
Abstract
Stock market prediction has long attracted the attention of academia and industry due to its potential for substantial financial returns. Despite the availability of various forecasting methods, such as CNN, LSTM, BiLSTM, GRU, and Transformer, the hyperparameter optimization of these models often faces limitations, particularly in single-objective optimization, where they can easily fall into local optima. To address this issue, this paper proposes an innovative multi-objective optimization algorithm—the Multi-Objective Escape Bird Algorithm (MOEBS)—and introduces the MOEBS-Transformer architecture to enhance the efficiency and effectiveness of hyper-parameter optimization for Transformer models. This study first validates the performance of MOEBS through a series of multi-objective benchmark tests on standard problem sets such as ZDT, DTLZ, and WFG, comparing it with other multi-objective optimization algorithms (e.g., MOMVO, MSSA, and MOEAD) using evaluation metrics such as GD, Spacing, IGD, and HV for comprehensive analysis. In the context of stock price prediction, we select the closing price datasets of Amazon, Google, and Uniqlo, using MOEBS to optimize the core hyper parameters of the Transformer while considering multiple objectives, including training set RMSE, testing set RMSE, and testing set error variance. In the experiments, this paper first compares CNN, LSTM, BiLSTM, GRU, and traditional Transformer models to establish the Transformer as the optimal model for stock market prediction. Subsequently, the study compares the MOEBS-Transformer with Transformer models optimized using various hyperparameter optimization methods, including MOMVO-Transformer, MSSA-Transformer, and MOEAD-Transformer. Additionally, it evaluates Transformer models optimized through conventional methods: Random Search (RS-Transformer), Grid Search (GS-Transformer), and Bayesian Optimization (BO-Transformer). By assessing the performance of these models using R2, RMSE, and RPD metrics on both training and testing sets, the results demonstrate that the Transformer model optimized by MOEBS significantly outperforms the other methods in terms of prediction accuracy and prediction stability. This research offers a new solution for complex optimization scenarios and lays a foundation for advancements in stock market prediction technologies.
Similar content being viewed by others

Introduction
Stock price forecasting is a key focus area within the financial industry, aiming to accurately forecast the future trajectory of stock prices through market data analysis. This task is influenced by a multitude of economic, political, and social factors, making it extremely complex and unpredictable. Factors such as global economic growth, policy changes, market sentiment, and unforeseen events can significantly impact stock prices1,2,3. Additionally, behaviors of market participants, companies’ financial performance, and macroeconomic conditions continually affect the stock market4,5,6. The dynamic interplay of these factors presents a challenge in accurately predicting stock price movements7,8,9,10.
With advancements in technology, particularly in computer science, artificial intelligence, and machine learning, modern financial analysis is undergoing a revolution. Machine learning techniques like support vector machines11, neural networks, and deep learning models have been widely utilized for stock market predictions12,13,14,15. These models can process vast amounts of complex data and identify trends elusive to people. Thus, machine learning demonstrates immense potential in enhancing the accuracy and efficiency of predictions16,17,18.
In the realm of deep learning, the Transformer model has garnered extensive attention and research due to its exceptional ability to handle long sequence data19. This model utilizes a unique attention mechanism to efficiently grasp intricate dependencies within time series data, thereby exhibiting outstanding performance in various tasks, particularly in natural language processing (NLP) and financial time series analysis20,21. However, despite the Transformer model’s potential across multiple domains, optimizing its hyper-parameters such as Learning rate, Number of Heads and regularization coefficient to achieve optimal performance remains a significant challenge22. In complex application scenarios like financial market analysis, traditional single-objective optimization methods often fall short as they typically focus on optimizing one performance metric while neglecting others that might be equally important23,24,25,26,27,28. Moreover, the single-objective optimization Transformer model performs well when handling specific tasks, but it also has significant limitations. Firstly, the model is optimized for only one task, meaning it can only focus on a single objective during training and inference, which limits its adaptability and flexibility, especially in scenarios that require handling complex, diverse tasks. Additionally, single-objective models cannot effectively utilize shared data across tasks in a multi-task learning setting, resulting in lower data efficiency. In multi-task learning, shared information and knowledge among tasks can significantly improve model performance, but the limitations of single-objective models prevent them from benefiting from these shared insights, reducing their generalization ability and adaptability to new tasks. Lastly, since each task requires a separate model to be trained independently, this increases the demand for computational resources and extends training time, decreasing overall efficiency.
Multi-Objective Optimization (MOO) offers a more comprehensive solution by simultaneously considering and optimizing multiple conflicting objectives29,30,31. This approach seeks not just to identify optimal solutions for one single objective but to find the best trade-offs among all objectives32,33. In practice, this often involves a process known as Pareto optimization, where the core concept is the Pareto front. The Pareto front comprises a set of non-dominated solutions, indicating a state where any improvement in one objective does not lead to the deterioration of any other objectives17,34. Therefore, adopting a multi-objective learning approach combined with Transformer models offers significant advantages. First, multi-objective learning allows the model to share data and knowledge across multiple related tasks, thereby utilizing existing data resources more efficiently and enhancing overall learning outcomes. Additionally, by simultaneously handling multiple tasks, the multi-task model can better capture diverse features within the data, improving the model’s generalization ability and making it more robust when faced with new tasks. Moreover, multi-objective learning reduces the need to independently train multiple single-objective models, thereby lowering computational resource consumption and shortening training time, ultimately increasing development efficiency. In summary, combining multi-objective learning with Transformer models not only overcomes the limitations of single-objective models but also enhances the model’s overall performance and practical value.
In order to realize the idea of combining multi-objective learning with Transformer models, we propose multi-objective Escaping Bird Search algorithm (MOEBS). First, the Escaping Bird Search (EBS) is a unique heuristic optimization method built upon the behavior of bird flocks evading predators in nature6,7. EBS tackles optimization problems by simulating this evasion behavior, showing good dynamic adaptability and global search capabilities6,12. Second, when introduced to multi-objective scenarios, we specifically developed MOEBS, an extension of EBS designed for multi-objective problems17. MOEBS leverages the dynamic evasion mechanism of EBS to emulate the maneuvers of birds evading predators in the search space, effectively exploring optimal solutions among various objectives35. This method places particular emphasis on archival strategies, systematically preserving non-dominated solutions from history, which gradually approach the Pareto front through iterative processes, offering key stakeholders a variety of viable optimal choices9,36,37. In order to assess the effectiveness of MOEBS, we conducted wilcoxon signed-rank test and detailed benchmark testing built upon problems like ZDT, DTLZ, WFG on the 5 standard multi-objective benchmark problem sets, and evaluated its effect using four indexes: Generational Distance(GD), Inverted Generational Distance(IGD),Hyper-volume (HV), and Spacing(SP)34. The experiment is not limited to MOEBS, but also compared with the following three MOO algorithms: Multi-Objective Multi-Verse Optimization (MOMVO), Multi-Objective Evolutionary Algorithm based on Decomposition (MOEAD), and Multi-Objective Salp Swarm Algorithm (MSSA)16,35. These experiments clearly demonstrate the outstanding performance of MOEBS in solving multi-objective optimization problems. Compared to the other three benchmark algorithms, MOEBS consistently matched or outperformed their performance across various evaluation metrics. The results not only validate the superiority of MOEBS in handling complex optimization tasks but also highlight its potential and value in the field of multi-objective optimization12.
To validate the superior optimization capability of MOEBS, we proposed the MOEBS-Transformer architecture and applied it to hyperparameter optimization tasks in machine learning, conducting experiments on the closing price datasets of Amazon, Google, and Uniqlo. Specifically, we optimized key hyperparameters of the Transformer model, including the number of attention heads, initial learning rate, and regularization coefficient. The performance of the optimized MOEBS-Transformer was compared against various optimization methods, including Random Search (RS)38, Grid Search (GS)39, Bayesian Optimization (BO)40, and Transformer models optimized using three multi-objective optimization algorithms: MOMVO, MSSA, and MOEAD. Additionally, to comprehensively assess the prediction performance of different models, we selected five classic deep learning models: Convolutional Neural Network (CNN)41, Long Short-Term Memory Network (LSTM)42, Bidirectional Long Short-Term Memory Network (BiLSTM)43, Gated Recurrent Unit (GRU)44, and the traditional Transformer model45, all tested on the same closing price datasets. The model performance was evaluated using metrics such as R2(coefficient of determination), RMSE (Root Mean Squared Error), and RPD (Residual Prediction Deviation). This structured comparison not only highlighted the effectiveness of the MOEBS-Transformer in optimizing hyperparameters but also demonstrated its superior performance relative to other optimization algorithms in terms of prediction accuracy and prediction stability. This comprehensive experimental design provides strong evidence and reliable support for the superior performance of MOEBS in complex optimization scenarios46. Comparative experiments showed that MOEBS-Transformer significantly outperformed other competitor models mentioned earlier across multiple performance indicators12,24 such as RMSE, RPD, and R247. These results not only demonstrate the effectiveness of MOEBS in real-world financial applications but also showcase its powerful potential in handling complex multi-objective scenarios, providing a new, more efficient tool for financial market analysis and prediction24. This comprehensive optimization strategy allows the Transformer model20to better adapt to the needs of financial market analysis, improving its competitiveness and efficiency in practical applications24.
Moreover, the innovation of this study lies in proposing MOEBS and MOEBS-Transformer, Transformer integrated with MOEBS for hyperparameter fine-tuning, to optimize the complex task of stock market prediction48,49,50. This method enhances the model’s performance by effectively and efficiently fine-tuning hyperparameters to achieve better performance in terms of financial time series prediction, offering a new efficient tool for financial time series analysis7,51,52,53. The significant contributions of this article can be summarized as follows:
-
Introduces a novel approach by integrating multi-objective optimization with Transformer models to enhance prediction accuracy in financial data.
-
Proposes a multi-objective extension of the Escaping Bird Search (EBS) algorithm, called MOEBS, which was validated through benchmark tests on problems like ZDT, DTLZ, and WFG, and compared with other advanced optimization methods using metrics such as GD, SP, IGD, and HV.
-
MOEBS is then applied to the optimization of hyperparameters of Transformer including learning rate, the number of attention heads, and regularization coefficient.
-
In experiments on the stock data of Amazon, Google, and Uniqlo, the performance of the MOEBS-Transformer model surpassed that of other competing algorithms, as evidenced by improvements in metrics such as RMSE, RPD, and R2.
-
Five deep learning models (CNN, LSTM, BiLSTM, GRU, and Transformer) were validated on multiple real-world datasets, providing substantial experimental evidence
-
The MOEBS-Transformer model proves to be a powerful tool for stock market prediction, offering enhanced accuracy and stability, making it valuable for both research and practical financial applications.
The structure of this paper is as follows. Section "Literature review" briefly introduces definitions and preliminary knowledge of MOO. The original EBS is conceptually reviewed, and the multi-objective version is presented in Section "Multiple Objective Escaping Bird Search Optimization". Section "Discussion of numerical experiment" includes the MOEBS experimental results in benchmark tests on problems like ZDT, DTLZ, and WFG. Section "Review of Classical Time Series Models and Experiments" utilizes five classic deep learning models (CNN, LSTM, BiLSTM, GRU, and Transformer) to conduct experiments on the closing prices of Amazon, Google, and Uniqlo. In section "Hyperparameter optimization experiments for the Transformer model", the experiments compared Transformer models under different hyperparameter optimization methods, including Random Search (RS), Grid Search (GS), Bayesian Optimization (BO), and multi-objective optimization methods such as MOEBS-Transformer, MOMVO-Transformer, MOEAD-Transformer, and MSSA-Transformer. Lastly, Section "Conclusion and future work" includes the conclusions, limitations and future work.
Literature review
In the first section, we provided a detailed overview of the research framework and experimental procedures of this study. In this section, we will build on the findings from various prior studies and analyses to offer an in-depth explanation of the Pareto front in the context of current multi-objective optimization problems.
Numerous practical challenges require optimizing several objectives that often conflict with one another and must be minimized or maximized simultaneously. Such types of challenges are known as Multi-Objective Optimization Problems (MOOPs)54,55. A MOOP aimed to minimize can be represented by the mathematical expression as below:
where \({f}_{1},{f}_{2},...,{f}_{m}\) specify the objective functions for minimization, m represents the quantity of objective functions, X denotes the decision variables vectors, p indicates the quantity of inequality constraints, s stands for the quantity of equality constraints, \({g}_{i}\) refers to the \({i}^{th}\)inequality constraint56, \({h}_{j}\) stands for the \({j}^{th}\) equality constraint, ndenotes the number of decision variables55, \({L}_{k}\) and \({U}_{k}\) stand for the lower and upper bound of the \({k}^{th}\)decision variable within the solution space31,33. MOO differs significantly from Single-Objective Optimization (SOO). In SOO, the aim is to find one single global optimal solution within the population, while MOO yields a set of various solutions named Pareto-optimal solutions32,57. For SOO, the objective function is scalar, meaning that comparing two candidate solutions requires only an evaluation of their objective function values58. In a minimization task, the solution with the lowest objective function value is considered the optimal59. Conversely, MOO involves vector-valued objective functions, and the comparison between 2 solutions is based on the concept of Pareto dominance, which allows for the evaluation of multiple objective function values simultaneously36,37. For a minimization problem, if X and Z are the candidate solutions, the set of all feasible solutions, considering the constraints, is denoted as Ω. The four distinct mathematical definitions that express the concepts of Pareto dominance are presented as below:
Pareto dominance
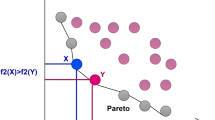
where, for the \(X\) solution to be considered superior (dominance) over the \(Z\) solution, it must not perform worse than Z in any objective function and must achieve a better value in at least one objective function. If this is satisfied, the X solution is said to dominate the Z solution (Pareto dominates), which is denoted as \(X\succ Z\). Figure 1 illustrates the concept of Pareto dominance. The red dots stand for the Dominant Solution, the blue dots stand for the Dominated Solution, and the green dots stand for the Indifferent Solution. The dominant solution is not inferior to the dominated solution on all goals and is superior to the dominated solution on at least one goal.

Pareto dominance.
Pareto optimal
where, every candidate within the Ω set is evaluated against the other solutions based on Pareto dominance (introduced in Def. 1). Following this evaluation, if no Z solution is found to dominate the X solution, X is considered a Pareto optimal solution. Figure 2 depicts the concept of Pareto optimal solutions. Within the figure, red dots represent Pareto Optimal Solutions and green dots represent Other Solutions. Pareto optimal solutions are the ones that are not dominated by others on all goals.

Pareto optimal.
Pareto optimal set (PS)
The set of Pareto optimal solution vectors.
Pareto optimal front (PF)
The set of Pareto optimal objective vectors.
In Fig. 3, red dots represent Pareto Optimal Solutions, green dots represent Other Solutions, and the solid blue line represents the Pareto front. The pareto front contains every Pareto optimal solution, showing the optimal tradeoff between different objectives within MOO.

Pareto front.
Multiple objective escaping bird search optimization
This section provides a detailed introduction to the fundamental concepts of the original Escaping Bird Search (EBS) optimization and delves into the multi-objective optimization mechanism within MOEBS, explaining how EBS has been extended and applied to optimize multi-objective problems.
Escaping bird search optimization
Within many natural ecosystems, the interaction between prey and predators is essential to the survival of species. Different organisms have evolved various strategies to evade predators and ensure their survival. This discussion focuses on avian prey-predator systems in open airspace. Typically, in these systems, the prey has a smaller size compared to the predator. Although the prey, with its smaller wingspan, might fly slower than its predator, it compensates for this disadvantage through other adaptive traits. For instance, these birds are able to alter their wing beat-rate during attacking and escaping maneuvers. Additionally, the great maneuverability of the prey serves as a crucial advantage in evading predators. The swift (Apus apus) is a gliding bird known for its remarkable ability to increase speed by sweeping its wings back and for making sharp turns by spreading them. Compared to many other birds, swifts exhibit exceptionally high maneuverability (as shown in Fig. 4). The unique shape of their wings, combined with their rapid wing beat-rate, allows them to execute swift turns in nearly any direction. In simulations, such a prey bird might employ one of the following strategies to evade a hunter bird.:

A swift (a) utilizing wing beat-rate during straight flight, (b) in a turning maneuver.
- Level maneuvering: The prey bird chooses to execute rapid turns to evade capture by a predator attacking from a horizontal approach. (the hunter-bird).
- Vertical maneuvering: To evade predator diving from above, the prey often employs a strategy of rapid upward climbing flights. Alternatively, when the predator is ascending to capture it, the prey may opt to dive downward as a means of escape.
Figure 5 provides an illustrative example of the strategies discussed above. The likelihood of a bird executing an aerial maneuver is influenced by factors such as its body area and velocity. A smaller body area reduces aerodynamic resistance force, enhancing maneuverability. These aerial maneuvers form the basis of a novel optimization algorithm named Escaping Bird Search (EBS). EBS is a population-based algorithm that explores the design space through aerial maneuvers performed by pairs of artificial birds, which serve as search agents. Within every randomly selected pair from the population, the bird with lower fitness is designated as the prey (escaping bird), while the other acts as the predator. The position of an artificial bird within the search space corresponds to a design vector, which is adjusted during the bird’s flight. A bird’s maneuverability can be influenced by aspects such as its body area, wing beat-rate, and speed. Within the current numerical emulation, Maneuver-Power (MP) of the \({i}^{th}\) artificial bird; \(M{P}_{i}\) can be denoted as:
where, the velocity vector \({V}_{i}\) is calculated by taking the difference between current and previous positions of the \({i}^{th}\) bird. \(\Vert {V}_{i}\Vert =\sqrt{{\sum }_{j}{V}_{i,j}^{2}}\) is computed as the norm of \({V}_{i}\). The influence of wing beat-rate variation on MP is represented by the parameter β that arbitrarily alternates between 0 and 2. The body factor \({b}_{i}\) models the impact of the bird’s body area (cost) using the normalization equation below:
where \({C}_{i}\) refers to the cost of the \({i}^{th}\) agent; \({C}_{max}\) and \({C}_{min}\) stands for maximum and minimum costs within the present population, accordingly. The infinitesimal constant ε, is introduced to avoid division by zero. Additionally, an Escaping Rate, ER is defined using MPs of the Attacking Bird, AB acting as the predator and the Escaping Bird, EB acting as the prey. This relationship is expressed as the following:
where, \(M{P}_{AB}\) and \(M{P}_{EB}\) refers to the MPs of the AB and the EB, correspondingly. In vertical maneuvers, the EB chooses a destination in the direction opposite to the predator. This behavior is emulated using the artificial flight model below:
where, \({X}_{AB}\) and \({X}_{EB}\) refer to the positions of the AB and the EB, accordingly. r stands for an arbitrarily generated number uniform distributed between 0 and 1. The escaping rate ER is computed by Eq. (8). The function \(Opp({X}_{AB})\) gives a vector’s opposite within the design space:

Aerial escape maneuvers in a prey-predator bird system (The dashed line represents the predator’s path immediately after missing the prey).
When \(ER\) is low, the artificial prey selects a horizontal maneuver by veering off its current path. This is modeled by changing to an arbitrarily generated position vector as follows:
where, \({X}_{L}\) and \({X}_{U}\) represent vectors of the lower and upper limits of the design variables, accordingly. The symbol ⊗ represents the element-wise multiplication and R stands for a vector of random values within the range [0,1]. The predator’s flight is primarily directed towards the prey’s position. Nevertheless, in this emulation, an additional direction is introduced: flying towards the global optimal position achieved by any prey so far; represented by \({X}_{Gbest}\). Hence, the predator maneuver is expressed as:
here, the arbitrary values \({r}_{1}\) and \({r}_{2}\) are separately generated in the range [0,1] and the Capturing Rate, CR, is denoted by:
When ER is large, CR is close to 0, and vice versa. This is why CR and ER are considered complementary to each other. Based on Eq. (8), ER models the combined effects of both the predator and the prey during an aerial encounter. Equation (12) represents a vector-sum position update, an approach commonly used by other swarm intelligence algorithms such as PSO. However, unlike PSO, EBS employs only 1 adaptive coefficient CR, instead of PSO’s cognitive and inertial factors. Additionally, the final component in Eq. (12) is not scaled by any predefined factor. The proposed algorithm, which is based on the emulated maneuvers of artificial predator-prey pairs, is constructed using 4 steps listed below.
Step 1. Initialize a population of N artificial birds with arbitrary positions. Spawn each \({i}^{th}\) bird in the upper and lower bounds of the design variables using the following:
where, the right-hand-side parameters are introduced in Eq. (11). Subsequently, calculate the cost function for every bird and initialize their velocities to 0. The initial population consists of both prey and predator birds to be differentiated in Step 3.
Step 2. Compute the MP for every bird using Eq. (6) using the normalized cost values from Eq. (7).
Step 3. Repeat below until the termination criterion is met:
For \(i=1,...N\) do:
-
Pick the \({i}^{th}\) bird and arbitrarily pair it with another bird within the population. Select the best as AB and the worst as EB.
-
Compute MP, ER and CR of the present pair of predator (AB) and prey (EB) using Eq. (6)-(8) and Eq. (13).
-
Offer a candidate solution for AB using Eq. (12).
-
Calculate cost of \({X}_{AB}^{Candidate}\)
-
Substitute \({X}_{AB}\) with \({X}_{AB}^{Candidate}\) if \({X}_{AB}^{Candidate}\) achieves less cost than \({X}_{AB}\) (greedy selection)
-
Terminate the main iteration once the Number of cost or fitness Function Evaluations; NFE reaches predetermined \(NF{E}_{max}\)
Generate a candidate solution for EB based on either level-turning using Eq. (11) or vertical-maneuver using Eq. (9). Alternate between the two using the condition below:
-
1)
Calculate cost of \({X}_{AB}^{Candidate}\)
-
2)
Substitute \({X}_{EB}\) with \({X}_{EB}^{Candidate}\) if \({X}_{EB}^{Candidate}\) achieves less cost than it (greedy selection) Terminate the main iteration once \(NFE\) reaches \(NF{E}_{max}\)
Update \(X{G}_{Best}\): If \(i=N\) and \(NFE\) < \(NF{E}_{max}\), return to Step 3, otherwise terminate the iteration and advance to Step 4.
Step 4: After exiting the main iteration, return the current \(X{G}_{Best}\) as the optimum solution. Clearly, EBS operates with only 2 control parameters of N and \(NF{E}_{max}\).
Multiple objective escaping bird search
To build a multi-objective extension of the base EBS, several primary modifications are necessary. These changes are somewhat analogous to those implemented in MOPSO (Coello et al., 2004). As previously discussed, in MOOPs, a set of non-dominated solutions, known as Pareto optimal solutions, can be achieved. To manage these solutions, a new feature, namely an archive, is introduced. It acts as a storage repository to retain the non-dominated solutions discovered throughout the optimization procedure over multiple iterations. Notably, the maximum capacity of the archive is a parameter determined by the user. By incorporating such a feature into EBS for MOO, 4 scenarios may arise:
-
(1)
A recently found Pareto solution can be dominated by at least one of the current solutions in the archive. In this case, the recently found solution would be ignored.
-
(2)
The new solution dominates one or more solutions in the archive. In this case, the dominated solutions are eliminated from the archive and the new solution would be added to the archive.
-
(3)
If neither the new solution nor archive members dominate each other, the new solution should be added to the archive.
-
(4)
If the archive is full, the grid mechanism should be run to re-arrange the segmentation of the objective space to find the most crowded segment, the best segment to eliminate a solution from.
In the grid mechanism, objective function space is divided into different regions. An example of such a mechanism is illustrated by Fig. 6. Notably, if a new solution introduced to the archive exceeds the established boundaries, a recalculation for the grid must be performed, resulting in the repositioning of each individual within it. Each hypercube within the grid stands for a region consisting of a certain number of individuals.

Grid mechanism.
From the provided graph, the most densely populated segment is identified with ease. The second feature introduced to EBS is the optimal solution selection technique. In the base EBS, identifying the optimal solution is straightforward, based on the objective function values of the candidates. However, for a multi-objective problem, determining the best solution is more complex because of the Pareto optimality. To choose the optimal solution, which serves as the leader for guiding the rest of the candidates in updating their positions during the optimization process, a leader selection mechanism is employed. This mechanism identifies the least populated segments of the objective space using a grid system and selects one of the non-dominated solutions within that segment as the leader. The selection process is then conducted based on the roulette wheel selection approach, after a lower fitness value is assigned to every segment.
where \(\lambda\) stands for a constant above 1. \({N}_{j}\) refers to the quantity of non-dominated particles within \({j}^{th}\) segment. The above formulation reveals that it allocates a lower probability to more populated segments. That is to say, the fewer particles within a segment, the greater its probability of being selected. This approach makes sure that the optimal solution (leader) in every iteration is chosen from one of the least populated segments of the objective function space. This strategy enhances the algorithm’s coverage by encouraging candidates to update their positions toward less-explored regions within the solution space. The framework of MOEBS is shown in Fig. 7. To summarize, the key strengths of the newly introduced MOEBS are as follows:

The framework of MOEBS.
-
The use of an external archive guarantees the efficient storage of the optimal non-dominated solutions gathered throughout the optimization process.
-
User determined parameters like the quantity of candidates generated through the diffusion process, allow MOEBS to effectively tackle complex MOO-problems.
-
Gradually reducing the parameter \(ER\) throughout the iteration process ensures a balanced trade-off between coverage and convergence in MOEBS.
-
Because MOEBS retains the updating mechanism from the basic EBS, it can efficiently explore the solution space.
-
Unlike many multi-objective algorithms, MOEBS requires only a few parameters to be tuned.
-
The grid mechanism enables MOEBS to identify the most and least populated regions within the solution space.
-
The leader selection mechanism allows MOEBS to enhance the diversity of the non-dominated solutions obtained.
-
By allocating lower probabilities to highly populated segments, MOEBS reduces the probability of local optima trapping.
The pseudo-code for MOEBS is included as follows:

MOEBS
Discussion of numerical experiment
In this section, we conducted comparative experiments on five standard multi-objective benchmark problems: ZDT60, DTLZ61, WFG60, UF61, and CF60. We compared the performance of MOEBS against other multi-objective optimization algorithms, including MOMVO, MOEAD, and MSSA. These experiments allowed us to thoroughly evaluate the effectiveness and advantages of MOEBS in multi-objective optimization tasks, providing strong evidence for its potential in real-world applications.
Experiment in the five standard multi-objective benchmark problem sets
In this section, we detail the experimental setup, display the experimental outcomes, and offer a review. For all experiments, the setup parameters are shown in Table 1. For testing cases, we selected 5 standard multi-objective benchmark problem sets. The effectiveness of MOEBS is evaluated across these benchmark problem sets, as outlined below:
-
ZDT problem set: ZDT1-ZDT4, ZDT6
-
DTLZ problem set: DTLZ1-DTLZ7
-
WFG problem set: WFG1-WFG10
-
UF problem set: UF1-UF10
-
CF problem set: CF1-CF10
The rationale for conducting a variety of experiments throughout a variety of benchmark problem sets is to create a platform that guarantees impartiality, trustworthiness, and fairness for the methods being compared. This setup minimizes the risk of unintended bias that could advantage a particular candidate because of advantageous testing configurations.
Discussion of Pareto front alignments of the algorithms on benchmark problem sets
Figure 8 illustrates the performance of the CF problem set, highlighting the strong performance of MOEBS. The results indicate that MSSA, MOMVO, and MOEAD also demonstrate a certain competitiveness, albeit with some differences. MSSA effectively satisfies constraints in certain experimental settings but generally falls short in terms of coverage and resolution of the Pareto front. Its solution sets tend to cluster in specific regions, occasionally deviating from the true Pareto front, thus limiting its exploration of the solution space’s breadth and depth. A similar situation is observed with MOMVO. On the other hand, MOEAD exhibits better solution distribution in some cases, but its consistency in satisfying complex constraints is not as robust as MOEBS. This inconsistency may stem from MOEAD’s algorithm structure and parameter adjustments, leading to instability in some test scenarios. However, MOEBS consistently outperforms in terms of solution coverage and deviation from the true Pareto front across various scenarios. Overall, while MSSA, MOMVO, and MOEAD show some optimization capabilities on the CF problem set, MOEBS demonstrates more significant advantages in solution quality, uniformity, and constraint satisfaction.


Results of Pareto fronts generated by all algorithms in CF1, CF2 and CF6.
The DTLZ problem set is designed to assess an algorithm’s capability to deal with multi-dimensional target optimization problems, especially in the case of up to three-dimensional or more targets. DTLZ problems usually involve complex nonlinear relationships and extensive search space. It can be observed from Fig. 9 that MOEBS has significant advantages in DTLZ problems, especially in problems such as DTLZ4 and DTLZ6, which can effectively cover the vast Pareto front and keep a highly uniform distribution of solutions. MSSA only managed to form a cluster of solutions on DTLZ2 and DTLZ4, showing a poor capability in terms of Pareto front coverage. MOMVO exhibits better solution distribution in some cases, but its consistency in satisfying complex constraints is not as robust as MOEBS as it completely fails to approximate the Pareto front in DTLZ6. Overall, MOEBS shows more obvious advantages in the quality, uniformity of generated results and the ability to satisfy constraints in this set.


Results of Pareto fronts generated by all algorithms in DTLZ2, DTLZ4 and DTLZ6.
The UF problem set is constructed to understand and compare the effectiveness of the algorithm in an unconstrained MOO environment. It is clear in Fig. 10 that MOEBS has demonstrated excellent performance on all 3 UF problems, especially in terms of fast convergence and wide coverage. MSSA, MOMVO, and MOEAD all fail to estimate the true Pareto front precisely enough. Their solutions tend to be clustered as well, yielding to poor Pareto front coverage. MOEBS shows a better distribution of solution sets in these tests, which indicates that it can explore the target space more efficiently in an unconstrained environment and achieve superior multi-objective optimization performance.


Results of Pareto fronts generated by all algorithms in UF1, UF4 and UF7.
The WFG test set is crafted to assess an algorithm’s ability to handle highly complex and nonlinear problems. For the three selected WFG problems, as illustrated in Fig. 11, MOEBS demonstrates exceptional solution diversity and coverage. Additionally, MOEBS shows superior continuity and uniformity in its solutions compared to the other three competitors. It effectively explores multiple target spaces, avoiding local optima. In contrast, MOMVO’s performance is inconsistent, particularly in WFG8, where it lacks the stability shown in the other two problems. Both MOEAD and MSSA exhibit limited exploration in high-dimensional target spaces, with their solution sets focusing on specific front regions.


Results of Pareto fronts produced by the algorithms in WFG5, WFG8 and WFG9.
Figure 12 presents the result on ZDT problem set. Both ZDT1 and ZDT4 are designed with smooth, continuous, and convex Pareto fronts. In both cases, the experimental outcomes demonstrate that MOEBS is able to closely approximate the ideal Pareto front, highlighting its strength when handling convex optimization problems. MOEBS efficiently explores the solution space and generates high-quality solution sets. However, MOEAD and MSSA achieve satisfactory results only in one problem, indicating their limited applicability. MOMVO approximates a close Pareto front but is clearly outperformed by MOEBS in ZDT1. Furthermore, MOEBS excels in ZDT3, a problem with a non-continuous Pareto front, where MOEAD and MSSA struggle significantly. These findings demonstrate that MOEBS is not only adept at addressing complex front shapes but also maintains efficient and stable optimization performance for basic convex front problems.


Results of PF generated by all algorithms on ZDT1, ZDT3 and ZDT4 problems.
Evaluation of MOO capability of the algorithms based on performance metrics
The test problem sets are regarded as some of the most challenging in the literature, offering a variety of multi-objective search spaces with distinct Pareto optimal fronts, including convex, non-convex, discontinuous, and multi-modal types. To evaluate the effectiveness, we have used Inverted Generational Distance (IGD)62, Spacing (SP)63, Generational Distance (GD)64and Hypervolume (HV)65 as metrics for measuring convergence and performance.
Inverted generational distance (IGD)
Inverted generational distance (IGD) is a metric that evaluates the quality of approximations to the Pareto front achieved by MOO algorithms. It is denoted by the following expression:
where \(n\) denotes the quantity of elements within \({PF}_{ture}\) and \({d}_{i}\) denotes the Euclidean distance from the solution \(i\) within \({PF}_{known}\) to its closest solution within \({PF}_{ture}\). A zero value means that all generated solutions rest exactly on the true Pareto front.
Figure 13 shows a schematic of IGD indicator. The dashed lines represent the Pareto front, the red dots represent the reference points, and the green dots stand for the generated solutions. The arrows show the distance of each generated solution to the closest reference point. IGD measures the ability of the generated solution set to approach the Pareto front by calculating the mean of these distances. The shorter the distance, the less the IGD value, indicating that the nearer the generated solution set is to the Pareto front, the better the algorithm performance.

Illustration of IGD.
Figure 14 present the box plot results of four different algorithms (MOMVO, MSSA, MOEAD, MOEBS) on ZTD, DTLZ and other 3 problem sets, analyzed through IGD. MOEBS generally shows the lowest median IGD and a relatively narrow interquartile range (IQR), indicating that it can consistently find solutions closest to the true Pareto front. MOMVO has a similar performance as MOEBS, while MSSA and MOEAD tend to have either higher median values or larger IQRs, indicating worth performance with inconsistencies.

IGD box plots on ZTD, DTLZ, WFG, UF, CF problem sets.
As shown in Table 2, the IGD calculates the mean distance between the approximate solution set and the real Pareto front. MOEBS performs particularly well on multiple test functions. In the ZDT series of problems, the mean IGD values of MOEBS for ZDT1, ZDT3 and ZDT6 problems are 0.004415, 0.005024 and 0.003504 respectively, which are the lowest values, and the standard deviation is also 0.000150, 0.000173 and 0.000139 respectively. It shows its excellent approximation ability and high stability. In the DTLZ series of problems, the mean IGD of MOEBS for DTLZ3 and DTLZ6 problems is 1.092400 and 0.005199, respectively, which is significantly lower than other algorithms, and the standard deviations are 0.899732 and 0.000359, respectively, which further proves its strong ability and consistency in MOOPs with high dimensions. In addition, in the WFG series of problems, MOEBS also performed well with an average IGD of 0.68266 on the WFG5 problem. Overall, MOEBS achieves the lowest mean on 16 problems sets, while MOMVO, MSSA, and MOEAD achieve the lowest on 9, 10, and 6 correspondingly. For the standard deviation, MOEBS achieves the lowest on 22 problem sets, while MOMVO, MSSA, and MOEAD achieve the lowest on 12, 7, and 0 correspondingly. These data show that MOEBS not only has a significant advantage in approximating the real Pareto front, but also excels in the consistency and stability of its results, making it more competitive in multi-objective optimization tasks.
Spacing (SP)
Spacing is utilized to quantify and assess the coverage. It indicates how uniformly the solutions achieved are distributed along the \({PF}_{known}\). It is defined as follows:
where \({N}_{pf}\) in \({PF}_{known}\) is the quantity of non-dominated solutions and \({d}_{i}\) refers to the Euclidean distance from the solution \(i\) within \({PF}_{known}\) to the nearest solution within \({PF}_{ture}\). When \(SP\) is low, the convergence is better in terms of robustness and reliability.
Figure 15 shows a diagram of the Spacing indicator. The green dot represents the generated solutions, and the black line represents the distance between the generated solutions. The Spacing index measures the distribution uniformity of the solution set by calculating the distance between the generated solution sets. The more uniform the Spacing, the lower the spacing value, denoting that the more uniformly distributed the solution set in the target space and the greater the diversity, the better the algorithm performance.

Illustration of Spacing.
Figure 16 present the box plot results of the four different algorithms on ZTD, DTLZ and other 3 problem sets, analyzed through Spacing. MOMVO tends to have low median values together with narrower IQRs, indicating great performance. For MOEBS, it generally shows higher spacing value with some level of inconsistency indicated by wider IQRs. This remains as a limitation of our proposed MOEBS and there is still room for improvement. MSSA and MOEAD show varied performance inconsistencies in terms of medians and IQRs.

Spacing box plots on ZTD, DTLZ, WFG, UF, CF problem sets.
In Table 3, the SP index measures the diversity and distribution uniformity of the solution set. MOEBS has the lowest SP mean and standard deviation on several test functions, which shows its significant advantages in solving MOOPs. For example, in the ZDT series of problems, the mean SP of MOEBS for ZDT1, ZDT3 and ZDT4 problems is 0.006526, 0.007169 and 0.006058, respectively, which are the lowest, indicating that its solution set is the most uniformly distributed in the target space. Overall, MOEBS achieves the lowest mean on 7 problems sets, while MOMVO, MSSA, and MOEAD achieve the lowest on 10, 6, and 18 correspondingly. For the standard deviation, MOEBS achieves the lowest on 9 problem sets, while MOMVO, MSSA, and MOEAD achieve on 13, 4, and 15 correspondingly. Compared with other cutting-edge algorithms, MOEBS has a matching performance in different types and dimensions of problems, fully demonstrating its wide applicability and superiority.
Hypervolume (HV)
HV computes the volume, within the objective space, covered by candidates of set A, mathematically. HV values are then computed as follow:
where, for every \(i \in A\) solution, a \({v}_{i}\) hypercube is constructed based on \(W\) the reference point and where the \(i\) solution stands for the diagonal of the hypercube.
Figure 17 shows a schematic of the HV metrics. The dashed lines stand for the Pareto front, and the reference points are located at the intersection of the two longest perpendicular solid lines in the coordinate axis. The green and blue areas together represent the hypervolume. The green area represents the volume covered from the reference point to each generated solution, while the blue area represents the sum of these volumes to form the total hypervolume. The HV index evaluates algorithm performance by calculating the total hypervolume covered by the generated solution set. The greater the hypervolume, the better the quality of the generated solution set, and the wider the distribution, the better the algorithm performance.

Illustration of Hypervolume.
Figure 18 present the box plot results of the 4 algorithms on ZTD, DTLZ and other 3 problem sets, analyzed through HV. MOEBS generally shows much higher median HV values in several plots, sometimes with a few large IQRs, indicating great performance with some inconsistencies. In contrast, all other three algorithms have varied performance, with better performance on some problems and worse performance on the others. This indicates that they might have potentials in specific problems domains, but their versatility is worse than MOEBS. Generally, MOEBS performs the best on HV, indicating the best solution distribution and coverage.

HV box plots on ZTD, DTLZ, WFG, UF, CF problem sets.
As the Table 4 shows, MOEBS performs particularly well on HV metrics across multiple test functions. Specifically, in the ZDT series of problems, the mean HV values of MOEBS for ZDT1 and ZDT6 problems are 0.719928 and 0.388432 respectively, both of which are the highest values, and the standard deviation is also small, indicating its strong coverage ability and stability. MOEBS performed well with mean HV values of 0.309414 and 0.309425 for WFG4 and WFG5 problems, respectively. In the CF series of problems, the mean HV of MOEBS for CF1 and CF2 problems is 0.571171 and 0.621633, respectively, with a small standard deviation, which further proves its powerful ability in complex constrained multi-objective optimization problems. Overall, MOEBS achieves the highest mean on 12 problems sets, while MOMVO, MSSA, and MOEAD achieve the highest on 14, 7, and 8 correspondingly. For the standard deviation, MOEBS achieves the lowest on 20 problem sets, while MOMVO, MSSA, and MOEAD achieve on 14, 6, and 4 correspondingly. Therefore, MOEBS has a matching performance as its competitors while maintaining the best consistency in terms of multi-objective optimization.
Generational distance (GD)
Distance between the true Pareto front (\({PF}_{ture}\)) and the achieved Pareto front (\({PF}_{known}\)) is denoted by generational distance. This metric is mathematically defined as follows:
where \({n}_{pf}\) in \({PF}_{known}\) represents the quantity of non-dominated solutions and \({dis}_{i}\) represents the Euclidean distance from the solution \(i\) within \({PF}_{known}\) to its nearest solution within in \({PF}_{ture}\). Notably, a lower GD value refers to better algorithm convergence.
Figure 19 shows a schematic diagram of the GD indicator. The dashed lines represent the Pareto fronts, the red dots represent the reference points, and the green dots stand for the generated solutions. The GD index measures the ability of the solution set to approach the Pareto front by computing the distance from the generated solution set to the closest Pareto front point. This distance between each green point and the nearest red point indicates the degree of deviation between the solution set and the Pareto front. The shorter the distance, the less the GD value, indicating the nearer the generated solution set is to the Pareto front, the better the algorithm performance.

Illustration of GD.
Figure 20 present the box plot results of4 algorithms on ZTD, DTLZ and other 3 problem sets, analyzed through GD. Clearly, MOEBS manages to achieve the lowest median together with a narrow IQR throughout different problems, outperforming the other competitors in terms of effectiveness and consistency. MSSA and MOEAD have huge variations in terms of performance, showing that their abilities to tackle problems with different setup are limited. MOMVO has a similar performance to MOEBS, but with a higher median and wider IQR in general. Overall, MOEBS performs the best in terms of GD.

GD box plot ZTD, DTLZ, WFG, UF, CF problem sets.
From Table 5, MOEBS performs well on the GD indicator on several functions, especially on the ZDT3, DTLZ6 and DTLZ7 problems. In the case of ZDT3, the GD average of MOEBS is only 0.000173 and the standard deviation is 0.000013, showing extremely high approximation ability and result consistency. Compared with the GD average of MOMVO, MSSA and MOEAD, which are 0.013133, 0.000724 and 0.000861, respectively. MOEBS was the best performer. For the DTLZ6 problem, the GD average of MOEBS is 0.000048 and the standard deviation is 0.000001, which once again proves its excellent performance and high stability in high-dimensional complex problems. The GD averages of other algorithms are 0.001612 (MOMVO), 0.074797 (MSSA) and 0.000051 (MOEAD), respectively. For the DTLZ7 problem, MOEBS has a GD mean of 0.004806 and a standard deviation of 0.003698, which is slightly higher than the other two functions, but still performs well, compared to MOMVO, MSSA, and MOEAD with GD averages of 0.010121, 1.216168, and 0.189027, respectively. Overall, MOEBS achieves the lowest mean on 8 problems sets, while MOMVO, MSSA, and MOEAD achieve the lowest on 1, 13, and 19 correspondingly. For the standard deviation, MOEBS achieves the lowest on 11 problem sets, while MOMVO, MSSA, and MOEAD achieve on 6, 12, and 12 correspondingly. These results highlight the remarkable performance of MOEBS matching state-of-the-art algorithms in terms of performance in multi-objective optimization problems.
Wilcoxon signed-rank test
In this section, we apply the Wilcoxon signed-rank test to review the performance of MOEBS together with the other competing algorithms, and the results are presented in Table 6. When the p-value is less than 0.05, the algorithm is considered to have a significant difference from MOEBS. Conversely, when the p-value is more than 0.05, there is no significant difference between the two algorithms. The symbols ‘ + / = / − ’ are used to indicate whether MOEBS performs better than, similar to, or worse than the competitors. We can see clearly from the table that MOEBS distinguishes from other competitors.
The results of the Wilcoxon signed-rank test in Table 6 indicate that MOEBS significantly outperforms MOMVO, MSSA, and MOEAD in multi-objective optimization. MOEBS demonstrates exceptional performance across IGD, and HV metrics, particularly in ZDT1 and ZDT2 tests, where it often receives a “ + ” in IGD and HV metrics, reflecting superior convergence and solution diversity, although the numbers of “ + ” is less than the “-” in SP metrics, presenting . Compared to MOVIVO and MSSA, MOEBS achieves a significant level of p < 0.05 in most tests, maintaining stable performance, especially in high-dimensional problems, showcasing strong adaptability and robustness to dimensional changes. This indicates that MOEBS not only excels in accuracy but also consistently provides higher-quality solutions across different dimensions.
Review of classical time series models and experiments
To validate the exceptional predictive performance of Transformer in data forecasting, this section utilizes five classic deep learning models (CNN, LSTM, BiLSTM, GRU, and Transformer) to conduct experiments on the closing prices of Amazon, Google, and Uniqlo. The following provides an introduction to these models and details of the experiments.
Overview of classical time series models
CNN (Convolutional Neural Network)
CNN extracts local features from input data through convolution operations, where convolutional filters scan the input to identify local patterns, such as edges in images or local patterns in time series. After convolution, pooling layers reduce feature dimensions, improving computational efficiency and reducing overfitting. For time series data, CNN excels at efficiently capturing short-term dependencies and local patterns, making it suitable for tasks like signal processing or preprocessing speech data41.
LSTM (Long Short-Term Memory)
LSTM is a specialized type of Recurrent Neural Network (RNN) that introduces memory cells and gating mechanisms (input gate, forget gate, output gate) to address the vanishing and exploding gradient problems in RNNs when handling long sequences. LSTM can dynamically “remember” or “forget” information based on the context of the time series. Its advantage for time series data lies in its ability to capture long-term dependencies, making it particularly suitable for tasks with long-term trends or complex dynamics, such as financial forecasting or weather prediction42.
BILSTM (Bidirectional Long Short-Term Memory)
BiLSTM extends LSTM by considering both forward and backward information in a time sequence. It consists of two LSTM networks: one processes the sequence in the forward direction, and the other processes it in the backward direction, combining the outputs of both. For time series data, its advantage lies in leveraging both past and future information, making it ideal for tasks that require global context, such as speech recognition, sentiment analysis, or natural language processing43.
GRU
GRU is a simplified variant of LSTM that uses gating mechanisms to control the flow of information without a separate memory cell. It has two main gates: the update gate, which determines how much of the past information to retain, and the reset gate, which decides how much of the previous information to forget. Compared to LSTM, GRU has fewer parameters, making it more computationally efficient while maintaining similar performance for many tasks. For time series data, GRU’s advantage lies in its ability to capture temporal dependencies with less computational complexity, making it suitable for tasks like stock price prediction, anomaly detection, or time series classification66.
Transformer
Transformers rely on the self-attention mechanism to model relationships between elements in a sequence without relying on recurrence or convolution. Through a global attention mechanism, Transformer computes dependencies across all elements of the input sequence and use multi-head attention to capture features from different subspaces. For time series data, their advantage is the ability to efficiently capture both global and local temporal dependencies while supporting parallel computation, making them suitable for handling long sequences, such as power load forecasting or multivariate time series analysis45.
Experimental methods and data
To verify the overall performance of the Transformer, the experiment selected stock closing price data from Amazon, Google, and Uniqlo. Meanwhile, Google, and Uniqlo were selected for the prediction experiments because they represent different types of markets: Amazon and Google are globally recognized tech companies, while Uniqlo is an international retail brand. Using stock price data from these companies helps evaluate the model’s applicability and generalization ability across different market conditions. It then compared five deep learning models: CNN, LSTM, BiLSTM, GRU, and Transformer. Using these three representative datasets, the experiment evaluated how each model performed under different market dynamics. The three stock datasets can be accessed in the supplementary information files.
Data description of Amazon stock closing price
Amazon operates in the technology and e-commerce sectors, with highly volatile stock prices influenced by market demand, technological advancements, and global economic fluctuations. The dataset is in a time series format, with the first column being the date and the second column the closing price, reflecting price changes from historical to recent times.
Data description of Google stock closing price
Google is a leading global internet technology company, with its stock prices affected by technological innovations, advertising revenues, and regulatory policies. While the price trends are relatively stable, there can be significant fluctuations during specific periods. The dataset is also in a time series format, with two columns: date and closing price, showing price trends at different time points.
Data description of Uniqlo stock closing price
As an apparel retail company, Uniqlo’s stock prices are greatly influenced by seasonal sales, market demand, and international trade conditions, showing cyclical variations. The Uniqlo dataset is also in a time series format, with two columns: date and closing price, helping assess the model’s ability to predict cyclical and trend patterns.
The experimental methods and performance valuation metrics
In this experiment, five machine learning models—CNN, LSTM, BiLSTM, GRU, and Transformer—were applied to three datasets: Amazon, Google, and Uniqlo. Each model was trained and tested on the same data, using an 8/2 split between the training and testing sets to ensure consistent evaluation across all models and datasets. The key metrics for evaluating the accuracy of stock market prediction models typically include R2 (coefficient of determination), RMSE (Root Mean Squared Error), and RPD (Ratio of Performance to Deviation). These metrics help quantify prediction errors and assess the model’s fit and stability. The performance of each model was evaluated using three key metrics:
Root Mean Square Error (RMSE) is a common metric for the difference between the prediction of a model versus the observation. It is the square root of the mean of the squared differences between prediction and actual observation. It offers a way to evaluate the magnitude of prediction errors and is particularly sensitive to large errors. The RMSE on the training set reflects the fit degree of the model on the training data.
where \(M\) stands for the quantity of samples within the training data used to compute the mean of squared differences between the actual values. \({Y}_{ i}\) and the predicted values \({Y}_{ptrd, i}\) for each sample, indicating the model’s accuracy on the training data.
Ratio of Performance to Deviation (RPD): RPD is the ratio of the standard deviation of the observed values to the RMSE of the predictions. This metric is used to assess the quality of predictive models, with higher values indicating better model performance. For RPD, we evaluate each candidate based on its performance on the test sample only, which can be calculated as below:
where \(N\) represents the quantity of samples within the test set, and the denominator is the RMSE in the test set, while the numerator \({\sigma }_{{Y}_{test}}\) stands for the standard deviation of the test data. In addition, this metric on test sample is positively correlated to the RMSE, hence, a supplementary metric indicating the optimization effectiveness and the predictive power of the model.
Coefficient of Determination (R2): R2 denotes the proportion of variance within the dependent variable that can be explained by the independent variables. Its value typically ranges between 0 and 1, with higher values signifying that a greater portion of the variance is captured and explained, indicating better predictive power. For R2 on the test set, the expression is formulated as below:
where \({Y}_{test,i}\) is the actual value of \({i}^{th}\) observation in the test sample, \({\widehat{Y}}_{test,i}\) is the predicted value of \({i}^{th}\) observation in the test sample, \({\overline{Y} }_{test}\) is the mean of the observed values in the test set, and \(N\) represents the quantity of samples within the test set.
Experimental results and analysis
The comparison results of 5 classical time series models in Amazon
As shown in Fig. 21, the comparison results of five models on the Amazon dataset are presented, with evaluation metrics including RMSE, R2, and RPD. The results indicate that the Transformer outperforms other models significantly on the test set, particularly in terms of prediction accuracy and fitting capability. It has the lowest RMSE on the test set, indicating higher prediction accuracy; an R2 close to 1, suggesting better trend capture; and a higher RPD, reflecting stronger stability and generalization. In contrast, LSTM, GRU, and BiLSTM exhibit higher RMSEs, lower (or even negative) R2 values on the test set, indicating limited fitting and prediction capabilities for stock price fluctuations. Additionally, other models have lower RPDs, suggesting that their stability and robustness are inferior to those of the Transformer. Therefore, the Transformer shows the best overall performance on the Amazon dataset.

Comparison of five model results on Amazon dataset.
Table 7 the comparison results of five models (CNN, LSTM, BiLSTM, GRU, and Transformer) on the Amazon stock dataset. On the training set, BiLSTM and GRU achieved lower RMSEs (7.6044 and 7.4646, respectively), which indicates a high degree of accuracy in fitting Amazon’s stock price trends. However, all models display very high \({R}_{2}\) values (greater than 0.99) on the training set, suggesting potential overfitting, particularly for LSTM, BiLSTM, and GRU, which generally perform well on training but show limitations on the test set.
On the test set, the Transformer stands out with an RMSE of 88.2008 and the highest \({R}_{2}\) of 0.98914, indicating that it generalizes better to unseen data and can more accurately predict stock price trends in Amazon’s highly volatile market. This suggests that the Transformer’s architecture, with its multi-head self-attention mechanism, effectively captures long-term dependencies and complex time series patterns, allowing it to better handle the variability inherent in stock price movements.
In contrast, models like LSTM, BiLSTM, and GRU perform poorly on the test set, with negative \({R}_{2}\) values (−1.1789, −0.35191, and −1.4, respectively), highlighting a tendency toward overfitting. These negative \({R}_{2}\) values (−1.1789, −0.35191, and −1.4, respectively), highlighting a tendency toward overfitting. These negative \({R}_{2}\)(0.97407), indicating limited capability in handling the complex dynamics of Amazon’s stock prices.
Overall, the results underscore the Transformer’s advantage in capturing long-term trends and intricate dependencies within time series data, making it a robust choice for stock prediction tasks in volatile sectors such as tech and e-commerce. This robustness is especially critical for industries like Amazon, where price movements are influenced by a combination of market dynamics, investor sentiment, and broader economic trends.
The comparison results of 5 classical time series models in Google
In Fig. 22, the results indicate that the Transformer outperforms other models on the test set, particularly in terms of prediction accuracy and robustness. It has a lower RMSE, indicating smaller prediction errors; an R2 close to 1, demonstrating excellent data fitting capability; and a higher RPD, reflecting its advantages in stability and generalization. In contrast, LSTM and BiLSTM exhibit higher RMSEs and significantly reduced R2 values on the test set, suggesting greater errors and overfitting when capturing Google’s stock price fluctuations. Additionally, the GRU’s performance on the test set is not as strong as the Transformer’s, while the CNN performs the worst, with the highest RMSE and lowest R2, showing weaker adaptability to complex time series. Therefore, the Transformer demonstrates the best overall performance on the Google dataset.

Comparison of five model results on Google dataset.
Table 8 shows that the Transformer performed the best on the training set, with the lowest RMSE (19.3469), the highest R2 (0.9899), and an RPD of 10.1062. This indicates that the Transformer excels at capturing long-term trends and patterns in historical data. In comparison, the RMSEs of LSTM and BiLSTM are 19.6892 and 20.7555, respectively. While they also demonstrate strong fitting capabilities, their RPDs are slightly lower than the Transformer’s, reflecting a relative weakness in extracting local features.
On the test set, the Transformer continues to exhibit excellent generalization ability, with a significantly reduced RMSE of 34.1159, an R2 of 0.98845, and an RPD of 9.3472, indicating high accuracy in predicting unseen data. In contrast, the test performance of LSTM and BiLSTM declines sharply, with RMSEs of 241.7605 and 229.149, and R2 values of only 0.42 and 0.47893, respectively, suggesting overfitting issues when handling the short-term fluctuations of Google’s stock price. This result reveals the limitations of traditional recurrent neural networks in handling complex volatility, especially when facing irregular changes in time series data.
Moreover, like other major corporations, Google’s stock price is generally stable but can experience sharp fluctuations during specific market events or policy changes, posing challenges for model adaptability. Compared to CNN, LSTM, and GRU, the Transformer’s multi-head self-attention mechanism more comprehensively captures both global features and local variations within the time series, making it more stable when dealing with both short- and long-term fluctuations in Google’s stock data. As a result, the Transformer demonstrates greater robustness and predictive capability in this highly volatile market environment.
The comparison results of 5 classical time series models in Uniqlo
In Fig. 23, the comparison results of five models on the Uniqlo dataset are presented, with evaluation metrics including RMSE, R2, and RPD. The results show that the Transformer outperforms other models on the test set, particularly in terms of prediction accuracy and robustness. Its RMSE on the test set is relatively low, indicating smaller prediction errors; the R2 is close to 1, demonstrating good fitting capability; and the RPD is higher, reflecting stability and generalization in predictions. In contrast, LSTM, GRU, and BiLSTM generally have higher RMSEs and slightly lower R2 on the test set, indicating some errors when handling short-term stock price fluctuations. Additionally, CNN performs the worst on the test set, with the highest RMSE and lowest R2, showing weaker prediction capability for Uniqlo’s stock prices. Therefore, the Transformer exhibits the best overall performance on the Uniqlo dataset.

Comparison of five model results on Uniqlo dataset.
Table 9 shows the comparison results of five models (CNN, LSTM, BiLSTM, GRU, and Transformer) on the Uniqlo stock dataset. RMSE (Root Mean Square Error) measures the difference between the predicted and actual values, R2 (Coefficient of Determination) evaluates how well the model fits the data variation, and RPD (Relative Percent Difference) reflects the stability of the model’s prediction capabilities. On the training set, the Transformer performs the best, with the lowest RMSE (833.9759), the highest R2 (0.99485), and an RPD of 13.9406, indicating that it captures more trends and patterns in Uniqlo’s historical data with strong accuracy and stability. In comparison, LSTM and BiLSTM also perform well, but their RPDs are slightly lower, suggesting a weaker ability to capture local features.
On the test set, the Transformer remains ahead, with an RMSE of 990.1383, an R2 of 0.95272, and an RPD of 4.599, indicating good generalization and prediction stability when dealing with unseen data. LSTM and GRU also achieve R2 values of 0.94264 and 0.94424, respectively, showing decent accuracy, but their RMSEs (1090.5964 and 1092.4503) and RPDs (4.1922 and 4.1686) are slightly higher than those of the Transformer, indicating slightly lower accuracy in handling short-term fluctuations. The Transformer demonstrates the most robust and accurate performance on the Uniqlo stock dataset. Its multi-head self-attention mechanism allows it to comprehensively capture both global features and local fluctuations in time series, showing stronger adaptability when dealing with complex market dynamics. While LSTM and GRU have strengths in capturing long- and short-term dependencies, their generalization capabilities are somewhat limited under complex market conditions. CNN, on the other hand, struggles with capturing long-term dependencies in time series, resulting in weaker performance.
Although the results of Transformer and the other four models are among the best, there is still room for improvement. For instance, optimizing and fine-tuning the hyperparameters of Transformer could significantly enhance its predictive performance. Section "Hyperparameter optimization experiments for the Transformer model" will provide a detailed comparison of the prediction results using different hyperparameter optimization methods, exploring further opportunities to improve the model’s effectiveness.
Hyperparameter optimization experiments for the Transformer model
Hyperparameter optimization is crucial for deep learning models because the right hyperparameters can significantly improve the model’s performance and training efficiency. Parameters such as learning rate, regularization coefficients, and model architecture directly affect the model’s fitting ability and generalization capacity. To verify the powerful optimization performance of MOEBS, this section conducted hyperparameter optimization experiments on the Transformer model across three datasets: Amazon, Google, and Uniqlo, focusing on three key metrics: R2, RMSE, and RPD. The experiments employed various methods, including Random Search (RS), Grid Search (GS), Bayesian Optimization (BO), as well as multi-objective optimization methods such as MOEBS-Transformer, MOMVO-Transformer, MOEAD-Transformer, and MSSA-Transformer. The results demonstrate that MOEBS significantly enhances the prediction accuracy and robustness of the Transformer model across all metrics. The key hyperparameters optimized in this study include:
-
1)
Number of attention heads \(\left({\text{n}}_{\text{head}}\right):\) Defines the number of hidden units in the self-attention layers of the Transformer. More hidden units allow the model to learn more complex patterns, but it increases computational cost.
-
2)
Initial Learning Rate \(\left({\eta }_{0}\right):\text{The learning rate controls how much the}\) model’s weights are updated with respect to the loss gradient during training. The learning rate is crucial for model convergence.
-
3)
Regularization coefficient \(\left({\lambda }_{L2}\right):\) L2 regularization coefficient is applied to prevent over- fitting by penalizing large weights.
Random search (RS) and its experimental procedures
Random Search (RS) is a widely used hyperparameter optimization technique due to its simplicity and effectiveness. In Random Search, hyperparameter values are randomly sampled from predefined ranges for a fixed number of iterations. For each trial, a model is trained using the sampled hyperparameters, and its performance is evaluated based on a chosen metric. The best performing set of hyperparameters is then selected.
In this section, we discuss how Random Search is applied to optimize the Transformer model for time series forecasting. Specifically, we focus on three critical hyperparameters: the number of hidden units, the initial learning rate, and the L2 regularization strength. The random search process consists of the following steps:
-
1)
Hyperparameter Sampling: For each trial, the number of hidden units, the initial learning rate, and the L2 regularization strength are sampled randomly from their respective ranges.
-
2)
Model Training: For each sampled hyperparameter set, a Transformer model is constructed and trained on the time series training data. The training uses the Adam optimizer with a maximum of 200 epochs and a mini-batch size of 256. The model is optimized to minimize the mean squared error (MSE) between the predicted and true values.
-
3)
Model Evaluation: After training, the model is evaluated on a test set, and the root mean square error (RMSE) is calculated. The RMSE is used as the primary metric to assess the model’s performance. The model with the lowest RMSE on the test set is selected as the best model.
Grid Search (GS) and its experimental procedures
Grid Search (GS) is a systematic hyperparameter optimization method that evaluates all possible combinations of hyperparameters within predefined ranges While Grid Search is computationally expensive compared to Random Search, it guarantees that all hyperparameter combinations are tested, ensuring the global optimum is found within the predefined grid.
In this section, we apply Grid Search to optimize the Transformer model for time series forecasting. The hyperparameters tuned include the number of hidden units, the initial learning rate, and L2 regularization strength. Grid Search proceeds as follows:
-
1)
Hyperparameter Grid Definition: The hyperparameter grid is defined by specifying ranges for the number of attention heads, the initial learning rate, and regularization coefficient. For each combination of these values, a model is trained and evaluated.
-
2)
Model Training: For each sampled hyperparameter set, a Transformer model is constructed and trained on the time series training data. The training uses the Adam optimizer with a maximum of 200 epochs and a mini-batch size of 256. The model is optimized to minimize the mean squared error (MSE) between the predicted and true values.
-
3)
Model Evaluation: After training, the model is evaluated on a test set, and the root mean square error (RMSE) is calculated. The RMSE is used as the primary metric to assess the model’s performance. The model with the lowest RMSE on the test set is selected as the best model.
Bayesian optimization (BO) and its experimental procedures
Bayesian optimization is an iterative strategy used for optimizing expensive objective functions. It is particularly effective for problems where the objective function is noisy, non-convex, or lacks an explicit mathematical form, such as hyperparameter tuning in machine learning models. The optimization procedure is based on building a probabilistic surrogate model of the objective function and using an acquisition function to guide the search for the optimal parameters.
Surrogate model
At the core of Bayesian optimization is the surrogate model, typically a Gaussian Process (GP). The GP is used to model the distribution of the objective function \(f\left(\theta \right)\) based on observed data. Formally, given a set of observed evaluations \(D=\{\left({\theta }_{1},f\left({\theta }_{1}\right)\right),\dots ,\left({\theta }_{n},f\left({\theta }_{n}\right)\right)\}\), the GP models the objective function \(f\left(\theta \right)\) as a sample from a multivariate normal distribution:
where, \(\mu \left(\theta \right)\) is the mean function, representing the expected value of the objective function at point\(\theta\), \((\theta ,\theta ^{\prime})\) is the covariance (kernel) function, which quantifies the correlation between the objective values at points \(\theta\) and \(\theta ^{\prime}\) The kernel function \(k(\theta ,\theta ^{\prime})\) plays a critical role in determining how smoothly the objective function is modeled and the degree to which information about \(f\left(\theta \right)\) at one point affects the predictions at nearby points.
Posterior distribution
As new points \(\theta\) are evaluated and their corresponding objective values \(f\left(\theta \right)\) are observed, the GP is updated. The posterior distribution of \(f\left(\theta \right)\),conditioned on the observed data \(D\), provides both a mean estimate \({\mu }_{n}\left(\theta \right)\) and an uncertainty measure \({\sigma }_{n}^{2}\left(\theta \right)\) for the objective function at any new point \(\theta :\)
where the posterior mean \({\mu }_{n}\left(\theta \right)\) represents the best estimate of the objective function at \(\theta\) given the data, and the posterior variance \({\sigma }_{n}^{2}\left(\theta \right)\) reflects the uncertainty about \(f\left(\theta \right)\) in regions of the parameter space that have not been well-explored.
Acquisition function
To decide where to evaluate the objective function next, Bayesian optimization uses an acquisition function \(a\left(\theta ;\widetilde{D}\right).\) The acquisition function balances two \(\text{objectives}:\)
-
1)
Exploration: Focusing on regions where the uncertainty \({\sigma }_{n}\left(\theta \right)\) is high.
-
2)
Exploitation: Focusing on regions where the mean estimate \({\mu }_{n}\left(\theta \right)\) is low, suggesting that good solutions may be found. A common acquisition function is the Expected Improvement (EI), which evaluates the expected amount by which a new evaluation at \(\theta\) will improve upon the current best objective value \(f\left({\theta }^{*}\right):\)
$$EI(\theta ) = E[\max (0,f({\theta^*}) - f(\theta ))] = {\sigma_n}(\theta )\left( {z\Phi (z) + \phi (z)} \right)$$(26)
where:
where \(\Phi \left(z\right)\) is the cumulative distribution function of the standard normal distribution. \(\phi \left(z\right)\) is the probability density function of the standard normal distribution. \({\sigma }_{n}\left(\theta \right)\) is the posterior standard deviation at \(\theta\), \(f\left({\theta }^{*}\right)\) is the current best observed value of the objective function. The next evaluation point \({\theta }_{n}+1\) is chosen to maximize the acquisition function:
Bayesian optimization procedure
The Bayesian optimization process proceeds iteratively as follows:
-
1)
Initialization: Evaluate the objective function \(f\left(\theta \right)\) at a small set of initial points \({\theta }_{1},\dots ,{\theta }_{n}.\)
-
2)
Fit the surrogate mModel: Using the observed data \(D=\{\left({\theta }_{i},f\left({\theta }_{i}\right)\right){\}}_{i=1}^{n}\), fit a Gaussian Process to model the objective function.
-
3)
Maximize acquisition function: Identify the next point \({\theta }_{n}+1\) by maximizing the acquisition function \(a\left(\theta ;D\right).\)
-
4)
Evaluate the Objective Function: Compute \(f\left({\theta }_{n+1}\right)\) and update the data set \(D=D\cup \{\left({\theta }_{n+1},f\left({\theta }_{n+1}\right)\right)\}.\)
-
5)
Update the surrogate model: Update the Gaussian Process with the new data and repeat the process until a stopping criterion is met (e.g., a fixed number of iterations or a convergence threshold).
Experimental optimization of the transformer model using four multi-objective algorithms
This section introduces the architecture of MOEBS-Transformer and compares it with three other Transformer models that utilize multi-objective optimization algorithms for hyperparameter tuning: MOMVO-Transformer, MOEAD-Transformer, and MSSA-Transformer. Additionally, it presents the objective functions employed in the optimization process.
Optimization algorithms for comparison
-
Transformer with hyperparameters optimized by MOMVO (MOMVO-Transformer)
-
Transformer with hyperparameters optimized by MOMVO (MOEAD-Transformer)
-
Transformer with hyperparameters optimized by MSSA (MSSA-Transformer)
Furthermore, MOEBS differs from MOMVO , MSSA, and MOEAD in several key aspects. MOEBS has unique advantages in multi-objective optimization, particularly in its global search capability and dynamic adaptability. While MOMVO, MSSA, and MOEAD are also powerful multi-objective optimization algorithms, they differ in exploration abilities and convergence speed. MOEBS excels in maintaining a better balance between multiple objectives and preserving the non-dominated solution set in multi-objective optimization.
Multi-objective algorithms-transformer model optimization objective functions
Here, we briefly introduce the three-objective function MOEBS is targeting on:
Root Mean Square Error (RMSE) is a common metric for the difference between the prediction of a model versus the observation. It is the square root of the mean of the squared differences between prediction and actual observation. It offers a way to evaluate the magnitude of prediction errors and is particularly sensitive to large errors. The RMSE on the training set reflects the fit degree of the model on the training data.
where \(M\) stands for the quantity of samples within the training data used to compute the mean of squared differences between the actual values. \({Y}_{train, i}\) and the predicted values \({Y}_{ptrd, train, i}\) for each sample, indicating the model’s accuracy on the training data.
The RMSE on the test set measures the model’s capability of generalization to new data. A good model not only needs to perform well on training sets, but more importantly, it needs to be able to perform consistently on previously unseen data.
where \(N\) represents the quantity of samples within the test set, and the formula uses \({Y}_{train, i}\) and \({Y}_{pred, train, i}\) to compute the mean value of squared discrepancies between the actual and predicted values for each sample in the test set, assessing the model’s capability of generalization.
The Variance of the test error refers to the consistency of the model’s effectiveness over multiple tests. The less the variance, the more stable the output of the model, and generally the stronger the generalization ability
where \({Var}_{test}\) utilizes \({Y}_{pred, train, i}\) and \({Y}_{pred, test, i}\) containing all actual and predicted values for the test set, to calculate the variance of the test prediction errors, which measures the stability and reliability of the model’s performance across different sets of test data.
To ensure the model’s generalization capability, we ultimately selected the solution from the Pareto front with the lowest test set RMSE. The corresponding parameters of this solution are considered the optimal hyperparameters identified by the multi-objective optimization algorithm. This selection approach balances the model’s performance across different objectives, ensuring stability and predictive accuracy in practical applications.
Systematic analysis of the comparison results for different hyperparameter optimization methods
To begin with, the MOEBS-Transformer architecture is proposed, incorporating multi-objective optimization into the hyperparameter optimization process of the Transformer model.The framework for MOEBS-Transformer is shown in Fig. 24 To validate the optimization performance of MOEBS, this chapter presents a systematic analysis of the results obtained from different hyperparameter optimization methods applied to the Transformer model. The analysis centers around three core metrics—R2, RMSE, and RPD—evaluated across three dataset dimensions (The detailed explanation of these three-evaluation metrics is presented in Sect.5.3). The models under evaluation include the MOEBS-Transformer, which incorporates multi-objective optimization, followed by the MOMVO-Transformer (MOMVO-optimized Transformer), MSSA-Transformer (MSSA-optimized Transformer), and MOEAD-Transformer (MOEAD-optimized Transformer). Additionally, Transformer models optimized using traditional methods, including RS-Transformer (Random Search-optimized Transformer), GS-Transformer (Grid Search-optimized Transformer), and BO-Transformer (Bayesian Optimization-optimized Transformer), are also evaluated. This in-depth comparison aims to determine the effectiveness of each optimization method in enhancing the Transformer’s accuracy, robustness, and generalization, providing insights into their performance across various datasets.

The framework of MOEBS-Transformer.
The comparison results of transformer models optimized by different algorithms in Amazon dataset
As shown in Fig. 25, the performance of the Transformer model optimized by different algorithms on the Amazon dataset varies significantly. For the R2 metric, the MOEBS-Transformer achieves the highest fit in both the training and test sets, demonstrating the best fitting capability. MOEAD-Transformer and MOMVO-Transformer also perform well in R2, just slightly below MOEBS-Transformer, indicating that multi-objective optimization algorithms effectively enhance model fitting performance. In contrast, GS-Transformer and RS-Transformer exhibit noticeably lower R2, especially on the test set, indicating their inability to effectively capture the global features of the data. Additionally, in terms of RMSE, the MOEBS-Transformer has the lowest test set RMSE (52.5328), highlighting its strong ability to improve model prediction accuracy. MOMVO-Transformer and MOEAD-Transformer also show lower RMSE, while GS-Transformer and RS-Transformer have higher RMSE, particularly with GS-Transformer reaching 346.4594 on the test set, reflecting the limitations of traditional methods when handling complex datasets.

Comparison of transformer models optimized by different algorithms on Amazon dataset.
From Table 10, the MOEBS-Transformer also demonstrates a significant advantage in RPD, achieving 16.1724 on the test set, indicating excellent stability and generalization. BO-Transformer performs well in RPD, achieving 36.2845 on the training set, reflecting the potential of Bayesian optimization in enhancing model stability. MOMVO-Transformer and MOEAD-Transformer also perform well in RPD on the test set, though still slightly below MOEBS-Transformer. On the other hand, GS-Transformer and RS-Transformer have the lowest RPD, with test set RPDs of 5.5287 and 8.2235, respectively, indicating a lack of robustness in handling data fluctuations and maintaining prediction stability. In summary, the MOEBS-Transformer outperforms other optimization methods in all three key metrics (R2, RMSE, RPD), validating its strong performance in hyperparameter optimization. Overall, multi-objective optimization algorithms perform better than Random Search, Grid Search, and Bayesian Optimization across all metrics, demonstrating their advantage in handling complex datasets and multi-dimensional optimization tasks.
The comparison results of transformer models optimized by different algorithms in Google
As shown in Fig. 26, the performance of the Transformer model optimized by different algorithms on the training and test sets of the Google dataset shows clear differences. On the training set, the MOEBS-Transformer achieves the lowest RMSE (15.7253), along with high R2 and RPD, at 0.9909 and 10.5716, respectively, demonstrating MOEBS’s effectiveness in improving the model’s fitting capability and stability. MOMVO-Transformer also performs well on the training set, with an R2 of 0.9907, and its RMSE and RPD are only slightly behind MOEBS-Transformer. Bayesian Optimization (BO-Transformer) also shows good results, achieving an R2 of 0.9896, with relatively low RMSE and RPD. In contrast, RS-Transformer and GS-Transformer have higher RMSE and RPD, indicating weaker optimization effects, particularly in terms of effectively fitting the data on the training set.

Comparison of transformer models optimized by different algorithms on Google dataset.
From Table 11, it can be seen that on the test set, MOEBS-Transformer continues to perform best, with an RMSE of 33.9834, an R2 of 0.9911, and an RPD of 10.5880, demonstrating excellent prediction accuracy and robustness on unseen data. MOMVO-Transformer and BO-Transformer also perform relatively well, with test set RMSEs of 36.4335 and 34.6023, respectively, and R2 values close to 0.99. In contrast, RS-Transformer and GS-Transformer perform poorly on the test set, particularly GS-Transformer, which has an RMSE of 136.7710 and an R2 of only 0.8144, indicating the limitations of traditional optimization methods in handling high-dimensional and complex data. Overall, the MOEBS-Transformer shows the best performance on both the training and test sets, while multi-objective optimization algorithms generally outperform random search and grid search in enhancing model fitting capability, prediction accuracy, and generalization.
The comparison results of transformer models optimized by different algorithms in Uniqlo
As presented in Fig. 27, the performance of the Transformer model optimized by different algorithms on the Uniqlo dataset varies across the training and test sets. As a globally recognized apparel brand, Uniqlo’s stock price data is influenced by market consumption trends, seasonal fluctuations, and other factors, exhibiting high volatility. On the training set, the MOEBS-Transformer performs the best, with the lowest RMSE (838.9390), an R2 of 0.9948, and an RPD of 13.9732, demonstrating its outstanding fitting capability in complex market data. MSSA-Transformer and MOEAD-Transformer also show good results in terms of R2 and RPD, but their RMSEs are slightly higher than that of MOEBS-Transformer. In contrast, the GS-Transformer has a significantly higher RMSE (2087.9704) on the training set, indicating the limitations of traditional methods in optimizing high-dimensional financial time series data.

Comparison of transformer models optimized by different algorithms on Uniqlo dataset.
According to the results in Table 12, MOEBS-Transformer continues to excel on the test set, with an RMSE reduced to 996.7573, an R2 of 0.9521, and an RPD of 4.6117, highlighting its strong generalization capability in handling highly uncertain test data. MOMVO-Transformer and MSSA-Transformer also achieve relatively high R2 values on the test set (0.9482 and 0.9519, respectively), but their RMSE and RPD metrics are slightly inferior to those of MOEBS-Transformer. On the other hand, RS-Transformer and GS-Transformer perform poorly on the test set, especially GS-Transformer, with an RMSE of 2180.3976 and an R2 of only 0.7707, reflecting its limitations in capturing complex fluctuation patterns. Overall, MOEBS-Transformer exhibits stronger adaptability and robustness in handling Uniqlo’s highly volatile data, while multi-objective optimization algorithms, in general, are more effective than traditional methods in dealing with such financial time series data.
Conclusion and future work
This paper introduces the multi-objective extension of the Escaping Bird Search algorithm, namely MOEBS (Multi-Objective Escaping Bird Search Optimization). By employing advanced optimization strategies, MOEBS achieves a precise balance in the distribution of Pareto front solutions (PFS), significantly enhancing coverage. A thorough evaluation based on standard benchmark datasets such as ZDT, DTLZ, WFG, UF, and CF demonstrates MOEBS’s robustness and effectiveness in addressing various multi-objective optimization challenges. Notably, the resulting Pareto front solutions exhibit a broad distribution. Analysis of evaluation metrics, including Hypervolume (HV), Generational Distance (GD), Inverted Generational Distance (IGD), and Spacing, confirms MOEBS’s advantages and its ability to balance exploration and exploitation.In this study, we first compared five deep learning models—CNN, LSTM, BiLSTM, GRU, and Transformer—to establish the advantages of the Transformer model across three datasets: Google, Amazon, and Uniqlo. To address the limitations in hyperparameter settings, we proposed the MOEBS-Transformer model. To validate the performance of the MOEBS-Transformer, we compared it with three Transformer models that utilized multi-objective optimization algorithms for hyperparameter tuning (MOMVO-Transformer, MOEAD-Transformer, and MSSA-Transformer). Additionally, we conducted comparisons with Transformer models optimized using traditional methods such as Random Search (RS), Grid Search (GS), and Bayesian Optimization (BO) (RS-Transformer, GS-Transformer, and BO-Transformer).Furthermore, we conducted comparative experiments on three metrics—R2, RMSE, and RPD—across the three datasets, which thoroughly verify the optimization effectiveness and broad applicability of MOEBS-Transformer. However, MOEBS does have limitations; its performance in terms of Spacing indicates a lack of uniformity in solution distribution, suggesting potential areas for improvement. Moreover, the MOEBS-Transformer still has room for enhancement, as it does not outperform all state-of-the-art algorithms across every metric, such as RMSE, highlighting the need to improve its capacity to learn from training data and generalize to unseen test data.
Future enhancements can be achieved by optimizing computational efficiency and extending the Transformer model to a more complicated structure. For instance, distributed computing or parallel algorithms can be introduced to enhance MOEBS’s computational efficiency, enabling it to handle larger-scale and higher-dimensional optimization problems. Additionally, incorporating time series analysis into the prediction model can enhance performance due to the inherent temporal dependencies and patterns in stock prices. The current research methodology can be extended to other financial assets, such as bonds, futures, and forex. The same models can be applied to optimize hyperparameters for these assets and use deep learning techniques for market prediction. While different financial assets exhibit different volatilities and behavior patterns, multi-objective optimization algorithms like MOEBS have broad applicability and can be adjusted and optimized for different markets and asset types. Additionally, Time series techniques allow the model to account for trends, seasonal effects, and cyclical behaviors, which are often present in financial data, thereby providing a more accurate and robust forecast. This approach leverages historical data to identify and exploit regularities over time, improving the model’s ability to predict future price movements. These improvements will make MOEBS-Transformer a more powerful tool in the field of stock price prediction. We can also explore cross-domain applications in time series analysis, such as weather forecasting, climate forecasting, economic forecasting, retail forecasting, etc., to further improve MOEBS-Transformer’s versatility30.
Data availability
All data sources and experimental results are provided within the manuscript or supplementary information files. For any further inquiries, please contact the corresponding author.
References
Yang, M., Zhang, J. & Bai, Z. A new approach to system design optimization of underwater gliders. IEEE/ASME Trans. Mechatron. 27(5), 3494-505 (2022).
Sharma, S., Shukla, S. & Singh, V. mLBOA: A modified butterfly optimization algorithm with lagrange interpolation for global optimization. J. Bionic. Eng. 19(4), 1161-176 (2022).
Jiang, F., Wang, L. & Bai, L. An improved whale algorithm and its application in truss optimization. J. Bionic. Eng. 18(3), 721-32 (2021).
Barboza, F., Kimura, H. & Altman, E. Machine learning models and bankruptcy prediction. Expert. Syst. Appl. 83, 405-17 (2017).
Son, H., Lee, S. & Kim, C. Data analytic approach for bankruptcy prediction. Expert. Syst.Appl. 138, 112816 (2019).
Storn, R. & Price, K. Differential evolution A simple and efficient heuristic for global optimization over continuous spaces. J. Global Optim. 11(4), 341-59 (1997).
Simon, D. Biogeography-based optimization. IEEE Trans. Evol. Comput. 12(6), 702-13 (2008).
Beheshti, Z. & Shamsuddin, S. M. H. A review of population-based meta-heuristic algorithms. Int. J. Adv. Soft Comput. Appl. 5(1), 1-5 (2013).
Heidari, A. A., Abbaspour, R. A. & Chen, H. Efficient boosted grey wolf optimizers for global search and kernel extreme learning machine training. Appl. Soft Comput. 81, 105521 (2019).
Mirjalili, S., Lewis, A. & Yang, X. Multi-objective multi-verse optimization: A nature-inspired algorithm for global optimization. Neural Comput. Appl. 27(2), 495-13 (2016).
Suthaharan, S., 2016 Support Vector Machine. In Machine Learning Models and Algorithms for Big Data Classification: Thinking with Examples for Effective Learning, 207-35 (2016).
Liu, Y., Li, Z. & Zheng, X. Chaotic simulated annealing multi-verse optimization enhanced kernel extreme learning machine for medical diagnosis. Comput. Biol. Med. 144, 105356 (2022).
Emam, M. M., Houssein, E. H. & Ghoniem, R. M. A modified reptile search algorithm for global optimization and image segmentation: Case study brain MRI images. Comput. Biol. Med. 152, 106404 (2023).
Das, S., Sahu, T. P. & Janghel, R. R. Stock market forecasting using intrinsic time-scale decomposition in fusion with cluster based modified CSA optimized ELM. J. King Saud Univ.-Comp. Inform. Sci. 34(10), 8777-793 (2022).
Das, S. et al. Effective forecasting of stock market price by using extreme learning machine optimized by PSO-based group oriented crow search algorithm. Neural Comput. Appl. 34(1), 555-1 (2022).
Mirjalili, S., Mirjalili, S. M. & Lewis, A. Multi-verse optimizer: A nature-inspired algorithm for global optimization. Neural Comput. Appl. 27(2), 495-13 (2016).
Chen, J., Zhu, F. & Zheng, X. Multi-threshold image segmentation based on an improved differential evolution: Case study of thyroid papillary carcinoma. Biomed. Signal Process. Control 85, 104893 (2023).
Das, S., Sahu, T. P. & Janghel, R. R. Oil and gold price prediction using optimized fuzzy inference system based extreme learning machine. Resour. Policy 79, 103109 (2022).
Vaswani, A., N. Shazeer, & N. Parmar. Attention is All You Need. (2017).
Zhou, H. M., Zhang, Y. & Liu, S. A modified particle swarm optimization algorithm for a batch-processing machine scheduling problem with arbitrary release times and non-identical job sizes. Comput. Ind. Eng. 123, 67-1 (2018).
Devlin, J., et al., BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proc. of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 1 4171-186 (2019).
Chen, H., Ghoniem, R. M. & Abbaspour, R. A. An efficient double adaptive random spare reinforced whale optimization algorithm.https://doi.org/10.1016/j.eswa.2019.113018 (2023).
Deb, K. Multi-Objective Optimization using Evolutionary Algorithms (Wiley, 2002).
Chen, H., Wang, J. & Shi, Y. Simulated annealing-based dynamic step shuffled frog leaping algorithm: Optimal performance design and feature selection. Neurocomputing 503, 325-62 (2024).
Das, S., Sahu, T. P. & Janghel, R. R. PSO-based group-oriented crow search algorithm (PGCSA). Eng. Comput. 38(2), 545-71 (2021).
Ouyang, K. et al. Escape: An optimization method based on crowd evacuation behaviors. Artif. Intell. Rev.58(1), 19 (2024).
Fu, S. et al. Red-billed blue magpie optimizer: a novel metaheuristic algorithm for 2D/3D UAV path planning and engineering design problems.Artif. Intell. Rev.57(6), 1-9 (2024).
Ouyang, K. and S. Fu, Graph Neural Networks Are Evolutionary Algorithms. arXiv:2412.17629 (2024).
Glover, F. Future paths for integer programming and links to artificial intelligence. Comput. Oper. Res. 13, 533-49 (1986).
Faramarzi, A., Heidarinejad, M. & Mirjalili, S. Equilibrium optimizer: A novel optimization algorithm. https://doi.org/10.1016/j.knosys.2019.105190 (2020).
Fu, Y. et al. Secretary bird optimization algorithm: A new metaheuristic for solving global optimization problems. Artif. Intell. Rev. 57(5), 123 (2024).
Pareto, V. Manual of Political Economy (Macmillan, 1906).
Kennedy, J. and R.C. Eberhart. Particle swarm optimization. (1995).
Deb, K. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 6(2), 182-97 (2002).
Zhou, Z. et al. A comprehensive review on evolutionary multi-objective optimization (EMO): Basic concepts, recent advances, and future directions. Complex. Intell. Syst. 8(4), 3299-332 (2011).
Ghorbani, N. & Babaei, E. Exchange market algorithm. Appl. Soft Comput. 19, 177-87 (2014).
Satapathy, S. & Naik, A. Social group optimization (SGO): a new population evolutionary optimization technique. Complex. Intell. Syst. 2(3), 173-03 (2016).
Bergstra, J. & Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 13(2), 281-05 (2012).
Hutter, F., H.H. Hoos, and K. Leyton-Brown. Sequential model-based optimization for general algorithm configuration. In Learning and Intelligent Optimization: 5th International Conference, LION 5, Rome, Italy, January 17-1. Selected Papers 5. (Springer, 2011).
Jones, D. R., Schonlau, M. & Welch, W. J. Efficient global optimization of expensive black-box functions. J. Global Optim. 13, 455-92 (1998).
LeCun, Y. et al. Gradient-based learning applied to document recognition. Proc. IEEE 86(11), 2278-324 (1998).
Hochreiter, S. Long Short-term Memory. https://doi.org/10.1162/neco.1997.9.8.1735 (1997).
Graves, A. and J. Schmidhuber. Framewise phoneme classification with bidirectional LSTM networks. In Proc. 2005 IEEE International Joint Conference on Neural Networks IEEE (2005).
Cho, K., Learning phrase representations using RNN encoder-decoder for statistical machine translation.arXiv:1406.1078(2014).
Vaswani, A., Attention is all you need. Advances in Neural Information Processing Systems (2017).
Macrotrends. Alphabet - 20 Year Stock Price History | GOOGL. 2024 August 26 2024 Available from: https://www.macrotrends.net/stocks/charts/GOOGL/alphabet/stock-price-history (2024)
Mirjalili, S., Lewis, A. & Yang, X. S. Grey wolf optimizer: Theory, literature review, and application in computational fluid dynamics problems. Adv. Eng. Softw. 69, 46-1 (2016).
Chen, H., Wang, Z. & Shi, Y. Multi-threshold image segmentation based on an improved differential evolution: Case study of thyroid papillary carcinoma. Biomed. Signal Process. Control 85, 104893 (2024).
Xiao, H., Zhang, H. & Zhao, L. Transformers in medical image segmentation: A review. Biomed. Signal Process. Control 84, 104791 (2023).
Heidari, A. A. et al. Harris hawks optimization: Algorithm and applications. Futur. Gener. Comput. Syst. 97, 849-72 (2019).
Liu, J. et al. Chaotic simulated annealing multi-verse optimization enhanced kernel extreme learning machine for medical diagnosis. Comput. Biol. Med. 144, 105356 (2023).
Zhou, Y., Lan, J. & Li, W. Prediction of stock market prices based on combination of random forest and RBF neural network. J. Comput. Des. Eng. 8(1), 95-06 (2021).
Mirjalili, S. et al. A bio-inspired optimizer for engineering design problems. Adv. Eng. Softw. 114, 163-91 (2017).
Azizi, M., Talatahari, S. & Gandomi, A. H. Fire hawk optimizer: A novel metaheuristic algorithm. Artif. Intell. Rev. 56(1), 287-63 (2023).
Pourpanah, F. et al. A review of artificial fish swarm algorithms: Recent advances and applications. Artif. Intell. Rev. 56(3), 1867-903 (2023).
Houssein, E. H., Chen, H. & Al-Atabany, W. Accurate multilevel thresholding image segmentation via oppositional Snake optimization algorithm: Real cases with liver disease. Comput. Biol. Med. 169, 107922 (2023).
Meng, Y. et al. Dynamics of collective cooperation under personalised strategy updates. Nat. Commun. 15(1), 3125 (2024).
Rahman, C. M. Group learning algorithm: A new metaheuristic algorithm. Neural Comput. Appl. 35(19), 14013-028 (2023).
Hanif, M. & Mohammad, N. Metaheuristic algorithms for elevator group control system: A holistic review. Soft Comput. 27(21), 15905-5936 (2023).
Huband, S. et al. A review of multiobjective test problems and a scalable test problem toolkit. IEEE Trans. Evolut. Comput. 10(5), 477-06 (2006).
Zhang, Q., et al., Multiobjective optimization test instances for the CEC 2009 special session and competition. (2008).
Knowles, J.D., L. Thiele, and E. Zitzler, A tutorial on the performance assessment of stochastic multiobjective optimizers. Tik report 214 (2006).
Han, H., Lu, W. & Qiao, J. An adaptive multiobjective particle swarm optimization based on multiple adaptive methods. IEEE Trans. Cybern. 47(9), 2754-767 (2017).
Van Veldhuizen, D. A. Multiobjective evolutionary algorithms: classifications, analyses, and new innovations (Air Force Institute of Technology, 1999).
Zitzler, E. & Thiele, L. Multiobjective evolutionary algorithms: a comparative case study and the strength Pareto approach. IEEE Trans. Evolut. Comput. 3(4), 257-71 (1999).
Cho, K., et al., Learning phrase representations using RNN encoder-decoder for statistical machine translationarXiv:1406.1078(2014).
Author information
Authors and Affiliations
Contributions
D.W. and K.O. designed the methodology and drafted the programming code. Z.W. curated the experimental data. D.W. conducted the experiments and led in writing the main manuscript. K.O. led in analyzing the experimental results. M.Q., J.Y., and J.Y. assisted in analyzing the experimental results. Z.W. and X.S. assisted in writing the main manuscript and led in providing visualization. M.Q. and Y.J. assisted in providing visualization. Z.W. and X.S. enhanced the programming code. X.S. and K.O. led in reviewing the manuscript and all the other authors assisted in reviewing the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wei, D., Wang, Z., Qiu, M. et al. Multiple objectives escaping bird search optimization and its application in stock market prediction based on transformer model. Sci Rep 15, 5730 (2025). https://doi.org/10.1038/s41598-025-88883-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-88883-8
Keywords
This article is cited by
-
A data driven model based approach for medium-to-long-term electricity price forecasting in power markets
Scientific Reports (2025)
-
Research on the relationship between pH and uranium concentration in leachate of sandstone uranium deposit in-situ leaching area based on TCN-transformer hybrid model
Journal of Radioanalytical and Nuclear Chemistry (2025)
