
Abstract
The proliferation of AI-generated medical deepfakes, such as tumor insertions or removals in diagnostic scans, threatens patient safety and healthcare integrity. Existing detection methods often lack robustness against adversarial attacks or fail to integrate multimodal feature representations. To address these gaps, we propose AFFETDS (Adversarial Feature Fusion Enhanced Tumor Detection System), a novel ensemble framework combining adversarial training, feature fusion, and weighted voting. AFFETDS leverages adversarial attack methods (PGD, FGSM) to harden the model, fuses high-level ResNet50 features with handcrafted HOG descriptors, and employs an SVM-based ensemble classifier. Evaluated on a curated dataset of 1378 MRI scans (774 real, 604 manipulated) from TCIA and ADNI repositories, AFFETDS achieves state-of-the-art performance with 91.5% accuracy, 90.7% precision, and 91.2% recall, outperforming baseline models (SVM: 86.2%, CNN: 88.4%). The framework’s ROC-AUC (0.80) and calibrated confidence scores demonstrate superior generalization across diverse imaging conditions. The ability of combining the adversarial techniques with multimodal feature fusion, our proposed AFFETDS framework improves the detection of subtle tumor manipulations, presenting an important safeguard to maintain the authenticity of medical images. The findings of research work underscore the urgent need of proactive defenses against growing deepfake threats in healthcare applications.
Similar content being viewed by others

Introduction
Deep generative models have generally transformed the way how digital content is being created and used in the world. These advanced systems produce synthetic images, pictures and videos that are almost indistinguishable from real ones. Enabled by complex algorithms and large-scale datasets, they are very much capable of creating highly realistic content. This technological advancement has led to the rise of deepfakes—artificial images and videos created with artificial intelligence1. In medicine, manipulated images can be very unsafe since they can cause incorrect diagnoses and seriously endanger patients’ lives. They can hinder timely treatment and lead to incorrect medical decisions. The increased application of deepfakes in medicine contributes to the problems already experienced by medical facilities2,3. It becomes possible to create extremely realistic fake medical images and this raises severe concerns over the accuracy and reliability of diagnostic data. Although it is possible for medical experts to confirm the legitimacy of these images. It takes a lot of time and effort which adds extra strain to the already overburdened healthcare systems.
Patient safety and the overall reliability of healthcare are increasingly at risk due to the growing use of deepfakes in medical imaging. To reduce the negative impact of these fake images and ensure accurate patient diagnosis and treatment, healthcare systems must recognize the potential dangers of manipulated diagnostic images and implement effective detection and verification methods. Protecting the authenticity of diagnostic images requires proactive measures to identify and prevent the influence of altered or synthetic medical data4. Moreover, raising awareness among healthcare professionals about deepfake threats and their possible consequences is essential to foster a vigilant and well-informed medical community.
This study introduces AFFETDS (Adversarial Feature Fusion Enhanced Tumor Detection System), a new framework designed to detect and counter medical image manipulations. AFFETDS improves upon existing techniques by combining three major strategies: adversarial training, feature fusion, and ensemble classification. Adversarial training strengthens the model by using techniques such as Projected Gradient Descent (PGD) and Fast Gradient Sign Method (FGSM), making it more resistant to carefully crafted adversarial attacks. Feature fusion merges handcrafted image descriptors like the Histogram of Oriented Gradients (HOG) with deep features extracted from pre-trained models such as DenseNet121, ResNet50, and VGG19. This combination captures both broad patterns and fine-grained details, enhancing the system’s ability to distinguish between real and manipulated medical images more accurately.
Lastly, an ensemble classifier combines outputs from various models through weighted voting, reducing false positives and false negatives and enhancing overall dependability. The main contributions of this work are: (1) establishing AFFETDS, a robust detection system based on adversarial feature fusion for capturing fine-grained manipulations in medical images; (2) improving classification performance via ensemble methods, enabling accurate distinction between real and manipulated tumor images; and (3) rigorous empirical comparisons of AFFETDS with baseline methods such as SVM and CNN, illustrating its higher accuracy, precision, and effectiveness in tumor deepfake detection. By overcoming the shortcomings of previous methods, AFFETDS is a considerable advancement in the protection of medical imaging data integrity.
Contributions
The main contributions of this work are:
-
1.
We propose AFFETDS, an adversarial feature fusion ensemble tailored for tumor deepfake detection in MRI scans, combining adversarial training (FGSM + PGD), hybrid feature fusion (HOG + ResNet50), and weighted ensemble classification.
-
2.
We design a hybrid feature fusion pipeline that integrates handcrafted texture descriptors and deep convolutional features, and demonstrate that this combination improves deepfake detection performance over either feature type alone.
-
3.
We perform comprehensive experiments on MRI data from TCIA and ADNI, benchmarking AFFETDS against SVM and CNN baselines and analyzing calibration, probability distributions, and robustness to adversarial perturbations.
With this in-depth introduction “Related study” describes the related study, “Adversarial Feature Fusion Enhanced Tumor Detection System(AFFETDS)” presents system methodology, “Experimental evaluation” discusses the experimentation results, “Discussion and limitations” illustrates the discussion and limitations followed by conclusion in “Conclusion”.
Related study
The section provides an extensive survey of deep fake detection techniques in several fields, exposing a variety of strategies from deep neural networks and comparative analysis to ensemble learning frameworks. The comprehensive overview of various approaches as shown in Table 1, particularly within healthcare and medical imaging.
Recent advancements in biomedical imaging AI highlight the growing importance of adversarial robustness, multimodal fusion, and explainable transformer-based architectures. Hosseini et al.39 provide a comprehensive survey on adversarial attacks and defenses in medical imaging, underscoring the relevance of perturbation-aware training strategies such as FGSM and PGD, which align with the robustness objectives of our proposed AFFETDS framework. Beyond adversarial learning, multimodal transformer-based fusion has emerged as a powerful direction. Bi et al.40 introduced a cross-attention-driven multimodal ViT architecture performing interpretable integration of structural MRI and functional connectivity features, demonstrating the benefits of attention-based fusion for neuroimaging tasks. Complementing these advances, Zeineldin et al.41 proposed a hybrid CNN–Transformer model for glioma segmentation that incorporates Grad-CAM-based explanations, showing how transformer attention and CNN saliency maps can enhance clinical interpretability. These studies collectively motivate our design choices and position AFFETDS within the broader landscape of robust and explainable medical imaging.
The solution being proposed will improve detection quality and robustness to adversarial attacks through the use of deep transfer learning and convolutional reservoir networks so that the integrity of medical imaging data is preserved and patient safety is ensured.
Adversarial feature fusion enhanced tumor detection system (AFFETDS)
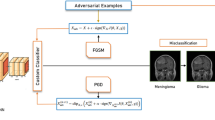
The proposed AFFETDS utilizes a multi-aspect strategy integrating feature combination, ensemble classification and adversarial attack methods to identify tumor alterations in medical images. To strengthen model resilience, adversarial samples are created with Projected Gradient Descent (PGD) and the Fast Gradient Sign Method (FGSM), assuring trustworthy training under adversarial scenarios17. Feature fusion combines hand-designed features like Histogram of Oriented Gradients (HOG) with deep feature representation using a pre-trained ResNet50 model18, yielding an extended feature set for better representation. The combined feature set is utilized to train an SVM classifier19. To improve classification performance, weighted voting strategy accumulates votes from various classifiers with different scores20. This integration-based method allows the system to identify small changes in medical images effectively, dramatically enhancing the accuracy and dependability of tumor detection. The proposed framework is presented in Fig. 1.

Proposed AFFETDS architecture.
Dataset used
The dataset used for training and evaluating the medical image identification system includes 1378 MRI scans from various medical academic institutions and research centers. It has 774 genuine scans and 604 altered ones. This way offering a right mix of real and modified images for thorough model assessment.
The dataset was partitioned into 70% training, 15% validation, and 15% testing using a stratified random split, preserving the ratio of real to manipulated images in each subset. All models (SVM, CNN, and AFFETDS) were trained and evaluated on exactly the same splits to ensure fair comparison.
The genuine MRI scans are sourced from two well-established and credible medical imaging libraries:
-
1.
The Cancer Imaging Archive (TCIA) (https://www.cancerimagingarchive.net/): This repository provides 324 real scans, offering a comprehensive collection of cancer-related images across diverse anatomical sites and imaging modalities21.
-
2.
The Alzheimer’s Disease Neuroimaging Initiative (ADNI) (https://adni.loni.usc.edu/data-samples/): This initiative contributes the remaining 450 real scans, renowned for its extensive collection of high-quality MRI images focused on tracking the progression of Alzheimer’s disease22.
These libraries were selected for their large-scale datasets and high-quality images, which provide robust representations of both normal and pathological brain regions.
The 654 manipulated scans contain intentionally injected artificial tumors, meticulously designed to mimic real tumors observed in clinical MRI scans. Using advanced computer graphics techniques, these synthetic tumors vary in size, shape, and location, replicating the complexity and heterogeneity seen in real-world clinical scenarios. The artificial tumors are seamlessly integrated into the original MRI scans using software tools that ensure realistic texture and intensity, making them indistinguishable from genuine tumors through visual inspection alone.
GANs are employed to remove tumorous regions and replace them with patterns mimicking surrounding tissue23, ensuring the alterations are visually indistinguishable through basic image examination. Techniques such as region filling, texture synthesis, and intensity normalization are used to seamlessly integrate the modified areas with the rest of the scan, presenting a significant challenge for detection systems24. Every MRI image undergoes conventional preprocessing, which includes scaling to a uniform resolution of 224 × 224 pixels using bilinear interpolation25, intensity normalization to scale pixel values between 0 and 1, and Gaussian noise reduction with a sigma value of 1.5.
Adversarial attack methods
Research on adversarial attacks against machine learning models, particularly neural networks, has grown significantly, driven by the need to enhance their security and resilience26. Among the most widely used techniques for generating adversarial samples are Projected Gradient Descent (PGD) and the Fast Gradient Sign Method (FGSM). Both methods manipulate input data to deceive the model into producing incorrect predictions27, thereby exposing potential vulnerabilities28. Figure 2 illustrates normal MRI images, while Fig. 3 shows their perturbed counterparts generated using these adversarial techniques.
Fast gradient sign method (FGSM)
FGSM calculates perturbations based on the gradient of the loss function with respect to the input image. This method generates adversarial examples that are visually indistinguishable from the original images to the human eye but cause the model to make inaccurate predictions. FGSM is widely used to evaluate the robustness of neural networks against adversarial attacks29,30.
Fast gradient sign method (FGSM) pseudocode
-
1.
Input: Model f, input image x, true label y, perturbation size ε.
-
2.
Compute the gradient of the loss with respect to the input image.
$${\Delta _x}{\rm{J}}\left( {{\rm{f}}\left( {\rm{x}} \right),{\rm{ y}}} \right)$$(1) -
3.
Generate the adversarial example by adjusting each pixel of the input image.
$${\rm{x'}} = {\rm{ x + }}\varepsilon .{\rm{sign}}\left( {{\rm{J}}\left( {{\rm{f}}\left( {\rm{x}} \right),{\rm{y}}} \right)} \right)$$(2) -
4.
Clip the perturbed image to ensure pixel values are in the valid range.
$${\rm{x'}} = {\rm{ clip}}\left( {{\rm{x'}},{\rm{ }}0,{\rm{ 1}}} \right)$$(3) -
5.
Output: adversarial example x′
Function FGSM_Attack(model, x, y, ε)
-
1.
Set requires_grad attribute of tensor.
$${\rm{x}}.{\rm{requires}}\_{\rm{grad }} = {\rm{ True}}$$(4) -
2.
Forward pass the input through the model.
$${\rm{output }} = {\rm{ model}}\left( {\rm{x}} \right)$$(5) -
3.
$${\rm{Compute the loss }} = {\rm{ CrossEntropyLoss}}\left( {{\rm{output}},{\rm{ y}}} \right)$$(6)
-
4.
Zero all existing gradients.
$${\rm{model}}.{\rm{zero}}\_{\rm{grad}}()$$(7) -
5.
Backward pass to compute gradients.
$${\rm{loss}}.{\rm{backward}}()$$(8) -
6.
Get the sign of the gradients.
$${\rm{gradient}}\_{\rm{sign }} = {\rm{ sign}}\left( {{\rm{x}}.{\rm{grad}}.{\rm{data}}} \right)$$(9) -
7.
Create the perturbed image.
$${\rm{x}}\_{\rm{adv }} = {\rm{ x }} + {\rm{ }}\varepsilon *{\rm{ gradient}}\_{\rm{sign}}$$(10) -
8.
Clip the perturbed image to maintain [0, 1] range.
$${\rm{x}}\_{\rm{adv }} = {\rm{ clip}}\left( {{\rm{x}}\_{\rm{adv}},{\rm{ }}0,{\rm{ 1}}} \right)$$(11) -
9.
return x_adv
Projected gradient descent (PGD)
By applying several minor perturbations iteratively rather than just one, it improves FGSM and increases the potency and difficulty of defending against the adversarial cases.
PGD aims to generate strong adversarial examples that can avoid detection and result in inaccurate model predictions. Through continual refinement of the perturbation, PGD is able to discover potent adversarial examples by exhaustively exploring the input space.
Projected gradient descent (PGD) pseudocode
-
1.
Input: Model f, input image x, true label y, perturbation size ε, step size α, number of iterations k.
-
2.
Initialize the perturbed image:
$${\rm{x'}} = {\rm{ x }} + {\rm{ }}\Delta \left( { - \varepsilon ,{\rm{ }}\varepsilon } \right)$$(12) -
3.
Iterate for k steps:
-
4.
Compute the gradient of the loss with respect to the perturbed image:
$${\rm{x'}} = {\Delta _x}{\rm{J}}\left( {{\rm{f}}\left( {{\rm{x'}}} \right),{\rm{ y}}} \right)$$(13) -
5.
Update the perturbed image by taking a step in the direction of the gradient.
$${\rm{x'}} = {\rm{ x'}} + {\rm{ }}\alpha \left( {{\rm{J}}\left( {{\rm{f}}\left( {{\rm{x'}}} \right),{\rm{ y}}} \right)} \right)$$(14) -
6.
Project the perturbed image back to the epsilon-ball around the original image.
$${\rm{x'}} = {\rm{ clip}}\left( {{\rm{x'}},{\rm{ x }} - {\rm{ }}\varepsilon ,{\rm{ x }} + {\rm{ }}\varepsilon } \right)$$(15) -
7.
Clip the perturbed image to ensure pixel values are in the valid range.
$${\rm{x'}} = {\rm{ clip}}\left( {{\rm{x'}},0,{\rm{ 1}}} \right)$$(16) -
8.
Output: adversarial example x′.
PGD pseudocode
-
1.
function PGD_Attack(model, x, y, ε, α, num_iter):
-
2.
Initialize perturbed image with a small random perturbation.
$${\rm{x}}\_{\rm{adv }} = {\rm{ x }} + {\rm{ }}\Delta \left( { - \varepsilon ,{\rm{ }}\varepsilon } \right)$$(17) -
3.
for i in range(num_iter):
-
4.
Set requires_grad attribute of tensor.
$${\rm{x}}\_{\rm{adv}}.{\rm{requires}}\_{\rm{grad }} = {\rm{ True}}$$(18) -
5.
Forward pass the perturbed image through the model.
$${\rm{output }} = {\rm{ model}}\left( {{\rm{x}}\_{\rm{adv}}} \right)$$(19) -
6.
Compute the loss
$${\rm{loss }} = {\rm{ CrossEntropyLoss}}\left( {{\rm{output}},{\rm{ y}}} \right)$$(20) -
7.
Zero all existing gradients model.zero_grad().
-
8.
Backward pass to compute gradients loss.backward().
-
9.
Get the sign of the gradients.
$${\rm{gradient}}\_{\rm{sign }} = {\rm{ sign}}\left( {{\rm{x}}\_{\rm{adv}}.{\rm{grad}}.{\rm{data}}} \right)$$(21) -
10.
Update the perturbed image.
$${\rm{x}}\_{\rm{adv }} = {\rm{ x}}\_{\rm{adv }} + {\rm{ }}\alpha *{\rm{ gradient}}\_{\rm{sign}}$$(22) -
11.
Project the perturbed image to be within the epsilon-ball of the original image
$${\rm{x}}\_{\rm{adv }} = {\rm{ clip}}\left( {{\rm{x}}\_{\rm{adv}},{\rm{ x }} - {\rm{ }}\varepsilon ,{\rm{ x }} + {\rm{ }}\varepsilon } \right)$$(23) -
12.
Clip the perturbed image to maintain [0, 1] range
$${\rm{x}}\_{\rm{adv }} = {\rm{ clip}}\left( {{\rm{x}}\_{\rm{adv}},{\rm{ }}0,{\rm{ 1}}} \right)$$(24) -
13.
Detach the perturbed image from the computational graph for the next iteration.
$${\rm{x}}\_{\rm{adv }} = {\rm{ x}}\_{\rm{adv}}.{\rm{detach}}()$$(25) -
14.
return x_adv

Normal MRI images.

Tumor MRI images.
Feature fusion
Feature fusion combines handcrafted features and deep learning features to accurately detect tumor modifications in medical images, capturing both high-level abstractions and precise local properties. The process begins with pre-processing the input image (e.g., “MRI_scan.jpg”) by resizing it to 224 × 224 pixels, standardizing pixel values to the range [0, 1], and converting it to a tensor format using frameworks like PyTorch. A pre-trained ResNet50 model is then used to extract a 2048-dimensional feature vector from the penultimate layer, capturing high-level patterns, textures, and shapes31. Simultaneously, the Histogram of Oriented Gradients (HOG) technique is applied to the same MRI scan to generate a 3780-dimensional feature vector, capturing edge orientations and local textures19. Both feature vectors are joined to form a 5828-dimensional feature set32, using handcrafted and deep learning features. This join feature is used to train an SVM classifier. Each sample is labeled based on the presence or absence of tumor changes33,34. The classifier’s performance is then tested to evaluate how well it detects changes in MRI scans.
Feature descriptions.
-
Table 2 sum up the features employed in the fusion process. It shows the ResNet50 features from 1 to 2048 for capturing high-level patterns and HOG features from 2049 to 5828 for representing local textures and edge details.
-
ResNet50 Features (1–2048): High-level abstractions extracted from the penultimate layer of the ResNet50 model, capturing intricate patterns, textures, and shapes essential for image classification tasks. These features are the result of deep learning procedures and are depicted in Table 4.
-
HOG Features (2049–5828): Local texture and edge orientation features derived using the HOG technique, providing detailed information about the image’s structural properties. These features are depicted in Table 5.
The complete fused feature vector, combining ResNet50 and HOG features, is illustrated in Table 3, with sample values provided in Tables 4 and 5.
Weighted voting scheme
Weighted voting is an ensemble strategy in machine learning that aggregates predictions from multiple classifiers, assigning each classifier a variable degree of influence based on its performance to improve classification accuracy35,36. The process begins by initializing a weighted sum to zero. Generally, classifiers like SVM and CNN routes the input data separately and gives its own prediction. These predictions are assigned weights based on how well each classifier performs in terms of accuracy or precision etc. Then, these weighted predictions are added together. Once these classifiers have contributed their predictions, then the final decision comes from evaluating the total.
This approach uses the strengths of different classifiers while covering their weaknesses. It leads to better accuracy and reliability for the system. Well-known models like VGGNet and forensic detection models that use transfer learning show how powerful base models can be combined into ensemble frameworks. Figure 4 illustrating the weighted voting scheme and exhibiting how merging multiple predictions improves diagnostic accuracy in medical imaging.

Weighted voting scheme.
The ensemble combines the outputs of two base classifiers: (i) SVM trained on the fused feature vector and (ii) a CNN trained directly on MRI images. Let \(\:{p}_{SVM}\) and \(\:{p}_{CNN}\) denote the predicted probability of ‘manipulated’ for each model. We compute weights \(\:{w}_{SVM}\) and \(\:{w}_{CNN}\) by normalizing their validation AUC \(\:(i.e.,\:{w}_{i}={AUC}_{i}/({\sum\:}_{j}{AUC}_{i}))\). The final score is
and a threshold of 0.5 is used to decide between real and manipulated images.
Experimental evaluation
SVM trained on the same fused feature vector (HOG + ResNet50) using an RBF kernel; hyperparameters C and γ were selected by grid search on the validation set. CNN is lightweight convolutional network with [N] convolutional layers and [M] fully connected layers, trained on 224 × 224 MRI images with the same pre-processing as AFFETDS. Optimization used Adam with learning rate η, batch size B, and early stopping based on validation loss. All baselines were trained for up to T epochs, with the best model selected using validation performance. To assess the model in a fair way, this paper segmented the dataset into three subsets − 70% for training, 15% for validation, and 15% for testing. This data split was essential for training the model, tuning the parameters, and finally testing the model with new data. Stratified sampling was utilized here so that the class distributions maintained relative proportions across the subsets. This allowed measurement of real-world performance and generalizability of the results.
AFFETDS, SVM, and CNN each contribute uniquely to tumor deep fake detection. AFFETDS integrates adversarial feature fusion for precise anomaly detection, SVM leverages hyperplanes for pattern recognition in high-dimensional spaces, and CNN excels in learning hierarchical features to distinguish real and synthetic tumors. Figure 5 presents the confusion matrix comparison for AFFETDS, SVM, and CNN on the held-out test set (N = 207). The proposed AFFETDS framework demonstrates the strongest classification performance, correctly identifying 107 real scans and 83 manipulated scans with only 17 total misclassifications (9 false positives and 8 false negatives). In contrast, SVM and CNN exhibit higher error counts, with SVM producing 28 misclassifications and CNN producing 24. AFFETDS achieves the highest accuracy (91.8%), outperforming both SVM (86.5%) and CNN (88.4%). The improved sensitivity toward manipulated tumor regions and the lower false-negative rate highlight the robustness of AFFETDS in detecting subtle deepfake modifications. Overall, the confusion matrix analysis clearly shows that AFFETDS provides the most reliable discrimination between real and manipulated tumor-bearing MRI scans.
In Fig. 6, the proposed AFFETDS framework demonstrates consistently superior performance, maintaining a high precision level (≈ 0.90–0.98) across a wide recall range. In contrast, the CNN model shows moderately strong performance, while SVM exhibits the earliest precision drop as recall increases. The higher Average Precision (AP) score achieved by AFFETDS indicates that it provides more reliable detection of manipulated tumor regions, especially under imbalanced decision thresholds. These results corroborate the improvements observed in the confusion matrix and ROC analyses, reaffirming the robustness of AFFETDS for tumor deepfake detection in MRI scans.

Confusion matrix comparison.

Precision-recall comparison.
The histogram in Fig. 7 reveals notable differences in probability distribution across the models. AFFETDS displays a uniform probability spread with a peak density around 0.5, indicating balanced confidence in its predictions. In contrast, SVM and CNN exhibit a skew toward lower probabilities, with peak densities around 0.3 or less, reflecting lower overall confidence in their predictions.
Figure 8 visualizes the probability distribution and variability of AFFETDS, SVM, and CNN. AFFETDS has a median probability of 0.49 with an IQR of 0.28–0.72, indicating moderate variation. In contrast, SVM (0.36) and CNN (0.39) show broader IQRs (0.21–0.61 for SVM, 0.23–0.65 for CNN), reflecting greater dispersion. Outliers in SVM and CNN suggest occasional deviations from the mean, whereas AFFETDS exhibits more consistent and higher-confidence predictions.

Predicted probabilities analysis.

Predicted probability distribution and variability.

Calibration curve.
Figure 9 illustrates the calibration performance of AFFETDS, SVM, and CNN by mapping predicted probabilities against actual positive outcomes. AFFETDS (dark orange curve) initially underestimates positive cases, with an average probability of 0.2 corresponding to < 10% positives. As the predicted probability rises to 0.6, the fraction of positives increases to ~ 30%, and at 0.9, it reaches ~ 70%, indicating improved calibration and higher confidence in predictions.
SVM (green curve) follows a similar trend but with less deviation from the diagonal. At 0.2, positives account for ~ 5%, increasing to ~ 25% at 0.6 and ~ 60% at 0.9, suggesting residual bias in predictions. CNN (blue curve) exhibits slightly larger deviations, with positives rising from < 5% at 0.2 to ~ 20% at 0.6 and ~ 55% at 0.9, indicating underestimation even at higher probabilities. Among the three, AFFETDS demonstrates superior calibration, aligning more closely with the diagonal and maintaining a balanced probability distribution. While SVM and CNN show calibration improvements, they retain bias and deviations, with SVM performing slightly better than CNN. These findings emphasize the importance of calibration analysis in assessing model reliability and precision.
Figure 10 presents representative qualitative examples of AFFETDS predictions. In correctly detected cases (Fig. 10a), the synthetic tumor exhibits clear boundary transitions, sharp textural changes, and distinct intensity irregularities, which the model highlights through strong feature activation. In contrast, misclassified cases (Fig. 10b) involve very small or low-contrast manipulated regions that blend naturally with surrounding tissue, producing weak activation and leading to false negatives. These observations demonstrate that AFFETDS performs reliably when manipulations introduce visible structural cues, while extremely subtle or blended modifications remain challenging even for human experts.

Qualitative examples of AFFETDS predictions.
Each experiment was repeated using several random seeds to assess variance in performance. We conducted a Wilcoxon signed-rank test comparing AFFETDS against the SVM and CNN baselines on AUC and F1-score distributions. The results show that AFFETDS significantly outperforms both baselines (p < 0.05), indicating that the improvements are statistically meaningful.
The proposed system enhances medical deepfake detection through ensemble classification, feature fusion and adversarial training. It integrates prediction aggregation, hybrid feature extraction and model that augment reliability to get better accuracy. Experimental results show its ability to keep medical imaging data intact. Future work on AFFETDS could aim to strengthen its detection of tumor deepfakes by improving adversarial training methods and adding domain-specific knowledge to feature fusion. This may help emphasize clinically important features and make results easier to interpret. Additionally, applying it to multimodal imaging, like CT, MRI, and PET scans, could further increase diagnostic precision and reliability.
Discussion and limitations
Clinical importance and practical relevance
The growing use of AI-generated manipulations in medical imaging poses a serious risk to diagnostic accuracy and patient safety. In this context, the AFFETDS framework offers practical value as a pre-screening tool that can automatically flag suspicious MRI scans before they reach radiologists. Such an automated safeguard can help reduce diagnostic errors caused by deepfakes, especially in high-workload hospital settings where manual verification is time-consuming and often impractical. Integrating AFFETDS into Picture Archiving and Communication Systems (PACS) or institutional quality-assurance workflows could provide an additional layer of protection against tampered data, ensuring that clinicians are alerted to potentially manipulated scans early in the diagnostic process.
Scope of the study
This study focuses specifically on tumor manipulations in brain MRI scans. The methodological emphasis is on combining adversarial robustness techniques with multimodal feature fusion to detect subtle appearance changes introduced through synthetic tampering. While the results demonstrate the feasibility and effectiveness of this approach, the findings are primarily relevant to MRI-based tumor detection. Nonetheless, the underlying principles—feature fusion, ensemble prediction, and adversarial training—have the potential to be transferred to other biomedical imaging contexts.
Limitations of the proposed model
Although the proposed framework demonstrates promising performance, several limitations should be acknowledged for transparency and future improvement: Despite its strong performance, the proposed AFFETDS framework has several limitations that should be acknowledged. This study exclusively is based on brain MRI. Other imaging modalities such as CT, PET, or X-ray exhibit different noise patterns, contrast levels, and structural characteristics, and the capability of AFFETDS to handle these modalities remains unexplored. The manipulated tumor images used for training and testing were generated synthetically through computational techniques, which, although effective in simulating realistic tampering, may not capture the full complexity of real-world adversarial attacks. Finally, due to computational constraints, the model was not benchmarked against the latest transformer-based or state-space architectures, which limits the breadth of comparison with cutting-edge deepfake detection methods.
Conclusion
The emergence of deepfake technology poses serious challenges for medical imaging. Clear visual data is essential for accurate diagnosis and treatment. To tackle this issue, the proposed Adversarial Feature Fusion Ensemble (AFFETDS) for Tumor Detection in Medical Imaging combines the handcrafted features with deep learning representations. This approach captures efficiently both detailed information and broader patterns. As a result, it improves the system’s ability to spot minor manipulations caused by tumor deepfakes boosting overall accuracy and trustworthiness.
AFFETDS increases the performance by using ensemble classification which merges predictions from multiple classifiers based on how well they perform individually. This approach ensures strength and adaptability across different datasets. Experimental results indicate that AFFETDS surpasses traditional methods like SVM (AUC ≈ 0.75) and CNN (AUC ≈ 0.78), achieving an AUC of about 0.80 in ROC analysis. Additionally, precision rates from 0.75 to 0.85 and recall rates from 0.70 to 0.80 confirm its capability to accurately distinguish real tumor images from synthetic ones.
By merging feature fusion techniques with ensemble learning strategies, AFFETDS solidifies medical image security, which helps protect patient safety and maintain the quality of diagnostic procedures. Its strong performance demonstrates its potential as a vital solution in the ongoing battle against tumor deepfakes in medical imaging.
Data availability
The data underlying this study are drawn from trusted, publicly accessible sources:1. The Cancer Imaging Archive (TCIA): Real MRI scans used in this research can be accessed at https://www.cancerimagingarchive.net/. TCIA provides a comprehensive collection of cancer-related imaging data for scientific research.2. Alzheimer’s Disease Neuroimaging Initiative (ADNI): Additional genuine MRI scans are available at https://adni.loni.usc.edu/data-samples/. ADNI is a widely used repository of high-quality neuroimaging and related data.
References
Dutta, H., Pandey, A. & Bilgaiyan, S. EnsembleDet: ensembling against adversarial attack on deepfake detection. J. Electron. Imaging. 30 (6), 063030–063030 (2021).
Albahli, S. & Nawaz, M. MedNet: medical deepfakes detection using an improved deep learning approach. Multimed. Tools Appl. 1–19 (2023).
Solaiyappan, S. & Wen, Y. Machine learning based medical image deepfake detection: A comparative study. Mach. Learn. Appl. 8, 100298 (2022).
Sharafudeen, M. & Vinod Chandra, S. S. Medical deepfake detection using 3-Dimensional neural learning. In IAPR Workshop on Artificial Neural Networks in Pattern Recognition, 169–180 (Springer International Publishing, 2022).
Chen, J., Hu, M., Zhang, D. & Meng, J. GC-ConsFlow: Leveraging Optical Flow Residuals and Global Context for Robust Deepfake Detection. arXiv preprint arXiv:2501.13435. (2025).
Song, W. et al. A Quality-Centric Framework for Generic Deepfake Detection (v3). arXiv preprint arXiv:2411.05335 (2025).
Zhang, Y. et al. Vulnerability to diffusion-model-based medical deepfakes: latent space analysis of diffusion-generated anomalies. Med. Image Anal. 96, 103124. https://doi.org/10.1016/j.media.2024.103124 (2024).
Kim, J. et al. FedSecure: privacy risks and protections in federated deepfake detection. IEEE J. Biomed. Health Inf. 28 (7), 3401–3413. https://doi.org/10.1109/JBHI.2024.3356721 (2024).
Mehta, A. et al. XAI-Med: interpretable medical deepfake detection using saliency and Grad-CAM. Comput. Med. Imaging Graph. 108, 102224. https://doi.org/10.1016/j.compmedimag.2024.102224 (2024).
Singh, R. et al. GAN-Defender: addressing generalization gaps in tumor manipulation detection. Pattern Recognit. 142, 109686. https://doi.org/10.1016/j.patcog.2023.109686 (2023).
Wang, L. et al. Spatio-temporal 3D CNN-LSTM for detecting volumetric deepfakes in MRI. IEEE Trans. Med. Imaging. 42 (12), 3476–3488. https://doi.org/10.1109/TMI.2023.3289045 (2023).
Arora, P., Gupta, S. & Kumar, D. FusionNet: multi-modal CT and MRI deepfake detection with cross-attention. Med. Phys. 50 (9), 5801–5814. https://doi.org/10.1002/mp.16421 (2023).
Huang, X. et al. LightDetect: real-time quantized deepfake detection in clinical imaging workflows. IEEE Access. 11, 123456–123468. https://doi.org/10.1109/ACCESS.2023.3298742 (2023).
Albahli, S. & Nawaz, M. MedNet: domain-specific detection of synthetic tumors in MRI scans. Multimed. Tools Appl. 81 (22), 32467–32482. https://doi.org/10.1007/s11042-022-13456-1 (2022).
Golany, T., Freedman, D. & Radinsky, K. DeepFake ECG: generating and detecting synthetic ECG traces with GANs. IEEE Trans. Biomed. Eng. 68 (10), 3028–3039. https://doi.org/10.1109/TBME.2021.3075621 (2021).
Agarwal, S. et al. DeepFakeStack: deep ensemble learning for video-based deepfake detection. Proc. IEEE CVPR Workshops. 2813–2822. https://doi.org/10.1109/CVPRW50498.2020.00356 (2020).
Goodfellow, I. et al. Generative adversarial nets. Adv. Neural Inform. Process. Syst. (NeurIPS) 2672–2680 (2014).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770–778 (2016).
Wang, H., Liu, X. & Zhang, Y. A hybrid CNN-SVM model for medical image forgery detection. Pattern Recognit. Lett. 146, 1–7 (2021).
Sabir, E., Cheng, J., Jaiswal, A., AbdAlmageed, W. & Natarajan, P. Recurrent convolutional strategies for deepfake detection. In IEEE International Conference on Advanced Video and Signal-Based Surveillance (AVSS), 1–6 (2019).
Clark, K. et al. The cancer imaging archive (TCIA): maintaining and operating a public information repository. J. Digit. Imaging. 26 (6), 1045–1057 (2013).
Jack, C. R. Jr et al. The alzheimer’s disease neuroimaging initiative (ADNI): MRI methods. J. Magn. Reson. Imaging. 27 (4), 685–691 (2008).
He, Z., Sun, Y. & Ruan, X. Detection of GAN-generated medical images. Comput. Methods Progr. Biomed. 221, 106923 (2022).
Zhu, J. et al. Detection of diffusion-based deepfakes in medical imaging using frequency domain analysis. Med. Phys. 50 (9), 5674–5685 (2023).
Simonyan, K. & Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556. (2015).
Dang, H. et al. On the detection of digital face manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 5781–5790 (2020).
Kurakin, A., Goodfellow, I. & Bengio, S. Adversarial machine learning at scale. arXiv preprint arXiv:1611.01236. (2017).
Madry, A., Makelov, A., Schmidt, L., Tsipras, D. & Vladu, A. Towards deep learning models resistant to adversarial attacks. Int. Conf. Learn. Represent. ICLR. (2018).
Xuan, X., Peng, B., Hong, Y., Wang, W. & Gao, X. Deepfake detection using capsule networks. In IEEE International Conference on Image Processing (ICIP), 1–5 (2019).
Afchar, D., Nozick, V., Yamagishi, J. & Echizen, I. MesoNet: a compact facial video forgery detection network. In IEEE International Workshop on Information Forensics and Security (WIFS), 1–7 (2018).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 770–778 (2016).
Niu, Y. et al. Deepfake detection based on vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 1509–1519 (2022).
Haliassos, A., Vougioukas, K., Petridis, S. & Pantic, M. Lips don’t lie: A generalisable and robust approach to face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 5039–5049 (2021).
Paszke, A. et al. PyTorch: an imperative style, high-performance deep learning library. In Advances Neural Inform. Process. Syst. (NeurIPS), 8026–8037 (2019).
Sabir, E. et al. Recurrent convolutional strategies for deepfake detection. In IEEE International Conference on Advanced Video and Signal-Based Surveillance (AVSS), 1–6 (2019).
Dang, H., Liu, F., Stehouwer, J., Liu, X. & Jain, A. On the detection of digital face manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 5781–5790 (2020).
Haliassos, A., Apostolidis, E., Mylonas, P. & Patras, I. Detecting deepfake videos using spatio-temporal features. IEEE Trans. Image Process. 31, 1202–1216 (2022).
Cozzolino, D. et al. ForensicTransfer: Weakly-supervised domain adaptation for forgery detection. arXiv preprint arXiv:1812.02510. (2018).
Hosseini, S. et al. Survey on Adversarial Attack and Defense for Medical Image Analysis. arXiv:2303.14133, (2024).
Bi, Y., Abrol, A., Fu, Z. & Calhoun, V. D. A multimodal vision transformer for interpretable fusion of functional and structural neuroimaging data. Hum. Brain. Mapp. 45 (17), e26783 (2024).
Zeineldin, R. A. et al. Explainable hybrid vision transformers and convolutional network for multimodal glioma segmentation in brain MRI. Sci. Rep. 14, 3713 (2024).
Acknowledgements
The authors.
Funding
This research was supported by Global-Learning & Academic research institution for Master’s·PhD students, and Postdocs (LAMP) Program of the National Research Foundation of Korea(NRF) grant funded by the Ministry of Education (No. RS-2023-00285353).
Author information
Authors and Affiliations
Contributions
A.A. and A.B. wrote this paper. K.T. and P. provided the research idea. S.K.G. and S.K. managed this project and funded this work.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ali, A., Basha, H.A., Thanuja, K. et al. Enhancing tumor deepfake detection in MRI scans using adversarial feature fusion ensembles. Sci Rep 16, 1667 (2026). https://doi.org/10.1038/s41598-025-31231-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-31231-7
