
Abstract
The FDA Sentinel Real-World Evidence Data Enterprise (RWE-DE) contains linked electronic health records with claims data for over 25 million patients. To demonstrate the applicability of the RWE-DE to a study previously considered infeasible in claims-based Sentinel network, we emulated a target trial using a case study comparing acute pancreatitis among new users of sodium-glucose cotransporter-2 inhibitors (SGLT-2i) with new users of dipeptidyl peptidase-4 inhibitors (DPP-4i) among 97,119 patients with type 2 diabetes mellitus from HealthVerity [2018–2020] and TriNetX [2013–2024] databases. We applied a previously validated computable phenotyping algorithm using EHRs to identify acute pancreatitis as the primary outcome. After confounding adjustment for >135 variables using propensity score fine stratification weighting, the hazard ratio (95% confidence interval) for acute pancreatitis following SGLT-2i initiation compared to DPP-4i initiation was 0.85 (0.67–1.07) for intent-to-treat and 0.84 (0.58–1.22) for per-protocol analysis. This study serves as a proof-of-concept for future safety assessments in Sentinel.
Similar content being viewed by others

Introduction
The U.S. FDA’s Sentinel System forms a critical component of the national active post-marketing surveillance of medical products1. Historically, Sentinel’s reliance on insurance claims data has led to insufficiency in addressing some emerging safety questions requiring more granular clinical information2. The FDA Sentinel Real-World Evidence Data Enterprise (RWE-DE), a data infrastructure linking large volumes of electronic health records (EHRs) with claims data, was created to help the FDA address emerging safety questions for which claims data may be insufficient3,4.
A common scenario where EHR linkage can be particularly helpful is when certain outcomes of interest may not be captured in administrative claims. For instance, when assessing the suitability of evaluating the potential risk of acute pancreatitis in Sentinel, the FDA considered that claims-based diagnosis codes for acute pancreatis may have poor positive predicted value (PPV)5, which was confirmed in a later validation study to be in the range of 55-66%6. Due to the potential for outcome misclassification that may have led to an underestimation of the effect, outcome ascertainment in linked EHR-claims data was proposed as an alternative. In this report, we describe results from a demonstration project that aimed to assess the applicability of the RWE-DE in a use case of the risk of acute pancreatitis following initiation of SGLT-2 inhibitors compared to dipeptidyl peptidase-4 inhibitors (DPP-4i) in patients with type 2 diabetes mellitus (T2DM). Specifically, we address the limitation of low PPV for pancreatitis in claims-based diagnosis codes by deploying a previously developed computable phenotyping algorithm using elements from EHRs in addition to claims diagnosis codes, which is reported to have a PPV of >90%7. Additionally, we also outline typical workflow of inferential studies utilizing EHR-claims linked data in Sentinel and provide readily usable analytic codes as a turnkey solution for conducting rigorous analyses in a timely way for future needs of the program.
Results
Study cohorts
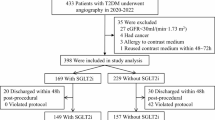
After applying all eligibility criteria, the final cohorts included 72,429 patients from HealthVerity (30,174 SGLT-2i initiators; 42,155 DPP-4i initiators) and 24,690 patients from TriNetX (11,943 SGLT-2i initiators; 12,747 DPP-4i initiators).
Table 1 summarizes the key patient characteristics of the included participants. For both data sources, the average age was lower in SGLT-2i group than DPP-4i group (57 years versus 60 years in HealthVerity; 55 years versus 56 years in TriNetX). Overall indicators of health including CFI and CCI were comparable between treatment groups in both data sources. Metformin was the most common comedication in both treatment groups across both data sources. The mean count of antidiabetic drug classes was generally comparable (HealthVerity: 1.4 ± 0.8 in the SGLT-2i group and 1.3 ± 0.8 in the DPP-4i; TriNetX: 1.2 ± 0.8 for the SGLT-2i group and 1.1 ± 0.8 for the DPP-4i group). For HealthVerity, the proportion of patients with myocardial infarction (1.7%, 1.1%), stable angina (4.3%, 3.7%), and heart failure (6%, 5.9%) was similarly distributed between the two treatment groups; while for TriNetX, the proportion was generally higher in the SGLT-2i groups for myocardial infarction (3.7%, 1.2%), stable angina (4.8%, 2.3%), and heart failure (13.3%, 5.7%), likely reflecting increasing use of SGLT-2i in more recent time periods after knowledge of their cardiovascular benefits accumulated.
Structural missing data investigation
Missingness in EHR-based variables was commonly observed as expected (Table 1). In HealthVerity, HbA1c results were available for 29.4% SGLT-2i initiators and 27.3% DPP-4i initiators (mean HbA1c: 8.7 ± 1.9, 8.6 ± 1.9). Serum creatinine and triglyceride levels were recorded for around 20–25% of the patients (mean serum creatinine: 0.9 ± 0.5, 0.9 ± 0.5; mean triglycerides: 176 ± 90.6; 171.4 ± 87.4). BMI was recorded for >60% of the patients in both groups (mean BMI: 32.4 ± 5.5, 31.6 ± 5.7). Blood pressure was recorded for >80% of the patients in both groups (mean systolic: 131.3 ± 16.5, 131.3 ± 16.8; mean diastolic: 79 ± 10.2; 78.3 ± 10.3). Total number of EHR encounters were comparable across both groups (mean EHR encounters: 3.4 ± 2.8, 3.5 ± 2.9). In TriNetX, HbA1c results were available for around 50% of the patients in both groups (mean HbA1c: 8.6 ± 2.0, 8.5 ± 1.9). Serum creatinine and triglyceride levels were recorded for 35–60% of the patients (mean serum creatinine: 0.9 ± 0.3, 0.9 ± 0.4; mean triglycerides: 174.2 ± 93.6; 174.3 ± 92.7). BMI was recorded for approximately half of the patients in both groups (mean BMI: 34.8 ± 8.0, 34.5 ± 7.9). Blood pressure was recorded for >60% of the patients in both groups (mean systolic: 134.6 ± 19.6, 134.2 ± 19.0; mean diastolic: 79.8 ± 12.2; 79.5 ± 11.6).
We observed a monotonic missingness pattern in EHR-based variables for both data sources, as patients with missing data for these key variables are likely to exhibit consistent gaps in other EHR-based measurements (Supplementary Figs. 1 and 2). For the missingness diagnostics (Supplementary Table 3), we observed differences in measured variables between those with and without missing data for EHR-based variables as seen by absolute standardized mean distribution, with medians of around 0.02–0.05. Next, for models predicting missingness, we observed relatively high area under the curve (AUCs) for each of these variables, especially in TriNetX. High AUCs suggest that missing at random (MAR) conditional on measured information may be a likely missingness mechanism. Finally, we evaluated associations between missingness indicator in each of these EHR variables and the outcome (acute pancreatitis outcome of interest). These results indicated that when adjusting for other measured variables, no significant association was observed between missingness indicator and the outcome. This observation provides some reassurance against missing not at random (MNAR) mechanism. Overall, we concluded that MAR may be a reasonable assumption regarding a missingness mechanism for these variables and therefore, multiple imputations are likely to provide best bias-variance trade-off8.
Acute pancreatitis risk
Table 2 shows a comparison of incidence rates (IRs) of acute pancreatitis in new users of SGLT-2i and DPP-4i in HealthVerity and TriNetX. The total event count was 236 and 138 in HealthVerity and was 107 and 41 in TriNetX, for ITT and PP causal contrasts, respectively. Overall, we observed event rates in the range of two to three per 1000 person-years across both data sources in the two follow-up schemes. Figure 1 compares the unadjusted cumulative incidence of acute pancreatitis in new users of SGLT-2i versus DPP-4i with T2DM, including both ITT and PP analyses in both data sources. Overall, the plots suggested that the cumulative incidence of acute pancreatitis was comparable between the two treatment groups for both ITT and PP approach in both data sources.

Cumulative incidence of acute pancreatitis before propensity score adjustment in the study cohort of patients with Type 2 diabetes mellitus initiating SGLT-2 inhibitors or DPP-4 inhibitors.
Supplementary Figs. 3 and 4 show high covariate balance across all covariates after the PS weighting procedure, reported as mean difference range between two treatment groups across 20 imputations. Figure 2 provides the hazard ratios (HRs) for acute pancreatitis in SGLT-2i initiators compared to DPP-4i initiators with T2DM in HealthVerity and TriNetX. In the claims-only analysis, the pooled adjusted HRs were 0.99 (0.84–1.16) for ITT and 0.94 (0.73–1.20); which notably moved downwards in the claims + EHR augmented analysis [pooled HR 0.85 (95% CI: 0.67–1.07) for ITT and 0.84 (0.58–1.22) for PP].

Relative risk of acute pancreatitis before and after propensity score adjustment in the study cohort of patients with Type 2 diabetes mellitus initiating SGLT-2 inhibitors compared to DPP-4 inhibitors. *Claims only analysis defined acute pancreatitis based on ICD codes alone and adjusted for >130 claims-based variables **Claims + EHR augmented analysis defined acute pancreatitis based on a phenotyping algorithm using EHR data and added 6 additional variables for confounding adjustment with missing data imputed using multiple imputation.
Subgroup analyses and robustness evaluation
For all subgroups considered (age <65 and ≥65, males, females, and history of acute pancreatitis risk factors), we found results consistent with the overall population (Fig. 3). In the two sensitivity analyses where we attempted to reduce missingness proportions for EHR-based covariates by increasing the lookback period and by restricting to those with ≥3 EHR encounters, we noted that the capture increased for all EHR-based covariates (Supplementary Fig. 5) and results did not change meaningfully from the primary analysis. The analysis of the stroke endpoint as a negative control outcome confirmed no difference in risk between SGLT-2i and DPP-4i (pooled HR 0.97, 95% CI 0.82–1.14).

Results from subgroup and sensitivity analysis (propensity score adjusted estimates from claims + EHR augmented analyses). *Acute pancreatitis risk factors included gallstones, tobacco use, or alcohol abuse † EHR loyalty cohort analysis was restricted to subjects with ≥3 EHR encounters in the 6-months before cohort entry.
Discussion
The primary contribution of this study is that it provides an insight into workflows and salient challenges for complex inferential analyses in the Sentinel System moving forward where diverse data types including insurance claims and EHRs from numerous data sources are expected to be routinely used. First and foremost, as soon as a safety concern arises regarding a medical product, it will be crucial to identify data elements that are essential for a given study to ensure fitness-for-purpose of the data sources. For instance, in this study, the need for additional clinical data including amylase and lipase test results to reliably identify acute pancreatitis drove the choice of utilizing the claims-EHR linked RWE-DE, which is relatively smaller with approximately 25 million total covered lives between the two sources used in this study, over the insurance claims-based Sentinel Distributed Database, which is much larger with 128.7 million members currently accruing new data. Next, availability of validated algorithms for complex outcomes that are insufficiently defined by diagnosis codes alone but are possible to identify with computable phenotyping will be critical to deploy in a scalable and timely way. Sentinel has made steady progress in this area with development and validation of numerous computable phenotypes that are likely to be of high interest as safety outcomes in the future including anaphylaxis, suicidal ideation, and sleep-related behaviors9,10. Finally, use of EHR data opens the possibility of more robust confounding adjustment for elements that are traditionally not captured by claims data such as BMI, vital signs, and laboratory test results. However, pervasive missingness in these variables in real-world data sources remain a challenge and appropriate methods to diagnose likely mechanisms and analytically correct missingness will continue to be of vital importance. Sentinel has made substantial advances in this area as well with development of reusable analytic tools and methods designed specifically to handle data missingness in EHR-based variables8,11,12. In this study, we were able to demonstrate use of these tools in routine analytic workflow in an efficient way.
In this use case of a large study involving more than 97,000 patients from the FDA Sentinel RWE-DE commercial network, the incidence of acute pancreatitis was low, and we did not observe evidence for a statistically significant difference in acute pancreatitis risk following initiation of SGLT-2 inhibitors compared to DPP-4 inhibitors in patients with T2DM. We noted that when using claims-only diagnosis codes for acute pancreatitis that are known to have poor PPV (0.55–0.65), the estimates were closer to the null versus when using Sentinel’s phenotyping algorithm for pancreatitis with a PPV of 0.90. These observations are consistent with the general expectations that non-differential misclassification of the outcome, as likely observed here with the claims-based definition, results in a bias towards the null and could result in masking of important differences in the outcome risk between exposures13. Future investigations focused on the outcome of acute pancreatitis should be wary of this potential bias when using claims-based definition. Our findings were consistent across two data sources and across subgroups of age, sex, and acute pancreatitis risk with and without additional adjustment for EHR-derived covariates. This study was conducted in collaboration with the FDA as a methodological demonstration and the findings of this study should be assessed considering the totality of the evidence and not this individual result. Further, direct interpretation of this comparison is inherently challenging as the comparator (DPP4-i) carries a label for acute pancreatitis.
As with any observational investigation, our study has important limitations. First, despite adjusting for many covariates, residual confounding may still be present as treatment decisions are made by treating physician non-randomly and the factors that influence treatment decisions cannot be readily assessed even using RWE-DE. While EHR data allowed us to capture laboratory test results and offered enhanced confounding adjustment, we also observed large missingness in capture of some of these results such as triglycerides which is an important risk factor for acute pancreatitis. As a result, residual confounding by factors that either not recorded or incompletely recorded is possible. Second, while the RWE-DE is one of the largest claims-EHR network constructed to be used for post-marketing safety surveillance purposes in the U.S, richer data from the claims-EHR linkages are obtained at the expense of a substantially smaller total available population size than claims-only networks. Therefore, when investigating rare adverse events such as acute pancreatitis, lack of precision may present challenges in drawing conclusions. As such, it should be noted that the conclusion of no difference in acute pancreatitis risk between SGLT2i and DPP4i in the primary and subgroup analyses in this study may reflect insufficient power for detecting differences small effect size power rather than definitive equivalence. Future work integrating more data sources may be helpful in increasing the population size for the RWE-DE. Finally, validated computable phenotyping algorithms may show performance degradation at different sites. However, it is often infeasible to develop and validate algorithms separately in each data source in near real time when investigating safety of medications in a large scale national post-marketing surveillance program like Sentinel. When resources permit, a smaller scale validation study using manual review of data from newer sites where the algorithm was applied may be considered.
In conclusion, the successful completion of this study in FDA Sentinel’s RWE-DE commercial network serves as a proof-of-concept for future protocol-based assessments in Sentinel requiring EHR data. Analytic pipelines and packages developed by the FDA Sentinel System provide key building blocks to achieve scalable and timely execution of complex analyses using claims-EHR linked data assets.
Methods
Data sources
We used data from the FDA Sentinel RWE-DE commercial network comprising two data partners—HealthVerity and TriNetX. HealthVerity included ambulatory care EHRs from three sources linked to closed medical claims and pharmacy data from 2018 through 2020 while TriNetX included inpatient and ambulatory care EHRs from 20 unique health care organizations (HCOS) linked to closed claims data for the period of 2013–20243.
Specification and emulation of the target trial
We leveraged the “PRocess guide for INferential studies using healthcare data from routine ClinIcal Practice to evaLuate causal Effects of Drugs (PRINCIPLED)” framework14, established specifically to guide conduct of inferential studies in Sentinel, for the proposed study. First, we developed the causal question by specifying a target trial protocol comparing the risk of acute pancreatitis in SGLT-2i initiators to DPP-4i (Table 3). We identified DPP-4i as a comparator group as they are also frequently used as second-line treatment for T2DM and may serve as realistic clinical comparators to SGLT-2i. Of note, the DPP-4i prescribing information includes a Warnings and Precaution for acute pancreatitis based upon post-marketing data and imbalances in clinical trials15. Next, the emulation of each component of the target trial protocol was described using fit-for-purpose linked claims-EHR data with exposure information coming from pharmacy claims and outcome and confounder information from both claims and EHR data as described below. The study protocol was publicly posted on the Sentinel website before the analysis began16. Key components of the target trial protocol are described below.
Eligibility criteria
Cohort entry was the day of first dispensing of either a SGLT-2i or DPP-4i. The eligibility criteria for the target trial included presence of T2DM diagnosis, no use of study medications, no history of end stage renal disease (ESRD), HIV, or acute pancreatitis, and no use of glucagon-like peptide-1 receptor agonists (GLP-1 RAs) within six months before study medication start. We excluded users of GLP-1 RAs because they share a similar mechanism with DPP-4is and there remains uncertainty regarding the risk of pancreatitis after their use, with some studies suggesting increased risk17,18. Patients with a history of pancreatitis, ESRD, or HIV were excluded as these patients may have elevated risk of future acute pancreatitis events which may not be attributable to the treatment19,20. We further required 6 months of medical and prescription coverage before cohort entry with an allowable enrollment gap of up to 30 days as well as at least one EHR encounter to ensure that patients had observable time in the data. This requirement ensured that patients had contact with the healthcare system to allow for adequate capture of clinical codes to measure eligibility criteria and baseline covariates.
Treatment strategies and follow-up
The two treatment strategies comprised initiation of SGLT-2i (canagliflozin, dapagliflozin, empagliflozin, ertugliflozin, bexagliflozin) or DPP-4i (alogliptin, linagliptin, saxagliptin, sitagliptin) assessed based on pharmacy dispensing data. We estimated observational analogues of the intent-to-treat (ITT or as-started) and per-protocol (PP or on-treatment) effect. Accordingly, follow-up began on the day after exposure initiation and continued until the first occurrence of any of the following: (1) outcome occurrence (acute pancreatitis); (2) health plan disenrollment; (3) recorded death; (4) end of available data; (5) discontinuation/switching from initiated treatment (only for PP analysis).
Outcome
The primary outcome measure was acute pancreatitis assessed using a validated phenotyping algorithm developed for use in Sentinel studies7. Briefly, the outcome was defined probabilistically conditional on information recorded in diagnosis codes and laboratory findings (amylase, lipase, triglycerides). Additionally, for TriNetX, features extracted from clinical notes using natural language processing (NLP), were used in the phenotyping model. In a validation study, it was observed that fixing the PPV at 0.90, the phenotyping model achieves sensitivity of 0.88 with structured features only and 0.92 when adding NLP features. A detailed list of structured diagnosis codes, lab tests, and NLP features used in the phenotyping model can be found in the Supplementary Table 1.
Covariates
Patient characteristics were assessed during 180 days before and including the cohort entry date. These included several claims-based characteristics such as demographics, medications, comorbidities, health service utilization metrics, and indices for general health including a Claims-based Frailty Index (CFI)21 and Combined Comorbidity Index (CCI)22. EHR-based characteristics such as laboratory test results (HbA1c, serum creatinine, triglycerides), vitals and lifestyle factors (body mass index, blood pressure, tobacco use) were also assessed. Supplementary Table 2 contains a detailed description of all covariates.
Statistical analysis
To investigate the added value of EHR data in this study, we first conducted a claims-only analysis that defined acute pancreatitis based on ICD codes alone and adjusted for >130 claims-based variables and then conducted a claims + EHR augmented analysis that defined acute pancreatitis based on the phenotyping algorithm and added 6 additional variables from EHRs for confounding adjustment, both described above.
In all analyses, we used a propensity score (PS) based fine-stratification weighting method with 50 strata for confounding adjustment by measured factors23. We estimated PS as the predicted probability of initiating SGLT-2i compared to DPP-4i given the baseline patient characteristics from fitting a multivariable logistic regression model separately by database. Fifty strata were created based on the distribution of PS in SGLT-2i initiators, and DPP-4i initiators were assigned into these strata based on their PS resulting in 50 unequally sized strata. In the weighting step, DPP-4i initiators in each stratum were weighted proportional to the number of SGLT-2i initiators to account for stratum membership and achieve balance. The PS fine-stratification weighting approach, as implemented in this study, targets the average treatment effect in the treated (ATT), which is considered to be a highly relevant estimand for drug safety investigations24,25. Notably, other PS-based approaches that target different estimands such as average treatment effect in the whole population or average treatment effect in an overlapping population are available and can also be considered depending on the research question of interest.
As diagnostics for PS models, we evaluated distributional overlap, weight distribution, and individual covariate balance using standardized differences post-weighting. In the weighted population, we estimated the hazard ratio for acute pancreatitis among initiators of SGLT-2i versus DPP-4i using Cox proportional hazards model. Cumulative incidence was calculated using cumulative incidence functions and reported stratified by treatment groups26.
Anticipating missing data in EHR-derived variables, we identified and described possible missingness patterns and mechanisms among partially observed covariates based on the observed data using the smdi R package11. After diagnosing the likely missingness mechanisms, we applied the corresponding multiple imputation methods to analytically address missingness in all EHR-based covariates. We created 20 imputed datasets where missing covariates were imputed based on random forest algorithms. In each of the imputed datasets, we fit the PS models and conducted PS fine stratification to calculate adjusted treatment effect estimates using the MatchThem R package27. The results were reported after pooling results using Rubin’s rule to account for variance both within and across the imputed datasets28.
Subgroup analyses and robustness evaluations
All subgroup and robustness evaluations were conducted with claims + EHR augmented analysis. We performed subgroup analyses in the following prespecified strata: age (<65 versus ≥65), sex (male versus female), and history of risk factors for acute pancreatitis (gallstones, tobacco use, alcohol abuse). We conducted two sensitivity analyses aimed at reducing missingness in EHR-based confounders and included: (1) increasing baseline window to 12 months before cohort entry, and (2) restricting the analysis to subjects with ≥3 EHR encounters in the 6 months before cohort entry. Finally, we evaluated ischemic stroke as a negative control outcome to detect net bias in the primary analysis29.
Data availability
The data used in this study are derived from the RWE-DE commercial network and are not publicly available. However, access to these data can be obtained through licensing agreements with the respective commercial data providers.
Code availability
Reusable R codes to conduct study specific diagnostic and inferential analyses are made available publicly at https://gitlab-scm.partners.org/rjd48/sentinel_ic_uc1.
References
Ball, R., Robb, M., Anderson, S. A. & Dal Pan, G. The FDA’s sentinel initiative—a comprehensive approach to medical product surveillance. Clin. Pharm. Ther. 99, 265–268 (2016).
Maro, J. C. et al. Six years of the US Food and Drug Administration’s postmarket active risk identification and analysis system in the Sentinel initiative: implications for real world evidence generation. Clin. Pharmacol. Ther. https://doi.org/10.1002/cpt.2979 (2023).
Desai, R. J. et al. The FDA Sentinel Real World Evidence Data Enterprise (RWE-DE). Pharmacoepidemiol. Drug Saf. https://doi.org/10.1002/pds.70028 (2024).
Schneeweiss, S., Desai, R. J. & Ball, R. Invited commentary: a future of data-rich pharmacoepidemiology studies- transitioning to large-scale linked EHR+claims data. Am. J. Epidemiol. https://doi.org/10.1093/aje/kwae226 (2024).
Moores, K., Gilchrist, B., Abrams, T. & Carnahan, R. Mini-Sentinel Systematic Evaluation of Health Outcome of Interest Definitions for Studies Using Administrative Data—Pancreatitis Report (2011).
Floyd, J. S. et al. Validation of acute pancreatitis among adults in an integrated healthcare system. Epidemiology. https://doi.org/10.1097/EDE.0000000000001541 (2023).
Sentinel Initiative. Advancing Scalable Natural Language Processing Approaches for Unstructured Electronic Health Record Data. Available at https://www.sentinelinitiative.org/methods-data-tools/methods/advancing-scalable-natural-language-processing-approaches-unstructured (2021).
Weberpals, J. et al. A principled approach to characterize and analyze partially observed confounder data from electronic health records. Clin. Epidemiol. 16, 329–343 (2024).
Walsh, C. G. et al. Scalable incident detection via natural language processing and probabilistic language models. Sci. Rep. https://doi.org/10.1038/s41598-024-72756-7 (2024).
Carrell, D. S. et al. Improving methods of identifying anaphylaxis for medical product safety surveillance using natural language processing and machine learning. Am. J. Epidemiol. 192, 283–295 (2023).
Weberpals, J. et al. smdi: an R package to perform structural missing data investigations on partially observed confounders in real-world evidence studies. JAMIA Open. https://doi.org/10.1093/jamiaopen/ooae008 (2024).
Williamson, B. D. et al. Assessing treatment effects in observational data with missing confounders: a comparative study of practical doubly-robust and traditional missing data methods. Preprint at https://doi.org/10.48550/arXiv.2412.15012 (2024).
Stayner, L. et al. Statistical Methods in Cancer Research Volume V: Bias Assessment in Case–Control and Cohort Studies for Hazard Identification (International Agency for Research on Cancer, 2024).
Desai, R. J. et al. Process guide for inferential studies using healthcare data from routine clinical practice to evaluate causal effects of drugs (PRINCIPLED): considerations from the FDA Sentinel Innovation Center. BMJ. https://doi.org/10.1136/bmj-2023-076460 (2024).
Elashoff, M., Matveyenko, A. V., Gier, B., Elashoff, R. & Butler, P. C. Pancreatitis, pancreatic, and thyroid cancer with glucagon-like peptide-1-based therapies. Gastroenterology. https://doi.org/10.1053/j.gastro.2011.02.018 (2011).
Sentinel Initiative. Risk of acute pancreatitis following SGLT2 inhibitor use in patients with type 2 diabetes mellitus. https://www.sentinelinitiative.org/sites/default/files/documents/Risk-of-Acute-Pancreatitis-Following-SGLT2-Inhibitor-Use-in-Patients-with-Type-2-Diabetes-Mellitus_Study-Protocol_19September2024.pdf (2024).
Sodhi, M., Rezaeianzadeh, R., Kezouh, A. & Etminan, M. GLP-1 agonists and gastrointestinal adverse events. JAMA. https://doi.org/10.1001/jama.2023.19574 (2023).
Cao, C. et al. GLP-1 receptor agonists and pancreatic safety concerns in type 2 diabetic patients: data from cardiovascular outcome trials. Endocrine https://doi.org/10.1007/s12020-020-02223-6 (2020).
Wang, H. et al. Hemodialysis and risk of acute pancreatitis: a systematic review and meta-analysis. Pancreatology. https://doi.org/10.1016/j.pan.2020.11.004 (2021).
Dassopoulos, T. & Ehrenpreis, E. D. Acute pancreatitis in human immunodeficiency virus-infected patients: a review. Am. J. Med. https://doi.org/10.1016/S0002-9343(99)00169-2 (1999).
Kim, D. H. et al. Measuring frailty in medicare data: development and validation of a claims-based frailty index. J. Gerontology: Ser. A 73, 980–987 (2018).
Gagne, J. J., Glynn, R. J., Avorn, J., Levin, R. & Schneeweiss, S. A combined comorbidity score predicted mortality in elderly patients better than existing scores. J. Clin. Epidemiol. 64, 749–759 (2011).
Desai, R. J., Rothman, K. J., Bateman, B. T., Hernandez-Diaz, S. & Huybrechts, K. F. A propensity-score-based fine stratification approach for confounding adjustment when exposure is infrequent. Epidemiology. https://doi.org/10.1097/EDE.0000000000000595 (2017).
Cafri, G. Why we should be prioritizing the average treatment effect on the treated over other Estimands when evaluating drug and device safety. Am. J. Epidemiol. 194, 3602–3608 (2025).
Desai R. J., Franklin J. M. Alternative approaches for confounding adjustment in observational studies using weighting based on thepropensity score: a primer for practitioners. BMJ 367, l5657 (2019).
Austin, P. C., Lee, D. S. & Fine, J. P. Introduction to the analysis of survival data in the presence of competing risks. Circulation. https://doi.org/10.1161/CIRCULATIONAHA.115.017719 (2016).
Pishgar, F., Greifer, N., Leyrat, C. & Stuart, E. MatchThem: Matching and Weighting after Multiple Imputation. The R. Journal. https://doi.org/10.32614/RJ-2021-073, https://journal.r-project.org/archive/2021/RJ-2021-073/ (2021).
Rubin, D. B. Multiple imputation for nonresponse in surveys. Wiley Series in Probability and Statistics (1987).
Shi, X., Miao, W. & Tchetgen Tchetgen, E. A selective review of negative control methods in epidemiology. Curr. Epidemiol. Rep. https://doi.org/10.1007/s40471-020-00243-4 (2020).
Acknowledgements
Many thanks are due to TriNetX (Cambridge, MA) and HealthVerity (Philadelphia, PA) for providing data for this analysis, with data from HealthVerity containing in part certain data from Veradigm. This project was supported by Master Agreement 75F40119D10037 from the US Food and Drug Administration (FDA). FDA coauthors reviewed the study protocol, statistical analysis plan, and the manuscript for scientific accuracy and clarity of presentation. Representatives of the FDA reviewed a draft of the manuscript for presence of confidential information and accuracy regarding statement of any FDA policy. The views expressed are those of the authors and not necessarily those of the US FDA.
Author information
Authors and Affiliations
Contributions
R.J.D., J.W., S.S., S.T., E.P., J.J.H., F.M.S., J.L. (Jie Li), J.T.J., and A.A. conceived and designed the study. R.J.D., J.W., S.S., S.T., E.P., H.P., R.S., and M.D. worked on protocol development. R.J.D., H.P., J.L. (Joyce Lii), R.H., and J.G.L. conducted data analysis. R.J.D. wrote the manuscript draft. R.S., M.D., and C.J. provided project management and administrative support. All authors reviewed and critically revised the manuscript draft.
Corresponding author
Ethics declarations
Competing interests
Dr. Desai reports serving as Principal Investigator on investigator-initiated grants to the Brigham and Women’s Hospital from Novartis, Vertex, and Bayer on unrelated projects. Dr. Schneeweiss is co-principal investigator of an investigator-initiated grant to the Brigham and Women’s Hospital from Boehringer Ingelheim unrelated to the topic of this study. He is a consultant to Aetion Inc., a software manufacturer of which he owns equity. His interests were declared, reviewed, and approved by the Brigham and Women’s Hospital and MGB HealthCare System in accordance with their institutional compliance policies. Dr. Weberpals is now an employee of AstraZeneca and owns stocks in AstraZeneca. Other authors declare no financial or non-financial competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Desai, R.J., Weberpals, J., Pillai, H. et al. Strengthening inferential studies in the FDA Sentinel initiative: results from a methodological demonstration project. npj Digit. Med. 9, 52 (2026). https://doi.org/10.1038/s41746-025-02234-5
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41746-025-02234-5
