
Abstract
Detecting small objects in unmanned aerial vehicle (UAV) imagery remains a formidable challenge attributed to sparse pixel representation, intricate background compositions, and stringent computational limitations on edge devices. Conventional detection methodologies encounter substantial difficulties in establishing adequate feature representations and integrating contextual information when processing targets typically occupying fewer than \(32 \times 32\) pixels. AGEC-DETR, an enhanced RT-DETR-based framework specifically engineered for UAV small object detection through three novel architectural components, is introduced. The Attention-Gated Enhanced Backbone (AGEB) incorporates single-head self-attention mechanisms alongside convolutional gated linear units to strengthen feature extraction while capturing both local and global contextual dependencies. The Efficient Small Object Pyramid maintains and amplifies small object characteristics through SPDConv and CSP-MSFE structures, effectively mitigating feature dilution prevalent in conventional pyramid architectures. The Context-Aware Fusion Module enables adaptive multi-scale feature integration via context-aware mechanisms, substantially enhancing target-background discrimination capabilities. Extensive validation on the VisDrone 2019 dataset reveals that the proposed approach achieves 23.1% AP and 18.8% \(\hbox {AP}_{\text {small}}\), demonstrating improvements of 2.3% and 3.1% respectively compared to baseline RT-DETR-R18. When contrasted with RT-DETR-R50, the method preserves superior accuracy while reducing parameters and computational overhead by 65.5% and 51.3% respectively. Cross-dataset evaluation on DOTA and UAVDT datasets validates the method’s robust generalization capabilities, establishing its suitability for deployment on resource-constrained UAV platforms across diverse applications including urban surveillance, traffic monitoring, and smart city infrastructure.
Similar content being viewed by others

Introduction
The proliferation and widespread adoption of unmanned aerial vehicle (UAV) technology has generated substantial demand for sophisticated information extraction from UAV-captured aerial imagery. UAVs exhibit remarkable potential across diverse domains encompassing surveillance operations, geological surveys, precision agriculture, and disaster response systems1. Nevertheless, these applications encounter significant obstacles when target objects occupy minimal image regions (typically constrained to 32\(\times\)32 pixels or fewer), creating fundamental challenges for contemporary object detection frameworks2.
Small object detection in UAV imagery constitutes a critical computer vision task confronting three primary technical barriers. Initially, limited pixel coverage of targets yields inadequate feature representation, complicating the extraction of discriminative visual characteristics. Subsequently, UAV aerial imagery typically encompasses complex and variable backgrounds, diverse illumination conditions, and perspective variations, further amplifying the difficulty of distinguishing small foreground targets from cluttered environments. Finally, stringent real-time performance requirements and computational efficiency constraints on UAV platforms restrict the deployment feasibility of sophisticated, resource-intensive models3. These challenges collectively represent the principal technical bottleneck in UAV-based small object detection systems.
Traditional small object detection approaches predominantly utilize hand-crafted features combined with conventional machine learning algorithms. These methodologies typically employ techniques including Histogram of Oriented Gradients (HOG), Scale-Invariant Feature Transform (SIFT), and Support Vector Machines (SVM) for feature extraction and classification tasks4. Although these methods demonstrated reasonable success in controlled environments, they encounter significant limitations when processing the inherent variability and complexity characteristic of real-world aerial imagery, particularly exhibiting substantial accuracy degradation when handling small objects under varying illumination conditions and complex background scenarios5.
The advent of deep learning has fundamentally revolutionized the research paradigm in small object detection6. Deep convolutional neural networks (CNNs) have achieved remarkable advances in object detection, demonstrating enhanced robustness compared to traditional approaches when processing complex scenes, occlusions, and illumination variations7. Wu et al. presented a comprehensive survey of deep learning-based UAV object detection methods, examining key challenges including small object detection, object rotation, and scale variations8. Feng et al. conducted detailed analysis of deep learning applications in small object detection, summarizing enhancement strategies for improving small object detection performance across four dimensions: input feature resolution enhancement, scale-aware training methodologies, contextual information integration, and data augmentation techniques.
Real-time object detection has emerged as an increasingly crucial technology in UAV remote sensing applications due to its superior detection efficiency and rapid response capabilities9. The YOLO (You Only Look Once) series of detectors has gained substantial popularity for their exceptional balance between accuracy and inference speed10. Redmon et al. initially introduced the YOLO methodology, reformulating object detection as a regression problem and achieving breakthrough performance in real-time object detection11. Subsequent research has continuously refined the YOLO architecture, persistently improving detection accuracy while maintaining high processing speeds12. Recent developments in the YOLO series have undergone multiple optimization iterations, with each version addressing specific detection challenges13.
The introduction of Vision Transformer (ViT) has introduced novel opportunities to the computer vision domain14. ViT demonstrates exceptional capabilities in capturing global context and modeling long-range dependencies, which proves essential for accurate object detection, particularly small objects in complex scenes15. Khan et al. provided comprehensive surveys of Transformers in computer vision, analyzing their application potential in tasks such as object detection. However, direct application of ViT to object detection tasks encounters challenges, particularly when processing multi-scale targets16. Rekavandi et al. specifically conducted benchmarking and surveys on Transformer applications in small object detection, demonstrating the superiority of Transformers in small object recognition tasks17.
DETR (DEtection TRansformer) formulates object detection as a direct set prediction problem, comprising a set-based global loss function and a Transformer encoder-decoder architecture18. DETR eliminates numerous hand-designed components including non-maximum suppression procedures and anchor generation, significantly simplifying the detection pipeline19. However, the original DETR model suffers from slow training convergence and suboptimal small object detection performance20. Shehzadi et al. conducted comprehensive surveys of DETR and its variants, analyzing 21 DETR improvement methods including backbone network modifications, query design strategies, and attention mechanism enhancements21.
Recent advancements in Transformer-based detection have addressed specific challenges in complex scenarios. Than et al. introduced Occlusion-Aware Efficient Transformer Attention (OAETA) and Multi-Scale Long-Range Feature Aggregation (MLFA) to improve detection of partially occluded objects 22. Ha et al. developed YOLO-SR with Balanced Detail Fusion and multi-scale dilation residual blocks specifically for SAR imagery ship detection under challenging conditions 23. Nguyen et al. proposed hybrid CNN-Transformer architectures with Multi-Scale Adaptive Attention Module (MSAAM) for enhanced small object detection in remote sensing 24, while Nguyen and Pham introduced focus-attention approaches to optimize DETR computational efficiency for high-resolution images 25.
In the domain of frequency-based analysis, Taghipour and Ghassemian 26 demonstrated the effectiveness of frequency-domain cues for separating fine, repetitive structures from background in hyperspectral anomaly detection, which aligns with our frequency-aware components (MSFE/DCAM) designed to amplify small-object textures under UAV conditions. Furthermore, Taghipour and Ghassemian 27 introduced attention-driven spatial-spectral fusion strategies that parallel our attention mechanisms (AGEB/CAFM), providing conceptual support for emphasizing salient targets while suppressing clutter in remote sensing applications.
RT-DETR, developed by Baidu, represents a state-of-the-art end-to-end object detector providing real-time performance while maintaining high accuracy28. It builds upon DETR’s foundational concepts while introducing a convolution-based backbone and an efficient hybrid encoder for real-time speed. RT-DETR surpasses YOLO in real-time object detection, marking a significant milestone in Transformer-based detection method development.
However, Transformer-based models continue to face considerable challenges when processing small objects in UAV aerial imagery: their substantial computational requirements and suboptimal detection of densely distributed small objects limit their applicability in UAV imaging scenarios. For UAV object detection evaluation, the VisDrone dataset has established itself as a critical benchmark in this field29. The dataset comprises 288 video sequences and 10,209 static images covering various scenarios from 14 different cities, providing a comprehensive evaluation platform for assessing UAV object detection algorithms. Du et al. detailed the construction process and challenge results of the VisDrone dataset, demonstrating current performance levels of UAV object detection algorithms30.
Despite significant advances in small object detection technology, three fundamental challenges persist in UAV aerial scenarios. First, insufficient feature representation: small objects occupy minimal pixels in images (typically fewer than 32\(\times\)32 pixels), and after multiple layers of convolution and downsampling, their feature information becomes severely diluted, resulting in inadequate discriminative features31. Second, inadequate context awareness: UAV aerial images typically contain complex and variable background environments, and existing methods often lack effective contextual information integration mechanisms, making it difficult to understand relationships between targets and their surrounding environments, leading to increased false detection rates32. Finally, computational resource constraints: UAV platforms impose strict requirements for algorithm real-time performance and computational efficiency. High-precision detection models typically require substantial computational resources, making them difficult to deploy on resource-constrained edge devices33.
Addressing these three fundamental challenges, this research proposes an improved RT-DETR-based small object detection algorithm specifically designed for UAV aerial imagery. The primary innovative contributions include:
-
An attention-gated enhanced backbone (AGEB) module that integrates single-head self-attention (SHSA) with convolutional gated linear units (CGLU) within the C2f structure to enhance feature extraction capabilities. This design effectively captures both local and global contextual information, addressing the critical issue of insufficient feature representation.
-
An efficient small object pyramid (ESOP) module that preserves and enhances small object features through SPDConv and CSP-MSFE architectures. This module effectively integrates low-level high-resolution feature information, resolving the problem of small object feature dilution in traditional feature pyramids while avoiding significant computational overhead increases.
-
A context-aware fusion module (CAFM) that adaptively guides multi-scale feature fusion. This innovation addresses the problem of insufficient contextual information integration in traditional feature fusion methods, significantly improving the model’s ability to distinguish small objects in complex backgrounds.
Through integrating these innovations within the RT-DETR framework, the proposed method achieves exceptional small object detection performance in UAV aerial imagery while maintaining real-time inference capabilities, addressing key challenges in this field.
Rather than pursuing abstract algorithmic breakthroughs, this research addresses three critical engineering challenges in UAV small object detection: feature dilution in resource-constrained environments, contextual insufficiency in complex aerial backgrounds, and computational efficiency requirements for edge deployment. Our AGEC-DETR framework integrates proven attention mechanisms, feature pyramids, and fusion methods in a synergistic manner specifically optimized for the constraints and requirements of UAV platforms, achieving dual improvements in detection performance and computational efficiency.
Methods
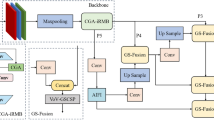
Targeting the core challenges of insufficient feature representation, inadequate context awareness, and computational resource constraints encountered in small object detection within UAV aerial imagery, this research proposes a small object detection algorithm based on improved RT-DETR named AGEC-DETR. The acronym AGEC-DETR represents Attention-Gated Enhanced backbone with Context-aware fusion in DETR. As illustrated in Figure 1, the overall architecture integrates three key innovative modules within the RT-DETR framework foundation: AGEB backbone network, ESOP, and CAFM modules.
Throughout this paper, we use the following notation conventions:
-
\(\oplus\) denotes element-wise addition
-
\(\odot\) denotes element-wise multiplication (Hadamard product)
-
\(\text {Cat}[\cdot ,\cdot ]\) denotes channel-wise concatenation
-
\(\Gamma\) denotes feature concatenation operation

The overall architecture of the improved RT-DETR framework for UAV small object detection. Cat represents channel-wise concatenation operation.
Attention-gated enhanced backbone (AGEB)
Traditional ResNet backbone networks exhibit substantial limitations when processing UAV aerial small object recognition tasks. Initially, the continuously stacked convolutional downsampling structure leads to rapid spatial resolution decline, causing severe loss of small object spatial information in deep features. Additionally, the singular feature fusion path in ResNet structures proves insufficient to adapt to complex scale variations and viewpoint differences in aerial imagery. Addressing these limitations, this research proposes the AGEB-based backbone network shown in Figure 2, which significantly enhances small object feature extraction capability through fusing spatial attention mechanisms and convolutional gated linear units, effectively resolving problems of feature dilution, insufficient context awareness, and target-background discrimination difficulties, thereby improving the model’s discrimination capability for small objects in complex backgrounds. The AGEB module specifically addresses the challenge of feature dilution that occurs when small objects lose critical spatial information through multiple downsampling layers.

Architecture of the attention-gated enhanced backbone (AGEB). \(\oplus\) represents element-wise addition, \(\odot\) represents element-wise multiplication (Hadamard product).
Through integrating these innovations in the RT-DETR framework, the proposed method achieves outstanding small object detection performance in UAV aerial imagery while maintaining real-time inference capability, resolving key challenges in this field.
The AGEB backbone network initially utilizes two consecutive standard convolution layers for feature downsampling, rapidly obtaining fundamental feature maps. Subsequently, C2f modules are introduced in shallow layers to preserve rich low-level feature information, while in intermediate and deep layer feature extraction processes, global contextual information is captured through single-head self-attention mechanisms, and dynamic feature selection and enhancement are performed using convolutional gated linear units.
The AGEB module achieves efficient feature extraction through fusing channel splitting strategies, attention mechanisms, and gating units. It initially maps and splits input features x into two parallel branches through an initial \(1 \times 1\) convolution layer, with the first branch directly preserved as a skip connection and the second branch progressively enhanced through n cascaded SHSA-CGLU (SCG) modules. Finally, all branch features are concatenated and fused through a \(1 \times 1\) convolution layer, outputting enhanced feature representations with dimension \(C_2\). The mathematical expression of this module is formulated as:
where \(x \in \mathbb {R}^{B\times C\times H\times W}\), \(F_0, F_1 \in \mathbb {R}^{B\times (C/2)\times H\times W}\), \(\Psi _i(F_1) \in \mathbb {R}^{B\times (C/2)\times H\times W}\), \(F_0\) and \(F_1\) represent two branches split from input feature x after cv1 convolution, \(\Psi _i\) denotes the transformation function of the i-th SCG module, Cat represents channel-wise feature concatenation operation, and \(\Phi _{1 \times 1}\) denotes the final \(1 \times 1\) convolution transformation. This design cleverly combines CSP concepts with attention mechanisms, significantly enhancing feature expression capability while maintaining computational efficiency.
The SCG comprises three key components in cascade: depth convolution residual unit, single-head self-attention mechanism, and convolutional gated linear unit. The overall transformation process of this module can be expressed through the following equation, clearly demonstrating the information flow and residual connections of each sub-module:
where the first \(\mathscr {F}_{DW}(x) + x\) represents the depth convolution residual unit, and the second \(\mathscr {F}_{DW}(x) + x\) represents the residual connection for the entire SCG block, \(\mathscr {F}_{DW}\) represents depth convolution transformation, \(\mathscr {F}_{SHSA}\) represents single-head self-attention transformation, and \(\mathscr {F}_{CGLU}\) represents convolutional gated linear unit transformation. As shown in Figure 3, the core operation of the SHSA single-head self-attention mechanism can be described as: initially splitting input feature x into two parts \(x_1\) and \(x_2\), performing self-attention computation on \(x_1\) and subsequently merging with \(x_2\).
The computation process can be expressed as:
where \(Q,K,V \in \mathbb {R}^{B\times (C/h)\times H\times W}\), h denotes the number of heads (\(h=1\) for single-head), \(\tau = 1.0\) is the softmax temperature, and the attention is computed after LayerNorm, Q, K, V represent query, key, and value matrices obtained from \(x_1\) through linear transformations, \(d_k\) is the scaling factor.

Detailed architecture of the single-head self-attention (SHSA) module.
The CGLU convolutional gated linear unit constitutes an efficient feature modulation mechanism that dynamically controls information flow in feature channels through gating, with its operation precisely expressed as:
where \(x_A\) and \(x_V\) represent feature pairs split from input x through \(1 \times 1\) convolution, \(\mathscr {D}\) represents depth-wise separable convolution and activation function operations, \(\odot\) represents Hadamard product, and \(\mathscr {P}\) represents the combination of \(1 \times 1\) convolution projection and Dropout operations.
The SCG-based AGEB backbone network demonstrates significant advantages in UAV small object recognition tasks. Compared to traditional ResNet backbones, the AGEB backbone achieves substantial improvement in detection accuracy, particularly excelling when processing extremely small objects occupying less than 1% of the image; its adaptive feature enhancement mechanism significantly improves the model’s robustness to environmental changes; through the fusion of attention mechanisms and gating units, the AGEB backbone can more accurately distinguish small foreground objects from complex backgrounds, reducing false detection rates. Moreover, despite introducing complex attention and gating mechanisms, the AGEB backbone maintains relatively low computational complexity through strategic module design and parameter sharing, making it suitable for deployment on resource-constrained UAV platforms. Overall, the AGEB backbone provides a balanced solution between accuracy and efficiency for UAV aerial small object recognition, offering novel technical pathways and theoretical support for practical applications in related fields.
Efficient small object pyramid (ESOP)
Traditional convolutional feature fusion frameworks (CCFF) encounter significant challenges when processing UAV aerial small object recognition tasks. These networks typically perform feature integration through simple feature concatenation or weighted summation, lacking effective representation capability for subtle differences between objects and backgrounds. Addressing these limitations, this research proposes the Efficient Small Object Pyramid (ESOP) feature fusion network, which effectively integrates spatial, frequency domain, and channel dimension feature representations through multi-dimensional information collaborative processing mechanisms, significantly improving the model’s detection capability for small objects. The ESOP module focuses on preserving high-resolution spatial details from shallow network layers that are crucial for small object detection.
The ESOP feature fusion network constructs a multi-level feature extraction and optimization framework from pixels to semantics, with its core innovation residing in the organic combination of Spatial Partition Dimensional Convolution (SPDConv), Cross Stage Partial Multi-Scale Frequency Enhancement (CSP-MSFE), and hierarchical feature interaction mechanisms. The network initially performs spatial reorganization and dimensionality reduction processing on shallow features through SPDConv, preserving key detail information of small objects; subsequently, upsampled high-level features are multi-source fused with processed shallow features, achieving comprehensive feature enhancement through CSP-MSFE; finally, deep associations between multi-scale features are established through RepC3 modules. The mathematical expression of the ESOP feature fusion network can be formalized as:
where \(\mathscr {R}\) represents RepC3 operation, \(\mathscr {M}\mathscr {S}\mathscr {F}\mathscr {E}_{CSP}\) represents CSP-MSFE module, \(\mathscr {C}\) denotes feature concatenation operation, \(\mathscr {U}\) represents upsampling operation, and SPD represents spatial partition dimensional convolution. \(X_{S2}\), \(X_{S4}\), and \(X_{S5}\) represent feature maps from Stage 2, Stage 4, and Stage 5 respectively, as shown in Figure 1.
As illustrated in Figure 4, the CSP-MSFE module is based on cross-stage partial network design concepts, achieving a balance between computational efficiency and feature expression capability through feature splitting and multi-scale frequency enhancement strategies.

Detailed architecture of CSP-MSFE.
The module initially projects input feature X to the same dimensional space through \(1 \times 1\) convolution, then splits the processed features into two parts: one part undergoes deep feature extraction through Multi-Scale Frequency Enhancement (MSFE), while the other part is directly preserved as identity mapping to retain original information. Finally, enhanced features are merged with identity features along the channel dimension and integrated through another \(1 \times 1\) convolution to form the final output. The computation process of CSP-MSFE can be described as:
where \(\mathscr {W}_2\) represents output \(1 \times 1\) convolution operation, \([\cdot ,\cdot ]\) represents channel-wise concatenation, \(\mathscr {F}_{MSFE}\) represents Multi-Scale Frequency Enhancement transformation function, and \(X_e\) and \(X_{1-e}\) are two parts split from input features after \(1 \times 1\) convolution according to ratios e and \(1-e\).
MSFE designs a multi-dimensional feature enhancement mechanism that simultaneously integrates directional-aware convolution, frequency domain channel attention, and frequency domain guidance modules. Initially, input features undergo preliminary processing through \(1 \times 1\) convolution and GELU activation function; subsequently, four types of depth-wise separable convolutions (\(1 \times 31\), \(31 \times 1\), \(31 \times 31\), and \(1 \times 1\)) are applied in parallel to capture multi-directional and multi-scale feature representations; simultaneously, features are enhanced in the frequency domain through Frequency Channel Attention (FCA) mechanisms, followed by further optimization of feature representations using Spatial Channel Attention (SCA); finally, the Frequency Guidance Module (FGM) performs fine adjustment on enhanced features and fuses them with original multi-directional features before generating final features through output convolution. The entire processing flow can be expressed as:
where \(\mathscr {W}_{in}\) and \(\mathscr {W}_{out}\) represent input and output \(1 \times 1\) convolutions respectively, \(\mathscr {D}_i\) represents different shaped depth-wise separable convolutions, and \(\sigma\) represents ReLU activation function. The summation is performed over four different directional convolution operations with kernel shapes 1\(\times\)31, 31\(\times\)1, 31\(\times\)31, and 1\(\times\)1, respectively.
Directional Convolution and Attention Mechanism (DCAM) integrates spatial and frequency domain information, with its computation process as:
where \(\mathscr {F}\) and \(\mathscr {F}^{-1}\) represent Fourier transform and inverse Fourier transform respectively, and \(A_f\) and \(A_s\) are frequency domain and spatial attention weights generated by \(1 \times 1\) convolution and global average pooling respectively.
The Frequency Guidance Module (FGM) further optimizes feature representations through frequency domain transformations and residual connections:
where \(\mathscr {W}_1\) and \(\mathscr {W}_2\) are \(1 \times 1\) convolution layers, \(\odot\) represents element-wise multiplication, and \(\alpha\) and \(\beta\) are learnable channel-wise scaling parameters. FGM achieves adaptive modulation of different frequency components through frequency domain multiplication operations, effectively enhancing frequency domain features specific to small objects, while residual connections ensure lossless information transmission.
For all FFT operations in Equations (9) and (10), we use the standard PyTorch FFT implementation with orthogonal normalization. Complex values are handled using magnitude \(|\cdot |\) for DCAM and element-wise multiplication \(\odot\) for FGM. The learnable parameters \(\alpha\) and \(\beta\) in Equation (10) are initialized using Xavier initialization with range constraints: \(\alpha \in [0.1, 2.0]\), \(\beta \in [0.1, 2.0]\), and are updated during training via gradient descent.
SPDConv (Spatial Partition Dimensional Convolution) module implements efficient spatial partition and dimensional reorganization strategies for low-level feature processing and transformation, as illustrated in Figure 5. The module adopts a grid partition method, dividing input feature map X according to \(2 \times 2\) pixel grids into four sub-feature maps, with each sub-feature map containing one-quarter of the original feature’s spatial resolution but retaining complete channel information. These four sub-feature maps are concatenated along the channel dimension, forming feature representations with quadrupled channel count but halved spatial resolution, followed by feature integration and dimensional adjustment through \(3 \times 3\) convolution. The mathematical expression of SPDConv is:
where \(\mathscr {W}_{3 \times 3}\) represents \(3 \times 3\) convolution operation, \(\mathscr {C}\) represents channel-wise concatenation operation, and \(X_{ij} = X[\ldots , i::2, j::2]\) represents sub-feature maps obtained by sampling from input feature X with specific strides.

Detailed architecture of SPDConv.
The ESOP feature fusion network significantly improves the performance of the improved RT-DETR model in UAV aerial small object detection tasks through its multi-dimensional feature enhancement and fusion mechanisms. The network preserves detail information of small objects through SPDConv processing of low-level features; achieves comprehensive feature enhancement through CSP-MSFE, improving feature discriminability; and establishes scale-invariant feature representations through multi-level feature interactions.
Context-aware fusion module (CAFM)
Traditional feature fusion methods, including simple feature concatenation and element-wise addition, ignore semantic differences and spatial distribution inconsistencies between cross-layer features, leading to mutual interference between high-level semantic information and low-level spatial details during the fusion process. Addressing this key challenge, the Context-Aware Fusion Module (CAFM) is proposed, as shown in Figure 6, which realizes intelligent selective fusion between features through introducing context-aware adaptive weight mechanisms. CAFM establishes dynamic interaction channels between features, effectively enhancing complementarity between different scale features while preserving their respective advantageous information, thereby resolving the problem of insufficient small object feature expression and significantly improving the model’s detection capability for small objects in UAV aerial imagery. The CAFM module enhances context recognition capabilities in complex aerial backgrounds where traditional fusion methods fail to distinguish targets from cluttered environments.

Detailed architecture of context-aware fusion module (CAFM).
The core principle of the context-guided fusion module involves achieving intelligent fusion of cross-layer features through context-aware adaptive mechanisms. Given feature maps from different levels \(X_l \in \mathbb {R}^{B\times C_l\times H\times W}\) and \(X_h \in \mathbb {R}^{B\times C_h\times H\times W}\), CAFM initially unifies feature channel dimensions through adjustment convolution layers, then utilizes context-aware mechanisms to generate adaptive weights, and finally generates enhanced feature representations through innovative cross-fusion strategies. The entire processing flow is formalized as the following mathematical expression:
where \(X'_l = \phi (X_l)\) represents low-level features adjusted through \(1\times 1\) convolution; \(W_l\) and \(W_h\) are adaptive weight functions corresponding to low-level and high-level features generated by the CAA module; \(\oplus\) represents element-wise addition; and \(\Gamma\) represents feature concatenation operation.
In specific implementation, CAFM initially concatenates adjusted features along the channel dimension, then generates weights through the CAA module, applies the decomposed weights to respective features, and finally completes fusion through cross-addition and concatenation:
where \(\text {Cat}[\cdot ,\cdot ]\) represents channel-wise concatenation, \(\Lambda _{CAA}\) represents the process of CAA module generating and decomposing adaptive weights, and \(\odot\) represents element-wise multiplication.
The Context-Aware Adaptive (CAA) module effectively captures long-range spatial dependencies and enhances perception of small objects by combining multi-scale contextual information with directional-aware convolution operations. To efficiently extract global context and generate precise attention weights, the following innovative processing flow is designed:
In this expression, \(\Pi _7\) represents average pooling operation with parameters (7,1,3) for reducing computational complexity while extracting main structural features; \(\psi\) and \(\varphi\) are standard convolution layers for feature transformation; \(\mathscr {D}_{k_h}^h\) and \(\mathscr {D}_{k_v}^v\) represent horizontal and vertical directional depth-wise separable convolutions with kernel sizes \(k_h\) and \(k_v\) respectively; \(\sigma\) is the Sigmoid activation function; and \(\odot\) represents element-wise multiplication.
The key innovation of the CAA module lies in its bidirectional depth-wise separable convolution design, which decomposes two-dimensional convolution into orthogonal one-dimensional operations, reducing computational complexity while expanding receptive field range. Horizontal convolution \(\mathscr {D}_{k_h}^h\) captures horizontal spatial dependencies, while vertical convolution \(\mathscr {D}_{k_v}^v\) captures vertical spatial dependencies, enabling the module to comprehensively understand contextual relationships between objects and their environments.
The Context-Aware Fusion Module (CAFM) combines context-aware adaptive weight generation with cross-enhanced feature fusion strategies, significantly improving the model’s detection performance for small-scale, low-contrast, and densely distributed objects. Compared to the baseline RT-DETR model, the improved method maintains computational efficiency and real-time performance while achieving higher detection accuracy and lower missed detection rates. CAFM enhances the model’s comprehensive utilization capability for different scale features through optimized contextual information extraction and adaptive feature fusion, making UAV small object detection systems more robust and adaptive in practical applications.
Our framework design addresses three fundamental challenges through targeted module design: AGEB tackles feature dilution after multi-layer downsampling by enhancing small target features, ESOP preserves high-resolution information in shallow layers to prevent detail loss, and CAFM improves context recognition in complex backgrounds. These three modules work synergistically to optimize the entire detection pipeline while maintaining lightweight design suitable for resource-constrained UAV platforms.
Results
To comprehensively evaluate the performance of the improved RT-DETR-based UAV small object recognition algorithm, this section provides detailed descriptions of experimental datasets, experimental environment and configuration, evaluation metrics, as well as ablation and comparative experimental results. Through systematic experiments, the effectiveness and superiority of the proposed improvement method in UAV aerial image small object detection are validated.
Dataset and implementation details
The VisDrone 2019 dataset is employed primarily for ablation and comparative experiments, while using DOTA34 and UAVDT35 datasets to validate the generalization performance of the proposed method.
The VisDrone 2019 dataset represents a large-scale UAV visual detection benchmark dataset constructed by the AISKYEYE team from the Machine Learning and Data Mining Laboratory at Tianjin University, specifically designed for evaluating object detection algorithms on UAV platforms. Small objects account for over 60% of this dataset, while large objects constitute only 5%, making it an ideal benchmark for evaluating small object detection performance. In this study, the official division is followed, using 6,471 images as the training set, 548 images as the validation set, and 3,190 images as the test set. To ensure compatibility with actual UAV platforms, all images are resized to 640\(\times\)640 pixels during experiments.
To validate the algorithm’s generalization capability, DOTA and UAVDT are also employed as auxiliary datasets. The DOTA (Dataset for Object Detection in Aerial Images) dataset contains 2,806 aerial images ranging in size from 800\(\times\)800 to 20,000\(\times\)20,000 pixels, providing annotations for 188,282 instances across 15 categories. The UAVDT (Unmanned Aerial Vehicle Detection and Tracking) dataset selects approximately 80,000 representative frames from 10 hours of raw video, annotating 835,879 target bounding boxes primarily including cars, trucks, buses, and small vehicles. These two datasets are used solely for validating model generalization performance across different scenarios, with primary algorithm development and evaluation based on the VisDrone 2019 dataset.
All experiments are conducted on a computing platform configured with Intel(R) Xeon(R) CPU E5-2680 V4 @2.40GHz \(\times\) 7 cores, 32 GB DDR4 memory, and NVIDIA GeForce RTX 3090 graphics card. The experimental deep learning framework employs Python 3.8 and PyTorch 1.13.1+CUDA11.7.
For model training, RT-DETR-R18 is used as the base architecture, integrating the proposed AGEB, ESOP, and CAFM modules. The batch size is set to 8, initial learning rate to 0.0001, optimizer to AdamW, weight decay coefficient to 0.0001, training for 300 epochs on the VisDrone 2019 dataset.
Evaluation metrics
Standard metrics from the COCO evaluation system are adopted to comprehensively assess object detection performance, particularly focusing on quantitative evaluation of small object detection capabilities. To provide a complete evaluation framework, we first introduce the fundamental metrics of Precision (P) and Recall (R), which form the foundation for more comprehensive evaluation indicators.
Precision measures the proportion of correctly identified positive instances among all predicted positive instances, mathematically expressed as:
where TP represents true positives (correctly detected objects) and FP represents false positives (incorrectly detected background regions as objects).
Recall quantifies the proportion of correctly identified positive instances among all actual positive instances, formulated as:
where FN represents false negatives (missed object detections).
Building upon these fundamental metrics, Average Precision (AP) serves as the core evaluation metric for object detection, reflecting the overall performance of detectors by integrating precision and recall across different confidence thresholds. AP is computed as the area under the precision-recall curve, expressed as:
where P(r) represents the precision as a function of recall r.
The COCO evaluation system calculates AP across multiple IoU thresholds, specifically expressed as:
where \(T = \{0.5, 0.55, 0.6, \ldots , 0.95\}\) represents a series of IoU thresholds, and \(AP_t\) represents the average precision at specific IoU threshold t.
Additionally, the following standard metrics are adopted: \(\hbox {AP}_{50}\) (average precision at IoU threshold 0.5) and \(\hbox {AP}_{small}\) (average precision for small objects with area < 32\(\times\)32 pixels). Considering the specificity of small objects in UAV aerial imagery, evaluation metrics are specifically introduced for ultra-small objects: \(\hbox {AP}_{tiny}\) (average precision for tiny objects with area < 16\(\times\)16 pixels) and \(\hbox {AP}_{vtiny}\) (average precision for very tiny objects with area < 8\(\times\)8 pixels). These metrics enable more detailed evaluation of algorithm detection capabilities for different scale small objects, holding important significance for UAV aerial scenario small object detection research.
Resolution-latency trade-off analysis
To evaluate the computational efficiency across different input resolutions, we test our trained AGEC-DETR model at two inference scales on the VisDrone dataset. Table 1 presents the performance comparison between \(640 \times 640\) and \(960 \times 960\) input resolutions.
Per-class \(\hbox {AP}_{\text {small}}\) analysis for frequent categories
Table 2 shows the \(\hbox {AP}_{\text {small}}\) breakdown for the five most frequent small object categories in VisDrone, demonstrating our method’s effectiveness on truly small targets.
Ablation studies
To validate the effectiveness of each proposed improvement module, a series of ablation experiments are conducted on the VisDrone 2019 test set, analyzing each module’s contribution to overall performance.
AGEB ablation study
The AGEB module significantly enhances the model’s small object feature extraction capability by integrating self-attention mechanisms with gated linear units. As shown in Table 3, experimental results demonstrate that the proposed AGEB module effectively improves object detection performance, achieving improvements of 2.0%, 2.1%, and 1.0% in AP, APsmall, and APtiny metrics respectively. This performance improvement is primarily attributed to precise spatial attention modeling by the SHSA mechanism and enhanced feature expression capability by CGLU.
Comparing effects of different application strategies, applying AGEB solely at the P4 position (layer 8, producing S5 features) already achieves significant improvement, proving the effectiveness of this module design. Multi-stage simultaneous application also shows improvement, but the effect is relatively moderate, indicating that excessive attention mechanisms may lead to feature representation redundancy. The proposed configuration applies AGEB at positions P3 and P4 (layers 6 and 8, producing S4 and S5 features), effectively controlling computational complexity while ensuring performance improvement.
ESOP module ablation study
The ESOP (Small Object Enhance Pyramid) module achieves optimization specifically for small object detection through innovative feature pyramid design. As presented in Table 4, experimental results show that this module achieves 0.5% and 0.8% improvements in AP and \(\hbox {AP}_{small}\) metrics respectively, validating its enhancement effect for small object detection. In Table 4, the size descriptors refer to the kernel sizes of directionalconvolutions in the MSFE module (e.g., Size-31 uses 1×31 and 31×1 convolutions) within different ESOP configurations. Specifically: Size-15 uses 1\(\times\)15 and 15\(\times\)1 separable convolutions, Size-31 uses 1\(\times\)31 and 1\(\times\)31 separable convolutions (our proposed configuration), and Size-63 uses 1\(\times\)63 and 63\(\times\)1 separable convolutions.
The proposed ESOP configuration effectively avoids computational redundancy problems of traditional P2 detection layers through carefully designed multi-branch feature learning strategies, while enhancing small object feature expression capability. Compared to other configurations, the design achieves optimal balance between computational complexity and detection performance while ensuring detection accuracy, providing strong support for precise detection of dense small objects in UAV aerial scenarios.
Overall ablation study
The overall ablation study reveals the synergistic effects and respective contribution characteristics of the three improvement modules, as detailed in Table 5. The AGEB module (A), as the core feature extraction enhancement component, contributes most significantly to performance improvement, increasing the AP metric by 2.0%, fully demonstrating the superiority of self-attention mechanisms in small object feature enhancement. The ESOP module (B) and CAFM module (C), while having relatively smaller individual contributions, play important auxiliary roles in feature pyramid optimization and contextual information fusion.
Module combination analysis shows that the A+B synergistic configuration achieves 22.30% AP performance, proving the effective combination of feature enhancement and pyramid optimization. Notably, the B+C combination performs poorly, further validating the fundamental role of strong feature extraction capability in the entire detection framework.
The complete three-module integration scheme (A+B+C) achieves optimal performance, reaching 23.10% and 18.80% in AP and \(\hbox {AP}_{small}\) metrics respectively, representing 3.0% and 3.1% improvements over the baseline model. This result fully validates the effectiveness of the proposed multi-module collaborative design strategy, demonstrating that complementary advantages between modules can significantly improve small object detection performance in UAV aerial imagery.
It is worth noting that while our method achieves significant improvements in overall AP and \(AP_{small}\) metrics, there are slight decreases in \(AP_{tiny}\) (from 2.5% to 2.4%) and \(AP_{vtiny}\) in some configurations. This trade-off occurs because our attention mechanisms are optimized for objects in the 16\(\times\)16 to 32\(\times\)32 pixel range, which represents the majority of small objects in UAV imagery. The slight performance decrease on ultra-tiny objects (< 8\(\times\)8 pixels) is acceptable given the substantial improvements in the more common small object categories and the overall detection performance.
Submodule ablation study
Table 6 presents the detailed ablation study results for individual subcomponents within each proposed module. Removing the attention mechanism from AGEB (AGEB w/o attention) achieves 21.2% AP, demonstrating that attention contributes significantly to the overall performance gain. Similarly, removing the gating mechanism (AGEB w/o gating) results in 21.0% AP, confirming the importance of the Contextual Gated Linear Unit for feature refinement. The ESOP module without frequency enhancement (ESOP w/o frequency) shows only marginal improvement over baseline (20.4% AP), validating the critical role of frequency-domain processing for small object detection. The CAFM module without context-weight mechanism (CAFM w/o context-weight) achieves 20.3% AP, indicating moderate but consistent contribution to overall performance.
The complete model achieves 23.1% AP and 18.8% \(AP_{small}\) with 14.84M parameters and 65.7 GFLOPs, demonstrating that the synergistic integration of all components significantly outperforms individual contributions and maintains computational efficiency.
Comparative experiments
To comprehensively evaluate the superiority of the proposed method, it is compared with current mainstream object detection algorithms on the VisDrone 2019 dataset test set. The comparative results are presented in Table 7.
Comparative experimental results demonstrate that the proposed method achieves 23.1% AP, surpassing all comparison algorithms and representing a 2.3% improvement over baseline RT-DETR-R18. More importantly, compared to RT-DETR-R50 with larger parameter count and computational requirements, the method not only leads by 1.5% in accuracy but also demonstrates significant efficiency advantages, reducing parameters and computation by 65.5% and 51.3% respectively, fully demonstrating the superiority of the proposed improvement strategy.
In the crucial \(\hbox {AP}_{small}\) metric, the method achieves 18.8%, representing a 3.1% improvement over RT-DETR-R18 and leading RT-DETR-R50 by 1.9%. This significant improvement fully proves the effectiveness of the specialized design strategy for small object detection proposed in this research.
Compared to the widely applied YOLO series algorithms, the method demonstrates clear technical advantages. Compared to YOLOv11s with similar parameter count, the method leads by 5.5% and 10.8% in AP and \(\hbox {AP}_{small}\) metrics respectively; compared to the best-performing YOLOv11m, while maintaining accuracy advantages, the method reduces parameters by 27.2%, with particularly outstanding advantages in small object detection.
Comprehensively considering detection accuracy, model size, and computational efficiency, the method achieves optimal balance between efficiency and accuracy. Compared to traditional two-stage detection algorithms like Cascade-RCNN-R50, the method leads by 3.4% and 8.9% in AP and \(\hbox {AP}_{small}\) metrics respectively, while parameter count and computation are only 21.4% and 27.8% of theirs, fully demonstrating the technical advantages of end-to-end detection frameworks combined with specialized optimization strategies.
Generalization experiments
To validate the generalization capability of the proposed method, additional validation experiments are conducted on DOTA and UAVDT datasets. The cross-dataset validation results are presented in Table 8.
Visualization analysis
Cross-dataset validation experiments further confirm the excellent generalization capability and universal value of the proposed method. On the DOTA dataset, the method achieves 1.3% and 0.8% improvements in AP and \(\hbox {AP}_{small}\) metrics respectively, validating the stability of the improvement strategy across different aerial scenarios. The performance on the UAVDT dataset is equally outstanding, with 1.3% and 1.1% improvements in AP and \(\hbox {AP}_{50}\) metrics respectively, fully demonstrating the cross-domain adaptation capability of the proposed method.
These results indicate that the AGEB, ESOP, and CAFM module designs proposed in this research possess good universality, not only performing excellently on the VisDrone 2019 dataset but also maintaining stable performance improvements in other aerial object detection scenarios, validating the practical value and promotion potential of the method.
Detection results visualization comparison
To intuitively demonstrate the detection effectiveness of the proposed AGEC-DETR algorithm, representative aerial scenarios from the VisDrone 2019 dataset are selected for visualization comparison analysis. Figure 7 shows detection result comparisons of different algorithms on the same test images.

Qualitative comparison of detection results on VisDrone 2019 dataset. (a) Overhead market scene with occlusions, (b) Urban traffic scene, (c) Open area scene. From top to bottom: original images, YOLOv11m, RT-DETR-R18, and the proposed method.
The comparative results in Figure 7 demonstrate the substantial advantages of the proposed AGEC-DETR algorithm in small object detection tasks. In scenario (a), which depicts an overhead market environment characterized by complex occlusion patterns and dense crowd distributions, YOLOv11m exhibits extensive false positive detections, incorrectly identifying background regions as targets due to the challenging visual conditions. RT-DETR-R18 also suffers from similar false detection issues, particularly when dealing with complex occlusion scenarios and cluttered backgrounds. In contrast, the approach leverages the attention enhancement mechanism within the AGEB module to substantially improve discrimination capabilities between true targets and background interference, thereby reducing false positive rates and achieving more precise target localization.
The urban traffic environment presented in scenario (b) poses greater challenges for conventional methods due to its complex background and densely distributed targets. YOLOv11m demonstrates insufficient recognition accuracy, with imprecise bounding box localization and suboptimal confidence scores for detected targets. RT-DETR-R18, while showing improved performance compared to YOLOv11m, still exhibits limited recognition precision in complex traffic scenarios. AGEC-DETR effectively enhances target recognition accuracy through the context-aware fusion mechanism of the CAFM module, resulting in more precise localization and higher confidence scores for small target identification.
Scenario (c), featuring an open area environment, provides additional validation for the algorithm’s effectiveness. Within this setting, both YOLOv11m and RT-DETR-R18 demonstrate classification errors by incorrectly identifying objects that do not belong to any target detection category as relevant objects of interest. AGEC-DETR successfully mitigates such misclassification issues through the feature pyramid optimization of the ESOP module combined with the intelligent fusion strategy of the CAFM module, substantially enhancing both detection accuracy and classification reliability.
Attention heatmap analysis
To deeply understand the internal working mechanisms of the proposed algorithm, Grad-CAM technology is employed to generate attention heatmaps on different datasets. Figure 8 shows attention distribution comparisons between RT-DETR-R18 baseline model and the improved method on VisDrone 2019, DOTA, and UAVDT datasets.

Attention heatmap visualization comparison between RT-DETR-R18 and the proposed method across different datasets. The heatmaps highlight the regions of focus, with brighter colors indicating higher attention weights.
From the heatmap analysis in Figure 8, significant improvement effects can be observed. In the VisDrone 2019 dataset parking lot scene, the baseline RT-DETR-R18’s attention distribution is relatively scattered, making it difficult to accurately focus on small target areas. The improved method achieves more precise attention localization through the single-head self-attention mechanism of the AGEB module, with heatmaps showing obvious target area focusing effects, particularly for small vehicle targets in the image.
In the complex aerial scene of the DOTA dataset, the baseline method’s attention is easily interfered with by background noise, resulting in insufficiently concentrated attention distribution. In contrast, the method effectively suppresses background interference through the context-aware mechanism of the CAFM module, with attention more focused on real target areas, directly explaining the internal reasons for detection accuracy improvement.
The UAVDT dataset traffic scene further validates the improvement effectiveness. The proposed method’s heatmaps show stronger target discrimination capability, particularly when processing densely distributed small targets, enabling more accurate distinction between adjacent targets and avoiding mutual attention interference.
These visualization results fully demonstrate the synergistic effects of each improvement module in AGEC-DETR: the AGEB module enhances feature extraction discrimination capability, the ESOP module optimizes multi-scale feature representation, and the CAFM module realizes intelligent feature fusion. The organic combination of the three enables the model to accurately locate and recognize small targets in complex aerial environments, providing more reliable technical support for UAV visual perception tasks.
Discussion
This research proposes AGEC-DETR, a UAV small object detection algorithm based on improved RT-DETR, which effectively addresses core technical challenges in UAV aerial image small object detection through collaborative design of three key innovative modules: AGEB, ESOP, and CAFM. The AGEB module achieves precise modeling and effective enhancement of small object features by fusing self-attention mechanisms with convolutional gated linear units. The ESOP module avoids computational redundancy problems of traditional feature pyramids through innovative multi-branch feature learning strategies while enhancing multi-scale small object feature expression capability. The CAFM module utilizes context-aware mechanisms to realize adaptive feature fusion, effectively improving target discrimination capability in complex backgrounds.
Experimental results fully validate the significant advantages of the proposed method. Comprehensive evaluation on the VisDrone 2019 dataset demonstrates that the method achieves excellent computational efficiency while maintaining high detection accuracy, particularly excelling in small object detection. Comprehensive comparisons with current mainstream object detection algorithms further confirm the method’s technical superiority, while cross-dataset validation experiments prove that the proposed method possesses good generalization capability and universal value.
Technically advanced and practically robust solutions are provided for UAV small object detection, with the multi-module collaborative optimization design concept offering important technical references for algorithm development in related fields. The proposed method is particularly suitable for deployment on resource-constrained UAV platforms, providing reliable technical support for practical application scenarios such as intelligent surveillance, emergency rescue, and environmental monitoring.
Future research will focus on algorithm robustness optimization under extreme environmental conditions, more lightweight network design oriented toward edge computing, and integration applications of multi-modal information fusion technology, further improving algorithm practicality, adaptability, and deployment flexibility to advance industrial applications of UAV intelligent perception technology.
Our method faces several limitations in practical deployment scenarios. Under extreme lighting conditions such as strong shadows or overexposure, the attention mechanisms may focus on irrelevant features, leading to decreased detection accuracy. In ultra-sparse target scenarios with fewer than 3 objects per image, the context-aware fusion may lack sufficient contextual information for optimal performance. Additionally, strong dynamic backgrounds with rapidly moving elements can interfere with the spatial attention mechanisms.
From an engineering perspective, our method achieves a favorable balance between accuracy and computational efficiency. With 14.84M parameters and 65.7 GFLOPs, the model is deployable on edge devices with moderate GPU capabilities. The 76.9 FPS inference speed meets real-time requirements for most UAV applications.
Data availability
The datasets used and analysed during the current study are available from the corresponding author on reasonable request. The VisDrone 2019, DOTA, and UAVDT datasets used in this study are publicly available benchmark datasets that can be accessed through their respective official websites.
References
Tang, G., Ni, J., Zhao, Y., Gu, Y. & Cao, W. A survey of object detection for uavs based on deep learning. Remote Sens. 16, 149. https://doi.org/10.3390/rs16010149 (2024).
Feng, Q., Xu, X. & Wang, Z. Deep learning-based small object detection: A survey. Math. Biosci. Eng. 20, 6551–6590. https://doi.org/10.3934/mbe.2023282 (2023).
Betti, A. & Tucci, M. Yolo-s: A lightweight and accurate yolo-like network for small target detection in aerial imagery. Sensors 23, 1865. https://doi.org/10.3390/s23041865 (2023).
Nguyen, N.-D., Do, T., Ngo, T. D. & Le, D.-D. An evaluation of deep learning methods for small object detection. J. Electr. Comput. Eng. 1–18, 2020. https://doi.org/10.1155/2020/3189691 (2020).
Tong, K., Wu, Y. & Zhou, F. Recent advances in small object detection based on deep learning: A review. Image Vision Comput. 97, 103910. https://doi.org/10.1016/j.imavis.2020.103910 (2020).
Liu, L. et al. Deep learning for generic object detection: A survey. Int. J. Comput. Vision 128, 261–318. https://doi.org/10.1007/s11263-019-01247-4 (2020).
Jiao, L. et al. A survey of deep learning-based object detection. IEEE Access 7, 128837–128868. https://doi.org/10.1109/ACCESS.2019.2939201 (2019).
Wu, X. et al. Deep learning for uav-based object detection and tracking: A survey. IEEE Geosci. Remote Sens. Mag. 10, 91–124. https://doi.org/10.1109/MGRS.2021.3115137 (2022).
Vijayakumar, A. & Vairavasundaram, S. Yolo-based object detection models: A review and its applications. Multimed. Tools Appl. 83, 1–40. https://doi.org/10.1007/s11042-024-18872-y (2024).
Agarwal, S., Terrail, J. O. d. & Jurie, F. Recent advances in object detection in the age of deep convolutional neural networks. arXiv preprint arXiv:1809.03193 (2018).
Redmon, J., Divvala, S., Girshick, R. & Farhadi, A. You only look once: Unified, real-time object detection. In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 779–788 (Las Vegas, NV, USA, 2016).
Bochkovskiy, A., Wang, C.-Y. & Liao, H.-Y. M. Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934 (2020).
Sirisha, U. & Praveen, S. P. Statistical analysis of design aspects of various yolo-based deep learning models for object detection. Int. J. Comput. Intell. Syst. 16, 1–23. https://doi.org/10.1007/s44196-023-00302-w (2023).
Dosovitskiy, A. et al. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations (2021).
Khan, S. et al. Transformers in vision: A survey. ACM Comput. Surv. 54, 1–41. https://doi.org/10.1145/3505244 (2022).
Liu, Z. et al. Video swin transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 3202–3211 (New Orleans, LA, USA, 2022).
Rekavandi, A. M. et al. Transformers in small object detection: A benchmark and survey of state-of-the-art. arXiv preprint arXiv:2309.04902 (2023).
Carion, N. et al. End-to-end object detection with transformers. In European Conference on Computer Vision, 213–229 (Springer, Glasgow, UK, 2020).
Liu, S. et al. Dab-detr: Dynamic anchor boxes are better queries for detr. In International Conference on Learning Representations (2022).
Zhu, X. et al. Deformable detr: Deformable transformers for end-to-end object detection. In International Conference on Learning Representations (2021).
Shehzadi, T. et al. Object detection with transformers: A review. arXiv preprint arXiv:2306.04670 (2023).
Than, P., Ha, C. & Nguyen, H. Long-range feature aggregation and occlusion-aware attention for robust autonomous driving detection. Signal Image Video Process. 19, 738. https://doi.org/10.1007/s11760-025-04290-6 (2025).
Ha, C. K., Nguyen, H. & Van, V. D. Yolo-sr: An optimized convolutional architecture for robust ship detection in sar imagery. Intell Syst. Appl. 26, 200538. https://doi.org/10.1016/j.iswa.2025.200538 (2025).
Nguyen, H. et al. Enhanced object recognition from remote sensing images based on hybrid convolution and transformer structure. Earth Sci. Inf. 18, 228. https://doi.org/10.1007/s12145-025-01751-x (2025).
Nguyen, H. & Pham, T. V. Focus-attention approach in optimizing detr for object detection from high-resolution images. Knowl. Based Syst. 296, 111939. https://doi.org/10.1016/j.knosys.2024.111939 (2024).
Taghipour, A. & Ghassemian, H. Hyperspectral anomaly detection based on frequency analysis of repeated spatial patterns. In 2020 International Conference on Machine Vision and Image Processing (MVIP), 1–6, https://doi.org/10.1109/MVIP49855.2020.9116895 (IEEE, 2020).
Taghipour, A. & Ghassemian, H. Visual attention-driven framework to incorporate spatial-spectral features for hyperspectral anomaly detection. Int. J. Remote Sens. 42, 2417–2448. https://doi.org/10.1080/01431161.2020.1854891 (2021).
Zhao, Y. et al. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 16965–16974 (Seattle, WA, USA, 2024).
Zhu, P. et al. Detection and tracking meet drones challenge. IEEE Transac. Pattern Anal. Mach. Intell. 44, 7380–7399. https://doi.org/10.1109/TPAMI.2021.3119563 (2021).
Du, D. et al. Visdrone-det2019: The vision meets drone object detection in image challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, 0–0 (Seoul, Republic of Korea, 2019).
Chen, C. et al. Rrnet: A hybrid detector for object detection in drone-captured images. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, 0–0 (Seoul, Republic of Korea, 2019).
Zhu, X., Lyu, S., Wang, X. & Zhao, Q. Tph-yolov5: Improved yolov5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, 2778–2788 (Montreal, BC, Canada, 2021).
Cai, Y. et al. Yolobile: Real-time object detection on mobile devices via compression-compilation co-design. In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, 955–963 (Virtual, 2021).
Xia, G.-S. et al. Dota: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 3974–3983 (Salt Lake City, UT, USA, 2018).
Du, D. et al. The unmanned aerial vehicle benchmark: Object detection and tracking. In Proceedings of the European Conference on Computer Vision, 370–386 (Springer, Munich, Germany, 2018).
Ren, S., He, K., Girshick, R. & Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv Neural Inf. Process. Syst. 28, 91–99 (2015).
Cai, Z. & Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 6154–6162 (Salt Lake City, UT, USA, 2018).
Lin, T.-Y., Goyal, P., Girshick, R., He, K. & Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, 2980–2988 (Venice, Italy, 2017).
Jocher, G., Chaurasia, A. & Qiu, J. Yolo by ultralytics (2023). Accessed on 1 January 2024.
Wang, A. et al. Yolov10: Real-time end-to-end object detection. arXiv preprint arXiv:2405.14458 (2024).
Jocher, G., Qiu, J. & Chaurasia, A. Ultralytics yolo11 (2024). Accessed on 1 November 2024.
Acknowledgements
The authors would like to thank the anonymous reviewers for their valuable comments and suggestions that helped improve the quality of this manuscript.
Funding
This work was supported in part by the Postgraduate Research and Practice Innovation Program of Jiangsu Province underGrant SJCX25_1300, in part by the Jinling Institute of Technology Senior Talent Research Launch Project under Grant jit-b-2021-09, in part by the 2024School level”Integration of Science and Education” Project under Grant 2024KJRH16, and in part by the Academic Degree andPostgraduate Education Reform Project of Jinling Institute ofTechnology under Grant YJSJG25_07.
Author information
Authors and Affiliations
Contributions
W.L. conceived the research idea, designed the overall methodology, supervised the project, and wrote the review & editing of the manuscript. Y.Z. implemented the software, conducted the methodology development, performed validation experiments, and wrote the original draft. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Li, W., Zhang, Y. Enhanced small object detection in UAV aerial imagery through attention gated backbone and context aware fusion. Sci Rep 16, 2366 (2026). https://doi.org/10.1038/s41598-025-32074-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-32074-y
