
Abstract
Real-time defect detection of high-speed railway catenary components remains challenging due to the prevalence of small-sized parts (e.g., cotter pins, fasteners) and the computational constraints of deployment platforms. While existing YOLO-based models offer a balance between speed and accuracy, they often struggle with small object detection and suffer from high computational costs. To address these limitations, this paper proposes an optimized YOLOv11m model, termed MSIM-YOLOv11m, which integrates three novel modules: large separable kernel attention (LSKA) for enhanced feature extraction, bidirectional feature pyramid network (BiFPN) for efficient multi-scale fusion, and adaptive kernel convolution (AKConv) for flexible feature learning. Experimental results on a dedicated catenary dataset show that the proposed model achieves a mAP50-95 of 78.3% and a small-target AP of 64.7%, while reducing computational cost by 50.5% compared to YOLOv9m. The model provides a lightweight and accurate solution suitable for real-time inspection applications.The code has been uploaded to https://github.com/1748125472/MSIM-Yolov11m/tree/master.
Similar content being viewed by others

Introduction
The catenary system is the only way for rail transit trains to obtain electric energy. Due to the long-term influence of the train’s own jitter and environmental factors, all kinds of parts in the catenary system, such as insulators, hanging strings, cotter pins, etc., are prone to defects, and due to the small size of some parts, it is difficult to be found in time once the defects occur1. Therefore, how to efficiently and accurately detect the defects of catenary parts is of great practical significance to ensure the operation safety of rail transit trains. At present, catenary defect detection has developed in the direction of intelligence, and catenary defect detection method based on deep learning has become the mainstream detection method.
In recent years, the operating mileage of high-speed electrified railways has grown rapidly, and the use of catenary insulation equipment has increased year by year. As an important equipment for electrical insulation and power support, the insulation performance of wrist arm insulator will have a huge impact on the safe operation of electrified railways2,3,4,5. Due to the unique nature of the application environment, the surface of the device is prone to visible damage and requires long-term monitoring to ensure safety6,7,8,9. At present, the general way of catenary detection is to use catenary detection vehicle to carry out full-line inspection, and combine manual fixed-point maintenance, but due to the problem of quantity, accuracy and efficiency, it is urgent to apply efficient intelligent image recognition technology to improve the level of monitoring and detection. At present, there are many studies on the use of deep learning to achieve object detection for high-speed rail catenary components, and the main research is to improve the image recognition rate. Object detection schemes based on deep learning can be roughly divided into two categories: two-stage detection schemes and single-stage detection schemes.
The two-stage detection protocol mainly includes R-CNN10, Fast RCNN11 and Faster R-CNN12, etc.Li Changjiang et al. designed a method based on Faster RCNN secondary cascade to complete the step-by-step positioning of the high-speed rail catenary support device, so as to locate the equipotential line, and then classify the fault, and the accuracy of identification was improved13. According to the three factors that affect the positioning of the screw of the diagonal brace sleeve, Wang Liyou improved the Faster R-CNN, and proposed a new image recognition method, which effectively improved the positioning accuracy of the screw14.
The single-stage detection scheme mainly includes SSD15 and YOLO16,17,18 series models. Peng Hao designed an improved version of the model based on YOLOv519, it is possible to inspect insulators with small sizes and insulators with a high degree of overlap. Song et al.20 proposed an insulator defect detection algorithm based on Flexible YOLOv7, which integrates the attention mechanism in the process of feature extraction, reduces the parameter redundancy in the model training process by using an efficient SPPCSPC21 structure, and introduces the E-IOU loss function to focus on high-quality anchors22. The detection accuracy of the original model was improved, the extraction performance of dense targets, occlusions, and small target feature regions was enhanced, and the positioning and detection accuracy were optimized. In Ref23 a multi-scale dense convolutional network based on multi-scale feature fusion (MSD2Net) was proposed, and a multi-scale feature fusion network based on deconvolution and multi-branch detection was proposed to solve the problem of poor insulator recognition. In Ref24, a rod insulator detection model was constructed based on the deformable part model and latent SVM (Support Vector Machine), and the sub-images of different devices were extracted from the original image, and the rod insulators were identified and detected from them. In Ref25, an automatic fault diagnosis system was proposed, which can effectively identify loose strand defects of wires and eliminate the possibility of potential faults through an improved feature extraction network and an image segmentation method based on MRF (Markov random field).
While transformer-based architectures (e.g., EAPT26) show promise in feature extraction, their computational complexity limits real-time deployment. Similarly, NHBS-Net’s attention pyramid design improves segmentation but lacks adaptability to dynamic railway environments27. Existing methods struggle with small components (e.g., cotter pins) due to limited feature fusion strategies and redundant parameters. And recent advances like SES-YOLOv528 enhance small object detection through graphics-oriented optimization, its reliance on single-scale feature extraction hinders performance in multi-component railway scenes. Similarly, detail-enhanced lightweight networks29 improve aerial image analysis but lack adaptive mechanisms for dynamic-scale targets like fasteners and insulators.
While the aforementioned studies have effectively realized the defect detection task of high-speed rail catenary parts through deep learning methods, several challenges remain: (1) Limited feature fusion strategies in existing methods lead to poor detection accuracy for small-volume parts such as cotter pins; (2) Many models contain parameter redundancies that hinder real-time deployment; (3) Most approaches lack adaptive mechanisms for handling dynamic-scale targets in complex railway environments.
To address these limitations, this paper proposes an optimized YOLOv11m-based detection framework with the following contributions:
-
1.
We propose MSIM-YOLOv11m, a novel and efficient detector that integrates LSKA, BiFPN, and AKConv in a cohesive manner, specifically designed for the challenges in high-speed railway catenary defect detection, such as small targets, multi-scale components, and the need for computational efficiency.
-
2.
We demonstrate how the LSKA module, with its large separable kernel attention, enhances the feature extraction for small targets, while the AKConv module adapts to the irregular shapes of catenary components. Combined with the BiFPN for multi-scale feature fusion, our model achieves a significant improvement in detecting small and complex catenary parts.
-
3.
Our model achieves a superior balance between accuracy and computational cost, attaining a mAP50-95 of 78.3% while reducing the FLOPs by 50.5% compared to YOLOv9m, making it more suitable for real-time applications.
-
4.
We build a dedicated dataset for high-speed railway catenary components and conduct comprehensive experiments, including ablation studies and comparisons with state-of-the-art detectors, to validate the effectiveness of our approach.
YOLOv11 detection model framework
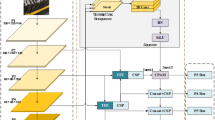
The network structure of the YOLOv11 detection model is mainly divided into three parts: the backbone, the neck, and the head, as shown in Fig. 1 show. YOLOv11 utilizes CIoU Loss as the bounding box loss function, which considers overlap, center distance, and aspect ratio consistency for improved localization.The backbone of YOLOv11 adopts an improved backbone architecture, introducing C3K2 blocks to replace the C2F blocks in previous versions. The C3K2 block is actually converted from the C2F module, and when the c3k parameter is FALSE, the C3K2 module is the C2F module. When c3k is true, the bottleneck module is replaced with the C3 module. This improvement improves the computational efficiency and enhances the feature extraction ability. In the neck structure, YOLOv11 incorporates the C2PSA module. C2PSA is an extension of the C2F module, which incorporates PSA (Pointwise Spatial Attention) blocks to enhance feature extraction and attention mechanisms. By introducing PSA blocks in the standard C2F module, C2PSA implements a more powerful attention mechanism, which improves the model’s ability to capture important features. YOLOv11 uses multiple C3K2 blocks and CBS layers in the detection head section to further refine the feature map, and finally output bounding boxes and category labels. In addition, YOLOv11 also uses deep separable convolutions on the cls branch of the head section to reduce redundant computation and improve efficiency. The adaptive anchor frame mechanism can automatically optimize the anchor frame configuration on different datasets to improve the detection accuracy.

YOLOv11 model process framework.
The YOLOv11m on which this article is based is a medium-sized model in the YOLOv11 series, compared with other versions of YOLOv11 (such as Nano, Small, Large, Extra-Large, etc.), its advantage lies in the ability to achieve a balance between accuracy and speed, YOLOv11m provides relatively fast processing speed while maintaining high accuracy, and compared to the Large and Extra-Large versions, YOLOv11m is more modest in terms of resource usage, it does not require excessive computing resources and storage space, while still being able to provide satisfactory performance.
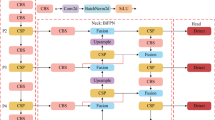
MSIM-Yolov11m model
LSKA attention mechanism
LSKA (large separable kernel attention)30 The core principle of the attention module is to decompose the two-dimensional convolutional kernel into concatenated horizontal and vertical one-dimensional convolution kernels. This decomposition method makes it possible to use deep convolutional layers with large convolutional kernels directly in the attention module without the need for additional modules. LSKA implementation steps: Decompose the original 2D convolution kernel into two 1D convolution kernels, one for the horizontal direction (1xK) and the other for the vertical direction (Kx1), as shown in Fig. 2.This decomposition significantly reduces computational complexity and memory usage. The decomposed 1D convolution kernel is then cascaded to simulate the effect of the original 2D convolution kernel. Through cascade, the LSKA is able to capture both local and global feature information. After the cascade operation, the LSKA also incorporates the attention mechanism to further improve the representation ability of the model by weighting the importance of different feature channels.

LSKA structure diagram.
LSKA replaces the standard attention layer in C2PSA, utilizing separable 1D convolution to reduce FLOP while enhancing the model’s feature extraction capabilities for more accurate detection results and good results in small object detection.
Bidirectional characteristic pyramid network
Bidirectional Feature Pyramid Network (BiFPN)31 is an efficient multi-scale feature fusion network which is optimized on the basis of traditional Feature Pyramid Network (FPN).The main principle is that BiFPN allows features to be fused in both top-down and bottom-up directions, so as to combine features of different scales more effectively. By adding weights to each input feature, the feature fusion process is optimized, so that the network can pay more attention to features with larger amount of information. Cross-scale connections are optimized by removing nodes with only one input edge, adding extra edges between input and output nodes at the same level, and treating each bidirectional path as a feature network layer. Figure 3 shows the comparison of BiFPN results with other pyramid networks.

Comparison between BiFPN and other pyramid network structure.
In our implementation, BiFPN integrates features from P3 to P7 levels (with strides of 8, 16, 32, 64, and 128 pixels respectively) extracted from the backbone network. Each bidirectional path is implemented as a repeatable block structure that enables efficient information exchange across scales.
FPN (Feature Pyramid Network) introduces a top-down path to fuse multi-scale features from Layer 3 to Layer 7 (P3–P7). PANet adds an additional bottom-up path to FPN. BiFPN improves the trade-off between accuracy and efficiency through efficient bidirectional cross-scale connections and repeatable block structures. It can be seen that BiFPN allows the bidirectional flow of feature information between different scales through the bidirectional path, and this bidirectional flow can be regarded as an effective information exchange between different scales. Such a design aims to improve the efficiency and effectiveness of feature fusion by enhancing the bidirectional flow of features, thereby improving the performance of object detection.
AKConv variable kernel convolution
AKConv(Alterable Kernel Convolution)32 The core idea is to provide the convolutional kernel with any number of parameters and any sample shape. This enables AKConv to extract features using any number of parameters, which is not implemented in standard and deformable convolution. This flexibility allows AKConv to better adapt to targets with changing shapes and sizes, improving the accuracy and efficiency of feature extraction. Traditional convolutional kernels usually have a fixed size and shape, such as a 3 × 3 or 5 × 5 square network. The core principle of AKConv is to allow the convolutional kernel to have any number of parameters, which means that the convolutional kernel is no longer limited to the standard square network, but can adopt more diverse and flexible shapes according to image characteristics and task requirements. When working with different images and targets, AKConv’s convolution kernel is able to automatically adjust its sampling shape. A new coordinate generation algorithm is introduced to generate initial sampling coordinates for convolutional kernels of varying sizes and shapes. Figure 4 shows the schematic structure of AKConv (Adapted from 32), and the three rows at the bottom show the changes in the sampling coordinates, which are the initial sampling position of the convolutional kernel without any offset, the learned offset that will be applied to the original coordinates, and the sampling coordinates after the offset is applied.

AKConv structure diagram.
The sampling network used by the traditional convolution operation is regular, while AKConv aims at the irregularly shaped convolutional kernel, so an arbitrary-size convolution algorithm is designed, which can generate the initial sampling coordinates of the convolution kernel \({P}_{n}\). The process first generates a regular sampling grid, then creates an irregular grid for the rest of the sampling points, and finally stitches the two parts of the grid into a complete sampling grid. In the algorithm, the point in the upper left corner (0,0) is used as the sampling origin. After the initial coordinates \({P}_{n}\) of the irregular convolution are defined, the convolution operation corresponding to the \({P}_{0}\) position is defined as follows Eq. (1).
where ω represents the convolution parameter. By replacing standard convolutions with AKConv in the neck, the model adapts kernel shapes to irregularly sized targets (e.g., windproof locating rings), improving small-object detection accuracy without increasing parameters.
Experimental setup
Experimental configuration
The experimental algorithms were implemented in Python 3.9 under the PyTorch 2.0.1 deep learning framework, using PyCharm as the integrated development environment. Network model training and related work were conducted on an NVIDIA GeForce RTX 4080 GPU.
Self-constructed catenary dataset
The image data used in the experiment is the data obtained from the inspection of the high-speed railway catenary of the Hohhot-Ulanqab section by the high-speed rail comprehensive inspection vehicle. A total of 10,043 images were manually annotated by labelimg. We randomly split the dataset into a training set (8034 images, 80%) and a validation set (2009 images, 20%). The random splitting ensures that the training and validation sets are from the same distribution and helps to avoid bias. The dataset format was YOLO format, and the detected label categories are shown in Fig. 5.

Dataset label categories.
For model training, images were resized to 640 × 640 pixels using bilinear interpolation and normalized using ImageNet standards (mean = [0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225]).
It is worth noting that, despite the growing number of studies on deep learning-based detection of high-speed railway catenary components, publicly available standardized datasets remain scarce. Most existing research relies on self-collected datasets that are often not released, which hinders fair comparison and reproducibility of methods. In this work, we have publicly released our self-constructed catenary component dataset on the AI Studio platform (https://aistudio.baidu.com/datasetdetail/343828).This initiative aims to facilitate future comparative studies and contribute to the standardization and openness of data in this research field. Although a single random split was used due to computational constraints, the dataset was stratified to preserve the distribution of object categories and sizes. Future work will include cross-validation to further enhance robustness.
Figure 6 shows the distribution of labels across categories in the training and validation sets. Small objects (area < 322 pixels) accounted for approximately 37.2% of all instances, primarily consisting of fasteners, cotter pins, and windproof locating rings.

Number of labels in the training and validation sets.
Public dataset validation: CPLID
To validate the generalization capability of our method, we conducted additional experiments on the publicly available CPLID (Chinese Power Line Insulator Dataset)33. This dataset contains 848 aerial insulator images with the following characteristics: 600 normal insulator images with bounding box annotations; 248 defective insulator images with dual annotations for insulator regions and defect areas. The two categories are shown in Fig. 7.

CPLID dataset.
Data Processing: We processed the CPLID dataset into a unified format for insulator condition classification. Insulator instances were labeled as “normal” or “defective” based on the presence of defect regions within insulator bounding boxes (IoU threshold: 0.3). The dataset was split into training (80%) and validation (20%) sets using stratified sampling.
Evaluation Protocol: All models were trained and evaluated on CPLID using the same configuration as our main experiments to ensure fair comparison.
Evaluate metrics
Considering that MSIM-Yolov11m is an improved algorithm based on YOLOv11m, to evaluate the detection effect of the catenary component detection model, the accuracy \(P\) (Precision), recall rate \(R\)(Recall),\(AP\) (Average Precision) and \(mAP\)(mean average precision) are still used as the evaluation indexes, and the specific expressions are as follows:
Among them, \(P\) is the proportion of true positive samples in the predicted positive samples, and \(R\) is the proportion of correctly predicted positive samples in the total positive samples;\({ T}_{P}\) (True Positive) is a positive example of a correct prediction; \({F}_{P}\)(False Positive) is a negative example that is incorrectly predicted as a positive example by the model; \({F}_{N}\) (False Negative) is a positive example that is incorrectly predicted as a negative example by the model; The \(AP\) value refers to the area enclosed by the \(P\)-\(R\) curve and the coordinate axis; \(mAP\) is an important indicator to measure the detection accuracy in object detection, representing the average \(AP\) of each category, the larger the value of \(mAP\), the better the detection effect of the algorithm, and the higher the recognition accuracy.
Additionally, we measure frames per second (FPS) and floating point operations (FLOPs) to assess real-time capability and computational efficiency. FPS quantifies the number of images processed per second, tested on an NVIDIA GeForce RTX 4080 GPU with a batch size of 8. FLOPs represent the total floating-point operations required for a single forward pass, calculated at an input resolution of 640 × 640. Higher FPS implies stronger real-time performance, while lower FLOPs indicate better suitability for resource-constrained environments.
Following COCO evaluation standards, we defined small objects as those with an area less than 322 pixels, and report APs for comprehensive evaluation.
Analysis of experimental results
Comparative experiments
For the dataset constructed in this paper, a variety of models and the MSIM-Yolov11m model in this paper are used to compare the detection effect of catenary parts. In this model training, the input image size is set to 640 × 640, the learning rate is set to 0.01, the threshold of the IOU of the regional recommendation network is set to 0.7, the batch size is set to 8, the optimization method is SGD, the momentum parameter is set to 0.937.
Our comparative analysis includes models that represent key developments in real-time object detection. While we recognize the value of broader comparisons, our selection focuses on models most relevant to our target application domain: SSD provides a baseline from the earlier generation of single-stage detectors, YOLO series (v8m, v9m, v10b, v11m) represent the state-of-the-art in real-time detection and serve as direct architectural comparisons. We specifically highlight comparison with YOLOv9m** as it represents a high-accuracy baseline, against which we demonstrate significant efficiency improvements. The performance metrics of the compared models are shown in Table 1.
The selection of comparison models—SSD, YOLOv8m, YOLOv9m, and YOLOv10b—is driven by their representativeness in balancing real-time performance and accuracy. SSD provides a lightweight baseline for real-time applications. YOLOv9m emphasizes high precision through deeper networks, while YOLOv8m optimizes the speed-accuracy trade-off. YOLOv10b incorporates advanced designs like task-aligned learning, underscoring the competitiveness of our multi-scale interaction module (MSIM) and adaptive attention.
Small target detection performance
In the high-speed rail catenary parts, the commonly used patter pins, bolts and other parts are usually small in size, and it is difficult to achieve good detection results, and the data set used in this paper includes fasteners, cotter pins and windproof positioning rings, which belong to the category of small labels, and the detection effect of these three types of small targets is more obvious while improving the overall detection effect, as shown in Table 2.
As shown in the results in the table, the MSIM-Yolov11m achieves better results in small target detection, with the fastener, cotter pin, and windproof locating ring increasing by 4.1%, 3.3%, and 5.5% on the mAP50-95 values, respectively.
Ablation experiments
The MSIM-Yolov11m high-speed rail catenary component detection model was tested to verify the effectiveness of the LSKA module, BiFPN module and AKConv convolution method, and Table 3 shows the results of network model detection under different improvement strategies in ablation experiments.
Comparing Table 3, it can be seen that the LSKA module, BiFPN module, and AKConv are helpful to improve the detection performance of the original model. Specifically, the attention layer in the C2PSA module of the YOLOv11m model was replaced with LSKA and combined into a C2PSA_LSKA module, and the feature extraction ability of the C2PSA module was enhanced by using the detached convolutional kernel characteristics of LSKA The detection effect of small targets was improved, and the mAP50-95 value was increased by 2.6%; By adding BiFPN to the concat layer as a concat_BiFPN layer, BiFPN can make full use of feature information at different scales through bottom-up feature fusion and top-down feature enhancement, thereby improving the accuracy of target detection, and the mAP50-95 value is increased by 2.8%. After replacing the convolution method in the neck layer of the original model with AKConv, the number of model parameters is further reduced because it can provide any number of parameters and arbitrary sampling shapes for the convolution kernel, and the mAP50-95 value is increased by 0.4%. Compared with the original model, although the frames per second (FPS) of the detected image in this algorithm are reduced, the detection accuracy is improved. The combination experiments show that LSKA and BiFPN have the most significant complementary effects, together contributing a 3.1% improvement in mAP50-95. While AKConv provides modest improvements alone, it contributes to parameter reduction and enhances performance when combined with other modules.
Cross-dataset validation on CPLID
To evaluate generalization capability, we conducted experiments on the public CPLID dataset. Table 4 shows the comparative results.
The results on the CPLID dataset demonstrate that our method achieves the best performance while maintaining efficiency, indicating good generalization to public datasets.
Conclusions
In this paper, we presented MSIM-YOLOv11m, a novel object detection model tailored for high-speed railway catenary defect detection. Our work goes beyond simply combining existing modules; it provides a systematic integration of LSKA, BiFPN, and AKConv, each addressing specific challenges in the catenary inspection task. The LSKA module enhances the attention on small and critical parts, the BiFPN module effectively fuses features across different scales to handle the size variation of components, and the AKConv module adapts to the irregular shapes of objects like windproof locating rings. This cohesive design leads to a model that not only achieves high accuracy (78.3% mAP50-95 on our self-constructed dataset) but also reduces the computational cost by 50.5% compared to YOLOv9m, demonstrating a significant step towards practical deployment.
Furthermore, the model’s generalization capability was validated on the public CPLID dataset, where it achieved a mAP50-95 of 87.5%, outperforming other YOLO variants. This result confirms the robustness and adaptability of our approach across different datasets and environmental conditions.
However, the study has several limitations. First, although cross-dataset validation was conducted, the model was primarily trained and validated on a self-collected dataset, which may still limit its generalizability to other railway environments. Second, due to technical constraints, we have not yet deployed and validated the model on actual edge devices, which is crucial for assessing its real-world applicability in inspection systems.
In future work, we plan to: (1) extend the dataset to include more fault categories and environmental variations; (2) explore collaboration opportunities to deploy the model on embedded platforms for real-time inference tests; (3) explore end-to-end recognition of defects beyond mere component detection, such as crack identification and wear assessment. Furthermore, although the current comparative study focuses on the most representative real-time detectors (e.g., the YOLO series), future work will include extensive comparisons with transformer-based models (e.g., DETR and its variants) and other specialized lightweight detectors to further position the performance of our method within the broader landscape of object detection research.
Data availability
The datasets generated and/or analysed during the current study are available in the https://aistudio.baidu.com/datasetdetail/343828.
References
Liang, J., Zhenhao, Y., Lu, L., Juheng, S. & Yuankai, L. Magnetic field prediction method based on residual U-net and self-attention transformer encoder. Trans. China Electrotech. Soc. 39(10), 2937–2952 (2024).
Jianpeng, B. I. A. N. et al. Damage identification and location of transmission line insulator in complex environment. High Voltage Eng. 48(2), 681–688 (2022).
Wang, C. et al. Mask detection method based on YOLO-GBC network. Electronics 12(2), 408 (2023).
Panigrahy, S. & Karmakar, S. Real-time condition monitoring of transmission line insulators using the YOLO object detection model with a UAV. IEEE Trans. Instrum. Measurement 73, 2514109 (2024).
Zhang, Y. et al. Simulation analysis on distribution rules of contamination particles on the surface of cantilever insulator. J. Railway Sci. Eng. 17(4), 1015–1024 (2020).
Jiang, X., Wang, R. & Yanhong, M. A. Insulator defect detection based on lightweight improved RT-DETR edge deployment algorithm [J/OL]. J. Electr. Eng. Technol. 40, 842–854 (2025).
Souza, B. J. et al. Hybrid-YOLO for classification of insulators defects in transmission lines based on UAV. Int. J. Electr. Energy Syst. 148, 108982 (2023).
Yaru, W. A. N. G. et al. MCIGLA plug-In suitable for YOLO series models for transmission line insulator defect detection. IEEE Trans. Instrum. Meas. 73, 9002912 (2024).
Li, L. et al. Research on detection method of insulator breakage based on context augmentation and feature refinement. High Volt. Eng. 49(8), 3405–3414 (2023).
Girshick, R., Donahue, J., Darrell, T. & Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In 2014 IEEE Conference on Computer Vision and Pattern Recognition. 580–587 (Columbus, OH, 2014).
Girshick, R. Fast R-CNN. In 2015 IEEE International Conference on Computer Vision (ICCV). 1440–1448 (Santiago, Chile, 2015).
Ren, S., He, K., Girshick, R. & Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 39(6), 1137–1149 (2017).
Li, C., Han, Z., Zhong, J., Wang, L. & Liu, Z. Equipotential fault detection of catenary support device for high-speed railway based on cascaded Faster R-CNN. J. China Railway Soc. 41(6), 68–73 (2019).
Wang, L. Research and implementation of missing small parts of catenary wrist arm support device based on deep learning (Southwest Jiaotong University, 2019).
Wei, L., Anguelov, D., Erhan, D., et al. SSD: Single shot MultiBox detector. In European Conference on Computer Vision. 21–37 (Springer, Cham, 2016).
Min, H. E. et al. MFI-YOLO: Multi-fault insulator detection based on an improved YOLOv8. IEEE Trans. Power Delivery 39(1), 168–179 (2024).
Zhang, J. et al. YOLO v7-ECA-PConv-NWD detects defective insulators on transmission lines. Electronics 12(18), 3969 (2023).
Kaijun, W. U., Zehao, X. U. & Hongquan, D. A. N. Rapid detection method for self explosion defects of glass insulators based on FasterNet and YOLOv5 improvement. High Voltage Technol. 50(05), 1865–1876 (2024).
Peng, H. Research on Insulator Detection Technology of UAV Inspection Image Based on YOLOv5[D] (China University of Mining and Technology, 2021).
Song, Z. et al. Fault detection and fault early warning method of transmission line insulator based on Flexible YOLOv7. High Voltage Eng. 49(12), 5084–5094 (2023).
Xiangming, Q. I., Rui, C. H. A. I. & Yimeng, G. A. O. Algorithm of reconstructed SPPCSPC and optimized downsampling for small object detection. Comput. Eng. Appl. 59(20), 158–166 (2023).
Lü, W., Liang, Z. & Chu, J. Traffic sign detection algorithm based on modified anchor-free model. Laser Optoelectron. Prog. 59(24), 2415002 (2022).
Lin, D., Fu, K., Wang, Y., Xu, G. & Sun, X. MARTA GANs: Unsupervised representation learning for remote sensing image classification. IEEE Geosci. Remote Sens. Lett. 14(11), 2092–2096 (2017).
Yu, Y., Li, X. & Liu, F. Attention GANs: Unsupervised deep feature learning for aerial scene classification. IEEE Trans. Geosci. Remote Sens. 58(1), 519–531 (2020).
Zhong, H. S. et al. Quantum computational advantage using photons. Science 370, 1460–1463 (2020).
Lin, X. et al. EAPT: Efficient attention pyramid transformer for image processing. IEEE Trans. Multimedia 25, 50–61 (2023).
Liu, R. et al. NHBS-Net: A feature fusion attention network for ultrasound neonatal hip bone segmentation. IEEE Trans. Med. Imaging. 40(12), 3446–3458 (2021).
Li, F., Yang, Z. & Gui, Y. SES-yolov5: Small object graphics detection and visualization applications. Vis. Comput. 41, 3129–3142 (2025).
Wang, X., Lin, C. & Pan, Y. Detail-enhanced lightweight network for small object detection in aerial images. Vis. Comput. 14, 8451–8466 (2025).
Lau, K. W., Po, L. M. & Rehman, Y. A. U. Large separable kernel attention: Rethinking the large kernel attention design in CNN. Expert Syst. Appl. 236, 121352.1-121352.15 (2024).
Tan, M., Pang, R. & Le, Q. V. EfficientDet: Scalable and efficient object detection. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 10778–10787 (Seattle, WA, 2020).
Zhang, X. et al. LDConv: Linear deformable convolution for improving convolutional neural networks. Image Vis. Comput. 149, 105190 (2023).
Tao, X. et al. Detection of power line insulator defects using aerial images analyzed with convolutional neural networks. IEEE Trans. Syst. Man Cybern. Syst. 50, 1486–1498 (2020).
Acknowledgements
Not applicable.
Funding
This research was funded by “Research on Video-based Dataset Construction Method, Scientific Research Project of Fuyang Normal University”, grant number “2021KYQD0028”; This research was funded by “Anhui Provincial Intelligent Computing and Information Innovation Application Engineering Research Center Open Project ‘Research on Intelligent Irrigation Technology Based on Cloud Decision-making’”, grant number “ICII202306”; This research was funded by “Anhui Provincial University Research Key Project ‘Research on Intelligent Identification of Crop Diseases and Insect Pests Based on Deep Learning’”, grant number “2024AH051464”.
Author information
Authors and Affiliations
Contributions
The authors confirm contribution to the paper as follows: Conceptualization, Zhijun Shen and Tao Jin; software, Tao Jin; validation, Tao Jin; resources, Zhijun Shen; data curation, Tao Jin; writing—original draft preparation, Tao Jin; writing—review and editing, Zhijun Shen; visualization, Haowen Geng; supervision, Zhijun Shen; project administration, Zhijun Shen; funding acquisition, Zhijun Shen. All authors reviewed the results and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval
Not applicable.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Jin, T., Shen, Z. & Geng, H. Optimized YOLOv11m for real-time high-speed railway catenary defect detection. Sci Rep 16, 200 (2026). https://doi.org/10.1038/s41598-025-29172-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-29172-2
