
Abstract
Clinical notes are crucial for patient assessment in the ICU but can be challenging to accurately and objectively analyze in time-constrained situations. We developed the GRACE-ICU model which integrates clinical notes and structured data to rapidly assess critical illness severity in older adults. Based on a cohort from a large U.S. teaching hospital, we fine-tuned a Clinical-Longformer model on pre-ICU notes and combined it with 10 significant structured variables via logistic regression. The receiver operating characteristic curve, calibration curve, decision curve analysis, and 11 metrics were obtained to evaluate its performance in internal, temporal, and external validations when compared with four types of baseline models. Our model outperformed the single-modal models and clinical commonly-used illness scores in both internal and temporal validation for early prediction of hospital mortality and provides interpretable, data-driven recommendations for clinical decision-making, with potential for broader applications. Further prospective studies are needed before clinical use.
Similar content being viewed by others

Introduction
Intensive care units (ICU), by caring for the critically ill members of our populations with often highly complex care needs, are a crucible for clinical decision-making1. With an increasing life expectancy in many countries, the proportion of older ICU patients is expected to significantly increase in the coming decades, especially very old patients2. Older patients (ie, age ≥65 years) present complex challenges in clinical management, as they have an inherently diminished capacity to withstand physiological stressors and often more comorbidities, which amplifies their risk of adverse events and mortality3.
The survival likelihood of geriatric patients in ICU is not just contingent on age and acute illness severity, but also influenced by their clinical condition preceding ICU admission2. In older individuals, the capacity for recovery is closely linked with geriatric syndromes, including frailty, cognitive decline, comorbidities, and functional decline4,5,6. Previous studies have identified that factors associated with ICU mortality included severity score, diagnosis at admission, and mechanical ventilation, whereas age, comorbidities, functional status, and severity score were associated with longer term mortality7. Integrating such a wide array of information in an objective manner is a challenging task even for experienced critical care clinicians. Furthermore, geriatric syndromes often interact with acute critical illness in ways that are not adequately captured by traditional scoring systems, which were not designed to account for age-related vulnerabilities. As such, an automated integrated risk scoring system can support triage decision-making, guide treatment plan formulation, and facilitate effective communication with patients and their families2,8. Accurate and geriatric-specific prediction models could support shared decision-making, guiding discussion about prognosis and care preferences in an informed and empathetic manner.
Assessment of a patient’s background and preICU admission state includes a comprehensive chart review of sometimes voluminous past medical history documents and clinical notes. These clinical notes contain important information about a patient’s premorbid state, symptoms, family history, disease history, interpretation of investigations (e.g., of chest X-rays, laboratory tests, etc.), and medications9. The wealth of information presented can be overwhelming and often lacks clear structure. They can only be interpreted and estimated by physician experts and not by traditional risk scores without manual comprehension and input. However, the rich details contained within clinical notes provide a more comprehensive and nuanced description of a patient’s condition compared to structured numeric data alone10.
Attempts to create a structure for pre-admission information have been made. Rios M et al. used word- and sentence-level sparse attention mechanism modeling of clinical texts to achieve early prediction of in-hospital mortality in ICU patients11. Zhang Dy et al. constructed a transformer prediction model with temporal attention to evaluate health status and hospital mortality based on dynamically recorded clinical texts12. Yang Hy et al. introduced a multimodal dynamic neural network model that integrates time series data and clinical notes to evaluate the risk of hospital mortality13. Although the above studies showed good predictive performance on their respective datasets, there is a lack of studies focusing on the assessment or modeling of disease risk for older patients by combining their clinical note records and structured clinical data. In addition, the above models, being oriented toward the general adult patients, do not take into account certain characteristics that are of particular importance in older patients, such as function, nutrition, frailty, and a greater tendency towards palliative care options. The consideration of these characteristics and information is critical and necessary for a more comprehensive and accurate assessment of patient prognosis and outcome in this population1.
This study aims to provide an objective, explainable, and user-friendly assessment of illness severity in critically ill older adults by integrating clinical notes through natural language understanding and structured data, incorporating geriatric-specific features. To achieve this, we fine-tune a pretrained clinical language model to distill the information contained in clinical notes before ICU admission (we term these as preICU notes). We incorporate structured data including laboratory tests, vital signs, treatment, and fluid output. Additionally, representations of nutrition, mobility, and physical frailty were constructed for analysis. Key variables were identified empirically and integrated into a scoring system for in-hospital mortality risk called GRACE-ICU (Geriatric Risk Assessment with Clinical-text Integrated EHR in the ICU) that is interpretable and user-friendly.
Results
Patient characteristics
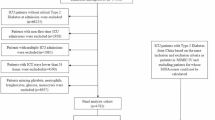
There were 32,554 older patients in the MIMIC cohort and 2283 patients in the eICU-CRD cohort after applying the exclusion and inclusion criteria in Fig. 1(b) and Supplementary Fig. 1. The MIMIC cohort was split into the derivation set with 29,761 patients (15.2% mortality rate) and the temporal validation set with 2793 patients (14.5% mortality rate) by time periods. The mortality rate in the external set was 10.7%. The patient characteristics are summarized in Table 1 and Supplementary Table 1. In all study sets, non survivors had older age, greater comorbidity, lower Braden scale (which quantifies pressure ulcer risk), physical frailty (the vast majority of patients lying in bed), higher proportion of choosing partial therapy, receiving vasopressor bolus, and receiving mechanical ventilation, higher SOFA score, longer duration in ICU, and shorter duration of hospital stay.

a It presents an overview of the development process of the illness score system for older patients in the ICU, including data acquisition, data processing, model development, and model evaluation. b The inclusion and exclusion criteria in MIMIC. c It illustrates the application scenario diagram of the predictive scoring system, Geriatric Risk Assessment with Clinical-text Integrated EHR in the ICU (GRACE-ICU). The icons utilized in the c are sourced from iconfont.cn, and they are permitted for non-commercial use under the MIT license (https://pub.dev/packages/iconfont/license).
Post-hoc experiments for the NLP risk score
We performed post-hoc experiments on the Clinical-Longformer model’s performance when fine-tuning at different learning rates in the internal and temporal sets. The AUROC, AUPRC, Brier score, and F1 with 95% CI at different learning rates are displayed in Supplementary Table 2. The performance of the models decreased with increasing learning rates in internal validation. A learning rate of 1e−5 was used in the final model with the following discrimination metrics in internal validation: AUROC 0.781 (0.754–0.806), AUPRC 0.423 (0.37–0.475), brier score 0.106 (0.098–0.115), and F1 0.417 (0.386–0.45).
Feature selection for the structured data
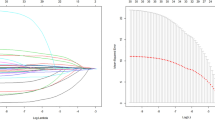
In Supplementary Table 3, univariable logistic regression showed that four variables were not significantly associated with hospital mortality. The Lasso LR model with 5-fold cross-validation was performed to select variables. The Lasso algorithm uses L1 regularization to perform shrinkage and selection of variables, obtaining 35 non-zero coefficient variables. The process of finding the optimal lambda by Lasso regression is shown in Supplementary Fig. 2. We removed a further 24 variables after performing a step algorithm in both directions. In Supplementary Table 4, the selected variables and their coefficients are listed by these two algorithms. The 10 most important variables, after multivariable analysis, identified from the variable selection process included shock index, code status, best state of activity (bed/not bed), mechanical ventilation (yes/no), lactate, CCI score, respiratory rate (mean), Braden Scale, GCS (min), and temperature (mean).
The prediction model and its nomogram plot
Combining the preICU risk score and the top 10 structured variables, we fit a multivariable logistic regression model as the final GRACE-ICU model on the development set. In Table 2, both the univariable and multivariable analyses demonstrated significant associations with hospital mortality (P < 0.001 for all variables). Higher shock index, higher preICU risk score, partial code status, being bedbound, mechanical ventilation, higher lactate, higher CCI score, higher respiratory rate, lower temperature, lower GCS, and lower Braden scale were found to be significantly associated with hospital mortality. A nomogram plot representing the final trained model was obtained and shown in Fig. 2. The illness severity score for older patients was calculated as follows:

Geriatric Risk Assessment with Clinical-text Integrated EHR in the ICU (GRACE-ICU) is calculated based on the preICU risk score that characterizes the severity of illness prior to ICU admission (obtained from clinical notes) and ten structured data measurements taken on the first day of ICU admission including shock index, code status, activity tolerance of bedbound, mechanical ventilation, lactate, comorbidity index score (CCI score), respiratory rate, temperature, glasgow coma scale (GCS), and braden scale.
Total points = 10*preICU_risk_score + 20.0938*(shock index-0.2) + 8.9542*code status (partial = 1, full = 0) + 6.1566*activity status (bed = 1, not bed = 0) + 3.0519*mechanical ventilation (received = 1, non-received = 0) + 1.5848*lactate + 1.5648*(CCI score-2) + 0.9605*(respiratory rate - 5) - 3.3721*(Temperature-40) - 1.6394*(GCS-15) - 1.0715*(Braden Scale-24).
Comparisons with baseline models
We made comparisons between the GRACE-ICU, the structured data score alone, the preICU risk score, SAPS II, and SOFA. In Fig. 3(a, b) and Supplementary Fig. 3(a), ROC curves are shown in internal, temporal, and external validation. The GRACE-ICU significantly outperformed the others except for a slight decrease in performance during external validation, considering the lack of sufficient note support for assessing pre-hospital illness severity. We computed detailed comparison metrics for all models and validation types using 500 rounds of bootstrapping (Supplementary Table 5 and Table 6). In internal validation, the AUROCs with 95% CI were 0.843 (0.822-0.862) for the GRACE-ICU, 0.81 (0.787–0.831) for the structured data score, 0.782 (0.757–0.804) for the preICU risk score, 0.746 (0.719–0.772) for the SAPSII score, 0.711 (0.68–0.741) for the SOFA score. For temporal validation, the AUROCs with 95% CI were 0.853 (0.832–0.873), 0.82 (0.798–0.843), 0.793 (0.766–0.819), 0.744 (0.718–0.77), and 0.736 (0.708–0.761), respectively. For external validation, the AUROCs with 95% CI were 0.8 (0.769–0.825), 0.832 (0.807–0.857), 0.669 (0.632–0.703), 0.776 (0.741–0.81), and 0.705 (0.673–0.738). In Fig. 3(c, d), and Supplementary Fig. 3(b), the GRACE-ICU showed a broader clinical decision net benefit in the internal, temporal validation, and external validation for DCA curves. The structured data score and preICU risk score performed better than the SAPSII and SOFA scores. In Fig. 3(e) and (f), the calibration performances were shown using the calibration curve. The GRACE-ICU both showed acceptable Brier scores in internal and temporal validation (Brier score: 0.097, 0.090). A detailed comparison of the predictive performance between GRACE-ICU, ELDER-ICU (geriatric score), RF and XGBoost (machine learning models), as well as an evaluation of their external validation performance, was provided in the Supplementary Table 6 and Table 7. The comparisons of AUROC, AUPRC, continuous NRI and IDI between GRACE-ICU and others were shown in Supplementary Table 8 and Table 9. The AUROC, AUPRC, and NRI of GRACE-ICU consistently and significantly outperformed that of the structured data score, preICU risk score, SAPSII, and SOFA in internal, temporal, and external validations, except for in the external validation where it was slightly lower than the structured data score. The IDI of GRACE-ICU shows a similar pattern to NRI, but there is no significant difference with SAPSII in external validation.

The five scoring systems are the Geriatric Risk Assessment with Clinical-text Integrated EHR in the ICU (GRACE-ICU, multimodal data based on the clinical notes and structured data), the structured data score (single-modal structured data), preICU risk score (single-modal clinical notes), simplified acute physiology score (SAPSII, a commonly used clinical score), and sequential organ failure assessment (SOFA, a commonly used clinical score). a, b Comparison of the discrimination of five scoring systems in the internal and temporal validations based on the receiver operating characteristic (ROC) curve. c, d Comparison of the clinical benefit of five scoring systems in the internal and temporal validations based on the decision curve analysis (DCA) curve. e, f Comparison of the calibration of five scoring systems in the internal and temporal validations based on the calibration plot.
Feature importance of clinical note type
We analyzed the discrimination performance of the 5 types of clinical notes. In Fig. 4 (a) & (b), we ranked prediction models fine-tuned on individual notes categories, by their AUROC with 500 bootstrap resamples. The order of importance was physical exam, history of present illness, chief complaint, past medical history, and medications on admission in both internal and temporal validation. The physical exam was most important for both [internal validation 0.835 (0.817–0.853), and temporal validation 0.843 (0.822–0.862)]. Among the models evaluated directly based on the external validation set, the model that incorporates the medication on admission showed the best performance with 0.832 (0.801–0.858). The details are displayed in Supplementary Table 10. Furthermore, the top 50 positive and negative tokens, except characters without semantic meaning, numbers, and punctuation marks, that significantly associated with the hospital death were also presented in the “Analysis of SHAP values from NLP module” section of the Results and Fig. 4 in the Supplementary.

The clinical note types include the merging all of them, physical exam, history of present illness, chief complaint, past medical history, and medications on admission. a, b Comparison of the discrimination of six types of clinical notes in the internal and temporal validations based on the area under the receiver operating characteristic curve (AUROC).
Subgroup performance
In Supplementary Table 11, we presented the results of three types of subgroup analyses compared with the entire population, including the proportion of each group, discrimination of AUROC and AUPRC, F1, and calibration of brier score. The assessment results tend to be more precise for patients who are younger, have fewer comorbidities, and exhibit less organ failures. In the internal validation, the performance was suboptimal for patients with a SOFA score above 10. In the temporal validation, the performance was suboptimal for patients with a SOFA score between 10 and 12. In the external validation, the performance was suboptimal for patients with a SOFA score between 6 to 8 and 10 to 12.
Envisioned use of the GRACE-ICU model
Figure 5 shows an example of how the GRACE-ICU model can be used to evaluate the risk of hospital mortality for a patient who has just spent her first day in the ICU. The patient was a 73-year-old elderly white female patient with a BMI of 28.97 and a CCI of 10 who was admitted to the CCU. She had a SOFA score of 7 on admission to the ICU, and was hospitalized for 2.67 days before CCU admission Fig. 5(a). Figure 5(b), (c) and (d) shows the patient’s clinical notes prior to ICU admission with a colored overlay showing the relative importance of text regions to the final model prediction with red highlights indicating a prediction of mortality and blue highlights indicating a prediction of survival. For the detailed analysis, refer to the ‘Envisioned use of the GRACE-ICU model’ subsection in the Supplementary Results. Figure 5(e) plots the trend of the dynamic changes of structured clinical variables on the first day of the ICU. Figure 5(f) shows the use of the GRACE-ICU for risk prediction. If we had only used the clinical notes before admission, the risk of death would have been underestimated (risk: 0.018, threshold: 0.1195) whereas if we had only used the structured clinical variables, the risk of death would have been overestimated (risk: 0.346, threshold: 0.1409). The combination of the two gave a more accurate assessment of the risk of death for the patient (risk: 0.085, threshold: 0.0996). We illustrate how GRACE-ICU estimates the risk of in-hospital death using different types of data for a very old patient who did not survive in Supplementary Fig. 5.

a A brief introduction of an older female patient during her hospitalization. b–d An explanation of the inference process for the preICU risk score, based on input clinical notes, to assess the illness severity of the patients admitted to the ICU. e The dynamic clinical measurements during the first day admitted in the ICU including temperature, respiration, glasgow coma scale (GCS), braden scale, shock index, lactate, partial pressure of oxygen (PaO2), platelet, urine output, and mechanical ventilation. f The calculation of the Geriatric Risk Assessment with Clinical-text Integrated EHR in the ICU.
Discussion
In this study, we developed and evaluated GRACE-ICU, a multi-modal illness severity scoring system for hospital mortality risk assessment of older patients in the ICU, that incorporates information clinical notes before ICU admission using NLP and clinical measurements from the first day of the ICU stay. We included eight categories of clinical data for analysis, including unstructured data of clinical notes (chief complaint, history of present illness, medications on admission, past medical history, and physical exam), and seven additional types of structured data (basic information, Braden scale, physical frailty, laboratory tests, vital signs, treatment, and urine output). By incorporating the factors commonly considered by physicians to assess the patient’s severity of disease, we used a DL language model to represent the past recorded notes as a score evaluating the illness severity when patients entered the ICU. We then fused information from unstructured notes data and structured numerical data to predict in-hospital mortality. The GRACE-ICU model performed better than conventional clinical risk scores with better discrimination and clinical decision benefit.
The GRACE-ICU score integrates unstructured clinical notes with structured numerical data to enhance prognostic accuracy for older ICU patients. By incorporating geriatric-specific factors such as frailty, activity tolerance, and nutritional status, it addresses the complexities unique to this population. The score’s interpretable nomogram facilitates shared decision-making, enabling clinicians to engage patients and families in informed discussions about prognosis and treatment options. It also reduces subjectivity through natural language processing, offering consistent and reliable assessments with the potential for improving ICU resource allocation. Practically, GRACE-ICU can be embedded into electronic medical records for real-time risk predictions, guiding timely interventions and personalized care plans. Its insights can support benchmarking efforts, quality improvement initiatives, and healthcare provider education. Furthermore, the score’s framework has implications for research and policy development, particularly in improving care for aging populations.
Critically ill patients are a highly heterogeneous group, and they often have many comorbidities. They might have completely different clinical trajectories and outcomes even though they have the same diagnosis and illness severity when admitted to the ICU14. Some of these differences depend on their premorbid condition. Although data such as clinical notes, vital signs, laboratory tests, and images, are used in daily clinical practice during patient assessment, clinical tools to better predict patient outcomes remain elusive in the ICU setting14. Studies of geriatric patient characteristics have shown that assessing preICU status, such as frailty, weakness, nutritional status, activities of daily living, and comorbidities, allow for more accurate illness severity assessment for older patients15. Meanwhile, improving the baseline assessment of elderly critically ill patients can better estimate their prognosis7. In this study, the preICU risk score, activity tolerance (whether bedbound), degree of pressure ulcer (braden scale) were individually ranked as the 2nd, 4th, and 11th most significant risk factors, respectively. In particular, the Braden scale, which was utilized for the first time in the prognostic assessment of older patients based on a larger cohort set, demonstrated a strong correlation with hospital mortality.
Despite advanced therapeutics, close monitoring, and intensive nursing care, older patients admitted to the ICU have a high mortality rate, with those aged 80 years or older having a mortality rate between 15 and 25% in the ICU16. Therefore, questions of overall prognosis, as well as risk and benefits in continued ICU care are of even greater importance compared to younger adults. In addition, older patients usually prefer less intensive care and a focus on comfort care rather than receiving aggressive treatments17. The patient’s choice of treatment options and preference for end-of-life issues in the early stages of an ICU admission also influences in-hospital outcomes1,8,18. A patient-centred approach should preserve patient dignity and ensure healthcare wishes are respected. In this study, code status ranked 3rd in importance in predicting hospital mortality.
Unstructured data occupy approximately 80% of EMR and possess an unparalleled wealth of information19. The huge volume and unstructured nature of textual data, combined with a large vocabulary of medical terms, complex syntax, limit its widespread use for analysis or prediction in clinical settings. NLP techniques have been used in recent years for the analysis of clinical text data, such as preprocessing, contextual feature detection, and entity extraction14. Clinical language models (LM), such as ClinicalBERT, PubMedBERT, and DRG-LLaMA, which were pretrained on biomedical and medical corpora, have shown increased proficiency and ability when fine-tuned for tasks such as predicting in-hospital mortality and length of hospital stay20,21. Compared with the traditional bag-of-words model, encoder-decoder model, and the base BERT model, clinical LLMs can better learn the semantic relationships between clinical words and capture the long-distance dependencies of semantics between notes, achieving good discriminative performance in specific prediction tasks after fine-tuning. Transformer models that use the full self-attention mechanism have significant memory consumption which limit the maximum length of model inputs. The Clinical-Longformer uses a sparse attention mechanism to overcome this issue which allows it to process longer clinical text present in this study. A small learning rate with early stopping achieved good performance in our experiments.
Although many models based on DL and ML have achieved good performance in risk prediction tasks, many studies fail to incorporate aspects of history taking and chart review22. A comprehensive review of a patient’s medical history, such as medication, smoking, alcohol, and family history, is an important part of patient assessment. By combining the current symptoms with the patient’s past medical history and current clinical observation, a physician can often get important insights into a patient’s illness severity23. We mirrored this clinical reasoning process in the design of the GRACE-ICU model by combining structured risk factors and the preICU risk score which encodes information from preICU clinical note, especially for physical exam and history of present illness, to predict hospital mortality. By displaying model weights in a nomogram format, clinicians can have a visual scale of the relative importance of each indicator on the predicted outcome. The strength of this approach likely lies in its holistic representation of the patient, achieved by combining contextual information from the patient’s background prior to ICU admission with acute status data recorded during the first day in the ICU.
The commonly used SOFA, APACHE, and SAPS scores focus more on acute changes in patient physiology and acute organ dysfunction, although more recent versions such as the SAPS-III and APACHE-IV scores have incorporated age, comorbidities, and preICU length of stay as inputs. However, they still underperform when assessing disease severity in older patients24. At the same time, the SAPS-III (35 input variables) and APACHE-IV (104 input variables) require many variables and the large number of variables can prove cumbersome in instances where manual data entry is necessary. In recent years, many studies using DL methods to predict patient outcomes have emerged, but the black box nature of these models prevent direct interpretation of the contribution of individual inputs to the final outcome, this may reduce trust and uptake by clinicians25. In this paper, we propose an interpretable multi-modal prediction model to address some of these challenges. The NLP module condenses rich semantic information contained across multiple sets of clinical texts into a single probabilistic estimate. The nomogram plot provides an intuitive visual scale and probability estimate that can be easily understood by medical staff which may increase trust and uptake. The results also showed that the predictive performance of our model significantly outperformed the SAPS II and SOFA scores in terms of AUROC (internal validation: 0.843 vs. 0.746, 0.711, temporal validation: 0.853 vs. 0.744, 0.736, external validation: 0.800 vs. 0.776, 0.705). Analysis of net clinical benefit also showed that our model was significantly better than the SAPS II and SOFA scoring systems.
This study has several limitations. First, external validation of the scoring system is needed to assess its generalizability and robustness to data drift when transferred to other populations. While this study has conducted external validation, further assessments in different types of hospitals and those from other countries are also highly necessary. Second, given the inherent complexity of older adults and the variations in treatment preferences across different diverse cultural contexts, GRACE-ICU may face challenges in handling the nuances of clinical terminology without adequate corpus. It’s necessary to expand the data sources and integrate relevant knowledge graphs for enhancing its precision in prognostic assessments. Third, the model was designed to provide a single static prediction at the end of the first day of ICU stay whereas dynamic prediction models can learn temporal patterns that predict disease trajectory and can support real-time feedback and guidance to physicians. Real-world continuous validation, refinement of the GRACE-ICU, and prospective trial evaluation are essential prerequisites before its deployment in clinical practice.
The multi-modal GRACE-ICU risk score provides accurate prediction of hospital mortality amongst older adults in the ICU. Its design highlights a practical method for the fusion of unstructured and structured data to develop interpretable and easy-to-use disease prediction models.
Methods
Study design and population
We conducted a retrospective study to develop and validate GRACE-ICU, a multi-modal illness severity score for older patients in the ICU. Hospital mortality served as our primary outcome of interest and was used to define disease severity. The GRACE-ICU score was designed to integrate the patient’s past medical history records from notes and common measurements taken on the first day in the ICU. Both unstructured data and structured data were collected. The data was divided and processed separately based on their data and then partitioned into development and validation sets. A deep-learning language model was used to estimate illness severity based on free-text clinical notes. Machine learning algorithms were utilized to identify the core structured variables and construct the GRACE-ICU risk score that integrating the disease severity representation by notes. Lastly, the GRACE-ICU model was compared against baseline clinical risk scores and models in different types of validation. The model performance was evaluated using standard classification metrics and measures such as discrimination, calibration, clinical net benefit, and degree for net reclassification. The entire research process is summarized and presented in Fig. 1(a).
This study utilized electronic health care records of older patients over 65 years old admitted to the Beth Israel Deaconess Medical Center (BIDMC) between 2001 to 2019, which was acquired from the open-access Medical Information Mart for Intensive Care Database (MIMIC) versions III and IV26,27, and patients in the eICU Collaborative Research Database (eICU-CRD) covering 208 US hospitals with 9.13% being teaching hospitals28. We excluded repeat ICU admissions, short ICU admissions of less than 24 hours, elective admissions, and admissions that were missing basic vital signs measurements (heart rate, respiratory rate, mean arterial pressure, systolic blood pressure, Glasgow Coma scale, temperature, and oxygen saturation)6,18. Patients were additionally excluded if no past medical history was documented. The cohort flow diagram is presented in Fig. 1(b) and Supplementary Fig. 1. We used BIDMC admissions from 2001 to 2016 as the development set for training and internal validation, BIDMC admissions from 2017 to 2019 as the temporal validation set, and ICU admissions from eICU-CRD as the external validation set.
Both MIMIC and eICU-CRD were designed for retrospective studies and have been rigorous de-identified. Informed consent was waived by the ethics committee, and all accessible data were anonymous. The former has been approved by the ethics committees of Massachusetts Institute of Technology (0403000206) and BIDMC (2001-P-001699/14), while the latter has been granted Health Insurance Portability and Accountability Act Certification (1031219-2)29.
Data acquisition
We collected commonly recorded preICU clinical note types and structured data from the first day in the ICU. In Fig. 1(c), we presented a summary of the eight clinical data types used in the GRACE-ICU model, including clinical notes (unstructured data), basic information, Braden Scale, physical frailty, vital signs, laboratory tests, treatments, and urine output (structured data). Clinical note types are detailed in Fig. 1(a), and included the chief complaint, history of present illness, medications on admission, past medical history and physical exam. We included seven types of structured variables covering basic information (age, body mass index [BMI], Charlson Comorbidity Index score [CCI score]), sex, and preICU length of stay); Braden scale; physical frailty measures including activity bed, activity sit, activity stand, and Geriatric nutritional risk index (GNRI)6; vital signs (heart rate, mean blood pressure [MBP], respiratory rate, systolic blood pressure [SBP], shock index, oxygen saturation [SpO2], temperature, Glasgow Coma Scale [GCS], and fraction of inspired [FiO2]); laboratory tests (alkaline phosphatase [ALP], alanine aminotransferase [ALT], anion gap, aspartate aminotransferase [AST], base excess, bicarbonate, bilirubin, blood urea nitrogen [BUN], BUN to creatinine ratio [BUN/creatinine], chloride, creatinine, estimated glomerular filtration rate [eGFR], glucose, hematocrit, hemoglobin, lactate, lymphocytes, magnesium, neutrophils, neutrophil lymphocyte ratio [NLR], partial pressure of carbon dioxide [PaCO2], partial pressure of oxygen [PaO2], ratio of PaO2 to FiO2 [P/F ratio], platelets, potassium, prothrombin time [PT], activated partial thromboplastin time [PTT], sodium, and white blood cell [WBC]), treatments (vasopressor, mechanical ventilation, code status, and continuous renal replacement therapy [CRRT]), and urine output. Additionally, we calculated the Sequential Organ Failure Assessment (SOFA) and Simplified Acute Physiology Score (SAPS) II for each ICU admission. The missing ratios of structured variables in both sets before feature construction were calculated and are presented in Supplementary Table 12. The proportions of the 5 types of clinical notes are presented in Supplementary Table 13.
Data processing
The unstructured and structured data were processed separately. Clinical notes were converted to lowercase, and special characters such as ‘==’, ‘--’, and ‘\n’ were removed. Considering the heterogeneity of note lengths, we employed a sliding window approach to split long notes into note-chunks, thereby mitigating information loss caused by truncating sentences longer than the model context length during model training. The window size and sliding step were adjusted and examined to acquire sentence sets with appropriate lengths. Subsequently, the preprocessed note chunks were tokenized and mapped onto an embedding matrix using the pretrained tokenizer of the chosen language model and its associated dictionary. Finally, each note-chunk was embedded into a fixed-length vector, effectively encapsulating the information it contained.
For the structured data, values exceeding the physiological boundaries of each variable were excluded. Clinically important statistics of each variable were calculated during the first day in the ICU, such as the highest, and lowest value for laboratory tests and the lowest, and average value for vital signs, presence or absence for treatments. Missing values was imputed in three ways: variables with a missing ratio below 30% were imputed by the median value of this variable (including BMI), variables with a missing ratio over 30% were imputed with 0, and additional missing indicator variables denoted by a ‘flag’ suffix, such as lactate_flag, were added. The missing values of FiO2 were imputed by 21%, and the indicator variable, ‘FiO2_flag’, was also constructed18. The categorical variables were further set as factor variables. All variables categorized by types, including unstructured and structured data, are listed in Supplementary Table 14.
The patients admitted to BIDMC between 2001 to 2016 were chosen as the development set, which randomly sampled 90% of patients’ data to train models, and the remaining 10% was used for internal validation. Patients from 2017 to 2019 were allocated as the temporal validation set. This ensured that there was no overlap at the ICU episode level between the two datasets. All patients extracted from eICU-CRD were chosen as the external set.
Model development
Natural language processing (NLP) module
We used a publicly available pretrained BERT model specialized for the clinical domain, known as the Clinical-Longformer30. The Clinical-Longformer was specifically designed to address the significant memory consumption of the base Bio-ClinicalBERT model by the use of sparse attention, and has been demonstrated to perform better in commonly used downstream clinical NLP tasks. Moreover, its pre-training corpus was based on the MIMIC-III dataset, which not only enriched the model’s understanding of medical terminologies and expressions but also significantly reduced the cost and workload of our fine-tuning process. We fine-tuned the Clinical-Longformer using 80% of the patients from the development set for the downstream task of mortality prediction. Additionally, 10% of patients’ data were allocated to evaluate the model’s performance across different sets of hyperparameters and to guard against overfitting. The remaining 10% of the patients were set aside for assessing the internal validation performance. Our fine-tuning used 2 NVIDIA A100-SXM4 GPUs. The sliding window size for the split sentence length was set to 240, with a sliding step of 20 for the overall notes or individual types of notes including chief complaint, history of present illness, medications on admission, past medical history, and physical exam. The number of epochs and batch size were separately determined as 2 and 16, respectively, based on preliminary experiments with their performance in the development set and consideration of hardware resources, as shown in Supplementary Table 15. Furthermore, a performance comparison was conducted between Clinical-Longformer and two other commonly used medical BERT models, Bio-ClinicalBert and Clinical-BigBird, to ensure its optimal performance, as shown in Supplementary Fig. 6. The Adam optimizer and a learning rate by linear changing with warmup were empirically adopted. The learning rates were selected from the range between 1e−5 and 5e−5 (interval 1e−5). By fine-tuning the Clinical-Longformer model, we estimated the probability of hospital mortality for each older patient based on their preICU admission clinical notes and termed this as the preICU risk score. Due to the nature of the sliding window approach used, patients who had multiple clinical note types, or who had longer notes split into note-chunks would have multiple probability predictions from this step. The final preICU risk score was determined by averaging these probabilities.
Structured variables selection
The development set was used to obtain the optimal risk variables. We initially used univariate logistic analysis to identify the relationship between the structured variables and the primary outcome. The odds ratios (ORs) with 95% confidence intervals (CIs) and P values of each variable were estimated and analyzed. Then, the least absolute shrinkage and selection operator (LASSO) regression algorithm with 5-fold cross-validation was employed for variable selection. Furthermore, a stepwise algorithm incorporating forward and backward directions that optimized the Akaike Information Criterion (AIC) was also conducted to select the optimal variables. The final set of variables were entered into a multivariable logistic regression (LR) model to acquire the ORs with 95% CIs, P values. To improve generalizability and simplify the risk score, variables with small coefficients or high missing ratios were excluded from subsequent analyses.
Construction of the clinical nomogram
The final GRACE-ICU model is a multivariable LR model that integrates the preICU risk score (the hospital mortality probability derived from the Clinical-Longformer model was multiplied by 10 and rounded up to match with the scales of other variables and facilitate physicians’ data entry and usage) and selected structured variables. The sensitivity analysis was used to evaluate the rationality of this approach, as shown in the Model evaluation and Supplementary Table 16. The final trained parameters of the GRACE-ICU model, using the development set, were used to construct an illness severity evaluation nomogram that provides a visual scale for the contribution of individual components.
Model evaluation
Comparisons and validation types
We compared the GRACE-ICU model against the NLP module in isolation, the structured data model in isolation, and the SOFA and SAPSII clinical scores. Furthermore, the ELDER-ICU6, a ML illness severity assessment model for older ICU adults, random forest (RF), and the eXtreme Gradient Boosting algorithm (XGBoost) were both evaluated to provide a more comprehensive assessment of the differences compared to the baseline models. We performed identical data preprocessing and interpolation procedures as those utilized during the training phase of the ELDER-ICU model. And the predictive performance of the ELDER-ICU model was directly assessed in validation cohorts. We selected the same variables as those used in the GRACE-ICU to train the XGBoost and RF models. In the pursuit of optimizing model performance, both XGBoost and RF algorithms employed Bayesian optimization for hyperparameter tuning. All models were evaluated in internal, temporal and external validation analyses.
Performance analysis and evaluation metrics
Receiver operating characteristic curves (ROC) was used to assess the discrimination of models. Calibration curves were employed to evaluate the consistency between the actual and predicted risk probabilities. Decision curve analysis (DCA) was conducted to assess the clinical utility and effectiveness of the models based on the net benefit across various probability thresholds. Comparison metrics included the area under the ROC curve (AUROC), area under the precision-recall curve (AUPRC), sensitivity, specificity, F1 score, precision, accuracy, and negative predictive value (NPV), net reclassification improvement (NRI), and integrated discrimination improvement (IDI). NRI was used to quantify the enhancement of the GRACE-ICU model in reclassifying individuals compared to other models. IDI was used to assess the overall improvement in predictive probabilities of the GRACE-ICU relative to other models. A positive NRI or IDI (greater than 0) indicates that the GRACE-ICU outperforms other models, whereas a non-positive value suggests the opposite31. All metrics with 95% CI were calculated using a non-parametric bootstrap with 500 resamples.
Relative importance of clinical note types
We performed experiments to investigate the relative importance of each clinical note type by fine-tuning the NLP model only on a single note type. The discrimination of AUROCs and AUPRCs for these models was compared to assess the importance of different categories of clinical notes on the primary outcome.
Sensitivity analysis of GRACE-ICU
We compared the performance of GRACE-ICU derived from preICU risk scores (both multiplied by 10 and un-multiplied) by analyzing the NRI (categorical and continuous, 95% CI) and IDI (95% CI), along with significance testing for differences.
Subgroup analysis
We conducted subgroup evaluations based on age (65 ~ 80 y, 80 ~ ), severity of comorbidities (CCI score: 3 ~ 5, 5 ~ 21)32, and extent of organ failure (SOFA: 0 ~ 2, 2 ~ 4, 4 ~ 6, 6 ~ 8, 8 ~ 10, 10 ~ 12, 12 ~ 24)33 upon ICU admission to assess the differences in the GRACE-ICU’s performance across internal, temporal, and external validations.
Interpretation of the NLP module
The SHapley Additive exPlanations (SHAP)34 approach was chosen to explain the NLP module. By overlaying the computed SHAP values on individual words, we created a visualization that uses two colors to highlight note regions that the model identified as higher risk (red) and lower risk (blue).
Statistical analysis
For the descriptive analysis, categorical variables were reported with numbers and proportions, while continuous variables were reported with their median values and interquartile range (IQR). The differences between groups were assessed by the Wilcoxon signed-rank test, X2 test, and Fisher’s test according to the sample size and variable type. A P value less than 0.05 was considered indicative of a statistically significant difference. Modeling and statistical analyses were performed using Python version 3.7.1, using the following packages: tableone, torch, transformers, and Clinical-Longformer; and R version 4.1, using the following packages: rms, glmnet, rmda, pROC, and PredictABEL.
Data availability
The raw data can be downloaded separately at https://physionet.org/content/mimiciii/1.4/, https://physionet.org/content/mimiciv/2.2/, https://physionet.org/content/mimic-iv-note/2.2/, and https://physionet.org/content/eicu-crd/2.0/.
Code availability
Code is available at https://github.com/liuxiaoliXRZS/GRACE-ICU.
References
Guidet, B., et al. The trajectory of very old critically ill patients. Intensive Care Med. 50, 181–194 (2024).
Guidet, B., et al. VIP2 study group. The contribution of frailty, cognition, activity of daily life and comorbidities on outcome in acutely admitted patients over 80 years in European ICUs: the VIP2 study. Intensive Care Med. 46, 57–69 (2020).
Ho, L. et al. Performance of models for predicting 1-year to 3-year mortality in older adults: a systematic review of externally validated models. Lancet Healthy Longev. 5, e227–e235 (2024).
Flaatten, H., et al. VIP1 study group. The impact of frailty on ICU and 30-day mortality and the level of care in very elderly patients (≥80 years). Intensive Care Med. 43, 1820–1828 (2017).
Level, C., et al. Outcome of older persons admitted to intensive care unit, mortality, prognosis factors, dependency scores and ability trajectory within 1 year: a prospective cohort study. Aging Clin. Exp. Res. 30, 1041–1051 (2018).
Liu, X. et al. Illness severity assessment of older adults in critical illness using machine learning (ELDER-ICU): an international multicentre study with subgroup bias evaluation. Lancet Digit Health 5, e657–e667 (2023).
Vallet, H., et al. Mortality of Older Patients Admitted to an ICU: A Systematic Review. Crit. Care Med. 49, 324–334 (2021).
van Heerden, P. V. et al. The wave of very old people in the intensive care unit-A challenge in decision-making. J. Crit. Care 60, 290–293 (2020).
Rabindra, B. & Awanish R. A new approach to extract meaningful clinical information from medical notes. 2017 11th International Conference on Software, Knowledge, Information Management and Applications (SKIMA). IEEE, 1-8 (2017).
Van Aken, B. et al. Assertion detection in clinical notes: Medical language models to the rescue? In Proc. Second Workshop on Natural Language Processing for Medical Conversations, 35-40 (2021).
Miguel, R. & Ameen A. H. Mortality Prediction Models with Clinical Notes Using Sparse Attention at the Word and Sentence Levels. arXiv preprint arXiv:2212.06267, 1-8 (2022).
Zhang, D., Thadajarassiri, J., Sen, C. & Rundensteiner, E. Time-aware transformer-based network for clinical notes series prediction. In Machine learning for healthcare conference (PMLR), 566-588 (2020).
Yang, H., Kuang, L. & Xia, F. Multimodal temporal-clinical note network for mortality prediction. J. Biomed. Semant. 12, 1–14 (2021).
Forte, J. C. & van der Horst, I. C. C. Comorbidities and medical history essential for mortality prediction in critically ill patients. Lancet Digit Health 1, e48–e49 (2019).
Cuthbertson, B. H. & Wunsch, H. Long-Term Outcomes after Critical Illness. The Best Predictor of the Future Is the Past. Am. J. Respir. Crit. Care Med 194, 132–134 (2016).
Leblanc, G., Boumendil, A. & Guidet, B. Ten things to know about critically ill elderly patients. Intensive Care Med 43, 217–219 (2017).
Philippart, F. et al. The ETHICA study (part I): elderly’s thoughts about intensive care unit admission for life-sustaining treatments. Intensive Care Med 39, 1565–1573 (2013).
Liu, X. et al. Clinically Interpretable Machine Learning Models for Early Prediction of Mortality in Older Patients with Multiple Organ Dysfunction Syndrome: An International Multicenter Retrospective Study. J. Gerontol. A Biol. Sci. Med Sci. 78, 718–726 (2023).
Kong, H. J. Managing unstructured big data in healthcare system. Healthc. Inform. Res. 25, 1–2 (2019).
Deznabi, I., Iyyer, M. & Fiterau, M. Predicting in-hospital mortality by combining clinical notes with time-series data. In Findings of the association for computational linguistics: ACL-IJCNLP, 4026-4031 (2021).
Wang, H., Gao, C., Dantona, C., Hull, B. & Sun, J. DRG-LLaMA : tuning LLaMA model to predict diagnosis-related group for hospitalized patients. NPJ Digit Med 7, 16 (2024).
Xiao, C., Choi, E. & Sun, J. Opportunities and challenges in developing deep learning models using electronic health records data: a systematic review. J. Am. Med Inf. Assoc. 25, 1419–1428 (2018).
Xu, X. et al. Predictive modeling of clinical events with mutual enhancement between longitudinal patient records and medical knowledge graph. In 2021 IEEE International Conference on Data Mining (ICDM), 777-786 (2021).
Liu, X. et al. Evaluating Prognostic Bias of Critical Illness Severity Scores Based on Age, Sex, and Primary Language in the United States: A Retrospective Multicenter Study. Crit. Care Explor 6, e1033 (2024).
Zhang, X. et al. KnowRisk: An interpretable knowledge-guided model for disease risk prediction. In 2019 IEEE International Conference on Data Mining (ICDM), 1492-1497 (2019).
Johnson, A. E., et al. MIMIC-III, a freely accessible critical care database. Sci. Data 160035, 1–9 (2016).
Johnson, A. E. W. et al. MIMIC-IV, a freely accessible electronic health record dataset. Sci. Data 10, 1–9 (2023).
Pollard, T. J., et al. The eICU Collaborative Research Database, a freely available multi-center database for critical care research. Sci. Data 180178, 1–13 (2018).
Sarkar, R. et al. Performance of intensive care unit severity scoring systems across different ethnicities in the USA: a retrospective observational study. Lancet Digit Health 3, e241–e249 (2021).
Li, Y. et al. A comparative study of pretrained language models for long clinical text. J. Am. Med. Inform. Assoc. 30, 340–347 (2023).
Barbour, S. J. et al. International IgA Nephropathy Network. Evaluating a New International Risk-Prediction Tool in IgA Nephropathy. JAMA Intern Med 179, 942–952 (2019).
Huang, Y. Q. et al. Charlson comorbidity index helps predict the risk of mortality for patients with type 2 diabetic nephropathy. J. Zhejiang Univ. Sci. B 15, 58–66 (2014).
Ferreira, F. L. et al. Serial evaluation of the SOFA score to predict outcome in critically ill patients. JAMA 286, 1754–1758 (2001).
Lundberg, S. M. et al. Explainable machine-learning predictions for the prevention of hypoxaemia during surgery. Nat. Biomed. Eng. 2, 749–760 (2018).
Acknowledgements
Z.Z. is funded by the National Natural Science Foundation of China (62171471) and Beijing Natural Science Foundation (7252299). X.L. is funded by the Beijing Natural Science Foundation (7252298). L.A.C. is funded by the National Institute of Health through R01 EB017205, DS-I Africa U54 TW012043-01 and Bridge2AI OT2OD032701, and the National Science Foundation through ITEST #2148451.
Author information
Authors and Affiliations
Contributions
X.L., W.Y., and Z.C. were in charge of data extraction, conducting experiments, and writing the initial draft. L.A.C., Z.Z., D.L., and M.F. contributed to the study design and funding support. D.C., W.Y., and M.Y. contributed to analyzing results and visualization of the data. S.H. and Z.Y. were responsible for computing resource preparation and hyperparameter tuning. C.L., Z.M., and X.S. verified the data and guided the literature review. All authors contributed to statistical analysis and discussion of experiment results. All authors had access to the raw study databases. All authors confirmed that they have read and approved the manuscript, and they had the final responsibility for the decision to submit for publication.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Liu, X., Yeung, W., Chen, Z. et al. GRACE-ICU: A multimodal nomogram-based approach for illness severity assessment of older adults in the ICU. npj Digit. Med. 8, 519 (2025). https://doi.org/10.1038/s41746-025-01875-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41746-025-01875-w
