
Abstract
Structural variations in retinal vessels predict clinical conditions related to vascular health. This study aims to describe the incidence and distribution of retinal arteriosclerosis and to develop risk prediction models for high-risk populations. Data were obtained from a retrospective health examination cohort at Hua Dong Sanatorium, China. The primary outcome was retinal arteriosclerosis. Candidate risk predictors were selected based on biological plausibility and potential predictive ability. Risk prediction models were developed using the Cox proportional hazards model. Predictive performance was evaluated through discrimination and calibration accuracy.Internal validation was performed using bootstrap resampling (100 iterations) to estimate optimism and to report optimism-corrected discrimination (C-index) and calibration (slope). In the derivation cohort, 10,323 individuals were diagnosed with retinal arteriosclerosis over 288,525 person-years (incidence density: 35.8 per 1,000 person-years). Males over 40 and females over 45 were identified as relatively high-risk groups. Risk predictors included age, body mass index, waist circumference, hip circumference, systolic blood pressure, diastolic blood pressure, smoking, hypertension, diabetes, high-density lipoprotein, and serum creatinine. The C-index of the risk prediction models was approximately 0.8 in the validation set. These models are accessible to potential users via an online application. The risk prediction models may facilitate early intervention by modifying risk factors, thereby reducing the incidence of retinal arteriosclerosis in high-risk populations.
Similar content being viewed by others

Introduction
The continued growth of the global elderly population increases the burden of retinal diseases worldwide1. Retinal arteriosclerosis (RA) measured noninvasively in the fundus is a progressive narrowing of small retinal arteries, impairing circulation2. It advances from mild arteriolar narrowing to severe sclerosis with hemorrhages. Risk factors include aging, hypertension, diabetes, hyperlipidemia, and smoking3. To a certain extent, RA reflects the conditions of vascular systems in the whole body, which is one of the earliest signs of adverse structural and functional changes in vascular walls4,5. Thus retinal vessels provide a window for detecting changes in the micro-vascular system associated with the progress of the cardiovascular disease6,7.
Clinical risk prediction model has been widely used in medical practice to tell an individual’s risk of disease in the future based on multiple individual characteristics8, which helps for improving the quality of life of the target population and optimize the utilization of medical resources9. It is well known that aging, hypertension, high fat intake, and diabetes can accelerate the process of vascular and retinal disease10,11,12, however, no large cohort studies have been conducted with retinal or fundus arteriosclerosis as an outcome up to now, and we still lack a comprehensive epidemiological understanding of the disease. Furthermore, there is also lack of risk prediction model for predicting the future risk of this disease in high risk populations.
This study aims to describe the recent incidence and distribution of RA, and further develop and validate risk prediction models for high risk populations, by using a retrospective large population-based cohort from East China. We hope that early intervention via changing modifiable risk factors from the risk prediction system to reduce the expectation of RA among high risk populations.
Materials and methods
Study population
This study analyzed data from Hua Dong Sanatorium, which has been reported previously13,14. Specifically, the major subjects of this retrospective longitudinal dynamic health examination data were non-manual workers or retirees living in East China, most of which took a health examination every one to two years. Due to missing data in 2014, we divided this cohort into two parts: one cohort is from January 2005 to December 2013, and the other is from January 2015 to December 2021. We took the latter as the descriptive subject and as the derivation cohort, and took the former as the validation cohort.
The outcome we were interested in was the occurrence of RA in any grade. In this study, we defined RA-free as “survival”, and the “survival probability” referred to the probability of remaining RA-free. The diagnosis of RA was performed by a trained ophthalmologist. Fundus photography was completed following a standardized Protocol. Subjects were classified concerning their retinal photography based on the Keith-Wagener-Barker classification. Detailed instructions for other data collection see in13,14.
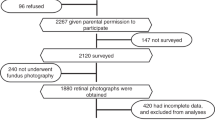
The selection process of the eligible individuals in the derivation cohort is as follows. First, 112,612 individuals with at least two health examination records were retained. Second, individuals without ophthalmic examination and those diagnosed with RA at the first health examination were excluded. Third, we excluded individuals observed for less than 3 months and those with an age less than 18 at the first health examination. Lastly, 90,240 individuals with 324,966 health examination records were left. Figure S1 presents the above process.
This study was approved by the Ethical Committee and Institutional Review Board of Hua Dong Sanatorium, Wuxi. Informed consent was waived because the data were analyzed retrospectively and anonymously, and was supported by the Ethical Committee. All methods were performed in accordance with the Declaration of Helsinki.
Construction and estimation of the risk prediction model
We conducted and reported risk prediction models according to the guidance of TRIPOD (Table S1)9. The outcome definition of RA followed the Keith–Wagner–Barker classification (Table S2). Due to the inherited difference between male and female15, we built risk prediction models of RA disease risk for males and females separately. We calculated the incidence density of RA in the derivation cohort by quartile age groups (Table S3-S4). Based on incidence density, males over 40 and females over 45 were considered to be at high risk in this study.
Predictor variables
We first described the baseline characteristics of males over 40 and females over 45 in the derivation cohort (see Table S5-S6). Among these characteristics, candidate predictor variables were selected mainly by the availability, explainability in biology, and potential predictive ability judged by the Cox regression model.
The results of univariable and multivariable Cox regression analyses see Table S7-S8. Continuous laboratory data would be log2 transformed if they were skewed or had a wide range. When conducting univariable Cox analysis, the linear relationships between continuous variables and risk of incidence were examined (Figure S2). An obvious nonlinear relationship would be fitted using restricted cubic splines16. Restricted cubic splines were implemented using the rcs() function in the rms package in R, with 3 knots placed at the 10th, 50th, and 90th percentiles of the predictor distribution in the derivation cohort, as determined by the datadist object. The same spline specification (number and locations of knots) was retained when non-linear terms were included in the multivariable Cox models and when generating predictions in the temporal validation cohort. We selected variables with p-value < 0.05 for the next multi-variable analysis. When conducting multivariable Cox analysis, the col-linearity diagnosis was first performed between variables. Variables with variance inflation factor (VIF) greater than 5, i.e., cholesterol (Table S9-S10) or thought to be closely related in biology, i.e., glycated hemoglobin (vs. fasting plasma glucose) were excluded.
For the risk prediction model, we considered variables that could increase the concordance index of the model while trying to reduce the complexity of the model. Finally, age, body mass index (BMI), waist circumference (WC), hip circumference (HC), diastolic pressure (DP), smoking, hypertension, diabetes, and serum creatinine (Scr) were selected as key predictors for male; age, BMI, WC, HC, systolic pressure (SP), DP, hypertension, diabetes, high density lipoprotein (HDL) and Scr as key predictors for female.
Derivation and validation models
Given that BMI had a missing value of 40% in the original data, we evaluated the mechanism of the loss of BMI. Following the suggestion of Desai17, describing differences between those with and without data on key variables concerning population characteristics serves as an assessment of the missing completely at random (MCAR) assumption, we compared the incidence of RA between samples with BMI and without BMI (see Figure S3), found that there was little difference between the two in either male or female population. Thus, the missing of BMI could be considered as the MCAR (Actually, the missing of the records of height and weight was completely random, and so did WC and HC). It can be considered that the result using the complete-case (CC) of BMI was unbiased. Finally, data with complete BMI was used. In these data, the other variables were all missing by less than 1%. Thus, we chose to delete these samples with missing values directly. The last derivation set version was: males over 40, n = 19,889; females over 45, n = 8,792.
The prediction model using the semi-parameter Cox model consists of two parts: the linear part in the exponential position and the unshaped baseline hazard18. In the final version, risk prediction models for RA were fitted within the above risk predictors using Cox proportional hazards models. Linear predictor (LP) or called predicted risk score (PRS) was calculated by the sum of each predictor’s value multiplied by its coefficient. The submission to the proportional hazard assumption of each risk factor was assessed by checking Schoenfeld residual plots (Figure S4). Linear or nonlinear relationships between continuous predictors and risk of incidence were also examined. The relationship between predictors and risk of incidence in males was reasonably approximates a linear relationship (Figure S5A) while age, HDL, and Scr presented a nonlinear relationship to the risk of incidence in females (Figure S5B).
In this study, the health examination cohort from January 2005 to December 2013 was used as the temporal external validation cohort. We chose the validation set consistent with the conditions of the derivation set, and individuals that appeared in the derivation set were eliminated in the validation set. Baseline characteristics of the derivation and validation set are summarized in Tables S11-S12. PRS in the validation set was obtained by the coefficients from the derivation set. We fitted a Cox model to the validation set with no covariates other than PRS with the regression coefficient constrained to one and obtained the estimated baseline hazard of the validation set18.
Evaluation of model performance
The overall performance measures of the risk predictive model are mainly assessed by discrimination and calibration8. In addition, the Brier score is deemed as a comprehensive index of evaluation model performance, with a range from 0 (for a perfect model) to 0.25 (for a non-informative model with a 50% incidence of the outcome)8.
Discrimination is the ability to differentiate between high-risk individuals and low-risk individuals19. The most intuitive method is to divide the population into different risk groups by PRS and observe the risk difference between the groups by Kaplan-Meier (K-M) curves19. Discrimination is also often measured by Harrell’s overall concordance (C) statistic, with a range from 0.5 to 1.0. We calculated the original C-index and corrected C-index by a bootstrap procedure resampled 100 times. In addition, the area under a receiver operating characteristic curve (AUC) is calculated in different time horizons20. Another approach to validation is to estimate the weight of PRS in the validation set18, known as the “calibration slope”. The discrimination in the validation set is about the same as the derivation set when the slope of PRS is approximately one18.
Calibration describes how accurately the estimates or predictions of risk from a model reflect the risk incidence in the observed data19. Usually, calibration plots are used to assess calibration. In this study, subjects were evenly divided into ten groups by PRS, then the mean predicted incidence probabilities of these groups (X-axis) were compared to the mean observed incidence probabilities (Y-axis) at 1, 3, and 5 years. Besides, we performed a more intuitive and sensitive assessment of the calibration. We divided individuals into three risk groups based on the tertiles of PRS calculated from the derivation set. We next plotted the observed K-M curves and the mean predicted probability K-M curves within each risk group to compare the bias.
We performed the above performance evaluation on the risk prediction models in the derivation set (internal) and validation set (external) respectively. If the estimated cumulative baseline hazard of the derivation set is very different from that of the validation set, the calibration of the risk predictive model would be very poor in the validation set. In such a situation, we would use the cumulative baseline hazard of the validation set to re-calibrate the models21,22.
To estimate the robustness of predictive accuracy of the risk predictive models constructed using the baseline information of the health examination cohort, we fitted a time-dependent covariates Cox regression model using subsequently updated health examination data of derivation set and calculated the Brier score and C-index over a series of points in time.
Online risk predictive app
Our risk predictive models of predicting RA-free probability are available for the potential users at the online app for male: https://lnzi.shinyapps.io/rarisk_male/ and for female: https://lnzi.shinyapps.io/rarisk_female/.
Statistical analysis
We used the event per variable (EPV) criterion to assess the adequacy of data instead of formally calculating the sample size9. Follow-up time was determined as the time from the first health examination to RA diagnosis, or the last health examination time, whichever came first. The incidence of RA was presented by K-M curves. Median follow-up time was computed via the reverse K-M method9. P-value < 0.05 was considered to be statistical significance. Data cleaning and analyses were performed using R version 4.1.3.
Results
The baseline information of 90,240 individuals aged 18.1–96.8 years in the health examination cohort from January 2015 to December 2021 is summarized in Table 1. The median age of the cohort population was 43 (inter-quartile range, IQR: 35–51). The median follow-up time was 3.14 years (95% credible interval, CI: 3.12–3.16). During a sum of 288524.7 person-years of follow-up, a total of 10,323 individuals were diagnosed with RA (incidence density: 35.8 per 1000 person-years).
Derivation and validation models
The baseline characteristics of the derivation set and validation set are summarized in Tables S10-S11. The median follow-up time of males in the derivation set was 3.61 years (95% CI: 3.47–3.70) and 6.62 years (95% CI: 6.60–6.65) in the validation set. The incidence density of RA in males was 71.2 per 1000 person-years in the derivation set and 46.4 per 1000 person-years in the validation set. The median follow-up time of females in the derivation set was 3.15 years (95% CI: 3.09–3.31) and 6.56 years (95% CI: 6.51–6.60) in the validation set. The incidence density of females was 47.8 per 1000 person-years in the derivation set and 31.2 per 1000 person-years in the validation set.
The coefficients of the male risk predictive model, as well as PRS equation structured from the derivation set, see Table 2. The coefficients of the female risk predictive model and PRS equation are structured from the derivation set (see Table 3).
The distribution of PRS in the derivation set and validation set were similar (see Figure S6). We modeled the relationship between PRS and hazard ratio (HR) in the derivation cohort, with a threshold specified to classify individuals into high- and low-risk categories. (Fig. 1). The baseline survival (disease-free) probabilities of derivation set and validation set in males and females see Table S14-S15, which can be used to calculate the disease-free probability for an individual in recent years. Note that there was an obvious difference in the cumulative hazard and baseline survival probability between the derivation set and validation set in both males and females (see also Figure S7).

The relationship of PRS to HR in the derivation set. (A) In males. (B) In females. The red number is the optimal cutoff value of PRS.
Evaluation of model performance
In internal validation, the original overall C-statistic of risk predictive models of males and females was 0.7740 and 0.7969, respectively, and the corrected C-statistic was 0.7736 and 0.7955. In external validation, the original C-statistic of the models of male and female was 0.7859 and 0.8156, respectively, and the corrected C-statistic was 0.7860 and 0.8160. Brier score and C-index at different time points from 1-year to 5-year of derivation set and validation set in males and females are shown in Fig. 2. Consistent with Fig. 2, time-dependent ROC curves at 1, 3, and 5 years showed good discrimination in both cohorts (Figure S11A-B).The calibration slope was 0.972 in males and 1.013 in females which were both close to 1. The observed K-M survival curves of the three risk groups grouped by PRS of the derivation set (see Table S15) were widely separated in the derivation set and validation set (Fig. 3, solid lines). These results corroborated the high discriminative power of the models. Of note, the C-statistics in the temporal validation cohort were slightly higher than those in the derivation cohort (0.7859 vs. 0.7740 in men and 0.8156 vs. 0.7969 in women). This small difference most likely reflects differences in case-mix and follow-up patterns between cohorts, rather than a truly superior performance of the model in the validation data.

Brier score and C-index at different time points from 1-year to 5-year of derivation set and validation set in males and females. (A) Brier score in males. (B) C-index in males. (C) Brier score in females. (D) C-index in females.

The observed K-M survival curves and the predicted survival curves of the three risk groups of derivation set and validation set in males and females. (A) K-M curves of derivation set in males. (B) K-M curves of the validation set in males before re-calibration. (C) K-M curves of the validation set in males after re-calibration. (D) K-M curves of derivation set in females. (E) K-M curves of the validation set in females before re-calibration. (F) K-M curves of the validation set in females after re-calibration.
In terms of calibration, the observed K-M survival curves of the three risk groups were close to the mean predicted survival curves in the internal validation (Figs. 3A and D and 4A and D). However, calibration in the temporal validation cohort showed notable overestimation of risk (Fig. 3B and E). Calibration plots also indicated poor agreement between predicted and observed risk probability at 1, 3, and 5 years in external validation (Fig. 4B and E). The predicted risk was overestimated in the validation set. The reason is the baseline disease-free probability of the validation set was much higher than that of the derivation set (Table S13-S14 and Figure S7). After re-calibrated the cumulative baseline hazard using the validation set, calibration accuracy had been well improved in both male and female models (see Figs. 3C and F and 4C and F).

Calibration plots of derivation set and validation set in males and females at 1, 3, and 5 years. (A) Calibration plots of derivation set in males. (B) Calibration plots of the validation set in males before re-calibration. (C) Calibration plots of the validation set in males after re-calibration. (D) Calibration plots of derivation set in females. (E) Calibration plots of the validation set in females before re-calibration. (F) Calibration plots of the validation set in females after re-calibration.
Brier score and C-index at different time points from 1-year to 5-year in males and females using subsequently updated health examination data of the derivation set as sensitivity analysis see Figure S8, which had not much difference to the baseline models. This may have something to do with the lack of movement in the indicators during the health examination period (see Figure S9 for example).
Discussion
A major issue in the older population is the high prevalence of sight-threatening conditions. The eye is thought of as a kind of “vascular” organ10. Ophthalmologists may play a key role in the early identification of older individuals with systemic vascular disease in the future23. Recent evidence also supports associations between retinal arteriosclerotic signs and subclinical atherosclerosis (e.g., coronary heart disease and carotid atherosclerosis or new-onset carotid plaque), reinforcing the value of fundus findings as systemic vascular markers24,25,26. However, before identifying changed micro-vascular features like RA, it is much preferable to make personalized risk stratification and early management feasible on a population basis in advance, which are important from the public healthcare perspective.
Although there have been many studies on the prevalence of arteriosclerosis or retinal atherosclerosis13,27,28,29, fewer studies have reported on the incidence12. Compared to the previous studies, our study reported the distribution of short-term incidence density of RA in different populations in terms of sex and age. In the study of12, researchers reported the incidence of retinal atherosclerosis of 8.2% (26,168/319,501) between January 2005 and April 2020 with a median follow-up of 2.9 (IQR: 1.6–4.6) years, which was lower than the whole population in our study of 11.4% (10,323/90,240) during a median follow-up of 3.14 (95%CI: 3.12–3.16) years. In the study of12, researchers summarized the distribution of characteristics of retinal atherosclerosis between the absent and the present, the results were similar to ours.
Aging, obesity, dyslipidemia, hypertension, and diabetes are well-known traditional risk factors for vascular and retinal diseases10,30. Besides, there is evidence of the increased risk of retinal disease from smoking by adversely affecting blood flow and decreasing HDL levels31,32. In this study, Scr was found to be a protective factor within its reference ranges (male: 53–106 µmol/L, female: 44–97 µmol/L, most people in the derivation set fell within the reference range, see Figure S10). Generally, Scr that is well outside the reference range predicts poor renal function. But for older adults with a normal level, higher Scr concentrations may indicate more robust musculature and improved nutritional status33. We would like to emphasize that these risk prediction models may not be suitable for individuals with poor renal function.
Our risk prediction models for RA were constructed with more quantitative predictors, and potential nonlinear patterns were identified. These helped to improve the accuracy of prediction models. But the calibration was poor in external temporal validation because of the wide difference in baseline survival probability between the derivation and validation set. Although the models discriminated well, calibration differed by calendar period. We developed the models in 2015–2021 to reflect contemporary screening and data capture after the 2014 relocation, and used 2005–2013 as an out-of-time validation cohort to examine transportability. The lower baseline hazard in 2005–2013 led to systematic overestimation of absolute risk when applying the 2015–2021 baseline, illustrating cohort/period effects that primarily impact calibration. Updating the baseline cumulative hazard in the validation cohort markedly improved calibration; therefore, our online tool reports absolute risk using the contemporary (2015–2021) baseline, and recalibration of baseline risk is recommended when applying the model to other periods or settings34. Therefore, considering that the derivation set reflected the more recent condition of RA, we used the baseline risk of the derivation set to calculate an individual’s disease-free survival probability in an online risk prediction app.
This study has some limitations. First, this population came from the health examination cohort in East China, which may have selection bias and may not be representative of other populations worldwide. In addition, the health examination data generated the lagging detection of the outcome, which would lead to the underestimation of the incidence density. Moreover, the true onset of RA is interval-censored between examinations; we therefore assigned the event time to the examination date when RA was first detected. This pragmatic choice may influence estimation of the baseline hazard and thus absolute risk and calibration, and may contribute to miscalibration in temporal validation if examination intervals or follow-up patterns differ across periods35. Second, genetic factors were not considered in this study. Genetic factors are quite important in the development of vascular structure variation36. This study also failed to consider personal diet, living habits, and medication history/use (e.g., antihypertensives, lipid-lowering, antidiabetic agents). That is why we included many quantitative variables in risk prediction models that may reflect a combination of these factors. Even when hypertension is included as a predictor, measured systolic and diastolic BP are prioritized because they distinguish treated/controlled from untreated/poorly controlled individuals and provide a continuous risk gradient; hypertension history is retained only when it adds incremental information without problematic collinearity.
In conclusion, this study described the recent short-term incidence density and distribution of RA among Chinese population according to the retrospective population-based health examination cohort. We hope the early intervention by changing the modifiable risk factors from our sketchy risk prediction system to reduce the expectation of RA for high risk populations. In the meantime, we appeal to more studies to improve our models by using other predictors such as genetic factors and medication history/use (e.g., antihypertensives, lipid-lowering, antidiabetic agents) and to accommodate more different populations.
Data availability
The datasets used and analyzed during the current study are available from the corresponding author upon reasonable request.
Abbreviations
- RA:
-
retinal arteriosclerosis
- VIF:
-
variables with a variance inflation factor
- BMI:
-
body mass index
- WC:
-
waist circumference
- HC:
-
hip circumference
- DP:
-
diastolic pressure
- Scr:
-
serum creatinine
- SP:
-
systolic pressure
- HDL:
-
high density lipoprotein
- MCAR:
-
missing completely at random
- CC:
-
complete-case
- LP:
-
linear predictor
- PRS:
-
predicted risk score
- K-M:
-
Kaplan-Meier
- C:
-
concordance
- AUC:
-
area under the curve
- CI:
-
credible interval
- EPV:
-
event per variable
- IQR:
-
inter-quartile range
- HR:
-
hazard ratio
References
Ben-Arzi, A., Ehrlich, R. & Neumann, R. Retinal Diseases: The Next Frontier in Pharmacodelivery. Pharmaceutics 14(5). (2022).
Micera, A., Bruno, L., Cacciamani, A., Rongioletti, M. & Squitti, R. Alzheimer’s disease and retinal degeneration: A glimpse at essential trace metals in ocular fluids and tissues. Curr. Alzheimer Res. 16(12), 1073–1083 (2019).
Liew, G., Wang, J. J., Mitchell, P. & Wong, T. Y. Retinal vascular imaging: A new tool in microvascular disease research. Circ. Cardiovasc. Imaging 1(2), 156–161 (2008).
Cavalcante, J. L., Lima, J. A., Redheuil, A. & Al-Mallah, M. H. Aortic stiffness: current understanding and future directions. J. Am. Coll. Cardiol. 57 (14), 1511–1522 (2011).
Klein, R. et al. Are retinal arteriolar abnormalities related to atherosclerosis? The atherosclerosis risk in communities study. Arterioscl Throm Vas. 20 (6), 1644–1650 (2000).
Liew, G. & Wang, J. J. [Retinal vascular signs: a window to the heart?]. Rev. Esp. Cardiol. 64 (6), 515–521 (2011).
Chang, J. et al. Association of Cardiovascular Mortality and Deep Learning-Funduscopic Atherosclerosis Score derived from Retinal Fundus Images. Am. J. Ophthalmol. 217, 121–130 (2020).
Steyerberg, E. W. et al. Assessing the performance of prediction models: a framework for traditional and novel measures. Epidemiology 21 (1), 128–138 (2010).
Moons, K. G. et al. Transparent Reporting of a multivariable prediction model for Individual Prognosis or Diagnosis (TRIPOD): explanation and elaboration. Ann. Intern. Med. 162 (1), W1–73 (2015).
Flammer, J. et al. The eye and the heart. Eur. Heart J. 34 (17), 1270–1278 (2013).
Roizenblatt, M., Naranjit, N., Maia, M. & Gehlbach, P. L. The Question of a Role for Statins in Age-Related Macular Degeneration. Int J. Mol. Sci 19(11). (2018).
Matsuoka, S. et al. Association of retinal atherosclerosis assessed using Keith-Wagener-Barker system with incident heart failure and other atherosclerotic cardiovascular disease: Analysis of 319,501 individuals from the general population. Atherosclerosis 348, 68–74 (2022).
Liu, Q. et al. Gender-Specific Association between Serum Uric Acid and Incident Fundus Arteriosclerosis in Chinese Population: A Retrospective Cross-Sectional Study. Sci. Rep. 10 (1), 8595 (2020).
Liu, Q. Q. et al. Gender-Specific Association Between Serum Uric Acid and Incident High Intraocular Pressure in Chinese Population: A Cross-Sectional Study. Invest Ophth Vis. Sci 61(11). (2020).
Ji, H. et al. Sex Differences in Myocardial and Vascular Aging. Circ. Res. 130 (4), 566–577 (2022).
Ferrando-Vivas, P. et al. Team IC-: Prognostic Factors for 30-Day Mortality in Critically Ill Patients With Coronavirus Disease 2019: An Observational Cohort Study. Crit. Care Med. 49 (1), 102–111 (2021).
Desai, M., Kubo, J., Esserman, D. & Terry, M. B. The handling of missing data in molecular epidemiology studies. Cancer Epidemiol. Biomarkers Prev. 20 (8), 1571–1579 (2011).
Royston, P. & Altman, D. G. External validation of a Cox prognostic model: principles and methods. BMC Med. Res. Methodol. 13, 33 (2013).
Graf, E., Schmoor, C., Sauerbrei, W. & Schumacher, M. Assessment and comparison of prognostic classification schemes for survival data. Stat. Med. 18 (17–18), 2529–2545 (1999).
Heagerty, P. J. & Zheng, Y. Survival model predictive accuracy and ROC curves. Biometrics 61 (1), 92–105 (2005).
Janssen, K. J., Moons, K. G., Kalkman, C. J., Grobbee, D. E. & Vergouwe, Y. Updating methods improved the performance of a clinical prediction model in new patients. J. Clin. Epidemiol. 61 (1), 76–86 (2008).
Moons, K. G. M. et al. Risk prediction models: II. External validation, model updating, and impact assessment. Heart 98 (9), 691–698 (2012).
Hafner, J., Zierfuss, B., H Schernthaner, G. & Schmidt-Erfurth, U. From the eye into the foot? Atherosclerosis 294, 41–43 (2020).
Zhang, W. et al. RETINAL MICROVASCULAR CHANGES AND RISK OF CORONARY HEART DISEASE: A Systematic Review and Meta-Analysis. Retina 44 (2), 333–344 (2024).
Jiang, Y. et al. Association of Retinal Arterial Narrowing With New-Onset Carotid Plaque: A Chinese Community-Based Nested Case-Control Cohort Study. J. Clin. Hypertens. (Greenwich). 27 (3), e14983 (2025).
Liu, C. et al. Sex-specific association between carotid atherosclerosis and fundus arteriosclerosis in a Chinese population: a retrospective cross-sectional study. Eur. J. Med. Res. 28 (1), 518 (2023).
Deal, J. A. et al. Retinal signs and risk of incident dementia in the Atherosclerosis Risk in Communities study. Alzheimers Dement. 15 (3), 477–486 (2019).
Matsuoka, S. et al. Association Between Blood Pressure Classification Using the 2017 ACC/AHA Blood Pressure Guideline and Retinal Atherosclerosis. Am. J. Hypertens. 34 (10), 1049–1056 (2021).
Meng, Y. et al. Association Between Folic Acid Supplementation and Retinal Atherosclerosis in Chinese Adults With Hypertension Complicated by Diabetes Mellitus. Front. Pharmacol. 9, 1159 (2018).
Soto, I., Krebs, M. P., Reagan, A. M. & Howell, G. R. Vascular Inflammation Risk Factors in Retinal Disease. Annu. Rev. Vis. Sci. 5, 99–122 (2019).
Fleckenstein, M. et al. Age-related macular degeneration. Nat. Rev. Dis. Primers. 7 (1), 31 (2021).
Yuen, V. L. et al. Effects of firsthand tobacco smoking on retinal vessel caliber: a systematic review and meta-analysis. Graefes Arch. Clin. Exp. Ophthalmol. 262 (5), 1397–1407 (2024).
Hsu, J., Johansen, K. L., Hsu, C. Y., Kaysen, G. A. & Chertow, G. M. Higher serum creatinine concentrations in black patients with chronic kidney disease: beyond nutritional status and body composition. Clin. J. Am. Soc. Nephrol. 3 (4), 992–997 (2008).
Booth, S. et al. Using temporal recalibration to improve the calibration of risk prediction models in competing risk settings when there are trends in survival over time. Stat. Med. 42 (27), 5007–5024 (2023).
Descallar, J., Ma, J., Zhu, H., Heritier, S. & Wolfe, R. Cause-specific hazard Cox models with partly interval censoring - Penalized likelihood estimation using Gaussian quadrature. Stat. Methods Med. Res. 33 (9), 1531–1545 (2024).
Dhande, I. S. & Doris, P. A. Genomics and Inflammation in Cardiovascular Disease. Compr. Physiol. 11 (4), 2433–2454 (2021).
Acknowledgements
We thank Dr. Chunxing Liu and Hua Dong Sanatorium for providing and granting access to the de-identified health examination cohort data used in this study.
Funding
This study was supported by the National Natural Science Foundation of China(82373688, 81773541), the Project of Jiangsu Province Engineering Research Centerof Molecular Target Therapy and Companion Diagnostics in Oncology, (No.SGK1202407), the Priority Academic Program Development of Jiangsu Higher Education Institutions at Soochow University, the State Key Laboratory of Radiation Medicine and Protection (GZK1201919), Jiangsu Key Laboratory of Preventive and Translational Medicine for Geriatric Diseases (KJS2222), and Suzhou Key Laboratory of Neuro-oncology and Nano-bionics (SZZD003),Jiangsu Province Engineering Research Center of Molecular Target Therapy and Companion Diagnostics in Oncology(SGK1202407).The funding institutions did not play any role in the design or conduct of this research; collection, management, analysis, and interpretation of the data, preparation, review, or approval of the manuscript; and decision to submit the manuscript for publication.
Author information
Authors and Affiliations
Contributions
Study conception and design: ZJ, XJQ, and TZXData collection and cleaning: ZJ, XJQ, WYY, GX, GYQ, WYMReal data analysis and interpretation: ZJ, GYQ, GX, WYM, and SJJDrafting of the manuscript: XJQ, SJJ, and TZXAll authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethics approval and consent to participate
The study was approved by the Ethics Committee of Hua Dong Sanatorium (No. 9, 2021), and all methods were carried out under relevant guidelines and regulations. The study was a retrospective cohort study. The informed consent was waived and the need for waiving the informed consent was also supported by the Ethical Committee of Hua Dong Sanatorium. The personal information of the study subjects was confidential.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhu, J., Xu, J., Gao, X. et al. Development and temporal validation of five year retinal arteriosclerosis risk prediction in high risk adults from an East China cohort. Sci Rep 16, 10835 (2026). https://doi.org/10.1038/s41598-026-42686-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-026-42686-7
