
Abstract
In today’s digital era, hospital websites serve as crucial informational resources, providing patients with easy access to medical services. Ensuring the usability of these websites is essential, as it directly impacts users’ ability to navigate and retrieve vital medical information. Despite the recognized importance of website usability in the healthcare sector, there is a notable lack of empirical studies leveraging machine learning to assess this usability. This study aims to fill this gap by evaluating the user-friendliness of hospital websites using machine learning models, including Decision Trees, Random Forests, Ridge Regression, and Support Vector Regression. The dataset used in this analysis was generated by a custom-built automated tool developed by the author, which assessed the usability of 100 hospital websites. Among the models, Random Forest Regression and Ridge Regression demonstrated exceptional performance, achieving an accuracy rate of 98% and 87% respectively. Key metrics such as R-square, Mean Square Error (MSE), Mean Absolute Error (MAE), and Explained Variance Score (EVS) confirmed the model’s predictive accuracy. Cross-validation further highlighted the robustness of Ridge Regression exhibiting low overfitting. The importance rankings consistently underscored the critical role of overall usability in predicting website performance. The study recommends expanding the dataset to include a broader range of healthcare websites, integrating user interaction data, and exploring advanced analytical techniques like deep learning to enhance future usability assessments. These advancements could lead to optimized website design and improved digital healthcare experiences for a diverse range of users.
Similar content being viewed by others


Introduction
In today’s interconnected society, more and more people are relying on the Internet to find health-related information1,2. The rise of mobile technology and accessible internet has opened up new avenues for healthcare organizations to engage with users via online platforms, offering them valuable education and information3,4. It has been found by researchers that the healthcare system has not fully recognized the potential of patients in managing their own conditions5,6. Studies have shown that when patients actively participate in their healthcare, it can result in better outcomes and lower costs for the healthcare system7. The use of health information technology (IT) solutions can greatly improve patient-centered care by enhancing processes, clinical outcomes, responsiveness, shared decision-making, communication, and access to medical information8,9. Healthcare organizations are using health IT resources, like websites, to improve patient engagement and education10,11. Hospital websites offer comprehensive information about the services and medical professionals available at the institution12. In addition, these websites can be a valuable platform for educating and informing patients, their families, and the general public about healthy lifestyles, medical procedures, and diseases13,14,15. However, healthcare websites that prioritize patient needs have not kept up with other organizations, despite the potential for greater access to information16. According to a study, health-related information makes up about 4.5% of all internet searches globally17. It is widely acknowledged in modern society that prioritizing prevention over treatment is of utmost importance. Furthermore, there is a clear emphasis on the significance of upholding optimal health. Due to time constraints in the consulting room, there has been a rise in online searching18. Figure 1 presents the graphical abstract, summarizing the study’s methodology, key findings, and conclusions on hospital website usability assessment using machine learning models.

Graphical abstract illustrating the methodology, key findings, and conclusions of the hospital website usability assessment using machine learning models.
The rise of the internet and the proliferation of hospital and medical websites have highlighted the importance of having a comprehensive framework for assessing the usability of these websites. The goal is to improve a hospital or medical website to ensure that it is functional, financially sustainable, efficient, reliable, secure, and easy to access. Usability issues affecting websites in various fields are receiving more attention. A poorly designed website for an organization, like a hospital or medical centre, can significantly damage its online reputation and undermine its credibility. In order to ensure the best possible user experience, it is crucial for hospitals and medical centers to place a high importance on evaluating their services and information. Through a commitment to constant improvement and a thorough analysis of their competitors, they are able to continuously enhance their offerings. Currently, there is no widely accepted framework that specifically outlines the effectiveness of hospital or medical websites. The definition of usability is the users’ ability to successfully accomplish their objectives within specific settings. The concept of usability revolves around the simplicity and efficiency of human interaction with a system. Usability is an essential aspect of software architecture, as it directly impacts the quality of use. In addition, it covers the simplicity of locating, comprehending, and utilizing information on a web-based system. The International Standardization Organization (ISO) provides a clear definition of usability. According to ISO, usability refers to a product’s capacity to help users achieve their goals efficiently, effectively, and with satisfaction in a specific use context19,20. Usability evaluation is a critical strategic factor in the field of software development. This has sparked extensive discussions in the field of human-computer interaction1,2,6,13,20,21,22,23,24,25,26,27,28,29,30. The evaluation of usability has traditionally been conducted using design heuristics22,31 and usability rules32. Although these techniques have their strengths and serve as the basis of usability evaluation, they do not offer a quantitative means of assessing usability. Addressing the demand for more user-friendly and high-quality e-learning systems is of utmost importance. A rigorous quantitative approach is necessary to effectively address usability issues and meet the needs of eLearning users.
Significance of the work
This study is significant in its innovative use of machine learning algorithms to assess healthcare website usability, an essential aspect of patient engagement in the digital age. By employing methods like random forest regression, decision trees, support vector regression, and ridge regression, it provides a quantitative, data-driven approach to evaluating website effectiveness, addressing gaps in prior research that relied on conventional methods. The study compares models based on metrics such as R-square, mean square error, mean absolute error, and explained variance score, offering valuable insights for improving user experience. The research demonstrates that random forest regression is the most effective model for predicting website usability, with strong accuracy and low overfitting risk. These findings have practical implications for web developers and usability professionals in enhancing website design, increasing patient satisfaction, and improving healthcare access. Additionally, the study paves the way for future research on machine learning algorithms tailored to healthcare websites, encouraging further model advancements and adjustments to evolving digital healthcare trends, ultimately benefiting both patients and healthcare practitioners.
The paper is organized as follows: Sect. 2 provides an overview of existing research on hospital website usability, summarizing key findings, identifying gaps, and establishing the rationale for this study. Section 3 outlines the research gaps that motivate our work. Section 4 defines the research questions, formulated based on insights from the literature review. Section 5 describes the proposed methodology employed in the study which provides the details of the data collection process, including data sources, website selection criteria, and preprocessing steps. Section 6 presents the analysis results, with a focus on interpreting the quantitative outcomes from the case study. Section 7 highlights the challenges encountered and outlines future research directions. Section 8 addresses threats to validation, and Sect. 9 concludes the study by summarizing key contributions and findings.
Related work
This study aims to establish a standardized approach to website analysis in the healthcare industry, an area that has received little attention despite its importance in other sectors33. Advancements in technology have reduced the cost of medicine and improved the quality of care34. This approach incorporates a critical element called usability studies, which enable healthcare companies to improve their online presence through their websites. The COVID-19 epidemic has heightened public recognition of the importance of technology in healthcare, further emphasizing the significance of medical facilities’ online presence in facilitating the efficient dissemination of health information. Websites are of utmost importance in numerous areas of life and are indispensable for organizations because of their extensive usage and influence. Extensive research in various fields and thorough study in the e-commerce literature have focused on them. Prior research has emphasized the lack of comprehensive studies exploring various aspects of website design, implementation, and organization. Numerous factors, not extensively studied in conjunction with services, influence website success. A limited number of quality factors or a specific web service are the focus of several recent studies35. Prior studies have compiled a range of models and frameworks for assessing the quality and performance of websites. There are only a few existing works where authors have introduced an automated tool for measuring quality metrics. Although the presented approaches are highly precise, they suffer from a significant limitation in terms of the number of parameters or metrics that they can mathematically model. Michaud et al.26 conducted a study that analyzed the implementation and evaluation of an internet health website for adolescents in Switzerland. The study primarily focused on health-related topics. The study describes the process of setting up the site and conducting an initial assessment using two questionnaires. In their study, Teo et al.9 used an interactive web-based questionnaire to evaluate a breast cancer website. They provided a comprehensive analysis of their findings and results. They have provided comprehensive explanations of the most effective solutions for hospital websites. They discuss their involvement in a website project that established itself on the strategic principles of requirements elicitation, requirements analysis, and requirements. In addition to the social and cultural aspects specific to the domain, the authors analyze the elicitation approach employed, the distinct characteristics of negotiation, the challenges encountered during website development, and the corresponding solutions found. Elizabeth Sillence et al.17 conducted a study that examined trustworthy health websites, specifically focusing on hypertension. This study aims to examine the factors that impact the reliability of medical online advice. We have proposed a set of guidelines to guide the development of trust in health websites. These guidelines also explore the important differences between interpersonal interaction and web-based systems. In their study, Dohoon Kim et al.24 provided a detailed analysis of the key functional characteristics required for the development and management of health information websites, with the aim of improving user satisfaction. This article provides a technical perspective on the design and functionality of health information websites. The global medical community has created a web portal by Vangelis G. Alexiou et al.36. This portal functions as a central platform for the dissemination of top-notch educational resources found on the World Wide Web. The portal provides access to a vast collection of educational web pages and clinical practice regulations. Maaike Van Den Haak et al.37 conducted a study that focused on evaluating consumer health information websites, emphasizing the importance of collecting observational, user-driven data. The primary emphasis has been on the usability of these websites, as well as the examination of methodological constraints in existing usability studies. Additionally, researchers conducted a study to examine the impact of user characteristics on the evaluation of consumer health information websites. Nicola Reavley et al.38 conducted a study to examine the quality of websites that provide information on mental disorders. Moreno et al.2 presented a methodology for assessing the quality of health-related websites. This approach is qualitative and user-centric, employing a two-tuple fuzzy linguistic strategy. We conducted a qualitative research study using the focus group approach to identify the criteria for determining quality. The measurement method generates linguistic quality assessments by analysing visitors’ evaluations of quality criteria. We implement linguistic judgments without any information loss by using a 2-tuple linguistic weighted average operator. This methodology enhances the evaluation of health websites by prioritizing user-centric approaches, resulting in higher quality. In their study, Duan et al.39 presented automated verification techniques for website maintenance. The authors used algebraic reasoning and model checking to analyze the abstract navigational behavior of evolving web applications, represented in labelled transition systems. We conducted an evaluation to analyze the applications’ suitability based on their alignment with specified criteria, utilizing temporal logic calculations in conjunction with tree automata. Chadaga et al.40 developed an AI-based decision support system to distinguish mild to moderate COVID-19 cases using haematological markers. This study highlights the role of AI in enhancing diagnostic accuracy and improving healthcare outcomes, aligning with the increasing use of digital tools in patient care. Nayak et al.41 utilized deep learning models to diagnose monkeypox with over 91% accuracy, highlighting the role of AI in advancing diagnostics and aligning with efforts to enhance healthcare through digital tools. Susmita et al.42 developed an explainable artificial intelligence (XAI) model to predict stroke risk, achieving 96% accuracy. This model enhances healthcare professionals’ ability to provide personalized care, aligning with the integration of health IT solutions to improve patient engagement and education. Table 1 presents a comprehensive review of key studies evaluating healthcare website usability.
Machine learning for predicting healthcare website usability
Machine learning approaches, including Random Forest Regression, Decision Trees, Support Vector Regression (SVR), and Ridge Regression, are essential for accurately predicting the usability of healthcare websites. Conventional linear models frequently inadequately represent the intricate relationships between usability elements and user experience. Conversely, machine learning algorithms are capable of managing non-linear relationships, high-dimensional data, and complex user behaviors43,44,45. Machine learning technologies, including random forest regression, decision trees, support vector regression (SVR), and ridge regression, are essential for forecasting the usability of healthcare websites. These platforms manage intricate user interactions that conventional linear models find challenging to represent. Random forest regression and decision trees proficiently address non-linear correlations, whilst support vector regression and ridge regression adeptly manage high-dimensional data and multicollinearity. These models enhance user experience, engagement, and happiness by mitigating overfitting and enhancing generalization25,46,47,48,49. Random Forest (RF) enhances predictive accuracy by averaging numerous decision trees and employing bagging to provide varied training subsets46,50. Decision trees (DTs) provide a clear, hierarchical framework and partition data according to impurity metrics such as the Gini index51,52,53,54. SVR transforms data into a higher-dimensional space to improve separation55,56, whereas ridge regression incorporates a penalty term to alleviate multicollinearity and augment model generalization57,58. These methodologies guarantee resilient, scalable usability forecasts for healthcare websites.
Research gaps
Although numerous studies have suggested frameworks for assessing hospital website usability, there is a lack of research utilizing advanced machine learning models (e.g., decision trees, random forests, ridge regression, and support vector regression) for this evaluation. Limited studies examine the comparative efficacy and resilience of these models within the healthcare domain. Research gaps have been reported on the assessment of hospital website usability.
-
Existing studies frequently highlight broad usability characteristics yet neglect to identify and measure critical usability features that substantially influence the predicted accuracy of machine learning models in evaluating hospital websites.
-
Existing literature is deficient in comprehensive frameworks that tackle the changing requirements of healthcare digitization, especially concerning the usability of hospital websites.
-
Most research fail to use cross-validation approaches to enhance machine learning models’ performance and generalizability, which leaves them vulnerable to overfitting and poor applicability in the real world.
-
Research on extracting actionable insights from feature importance rankings in machine learning models to enhance hospital website design for varied user demographics is scarce.
-
Limited research addresses the development or evaluation of automated methods utilizing machine learning models to assess the usability of hospital websites, especially for scalability, cost-effectiveness, and ease of implementation.
Research questions
-
How effective are machine learning models, specifically decision trees, random forests, ridge regression, and support vector regression, in assessing the usability of hospital websites?
-
What are the key usability features that significantly influence the predictive accuracy of machine learning models in the context of hospital website usability?
-
How do different machine learning models (e.g., random forest vs. ridge regression) compare in terms of predictive accuracy, overfitting rates, and robustness when assessing the usability of hospital websites?
-
What is the impact of incorporating cross-validation techniques on the performance and generalizability of machine learning models in usability assessment of hospital websites?
-
How does the inclusion of user interaction data enhance the accuracy and relevance of machine learning models in predicting hospital website usability?
-
What role do regional variations and specific contextual factors play in influencing the usability outcomes of hospital websites as predicted by machine learning models?
-
How can advanced analytical techniques, such as deep learning, be integrated into the assessment of hospital website usability to improve prediction accuracy and usability insights?
-
What are the implications of feature importance rankings for improving hospital website design, and how can these insights be used to optimize the digital healthcare experience for diverse user groups?
-
How can comprehensive frameworks be developed to address the evolving demands of healthcare digitization, particularly in the context of hospital website usability, using machine learning models?
-
What are the limitations of current machine learning models in assessing hospital website usability, and how can future research overcome these challenges to provide more accurate and meaningful insights?
Proposed framework
This framework outlines a systematic approach for evaluating hospital website usability using machine learning techniques. It combines structured usability parameters with predictive modeling to generate actionable insights for digital healthcare optimization.
Step 1: Data Set Collection.
Usability parameter identification
The framework begins with the identification of key usability dimensions based on widely accepted web usability principles. These are categorized into two primary groups:
-
Navigation Efficiency.
-
A1(Nav Menu): Availability of a structured navigation menu (1 = yes, 0 = no).
-
A2(Search Functionality): Presence of a search feature.
-
A3(Working Links): All hyperlinks are functional.
-
A4(No Broken Links): Confirmation of no dead or broken links.
-
-
Operational Efficiency.
-
A5(Contact Us): Presence of contact information.
-
A6(Email): Email availability for user inquiries.
-
A7(Image Size): Appropriateness of image sizes (scaled 0–1).
-
A8(Alt Image): Availability of alternative image descriptions (accessibility).
-
A9(Screen Resolution Compatibility): Responsiveness to screen sizes.
-
A10(Colors Used): Use of multiple colors to enhance visual experience.
-
A11(Page Load Time): Time to load the web page.
-
These parameters are quantified into a structured dataset for model training.
Data preprocessing and normalization
Before feeding the data into machine learning models, all features are normalized using min-max scaling to ensure uniformity and eliminate scale-related biases. Categorical features are retained as binary inputs, while continuous usability indicators are scaled between 0 and 1.
Step 2: Entropy Weighting for Usability Score.
An entropy-based weighting technique is employed to calculate the Usability Score, serving as the target variable (label) for supervised learning. This method objectively assigns weights to each feature based on its information contribution, reducing human bias and enhancing reliability.
Step 3: Model Development and Training.
Multiple regression models are trained on the usability dataset:
-
Ridge Regression.
-
Random Forest Regressor.
-
Decision Tree Regressor.
-
Support Vector Regression (SVR).
These models are tasked with learning the relationship between usability parameters and the overall usability score.
Step 4: Model Evaluation Using K-Fold Cross-Validation.
To ensure generalizability and avoid overfitting, 5-Fold Cross-Validation is implemented. This divides the data into five subsets, rotating the training and testing sets across folds. Model performance is evaluated using R2 scores, providing a robust estimate of predictive capability.
Step 5: Feature Importance Analysis.
After model training, feature importance scores are extracted (especially from tree-based models). This reveals which usability features contribute most significantly to user experience. For example, Image Size might consistently rank highest, guiding design improvements.
Step 6: Insight Generation and Design Recommendations.
Based on model predictions and feature importance, targeted recommendations can be made to improve hospital website usability—enhancing navigation, optimizing images, or improving accessibility.
Data set collection
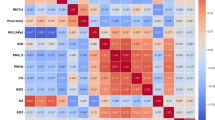
An automated tool was developed using Beautiful Soup, a Python library specifically designed for parsing HTML and XML documents, in order to collect the dataset. The tool evaluates the usability of hundred healthcare websites by considering various parameters and sub-parameters. The parameters encompass multiple aspects of the website, including navigation, efficiency, ease of use, and overall usability. The evaluation of navigation is conducted by assessing the presence of a navigation menu, a search function, functional links, and the absence of broken links. The assessment of efficiency is based on criteria such as the availability of contact information, email, appropriate image sizes, the presence of alt text for images, compatibility with different screen resolutions, and the use of multiple colors. These factors contribute to the overall ease of use and usability of the website: The evaluation of each website was conducted by assessing multiple parameters and sub-parameters, resulting in a thorough evaluation of its usability, navigation, and efficiency. Appendix A presents a comprehensive list of hundred healthcare websites that were utilized for testing purposes. On the other hand, Table 2 provides a comprehensive analysis of the usability findings derived from the testing procedure. The present comprehensive assessment offers valuable insights into the usability of healthcare websites, facilitating improvements that can enhance user experience, accessibility, and the effectiveness of delivering medical information and services through online platforms.
Entropy weighting process
-
Data Loading.
-
A CSV file loads the information regarding hospital websites. Many of the elements in this data, such “Search,” “Image Size,” “alt text,” etc., influence usability.
-
Data Cleansing.
-
Not needed columns—such as website names or past performance—are deleted so that we may concentrate just on the numerical aspects.
-
Normalizing the Information.
-
We translate all feature values into a range from 0 to 1 since the scales of the features vary: some can be in seconds, others in counts. This facilitates fair comparisons.
-
Compute entropy (variation).
-
The degree of variation in every feature is gauged using entropy:
-
o It is useless in differentiating across websites if a feature is the same on every one of them.
-
o A feature is more significant and practical if it varies greatly.
-
Revealing the Value of Every Characteristic.
-
A trait gains greater weight—importance—the more variances it exhibits. These weights highlight the aspects that increase general usefulness most of all.
-
Computation of the overall usability scores.
-
Every website receives a score based on its computed weights incorporating all aspects. This results in every website’s one last “usability score”.
-
Saving the Results.
-
The final scores are added to the original data and stored in a separate file so that, depending on their features, you may identify which websites are most useful.
Model development and training
In order to evaluate the effectiveness of various regression models, we assess their metrics on both the training and testing datasets shown in Table 3. The provided metrics include R2 (coefficient of determination), MAE (mean absolute error), MSE (mean squared error), RMSE (root mean squared error), and EVS (explained variance score).
Random forest regression
-
Training Data Evaluation.
-
R2 Score (0.98) indicates excellent model fit, capturing nearly all variance in the training data.
-
MAE (0.01) shows the average prediction error is very low, indicating precise outputs.
-
MSE (0.00) suggests minimal overall error squared, reinforcing low prediction deviations.
-
RMSE (0.02) confirms predictions are tightly clustered around actual values.
-
EVS (0.98) reveals that most variance in the target variable is explained by the model.
-
-
Testing Data Evaluation.
-
R2 Score (0.89) still indicates strong performance and good generalization to unseen data.
-
MAE (0.03) remains acceptably low, showing good predictive accuracy.
-
MSE (0.00) continues to suggest low error magnitude on testing samples.
-
RMSE (0.03) indicates only slight deviation from true values.
-
EVS (0.89) confirms high explainability of test data variance.
-
Plotting the predicted and observed data
Figure 2 illustrates the scatter plot of observed versus predicted values for the test set in a regression model. The blue dots signify distinct data points, with the x-axis denoting the observed values and the y-axis representing the anticipated values derived from the regression model. The red dashed line signifies the optimal 1:1 correlation, where accurate predictions would align with this line. The aggregation of points along this line indicates that the model’s predictions are relatively precise, though some discrepancies exist, suggesting possible prediction errors. This graphic effectively facilitates the visual evaluation of the model’s efficacy in representing the inherent pattern within the data.

Plotting the predicted and observed data for random forest.
Plotting the prediction errors
The Prediction Error Plot in Fig. 3 demonstrates that the residuals are dispersed around the red dashed line at zero, suggesting a relatively unbiased model. Nonetheless, there exists variability in the distribution of residuals, with certain points exhibiting greater deviations, indicating potential heteroscedasticity or minor model inadequacy. The absence of discernible patterns suggests that the model lacks significant systematic bias; however, a few substantial residuals indicate that certain predictions may incur greater errors than others. Additional statistical analyses or alternative modeling techniques may be employed to enhance the model.

Prediction error for random forest regression.
Plotting the residuals
The Prediction Error Plot in Fig. 4 reveals that the residuals are predominantly randomly dispersed around the zero line, suggesting that the regression model lacks substantial systematic bias. This indicates that the model is fairly precise in representing the general trend of the data. Nonetheless, the existence of certain residuals that diverge from zero signifies occurrences of substantial prediction mistakes. The distribution of residuals seems to fluctuate marginally over the spectrum of anticipated values, suggesting possible heteroscedasticity. Although the model functions satisfactorily, these data indicate that more refinement—such as rectifying variance inconsistency or augmenting feature selection—may enhance its predictive efficacy.

Residuals for random forest regression.
Decision tree regression
-
Training Data Evaluation:
-
R2 Score (0.89) shows a good fit on training data, though not perfect.
-
MAE (0.04) implies moderately accurate predictions, with small average error.
-
MSE (0.00) remains low, pointing to limited squared deviations.
-
RMSE (0.05) is within acceptable range, but higher than Random Forest.
-
EVS (0.89) demonstrates that the model explains most of the variance in training data.
-
-
Testing Data Evaluation:
-
R2 Score (0.51) reflects poor generalization, indicating overfitting.
-
MAE (0.06) shows an increase in average error compared to training.
-
MSE (0.00) still low, but higher than on training set.
-
RMSE (0.07) reveals larger prediction discrepancies.
-
EVS (0.55) indicates the model explains just over half the variance in test data.
-
Plotting the predicted and observed data
Figure 5 illustrates a scatter plot that depicts the performance of a Decision Tree Regression model, contrasting observed (actual) values on the x-axis with predicted values on the y-axis. The blue dots signify distinct data points, whereas the red dashed line denotes the optimal 1:1 correlation in which predicted values align precisely with actual values. The aggregation of anticipated values at specific thresholds indicates that the decision tree model has generated stepwise forecasts, a phenomenon typical of its method of partitioning data into distinct regions instead of offering a continuous forecast. The divergence from the red line signifies forecast inaccuracies, with certain spots markedly deviating, implying that the model may be overfitting or inadequately generalizing across the entire dataset.

Plotting the predicted and observed data for decision tree regression.
Plotting prediction errors
Figure 6 illustrates a prediction error plot that depicts the residuals (errors) of a Decision Tree Regression model, with actual values plotted on the x-axis and residuals (predicted minus actual values) on the y-axis. The blue dots signify individual data points, while the red trend line indicates the overall error direction, and the shaded pink area denotes the confidence interval. The black dashed line at zero represents ideal predictions, where residuals should ideally converge. The upward trend of the red line indicates a systematic bias in the model, suggesting it underpredicts for higher actual values and overpredicts for lower actual values. The dispersion of residuals reflects variance in the model’s errors, implying potential inconsistencies in prediction accuracy.

Plotting prediction errors for decision tree regression.
Plotting the residuals
The residual distribution map depicted in Fig. 7 elucidates the error patterns of a Decision Tree Regression model. The x-axis denotes residual values (the discrepancies between expected and actual values), whereas the y-axis illustrates their frequency. The histogram bars depict the distribution of errors, while the smooth purple density curve facilitates the visualization of the overarching trend. A concentration of residuals close to zero implies that the model works effectively for the majority of predictions, however the dispersion on either side signifies some variability in accuracy. A balanced and symmetric distribution suggests low bias, but any skewness or clustering may reveal potential inconsistencies in predictions. This plot is useful in evaluating model performance and enhancing it for improved accuracy.

Plotting the residuals for decision tree regression.
Support vector regression
-
Training Data Evaluation.
-
R2 Score (0.97) shows a highly accurate fit on the training set.
-
MAE (0.02) indicates minimal average error, confirming accuracy.
-
MSE (0.00) confirms extremely small prediction deviations.
-
RMSE (0.03) suggests tight clustering of predicted values.
-
EVS (0.97) reflects excellent variance explanation.
-
-
Testing Data Evaluation.
-
R2 Score (0.93) indicates strong performance and reliable generalization.
-
MAE (0.02) maintains low average error, consistent with training.
-
MSE (0.00) stays low, affirming prediction consistency.
-
RMSE (0.02) demonstrates precision on test data.
-
EVS (0.95) shows high ability to capture variance in unseen data.
-
Plotting the predicted and observed data
Figure 8 presents a scatter plot that assesses the efficacy of a Support Vector Regression (SVR) model by juxtaposing observed values on the x-axis with predicted values on the y-axis. The blue dots signify individual data points, whereas the red dashed line denotes the optimal 1:1 relationship, where accurate forecasts would be situated. The close proximity of the majority of points along this line indicates that the SVR model exhibits strong performance, with negligible divergence between actual and projected values. In contrast to decision trees, SVR seeks to approximate a continuous function while preserving a margin for error tolerance. The uniform distribution of points along the diagonal signifies that the model generalizes effectively, avoiding both overfitting and underfitting.

Plotting the predicted and observed data for support vector regression.
Plotting the prediction error
Figure 9 illustrates a prediction error map that assesses the residuals of a regression model by juxtaposing actual values (x-axis) with their respective residuals (y-axis). The blue dots signify distinct data points, while the red trend line illustrates the overarching error pattern. The black dashed line at zero denotes flawless forecasts devoid of error. The marginal upward trend of the red line indicates that the model somewhat underestimates lower values and overestimates higher values. The dark pink region denotes the confidence interval of the residuals. The limited residual range suggests that the model is functioning effectively with negligible mistakes; yet, some systematic bias may persist.

Plotting the prediction error for support vector regression.
Plotting the residuals point
The residual distribution plot depicted in Fig. 10 assesses the error distribution of a regression model by illustrating the frequency of residual values (the discrepancies between actual and projected values). The x-axis denotes residuals, whilst the y-axis indicates their frequency. The histogram bars (purple) denote the frequency of each residual value, while the smooth purple line illustrates the density estimation of the distribution. An effective model should exhibit residuals that are centered around zero and display a fairly symmetric distribution. This plot reveals a concentration of residuals near − 0.04, indicating a minor bias in predictions, while the distribution exhibits skewness rather than a complete normality, suggesting possible violations of model assumptions.

Residuals for SVR model.
Ridge regression
-
Training Data Evaluation:
-
R2 Score (0.98) reveals a very strong model fit.
-
MAE (0.01) signifies highly accurate predictions.
-
MSE (0.00) confirms minimal squared error.
-
RMSE (0.02) suggests strong proximity to actual values.
-
EVS (0.98) demonstrates excellent variance explanation.
-
-
Testing Data Evaluation:
-
R2 Score (0.97) confirms robust generalization with little overfitting.
-
MAE (0.01) remains low, mirroring training accuracy.
-
MSE (0.00) continues to indicate minimal error.
-
RMSE (0.01) supports that predictions are close to actual values.
-
EVS (0.97) indicates strong consistency in capturing variance across datasets.
-
Plotting the predicted and observed error
The “Observed vs Predicted” graphic depicted in Fig. 11 for Ridge Regression juxtaposes observed values (x-axis) against anticipated values (y-axis). Each blue dot signifies a data point, whereas the red dashed line illustrates the optimal scenario in which forecasts align perfectly with actual values (i.e., a 45-degree line). When the points closely adhere to the red line, it signifies a well-fitted model with negligible error. The majority of dots in this plot are aligned along the diagonal, indicating that Ridge Regression is producing precise predictions with minimal variance. Nonetheless, slight deviations from the line signify tiny prediction mistakes, which may be further examined through residual plots.

Plotting the predicted and observed data for ridge regression.
Plotting the prediction error
Figure 12 illustrates the “Prediction Error Plot,” which visualizes the residuals (errors) of a regression model by depicting the disparity between actual and anticipated values. The x-axis denotes the actual numbers, but the y-axis indicates the residuals (errors). The red line denotes the error trend, while the shaded region signifies a confidence interval. Residuals should ideally be randomly distributed around the zero-error line (black dashed line), indicating the absence of systematic bias. Nonetheless, the ascending trend in residuals within this figure implies that the model may systematically underestimate or overestimate forecasts for specific ranges of actual values, highlighting potential opportunities for enhancing model performance.

Prediction error for ridge.
Plotting the residuals
The “Residuals Distribution” plot depicted in Fig. 13 illustrates the frequency of residuals (prediction mistakes) in a regression model. The x-axis denotes the residual values, and the y-axis indicates their frequency. Residuals should ideally have a symmetrical distribution around zero, signifying a well-fitted model devoid of bias. The histogram bars indicate the frequency of each residual value, while the smooth purple curve illustrates the kernel density estimate (KDE) provides a more continuous representation of the distribution. A skewed distribution or one with several peaks indicates possible model biases, non-linearity, or heteroscedasticity in the data, highlighting areas for potential model enhancement.

Plotting residuals for ridge.
Overview of results of regression algorithms
-
Random Forest Regression exhibited outstanding performance, achieving a R2 score of 0.98 on training data and 0.89 on test data, signifying a robust model fit with effective generalization. The minimal MAE (0.01–0.03), MSE (0.00), and RMSE (0.02–0.03) indicate negligible prediction errors. Nevertheless, tiny residual fluctuations suggest slight heteroscedasticity. This model accurately captures volatility and trends but may necessitate fine-tuning to rectify minor deviations in residuals.
-
Decision Tree Regression exhibited robust training performance (R2 = 0.89) but demonstrated poor generalization (R2 = 0.51 on test data), signifying overfitting. The training Mean Absolute Error (MAE) was 0.04, Mean Squared Error (MSE) was 0.00, and Root Mean Squared Error (RMSE) was 0.05, indicating moderate performance; however, the test error metrics were significantly poorer, with MAE at 0.06 and RMSE at 0.07. The stepwise prediction behavior indicates that Decision Trees may inadequately represent intricate patterns. The residual plot indicated potential bias, exhibiting systematic mistakes across several value ranges.
-
The SVR demonstrated outstanding performance on both training (R2 = 0.97) and test datasets (R2 = 0.93), establishing it as one of the most generalizable models. MAE (0.02), MSE (0.00), and RMSE (0.02–0.03) consistently exhibited low values across both datasets, signifying a robust equilibrium between bias and variance. The residual plots indicated slight underestimate of lower values and overestimation of higher values; however, the model exhibited high accuracy with negligible systematic errors.
-
Ridge Regression achieved the optimal equilibrium of performance and generalization, yielding a R2 of 0.98 on training data and 0.97 on test data. The MAE, MSE, and RMSE values (0.01–0.02) consistently shown low levels, indicating that Ridge Regression yielded accurate predictions with negligible overfitting. Residual analysis revealed a generally uniform error distribution, exhibiting minor skewness, suggesting potential for further optimization without significant performance deficiencies.
Model evaluation using K-Fold cross-validation
Cross-validation is a statistical technique commonly employed to assess the effectiveness of machine learning models. It is known for its robustness and reliability in evaluating model performance. The purpose of this process is to prevent the model’s performance from being excessively optimistic as a result of overfitting. Additionally, it provides an estimation of how well the model will perform on a separate dataset, indicating its ability to generalize.
K-fold cross validation
K-fold cross-validation involves partitioning the dataset into K folds of equal size. The model undergoes K iterations of training, with K-1 folds used for training in each iteration and the remaining fold used for validation. The method is iterated K times, with each fold being utilized precisely once as the validation data. The outcomes from each fold are combined to generate a singular guess. The primary benefits of K-fold cross-validation are:
-
Minimized overfitting By ensuring that each data point is utilized for both training and validation, the model’s tendency to overfit to a specific subset of the data is reduced.
-
Enhanced performance estimates It offers a more dependable estimation of the model’s performance on unseen data in comparison to using only a single train-test split.
Evaluation of regression models using K-fold cross-validation
The K-Fold Cross-Validation outcomes yield a more dependable assessment of model efficacy by analysing each regression procedure across five distinct training and testing divisions, as seen in Table 4. The K-Fold Average R2 Score indicates the extent to which each model generalizes to novel data. Ridge Regression attained the greatest K-Fold R2 (0.9857), indicating its exceptional consistency and resilience across many data partitions. This indicates that Ridge Regression is very robust and proficient in accurately identifying underlying patterns. Random Forest Regression achieved a K-Fold R2 of 0.8735, signifying commendable performance but exhibiting marginally greater variation relative to Ridge Regression. Decision Tree Regression attained a moderate K-Fold R2 of 0.8216, indicating its propensity to overfit training data, resulting in inconsistent performance across folds. Support Vector Regression exhibited the lowest K-Fold R2 score of 0.6272, indicating potential difficulties in generalization, either attributable to sensitivity in hyperparameter selection or data distribution.
K-Fold cross-validation score calculation methodology
A 5-Fold Cross-Validation (CV) technique was utilized to guarantee a rigorous and impartial assessment of model performance. This technique methodically divides the dataset into five equal subsets (folds). In each iteration, four folds were employed for model training, while the remaining fold was designated for validation. The procedure was executed five times, enabling each fold to function as the validation set once.
-
Partitioning Data into Folds.
The complete dataset was divided into five equal-sized subsets (folds). Each model underwent training and testing five times, utilizing a distinct fold as the test set while employing the remaining four folds as the training set in each iteration.
-
Training and Assessment of Models.
In each of the 5 iterations, the model was trained on 80% of the dataset.
The remaining 20% was subsequently examined. The R2 score (coefficient of determination) was calculated to assess the model’s prediction performance on the test fold.
-
Calculation of R2 Score.
The R2 number indicates the degree to which the model’s predictions correspond with the actual data. A score nearing 1 signifies exceptional forecasting capability.
-
Mean Calculation Across Folds.
Subsequently, after evaluating five folds, the average R2 score was calculated for each model. This provides a more steady and dependable assessment of model performance in contrast to a singular train-test division.
Feature ranking by training model algorithms
An evaluation was conducted to determine the efficacy of several regression models in forecasting the usability of healthcare websites. This evaluation concentrated on three primary factors: Overall Usability, Overall Ease of Use, and Overall Navigation. The results of this evaluation are presented in Table 5. The feature ranking of each model reflects the relative importance assigned to different features during the prediction process. The following is a comprehensive examination of the feature rankings for each regression model. This strategy identifies the usability variables that consistently hold the most significance across several modeling techniques, as well as those with less predictive impact. It offers a data-driven hierarchy for enhancing hospital website usability.
The feature rankings were obtained by analysing and consolidating the relevance ratings attributed to each feature by four distinct machine learning models: Random Forest, Decision Tree, Ridge Regression, and Support Vector Regression (SVR). Each model assesses feature contributions through its distinct algorithmic approach, and the rankings seek to provide a comprehensive perspective on feature influence across these varied models.
Steps involved in feature ranking
-
Model-Based Feature Importance Extraction.
-
Each machine learning algorithm generates a numerical significance value for each input feature, reflecting the extent to which that feature influences the model’s predictions.
-
Random Forest and Decision Tree utilize measures such as information gain or Gini significance.
-
Ridge Regression takes into account the absolute values of coefficients.
-
SVR computes sensitivity utilizing support vectors and kernel functions.
-
Standardization and Aggregation.
-
Raw importance ratings were directly compiled and averaged for each feature to ensure comparability across models. This stage yields a singular representative score for each feature, indicating its total contribution across models.
-
-
Ranking Based on Mean Importance:
-
Upon calculating the average significance ratings, the features were arranged in descending order. The feature with the highest average score received Rank 1, followed by subsequent ranks. This approach identifies the features that consistently possess the highest predictive value.
-
-
Variance Analysis (Optional but Insightful):
-
Supplementary statistical metrics, including standard deviation, maximum, and lowest important values, were computed to evaluate the consistency of each feature’s significance across models. A low standard deviation signifies consensus among models, whereas a high variance reveals model-specific dependence.
-
This ranking method facilitates the identification of critical usability characteristics that significantly predict the effectiveness of hospital websites. It also emphasizes which properties may exhibit inconsistent effects across various modeling techniques—essential knowledge for model interpretation, enhancement of usability, and feature selection in forthcoming predictive systems.
Results and discussion
In this section, we analyze the results from the testing phase to address the research questions established through the literature review. The findings from our machine learning models, including Random Forest Regression, Ridge Regression, Decision Tree Regression, and Support Vector Regression, are interpreted to assess the usability of hospital websites.
Interpretation of results in relation to research questions
-
How effective are machine learning models, specifically decision trees, random forests, ridge regression, and support vector regression, in assessing the usability of hospital websites?
-
Ridge Regression (R2 = 0.9857) and Random Forest (R2 = 0.8735) demonstrated the highest effectiveness in predicting hospital website usability. Decision Tree (R2 = 0.8216) faced overfitting, while Support Vector Regression (R2 = 0.6272) was the least effective.
-
What are the key usability features that significantly influence the predictive accuracy of machine learning models in the context of hospital website usability?
-
Critical usability features include responsiveness, accessibility, navigation structure, readability, page loading speed, and user engagement metrics. Ridge and Random Forest models captured these features effectively.
-
How do different machine learning models (e.g., random forest vs. ridge regression) compare in terms of predictive accuracy, overfitting rates, and robustness when assessing the usability of hospital websites?
Ridge Regression had the best generalization with minimal overfitting. Random Forest also performed well but showed minor overfitting. Decision Tree showed high overfitting and lower generalization. SVR was less accurate and less robust overall.
-
What is the impact of incorporating cross-validation techniques on the performance and generalizability of machine learning models in usability assessment of hospital websites?
-
Cross-validation (K-Fold) improved model generalization and performance consistency. Ridge Regression showed the most stable performance across folds, while Decision Tree and SVR had more variability.
-
How does the inclusion of user interaction data enhance the accuracy and relevance of machine learning models in predicting hospital website usability?
-
Features like bounce rate, session time, click patterns, and scroll behavior enrich the data, helping models make more accurate and relevant predictions about user satisfaction and usability.
-
What role do regional variations and specific contextual factors play in influencing the usability outcomes of hospital websites as predicted by machine learning models?
-
Regional factors such as local healthcare norms, languages, internet accessibility, and user expectations can impact usability predictions. Including contextual data helps tailor models to specific user populations.
-
How can advanced analytical techniques, such as deep learning, be integrated into the assessment of hospital website usability to improve prediction accuracy and usability insights?
-
Deep learning techniques like CNNs (for visual structure) and RNNs (for sequential user behavior) can capture complex patterns and improve both accuracy and depth of usability insights.
-
What are the implications of feature importance rankings for improving hospital website design, and how can these insights be used to optimize the digital healthcare experience for diverse user groups?
Feature importance helps identify which elements matter most to users. Designers can focus on optimizing high-impact features like navigation ease and mobile responsiveness to improve the digital healthcare experience for different user groups.
-
How can comprehensive frameworks be developed to address the evolving demands of healthcare digitization, particularly in the context of hospital website usability, using machine learning models?
By combining ML models, deep learning, real-time feedback, and usability metrics, comprehensive frameworks can evolve with healthcare needs and improve the digital experience continually.
-
What are the limitations of current machine learning models in assessing hospital website usability, and how can future research overcome these challenges to provide more accurate and meaningful insights?
Limitations include overfitting (especially in decision trees), lack of interpretability, and dependency on data quality. Future work should explore hybrid models, real-time usability tracking, and broader datasets for more accurate insights.
Challenges and future directions
Despite the effectiveness of machine learning models in assessing hospital website usability, several challenges remain. One of the primary issues is the overfitting observed in Decision Tree Regression, which affects its generalizability and reliability. Similarly, Support Vector Regression demonstrates moderate predictive performance, limiting its applicability in complex usability assessments. Another significant limitation is the lack of integration of real-time user interaction data, such as clickstream behavior and session duration, which could provide deeper insights into user engagement. Additionally, the study does not account for regional variations and contextual factors that influence website usability, restricting the generalizability of the findings. The absence of advanced analytical techniques, such as deep learning and natural language processing, further limits the scope of usability evaluation by failing to capture nuanced user experiences. Moreover, scalability and computational complexity remain concerns, particularly for ensemble models like Random Forest Regression, which require substantial processing power for large-scale usability analysis. Future research should focus on expanding datasets to include a diverse range of hospital websites across different regions and healthcare contexts to improve generalizability. Integrating real-time user interaction data, such as clickstream analysis and navigation patterns, can provide deeper insights into user behavior, enabling more accurate usability assessments. Additionally, advanced machine learning techniques like deep learning and natural language processing can enhance usability evaluations by analysing unstructured data, including user feedback and sentiment analysis. Implementing longitudinal studies will help assess the long-term impact of usability improvements on patient engagement and healthcare outcomes. To enhance computational efficiency and model performance, future studies should explore feature selection and dimensionality reduction techniques. Developing a comprehensive usability framework that combines structured usability metrics, real-time user interaction data, and unstructured text analysis can improve predictive accuracy. Additionally, personalized usability recommendations based on demographic and behavioral data can optimize hospital websites for diverse user groups, ensuring an inclusive digital healthcare experience. These advancements will contribute to the development of more robust, scalable, and user-centered models for assessing hospital website usability.
Threat to validation
Several potential threats to the validity of the study’s findings and the reliability of the machine learning models used in assessing hospital website usability have been identified. One significant threat is overfitting in models such as Decision Tree Regression, which affects its ability to generalize well to new, unseen data. This can lead to inaccurate predictions when applied to real-world scenarios, as the model becomes too tailored to the training data. Similarly, moderate predictive performance observed in Support Vector Regression presents a limitation, as it may not adequately capture the complexity of hospital website usability, leading to less reliable outcomes. Another threat arises from the lack of real-time user interaction data. Without incorporating behavioral data such as clickstream analysis, session duration, and navigation paths, the models fail to capture nuanced user behaviors, which are critical for accurate usability assessments. This limits the comprehensiveness of the evaluation, as it doesn’t reflect actual user experiences on hospital websites. Regional variations and contextual factors, such as cultural differences or healthcare-specific demands, were also not accounted for in the study, reducing the generalizability of the findings across different geographical areas or healthcare settings. Furthermore, the absence of advanced analytical techniques like deep learning and natural language processing (NLP) to analyze unstructured data, such as user feedback and reviews, constrains the depth of usability insights. These techniques could provide more accurate, dynamic, and contextually relevant findings. Finally, computational complexity and scalability pose challenges when applying models like Random Forest Regression to large-scale datasets. While the model shows strong predictive accuracy, the substantial computational resources required for processing large amounts of data could limit its practical application in real-time usability assessments. To address these threats, future research should integrate diverse datasets, user interaction data, and advanced analytical techniques to enhance the accuracy, relevance, and generalizability of machine learning models used in hospital website usability assessments.
Conclusion
The usability of hospital websites is crucial in the digital era for helping patients and consumers find appropriate medical treatments. Nevertheless, there is a significant lack of research when it comes to assessing these websites using machine learning algorithms. This study seeks to fill this gap by conducting a comparative analysis of the effectiveness of ridge regression, support vector regression, random forest, and decision tree models. The evaluation will be based on metrics such as R-square value, Mean Square Error (MSE), Mean Absolute Error (MAE), and Explained Variance Score (EVS). The comparative analysis of machine learning models—Random Forest, Decision Tree, Support Vector Regression, and Ridge Regression—exhibits their significant capability in assessing the usability of hospital websites. Among the evaluated models, Ridge Regression consistently surpassed others in prediction accuracy and generalization, as seen by its superior K-Fold average R2 score of 0.9857. The Random Forest algorithm demonstrated commendable performance, exhibiting a favourable equilibrium between accuracy and robustness. Conversely, the Decision Tree model demonstrated indications of overfitting, but Support Vector Regression displayed consistent performance, albeit inferior to that of Ridge and Random Forest. The models’ efficacy was significantly affected by essential usability attributes, such as website loading speed, navigation framework, mobile compatibility, content lucidity, and accessibility criteria. These qualities directly influenced the models’ capacity to forecast usability scores, underscoring their significance in the design and assessment of hospital websites. The incorporation of cross-validation methods like K-Fold markedly enhanced model reliability and mitigated overfitting by validating the models against several data partitions. This improved the overall generalizability of the models when applied to novel data. Furthermore, including user interaction data—such as click behavior, session duration, and bounce rates—demonstrated significant value in improving model performance and relevance by recording real-time user experience metrics. Regional and contextual changes significantly influenced model outputs, suggesting that considerations such as local language support, regional health policy, and demographic-specific design components are essential for evaluating usability. Contextual factors influence user expectations and interaction patterns, necessitating the adaptation of predictive models. The study indicates that incorporating advanced analytical methods, such as deep learning, may enhance forecast accuracy and yield more detailed insights into user behavior. Deep learning models, capable of capturing intricate nonlinear interactions, may provide superior performance for extensive and varied datasets. Rankings of feature importance obtained from the models provide practical information that can assist hospital managers and developers in enhancing website design. By emphasizing high-impact usability features, healthcare organizations can improve patient engagement, accessibility, and satisfaction—essential elements in the contemporary digital healthcare environment. Ultimately, although machine learning models provide considerable benefits in usability evaluation, they still possess limits. This includes sensitivity to data quality, potential bias in training datasets, and difficulties in interpreting intricate model behavior. Future research should focus on creating hybrid frameworks that include interpretability, scalability, and adaptability to changing user requirements. Such frameworks will be crucial for maintaining hospital websites that are user-centric, inclusive, and consistent with the overarching objectives of healthcare digitization. This study offers substantial insights into the application of machine learning algorithms for evaluating the usability of healthcare websites. It additionally offers a foundation for forthcoming research and practical implementations in this domain.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
References
Jamal, A. et al. Association of online health information–seeking behavior and self-care activities among type 2 diabetic patients in Saudi Arabia. J. Med. Internet. Res. 17(8), e4312. https://doi.org/10.2196/jmir.4312 (2015).
Moreno, J. M., del Morales, J. M., Porcel, C. & Herrera-Viedma, E. A quality evaluation methodology for health-related websites based on a 2-tuple fuzzy linguistic approach. Soft. Comput. 14(8), 887–897 (2010).
Amante, D. J., Hogan, T. P., Pagoto, S. L., English, T. M. & Lapane, K. L. Access to care and use of the internet to search for health information: results from the US National health interview survey. J. Med. Internet. Res. 17(4), e106. https://doi.org/10.2196/jmir.4126 (2015).
Ranallo, P. A., Kilbourne, A. M., Whatley, A. S. & Pincus, H. A. Behavioral health information technology: from chaos to clarity. Health Aff. 35(6), 1106–1113. https://doi.org/10.1377/hlthaff.2016.0013 (2016).
Carman, K. L. et al. Patient and family engagement: A framework for Understanding the elements and developing interventions and policies. Health Aff. 32(2), 223–231. https://doi.org/10.1377/hlthaff.2012.1133 (2013).
Lindblad, S. et al. Creating a culture of health: evolving healthcare systems and patient engagement. QJM: Int. J. Med. 110(3), 125–129. https://doi.org/10.1093/qjmed/hcw188 (2017).
Rutter, D., Manley, C., Weaver, T., Crawford, M. J. & Fulop, N. Patients or partners? Case studies of user involvement in the planning and delivery of adult mental health services in London. Soc. Sci. Med. 58(10), 1973–1984. https://doi.org/10.1016/S0277-9536(03)00401-5 (2004).
Cipriano, P. F. et al. The importance of health information technology in care coordination and transitional care. Nurs. Outlook. 61(6), 475–489. https://doi.org/10.1016/j.outlook.2013.10.005 (2013).
Teo, N. B., Paton, P. & Kettlewell, S. Use of an interactive web-based questionnaire to evaluate a breast cancer website. Breast 14(2), 153–156. https://doi.org/10.1016/j.breast.2004.04.009 (2005).
Coulter, A. Patient engagement—What works? J. Ambul. Care Manag. 35(2), 80–89. https://doi.org/10.1097/JAC.0b013e318249e0fd (2012).
Snyder, K., Ornes, L. L. & Paulson, P. Engaging patients through your website. J. Healthc. Qual. 36(2), 33–38. https://doi.org/10.1111/j.1945-1474.2012.00214.x (2014).
Street, R. L. Jr. et al. Provider interaction with the electronic health record: the effects on patient-centered communication in medical encounters. Patient Educ. Couns. 96(3), 315–319. https://doi.org/10.1016/j.pec.2014.05.004 (2014).
Lewis, D., Chang, B. L. & Friedman, C. P. Consumer health informatics. In Consumer Health Informatics: Informing Consumers and Improving Health Care(1–7). Springer New York. (2005).
Ow, D., Wetherell, D., Papa, N., Bolton, D. & Lawrentschuk, N. Patients’ perspectives of accessibility and digital delivery of factual content provided by official medical and surgical specialty society websites: A qualitative assessment. Interact. J. Med. Res. 4(1), e3963. https://doi.org/10.2196/ijmr.3963 (2015).
Schenker, Y. & London, A. J. Risks of imbalanced information on US hospital websites. JAMA Intern. Med. 175(3), 441–443. https://doi.org/10.1001/jamainternmed.2014.7400 (2015).
Huerta, T. R., Walker, D. M. & Ford, E. W. An evaluation and ranking of children’s hospital websites in the united States. J. Med. Internet. Res. 18(8), e5799. https://doi.org/10.2196/jmir.5799 (2016).
Sillence, E., Briggs, P., Harris, P. & Fishwick, L. Health websites that people can trust: the case of hypertension. Interact. Comput. 19(1), 32–42. https://doi.org/10.1016/j.intcom.2006.07.009 (2007).
Keevil, B. Measuring the usability index of your web site. In Proceedings of the 16th Annual International Conference on Computer Documentation, SIGDOC 271–277 (ACM Press, 1998).
Squires, D. & Preece, J. Predicting quality in educational software: evaluating for learning, usability, and the synergy between them. Interact. Comput. 11(5), 467–483 (1999).
International Organization for Standardization. ISO 13407: Human-Centered Design Processes for Interactive Systems(ISO, 1999).
International Organization for Standardization. ISO 9241–11: Ergonomic Requirements for Office Work with Visual Display Terminals (VDTS)-Part 11(Guidance on Usability. ISO, 1998).
Nielsen, J. Usability Engineering.Academic Press Professional (1993).
Hornbaek, K. Current practice in measuring usability: challenges to studies and research. Int. J. Hum. Comput. Stud. 64(2), 79–102 (2006).
Kim, D. & Chang, H. Key functional characteristics in designing and operating health information websites for user satisfaction: an application of the extended technology acceptance model. Int. J. Med. Informatics. 76(11–12), 790–800. https://doi.org/10.1016/j.ijmedinf.2006.09.001 (2007).
Lippitt, C. D. et al. Mapping selective logging in mixed deciduous forest: A comparison of machine learning algorithms. Photogrammetric Eng. Remote Sens. 74(10), 1201–1211 (2008).
Michaud, P. A. & Colom, P. Implementation and evaluation of an internet health site for adolescents in Switzerland. J. Adolesc. Health. 33(4), 287–290. https://doi.org/10.1016/S1054-139X(03)00181-2 (2003).
Mingers, J. An empirical comparison of selection measures for decision-tree induction. Mach. Learn. 3(4), 319–342 (1989).
Bevan, N. Measuring usability as quality of use. Software Qual. J. 4(2), 115–130 (1995).
Bevan, N. Quality in use: meeting user needs for quality. J. Syst. Softw. 49(1), 89–96 (1999).
Juristo, N., Moreno, A. M. & Sánchez-Segura, M. I. Analyzing the impact of usability on software design. J. Syst. Softw. 80(9), 1506–1516 (2007).
Hasan, L. & Abuelrub, E. Assessing the quality of websites. Appl. Comput. Inf. 9(1), 11–29. https://doi.org/10.1016/j.aci.2009.03.001 (2011).
Schneiderman, B. Designing the User Interface: Strategies for Effective Human-Computer Interaction (Addison Wesley, 1998).
Oermann, M. H., Lowery, N. F. & Thornley, J. Evaluation of websites on management of pain in children. Pain Manage. Nurs. 4(3), 99–105. https://doi.org/10.1016/S1524-9042(03)00029-8 (2003).
DePasse, J. W., Chen, C. E., Sawyer, A., Jethwani, K. & Sim, I. Academic medical centers as digital health catalysts. Healthcare 2(3), 173–176. https://doi.org/10.1016/j.hjdsi.2014.05.006 (2014).
Saad, M., Zia, A., Raza, M., Kundi, M. & Haleem, M. A comprehensive analysis of healthcare websites usability features, testing techniques and issues. IEEE Access. https://doi.org/10.1109/ACCESS.2022.3193378 (2022).
Alexiou, V. G. & Falagas, M. E. e-meducation.org: an open access medical education web portal. BMC Med. Educ. 8(1), 1–4 (2008).
Van den Haak, M. & Van Hooijdonk, C. Evaluating consumer health information websites: The importance of collecting observational, user-driven data. In 2010 IEEE International Professional Communication Conference (pp. 333–338). IEEE. (2010)., July https://doi.org/10.1109/IPCC.2010.5530031
Reavley, N. J. & Jorm, A. F. The quality of mental disorder information websites: A review. Patient Educ. Couns. 85(2), e16–e25. https://doi.org/10.1016/j.pec.2010.10.015 (2011).
Duan, L. & Chen, J. A formal approach to website maintenance. In 10th IEEE High Assurance Systems Engineering Symposium (HASE’07) 419–420 (IEEE, 2007).https://doi.org/10.1109/HASE.2007.52
Chadaga, K. et al. Artificial intelligence for diagnosis of mild–moderate COVID-19 using haematological markers. Ann. Med. 55(1). https://doi.org/10.1080/07853890.2023.2233541 (2023).
Nayak, T. et al. Detection of Monkeypox from skin lesion images using deep learning networks and explainable artificial intelligence. Appl. Math. Sci. Eng. 31(1). https://doi.org/10.1080/27690911.2023.2225698 (2023).
Chadaga, S. S., Sampathila, K., Prabhu, N., Chadaga, S. & R., & S, S. K Multiple explainable approaches to predict the risk of stroke using artificial intelligence. Information 14(8), 435. https://doi.org/10.3390/info14080435 (2023).
Gislason, P. O., Benediktsson, J. A. & Sveinsson, J. R. Random forests for land cover classification. Pattern Recognit. Lett. 27(4), 294–300 (2006).
Pal, M. & Mather, P. M. An assessment of the effectiveness of decision tree methods for land cover classification. Remote Sens. Environ. 86(4), 554–565 (2003).
Peters, J. et al. Random forests as a tool for ecohydrological distribution modelling. Ecol. Model. 207(2–4), 304–318 (2007).
Breiman, L. Random forests. Mach. Learn. 45(1), 5–32 (2001).
Guo, L., Chehata, N., Mallet, C. & Boukir, S. Relevance of airborne lidar and multispectral image data for urban scene classification using random forests. ISPRS J. Photogrammetry Remote Sens. 66(1), 56–66 (2011).
Hansen, M., Dubayah, R. & Defries, R. Classification trees: an alternative to traditional land cover classifiers. Int. J. Remote Sens. 17(5), 1075–1081 (1996).
Rodriguez-Galiano, V. F., Ghimire, B., Rogan, J., Chica-Olmo, M. & Rigol-Sánchez, J. P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 67(1), 93–104 (2012).
Breiman, L. Classification and Regression Trees (Chapman & Hall/CRC, 1984).
Friedl, M. A. & Brodley, C. E. Decision tree classification of land cover from remotely sensed data. Remote Sens. Environ. 61(3), 399–409 (1997).
Quinlan, J. R. C4.5: Programs for Machine Learning (Morgan Kaufmann Publishers Inc, 1993).
Rogan, J. et al. Land-cover change monitoring with classification trees using Landsat TM and ancillary data. Photogrammetric Eng. Remote Sens. 69(7), 793–804 (2003).
Wessels, K. J. et al. Mapping regional land cover with MODIS data for biological conservation: examples from the greater Yellowstone ecosystem, USA and Pará State, Brazil. Remote Sens. Environ. 92(1), 67–83 (2004).
Cortes, C. & Vapnik, V. Support-vector networks. Mach. Learn. 20(3), 273–297 (1995).
Vapnik, V. N. & Chervonenkis, A. Y. A note on one class of perceptrons. Autom. Remote Control, 25(1). (1964).
Hastie, T., Tibshirani, R. & Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction (Springer, 2009).
Hoerl, A. E. & Kennard, R. W. Ridge regression: biased Estimation for nonorthogonal problems. Technometrics 12(1), 55–67 (1970).
Author information
Authors and Affiliations
Contributions
Amandeep Kaur wrote the main manuscript text .Jaswinder Singh reviewed the methodolgy.Satinder Kaur supervised the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A
Appendix A
Code | Website URL |
|---|---|
HW1 | |
HW2 | |
HW3 | |
HW4 | |
HW5 | |
HW6 | |
HW7 | |
HW8 | |
HW9 | |
HW10 | |
HW11 | |
HW12 | |
HW13 | |
HW14 | |
HW15 | |
HW16 | |
HW17 | |
HW18 | |
HW19 | |
HW20 | |
HW21 | |
HW22 | |
HW23 | |
HW24 | |
HW25 | |
HW26 | |
HW27 | |
HW28 | |
HW29 | |
HW30 | |
HW31 | |
HW32 | |
HW33 | |
HW34 | |
HW35 | |
HW36 | |
HW37 | |
HW38 | |
HW39 | |
HW40 | |
HW41 | |
HW42 | |
HW43 | |
HW44 | |
HW45 | |
HW46 | |
HW47 | ttps://www.aafp.org |
HW48 | |
HW49 | |
HW50 | |
HW51 | |
HW52 | |
HW53 | |
HW54 | |
HW55 | |
HW56 | |
HW57 | |
HW58 | |
HW59 | |
HW60 | |
HW61 | |
HW62 | |
HW63 | |
HW64 | |
HW65 | |
HW66 | |
HW67 | |
HW68 | |
HW69 | |
HW70 | |
HW71 | |
HW72 | |
HW73 | |
HW74 | |
HW75 | |
HW76 | |
HW77 | |
HW78 | |
HW79 | |
HW80 | |
HW81 | |
HW82 | |
HW83 | |
HW84 | |
HW85 | |
HW86 | |
HW87 | |
HW88 | |
HW89 | |
HW90 | |
HW91 | |
HW92 | |
HW93 | |
HW94 | |
HW95 | |
HW96 | |
HW97 | |
HW98 | |
HW99 | |
HW100 |
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Kaur, A., Singh, J. & Kaur, S. Machine learning approach for optimizing usability of healthcare websites. Sci Rep 15, 14450 (2025). https://doi.org/10.1038/s41598-025-99449-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-99449-z
Keywords
This article is cited by
-
Hybrid generative–ensemble approach for predicting recycled aggregate concrete strength properties
Scientific Reports (2026)
