in the correct call. In CYP4F2, sample NA18966 was assigned a *3/*3 diplotype by TAS-LRS, whereas GeT-RM, microarray, and short-read data supported a *1/*3 call. Similarly to ABCB1, IGV analysis revealed that the incorrect call was due to low read depth, with very few reads spanning haplotype 1 (Fig. 4b).

Examples of discordant calls caused by allele imbalance. (a) Discordant ABCB1 diplotype call in HG01572. rs2032582 was incorrectly called as homozygous alternate (TT) in long-read data, while short-read data supported a heterozygous genotype (TC). The C allele is present in the long reads, but its coverage is too low to meet the variant calling threshold. (b) Discordant CYP4F2 call in sample NA18966. TAS-LRS wrongly called the rs2108622 as homozygous alternate, whereas other platforms including GeT-RM, microarray (GSAv3), and short-read pipelines showed the diplotype as *1/*3. IGV plots show insufficient coverage of haplotype 1 for this specific sample.
Lastly, no-calls were observed in CYP2A6, CYP2D6, HLA-A, HLA-B, and SLCO1B1. For CYP2A6, a no-call arose from limitations in the current logic for combining a 3′ UTR conversion with a deletion; and algorithmic improvements are expected to resolve this. In CYP2D6, no calls were partly attributed to lower sequencing depth, where out of four HG005 replicates, the replicate with a no-call had the lowest sequencing depth (18x compared to a mean depth of 20.5x for the remaining samples). In addition, a no-call for NA19174 was observed despite having 32x coverage, due to a low-quality indel call at rs72549356, which did not match the expected variant. Note however that this indel was correctly detected in two other replicates at 37x and 26x. HLA-A and HLA-B no-calls were due to diplotype quality scores below the 0.95 threshold, also linked to insufficient depth. For SLCO1B1, no-calls were related to unresolved ambiguous diplotypes: in the two no-call replicates of HG001, the workflow identified two possible diplotypes, *1/*15 and *1/*46, which share two SNPs, rs2306283 and rs4149056, but differ in a third SNP, rs71581941, present only in *46; and due to insufficient evidence to detect the *46-defining SNP, it conservatively assigned a no-call.
In addition to the diplotype concordance analysis described above, in which results were compared against available truth data, we conducted a direct comparison between our TAS-LRS workflow and orthogonal testing platforms, including short-read 30x whole-genome sequencing (SR-WGS) analyzed with multiple bioinformatics workflows, and microarrays (Illumina GSAv3) (see "Methods"). Although limited to a subset of samples with available data (N = 11), the analysis showed that TAS-LRS was able to achieve consistently high concordance rates (> 95%), outperforming other platforms in 13 of 20 genes evaluated (Supplementary Table 6). Across platforms, genes with complex structural variation or multiple gene copies, such as CYP2D6 and CYP2A6, and highly polymorphic genes like UGT1A1 and HLA-B, posed particular challenges for both SR-WGS and microarrays. Microarrays, as expected, presented challenges with diplotype resolution for alleles requiring phasing or detection of SVs. While DRAGEN achieved the highest concordance among short-read workflows, it exhibited lower callability compared to TAS-LRS, whereas other pipelines, such as StellarPGx and PyPGx, showed high variability across genes. Importantly, short-read workflows often rely on population-based haplotype inference for diplotype assignment, introducing uncertainty when encountering novel or rare allele combinations. In contrast, TAS-LRS simplifies interpretation by directly delivering phased diplotypes from sequencing reads, minimizing reliance on statistical inference, and potentially reducing manual curation efforts in clinical laboratories.
Finally, since the PGx workflow ultimately generates metabolizer profiles for clinical reporting, we evaluated phenotype concordance across 13 genes with established phenotype interpretation tables. The classification system mirrored that used for diplotypes: concordant (matching the expected result based on either the reference or the improved diplotype call), discordant (not matching the expected result), or indeterminate. As expected, and consistent with diplotype concordance results, the majority of phenotypes were concordant (341/348, 97.99%), with only seven cases (2.01%) classified as indeterminate due to a no-call or insufficient copy number information, and no discordant phenotypes observed (Supplementary Fig. 5). We subsequently focused on samples previously identified to have improved diplotype calls (Fig. 2), since these are the ones more likely to lead to conflicting phenotype interpretations. Among the 52 improved diplotypes across the 13 genes evaluated, the majority (n = 36, 69.23%) had no impact on phenotype interpretation. However, in 10 cases (19.23%), phenotype assignment was not possible due to the presence of novel alleles with uncharacterized function. This highlights a key trade-off of higher-resolution sequencing technologies: while they improve variant detection, they also increase the likelihood of identifying previously unreported alleles that require functional characterization before clinical recommendations can be made. These findings emphasize the need for ongoing curation efforts, and in the future, approaches such as in silico functional prediction or targeted functional assays could aid in assigning provisional phenotype classifications and further enhance clinical utility. Finally, six cases (11.54%) resulted in improved phenotype classification. An example is shown in Supplementary Fig. 7, where TAS-LRS resolves a previously unphased copy number change in CYP2D6 for a clinical sample tested with microarrays, allowing for an unambiguous phenotypic interpretation. Without accurate resolution, this genotype could have led to inappropriate drug therapy recommendations and potential adverse outcomes.
Precision and specificity studies
To evaluate the precision of our assay, we performed reproducibility and repeatability studies using a subset of validation runs. Reproducibility was assessed by analyzing both inter- and intra-run consistency using GIAB replicates sequenced in three different runs (Supplementary Table 3). Across all performance metrics evaluated, inter-run and intra-run coefficients of variation remained below 5% (Supplementary Table 7), demonstrating high reproducibility. Repeatability was tested by running the analysis pipeline three times on the same input data from the same GIAB runs and starting from basecalling. Results were fully consistent across all repetitions, confirming the absence of stochastic variability in the analysis workflow.
Similarly, specificity was examined through interference and cross-contamination studies. To assess potential interference, three distinct blood samples were spiked with triglycerides at a concentration three times the optimal threshold based on the Singapore Ministry of Health 2016 Hyperlipidemia Guidelines (> 450 mg/dL), simulating patients with severely elevated triglyceride levels (see "Methods". Each sample was processed in triplicate, with two spiked replicates and one non-spiked control. While all non-spiked samples met the minimum DNA concentration requirements for downstream processing (min. 100 ng/ul for 3-plex sequencing), none of the spiked samples did (Supplementary Table 8). These results indicate that the test is not recommended for patients with significantly elevated triglyceride levels, as it may result in higher failure rates. This limitation should be clearly noted in clinical protocols and pre-test consultations, where severely elevated triglyceride levels could be considered an exclusion criterion or flagged for alternative sampling methods. No workaround, such as dilution or alternative extraction kits, was attempted in this study; however, future work may explore such options. Lastly, cross-contamination was assessed using VerifyBamID230 to detect human DNA contamination in each sample. No signs of contamination were observed, with FREEMIX values consistently ≤ 3%, confirming high specificity (Supplementary Table 9).
Off-Target signal analysis and genome-wide genotyping
Lastly, we investigated the potential use of off-target signal, generated from reads not selected during the adaptive sampling process (Fig. 1a), to obtain genome-wide genotype calls. This capability is unique to the TAS-LRS workflow, as conventional targeted assays typically limit coverage to predefined regions, thus limiting genome-wide analysis. In our dataset, the mean off-target sequencing depth across all runs was 3.0x (Supplementary Table 3). Previous studies using both short-read and long-read sequencing have demonstrated that genome-wide genotyping from such low-coverage data is feasible through imputation techniques31,32. To assess this, we used the 1KGP reference panel to impute genotype calls in sample HG005 (Han Chinese), which is not part of the panel, to avoid bias. Imputation was performed using GLIMPSE, with results compared to those obtained from short-read sequencing downsampled to an equivalent depth and from a microarray dataset (see "Methods").
Our results show that imputation based on the off-target TAS-LRS signal (mean coverage of 2.0x for the selected HG005 replicates) achieved high accuracy, closely matching that of short-read datasets and outperforming microarrays, particularly for rare variants with a minor allele frequency (MAF) < 1% (Fig. 5). This outcome highlights the unbiased nature of sequencing-based methods, which randomly sample DNA fragments across the genome, in contrast to microarrays that rely on predefined marker panels often biased toward common variants. Furthermore, the comparable imputation accuracy between short-read and long-read datasets demonstrates that, despite the lower base quality of ONT reads, TAS-LRS can generate equally reliable variant calls from imputation.

Genome-wide imputation accuracy across technologies. Imputation was performed using GLIMPSE2 (for TAS-LRS and short-read WGS) and Minimac4 (for microarray data), with the 1KGP reference panel which excludes the test samples (HG002 and HG005 from GIAB). Line plots show imputation accuracy (R2) across allele frequency bins. Rare variants are defined as those with minor allele frequency < 1%. Shaded areas indicate 95% confidence intervals across replicates.
Discussion
Here, we introduce and validate an end-to-end pharmacogenomics (PGx) workflow based on targeted adaptive sampling long-read sequencing (TAS-LRS), developed to support clinical implementation in a CAP-accredited setting. The workflow combines an optimized laboratory protocol with a custom bioinformatics pipeline capable of resolving small variants, structural variants, and complex star alleles across 35 clinically relevant pharmacogenes, while also enabling genome-wide genotyping from off-target reads. Long-read sequencing technologies have gained increasing traction in recent years (i.e. they were named Method of the Year in 202318 ) due to their ability to resolve complex genomic loci previously inaccessible with short-read sequencing. This capability is particularly relevant in PGx, where many pharmacogenes are highly polymorphic and reside in structurally challenging regions of the genome, often involving segmental duplications, tandem repeats, and pseudogenes33. A prominent example is CYP2D6, which encodes the cytochrome P450 2D6 enzyme responsible for metabolizing approximately 20% of clinically prescribed medications. To date, the CYP2D6 locus includes over 170 catalogued star alleles, encompassing gene deletions, duplications, and hybrid rearrangements involving the closely related pseudogenes CYP2D7 and CYP2D829, with certain tandem hybrids, such as *36+*10, observed in up to 30% of East Asian populations34,35,36. Several prior studies have demonstrated the feasibility of using long-read platforms such as Oxford Nanopore and PacBio to resolve complex PGx loci, including early proof-of-concept work by Liau et al.37,38, Charnaud et al.39 and Turner et al.23 for CYP2D6, and by Graansma et al.40 for CYP2C19. Most recently, Deserranno et al.26 showcased the potential of nanopore adaptive sampling for PGx profiling across more than 1,000 genes. However, such efforts have been limited in sample size, gene coverage, or lack of formal validation frameworks. To our knowledge, ours is the first study to present a comprehensive analytical and clinical validation of a long-read-based PGx workflow, establishing key performance metrics (including LOD, accuracy, precision and specificity) to support its routine use in clinical diagnostics.
By analysing data from 10 sequencing runs comprising 17 unique reference and clinical samples, we demonstrated that our optimized adaptive sampling protocol yields consistent coverage, with a mean on-target depth of 25.2x and off-target depth of 3.0x, corresponding to an average enrichment of 8.5x, in line with expectations for TAS-LRS. We evaluated the impact of DNA input and basecalling mode on variant calling performance and observed that the SUP model consistently outperformed HAC for both small variants and structural variants in the target pharmacogenes. Notably, structural variant detection was more sensitive to sequencing depth, with 25x sufficient to recover all expected events in our dataset. However, further calibration is needed before establishing this as a universal threshold for clinical applications. To assess the clinical relevance of our workflow, we evaluated star allele and phenotype concordance across the 35 target pharmacogenes. Of 520 total diplotype calls, 507 (97.5%) were either concordant with the expected result (n = 446) or classified as improved upon manual curation (n = 61). Only two discordant calls (0.4%) and ten no-calls (1.9%) were observed, all attributable to insufficient coverage, which can be addressed through further protocol optimizations, such as improved DNA shearing, increased library loading and algorithmic refinements. To address loci prone to coverage variability (e.g., G6PD, SLC19A1), we recommend repeat sequencing or supplementary testing in cases where critical alleles cannot be confidently resolved. In addition, in a clinical setting, no-calls and ambiguous results should undergo review by a clinical scientist, with additional testing performed as necessary to ensure the reliability of reported genotypes.
As shown in previous long-read studies39,41, our findings underscore that accurate haplotype reconstruction, and not just variant detection, is essential for clinical PGx, particularly in genes with complex allelic architecture. For example, the NAT2 diplotype in sample NA19174 was ambiguously reported as *4/*5 or *5/*6 in short-read datasets and reference truth sets. TAS-LRS resolved this to *5.002/*6.002, with phasing clearly supported by IGV alignments. Similarly, in CYP2B6, we observed an alternate phasing of four variants initially assigned to *18/*20, revealing a novel allele combination with well-supported haplotype structure. However, a key challenge remains in interpreting novel diplotypes for clinical actionability. While most improved calls (69.2%) maintained consistent phenotype interpretations, 10 of the 52 evaluated (19.2%) could not be mapped to known metabolizer categories due to the presence of novel or rare alleles. This limitation has also been noted in previous long-read PGx studies40, where increased resolution reveals variants not yet accommodated by current clinical guidelines. In clinical practice, novel or uncharacterized diplotypes would be reported with annotation of uncertain significance, with parallel efforts to expand reference databases and generate functional evidence to support future clinical interpretation. Conversely, in six cases (11.5%), improved genotyping enabled more definitive phenotype classification. For instance, in a clinical sample previously tested with microarrays, TAS-LRS resolved a copy number event in CYP2D6 that had previously been unphased, enabling unambiguous assignment of metabolizer status.
While most of our validation focused on benchmarking against established truth sets and clinical workflows, we also compared TAS-LRS to orthogonal testing platforms where matched data were available. Current PGx genotyping technologies largely rely on microarrays or short-read sequencing, and therefore we included both in our evaluation. We observed that TAS-LRS achieved high concordance rates (> 95%) and outperformed other platforms in 13 of the 20 genes assessed. As expected, microarrays showed the greatest limitations in resolving PGx diplotypes, consistent with prior reports20. It is important to note that we used the Illumina Global Screening Array v3 (GSAv3) chip, which is not specifically optimized for pharmacogenomic applications, and that newer arrays and PGx-focused designs may offer better performance. Nonetheless, microarrays inherently depend on prior knowledge of which variants to interrogate and are limited in their ability to discover novel alleles. Conversely, short-read sequencing performed better than microarrays but showed substantial variability across analysis pipelines. Among the evaluated algorithms, DRAGEN achieved the highest concordance, albeit with lower callability, a trade-off that could potentially be improved through further algorithmic refinement. Other notable short-read genotyping tools, such as Aldy 442 and Cyrius43, were not included in this evaluation but warrant future benchmarking. Overall, short-read algorithms use read-level evidence constrained by known allele definitions to enhance accuracy, but phasing remains limited, as it often depends on computational reconstruction guided by known haplotype structures, an approach that is less accurate when novel or rare variant combinations are present. In contrast, long-read sequencing improves direct phasing of complex diplotypes and detection of novel allele configurations at the individual level. For example, we resolved previously uncharacterized phasing patterns in NAT2, CYP2B6 and DPYD that were not captured by short-read approaches. Collectively, our findings align with those reported by Barthélémy et al. (2023)24, who conducted a comparison of PacBio HiFi and Illumina short-read sequencing across a panel of pharmacogenes, and demonstrated that long-read sequencing not only improved haplotype resolution but also enabled accurate detection of structural variants, such as complex CYP2D6 rearrangements and UGT1A1 promoter repeats, that were miscalled or missed entirely by short-read methods. Recent developments in pangenome references and graph-based genotyping may further improve SV detection in such challenging regions. In particular, the draft human pangenome has been shown to improve SV calling at clinically relevant loci such as CYP2D6 using long-reads44. Furthermore, it is worth noting that our study was based on a relatively well-characterized sample set, with only three clinical specimens included. The frequency of novel or population-specific alleles is likely to be higher in routine clinical cohorts. For instance, in a previous study of approximately 1,800 Singaporean individuals of Chinese, Malay, and Indian ancestry, we found that ~ 1% carried potentially novel CYP2D6 haplotypes based on short-read whole-genome sequencing36. As long-read sequencing is applied to more diverse populations, we anticipate the discovery of additional novel variants that may have clinical relevance in pharmacogenomic decision-making.
In addition to enabling high-resolution PGx genotyping, TAS-LRS generates off-target reads that can be leveraged for genome-wide imputation. Imputation from low-pass sequencing is well established in the context of short-read data, and here we apply similar approaches to off-target signal from long-read sequencing31. Our results show that imputation accuracy from TAS-LRS off-target reads is comparable to that of short-read low-pass sequencing and exceeds that of microarrays, particularly for rare variants with a minor allele frequency (MAF) below 1%. This expands the utility of the assay beyond targeted PGx testing, enabling additional applications such as Polygenic Risk Score (PRS) development. Supporting this potential, Nakamura et al. (2024)32 demonstrated that PRSs derived from off-target long-read data in 33 hereditary cancer patients achieved accuracy comparable to those calculated from short-read sequencing. Altogether, these findings highlight the added value of adaptive sampling over conventional targeted sequencing methods, which typically rely on fixed panels enriched through PCR amplification or hybridization-based capture workflows that require custom library preparation. In contrast, adaptive sampling allows flexible updates to target content via simple BED file modifications, avoiding the need to redesign or reorder panels. This reduces wet-lab complexity, hands-on time, and consumable costs, and positions TAS-LRS as a versatile platform adaptable to a range of clinical contexts, including primary care, oncology, cardiovascular disease, and psychiatry.
In conclusion, our work demonstrates a robust clinical implementation of PGx testing using adaptive-sampling-based long-read sequencing. TAS-LRS combines accurate detection of small and structural variants, phasing without the need for parental data, and the ability to identify novel alleles, which are critical capabilities for PGx implementation given the complexity of pharmacogenes and the importance of haplotype resolution in predicting drug response. Beyond analytical performance, the simplicity and flexibility of the TAS-LRS protocol make it well suited for mainstream clinical adoption. Unlike fixed-panel assays, TAS-LRS allows rapid reconfiguration of target content without extensive redesign of experimental protocols, while simultaneously generating genome-wide data suitable for imputation. From DNA extraction to final report generation, the TAS-LRS workflow can typically be completed within 3 to 4 days, with faster turnaround possible for smaller batches or with higher parallelization. This positions TAS-LRS as a flexible platform that bridges targeted testing and broader genomic analysis, making it particularly compelling for national screening programs where both clinical relevance and research utility are priorities. In this context, and looking ahead, a unified assay integrating pharmacogenomics, polygenic risk, and monogenic variant analysis with potential for regulatory annotation through methylation profiling could enable comprehensive risk stratification from a single sample. A 2021 study of 450,000 patients estimated that one in seven pathogenic variants are technically challenging using current short read-based technologies45. These include complex rearrangements, small CNVs and genes with pseudogenes45 which may benefit from the use of long-read data. It is estimated that there are more than 1000 genes present in genomic loci that are inaccessible due to high sequence complexity or repetitiveness46, including genes that are clinically relevant. To address these limitations, targeted long-read panels have been developed for challenging genes such as SMN1/2, associated with spinal muscular atrophy, GBA, associated with Gaucher and Parkinson’s disease, and PMS2, associated with Lynch Syndrome47. In practice, the improved diagnostic yield of long-read sequencing has also been demonstrated in a recent study on a rare disease cohort of 41 families where long-reads were able to identify diagnostic variants in 11 individuals, enabling the diagnoses of 3 individuals who were undiagnosed by short-read sequencing48. In addition to enhanced phasing and alignment, this study also leveraged methylation profiles derived from the same long-read data for improved diagnostic performance. While long-read sequencing has historically been limited by cost, adaptive sampling enables multiplexing to reduce per-sample expenses. In this study, we demonstrated three-sample multiplexing, with four-sample runs already feasible and robust using current protocols. With further scaling and improved throughput, the cost of TAS-LRS could approach that of short-read whole-genome sequencing and may undercut combined short-read PGx panel and array workflows, especially as efforts to support five or more samples per run continue. Ultimately, the choice between long-read and short-read technologies will depend on context, scale, and clinical need; however, our findings demonstrate that long-read sequencing has matured beyond a research tool and now represents a viable option for clinical pharmacogenomics at scale.
Materials and methods
End-to-end workflow for pre-emptive PGx testing
Our pre-emptive PGx workflow follows four main steps: (i) pre-test consultation (optional), (ii) sample preparation and sequencing, (iii) bioinformatics analysis and reporting, and (iv) post-test consultation (Fig. 1). As this study focuses on generating evidence for implementation in a clinical laboratory, steps 1 and 4 were not performed but details are included below for completeness.
Pre-test consultation (optional)
The patient eligibility assessment is a critical step in the TAS-LRS workflow to ensure appropriate test use. Eligibility criteria comprise excluding patients with conditions that may interfere with DNA integrity, such as recent blood transfusions or stem cell transplants, as well as those with impaired liver function, including patients with autoimmune hepatitis or a history of liver transplantation. For eligible patients, pre-test consultation is optional and offered based on institutional policy or clinician discretion. When provided, it includes counselling on the scope of PGx testing, potential actionable findings, and implications for medication management. Informed consent is obtained prior to sample collection.
Sample Preparation and sequencing
Sample preparation and sequencing follow the standard ONT laboratory workflow, optimized for multiplexing, as summarized in Supplementary Fig. 8. The detailed protocol is described below.
Whole blood extraction
Whole blood samples were collected in K2EDTA tubes (VACUETTE) with a minimum volume of 3 mL. DNA was extracted from 300 µL of whole blood using the Monarch Genomic DNA Purification Kit (New England Biolabs), following the manufacturer’s protocol for non-nucleated mammalian whole blood with several modifications to accommodate the increased requirements for input volume for long-read sequencing (Supplementary Fig. 9): (i) the lysis mastermix was scaled up threefold, and the lysis incubation time was extended to 25 min; (ii) after lysis, samples were split into two parts, with 1.5x the volume of binding buffer added per part; (iii) following binding, DNA from both fractions was concentrated into a single spin column and processed through the standard washing steps; and (iv) a double elution with preheated elution buffer was performed to maximize recovery. DNA yield and purity were assessed using the Nanodrop 2000, with a mean yield of 46.53 ng/µL across all samples.
To meet the yield requirement for TAS-LRS 3-plex (> 100 ng/µL), the extracted genomic DNA (gDNA) was further concentrated using Solid-Phase Reversible Immobilization (SPRI) beads from MGI Tech Co., Ltd. (Supplementary Fig. 10). Note that a lower DNA input is feasible at alternative plexities, and this is currently under investigation. A 2x volume of SPRI beads was added, and DNA was eluted in 30 µL of elution buffer. Final DNA quantification was performed using the 1x double-stranded DNA (dsDNA) High Sensitivity Qubit Assay (Thermo Fisher Scientific), yielding a mean concentration of 108.3 ng/µL per sample.
Genomic DNA shearing
Genomic DNA from cell lines and extracted blood samples was mechanically sheared to an average fragment length of 23 kb. DNA concentration was measured using the 1x dsDNA High Sensitivity Qubit Assay (Thermo Fisher Scientific), while fragment size distribution was assessed with the Agilent Genomic DNA kit on the Tapestation (Agilent).
Library preparation and sequencing
Genomic DNA samples underwent library preparation following the ONT Ligation Sequencing gDNA - Native Barcoding Kit 24 V14 protocol. The process included end-repair, native barcoding, and adapter ligation. Samples were pooled in sets of three, with 800 ng or 1000 ng of input per sample. The final libraries yielded a mean of 56.69 fmol (> 35 fmol) per pool.
Sequencing was performed on the PromethION Flow Cell R10 (M version) using the P2 Solo Sequencer (MinION release 24.02.16). The library was divided into three portions and loaded in a tapered manner across three time points. At the first time point, the initial portion of the library was loaded, and sequencing began in whole-genome mode (without adaptive sampling), to monitor QC (N50 within the expected range). After one hour, adaptive sampling was activated. A custom BED file was used to define the target regions (N = 326). Each region was extended by 20 kb upstream and downstream, and overlapping regions were merged into non-redundant intervals using bedtools49, covering a total of 1.3% of the human genome. At the second time point (20–24 h after sequencing began, or when fewer than 2000 pores remained active), the flow cell was washed following ONT’s Flow Cell Wash Kit protocol, and the second portion of the library was loaded. At the third time point (40–48 h), the second portion of the library was retrieved, and merged with the third portion. The flow cell was washed and reloaded with the mixed library. This loading strategy achieved a mean on-target sequencing depth of 25.2x per sample and an average enrichment ratio of 8.5x. The mean on-target N50 post-sequencing was 7,889 bp (Supplementary Table 3).
Quality control
Details of the QC metrics applied throughout the workflow are provided in Supplementary Table 10.
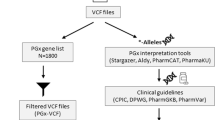
Bioinformatics analysis and reporting
Bioinformatics analysis and variant interpretation utilize a combination of third-party and in-house tools for basecalling, read mapping, variant calling, and pharmacogenomic annotation (Supplementary Fig. 11). Additionally, the workflow includes genome-wide imputation from off-target signals. Detailed descriptions of each step are provided below.
Basecalling and read mapping
POD5 files were basecalled using Dorado v0.8.1 in either high-accuracy (HAC) or super-accuracy (SUP) mode with the corresponding models (dna_r10.4.1_e8.2_400bps_HAC@v5.0.0 or SUP@v5.0.0). Reads from the initial 1-hour WholeGenome Sequencing (WGS) and subsequent adaptive sampling were filtered for Q-scores > 10. Passing reads were demultiplexed using Dorado’s demux function, then combined per sample and mapped to the GRCh38 reference genome using Minimap2 v2.22.
Summary statistics were generated from unmapped BAM files using Dorado’s summary function and processed with custom scripts. Summary metrics for the 1-hour WGS and adaptive sampling stages are presented in Supplementary Tables 3a and 3b, respectively. N50 values were estimated using Cramino v0.14.550 after subsetting reads into on-target and off-target regions. Median coverage depths for these regions were calculated using mosdepth v0.3.651.
Genotyping of target pharmacogenes
Small variants
Small variants (SNPs and indels) were called using Clair3 v1.0.5 with either the r1041_e82_400bps_hac_v500 or r1041_e82_400bps_sup_v500 model, as appropriate, and subsequently phased using WhatsHap v2.22. For depth of coverage analysis, SUP base-called HG005 CRAM files were merged and then randomly downsampled using samtools v 1.15.1 with the --subsample command to generate CRAM files at target coverages. Three replicates per target coverage were generated prior to Clair3 v1.0.5 variant calling.
Structural variants
For all pharmacogenes except CYP2D6, gene-level copy number was estimated by normalizing the mean on-target depth across each region of interest to the overall mean across all on-target regions. Coverage was calculated using mosdepth v0.3.6 with the --no-per-base option and 100 bp non-overlapping windows.
For hybrid genes (e.g., CYP2D6/CYP2D7, CYP2A6/CYP2A7), hybrid detection was performed by classifying reads based on distinguishing variants catalogued in PharmVar v6.2.2 or reported by Chen et al. (2021). In brief, for each read, the number of variants supporting a conversion were counted in exons and introns with gene-distinguishing variants. If at least half the variants supporting a specific gene of origin were present, the corresponding intron/exon was assigned according to the corresponding origin (e.g. from CYP2D6 or CYP2D7). For each read, the region (exon/intron number) and type of transition (e.g. CYP2D6 to CYP2D7 or reverse) was identified. If at least 3 reads supporting the same switch were identified, potential haplotypes were assigned based on existing PharmVar classifications (Supplementary Fig. 12).
Due to the complex structural variability of CYP2D6, including common duplications, deletions, and gene conversions with CYP2D7, its structural analysis is described in detail in a dedicated section.
Star-alleles
Based on the Variant Call Format (VCF) calls, star alleles for CYP2B6, CYP2C19, CYP2C9, CYP3A4, CYP3A5, CYP4F2, DPYD, G6PD, NUDT15, SLCO1B1, TPMT and UGT1A1 were assigned using PharmCAT52 version 2.2.3 with CPIC allele definitions v1.22.2 and star alleles for NAT2, CYP2C8 and ABCB1 were assigned using PyPGx version 0.25.053. Definitions for NAT2 were updated according to PharmVar (accessed: 2024-09-10).
HLA typing
HLA calls were made using HLA-LA54 version 1.0.3 applying a threshold cutoff of 0.95.
CYP2D6 calling
An in-house developed caller was used to resolve diplotype calls in CYP2D6. As shown in Supplementary Fig. 12, for CYP2D6, reads mapping to positions 42,001,498 to 42,255,865 on GRCh38 chromosome 22 were extracted. As a first step, reads corresponding to potential hybrid alleles, if detected, were removed. The remaining non-hybrid alignments were used as input for Clair3 (v1.0.9), with a reference VCF containing CYP2D6 variants of interest, and for NanoCaller (v3.6.0). Variant calls from Clair3 and NanoCaller were then merged before phasing using WhatsHap (v2.2). The resulting phased VCF was processed with PharmCAT (v2.2.3) using the “--research-mode cyp2d6,combination” flag, which enables the calling of both full and partial CYP2D6 diplotypes. Partial diplotypes were only considered in cases where hybrid genes or structural variants were detected, as these are known to reduce variant calling accuracy in the region. When multiple diplotype candidates shared the same PharmCAT match score, the diplotype with the numerically lower star allele designation was reported, along with a warning indicating that multiple interpretations were possible.
Following initial star allele assignment, gene copy number was refined. Duplications were flagged if reads supporting duplication of the CYP2D6-like downstream region (REP6) were detected. In cases where a duplication or more than two star alleles, including hybrids, were identified, diplotypes were resolved by identifying the WhatsHap-assigned haplogroup most frequently associated with structural features (e.g. REP6 or REP7) and then identifying the star allele most frequently assigned to the same haplogroup to link the structural feature to the appropriate star allele. If direct evidence was insufficient, the haplotype background associated with REP6 or REP7 was inferred to determine likely combinations of hybrid and non-hybrid star alleles or duplications. For duplications involving non-identical star alleles, B-allele frequencies of heterozygous SNPs that differentiate between the alleles were used to estimate copy number. In brief, based on the potential star alleles, allele frequencies of key distinguishing SNPs were fetched and star alleles associated with the higher allele frequencies were assumed to be duplicated and copy numbers assigned accordingly. For duplications involving identical star alleles, copy number was estimated from normalized read depth. Deletions were called if at least one read spanning a known deletion breakpoint in the CYP2D6 region was detected, or if the region spanning positions 42,125,000 to 42,135,000 showed a normalized copy number below 1.5.
As described in the “Structural variants” section, regions of reads mapping to CYP2D6 were classified as originating from CYP2D6 or CYP2D7 based on distinguishing variants. Reads showing a switch between the two homologs were classified as hybrids, and assigned star alleles based on switch position, per PharmVar definitions.
Warnings were issued in the following cases: (1) multiple potential diplotypes detected, (2) a partial genotype was reported, (3) copy number estimates from read depth were not supported by structural variant signature reads, or (4) unexpected genotype combinations were observed, suggesting reduced call quality.
Imputation
Genome-wide genotype imputation was performed in HG005 samples using GLIMPSE2 v2.0.031 and a reference panel comprising 2504 high-coverage samples from the 1000 Genomes Project. Whole-genome CRAM files from earlier processing steps were utilized as input.
Post-test consultation
The final report includes diplotype calls interpreted into metabolizer phenotypes based on PharmGKB guidelines55, along with actionable recommendations from consortia such as CPIC56 and DPWG57. Results are compiled into a structured PDF for physician review, forming the basis for post-test consultation, where findings are communicated to the patient and integrated into their treatment plan (example report: Supplementary File 1).
Validation samples
Genome in a Bottle (GIAB) gDNA samples were obtained from the National Institute of Standards and Technology (NIST). Additional cell line gDNA samples from the GeT-RM program were sourced from the Coriell Institute for Medical Research.
CAP (College of American Pathologists) samples were obtained from previous CAP PGx surveys. These samples were previously analysed in house and submitted to CAP for verification of results, and the verified results were used as a truth set benchmark.
Whole blood samples were obtained from the Molecular Diagnostic Laboratory at Tan Tock Seng Hospital (TTSH), Singapore. Genotype results were based on specific variants detected using microarray technology (Axiom).
For the interference study, a subset of whole blood samples was spiked with > 4.5 mg/dL of triglycerides (Merck) to simulate conditions of hyperlipidaemia or elevated blood triglyceride levels, in accordance with the Ministry of Health’s 2016 Hyperlipidaemia Guidelines.
Performance evaluation
Reference data sources used to evaluate calling performance at the variant, diplotype and phenotype levels are described below and summarized in Supplementary Table 11.
LOD study - variant calling performance for SNPs and indels
For small variants (SNPs and indels), hard-filtered Genomic Variant Call Format (gVCF) calls generated by DRAGEN v4.2.7 (available at https://registry.opendata.aws/ilmn-dragen-1kgp) were processed using the GenotypeGVCFs module from GATK v4.5.0.058 to extract variants of interest. These were then compared to Clair3 variant calls using custom in-house scripts.
Performance metrics used in our analysis are defined as follows:
-
Callability: The proportion of loci with successfully obtained genotype calls relative to the total number of loci evaluated.
-
Genotype concordance: The proportion of loci with accurate genotype calls among those that were successfully genotyped.
-
Analytical sensitivity: The proportion of variant sites that were correctly detected.
-
Analytical specificity: The proportion of non-variant sites that were correctly identified.
-
Precision: The proportion of correctly genotyped variants relative to the total number of variants reported.
False negative and false positive calls were manually reviewed. All metrics were calculated on a per-sample basis, and confidence intervals around the mean values were estimated using Student’s t-test.
LOD study - Variant calling performance for SVs
Expected SVs were determined using GeT-RM diplotype calls for CYP2D6 and StellarPGx diplotype calls for CYP2A6. In cases where discrepancies between reference and observed calls were noted, results were manually reviewed to confirm the SV status.
Calls for deletions, duplications, and hybrid alleles were classified as:
-
True positives if the expected SV was correctly identified by the pipeline for a given sample,
-
False negatives if no SV was called when one was expected, and.
-
False positives if an SV was called when none was expected.
For CYP2A6, *46 alleles (3’ UTR conversions) were considered hybrid alleles and evaluated accordingly. Additionally, a *47 allele (a CYP2A7:CYP2A6 hybrid consisting of exons 1–8 from CYP2A7) that was classified by the pipeline as *4 (gene deletion) was still considered concordant with the expected SV.
Performance metrics were calculated using calls from both genes across all samples and sequencing runs. Confidence intervals were estimated according to the method described by Newcombe and Altman59.
Accuracy study - Diplotype concordance in pharmacogenes with complex allele definitions
For HG001, HG01190, NA18861, NA18966, NA19174 and NA19226, GeT-RM calls for CYP2A6, CYP2B6, CYP2C19, CYP2C8, CYP2C9, CYP2D6, CYP3A4, CYP4F2, DPYD, NAT2, SLCO1B1 and TPMT from the consolidated GeT-RM table dated 20,240,418 60,61 were used as a truth set. For HG00337, HG005, HG01097, HG01572 and HG03259 diplotype calls were compared against PyPGx diplotypes based on dragen v4.2.7 generated CRAM files. For NAT2, diplotype definitions were compared taking into account the differences between previous and current allele definitions.
For all samples, ABCB1, G6PD, NUDT15 and UGT1A1 calls were compared against PyPGx calls and HLA-A and HLA-B calls were compared against calls from optitype v1.3.562 based on dragen v4.2.7-generated Compressed Reference-Aligned Mapping (CRAM) files.
Calls were classified as concordant if matching to the truth set. When not matching, calls were considered improved if the TAS-LRS-based call agreed with evidence from manual checks based on IGV plots or based on consensus calls from other programs (see Accuracy study - Diplotype calling performance across multiple testing platforms below).
Accuracy study - phenotype concordance in pharmacogenes with complex allele definitions
Phenotypes were classified as “Concordant to reference” if TAS-LRS-based calls matched the expected phenotype based on the truth sets described above. To account for differences due to an improvement in diplotype calls, calls were classified as “Concordant with updated call” if the reported phenotype matched the expected phenotype based on improved diplotype calls and calls were classified as “indeterminate due to insufficient information” if a phenotype could not be assigned due to a no call for the diplotype or if a call could not be assigned due to the lack of sufficient information on Copy Number Variation (CNV) to distinguish from samples with indeterminate calls due to the underlying diplotype not having a known phenotype.
Accuracy study - diplotype calling performance across multiple testing platforms
Orthogonal short-read data
Star allele and HLA calls from DRAGEN v4.2.7 were obtained from the Illumina DRAGEN 1000 Genomes Project dataset (https://registry.opendata.aws/ilmn-dragen-1kgp; accessed 16 February 2025), except for sample HG005, for which calls were derived using DRAGEN v4.0.3. For PyPGx and StellarPGx comparisons, diplotype calls were generated by processing the corresponding CRAM files from the same dataset using PyPGx (v0.25.0)53 and StellarPGx (v1.2.7)63 .
Orthogonal microarray data
For microarray calls, star alleles and genotypes were called from the Illumina Global Screening Array v3, as previously described20.
Calls were considered matching if they were concordant with results from manual inspection of long-read IGV plots or consistent with consensus calls across multiple tools. The percentage of matching calls was calculated as the total number of concordant calls divided by the total number of calls. Callability was defined as the proportion of successfully generated calls relative to the total number of samples evaluated. Both metrics were aggregated across all samples and sequencing runs, and confidence intervals were calculated using the method described by Newcombe and Altman59.
Precision study - Reproducibility and repeatability
Assay precision was assessed by evaluating both reproducibility and repeatability of the performance metrics described in "LOD study - Variant calling performance for SNPs and indels". Reproducibility was determined by analyzing inter- and intra-run variability across HG001 and HG005 samples sequenced in three independent runs. Repeatability was assessed by reanalyzing the same runs starting from the basecalling step. Variability was quantified by calculating the coefficient of variation (CV) for each performance metric.
Imputation accuracy
To compare imputation accuracy, FASTQ files from five replicates of HG005—generated on the MGI DNBSeq T7 platform —were aligned to the GRCh38 reference genome using DRAGEN-GATK v1.3.0 and subsequently downsampled to 2× coverage to match the average off-target depth of HG005 TAS-LRS samples (N = 4). Imputation was performed using GLIMPSE v2.0.0 as described above.
For microarray data, variant calls from five replicates of HG005—generated using the Infinium Global Screening Array v3 (Illumina)—were phased with Eagle v2.4.1 and imputed using Minimac4 v1.0.3 with the 1000 Genomes Project reference panel.
Imputation concordance (R2) was assessed using the GLIMPSE2_concordance script from the GLIMPSE v2.0.0 package, with the following parameters: “--gt-val --min-tar-gp 0.8 --ac-bins 1 5 10 20 50 100 200 500 1000 2000 3202”. Genome-wide NIST reference calls were used as the truth set for benchmarking.
Data availability
The data supporting the findings of this study are available within the article and its supplementary materials. The underlying sequencing datasets to the European Genome-Phenome Archive (EGA) under study accession number EGAS50000001116. The contact person for data access is the corresponding author, and data access requests will be handled through the EGA portal.
Abbreviations
- PGx:
-
pharmacogenomics
- ADRs:
-
adverse drug reactions
- CPIC:
-
Clinical pharmacogenetics implementation consortium
- DPWG:
-
Dutch pharmacogenetics working group
- PCR:
-
Polymerase chain reaction
- TAS-LRS:
-
Targeted adaptive sampling–long read sequencing
- ONT:
-
Oxford nanopore technologies
- LOD:
-
Limit of detection
- QC:
-
Quality control
- VIP:
-
Very important pharmacogene
- PharmGKB:
-
Pharmacogenomics knowledgebase
- FDA:
-
Food and drug administration
- CAP:
-
College of american pathologists
- CLSI:
-
Clinical and laboratory standards institute
- CLIA:
-
Clinical laboratory improvement amendments
- IVDR:
-
In Vitro diagnostic regulation
- EQA:
-
External quality assessment
- SV:
-
structural variant
- SNV:
-
single nucleotide variant
- CNV:
-
copy number variant
- WGS:
-
whole-genome sequencing
- HAC/SUP:
-
high-accuracy / super-accuracy
- SNPs:
-
single nucleotide polymorphisms
- NIST:
-
National institute of standards and technology
- 1KGP:
-
1000 genomes project
- GeT-RM:
-
Genetic testing reference materials
- IGV:
-
Integrative genomics viewer
- DRAGEN:
-
Dynamic read analysis for genetics
- GIAB:
-
Genome in a bottle
- MAF:
-
minor allele frequency
- GSAv3:
-
Global screening array v3
- PRS:
-
Polygenic risk score
- BED:
-
Browser extensible data
- gDNA:
-
genomic DNA
- SPRI:
-
Solid-phase reversible immobilization, dsDNA, double-stranded DNA
- VCF:
-
Variant call format
- gVCF:
-
genomic VCF
- CRAM:
-
Compressed reference-aligned mapping
- CV(%):
-
coefficient of variation
References
Pirmohamed, M. Pharmacogenomics: current status and future perspectives. Nat. Rev. Genet. 24, 350–362 (2023).
Caspar, S. M., Schneider, T., Meienberg, J. & Matyas, G. Added value of clinical sequencing: WGS-Based profiling of pharmacogenes. Int. J. Mol. Sci. 21, 2308 (2020).
Chan, S. L. et al. Prevalence and characteristics of adverse drug reactions at admission to hospital: a prospective observational study. Br. J. Clin. Pharmacol. 82, 1636–1646 (2016).
Nguyen, D. V., Vidal, C., Chu, H. C. & van Nunen, S. Human leukocyte antigen-associated severe cutaneous adverse drug reactions: from bedside to bench and beyond. Asia Pac. Allergy. 9, e20 (2019).
Clopidogrel Therapy & CYP2C19 Genotype - Medical Genetics Summaries. and - NCBI Bookshelf. https://www.ncbi.nlm.nih.gov/books/NBK84114/
Codeine Therapy & CYP2D6 Genotype - Medical Genetics Summaries. and - NCBI Bookshelf. https://www.ncbi.nlm.nih.gov/books/NBK100662/
Dunnenberger, H. M. et al. Preemptive clinical pharmacogenetics implementation: current programs in five united States medical centers. Annu. Rev. Pharmacol. Toxicol. 55, 1–18 (2015).
Chanfreau-Coffinier, C. et al. Projected prevalence of actionable Pharmacogenetic variants and level A drugs prescribed among US veterans health administration pharmacy users. JAMA Netw. Open. 2, e195345 (2019).
Hockings, J. K. et al. Pharmacogenomics: an evolving clinical tool for precision medicine. Clevel. Clin. J. Med. 87, 91–99 (2020).
Ji, Y. et al. Preemptive Pharmacogenomic testing for precision medicine A comprehensive analysis of five actionable Pharmacogenomic genes using Next-Generation DNA sequencing and a customized CYP2D6 genotyping cascade. J. Mol. Diagn. 18, 438–445 (2016).
Bank, P. et al. Comparison of the guidelines of the clinical pharmacogenetics implementation consortium and the Dutch pharmacogenetics working group. Clin. Pharmacol. Ther. 103, 599–618 (2018).
Abdullah-Koolmees, H., van Keulen, A. M., Nijenhuis, M. & Deneer, V. H. M. Pharmacogenetics guidelines: overview and comparison of the DPWG, CPIC, CPNDS, and RNPGx guidelines. Front. Pharmacol. 11, 595219 (2021).
Elliott, L. S. et al. Clinical impact of Pharmacogenetic profiling with a clinical decision support tool in polypharmacy home health patients: A prospective pilot randomized controlled trial. PLoS ONE. 12, e0170905 (2017).
Swen, J. J. et al. A 12-gene Pharmacogenetic panel to prevent adverse drug reactions: an open-label, multicentre, controlled, cluster-randomised crossover implementation study. Lancet 401, 347–356 (2023).
Tredici, A. L. D. et al. Real-World impact of Pharmacogenomic testing on medication use and healthcare resource utilization in patients with major depressive disorder. J. Clin. Psychopharmacol. https://doi.org/10.1097/jcp.0000000000001999 (2025).
Wang, L. et al. Implementation of preemptive DNA sequence–based pharmacogenomics testing across a large academic medical center: the Mayo-Baylor RIGHT 10K study. Genet. Med. 24, 1062–1072 (2022).
van der Lee, M., Kriek, M., Guchelaar, H. J. & Swen J. J. Technol. Pharmacogenomics: Rev. Genes 11, 1456 (2020).
Marx, V. Method of the year: long-read sequencing. Nat. Methods. 20, 6–11 (2023).
Consortium, H. G. S. V. et al. Fully phased human genome assembly without parental data using single-cell strand sequencing and long reads. Nat. Biotechnol. 39, 302–308 (2021).
Gan, P. et al. Development and validation of a pharmacogenomics reporting workflow based on the illumina global screening array chip. Front. Pharmacol. 15, 1349203 (2024).
Yang, Y., Botton, M. R., Scott, E. R. & Scott, S. A. Sequencing the CYP2D6 gene: from variant allele discovery to clinical Pharmacogenetic testing. Pharmacogenomics 18, 673–685 (2017).
Twesigomwe, D. et al. A systematic comparison of pharmacogene star allele calling bioinformatics algorithms: a focus on CYP2D6 genotyping. Npj Genom Med. 5, 30 (2020).
Turner, A. J. et al. Characterization of complex structural variation in the CYP2D6-CYP2D7-CYP2D8 gene loci using single-molecule long-read sequencing. Front. Pharmacol. 14, 1195778 (2023).
Barthélémy, D. et al. Direct comparative analysis of a pharmacogenomics panel with PacBio Hifi® Long-Read and illumina Short-Read sequencing. J. Pers. Med. 13, 1655 (2023).
Adaptive sampling with Oxford Nanopore. https://nanoporetech.com/resource-centre/adaptive-sampling-oxford-nanopore
Deserranno, K., Tilleman, L., Rubben, K., Deforce, D. & Nieuwerburgh, F. V. Targeted haplotyping in pharmacogenomics using Oxford nanopore technologies’ adaptive sampling. Front. Pharmacol. 14, 1286764 (2023).
Nakamura, W. et al. A comprehensive workflow for target adaptive sampling long-read sequencing applied to hereditary cancer patient genomes. MedRxiv 2023.05.30.23289318 https://doi.org/10.1101/2023.05.30.23289318 (2023).
Huebner, T., Steffens, M. & Scholl, C. Current status of the analytical validation of next generation sequencing applications for Pharmacogenetic profiling. Mol. Biol. Rep. 50, 9587–9599 (2023).
Gaedigk, A., Casey, S. T., Whirl-Carrillo, M., Miller, N. A. & Klein, T. E. Pharmacogene variation consortium: A global resource and repository for pharmacogene variation. Clin. Pharmacol. Ther. 110, 542–545 (2021).
Zhang, F. et al. Ancestry-agnostic Estimation of DNA sample contamination from sequence reads. Genome Res. https://doi.org/10.1101/gr.246934.118 (2020).
Rubinacci, S., Ribeiro, D. M., Hofmeister, R. J. & Delaneau, O. Efficient phasing and imputation of low-coverage sequencing data using large reference panels. Nat. Genet. 53, 120–126 (2021).
Nakamura, W. et al. Assessing the efficacy of target adaptive sampling long-read sequencing through hereditary cancer patient genomes. Npj Genom Med. 9, 11 (2024).
Caspar, S. M., Schneider, T., Stoll, P., Meienberg, J. & Matyas, G. Potential of whole-genome sequencing-based Pharmacogenetic profiling. Pharmacogenomics 22, 177–190 (2021).
Chan, W. et al. CYP2D6 allele frequencies, copy number variants, and tandems in the population of Hong Kong. J. Clin. Lab. Anal. 33, e22634 (2019).
Dorji, P. W., Tshering, G. & Na-Bangchang, K. CYP2C9, CYP2C19, CYP2D6 and CYP3A5 polymorphisms in South‐East and East Asian populations: A systematic review. J. Clin. Pharm. Ther. 44, 508–524 (2019).
Maulana, Y. et al. The variation landscape of CYP2D6 in a multi-ethnic Asian population. Sci. Rep. 14, 16725 (2024).
Liau, Y. et al. A multiplex pharmacogenetics assay using the minion nanopore sequencing device. Pharmacogenet Genom. 29, 207–215 (2019).
Liau, Y. et al. Nanopore sequencing of the pharmacogene CYP2D6 allows simultaneous haplotyping and detection of duplications. Pharmacogenomics 20, 1033–1047 (2019).
Charnaud, S. et al. PacBio long-read amplicon sequencing enables scalable high-resolution population allele typing of the complex CYP2D6 locus. Commun. Biol. 5, 168 (2022).
Graansma, L. J. et al. From gene to dose: Long-read sequencing and *-allele tools to refine phenotype predictions of CYP2C19. Front. Pharmacol. 14, 1076574 (2023).
Lee, M. et al. Application of long-read sequencing to elucidate complex Pharmacogenomic regions: a proof of principle. Pharmacogenomics J. 22, 75–81 (2022).
Hari, A. et al. An efficient genotyper and star-allele caller for pharmacogenomics. Genome Res. 33, 61–70 (2023).
Halman, A., Conyers, R. & BCyrius An upgraded version of Cyrius for accurate CYP2D6 genotyping from Short-Read sequencing data. Pharmacol. Res. Perspect. 13, e70065 (2025).
Liao, W. W. et al. A draft human pangenome reference. Nature 617, 312–324 (2023).
Lincoln, S. E. et al. One in seven pathogenic variants can be challenging to detect by NGS: an analysis of 450,000 patients with implications for clinical sensitivity and genetic test implementation. Genet. Sci. 23, 1673–1680 (2021).
Wagner, J. et al. Benchmarking challenging small variants with linked and long reads. Cell Genom 2, (2022).
Mahmoud, M. et al. Closing the gap: solving complex medically relevant genes at scale. MedRxiv 2024.03.14.24304179 https://doi.org/10.1101/2024.03.14.24304179 (2024).
Negi, S. et al. Advancing long-read nanopore genome assembly and accurate variant calling for rare disease detection. Am. J. Hum. Genet. 112, 428–449 (2025).
Quinlan, A. R. & BEDTools The Swiss-Army Tool for Genome Feature Analysis. Curr. Protoc. Bioinform. 47, 11.12.1-11.12.34 (2014).
Coster, W. D. & Rademakers, R. NanoPack2: population-scale evaluation of long-read sequencing data. Bioinformatics 39, btad311 (2023).
Pedersen, B. S. & Quinlan, A. R. Mosdepth: quick coverage calculation for genomes and exomes. Bioinformatics 34, 867–868 (2017).
Sangkuhl, K. et al. Pharmacogenomics clinical annotation tool (PharmCAT). Clin. Pharmacol. Ther. 107, 203–210 (2020).
Lee, S., Shin, J. Y., Kwon, N. J., Kim, C. & Seo, J. S. ClinPharmSeq: A targeted sequencing panel for clinical pharmacogenetics implementation. PLoS ONE. 17, e0272129 (2022).
Dilthey, A. T. et al. HLA*LA—HLA typing from linearly projected graph alignments. Bioinformatics 35, 4394–4396 (2019).
PharmGKB - Clinical Guideline Annotations. https://www.pharmgkb.org/guidelineAnnotations
Guidelines, C. P. I. C. https://cpicpgx.org/guidelines/
DPWG. Dutch Pharmacogenetics Working Group. https://www.pharmgkb.org/page/dpwg
van der Auwera, G. & O’Connor, B. D. Genomics in the Cloud: Using Docker, GATK, and WDL in Terra. (O’Reilly Media, Incorporated).
Altman, D. G., Machin, D., Bryant, T. N. & Gardner, M. J. Proportions and their Differences, in Statistics with Confidence: Confidence Intervals and Statistical Guidelines. (BMJ Books).
Pratt, V. M. et al. Characterization of 137 genomic DNA reference materials for 28 Pharmacogenetic genes A GeT-RM collaborative project. J. Mol. Diagnostics. 18, 109–123 (2016).
Gaedigk, A. et al. CYP2C8, CYP2C9, and CYP2C19 characterization using Next-Generation sequencing and haplotype analysis A GeT-RM collaborative project. J. Mol. Diagn. 24, 337–350 (2022).
Szolek, A. et al. OptiType: precision HLA typing from next-generation sequencing data. Bioinformatics 30, 3310–3316 (2014).
Twesigomwe, D. et al. StellarPGx: A nextflow pipeline for calling star alleles in cytochrome P450 genes. Clin. Pharmacol. Ther. https://doi.org/10.1002/cpt.2173 (2021).
Acknowledgements
We thank the clinical operations team at NalaGenetics, including Dr. Latifah Anandari and Kavimozhi Kandasamy, for their support throughout the study. We are also grateful to the laboratory team at Tan Tock Seng Hospital (TTSH), including Sim Wey Cheng, Lim Chia Wei and Grace Toh Li-Xian, for their assistance with sample processing. Special thanks to Dr. Elaine Lo (National University Hospital) for her clinical insights and guidance. We acknowledge the team at Oxford Nanopore Technologies (ONT) - Mavis Tan, Miles Benton, Lin Yang, Simon Dunbar, Lei Tong, Jerald Yam, Nicholas Ong, Vania Wikasa and Germaine Kwok - for their technical support and collaboration.
Funding
This work was supported by the Enterprise Development Grant (EDG) by Enterprise Singapore.
Author information
Authors and Affiliations
Contributions
PHPG and HLY contributed equally to this work. PHPG supervised and contributed to developing the software and pipeline, performed data analysis and co-wrote the manuscript. HLY conducted the laboratory work. MIBH contributed to developing the software and pipeline and assisted with data analysis. YM and KNR assisted with data analysis. MND assisted with the curation of guidelines to interpret diplotype calls. AQHN supervised the laboratory procedures. AI and LS contributed to funding acquisition and supervised the study. LLG provided clinical samples and supervised the study. MGP conceived the study, secured funding, supervised the project, and co-wrote the manuscript.
Corresponding author
Ethics declarations
Competing interests
The author declares no competing interests.
Ethics statement
All patient samples were obtained with informed consent in accordance with institutional guidelines. The study protocol was reviewed and approved by the institutional ethics review board at Tan Tock Seng Hospital (Singapore). All methods were carried out in accordance with relevant guidelines and regulations. No additional ethical approval was required for the use of publicly available reference materials.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Gan, P.H.P., Yeo, H.L., Bin Hajis, M.I. et al. Targeted adaptive sampling enables clinical pharmacogenomics testing and genome-wide genotyping. Sci Rep 15, 39346 (2025). https://doi.org/10.1038/s41598-025-22941-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-22941-z
