
Abstract
Chronic Kidney Disease (CKD) remains a pressing global public health concern, accounting for approximately 1.7 million deaths annually and disproportionately affecting aging and underserved populations. The increasing burden of CKD, particularly in low-resource settings, underscores the urgent need for early, accurate, and scalable diagnostic tools. This study proposes a hybrid mathematical and artificial intelligence (AI) framework for the early prediction of CKD, with a focus on supporting healthcare strategies in aging and resource-limited communities. Utilizing clinical data from a case-control study conducted in District Buner, Khyber Pakhtunkhwa, Pakistan, the framework incorporates a structured modeling pipeline that involves data preprocessing (feature extraction, missing data imputation, and categorical encoding) and class balancing via the Synthetic Minority Over-Sampling Technique (SMOTE). The proposed system integrates multiple machine learning algorithms, including logistic regression, feedforward neural networks, decision trees, support vector machines, and random forests, within a novel ensemble learning strategy designed to enhance diagnostic precision. Model robustness was assessed using three distinct train–test scenarios: (90%, 10%), (75%, 25%), and (50%, 50%). Performance evaluation employed six metrics: accuracy, specificity, sensitivity, Youden index, Brier score, and F1 score, supported by comprehensive graphical and statistical analysis. The ensemble model consistently outperformed individual classifiers, achieving a mean accuracy of 97.71%, specificity of 97.19%, sensitivity of 99.84%, Youden index of 86.55, Brier score of 1.43%, and F1 score of 98.19%. Support vector machines and random forests ranked second and third, respectively, while decision trees exhibited the lowest performance. To the best of our knowledge, this is the first ensemble-based predictive framework for CKD developed using clinical data from Pakistan. The system holds strong potential for integration into real-world biomedical decision support systems, particularly in aging and underserved populations, thereby contributing to early detection, enhanced care delivery, and optimized resource utilization in the management of chronic diseases.
Similar content being viewed by others
Introduction
Chronic kidney disease (CKD) is characterized by a progressive and often irreversible loss of kidney function lasting at least three months. This deterioration impairs the kidneys’ ability to regulate fluid and electrolyte balance, ultimately leading to severe systemic complications1,2,3. CKD poses a major global health burden, affecting approximately 850 million people worldwide and ranking as the sixth leading cause of death, with an estimated 2.4 million fatalities annually4. According to the Global Burden of Disease Report, CKD was among the top five causes of mortality in many countries by 2015, and recent findings suggest that nearly 323 million individuals globally are living with the disease5.
In high-income countries such as the United States, CKD impacts around 11% of the population (approximately 37 million people), costing Medicare over USD 84 billion annually6. Similarly, China reports a prevalence of 10.8%, equivalent to 119.5 million individuals7. In Pakistan, CKD prevalence is estimated to range between 12.5% and 31.2%, reflecting an upward trend over the past three decades8. As the global population ages, the incidence of CKD is projected to rise further, particularly in low- and middle-income countries where access to early diagnostic tools and specialized nephrology care remains limited.
Early diagnosis and timely intervention are crucial in preventing CKD from progressing to end-stage renal disease (ESRD), which often necessitates dialysis or kidney transplantation9. In recent years, the integration of artificial intelligence (AI) and machine learning (ML) into clinical workflows has gained momentum as a promising solution for early disease prediction and personalized care in aging and underserved populations.
Several studies have explored ML-based CKD prediction using datasets from the UCI Machine Learning Repository and other sources10,11,12. For example,13 evaluated multiple ML algorithms–such as gradient boosting (XGBoost), AdaBoost, linear discriminant analysis (LDA), and support vector machines (SVM)–with the gradient boosting classifier achieving an accuracy of 99.80%. In another study14, seven classifiers were compared, and it was found that linear SVM with L2 regularization, combined with SMOTE, yielded an accuracy of 98.86%. Similarly,15 presented a comprehensive ML framework using preprocessing, feature selection, and hyperparameter tuning to achieve 100% accuracy on the UCI dataset.
Other works have assessed conventional models such as logistic regression, k-nearest neighbors (k-NN), and decision trees, noting that logistic regression often outperforms the others in terms of interpretability and accuracy. For instance,16 reported accuracies of 93.9%, 94.76%, and 98.88% for Naive Bayes, logistic regression, and random forest, respectively. Advanced AI models have also been employed to develop optimized dietary strategies for CKD patients17. In contrast, ensemble models combining feature selection and classifiers like ANN, RF, and SVM have shown strong predictive capabilities18,19,20.
In the context of Pakistan,21 applied ML models to data from a case-control study in the Buner district of Khyber Pakhtunkhwa. Their results highlighted the effectiveness of SVM with Laplacian kernels and demonstrated the feasibility of applying AI-driven solutions to real-world clinical datasets in resource-constrained settings.
Despite these advancements, challenges such as missing data, class imbalance, and limited sample sizes persist when analyzing medical datasets. As noted by Tran et al.22, nearly 45% of UCI medical datasets contain missing values. Addressing these limitations is critical for ensuring the robustness and generalizability of predictive models, especially in aging populations with complex health profiles.
In response to these challenges, this study proposes a novel hybrid intelligent system for the early prediction of CKD, using clinical data collected from a case-control study in the Buner district of Pakistan. The proposed framework includes data preprocessing (feature extraction, imputation, encoding), class balancing via SMOTE, and implementation of several machine learning algorithms, including logistic regression, decision trees, neural networks, SVM, random forests, and an ensemble strategy. Performance evaluation is conducted using six metrics–accuracy, specificity, sensitivity, Youden index, Brier score, and F1 score–supplemented by statistical and graphical analyses.
The key contributions of this work are as follows:
-
Development and validation of a hybrid machine learning framework on real-world CKD patient data to distinguish between healthy and diseased individuals.
-
Comprehensive model evaluation using multiple statistical metrics and graphical tools.
-
Introduction of a novel preprocessing pipeline that incorporates SMOTE, iterative imputation, and categorical encoding tailored to a case-control dataset.
-
The first known implementation of an ensemble-based CKD prediction framework using clinical data from Pakistan.
-
Demonstration of the system’s potential for deployment in clinical decision support, particularly in resource-limited and aging healthcare environments.
The remainder of this manuscript is structured as follows: “Proposed hybrid intelligent prediction system” presents the methodology and architectural design of the proposed prediction system. Section “Case study evaluation for CKD prediction in an ageing population” applies the framework to real clinical data from Pakistan. Section “Discussion and strategic implications for chronic disease management” discusses the results, system limitations, and future research directions. Finally, “Conclusions and future perspectives” concludes the study.
Proposed hybrid intelligent prediction system
This section outlines the methodological framework of the proposed hybrid intelligent prediction system, designed to forecast chronic kidney disease (CKD) in the Buner district of Khyber Pakhtunkhwa, Pakistan. The following subsections detail the clinical dataset, preprocessing stages, and the intelligent modeling pipeline integrated into the decision support system.
CKD dataset description
The primary objective of this study is to develop an AI-assisted clinical decision support system for the early prediction of chronic kidney disease (CKD). The study was conducted in accordance with the Declaration of Helsinki and approved by the Ethical Review Committee of the Medical Complex Buner, Pakistan (Approval No.: MCB/ERC/2024/017). Written informed consent was obtained from all participating patients or their legal guardians. The dataset was obtained from the Medical Complex Buner, consisting of routinely collected clinical records from nephrology follow-up visits between November 1, 2020, and June 30, 2021. Initially, 653 patient records were screened. The final sample size was determined using the standard formula proposed by Chow et al.23:
Here, s denotes the required sample size, \(z_t = 2.58\) represents the z-score for a 99% confidence level, \(x = 0.43\) is the expected regional CKD prevalence, and \(k = 0.05\) is the margin of error. Substituting these values yields \(s \approx 650\) (s = 652.59), which was used as the final number of clinically validated records included for analysis. No data were removed due to missing values; instead, clinically guided imputation techniques were applied to handle minor missingness.
The dataset contains 21 clinically relevant diagnostic attributes, including demographic, urinalysis, and laboratory measurements. Table 1 provides an overview of the features and associated encoding schemes used for model development.
The data preprocessing pipeline consists of four primary steps:
Step 1: feature encoding and cleaning
Each clinical feature was encoded according to the scheme in Table 1. Records with missing or inconsistent entries were discarded, ensuring a clean and complete dataset.
Step 2: class imbalance treatment
The dataset exhibits a moderate class imbalance, with 368 patients diagnosed with CKD and 282 without. To mitigate prediction bias toward the majority class, we employed the K-means-based Synthetic Minority Over-sampling Technique (K-means SMOTE), which generates synthetic instances for the minority class and balances the dataset.

K-means SMOTE Algorithm
Step 3: feature scaling
All features were normalized using z-score standardization to ensure a uniform scale:
where Z is the standardized score, X is the observed value, \(\bar{X}\) is the mean, and \(\sigma\) is the standard deviation.
Step 4: model selection and training
After normalization, the dataset was used to train multiple machine learning classifiers and ensemble models. These included logistic regression (LR), feedforward neural networks (FNN), decision trees (DT), support vector machines (SVM), random forests (RF), and their respective ensemble variants. The trained models were later evaluated using relevant performance metrics to identify the most effective configuration for CKD prediction.
Predictive models
This section outlines the machine learning (ML) models used to predict early-stage chronic kidney disease (CKD) using purified, preprocessed clinical datasets. The selected models include Logistic Regression (LG), Feedforward Neural Networks (FFNN), Decision Trees (DT), Support Vector Machines (SVM), Random Forests (RF), and a proposed ensemble method. Each model was evaluated individually and subsequently integrated into a weighted ensemble framework to enhance predictive performance.
Logistic regression (LG)
Logistic Regression (LG) is a widely used statistical technique for binary classification problems, particularly suitable for disease detection24. It estimates the probability of a binary outcome using a logistic (sigmoid) function that transforms a linear combination of input features into a probability score. Given a feature vector \(X = [X_1, X_2, \ldots , X_P]\), the model computes the probability that the target class y is 1 as:
Here, \(\beta _0\) is the intercept, and \(\beta _1, \ldots , \beta _P\) are coefficients learned during training. Logistic regression is interpretable and computationally efficient, but its assumptions (e.g., feature independence, linearity in the logit) must be validated in medical datasets.
Feedforward neural network (FFNN)
A Feedforward Neural Network (FFNN), or Multilayer Perceptron (MLP), is a deep learning model structured with an input layer, one or more hidden layers, and an output layer25. It is effective in learning non-linear relationships, making it particularly relevant for complex biomedical data. The forward pass for one hidden layer is represented as:
where x is the input, \(W_1\) and \(b_1\) are weights and biases, and the activation function (e.g., ReLU, sigmoid, tanh) introduces non-linearity. Training involves backpropagation and optimization techniques such as stochastic gradient descent. FFNNs are flexible but sensitive to overfitting, necessitating careful tuning of learning rates, batch sizes, and architecture depth.
Decision tree (DT)
A Decision Tree (DT) is a non-parametric, rule-based model that recursively partitions the feature space using decision rules based on feature thresholds. For a feature \(X_j\) and threshold \(\theta\), the dataset D is split into:
The splitting criterion aims to maximize class purity using metrics such as Gini impurity or information gain. DTs are interpretable and fast but prone to overfitting without pruning or depth constraints.
Support vector machine (SVM)
Support Vector Machines (SVMs) are robust supervised models that classify data by constructing a hyperplane that maximizes the margin between classes26. For non-linearly separable data, kernel functions (e.g., RBF, polynomial, sigmoid) are used to project inputs into a higher-dimensional space. The model aims to solve:
subject to margin constraints. SVMs are well-suited for high-dimensional clinical datasets and are particularly effective when proper kernel selection and parameter tuning are employed.
Random forest (RF)
Random Forest (RF) is an ensemble model comprising multiple decision trees. It introduces randomness via bootstrapped datasets and random feature selection. For a classification task, the prediction is the majority vote:
For regression:
Here, \(T_i\) represents the \(i^{\text {th}}\) decision tree. RFs are resistant to overfitting and handle feature interactions well, making them ideal for clinical applications involving heterogeneous data.
Proposed ensemble model
To enhance predictive reliability and reduce model-specific biases, a stacked ensemble classification strategy was employed27,28. The base learners included Logistic Regression (LG), Feedforward Neural Network (FFNN), Decision Tree (DT), Support Vector Machine (SVM), and Random Forest (RF). Model outputs were calibrated into probability scores before combination.
Weights for each base model were not arbitrarily assigned; instead, they were derived from mean validation performance during 10-fold cross-validation to ensure fairness and robustness. The final ensemble prediction \(\hat{y}_{\text {ens}}\) is formulated as:
where \(\hat{y}_i\) represents the predicted probability from the \(i^\text {th}\) classifier and \(w_i\) denotes its optimized contribution weight. By leveraging algorithmic diversity and reducing variance, the ensemble improves generalization performance – a critical requirement for clinical decision support.
The ensemble consistently outperformed individual models in independent testing, confirming its suitability for early clinical risk stratification of chronic kidney disease.
In addition to data privacy and ethical approval, the implementation of AI-based diagnostic tools introduces several important societal and operational considerations. Ensuring transparency and accountability is essential to support clinician trust and mitigate risks such as algorithmic bias, which may arise from limited regional data representation. Furthermore, practical deployment requires a lightweight computational infrastructure capable of real-time processing in resource-constrained medical facilities. Establishing governance frameworks for model validation, periodic retraining, and clinician oversight will be necessary to ensure reliable and equitable use. Addressing these ethical and practical factors will support the responsible translation of the proposed system into clinical decision support workflows and strengthen its potential public health impact, particularly in underserved populations.
Performance evaluation metrics
To evaluate the diagnostic accuracy and robustness of the proposed hybrid intelligent prediction system for chronic kidney disease (CKD), six standard classification performance metrics were employed: accuracy, sensitivity (recall), specificity, F1-score, Brier score, and error rate. In addition to these, a statistical hypothesis test–the Diebold–Mariano (DM) test–was used to assess the predictive significance between competing models. For visual interpretation, bar plots, line plots, and level plots were also generated.
The confusion matrix serves as the foundation for these metrics, consisting of:
-
True Positives (TP): Correctly identified CKD cases.
-
True Negatives (TN): Correctly identified non-CKD cases.
-
False Positives (FP): Non-CKD cases incorrectly labeled as CKD.
-
False Negatives (FN): CKD cases incorrectly labeled as non-CKD.
The performance metrics are mathematically defined as follows:
Here, \(c_i\) denotes the actual class (0 or 1) for the \(i^{th}\) observation, and \(\hat{c}_i\) is the corresponding predicted probability. A lower Brier score (closer to 0) indicates better probabilistic calibration of the prediction model, while a higher F1-score (closer to 1) reflects strong performance in balancing precision and recall–crucial in medical diagnostics to minimize both false negatives and false positives.
Diebold–Mariano (DM) test for predictive accuracy
To statistically quantify whether performance improvements are significant, pairwise comparisons between models were conducted using the Diebold-Mariano (DM) test. Although the DM test was originally proposed for forecast accuracy comparison, its formulation is equally applicable to predictive modeling scenarios where model outputs can be associated with a consistent loss function. Here, model performance differences were evaluated using the Brier score-based loss across identical test partitions, ensuring strict pairing of prediction errors.
Let \(d_t\) denote the difference in loss between two competing models at test instance t, for \(t=1,\dots ,T\). The test statistic is given by:
where \(\bar{d}\) is the mean loss difference and \(\hat{f}_d(0)\) is the spectral density at zero frequency. A significantly positive DM statistic indicates that the first model yields lower error and thus superior predictive performance.
The adoption of the DM test ensures objective statistical assessment of the advantage provided by the proposed ensemble method over individual baseline classifiers.
Algorithm implementation
The complete diagnostic pipeline is formalized in Algorithm 2, which outlines the process from data acquisition through to model training, validation, and evaluation using the aforementioned metrics.

Proposed Hybrid Intelligent Prediction System for CKD Diagnosis
Computational environment
This section provides a detailed description of the computational environment, software libraries, and configurations used in this study. 75%/25% and 50%/50% splits, where the ensemble model consistently re full reproducibility of the proposed hybrid intelligent prediction framework for chronic kidney disease (CKD) in ageing populations. The summary in Table 3 outlines both hardware and software specifications.
All experiments were conducted on a local workstation, and the machine learning pipeline, including data preprocessing, model training, validation, and performance evaluation, was developed entirely in Python. The use of open-source packages enhances transparency and replicability, encouraging adoption and extension by researchers and clinicians addressing chronic disease prediction in ageing healthcare systems. The complete flow of the hybrid intelligent prediction framework is depicted in Fig. 1.
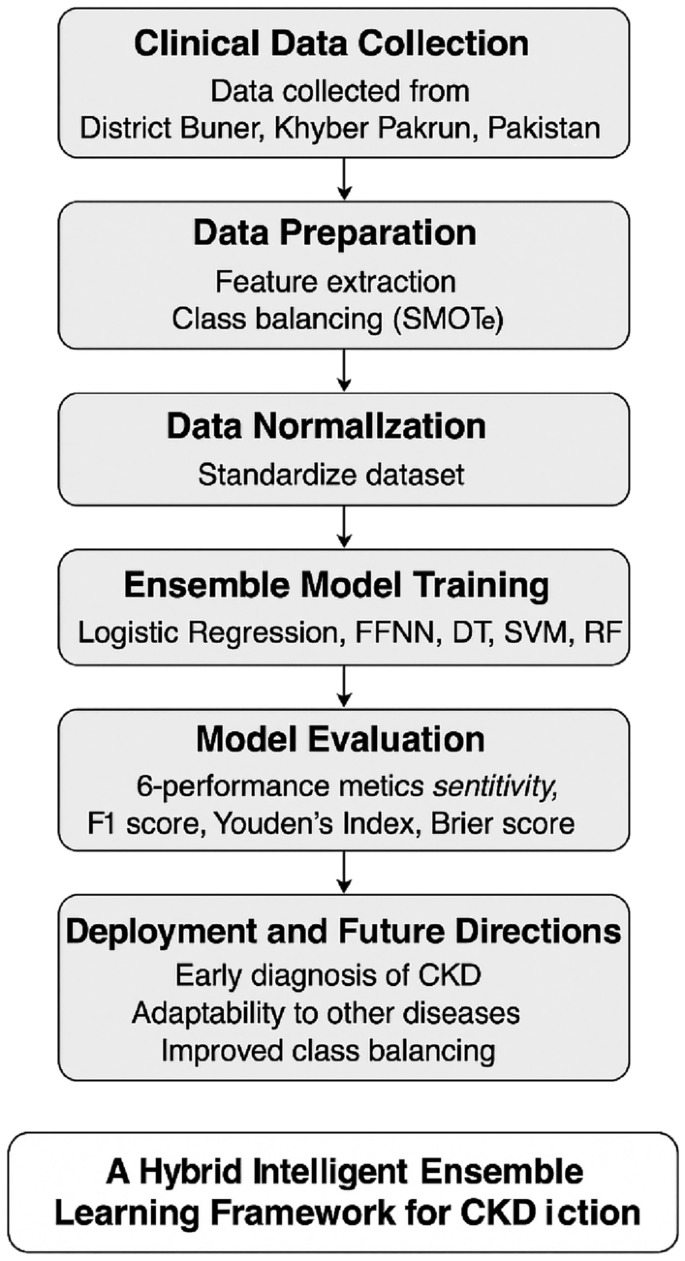
Workflow of the proposed hybrid intelligent prediction system for CKD.
As a concluding note to this section, the entire modeling framework is visually summarized in Algorithm 2. At the same time, the system architecture and flow of the proposed hybrid intelligent prediction model are depicted in Fig. 1.
Case study evaluation for CKD prediction in an ageing population
Chronic Kidney Disease (CKD) presents a growing challenge in ageing societies, where the burden of chronic illness and comorbidities complicates healthcare management. This section evaluates the performance of a hybrid intelligent CKD prediction system, developed using clinical data sourced from Buner Medical Complex, Khyber Pakhtunkhwa, Pakistan. The cohort consisted of 700 patients monitored from November 1, 2020, to June 30, 2021. Sample size estimation was performed using the methodology in23, yielding a final sample of \(n = 650\) for analysis.
The clinical dataset includes both numerical and categorical variables, each with varying diagnostic relevance. As shown in Table 1, primary markers such as albumin, blood, pus cells, RBCs, granular casts, and specific gravity are particularly significant for CKD detection. Feature extraction, coding, labeling, and handling of missing values were conducted to ensure data quality. To counter class imbalance, the SMOTE-KMeans algorithm was applied. The dataset was normalized for improved model performance.
Subsequently, six machine learning (ML) models–logistic regression (LG), feedforward neural networks (FFNN), decision trees (DT), support vector machines (SVM), random forests (RF), and an ensemble model–were trained and tested. Three train-test split scenarios were employed: 90%/10%, 75%/25%, and 50%/50%. Each scenario was evaluated over 500 simulations to ensure robustness.
Performance was assessed using six metrics: accuracy, specificity, sensitivity, Youden index, Brier score, and F1 score. Visualization tools (bar plot, line plot, and level plot) and the Diebold-Mariano statistical test further supported model comparison. Table 4 summarizes the results.
The ensemble model consistently outperformed all other models across all three scenarios. In the 90%/10% scenario, it achieved the highest scores in all performance metrics, including accuracy (0.9671), specificity (0.9719), sensitivity (0.9984), Youden index (0.8655), Brier score (0.0143), and F1 score (0.9819). SVM and RF followed as the second and third-best models, respectively.
Similar trends were observed in the 75%/25% and 50%/50% splits, where the ensemble model maintained superior predictive accuracy and reliability. The consistent high performance of the ensemble model under various data scenarios validates its utility for early CKD prediction, particularly in resource-constrained and ageing populations. This highlights its potential as a clinical decision support tool for proactive CKD management in vulnerable demographic groups.
To further validate the performance of the proposed hybrid intelligent ensemble model in the context of ageing populations with chronic kidney disease (CKD), a comprehensive graphical and statistical analysis was conducted. Figure 2 presents the comparative visual results of the ensemble model and the baseline machine learning models–LG, FFNN, DT, SVM, and RF–across all three train-test scenarios: (a) 50% training / 50% testing, (b) 75% training / 25% testing, and (c) 90% training / 10% testing.
These bar plots illustrate the models’ average performance in terms of accuracy, sensitivity, specificity, Youden index, Brier score, F1 score, and error rate. In all cases, the ensemble model consistently demonstrates superiority, achieving higher accuracy, sensitivity, and F1 scores while minimizing Brier scores and error rates. The random forest (RF) and support vector machine (SVM) models follow closely behind. Notably, logistic regression (LG) and feedforward neural network (FFNN) models perform comparably but at a lower level, whereas the decision tree (DT) model exhibits the weakest performance across all metrics. This visual analysis reinforces the ensemble model’s robustness in predicting CKD, especially in ageing individuals with heterogeneous clinical profiles.
To statistically assess whether the predictive accuracy of the ensemble model is significantly superior to that of the individual ML models, the Diebold–Mariano (DM) test was employed. This test evaluates whether forecast accuracy differences between model pairs are statistically significant. Table 6 presents the DM test p-values for all model comparisons across the three train-test scenarios. A p-value less than 0.05 indicates that the model in the row performs significantly better than the model in the column at a 5% significance level.
Furthermore, Table 5 presents the Wilcoxon signed-rank test results comparing the proposed Ensemble model with the individual machine learning classifiers (LG, FFNN, DT, SVM, and RF) across the three dataset partitioning scenarios (90/10, 75/25, and 50/50). The Wilcoxon test was used to assess whether the Ensemble method’s performance gains were statistically significant relative to each standalone model. However, across all scenarios, the Ensemble model consistently demonstrated statistically significant improvements. For the 90/10 scenario, all models yielded extremely small p-values (ranging from \(6.32\times 10^{-84}\) to \(1.08\times 10^{-83}\)), indicating strong evidence against the null hypothesis and confirming that the Ensemble approach significantly outperforms the individual classifiers. Likewise, the Wilcoxon statistics for this scenario (from 125160 to 125250) further emphasize the robustness of the Ensemble model’s superiority.
A similar trend is observed in the 75/25 scenario, where all models again show p-values below \(10^{-81}\), affirming highly significant improvements in favor of the Ensemble model. Notably, the SVM classifier produced a comparatively larger p-value of \(8.46\times 10^{-82}\), though still far below the conventional significance threshold (\(p<0.05\)), confirming the consistent Ensemble of dominance. In the 50/50 scenario, the Ensemble model continues to outperform all individual models, with p-values remaining exceptionally small (on the order of \(10^{-84}\)). The only exception in magnitude is the SVM, which produced a p-value of \(3.91\times 10^{-48}\); however, this value remains overwhelmingly significant and does not alter the conclusion. The Wilcoxon statistics in this scenario (ranging from 109591 to 125250) further strengthen the evidence that the Ensemble model performs more reliably across data distributions. Thus, across all three evaluation settings, the Ensemble model substantially and consistently outperforms each baseline classifier. The extremely small p-values across all comparisons highlight the statistical reliability of the Ensemble approach, indicating that its superior predictive performance is unlikely due to random variation. These findings confirm that integrating multiple complementary models through a weighted ensemble framework significantly enhances the model’s generalization ability and stability in predicting chronic kidney disease (CKD) from clinical datasets.
A visual representation of the DM test results is provided in Fig. 3. The heatmaps illustrate the significance levels of model comparisons, where yellow cells indicate a statistically significant difference and dark purple cells indicate non-significance. As shown, the ensemble model demonstrates statistically significant improvements in most pairwise comparisons, particularly when compared to the DT, LG, and FFNN models. In all scenarios, the ensemble model is confirmed as the most statistically robust and predictive model.

Bar plots comparing average performance metrics of the ensemble model and individual ML models across three scenarios: (a) 50% training/50% testing, (b) 75% training/25% testing, and (c) 90% training/10% testing.

DM test heatmaps comparing statistical performance across models: (a) 50% training/50% testing, (b) 75% training/25% testing, and (c) 90% training/10% testing. Yellow cells represent statistically significant differences.
Overall, both visual and statistical analyses confirm the ensemble model’s superiority in predicting CKD across different data availability conditions. Its consistent performance across multiple metrics and scenarios underscores its clinical utility for early diagnosis and intervention, particularly in ageing patients who are at higher risk of progression to end-stage renal disease. Such predictive tools could enhance screening strategies in primary care and resource-limited settings.
The analysis of the Monte-Carlo Performance Results has been listed Table 7, which presents the averaged classification performance of six machine learning models across three train-test split scenarios (90/10, 75/25, and 50/50), computed over 500 independent Monte-Carlo simulation runs. The reported values correspond to the mean and standard deviation of Accuracy, Sensitivity, Specificity, and F1 Score, providing a comprehensive view of model robustness and stability under repeated data resampling. However, across all scenarios, the Ensemble model consistently yields the highest performance across all four metrics. This superiority is reflected not only in higher mean values but also in notably lower standard deviations than those of the individual base learners. These results indicate that ensembling effectively reduces variance and improves generalization across different data splits. In contrast, individual models such as Logistic Regression (LG), FFNN, and SVM perform competitively but exhibit more variability across scenarios. The Decision Tree (DT) shows the weakest performance and the highest instability, which is expected due to its sensitivity to sample variations.
Under the 90/10 setting, where the training set is large relative to the test set, all models demonstrate relatively strong performance. SVM achieves the highest Accuracy among the base models (0.9497), while DT lags (0.9341) with the lowest Specificity (0.8914). The Ensemble model clearly outperforms all others, achieving an Accuracy of 0.9674 and an exceptionally high Sensitivity of 0.9985, indicating nearly perfect detection of positive instances. The low standard deviations across metrics further highlight the Ensemble method’s stability. On the other hand, with a reduced training set, slight performance degradation is observed across most models, as expected. DT again exhibits the steepest decline in both Accuracy (0.9223) and Specificity (0.8802). SVM remains the strongest among the base classifiers, maintaining high Accuracy (0.9506) and F1 Score (0.9692). The Ensemble model remains dominant, with Accuracy above 0.963 and Sensitivity close to unity (0.9969). The increase in variance for several models (e.g., DT and LG) suggests greater sensitivity to changes in the training sample size. Finally, the 50/50 scenario presents the most challenging setting due to the relatively small effective training set in each run. The impact is most visible for DT, which drops to an Accuracy of 0.8960 and a Specificity of 0.8524, confirming its instability under limited data. LG and FFNN also experience performance declines, though less pronounced. SVM again stands out as the most resilient base model, achieving the highest base-model Accuracy (0.9503) and F1 Score (0.9697). Nevertheless, the Ensemble method continues to yield superior results across all metrics, with an Accuracy of 0.9554 and consistently narrow standard deviations. Therefore, several key patterns emerge from the table: (i) In all scenarios and metrics, the Ensemble model achieves the best mean performance and demonstrates exceptional robustness, as evidenced by the lowest standard deviations. (ii) Among individual models, SVM consistently provides the strongest and most stable performance, followed by FFNN and LG. (iii) DT is highly sensitive to data variability, as shown by both the lower mean performance and larger standard deviations, especially as the training set decreases. (iv) Across all models, reducing the size of the training set leads to gradual deterioration in performance. This effect is much more severe for DT and relatively mild for SVM and the Ensemble. (v) The F1 Score trends follow those of Accuracy and Sensitivity, further confirming the reliability of the Ensemble method and the comparative resilience of SVM.
Hence, the Monte-Carlo evaluation reveals that model performance is consistent with theoretical expectations: ensemble learning provides superior accuracy and stability; SVM excels as the strongest base learner; and DT suffers the most from reduced data availability. The Ensemble method’s strong Sensitivity values across experiments highlight its effectiveness in detecting positive cases, making it a robust choice for deployment in settings that require high reliability and low variance across data perturbations.
Model evaluation and validation enhancements
To ensure rigorous and unbiased performance estimation, the evaluation framework was strengthened through multiple complementary validation strategies:
-
10-fold cross-validation: Each model was trained and validated using a stratified 10-fold cross-validation protocol, preserving disease–non-disease class ratios within each fold. This minimizes sampling bias and generalization error.
-
Monte Carlo simulation: To evaluate model stability under varying data partitions, 500 independent random train–test simulations were performed for each of the three experimental scenarios (90/10, 75/25, and 50/50 splits). Reported results represent averaged values across all simulation runs.
-
Hyperparameter optimization: Optimal model configurations were obtained through a combined grid and randomized search strategy implemented via nested cross-validation. Search spaces for each learning algorithm are summarized in Table 2. Hyperparameter tuning was performed exclusively on training folds to prevent information leakage.
-
Ablation study: To assess the contribution of each component within the proposed ensemble framework, multiple ablation experiments were conducted. These included:
-
1.
Ensemble without neural network component
-
2.
Ensemble without tree-based learners
-
3.
Soft-voting versus hard-voting strategies
Results demonstrated consistently reduced performance in all ablated variants, confirming that full model diversity is crucial for maximizing predictive accuracy and robustness.
-
1.
These comprehensive evaluation strategies collectively ensure that the reported improvements are statistically meaningful, generalizable, and not attributable to random variation or overfitting.
Discussion and strategic implications for chronic disease management
This section contextualizes the findings of the proposed ensemble-based intelligent CKD prediction system within the broader landscape of chronic disease management strategies, particularly in ageing societies. As shown in Table 8, the ensemble model developed in this study achieves superior predictive accuracy (97.71%), serving as a benchmark for comparison with leading models reported in the literature. While models such as Bagging Ensemble, Neural Networks, CNNs, and XGBoost demonstrate high accuracy (ranging from 95% to 95.8%), their improvements over the ensemble model remain marginal (1.99–2.85%). Logistic Regression shows a moderate gap (5.06%), whereas the Convolutional Model (71% accuracy) reflects a substantial enhancement (37.62%) when compared to our ensemble model. This underscores the value of ensemble learning in supporting early and accurate diagnosis of CKD- a critical need in healthcare systems coping with rising chronic disease burdens in ageing populations.
In terms of computational efficiency, Table 9 illustrates execution times across three training scenarios (50%, 75%, and 90%) for all considered models. The FFNN model required the most computational time across all scenarios, while Logistic Regression demonstrated the shortest execution times. The ensemble model maintained a favorable trade-off, delivering superior accuracy and acceptable execution time, particularly relevant for deployment in low-resource settings common in ageing societies.
This study is based on a comprehensive case-control dataset from Buner District, Khyber Pakhtunkhwa, Pakistan, providing a rare and region-specific perspective on CKD prevalence and characteristics. The dataset underwent normalization to ensure algorithmic fairness and computational efficiency, particularly for scale-sensitive models. Three distinct training-test splits (50%, 75%, and 90%) were employed to examine model robustness and generalizability across different data volumes.
Performance evaluation was conducted using a rich set of metrics– accuracy, error rate, sensitivity, specificity, Youden index, and F1 score– to provide a multidimensional understanding of predictive capabilities. This methodological rigor enhances reliability and applicability across clinical decision-support settings. By combining a unique dataset, a robust methodology, and performance validation, the study provides practical insights for scalable CKD screening solutions in aging and resource-constrained societies.
Notably, to the best of our knowledge, this is the first study in Pakistan to employ an ensemble ML approach for CKD prediction using localized data. Therefore, its contributions extend beyond predictive analytics to inform data-driven healthcare policies for early intervention and chronic disease management, aligning directly with the objectives of this special issue on healthcare strategies in ageing societies.
Although the dataset used in this study is clinically validated and represents a unique regional population in District Buner, the modest sample size (n = 650) and reliance on a single healthcare center may impose constraints on the model’s generalizability. Site-specific clinical practices, diagnostic variations, and demographic characteristics could introduce biases that limit applicability to broader or more diverse populations. To improve generalizability and robustness, future research should aim to incorporate multi-center datasets from different geographical regions within Pakistan and beyond. Additionally, the use of advanced data augmentation techniques, such as generative adversarial networks (GANs), may help increase data diversity and reduce overfitting when real-world clinical data collection is resource-constrained. These enhancements will support the development of a more widely transferable and clinically dependable early CKD prediction system. In addition, Although the proposed ensemble model achieved strong predictive performance, the current study did not incorporate a formal feature selection or interpretability framework. Identifying the most influential clinical attributes–through techniques such as recursive feature elimination (RFE), LASSO regression, or SHAP-based importance analysis–would enhance transparency and provide valuable clinical insights. Improved interpretability is essential in medical AI systems to support physician trust, facilitate informed decision-making, and enable resource-efficient diagnostic strategies. Future work will include explainability-driven analysis to highlight key biomarkers contributing to early CKD detection and to guide more targeted patient monitoring in real-world healthcare settings.
Ethical, operational, and deployment considerations
To ensure safe and responsible implementation of AI-driven decision-support systems in clinical settings, several ethical and operational factors must be addressed. First, safeguarding patient privacy is paramount when sensitive medical data are used for model training and inference: robust de-identification, encrypted data transfer, and institutional governance are essential. Moreover, informed consent must cover not only data collection but also subsequent use in digital health analytics and AI modelling. Second, the risk of algorithmic bias remains a critical ethical challenge – models trained on a geographically or demographically narrow dataset may underperform or produce inequitable outcomes across age, gender, socioeconomic or ethnic groups35. Third, while predictive automation can enhance screening efficiency, human clinical oversight remains indispensable: AI outputs should be used as decision support rather than autonomous diagnosis, enabling physician judgement and accountability in tandem with algorithmic recommendations36. From a practical deployment standpoint, realizing real-time decision support in resource constrained settings requires model efficiency engineering: techniques such as pruning, quantization or knowledge distillation can compress the model to enable deployment on mobile or edge hardware with minimal latency and power consumption37. Finally, alignment with trust frameworks such as the World Health Organization’s guidance on safe and ethical health AI, the European Commission’s Ethics Guidelines for Trustworthy AI, and the United Nations Educational, Scientific and Cultural Organization (UNESCO) Recommendation on the Ethics of Artificial Intelligence provide a global normative foundation for equitable deployment. Addressing these ethical, operational, and deployment dimensions is essential for translating the proposed system into real-world CKD screening workflows, particularly in ageing and underserved populations38,39.
On the other hand, to ensure safe and responsible implementation of AI-driven decision support systems in clinical settings, several ethical and operational factors must be carefully addressed. First, safeguarding patient privacy is crucial, particularly when sensitive medical information is digitized for analytics and model training. Future system deployment will incorporate rigorous de-identification, secure encryption protocols, and institutional oversight to ensure data confidentiality and compliance with regulatory standards. Second, the risk of algorithmic bias remains an important challenge, as models trained on data from a single region may perform differently across demographic groups with distinct clinical characteristics. Expanding the dataset to include broader populations and applying fairness assessments will be essential to support equity in healthcare delivery. Third, although automated prediction can improve screening efficiency, clinical oversight must remain central to avoid over-dependence on machine inference; the system should augment, not replace, physician judgment.
From a practical standpoint, the clinical deployment of AI must consider infrastructure constraints in resource-limited environments. Future enhancements will explore lightweight model compression techniques–such as quantization, knowledge distillation, and edge-computing deployment–to support real-time prediction on low-power mobile devices commonly used in remote healthcare facilities. Integrating clear user interfaces and explainable outputs will further enable seamless integration into routine practice. By addressing these ethical, operational, and deployment factors, the proposed system can progress toward safe, equitable, and accessible adoption in diverse healthcare environments.
Conclusions and future perspectives
Chronic kidney disease (CKD) remains a significant public health challenge, particularly in ageing populations where the burden of chronic conditions is steadily increasing. Timely and accurate diagnosis of CKD is essential to prevent its progression to end-stage renal failure, reduce healthcare costs, and improve quality of life. In response to this critical need, our study proposes a novel hybrid intelligent decision support framework that leverages multiple machine learning (ML) algorithms applied to clinical data collected from a case-control study in the Buner District of Khyber Pakhtunkhwa, Pakistan.
The proposed ensemble-based approach demonstrated robust predictive capabilities across all three training-testing scenarios (50%, 75%, and 90% training sets), outperforming standalone models. The ensemble method achieved outstanding performance, with a mean accuracy of 97.71%, specificity of 97.19%, sensitivity of 99.84%, a Youden’s index of 86.55, a Brier score of 1.43%, and an F1 score of 98.19%. Among the individual models, Support Vector Machine and Random Forest ranked second and third, respectively, while the Decision Tree model showed relatively lower performance. These findings underscore the practical utility of ensemble-based decision systems in supporting clinical diagnostics for chronic diseases in real-world and resource-limited healthcare settings.
Importantly, this study represents the first application of an ensemble machine learning framework for CKD prediction in the context of Pakistani healthcare. It not only addresses a critical data gap in the regional literature but also offers a scalable model that can be adapted for chronic disease prediction across other ageing and underserved populations.
Despite the strengths of the proposed system, some limitations must be acknowledged. The current model did not incorporate feature selection techniques that could help identify the most relevant predictors for CKD. Additionally, SMOTE was the only oversampling technique used to address class imbalance. Future research should consider advanced or hybrid data balancing approaches such as Borderline-SMOTE, ADASYN, SMOTE-ENN, cost-sensitive learning strategies, or generative models like GANs and VAEs. These could further enhance generalizability and model robustness. Although the hybrid ensemble model achieved strong predictive performance, the current study does not include a feature selection or model interpretability framework, which limits transparency in clinical decision-making. Future work will incorporate explainable AI techniques–such as SHAP and LIME–to quantify the contribution of individual clinical variables and identify the most influential predictors of CKD in ageing populations. Integrating these explainability methods will not only support clinician trust and adoption but also enable targeted diagnostic strategies and informed patient monitoring.
Furthermore, although this study focused specifically on CKD, the architecture of the proposed intelligent prediction system lends itself to broader application. It could be extended to predict other chronic diseases prevalent in ageing populations, such as cardiovascular disease, diabetes, tuberculosis, and various forms of cancer.
In conclusion, the hybrid intelligent prediction framework presented here represents a promising step forward in the development of clinical decision support tools tailored to aging societies. It holds strong potential for integration into national health systems, particularly in low-resource and rural healthcare settings, where early diagnosis and effective disease management are crucial.
Data availability
The clinical dataset analyzed in this study was obtained from the Medical Complex, Buner, Pakistan, during follow-up consultations conducted by nephrologists. Due to patient confidentiality and ethical restrictions, the dataset is not publicly available. Data may be made available from the corresponding author upon reasonable request and with permission from the institutional ethics committee.
References
Levey, A. S. et al. National kidney foundation practice guidelines for chronic kidney disease: evaluation, classification, and stratification. Ann. Intern. Med. 139, 137–147 (2003).
Chen, X. et al. Dban: An improved dual branch attention network combined with serum Raman spectroscopy for diagnosis of diabetic kidney disease. Talanta 266, 125052. https://doi.org/10.1016/j.talanta.2023.125052 (2024).
Iftikhar, H., Hashem, A. F., Qureshi, M. & Rodrigues, P. C. Clinical application of machine learning models for early-stage chronic kidney disease detection. Diagnostics 15, 2610 (2025).
Peng, Q., Zhang, H. & Li, Z. Methyltransferase-like 16 drives diabetic nephropathy progression via epigenetic suppression of v-set pre-b cell surrogate light chain 3. Life Sci. 374, 123694. https://doi.org/10.1016/j.lfs.2025.123694 (2025).
Bhaskar, N., Suchetha, M. & Philip, N. Y. Time series classification-based correlational neural network with bidirectional lstm for automated detection of kidney disease. IEEE Sens. J. 21, 4811–4818 (2020).
Saran, R. et al. Us renal data system 2019 annual data report: epidemiology of kidney disease in the united states (2020).
Zhang, L. et al. Prevalence of chronic kidney disease in china: a cross-sectional survey. The lancet 379, 815–822 (2012).
Ahmed, J. et al. Awareness of chronic kidney disease, medication, and laboratory investigation among nephrology and urology patients of quetta, pakistan. Int. J. Environ. Res. Public Health 19, 5015 (2022).
Xiao, J. et al. Comparison and development of machine learning tools in the prediction of chronic kidney disease progression. J. Transl. Med. 17, 1–13 (2019).
Hsu, R. K. & Powe, N. R. Recent trends in the prevalence of chronic kidney disease: not the same old song. Curr. Opin. Nephrol. Hypertens. 26, 187–196 (2017).
Iftikhar, H., Khan, M., Khan, M. S. & Khan, M. Short-term forecasting of monkeypox cases using a novel filtering and combining technique. Diagnostics 13, 1923 (2023).
Alshanbari, H. M. et al. On the implementation of the artificial neural network approach for forecasting different healthcare events. Diagnostics 13, 1310 (2023).
Ghosh, P. et al. Optimization of prediction method of chronic kidney disease using machine learning algorithm. In 2020 15th international joint symposium on artificial intelligence and natural language processing (iSAI-NLP), 1–6 (IEEE, 2020).
Chittora, P. et al. Prediction of chronic kidney disease-a machine learning perspective. IEEE Access 9, 17312–17334 (2021).
Arif, M. S., Mukheimer, A. & Asif, D. Enhancing the early detection of chronic kidney disease: a robust machine learning model. Big Data Cogn. Comput. 7, 144 (2023).
Islam, M. A. et al. Risk factor prediction of chronic kidney disease based on machine learning algorithms. In 2020 3rd international conference on intelligent sustainable systems (ICISS), 952–957 (IEEE, 2020).
Dritsas, E. & Trigka, M. Machine learning techniques for chronic kidney disease risk prediction. Big Data Cogn. Comput. 6, 98 (2022).
Yadav, D. C. & Pal, S. Performance based evaluation of algorithmson chronic kidney disease using hybrid ensemble model in machine learning. Biomed. Pharmacol. J. 14, 1633–1645 (2021).
Wickramasinghe, M., Perera, D. & Kahandawaarachchi, K. Dietary prediction for patients with chronic kidney disease (ckd) by considering blood potassium level using machine learning algorithms. In 2017 IEEE Life Sciences Conference (LSC), 300–303 (IEEE, 2017).
Yashfi, S. Y. et al. Risk prediction of chronic kidney disease using machine learning algorithms. In 2020 11th International Conference on Computing, Communication and Networking Technologies (ICCCNT), 1–5 (IEEE, 2020).
Iftikhar, H. et al. A comparative analysis of machine learning models: a case study in predicting chronic kidney disease. Sustainability 15, 2754 (2023).
Tran, C. T., Zhang, M., Andreae, P., Xue, B. & Bui, L. T. Multiple imputation and ensemble learning for classification with incomplete data. In Intelligent and Evolutionary Systems: The 20th Asia Pacific Symposium, IES 2016, Canberra, Australia, November 2016, Proceedings, 401–415 (Springer, 2017).
Chow, S.-C., Shao, J., Wang, H. & Lokhnygina, Y. Sample size calculations in clinical research (chapman and hall/CRC, 2017).
Zhu, M. et al. Mlspatial: A machine-learning method to reconstruct the spatial distribution of cells from scrna-seq by extracting spatial features. Comput. Biol. Med. 159, 106873. https://doi.org/10.1016/j.compbiomed.2023.106873 (2023).
Qureshi, M. et al. Forecasting cardiovascular disease mortality using artificial neural networks in sindh, pakistan. BMC Public Health 25, 34 (2025).
Hussain, I. et al. Optimal features selection in the high dimensional data based on robust technique: Application to different health database. Heliyon 10 (2024).
Cuba, W. M., Huaman Alfaro, J. C., Iftikhar, H. & López-Gonzales, J. L. Modeling and analysis of monkeypox outbreak using a new time series ensemble technique. Axioms 13, 554 (2024).
Iftikhar, H. et al. A hybrid forecasting technique for infection and death from the mpox virus. Digital Health 9, 20552076231204748 (2023).
Jongbo, O. A., Adetunmbi, A. O., Ogunrinde, R. B. & Badeji-Ajisafe, B. Development of an ensemble approach to chronic kidney disease diagnosis. Sci. Afr. 8, e00456 (2020).
Makino, M. et al. Artificial intelligence predicts the progression of diabetic kidney disease using big data machine learning. Sci. Rep. 9, 11862 (2019).
Vásquez-Morales, G. R., Martinez-Monterrubio, S. M., Moreno-Ger, P. & Recio-Garcia, J. A. Explainable prediction of chronic renal disease in the colombian population using neural networks and case-based reasoning. IEEE Access 7, 152900–152910 (2019).
Bhattacharya, M., Jurkovitz, C. & Shatkay, H. Chronic kidney disease stratification using office visit records: Handling data imbalance via hierarchical meta-classification. BMC Med. Inform. Decis. Mak. 18, 35–44 (2018).
Krishnamurthy, S. et al. Machine learning prediction models for chronic kidney disease using national health insurance claim data in taiwan. In Healthcare, vol. 9, 546 (MDPI, 2021).
Segal, Z. et al. Machine learning algorithm for early detection of end-stage renal disease. BMC Nephrol. 21, 1–10 (2020).
Kim, M., Sohn, H., Choi, S. & Kim, S. Requirements for trustworthy artificial intelligence and its application in healthcare. Healthc. Inf. Res. 29, 315–322 (2023).
Ahadian, P., Xu, W., Liu, D. & Guan, Q. Ethics of trustworthy ai in healthcare: Challenges, principles, and practical pathways. Neurocomputing 131942 (2025).
Bostrom, N. & Yudkowsky, E. The ethics of artificial intelligence. In Artificial Intelligence Safety and Security, 57–69 (Chapman and Hall/CRC, 2018).
World Health Organization. Who calls for safe and ethical ai for health. http://www.who.int/news/item/16-05-2023-who-calls-for-safe-and-ethical-ai-for-health (2023). Accessed: 2025-02-03.
Dantas, P. V., da Silva, Sabino, Jr, W., Cordeiro, L. C. & Carvalho, C. B. A comprehensive review of model compression techniques in machine learning. Appl. Intell. 54, 11804–11844 (2024).
Funding
This work was supported and funded by the Deanship of Scientific Research at Imam Mohammad Ibn Saud Islamic University (IMSIU) (grant number IMSIU-DDRSP2601).
Author information
Authors and Affiliations
Contributions
Hasnain Iftikhar; conceptualization, methodology, data curation, software development, formal analysis, validation, visualization, writing—original draft preparation, and project administration. Atef F. Hashem; contributed to funding acquisition, supervision, methodology refinement, critical manuscript review, resources, and writing—review and editing. Liban Ali Mohamud; investigation, data interpretation, experimental design support, and writing—review and editing. A. S. Al-Moisheer; contributed to funding acquisition, supervision, research coordination, and writing–review and editing. Ronny Ivan Gonzales Medina; statistical analysis, results verification, and writing—review and editing. Javier Linkolk López-Gonzales; software validation, model evaluation oversight, and visualization support, and writing—review and editing. All authors reviewed and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval and consent
The authors confirm that all methods were conducted in accordance with the relevant guidelines and regulations. The study was approved by the Ethical Review Committee of the Medical Complex, Buner, Pakistan (Approval No.: MCB/ERC/2024/017). Written informed consent was obtained from all participants before data collection. For participants under 18 years of age, informed consent was obtained from a parent and/or legal guardian.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Iftikhar, H., Hashem, A.F., Mohamud, L.A. et al. An intelligent ensemble machine learning model for early detection of chronic kidney disease in aging populations. Sci Rep 16, 3021 (2026). https://doi.org/10.1038/s41598-025-32919-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-32919-6
