
Abstract
Visual impairment is an inability to see something to a level that the eye is unable to see, even with usual means, such as glasses or lenses. Therefore, satisfying the everyday tasks of life becomes very hard for them. To help them, having more accurate and comprehensive object detection becomes essential. In this regard, one cares not only about categorizing images but also about accurately assessing the position and class of objects within the images, which is recognized as object detection. Robust object detection enables reliable DL-based recognition of specific objects in indoor and outdoor scenes, assisting visually impaired users. This manuscript proposes a Smart Assistive System for Visually Challenged People through Object Detection Using the Tunicate Swarm Algorithm (SASVCP-ODTSA) method. The SASVCP-ODTSA method aims to detect objects using advanced techniques to assist individuals with disabilities automatically. To accomplish this, the image pre-processing phase utilizes median filtering (MF) to remove noise, thereby enhancing image quality. Furthermore, the YOLOV8 method is used for object detection. For the feature extraction process, the CapsNet model is employed. Moreover, the deep belief network (DBN) model is implemented for the detection and classification process. The classification performance of the deep belief network (DBN) is improved by optimizing its parameters using the tunicate swarm algorithm (TSA) model. The experimental evaluation of the SASVCP-ODTSA model is examined using the Indoor Object Detection dataset. The comparison analysis of the SASVCP-ODTSA approach revealed a superior accuracy value of 99.58% compared to existing models.
Similar content being viewed by others
Introduction
An individual’s life relies heavily on the basic five senses, with vision being arguably the most crucial. Visual impairment is a significant loss of vision that can’t be corrected with standard means, such as glasses or lenses1. Without adequate vision, everyday activities become extremely difficult for people with visual impairments. That will result in challenges that may require assistance from others to manage and, in some cases, pose risks to themselves or those around them2. With advancements in the field of science, numerous studies have been conducted to develop devices for individuals who are visually impaired. Those devices are durable and simple; however, they lack accuracy and usability concerns3. A crucial issue for many visually impaired individuals is that they’re unable to be fully independent and are restricted by their vision4. Visually impaired people encounter difficulties in such activities, and object detection should be an essential feature they may rely on regularly5. Object detection involves locating specific items within a visual frame. Advanced detection techniques allow recognition of diverse elements in a single picture6. Object detection becomes significant in various applications, including cancer diagnosis, vehicle detection, surveillance, and object recognition in both outdoor and indoor activities. As image analysis grows more complex, precise object recognition with accurate class and location identification becomes crucial7.
This involves not just image understanding but also detailed detection of objects within the images. Robust object detection methods are crucial for the development of high-tech video and image processing systems8. Object detection techniques can search for a specific object class, such as dogs, faces, cars, aeroplanes, or people. Currently, research is being conducted to develop smart systems that improve the safety and independent mobility. This assistive model relies on artificial intelligence (AI) methods and progressive smartphone application devices9. AI is introducing new approaches to help visually impaired people access the world. Several studies have been executed in the realm of practical object detection through DL. Object images are crucial in the lives of visually impaired people and are interpreted by DL neural networks10. The growing demand for independence among individuals with visual impairments emphasizes the need for intelligent assistive technologies that can accurately perceive and interpret their surroundings. Conventional tools, such as walking sticks or basic sensor-based devices, offer limited support in complex settings. It becomes possible to design systems that provide more precise environmental awareness due to the enhancements in DL and real-time object detection. These technologies not only improve mobility but also enhance safety and confidence in daily activities. Thus, developing a reliable, scalable, and intelligent assistive solution becomes crucial to address these unmet needs effectively.
This manuscript proposes a Smart Assistive System for Visually Challenged People through Object Detection Using the Tunicate Swarm Algorithm (SASVCP-ODTSA) method. The SASVCP-ODTSA method aims to detect objects using advanced techniques to assist individuals with disabilities automatically. To accomplish this, the image pre-processing phase utilizes median filtering (MF) to remove noise, thereby enhancing image quality. Furthermore, the YOLOV8 method is used for object detection. For the feature extraction process, the CapsNet model is employed. Moreover, the deep belief network (DBN) model is implemented for the detection and classification process. The classification performance of the deep belief network (DBN) is improved by optimizing its parameters using the tunicate swarm algorithm (TSA) model. The experimental evaluation of the SASVCP-ODTSA model is examined using the Indoor Object Detection dataset. The key contribution of the SASVCP-ODTSA model is listed below.
-
The SASVCP-ODTSA technique applies MF-based pre-processing to remove salt-and-pepper noise from input images, improving visual clarity and ensuring cleaner input for subsequent stages, which contributes to enhanced object detection accuracy and overall model robustness.
-
The SASVCP-ODTSA method utilizes YOLOv8-based object detection to accurately identify key regions within input images, thereby improving the model’s responsiveness and efficiency in real-time scenarios while significantly enhancing its robustness in dynamic and crowded environments.
-
The SASVCP-ODTSA approach utilizes CapsNet-based feature extraction to capture spatial hierarchies and relationships within images, enabling more detailed and discriminative representations that outperform conventional CNNs, thereby improving classification accuracy and feature robustness across varied input conditions.
-
The SASVCP-ODTSA model utilizes a DBN-based classification approach to learn high-level abstractions from extracted features, thereby enhancing the technique’s ability to classify diseases or objects accurately. This approach enhances robustness and reliability, facilitating more informed decision-making in complex scenarios.
-
The SASVCP-ODTSA methodology utilizes the TSA model to optimize the parameters of the DBN, resulting in improved accuracy and faster convergence. This tuning process improves the overall reliability and robustness of the classification model. By effectively searching the parameter space, TSA ensures better model generalization and performance.
-
The SASVCP-ODTSA model uniquely integrates CapsNet and DBN within a YOLOv8 detection framework optimized by TSA, which incorporates spatial awareness, deep feature learning, and bio-inspired optimization. This novel incorporation improves both detection and classification accuracy, specifically in complex medical and surveillance scenarios. The approach addresses the limitations of conventional methods by simultaneously improving feature representation and parameter tuning.
Related works
Venkata et al.11 explored DL and introduced OD methods, namely YOLO, convolutional neural networks (CNN), and region-based CNN (R-CNN). It exclusively uses Google Translator for the oral classification of identified objects, contributing a fundamental accessibility attribute for visually disabled persons. Alsolai et al.12 presented a sine cosine optimizer with a DL–based object detector (SCODL–ODC) approach. The proposed SCODL–ODC approach classifies and detects objects to assist users in navigating their surroundings proficiently and avoiding problems. To fulfil this, the suggested technique utilizes a YOLOv5 object detector initially for precise object detection, and the SCO paradigm executes the hyperparameter tuning process. In13, object detection is performed effectively through a technique named YOLO, which addresses several difficulties while offering more benefits than other solutions. Comparing other procedures, such as Fast-CNN or CNN, these process images moderately by concentrating on specific regions. YOLO is distinctive in that it processes complete images instantly while also forecasting class probabilities and bounding boxes for objects. Dzhurynskyi et al.14 proposed an innovative generative framework trained on text stimuli, incorporating a vector-quantized variational autoencoder (VQ-VAE) and a bidirectional and auto-regressive transformer (BART). These models transform textual descriptions into tactile images, addressing the need for accessibility and legibility. Current advancements in generative methods, notably the VAE diffusion model and GAN. In15, a two-step development technique for the LR image object detection (TELOD) architecture was projected. Firstly, a TDEN was established as an SR sub-network. In TDEN, the super-resolution (SR) descriptions will be attained through the recurrent link between a resolution enhancement branch (REB) and an image restoration branch (IRB) for enhancing LR images. Islam et al.16 created an inexpensive assistive method of problem detection and a nearby landscape representation for helping visually challenged individuals through DL models. SSDLite MobileNet-V2 and TensorFlow OD API are employed for creating the presented object detection system. The gradient PSO procedure is used in this study to optimize the final step and the related hyperparameters of the MobileNetV2 technique. Alahmadi et al.17 concentrated on creating visual navigation systems for assisting visually impaired people; however, there’s a necessity for the enhancement of speed, inclusion, and accuracy of a wide variety of object classes, which might hinder VIPs’ day-to-day lives. This research presents an adapted form of YOLOv4_Resnet101 as a support network, trained on numerous object categories, to assist people with disabilities in navigating environments.
Ikram et al.18 proposed a real-time obstacle detection and recognition system using advanced DL models, including detection transformer (DETR), faster region-based CNN (Faster R-CNN), and you only look once version 8 (YOLOv8). The model utilizes image pre-processing, data augmentation, and deployment optimization via TensorFlow Lite to enable accurate and efficient object classification and audio feedback on edge devices. Talaat et al.19 developed SightAid, a wearable vision system utilizing a DL-based technique with convolutional and fully connected layers for real-time object detection and recognition by integrating augmented reality displays and audio-haptic feedback. Ngo et al.20 introduced a portable assistive system using edge computing and DL methods, including CNNs for object detection and emotion recognition. The system utilizes webcam-based image capture and supports functionalities such as facial recognition, emotion detection, age detection, and gender detection, providing real-time audio feedback via a remote-controlled interface. Dahri et al.21 presented a deep CNN methodology with customized parameters for accurate indoor scene recognition across seven unique interior types. Talaat et al.22 presented SafeStride, an assistive navigation system utilizing CNN, long short-term memory (LSTM), and gated recurrent unit (GRU) models for real-time obstacle detection and path planning. The system integrates ultrasonic sensors, cameras, and inertial measurement units (IMUs) to improve environmental awareness and ensure safe, independent mobility. Atitallah et al.23 introduced a modified YOLO version 5 (YOLOv5) model optimized through width scaling, quantization, and channel pruning. The system aims to accurately detect both indoor and outdoor objects, thereby improving navigation assistance. Chaudhary and Verma24 enhanced outdoor navigation for visually impaired individuals by classifying road surfaces using the EfficientNetB0 model integrated with the unified spatial-channel attention (USCA) model. The system processes images from a wearable camera to provide real-time feedback. Abidi, Alkhalefah, and Siddiquee25 presented an intelligent assistive model by employing the gradient support vector boosting-based crossover golden jackal (GSB-CGJ) technique. This model integrates optimized support vector machine (SVM) and adaptive boosting (AdaBoost) techniques for accurate, real-time object recognition and localization. Kadam et al.26 developed a real-time hazardous object detection system using a lightweight DL model deployed on a Raspberry Pi edge device. The model also employs edge-based object classification techniques. Arsalwad et al.27 introduced a low-cost, AI-powered real-time assistive system using YOLO DL on a Raspberry Pi 4. The method integrates optical character recognition (OCR) and Google text-to-speech (TTS) technologies, integrated with a built-in natural language processing (NLP) interface, to provide accurate object detection, intent recognition, and multilingual audio feedback.
Despite crucial improvements, various limitations still exist across existing assistive systems for visually impaired users. The DETR, YOLOv8, and EfficientNetB0 models require high computational resources, which restricts their deployment on low-power edge devices. Few techniques lack a unified approach for seamless navigation in diverse settings as they primarily concentrate on either indoor or outdoor environments. Furthermore, the integration of multimodal sensors remains limited, which affects the accuracy of environmental perception. Many works do not adequately address real-time processing constraints or provide comprehensive evaluations of system latency and user adaptability. There is also a research gap while addressing personalized feedback mechanisms and multilingual support across varied user needs. Finally, limited studies incorporate robust security and privacy measures, which are crucial for user acceptance in real-world applications. Moreover, there is a lack of extensive testing on diverse populations and real-world scenarios, which is significant to ensure the generalizability and reliability of the model.
Materials and methods
In this paper, a new SASVCP-ODTSA method is proposed. The aim is to automatically detect objects and assist people with disabilities by employing advanced techniques. It comprises different stages of image pre-processing using MF, object detection, feature extraction, detection and classification, and parameter tuning process. Figure 1 demonstrates the process of the SASVCP-ODTSA approach.

Overall process of the SASVCP-ODTSA method.
Image pre-processing
Initially, the image pre-processing phase utilizes MF to mitigate noise, thereby enhancing image quality28. This model is chosen for its robust capability to eliminate impulsive noise, such as salt-and-pepper noise, while preserving crucial edge details. Unlike mean filters, MF does not blur edges, which is significant for maintaining the structural integrity of objects in images. The model’s easy implementation and computational efficiency makes the model appropriate for real-time applications. Additionally, MF is nonlinear, enabling it to better handle outliers compared to linear filters. These merits make MF an effective choice for enhancing image quality before detection and classification tasks.
MF is a nonlinear digital filtering method typically used to remove noise from images. It works by substituting every pixel’s value with the median value of its neighbouring pixels, successfully maintaining edges while removing smaller-scale noise. During object detection, MF is particularly beneficial in the pre-processing stage, enhancing the image quality. This enhances the performance of the detection method and feature extraction by decreasing visual misrepresentations. Unlike linear filters, it preserves sharp limits that are important for precisely recognizing object contours. MF is primarily successful against salt-and-pepper noise and is widely applied in real-time vision systems due to its effectiveness and simplicity.
YOLOV8-based object detection
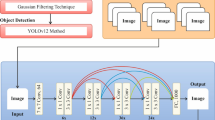
Next, the YOLOV8 method is used for object detection29. This method is chosen for its exceptional balance of speed and accuracy, making it highly appropriate for real-time applications. It improves upon previous YOLO versions with an improved architecture, improved feature extraction, and optimized training strategies, resulting in more precise localization and classification. The computational complexity is reduced by the single-stage detection approach of the model compared to two-stage detectors, enabling faster inference without sacrificing performance. Its robustness in detecting multiple objects under varying conditions additionally strengthens its applicability. These advantages make YOLOv8 an ideal and efficient choice for scalable object detection tasks. Furthermore, its fast-processing speed enables real-time performance on resource-constrained devices, improving practical deployment. Figure 2 depicts the framework of the YOLOV8 method.

Structure of YOLOV8 model.
Building upon the prior versions of YOLO, YOLO-V8 indicates an early advancement in the YOLO family of object detection methods. Performance, architecture, and functionality have been considerably improved compared to prior versions of YOLO. This model utilizes an identical backbone to YOLO-v5, with few changes to the CSP layer, now referred to as the C2f modules. This part deliberates the structure modules of YOLO-v8. Its framework is separated into three major sections: the neck, the head, and the backbone.
Backbone CSPDarknet53 is the backbone of YOLO-v8. CSP-Darknet53 builds upon its precursor, Darknet53, with the primary goal of enhancing feature extraction while minimizing computational cost. Cross-Stage Partial (CSP) links are applied to enhance the flow of gradient and reduce computational cost. CSPDarknet53 comprises a sequence of (1) convolutional layers, all with a novel filter size; (2) Residual blocks to facilitate learning residual functions, thereby enhancing training efficacy and precision; and (3) CSP Modules, which split feature mapping into dual portions. A split passes through a transformation series, whereas another resists. This split-and‐transform tactic supports diminishing redundancy while improving feature representation.
Neck It involves a Path Aggregation Network (PAN) and a Feature Pyramid Network (FPN). FPN guarantees features of different dimensions are identified. The FPN is designed for creating feature maps at various scales. However, augmenting the feature channels gradually reduces the spatial resolution of the input images. Lateral links in FPN enhance spatial information by incorporating features of higher resolution from the upper layers, complemented by lower-resolution features from the deeper layers. PAN balances FPN by improving the feature pyramid with added bottom-up routes. It groups features from dissimilar network levels to enhance detection precision. Skip Connections in PAN supports capturing context from various levels, confirming that features at each scale are successfully incorporated.
Head YOLOv8 utilizes a single unified output head, unlike preceding iterations of YOLO, which execute multiple output heads (e.g., medium, small, and large). This head forecasts objectness scores, bounding boxes, and class probabilities. To decrease computational cost and the required prediction counts, this method utilizes an anchor-free approach, which quickly forecasts an object’s centre. This approach accelerates detection and streamlines the post-processing phases.
Feature extraction using CapsNet method
In this section, the CapsNet model is utilized30. This model is chosen for its capability to capture spatial hierarchies and preserve the relationships between object parts more effectively than conventional CNNs. Unlike conventional convolutional networks that lose pose and orientation information through pooling, CapsNet maintains this information using dynamic routing, resulting in richer and more informative feature representations. Object recognition across various viewpoints and deformations is enhanced by this capability, thereby improving the model’s robustness. Additionally, this model requires fewer training samples to generalize effectively, making it advantageous for intrinsic image analysis tasks where data may be limited. Overall, CapsNet presents an improved accuracy and interpretability compared to other feature extraction methods.
CapsNets presented an innovative structural model by clearly depicting pose parameters utilizing vectors. During this structure, all capsules are identified by an output vector \(\:\left({v}_{i}\right)\) in the posture area; here, the length of vector \(\:\left(\left|\left|{v}_{i}\right|\right|\right)\) represents the likelihood of recognizing a particular object. A fundamental concept in CapsNets is dynamic routing, a mechanism for iteratively modifying the coupling coefficients among capsules in successive layers. Dynamical routing involves improving the recurrent coupling coefficient, represented as \(\:{c}_{ij}\), which reflects the agreement among capsules in \(\:layers\:l+1\) and \(\:l\). The routing process starts with low coupling weights, then refines them using a softmax-based approach, and finally computes a weighted combination of outputs from top-level capsules.
Here, \(\:\widehat{u}\) depicts the predicted vector from capsule \(\:i,\:\)and \(\:\alpha\:\) denotes the routing coefficient.
In Eq. (2), \(\:{\widehat{u}}_{j|i}\) signifies the prediction vector, \(\:{c}_{ij}\) denotes the coupling coefficient, and \(\:{s}_{i}\) represents the weighted summation of the predicted vector. The function of squashing is important in CapsNets, ensuring that vectors are condensed to a single component length while maintaining their direction. Squash\(\:\left({s}_{j}\right)\) indicates the function of squashing.
The function of loss in CapsNets includes margin loss, which equates the vector prediction with the targeted vector.
In Eq. (4), \(\:{m}^{+}\) and \(\:{m}^{-}\) represented margin parameters, \(\:\lambda\:\) refers to a down-weighting parameter, and \(\:{T}_{j}\) is signified as \(\:1\) for the target capsule. CapsNets explicitly depict spatial hierarchies and deformations, utilizing their unique benefits, even though challenges such as limited availability and computational intensity equivalent to those of conventional neural networks are carefully deliberated.
Detection and classification process
Moreover, the DBN technique is utilized for both classification and detection processes31. This technique is employed for its robust capability in learning hierarchical feature representations from complex data. This model integrates various layers of unsupervised learning with fine-tuned supervised training, enabling it to capture complex patterns and dependencies that traditional classifiers might overlook. Their generative nature facilitates the better modelling of input data distributions, leading to enhanced generalization and robustness against noise. Compared to shallow models, DBNs can effectually handle high-dimensional features, making them appropriate for medical or object detection tasks. Moreover, DBNs often require fewer labelled samples, thereby mitigating reliance on large annotated datasets while maintaining high accuracy.
DBNs include numerous Restricted Boltzmann Machines (RBMs) stacked together. Every RBM in the method consists of an interrelated visible layer (VL) and hidden layer (HL) organized in an arbitrary combination. The links among units in the HL and VL are fully connected (FC), enabling strong unsupervised learning for data. The network architecture demonstrates the lack of connections inside individual HL and VL.
When RBM utilizes \(\:v\) to characterize the VL and \(\:h\) to signify the HL, then the energy equation of the method is
.
Here, \(\:{v}_{i}\) characterizes the state of VL unit \(\:i;{h}_{j}\) denotes state of HL unit \(\:j;{a}_{i}\) signifies the bias of VL unit \(\:i;{b}_{j}\) refers to bias of HL unit \(\:j\); The number of each unit in the VL \(\:m;n\) symbolizes number of each component in the HL; \(\:{w}_{ij}\) refers to linking weights among units \(\:i\) in the VL and units \(\:j\) in the HL; \(\:\theta\:\) stands for set of each parameter \(\:\{{a}_{i},\:{b}_{i},\:{w}_{ij}\}.\).
The combined likelihood distribution of a provided state is
.
Here, \(\:Z\left(\theta\:\right)\) refers to the partition function, stated as \(\:Z\left(\theta\:\right)={\sum\:}_{v}{\sum\:}_{h}{e}^{-E(v,h|\theta\:)}.\).
Owing to the independence among the units in the VL and the units in the HL of RBM, its conditional likelihood distribution is:
RBM accepts unsupervised greedy training methods for parameter training to maximize the logarithmic probability function of the technique, as well as \(\:{a}_{i},\) \(\:{b}_{j}\), and \(\:lgP\left(v\right|\theta\:)\). By capturing partial products of the probability function and incorporating Gibbs sampling, the upgraded iteration equations for the parameters \(\:{a}_{i},\) \(\:{b}_{i}\) and \(\:{w}_{ij}\) are gained as demonstrated:
Now, \(\:<\cdot\:{>}_{data}\) characterizes the mathematical predictable value of the model distribution; it represents the mathematical predictable value of the distribution after additional reconstruction of the method; \(\:<\cdot\:{>}_{recon}\epsilon\:\) denotes the learning rate.
Parameter tuning process
The parameter tuning process is implemented through TSA to improve the classification performance of the DBN classifier32. This model is chosen for its effective convergence behaviour and robust global search capability, inspired by the foraging patterns of tunicates. This model effectively balances exploration and exploitation through biologically motivated movement strategies, thereby avoiding local optima more efficiently than many conventional optimizers. The model also requires fewer control parameters, mitigating the complexity of hyperparameter setup compared to models like GA or PSO. TSA is computationally lightweight, making it ideal for tuning DL models without significantly increasing runtime. Its adaptability and simplicity provide improved stability and performance in complex optimization tasks, resulting in enhanced accuracy and faster convergence of the tuned model. Moreover, its capability in balancing exploration and exploitation effectively assists in avoiding local minima, ensuring more reliable optimization outcomes. This makes it particularly appropriate for fine-tuning hyperparameters in DL models.
TSA is a meta-heuristic model; it is a swarm intelligence optimizer method inspired by tunicate foraging behaviour to mimic tunicate swarm behaviour and jet propulsion. The jet propulsion of tunicates contains three key modules: avoiding conflicts among tunicate individuals, moving in the direction of the optimal tunicate position, and approaching the optimal tunicate position.
-
1.
Avoiding conflicts among tunicates. The novel positional equation to calculate tunicates is presented below
$$\:A=\frac{G}{S}$$(12)$$\:G={c}_{2}+{c}_{3}-F$$(13)$$\:F=2\cdot\:{c}_{1}$$(14).
Whereas \(\:A\) denotes novel searching location; \(\:G\) refers to gravity force; \(\:F\) stands for the flow of water circulation in the deeper ocean; \(\:{c}_{1},\) \(\:{c}_{2}\), and \(\:{c}_{3}\) are randomly generated numbers among the intervals [0,1]; \(\:S\) signifies social force amongst the tunicate individuals that is calculated as shown:
$$\:S=\left|{P}_{\text{m}\text{i}\text{n}}+{c}_{1}\cdot\:\left({P}_{\text{m}\text{a}\text{x}}-{P}_{\text{m}\text{i}\text{n}}\right)\right|$$(15)Whereas \(\:{P}_{\text{m}\text{i}\text{n}}\) and \(\:{P}_{\text{m}\text{a}\text{x}}\) characterize the primary and auxiliary velocities of the social interaction of the tunicate individuals, with values of 1 and 4, correspondingly.
-
2.
Move toward the optimal tunicate position. Afterwards, to prevent conflicts among tunicate individuals, all tunicate individuals in the swarm move towards the best tunicate location. The computation equation is as demonstrated:
$$\:PD=\left|FS-{r}_{and}\cdot\:{P}_{p}\left(t\right)\right|$$(16)Whereas \(\:PD\) refers to the distance between the tunicate and the food; \(\:FS\) denotes the location of the source of food that represents the best location; \(\:{r}_{and}\) denotes an arbitrary number in (\(\:\text{0,1});{P}_{p}(x)\) represents the location of the tunicate individuals in the present iteration; and \(\:t\) denotes present iteration counts.
-
3.
Converge toward the best tunicate. Tunicate individuals will slowly move nearer to the location of the optimal tunicate individuals, which is measured by the succeeding equation:
$$\:{P}_{p}\left({t}^{{\prime\:}}\right)=\left\{\begin{array}{l}FS+A\cdot\:PD,\:if\:{r}_{and}\ge\:0.5\\\:FS-A\cdot\:PD,\:if\:{r}_{and}<0.5\end{array}\right.$$(17)Whereas \(\:{P}_{p}\left({t}^{{\prime\:}}\right)\) refers to an upgraded location.
-
4.
Swarm behavior. To mimic the mathematical representation of the swarming behaviour of tunicates, the initial dual best solutions are protected, and the locations of the remaining tunicate individuals are upgraded based on the optimal tunicate locations. The mathematical modelling of the behaviour is described as:
$$\:{P}_{p}\left(t+1\right)=\frac{{P}_{p}\left(t\right)+{P}_{p}\left({t}^{{\prime\:}}\right)}{2+{c}_{1}}$$(18)Table 1 specifies the hyperparameters of the DBN classifier. The tunicate foraging behavior is simulated by utilizing a swarm of individuals whose positions are arbitrarily initialized and updated iteratively. The conflict is avoided by the movement strategy and move toward the best tunicate, and converge to the optimal position while also effectually balancing the exploration and exploitation phase. The DBN classification performance is also defined by the objective function, and the algorithm is terminated by utilizing a maximum iteration number or minimal objective change, with a small set of control parameters ensuring computational efficiency and reproducibility.
Table 1 Summary of key TSA components utilized for hyperparameter tuning.
Algorithm 1 describes the TSA model.

TSA technique.
The fitness choice is a crucial feature that influences the performance of the TSA. The hyperparameter selection process consists of the solution encoding model to evaluate the efficacy of the candidate solutions. The TSA employs precision as the central measure to model the fitness function, as stated.
Here, \(\:TP\) and \(\:FP\) represent the true and false positive values, respectively.
Result analysis and discussion
In this section, the experimental validation of the SASVCP-ODTSA model is investigated under the Indoor object detection dataset33. The model is simulated using Python 3.6.5 on a PC with an i5-8600k, 250GB SSD, GeForce 1050Ti 4GB, 16GB RAM, and 1 TB HDD. Parameters include a learning rate of 0.01, ReLU activation, 50 epochs, a dropout rate of 0.5, and a batch size of 5. This dataset comprises 6642 counts of 10 objects. Table 2 describes the dataset. Figure 3 signifies the sample images of the SASVCP-ODTSA model.

The sample images of the SASVCP-ODTSA model.
Figure 4 provides the classifier outcomes of the SASVCP-ODTSA method. Figure 4a and b illustrate the confusion matrix for 70% and 30% splits, highlighting accurate class predictions. Figure 4c and d illustrate robust PR and ROC performance across all classes.

Classifier outcome of SASVCP-ODTSA model (a,b) 70% and 30% confusion matrices (c,d) PR-curve and ROC-curve.
Table 3; Fig. 5 describe the object detection of the SASVCP-ODTSA method under 70%TRPHE and 30%TSPHE. According to 70% TRPHE, the presented SASVCP-ODTSA method achieves an average \(\:acc{u}_{y}\), \(\:pre{c}_{n}\), \(\:rec{a}_{l}\), \(\:{F1}_{Score}\), \(\:{AUC}_{Score}\), and Kappa of 99.57%, 93.43%, 86.83%, 88.49%, 93.28%, 93.34, consistently. In addition, depending on 30%TSPHE, the suggested SASVCP-ODTSA approach obtains average \(\:acc{u}_{y}\), \(\:pre{c}_{n}\), \(\:rec{a}_{l}\), \(\:{F1}_{Score}\), \(\:{AUC}_{Score}\), and Kappa of 99.58%, 91.77%, 84.71%, 87.15%, 92.20%, 92.27%, respectively.

Average outcome of SASVCP-ODTSA model under 70%TRPHE and 30%TSPHE.
In Fig. 6, the training (TRNG) \(\:acc{u}_{y}\) and validation (VALID) \(\:acc{u}_{y}\) outcomes of the SASVCP-ODTSA method over 0–25 epochs is shown. The figure highlights that both \(\:acc{u}_{y}\) values exhibit growing tendencies, with better outcomes across various iterations. Additionally, both \(\:acc{u}_{y}\:s\)tays adjacent over the epoch counts, which represents reduced overfitting and exposes the heightened output of the SASVCP-ODTSA model.

\(\:Acc{u}_{y}\) curve of SASVCP-ODTSA technique.
In Fig. 7, the TRNG loss and VALID loss graph of the SASVCP-ODTSA method is determined. Both the values are measured for 0–25 epochs. It is noted that both values showed a tendency to decrease, indicating the capability of the SASVCP-ODTSA approach to balance a tradeoff between simplification and data fitting. The constant decline in loss values further assures the enhanced performance of the SASVCP-ODTSA approach.

Loss curve of SASVCP-ODTSA technique.
Table 4; Fig. 8 present the comparison analysis of the SASVCP-ODTSA model with recent techniques34,35,36. The outcomes highlighted that the Libra RCNN, Cascade RCNN + res2net + DCNv2, YOLOv3, YOLOXs, ResNet18 + LSA, IOD155 + TF-IDF, PointNet++, and CBORM techniques exhibited poor performance. Additionally, the SASVCP-ODTSA approach indicated better performance with higher \(\:acc{u}_{y}\), \(\:pre{c}_{n}\), \(\:rec{a}_{l},\) and \(\:{F1}_{score}\) of 99.58%, 91.77%, 84.71%, and 87.15%, appropriately.

Comparison evaluation of the SASVCP-ODTSA model with existing techniques.
The time consumed (TC) result of SASVCP-ODTSA model with recent methods are exemplified in Fig. 9. According to TC; the SASVCP-ODTSA approach gives the lower value of 6.45 s while the Libra RCNN, Cascade RCNN + res2net + DCNv2, YOLOv3, YOLOXs, ResNet18 + LSA, IOD155 + tfidf, PointNet++, and CBORM methodologies reach superior TC of 16.14 s, 20.96 s, 14.91 s, 20.60 s, 18.36 s, 9.36 s, 10.34ec, and 21.13 s, correspondingly.

TC outcome of SASVCP-ODTSA model with existing approaches.
Table 5; Fig. 10 present the error analysis of the SASVCP-ODTSA technique in comparison to existing models. The error analysis reveals that the highest \(\:acc{u}_{y}\) of 10.57%, \(\:pre{c}_{n}\) of 14.04%, \(\:rec{a}_{l}\) of 28.79%, and \(\:{F1}_{score}\) of 18.78% were achieved by the IOD155 + tfidf technique, indicating its relatively better overall performance. PointNet + + exhibits a balanced \(\:rec{a}_{l}\) of 27.12% and the highest \(\:{F1}_{score}\) of 26.33%, despite a moderate \(\:acc{u}_{y}\) of 5.87% and \(\:pre{c}_{n}\) of 12.58%. Libra RCNN and Cascade RCNN + res2net + DCNv2 exhibit \(\:acc{u}_{y}\) of 7.21% and 8.95%, \(\:pre{c}_{n}\) of 9.32% and 15.65%, \(\:rec{a}_{l}\) of 27.70% and 29.18%, and \(\:{F1}_{score}\) of 16.44% and 17.51%, respectively, highlighting their robust recall but lower \(\:pre{c}_{n}\). YOLOv3 and YOLOXs present precision values of 20.86% and 19.72% but comparatively lower \(\:acc{u}_{y}\) and \(\:{F1}_{score}\). The ResNet18 + LSA model achieves the highest \(\:pre{c}_{n}\) among diverse models at 15.55%, with an \(\:{F1}_{score}\) of 23.07%, yet low \(\:acc{u}_{y}\) of 2.32%. The CBORM model and SASVCP-ODTSA technique illustrate the lowest \(\:acc{u}_{y}\) and \(\:{F1}_{score}\) values, with SASVCP-ODTSA performing the weakest overall at \(\:acc{u}_{y}\) of 0.42%, \(\:pre{c}_{n}\) of 8.23%, \(\:rec{a}_{l}\) of 15.29%, and \(\:{F1}_{score}\) of 12.85%. These results emphasize variability in the balance of metrics across models, with no single technique excelling in all areas, underscoring the requirement for further optimization.

Error analysis of SASVCP-ODTSA technique with existing models.
Table 6; Fig. 11 demonstrate the comparative performance evaluation of the SASVCP-ODTSA methodology through ablation study. The CapsNet technique alone attains an \(\:acc{u}_{y}\) of 97.76%, \(\:pre{c}_{n}\) of 89.84%, \(\:rec{a}_{l}\) of 82.73%, and \(\:{F1}_{score}\) of 84.98%, serving as a robust baseline. Incorporating the TSA model improves results with \(\:acc{u}_{y}\) of 98.29%, \(\:pre{c}_{n}\) of 90.46%, \(\:rec{a}_{l}\) of 83.24%, and \(\:{F1}_{score}\) of 85.62%, indicating better parameter tuning. Further enhancement is observed with DBN, reaching \(\:acc{u}_{y}\) of 99.05%, \(\:pre{c}_{n}\) of 91.10%, \(\:rec{a}_{l}\) of 83.96%, and \(\:{F1}_{score}\) of 86.35%, confirming its strength in classification. The full integration in the SASVCP-ODTSA model provides the best results, with \(\:acc{u}_{y}\) of 99.58%, \(\:pre{c}_{n}\) of 91.77%, \(\:rec{a}_{l}\) of 84.71%, and \(\:{F1}_{score}\) of 87.15%, validating the combined contribution of all components for optimal performance. This confirms that the integrated modules significantly improve the detection and classification capabilities of the model across diverse object classes.

Result analysis of the ablation study of the SASVCP-ODTSA methodology.
Conclusion
This manuscript designs and develops a SASVCP-ODTSA method. The primary intention of the SASVCP-ODTSA method is to automatically detect objects and aid people with disabilities by employing advanced techniques. To accomplish this, the image pre-processing phase utilizes MF to remove noise, thereby enhancing image quality. Furthermore, the YOLOV8 method is used for object detection. For the feature extraction process, the CapsNet model is employed. Moreover, the DBN technique is primarily applied to the detection and classification processes. For improving the classification performance of the DBN classifier, the parameter tuning process is performed using the TSA model. The experimental evaluation of the SASVCP-ODTSA model is examined using the Indoor Object Detection dataset. The comparison analysis of the SASVCP-ODTSA approach revealed a superior accuracy value of 99.58% compared to existing models. The limitations of the SASVCP-ODTSA approach comprise its reliance on a fixed indoor dataset, which restricts adaptability to diverse and dynamic real-world environments. The model may face performance degradation under varying lighting conditions, occlusions, or cluttered backgrounds. Another limitation includes its lack of testing on low-resource or edge devices. The technique also lacks integration with multilingual or audio feedback, limiting its usability for a broader user base. Future directions include expanding dataset diversity, incorporating adaptive learning mechanisms, and validating on wearable or mobile platforms for real-time assistive use.
Data availability
The data supporting this study’s findings are openly available in the Kaggle repository at (https://www.kaggle.com/datasets/thepbordin/indoor-object-detection), reference number33.
References
Prashar, D., Chakraborty, G. & Jha, S. Energy efficient laser based embedded system for blind turn traffic control. J. Cybersecur. Inform. Manage. 2(2), 35–43 (2020).
Kaur, R. & Singh, S. A comprehensive review of object detection with deep learning. Digit. Signal Process. 132, 03812 (2023).
Boukerche, A. & Hou, Z. Object detection using deep learning methods in traffic scenarios. ACM Comput. Surv. (CSUR) 54(2), 1–35 (2021).
Arya, C. et al. April. Object detection using deep learning: a review. In Journal of Physics: Conference Series, Vol. 1854, No. 1, 012012 (IOP Publishing, 2021).
Hoeser, T. & Kuenzer, C. Object detection and image segmentation with deep learning on earth observation data: A review-part i: Evolution and recent trends. Remote Sens. 12(10), 1667 (2020).
Cynthia, E. P. et al. Convolutional neural network and deep learning approach for image detection and identification. In Journal of Physics: Conference Series, Vol. 2394, No. 1, 012019 (IOP Publishing, 2022).
Xiao, Y. et al. A review of object detection based on deep learning. Multimedia Tools Appl. 79, 23729–23791 (2020).
Jiao, L. et al. A survey of deep learning-based object detection. IEEE access. 7, 128837–128868 (2019).
Wang, W. et al. Salient object detection in the deep learning era: an in-depth survey. IEEE Trans. Pattern Anal. Mach. Intell. 44 (6), 3239–3259 (2021).
Gogineni, H. B., Bhuyan, H. K. & Lydia, L. Leveraging Marine Predators Algorithm with Deep Learning Object Detection for Accurate and Efficient Detection of Pedestrians. (2023).
Venkata, G., Shaik, M. F., Babu, G. U., Hariharan, M. & Patro, K. K. Deep Learning-Powered visual augmentation for the visually impaired. In Blockchain-Enabled Internet of Things Applications in Healthcare: Current Practices and Future Directions, 218–233 (Bentham Science, 2025).
Alsolai, H., Al-Wesabi, F. N., Motwakel, A. & Drar, S. Sine cosine optimization with deep Learning–Driven object detector for visually impaired persons. J. Math. 2025(1), 5071695 (2025).
Sudeshna, M. P., Karthika, G. K., Prathyusha, K. & Indhu, K. Object detection and recognitions using webcams with voice using Yolo algorithm. Environments. 25(01) (2025).
Dzhurynskyi, Y., Mayik, V. & Mayik, L. Enhancing accessibility: automated tactile graphics generation for individuals with visual impairments. Computation. 12(12), 251 (2024).
Li, M. et al. Object detection on low-resolution images with two-stage enhancement. Knowl. Based Syst. 299, 111985 (2024).
Islam, R. B., Akhter, S., Iqbal, F., Rahman, M. S. U. & Khan, R. Deep learning based object detection and surrounding environment description for visually impaired people. Heliyon. 9(6). (2023).
Alahmadi, T. J., Rahman, A. U., Alkahtani, H. K. & Kholidy, H. Enhancing object detection for VIPs using YOLOv4_Resnet101 and text-to-speech conversion model. Multimodal Technol. Interact. 7(8), 77 (2023).
Ikram, S., Bajwa, I., Gyawali, S., Ikram, A. & Alsubaie, N. Enhancing object detection in assistive technology for the visually impaired: A DETR-based approach. IEEE Access (2025).
Talaat, F. M., Farsi, M., Badawy, M. & Elhosseini, M. SightAid: empowering the visually impaired in the Kingdom of Saudi Arabia (KSA) with deep learning-based intelligent wearable vision system. Neural Comput. Appl. 36(19), 11075–11095 (2024).
Ngo, H. H., Le, H. L. & Lin, F. C. Deep-learning-based cognitive assistance embedded systems for people with visual impairment. Appl. Sci. 15(11), 5887 (2025).
Dahri, F. H., Abro, G. E. M., Dahri, N. A., Laghari, A. A. & Ali, Z. A. Advancing robotic automation with custom sequential deep CNN-Based indoor scene recognition. IECE Trans. Intell. Syst. 2 (1), 14–26 (2024).
Talaat, F. M., El-Shafai, W., Soliman, N. F., Algarni, A. D. & El-Samie, F. E. A. Intelligent wearable vision systems for the visually impaired in Saudi Arabia. Neural Comput. Appl.. 1–21 (2025).
Atitallah, A. B. et al. An effective obstacle detection system using deep learning advantages to aid blind and visually impaired navigation. Ain Shams Eng. J. 15(2), 102387 (2024).
Chaudhary, A. & Verma, P. Improving freedom of visually impaired individuals with innovative EfficientNet and unified spatial-channel attention: A deep learning-based road surface detection system. Tehnički Glasnik. 19 (1), 17–25 (2025).
Abidi, M. H., Alkhalefah, H. & Siddiquee, A. N. Enhancing navigation and object recognition for visually impaired individuals: a gradient support vector boosting-based crossover Golden Jackal Algorithm Approach. J. Disability Res. 3(5), 20240057 (2024).
Kadam, U. et al. Hazardous object detection for visually impaired people using edge device. SN Comput. Sci. 6 (1), 1–13 (2025).
Arsalwad, G. et al. YOLOInsight: artificial intelligence-powered assistive device for visually impaired using internet of things and real-time object detection. Cureus. 1(1) (2024).
Ullah, F., Kumar, K., Rahim, T., Khan, J. & Jung, Y. A new hybrid image denoising algorithm using adaptive and modified decision-based filters for enhanced image quality. Sci. Rep. 15(1), 8971 (2025).
Olamofe, J., Qian, L. & Field, K. G. Performance evaluation of image super-resolution for cavity detection in irradiated materials. IEEE Access (2025).
Mathew, M. P., Elayidom, S., VP, J. R. & KM, A. A depth-wise separable VGG19-capsule network for enhanced bell pepper and grape leaf disease classification with ensemble activation. Environ. Res. Commun. (2025).
Xu, W. et al. Load demand prediction based on improved algorithm and deep confidence network. Scalable Computing: Pract. Experience. 26 (3), 1222–1230 (2025).
Chen, J. et al. Predicting porosity in grain compression experiments using random forest and metaheuristic optimization algorithms. Food Sci. Nutr. 13 (4), e70107 (2025).
https://www.kaggle.com/datasets/thepbordin/indoor-object-detection.
Fan, Z., Mei, W., Liu, W., Chen, M. & Qiu, Z. I-DINO: High-quality object detection for indoor scenes. Electronics. 13(22), 4419 (2024).
Heikel, E. & Espinosa-Leal, L. Indoor scene recognition via object detection and TF-IDF. J. Imaging. 8(8), 209 (2022).
Luo, N., Wang, Q., Wei, Q. & Jing, C. Object-level segmentation of indoor point clouds by the convexity of adjacent object regions. IEEE Access. 7, 171934–171949 (2019).
Acknowledgements
The authors thank the King Salman Center for Disability Research for funding this work through Research Group no KSRG-2024- 221.
Author information
Authors and Affiliations
Contributions
Abdullah M. Alashjaee: Conceptualization, methodology, validation, investigation, writing—original draft preparation, fundingAsma A. Alhashmi: Conceptualization, methodology, writing—original draft preparation, writing—review and editingAbdulbasit A. Darem: methodology, validation, writing—original draft preparation.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Alashjaee, A.M., Alhashmi, A.A. & Darem, A.A. A smart assistive system for visually challenged people through efficient object detection using deep learning with tunicate swarm algorithm. Sci Rep 15, 45540 (2025). https://doi.org/10.1038/s41598-025-29947-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-29947-7
