
Abstract
Effective postoperative management in orthopedic surgery is often hindered by challenges such as poor patient adherence to rehabilitation protocols, insufficient monitoring of wound healing, inadequate pain control, and limited access to timely psychological and functional support. To address these issues, we conducted a randomized controlled trial (registered in the Chinese Clinical Trial Registry, ChiCTR2500101273, April 23, 2025) that evaluated the use of a GPT-4–powered AI agent delivered via WeChat for postoperative care in 261 patients, with 140 assigned to the AI group and 121 to the doctor-led group. In the intervention arm, patients interacted with a GPT-4–based WeChat agent that delivered real-time, context-aware support, while the control arm received routine physician communication. The AI system responded far more rapidly (0.5 ± 0.6 vs. 358 ± 47.5 min, p < 0.05) and provided feedback of higher perceived quality, though with slightly reduced accuracy (93.9% vs. 98.1%, p < 0.05). At 1 and 3 months, the AI group achieved significantly better outcomes in knee function (IKDC), physical health (PCS), and overall satisfaction (all p < 0.05). By the 6-month follow-up, group differences were no longer significant (p > 0.05), suggesting equivalent long-term outcomes. Overall, GPT-4–enabled WeChat agent may provide short-term benefits in postoperative functional recovery and patient experience, whereas long-term outcomes remain comparable to doctor-led care. These findings support the potential value of LLM-based tools as a supplementary component of postoperative management.
Similar content being viewed by others
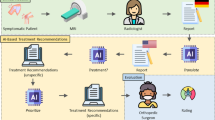

Introduction
Recent advances in large language models (LLMs), such as GPT-4 (Generative Pre-trained Transformer-4)1, have demonstrated remarkable capabilities in synthesizing complex medical data, aiding diagnostic decision-making, and converting intricate clinical concepts into comprehensible language2,3,4. This level of sophistication supports personalized patient education and may improve adherence to rehabilitation protocols. Furthermore, GPT-4 has shown potential in multimodal tasks—like image or table-based reasoning—expanding its utility in diverse clinical scenarios5. Such remarkable capabilities are prompting scientists and clinicians alike to critically reexamine the ethical considerations surrounding ChatGPT in medicine, as well as the broader regulatory challenges posed by large language models in clinical practice6,7. However, multiple recent studies have documented that LLM-based applications frequently underperform in several key clinical tasks—ranging from suboptimal medical billing code generation8, high error rates in oncology-related inquiries9 and potentially harmful, time-intensive patient interactions10, to misleading risk stratification for chest pain and breast cancer11,12—thus highlighting the urgent need for rigorous validation and stronger regulatory oversight. Agent in LLMs optimize practical applications through advanced prompting and Retrieval-Augmented Generation (RAG). By integrating localized knowledge bases, such as medical records or guidelines, agents tailor LLM outputs to real-world scenarios, ensuring context-aware and reliable responses for tasks like postoperative management and personalized rehabilitation.
Postoperative management is a critical component in improving outcomes for patients undergoing surgery13,14,15. Traditional follow-up methods often rely on in-person consultations, which can be limited by traffic difficulties, patient noncompliance, and insufficient support for anxiety management16. These challenges may contribute to delayed recovery, reduced functional outcomes, and lower patient satisfaction. Increasing evidence suggests that timely and accessible interventions, particularly those addressing psychological factors such as anxiety, play a pivotal role in optimizing postoperative care and enhancing overall patient well-being17,18. Nevertheless, while early AI-driven healthcare applications have shown encouraging potential, there remains a paucity of well-designed randomized controlled trials (RCTs) assessing whether these interventions can genuinely enhance patient-reported outcomes in the postoperative setting; consequently, significant gaps persist in understanding how AI-based solutions may alleviate anxiety, hasten functional recovery, and elevate patient satisfaction.
In the current study, we integrated GPT-4 with a locally curated knowledge base and deployed it on WeChat, a widely used social media platform in China, to deliver real-time, context-aware postoperative support after orthopedic surgery (Fig. 1a, b). By providing patients with on-demand access to accurate guidance, we hypothesize that this AI-driven intervention can reduce anxiety, improve functional and mental component outcomes, and ultimately enhance satisfaction compared to standard postoperative care. A subgroup analysis focusing on sports medicine and joint surgery patients will further elucidate whether groups benefit more from an AI-supported model of postoperative management. This study aims to provide robust evidence regarding the utility of a WeChat-based LLM agent, offering a scalable strategy to overcome traditional barriers and optimize care for diverse surgical populations.

a Workflow of the AI agent. Step 1: Loading and processing of unstructured text. Step 2: Text embedding and vector similarity search. Step 3: Prompt Template and response from the large language models. b Example patient interaction with the AI agent regarding knee soreness after ACL surgery. c CONSORT Flow Diagram of Participant Recruitment, Randomization, and Follow-Up. A total of 311 patients were assessed for eligibility, with 11 excluded. The remaining 300 were randomized into two groups: 150 in the AI Agent group and 150 in the Doctor group. During follow-up, 10 patients from the AI group and 29 from the Doctor group were lost due to withdrawal, death, or loss of contact.
Results
Validation of AI reliability and response accuracy
To evaluate the reliability and safety of the AI system, a comprehensive validation and auditing process was conducted. Expert reviewers compared AI-generated outputs with gold-standard reference answers to calculate key performance metrics, yielding a recall of 92.8%, precision of 94.5%, and coverage of 88.3%, reflecting high response fidelity and broad content coverage of the localized knowledge base. Concurrently, a structured auditing protocol was applied to assess real-world AI–patient interactions. The hallucination rate, defined as the proportion of responses containing unverifiable or clinically irrelevant information, was 6.3%, corresponding to an overall factual accuracy of 93.7%, with an inter-rater agreement of κ = 0.87, indicating substantial reliability.
Baseline characteristics
A total of 311 patients were assessed for eligibility (Fig. 1c), of whom 11 were excluded due to not meeting inclusion criteria (n = 6), declining to participate (n = 4), or other reasons (n = 1). The remaining 300 patients were randomized into two groups: 150 in the AI intervention group and 150 in the Doctor intervention group. During follow-up, 10 patients from the AI group and 29 patients from the Doctor group were lost to follow-up due to withdrawal of consent, death, or loss of contact. Consequently, the final analysis included 140 patients in the AI group and 121 patients in the Doctor group (Fig. 1c). Both interventions were delivered as planned, with high protocol adherence and no significant deviations from the intended procedures. As part of standard concomitant care, all participants underwent routine postoperative outpatient follow-up at 1, 3, and 6 months.
Baseline characteristics were comparable between the two groups, with no statistically significant differences observed (Table 1). The distribution of surgical sites (hip vs. knee) was balanced, with 23.6% hip surgeries and 76.4% knee surgeries in the AI group compared to 29.8% and 70.2% in the Doctor group (p = 0.26). Similarly, the distribution of surgical types (arthroscopy vs. arthroplasty) was consistent between groups (p = 0.80). Demographic variables, including age, height, and weight, were also similar. The mean age was 46.6 ± 18.5 years in the AI group and 48.0 ± 17.7 years in the Doctor group (p = 0.54). Mean height and weight were 167.1 ± 9.6 cm and 71.7 ± 15.3 kg in the AI group and 165.6 ± 8.9 cm and 72.0 ± 13.9 kg in the Doctor group (p = 0.38 and p = 0.29, respectively). Baseline knowledge scores were also comparable, with a mean of 5.6 ± 2.9 in the AI group and 5.9 ± 2.9 in the Doctor group (p = 0.76). These findings confirm that the two groups were well matched at baseline, minimizing the risk of bias in subsequent outcome analyses.
Postoperative outcome improvements
Both the AI group and the Doctor group demonstrated significant improvements across all assessed metrics, including GAD-7, Function Score, PCS, and MCS, at the 6-month follow-up compared to preoperative values (Fig. 2). Notably, at the 1-month follow-up, the AI group showed a more rapid improvement in certain metrics. For GAD-7 scores, the AI group exhibited a significant reduction from 24.15 ± 20.51 preoperatively to 17.96 ± 15.27 (p < 0.05), while the Doctor group showed a reduction from 25.07 ± 23.15 to 19.99 ± 17.9 (p < 0.05). Similarly, in MCS scores, the AI group improved significantly from 45.48 ± 6.74 preoperatively to 49.5 ± 5.84 (p < 0.05) at 1 month, whereas the Doctor group increased from 45.13 ± 9.30 to 49.15 ± 5.75, but without reaching statistical significance (p > 0.05). By the 3-month follow-up, the Doctor group also demonstrated a significant improvement in MCS scores compared to baseline (p < 0.05). These findings suggest that while both groups achieved substantial improvements by 6 months, the AI group facilitated more rapid improvements in anxiety and mental health during the early postoperative period, emphasizing the potential of AI-driven interventions to accelerate psychological recovery.

A In the AI group, GAD-7 scores decreased significantly at each postoperative time point, with the greatest reduction observed at 6 months. Function scores, PCS and MCS also improved progressively, with statistically significant increases as early as 1 month postoperatively and sustained improvements through 6 months. B In the Doctor group, all key metrics also showed significant improvement over time. However, early gains in anxiety reduction and MCS were slower to reach significance compared to the AI group, suggesting a delayed psychological recovery.
Comparison between AI and doctor groups
During the follow-up period (Table 2), a total of 2025 inquiries were recorded in the AI group and 1728 in the doctor group (p < 0.05). The inquiry rate—defined as the proportion of patients who actively initiated at least one consultation—was 82% in the AI group and 77% in the doctor group (p > 0.05), indicating comparable patient adherence and engagement across groups. Regarding response metrics, the AI group provided significantly longer responses (188.5 ± 16.6 words vs. 11 ± 5.6 words, p < 0.05) and faster response times (0.5 ± 0.6 min vs. 358 ± 47.5 min, p < 0.05). While the Doctor group achieved slightly higher response accuracy (98.1% vs. 93.9%, p < 0.05), the AI group outperformed in response quality, with a higher mean score (8.4 ± 0.9 vs. 7.2 ± 0.9, p < 0.05). In terms of post-discharge subjective scores, the AI group demonstrated significantly higher satisfaction (98 ± 7.5 vs. 93 ± 13, p < 0.05, d = 0.48), expectation (96 ± 10.0 vs. 92 ± 13, p < 0.05, d = 0.35), and knowledge scores (51 ± 16.0 vs. 47 ± 15, p < 0.05, d = 0.26) compared to the Doctor group (Fig. 3A), reflecting moderate to small effect sizes and suggesting enhanced engagement and educational support offered by the AI-driven intervention. At the 1-month follow-up (Fig. 3B), the AI group showed greater improvements in Function Scores (57.69 ± 9.64 vs. 54.72 ± 10.3, p < 0.05, cohen’s d = 0.30) and PCS (46.67 ± 6.89 vs. 43.22 ± 5.39, p < 0.05, d = 0.56), but GAD-7 and MCS scores were comparable between groups (p > 0.05). By 3 months (Fig. 3C), the AI group maintained its advantage in Function Scores (69.18 ± 9.15 vs. 65.96 ± 9.90, p < 0.05, d = 0.34), PCS (58.14 ± 8.06 vs. 54.0 ± 7.78, p < 0.05, d = 0.52). At 6 months (Fig. 3D), both groups reached comparable levels across all metrics, with no significant differences in GAD-7, Function Scores, PCS, or MCS (p > 0.05).

A Patients in the AI group reported significantly higher post-discharge satisfaction, expectation alignment, and knowledge scores compared to the Doctor group, reflecting improved patient education and engagement. B At the 1-month follow-up, the AI group showed significantly greater improvements in function and physical health, while GAD-7 and MCS scores were comparable between groups. C At 3 months, the AI group continued to outperform in function and PCS, indicating more sustained physical recovery benefits, but no significant differences in GAD-7 or MCS were observed. D By 6 months, all outcome measures showed no significant differences between the groups, suggesting convergence in long-term outcomes. E, F Pie charts illustrating the distribution of patient questions in the AI group and Doctor group, categorized into the following question types: (A) Symptom consultation, (B) Surgical information, (C) Postoperative care, (D) Postoperative recovery, (E) Medication consultation, (F) Postoperative complications and recurrence, (G) Lifestyle recommendations, (H) Other questions.
The analysis of patient inquiries revealed distinct patterns in the types of questions posed by the AI group and the Doctor group (Fig. 3E, F). In the AI group, most inquiries centered on postoperative rehabilitation (D, 42.2%), followed by surgical information (B, 12.8%), symptom consultation (A, 11.4%), and postoperative care (C, 9.2%). In contrast, the Doctor group exhibited a different distribution, with the largest proportion of inquiries focusing on symptom consultation (A, 27.1%), followed by medication consultation (E, 16.2%), postoperative rehabilitation (D, 16.6%), and surgical information (B, 12.6%).
Subgroup analysis between surgical type
Patients were allocated into two subgroups based on surgical type, comprising a sports medicine subgroup (73 patients in the AI group vs. 61 in the doctor group) and a joint replacement subgroup (67 patients in the AI group vs. 60 in the doctor group). Within the sports medicine subgroup (Fig. 4), participants in the AI group reported significantly higher satisfaction (98.71 ± 9.44 vs. 92.44 ± 10.78, p < 0.05, d = 0.62), expectation (97.62 ± 8.67 vs. 91.48 ± 12.36, p < 0.05, d = 0.57), and knowledge (58.01 ± 17.77 vs. 48.56 ± 15.02, p < 0.05, d = 0.57) at discharge. At the 1-month follow-up, the AI group exhibited lower anxiety (GAD-7: 15.59 ± 14.58 vs. 20.06 ± 17.80, p < 0.05, d = 0.57), better functional recovery (IKDC: 57.91 ± 7.83 vs. 51.47 ± 9.91, p < 0.05, d = 0.72), and higher physical health scores (PCS: 47.49 ± 7.16 vs. 42.60 ± 5.12, p < 0.05, d = 0.79). These improvements persisted at 3 months, as evidenced by significantly higher IKDC (69.14 ± 9.46 vs. 64.18 ± 9.36, p < 0.05, d = 0.53) and PCS (58.80 ± 8.39 vs. 54.08 ± 7.62, p < 0.05, d = 0.59) scores, although group differences in GAD-7 and MCS were not significant (p > 0.05). By 6 months, both groups displayed similar outcomes across all measured parameters (p > 0.05).

A Patients in the AI group reported significantly higher post-discharge satisfaction, alignment with expectations, and knowledge scores compared to those in the Doctor group, indicating superior patient experience and education. B At 1-month follow-up, the AI group demonstrated significantly lower anxiety, better knee function, and higher physical health scores, suggesting accelerated early recovery. C These functional advantages persisted at 3 months in IKDC and PCS, while anxiety and mental health outcomes were comparable between groups. D By 6 months, differences across all outcome measures diminished, with no significant differences observed.
In the joint replacement subgroup (Fig. 5), the AI group also demonstrated marked advantages during the early postoperative phase. Immediately following discharge, satisfaction (99.1 ± 4.17 vs. 92.0 ± 15.27, p < 0.05, d = 0.65) and knowledge (49.03 ± 10.2 vs. 42.58 ± 13.48, p < 0.05, d = 0.54) scores were significantly higher in the AI group, while expectation (96.12 ± 9.37 vs. 92.33 ± 12.8, p > 0.05) did not differ significantly. At the 1-month follow-up, participants in the AI group outperformed the doctor group in functional (FJS: 37.82 ± 18.2 vs. 31.45 ± 21.11, p < 0.05, d = 0.32) and physical health (PCS: 46.86 ± 6.64 vs. 40.82 ± 5.35, p < 0.05, d = 1.00) measures, whereas GAD-7 and MCS remained comparable (p > 0.05). By 3 months, the AI group retained its lead in FJS (58.0 ± 21.08 vs. 51.09 ± 22.63, p < 0.05, d = 0.32) and PCS (59.61 ± 7.47 vs. 51.88 ± 7.42, p < 0.05, d = 1.00), with no significant difference observed in GAD-7 or MCS (p > 0.05). At 6 months, none of the measured outcomes differed significantly between the two groups (p > 0.05).

A At discharge, patients in the AI group reported significantly higher satisfaction and knowledge scores compared to the Doctor group, although expectation scores were similar. B At 1-month follow-up, the AI group showed significantly better functional outcomes and higher physical health scores, while no significant differences were observed in anxiety or mental health. C These functional and physical advantages were maintained at 3 months, as evidenced by persistently higher FJS and PCS scores in the AI group, with no group differences in GAD-7 or MCS. D By 6 months, outcome measures across all domains were comparable between the two groups.
Subgroup analysis by age
To evaluate the impact of age on the effectiveness of AI-assisted postoperative management, we conducted a subgroup analysis by dividing participants into two age groups (Fig. 6): younger patients (<45 years) and older patients (≥45 years). Within the AI group, younger patients reported significantly higher knowledge scores than older patients (54.0 ± 17.7 vs. 45.0 ± 12.0, p < 0.001, Cohen’s d = 0.61), whereas no significant differences were observed in satisfaction or expectation scores (96.7 ± 9.8 vs. 98.7 ± 4.9; 96.0 ± 10.0 vs. 95.7 ± 10.0, respectively). A similar pattern was observed in the Doctor group, where younger patients also scored higher in knowledge (52.0 ± 14.9 vs. 43.0 ± 13.6, p < 0.001, d = 0.63), with satisfaction and expectation remaining statistically comparable. When comparing the AI and Doctor groups among younger patients, the AI group demonstrated significantly higher knowledge scores (59.4 ± 17.7 vs. 52.1 ± 14.9, p < 0.01, d = 0.45), while satisfaction and expectation scores were similar. In contrast, among older patients, knowledge scores were nearly identical between AI and Doctor groups (45.1 ± 11.6 vs. 45.0 ± 13.6, p > 0.05, d = 0.00), with no differences observed in satisfaction or expectation. These results suggest that younger patients may benefit more from AI-based follow-up in terms of knowledge acquisition, while the impact of AI on older adults was more limited across subjective domains.

A, B Within both AI and Doctor groups, younger patients (<45 years) showed significantly higher knowledge scores compared to older patients (≥45 years), while satisfaction and expectation scores were comparable. C, D Between-group comparisons revealed that, among younger patients, the AI group demonstrated significantly higher knowledge scores than the Doctor group with no significant differences in satisfaction or expectation. In older patients, no significant differences were observed between groups. E GAD-7 scores declined steadily over time in all subgroups, with no significant age- or group-related differences at any time point. F Younger patients in the AI group achieved significantly greater improvement in function scores at 1-month post-op suggesting enhanced early physical recovery. G For PCS, younger AI patients consistently outperformed others at 1 and 3 months, with statistically significant differences versus younger Doctor-group patients. H No significant differences in MCS were observed across any subgroup or time point.
Longitudinal analysis of GAD-7 scores revealed a steady decline in anxiety levels across all subgroups over the 6-month follow-up period, with no statistically significant differences observed between age groups or intervention types (Fig. 6E). For functional outcomes, younger patients in the AI group demonstrated significantly greater improvement in Function Score at 1 month compared to their counterparts in the Doctor group (58.5 ± 7.8 vs. 52.7 ± 10.5, p < 0.05, Cohen’s d = 0.63), suggesting a moderate effect size (Fig. 6F).Similarly, PCS scores at both 1 and 3 months were significantly higher in the younger AI group compared to the younger Doctor group (1 month: 46.4 ± 6.9 vs. 44.5 ± 5.4, p < 0.05, d = 0.30; 3 months: 57.7 ± 7.3 vs. 55.8 ± 7.4, p < 0.05, d = 0.26), indicating small but consistent effects in favor of AI-supported recovery (Fig. 6G). Among older patients (≥45 years), no significant differences in Function or PCS scores were observed between the two groups throughout the follow-up period. Furthermore, MCS scores did not differ significantly between age groups or intervention types at any time point (Fig. 6H).
Discussion
In this study, patients were randomly assigned to two groups prior to surgery: the AI group, which interacted with the agent via WeChat, and the doctor group, which communicated with their doctor through WeChat. The comparison between the AI and doctor groups highlighted their complementary strengths. The AI agent demonstrated high efficiency and provided detailed feedback, promptly addressing patients’ needs, while the doctor group exhibited slightly higher accuracy, underscoring the value of human expertise. The AI-based follow-up demonstrated modest but statistically significant early advantages, particularly within the first three months. However, these effects diminished by the 6-month follow-up, suggesting that AI assistance may be most beneficial during the early recovery period, while traditional care achieves comparable long-term outcomes.
Previous studies have highlighted the benefits of using mobile devices by physicians for patient follow-up and education, demonstrating positive outcomes19. For example, mobile applications for postoperative communication have been shown to significantly reduce emergency department visits following procedures such as circumcision. Additionally, digital follow-up using mobile applications has demonstrated high feasibility and patient satisfaction, offering the potential to enhance postoperative monitoring, facilitate early detection of complications, and reduce readmission rates, particularly in cases like colorectal resection20. Furthermore, the NL-Mapp, a nurse-led supportive mobile application, has shown significant improvements in pain management, shoulder function, anxiety, body image, and sexual adaptation in breast cancer patients post-surgery, emphasizing its potential as an effective tool for managing postoperative symptoms and improving recovery outcomes21. Most existing studies focus on developing new mobile applications rather than utilizing widely used social platforms, which may limit accessibility and user engagement. Furthermore, psychological aspects, such as mental health and emotional well-being, are often neglected, underscoring the need for a more holistic approach to postoperative care.
Despite its efficiency, the AI group exhibited a slightly lower response accuracy compared to the Doctor group. This discrepancy primarily arose when the AI agent encountered questions beyond the scope of the localized medical knowledge base. Although the knowledge base was updated monthly to incorporate new clinical information, some patients still posed questions that fell outside the pre-defined content. In such cases, the agent occasionally generated responses based on general or non-localized data, resulting in hallucinations. For example, one patient inquired about medical insurance reimbursement policies. Due to the absence of relevant local information in the knowledge base, the agent provided an answer related to U.S. insurance policies, which was not applicable in the Chinese healthcare context. Fortunately, our error-correction mechanism enabled clinicians to promptly intervene, review the AI’s response, and provide accurate information before any misinformation could cause harm. While no adverse consequences resulted from these incidents, this limitation highlights the potential risk of misinformation when AI systems encounter topics beyond their training data. Strengthening the knowledge base and implementing more rigorous contextual validation are essential to further mitigate this risk.
The results demonstrated significant improvements in psychological health (GAD-7), functional recovery (function scores), and quality of life (PCS and MCS) in both groups following surgery. Notably, the AI group exhibited superior functional scores and PCS at 1 and 3 months postoperatively compared to the doctor-led group, while no significant differences were observed in MCS or GAD-7 between the two groups. Additionally, the AI group reported significantly higher levels of satisfaction, expectation, and knowledge acquisition at discharge, highlighting the potential of the AI agent in enhancing patient education and postoperative management. However, by 6 months postoperatively, the differences between the two groups in key outcomes diminished, suggesting that traditional doctor-led management may achieve comparable effectiveness in long-term follow-up.
The categorization of patient inquiries further supports the advantages of the AI group in early postoperative management. Feedback in the AI group was predominantly focused on “rehabilitation-related issues,” whereas the doctor group primarily addressed “symptom-related issues.” This difference may stem from patients’ ability to discern whether they are interacting with an AI or a human doctor, influencing the types of questions they choose to ask. Overall, these findings indicated that a large language model-based AI agent can significantly enhance early postoperative functional recovery.
In the sports medicine subgroup, AI-assisted patients demonstrated significant early postoperative benefits (1 and 3 months), with lower GAD-7 and higher knee function (IKDC) and PCS compared to the doctor-led group. These findings underscored the AI agent’s ability to alleviate anxiety, enhance functional recovery, and improve physical health. However, MCS showed no significant differences between groups, and by 6 months, all outcome differences diminished, suggesting comparable long-term outcomes with traditional management. In the arthroplasty subgroup, the AI group showed similar early advantages in function (FJS) and PCS but limited impact on GAD-7 and MCS. This may reflect the older age and distinct recovery priorities of joint replacement patients, such as basic function and pain management, which could limit their responsiveness to AI interventions.
Subgroup analysis by age suggested that younger patients (<45 years) may derive greater benefit from AI-assisted postoperative management, particularly in terms of functional recovery and physical health (PCS). Compared to their counterparts in the Doctor group, younger AI users showed significantly better functional scores at 1 month and higher PCS at both 1 and 3 months postoperatively. They also demonstrated significantly higher knowledge scores at discharge, indicating improved engagement with digital follow-up. Although GAD-7 scores improved over time in all subgroups, no statistically significant differences were observed between age groups or intervention types, suggesting that the impact of AI on anxiety may be limited or more variable. In contrast, older patients (≥45 years) showed no significant differences across any outcomes, highlighting that age may influence receptiveness to AI-based follow-up, especially in the early stages of recovery.
This study has several limitations. First, as a single-center study of Chinese-speaking orthopedic patients using the WeChat platform, the findings may be influenced by regional and cultural factors and may not generalize to other healthcare systems. Differences in communication tools (e.g., WhatsApp, LINE, hospital apps) and varying digital literacy among older adults could also limit broader applicability. Second, online follow-up demands a high level of digital health literacy, which may result in noncompliance or loss to follow-up among older patients or those unfamiliar with smart devices, potentially limiting the representativeness of the findings. Third, the follow-up period of this study was limited to six months, which may be insufficient to evaluate long-term complications and sustained functional recovery comprehensively. Fourth, A notable limitation of this investigation is the absence of standardized communication protocols between the intervention and doctor group. Communication in both cohorts was exclusively patient-initiated, lacking proactive follow-up from responders, potentially introducing variability in interaction frequency and content. Furthermore, this passive communication model may limit timely recognition of patient needs and reduce data continuity, thereby constraining the comprehensiveness of postoperative monitoring and early intervention. Lastly, with rapid advancements in artificial intelligence, the capabilities and applicability of the current language model may soon be surpassed by more advanced iterations, potentially rendering some conclusions of this study obsolete. Moreover, given that this is an exploratory single-center trial conducted on the WeChat platform, the findings should be interpreted with caution and require validation in multicenter, longer-term studies.
In conclusion, this randomized trial suggests that a GPT-4–based WeChat agent may offer short-term benefits in patient experience, functional recovery, and physical health after orthopedic surgery. These early advantages diminished by 6 months, indicating that long-term outcomes remained comparable between AI-assisted and doctor-led care. The findings support the potential role of LLM-based agents as a supplementary tool in postoperative management, while underscoring the need for larger, multicenter studies to confirm their effectiveness and generalizability.
Methods
AI agent development
The AI agent, powered by GPT-4 (version GPT-4-1106) and integrated with a locally customized medical knowledge base, was developed to autonomously address patient inquiries regarding their specific medical conditions. The localized medical knowledge base underpinning the GPT-4 agent was developed from two primary sources. First, authoritative clinical practice guidelines for enhanced recovery after surgery (ERAS) were incorporated, including the Chinese Orthopaedic Association ERAS Guideline (2022) and the American Academy of Orthopaedic Surgeons (AAOS) Clinical Practice Guideline for Hip and Knee Arthroplasty (2023). These documents provided evidence-based recommendations for postoperative pain control, early mobilization, and rehabilitation planning. Second, a real-world question–answer dataset was constructed by collecting and categorizing the most frequently asked patient inquiries during a 3-month pilot period. The combined database ensured that the agent could respond to both standardized medical instructions and individualized daily concerns.
All entries were manually reviewed and verified by two orthopedic surgeons to ensure clinical accuracy, consistency, and local applicability. The database was updated monthly to incorporate new institutional policies and guideline revisions. Validation of the knowledge base was performed using an independent set of 200 postoperative queries not included in training. Additionally, all items were cross-checked against the standard rehabilitation protocols and clinical pathways approved by the First Affiliated Hospital of China Medical University, confirming alignment with institutional guidelines and minimizing the risk of misinformation.
To ensure safety and reliability, a structured auditing system was established for all AI–patient interactions. Each prompt and AI-generated response was automatically logged and de-identified. A two-tier audit protocol was implemented. First, a daily review was performed by two orthopedic surgeons to detect potential hallucinations, misinformation, or unsafe advice. Second, a monthly structured audit was conducted on a randomly selected set of 200 interactions using a four-domain evaluation checklist that assessed factual accuracy, contextual relevance, guideline consistency, and patient safety. Two independent reviewers performed the audit, and disagreements were resolved through consensus.
Deployed on the WeChat platform, the agent offered timely, on-demand assistance tailored to individual patient needs. This agent was developed to enhance patient engagement, improve adherence to postoperative care plans, and support the overall recovery process (Fig. 1a, b).
Study design
This single-center, prospective, randomized controlled trial evaluated the effectiveness of a WeChat-based LLMs agent compared to traditional doctor-patient communication for postoperative management. The study protocol was reviewed and approved by the Ethics Committee of the First Affiliated Hospital of China Medical University (Ethics Approval Number: 2023-489-2). Written informed consent was obtained from all participants prior to enrollment. The sample size calculation was performed to ensure sufficient statistical power to detect clinically meaningful differences. The study was designed with a power of 0.90, an effect size (Cohen’s d) of 0.4, and a significance level (α) of 0.05, using a two-sided hypothesis test. To account for a potential 10% dropout rate, the sample size per group was adjusted to 147 (132/(1 − 0.10) ≈ 147), resulting in a total of 294 participants. For simplicity and to ensure a robust sample size, the final target enrollment was rounded to 300 participants. This randomized controlled trial was registered in the Chinese Clinical Trial Registry (ChiCTR2500101273) under the title “Evaluation of the Benefits of Large Language Model-Based AI Doctor Assistants in Orthopedic Patients: A Randomized Controlled Study” on April 23, 2025. All analyses were conducted using the intention-to-treat (ITT) principle to preserve the benefits of randomization and minimize bias. Participants were analyzed according to the group to which they were originally assigned, regardless of adherence to the intervention protocol or loss to follow-up.
Patients in the agent group were added to WeChat and received responses exclusively from the AI agent, while those in the doctor group communicated with their attending physician via WeChat, which is part of our routine postoperative management rather than a study-specific procedure. In the doctor group, one attending doctor handled all patient messages under standard ward workflow. Neither group received proactive follow-up, and all physician responses were drawn from regular communication records without any artificial delay. Additionally, patients from both groups underwent standardized assessments during routine outpatient visits at 1, 3, and 6 months postoperatively, where functional scores, anxiety levels, and satisfaction were evaluated. This study was conducted in strict accordance with the Health Insurance Portability and Accountability Act (HIPAA) regulations to safeguard the confidentiality and security of patient information. All personal health data collected during the study were thoroughly de-identified and securely stored to prevent unauthorized access. Access to identifiable information was strictly limited to authorized personnel, and any data sharing adhered to HIPAA requirements to ensure patient privacy and data protection.
Patient recruitment
Between December 2023 and June 2024, 300 patients were enrolled and randomly assigned in a 1:1 ratio to the AI group (LLM agent) or the Doctor group (traditional communication). Randomization was performed using sealed, opaque, and sequentially numbered envelopes prepared by an independent researcher not involved in participant recruitment or assignment, ensuring allocation concealment, and minimizing the risk of bias during group assignment. Inclusion Criteria: (1) Aged 18–75 years. (2) Undergoing sports medicine procedures (e.g., ACL reconstruction, meniscus repair) or joint replacement surgeries (e.g., hip or knee arthroplasty). (3) Able to use WeChat for communication and follow-up. Exclusion Criteria: (1) Severe complications or comorbidities likely to affect outcomes. (2) Severe psychological disorders (e.g., major depression, schizophrenia) or cognitive impairments. (3) Participation in other clinical trials or interventions that might interfere with the outcomes of this study. (4) Inability to use WeChat or unfamiliarity with digital tools.
Outcome measures and follow-up
The primary objectives were to evaluate the quality of AI-generated responses and assess the impact of the proposed approaches on postoperative anxiety (GAD-7 scores), functional recovery (e.g., IKDC, FJS), and health-related quality of life (HRQoL, including PCS and MCS scores)3,22,23,24,25. Patient adherence to the communication platform was evaluated using the inquiry rate, defined as the proportion of patients who initiated at least one message or question during follow-up, divided by the total number of participants in each group.
The response quality of both the AI and doctor groups was assessed using a 10-point Likert scale covering comprehensiveness, clarity, relevance, and accuracy. Each response was independently reviewed by two senior orthopedic clinicians, blinded to group allocation. Any discrepancies were resolved through discussion, and the average of all ratings was used for analysis to ensure objective and consistent evaluation.
Patient satisfaction, expectation, and disease-related knowledge were measured at discharge through customized questionnaires. Each domain included multiple items rated on a 0–10 scale, with higher scores indicating greater satisfaction, expectation, or understanding. Post-operation outcome measures were assessed at 1, 3, and 6 months postoperatively to evaluate psychological well-being, functional recovery, and health-related quality of life. Subjective metrics, including Satisfaction, Expectation, and Knowledge, were assessed post-discharge using a custom-designed questionnaire specifically developed for this study. To facilitate statistical analysis, the metrics were standardized to a 0–100 scale, with higher scores indicating better outcomes. Patients rated their satisfaction with postoperative management (e.g., quality of care, communication, and support), the alignment of the care received with their preoperative expectations, and their perceived understanding of their medical condition, recovery process, and management plan. The questionnaire, designed to be concise and patient-friendly, was delivered via the WeChat platform within one week after discharge to ensure convenience and minimize recall bias. Its content was validated by clinical experts to ensure relevance and comprehensiveness.
Anxiety was measured using the GAD-7 scale, a validated tool widely used to assess the severity of anxiety symptoms. Scores range from 0 to 21, with higher scores indicating more severe anxiety. The GAD-7 was administered to track changes in psychological well-being throughout the follow-up period. Functional recovery was evaluated using tools tailored to the type of surgical procedure performed: For patients undergoing sports medicine procedures, the International Knee Documentation Committee Subjective Knee Form was used to assess symptoms, knee function, and activity limitations. For patients undergoing joint replacement surgeries, the Forgotten Joint Score was employed to evaluate the degree to which the replaced joint integrated into the patient’s daily life.
Health-Related Quality of Life was assessed using the 36-item Short-Form Health Survey (SF-36), specifically its PCS and MCS scores. The PCS measured physical functioning, bodily pain, and physical health-related role limitations. The MCS evaluated emotional well-being, social functioning, and limitations due to mental health conditions.
Statistical analysis
Data were collected and organized using Microsoft Excel and analyzed using GraphPad Prism software. Baseline characteristics were compared using the chi-square test for categorical variables and independent samples t test for continuous variables. For comparisons involving multiple groups, one-way analysis of variance (ANOVA) was applied. Missing data were imputed using median substitution to minimize potential bias. A p-value of <0.05 was considered statistically significant (*p < 0.05, **p < 0.01, ***p < 0.001). All statistical tests were conducted using a two-tailed approach to ensure the robustness and reliability of the findings. Effect sizes for between-group differences were quantified using Cohen’s d and interpreted according to conventional thresholds (small: 0.2, medium: 0.5, large: 0.8).
Data availability
The datasets generated and/or analyzed during the current study are not publicly available due to informed consent agreements with participants. However, data may be made available from the corresponding author upon reasonable request, particularly for purposes such as meta-analysis or replication. The complete implementation of the WeChat-based GPT-4 agent used in this study (the ortho-chat-on-wechat project) is openly available on GitHub at: https://github.com/lijutan0/ortho-chat-on-wechat. Researchers may clone or fork the repository to reproduce our results or adapt the system for further development.
References
Sanderson, K. GPT-4 is here: what scientists think. Nature 615, 773 (2023).
Freyer, O., Wiest, I. C., Kather, J. N. & Gilbert, S. A future role for health applications of large language models depends on regulators enforcing safety standards. Lancet Digit Health 6, e662–e672 (2024).
Lee, P., Bubeck, S. & Petro, J. Benefits, limits, and risks of GPT-4 as an AI chatbot for medicine. N. Engl. J. Med. 388, 1233–1239 (2023).
Russe, M. F. et al. Performance of ChatGPT, human radiologists, and context-aware ChatGPT in identifying AO codes from radiology reports. Sci. Rep. 13, 14215 (2023).
Yin, S. et al. A survey on multimodal large language models. Natl. Sci. Rev. 11, nwae403 (2024).
Ong, J. C. L. et al. Ethical and regulatory challenges of large language models in medicine. Lancet Digit Health 6, e428–e432 (2024).
Haltaufderheide, J. & Ranisch, R. The ethics of ChatGPT in medicine and healthcare: a systematic review on Large Language Models (LLMs). NPJ Digit Med. 7, 183 (2024).
Soroush, A. et al. Large language models are poor medical coders — benchmarking of medical code querying. NEJM AI 1 https://doi.org/10.1056/AIdbp2300040 (2024).
Rydzewski, N. R. et al. Comparative evaluation of LLMs in clinical oncology. NEJM AI 1 https://doi.org/10.1056/aioa2300151 (2024).
Chen, S. et al. The effect of using a large language model to respond to patient messages. Lancet Digit Health 6, e379–e381 (2024).
Heston, T. F. & Lewis, L. M. ChatGPT provides inconsistent risk-stratification of patients with atraumatic chest pain. PLoS One 19, e0301854 (2024).
Cozzi, A. et al. BI-RADS category assignments by GPT-3.5, GPT-4, and Google Bard: a multilanguage study. Radiology 311, e232133 (2024).
Finucane, P. & Phillips, G. D. Preoperative assessment and postoperative management of the elderly surgical patient. Med. J. Aust. 163, 328–330 (1995).
Reilly, J. J. Jr. Benefits of aggressive perioperative management in patients undergoing thoracotomy. Chest 107, 312S–315S (1995).
Engelman, D. T. et al. Guidelines for perioperative care in cardiac surgery: enhanced recovery after surgery society recommendations. JAMA Surg. 154, 755–766 (2019).
Anderson, J., Walsh, J., Anderson, M. & Burnley, R. Patient satisfaction with remote consultations in a primary care setting. Cureus 13, e17814 (2021).
Xu, H. & Shi, Y. Effectiveness of nursing care intervention for alleviation of anxiety, pain and functional improvement amongst patients undergoing ambulatory surgery: a systematic review and meta-analysis. Pak. J. Med. Sci. 40, 1287–1293 (2024).
Rollins, K. E., Lobo, D. N. & Joshi, G. P. Enhanced recovery after surgery: current status and future progress. Best. Pr. Res. Clin. Anaesthesiol. 35, 479–489 (2021).
Sanci, A., Ergin, I. E., Ozturk, A. & Asdemir, A. Mobile app communication to prevent ER visits post-circumcision: a prospective observational study. Int. Urol. Nephrol. https://doi.org/10.1007/s11255-024-04345-6 (2024).
Bertoni, S. et al. Digital postoperative follow-up after colorectal resection: a multi-center preliminary qualitative study on a patient reporting and monitoring application. Updates Surg. 76, 139–146 (2024).
Aydin, A. & Gursoy, A. Nurse-led support impact via a mobile app for breast cancer patients after surgery: a quasi-experimental study (step 2). Support Care Cancer 32, 598 (2024).
Toussaint, A. et al. Sensitivity to change and minimal clinically important difference of the 7-item Generalized Anxiety Disorder Questionnaire (GAD-7). J. Affect Disord. 265, 395–401 (2020).
Collins, N. J., Misra, D., Felson, D. T., Crossley, K. M. & Roos, E. M. Measures of knee function: International Knee Documentation Committee (IKDC) Subjective Knee Evaluation Form, Knee Injury and Osteoarthritis Outcome Score (KOOS), Knee Injury and Osteoarthritis Outcome Score Physical Function Short Form (KOOS-PS), Knee Outcome Survey Activities of Daily Living Scale (KOS-ADL), Lysholm Knee Scoring Scale, Oxford Knee Score (OKS), Western Ontario and McMaster Universities Osteoarthritis Index (WOMAC), Activity Rating Scale (ARS), and Tegner Activity Score (TAS). Arthritis Care Res. 63, S208–S228 (2011).
Lee, J. Y., Yeo, W. W., Chia, Z. Y. & Chang, P. Normative FJS-12 scores for the knee in an Asian population: a cross-sectional study. Knee Surg. Relat. Res. 33, 40 (2021).
Singh, R., Wilborn, D., Lintzeri, D. A. & Blume-Peytavi, U. Health-related quality of life (hrQoL) among patients with primary cicatricial alopecia (PCA): A systematic review. J. Eur. Acad. Dermatol. Venereol. 37, 2462–2473 (2023).
Acknowledgements
This work was supported by the Basic Scientific Research Project of the Liaoning Provincial Department of Education (Project No. LJ212410159035), the Regional Innovation and Development Joint Fund of the National Natural Science Foundation of China (Project No. U24A20700), and the Doctoral Start-up Project of Liaoning Province (Project No. 2024-BSLH-321).
Author information
Authors and Affiliations
Contributions
S.F. served as the guarantor for the overall content. J.L. was responsible for the experimental design. Z.Z, Y.Z., and Y.G. were responsible for data collection. Yi.Z. conducted the mental health evaluations. X.L. assessed the information security generated by the agent. All authors have read and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Li, J., Zhang, Y., Zhang, Z. et al. A randomized controlled trial of a WeChat-based artificial intelligence agent for postoperative care in orthopedic patients. npj Digit. Med. 9, 105 (2026). https://doi.org/10.1038/s41746-025-02269-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41746-025-02269-8
