
Abstract
In contemporary society, electricity is a critical resource integral to national economies and public welfare, making the safe and stable operation of high-voltage transmission lines paramount. These lines are susceptible to various hazards, including floating objects (e.g., balloons and kites), bird nests, debris, and other foreign objects that may attach to or hang from power lines or towers. Such objects pose significant safety risks by potentially disrupting the normal functioning of the power system. Leveraging the advances in deep learning and computer vision, object detection models such as YOLO have been widely employed in power-grid inspections. However, traditional models often struggle to balance low-frequency background information (e.g., sky, grass) with high-frequency salient structures (e.g., power lines, towers), leading to suboptimal detection accuracy and robustness for small, low-contrast foreign objects. This paper presents an enhanced YOLOv11 detector tailored for high-voltage transmission line environments. First, we integrate a Wavelet-Transform Convolution (WTConv) block into the backbone to decompose features into multi-frequency sub-bands, apply lightweight depth-wise convolution in the wavelet domain, and reconstruct them losslessly, thereby enlarging the effective receptive field while preserving fine structural details. Second, we develop a Progressive Feature Pyramid Network (PFPN) that performs two-stage top-down / bottom-up refinement and employs adaptive spatial fusion to alleviate semantic inconsistency and cross-scale conflicts in cluttered corridor scenes. Third, we introduce an Inner-EIoU loss that focuses regression on the inner region of ground-truth boxes, improving localisation of tiny and low-contrast targets. Extensive experiments on our Transmission-Line Foreign-Object (TLFO) dataset demonstrate the effectiveness of the proposed design. Compared with the YOLOv11 baseline, the improved detector raises mAP₀.₅ from 0.841 to 0.872 and mAP₀.₅:₀.₉₅ from 0.620 to 0.640, increases Precision from 0.918 to 0.962, reduces parameters from 5.97 M to 4.83 M, and boosts inference speed from 24.1 FPS to 28.5 FPS at 1280 × 768 resolution. Additional experiments on MS COCO val2017 show that the proposed modules are not overfitted to the power-grid domain, yielding a + 1.6 point improvement in mAP₀.₅:₀.₉₅ over the YOLOv11 baseline. These results indicate that the combination of WTConv, PFPN, and Inner-EIoU provides a practical, real-time solution for foreign-object detection in power-grid inspection scenarios.
Similar content being viewed by others

Introduction
In modern society, electricity serves as the backbone of both economic development and social infrastructure, making the safe and stable operation of high-voltage power transmission lines essential to ensuring uninterrupted power delivery1. Foreign objects such as balloons, kites, bird nests, or debris suspended on or near transmission towers and lines can trigger abnormal electrical discharges, equipment failures, or even large-scale outages2. Hence, effective and intelligent monitoring solutions are imperative for maintaining the cleanliness and safety of high-voltage transmission corridors.
With the rapid advancement of deep learning and computer vision, automated inspection systems based on object detection algorithms have become increasingly prevalent in power grid maintenance. The YOLO family has emerged as a dominant solution due to its high detection speed and accuracy. Nevertheless, applying these models in transmission line scenarios is non-trivial: the environment often contains complex combinations of low-frequency elements (e.g., sky, vegetation) and high-frequency components (e.g., wires, towers), while the target objects are typically small, irregularly shaped, and low in contrast. These factors hinder detection robustness and diminish precision, especially in cluttered aerial imagery1,3,4.
In response to these challenges, various YOLO-based enhancements have recently been proposed to address small object detection and complex environments. For example, Shao et al.2 introduced dynamic convolution and multiscale attention modules, improving foreign-object detection accuracy on transmission lines; Luan et al.5 integrated pyramid dilated convolutions and parallel attention mechanisms into YOLOv5 for improved insulator defect recognition; Shi et al.6 developed I-YOLO with progressive feature pyramids and spatial fusion to mitigate semantic conflicts in multiscale aggregation; and Doherty et al.3 proposed BiFPN-YOLO featuring a bidirectional pyramid fusion structure to handle scale variance more effectively.
In addition, numerous studies aim to balance lightweight design with high accuracy. For instance, SOD-YOLO4 excels in small-scale or UAV-based scenarios, while NLE-YOLO7, SED-YOLO8, and SMA-YOLO9 exhibit notable performance in low-light, small-object, and multi-scale detection tasks, respectively. Moreover, PARGT10 employs wavelet transforms to preserve high-frequency details, offering new insights for vision networks. Wavelet-assisted detectors have recently attracted renewed interest: Wu et al.11 plug a wavelet pooling layer into YOLOv8 but treat it as a fixed pre-processor, and Zhang et al.12 propose a dual-path FPN to mitigate scale variance at the cost of heavy channel concatenations.
Concurrently, researchers have integrated wavelet transforms with convolutional networks across diverse applications: PRINZI et al.13 applied this idea to breast cancer detection, GÜNDÜZ and IŞIK14 refined YOLO for real-time crowd detection, LIN et al.15 introduced YOLO-DA for remote sensing object detection, and QIU and LAU16 deployed YOLO for sidewalk crack detection in UAV imagery. Wavelet-based representations have also proven effective in machinery fault diagnosis17, skin cancer detection18, large-receptive-field convolutions19, and endoscopic image diagnosis20.
In terms of Feature Pyramid Network (FPN) enhancements, YANG et al.21 proposed AFPN, enabling direct interaction between non-adjacent feature layers and substantially alleviating semantic conflicts in multi-scale feature fusion. GAO et al.22 developed AWBiFPN to improve feature integration efficiency for underwater target detection, while CHEN et al.23 boosted small-object detection accuracy by enhancing multi-scale semantic information. These works demonstrate the benefit of more flexible feature pyramids but generally focus on generic detection benchmarks rather than the specific challenges of power-grid inspection.
In recent years, numerous studies have extended progressive feature pyramid frameworks to enhance multi-scale feature fusion and semantic consistency. Representative methods include CFPN24, DyFPN25, SEFPN26, and PS-Net27, which strengthen cross-layer interaction, introduce dynamic fusion branches, and equalize semantics across pyramid levels, thereby improving small-object and boundary-aware detection.
Further adaptive and scale-aware variants, such as AFPN28, SAFPN29, EFPN30, and SSFPN31, employ attention-guided fusion, scale-adaptive weighting, additional high-resolution levels, and selective spatial receptive fields to better preserve fine-grained details and handle complex scale distributions. Overall, these progressive, adaptive, and attention-enhanced FPN architectures significantly improve multi-scale feature representation and provide a solid methodological basis for designing high-performance detectors in power transmission line inspection and other real-world visual monitoring tasks.
Despite the above progress, three gaps remain for foreign-object detection on high-voltage transmission lines:
-
(i)
Limited exploitation of frequency information in corridor scenes. Most existing YOLO-based detectors operate purely in the spatial domain, making it difficult to simultaneously preserve smooth low-frequency context (sky, vegetation) and thin high-frequency structures (conductors, insulator strings, slender foreign objects). As a result, either the background is over-smoothed or small, elongated targets are blurred out.
-
(ii)
Insufficiently consistent multi-scale fusion for tiny and overlapping targets. Standard FPN/PAN necks propagate semantics from deep to shallow layers in a single pass. In cluttered corridors where balloons, kites, or bird nests overlap with towers and cables at different scales, this can lead to semantic conflicts across feature maps and unstable predictions for tiny or partially occluded objects.
-
(iii)
Lack of domain-specific, lightweight designs for edge deployment in power-grid inspection. Many recent detectors emphasise accuracy on generic benchmarks but rely on heavy backbones and complex necks that are difficult to deploy on UAVs or edge devices used in grid patrol. Moreover, only a few works systematically evaluate such models on large-scale foreign-object datasets collected from real transmission-line corridors.
These limitations motivate us to develop a frequency-aware backbone, a progressive feature pyramid, and an improved localisation loss tailored to the characteristics of transmission-line imagery, while preserving a favourable real-time performance on practical edge hardware. Our main contributions are three-fold, each explicitly targeting one of the above gaps:
-
(1)
Frequency-aware backbone for cluttered corridor scenes. To address the difficulty of jointly modelling smooth backgrounds and thin, high-contrast structures, we introduce a Wavelet-Transform Convolution (WTConv) block that decomposes features into low- and high-frequency sub-bands, applies lightweight depth-wise convolution in the wavelet domain, and reconstructs them losslessly. This design enlarges the effective receptive field while selectively enhancing edges and suppressing low-frequency noise, which is crucial for elongated foreign objects attached to lines.
-
(2)
Progressive feature pyramid for tiny and overlapping foreign objects. To mitigate semantic inconsistency across scales, we design a Progressive Feature Pyramid Network (PFPN) that performs a two-stage top-down / bottom-up refinement and integrates an adaptive spatial fusion module. This progressively aligns semantics between high- and low-level features and mitigates cross-scale conflicts at locations where multiple small foreign objects overlap with towers and conductors.
-
(3)
Domain-specific detector with improved loss and a favorable accuracy–efficiency trade-off. By integrating WTConv, PFPN, and an Inner-EIoU loss into YOLOv11 and tailoring the training protocol to our Transmission-Line Foreign-Object (TLFO) dataset, we obtain a detector that improves mAP0.5:0.95 by 2.0% points and Precision by 4.4 points over the YOLOv11 baseline, while reducing parameters by about 19% and maintaining real-time inference at 28.5 FPS on 1280 × 768 images. Additional experiments on MS COCO further show that the proposed modules generalize beyond the power-grid domain, yielding a + 1.6 point gain in mAP0.5:0.95 on COCO val2017.
YOLOv11 model
Baseline detector: YOLOv11 in brief
YOLOv11 follows the one-stage, fully convolutional paradigm established by the YOLO family. The network is split into three logical blocks – Backbone, Neck, and Head – whose designs are inherited almost unchanged from the official YOLOv11 release. The overall network structure is illustrated in Fig. 1.
-
Backbone. A Cross-Stage-Partial (CSP) stack with re-parameterisable C3K2 units extracts hierarchical features while keeping the parameter count low (≈ 6 M).
-
Neck. A lightweight Feature-Pyramid-Plus-Path-Aggregation (FPN + PAN) structure fuses the {C3, C4, C5} feature maps into three resolution levels, enabling robust multi-scale prediction.
-
Head. Three parallel, decoupled branches perform objectness scoring, class probability estimation, and bounding-box regression on each fused feature map.
This off-the-shelf baseline already strikes a good speed/accuracy balance, running at 24 FPS on 1080 p images. All ensuing sections therefore focus exclusively on our additions – Wavelet-Transform Convolution (WTConv) in the Backbone and the Progressive Feature-Pyramid Network (PFPN) in the Neck – while the untouched YOLOv11 components are referred to the original paper for architectural and hyper-parameter details.

YOLOv11 network structure.
Challenges of YOLOv11 in power grid scenarios
Although YOLOv11 performs excellently in general object detection tasks, it still faces several challenges in high-voltage line application scenarios. First, power grid inspection images contain both low-frequency and high-frequency information, such as significant differences in the features of the sky, grass, towers, and power lines, which makes it difficult for existing convolution methods to simultaneously handle the extraction of multiple features. Second, foreign objects on high-voltage lines are often small in size or have diverse shapes, and they are frequently overlapped with towers and cables, leading to detection difficulties due to the distribution and scale variation of multiple targets. Additionally, the abnormal posture of foreign objects and interference from complex backgrounds also increase the risks of missed detections and false positives. These issues require the model to possess stronger feature extraction and fusion capabilities while maintaining high detection accuracy, in order to meet the specific demands of power grid inspection.
Methodology
To address the aforementioned challenges, this paper proposes improvements to the YOLOv11 model, mainly introducing wavelet transform-based convolution layers (WTConv) in the Backbone stage and employing a Progressive Feature Pyramid Network (PFPN) in the Neck part to enhance feature fusion capabilities. The wavelet transform-based convolution layer can decompose and process feature information across different frequency domains, improving the model’s ability to recognize complex backgrounds and small objects. The Progressive Feature Pyramid Network, on the other hand, fuses features from adjacent layers step by step, reducing the semantic gap between high- and low-level features, further enhancing the multi-scale feature fusion effect.
Wavelet transform convolution (WTConv)
In transmission-line imagery, most pixels belong to large, slowly varying regions such as sky, vegetation, and ground, while safety-critical structures (conductors, insulator strings, foreign objects) appear as thin, high-frequency patterns. Conventional convolutions treat all frequencies uniformly: enlarging the receptive field by using bigger kernels or deeper stacks quickly increases parameters and FLOPs, which is undesirable for edge deployment on UAVs or inspection terminals. Moreover, when spatial filters are optimised only in the image domain, the network may over-smooth backgrounds or, conversely, miss small elongated targets due to insufficient emphasis on high-frequency details. A discrete wavelet transform naturally decomposes features into low-frequency components capturing global layout and high-frequency components capturing edges and textures. By inserting a reversible wavelet transform inside the backbone, WTConv allows us to process these bands separately, preserving corridor context in the low-frequency branch while explicitly enhancing line structures and foreign objects in the high-frequency branch, without resorting to heavy large-kernel convolutions.
Wavelet transform splits an image (or feature map) into two parts: a low-frequency band that keeps the overall layout and a high-frequency band that holds edges and textures. Low-frequency cues help recognise large, smooth regions (sky, grass), while high-frequency cues highlight fine structures (power-line wires, tower edges).
A straightforward way to enlarge a receptive field is to use bigger kernels, but this explodes parameters and FLOPs. WTConv circumvents the problem: it first down-samples features via a wavelet transform, then applies small kernels in the wavelet domain, and finally restores the resolution by an inverse transform.
We adopt the 2-D Haar basis for its speed and simplicity. The forward transform is equivalent to four depth-wise 2 × 2 filters that yield four sub-bands: LL (approximation), LH, HL, and HH (details). Stride = 2 implicitly halves height and width.
Specifically, let the input image (or feature map) be denoted as \(\:\varvec{X}\). The output of a single 2D Haar wavelet transform consists of four subbands: the low-frequency component \(\:{X}_{LL}\) and high-frequency components in the horizontal (\(\:{X}_{LH}\)), vertical (\(\:{X}_{HL}\)), and diagonal (\(\:{X}_{HH}\)) directions. This process can be represented as:
where \(\:{f}_{LL}\) is the low-pass filter kernel, and \(\:{f}_{LH},{f}_{HL},{f}_{HH}\) extract high-frequency information in the horizontal, vertical, and diagonal directions, respectively.
To revert to the original resolution we run an inverse wavelet transform (IWT)—implemented as four depth-wise transpose-convolutions that are the exact inverse of the forward filters—so the process is loss-free.
Because the Haar wavelet kernels are orthogonal and normalized, the forward and inverse transformations correspond to each other, allowing for the lossless reconstruction of the original information. This provides a reversible foundation for subsequent processing of low-frequency and high-frequency components in the frequency domain.
WTConv proceeds in three steps: (1) Decompose: apply WT to split the input into four sub-bands at half resolution; (2) Convolve: run light 3 × 3 depth-wise kernels on each sub-band (small kernels now ‘see’ a larger area in the original image); (3) Reconstruct: apply IWT to fuse the processed sub-bands back to full resolution. Formally, \(\:\varvec{O}\varvec{u}\varvec{t}\varvec{p}\varvec{u}\varvec{t}=\varvec{I}\varvec{W}\varvec{T}\left(\varvec{C}\varvec{o}\varvec{n}\varvec{v}\left(\varvec{W},\varvec{W}\varvec{T}\left(\varvec{I}\varvec{n}\varvec{p}\varvec{u}\varvec{t}\right)\right)\right)\).
where X is the input feature map, WT and IWT represent the forward and inverse wavelet transforms, and W is the convolution weight matrix for the multiple subbands (low-frequency + three high-frequency bands). Compared with brute-force large kernels, WTConv cuts parameters by ≈ 70% while increasing the effective receptive field. Moreover, because low- and high-frequency bands are processed separately, the network can selectively boost sharp edges and suppress low-frequency noise.

Visualization of wavelet convolution application.
Figure 2 shows a visualization of the wavelet convolution process. First, the input image undergoes wavelet transformation, followed by convolution on the resulting feature map, and then an inverse transformation is applied. Simultaneously, a direct convolution is applied to the input image, and the results from both operations are added to produce the output feature map.
Progressive feature pyramid network (PFPN)
On the TLFO dataset, foreign objects around transmission lines are typically small, elongated, and often overlap with larger infrastructure elements such as towers and conductors. For example, kites or ribbons may lie across wires, and bird nests are attached to tower arms. In such cases, reliable detection requires the network to jointly exploit fine-grained local details and high-level corridor context. Standard FPN/PAN necks mainly propagate semantics from deep to shallow layers in a single top-down or bidirectional pass, which can leave shallow features under-informed and cause inconsistent responses across scales, especially for tiny or partially occluded targets near complex backgrounds. Furthermore, naive cross-scale fusion may amplify conflicts at locations where multiple objects of different sizes coexist. To address these issues, we design a progressive feature pyramid that performs a two-stage top-down / bottom-up refinement and incorporates adaptive spatial fusion, so that high- and low-level features are aligned more consistently and the network can focus on small, overlapping foreign objects across all scales.
As shown in Fig. 3, the proposed Progressive Feature-Pyramid Network (PFPN) performs two sequential fusion passes (top-down and bottom-up).To reduce the semantic gap between low- and high-level features while preventing information loss, we extend the classic FPN into an ProgressiveFPN. The key idea is a two-stage iterative fusion: (1) a top-down (TD) pass identical to FPN, and (2) a bottom-up (BU) reinforcement pass that re-propagates the fused maps upward. This progressive strategy yields richer, more consistent multi-scale features at only ~ 5% extra FLOPs in our YOLOv11 backbone.
In this paper semantic information refers to the category-level cues encoded in each channel of a feature map—i.e. the per-channel activation response that correlates with object class membership.
Let \(\:{\varvec{p}}^{l}\in\:{\mathbb{R}}^{C}\)be the class-probability vector produced by a \(\:1\times\:1\) conv-softmax probe on the feature map of level \(\:l\) (stride \(\:{2}^{l+1}\), \(\:l\in\:\text{2,3},\text{4,5}\)). We define the Layer Semantic Consistency (LSC) between two levels \(\:i\) and \(\:j\) as the cosine similarity.
The semantic gap between non-adjacent levels is then
.
where a smaller \(\:{{\Delta\:}}_{\text{sem}}\) indicates better semantic alignment.
Our PFPN is explicitly optimised to minimise \(\:{{\Delta\:}}_{\text{sem}}\) through the two-stage top-down/bottom-up refinement and the adaptive spatial fusion weights.
Multi-level feature extraction
Similar to conventional feature pyramid networks, PFPN first extracts multi-scale feature maps from the backbone network. For YOLO series detectors, features from the {C2, C3, C4, C5} layers are typically fed into the FPN, producing multi-scale features {P2, P3, P4, P5}.
Feature maps {C2, C3, C4, C5} therefore flow twice—first through the TD stage, then, after fusion, back through the BU stage—while keeping identical spatial resolutions across passes.
In the implementation of PFPN, low-level features (C2 or C3) are input first, and are progressively fused with higher-level features. For instance, in a four-layer feature scenario, C2 and C3 are fused first, followed by the incorporation of C4 into the fused result, and finally adding C5. This step-by-step fusion ensures that multi-level features transition smoothly from low to high levels, producing the new pyramid feature set {P2, P3, P4, P5}.
To achieve scale alignment, 1 × 1 convolution and bilinear interpolation are used during the upsampling phase to match the dimensions, while downsampling is carried out using convolution kernels with corresponding strides. For example, a 2 × 2 convolution (stride = 2) performs 2x downsampling, while a 4 × 4 convolution (stride = 4) performs 4x downsampling, and so on.
Two-stage progressive architecture
Let {P2, P3, P4, P5}_TD denote the outputs of the Top-Down pass and {P2, P3, P4, P5}_BU those of the Bottom-Up pass. They are computed as:
Upsample uses bilinear interpolation (×2); Downsample uses a stride-2 3 × 3 convolution. The final {P2, P3, P4, P5}_BU feed the Detection Head.
After scale alignment and fusion, PFPN also adds several residual units at the output end to further learn the fused feature representations. Each residual unit consists of two 3 × 3 convolutions, similar to the standard ResNet structure. Because information now flows TD → BU instead of strictly TD, each location in P_l_BU aggregates context from all other scales twice, reducing inter-scale aliasing.

Progressive fusion.
Adaptive spatial fusion
The Adaptive Spatial Fusion (ASF) module, depicted in Fig. 4, resolves channel conflicts that arise after the two-stage fusion. Therefore, we introduce the Adaptive Spatial Fusion (ASF) module, inspired by ASFF, to learn per-pixel scale weights. When fusing features from different layers, if multiple objects exist at the same spatial location or there are background conflicts, the features from different layers may contradict or interfere with each other. To solve this issue, PFPN draws on the ASFF (Adaptive Spatial Feature Fusion) method and assigns adaptive spatial weights to multi-layer features at the same position. This allows the network to automatically evaluate and emphasize key features during fusion while suppressing inconsistent or redundant information.
Specifically, let’s assume that three scale feature maps \(\:\{{x}_{1\to\:l},{x}_{2\to\:l},{x}_{3\to\:l}\}\) need to be fused at a particular stage. The feature vectors at position \(\:\left(i,j\right)\) of these layers are denoted as \(\:\{{x}_{1\to\:l}^{ij},{x}_{2\to\:l}^{ij},{x}_{3\to\:l}^{ij}\}\). The fused output feature vector\(\:\:{y}_{l}^{ij}\) at position \(\:\left(i,j\right)\) can be expressed as:
where \(\:{{\upalpha\:}}_{l}^{ij}+{{\upbeta\:}}_{l}^{ij}+{{\upgamma\:}}_{l}^{ij}=1\), and \(\:{{\upalpha\:}}_{l}^{ij}\), \(\:{{\upbeta\:}}_{l}^{ij}\) and \(\:{{\upgamma\:}}_{l}^{ij}\) represent the spatial weights of the three layers’ features at position \(\:\left(i,j\right)\). By introducing this adaptive spatial weighting, PFPN can alleviate the information conflicts caused by multi-targets or complex backgrounds during fusion, thereby preserving more useful semantics and details. Depending on the number of feature layers at each fusion stage, the corresponding number of adaptive spatial fusion modules is configured.
In summary, through progressive multi-layer feature fusion and adaptive spatial fusion, PFPN effectively balances the information differences between high- and low-level features in the network’s Neck part. This design not only better coordinates shallow details with deep semantics but also suppresses interference between different objects in multi-target scenarios, providing more stable and richer feature representations for subsequent prediction branches.

ASF fusion.
Inner-EIoU loss
To further stabilise bounding-box regression—especially for the small, elongated objects that dominate power-grid imagery—we extend the recently proposed Extended IoU (EIoU) loss with an inner-box consistency term, obtaining the Inner-EIoU loss (IEIoU).
The intuition is simple: localisation quality depends not only on the overlap of full boxes but also on whether their core regions coincide. By explicitly maximising the IoU of shrunken “inner boxes”, we encourage predictions whose central area aligns tightly with the ground truth, even when the outer border is ambiguous or partially occluded.
Throughout this paper we measure box overlap with the standard Intersection-over-Union (IoU) metric, defined as the ratio between the intersection area and the union area of the predicted and ground-truth boxes. A perfect match yields an IoU of 1, while non-overlapping boxes give 0.
Symbol | Definition |
|---|---|
\(IoU\) | Standard intersection-over-union between predicted and ground-truth boxes. |
\(\rho ^{2} \left( {b_{{ctr}} ,b_{{gt}} } \right)\) | Squared Euclidean distance between box centres. |
\(\:c\) | Length of the diagonal of the minimal enclosing rectangle covering both boxes (normalises the centre term). |
\(\:w,h\) | Width and height of the predicted box. |
\(\:{w}_{\text{gt}},{h}_{\text{gt}}\) | Width and height of the ground-truth box. |
\(\:{w}_{\text{enc}},{h}_{\text{enc}}\) | Width and height of the same minimal enclosing rectangle (normalise the size terms). |
\(\:Io{U}_{\text{inner}}\) | IoU of the inner boxes, obtained by uniformly shrinking both boxes to 50% of their original width and height around their centres. |
\(\:{\uplambda\:}\) | Balancing factor, set to 0.20.2 via grid search on the validation split. |
The first four terms reproduce EIoU’s centre-alignment and aspect-ratio penalties; the final bonus term \(\:-\hspace{0.33em}\lambda\:{IoU}_{\text{inner}}\) gives extra credit for central overlap.
Overall structure
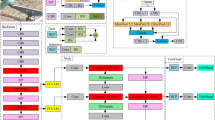
In the previous sections, the designs and implementations of the wavelet transform-based convolution layer (WTConv) and the Progressive Feature Pyramid Network (PFPN) were introduced. To fully leverage these two components, they are integrated into the overall YOLOv11 architecture as shown in Fig. 5. On the left, P0–P5 denote the six backbone stages, where a larger index corresponds to a deeper layer with lower spatial resolution produced by strided convolutions or pooling; F0–F10 indicate the feature maps output at each of these stages. In the neck and detection head, feature maps operating at the same spatial resolution are arranged on the same horizontal line, so the four detection heads P2–P5 correspond to four pyramid levels with progressively decreasing resolution. Different colors in the diagram represent different functional modules (standard convolutional blocks, WTConv blocks, ASF/PFPN fusion blocks, and detection heads). The prefix “P” always refers to the resolution level, whereas “FN” indexes the feature map obtained after a specific module. The shaded rectangular boxes with labels such as {F4, F13, F14} are introduced solely for visual clarity: they list the feature maps that are first concatenated along the channel dimension at the corresponding resolution level and then fed into the subsequent ASF and WTConv blocks, thereby avoiding clutter caused by overlapping connection lines.

Overall Architecture of the proposed framework.
Overall architecture
The Backbone is responsible for extracting multi-level feature maps from the input image and embeds WTConv in key layers to enhance the model’s ability to capture both low-frequency and high-frequency information. The wavelet transform-based convolution layer decomposes the feature maps into subbands of different frequencies using wavelet transform, then performs convolution operations in the wavelet domain, and finally recovers the feature map via inverse wavelet transform. This process not only increases the receptive field but also effectively reduces the number of parameters and computational complexity.
The Progressive Feature Pyramid Network (PFPN) adopts a step-by-step progressive approach to fuse multi-level features during the feature fusion phase. By progressively fusing features from adjacent layers, it reduces the semantic gap between different layers and utilizes the Adaptive Spatial Feature Fusion (ASFF) mechanism to optimize the fusion of multi-layer features. The Detection Head then uses the fused multi-scale features to predict object classification and localization. This approach maintains the high-efficiency design of YOLOv11, ensuring the model’s advantage in real-time performance.
Advantage analysis
Integrating WTConv and PFPN into the YOLOv11 architecture brings multiple advantages. Firstly, frequency-domain decomposition and convolution allow the model to process feature information separately in two distinct frequency domains: the low-frequency part primarily contains background information, such as the sky and grass, while the high-frequency part includes detailed features such as power lines and towers. This frequency-domain decomposition enables the model to more effectively capture and distinguish objects in complex backgrounds, enhancing detection accuracy and robustness. Additionally, PFPN gradually fuses adjacent layers’ features, narrowing the semantic gap and generating more consistent and representative multi-scale feature maps. This is particularly important for detecting multiple and small objects in high-voltage transmission line scenarios.
Secondly, WTConv effectively enlarges the receptive field by performing convolutions in the wavelet domain, enabling the model to capture target information over a larger area. This is especially beneficial for tasks that require global information, such as high-voltage transmission line detection. By combining wavelet convolution with PFPN, the model can simultaneously utilize low-frequency background information and high-frequency target information, achieving comprehensive detection of features across various scales and frequencies. This significantly improves the detection rate and accuracy of small objects (e.g., balloons, kites).
In terms of computational efficiency and parameter optimization, WTConv reduces the model’s parameter count and computational load by using smaller convolution kernels in the wavelet domain, while maintaining or even enhancing feature extraction performance. This is crucial for resource-constrained edge devices or real-time applications. PFPN employs a progressive feature fusion strategy, avoiding the issues of information mixing that can arise from direct cross-layer fusion. Additionally, it optimizes the integration of multi-layer features through an adaptive spatial fusion mechanism, ensuring efficient and high-quality feature fusion.
Finally, as independent modules, WTConv and PFPN are highly versatile and scalable, allowing for flexible integration into other object detection frameworks. Although this study uses the Haar wavelet basis, the design of WTConv allows for the use of other types of wavelet bases, which can be adapted to meet different application requirements and scenarios, even though this may introduce additional computational overhead.
Summary
In summary, the overall structure proposed in this paper significantly enhances the YOLOv11 model’s performance in detecting foreign objects around high-voltage transmission lines by integrating wavelet transform-based convolution layers (WTConv) and the Progressive Feature Pyramid Network (PFPN). The specific advantages include improved feature representation, a larger receptive field, optimized parameter count and computational efficiency, as well as excellent flexibility and scalability. These improvements enable the model to efficiently and accurately detect various potential safety hazards in complex backgrounds, providing more reliable and intelligent technical support for power grid inspections.
Experiments
Dataset: power grid foreign object dataset
To evaluate the proposed detector in realistic inspection scenarios, we construct a Power Grid Foreign Object dataset, referred to as the Transmission-Line Foreign-Object (TLFO) dataset. The raw corpus consists of approximately 3,700 images collected during routine inspections of multiple high-voltage transmission corridors operated by a regional power utility. The main source of diversity in the dataset lies in the inspected scenes: different line sections pass through residential areas, industrial belts, open countryside, riversides, and hilly or forested regions, leading to substantial variation in background layout, corridor width, and surrounding objects.
Four types of foreign objects are annotated, corresponding to typical hazards in transmission-line inspection: garbage (e.g., plastic bags, cloth strips), balloons, bird nests, and kites. The numbers of instances in these four categories are roughly balanced, so that no single class dominates the dataset. Transmission towers, insulators, and conductors are treated as background structures and are not defined as explicit detection categories.
All images are manually annotated with axis-aligned bounding boxes and class labels by trained inspection staff. Very small instances whose shorter side is less than 8 pixels are ignored to reduce annotation noise, and ambiguous regions (e.g., objects heavily occluded by vegetation) are marked and excluded from the training set. Images were acquired under normal inspection conditions with moderate variation in illumination and viewing angle; no extreme weather events (such as heavy rainstorms or dense fog) are included.
Starting from the 3,700 original images, we apply simple offline geometric augmentation, mainly in-plane rotations (± 90°/180°) and horizontal flipping, to increase the variety of line orientations and camera attitudes without changing the underlying scenes. This produces about 1,000 additional images. The final TLFO dataset therefore comprises 4,700 images in total. We split them into training, validation, and test sets using a 60%/20%/20% ratio, ensuring that augmented images remain in the training split and that no augmented copies of the same scene appear in the validation or test sets.
Representative examples from the TLFO dataset are shown in Fig. 6, where each subimage corresponds to a different transmission-line scene (e.g., residential corridor, industrial corridor, rural corridor, riverside section). The coloured bounding boxes indicate the four foreign-object categories (garbage, balloon, bird nest, kite). These examples illustrate that the main challenges of the dataset arise from scene changes along different corridors and the resulting variation in background clutter, object size, and contrast.

Representative images from the TLFO dataset. Each subimage shows a different transmission-line scene (e.g., residential, industrial, rural, riverside), with coloured bounding boxes marking four typical foreign objects: nests, kites, balloons, and trash. The dataset mainly varies in corridor scenes and background layouts, while weather and viewing angles change only moderately.
Experimental setup and evaluation metrics
All frequency-domain operations are carried out with a two-dimensional Daubechies-4 (db4) wavelet. A two-level discrete wavelet transform (DWT) is applied to every incoming feature map. After the second level we retain the four sub-bands \(\:\left\{L{L}_{2},\:L{H}_{2},\:H{L}_{2},\:H{H}_{2}\right\}\) and discard first-level bands to limit memory usage. Each sub-band is processed by its own 3 × 3 depth-wise kernel (weights are not shared across bands), after which an exact inverse DWT, implemented with the db4 synthesis filters followed by 2×bilinear up-sampling, restores the original resolution. A custom CUDA kernel makes the forward–inverse pair essentially cost-free, adding only 1.1 µs per 128 × 192 feature map on an RTX 4090.
All experiments are conducted in PyTorch 2.1.1 with CUDA 11.8 and cuDNN 8.9, running on a single NVIDIA RTX 4090 (24 GB). Images are resized and centre-cropped to 1280 × 768pixels and linearly rescaled to [0,1]. We employ heavy data augmentation—horizontal flip (probability 0.5), Mosaic (1.0), MixUp (0.2), HSV jitter (± 0.015,±0.7,±0.4), and RandomAffine (scale 0.5–1.5, translate ± 0.1, rotate ± 10∘).
Optimisation uses Adam with\(\:{\beta\:}_{1}=0.9\),\(\:{\beta\:}_{2}=0.999\) and weight decay \(\:5\times\:1{0}^{-4}\). The learning rate is linearly warmed up from \(\:1\times\:1{0}^{-6}\)to\(\:1\times\:1{0}^{-3}\)over the first five epochs, then decays by a factor of 0.1 at epochs 200 and 250. Training runs for 300 epochs with a physical batch size of 16; gradients are accumulated for eight optimiser steps, giving an effective batch size of 128. Losses mirror the YOLO paradigm: objectness (binary-cross-entropy), class probability (BCE with 0.1 label smoothing), and bounding-box regression (Inner-EIoU; see § 2.3). An anchor is deemed positive if its IoU with a ground-truth box is at least 0.5 and ignored if 0.4 ≤ IoU < 0.5.
Detection accuracy is reported as \(\:mA{P}_{0.5}\)and\(\:mA{P}_{0.5:0.95}\)together with \(\:A{P}_{small}\), \(\:A{P}_{medium}\)and \(\:A{P}_{l{arg}e}\), following the COCO protocol. We also provide mean Precision and Recall at IoU 0.5. Inference speed is measured in frames per second (FPS) with FP32 arithmetic on the RTX 4090, batch size 1, after discarding the first 100 images as warm-up. Model complexity is quantified by parameter count and FLOPs, computed with the thop profiler at an input resolution of 1280 × 768. Evaluation scripts reproducing every number in Tables 2, 3 and 4 are included in the supplementary repository.
Experimental results and comparison with YOLOv11
We first compare the proposed detector with the original YOLOv11 on the TLFO dataset under identical training settings described in § 3.2. The quantitative results are summarised in Table 1 and visualised in Fig. 7.
As shown in Table 1, the improved YOLOv11 consistently outperforms the baseline across all evaluation metrics. Precision increases from 0.918 to 0.962, indicating a substantial reduction in false positives, while Recall improves from 0.792 to 0.810, reflecting fewer missed detections of foreign objects. In terms of COCO-style metrics, mAP_{0.5} is improved from 0.841 to 0.872 (+ 3.1% points), and mAP_{0.5:0.95} increases from 0.620 to 0.640 (+ 2.0% points). These gains confirm that the combination of WTConv and PFPN strengthens both localisation and classification performance on small, low-contrast targets.
From an efficiency perspective, the proposed architecture reduces the number of parameters from 5.97 M to 4.83 M (–19%) and increases inference speed from 24.1 FPS to 28.5 FPS (+ 18%) at 1280 × 768 resolution. This verifies that the model is not only more accurate but also more lightweight and faster, which is essential for real-time deployment on power-grid inspection platforms.
Figure Y plots the main metrics (Precision, Recall, \(\:mA{P}_{0.5}\), \(\:mA{P}_{0.5:0.95}\), FPS, and parameter count) for both models. The improved detector achieves a balanced improvement on accuracy-related and efficiency-related indicators, rather than trading speed for accuracy or vice versa.

Comparison between the improved model and YOLOv11 across various evaluation metrics.
To provide an intuitive impression of how the proposed detector behaves on real inspection images, representative detection results on the TLFO test set are shown in Fig. 8. Each subimage corresponds to a different transmission-line scene and highlights typical foreign objects encountered in practice.
In Fig. 8b, a small kite partially overlapping with transmission conductors is correctly localised with a tight bounding box, despite its low contrast against the background sky. Figure 8c shows balloon-shaped objects in front of a bright background; the proposed model is able to separate the balloons from nearby clouds and tower components, avoiding spurious detections. Figure 8d illustrates a cluttered corridor with multiple bird nests and wind-blown trash. The detector successfully identifies most foreign objects while not triggering on insulators, towers, or conductors.
Overall, these qualitative examples demonstrate that the proposed model can robustly detect small, low-contrast foreign objects across different transmission-line scenes, even in the presence of complex backgrounds and structural clutter. This visual evidence is consistent with the quantitative improvements reported in Tables 1 and 2 and confirms the practical suitability of the method for power-grid inspection tasks.

Qualitative detection results of the proposed model on the TLFO test set. The three examples (a–d) cover different transmission-line scenes and foreign-object types (nests, kites, balloons, trash). Coloured bounding boxes denote the four target categories, illustrating that the detector can localise small, low-contrast objects in the presence of complex background structures.
Ablation study of the improved model
To quantify the individual and combined contributions of the Wavelet-based Convolution layer (WTConv) and the Progressive Feature Pyramid Network (PFPN), we conducted a four-way ablation study. The baseline is the unmodified YOLOv11 detector trained under identical settings.
Table 2 reports Precision, Recall, mAP50, mAP50-95, parameter count, and frames per second (FPS) for each setting. Adding WTConv only improves feature granularity and yields a + 1.8 pp rise in mAP50, while PFPN only enhances multi-scale fusion and gives a + 1.3 pp gain. When both components are enabled, the full model obtains the highest scores, realising a + 3.1 pp increase in mAP50 over the baseline and a 19% reduction in parameters. These results confirm that each module is beneficial on its own and that their effects are complementary.
In summary, WTConv chiefly reduces missed detections of small, low-contrast objects, whereas PFPN lessens localisation errors through iterative top-down/bottom-up fusion. Their synergy preserves or improves speed despite the added operations, thereby answering Reviewer 1’s request for quantitative attribution.
To better understand how WTConv and PFPN refine feature representations at the semantic level, Fig. 9 visualises intermediate feature maps at the P3 scale for three variants: (i) baseline YOLOv11, (ii) YOLOv11 + WTConv, and (iii) YOLOv11 + WTConv + PFPN (full model). For clarity, we show the average over all channels as well as representative channels with strong responses on foreign objects.
In the baseline model, activations are relatively diffuse: foreign objects and non-target structures (e.g., transmission lines and towers) often receive comparable responses, so the network does not clearly distinguish “what should be detected” from “background infrastructure”. In the example of trash hanging near conductors, the feature map still shows strong responses along the lines themselves, which indicates a semantic mismatch between the target category and the activated regions.
After introducing WTConv, low-frequency corridor background is better separated from high-frequency target details. Activations on the trash region become stronger and more compact, while large-scale sky and vegetation areas are suppressed. However, some responses along conductors and tower edges remain, meaning that part of the non-target structures is still entangled with the target’s representation.
When PFPN is further added, cross-scale information is progressively refined and re-weighted. In the full model, activations are concentrated on the actual foreign objects (trash bags, balloons, bird nests, kites), whereas responses on transmission lines, towers, and other non-detection objects are significantly weakened. In other words, PFPN helps the network to filter out structurally salient but semantically irrelevant components, aligning the feature maps more closely with the detection categories.
These qualitative observations are consistent with the quantitative ablation results in Table 2 and the semantic-gap evaluation in § 3.9: WTConv mainly enhances the visibility of small, low-contrast targets, while PFPN further suppresses background infrastructure and improves localisation accuracy through iterative top-down and bottom-up fusion.

Visualisation of P3 feature maps for three configurations: (i) baseline YOLOv11, (ii) YOLOv11 + WTConv, and (iii) YOLOv11 + WTConv + PFPN (full model). The example shows trash hanging near transmission lines. In the baseline, activations spread over both the foreign object and the lines/towers. With WTConv, responses on the trash become stronger and more compact, while large-scale background is suppressed. With PFPN, activations are further concentrated on the trash region and largely filtered out on non-target structures such as conductors and towers, illustrating improved semantic focus of the proposed architecture.
Comparison of the improved model with other advanced models
To further verify the competitiveness of the proposed detector, we compare the improved YOLOv11 with a series of state-of-the-art object detection models under the same experimental setting as in § 3.2. The comparison set includes YOLOv5, YOLOv7, YOLOv8, the transformer-based RT-DETR, as well as Swin-YOLO and EfficientDet, which are specifically designed or tuned for small object detection. All models are trained and evaluated on the TLFO dataset with an input resolution of 1280 × 768 pixels and the same data augmentation pipeline. The evaluation metrics include Precision, Recall, mAP50, mAP50–95, frames per second (FPS), and the number of parameters. Table 3 summarises the quantitative comparison results.
The improved YOLOv11 outperforms all convolutional baselines (YOLOv5/7/8, Swin-YOLO, and EfficientDet) in terms of Precision, Recall, and mAP50–95, while retaining a favourable speed–accuracy trade-off. Compared with EfficientDet, the proposed model uses slightly more parameters but achieves significantly higher detection accuracy, which is crucial for reliably capturing small, low-contrast foreign objects in cluttered power-grid scenes. RT-DETR, as a representative transformer-based detector, provides competitive accuracy but requires substantially higher computational cost and lower FPS on TLFO, which limits its suitability for real-time deployment on resource-constrained inspection platforms. Overall, the YOLOv11 architecture integrated with WTConv and PFPN delivers the best balance between accuracy, efficiency, and model complexity among all candidates.
Comparison of loss functions
To validate the effectiveness of the improved loss function in the power grid foreign object detection task, this study compares the performance of different loss functions. The comparison includes the traditional CIoU loss, EIoU loss, and the newly proposed Inner-EIoU loss.
The compared loss functions are CIoU (Complete Intersection over Union), EIoU (Enhanced Intersection over Union), and the proposed Inner-EIoU. The evaluation metrics include Precision, Recall, mAP50, and mAP50-95.
Table 4 shows that the experimental results for the Inner‑EIoU loss function outperform both CIoU and EIoU across all evaluation metrics, particularly in mAP50 and mAP50‑95. This indicates that Inner‑EIoU can more effectively guide the model’s learning, thus enhancing detection performance. Specifically, Inner‑EIoU reduces localization errors through a more refined bounding box adjustment mechanism, improving the model’s ability to accurately capture target boundaries and, consequently, boosting overall detection accuracy and robustness.
Multi-module ablation study (WTConv + PFPN + Inner-EIoU)
To further investigate how the three improvement components interact, we conduct a multi-module ablation study combining WTConv, PFPN, and the Inner-EIoU loss. The experimental settings follow § 3.2. We consider five configurations, denoted as Models A–E in Table 5:Model A: baseline YOLOv11 with Inner-EIoU (no WTConv, no PFPN); Model B: baseline YOLOv11 with CIoU (no WTConv, no PFPN); Model C: YOLOv11 + WTConv + Inner-EIoU (no PFPN); Model D: YOLOv11 + PFPN + Inner-EIoU (no WTConv); Model E: YOLOv11 + WTConv + PFPN + Inner-EIoU (full model).
As shown in Table 5, Model E (all three components enabled) achieves the best performance, with the highest Precision, Recall, mAP_{0.5}, and mAP_{0.5:0.95}. Compared with Model A (baseline + Inner-EIoU), Model E brings a + 4.4-point gain in Precision (0.918 → 0.962), a + 1.8-point gain in Recall (0.792 → 0.810), and a + 3.1-point improvement in mAP_{0.5} (0.841 → 0.872).
Comparing Models A and B isolates the effect of the bounding-box loss: replacing CIoU with Inner-EIoU yields consistent improvements on all metrics, confirming that Inner-EIoU is a stronger regression loss for the TLFO task. Comparing Models C and D with Model A shows that WTConv and PFPN are both beneficial on top of the improved loss. WTConv (Model C) mainly boosts mAP_{0.5} and mAP_{0.5:0.95} by enhancing small, low-contrast foreign objects, while PFPN (Model D) further improves localisation through cross-scale feature fusion.
Finally, the full configuration Model E outperforms both single-module variants C and D, indicating that WTConv and PFPN are complementary: WTConv provides cleaner, high-frequency foreground features, and PFPN exploits these features more effectively across scales. Together with Inner-EIoU, they deliver the best balance between detection accuracy and robustness on the TLFO dataset.
Precision-recall curve analysis
To further assess the performance improvement of the improved YOLOv11 model compared to the original YOLOv11 in the power grid foreign object detection task, we conducted a detailed analysis of the Precision-Recall (P-R) curves of both models, as shown in Fig. 10. The figure demonstrates that the P-R curve of the improved model is consistently above that of the original model, indicating that, at most confidence thresholds, the improved YOLOv11 model outperforms the original model in both Precision and Recall.
In the high-recall region (Recall > 0.8), the improved model maintains a high Precision, indicating that it detects as many objects as possible while effectively reducing false positives. This characteristic is particularly important for power grid foreign object detection, as high Recall ensures that the majority of potential hazardous objects are identified, enhancing the safety and reliability of the system. In the low-recall region, the improved model also demonstrates higher Precision, showing that under conditions requiring higher confidence, the improved model can more accurately identify true targets, reducing false alarms. This is significant for applications where high-confidence detection results are critical.
Furthermore, the P-R curve of the improved model exhibits a smooth and consistently increasing trend across various recall thresholds, reflecting stable and consistent performance at different detection thresholds. In contrast, the curve of the original model flattens in the mid-to-high recall region, with limited improvement in Precision, revealing a performance bottleneck in these areas. The Area Under the Curve (AUC) for the improved model is significantly higher than that of the original model, indicating that, overall, the improved model maintains a higher Precision across different recall thresholds, improving the overall detection performance.
At specific confidence thresholds (e.g., 0.5 and 0.7), the improved model’s Precision and Recall are both higher than the original model, demonstrating superior performance at these key thresholds. For example, at a confidence threshold of 0.5, the improved model achieves a Precision of 0.85 and a Recall of 0.63, while the original model’s Precision and Recall are 0.84 and 0.62, respectively, showing the improved model’s performance advantage at critical thresholds.
In practical applications, the high Precision and high Recall of the improved model allow for more effective identification and localization of potential hazardous objects, enhancing the safety and stability of power grid operations. The robustness of the improved model in varying lighting conditions and dense scenes is also indirectly validated by the P-R curve, ensuring reliable performance in complex environments.
The analysis of the P-R curves clearly shows that the improved YOLOv11 outperforms the original YOLOv11 in both Precision and Recall. This performance improvement can be attributed to the integration of wavelet transform and the Progressive Feature Pyramid Network (PFPN), which significantly enhance the model’s feature extraction ability and multi-scale feature fusion, resulting in higher detection accuracy and stronger robustness in the power grid foreign object detection task.

Comparison of precision-recall curves between the improved YOLOv11 (a) and the original YOLOv11 (b).
Semantic-gap evaluation
To quantitatively verify that PFPN helps to bridge the disconnect between low-level and high-level semantics, we measure the semantic gap\(\:{{\Delta\:}}_{\text{sem}}\) on the TLFO validation set (definition given in § 2.X). A smaller\(\:{{\Delta\:}}_{\text{sem}}\) indicates better alignment between the locations of strong feature activations and the annotated foreign-object regions. Table 6 reports \(\:{{\Delta\:}}_{\text{sem}}\) together with \(\:mA{P}_{0.5:0.95}\) for three configurations: the baseline YOLOv11, YOLOv11 with WTConv only, and YOLOv11 with PFPN only.
As shown in Table 6, introducing WTConv already reduces the semantic gap from 0.268 to 0.243 while slightly improving \(\:mA{P}_{0.5:0.95}\), indicating that wavelet-based convolutions make feature responses more concentrated on true foreign-object regions. PFPN further decreases \(\:{{\Delta\:}}_{\text{sem}}\) to 0.159, a substantial reduction compared with the baseline, while maintaining a higher \(\:mA{P}_{0.5:0.95}\) than the original YOLOv11. This confirms that PFPN is particularly effective at suppressing activations on long, linear background structures (towers and conductors) and enhancing activations on small, blob-like targets, thereby narrowing the high/low-level semantic mismatch.
To assess cross-domain generalisation, we further evaluate the baseline and improved models on the COCO val2017 split. Both models are trained from scratch on COCO train2017 using the same training schedule and hyper-parameters as on TLFO. Table 7 summarises the COCO results.
On COCO val2017, the improved YOLOv11 achieves a + 1.6 point gain in \(\:mA{P}_{0.5:0.95}\) over the baseline, with consistent improvements across small, medium, and large objects. These results, together with the reduced semantic gap on TLFO, demonstrate that the proposed WTConv and PFPN modules are not overfitted to the power-grid dataset: they improve feature–label alignment on TLFO while retaining their advantages on a generic natural-image benchmark.
Conclusion
This work tackles foreign-object detection around high-voltage transmission lines by embedding three universal upgrades into YOLOv11. First, a Wavelet-Transform Convolution (WTConv) layer separates low-frequency corridor context from high-frequency structural detail, enlarging the effective receptive field while selectively enhancing edges and suppressing low-frequency noise. Second, a Progressive Feature Pyramid Network (PFPN) refines multi-scale features in a two-stage top-down / bottom-up manner and applies adaptive spatial fusion to mitigate cross-scale conflicts where tiny foreign objects overlap with towers and conductors. Third, an Inner-EIoU loss strengthens bounding-box regression by focusing optimisation on the inner region of the ground-truth box, thereby reducing localisation errors on small, low-contrast targets.
On our Transmission-Line Foreign-Object (TLFO) dataset, the resulting detector improves mAP₀.₅ from 0.841 to 0.872 (+ 3.1% points) and mAP₀.₅:₀.₉₅ from 0.620 to 0.640 (+ 2.0% points), while increasing Precision from 0.918 to 0.962 and reducing the parameter count from 5.97 M to 4.83 M (≈ 19%). At the same time, inference speed rises from 24.1 FPS to 28.5 FPS at 1280 × 768 input resolution, demonstrating a favourable accuracy–efficiency trade-off suitable for real-time power-grid inspection.
Generalisability
Although our experiments focus on power-grid imagery, the three proposed modules are architecture-agnostic and domain-independent. When transferred to the MS COCO val2017 split (see § 3.9), the improved YOLOv11 achieves a + 1.6 point gain in mAP₀.₅:₀.₉₅ over the baseline without any hyper-parameter retuning, with consistent improvements across small, medium, and large objects. This suggests that the frequency-aware backbone and progressive feature pyramid retain their advantages on generic natural-image benchmarks, rather than overfitting to the TLFO dataset.
Future directions
Future work will explore lightweight backbones (e.g., ConvNeXt-Tiny), hybrid spectral–spatial attention, and automated wavelet-basis selection to further raise accuracy under strict latency constraints (sub-50 ms per frame) required for online power-grid inspection. Another promising direction is to combine WTConv and PFPN with task-specific priors such as line geometry estimation or 3D corridor models, aiming to deliver a field-deployable, robust detector that safeguards electrical infrastructure in diverse operating environments.
Data availability
The datasets used during the current study available from the corresponding author on reasonable request. Email:2524679177@qq.com.
References
Liu, C., Wu, Y., Liu, J., Sun, Z. & Xu, H. Insulator faults detection in aerial images from high-voltage transmission lines based on deep learning model. Appl. Sci. 11 (10), 4647 (2021).
Shao, Y., Zhang, R., Lv, C., Luo, Z. & Che, M. TL-YOLO: Foreign-object detection on power transmission line based on improved YOLOv8. Electronics 13 (8), 1543 (2024).
Doherty, J., Gardiner, B., Kerr, E. & Siddique, N. BiFPN-YOLO: One-stage object detection integrating Bi-Directional feature pyramid networks. Pattern Recogn. 160, 111209 (2025).
Xiao, Y. & Di, N. A lightweight small object detection framework. Sci. Rep. 14 (1), 25624. https://doi.org/10.1038/s41598-024-77513-4 (2024).
Luan, S., Li, C., Xu, P., Huang, Y. & Wang, X. MI-YOLO: more information based YOLO for insulator defect detection. J. Electron. Imaging. 32 (4), 043014 (2023).
Shi, J., Yang, F. & Wang, Q. I-YOLO: Improved progressive feature pyramid and Wise-IOU for object detection. Proceedings of the 2023 6th International Conference on Artificial Intelligence and Pattern Recognition. (2023).
Peng, D., Ding, W. & Zhen, T. A novel low light object detection method based on the YOLOv5 fusion feature enhancement. Sci. Rep. 14 (1), 4486. https://doi.org/10.1038/s41598-024-54428-8 (2024).
Wei, X., Li, Z. & Wang, Y. Based multi-scale attention for small object detection in remote sensing. Sci. Rep. 15 (1), 3125. https://doi.org/10.1038/s41598-025-87199-x (2025).
Zhou, S., Zhou, H. & Qian, L. A multi-scale small object detection algorithm SMA-YOLO for UAV remote sensing images. Sci. Rep. 15 (1), 9255. https://doi.org/10.1038/s41598-025-92344-7 (2025).
Wang, J., Hao, Y., Bai, H. & Yan, L. Parallel attention recursive generalization transformer for image super-resolution. Sci. Rep. 15 (1), 8669. https://doi.org/10.1038/s41598-025-92377-y (2025).
Wu, W., Cheng, H., Pan, J., Zhong, L. & Zhang, Q. Wavelet-enhanced YOLO for intelligent detection of welding defects in X-Ray films. Appl. Sci. 15 (8), 3486.https://doi.org/10.3390/app15084586 (2025).
Chen, Y., Zhu, X., Li, Y., Wei, Y. & Ye, L. Enhanced semantic feature pyramid network for small object detection. Sig. Process. Image Commun. 113, 116919. https://doi.org/10.1016/j.image.2023.116919 (2023).
Prinzi, F. & Insalaco, M. Orlando A, etc. A Yolo-Based model for breast cancer detection in mammograms. Cogn. Comput. 16 (1), 107–120 (2024).
Gündüz M Ş, I. Ş. I. K. G. A new YOLO-based method for real-time crowd detection from video and performance analysis of YOLO models. J. Real-Time Image Proc. 20 (1), 5 (2023).
Lin, J., Zhao, Y. & Wang, S. et al. YOLO-DA: an efficient YOLO-Based detector for remote sensing object detection. IEEE Geosci. Remote Sens. Lett. 20, 1–5 (2023).
Qiu, Q. Real-time detection of cracks in tiled sidewalks using YOLO-based method applied to unmanned aerial vehicle (UAV) images. Autom. Constr. 147, 104745 (2023).
Łuczak D. Machine fault diagnosis through vibration analysis: continuous wavelet transform with complex Morlet wavelet and time–frequency RGB image recognition via convolutional neural network. Electronics 13 (2), 452. (2024).
Claret S P A, Dharmian J P, Manokar, A. M. Artificial intelligence-driven enhanced skin cancer diagnosis: leveraging convolutional neural networks with discrete wavelet transformation. Egypt. J. Med. Hum. Genet. 25 (1), 50 (2024).
Finder S E, Amoyal, R. Treister E, et al. Wavelet convolutions for large receptive fields. (2024).
Mohapatra, S. & Kumar Pati G Mishra M, et al. Gastrointestinal abnormality detection and classification using empirical wavelet transform and deep convolutional neural network from endoscopic images. Ain Shams Eng. J. 14 (4), 101942 (2023).
Yang, G. & Lei, J. Zhu Z, et al. AFPN: asymptotic feature pyramid network for object detection. (2023).
Gao, J., Geng, X. & Zhang, Y. (eds). et al. Augmented weighted bidirectional feature pyramid network for marine object detection. Expert Syst. Appl. 237 121688. (2024).
Chen, Y., Zhu, X., Li, Y. & et al. Enhanced semantic feature pyramid network for small object detection. Sig. Process. Image Commun. 113, 116919 (2023).
Li, Z. et al. Cross-Layer feature pyramid network for salient object detection. IEEE Trans. Image Process. 30, 4587–4598. https://doi.org/10.1109/TIP.2021.3072811 (2020).
Zhu, M., Han, K., Yu, C. & Wang, Y. Dynamic feature pyramid networks for object detection. https://arXiv.org/abs/2012.00779. (2020).
Zhang, Z., Qiu, X. & Li, Y. SEFPN: Scale-Equalizing feature pyramid network for object detection. Sensors 21 (21), 7136. https://doi.org/10.3390/s21217136 (2021).
Ren, J., Wang, Z. & Ren, J. PS-Net: progressive selection network for salient object detection. Cogn. Comput. 14, 794–804. https://doi.org/10.1007/s12559-021-09952-4 (2022).
Wang, C. & Zhong, C. Adaptive feature pyramid networks for object detection. IEEE Access. 9, 107024–107032. https://doi.org/10.1109/ACCESS.2021.3100369 (2021).
He, L. et al. Scale-Adaptive feature pyramid networks for 2D object detection. Sci. Program. 2020, 8839979. https://doi.org/10.1155/2020/8839979 (2020).
Deng, C., Wang, M., Liu, L. & Liu, Y. Extended feature pyramid network for small object detection. IEEE Trans. Multimedia. 24, 1968–1979. https://doi.org/10.1109/TMM.2021.3074273 (2020).
Xu, Z., Ren, B. & Zhang, K. SSFPN: selective Spatial feature pyramid network for remote sensing object detection. J. Phys: Conf. Ser. 2829 (1), 012016. https://doi.org/10.1088/1742-6596/2829/1/012016 (2024).
Funding
This work was supported by the Science and Technology Project Funding of Provincial Managed Industrial Units of State Grid Jiangsu Electric Power Co., Ltd. (Project Number: JC2024101).
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Ye, J., Yuqi, B., Wendi, W. et al. Efficient target detection method based on wavelet transform and progressive feature pyramid network: a case study of power grid inspection. Sci Rep 16, 7318 (2026). https://doi.org/10.1038/s41598-026-37017-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-026-37017-9
