
Abstract
Social determinants of health (SDoH) significantly influence health outcomes, shaping disease progression, treatment adherence, and health disparities. However, their documentation in structured electronic health records (EHRs) is often incomplete or missing. This study presents an approach based on large language models (LLMs) for extracting 13 SDoH categories from French clinical notes. We trained Flan-T5-Large on annotated social history sections from clinical notes at Nantes University Hospital, France. We evaluated the model at two levels: (i) identification of SDoH categories and associated values, and (ii) extraction of detailed SDoH with associated temporal and quantitative information. The model performance was assessed across four datasets, including two that we publicly release as open resources. The model achieved strong performance for identifying well-documented categories such as living condition, marital status, descendants, job, tobacco, and alcohol use (F1 score > 0.80). Performance was lower for categories with limited training data or highly variable expressions, such as employment status, housing, physical activity, income, and education. Our model identified 95.8% of patients with at least one SDoH, compared to 2.8% for ICD-10 codes from structured EHR data. Our error analysis showed that performance limitations were linked to annotation inconsistencies, reliance on English-centric tokenizer, and reduced generalizability due to the model being trained on social history sections only. These results demonstrate the effectiveness of NLP in improving the completeness of real-world SDoH data in a non-English EHR system.
Similar content being viewed by others

Introduction
Social determinants of health (SDoH) are the conditions in which people grow, live, work, and age that influence their quality of life and health4. These determinants encompass a broad range of socioeconomic factors, including family support, employment status, and education, as well as health-related behaviors, such as substance use and physical activity5.
Despite a continuous increase in overall life expectancy, social inequalities in health persist and are widening throughout the life course1,2. Medical progress can prolong the life expectancy of individuals with severe diseases, but care management cannot be disconnected from the socio-economic environments where patients live3. The outcomes of chronic diseases are shaped by a combination of behaviors and exposures, resulting in a complex socio-biological process that determines both individual and societal health status4.
In addition to shaping behaviors, socioeconomic conditions also determine individuals’ exposure to environmental risks, such as air pollution, noise, and extreme weather events, which further impact health outcomes6. Together, social and behavioral factors are major drivers of health disparities, contributing to 47% and 34% of patient outcomes, respectively7.
In clinical settings, SDoH are documented in the electronic health records (EHR) through both structured data (e.g., coded fields) and unstructured data (e.g., clinical notes)8. However, unstructured clinical notes provide more intricate and detailed representations of SDoH than structured data9,10. To enable large-scale secondary use of EHR data, there is an increasing need for automated methods to extract and structure patient SDoH, enhancing our ability to study the impact of social inequalities on health11. In this context, studying SDoH in clinical sciences is essential for understanding how factors like income, education, housing, and social environments shape health outcomes beyond technico-biological variables. Integrating insights from SDoH into clinical practice highlights opportunities for early intervention, holistic patient care, and addressing health inequities at their root. Furthermore, recognizing the actionable nature of SDoH enables the development of evidence-based public health policies that target structural barriers and improve population health at scale12.
In recent years, automatic extraction of SDoH has been widely studied in the English language using natural language processing (NLP)13. Progress has been accelerated by the dissemination of annotated corpora and shared task challenges, for example the i2b2 NLP Smoking Challenge on identifying patients’ smoking status with a corpus of 502 clinical notes14 and the 2022 n2c2 exploring the extraction of SDoH from 4,405 social history sections from clinical notes, including substance use (alcohol, drug and tobacco), employment and living conditions15. Most subsequent studies have focused on U.S. hospital settings, showing that NLP methods applied to unstructured data from EHRs can reliably identify key social risk factors16,17,18,19,20.
In terms of coverage, the most commonly addressed SDoH are smoking status, substance abuse (alcohol and drug) and housing instability13, which are well known for their impact on health, and thus are well documented in EHRs8. In contrast, other SDoH, such as education, employment status, social support and isolation, remain underexplored and present ongoing challenges for NLP systems13.
To address SDoH identification and extraction, a range of NLP methods have been developed. Early approaches relied on rule-based systems and keyword matching, offering high precision but limited generalizability21. Subsequently, semantic word embedding methods such as word2vec22 enabled more nuanced lexical representations, supporting downstream machine learning classifiers for SDoH identification23,24,25,26,27. More advanced approaches have leveraged deep learning architectures, CNNs28, LSTMs28, and transformer-based models such as BERT28,29,30,31, which have demonstrated improved performance in extracting contextually rich SDoH information.
Recent studies have also shown the potential of large language models (LLMs) for the identification and classification of SDoH in clinical notes. Decoder-only models such as GPT-432 have been used in zero- and few-shot settings33, while encoder-decoder models such as Flan-T549 have been applied for generative SDoH extraction tasks, and are the current state-of-the-art approaches for SDoH extraction15,20,31,33,34,35.
However, most of available work is focused on English language, while resources for other languages remain scarce14,36. The extraction of smoking status from clinical narrative texts has been studied in Spanish37, Finnish38, Swedish39, and in a Korean-English bilingual setting40, but none of the underlying corpora are available. To our knowledge, the extraction of SDoH in French clinical texts has not been addressed.
In this work, we propose a sequence-to-sequence approach based on a large language model for extracting SDoH from French clinical texts. Our study focuses on 13 SDoH categories: living condition, marital status, descendants, employment status, occupation, tobacco use, alcohol use, drug use, housing, education, physical activity, income, and ethnicity/country of birth. To support model development and evaluation, we constructed and manually annotated four datasets consisting of social history sections from clinical notes. Two of these datasets are publicly released to promote reproducibility and support the development of new methods for SDoH extraction in French.
Methods
Data
To train and evaluate the proposed SDoH model, we used four datasets: MUSCADET-InHouse, MUSCADET-Synthetic, UW-FrenchSDOH and InHouse Tuberculosis/ALS.
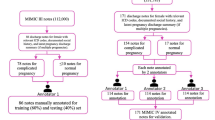
MUSCADET-InHouse was obtained from clinical notes from the Nantes biomedical data warehouse (NBDW), as summarized in Fig. 1. The NBDW encompasses nearly 1.5 million patients who received care at the Nantes University Hospital, over the past 20 years. It includes different dimensions of patient-related data: structured data (e.g. Classification Commune des Actes Médicaux billing codes, a French coding system of clinical procedures; ICD-10 codes; laboratory results; drug administrations), and unstructured data such as outpatient and inpatient clinical notes, radiology and operative reports41. The NBDW was authorized by the French authority of data protection (Commission Nationale de l’Informatique et des Libertés) (Registration code n° 920242). The present study is compliant with French regulatory and General Data Protection Regulation requirements, including informed consent. This study was approved by the Nantes Ethics Group in Healthcare (Groupe Nantais d’Éthique dans le Domaine de la Santé – GNEDS) (Registration code n° 23-3-01-110). All methods were carried out in accordance with relevant guidelines and regulations. A total of 1,144,443 clinical notes were selected from the NBDW according to the following inclusion criteria: age ≥ 18 years, the presence of clinical notes within the NBDW between August 1, 2018, and June 1, 2022. The non-inclusion criterion was patient opposition to data reuse. We then focused on semi-structured clinical notes containing predefined sections (e.g., ‘History’, ‘Medications’, ‘Social History’, etc.), with a particular emphasis on two categories: consultation reports and hospital stay reports. These two types of notes span multiple medical specialties, resulting in a total of 206,973 clinical notes covering diverse patient profiles. The clinical notes selected in the previous step were filtered to retain only those containing a social history section, for a total of 32,666 clinical notes. The social history section was extracted using a rule-based approach. Finally, 1,700 social history sections were randomly selected to constitute our corpus for annotation. This dataset was randomly divided into training (70%), validation (10%) and test (20%) sets for our experiments.
To assess the generalization capabilities of our model, we constructed three external test datasets. For reproducibility, we introduce two open-source datasets: MUSCADET-Synthetic and UW-FrenchSDOH.
MUSCADET-Synthetic comprises synthetic social history section texts written by a physician. These synthetic documents follow the template of real medical records but were entirely written from scratch, ensuring that they do not reference any real patient. The corpus includes 340 documents, matching the test set size of MUSCADET-InHouse.
UW-FrenchSDOH is the second dataset, an automatically translated version of an existing dataset from the University of Washington (UW)42,43. It consists of 364 social history sections collected from MTSamples. The dataset was translated into French using GPT-4o (gpt-4o-2024-11-20) and manually corrected during annotation.
InHouse Tuberculosis and ALS. Since other datasets focus only on social history sections, it was essential to assess the model’s effectiveness in a broader clinical context, particularly on non-SDoH texts, to determine its propensity for false positives. To this end, we applied the model to full clinical notes in two use cases, focusing on patients hospitalized for tuberculosis or amyotrophic lateral sclerosis (ALS). These diseases were selected due to the significant impact of SDoH on their outcomes44,45,46. Both groups of patients and related clinical notes were selected on ICD-10 criteria: A15-A19 for tuberculosis and G12.2 for ALS. A total of 1,186 patients were identified for tuberculosis and 647 for ALS. We included the first clinical note recorded for each patient visit associated with the respective ICD-10 code as the principal diagnosis. For each disease, 200 clinical notes were fully annotated to serve as a test set, for a total of 400 clinical notes.

MUSCADET-InHouse corpus construction flow-chart.
Annotation scheme
The annotation scheme was designed to provide a broad coverage of SDoH, with a fine-grained description of the determinants. The annotation scheme includes entities, attributes, and relations between entities.
The annotation scheme comprises 25 entities related to SDoH, covering 13 SDoH categories (living condition, marital status, descendants, employment status, job, tobacco use, alcohol use, drug use, housing, education, physical activity, income and ethnicity/country of birth) and 6 entities related to relations (StatusTime, History, Duration, Amount, Frequency, Type). SDoH entities are either text span-only (Job, Income, Education, Ethnicity, Alcohol, Tobacco, Drug) or labeled with categories (Living, MaritalStatus, Descendants, Employment, Housing, PhysicalActivity), while all relation entities are span-only. Table 1 presents all entities.
The annotation scheme also includes six relations (Table 2):
-
Status: encodes the status (current, past, or none) of the substance use (alcohol, tobacco, or drugs).
-
History: links any event to its date of occurrence.
-
Duration: encodes the duration of exposure to substance use.
-
Amount: encodes the quantity of substance use or the number of children in a lineage. Units of measurement: number of glasses, number of cigarettes, number of children, grams, etc.
-
Frequency: gives the frequency of an event’s occurrence. This relation is also used when the amount related to substance use is not precise enough. For example: drinks occasionally.
-
Type: details certain entities, such as the type of lineage or the type of substance use.
Following the work on SHAC corpus47, we annotated the substance use (tobacco, alcohol, and drugs) using an event-based scheme characterized by a trigger entity and status-related attributes.
We used the BRAT Rapid Annotation Tool (BRAT) for datasets annotation48. For the MUSCADET-InHouse dataset, the annotation process was carried out in three phases, with inter-annotator agreement calculated at the end of the first two phases: (1) a preliminary annotation phase on 100 documents by three annotators (PCDB, a physician; AB, an NLP researcher; and MK, an epidemiologist) to evaluate the annotation scheme and refine the guidelines; (2) a second annotation phase on 200 documents by two annotators (PCDB, AB) to validate the modifications made to the guidelines following the first phase; and (3) a final annotation phase during which each annotator worked independently according to the finalized annotation guidelines.
For the MUSCADET-Synthetic dataset, all texts were annotated by three annotators (PCDB, AB, MK). The UW-FrenchSDOH dataset was annotated by a single annotator (AB), while the InHouse Tuberculosis and ALS dataset was annotated by two annotators (PCDB, AB). We computed inter-annotator agreement (IAA) values for entities using F-measure from the open-source tool bratiaa (https://github.com/kldtz/bratiaa) for each annotator pair. For relation annotations, F-measure scores were performed using an in-house script. The BRAT configuration files and the scripts for IAA computation are available in the project’s repository (https://github.com/CliniqueDesDonnees/SDoH).
Annotation statistics
Table 3 presents the distribution of entity types across all datasets. The most frequent entities are Living_WithOthers, MaritalStatus_InRelationship, Descendants_Yes, Job, Tobacco, Alcohol, and Housing_Yes, while the remaining entities appear less frequently. Similarly, Table 4 presents the distribution of relation types across all datasets. The most common relations are Status, Amount, and Type, the latter two being highly associated with the entity Descendants_Yes. Distribution of all possible entity-relations pairs are presented in Supplemental Table 3.
Experiment
Following recent studies on SDoH extraction leveraging large language models (LLMs)33,34, we used the Flan-T5-Large model49 in our experiments. We formulated SDoH extraction as a text-to-structure translation task, where the model receives a social history section from a clinical note and generates a linearized sequence of SDoH events. This sequence-to-sequence (seq2seq) formulation allows the model to jointly predict entities, attributes, and their relations within a single decoding pass. As illustrated in Fig. 2, the output events are ordered from left to right according to their token offsets in the original text.
To train the model, Flan-T5-Large was fine-tuned on the MUSCADET-InHouse training set, with input-output representations presented in Fig. 2. The model was fine-tuned for 10 epochs on two 24GB NVIDIA RTX 4090 GPUs.

Example of the model input-output format used for fine-tuning: (1) annotated social history section as input and (2) the corresponding structured sequence of SDoH events as output. Example translated into English: Social History: Lives with his wife and two daughters. Does the housework, gardening, and drives. Has been tobacco-free for 33 years and alcohol-free for 15 years.
During inference for evaluation, the sequence of SDoH events generated by the model was post-processed to recover token offsets corresponding to entities and relations. The source text was then searched for tokens matching the SDoH events in the output sequence. However, the output sequence tokens often matched multiple offsets in the source text. Ambiguities were resolved by applying distinct strategies for entities and relations. For entities, when multiple non-overlapping matches were found, we selected the leftmost occurrence in the source text that had not already been extracted. For relations, we selected the match nearest to the associated entity to ensure contextual accuracy.
For the InHouse Tuberculosis and ALS dataset, we evaluated the model using both the full clinical notes and the social history sections alone after preprocessing to assess its robustness on non-social history section texts.
Evaluation
We conducted the evaluation at two levels: (i) SDoH factors and associated values, and (ii) the fine-grained SDoH extraction including all entities and relations.
In the level 1 evaluation, we assessed the exact match presence of labeled entities in the gold standard and the model’s predictions. For alcohol, tobacco, and drug use, we included the corresponding Status relations to convert span-only entities into labeled entities (e.g., for Tobacco: Tobacco_StatusTime: current, Tobacco_StatusTime: past, Tobacco_StatusTime: none).
In the level 2 evaluation, we evaluated the extraction of SDoH as a slot-filling task, following prior work on evaluating SDoH extraction models in the context of 2022 n2c2/UW Shared Task15. This approach allows for multiple equivalent span annotations. Figure 3 illustrates this by presenting the same sentence with two equivalent sets of annotations.
Event equivalence was defined using two criteria for model evaluation: exact-match spans and overlap-match spans. In the exact match setting, two events were considered equivalent if the entity offsets matched exactly between the gold standard and predictions, and their associated relation offsets also matched exactly. In the overlap match setting, two events were considered equivalent if the entity offsets shared at least one overlapping character between the gold standard and predictions, and their associated relation offsets also shared at least one overlapping character.
The performance of the model for all evaluation settings was measured using macro precision (P), recall (R), and F1-score (F1). For level 2 evaluation, the performance was measured on each SDoH category by averaging the performance of all possible entity-relation pairs within this SDoH category (distribution of all possible entity-relation pairs in Supplemental Table 3).

Examples of substance use annotated as events. Annotations (1) and (2) are considered equivalent. English translation of the example: Active smoking at 17 cigarettes per day.
Comparison with structured EHR data
To assess the completeness of SDoH documentation in structured versus unstructured EHR data, we collected Z-codes for all patients in the MUSCADET-InHouse dataset. Z-codes are ICD-10 codes that describe factors that influence health status and healthcare utilization when the primary reason for the encounter is not a specific disease or injury, which partially include SDoH-related codes. All collected Z-codes for MUSCADET-InHouse patients were manually mapped to SDoH categories if relevant (see Supplementary Table 1). We compared the presence of one or more SDoH categories in manually annotated text from MUSCADET-InHouse against the corresponding patient’s Z-codes from structured EHR data.
Results
Inter-annotator agreement
Table 5 presents the inter-annotator agreement scores (F-measure). During the first phase of annotation for the MUSCADET-InHouse dataset, the average entity agreement was 0.689 before adjudication; it improved to 0.725 in the second phase. A similar trend was observed for relations, with an F-measure of 0.795 in the first phase, increasing to 0.829 in the second phase. For the MUSCADET-Synthetic dataset, the average agreement was 0.742 for entities and 0.788 for relations.
Model performance
Table 6 shows the macro-averaged performance of the fine-tuned Flan-T5-Large model on all datasets. The model demonstrates stable performance when evaluated on the social history sections alone, achieving a macro-F1 score ranging from 0.7618 to 0.7863 in the level 1 evaluation setting (SDoH entities with associated values), and from 0.3934 to 0.4804 in the level 2 (SDoH extraction with all entities and relations) under the exact match criteria. However, when applied to full clinical notes from the inhouse tuberculosis and ALS dataset, the model produces a high number of false positives, resulting in a substantial drop in performance, yielding a macro-F1 of 0.4017 in level 1, and 0.0451 in level 2 evaluation. The model’s performance on the UW-FrenchSDOH dataset is slightly lower in the level 2 evaluation, likely due to the dataset being a translated dataset from english to French. Although the SDoH-related terms are accurately translated, the word order and writing style retain Anglophone patterns. Since the model was not trained on such translated or non-native-like data, it struggles to extract SDoH text spans precisely.
Table 7 presents the model’s performance for each SDoH category. Some categories, such as living condition, marital status, descendants, job, tobacco and alcohol use, are well modeled by Flan-T5-Large with F1 scores over 0.80. These SDoH categories are often expressed in consistent, structured ways in clinical documents, making it easier for the model to learn their patterns. In contrast, categories such as employment status, housing, physical activity, income, and education present greater challenges. The model struggles to achieve consistent performance on these categories, likely due to the greater linguistic variability and contextual diversity in how they are documented in the clinical notes. This variability, along with the scarcity of certain SDoH categories, make generalization more difficult, especially when annotations vary in phrasing or context.
Impact of applying model on non-social history section text
Applying the model to entire clinical documents significantly increases the number of incorrect predictions (false positives). Specifically, the model’s performance on full-text documents is considerably lower than when applied to social history sections only, with a macro-F1 of 0.4017 compared to 0.7893 in the level 1 evaluation setting. This discrepancy is expected, as the model was trained exclusively on social history sections and does not generalize effectively to other parts of the clinical notes.
While restricting inference to social history sections improves precision and overall performance, this approach risks missing important SDoH information that may appear elsewhere in the document. Thus, there is a trade-off between achieving high precision and ensuring comprehensive recall of patient-related social information.
To assess the extent of information missed under this constraint, we compared the number of SDoH annotations in the InHouse Tuberculosis and ALS dataset across full documents versus social history sections only. Across the full dataset, 665 annotations were identified, of which 461 (69.3%) were located within the social history sections. This indicates that 204 annotations (30.7%) lie outside these sections. Among these, 87 annotations occurred in documents that do not include a social history section, while the remaining 117 were found outside the social history section in documents that did include one. Notably, 81 of the 117 were redundant—i.e., SDoH categories that were already mentioned within the corresponding social history section. The remaining 36 annotations represented unique SDoH information not captured in the social history sections. These were primarily related to substance use (tobacco, alcohol, and drug use), commonly discussed in sections such as medical history or risk factors.
In total, restricting model inference to social history sections results in 123 missed unique SDoH annotations (87 from documents without a social history section, and 36 unique mentions from documents with one), accounting for approximately 18.5% of all SDoH annotations in the InHouse Tuberculosis and ALS dataset.
Error analysis
Supplementary Table 2 provides an overview of the primary differences observed between the model outputs and the reference annotations. Through qualitative inspection, we categorized these discrepancies into eight distinct error types: (1) human annotation errors, (2) false positives, (3) false negatives, (4) difficulties in adhering to the structured output format, and (5) cases where the predicted text span was correct but the associated label was incorrect. Additional discrepancies labeled as errors were, in fact, not entirely incorrect; these resulted from (6) post-processing rules—for instance, when multiple identical text spans were present—or from (7) model predictions that differed from the ground truth annotation in terms of text spans but were nonetheless valid in the context of the slot-filling task. A small number of errors also stemmed from (8) limitations of the tokenizer, which did not support several French characters, such as ï. This led the model to generate incorrect forms, such as producing ‘cocane’ instead of ‘cocaïne’, thereby introducing errors in post-processing.
Comparison with structured EHR data
Manual annotation of the MUSCADET-InHouse dataset identified at least one SDoH category in 98.5% of patients (1621/1646). In contrast, structured EHR data, based on Z-codes, captured SDoH information in only 2.8% of cases (46/1646). Among these, 17 SDoH mentions overlapped between the two sources. The remaining non-overlapping instances from the structured data were mainly associated with Z-codes such as Z29.0 and Z60.20, which correspond to living alone.
Discussion
We developed a sequence-to-sequence model to extract 13 SDoH categories from French clinical notes, demonstrating the potential of large language models for enhancing the collection of real-world SDoH data. Our model performed well in identifying SDoH mentions in clinical notes and showed consistent performance across four datasets, including two that are publicly available to the research community. SDoH mentions extracted from clinical notes identified 95.8% patients with relevant information, compared to 2.8% for ICD-10 codes from structured EHR data, underscoring the added value of unstructured data.
These results highlight the effectiveness of NLP approaches in leveraging unstructured clinical notes to improve the completeness of real-world data, which is often missing or sparsely represented in structured EHR data. For example, ICD-10 Z-codes describing SDoH (e.g., ‘Problems relating to housing and economic circumstances’) are used in less than 5% of cases by clinicians in routine discharge coding practice, whereas automated NLP systems can recover comparable information with far less effort, requiring about one day of processing versus nine person-days per physician50. Yet clinician documentation habits remain a bottleneck: in a U.S. study of > 5 million patients, structured data such as address and race were well-documented, while housing, income, and social isolation were mentioned in less than 5% of records51. Greater clinician awareness and consistent recording of these factors are therefore essential.
Our model achieved strong performance (macro-F1 > 0.80) in identifying well-documented SDoH categories (living condition, marital status, descendants, smoking status, alcohol use, employment and physical activity) but lower scores for housing status and drug use. These discrepancies were primarily due to inconsistencies in human annotation, limited training data, and highly variable language, ranging from direct mentions (e.g., “apartment,” “house”) to more indirect or context-dependent references (e.g., “nursing home,” “home nurse,” “in-home assistance”). These results highlight the strengths of our approach in extracting high-level SDoH categories (level 1 evaluation), which is particularly relevant for secondary use applications. Since the output is already structured for each SDoH category, it can be directly integrated into clinical databases and research cohorts without requiring additional post-processing. However, when more granular detail is needed, fine-grained SDoH extraction with entities and relations (level 2) involves additional post-processing steps and result in lower and less stable performance across SDoH categories. This indicates that while the model is reliable for detecting whether broad SDoH concepts are present (useful for screening, surveillance, or cohort characterization52, its outputs should be treated with caution when detailed entity or relation-level information is required for tasks in clinical practice such as care planning or automated decision support.
Direct comparisons with previous studies are challenging due to methodological differences in annotation schemes, evaluation strategies, and underlying SDoH distribution. To the best of our knowledge, the study by Romanowski et al.34 is the only prior work using a model training and evaluation approach comparable to ours. Even though some entities overlap, the annotation of entities and relations differs between the two studies, which limits strict comparability. In addition, distribution of entities and relations is not equivalent across French and English. For example, substance use is more frequently represented in the English datasets than in our datasets which may reflect the higher burden of substance abuse in the US53. Among the most comparable categories, such as alcohol, tobacco, and drug use, our results tended to be lower than those reported in English, which may reflect both linguistic challenges and differences in data availability. These observations underscore the need for multilingual benchmarks and harmonized annotation practices to enable robust cross-study comparison in SDoH extraction.
Our error analysis revealed several limitations in using language models to extract SDoH from French clinical notes. While such models are generally capable of identifying the presence of relevant concepts (level 1 evaluation), they often struggle to precisely extract detailed information (level 2 evaluation). This performance gap may be explained by multiple factors, including the relatively small number of models’ parameters compared to state-of-the-art architectures, and quality issues in the annotated data. Indeed, model performance is inherently limited by the quality and consistency of the annotations, which are challenging in the SDoH domain due to its conceptual complexity. Annotator bias and inconsistency further reduce reliability and, consequently, model accuracy.
Additional errors stem from the use of English-based tokenizers, which often mishandle accented characters. As a result, post-processing becomes difficult: the predicted spans cannot be reliably aligned with gold annotations, and character offsets are often miscalculated during evaluation. These issues underscore the need for tokenizers and models tailored to specific languages, as most publicly available models are English-centric and may not generalize well to other languages or multilingual contexts54,55.
Moreover, the generation-based approach introduces alignment errors during post-processing. Specifically, selecting the leftmost matching text span to align the generated SDoH outputs can result in incorrect mappings. Similarly, associating predicted entities with their nearest potential relation arguments can introduce a proximity bias, potentially overlooking longer-range dependencies. Together, these findings suggest that our current generation-based method is promising for high-level SDoH categorization, but more robust modeling and evaluation approaches are required before they can be reliably used for fine-grained extraction in clinical or research workflows.
Applying NLP to EHR data poses a persistent challenge of transferability. Models often struggle to maintain consistent performance across different patient sub-populations within the same institution, and even more so across hospitals or over time as clinical language and practices evolve. This limits the reliability, equity, and generalizability of NLP-driven insights, underscoring the importance of adaptable, continuously validated models in clinical settings. This highlights the need for ongoing ad-hoc validation studies, underlying the importance of methodological transparency in studies like ours, including the release of code and data. In this context, the choice of model and approach for retrieving SDoH also matters. Recently, the use of LLMs in clinical tasks has expanded rapidly, with proprietary models such as GPT-4 often achieving top performance in benchmarks. However, for SDoH extraction, existing studies suggest that their performance remains limited and often comparable to other deep learning methods that are less computationally intensive33. Beyond performance, proprietary models also raise concerns regarding reproducibility, transparency, bias, and data privacy. In contrast, open-source models like Flan-T5 can be fine-tuned and adapted to the target language and local contexts, offering a more controllable and reproducible approach in low-resource hospital settings.
Another key challenge in SDoH research is the scarcity of resources in languages other than English, which limits the development of NLP methods that account for social and cultural variability across healthcare systems. SDoH are deeply context-dependent, shaped by language, culture, policy, and local healthcare practice, making it essential to develop corpora that reflect diverse populations56. A major motivation behind our work is to address this gap by providing a French-language SDoH corpus that is openly accessible and free from legal constraints. Given the sensitivity of medical data under the General Data Protection Regulation (GDPR), we adopted a dual approach to ensure compliance: generating synthetic social history sections authored by a physician and translating a publicly available English-language dataset from the University of Washington into French. This approach enables us to uphold privacy standards while advancing FAIR (Findability, Accessibility, Interoperability, and Reusability) research principles. By introducing a corpus tailored to the French clinical context, we aim to promote inclusivity and facilitate the development of NLP methods for French-speaking populations and foster multilingual research in SDoH extraction.
Our study has several limitations that affect the generalizability of our findings. First, our training dataset was derived from a predominantly Caucasian population treated at one comprehensive center, Nantes University hospital. This demographic skew impacted certain SDoH categories, such as ethnicity, which are more likely to be documented for non-caucasian individuals. In addition, ethnic data are not usually collected by French physicians unless deemed relevant for healthcare purposes. In general, we observed variation in the amount of SDoH information available across populations. On average, patients born in France (n = 1397, mean = 5.45 (SD 2.32) SDoH mentions) had more SDoH information recorded (P < 0.01 using a Student’s t-test) than patients born outside France (n = 239, mean = 4.87 (SD 2.29) SDoH mentions), suggesting possible disparities in data completeness. A second limitation is that we trained our model only on the social history sections of clinical notes, rather than on full-text documents. While this decision reduced annotation effort, it limited the model’s ability to generalize to other sections. As a result, the model is not directly applicable to raw clinical notes and requires a preprocessing step to isolate the relevant sections prior to inference. This design choice may also reduce recall, as SDoH can also appear in other sections of clinical notes. Furthermore, because not all clinical notes include a social history section, information may be missed for certain patients.
The availability and quality of SDoH documentation in EHRs is often limited and inconsistent. Real-world data are primarily collected for clinical and administrative purposes by physicians during patient care, rather than for secondary use in research. Consequently, certain SDoH categories, apart from substance use, which is well known as a risk factor, are often overlooked during consultations. Several factors contribute to this under-documentation: lack of awareness among healthcare providers about the relevance of social factors to health outcomes, discomfort with asking about these factors, and restricted resources, staffing, and time to conduct screenings, which often compete with medical priorities57. Moreover, as Nantes University Hospital serves as the comprehensive center in our region, physicians there tend to focus more on medical care and less on the social environment than general practitioners58. As a result, SDoH information is frequently missing or incomplete, even in unstructured formats within the EHR. This under-documentation limits the ability to study social determinants at scale and hinders efforts to reduce health disparities. It also impairs the capacity of health systems to implement targeted, equity-oriented interventions based on complete, representative patient data.
Conclusion
Social determinants of health have a profound impact on both individual and population health outcomes, influencing morbidity, mortality, and healthcare access. Yet, SDoH are often under-documented in EHRs, particularly in structured data. In this work, we developed and evaluated a sequence-to-sequence language model to extract 13 SDoH categories from French clinical notes, demonstrating the effectiveness of NLP for improving the completeness of real-world health data. Our model consistently outperformed structured EHR data by identifying the majority of relevant SDoH across all patients and showed robust performance across multiple datasets, including publicly available benchmarks.
Future work will explore data augmentation techniques and the use of synthetic clinical text to improve the model’s generalization, and facilitate the open-source release of both the model and annotated training dataset to support reproducibility and multilingual SDoH research. Ultimately, advancing automated SDoH extraction from unstructured clinical text can support more equitable healthcare by enabling richer, more representative data for research, policy-making, and population health interventions.
Data availability
MUSCADET-Synthetic and UW-FrenchSDOH datasets are available on Github with no restrictions to access (https://github.com/CliniqueDesDonnees/SDoH). MUSCADET-InHouse and InHouse Tuberculosis and ALS datasets were derived from the Nantes University Hospital data warehouse and contains de-identified clinical notes. However, due to patient privacy considerations and restrictions imposed by the General Data Protection Regulation (GDPR) and the French Data Protection Authority (Commission Nationale de l’Informatique et des Libertés, CNIL), these datasets cannot be made publicly available. Interested parties may contact the primary author for any questions regarding data access policy.
Code availability
All scripts used in our experiments are available on Github (https://github.com/CliniqueDesDonnees/SDoH).
References
Merville, O. et al. Unpacking occupational and sex divides to understand the moderate progress in life expectancy in recent years (France, 2010’s). Int. J. Equity Health. 23, 239. https://doi.org/10.1186/s12939-024-02310-4 (2024).
Chetty, R. et al. The association between income and life expectancy in the united States, 2001–2014. JAMA 315 (16), 1750–1766. https://doi.org/10.1001/jama.2016.4226 (2016).
Marmot, M. Social determinants of health inequalities. Lancet 365, 1099–1104. https://doi.org/10.1016/S0140-6736(05)71146-6 (2005).
Halfon, N., Larson, K., Lu, M., Tullis, E. & Russ, S. Lifecourse health development: past, present and future. Matern. Child. Health J. 18 (2), 344–365. https://doi.org/10.1007/s10995-013-1346-2 (2014).
Alderwick, H. & Gottlieb, L. M. Meanings and misunderstandings: A social determinants of health lexicon for health care systems. Milbank Q. 97 (2), 407–419. https://doi.org/10.1111/1468-0009.12390 (2019).
Nettle, D. Why are there social gradients in preventative health behavior? A perspective from behavioral ecology. PLoS One. 5 (10), e13371 (2010).
Hood, C. M., Gennuso, K. P., Swain, G. R. & Catlin, B. B. County health rankings: relationships between determinant factors and health outcomes. Am. J. Prev. Med. 50 (2), 129–135. https://doi.org/10.1016/j.amepre.2015.08.024 (2016).
Wang, M., Pantell, M. S., Gottlieb, L. M. & Adler-Milstein, J. Documentation and review of social determinants of health data in the EHR: measures and associated insights. J. Am. Med. Inf. Assoc. 28, 2608–2616 (2021).
Chen, E. S., Manaktala, S., Sarkar, I. N. & Melton, G. B. A multi-site content analysis of social history information in clinical notes. AMIA Annu. Symp. Proc. 2011,227–236 (2011).
Fernandes, S. et al. Use of Z-codes related to social determinants of health among adult inpatients in france: a nationwide study from 2014 to 2022. BMC Public. Health. 25, 2225. https://doi.org/10.1186/s12889-025-23442-4 (2025).
Bazoge, A., Morin, E., Daille, B. & Gourraud, P. Applying natural Language processing to textual data from clinical data warehouses: systematic review. JMIR Med. Inf. 11, e42477. https://doi.org/10.2196/42477 (2023). https://medinform.jmir.org/2023/1/e42477
Hacker, K., Auerbach, J., Ikeda, R., Philip, C. & Houry, D. Social determinants of Health-An approach taken at CDC. J. Public. Health Manag. Pract. 28(6), 589–594. https://doi.org/10.1097/PHH.0000000000001626 (2022).
Patra, B. G. et al. Extracting social determinants of health from electronic health records using natural Language processing: a systematic review. J. Am. Med. Inform. Assoc. 28, 2716–2727. https://doi.org/10.1093/jamia/ocab170 (2021).
Uzuner, O., Goldstein, I., Luo, Y. & Kohane, I. Identifying patient smoking status from medical discharge records. J. Am. Med. Inf. Assoc. 15 (1), 14–24. https://doi.org/10.1197/jamia.M2408 (2008).
Lybarger, K., Yetisgen, M. & Uzuner, Ö. The 2022 n2c2/UW shared task on extracting social determinants of health. J. Am. Med. Inform. Assoc. 30 (8), 1367–1378 (2023).
Wray, C. M. et al. Examining the interfacility variation of social determinants of health in the veterans health administration. Fed. Pract. 38, 15 (2021).
Feller, D. J. et al. Towards the inference of social and behavioral determinants of sexual health: development of a gold-standard corpus with semi-supervised learning. AMIA Annu Symp. Proc. 2018, 422 (2018).
Afshar, M. et al. Natural language processing and machine learning to identify alcohol misuse from the electronic health record in trauma patients: development and internal validation. J. Am. Med. Inf. Assoc. 26, 254–261 (2019).
Stemerman, R. et al. Identification of social determinants of health using multi-label classification of electronic health record clinical notes. JAMIA Open. 4, ooaa069 (2021).
Patra, B. G. et al. Extracting social support and social isolation information from clinical psychiatry notes: comparing a rule-based natural language processing system and a large Language model. J. Am. Med. Inform. Assoc. 32(1), 218–226 (2025).
Conway, M. et al. Moonstone: a novel natural language processing system for inferring social risk from clinical narratives. J. Biomed. Semant. 10 (1), 6. https://doi.org/10.1186/s13326-019-0198-0 (2019).
Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S. & Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 26. (2013).
Bejan, C. A. et al. Mining 100 million notes to find homelessness and adverse childhood experiences: 2 case studies of rare and severe social determinants of health in electronic health records. J. Am. Med. Inf. Assoc. 25 (1), 61–71. https://doi.org/10.1093/jamia/ocx059 (2018).
Topaz, M., Murga, L., Bar-Bachar, O., Cato, K. & Collins, S. Extracting alcohol and substance abuse status from clinical notes: the added value of nursing data. Stud. Health Technol. Inf. 264, 1056–1060. https://doi.org/10.3233/SHTI190386 (2019).
Gundlapalli, A. V. et al. Using natural language processing on the free text of clinical documents to screen for evidence of homelessness among US veterans. AMIA Annu Symp Proc. 2013, 537–546 (2013).
Rouillard, C. J., Nasser, M. A., Hu, H. & Roblin, D. W. Evaluation of a natural language processing approach to identify social determinants of health in electronic health records in a diverse community cohort. Med. Care. 60 (3), 248–255. https://doi.org/10.1097/MLR.0000000000001683 (2022).
Feller, D. J. et al. Bear don’t walk, detecting social and behavioral determinants of health with structured and free-text clinical data. Appl. Clin. Inform. 11(1), 172–181. https://doi.org/10.1055/s-0040-1702214 (2020).
Han, S. et al. Classifying social determinants of health from unstructured electronic health records using deep learning-based natural Language processing. J. Biomed. Inf. 127, 103984. https://doi.org/10.1016/j.jbi.2021.103984 (2022).
Yu, Z. et al. A study of social and behavioral determinants of health in lung cancer patients using transformers-based natural language processing models. AMIA Annu. Symp. Proc. 2021, 1225–1233 (2022).
Richie, R., Ruiz, V. M., Han, S., Shi, L. & Tsui, F. R. Extracting social determinants of health events with transformer-based multitask, multilabel named entity recognition. J. Am. Med. Inf. Assoc. 30 (8), 1379–1388. https://doi.org/10.1093/jamia/ocad046 (2023).
Gong, L., Bresnick, J., Zhang, A., Wu, C. & Jha, K. Boosting social determinants of health extraction with semantic knowledge augmented large language model. AMIA Annu Symp Proc. 2024, 453–462 (2025).
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023).
Guevara, M. et al. Large language models to identify social determinants of health in electronic health records. Npj Digit. Med. 7, 6 (2024).
Romanowski, B., Ben Abacha, A. & Fan, Y. Extracting social determinants of health from clinical note text with classification and sequence-to-sequence approaches. J. Am. Med. Inf. Assoc. (2023).
Keloth, V. K. et al. Social determinants of health extraction from clinical notes across institutions using large Language models. Npj Digit. Med. 8, 287. https://doi.org/10.1038/s41746-025-01645-8 (2025).
Chen, M., Tan, X. & Padman, R. Social determinants of health in electronic health records and their impact on analysis and risk prediction: A systematic review. J. Am. Med. Inf. Assoc. 27 (11), 1764–1773. https://doi.org/10.1093/jamia/ocaa143 (2020).
Figueroa, R. L., Soto, D. A. & Pino, E. J. Identifying and extracting patient smoking status information from clinical narrative texts in Spanish. Annu. Int. Conf. IEEE Eng. Med. Biol. Soc. 2014, 2710–2713. https://doi.org/10.1109/EMBC.2014.6944182 (2014).
Karlsson, A. et al. Impact of deep learning-determined smoking status on mortality of cancer patients: never too late to quit. ESMO Open. 6 (3), 100175 (2021).
Caccamisi, A., Jørgensen, L., Dalianis, H. & Rosenlund, M. Natural language processing and machine learning to enable automatic extraction and classification of patients’ smoking status from electronic medical records. Ups J. Med. Sci. 125 (4), 316–324 (2020).
Bae, Y. S. et al. Keyword extraction algorithm for classifying smoking status from unstructured bilingual electronic health records based on natural Language processing. Appl. Sci. 11 (19), 8812. https://doi.org/10.3390/app11198812 (2021).
Karakachoff, M. et al. Implementing a biomedical data warehouse from blueprint to bedside in a regional French university hospital setting: unveiling Processes, overcoming Challenges, and extracting clinical insight. JMIR Med. Inf. 12, e50194. https://doi.org/10.2196/50194 (2024).
Yetisgen, M., Pellicer, E., Crosslin, D. R. & Vanderwende, L. Automatic identification of lifestyle and environmental factors from social history in clinical text. In Proceedings of AMIA 2016 Joint Summits on Translational Science, San Francisco (2016).
Yetisgen, M. & Vanderwende, L. Automatic identification of substance abuse from social history in clinical text. In Artificial Intelligence in Medicine. AIME 2017. Lecture Notes in Computer Science, vol 10259 (eds ten Teije, A.,et al.) https://doi.org/10.1007/978-3-319-59758-4_18 (Springer, 2017).
Költringer, F. A. et al. The social determinants of national tuberculosis incidence rates in 116 countries: a longitudinal ecological study between 2005–2015. BMC Public. Health. 23, 337 (2023).
Hargreaves, J. R. et al. The social determinants of tuberculosis: from evidence to action. Am. J. Public. Health. 101 (4), 654–662. https://doi.org/10.2105/AJPH.2010.199505 (2011).
Alonso, A., Logroscino, G., Jick, S. S. & Hernán, M. A. Association of smoking with amyotrophic lateral sclerosis risk and survival in men and women: a prospective study. BMC Neurol. 10, 6. https://doi.org/10.1186/1471-2377-10-6 (2010). PMID: 20074360; PMCID: PMC2820482.
Lybarger, K., Ostendorf, M. & Yetisgen, M. Annotating social determinants of health using active learning, and characterizing determinants using neural event extraction. J. Biomed. Inf. 113, 103631. https://doi.org/10.1016/j.jbi.2020.103631 (2021). Epub 2020 Dec 5. PMID: 33290878; PMCID: PMC7856628.
Pontus Stenetorp, S. et al. brat: a Web-based tool for NLP-assisted text annotation. In Proceedings of the Demonstrations at the 13th Conference of the European Chapter of the Association for Computational Linguistics, 102–107 (Association for Computational Linguistics, 2012).
Chung, H. W., Hou, L., Longpre, S., Zoph, B., Tay, Y., Fedus, W., et al. Scaling instruction-finetuned language models. J. Mach. Learn. Res. 25(70), 1–53 (2024).
Gauthier, M. P. et al. Automating access to real-world evidence. JTO Clin. Res. Rep. 3 (6), 100340. https://doi.org/10.1016/j.jtocrr.2022.100340 (2022).
Hatef, E. et al. Assessing the availability of data on social and behavioral determinants in structured and unstructured electronic health records: A retrospective analysis of a multilevel health care system. JMIR Med. Inf. 7 (3), e13802. https://doi.org/10.2196/13802 (2019).
Mitra, A. et al. Associations between natural language processing-enriched social determinants of health and suicide death among US veterans. JAMA Netw. Open. 6 (3), e233079. https://doi.org/10.1001/jamanetworkopen.2023.3079 (2023).
Kim, S. et al. Global, regional, and National trends in drug use disorder mortality rates across 73 countries from 1990 to 2021, with projections up to 2040: a global time-series analysis and modelling study. EClinicalMedicine 79, 102985. https://doi.org/10.1016/j.eclinm.2024.102985 (2024).
Zhang, X., Li, S., Hauer, B., Shi, N. & Kondrak, G. Don’t Trust ChatGPT when your Question is not in English: A study of multilingual abilities and types of LLMs. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 7915–7927 (Association for Computational Linguistics, 2023).
Wendler, C., Veselovsky, V., Monea, G. & West, R. Do Llamas Work in English? On the latent language of multilingual transformers. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, vol. 1: Long Papers, 15366–15394 (Association for Computational Linguistics, 2024).
Fahim, F. & Antonios, A. Geographic and geopolitical biases of language models. In Proceedings of the 3rd Workshop on Multi-lingual Representation Learning (MRL), 139–163 (Association for Computational Linguistics, 2023).
Park, J., Phillips, R. & Bazemore, A. Factors associated with documenting social determinants of health in electronic health records by family physicians. Ann. Fam. Med. 22 (Suppl 1), 6245. https://doi.org/10.1370/afm.22.s1.6245 (2024).
Loo, S. et al. Implementing social determinants of health screening in US emergency departments. JAMA Netw. Open. 8 (3), e250137. https://doi.org/10.1001/jamanetworkopen.2025.0137 (2025).
Acknowledgements
This work was financially supported, in part, by the Agence Nationale de la Recherche (ANR) AIBy4 under contract ANR-20-THIA-0011, ANR MALADES under contract ANR-23-IAS1-0005, a grant from the French Ministry of Health (DAtAE2023-15744432) and the cluster DELPHI - NExT under contract ANR-16-IDEX-0007, integrated to France 2030 plan, by Région Pays de la Loire and by Nantes Métropole. We would also like to thank Emilie Varey for her administrative support in managing the project.
Funding
This work was financially supported, in part, by the Agence Nationale de la Recherche (ANR) AIBy4 under contract ANR-20-THIA-0011, ANR MALADES under contract ANR-23-IAS1-0005, a grant from the French Ministry of Health (DAtAE2023-15744432) and the cluster DELPHI - NExT under contract ANR-16-IDEX-0007, integrated to France 2030 plan, by Région Pays de la Loire and by Nantes Métropole.
Author information
Authors and Affiliations
Contributions
A.B.: Conceptualization, methodology (model training and evaluation), investigation, resources, data curation, writing- original draft, formal analysis, visualization. P.C.D.B.: Conceptualization, investigation, resources, data curation, writing-original draft preparation, formal analysis, visualization, funding acquisition. M.H.: Resources, methodology, investigation, formal analysis. R.B.: Supervision, writing-reviewing and editing. E.M.: Supervision, writing-reviewing and editing. R.D.: Supervision, writing-reviewing and editing. B.D.: Supervision, writing-reviewing and editing. P.A.G.: Supervision, writing-reviewing and editing. M.K.: Conceptualization, methodology, investigation, writing-reviewing and editing, project administration, supervision.
Corresponding author
Ethics declarations
Competing interests
P.A. Gourraud is the founder of Methodomics (2008, www.methodomics.com) and of its spin-off Big Data Santé (2018, commercial name: “Octopize”). He acts as a consultant and/or contributor for several pharmaceutical and medical device companies. All related activities are conducted under institutional (university or hospital) contracts with the following entities: AstraZeneca, Amgen, Biogen, Boston Scientific, Cemka, Cook, Docaposte/Heva, Edimark, Ellipses, Elsevier, Grunenthal, Janssen, IAGE, Lek, Methodomics, Merck, Mérieux, Novartis, Octopize, Sanofi-Genzyme, Lifen, TuneInsight, and Aspire UAE. He serves as an unpaid board member of AXA mutual insurance (since 2021). He does not prescribe medications or medical devices and receives no personal remuneration. All other authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bazoge, A., Constant dit Beaufils, P., Hmitouch, M. et al. Improving social determinants of health documentation in French electronic health records using large language models. Sci Rep 15, 45427 (2025). https://doi.org/10.1038/s41598-025-29987-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-29987-z
