
Abstract
The lateral occipitotemporal cortex (LOTC) is crucial for object, body, and expression perception, but its functions in computing body representation and action information remain poorly understood. Using ultrahigh-field 7 T fMRI and data-driven methods, we detected four different body-selective subdivisions within the LOTC network, each with distinct connectivity profiles and differentially involved in computing different body expressions. Stronger connectivity was observed for the posterior-ventral subdivision to the visual cortex, the posterior-dorsal subdivision to the precuneus, and the anterior subdivisions to the frontal cortex, regardless of the type of threatening condition. In contrast, defensive expressions enhanced the cingulate cortex connectivity to all four LOTC subdivisions. However, aggressive expressions selectively increased the middle frontal gyrus connectivity to the anterior subdivision, while decreasing its connectivity to the posterior-dorsal subdivision. These findings go beyond classical models based on body-category selectivity in the extrastriate body area with subsequent processing of emotion expression in higher-order areas and indicate emotion expression-specific information flows of body-related computation in different LOTC subdivisions.
Similar content being viewed by others
Introduction
Survival prompts organisms to rapidly sample social information that may signal threat and aggression in the environment so that they can prioritize adaptive behavior. The speed and automaticity of social threat perception suggest that the brain is finely tuned to extract social information from ongoing observations of whole-body postures and movements of others and to compute their behavioral relevance. Since the first reports of a body-selective area in the extrastriate cortex (EBA)1, body processing has been widely linked to the lateral occipitotemporal cortex (LOTC). Within the LOTC, multiple levels of body information have been identified, including body feature extraction2,3, emotion recognition4,5,6,7, as well as higher-level social aspects8,9. Selectivity for haptic body parts10, biological motion11,12, and action concepts or verbs10,13,14,15,16 has also been observed in these areas, underscoring the complex nature and functional organization of LOTC body areas.
However, the functional organization within LOTC may not be constrained to abstract categorical representations but can be modulated by the flexible large-scale cortical dynamics during naturalistic vision17,18. Understanding interactions between the LOTC and the rest of the brain becomes crucial when studying the higher-level visual information, such as social cues. LOTC body areas have been shown to engage with a broader body-processing network, including the fusiform body area (FBA), posterior superior temporal cortex (pSTS), and subcortical structures18,19,20. Importantly, different connectivity profiles have been revealed between the EBA and FBA despite their similar categorical selectivity21. The EBA, for instance, exhibits stronger connectivity to the dorsal visuomotor regions such as the superior parietal lobe (SPL), intraparietal sulcus (IPS), and inferior frontal gyrus (IFG). In line with previous studies suggesting functional distinctions between EBA and FBA22,23,24, these connectivity differences point to a potential for using whole-brain dynamics to clarify the divergent roles of local body-selective areas. A key challenge, then, is to identify the heterogeneous subregions within the LOTC, track their global connectivity during naturalistic perception, and determine how connectivity profiles inform LOTC’s functional organization.
In this study, we developed an integrated approach to investigate jointly the LOTC subdivisions, their whole-brain connectivity, and their context-sensitive modulations. In brief, independent component analysis (ICA) was conducted to decompose brain voxels into different components based on their temporal covariance and to extract the latent time-course for each component. These component time-courses were then used to evaluate both condition-dependent responses and connectivity patterns. Unlike voxel-wise contrast analysis, ICA utilizes all data points from the temporal dimension to estimate potential subdivisions, thus providing better within-area homogeneity than obtained from using ROIs defined with a limited number of contrasts. We did ICA in two iterations: first, with data from Li et al. 20, a whole-brain ICA was conducted to extract the LOTC network; next, in our main experiment on the same participants, we presented different conditions of videos and conducted ICA within the LOTC network to extract the subdivisions. The extracted time-courses were then used to track the connectivity and the condition-dependent modulation for each LOTC subdivision. Moreover, we used naturalistic videos rather than static images as the stimuli. Compared to static stimuli, these videos convey richer, more ecologically valid social cues and are expected to elicit more robust and distributed whole-brain dynamics during body processing17,18.
We selected two of the most behaviorally relevant whole-body actions: an aggressive action, which provides a socially threatening cue toward the observer, and a defensive action, which shows a response to a threat in the environment. We hypothesized that these two whole-body actions would be supported by a stable, generalizable, and ecologically relevant network of brain activity25,26,27.
Results
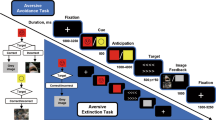
Nineteen participants were collected in the study, two of whom were excluded from both experiments, and another one was excluded from the main experiment due to a large distortion of the functional or anatomical images. Participants underwent a single scanning session consisting of two different parts. The first part consisted of a blocked design with twelve categories of videos (body/face/object * human/monkey * normal/scramble; 10 videos/category). This part of the experiment (termed “Network localizer” below) has been reported elsewhere20 and was used in the current study only to define the LOTC network. The second part (termed “Main experiment” below) consisted of a mixed block/event-related design28 with five different video conditions (aggressive body, defensive body, neutral body, neutral face, and neutral; 10 videos/condition). Each block contained one condition of videos presented with jittered inter-stimulus intervals. The main experiment was used to define the LOTC subdivisions, to test their whole-brain connectivity as well as conditional modulations (Fig. 1).

Five video conditions (aggressive/defensive/ neutral body, neutral face, object) were presented in a mixed block/event-related design, in which the stimuli were blocked for each condition, with a jittered inter-trial interval around 3 s. For each condition, ten different videos were included and repeated 10 times across five runs. GLM was conducted to estimate the response for each different video, resulting in 50 betas extracted for each participant. The video-wise betas were then entered into an ICA procedure within the body-sensitive LOTC network identified by the localizer experiment. Subdivisions of the LOTC network were defined by higher component responses for body videos than for non-body videos. To track the whole-brain connectivity of each selected subdivision, the video-wise betas were z-scored and convolved with the hemodynamic response function within each condition, resulting in five reconstructed time-courses for each component. The reconstructed time-courses for all selected components were then added to a whole-brain GLM design matrix as the predictors for seed-based connectivity. Finally, two-factor ANOVA was conducted with connectivity betas across all participants to test their modulations from the body conditions or the seed components.
LOTC network extraction
In the network localizer experiment, 75 independent components (ICs) were extracted from each subject’s pre-processed functional images. Noise-induced ICs were identified and excluded according to the spatial overlap with the white matter/cerebrospinal fluid mask, the mean response, and the r2 of the general linear modeling (GLM) fitting on the IC time-course. The details of these criteria are described in Li et al. 20. By conducting a GLM on the IC time-courses of the localizer data, the body-selective temporo-occipital network was identified by the analysis of the contrast [2*human body (normal−scramble) > human face (normal−scramble) + human object (normal−scramble)]. It exhibited a significant preference for human bodies over objects (Fig. 2a, t(16) = 4.24, Benjamini–Hochberg false discovery rate corrected q = 0.006, right-tailed) in the bilateral LOTC and also included bilateral fusiform cortex, superior parietal lobe (SPL), posterior superior temporal sulcus (pSTS)/temporoparietal junction (TPJ), pulvinar, and amygdala.

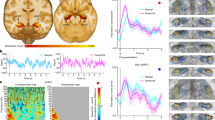
a The coverage of the LOTC network as defined in the network localizer experiment. b Beta plots of the four LOTC subdivisions from the main experiment, with individual data plotted as scatters and lines. Zero-point indicates the mean beta value across all masked voxels. Outline colors indicate the component indexes, and error bars represent ± SEM. Source data are attached in Supplementary Data 1. c Map of voxels with significantly higher contribution from each of the subdivisions. The voxel-wise IC weight from each subdivision was compared to the other three subdivisions and entered a group-level t-test against zero (two-tailed). The resulting map was corrected by a cluster-threshold statistical procedure based on Monte-Carlo simulation (initial p < 0.005, alpha level = 0.05, iteration = 5000). Slice numbers indicate the Z coordinates in the Talairach space. d The position of the dominance of subdivisions and the atlas defined hMT (yellow) projected on a Talairach template brain surface.
Subdivisions of the LOTC network
In the main experiment, following the identification of the body network defined above (termed as LOTC network below), we examined subdivisions with body selectivity within the network. A whole-brain GLM analysis was conducted to estimate the responses for each different video, resulting in fifty beta values (5 conditions * 10 videos) for each subject. The analysis for the main experiment is illustrated in Fig. 1. An ICA procedure was then conducted within the predefined LOTC network on each subject’s 50 betas, resulting in 15 ICs along with their video-wise betas. The component betas were then averaged by condition and entered a group-level t-test for the contrast of [(aggressive body + defensive body + neutral body) > (face + object)] to select body selective subdivisions. After multiple comparison correction, four adjacent subdivisions showed significant body selectivity (C04, t(15) = 8.08, corrected q < 0.001; C06, t(15) = 4.21, corrected q = 0.002; C07, t(15) = 2.66, corrected q = 0.033; C09, t(15) = 4.90, corrected q < 0.001; all right-tailed; Fig. 2b; Supplementary Data 1). The decomposed beta values are shown in Fig. 2b. Since the data were spatially demeaned before entering the ICA, the zero point in the plots indicates the averaged beta value across all masked voxels, and the signs of the beta values only indicate the relative magnitude difference compared to the global mean.
By comparing the spatial maps of the four independent components (i.e., C04, C06, C07, C09), we further investigated the voxels that were specifically dominant in each of the subdivisions. As shown in Fig. 2c (or Supplementary Fig. 1 separately plotted for each color), non-overlapping clusters were identified where the component weights exhibited significantly larger values for one of the components than for the other three. Subdivisions C04 and C09 were distributed bilaterally, covering the inferior lateral-occipital cortex (Fig. 2c, green component, LOCi for abbreviation; Supplementary Fig. 1a) and the superior lateral-occipital cortex (Fig. 2c, purple component, LOCs for abbreviation; Supplementary Fig. 1b) regions, respectively. The C06 and C07 had a unilateral distribution and covered the posterior middle temporal gyrus on the left (Fig. 2c, red component, lpMTG; Supplementary Fig. 1c) and right (Fig. 2c, blue component, rpMTG; Supplementary Fig. 1d) hemispheres, respectively. Consistent with a previous study on the subdivisions of EBA29, these body subdivisions partially overlapped with and surrounded the atlas-defined hMT region30 in each hemisphere (Fig. 2d).
Connectivity profiles of the LOTC subdivisions and the conditional modulations
To track the connectivity between the body subdivisions and the rest of the brain, a whole-brain GLM was conducted with the IC responses as predictors. Since the IC responses were extracted item-wise, the time-courses of each IC can be reconstructed by convolving the betas with a canonical hemodynamic response function (HRF) according to the on/offsets of the corresponding videos. The IC time-courses were modeled separately for each IC and each condition, resulting in 5 conditions * 4 subdivisions (LOCi, LOCs, lpMTG, and rpMTG) = 20 seed-based connectivity terms added to the GLM. Next, to assess connectivity modulated by the expression type, the resulting betas were entered in a voxel-wise ANOVA with the three body conditions (aggressive/defensive/neutral)*4 seeds. A significant main effect of seed was found in widely distributed clusters, showing that different LOTC body regions have differentiated connectivity profiles (Fig. 3a; or Supplementary Fig. 2 separately plotted for each color; Table 1; Supplementary Data 2). The LOCi and the LOCs showed stronger connectivity to the visual cortex (Supplementary Fig. 2a) and posterior cingulate cortex (PCC) (Supplementary Fig. 2b), while the two pMTG were connected more dominantly to the middle and posterior insula, supramarginal gyrus (SMG), and frontal regions (Supplementary Fig. 2c and d).

a Clusters with a significant main effect of the seed on connectivity. Cluster colors indicate the seed with the highest connectivity to the corresponding clusters. b Clusters with a significant main effect of the body condition on LOTC connectivity (averaged across subdivisions). c FEF cluster with significant interaction between the body condition and the seed. In b and c, box plots show the connectivity betas for each ROI, with whiskers (error bars) representing min/max value within 1.5 times the interquartile range from the lower or upper quartile, and the scatters plotted for individual data beyond the upper and lower bounds. For all box plots, asterisks indicate the significant pairwise comparisons after Bonferroni correction (*p < 0.05; **p < 0.01; ***p < 0.001; ****p < 0.0001). Detailed results for the cluster-level statistics are shown in Table 1. Source data are attached in Supplementary Data 2.
Within the areas showing a significant main effect of body condition, threatening modulations were found in the anterior/posterior cingulate cortex (ACC/PCC) and caudate. Subsequent post-hoc tests revealed a significant enhancement of overall seed connectivity specifically for the defensive body condition (Fig. 3b; Table 1; Supplementary Data 2). On the other hand, significant interaction effects between body condition and seed were found in the middle-frontal gyrus/frontal eye field and in the cerebellum. In both clusters, the aggressive body condition significantly increased connectivity to the lpMTG, while it decreased the connectivity to the LOCs (Fig. 3c; Table 1; Supplementary Data 2).
Testing the low-level feature contribution through cross-subject correlation
The connectivity analysis reported above was based on the response variance across videos within each condition. However, such variance can be driven both by the subjective perception and by the low-level visual features (e.g., motion energy) of the videos. To test the contribution of low-level features, we calculated the cross-subject correlation (CSC) on each subdivision’s response profile. We assumed that the higher-level factors, such as affordance or valence, are dependent on each participant’s perception, leading to larger cross-subject variability, while the low-level video features are shared across all participants, resulting in higher CSC. The CSC was calculated with the subdivision responses for all body videos between each pair of participants and was averaged across all combinations of pairs to get a group-level CSC measure. A permutation test was conducted by recalculating the CSC 5000 times after shuffling the video labels within each body condition for each participant, providing a null distribution of CSC with disrupted video-wise correspondence. The results indicated that only the LOCi subdivision showed a significant video-dependent CSC (r = 0.26, p = 0.004) while the other three subdivisions showed no significant CSC (lpMTG: r = −0.01, p = 0.655; rpMTG: r = 0.03, p = 0.349; LOCs: r = 0.07, p = 0.113).
Discussion
We developed an integrated approach to investigate the body-selective subdivisions of the LOTC, their whole-brain connectivity, and their condition-dependent modulations. Our results provide a novel perspective on whole-body action representation by focusing on the local-global interaction of the LOTC body areas, suggesting a distributed network dynamic that varies with the demands of expression representation.
We applied ICA analysis to resolve the heterogeneous functional subdivisions within the LOTC. The current ICA approach utilizes information from all stimuli and defines the potential clusters based on shared response patterns rather than relying on a limited set of contrasts, removing the assumptions of hard boundaries between the LOTC subdivisions. As a result, four body-selective subdivisions were identified within the LOTC body network20. The largest subdivision was the bilateral LOCi located in the inferior division of LOC and the lateral occipital sulcus (LOS). Another one, the bilateral LOCs, was defined in the superior division of the LOC. Anterior to the LOCi and LOCs, two unilateral subdivisions were found in the posterior middle temporal gyrus (MTG), one on the left hemisphere and one on the right (lpMTG and rpMTG). Overall, our findings provide evidence for a distributed functional organization within the LOTC, consistent with an early proposal by Weiner and Grill-Spector31. Our novel approach also supports earlier observations of an anterior-posterior separation of body areas29.
To investigate the connectivity profiles of the detected subdivisions, we applied a seed-based connectivity framework where the time-course from a seed region was fitted to the time-courses of the other voxels in the brain. A traditional way to define the representative time-course from the seed region is to average the time-courses of all voxels within the region. However, when the voxel profiles are heterogeneous, the averaged signal may not reflect the shared response pattern across the voxels. In contrast, the present ICA approach extracted the time-course based on the temporal covariance across voxels, which directly reflects the shared profile for the selected seed. Thus, we would expect better dissociations for the seed-based connectivity from different seed regions.
We compared connectivity profiles of the different subdivisions using an ANOVA, with seed region and threatening conditions as factors. A significant main effect of the seed regions was observed, indicating distinct global connectivity profiles. The only cluster showing stronger connectivity to the LOCi was early visual areas (EVA)/V2, suggesting LOCi’s role in low-level visual feature computation, as also supported by CSC analysis. Regarding the LOCs, the strongest connectivity was found with typical default mode network (DMN) nodes, including PCC, precuneus (pC), retrosplenial cortex (RSC), and superior frontal gyrus (SFG). Compared to the LOCi and LOCs, the two anterior subdivisions, lpMTG and rpMTG, exhibited more widespread connectivity, suggesting that the pMTG may serve as network hubs connecting the LOTC network to the whole-brain computation. Both pMTG subdivisions showed the highest connectivity to SMG and insula. However, in the case of the rpMTG, this connectivity extended further to encompass the MFG, angular gyrus, and SFG. Also, different from the LOCs, the anterior subdivisions were linked to regions of the ventral attention network (VAN), central executive network (CEN), and salience networks (SN). The asymmetric results are consistent with the right-lateralized distribution of the VAN32.
These results provided a novel opportunity to understand the functional roles of the LOTC subdivisions from a whole-brain network perspective, particularly emphasizing the segregation between the DMN and the SN/CEN connectivity. The DMN is typically involved in self-centered social perception, including inferring others’ mental state and environments, evaluating personal significance, and predicting future events based on one’s autobiographical memory and experiences33,34,35,36. One of the core hubs of DMN, covering the PCC, pC, and RSC, is believed to facilitate flexible cognition by collecting multisensory inputs and autobiographical memory, balancing between the internal thoughts and external task demands, and further regulating the whole-brain level dynamics37,38,39,40. Here, the strong connectivity was observed between the LOCs subdivision and the PCC/pC/RSC regions. Such results indicate that the LOC's subdivision may serve as an entrance point for perceiving and understanding whole-body actions.
In contrast, the anterior LOTC subdivisions (pMTG) connected extensively to goal-directed networks (SN, CEN, and VAN), including by insula, dorsal lateral prefrontal cortex (dlPFC), and MFG. Unlike the task-negative DMN, these networks are highly interactive and modulated by the task demands32,41,42,43,44. Operating jointly, these networks enable efficient processing of task-relevant information, including relevant input detection, attention modulation, and decision-making. Thus, the connectivity of the pMTG subdivisions may reflect their involvement in a response circuit finetuned to the whole-body social cues.
Unlike traditional resting-state analysis, the current network analysis was stimulus-driven, based on a passive viewing task without requiring active interpretation. Thus, our results suggest an intrinsic segregation of two essential functions during whole-body action perception, comprehension, and response, with separated information flow through LOCs and pMTG subdivisions into the distributed global computation.
To further investigate network dynamics, we assessed LOTC connectivity changes during viewing defensive vs. aggressive body actions. Both conditions carry threat-related cues, which are expected to trigger effective adaptive behavior25; yet, they differ in terms of uncertainty, proximity, and emergency25,27,45. In the defensive/fearful videos, actors’ movements signal uncertain, potential threats in the environment. Observers must infer danger from the ambiguous behavior of conspecifics before any response, requiring integration of sensory input with memory and prior experience. In line with this, our results showed that viewing defensive videos enhanced LOTC’s overall connectivity to the anterior and posterior cingulate cortex, known hubs for social cognition43,46,47,48,49 and peripersonal space processing50,51,52. This supports the idea of a global recruitment of LOTC in response to defensive/fearful body action perception, as well as with findings on the role of peripersonal space50.
Unlike the defensive/fearful ones, the aggressive/attacking videos contain explicit threat signals directly toward the observer25,53,54. When confronted by direct threats, rapid responses are required to minimize future harm27, sometimes independent of conscious awareness55,56. Correspondingly, our results revealed an alternating connectivity between left FEF and LOTC subdivisions during aggressive/attacking conditions, where the connectivity was suppressed to the LOCs subdivision but enhanced to the left pMTG subdivision. As discussed above, we suggest that the LOC subdivisions and the pMTG subdivision were involved differently in mentalization and responding networks. The finding of the aggressive expression modulated connectivity may thus reflect a switch between the two kinds of computations. Moreover, since the recognition of the action and its emotional valence is not required in our task, we suggest that such a switch in the brain dynamics is reflective. This is in line with previous studies showing that threat-induced brain activity can be independent of task demands57, as well as with the role of left FEF in modulating internal attention44. The current study explored how global connectivity can help clarify the functional organization of the LOTC. However, questions remain about the functions of the subdivisions reported here for general body perception. First, we found that LOCi subdivision may respond to low-level features, while other studies have revealed neural representations for body contraction3, head orientation58, and body kinematics59 within LOTC regions. Thus, it remains to test whether there exists a gradient from low- to mid/high-level feature encoding across LOTC subdivisions. Secondly, the current study was based on a functional connectivity framework and a data-driven approach. However, the anatomical basis underlying functional connectivity patterns is yet unclear. Previous studies have shown that the anterior and posterior LOTC differ in their connections through the inferior longitudinal fasciculus, while the superior and inferior LOTC differ in their connections through the arcuate and superior longitudinal fasciculi60. It is still an open question whether the white matter tractography supports the functional divergence within LOTC. Finally, our study compared two typical threatening body expressions and found evidence in support of a potential early divergence of information flow within LOTC. To what extent these findings generalize to other body actions is a matter of future research. New feature-rich datasets have become available, providing a large sample of naturalistic human actions61,62. We would expect the current data-driven approaches could serve as a primer for future studies that will benefit from large dataset analysis.
Methods
The study consisted of two parts: a network analysis to identify the temporo-occipital network associated with body action perception. This was accomplished through a data-driven strategy based on our previous study20. Next, the main experiment was employed to extract subdivisions within this network and investigate their connectivity profiles as well as their modulation by threatening body conditions.
Participants
Nineteen healthy participants (age = 24.58 ± 3.20 years; 6 males, all right-handed) took part in the experiment. All participants had a normal or corrected-to-normal vision and no medical history of any psychiatric or neurological disorders. All participants provided informed written consent before the start of the experiment and received a monetary reward (vouchers) or course credits for their participation. The experiment was approved by the Ethical Committee at Maastricht University and was performed in accordance with the Declaration of Helsinki.
Network localizer
The functional localizer used a blocked design with twelve categories of videos consisting of three factors: (body/face/object) * (human/monkey) * (normal/scramble). Each category consisted of ten 1000-ms videos, which were presented in a random order following a block design. Within each block, the videos were separated by a fixed 500-ms inter-trial interval, while two consecutive blocks were interleaved by an inter-block interval jittered around 11 s. The order of block conditions was randomized for each participant, and each condition was repeated six times within three runs. Each run contained a catch block where, in one of the trials, the fixation point changed its shape from a “+” to a “o”. Participants were instructed to press a button when they detected a change in the fixation shape. The total length of each run was 735 s on average, corresponding to 735 volumes at 1000 ms repetition time (TR). A detailed description of the localizer stimuli and design can be found in Li et al. 20.
Main experiment
For the main experiment, the stimuli were presented following a mixed block/event-related design28 consisting of five conditions of videos: three human body conditions (aggressive, defensive, and neutral), one neutral human face condition and one neutral object condition (Fig. 1). Each condition consisted of 10 different 1000-ms videos at 60 frames/s (i.e., total of 60 frames). The body and face videos were chosen from the stimulus set first described in Kret et al. 63 and Poyo Solanus et al. 64. Body videos depicted a male actor performing an emotional body movement in an aggressive-angry, defensive-fearful, or neutral fashion. All actors in the body videos were dressed in black, and their faces were blurred with a Gaussian filter with Ulead Video Studio (https://www.videostudiopro.com/en/pages/old-brands/ulead) and Adobe After Effects (https://www.adobe.com/products/aftereffects) to avoid triggering facial perception-related processes. The facial condition consisted of neutral facial movements such as pulling the nose or coughing. The object condition videos consisted of moving artificial objects with the aspect ratio matched to human bodies.
The experiment used a block design with a jittered inter-trial interval of around 3 s and a fixed inter-block interval of 12 s. Each video was centered and presented on a uniform gray background. Stimulus size was 3.5°*7.5° visual angle for bodies and objects, and 3.5°*3.5° visual angle for faces. The order of blocks was randomized for each participant, and each condition was repeated 10 times within five runs. In each run, two extra blocks were inserted containing a catch trial with a change in the shape of the fixation cross. Participants were instructed to detect the fixation shape changes and press a response button. The experiment used a fixation shape detection task, but no emotion recognition task, since explicit emotion recognition strongly impacts the results in body sensitive areas2,7,25,57. The total length of each run was 480 s (480 volumes).
The main experiment and the localizer experiment were programmed using the Psychtoolbox (https://www.psychtoolbox.net) implemented in Matlab 2018b (https://www.mathworks.com). Stimuli were projected onto a screen positioned at the end of the scanner bore with a Panasonic PT-EZ57OEL projector (screen size = 30*18 cm, resolution = 1920*1200 pixels). Participants viewed the stimuli through a mirror attached to the head coil (screen-to-eye distance = 99 cm, visual angle = 17.23*10.38 degrees).
fMRI data acquisition
All images were acquired with a Siemens 7T MAGNETOM scanner with a 1-transmitter/32-receiver head coil (Nova Medical) at the Maastricht Brain Imaging Centre (MBIC) of Maastricht University, the Netherlands. Functional images were collected using the T2*-weighted multi-band accelerated EPI 2D BOLD sequence (TR/TE = 1000/20 ms, multiband acceleration factor = 3, flip angle = 54°, in-plane isotropic resolution = 1.6 mm, number of slices per volume = 68, matrix size = 128*128, volume number = 735 for the network localizer and 480 for the main experiment). T1-weighted anatomical images were obtained using the 3D-MP2RAGE sequence (TR/TE = 5000/2.47 ms, Inverse time TI1/I2 = 900/2750 ms, flip angle FA1/FA2 = 5/3°, in-plane isotropic resolution = 0.7 mm, matrix size = 320*320, slice number = 240). Physiological parameters such as heart and respiration rates were recorded using pulse oximetry on the index finger of the left hand and a respiratory belt.
fMRI image preprocessing
Anatomical and functional images were preprocessed using Brainvoyager 2265 and the Neuroelf toolbox (https://neuroelf.net/) in Matlab 2018b. For anatomical images, brain extraction was conducted with INV2 images to correct for MP2RAGE background noise. The resolution was then downsampled to 0.8 mm for better alignment to the 1.6 mm resolution of functional images. For functional images, the preprocessing steps included EPI distortion correction66, slice scan time correction, 3D head-motion correction, and high-pass temporal filtering (GLM with Fourier basis set of 3 cycles, including linear trend). Coregistration was first conducted between the anatomical image and its most adjacent functional run using a boundary-based registration (BBR) algorithm67, and all the other functional runs were coregistered to the aligned run. Individual images were normalized to Talairach space68 and subjected to 3 mm Gaussian spatial smoothing. Trilinear/sinc interpolation was used in the motion correction step, and sinc interpolation was used in all the other steps.
Physiological parameters were collected as confound factors for the functional imaging data. The physiological data were preprocessed using the RETROspective Image CORrection (RETROICOR)69,70 pipeline, which uses Fourier expansions of different orders for the phase of cardiac pulsation (3rd order), respiration (4th order), and cardio-respiratory interaction (1st order). Eighteen physiological confound factors were finally created for each participant.
The anatomical labeling of the brain areas reported in this study was performed according to the Talairach Daemon (http://www.talairach.org/daemon.html) in combination with the Multilevel Human Brain Atlas (https://ebrains.eu/service/human-brain-atlas).
LOTC network extraction
Body-related brain networks were extracted using independent component analysis (ICA), which decomposes the whole-brain time-courses into multiple spatially independent components (ICs) based on maximal temporal coherence. Subsequently, the original time-course of each voxel can be calculated as a weighted sum of different IC time-courses. Voxels showing high weights for the same IC suggest that they may have shared fluctuations and may belong to the same brain network. ICA has been widely used in both resting-state and task-based fMRI to identify large-scale networks in human and animal brains71,72,73. However, since subject-wise ICA is a data-driven approach, a significant issue is that the order of the ICs is arbitrary, making it unsuitable for direct group-level inference across subjects. Thus, the current study employed another approach called group ICA using the Group ICA of fMRI Toolbox (GIFT)74. Instead of directly estimating ICs on each subject, the group ICA first applies dimensionality reduction on each participant’s data using principal component analysis (PCA) on the time dimension. It then estimates a set of shared group-level ICs by temporally concatenating data from all participants using the Infomax algorithm implemented in the GIFT74. The group ICs are then entered in a back-reconstruction step for each participant separately, resulting in subject-level ICs time-courses and spatial weights, which reflect both the individual-specificity and the group-level correspondence75. Here, we used the group-information-guided ICA (GIG-ICA)76 for the back-reconstruction of the subject components, which estimates the ICs with multi-objective optimization to maximize the spatial independence and the similarity to the group-IC maps at the same time.
We estimated 75 spatially independent components to identify body-selective networks within the localizer experiment20. The stability of group ICA was assessed by the ICASSO module implemented in the GIFT, which repeated the Infomax decomposition 20 times and resulted in an index of stability (Iq) for each IC77. Prior to the group-ICA, physiological and motion confounds were regressed out from the preprocessed functional images. The resulting time courses were then transformed into percentages of signal change to enhance the ICA stability78. Components showing large white matter/cerebrospinal fluid predominance were excluded from further analysis.
To identify body-selective networks, we conducted a GLM on each reconstructed subject-level IC time course to estimate how each condition modulated the IC response. In the design matrix, each condition’s predictor was modeled as a boxcar function with the same duration of the block and convolved with a canonical hemodynamic response function (HRF). Within subjects, the estimated betas were first averaged across all runs and then used to calculate the contrast of [2*human body (normal-scramble)–(human face (normal-scramble) + human object (normal-scramble))]. Right-tailed t-tests and Benjamini–Hochberg multiple comparison corrections were conducted at the group level to find significant body sensitivity.
To define the group-level coverage of the IC networks, the individual IC maps were normalized to z-scores and averaged across all runs for each participant. A group t-test against zero was computed using the z-scored maps of each subject and corrected using a cluster-threshold statistical procedure based on Monte-Carlo simulation (initial p < 0.005, alpha level = 0.05, iteration = 5000). The group-level coverage of the network was then used as the initial mask for the subdivision extraction in the main experiment.
Subdivisions of LOTC network and seed-based connectivity
The analysis for the main experiment is illustrated in Fig. 1. First, a fixed-effects GLM was conducted on each participant’s functional images with each video treated as a separate predictor, resulting in fifty betas for each voxel for each participant. Next, a group-ICA decomposition was conducted directly on the estimated video betas within the regions defined by the LOTC body network localizer. The goal of this step is to separate the voxels within the LOTC network into multiple spatially independent clusters while maintaining the response coherence across the fifty videos. We extracted fifteen ICs in this step, each with a distinct response profile to the fifty videos. To identify the components of interest, we averaged the responses for each condition within each subject for each IC separately. We then computed a group-level component-wise t-test for the contrast of [(aggressive body + defensive body + neutral body) > (face + object)]. ICs showing a significant difference were identified as body selective subdivisions and subsequently used for the following analysis.
To track the connectivity between the LOTC subdivisions and the rest of the brain, a whole-brain GLM was performed on the BOLD responses using the subdivision IC response profiles as predictors (Fig. 1). Since the ICs’ responses indicate how strongly brain activity related to each stimulus is represented within each component, they do not contain any temporal information. Therefore, we first reconstructed the time courses of each IC by convolving the responses with a canonical HRF based on the onsets and offsets of the corresponding videos. These reconstructed time courses of the subdivisions were then added to a GLM design matrix to reflect their seed-based connectivity. Before convolving the HRF, the IC betas were normalized within each condition so that the reconstructed time-courses reflected the item-to-item variance while omitting the categorical baseline modulations. Moreover, the IC time courses were modeled separately for each subdivision and each condition. A set of standard event-related predictors was also added, which was constructed by convolving each stimulus duration with the HRF and binned for each condition, to account for the stimulus-driven responses. The coverage of all seed regions was masked out from the whole-brain connectivity GLM, since the potential signal spreading between adjacent seed regions may inflate the connectivity estimation.
The resulting betas for the connectivity terms were then entered in a voxel-wise random-effects ANOVA with factors Body conditions (aggressive/defensive/neutral) and Seeds (LOCi/LOCs/rpMTG/lpMTG) to assess the expression type-modulated connectivity. Statistical maps of significant main and interaction effects were corrected with the Monte Carlo cluster-threshold (initial p < 0.005, alpha level = 0.05, iteration = 3000). Further multiple comparisons and simple effect tests were conducted at the ROI level for each significant cluster.
Cross-subject correlation analysis
Cross-subject correlation (CSC) analysis was conducted to compare the video-wise response similarity across participants. Higher correlation was expected if the responses were driven by subject-independent low-level visual features from the videos, while lower CSC could suggest more involvement of subject-specific computation of higher-level affective features. For each LOTC subdivision, the responses for all 50 videos were demeaned for each participant to normalize the baseline difference. Next, pairwise Pearson correlation was calculated across all participants based on the 30 body video responses, and the Pearson r values from all pairs of calculations were averaged as a group-level CSC measure. A permutation test was conducted by recalculating the group CSC after shuffling the video labels within each body condition for each participant. The within-condition permutation disrupted the video correspondence across participants while preserving the condition-wise modulation, resulting in a null distribution specific to the single video effect. The permutation procedure was repeated 5000 times for each subdivision, and the proportion of permutation CSC samples above the corresponding empirical CSC was calculated as a statistical significance measure.
Statistics and reproducibility
For spatial coverage of group-level ICs, the individual IC maps were normalized to z-scores and averaged across all runs for each participant. A group t-test against zero (n = 16 participants) was computed using the z-scored maps of each subject and corrected using a cluster-threshold statistical procedure based on Monte-Carlo simulation (initial p < 0.005, alpha level = 0.05, iteration = 5000). For GLM and contrast analysis on IC time-courses, random-effect t-tests and Benjamini–Hochberg multiple comparison corrections were conducted at the group level to test the significance. For whole-brain analysis of connectivity GLM, random-effects ANOVA was conducted and tested for significant main and interaction effects at the group level. Statistical maps were corrected with the Monte Carlo cluster-threshold (initial p < 0.005, alpha level = 0.05, iteration = 3000). For CSC analysis, the significance was tested at a group level with a permutation test. The within-condition permutation disrupted the video correspondence across participants while preserving the condition-wise modulation, resulting in a null distribution specific to the single video effect. The permutation procedure was repeated 5000 times for each subdivision, and the proportion of permutation CSC samples above the corresponding empirical CSC was calculated as a statistical significance measure.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The neuroimaging data of the current study are not available on a public repository but can be provided upon request to the corresponding author.
Code availability
Core functions for the group ICA analysis were provided by the Matlab-based GIFT toolbox (https://github.com/trendscenter/gift). Customized scripts for the post-analysis on the IC time-course analysis are available upon request to the first author or the corresponding author.
References
Downing, P. & Kanwisher, N. A cortical area specialized for visual processing of the human body. J. Vis. 1, 2470–2473 (2001).
Marrazzo, G., Vaessen, M. J. & de Gelder, B. Decoding the difference between explicit and implicit body expression representation in high level visual, prefrontal and inferior parietal cortex. NeuroImage 243, 118545 (2021).
Poyo Solanas, M., Vaessen, M. & de Gelder, B. Computation-based feature representation of body expressions in the human brain. Cereb. Cortex 30, 6376–6390 (2020).
de Gelder, B., Snyder, J., Greve, D., Gerard, G. & Hadjikhani, N. Fear fosters flight: a mechanism for fear contagion when perceiving emotion expressed by a whole body. Proc. Natl. Acad. Sci. USA 101, 16701–16706 (2004).
Grèzes, J., Pichon, S. & de Gelder, B. Perceiving fear in dynamic body expressions. NeuroImage 35, 959–967 (2007).
Peelen, M. V., Atkinson, A. P., Andersson, F. & Vuilleumier, P. Emotional modulation of body-selective visual areas. Soc. Cogn. Affect. Neurosci. 2, 274–283 (2007).
Pichon, S. & de Gelder, B. & Grèzes, J. Emotional modulation of visual and motor areas by dynamic body expressions of anger. Soc. Neurosci. 3, 199–212 (2008).
Kret, M. E., Denollet, J., Grèzes, J. & de Gelder, B. The role of negative affectivity and social inhibition in perceiving social threat: an fMRI study. Neuropsychologia 49, 1187–1193 (2011).
Moreau, Q., Parrotta, E., Pesci, U. G., Era, V. & Candidi, M. Early categorization of social affordances during the visual encoding of bodily stimuli. NeuroImage 274, 120151 (2023).
Costantini, M., Urgesi, C., Galati, G., Romani, G. L. & Aglioti, S. M. Haptic perception and body representation in lateral and medial occipito-temporal cortices. Neuropsychologia 49, 821–829 (2011).
Jastorff, J. & Orban, G. A. Human functional magnetic resonance imaging reveals separation and integration of shape and motion cues in biological motion processing. J. Neurosci. 29, 7315–7329 (2009).
Grosbras, M. H., Beaton, S. & Eickhoff, S. B. Brain regions involved in human movement perception: a quantitative voxel-based meta-analysis. Hum. Brain Mapp. 33, 431–454 (2012).
Watson, C. E., Cardillo, E. R., Ianni, G. R. & Chatterjee, A. Action concepts in the brain: an activation likelihood estimation meta-analysis. J. Cogn. Neurosci. 25, 1191–1205 (2013).
Bedny, M., Pascual-Leone, A., Dravida, S. & Saxe, R. A sensitive period for language in the visual cortex: distinct patterns of plasticity in congenitally versus late blind adults. Brain Lang. 122, 162–170 (2012).
Peelen, M. V., Romagno, D. & Caramazza, A. Independent representations of verbs and actions in left lateral temporal cortex. J. Cogn. Neurosci. 24, 2096–2107 (2012).
Hernández, M., Fairhall, S. L., Lenci, A., Baroni, M. & Caramazza, A. Predication drives verb cortical signatures. J. Cogn. Neurosci. 26, 1829–1839 (2014).
Leopold, D. A. The big mixup: neural representation during natural modes of primate visual behavior. Curr. Opin. Neurobiol. 88, 102913 (2024).
de Gelder, B. & Poyo Solanas, M. A computational neuroethology perspective on body and expression perception. Trends Cogn. Sci. 25, 744–756 (2021).
Caspers, S., Zilles, K., Laird, A. R. & Eickhoff, S. B. ALE meta-analysis of action observation and imitation in the human brain. NeuroImage 50, 1148–1167 (2010).
Li, B. et al. A large-scale brain network of species-specific dynamic human body perception. Prog. Neurobiol. 221, 102398 (2023).
Zimmermann, M., Mars, R. B., De Lange, F. P., Toni, I. & Verhagen, L. Is the extrastriate body area part of the dorsal visuomotor stream? Brain Struct. Funct. 223, 31–46 (2018).
Downing, P. E. & Peelen, M. V. The role of occipitotemporal body-selective regions in person perception. Cogn. Neurosci. 2, 186–203 (2011).
Taylor, J. C., Wiggett, A. J. & Downing, P. E. Functional MRI analysis of body and body part representations in the extrastriate and fusiform body areas. J. Neurophysiol. 98, 1626–1633 (2007).
Schwarzlose, R. F., Swisher, J. D., Dang, S. & Kanwisher, N. The distribution of category and location information across object-selective regions in human visual cortex. Proc. Natl. Acad. Sci. USA 105, 4447–4452 (2008).
Pichon, S., de Gelder, B. & Grèzes, J. Two different faces of threat. Comparing the neural systems for recognizing fear and anger in dynamic body expressions. NeuroImage 47, 1873–1883 (2009).
Orban, G. A., Lanzilotto, M. & Bonini, L. From observed action identity to social affordances. Trends Cogn. Sci. 25, 493–505 (2021).
Levy, I. & Schiller, D. Neural computations of threat. Trends Cogn. Sci. 25, 151–171 (2021).
Visscher, K. M. et al. Mixed blocked/event-related designs separate transient and sustained activity in fMRI. Neuroimage 19, 1694–1708 (2003).
Weiner, K. S. & Grill-Spector, K. Not one extrastriate body area: using anatomical landmarks, hMT+, and visual field maps to parcellate limb-selective activations in human lateral occipitotemporal cortex. Neuroimage 56, 2183–2199 (2011).
Rosenke, M., Van Hoof, R., Van Den Hurk, J., Grill-Spector, K. & Goebel, R. A probabilistic functional atlas of human occipito-temporal visual cortex. Cereb. Cortex 31, 603–619 (2021).
Weiner, K. S. & Grill-Spector, K. Sparsely-distributed organization of face and limb activations in human ventral temporal cortex. Neuroimage 52, 1559–1573 (2010).
Vossel, S., Geng, J. J. & Fink, G. R. Dorsal and ventral attention systems: distinct neural circuits but collaborative roles. Neuroscientist 20, 150–159 (2014).
Spreng, R. N., Mar, R. A. & Kim, A. S. The common neural basis of autobiographical memory, prospection, navigation, theory of mind, and the default mode: a quantitative meta-analysis. J. Cogn. Neurosci. 21, 489–510 (2009).
Andrews-Hanna, J. R. The brain’s default network and its adaptive role in internal mentation. Neuroscientist 18, 251–270 (2012).
Roy, M., Shohamy, D. & Wager, T. D. Ventromedial prefrontal-subcortical systems and the generation of affective meaning. Trends Cogn. Sci. 16, 147–156 (2012).
Catani, M., Dell’Acqua, F. & De Schotten, M. T. A revised limbic system model for memory, emotion and behaviour. Neurosci. Biobehav. Rev. 37, 1724–1737 (2013).
Brewer, J. A., Garrison, K. A. & Whitfield-Gabrieli, S. What about the “self” is processed in the posterior cingulate cortex? Front. Hum. Neurosci. 7, 647 (2013).
Leech, R. & Sharp, D. J. The role of the posterior cingulate cortex in cognition and disease. Brain 137, 12–32 (2014).
Fransson, P. & Marrelec, G. The precuneus/posterior cingulate cortex plays a pivotal role in the default mode network: evidence from a partial correlation network analysis. Neuroimage 42, 1178–1184 (2008).
Leech, R., Braga, R. & Sharp, D. J. Echoes of the brain within the posterior cingulate cortex. J. Neurosci. 32, 215–222 (2012).
Uddin, L. Q. Salience Network of the Human Brain (Academic Press, 2016).
Schimmelpfennig, J., Topczewski, J., Zajkowski, W. & Jankowiak-Siuda, K. The role of the salience network in cognitive and affective deficits. Front. Hum. Neurosci. 17, 1133367 (2023).
Seeley, W. W. The salience network: a neural system for perceiving and responding to homeostatic demands. J. Neurosci. 39, 9878–9882 (2019).
Corbetta, M., Patel, G. & Shulman, G. L. The reorienting system of the human brain: from environment to theory of mind. Neuron 58, 306–324 (2008).
Mobbs, D., Headley, D. B., Ding, W. & Dayan, P. Space, time, and fear: survival computations along defensive circuits. Trends Cogn. Sci. 24, 228–241 (2020).
Torta, D. M. & Cauda, F. Different functions in the cingulate cortex, a meta-analytic connectivity modeling study. Neuroimage 56, 2157–2172 (2011).
Lavin, C., Melis, C., Mikulan, E., Gelormini, C., Huepe, D., & Ibañez, A. The anterior cingulate cortex: an integrative hub for human socially-driven interactions. Front. Neurosci. 7 64 (2013).
Bubb, E. J., Kinnavane, L. & Aggleton, J. P. Hippocampal–diencephalic–cingulate networks for memory and emotion: an anatomical guide. Brain Neurosci. Adv. 1, 2398212817723443 (2017).
Lyu, D. et al. Causal evidence for the processing of bodily self in the anterior precuneus. Neuron 111, 2502–2512 (2023).
Basile, G. A. et al. Neuroanatomical correlates of peripersonal space: bridging the gap between perception, action, emotion and social cognition. Brain Struct. Funct. 229, 1047–1072 (2024).
Cléry, J. et al. The prediction of impact of a looming stimulus onto the body is subserved by multisensory integration mechanisms. J. Neurosci. 37, 10656–10670 (2017).
Huang, R. S., Chen, C. F. & Sereno, M. I. Spatiotemporal integration of looming visual and tactile stimuli near the face. Hum. Brain Mapp. 39, 2156–2176 (2018).
Frijda, N. H. The Emotions (Cambridge University Press, 1986).
de Gelder, B., Poyo Solanas, M. & Seinfeld, S. The aggressive body: Understanding aggression combining virtual reality, computational movement features, and neuroimaging. In Handbook of anger, aggression, and violence (eds. Martin, C. R., Preedy, V. R. & Patel, V. B.) pp. 1791–1804 (Springer Nature Switzerland AG, 2023).
Zhan, M., Hortensius, R. & de Gelder, B. The body as a tool for anger awareness—differential effects of angry facial and bodily expressions on suppression from awareness. PLoS ONE 10, e0139768 (2015).
Poyo Solanas, M., Zhan, M. & de Gelder, B. Gradual relation between perceptual awareness, recognition and pupillary responses to social threat. Curr. Res. Behav. Sci. 5, 100134 (2023).
Pichon, S., De Gelder, B. & Grèzes, J. Threat prompts defensive brain responses independently of attentional control. Cereb. Cortex 22, 274–285 (2012).
Zhan, M., Goebel, R. & de Gelder, B. Subjective understanding of actions and emotions involves the interplay of the semantic and action observation networks in the brain. Preprint at bioRxiv https://doi.org/10.1101/2021.04.15.439961 (2021).
Marrazzo, G., De Martino, F., Lage-Castellanos, A., Vaessen, M. J. & de Gelder, B. Voxelwise encoding models of body stimuli reveal a representational gradient from low-level visual features to postural features in occipitotemporal cortex. NeuroImage 277, 120240 (2023).
Glasser, M. F. et al. A multi-modal parcellation of human cerebral cortex. Nature 536, 171–178 (2016).
Urgen, B. A., Nizamoğlu, H., Eroğlu, A. & Orban, G. A. A large video set of natural human actions for visual and cognitive neuroscience studies and its validation with fMRI. Brain Sci. 13, 61 (2022).
Zhou, M. et al. A large-scale fMRI dataset for human action recognition. Sci. Data 10, 415 (2023).
Kret, M. E., Pichon, S., Grèzes, J. & De Gelder, B. Similarities and differences in perceiving threat from dynamic faces and bodies. An fMRI study. NeuroImage 54, 1755–1762 (2011).
Poyo Solanas, M., Vaessen, M. J. & de Gelder, B. The role of computational and subjective features in emotional body expressions. Sci. Rep. 10, 1–13 (2020).
Goebel, R. BrainVoyager—past, present, future. Neuroimage 62, 748–756 (2012).
Breman, H. et al. An image registration-based method for epi distortion correction based on opposite phase encoding (COPE). In Lecture Notes in Computer Science, Biomedical Image Registration. WBIR 2020. (eds Špiclin, Ž., McClelland, J., Kybic, J. & Goksel, O.) Vol. 12120, 122–130 (Springer, Cham., 2020).
Greve, D. N. & Fischl, B. Accurate and robust brain image alignment using boundary-based registration. NeuroImage 48, 63–72 (2009).
Collins, D. L., Neelin, P., Peters, T. M. & Evans, A. C. Automatic 3d intersubject registration of MR volumetric data in standardized Talairach space. J. Comput. Assist. Tomogr. 18, 192–205 (1994).
Glover, G. H., Li, T. Q. & Ress, D. Image-based method for retrospective correction of physiological motion effects in fMRI: RETROICOR. Magn. Reson. Med. 44, 162–167 (2000).
Harvey, A. K. et al. Brainstem functional magnetic resonance imaging: disentangling signal from physiological noise. J. Magn. Reson. Imaging 28, 1337–1344 (2008).
Du, Y. et al. Identifying dynamic functional connectivity biomarkers using GIG-ICA: application to schizophrenia, schizoaffective disorder, and psychotic bipolar disorder. Hum. Brain Mapp. 38, 2683–2708 (2017).
Jarrahi, B. et al. Differential functional brain network connectivity during visceral interoception as revealed by independent component analysis of fMRI time-series. Hum. Brain Mapp. 36, 4438–4468 (2015).
Jung, J. Y., Bungert, A., Bowtell, R. & Jackson, S. R. Modulating brain networks with transcranial magnetic stimulation over the primary motor cortex: a concurrent TMS/fMRI study. Front. Hum. Neurosci. 14, 31 (2020).
Calhoun, V. D., Adali, T., Pearlson, G. D. & Pekar, J. J. A method for making group inferences from functional MRI data using independent component analysis. Hum. Brain Mapp. 14, 140–151 (2001).
Calhoun, V. D., Liu, J. & Adalı, T. A review of group ICA for fMRI data and ICA for joint inference of imaging, genetic, and ERP data. Neuroimage 45, S163–S172 (2009).
Du, Y. & Fan, Y. Group information guided ICA for fMRI data analysis. Neuroimage 69, 157–197 (2013).
Himberg, J., Hyvärinen, A. & Esposito, F. Validating the independent components of neuroimaging time series via clustering and visualization. NeuroImage 22, 1214–1222 (2004).
Allen, E. A. et al. A baseline for the multivariate comparison of resting-state networks. Front. Syst. Neurosci. 5, 2 (2011).
Acknowledgements
This work was supported by the European Research Council ERC Synergy grant (Grant agreement 856495, Relevance), by the European Union’s Horizon 2020 research and innovation program (Grant agreement 101017884, GuestXR), and the European Union’s Horizon Europe research and innovation program (Grant agreement 101070278, ReSilence).
Author information
Authors and Affiliations
Contributions
All authors were involved in the conceptualization and the design of the study; B.L., M.P., and G.M. acquired the fMRI data for both experiments; B.L. pre-processed and analyzed the data; B.L. and B.D.G. wrote the initial manuscript, and all authors edited the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Communications Biology thanks Guy Orban, Gianpaolo Basile and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Primary Handling Editor: Benjamin Bessieres. [A peer review file is available].
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Li, B., Marrazzo, G., Poyo Solanas, M. et al. Distinct information flows for different whole-body actions across LOTC subdivisions. Commun Biol 9, 74 (2026). https://doi.org/10.1038/s42003-025-09339-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s42003-025-09339-3
