
Abstract
Fast and accurate extraction of multi-scale semantic information is crucial for indoor applications such as navigation and personalized services. This paper focuses on large-scale indoor scene categories and small-scale indoor element semantics, proposing an RGB-based dual-task model for scene recognition and semantic segmentation. The model employs a pyramid pooling module to create a shared feature layer for both tasks. The scene recognition branch incorporates an SE attention mechanism and a Transformer module to enhance scene understanding, while the semantic segmentation branch fuses low-level features from ResNet50 to improve learning of shapes and textures. This paper investigates the fusion methods of scene-level and element-level features and explores the optimal training strategy for the dual-task model. It also discusses and analyzes the impact of different weight combinations of dual-task Loss values on the model’s performance. The experimental results demonstrate that the overall accuracy (OA) of scene recognition and semantic segmentation of this method is 98.4%, and the overall accuracy (OA) of semantic segmentation is 82.6%. The average time for processing a single scene is approximately 0.037 s, which is superior to the latest models compared in this paper. It is found that the optimal training strategy for a single task is conducive to enhancing the accuracy of dual tasks. Moreover, when the loss weights of the two tasks in this method are both 1, the comprehensive effect of the model is the best.
Similar content being viewed by others

Introduction
Indoor multi-scale semantic information is a necessary prerequisite for many indoor services such as indoor navigation1, safety monitoring2, and object retrieval. Given the detail-oriented characteristics3 and flexibility requirements4 of indoor services, generally speaking, indoor multi-scale semantic information mainly includes scene category semantics5 and indoor element semantics6, both types of information are extremely important in indoor services. Among them, scene category semantics provides indoor service carriers with essential prior knowledge about the scene7 (such as the functionality of the room, etc.), and feature category semantics can support specific fine-grained service content (such as navigation and picking up items, etc.). The accuracy and efficiency of extracting these two types of cognitive information directly affect the capabilities of indoor services, and therefore are hot issues in current research.
However, due to the complexity of indoor scenes, spatial variability, and the similarity of indoor objects, the spatial layout of indoor scenes changes frequently8. For example, each type of indoor environment, such as bedroom, living room, kitchen, etc., has unique functions, layouts, and elements, moreover, even within the same type of indoor scenes, the types, colors, and layouts of furniture and decorations can vary greatly. This difference increases the complexity of scene recognition. At present, most indoor scene recognition technologies focus on extracting global features while neglecting attention to detail9. However, indoor scenes are usually strongly correlated with indoor elements. For example, bedrooms are usually strongly correlated with beds, and living rooms are strongly correlated with sofas. If we only focus on global features and ignore local features, it may lead to different scenes with similar furniture and decorations, especially when dealing with indoor environments with high variability and complex structures, which may affect the accuracy of overall scene recognition.
In addition, indoor semantic segmentation technology aims to classify each pixel in an image into a predefined semantic category10, such as wall, floor, furniture, etc. For complex indoor scenes, traditional methods primarily rely only on local features for analysis, which may not be able to fully understand the layout and function of the entire environment. In addition, the functionality of indoor scenes can also provide valuable prior knowledge for the determination of feature categories. Existing methods lack this part of contextual information, which may cause semantic segmentation models to misclassify semantic categories in complex indoor scenes11. In addition, traditional methods often consider scene recognition and semantic segmentation as separate tasks, while there is a strong correlation between scenes and features. It is an urgent to build a multi-task model that can integrate scene-level and feature-level features to realize indoor contextual information to help improve the accuracy of multi-scale semantic information extraction.
In order to solve the above problems, this paper constructs a task-level dual-task model for scene recognition and semantic segmentation. The model takes into account both the global features of indoor scenes and the features of target objects, improving the robustness of scene recognition and the accuracy of semantic segmentation. The main contributions of this paper are as follows:
-
(1)
A dual-task model for indoor scene recognition and semantic segmentation was constructed. This model takes into account both global features and object-level features of indoor scenes, realizes task-level multi-scale feature fusion, and can simultaneously meet the needs of scene recognition and semantic segmentation tasks through a single training. It also has dual-task configurability, which improves the effect and efficiency of scene recognition and semantic segmentation.
-
(2)
We explored the impact of the model storage strategy on multi-tasks under the dual-task model and proved that the optimal storage strategy for a single task in the dual-task model is more conducive to improving the overall effect of the model. This conclusion can be extended to the multi-task field and provide recommendations for the optimal model training strategy for the parallel training of multi-task models.
The structure of this paper is arranged as follows: “Related work” mainly introduces the related work in indoor scene recognition, semantic segmentation, and multi-scale semantic information extraction; “Methods” elaborates on the details the proposed method from the aspects of data preprocessing, data loading, and dual-task model construction; “Experiment and analysis” experimentally verifies the proposed method; “Discussion” discusses the impact of model preservation strategies and loss combination methods with different weights of dual tasks on the dual-task model; “Conclusion” lists the conclusions of this paper.
Related work
As two important contents in the field of indoor research, scene recognition and semantic segmentation have been the research focus in the field of computer vision in recent years. Many scholars have conducted a series of studies on improving the efficiency and accuracy of these two tasks.
Scene cognition
There are many studies on indoor scene recognition models based on RGB data, which is mainly since RGB data can well reflect the color and texture information of indoor scenes and has low acquisition cost. However, due to the large changes in indoor environments, the performance of current scene recognition methods has dropped significantly when dealing with these changes.
Indoor scenes are often associated with indoor elements. By establishing the relationship between scenes and elements, scene recognition can be achieved. The combination of the YOLO model and the TF-IDF method can identify scene objects in indoor environments and use these detected objects as features for room category prediction. Although this achieves indoor scene recognition based on object-level information, the semantic relationships between objects is missing, resulting in low recognition accuracy12.
To address this problem, on the one hand, construct scene representations by extracting object features and learning object relationships and use segmentation networks and Object Feature Aggregation Modules (OFAM) to effectively improve recognition accuracy13. On the other hand, we can start from the semantic information of the scene and use adaptive methods to effectively reduce the negative impact of semantic ambiguity and accurately model the relationship between semantic regions to improve the accuracy of scene recognition14. The quality of scene parsing will also affect the results of scene recognition. The proposed joint Bayesian object relationship model (BORM) can effectively improve the advantages of scene parsing. This model combines the object model (IOM) with the scene parsing algorithm, enhances object knowledge on the ADE20K dataset, analyzes object relationships through Bayesian modeling, and combines it with the PlacesCNN model to form a joint Bayesian object relationship model (CBORM)15. Fusion of multi-modal data (including images and semantic descriptions) existing in scene recognition tasks16, on this basis, using CCG (Correlative Context Gating) to fuse object and scene information, and introducing scene consistency loss (SCL) can improve the model accuracy and robustness17. Multiple convolutional neural networks (Multi-CNN) are utilized to split the training images into two directions and input into three deep CNN models. Subsequently, the features extracted from these models are integrated through multiple fusion strategies and used SoftMax classifier performs the final classification18. At the same time, it is also necessary to ensure the accuracy of classification of recognition results. Fu et al. proposed an innovative context acquisition module-Thrifty Attention, which is designed to efficiently capture remote dependencies and introduce a recursive version of Thrifty Attention. (Recurrent Thrifty Attention, RTA), as a universal global context information acquisition module, can be seamlessly integrated into any deep convolutional neural network. After applying RTA in the classic ResNet architecture, it has demonstrated significant classification accuracy19.
Although these methods have integrated the information about elements in the scene to improve the accuracy of scene recognition, they ignore the irrelevance and strong correlations between elements and scenes, which is reflected in the fact that some elements can appear in any scene, but some elements only appear in fixed scenes. This paper achieves scene recognition by first suppressing unimportant features in the scene and then strengthening the global contextual relationship.
Semantic segmentation
Indoor RGB semantic segmentation technology has made significant progress in identifying and classifying different objects and regions in RGB images through deep learning. However, due to the complexity and variability of indoor scenes and the presence of occlusions, existing models still have challenges in labeling data.
Identifying semantic tags attached to indoor spaces is a more straightforward method. For example, an indoor semantic map is constructed by identifying room numbers as environment semantic identifiers and assigning semantic labels to grid maps20. However, this method has greater limitations, acquires less semantic information, and is significantly affected by the quality of the semantic tags. Therefore, semantic segmentation methods based on deep learning have become the current mainstream. Zhang et al. built a visual semantic database based on the MASK R-CNN network. This database contains RGB images, depth images, CNN features, key points, descriptors, and object category information from key frames. When building the semantic database, the object category and location information contained in the key frames are first extracted through the MASK R-CNN network, and the key points and corresponding descriptions are identified through the SURF (Speed Up Robust Feature) algorithm21. To enhance the semantic model’s understanding of three-dimensional space, Wang et al. used stereo image data to perform plane extraction, object recognition, and region reasoning22. However, the efficiency of semantic extraction in three-dimensional scenes is low, and the performance loss is large. To address this problem, a lightweight object detection network called S-SSD (ShuffleNet-SSD) was proposed. By improving the SSD network, the semantic information of indoor objects can be extracted in real time23. Visual-based semantic information extraction faces the problem of difficulty in improving accuracy in complex scenes with complex backgrounds, similar materials and textures, object occlusion, and limited viewing angles. To solve these challenges, Liu et al. used SegNet to extract semantic information of the environment and determined static and dynamic object attributes through prior knowledge. However, errors are inevitable when using convolutional neural networks to extract semantic information. If only one object is extracted from each key frame, the score of the detected object must exceed a threshold, and the object can be marked only if it is detected in 15 consecutive frames, which can effectively reduce the error rate24.
These methods lack the understanding of the indoor contextual information of the scene. In complex indoor scenes, the use of the PSPNet network can enhance the capture of global features. This paper achieves semantic segmentation by fusing scene information to enhance the network’s capture of elements within the scene.
Multi-scale information extraction
Multi-scale information extraction methods aim to extract features at different scales (sizes) from images to improve the efficiency and generalization ability of the model. For tasks that require identifying the same object at different scales, multi-scale feature extraction can significantly improve the recognition accuracy.
Regarding the multi-scale information extraction and fusion method, Ma et al. introduced a new convolutional neural network (CNN) framework, Multi-scale Spatial Context-based Deep Network for Semantic Edge Detection (MSC-SED), which introduced a Context Aggregation Module (CAM) and a Location-aware Fusion Module (LAM) to improve the expressiveness of features and selectively integrate low-level features, so that the fusion process to adapt to different location requirements. However, the complex structure of MSC-SED will increase the computational overhead and affect the efficiency in practical applications25. Model lightweighting can effectively reduce computational overhead. A new lightweight network called MSCFNet was proposed. This network structure efficiently fuses multi-scale context information by introducing an asymmetric residual module and an attention module, which reduces computational overhead while not reducing model efficiency26. When fusing multi-scale information, the scale of the scene and object will change. The introduction of inter-class and intra-class region refinement (IIRR) and multi-scale collaborative learning (MCL) to construct a multi-scale perceptual relationship network solves the problem of scene and object scale changes27. For the case of inconsistent target sizes in scene images, Shang et al. proposed an end-to-end multi-scale adaptive feature fusion network, which includes a multi-scale context extraction module (MCM) and an adaptive fusion module (AFM). These two modules are used to deal with the problem of target size differences in high-resolution remote sensing images28. Due to the complexity of indoor space, different spaces have similarities. For example, living rooms and offices have the same type of elements. Relying solely on extracted features may result in scene misjudgment. To address this problem, Jiang et al. constructed a point cloud-based indoor scene recognition and semantic segmentation dual-task model, and constructed association rules between common indoor scenes and indoor elements to correct deep learning recognition results29. However, there are still cases where association rules cannot correct highly similar scenes. The similarity of indoor scenes in 2D image data is low. Therefore, this paper uses image data to extract multi-scale semantic information of indoor scenes.
Methods
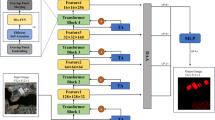
The dual-task model constructed in this paper is mainly based on the perspective of multi-feature fusion. Different from the method of feature fusion of conventional single-task models (such as high-level features such as shape and semantics and low-level features such as color and texture, etc.), the fusion in this paper is a task-level fusion method, that is, the overall features of an entire image, extracted through the large scene task of scene recognition are fused with the features of the internal elements of the scene obtained via semantic segmentation to achieve task-level multi-scale feature fusion. The flowchart of the proposed method is shown in Fig. 1, which is mainly divided into four main steps: multi-label data loading, dual-task model construction, loss weight processing, and model saving.

Indoor scene recognition and semantic segmentation process based on RGB images.
Data loading mainly modifies the information content of RGB image data. In addition to outputting the (R, G, B) information of the image, it also outputs object category and scene category information. When constructing the dual-task model, this paper uses the backbone network ResNet50, and uses the pyramid pooling module to construct a common feature layer as a common feature of scene recognition and semantic segmentation. Together with the subsequent loss weight processing, it realizes the fusion of scene-level multi-scale features. The semantic segmentation branch fuses the underlying feature map of ResNet50, and the scene recognition branch uses the attention mechanism to enhance the understanding of the scene. In the processing of Loss weights, the Loss function of the dual tasks are modified, the dual-task state hyperparameters are set, etc., to improve the running efficiency of the model. At the same time, this paper proposes a single-task optimal training strategy, that is, when the effect of one of the dual tasks reaches the optimal, the feature of the task is used as the common feature of the next round of dual tasks, which can achieve a common improvement in the effect of the dual tasks.
Loading multi-label datasets
As shown in Fig. 2, in order to meet the needs of semantic segmentation and scene recognition, this paper adds two labels, scene category and object category, to the output of the traditional dataset, and outputs three labels, scene category, object category, and RGB. And based on the loading method of scene category, all categories in the same scene are regarded as a whole and only one scene label is assigned.

Data loading method.
Dual-task model construction
In order to enhance the correlation between scenes and elements, this paper first uses the ResNet50 to generate both low-level feature maps and high-level feature maps, and then extracts the multi-scale contextual information from the high-level feature maps as the common features of the two tasks through the pyramid pooling module of the PSPNet30. For scene recognition tasks, there are few typical elements that can determine the scene category (such as the bed is very important for the bedroom), so the attention mechanism is introduced to suppress unimportant features and enhance the understanding of contextual information. For semantic segmentation tasks, the features of any element are important. In order to avoid the loss of shape and texture features after channel dimensionality reduction of the common features of the two tasks, the low-level feature map is fused with the feature map after dimensionality reduction.
The steps to construct the dual-task model are as follows: ① Use ResNet50 as the backbone network31 to extract image features, and then use the pyramid pooling module of PSPNet as the common feature layer for scene recognition and semantic segmentation to unify the initial features of the two tasks and ensures that their feature dimensions of the two tasks are complementary; ② Use the Cross Entropy function32 as the loss function to calculate the loss of scene recognition and semantic segmentation respectively, and add the values of the two losses for the new model; ③ Model storage strategy, adopt the single-task optimal strategy to improve the feature complementarity function of dual-task model training. The dual-task model structure is shown in Fig. 3.

Dual-task model structure.
Scene recognition branch
Generally speaking, indoor scenes are determined by their internal elements. For example, if there is a bed in the space, then the space is most likely a bedroom. However, apart from this typical element, the other elements of the indoor space play a smaller role. Therefore, when recognizing the scene, we only focus on the key elements. Capturing global contextual information can effectively improve the scene recognition capability.
This paper performs a 3 × 3 convolution on the feature map output by PSPNet, and then performs a Drop operation with a weight of 0.1. The result is then convolved with a 1 × 1 convolution, and the number of output channels is the number of scene categories. The SE attention module33 is used to enhance the feature expression of each scene and suppress unimportant features in the scene. The 60 × 60 × 6 feature map output by the SE module is divided into 10 smaller 6 × 6 × 6 feature maps and input into the Transformer module34. The Transformer module includes 3 layers of encoders and 1 layer of decoder, and finally outputs through a linear layer. The scene recognition branch structure diagram is shown in Fig. 4.

Scene recognition branch structure diagram.
Semantic segmentation branch
Indoor features usually present multi-scale characteristics. For example, the bed and window in the bedroom image occupy a large area, while small-volume features such as lights and fans are relatively small. Since the feature map output by the PSPNet network has a large number of channels, in order to reduce the amount of calculation and memory consumption, this paper performs a 3 × 3 convolution to the 60 × 60 × 4096 feature map. However, due to the complexity of indoor scenes and the occlusion between features, this processing method may lead to the loss of shape and texture features.
This paper takes advantage of the ResNet50 intermediate layer in extracting image shape and texture features. After convolution, the feature map output by PSPNet is fused with the bottom feature map of ResNet50. This process aims to give full play to the complementary role of shape and texture features, thereby enhancing the overall expressiveness of image features. The fused feature map is convolved once with a 1 × 1 convolution, and the number of output channels is the number of indoor categories. Finally, the image is scaled by BiLinear35 to output a 480 × 480 × 23 feature map for semantic segmentation. The semantic segmentation branch structure is shown in Fig. 5.

Semantic segmentation branch structure diagram.
Choice of loss function
This paper selected six typical indoor scenes and screened out 23 types of indoor elements. The purpose of the scene recognition task in this paper is to identify what scene the image is in, which is a classification task; the purpose of the semantic segmentation task is to identify the element category in the scene, which is also a classification task. Therefore, the Loss function of scene recognition and semantic segmentation in this paper both use the cross entropy function. After the model calculates the loss value Loss1 of the scene recognition task and the loss value Loss2 of the semantic segmentation task, the final loss of the model is obtained by weighted addition.
In formula (1), k1 and k2 represent the weights of scene recognition and semantic segmentation tasks respectively, and their value range is [0, 1]. In specific applications, the values of k1 and k2 can be set independently according to the importance of the tasks. When the values of k1 and k2 are both 1, it means that the two tasks are equally important.
Optimal training strategy for dual-task model
One of the purposes of building a dual-task model is to integrate global features and object features in scene recognition and semantic segmentation tasks to improve the effects of the two tasks. Therefore, this paper adopts the single-task optimal strategy to save model parameters and optimizes the model parameter storage strategy (as shown in Fig. 6). This paper uses overall accuracy (OA) as the preservation index for scene recognition. Since there are many categories that occupy a large pixel ratio among the 23 types of indoor elements screened in this paper, in this case, there is a certain positive correlation between overall accuracy (OA) and mean intersection over union (mIoU), that is, when the OA of the model improves, its mIoU also tends to improve. Therefore, the average of overall accuracy (OA) and mean intersection over union (mIoU) is used as the preservation index for semantic segmentation.

Dual-task model preservation strategy.
During the training process, when the performance of either the scene recognition or semantic segmentation task is higher than the current optimal saving index of the task, the model parameters can be saved (the initial indexes of both tasks are set to 0). Saving the model when the saving index for semantic segmentation is higher than its current optimal saving index allows the scene recognition task to use the feature-level features provided by the optimal results of semantic segmentation for scene recognition, and saving the model when the saving index for scene recognition is higher than its current optimal saving index allows the semantic segmentation task to use the indoor global features provided by the optimal result of scene recognition for semantic segmentation. The single-task optimal training process is shown in Fig. 7.

Schematic diagram of model saving for the optimal training method for a single task.
Experiment and analysis
Experimental data
This paper uses the ADE20K dataset36. After screening the dataset, we selected three indoor scene datasets with a total of 2722 images. The three categories of indoor scenes are mainly home scenes, office scenes, and consumer scenes. In this dataset, home scenes mainly include bedrooms, kitchens, and parlor, office scenes mainly include conference rooms and offices, and consumer scenes mainly include supermarkets. In order to simulate the images acquired by the robot, the dataset is enhanced and the effect of expanding the dataset is achieved. After data enhancement, the dataset has a total of 10,888 images, so the training set and validation set are constructed in a ratio of 7:3. The training set has a total of 1906 images, and the original validation set has a total of 816 images. The original number of each scene dataset is shown in Table 1.
The true labels of objects in the training set and validation set are obtained from the ADE20K dataset, where the true labels of the scenes are manually annotated.
Usually there are typically many kinds of indoor elements. Among the three categories of scene datasets constructed, 23 types of indoor elements that meet the three major indoor environments (wall, floor, ceiling, bed, windowpane, cabinet, person, door, table, curtain, chair, sofa, rug, wardrobe, light, refrigerator, pillow, bookcase, book, computer, cooktop, ashcan, and fan) were selected based on the 2475 training sets constructed, plus the background class, a total of 24 semantic categories.
Through data augmentation37, the selected data are rotated by 45°, flipped horizontally, and flipped vertically, and the dataset that is expanded to four times its original size, with a total of 10,888 images. The training set has 7624 images and the validation set has 3264 images. The effect after data augmentation is shown in Fig. 8. It is worth noting that in order to ensure the accuracy of model evaluation, the validation set does not include any enhanced images from the original training set.

Image enhancement effect diagram.
Experimental environment
-
(1)
Experimental details.
During model training, the batch size was set to 4, the training momentum was set to 0.9, the learning rate was set to 0.0001, the decay rate was set to 0.001, the optimizer used in the model was SGD (Stochastic Gradient Descent)38, the epoch was 100, and the total iterations were 247,500. When any of the saved indicators of the scene recognition and semantic segmentation tasks was greater than the current optimal indicator, the optimal model was set to be saved once.
-
(2)
Evaluation indicators.
This paper uses mean accuracy (mAcc), overall accuracy (OA), Top-1, and Top-5 to evaluate the scene recognition results, and uses mean accuracy (mAcc), overall accuracy (OA), mean intersection over union (mIoU), recall, precision, and F1 to evaluate the semantic segmentation results.
TP (True positive) indicates the number of samples predicted by the model as positive examples, and the actual value is also positive; FP (False positive) indicates the number of samples predicted by the model as positive examples, and the actual value is negative; TN (true negative) indicates the number of samples predicted by the model as negative examples, and the actual value is also negative; FN (False negative) indicates the number of samples predicted by the model as positive examples, and the actual value is negative39. Top-1 accuracy: whether the highest probability category predicted by the model is the actual label. If the predicted first category matches the true label, it is counted as correct. Top-5 accuracy: whether the true label is included in the top five categories predicted by the model. If the true label is in the top five, it is counted as correct40.
Scene recognition results and analysis
The core idea of the scene recognition model presented in this paper is to let the model learn both global features and object features of the scene at the same time. In addition, the semantic segmentation module also provides element-level semantic features for the scene recognition task to improve the effect of the scene recognition model. As shown in Fig. 9, with the increase in the number of training times, the loss change curve on the dual tasks shows that the contribution of semantic segmentation to scene recognition is gradually increasing. At the same time, the global features obtained by scene recognition also provide additional features for the semantic segmentation model, which plays a role in promoting the mutual promotion of the two tasks.

Loss and Acc change curves of dual tasks.
In Fig. 9, panel (a) illustrates the curve diagram of the change of Loss during dual-task training, while panel (b) presents the curve diagram of the change of Acc during dual-task training verification.
This paper uses the PSPNet model to realize scene recognition and conducts ablation experiments. There are four groups of model experiments in total. The model training is carried out under the same environment configuration and the relevant model parameters are set to be consistent. The specific results are shown in Table 2.
The comparative analysis presented in Table 2 indicates that the overall scene recognition mean accuracy (mACC) for the proposed method is 98.3%, and the overall accuracy (OA) is 98.4%, both of which are higher than the comparison method. After adding the SE attention mechanism, the mACC and OA improve by 1.2% and 1.1% respectively compared to the baseline model; after adding the Transformer module, the baseline model by 1.6% and 1.5% respectively; and the proposed method adds both modules at the same time, achieving the best training effect, and the mACC and OA are improved by 4.2% and 4.2% respectively compared with the original model, indicating that the proposed method can not only realize indoor scene recognition, but also has a high scene recognition accuracy.
In order to intuitively analyze the specific impact of adding different modules on scene recognition, the ACC values of the six indoor scenes selected for this paper are compared and analyzed, as shown in Table 3.
As shown in Table 3, if only the SE attention module or the Transofmer module is added, the accuracy of each scene is improved, but the improvement is small for conference and parlor. After adding both modules at the same time, the recognition accuracy of all scenes is higher than that of other methods, and the improvement is greater in conference and parlor.
In order to analyze the model’s prediction results of the model for each sample, this paper examines the Top-1 and Top-5 of the six scenarios, as presented in Table 4.
As shown in Table 4, the predictions made by the proposed method for the six scenarios are highly consistent with the true labels, with all predicted labels ranking within the top five.
Semantic segmentation results and analysis
This paper enhances the PSPNet model to achieve improved indoor semantic segmentation. To evaluate the effectiveness of the proposed method, four established semantic segmentation models, U-Net, DeeplabV3 + , Seg-Net, and PSPNet, are selected as control groups. These models are trained under identical environmental configurations, with consistent parameter settings. The mIoU, OA, Precision, Recall, and F1 scores are calculated for each model, along with the parameter size and inference time. Table 5 presents the evaluation metrics for the semantic segmentation results of each model. Table 6 compares the segmentation accuracy of 23 categories in the dataset, while Fig. 10 illustrates a comparative chart of the semantic segmentation results.

Semantic segmentation comparison.
As shown in Table 5, among the six indoor scene datasets constructed in this paper, the mIoU of SegNet, which is 0.4% higher than that of this method, the other evaluation indicators are higher than other methods. The OA, Precision, Recall, and F1 of this method are 82.6%, 70.4%, 81.3%, and 75.4%, respectively. They are 6.7%, 8.6%, 9.8%, and 9% higher than U-net, 3.1%, 4.1%, 3.4%, and 3.7% higher than DeeplabV3 + , 2.5%, 2.5%, 2.2%, and 2.3% higher than Seg-Net, and 1.7%, 1.3%, 1.4%, and 1.3% higher than PSPNet. Under the same training parameters, this method performs better than other models. The current parameter size (~ 360 M) of the model in this paper is larger than that of the other models. Nevertheless, the model in this paper achieves an inference time of 0.037 s per image, and compared with other models that only achieve semantic segmentation, the model in this paper can also achieve scene recognition.
In order to more intuitively analyze the recognition results of each model for the 23 types of elements selected in this paper, the ACC of each comparison model in recognizing these 23 types was calculated, and the visualization effects of the predicted results were then compared, as illustrated in Table 6 and Fig. 9.
As shown in Table 6, for indoor elements with large volume (such as wall, floor, ceiling, etc.), the recognition accuracy of various methods is very high, but for elements with small volume (such as book, ashcan, pillow, etc.), the recognition accuracy of various methods is very low, and some methods cannot even recognize some categories. In the 23 categories of data sets selected from the six indoor scenes constructed in this paper, only PSPNet and this method can recognize all of them, and the other three methods have categories that cannot be recognized or the category recognition accuracy is extremely low. And among the 23 categories, only the cooktop, rug, and wall have a higher recognition accuracy of PSPNet than this method, and the remaining 20 categories of this method are higher than PSPNet. As shown in the model comparison diagram in Fig. 10, other methods have category recognition errors or category recognition errors, such as failure to recognize refrigerators or incomplete refrigerator recognition, and poor effect on feature edge segmentation. It can be seen that this paper integrates the underlying feature map of ResNet50, which has a good effect on the recognition of shape and texture features.
Discussion
Impact of model training strategy on the model
This paper optimizes the storage strategy of the dual-task model to enhance the model’s overall effect of the model. In order to verify the effectiveness of the single-task optimal strategy, this paper compares the single-task optimal preservation model with the full-task optimal preservation model strategy with the same parameters, environment, and dataset.
-
(1)
Analysis of the impact on scene recognition.
To better illustrate the effects of different model preservation strategies on scene recognition, Fig. 11 presents the Loss and Acc change curves of different model preservation strategies during training, Table 6 details the influence of different model preservation strategies on overall scene recognition, and Table 7 shows the impact of different model preservation strategies on single scene recognition.

Loss and Acc change curves for different model preservation strategies.
In Fig. 11, panel (a) illustrates the loss change curve of Loss during training with different model preservation strategies, and panel (b) depicts the accuracy change curve of Acc during training verification with different model preservation strategies.
As illustrated in Fig. 11, the single-task optimal preservation strategy, the loss converges faster and the Acc improves faster during model training. As shown in Tables 7 and 8, the single-task optimal preservation model strategy has 1.5% and 1.6% higher mACC and OA than the full-task optimal preservation model strategy. In the six scenarios, the ACC of the former is higher than that of the latter, so the single-task optimal preservation strategy proposed in this paper is effective.
-
(2)
Analysis of the impact on semantic segmentation.
Table 9 compares the evaluation indicators of different model preservation strategies in the semantic segmentation branch, and Table 10 examines the recognition accuracy and IoU of different model preservation strategies in various categories.
It can be seen from Table 9 that the evaluation indicators for the single-task optimal preservation strategy are better than those of the dual-task optimal preservation strategy. It can be seen from Table 10 shows that the ACC and IoU of the dual-task optimal preservation strategy for large-volume elements (such as wall, floor, bed, etc.) are not much different from those of the single-task optimal preservation strategy, but the accuracy and IoU for small-volume and complex-shaped elements (such as chair, light, cooktop, etc.) are quite different.
In order to more intuitively illustrate the differences between the two, the following figure shows the model segmentation results of different preservation strategies, as shown in Fig. 12.

Comparison of segmentation using different model saving strategies.
As illustrated in Fig. 12, the dual-task optimal preservation strategy exhibits poor segmentation accuracy and misidentifies many indoor feature categories, such as incorrectly identifying a chair as a sofa and a table as a refrigerator. Again, in Table 10, the recognition accuracy for chairs and tables in the dual-task optimal preservation strategy is 20% to 30% lower than that of the single-task optimal preservation strategy.
The impact of different weights of loss on the model
This section discusses the impact of different loss weights on the model and utilizes formula (1) to compare different combinations of k1 and k2. Here, k1 represents the weight for scene recognition, and k2 denotes the weight for semantic segmentation. This paper examines four sets of Loss with different weights for verification, namely (k1 = 0.5, k2 = 0.5), (k1 = 0.5, k2 = 1), (k1 = 1, k2 = 0.5), and (k1 = 1, k2 = 1), and the relevant model parameters are set to be consistent. The change curve of Loss of four different weight combinations of weights during training is illustrated in Fig. 13. The experimental comparison data is presented in Tables 10 and 11, and the semantic segmentation comparison chart is shown in Fig. 14.

Comparison of Loss changes of four combinations.

Comparison of different loss weight combinations.
In Fig. 13, panel (a) presents a scene recognition loss change comparison curve, and (b) is a semantic segmentation loss change comparison curve.
As illustrated in Fig. 13, the model loss converges only when k1 = k2 = 1, and the rest of the fluctuations are large. Excluding this combination, when k1 = 1, k2 = 0.5, as shown in Fig. 12a, the loss for this combination in the scene recognition branch is lower than the other two combinations; similarly, when k1 = 0.5, k1 = 1, as shown in Fig. 12b, the loss for this combination in the semantic segmentation branch is also lower than the other two combinations. This indicates that the weights of different tasks will directly affect the training effect of each branch.
It can be observed from Table 11 that when k1 = k2 = 1, the OA and mACC of scene recognition are the highest; when k1 = k2 = 0.5, the OA and mACC are the lowest; when k1 = = 0.5, k2 = 1 or k1 = 1, k2 = 0.5, the OA and mACC are lower than the combination of k1 = k2 = 1, and higher than the combination of k1 = k2 = 0.5, indicating that the fusion of semantic information and scene information in the proposed method is feasible, and the weight of semantic segmentation will affect scene recognition.
As shown in Table 12, when k1 = k2 = 1, the evaluation indexes of semantic segmentation are the highest; when k1 = k2 = 0.5, the evaluation indexes are the highest and the lowest; when k1 = 0.5, k2 = 1 or k1 = 1, k2 = 0.5, the evaluation indexes are also consistent with the performance of scene recognition, which once again shows that the fusion of semantic information and scene information in this method is feasible, and the recognition of these two tasks will affect each other. Figure 14 illustrates the segmentation effects of the four combinations.
As illustrated in Fig. 14, when k1 = k2 = 1, the model segmentation effect is the best and the recognition accuracy is the highest. Compared with other combinations, this combination recognizes more elements and the segmented shape texture is better.
Effect of the proposed method in real scenarios
This paper took several real scenes to see the segmentation effect of this method in real scenes. The segmentation effect is shown in Fig. 15.

Segmentation effect of the model in real scenes.
As illustrated in Fig. 15, the model has a good segmentation in organized indoor scenes, but it also recognizes the projector as a light; in messy indoor scenes, the model has a good segmentation effect on large volume elements, but it also fails to accurately recognize the computer and recognizes it as a table. The possible reason is that there are few computer sample images in the training set. Among the 10,888 training images, only 12 images contain computer elements, resulting in insufficient feature learning for the computer during model training.
Conclusion
This paper proposes a dual-task model for indoor scene recognition and semantic segmentation. This method achieves scene recognition by analyzing the correlation between indoor scenes and indoor elements, and realizes semantic segmentation by improving PSPNet. The dual-task model developed in this paper has 360.01 M parameters and takes about 0.037 s to complete the dual tasks. It demonstrates a rapid recognition speed and draws the following conclusions:
-
(1)
The proposed method demonstrates a remarkably high recognition effect on the six selected scenes, with OA and mACC of 98.4% and 98.3% respectively.
-
(2)
The semantic segmentation effect is higher than the existing method and can identify all categories, with OA, Precision, Recall and F1 of 82.6%, 70.4%, 81.3%, and 75.4%, respectively, all of which exceed the results of other methods.
-
(3)
The scene recognition OA of the single-task optimal preservation strategy is 1.6% higher than the dual-task optimal preservation strategy, and the OA, Precision, Recall, and F1 of semantic segmentation are 5.2%, 4.6%, 5.5%, and 4.9% higher than the dual-task optimal preservation strategy. It verifies that the optimal training strategy for a single task is conducive to improving the accuracy of the dual task.
-
(4)
When the loss weight is k1 = k2 = 1 during dual-task training, the model has the highest accuracy. Other k1 and k2 combinations are lower than this combination in scene recognition and semantic segmentation.
We plan to expand the scenarios and elements and optimize the model to be able to recognize more scenarios and elements and improve recognition accuracy. And not limited to indoor scenes, we plan to apply it to identify mesoscale land use types in remote sensing images, and to achieve finer boundary delineation and pixel-level classification for various land use types.
Data availability
For this study, the ADE20K dataset was utilized. Regarding data availability and access, ADE20K is a publicly available dataset that can be obtained by searching on the official MIT CSAIL website (www.csail.mit.edu). This makes it easy for researchers and others interested in the relevant field to acquire and utilize this valuable resource for their research and projects. The use of ADE20K in this study complies with its terms and conditions of availability.
References
Dang, T.-V. & Bui, N.-T.J.E. Multi-scale fully convolutional network-based semantic segmentation for mobile robot navigation. Electronics 12(3), 533 (2023).
Cao, Z. et al. Haze removal of railway monitoring images using multi-scale residual network. IEEE Trans. Intell. Transport. Syst. 22(12), 7460–7473 (2020).
Hagedorn, B., Trapp, M., Glander, T., et al. Towards an indoor level-of-detail model for route visualization. In Proceedings of the 2009 Tenth International Conference on Mobile Data Management: Systems, Services and Middleware, F (IEEE, 2009).
Chung, W., Kim, G. & Kim, M. J. A. R. Development of the multi-functional indoor service robot PSR systems. Autonom. Robots. 22, 1–17 (2007).
Wu, Z., Fu, Y., Jiang, Y.-G., et al. Harnessing object and scene semantics for large-scale video understanding. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, F (2016).
Chen, Q., Chen, J. & Huang, W. Visualizing large-scale building information modeling models within indoor and outdoor environments using a semantics-based method. ISPRS Int. J. Geo-Inf. 10(11), 756 (2021).
Yu, C., Wang, J., Gao, C., et al. Context prior for scene segmentation. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, F (2020).
Wald, J., Dhamo, H., Navab, N., et al. Learning 3d semantic scene graphs from 3d indoor reconstructions. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, F (2020).
Ahmed, A., Jalal, A. & Kim, K. J. S. A novel statistical method for scene classification based on multi-object categorization and logistic regression. Sensors 20(14), 3871 (2020).
Fooladgar, F. & Kasaei, S. J. A survey on indoor RGB-D semantic segmentation: from hand-crafted features to deep convolutional neural networks. Multimed. Tools Appl. 79(7), 4499–4524 (2020).
Hernandez, A. C. et al. Exploiting the confusions of semantic places to improve service robotic tasks in indoor environments. Robot. Autonom. Syst. 159, 104290 (2023).
Heikel, E. & Espinosa-Leal, L. J. J. O. I. Indoor scene recognition via object detection and TF-IDF. J. Imaging 8(8), 209 (2022).
Miao, B., Zhou, L., Mian, A. S., et al. Object-to-scene: Learning to transfer object knowledge to indoor scene recognition. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), F (IEEE, 2021).
Song, C., Ma, X. Srrm: Semantic region relation model for indoor scene recognition. In Proceedings of the 2023 International Joint Conference on Neural Networks (IJCNN), F (IEEE, 2023).
Zhou, L., Cen, J., Wang, X., et al. Borm: Bayesian object relation model for indoor scene recognition. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), F. (IEEE, 2021).
Costa, W. D. L., Ismayilov, R., Strisciuglio, N., et al. Indoor scene recognition from images under visual corruptions. (2024).
Seong, H., Hyun, J. & Kim, E. FOSNet: An end-to-end trainable deep neural network for scene recognition. IEEE Access. 8, 82066–82077 (2020).
Chen, L. et al. Advanced feature fusion algorithm based on multiple convolutional neural network for scene recognition. Comput. Model. Eng. Sci. 122(2), 505–523 (2020).
Fu, L. et al. Recurrent thrifty attention network for remote sensing scene recognition. IEEE Trans. Geosci. Remote Sens. 59(10), 8257–8268 (2020).
Liang, J., Song, W., Shen, L., et al. Indoor semantic map building for robot navigation. In Proceedings of the 2019 IEEE 8th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), F (IEEE, 2019)
Zhang, W., Liu, G. & Tian, G. J. I. A. A coarse to fine indoor visual localization method using environmental semantic information. IEEE Access 7, 21963–21970 (2019).
Wang, T., Chen, Q. Object semantic map representation for indoor mobile robots. In Proceedings of the Proceedings 2011 International Conference on System Science and Engineering, F (IEEE, 2011).
Gao, X., Jiang, L., Guang, X., et al. Real-time indoor semantic map construction combined with the lightweight object detection network. In Proceedings of the Journal of Physics: Conference Series, F (IOP Publishing, 2020).
Liu, T., Zhao, H., Liu, Y., et al. RGB-D SLAM based on semantic information and geometric constraints in indoor dynamic scenes. In Proceedings of the Journal of Physics: Conference Series, F (IOP Publishing, 2020).
Ma, W. et al. Multi-scale spatial context-based semantic edge detection. Inf. Fusion 64(238), 251 (2020).
Gao, G. et al. MSCFNet: A lightweight network with multi-scale context fusion for real-time semantic segmentation. IEEE Trans. Intell. Transport. Syst. 23(12), 25489–25499 (2021).
He, P. et al. MANet: Multi-scale aware-relation network for semantic segmentation in aerial scenes. IEEE Trans. Geosci. Remote Sens. 60, 1–15 (2022).
Shang, R. et al. Multi-scale adaptive feature fusion network for semantic segmentation in remote sensing images. Remote Sens. 12(5), 872 (2020).
Jiang, J. et al. Construction of a dual-task model for indoor scene recognition and semantic segmentation based on point clouds. ISPRS Ann. Photogram. Remote Sens. Spat. Inf. Sci. 10, 469–478 (2023).
Zhao, H., Shi, J., Qi, X., et al. Pyramid scene parsing network. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, F (2017).
He, K., Zhang, X., Ren, S., et al. Deep residual learning for image recognition. In Proceedings of the Proceedings of the IEEE conference on computer vision and pattern recognition, F (2016).
Mao, A., Mohri, M., Zhong, Y. Cross-entropy loss functions: Theoretical analysis and applications. In Proceedings of the International Conference on Machine Learning, F. (PMLR, 2023).
Hu, J., Shen, L., Sun, G. Squeeze-and-excitation networks. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, F (2018).
Vaswani, A. Attention is all you need. Adv. Neural Inf. Process. Syst. (2017).
Vanantwerp, J. G. & Braatz, R. D. A tutorial on linear and bilinear matrix inequalities. J. Process Control 10(4), 363–385 (2000).
Zhou, B., Zhao, H., Puig, X., et al. Scene parsing through ade20k dataset. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, F (2017).
Frieden, B. Image enhancement and restoration. Picture Process. Digit. Filter. 177–248 (2005).
Amari, S.-I.J.N. Backpropagation and stochastic gradient descent method. Neurocomputing 5(4–5), 185–196 (1993).
Jiang, J. et al. Construction of indoor obstacle element map based on scene-aware priori obstacle rules. ISPRS J. Photogram. Remote Sens. 195, 43–64 (2023).
López-Cifuentes, A. et al. Semantic-aware scene recognition. Pattern Recogn. 102, 107256 (2020).
Funding
This research was funded by Guangxi Natural Science Foundation of China(Grant no. 2025GXNSFBA069341), National Natural Science Foundation of China (Grant no. 41961063), the Technology Innovation Center for Natural Resources Monitoring and Evaluation of Beibu Gulf Economic Zone, Ministry of Natural Resources (Grant no. BBW2024004).
Author information
Authors and Affiliations
Contributions
Mr. J.W.L. undertook the main writing work of the paper. Mr. G.W.Y. was responsible for the specific implementation of the experiment. Mr. J.W.J. designed the research method of this study. Mr. Z.C. analyzed and organized the experimental data. Mr. X.Z. was responsible for the data required for the experiment. Mr. B.S. performed data annotation work.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Li, J.W., Yan, G.W., Jiang, J.W. et al. Construction of a multiscale feature fusion model for indoor scene recognition and semantic segmentation. Sci Rep 15, 14701 (2025). https://doi.org/10.1038/s41598-025-95465-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-95465-1
