
Abstract
Poly(ADP-ribose) polymerase inhibitors (PARPis) have improved the prognosis of patients with high-grade serous ovarian carcinoma (HGSOC). However, PARPis are not effective for all HGSOC patients. Spatial transcriptomics is a powerful tool for characterizing the tumor microenvironment. We used Visium to analyze eight tumor samples from HGSOC patients with clinical information on PARPi sensitivity. Two complementary analyses were performed: an integrated analysis across all samples, without considering spatial information, and an analysis with spatial information within each sample. Both approaches indicated that midkine (MDK) signaling is involved in PARPi resistance. Furthermore, we identified receptors that enhance MDK signaling in cancer cells. To assess the generalizability of this finding, we deconvolved bulk RNA-sequencing data using single-cell RNA-sequencing data as a reference to examine the relationship between receptor expression levels and overall survival (OS). This analysis revealed that high SDC4 expression in cancer cells is associated with poor OS in HGSOC patients.
Similar content being viewed by others

Introduction
The development of poly(ADP-ribose) polymerase inhibitors (PARPis) was an epoch-making breakthrough in the treatment of advanced ovarian cancer1. It has, in particular, significantly improved the prognosis for ovarian cancer patients with homologous recombination deficiency (HRD)2. However, a substantial proportion of homologous recombination proficient (HRP) tumors exhibit primary resistance to PARPis3. Despite its clinical significance, the molecular basis of this primary resistance remains poorly understood, and only limited evidence is currently available. In contrast, several mechanisms of acquired resistance have been elucidated, with three major mechanisms identified: drug target-related alterations, stabilization of the replication fork, and restoration of homologous recombination repair4. Among the three, restoration of homologous recombination repair, or more specifically, BRCA reversion mutation has been the focus of clinical attention5, for exposure to platinum-based chemotherapy or PARPis can induce reversion mutations that restore the open reading frame of the BRCA gene6,7. This restoration reactivates homologous recombination function, thereby diminishing the effect of PARPis.
In recent years, the application of single-cell RNA sequencing (scRNA-seq) has begun to clarify the relationship between PARPi sensitivity and the tumor microenvironment (TME)8,9. However, in scRNA-seq, spatial information is lost during the sampling process. Furthermore, the biased mechanical extraction process may lead to the loss of fragile cells, resulting in a distribution of cell populations that differs from that of the actual tissue10. Spatial transcriptomics (ST), which enables unbiased probe-based comprehensive RNA transcriptome analysis and provides gene expression information while preserving spatial context, has attracted attention as a powerful tool for elucidating the functions of the TME11. In Visium, which is a sequence-based ST approach, spots are arranged at intervals of 100 µm12. Using a grid of approximately 5000 spots equipped with uniquely barcoded oligo-dT primers, RNAs can be sampled from tissue sections overlaid onto the capture area. One of the most important challenges associated with Visium is the coexistence of multiple cells within a spot. Performing cell-type deconvolution is a crucial analytical process for distinguishing the spatial distributions of different cell types13. In recent years, many deconvolution tools have been developed14,15. Some tools use single-cell references, whereas others are reference free. The accuracy, robustness, and usability of each tool have been evaluated, enabling users to select the tool that best suits their needs. Furthermore, the development of third-party tools has been remarkable, enabling a variety of analyses with the Visium platform16,17,18.
In this study, we used Visium to investigate spatial transcriptome profiles in both PARPi-sensitive and PARPi-resistant high-grade serous ovarian carcinoma (HGSOC) patients. First, we annotated spots using two deconvolution tools and subsequently analyzed the data using two distinct approaches: an integrated analysis across all samples without considering spatial information and an analysis with spatial information within each sample. These analyses revealed that midkine (MDK) signaling to malignant spots was upregulated in the resistant group. We then validated the effect of MDK on PARPi sensitivity in ovarian cancer cell lines. To further investigate the ligand–receptor relationship of MDK signaling, we used large-scale public bulk RNA sequencing (RNA-seq) data. For the bulk RNA-seq analysis, deconvolution was performed using public scRNA-seq data to estimate gene expression in cancer cells. This analysis revealed that high expression of SDC4 in cancer cells is associated with a poor prognosis for HGSOC patients. Our integrated approach suggests a potential broad mechanism of drug resistance, including PARPis, that is independent of HRD, which requires further investigation.
Results
Spatial transcriptome profiling and deconvolution of eight HGSOC samples
A total of eight formalin-fixed, paraffin-embedded (FFPE) samples from advanced stage HGSOC patients were analyzed using Visium (Fig. 1a). The patient backgrounds are summarized in Table 1. We defined the resistant group as patients who experienced recurrence within six months after initiating PARPi maintenance therapy and the sensitive group as those who did not experience recurrence for more than six months. Additionally, the gene mutations in TP53 and BRCA1/2 in the two groups were investigated using whole-exome sequencing (WES) of tumor tissue and normal uterine tissue, which were collected simultaneously during surgery (Table S1). WES was performed on seven samples, excluding the sensitive2 sample, which was an unsuitable sample. TP53 somatic mutations were identified in all seven patients, and a BRCA2 germline mutation was detected in the sensitive3 sample. The number of Visium spots ranged from 1152 to 3291 per sample, and the median number of genes detected per sample ranged from 5705 to 8029 (Table S2). For each section, we performed gene expression clustering using the R package Seurat (version 5.1.0) and identified 16–19 clusters per sample (Table S2).

a Schematic diagram of the sample collection and data analysis workflow. b Hematoxylin and eosin (HE)-stained images and annotations using SpaCET and STdeconvolve. The final annotation was determined from the two results. Representative images from the resistant2 sample are shown. c Final annotation results for each sample. The spots were annotated as malignant, CAF, endothelial, macrophage, or mixed. d Proportions of annotations and UMAP generated after the eight annotated samples were integrated. Most spots were annotated as malignant, CAF, or mixed. e Expression levels of representative markers in malignant spots, CAF spots, and macrophage spots.
Each Visium spot contains multiple cells, and its gene expression profile represents a mixture of different cell types. Many deconvolution methods have been established to estimate the cellular composition of each spot; in this study, we first used SpaCET17. In brief, after checking the key quality control metrics (Supplementary Fig. 1), we specified the cancer type (e.g., “OV”) to distinguish malignant spots from nonmalignant spots using copy number alterations (CNA) included in The Cancer Genome ATLAS (TCGA) database. Fractions of cell types were subsequently estimated (Supplementary Fig. 2). We assigned the cell type with the highest fraction as the annotation for each spot (Fig. 1b). To extract pure spots, we employed an extra annotation method using STdeconvolve19, a tool that allows for deconvolution without referencing scRNA-seq data. To compare the annotations of the two methods, we performed cell type annotations on the basis of SpaCET annotations in the STdeconvolve analysis (Supplementary Fig. 3). We adopted annotations that were consistent between the two methods; the spots with different results were classified as “mixed” spots for subsequent analysis. Through these analyses, we were able to identify the purer spots (Fig. 1b). The annotation results for the eight samples are shown in Fig. 1c. We summarized the number of annotations per spot for each sample (Fig. 1d). After annotating the spots, we integrated the data from the eight samples without spatial information. Uniform manifold approximation and projection (UMAP) and the expression levels of reported markers are shown in Fig. 1d, e. Finally, for each sample, we visualized the spatial distribution of the reported marker expression (Supplementary Fig. 4). As a result of these preliminary analyses, we successfully annotated each Visium spot and characterized its features. These results prepare the dataset for the next stage of analysis.
Comparison of the spot profile between the sensitive group and the resistant group in each tissue
Using the “FindMarkers” function in Seurat, we compared the profiles of cancer-associated fibroblast (CAF) spots, mixed spots, and malignant spots to identify which genes were highly expressed in each spot and to examine differences in their overall profiles (Data S1). We then generated a heatmap of the top five expressed genes for each group (Fig. 2a) and a heatmap showing the correlation among the groups (Fig. 2b). In the CAF spots, an increase in THBS2, which is a disulfide-linked homotrimeric glycoprotein that mediates cell-to-cell and cell-to-matrix interactions20, and MFAP4, which is believed to be an extracellular matrix protein involved in cell adhesion or intercellular interactions21, was detected. In the mixed spots, an increase in the expression of immunoglobulin-related genes such as IGKC, IGHG1, IGLV3-1, and IGKV4-1 was observed, suggesting the presence of a large number of plasma cells within the spots. In the malignant spots, an increase in ERBB3, which encodes a member of the epidermal growth factor receptor (EGFR) family22, and OVOL2, which is involved in epithelial development and differentiation23, were detected. Correlation analysis revealed that the mixed spots exhibited an intermediate profile between the CAF spots and the malignant spots (Fig. 2b).

a Heatmap of the expression levels of the top five genes in the malignant spots, CAF spots, and mixed spots from the integrated analysis of the eight samples. b Heatmap of Pearson’s correlation coefficients for gene expression among the malignant spots, CAF spots, and mixed spots. c–e Volcano plots of the DEGs between the sensitive group and the resistant groups in c the CAF spots, d mixed spots, and e malignant spots, analyzed by pseudobulk analysis. f Enrichment analysis was performed using Metascape on the top 20 pathways upregulated in the CAF spots in the resistant group. In the bar plot, enrichment significance (−log10(p value)) is represented by both bar length and color intensity.
To clarify the differences in the profiles between the sensitive and resistant groups in each spot, we performed pseudobulk analysis to identify differentially expressed genes (DEGs) (Fig. 2c–e and Data S2–S4). This analysis revealed that seven, eight, and eight genes were significantly upregulated in the CAF spots, mixed spots, and malignant spots, respectively. Furthermore, only one gene was downregulated in both the CAF spots and mixed spots, which was TNFSF1024, also known as TRAIL. TRAIL is an immune system cytokine messenger belonging to the tumor necrosis factor (TNF) family. It is reported to selectively target cancer cells without affecting surrounding normal tissue by transmitting apoptosis-inducing signals into the cells through specific binding to death receptors on the surface of cancer cells25. In the malignant spots, VEGFA was downregulated.
Since only a small number of DEGs were identified in the pseudobulk analysis, further analysis was performed on the DEGs identified using the findmarker function. For each of these three groups, we investigated genes upregulated in the resistant group using a cutoff of log2FC > 1. We found that 184, 179, and 190 genes were upregulated in the CAF spots, mixed spots, and malignant spots, respectively (Data S5). Among them, a total of 89 genes were commonly upregulated in the resistant group across all three groups (Supplementary Fig. 5A). For each of these three groups, we performed enrichment analyses using Metascape26 on the genes that were upregulated in the resistant group. In the CAF spots, pathways such as “M5884: NABA CORE MATRISOME,” “GO:0001944: vasculature development,” and “GO:0070848: response to growth factor” were upregulated (Fig. 2f). This suggests that cell proliferation, angiogenesis, and epithelial–mesenchymal transition (EMT) are promoted in the resistant group. In the mixed spots and the malignant spots, identical or similar pathways were also upregulated, such as “M5884: NABA CORE MATRISOME,” “GO:0001944: vasculature development,” and “GO:0001568: blood vessel development” (Supplementary Fig. 5B, C).
Recently, CAF subtypes have attracted increasing attention27. Marker genes for CAF subtypes have been reported in numerous cancer types28. In the pseudobulk analysis, none of these markers exhibited significant differences between the two groups. Here, we present violin plots showing the expression levels of the representative markers for myofibroblastic CAFs (myCAFs), inflammatory CAFs (iCAFs), and antigen-presenting CAFs (apCAFs) (Supplementary Fig. 6). Although none of the differences in the marker genes between the groups were significant, the expression of myCAF and apCAF markers tended to be higher in the sensitive group, whereas the iCAF markers tended to be higher in the resistant group.
Differences in interspot interactions between the sensitive group and the resistant group
To examine signaling to malignant spots, we utilized CellChat16. First, we combined data from all eight samples and performed communication analysis for the sensitive group and the resistant group separately without considering spatial information (see Methods). We calculated the number of interactions and the interaction strength (Fig. 3a, b). CAF spots, macrophage spots, and mixed spots in the sensitive group had 92, 89, and 189 signal interactions, respectively, with malignant spots. In contrast, the resistant group had 174, 163, and 129 interactions, respectively. These findings indicate that the number of signals from the CAF spots and macrophage spots to the malignant spots increased in the resistant group, whereas the number of signals from the mixed spots decreased. Additionally, the strengths of the interactions from the CAF spots, macrophage spots, and mixed spots to the malignant spots in the sensitive group were 1.76, 3.27, and 1.36, respectively. In the resistant group, these values were 1.82, 3.92, and 1.51, respectively. This result shows that the interaction strength increased for all the spot types in the resistant group. The signals from the CAF spots to the malignant spots revealed that the MDK signaling pathway exhibited greater upregulation in the resistant group (MDK signaling contribution: 0.000 in the sensitive group vs. 0.444 in the resistant group) (Fig. 3c and Data S6). A similar result was obtained for signals from the mixed spots to the malignant spots (MDK signaling contribution: 0.000 in the sensitive group vs. 0.430 in the resistant group) (Supplementary Fig. 7 and Data S7). Next, we performed interaction analysis for each sample with spatial information (see “Methods”). For each sample, we extracted malignant spots, CAF spots, and mixed spots; set the interaction range to 100 µm; and analyzed secreted signals. Taking the resistant2 sample as a representative example, the locations of each spot and the top three upregulated signals and their probability values, which indicate the strength of the interaction from CAF spots to malignant spots and from mixed spots to malignant spots, are shown in Fig. 3d, e. The detailed results of the top 10 signals for each sample are presented in Supplementary Figs. 8 and 9. For signals from the CAF spots to the malignant spots, increased MDK was not observed in the sensitive group, whereas MDK expression was upregulated in all the samples of the resistant group (Supplementary Fig. 8 and Data S8). Furthermore, analysis of the signals from the mixed spots to the malignant spots revealed that MDK was upregulated in three out of the four samples in the sensitive group and all four samples in the resistant group (Supplementary Fig. 9 and Data S9).

a Comparison of the number of interactions among the malignant spots, CAF spots, macrophage spots, and mixed spots between the sensitive group and the resistant group. b Comparison of the interaction strength among the malignant spots, CAF spots, macrophage spots, and mixed spots between the two groups. c Comparison of the secreted signals from the CAF spots to the malignant spots between the two groups. Left: relative information flow; right: absolute values of information flow. d, e Signaling interactions targeting malignant spots in the resistant2 sample. Comparison of signals originating from d CAF spots and e mixed spots. Spatial relationships and the top three upregulated signals are shown. f Effects of MDK alone on cell proliferation. g Effects of co-administration of MDK and olaparib. h Effects of co-administration of MDK and cisplatin. Welch’s t test was used. NS not significant, *p < 0.05.
MDK reduces the cytotoxic effect of PARPis and cisplatin
To examine whether MDK promotes resistance to PARPis, we conducted experiments using the human ovarian cancer cell lines A2780, SKOV3, KURAMOCHI, and COV362. Treatment with MDK alone did not significantly influence the proliferation of any of the cell lines (Fig. 3f). However, when olaparib was administered following MDK treatment, the cytotoxic effect of olaparib was reduced in A2780, SKOV3, KURAMOCHI, and COV362 cells (Fig. 3g). In addition, when cisplatin was administered following MDK treatment, the cytotoxic effect of cisplatin was reduced in A2780 and SKOV3 cells (Fig. 3h). We also examined the GRN and GAS signaling pathways, which were found to be upregulated in the integrated analysis of the eight samples. According to CellChat, Gas6 is registered as the ligand of the GAS signaling pathway, and GRN as the ligand of the GRN signaling pathway. Therefore, we administered Gas6 and GRN to ovarian cancer cell lines. However, neither treatment produced a significant change in the effect of olaparib (Supplementary Fig. 10A, B).
Investigation of ligand–receptor pairs contributing to increased MDK signaling
In the CellChat database, the MDK signaling pathway is registered as consisting of a single ligand, MDK, and nine receptors (Fig. 4a). Using CellChat, it is possible to investigate the contribution of each ligand–receptor pair to the increase in MDK signaling. Therefore, we investigated the contribution of each ligand–receptor pair in the four samples of the resistant group. We found that SDC4 contributed to the increase in midkine signaling in four out of four samples, NCL in three out of four samples, ITGA6_ITGB1 complex in two out of four samples, and ALK in one out of four samples (Fig. 4b).

a A list of ligand–receptor pairs for MDK signaling from the CellChat database. MDK is the sole ligand, and nine receptors are listed. b Contribution of ligand–receptor pairs to the increased MDK signaling from the CAF spots to the malignant spots in the resistant group. The “Probability” score indicates the contribution of each pair, with a higher score signifying a greater impact. c UMAP from an integrated analysis of 25 samples from four public scRNA-seq dataset (GSE154600, GSE158937, GSE184880, and GSE211956). d Deconvolution of 497 bulk RNA-seq samples to estimate cell type proportions. Proportions were estimated using BayesPrism with a scRNA-seq dataset as a reference. Left: Estimated cell type abundance for each of the 497 samples. Right: Box plot summarizing proportions of major cell types (mean abundance >1%) across all samples. e Kaplan–Meier analysis of overall survival based on the expression of four receptors that were upregulated in the resistant group. Patients were stratified into high- and low-expression groups according to the deconvoluted expression levels within malignant cells.
Validation using public scRNA-seq and bulk RNA-seq data
The area that Visium can analyze is limited to 6.5 mm square, allowing examination of only a tiny part of the tissue. Therefore, to ensure the generalizability of our Visium analysis, we used public bulk RNA-seq data to investigate the association between the expression levels of the cancer cell receptors examined in this study and patient prognosis. We extracted data from 497 ovarian cancer cases with available prognostic information and RNA-seq data from the Genomic Data Commons (GDC) Data Portal.
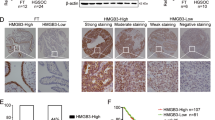
Because bulk RNA-seq expression levels represent the sum from multiple cell types, and differences in cellular proportions affect gene expression, we performed deconvolution using BayesPrism29. First, to create a reference, we integrated four public scRNA-seq datasets (GSE154600, GSE158937, GSE184880, and GSE211956) comprising 25 samples. We then conducted annotations using previously reported markers (Fig. 4c and Supplementary Fig. S11A). We used Harmony30 to integrate the data and correct for batch effects, and inferCNV (version 1.20.0)31 to identify cancer cells (Supplementary Fig. S11B). Additionally, we created feature plots for MDK and the genes related to the four receptors identified in our Visium analysis (Supplementary Fig. S11C). The feature plot revealed that MDK is expressed in both fibroblasts and epithelial cells, and that among the identified receptor-related genes, SDC4 tends to be specifically expressed in cancer cells. Using this data as a reference, we performed deconvolution on the 497 bulk RNA-seq samples to calculate cellular proportions (Fig. 4d and Data S10). A graph of the cellular proportions and a box plot of the proportions for cell types present at >1% in all samples are shown. Subsequently, for the four receptors identified in our Visium analysis, we estimated their expression levels in cancer cells for each bulk RNA sample and showed the relationship with overall survival (OS) using Kaplan-Meier curves and the log-rank test (Fig. 4e). The log-rank test showed that SDC4 was associated with poor prognosis in ovarian cancer patients (p = 0.047). Furthermore, examination of these receptors in the scRNA-seq data showed that SDC4 was specifically expressed in cancer cells (Supplementary Fig. S11D). Our Visium analysis showed that the MDK-SDC4 ligand–receptor pair increased MDK signaling in all four resistant samples. Taken together with this finding, our results suggest that high SDC4 expression in cancer cells is associated with a poor prognosis in patients with ovarian cancer.
Discussion
Much of the recent research into drug resistance to PARPis in HGSOC patients has been largely focused on HRD status, including BRCA1/2 mutations. In this study, we performed ST on HGSOC samples with PARPi sensitivity information and conducted an analysis of factors involved in PARPi resistance at the transcriptomic level. The diversity of our patient samples, together with in vitro and previously published data, indicates that elevated MDK signaling may be involved in a broad mechanism of drug resistance, including PARPis. Although the relationship between our findings and BRCA mutations has not been elucidated, we believe that this work contributes to the understanding of PARPi resistance mechanisms beyond HRD status.
Visium can be used to obtain comprehensive RNA transcriptome data for each spot, enabling comprehensive analysis using a single sample. However, when analyzing multiple samples, integrating spatial information is challenging, leading to issues with biases among patients and among samples. To address this challenge, we first integrated the data from the eight samples without considering spatial information and performed interspot interaction analysis. We subsequently conducted an interspot interaction analysis for each sample with spatial information to validate the results of the integrated analysis. This approach effectively minimizes biases between patients and samples. Using this method, our analyses identified upregulated MDK signaling in the resistant group.
Furthermore, we conducted a detailed investigation of the MDK signaling pathway, specifically focusing on the ligand–receptor pairs responsible for its upregulation. Since the ligand MDK is widely expressed in normal tissues, we reasoned that elucidating the role of its specific receptors on cancer cells would be important. By analyzing the contribution of each ligand–receptor pair, we found that the expression levels of SDC4, NCL, ITGA6_ITGB1, and ALK in cancer cells contribute to elevated MDK signaling.
While Visium provides a large amount of information, it only allows for the observation of a small fraction of the entire tumor tissue. Moreover, the high cost of Visium limits the number of samples that can be analyzed. To overcome these limitations and validate the clinical significance of the identified receptors on a larger scale, we utilized publicly available scRNA-seq and bulk RNA-seq datasets. Using these datasets, we analyzed the association between the expression of the identified receptors and the patient prognosis in ovarian cancer. A major challenge with bulk RNA-seq data is that gene expression levels reflect the proportions of different cell types in the mixed-cell tissue samples. To accurately assess receptor expressions specifically within cancer cells, we applied a deconvolution method. This approach enabled us to estimate the fraction of cancer cells in the bulk tissue data and thereby calculate the cell-type-specific expression of the receptors in cancer cells. This approach provided large-scale statistical support for our Visium analysis, thereby strengthening the biological and clinical validity of our findings.
MDK is a growth factor that is reportedly involved in fetal development32. MDK is also currently believed to be widely involved in the maintenance of normal tissues and the development of a variety of diseases33. In cancer, MDK is highly expressed in various malignant tumors34,35,36,37, and its association has been reported in various contexts, including cell proliferation38, angiogenesis39, epithelial‒mesenchymal transition40, and cancer immunity41,42. Although no studies have yet reported a direct association between MDK and resistance to PARPis, several studies have suggested a link between MDK and cisplatin resistance. For example, MDK is known to increase the expression of the long noncoding RNA ANRIL in cancer cell lines, which upregulates the expression of MRP1, a protein that facilitates drug efflux43. The function of MRP1 is broadly related to drug resistance44 and may represent an underlying mechanism of PARPi resistance that is independent of HRD. We validated the relationship between MDK and cisplatin in ovarian cancer cell lines. Our results showed that MDK significantly reduced the sensitivity of A2780 and SKOV3 cells to cisplatin. While our initial findings concerned PARPi resistance, we hypothesize that this represents a broader mechanism of drug resistance not specific to PARPis. This hypothesis is supported by several observations. Specifically, the association was observed across Visium samples with diverse clinical backgrounds, suggesting a potentially universal mechanism. In addition, the correlation between MDK expression and poor overall survival in public datasets suggests that MDK contributes to a fundamental malignant phenotype, which often includes multi-drug resistance. Therefore, we propose that the MDK signaling pathway may drive a broad mechanism of drug resistance within the TME.
Our study has several limitations. First, the resolution of Visium constitutes a limitation. Each Visium spot has a diameter of 55 μm, including multiple cells. Furthermore, there are gaps between spots, which hinder interaction analyses. To address the issue of mixed cell populations, we employed a deconvolution method to estimate the proportion of each cell type. To account for the gaps between spots, we restricted our interaction analysis to secreted signaling. However, as these analytical approaches have their limitations, validation using higher-resolution spatial transcriptomics technologies is desirable. A second limitation is related to our analysis of MDK signaling. While we investigated MDK signaling by focusing on cancer cell receptors such as SDC4, it is a complex pathway of multiple ligand–receptor interactions that leads to signal elevation. Ideally, the contribution of each of these ligand–receptor interactions should be incorporated as parameters into prognostic analyses. However, the resolution of the Visium makes such a detailed analysis unfeasible at present, leaving it as a topic for future investigation. The final limitation is the timing of sample collection and the small sample size. Ideally, to investigate the mechanisms underlying PARPi resistance, tumor samples should be obtained immediately before PARPi administration. However, according to current clinical guidelines in Japan, doctors administer platinum-based chemotherapy before initiating PARPi maintenance therapy, which makes it difficult to collect samples immediately before PARPi treatment. Regarding the sample size, the Visium analysis was limited to only eight samples, and therefore, the potential impact of MDK signaling on PARPi-resistant phenotypes should be interpreted with caution. Owing to the timing of sample collection and the small sample size, this work provides limited insights into the mechanisms of PARPi resistance. However, we believe our results provide valuable insights into a tumor microenvironment associated with broad drug resistance mechanisms, including PARPis.
Methods
Sample collection
Eight patients diagnosed with stage III–IV HGSOC at Nagoya University Hospital (Aichi, Japan) were included in this study. The details of the samples and patient information are summarized in Table 1. These samples were used with the approval of the Ethics Review Committee, Nagoya University Graduate School of Medicine (2017-0053). For this study, approval for an opt-out consent method was provided by the Ethics Review Committee. This study adhered to the principles of the Declaration of Helsinki.
Whole-exome sequencing
We used FFPE tumor samples and FFPE normal uterine samples from seven patients for WES. DNA was extracted using a QIAamp DNA FFPE Tissue Kit (QIAGEN). The DNA concentration was measured on a Qubit 4.0 fluorometer (Invitrogen; Thermo Fisher Scientific, Inc.) with a Qubit dsDNA BR Assay Kit (Invitrogen; Thermo Fisher Scientific, Inc.). Library preparation was performed at GENEWIZ (Azenta Life Sciences, New Jersey, USA). Paired-end sequencing (2 × 150 bp) was carried out on an Illumina instrument, generating raw FASTQ files. Quality control and adapter removal were performed using fastp45, and the trimmed reads were aligned to the human reference genome GRCh38 (hg38) using the BWA-MEM algorithm46. Following the Genome Analysis Toolkit (GATK) Best Practices, we used GATK v4.6.1.047 to mark duplicates and recalibrate base quality scores. Germline variants were called using GATK HaplotypeCaller, and standard filtering was applied according to the following criteria for single-nucleotide polymorphisms (SNPs): QualByDepth (QD) < 2.0, FisherStrand (FS) > 60.0, RMSMappingQuality (MQ) < 40.0, StrandOddsRatio (SOR) > 4.0, MappingQualityRankSumTest (MQRankSum) < −12.5, and ReadPosRankSumTest (ReadPosRankSum) < -8.0. The criteria for indels were FS > 200.0 and SOR > 10.0. In addition, variants with an assigned genotype quality (GQ) < 10 at the genotype level were removed. Somatic variants were called using GATK Mutect2, which uses Genome Aggregation Database (gnomAD) data and a panel of normal samples. Next, we estimated sample contamination rates using GATK GetPileupSummaries and CalculateContamination and modeled read orientation artifacts (F1R2) using GATK LearnReadOrientationModel. These contamination estimates and orientation biases were accounted for by filtering variants with GATK FilterMutectCalls. We further filtered out somatic variants with GQ < 20 using GATK VariantFiltration, and these filtered variants were excluded from the final set of somatic variants. Finally, VCF files were annotated using ClinVar48; variants labeled “Pathogenic” or “Likely pathogenic” were considered pathogenic mutations.
ST data loading and preprocessing
We performed ST on the eight FFPE HGSOC samples using the Visium Spatial Gene Expression for FFPE platform (10× Genomics, USA). This approach enabled the capture of comprehensive RNA transcriptomes from each spot on the slide-mounted FFPE tissue sections. Sections of 5 μm thickness were prepared using a microtome and placed on Visium Spatial Slides. The tissue sections were stained with H&E and imaged using a BZ-X700 fluorescence microscope (Keyence, Osaka, Japan), followed by removal of the coverslip, destaining, and decrosslinking. Probe extension and library construction steps were performed according to the standard Visium workflow for FFPE samples. The resulting libraries were sequenced on a HiSeq platform (Illumina, San Diego, CA) with paired-end reads by Azenta (South Plainfield, NJ). The sequencing data generated from Visium were processed using Space Ranger (version 2.0.1, 10× Genomics). Subsequent normalization, quality control, and dimensionality reduction steps were performed in R using the Seurat package (version 5.1.0). Specifically, normalization was conducted with the “SCTransform” function, followed by principal component analysis (PCA). The top 30 principal components were used for dimensionality reduction and clustering. All dimensionality reduction and clustering procedures were carried out according to the Seurat v5.1.0 vignette.
Deconvolution analysis using SpaCET
Visium data were analyzed using the SpaCET R package (version 1.2.0). First, the data generated by Space Ranger were processed using the “create.SpaCET.object.10X” function. Quality control metrics, including the number of unique molecular identifiers (UMIs) counts and the number of expressed genes per spot, were calculated and visualized with “SpaCET.quality.control” and “SpaCET.visualize.spatialFeature”. Next, deconvolution of the spots into various cell types was performed with the “SpaCET.deconvolution” function, setting the cancer type parameter (cancerType = “OV”) to model malignant cells. Cell type proportion data were extracted from the SpaCET object, and we annotated each spot with the cell type showing the greatest proportion. The intraspot analysis also involved the calculation of the ligand‒receptor network scores with the “SpaCET.CCI.LRNetworkScore” function. Specific cell type pairs (e.g., B cells and CD8 T cells) were analyzed using the “SpaCET.CCI.cellTypePair” function to assess their colocalization. The spatial distributions of the tumor spots, interface spots, and stroma spots were investigated with the “SpaCET.identify.interface” function and the “SpaCET.combine.interface” function. Finally, the colocalization spots were visualized on the Visium slide.
Data preprocessing for STdeconvolve
We applied the “cleanCounts” function from the STdeconvolve package (version 1.9.0) to remove low-quality spots with a library size of less than 100 and genes detected in fewer than 10 reads. For feature selection, we employed the “restrictCorpus” function to filter out genes detected in 100% of the spots and those present in 5% or less of the spots.
Topic modeling and deconvolution using STdeconvolve
After preprocessing, we performed reference-free deconvolution using latent Dirichlet allocation (LDA) as implemented in the STdeconvolve package. We fitted multiple LDA models with varying K values, indicating the number of latent cell-type topics, using the “fitLDA” function. Model selection was based on perplexity, and we selected the model with the lowest perplexity. During model fitting, we ensured that the Dirichlet parameter alpha was less than 1 to promote sparse cell-type distributions within each spot. A symmetric Dirichlet distribution with alpha <1 results in each spot being composed of only a few cell types, facilitating the identification of distinct cell populations. From the selected LDA model, we extracted the topic-specific gene expression profiles (beta matrix) and the spot-level cell-type proportion estimates (theta matrix) using the “getBetaTheta” function. To ensure meaningful cell-type annotations, we filtered out cell types that contributed less than 5% of the composition of any given spot (using perc.filt = 0.05). Additionally, the beta matrix was scaled by a depth factor of 1000 for interpretability. This approach resulted in a final set of latent cell types along with their corresponding spatial distributions.
Spatial visualization and comparison to known annotations
To visualize the spatial distribution of the identified cell types, we utilized the “vizAllTopics” function from the STdeconvolve package. This function generated scatterplots that displayed the proportions of each cell type overlaid on the original tissue grid, allowing us to observe their spatial patterns. Using the “getCorrMtx” function, we calculated correlation matrices between the deconvolved cell types and preannotated cell types on the basis of previously reported marker genes, which served as a reference. To ensure consistency with the annotations generated by SpaCET, we selected the following reported marker genes: malignant spots (EPCAM, KRT18), CAF spots (PDPN, DCN), lymphocyte spots (CD3D, CD3E), endothelial spots (PECAM1, VWF), and macrophage spots (C1QB, CD14). The “correlationPlot” function was employed to create heatmaps of the correlation matrices. These heatmaps allowed us to evaluate how closely the deconvolved latent cell types matched the reference. Finally, we selected the reference with the greatest correlation with the annotations in STdeconvolve.
Analysis of the integrated eight samples
Analyses were performed on the Visium data of the eight HGSOC samples (S1–S4, R1–R4). We imported gene expression matrices using the “Read10X” function and created Seurat objects from each sample using the “CreateSeuratObject” function. Data normalization, quality control, and dimensionality reduction were conducted with the Seurat R package, employing the “SCTransform” function for normalization and PCA to identify the top 30 principal components for subsequent analyses. To correct batch effects between datasets, we applied the Harmony algorithm30. After data integration, we performed clustering with the “FindNeighbors” and “FindClusters” functions (resolution = 0.3) and visualized the results using UMAP dimensionality reduction through the “RunUMAP” function. These procedures were carried out according to the official Seurat v5.1.0 vignette.
Analysis of DEGs between the sensitive group and the resistant group
To examine differences in the transcriptomic profiles of the CAF spots between the sensitive group and the resistant group, we conducted pseudobulk analyses. The expression data were aggregated with the “AggregateExpression” function, thereby creating a pseudobulk dataset in which expression values from the spots belonging to the same group (sensitive or resistant) and the same sample (S1–4, R1–4) were summed. We then used the DESeq249 method to identify the DEGs between “CAF resistant” and “CAF sensitive.” To visualize the results, volcano plots were generated with the ggplot2 package (version 3.5.1). DEGs were defined as those with a log2-fold change greater than 1.0 and an adjusted p value less than 0.05. The same analysis was conducted on the mixed spots and malignant spots.
Enrichment analysis between the sensitive group and the resistant group
Functional enrichment analyses were performed with Metascape. We prepared lists of upregulated genes for the CAF spots, mixed spots, and malignant spots, respectively, defining upregulated genes as those with a log2 fold change greater than 1. Each list was then analyzed and visualized with Metascape.
Analysis of CAF subtypes
To characterize subtypes of CAF states, we also selected the reported marker genes (myofibroblast CAFs: MMP11 and ACTA2; inflammatory CAFs: CXCL12 and CD34; and antigen-presenting CAFs: IGFBP3 and CD74) and visualized their expression distributions with the “VlnPlot” function.
Interspot interaction analysis of the integration of the eight samples
From the integrated Seurat objects of the eight samples, we extracted malignant spots, CAF spots, macrophage spots, and mixed spots. Next, we divided these objects into a sensitive group and a resistant group, and subsequent analyses were conducted in these groups separately. Using the CellChat package (version 2.1.2), we extracted the normalized expression data of the SCT assay from the Seurat object and generated a CellChat object with the “createCellChat” function. We applied the human ligand‒receptor interaction database (CellChatDB.human) and used the “subsetDB” function to retain only “Secreted Signaling” interactions, thereby narrowing our analysis to secreted signaling pathways. We estimated the communication probabilities among the spot groups using the “computeCommunProb” function with a truncated mean approach. We subsequently computed pathway-specific communication probabilities with the “computeCommunProbPathway” function and aggregated the entire interspot communication network with the “aggregateNet” function. The analyses for the sensitive group and the resistant group were merged with the “mergeCellChat” function. Using the integrated CellChat object, we employed the “compareInteractions” function to assess the differences in interspot interactions between the two groups. Additionally, by setting the CAF spots as the “sources.use” and the malignant spots as the “target.use,” we employed the “rankNet” function to compare differences between the two groups. The same analysis was conducted from the mixed spots to the malignant spots. The results were visualized in stacked and nonstacked bar charts.
Interspot interaction analysis considering spatial information within each sample
For analysis using spatial information, we created a Seurat object for each sample and extracted the CAF spots, malignant spots, and mixed spots. We obtained the normalized expression data of the SCT assay and spot annotations from the Seurat object. Using the “GetTissueCoordinates” function, we extracted the spatial coordinates (x and y) of each spot. To convert pixel measurements into actual physical distances (µm), we read a scaling factor JSON file with the “fromJSON” function from the jsonlite package and defined a theoretical spot size of 65 µm, according to the CellChat tutorial. With these values, we computed a conversion factor and set an acceptable tolerance (half the spot size), resulting in a spatial factor data frame. We calculated the Euclidean distances between spots in micrometers via the “computeCellDistance” function, incorporating spatial factors (ratio and tol) to consider spatial distance information. The minimum nonzero distance of approximately 100 µm was consistent with the resolution of Visium. We generated a CellChat object from the normalized expression data of the SCT assay, metadata, and spatial coordinates via the “createCellChat” function, specified data.type = “spatial”, and incorporated spatial factors. We applied the human ligand‒receptor interaction database (CellChatDB.human) and used the “subsetDB” function to retain only “Secreted Signaling” interactions, narrowing our analysis to secreted signaling pathways. We identified overexpressed genes in each spot population with the “identifyOverExpressedGenes” function. We then used the “identifyOverExpressedInteractions” function to detect overexpressed ligand‒receptor interactions. To estimate the communication probabilities between spots while considering spatial constraints, we used the “computeCommunProb” function with the following parameters: type = “truncatedMean”, trim = 0.1, interaction.range = 250 µm, scale.distance = spatial.factors$ratio for pixel-to-µm conversion, contact.range = 100 µm, and nboot = 20. We computed the communication probabilities for each signaling pathway with the “computeCommunProbPathway” function, enabling the assessment of signaling strength on a pathway-by-pathway basis under spatially informed conditions. Finally, we extracted data from the netP and net slots of the CellChat object using the “subsetCommunication” function. To visualize the data, each dataset was preprocessed by arranging the signaling pathways in descending order according to their probability values and selecting the top ten pathways to highlight the most significant interactions.
Public scRNA-seq data collection and processing
Datasets of scRNA-seq were obtained from four public Gene Expression Omnibus (GEO) repositories: GSE184880 (12 samples: 5 normal, 7 tumor), GSE158937 (3 tumor samples), GSE154600 (5 tumor samples), and GSE211956 (5 chemotherapy-treated tumor samples). Quality control was performed by calculating mitochondrial gene percentages using the “PercentageFeatureSet” function. Cells were filtered based on the following criteria: 500 < nFeature_RNA < 10,000, nCount_RNA < 100,000, and mitochondrial content <15%. Doublet detection was performed on each sample independently using DoubletFinder50 with optimized pK values determined through BCmetric optimization. Expected doublet rates were set at 5% of total cells per sample. Only singlet cells were retained for downstream analysis. After doublet removal, samples were re-merged and normalized using “NormalizeData.” The top 4000 highly variable features were identified using “FindVariableFeatures.” Data scaling and PCA were performed with 50 principal components. Batch effects were corrected using Harmony integration. UMAP dimensionality reduction was applied for visualization. Cell type annotation was performed based on previously reported marker gene expression patterns, identifying nine major cell types: epithelial, fibroblast, T cell, B cell, plasma cell, monocytes, endothelial, mesothelial, and smooth muscle cells/pericytes.
CNA analysis with InferCNV
To distinguish malignant from non-malignant epithelial cells, inferCNV was employed to detect large-scale chromosomal CNAs from scRNA-seq data. For all datasets (GSE184880, GSE158937, GSE154600, and GSE211956), monocytes were used as the normal reference cells. Gene position information was obtained from GENCODE v48 annotation. InferCNV was run with a cutoff of 0.1, with denoising enabled and i3 Hidden Markov Model (HMM).
Bulk RNA-seq data collection and processing
Bulk RNA-seq data were obtained from the GDC Data Portal. Cases were selected using the COHORT BUILDER with the following criteria: primary site as “ovary,” tumor descriptor as “primary,” data category as “transcriptome profiling,” and experimental strategy as “RNA-Seq,” resulting in 497 eligible cases. The corresponding gene expression quantification files were downloaded for deconvolution analysis. Clinical data for these 497 cases were also downloaded from the GDC portal. Among these, 425 cases had complete survival information including vital status, days to death, and days to follow up, which were used for subsequent survival analyses. The resulting expression matrix was used for both deconvolution and survival analyses.
Cell type deconvolution using BayesPrism
BayesPrism was employed to deconvolute bulk RNA-seq data into cell type proportions using the annotated scRNA-seq data as reference. Prior to deconvolution, scRNA-seq data underwent additional quality control using “plot.scRNA.outlier” to identify outlier cells. Ribosomal, mitochondrial, and sex chromosome genes were removed using “cleanup.genes.” Only protein-coding genes were retained through “select.gene.type.” Hierarchical cell type labels were created with malignant epithelial cells which identified using inferCNV marked as “tumor” and further subdivided by their original cluster identities. Differential expression analysis identified marker genes using “get.exp.stat” with pseudo-count of 0.1, selecting markers with p value < 0.01 and log fold change >0.1. BayesPrism was run with outlier.cut = 0.01 and outlier.fraction = 0.10. The algorithm estimated cell type proportions (theta), coefficient of variation (theta.cv), and tumor-specific expression profiles (Z.tumor) using the “get.exp” function with “type” and “tumor” parameters.
Survival analysis using Kaplan–Meier curves
Overall survival analysis was performed on the 425 cases with complete clinical follow-up data. Selected genes (NCL, SDC4, ALK) and a combined score (ITGA6_ITGB1) were analyzed using the tumor-specific expression values derived from BayesPrism deconvolution. For combined scores, geometric mean of constituent gene expressions was calculated. Survival time was censored at 10 years (3650 days). The stratification method tested all unique expression values between the 25% and 75% percentiles as potential cutoffs, selecting the one yielding the minimum log-rank p value. Kaplan–Meier curves were generated using the “survival” and “survminer” packages.
Cell lines and cell culture
The SKOV3 cell line was obtained from the American Type Culture Collection (ATCC), the COV362 cell line and the A2780 cell line were obtained from the European Collection of Cell Cultures (ECACC), and the KURAMOCHI cell line was obtained from the Japanese Collection of Research Bioresources (JCRB) cell bank. All cells were grown in RPMI 1640 medium (Nacalai Tesque) supplemented with 10% fetal bovine serum (FBS) and 1% antibiotic-antimycotic (AA).
Chemicals
Olaparib (aPARPi) was purchased from Selleck Chemicals and dissolved in DMSO to prepare stock solutions. Cisplatin was purchased from Nichi-Iko Pharmaceuticals. Recombinant Human Midkine Protein (258-MD), Reconbinant Human Gas6 Protein (885-GSB) and Recombinant Human Progranulin Protein (2420-PG) were purchased from R&D Systems and dissolved in PBS.
Cell proliferation assay
The cells were seeded into 96-well plates at a density of 3000 cells per well. After attachment, recombinant proteins (MDK, Gas6, or GRN; each at 1 ng/dL) were added. Twenty-four hours later, 50 µM olaparib and 100 µM cisplatin were added, and the cells were cultured for an additional 72 h. Cell viability was assessed using the CellTiter-Glo 2.0 Cell Viability Assay (Promega). Luminescence was measured with a microplate reader (Molecular Devices) 10 minutes after reagent addition. Viability was expressed as a percentage relative to untreated control cells. All the experiments were performed in triplicate.
Statistical analysis
Statistical analyses were conducted using RStudio and R software (version 4.4.0). Welch’s t test was used to determine significant differences between the two groups. A p value < 0.05 was considered statistically significant.
Data availability
The data generated in this study are available from the GEO under accession number GSE288483 (Visium spatial transcriptomics data). The WES data from this study are available on Figshare as "Whole-exome sequencing (WES) variant call files (VCF) for a high-grade serous ovarian carcinoma (HGSOC) cohort" (DOI: 10.6084/m9.figshare.30158452). Any additional information required to reanalyze the data reported in this paper is available from the corresponding author, Yusuke Yamamoto (yuyamamo@ncc.go.jp), upon request.
References
Mirza, M. R. et al. The forefront of ovarian cancer therapy: update on PARP inhibitors. Ann. Oncol. 31, 1148–1159 (2020).
Ray-Coquard, I. et al. Olaparib plus bevacizumab as first-line maintenance in ovarian cancer. N. Engl. J. Med. 381, 2416–2428 (2019).
Bhamidipati, D. et al. PARP inhibitors: enhancing efficacy through rational combinations. Br. J. Cancer 129, 904–916 (2023).
Dias, M. P. et al. Understanding and overcoming resistance to PARP inhibitors in cancer therapy. Nat. Rev. Clin. Oncol. 18, 773–791 (2021).
Lin, K. K. et al. BRCA reversion mutations in circulating tumor DNA predict primary and acquired resistance to the PARP inhibitor rucaparib in high-grade ovarian carcinoma. Cancer Discov. 9, 210–219 (2019).
Sakai, W. et al. Secondary mutations as a mechanism of cisplatin resistance in BRCA2-mutated cancers. Nature 451, 1116–1120 (2008).
Quigley, D. et al. Analysis of circulating cell-free DNA identifies multiclonal heterogeneity of BRCA2 reversion mutations associated with resistance to PARP inhibitors. Cancer Discov. 7, 999–1005 (2017).
Li, X. et al. C5aR1 inhibition reprograms tumor-associated macrophages and reverses PARP inhibitor resistance in breast cancer. Nat. Commun. 15, 4485 (2024).
Luo, Y. et al. Neoadjuvant PARPi or chemotherapy in ovarian cancer informs targeting effector Treg cells for homologous-recombination-deficient tumors. Cell 187, 4905–4925 (2024).
Denisenko, E. et al. Systematic assessment of tissue dissociation and storage biases in single-cell and single-nucleus RNA-seq workflows. Genome Biol. 21, 130 (2020).
Rao, A. et al. Exploring tissue architecture using spatial transcriptomics. Nature 596, 211–220 (2021).
Ståhl, P. L. et al. Visualization and analysis of gene expression in tissue sections by spatial transcriptomics. Science 353, 78–82 (2016).
Cable, D. M. et al. Robust decomposition of cell type mixtures in spatial transcriptomics. Nat. Biotechnol. 40, 517–526 (2022).
Li, B. et al. Benchmarking spatial and single-cell transcriptomics integration methods for transcript distribution prediction and cell type deconvolution. Nat. Methods 19, 662–670 (2022).
Li, H. et al. A comprehensive benchmarking with practical guidelines for cellular deconvolution of spatial transcriptomics. Nat. Commun. 14, 1548 (2023).
Jin, S., Plikus, M. V. & Nie, Q. CellChat for systematic analysis of cell-cell communication from single-cell transcriptomics. Nat. Protoc. 20, 180–219 (2025).
Ru, B., Huang, J., Zhang, Y., Aldape, K. & Jiang, P. Estimation of cell lineages in tumors from spatial transcriptomics data. Nat. Commun. 14, 568 (2023).
Cang, Z. et al. Screening cell-cell communication in spatial transcriptomics via collective optimal transport. Nat. Methods 20, 218–228 (2023).
Miller, B. F., Huang, F., Atta, L., Sahoo, A. & Fan, J. Reference-free cell type deconvolution of multi-cellular pixel-resolution spatially resolved transcriptomics data. Nat. Commun. 13, 2339 (2022).
Huang, J. et al. Molecular mechanisms of Thrombospondin-2 modulates tumor vasculogenic mimicry by PI3K/AKT/mTOR signaling pathway. Biomed. Pharmacother. 167, 115455 (2023).
Kanaan, R., Medlej-Hashim, M., Jounblat, R., Pilecki, B. & Sorensen, G. L. Microfibrillar-associated protein 4 in health and disease. Matrix Biol. 111, 1–25 (2022).
Wang, Z. ErbB receptors and cancer. Methods Mol. Biol. 1652, 3–35 (2017).
Frisch, S. M., Farris, J. C. & Pifer, P. M. Roles of Grainyhead-like transcription factors in cancer. Oncogene 36, 6067–6073 (2017).
Kuribayashi, K. et al. TNFSF10 (TRAIL), a p53 target gene that mediates p53-dependent cell death. Cancer Biol. Ther. 7, 2034–2038 (2008).
Yuan, X. et al. Developing TRAIL/TRAIL-death receptor-based cancer therapies. Cancer Metastasis Rev. 37, 733–748 (2018).
Zhou, Y. et al. Metascape provides a biologist-oriented resource for the analysis of systems-level datasets. Nat. Commun. 10, 1523 (2019).
Chhabra, Y. & Weeraratna, A. T. Fibroblasts in cancer: unity in heterogeneity. Cell 186, 1580–1609 (2023).
Cords, L., de Souza, N. & Bodenmiller, B. Classifying cancer-associated fibroblasts – the good, the bad, and the target. Cancer Cell 42, 1480–1485 (2024).
Chu, T., Wang, Z., Pe’er, D. & Danko, C. G. Cell type and gene expression deconvolution with BayesPrism enables Bayesian integrative analysis across bulk and single-cell RNA sequencing in oncology. Nat. Cancer 3, 505–517 (2022).
Korsunsky, I. et al. Fast, sensitive and accurate integration of single-cell data with Harmony. Nat. Methods 16, 1289–1296 (2019).
Patel, A. P. et al. Single-cell RNA-seq highlights intratumoral heterogeneity in primary glioblastoma. Science 344, 1396–1401 (2014).
Kadomatsu, K., Tomomura, M. & Muramatsu, T. cDNA cloning and sequencing of a new gene intensely expressed in early differentiation stages of embryonal carcinoma cells and in mid-gestation period of mouse embryogenesis. Biochem. Biophys. Res. Commun. 151, 1312–1318 (1988).
Neumaier, E. E., Rothhammer, V. & Linnerbauer, M. The role of midkine in health and disease. Front. Immunol. 14, 1310094 (2023).
Filippou, P. S., Karagiannis, G. S. & Constantinidou, A. Midkine (MDK) growth factor: a key player in cancer progression and a promising therapeutic target. Oncogene 39, 2040–2054 (2020).
Ohhashi, S. et al. Midkine mRNA is overexpressed in pancreatic cancer. Dig. Dis. Sci. 54, 811–815 (2009).
Yuan, K. et al. MDK protein overexpression correlates with the malignant status and prognosis of non-small cell lung cancer. Arch. Med. Res. 46, 635–641 (2015).
Rice, G. E., Edgell, T. A. & Autelitano, D. J. Evaluation of midkine and anterior gradient 2 in a multimarker panel for the detection of ovarian cancer. J. Exp. Clin. Cancer Res. 29, 62 (2010).
Sandra, F., Harada, H., Nakamura, N. & Ohishi, M. Midkine induced growth of ameloblastoma through MAPK and Akt pathways. Oral. Oncol. 40, 274–280 (2004).
Choudhuri, R., Zhang, H. T., Donnini, S., Ziche, M. & Bicknell, R. An angiogenic role for the neurokines midkine and pleiotrophin in tumorigenesis. Cancer Res. 57, 1814–1819 (1997).
Grupp, K. et al. Expression of ICAM-1, E-cadherin, periostin and midkine in metastases of pancreatic ductal adenocarcinomas. Exp. Mol. Pathol. 104, 109–113 (2018).
Weckbach, L. T., Muramatsu, T. & Walzog, B. Midkine in inflammation. Sci. World J. 11, 2491–2505 (2011).
Haffner-Luntzer, M. et al. Midkine-deficiency delays chondrogenesis during the early phase of fracture healing in mice. PLoS ONE 9, e116282 (2014).
Zhang, D. et al. Midkine derived from cancer-associated fibroblasts promotes cisplatin-resistance via up-regulation of the expression of lncRNA ANRIL in tumour cells. Sci. Rep. 7, 16231 (2017).
Choudhuri, S. & Klaassen, C. D. Structure, function, expression, genomic organization, and single nucleotide polymorphisms of human ABCB1 (MDR1), ABCC (MRP), and ABCG2 (BCRP) efflux transporters. Int. J. Toxicol. 25, 231–259 (2006).
Chen, S. Ultrafast one-pass FASTQ data preprocessing, quality control, and deduplication using fastp. Imeta 2, e107 (2023).
Li, H. & Durbin, R. Fast and accurate long-read alignment with Burrows-Wheeler transform. Bioinformatics 26, 589–595 (2010).
McKenna, A. et al. The Genome Analysis Toolkit: a MapReduce framework for analyzing next-generation DNA sequencing data. Genome Res. 20, 1297–1303 (2010).
Landrum, M. J. et al. ClinVar: improvements to accessing data. Nucleic Acids Res. 48, D835–D844 (2020).
Love, M. I., Huber, W. & Anders, S. Moderated estimation of fold change and dispersion for RNA-seq data with DESeq2. Genome Biol. 15, 550 (2014).
McGinnis, C. S., Murrow, L. M. & Gartner, Z. J. DoubletFinder: doublet detection in single-cell RNA sequencing data using artificial nearest neighbors. Cell Syst. 8, 329.e4–337.e4 (2019).
Acknowledgements
We would like to thank the members of the Department of Obstetrics and Gynecology at Nagoya University Graduate School of Medicine. We are also very grateful to all the patients who agreed to participate in this study. Figure 1a was created in BioRender. Suzuki, H. (2025) https://BioRender.com/v27n680. This study was funded by a Grant-in-Aid for Scientific Research, the Japan Society for the Promotion of Science (JSPS KAKENHI Grant Numbers 21H03075, 22K18394, 23K15832, and 24K02586), the Fusion Oriented Research for Disruptive Science and Technology (FOREST; JPMJFR204J) from the Japan Science and Technology Agency, the Tokai Pathways to Global Excellence (T-GEx), part of the NEXT Strategic Professional Development Program for Young Researchers, the Uehara Memorial Foundation (202210177), Project Mirai Cancer Research Grants, and the Chemo Sero Therapeutic Research Institute. This work was also subsidized by New Energy and Industrial Technology Development Organization (NEDO). The funders played no role in study design, data collection, analysis and interpretation of data, or the writing of this manuscript.
Author information
Authors and Affiliations
Contributions
Conceptualization: K.Y., A.Y. and Y.Y. Methodology: H.S., K.Y., A.Y., and Y.Y. Sample collection and sequencing: K.Y., K.S., M.K., and E.A.-I. Analyses: H.S. and Y.H. Investigation: H.S. and K.Y. Poject administration: K.Y., A.Y., and Y.Y. Supervision: A.Y., H.K., and Y.Y. Writing—original draft: H.S. Writing—review and editing: all authors.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Suzuki, H., Yoshida, K., Yokoi, A. et al. Exploring drug resistance via intercellular crosstalk using spatial transcriptomics in high-grade serous ovarian carcinoma. npj Precis. Onc. 9, 345 (2025). https://doi.org/10.1038/s41698-025-01122-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41698-025-01122-1
