
Abstract
The acceleration of technological innovation is critical to the high-quality development of artificial intelligence clusters, and the formation and persistence of regional innovation cannot be separated from the government. This article adopts location quotient and social network analysis to identify artificial intelligence clusters in China. This paper then applies dynamic panel system generalised method of moments model to investigate the relationship between industry policies and technological innovation, and the moderating role of network centrality in this link. The results are as follows: First, twenty-nine artificial intelligence clusters are identified. Interregional cooperation is the main form of collaboration for these clusters. Second, industry policies can effectively promote technological innovation in the artificial intelligence clusters. Third, the high network centrality of clusters diminishes the positive influence of industry policies on technological innovation in the artificial intelligence clusters. This research focuses on the effectiveness of industry policies from a cluster perspective, which provides guidance for fostering innovation in artificial intelligence clusters.
Similar content being viewed by others

Introduction
Artificial intelligence (AI) serves as the core driving force behind the new wave of the Industrial Revolution and is expected to become a new engine for enhancing innovation efficiency (Li et al., 2023). The exceptional activities in global innovation within AI technology indicate that AI has become the focus of the attention and development of countries worldwide. Many countries have formulated development policies for the AI industry. For instance, the Select Committee on AI was established in the U.S. to accelerate the development of AI in 2018.Footnote 1 The 2021 Coordinated Plan on Artificial Intelligence aimed to promote the investment and policy adjustment of AI in the European Union.Footnote 2 In 2017, the Chinese government issued the New Generation of Artificial Intelligence Development Plan, pointing out that the competitiveness of the AI industry should reach the highest level in the world by 2030.Footnote 3 Further, clusters are important sources of regional competitive advantage (Porter, 2000). Since the knowledge externalities or spillovers caused by the geographical agglomeration of innovation are the reasons for the existence and success of clusters (Baptista and Swann, 1998), innovation has been regarded as a pivotal factor driving the progress of cluster development. AI innovation has developed pronounced clustering characteristics (e.g., Ho et al., 2021). Exploring ways to accelerate the development of AI clusters and enhance their innovation levels is highly important for driving industrial transformation and upgrading, as well as improving international competitive advantages.
Cluster innovation is considered a kind of network innovation (e.g., Kong et al., 2020). The global cluster network lens asserts the imperative of exploring interregional connections on a global scale beyond the singular local perspective (Bathelt and Li, 2014). Therefore, an AI cluster is a geographical innovation area formed through the local and translocal interactions of AI enterprises and related institutions. Moreover, a variety of methods, including location quotient (LQ) (e.g., Tian et al., 2020) and social network analysis (SNA) (e.g., Luo et al., 2023), have been applied to identify industrial clusters. The scientific and effective identification of clusters is thus a hot topic.
Innovation clusters, which serve as important drivers of national competitiveness and regional economic growth, have received extensive attention from policymakers globally (Kowalski, 2020). Under the mechanism of perfect competition, the phenomenon of market failure is inevitably encountered in the development of clusters. A well-positioned policymaker plays an indispensable role in compensating for market failures (Tian, 2020). Industry policies (IP) can generate innovative behaviours and enhance innovation capabilities (e.g., Zhao et al., 2019). Innovation thus serves as a crucial criterion for assessing the effectiveness of IP (Mallinson, 2021). However, policies may also lead to distortions in the allocation of innovation resources (Huang et al., 2024), exerting a negative impact on innovative activities. Therefore, when studying technological innovation (TI) within AI clusters, evaluating policy effectiveness is necessary, which provides a reference for the government in formulating cluster development plans.
A cluster is characterised as a complex network composed of firms, research institutions, and universities (Leydesdorff and Fritsch, 2006). As regions where knowledge production and knowledge spillovers coexist, AI clusters serve as effective spatial units for studying innovation network. Network centrality (NC) is a crucial metric that reflects the structure of a network and describes the extent to which a participant is closely connected to other participants (Chen et al., 2023). Based on social network theory, NC provides nodes with an advantage in acquiring knowledge and resources (Lubik et al., 2012), but maintaining this advantageous position necessitates continuous investment (Powell, 1998). Furthermore, the resources of a cluster must be allocated both vertically (intraregion) and horizontally (interregion). The current research on innovation networks among clusters is not comprehensive. Therefore, it is imperative to consider how TI is affected by IP under the influence of NC.
We propose the following research questions according to the above discussion: (1) Where are the AI clusters located? (2) How does IP affect TI within AI clusters? (3) What role does NC play in the aforementioned influence? The market scale of the AI industry in China will reach 1.73 trillion yuan ($240.4 billion) by 2035, which will account for 30.6% of the global total.Footnote 4 Therefore, we select China as an intriguing case with the aim of providing a reference for other countries. To be specific, by using patents from the AI industry in China from 2011 to 2020, this paper adopts LQ and SNA to identify AI clusters, and uses the dynamic panel system generalised method of moments (System-GMM) model to explore the influence of IP on TI and the moderating effect of NC.
This paper makes three contributions. First, scholars have identified clusters via LQ or SNA. However, few studies have concurrently combined these two methods to identify clusters. Based on the global cluster network lens, this paper identifies AI clusters from the perspectives of spatial agglomeration and innovation connection. This identification method simultaneously examines innovation linkages within and across regions. Second, previous research has paid attention to the impact of IP on industrial innovation. A unified conclusion remains elusive with regard to whether IP has a beneficial or adverse influence on innovation. In fact, efficient resource allocation can be achieved in clusters due to the integration of business processes among members (Gattorna, 2016). Clusters are more innovative than other regions (Porter, 2000). Clusters are therefore representative of the policy-innovation research framework. We uncover the positive effect of IP on TI from the perspective of clusters rather than that of the whole industry. Third, based on the establishment of interregional networks, this paper reveals that NC can negatively moderate the IP–TI link. Given the scarcity of NC as a moderator in the policy research field, our research contributes to a novel theoretical lens that elucidates the influence of social networks on the function of IP in clusters.
The rest of this paper is organised as follows: Section 2 “Theoretical foundation and mechanistic analysis” imparts the theoretical foundation and mechanistic analysis. The methodology, which includes the identification of clusters, variables, and an empirical approach, is given in Section 3 “Methodology”. The empirical results are shown in Section 4 “Empirical results”. Section 5 “Discussion” presents the discussion. The implications, limitations, and directions for future research are given in Section 6 “Implications, limitations and future research”. The conclusions are summarised in Section 7 “Conclusions”.
Theoretical foundation and mechanistic analysis
Theoretical foundation
Global cluster network lens
For high-tech industries, the network model has become a typical development pattern (Chen et al., 2023). Both intraregional and interregional collaboration can have a decisive impact on regional innovation (Sun and Cao, 2015). It is essential to establish and maintain an innovation network. A cluster is a complex network composed of firms, research institutions, and universities (Leydesdorff and Fritsch, 2006). Many scholars have emphasised the importance of interregional connections, arguing that understanding how to sustain competitiveness by transcending the boundaries of clusters is of paramount significance (e.g., Fitjar and Rodríguez-Pose, 2011). The global cluster network lens asserts the imperative of exploring interregional connections on a global scale beyond the singular local perspective (Bathelt and Li, 2014). This shift from a single cluster to multiple clusters is a deepening of “from local buzzing to global pipeline”.Footnote 5 This paper thereby defines an AI cluster as an innovation-agglomerated area formed through the local and translocal interactions of enterprises and related institutions in the AI sector.
Government intervention theory
Market failures are inevitable in the process of industrial development and evolution. It is hard for regions to foster industrial innovation solely by depending on market mechanisms, thus necessitating government intervention. The objective of government intervention is to enhance the effectiveness of the market mechanism in allocating resources. According to government intervention theory, there are two opposing viewpoints regarding the influence of government intervention on innovation. From a validity viewpoint, government intervention can alleviate the polarization of innovation resources generated by market failures, thus achieving the efficient allocation of innovative resources (Wonglimpiyarat, 2011). A number of current studies have confirmed the positive effect of government intervention on innovation in some high-tech industries. Lin and Luan (2020) and Li et al. (2022) reported the positive impact of government subsidies on innovation in the photovoltaic industry and the new energy vehicle industry, respectively. Lin and Chen (2023) noted that the feed-in tariff policy facilitated innovation in the wind power industry. On the contrary, the invalidity viewpoint suggests that market mechanisms may be disrupted by government intervention, leading to misallocations of innovative resources (Acemoglu et al., 2018). In particular, mismatches in innovative resource allocation are pronounced in high-tech industries, which are subject to government intervention (Zhang et al., 2021). Hong et al. (2016) contended that innovation efficiency could be weakened by government grants in high-tech industries. This conclusion was verified in the integrated circuit industry (e.g., Song and Wen, 2023). Although the IP–TI relationship is noteworthy, scholars have focused on the whole industry. The impact of IP on TI in the AI industry has not been discussed from a cluster perspective. Hence, it is imperative to explore how IP affects TI in AI clusters.
Social network theory
Social network theory proposes that the connections among interdependent social actors have a substantial influence on each actor in a network. In the high-tech sector, the number of various types of cooperative relationships between organizations is increasing (Vermeer and Thomas, 2020), forming intricate innovation networks, such as the innovation network of the integrated circuit industry (e.g., Chen et al., 2023). NC is a crucial metric that reflects the structure of a network, describing the extent to which a participant is closely connected to other participants (Chen et al., 2023). As higher NC facilitates the acquisition of information and knowledge from network neighbours (Yao et al., 2020), the NC of a cluster determines the extent and level of cooperation with other regions. Moreover, the central position requires significant investment to maintain (Powell, 1998). Network members need to continually invest in maintaining cooperative relationships from the perspective of the social costs involved in constructing a social network. Specifically, nodes with high centrality require long-term investments of capital and labour to maintain cooperation with other nodes (Wang et al., 2024). Hence, when studying the TI of AI clusters, the significant role of NC cannot be overlooked.
Above all, the TI of AI clusters cannot be separated from IP and NC, but whether IP and NC have beneficial or adverse influences on innovation remains puzzling. In the next section, we further explore the internal mechanism of the impact of IP on TI and the moderating role of NC.
Mechanistic analysis
Innovative activity in clusters is a complex process characterised by accumulation, continuity, long-term cycles, and high risk. IP influences resource allocation through both capital and labour, thereby promoting cluster innovation. In terms of capital, IP can directly impact innovation by filling funding gaps (e.g., Almus and Czarnitzki, 2003). Moreover, IP can convey economic signals to the market (Yan et al., 2022). More investors can be attracted by such signals to fund fields favoured by policies (Kleer, 2010; Wu, 2017), providing capital support for TI. In terms of labour, human resources serve as a critical factor for fostering innovation (Sanz-Valle and Jiménez-Jiménez, 2018). At present, the AI industry is confronted with a substantial talent deficit. In particular, there will be a shortage of four million people for AI roles in China by 2030.Footnote 6 On the one hand, talent introduction can inject outstanding professionals into the AI industry, thereby stimulating innovative vitality. On the other hand, incentive subsidies provide substantial compensation to talent, motivating individuals to accelerate the pace of innovation.
However, IP can lead to a misallocation of capital and labour, which is a main barrier to advancing the quality of TI (Huang et al., 2024). Government intervention hampers the free flow of capital from less productive enterprises to more productive ones, thereby allowing some less productive enterprises to remain profitable and survive at lower capital prices, which impedes the effective allocation of innovation capital in a cross-section, referred to as “connotation misallocation” (Banerjee and Moll, 2010). Policy bias can lead to “extension misallocation” due to the influence of the “survival of the fittest” process, which is characterised by a loss in innovative efficiency and a decline in innovative capability (Zhang et al., 2021). Moreover, policy intervention in labour mobility results in the distortion of labour allocation. Policy restrictions on the free flow of talent impede the conduct of innovative activities. Stringent labour market control diminishes the impetus for enterprise innovation by escalating the cost of talent. In particular, the negative effect of a distorted labour market is more pronounced in developing countries than in developed ones (Zhang et al., 2021).
In accordance with social network theory, NC provides nodes with an advantage in acquiring knowledge and resources (Lubik et al., 2012), but maintaining this advantageous position necessitates continuous investment (Powell, 1998). Capital and labour are two important inputs, and their levels are closely associated with IP (Fu and Mu, 2014). Hence, NC can influence the role of IP in fostering innovation. Social capital is divided into internal social capital (ISC) and external social capital (ESC). ISC refers to the resources provided by internal social relationships, whereas the connections of external relationships provide ESC. A well-developed external network is able to provide R&D resources for the internal network (Helble and Chong, 2004). That is, ESC can bring about more resources than ISC. Clusters with high centrality have more channels to acquire ESC, which directly facilitates the filling of funding gaps and the introduction of talent, while amplifying the economic signalling and talent incentive roles of IP. TI can thus be continually achieved. Nevertheless, clusters need to trade off the allocation of resources between intraregional and interregional activities. Interregional cooperation may crowd out local resources, resulting in a shortage of funds and a loss of talent within clusters. That is, clusters with high NC may not suffice to balance interregional collaboration, weakening the positive influence of IP on TI. To sum up, the moderating direction of NC depends on the interplay between the aforementioned two forces.
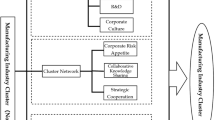
The mechanism of our paper is summarised in Fig. 1.

The figure is created using Microsoft Visio.
Methodology
Identification of clusters
Space unit selection
There are no clear criteria for defining the geographical boundaries of industrial clusters. Using spatial data based on administrative units to delineate the scope of clusters is an effective measure for quantitatively identifying industrial clusters (e.g., Brenner, 2006). In China, administrative regions at or above the prefecture level are commonly used as cluster boundaries.Footnote 7 Therefore, we select administrative regions at the prefecture level and above in the Chinese mainland as the spatial units.Footnote 8
Data source
Patents stand as a critical representation of innovation (Wang et al., 2024). According to the definition of AI clusters in Section “Global cluster network lens”, this article uses patents as the data for identifying AI clusters. The steps for acquiring data are given as follows:
Step 1: The Relationship Table of Strategic Emerging Industry Classification and International Patent Classification (2021) (Trial), released by the China National Intellectual Property Administration (CNIPA), lists the patent codes for the AI industry.Footnote 9 We retrieve patent applications on the patent platform of the CNIPA according to the patent codes.Footnote 10 Step 2: Since individuals do not contain address information, patents involving individual applicants are excluded. Step 3: To ensure the availability of data for regression analysis, we select patentees located in the Chinese mainland.
Moreover, the Decision of the State Council on Accelerating the Cultivation and Development of Strategic Emerging Industries, issued in October 2010, repeatedly emphasised smart manufacturingFootnote 11, which enhanced the development of the AI industry. Furthermore, there is a lag between the application and publication of patents. We thereby set the study period from 2011 to 2020. Ultimately, we obtain a total of 600,811Footnote 12 patents, of which 555,062 are independent patents and 45,749 are cooperative patents.Footnote 13,Footnote 14
Steps for identification
A broad range of research has identified and analysed clusters via different methods. Some scholars have used quantitative methods to identify clusters, such as LQ (e.g., Tian et al., 2020). Further, since the focus of research on innovation has switched from aggregate-level diffusion to social network (Muller and Peres, 2019), SNA has been applied to cluster research (e.g., Luo et al., 2023). In fact, agglomeration and network are two important dimensions for industrial clusters. The essence of clusters is an innovation network based on specialised agglomeration. Therefore, the identification of AI clusters should be considered comprehensively from the aspects of spatial agglomeration and industrial linkage. Referring to the study of Zhou et al. (2019), we use LQ and SNA to identify AI clusters. To be specific, there are three steps for identification.
-
Step 1. Delimiting the spatial agglomeration areas.
The LQ of innovation output can be used to determine whether there is innovation agglomeration in a region. The formula of LQ is presented as follows:
$${{\rm{LQ}}}_{{\rm{i}}}=\frac{\frac{{{\rm{A}}}_{{\rm{i}}}}{{{\rm{P}}}_{{\rm{i}}}}}{\frac{{\rm{A}}}{{\rm{P}}}}$$(1)where \({\rm{i}}\) represents region. \({{\rm{LQ}}}_{{\rm{i}}}\) is the location quotient of region \({\rm{i}}\). The number of patent applications of the AI industry in region \({\rm{i}}\) is denoted by \({{\rm{A}}}_{{\rm{i}}}\). \({{\rm{P}}}_{{\rm{i}}}\) is the number of patent applications in region \({\rm{i}}\). \({\rm{A}}\) represents the number of patent applications of the AI industry. \({\rm{P}}\) is the number of patent applications in the nation as a whole. Generally, a region with a value of LQ greater than 1 is considered to be specialised in a specific industry (Kowalewksi, 2015). The LQ of a region is measured through the mean number of patent applications from 2011 to 2020, which can avoid large fluctuations in data from a single year that discredit the results.
-
Step 2. Identifying the potential clusters.
The AI industry in some regions has a small scale and low innovation output. However, compared with other industries, the AI industry accounts for a larger proportion in these regions, resulting in a high value of LQ. These regions may be misperceived as potential clusters. Galliano et al. (2015) believed that potential clusters could be identified by setting a specialization threshold. Drawing on the research of (Zhou et al., 2019), we set the 80th percentile of patent applications across all regions as the lower threshold limit. Spatial agglomeration areas that do not reach the threshold are excluded, and the remaining regions are considered potential clusters.
-
Step 3. Measuring the innovation linkages of potential clusters.
Collaborative patents can share, overflow, and transfer technological knowledge, which is an open innovation of technological knowledge flow and innovation resource integration based on relational embeddedness. We match the addresses of the organizations that filed the joint patent applications with the space units (see Section “Space unit selection”). Networks between innovation organizations are transformed into intraregional and interregional networks containing potential clusters. This paper takes potential clusters that simultaneously have intraregional and interregional innovation linkages as AI clusters.
Variables
Dependent variable
Patents are categorised into three types in China: invention, utility model, and design (Chen et al., 2022). Invention patents pursue radical changes. Patents granted have to undergo specific processes of examination and approval, resulting in longer time delays (Wang and Wang, 2024). Comparatively, patent applications are more representative of innovative vitality, as they are more proximate to the time period during which innovation activities took place (Ai et al., 2024). TI is thus measured by the number of invention patent applications in this paper. Furthermore, to accurately quantify the level of TI, independent patents are counted directly by number. With respect to cooperative patents, the number of patents is divided equally according to the patentees. For instance, if there are three patentees for one patent, the TI of the cluster corresponding to each patentee is recorded as 1/3.
Independent variable
This paper uses the number of incentive policies enacted by local governments to measure IP (e.g., Wang et al., 2024). We search for policies in the Pkulaw database by using “Artificial Intelligence” as the keyword in the title and full text.Footnote 15 Policies in China are issued mostly in the form of local regulations and local government rules rather than laws. Therefore, local regulations and rules, as well as local working documents, are chosen as policy texts. We obtain 6758 policy texts from 2011 to 2020. Then, we match each policy to its corresponding cluster based on the document-making organ of the policy. For clusters that are not municipalities directly governed by the central government, the number of policy texts at the provincial level is summed up to the prefecture-level level.
Moderating variable
NC is selected as the moderating variable in this research. Closeness centrality, degree centrality, and betweenness centrality are three indicators used to evaluate NC. Although these three indicators can illustrate the role of nodes in a social network, their definitions and measurements are different. Closeness centrality assesses a node’s accessibility to all other nodes via the shortest paths (Crucitti et al., 2006). That is, the closeness centrality of a node indicates how quickly it can access other nodes. Moreover, the effective information acquisition and competitive advantage of a node can be achieved via closeness centrality (Kim, 2019). Therefore, closeness centrality is adopted to assess NC. The equation for closeness centrality is shown as follows (Chen et al., 2023):
where \({{\rm{NC}}}_{{\rm{i}}}\) stands for the closeness centrality of region \({\rm{i}}\). \({\rm{n}}\) is the overall region count. The shortest length connecting regions \({\rm{i}}\) and j is represented by \({{\rm{d}}}_{{\rm{ij}}}\). Regions with higher NC are more accessible to additional nodes.
Control variables
To circumvent the endogeneity concerns caused by city characteristics, this paper adds economic development (ED), infrastructure construction (IC), and innovation environment (IE) as control variables. The per capita gross domestic product can be used to measure ED (e.g., Gao and Yuan, 2022). The per capita road area is the metric for IC (e.g., Wang et al., 2022). Financial expenditures on science and technology act as positive elements that influence IE (Guo et al., 2024); thus, this research uses fiscal expenditures on science to express IE. The data for the control variables are derived from the “China Regional Economic Database” and the “China Urban Database” in the Express Professional Superior (EPS). The “China Urban Statistical Yearbook” and the “China Statistical Yearbook” help supplement missing data.
All the variables are logarithmically transformed before regression. Notably, some variables cannot carry out this transition directly since they contain at least one zero value. We add 1 to all of the values of the corresponding variables before logarithmic transformation (e.g., Chen and Wang, 2022b).
Empirical approach
To alleviate the estimation bias caused by endogeneity, this research utilizes the System-GMM method proposed by Blundell and Bond (1998) to investigate the impact of IP on TI and to identify the moderating role of NC in the IP–TI link. We construct the model shown in Eq. (3).
where the cluster is denoted by \({\rm{i}}\). \({\rm{t}}\) is the year. \({{\rm{TI}}}_{{\rm{it}}}\) represents TI, and \({{\rm{TI}}}_{{\rm{it}}-1}\) is the lagged one-period term of TI. \({{\rm{IP}}}_{{\rm{it}}}\) is IP. \({{\rm{NC}}}_{{\rm{it}}}\) refers to NC. The control variables are represented as Controlit. α0 is the constant term. \({{\rm{\eta }}}_{{\rm{i}}}\) denotes a fixed effect of cluster. The random error term is represented by \({{\rm{\varepsilon }}}_{{\rm{it}}}\).
Strictly exogenous instruments are not necessary when selecting lagged variables as instruments; thus the System-GMM method can address endogeneity issues (Chen and Wang, 2022b). Specifically, the lagged one-period term of the dependent variable is treated as the instrumental variable (IV) (e.g., Chen and Wang, 2022a). Referring to the practice of Ye and Liu (2020), we regard the lagged one-period term of the dependent variable and independent variable as endogenous variables, and control variables as exogenous variables. Two-step (System-GMM) methodology is adopted to estimate the coefficient values.
Furthermore, when the model does not include the moderating variable, the panel data are balanced. In the case of considering the moderating variable, since noncluster nodes are included in the innovation networks, we only put the data of cluster nodes into the regression after calculating the NC of each node within the networks. Panel data thus becomes unbalanced.Footnote 16 The interaction term of IP and NC (i.e., \({{\rm{IP}}}_{{\rm{it}}}* {{\rm{NC}}}_{{\rm{it}}}\)) is centralised before regression to ensure the estimation accuracy of the moderating effect (e.g., He et al., 2022).
Empirical results
Cluster identification
This research calculates the LQ of innovation output across the administrative regions in the AI industry. The results show that there are thirty-three cities whose LQ is greater than 1.Footnote 17 Four regions (Fuxin, Jilin, Sanya, and Shanwei) that do not meet the threshold of the innovation scale are excluded.Footnote 18 The twenty-nine retained regions (Beijing, Shenzhen, Nanjing, Hangzhou, Xi’an, Shanghai, Wuhan, Harbin, Zhuhai, Guangzhou, Guilin, Jinan, Chengdu, Hefei, Changsha, Nanchang, Qinhuangdao, Shenyang, Changchun, Fuzhou, Xiamen, Mianyang, Kunming, Dalian, Dongguan, Chongqing, Tianjin, Taiyuan, and Zhengzhou) are regarded as potential AI clusters. The potential AI clusters are illustrated in Fig. 2.

The figure is drawn using Microsoft Excel.
To investigate the local and external innovation connections of potential AI clusters, we calculate the total volume of intraregional and interregional collaborations for these clusters, respectively. The outcomes are depicted in Table 1. The high total volume of intraregional collaborations in clusters such as Beijing, Shenzhen, Nanjing, Guangzhou, Shanghai, Hangzhou, Zhuhai, Wuhan, Chengdu, Tianjin, Jinan, and others indicates their focus on internal innovation activities. The high total volume of interregional collaborations among clusters such as Beijing, Nanjing, Shenzhen, Hangzhou, Shanghai, Guangzhou, Wuhan, Chengdu, Jinan, Tianjin, Nanchang, Hefei, and others indicates their emphasis on external resource acquisition. In conclusion, all twenty-nine potential AI clusters have both intraregional and interregional innovation collaborations, satisfying the criteria for cluster identification.
Because the total volume of interregional collaborations exceeds that of intraregional collaborations in each AI cluster, we can conclude that interregional cooperation is the main form of collaboration for AI clusters. Further, the innovation network of interregional cooperation is constructed in this research. To be specific, we match each region involved in interregional cooperation patents with other regions.Footnote 19 Connections containing the AI clusters are regarded as network edges. Using the total collaboration volume as the weight of network nodes and the number of collaborations as the weight of network edges, we depict the innovation network for the AI clusters in Fig. 3. We find that the innovation network containing the AI clusters is highly dense. Beijing occupies an absolutely central position. The roles of Nanjing, Hangzhou, and Shanghai as significant cities in Eastern China are prominently highlighted. Shenzhen and Guangzhou, two major cities in Southern China, serve as pivotal hubs. Wuhan and Chengdu, representing Central and Western China, respectively, actively engage in innovation collaborations with other areas.

The figure is generated in VOSviewer software.
Descriptive statistics
This study performs descriptive statistics for all the variables. The outcomes are displayed in Table 2. The mean values of TI, IP, and NC are 5.898, 2.006, and 2.682, respectively. Moreover, the standard deviations of TI and IP are relatively high, which elucidates that gaps in both TI and IP exist across different AI clusters.
Correlation analysis
We observe a positive correlation between IP and TI from Table 3, which indicates that IP may enhance TI in the AI clusters. The correlation coefficients between each variable are less than 0.800. In addition, this research conducts a variance inflation factor (VIF) test. The maximum VIF of 3.410 is lower than 10, illustrating that there is no severe concern about multicollinearity in this study (e.g., Chen et al., 2024).
Regression analysis
The results of regression analysis of IP and TI are reported in Table 4. All p-values of AR(1) are less than 0.1, while those of AR(2) are greater than 0.1, indicating the presence of first-order autocorrelation but the absence of second-order autocorrelation in the random disturbance term. We thus accept the null hypothesis of “no autocorrelation in the random disturbance term”. Furthermore, the p-values of the Sargan test are all greater than 0.1, which illustrates that the problem of overidentification of instrumental variables does not exist, thereby allowing for estimation using System-GMM.
Model l contains only the control variables. The results displayed in Model 2 indicate that the coefficient of IP on TI is 0.037 and significant. IP can promote TI in the AI clusters. That is, the positive effects of IP on TI dominate over the negative ones. Moving on to Model 3, the interaction between IP and NC (i.e., IP*NC) is significantly negative, which illustrates that the high NC of clusters diminishes the positive impact of IP on TI in the AI clusters. Further, this paper visualizes the moderating effect of NC on the IP–TI connection. As shown in Fig. 4, IP responds to less TI with a high value of NC.

The figure is produced using Microsoft Excel.
Robustness checks
Sensitivity analysis
Quartiles are a scientifically and widely used classification method. In this section, we use the third quartile (i.e., the 75th percentile) instead of the 80th percentile for reidentifying potential clusters. The 75th percentile of patent applications for all regions is 386. The four regions (Fuxin, Jilin, Sanya, and Shanwei) are still excluded (see Supplementary Table B), which is consistent with the conclusion in Section “Cluster identification”. In addition, to avoid overlapping with the 75th percentile, we allow a fluctuation of ±4 percentage points around the 80th percentile and conduct multiple tests between the 76th and 84th percentiles. The results are shown in Fig. 5. The threshold for patent applications falls between 374 and 969 when a certain degree of error exists, and the aforementioned four regions remain excluded. Therefore, the conclusion of the twenty-nine AI clusters identified in this paper is robust.

The figure is produced using Microsoft Excel.
Placebo test
Conducting a placebo test serves to rule out the possibility that random factors unrelated to IP account for the observed effects, thereby guaranteeing a more reliable estimation. Drawing on the study of Zeng et al. (2024), we randomly shuffle IP across all clusters and then estimate the impact of randomly assigned IP on TI using System-GMM regression. This procedure is repeated 1000 times. If the correlation between IP and TI still exists, the previous conclusions are due to randomness rather than IP. The kernel density of the estimated coefficients plotted in Fig. 6 indicates that the coefficient of IP is 0.002, which is far from the real IP coefficient of 0.037. Therefore, the improvement of TI is driven by IP, not by random factors.

The red solid line represents the random IP coefficient, whereas the red dotted line denotes the real IP coefficient. The figure is produced using Stata software.
Policy penetration
Measuring IP by the number of incentive policies may not reflect implementation rigor. Enterprises act as the principal agents of innovation (Lei and Xie, 2023). To assess the impact of IP more accurately, we examine whether IP effectively reaches enterprises in practice. To be specific, the penetration process for IP is achieved in the following sequence: the release of IP documents, the government support (GS) obtained by enterprises, and the generation of TI. Drawing on the study of Xu et al. (2023), this article constructs the following mediation effect model:
where \({{{\rm{TI}}}^{\wedge}}_{\rm{jt}}\) represents the number of invention patent applications of enterprise \({\rm{j}}\) in year \({\rm{t}}\). \({{\rm{IP}}}_{{\rm{jt}}}\) is the number of incentive policies in the cluster where enterprise \({\rm{j}}\) is located. \({{\rm{GS}}}_{{\rm{jt}}}\) is measured by the government subsidies of enterprise \({\rm{j}}\) (e.g., Chen and Wang, 2022b). \({\text{Control}}_{\text{jt}}\) represents control variables, including enterprise profitability (EP), capital structure (CS), and operating capacity (OC). EP is calculated by the return on total assets (e.g., Chen and Wang, 2022a). The asset‒liability ratio stands for CS (e.g., Peng and Tao, 2022). OC is represented by the asset turnover ratio (e.g., Xu and Chen, 2020). The other symbols serve the same purpose as Eq. (3).
The mediation mechanism is plotted in Fig. 7. If the coefficients c, a, and b are all significant, GS has a mediating effect (Zhong and Zhang, 2024).

The figure is created using Microsoft Visio.
We acquire an AI enterprise list from the China Stock Market and Accounting Research (CSMAR) database.Footnote 20 Based on geographical location, we select 125 firms within clusters as our research samples.Footnote 21 The enterprise data come from the CSMAR database. System-GMM estimation is applied to investigate the mediating impact of GS. As displayed in Table 5, all p-values for AR(1) are less than 0.1, while those for AR(2) and the Sargan test exceed 0.1; thus, the adoption of System-GMM is appropriate. The results show that the coefficients for IP → TI^, IP → GS, and GS → TI^ are all significantly positive at the 1% level. Hence, IP promotes TI^ by strengthening GS. The conclusion verifies the penetration effect of IP.
Changing the regression model
Poisson regression is usually used for models where the dependent variable is count data. In this study, the dependent variable is “excessively dispersed”, i.e., the mean is less than the variance.Footnote 22 We thereby adopt negative binomial regression. The results displayed in Table 6 indicate that the coefficient of IP is significantly positive and that the coefficient of interaction between IP and NC is significantly negative. Therefore, the empirical outcomes of this research are reliable.
Discussion
First, considering that SNA is based on the global cluster network lens, this paper recognizes twenty-nine AI clusters from the perspectives of spatial agglomeration and innovation connections. In fact, the clusters identified in this paper show some alignment with the AI regions currently prioritised for development in China. For instance, the National New Generation AI Innovation and Development Pilot Zones and the National AI Innovation and Application Pilot Zones mainly take the clusters identified as the core bearing areas.Footnote 23,Footnote 24 Nearly half of China’s listed AI companies are concentrated in the twenty-nine AI clusters. Moreover, we discover that interregional innovation collaborations outnumber intraregional ones for every AI cluster. Unlike traditional cluster theory’s emphasis on geographically proximate intraregional collaboration, our findings highlight the critical role of interregional linkages in forming clusters. An investigation into the innovation performance of southwestern Norway provides support for our conclusion (Fitjar and Rodríguez-Pose, 2011). Hence, the validity of the global cluster network lens and the rationality of the joint identification method are elucidated.
Second, this paper reveals that IP can promote TI in the AI clusters. This positive relationship was verified in the photovoltaic industry (e.g., Lin and Luan, 2020), the new energy vehicle industry (e.g., Li et al., 2022), and the wind power industry (e.g., Lin and Chen, 2023). In contrast, financial subsidies inhibited TI in the integrated circuit industry (e.g., Song and Wen, 2023). As each industry displays its own specificity in terms of innovative development, the impact of IP on TI exhibits industry heterogeneity (Wang et al., 2024). Specifically, encompassing frontier fields such as machine learning, deep learning, and natural language processing, the AI industry is characterised by great difficulty and uncertainty. Experiences from various nations (e.g., Canada, South Korea, and the UK) indicate that the AI industry requires robust policy support to ensure adequate provision of capital and labour (Lauterbach, 2019), which provides clues for understanding the mechanism between IP and TI. Further, we examine the penetration effect of IP (see Section “Policy penetration”), confirming our findings from the perspective of enterprises.
Third, this paper takes NC into the research framework of IP and TI. As discussed in Section “Mechanistic analysis”, the moderating direction of NC is uncertain. Some studies have shown that NC is conducive to the development of innovation by exerting a moderating effect (e.g., Shi and Zhang, 2019). However, our study reaches the opposite conclusion, suggesting that high NC is not always advantageous, which is consistent with the viewpoint of Lyu et al. (2020) and Lu et al. (2023). In fact, cultivating innovation in the AI sector requires substantial capital and highly skilled labour. On the one hand, clusters with high NC are predominantly situated in relatively developed regions. Procedures for obtaining ESC are more complex in these regions, such as multiple approval steps for capital absorption and rigorous talent qualification standards, resulting in diminished efficiency in acquiring ESC. On the other hand, regions collaborating with high-NC clusters are comparatively less developed. These regions absorb ESC by lowering resource access thresholds and simplifying procedures, which accelerates capital shortage and brain drain in high-NC clusters. Therefore, the crowding-out effect in resource allocation caused by interregional cooperation exceeds the power of ESC acquisition, manifesting as a negative moderation effect of NC.
Implications, limitations and future research
Theoretical implications
Several theoretical implications are presented as follows: First, this paper identifies AI clusters from the perspectives of spatial agglomeration and innovation connections. This approach moves beyond two strands of literature: (1) agglomeration-based cluster research (e.g., Tian et al., 2020) and (2) SNA for cluster studies (e.g., Luo et al., 2023). This synthesis probes the domain of innovation linkages among clusters to validate the global cluster network lens. Second, our concern for AI clusters unquestionably aids in further understanding this pioneering industry. This paper extends beyond the current research on the IP–TI link, which focuses on the entire industry (e.g., Lin and Luan, 2020; Li et al., 2022; Lin and Chen, 2023; Song and Wen, 2023). By identifying the positive IP–TI nexus from a cluster perspective, this research expands government intervention theory in the field of AI clusters. Third, this paper highlights the significance of NC in the IP–TI link. Given the scarcity of NC as a moderator in the policy research field, the findings contribute to a novel theoretical lens that elucidates the influence of social networks on the role that IP plays in TI for clusters, which deepens the conceptual grasp of social network theory.
Practical implications
Some practical implications can be drawn. On the one hand, the positive IP–TI connection has been verified in this paper; thus, government power should be injected into the development of AI clusters. Regarding capital, government-led AI industry funds should be established to finance strategic R&D initiatives in core technologies. With respect to labour, the government should attract talent to the AI industry through measures such as targeted talent subsidies while enhancing career advancement mechanisms and recognition systems to stimulate innovative vitality. Moreover, AI clusters should seek the support of IP. For example, organizations within clusters could establish a regular communication mechanism to accurately convey industrial demands to government departments. Enterprises should leverage their collective technological strengths to actively secure industry-specific development funds. On the other hand, since NC is not conducive to the beneficial effect of IP on TI, the government should encourage innovation cooperation within AI clusters by providing special subsidies for joint R&D projects, establishing industry-university-research cooperation platforms, and instituting structured knowledge-sharing forums. Governments should conduct regular analysis of intra- and interregional innovation cooperation and dynamically adjust IP according to the imbalance of cooperation. In addition, AI clusters must reasonably trade off the allocation of resources between intraregional and interregional activities. Organizations within clusters should focus on fostering internal innovation cooperation. If interregional cooperation is necessary, evaluating and seeking potential partners based on R&D alignment and technological complementarity can reduce the costs of innovation.
Limitations and future research
This research has several limitations, and future research can be improved in the following aspects: First, owing to data availability constraints, we measure TI solely based on invention patent applications. However, TI in the AI industry is inherently multifaceted. Future research could collect primary data to comprehensively measure TI by supplementing with indicators, such as R&D outputs, commercial performance, and practical technological applications. Second, this study identifies only AI industry clusters. We encourage future research to extend the research framework to other high-tech industries, such as nanotechnology and 3D printing. Third, owing to space limitations, this paper detects only the moderating effect of NC in the IP–TI link. Future research could further investigate other moderating factors, such as structural holes, which also serves as an important indicator reflecting network characteristics. Fourth, IP possesses the distinctive features of China in this paper. Whether the research conclusions are applicable to other countries and regions remains uncertain. For comparison with the findings of our study, further research requires utilising datasets from other countries and regions to obtain additional empirical evidence. Finally, this study focuses on investigating whether IP can influence TI. We do not consider the humanistic implications of technological advancements. To advance AI innovation, researchers are encouraged to examine human-machine interaction—a key frontier in AI research (e.g., Schleidgen et al., 2023; Ho and Vuong, 2024).
Conclusions
This paper starts from a global concern about how to accelerate the development of AI clusters and enhance their innovation levels. The formation and persistence of regional innovation cannot be separated from the government. The innovation behaviour of clusters is considered a kind of network innovation, and the resources of a cluster must be allocated both vertically (intraregion) and horizontally (interregion). We aim to detect where the AI clusters are located, whether and how IP affects TI, and how NC moderates this relationship. By using patents from the AI industry in China from 2011 to 2020, this paper adopts the LQ and SNA to identify industrial clusters. We then apply System-GMM estimation to explore the influence of IP on TI and the moderating role of NC in the IP–TI connection. The findings are as follows: First, twenty-nine AI clusters are identified. Interregional cooperation is the main form of collaboration for AI clusters. Second, IP can effectively increase the level of TI in the AI clusters. Third, the high NC of clusters diminishes the positive impact of IP on TI in the AI clusters. Our study makes three contributions. First, based on the global cluster network lens, this paper identifies AI clusters from the perspectives of spatial agglomeration and innovation connection, which simultaneously examines innovation linkages within and across regions. Second, according to government intervention theory, we uncover the positive effect of IP on TI from the perspective of clusters rather than that of the whole industry and address the gap in knowledge about the IP–TI connection in the AI industry. Third, given the scarcity of NC as a moderator in the policy research field, our research offers a novel theoretical lens that elucidates the influence of social networks on the function of IP in clusters.
Data availability
All data are obtained from official reports and databases available online, and their sources are described in this published article. The authors are not authorised to disclose the raw data, but the processed datasets generated and/or analysed during the current study are available from the corresponding authors on reasonable request.
Notes
Content is available at https://bidenwhitehouse.archives.gov/ostp/ostps-teams/nstc/select-committee-on-artificial-intelligence (accessed 7 May, 2025).
Coordinated Plan on Artificial Intelligence 2021 Review. Content is available at https://digital-strategy.ec.europa.eu/en/library/coordinated-plan-artificial-intelligence-2021-review (accessed 7 May, 2025).
The State Council Issues the “New Generation Artificial Intelligence Development Plan”. Content is available at https://www.gov.cn/xinwen/2017-07/20/content_5212064.htm (accessed 7 May, 2025).
China AI industry to see scale reach over $240b. Content is available at https://govt.chinadaily.com.cn/s/202401/18/WS65aced22498ed2d7b7ea5f29/china-ai-industry-to-see-scale-reach-over-240b.html (accessed 7 May, 2025).
The school of relational economic geography proposed the “local buzz-global pipelines” theoretical model, paying attention to the coupling of knowledge networks at different spatial scales of “local-global” (Bathelt et al. (2004)).
How businesses can close China’s AI talent gap. Content is available at https://www.mckinsey.com/capabilities/quantumblack/our-insights/how-businesses-can-close-chinas-ai-talent-gap (accessed 7 May, 2025).
For example, the National Development and Reform Commission of China announced the first batch of 66 national-level strategic emerging industry clusters in December 2019. With the exception of a few clusters that use economic zones or high-tech zones within cities as their boundaries, over 90% of these 66 clusters are directly based on administrative regions at or above the prefecture level. The list is available at https://jxjr.jiangxi.gov.cn/jxsdfjrjdglj/col/col14218/content/content_1864601431765647360.html (accessed 7 May, 2025).
Due to changes in administrative areas, we chose administrative areas in 2020 as the delineation criterion. The list can be obtained at https://www.mca.gov.cn/mzsj/xzqh/2020/20201201.html (accessed 7 May, 2025).
The content of the document can be found at https://www.cnipa.gov.cn/art/2021/2/9/art_543_156705.html (accessed 7 May, 2025).
The identification of AI clusters should consider industrial linkage (see Section “Steps for identification”). We use patent applications rather than patents granted because there is already a connection between different organizations at the application stage. Furthermore, the website of the patent platform of the CNIPA is https://pss-system.cponline.cnipa.gov.cn (accessed 7 May, 2025).
The content of the document can be found at https://www.gov.cn/zwgk/2010-10/18/content_1724848.htm (accessed 7 May, 2025).
All commas in numerical values within this article serve as thousand separators, while dots function as decimal markers.
Following the approach of Wang et al. (2024), collaborative patents are defined by the presence of multiple patentees. Specifically, a cooperative patent must list entities such as companies, universities, or research institutions as joint applicants
The number of patents is counted by the number of first patentees. For example, if a patent has two patentees, we consider it to be one patent, not two.
The Pkulaw database is the largest law and regulatory database in China (Wang et al. (2024)). Moreover, the website of the database is https://www.pkulaw.com (accessed 7 May, 2025).
Real-world network is dynamic. Clusters may emerge or fade within a network, which dynamically describes compositions and interactions. We establish innovation networks for each year, containing AI clusters, as a way to calculate the NC of clusters. The metric for NC can be reviewed in Section “Moderating variable”.
LQ for each region can be found in Supplementary Table A.
The 80th percentile of patent applications for all regions is 598.6. Furthermore, the innovation scale of regions with LQ greater than 1 can be found in Supplementary Table B.
For example, if a patent is jointly applied by three patentees, A, B, and C, then three undirected connections are formed: A-B, A-C, and B-C. Then, a collaboration network can be constructed by geolocating each patentee within its corresponding administrative region.
The CSMAR database is a specialised database for Chinese enterprise research (Chen et al., 2022).
To maintain balanced panel data in regression analysis, we eliminate samples with missing data.
Since the dependent variable is a count variable, logarithmic transformation is not applied during regression. Therefore, we calculate the mean and variance of TI without taking the logarithm, which are 1,433.433 and 11,026,756.270, respectively.
The number of National New Generation Artificial Intelligence Innovation and Development Pilot Zones has reached seventeen. Content is available at https://www.gov.cn/xinwen/2021-12/06/content_5657953.htm (accessed 7 May 2025).
Chinese tech giants gravitate toward ChatGPT-like products, services. Content is available at https://www.chinadaily.com.cn/a/202302/15/WS63ec50c8a31057c47ebaeed1.html (accessed 7 May 2025).
References
Acemoglu D, Akcigit U, Alp H, Bloom N, Kerr W (2018) Innovation, reallocation, and growth. Am Econ Rev 108(11):3450–3491. https://doi.org/10.1257/aer.20130470
Ai H, Islam N, Kumar Mangla S, Song M, Tan X (2024) Circular economy, open innovation, and green innovation: empirical evidence from prefecture-level cities in China. IEEE Trans Eng Manag 71:5706–5719. https://doi.org/10.1109/tem.2024.3357350
Almus M, Czarnitzki D (2003) The effects of public R&D subsidies on firms’ innovation activities: the case of Eastern Germany. J Bus Econ Stat 21(2):226–236. https://doi.org/10.1198/073500103288618918
Banerjee AV, Moll B (2010) Why does misallocation persist? Am Econ J Macroecon 2(1):189–206. https://doi.org/10.1257/mac.2.1.189
Baptista R, Swann P (1998) Do firms in clusters innovate more? Res Policy 27(5):525–540. https://doi.org/10.1016/s0048-7333(98)00065-1
Bathelt H, Li PF (2014) Global cluster networks-foreign direct investment flows from Canada to China. J Econ Geogr 14(1):45–71. https://doi.org/10.1093/jeg/lbt005
Bathelt H, Malmberg A, Maskell P (2004) Clusters and knowledge: local buzz, global pipelines and the process of knowledge creation. Prog Hum Geogr 28(1):31–56. https://doi.org/10.1191/0309132504ph469oa
Blundell R, Bond S (1998) Initial conditions and moment restrictions in dynamic panel data models. J Econ 87(1):115–143. https://doi.org/10.1016/s0304-4076(98)00009-8
Brenner T (2006) Identification of local industrial clusters in Germany. Reg Stud 40(9):991–1004. https://doi.org/10.1080/00343400601047408
Chen J, Wang TC (2022a) Government subsidies, R&D expenditures and overcapacity: empirical analysis in photovoltaic companies. Chin Manag Stud 17(2):343–364. https://doi.org/10.1108/cms-08-2021-0349
Chen QL, Gong ZY, Wu JF, Wang TC (2024) Does digital transformation affect carbon performance through talent? The moderating role of employee structure. J Clean Prod 435:140581. https://doi.org/10.1016/j.jclepro.2024.140581
Chen QL, Sun T, Wang TC (2022) Synergy effect of talent policies on corporate innovation—evidence from China. Front Psychol 13:1069776. https://doi.org/10.3389/fpsyg.2022.1069776
Chen QL, Sun T, Wang TC (2023) Network centrality, support organizations, exploratory innovation: empirical analysis of China’s integrated circuit industry. Heliyon 9(7):e17709. https://doi.org/10.1016/j.heliyon.2023.e17709
Chen QL, Wang TC (2022b) Government support, talent, coupling of innovation chain and capital chain: empirical analysis in integrated circuit enterprises. Chin Manag Stud 17(4):883–905. https://doi.org/10.1108/cms-10-2021-0447
Crucitti P, Latora V, Porta S (2006) Centrality in networks of urban streets. Chaos Interdiscip J Nonlinear Sci 16(1):015113. https://doi.org/10.1063/1.2150162
Fitjar RD, Rodríguez-Pose A (2011) Innovating in the periphery: firms, values and innovation in Southwest Norway. Eur Plan Stud 19(4):555–574. https://doi.org/10.1080/09654313.2011.548467
Fu XL, Mu RP (2014) Enhancing China’s innovation performance: the policy choices. China World Econ 22(2):42–60. https://doi.org/10.1111/j.1749-124X.2014.12061.x
Galliano D, Magrini MB, Triboulet P (2015) Marshall’s versus Jacobs’ externalities in firm innovation performance: the case of French Industry. Reg Stud 49(11):1840–1858. https://doi.org/10.1080/00343404.2014.950561
Gao K, Yuan Y (2022) Government intervention, spillover effect and urban innovation performance: empirical evidence from national innovative city pilot policy in China. Technol Soc 70:102035. https://doi.org/10.1016/j.techsoc.2022.102035
Gattorna J (2016) Dynamic supply chain alignment: a new business model for peak performance in enterprise supply chains across all geographies. CRC Press
Guo Q, Wang H, Lu X, Qu L (2024) Effects of innovation environment on carbon intensity: the moderating role of information industry. Int Rev Econ Financ 92:967–977. https://doi.org/10.1016/j.iref.2024.02.059
He ZX, Cao CS, Kuai LY, Zhou YQ, Wang JM (2022) Impact of policies on wind power innovation at different income levels: regional differences in China based on dynamic panel estimation. Technol Soc 71:102125. https://doi.org/10.1016/j.techsoc.2022.102125
Helble Y, Chong LC (2004) The importance of internal and external R&D network linkages for R&D organisations: evidence from Singapore. R D Manag 34(5):605–612. https://doi.org/10.1111/j.1467-9310.2004.00366.x
Ho M-T, Mantello P, Nguyen H-KT, Vuong Q-H (2021) Affective computing scholarship and the rise of China: a view from 25 years of bibliometric data. Humanit Soc Sci Commun 8(1). https://doi.org/10.1057/s41599-021-00959-8
Ho M-T, Vuong Q-H (2024) Five premises to understand human–computer interactions as AI is changing the world. Ai Soc 40(2):1161–1162. https://doi.org/10.1007/s00146-024-01913-3
Hong J, Feng B, Wu YR, Wang LB (2016) Do government grants promote innovation efficiency in China’s high-tech industries? Technovation 57-58:4–13. https://doi.org/10.1016/j.technovation.2016.06.001
Huang XL, Wang XY, Ge PF (2024) Selective industrial policy and innovation resource misallocation. Econ Anal Policy 82:124–146. https://doi.org/10.1016/j.eap.2024.02.034
Kim D-Y (2019) Closeness centrality: a social network perspective. J Int Interdiscip Bus Res 6(1):115–122. https://scholars.fhsu.edu/jiibr/vol6/iss1/8
Kleer R (2010) Government R&D subsidies as a signal for private investors. Res Policy 39(10):1361–1374. https://doi.org/10.1016/j.respol.2010.08.001
Kong XD, Xu Q, Zhu T (2020) Dynamic evolution of knowledge sharing behavior among enterprises in the cluster innovation network based on evolutionary game theory. Sustainability 12(1):75. https://doi.org/10.3390/su12010075
Kowalewksi J (2015) Regionalization of national input-output tables: empirical evidence on the use of the FLQ formula. Reg Stud 49(2):240–250. https://doi.org/10.1080/00343404.2013.766318
Kowalski AM (2020) Towards an Asian model of clusters and cluster policy: the super cluster strategy. J Compet 12(4):74–90. https://doi.org/10.7441/joc.2020.04.05
Lauterbach A (2019) Artificial intelligence and policy: quo vadis? Digit Policy Regul Gov 21(3):238–263. https://doi.org/10.1108/dprg-09-2018-0054
Lei T, Xie P (2023) Fostering enterprise innovation: the impact of China’s pilot free trade zones. J Knowl Econ 15(3):10412–10441. https://doi.org/10.1007/s13132-023-01501-8
Leydesdorff L, Fritsch M (2006) Measuring the knowledge base of regional innovation systems in Germany in terms of a Triple Helix dynamics. Res Policy 35(10):1538–1553. https://doi.org/10.1016/j.respol.2006.09.027
Li CM, Xu Y, Zheng H, Wang ZY, Han HT, Zeng LE (2023) Artificial intelligence, resource reallocation, and corporate innovation efficiency: evidence from China’s listed companies. Resour Policy 81:103324. https://doi.org/10.1016/j.resourpol.2023.103324
Li H, Qi H, Cao H, Yuan L (2022) Industrial policy and technological innovation of new energy vehicle industry in China. Energies 15(24). https://doi.org/10.3390/en15249264
Lin B, Chen Y (2023) Impact of the feed-in tariff policy on renewable innovation: evidence from wind power industry and photovoltaic power industry in China. Energy J 44(2):29–46. https://doi.org/10.5547/01956574.44.2.blin
Lin BQ, Luan RR (2020) Do government subsidies promote efficiency in technological innovation of China’s photovoltaic enterprises? J Clean Prod 254:120108. https://doi.org/10.1016/j.jclepro.2020.120108
Lu C, Liu Z, Liao S, Xu Y, Fu L (2023) Is an imitation strategy an enabler or a hindrance for exploitative or exploratory innovation?—The moderating effect of embeddedness in knowledge networks. IEEE Trans Eng Manag 70(8):2955–2967. https://doi.org/10.1109/tem.2022.3208750
Lubik S, Lim S, Platts K, Minshall T (2012) Market‐pull and technology‐push in manufacturing start‐ups in emerging industries. J Manuf Technol Manag 24(1):10–27. https://doi.org/10.1108/17410381311287463
Luo YC, Zheng JZ, Ma J (2023) Research on innovation features and optimization strategies of industrial clusters from the perspective of TLCN. Kybernetes 52(10):3965–3985. https://doi.org/10.1108/k-01-2022-0055
Lyu Y, Zhu Y, Han S, He B, Bao L (2020) Open innovation and innovation “Radicalness”—the moderating effect of network embeddedness. Technol Soc 62. https://doi.org/10.1016/j.techsoc.2020.101292
Mallinson DJ (2021) Policy innovation adoption across the diffusion life course. Policy Stud J 49(2):335–358. https://doi.org/10.1111/psj.12406
Muller E, Peres R (2019) The effect of social networks structure on innovation performance: a review and directions for research. Int J Res Mark 36(1):3–19. https://doi.org/10.1016/j.ijresmar.2018.05.003
Peng Y, Tao C (2022) Can digital transformation promote enterprise performance?—From the perspective of public policy and innovation. J Innov Knowl 7(3). https://doi.org/10.1016/j.jik.2022.100198
Porter ME (2000) Location, competition, and economic development: local clusters in a global economy. Econ Dev Q 14(1):15–34. https://doi.org/10.1177/089124240001400105
Powell WW (1998) Learning from collaboration: knowledge and networks in the biotechnology and pharmaceutical industries. Calif Manag Rev 40(3):228–240. https://doi.org/10.2307/41165952
Sanz-Valle R, Jiménez-Jiménez D (2018) HRM and product innovation: does innovative work behaviour mediate that relationship? Manag Decis 56(6):1417–1429. https://doi.org/10.1108/Md-04-2017-0404
Schleidgen S, Friedrich O, Gerlek S, Assadi G, Seifert J (2023) The concept of “interaction” in debates on human–machine interaction. Humanit Soc Sci Commun 10(1). https://doi.org/10.1057/s41599-023-02060-8
Shi X, Zhang Q (2019) Network inertia and inbound open innovation: is there a bidirectional relationship? Scientometrics 122(2):791–815. https://doi.org/10.1007/s11192-019-03321-7
Song L, Wen YT (2023) Financial subsidies, tax incentives and technological innovation in China’s integrated circuit industry. J Innov Knowl 8(3):100406. https://doi.org/10.1016/j.jik.2023.100406
Sun YT, Cao C (2015) Intra- and inter-regional research collaboration across organizational boundaries: evolving patterns in China. Technol Forecast Soc Change 96:215–231. https://doi.org/10.1016/j.techfore.2015.03.013
Tian GQ (2020) From industrial policy to competition policy: a discussion based on two debates. China Econ Rev 62:101505. https://doi.org/10.1016/j.chieco.2020.101505
Tian Z, Gottlieb PD, Goetz SJ (2020) Measuring industry co-location across county borders [Article]. Spat Econ Anal 15(1):92–113. https://doi.org/10.1080/17421772.2020.1673898
Vermeer L, Thomas M (2020) Pharmaceutical/high-tech alliances; transforming healthcare? Strateg Dir 36(12):43–46. https://doi.org/10.1108/SD-06-2020-0113
Wang C, Wang L (2024) Does broadband infrastructure promote urban innovation? Evidence from “Broadband China” demonstration policy. Struct Change Econ Dyn 69:349–362. https://doi.org/10.1016/j.strueco.2024.01.005
Wang KL, Pang SQ, Zhang FQ, Miao Z, Sun HP (2022) The impact assessment of smart city policy on urban green total-factor productivity: evidence from China. Environ Impact Assess Rev 94:106756. https://doi.org/10.1016/j.eiar.2022.106756
Wang TC, Sun T, Chen QL (2024) Curvilinear effect of policy intensity on innovation performance in the integrated circuit industry: too much of a good thing? Econ Anal Policy 82:1337–1352. https://doi.org/10.1016/j.eap.2024.05.009
Wonglimpiyarat J (2011) Government programmes in financing innovations: comparative innovation system cases of Malaysia and Thailand. Technol Soc 33(1-2):156–164. https://doi.org/10.1016/j.techsoc.2011.03.009
Wu AH (2017) The signal effect of government R&D subsidies in China: does ownership matter? [Article]. Technol Forecast Soc Change 117:339–345. https://doi.org/10.1016/j.techfore.2016.08.033
Xu XL, Chen HH (2020) Exploring the innovation efficiency of new energy vehicle enterprises in China. Clean Technol Environ Policy 22(8):1671–1685. https://doi.org/10.1007/s10098-020-01908-w
Xu Y, Yuan L, Khalfaoui R, Radulescu M, Mallek S, Zhao X (2023) Making technological innovation greener: does firm digital transformation work? Technol Forecast Soc Change 197. https://doi.org/10.1016/j.techfore.2023.122928
Yan YY, Wang JM, Qiao SJ (2022) Effects of industrial policy on firms’ innovation outputs: evidence from China. SAGE Open 12(3):215824402211229. https://doi.org/10.1177/21582440221122988
Yao L, Li J, Li J (2020) Urban innovation and intercity patent collaboration: a network analysis of China’s national innovation system. Technol Forecast Soc Change 160:120185. https://doi.org/10.1016/j.techfore.2020.120185
Ye XS, Liu J (2020) The impact of government support and market-oriented reforms on manufacturing technology progress. Econ Res J 55(05):83–98
Zeng J, Peng M, Chan KC (2024) The impact of low-carbon city policy on corporate cost stickiness. Int Rev Econ Finance 96. https://doi.org/10.1016/j.iref.2024.103595
Zhang ZW, Wang ZL, Liang S (2021) The effect of government intervention on the resource misallocation in innovation: ownership differences. Asia Pac J Account Econ 30(1):230–246. https://doi.org/10.1080/16081625.2021.1977662
Zhao QY, Li ZY, Zhao ZX, Ma JQ (2019) Industrial policy and innovation capability of strategic emerging industries: empirical evidence from Chinese new energy vehicle industry. Sustainability 11(10):2785. https://doi.org/10.3390/su11102785
Zhong C, Zhang C (2024) Can data elements enhance urban innovation? Evidence from China. China Econ Rev 88. https://doi.org/10.1016/j.chieco.2024.102307
Zhou C, Cao XZ, Zeng G (2019) Cluster network mode and evolution path of Innovation in China’s electronic information industry. Geogr Res 38(09):2212–2225. https://doi.org/10.11821/dlyj020180964
Acknowledgements
The work of this paper is supported by the National Social Science Fund of China (Grant No. 24BJY021).
Author information
Authors and Affiliations
Contributions
Tianchi Wang: design and theoretical framework development, methodology, data collection, visualisation, writing original draft, reviewing and editing. Ning Yu: formal analysis, writing original draft, reviewing, and editing. Wei Zhou: data collection, formal analysis, reviewing, and editing. Qiuling Chen: reviewing and editing, supervision, project administration. Wei Zhou and Qiuling Chen are co-corresponding authors.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval
This article does not contain any studies with human participants performed by any of the authors.
Informed consent
This article does not contain any studies with human participants performed by any of the authors.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wang, T., Yu, N., Zhou, W. et al. Industry policies and technological innovation in artificial intelligence clusters: are central positions superior?. Humanit Soc Sci Commun 12, 1262 (2025). https://doi.org/10.1057/s41599-025-05453-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1057/s41599-025-05453-z
