
Abstract
Bladder cancer (BC) is the most common urologic malignancy, facing enormous diagnostic challenges. Urinary extracellular vesicles (EVs) are promising source for developing diagnostic markers for bladder cancer because of the direct contact between urine and bladder. This study pioneers urinary EV N-glycomics for bladder cancer diagnosis. We have generated a comprehensive N-glycome landscape of urinary EVs through high-throughput N-glycome analysis, identifying a total of 252 N-glycans from 333 individuals. In bladder cancer patients, urinary EVs exhibit decreased fucosylation and increased sialylation level. An Eight N-glycan diagnostic model demonstrates strong performance in both validation cohorts, achieving ROC AUC values of 0.88 and 0.86, respectively. Furthermore, this model successfully differentiates both non-muscle invasive bladder cancer (NMIBC) and muscle-invasive bladder cancer (MIBC) from healthy individuals, underscoring the model’s superiority. Moreover, urinary EVs N-glycoproteomic analysis reveals that the glycoproteins carrying cancer-associated N-glycan signatures are closely associated with immune activities. The N-glycome comparative analysis of EVs and their source cells indicate that the glycosylation profiles of EVs do not completely match the glycosylation backgrounds of their source cells. In summary, our study establishes urinary EV N-glycomics as a non-invasive BC screening tool and provide a framework for EV glycan biomarker discovery across cancers.
Similar content being viewed by others

Introduction
Bladder Cancer (BC) represents the most common malignant tumors within the urinary system1. In 2022, worldwide incidence of BC was reported at approximately 614,000 new cases, with 220,000 deaths2. According to the depth of invasion into the bladder wall, BC can be classified into two principal categories including non-muscle invasive bladder cancer (NMIBC) and muscle-invasive bladder cancer (MIBC). NMIBC represents about 75% of cases and notorious for its high recurrence risk, with 50% to 70% of patients experiencing recurrence within five years and potential progression to MIBC, which necessitates frequent monitoring3. MIBC accounts for the remaining 25%, characterized by a higher metastasis risk and a significantly lower five-year survival rate, often below 10%, requiring regular assessment to update patient conditions4.
Clinically, cystoscopy, urine cytology, and imaging techniques constitute the common modalities for diagnosing BC. Cystoscopy, regarded as the gold standard for diagnosing BC, is an inherently invasive procedure that often results in significant discomfort.5 However, cystoscopy is inevasibly invasive and causes unbearable discomfort. Urine cytology, while non-invasive, shows low sensitivity, especially for low-grade cancers6,7. Imaging techniques like ultrasonography, computed tomography (CT), computed tomography urography (CTU) and others help in determining the extent of lesions but shares the low sensitivity issue8. During the past decades, several urine-derived markers, including nuclear matrix protein 22 (NMP22), bladder tumor antigen tests (BTA stat and BTA trak), immuno-cytometry, fibrinogen degradation products, and urinary fluorescence in situ hybridization (FISH), have been developed to improve the diagnosis of BC9,10. Despite their enhanced sensitivity, these markers still fall short for low-grade cancers and do not eliminate the need for cystoscopy. They also exhibit low specificity, getting affected by conditions like stones, limiting their clinical adoption11. Moreover, benign diseases and other malignant tumors of the urinary system can also confound the diagnosis of BC. Consequently, currently clinical diagnostic methods still fail to fulfill the actual needs for frequent examinations, necessitating the further development of diagnostic markers.
Liquid biopsy, owing to its non-invasive nature and broad applicability in the field of precision medicine, has garnered increasing attention12. Urine, compared with other body fluids such as plasma, serum, and cerebrospinal fluid, has been acknowledged as an ideal source for the development of liquid biopsy techniques, owing to its relatively simple composition and easy accessibility. For the development of diagnostic markers for bladder cancer, urine stands out as the optimal choice, primarily because it not only frequently comes into direct contact with the bladder mucosa and bladder tumors but also offers advantages such as being noninvasive, easily obtainable repeatedly, and circumventing special compliance13. Meanwhile, extracellular vesicles (EVs) are vesicles encapsulated by a double membrane and released by nearly all cell types, found extensively in various body fluids14. EVs represent a valuable source of biomarkers, not only reflecting the physiological and pathological status of their origin cells but also influencing cancer invasion, metastasis, and progression15,16,17. For instance, Braun et al. demonstrated bioprocess changes during renal transplantation and identified the prognostic marker phosphoenol pyruvate carboxykinase (PCK2) through an unbiased proteomic analysis of urinary EVs in renal transplant living donors and recipients18. Xu et al. found extracellular matrix protein 1 (ECM1) protein levels in circulating sEVs are markedly elevated in obesity individuals. And the increased ECM1 in sEVs, facilitated by integrin-β2, enhances the invasive and migratory capabilities of breast cancer cells, promoting cancer progression and metastasis in obese conditions19. Furthermore, urinary EVs, originating from kidney, bladder, and genitourinary tract cells, possess the potential to mirror the health status of the bladder and other urinary organs, thereby serving as an ideal marker source20.
Glycosylation, a crucial post-translational modification, plays a key role in cell surface recognition, signaling, and intercellular interactions21. Aberrant glycosylation patterns have been linked to the onset of various diseases, including BC22,23,24,25,26. Yet, the exploration of disease markers through glycosylation changes in urinary EVs remains overlooked. Thus, by analyzing the N-glycan composition of urinary EVs, we expect to unveil glycosylation pattern changes associated with BC, which not only aids in deciphering the molecular mechanisms of BC but also paves the way for diagnostic tool development.
In this work, we advance the development of BC diagnostic markers through urinary EVs N-glycomics, representing the largest clinical cohort study in BC glycosylation research. By analyzing urinary EVs N-glycomes across 333 individuals, we obtain a comprehensive N-glycome profile. Utilizing this foundation, eight potential glycan markers are identified through differential analysis among four sample groups in the discovery cohort: BC patients, urologic-associated Benign patients (UB), patients with urologic malignancies (UM) and healthy controls (HC). Machine learning techniques are employed to build a diagnostic model, validated in two independent validation cohorts with ROC AUC values of 0.88 and 0.86, respectively, demonstrating its robust diagnostic capability. Our research establishes a groundwork for developing EV-based glycoassays for BC screening in clinical settings and offers insights into novel biomarker development for various cancers.
Results
Patients, sample collection, and study design
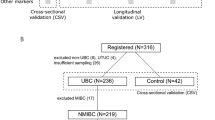
The workflow of this study is shown in Fig. 1. Urine samples from 333 clinical individuals were collected and the clinical characteristics of these participants are presented in Supplementary Data 1. In the discovery cohort, we included a total of 132 individuals for screening of N-glycan candidate markers. The diagnostic model was developed and validated in two independent clinical cohorts (validation cohort 1: n = 83; validation cohort 2: n = 118). First, EVs were isolated from 1 mL urine using the EVTrap beads. This EVTrap beads have a high affinity toward EVs because of the combination of hydrophilic and aromatic lipophilic groups modified on beads27. Compared with the traditional EV isolation methods, it is easier to perform and more time-efficient, making it more suitable for large cohort studies. Immediately thereafter, N-glycans were enriched using a high-throughput sample preparation method developed by our groups on a 96-well plate. In addition, we randomly selected 45 samples from all participants and pooled them to serve as quality control (QC) samples during the whole experimental process. We investigated the experimental stability of our workflow by repeated measurements of the QC samples. Finally, the N-glycome data for each individual were acquired using MALDI-TOF-MS. Throughout the experiment, a total of 252 N-glycans were identified. By analyzing the N-glycome data from 132 individuals across four sample groups during the discovery phase, a comprehensive N-glycome map of urinary EVs was generated. Then, differential analysis was used to explore N-glycome alterations in urinary EVs of bladder cancer patients and to identify the potential glycan markers for diagnostic model construction. The diagnostic model was further evaluated in two validation cohorts, demonstrating its efficacy in distinguishing between bladder cancer patients and healthy individuals.

The urine samples from 333 individuals were collected for EV isolation. Alterations in the urinary EVs N-glycome among urologically related diseases and healthy individuals can unearth potential diagnostic markers for bladder cancer. In the discovery phase, 132 samples were classified into four subgroups: bladder cancer (BC, n = 45), urologic-associated benign patients (UB, n = 31), patients with other urologic malignancies (UM, n = 25) and healthy controls (HC, n = 31). By analyzing the N-glycome data in the discovery cohort, the N-glycome profiles of urinary EVs were constructed. Then, a bladder cancer diagnostic model was constructed using logistic regression algorithms. The diagnostic model was subsequently evaluated and validated in two validation cohorts (Validation cohort 1: n = 83; BC, n = 47; HC, n = 36; Validation cohort 2: n = 118; BC, n = 29; UB, n = 30; UM, n = 29; HC, n = 30;). Blue square: N-acetylglucosamine (GlcNAc); green circle: mannose (Man); yellow circle: galactose (Gal); purple diamond: N-acetylneuraminic acid (Neu5Ac); red triangle: fucose (Fuc). Created with BioRender.com.
Characterization of EVs and quality control
During the discovery phase, four subgroups comprising 45 BC samples, 31 UB samples, 25 UM samples, and 31 HC samples were included. The characteristics of these participants, including identified N-glycans number, sex, age, BMI, hematuria, urinary tract infection status, TNM staging, and histologic grading, are as shown in Fig. 2a. First, we characterized the isolated EVs by nanoparticle tracking analysis (NTA), Western blot (WB), and transmission electron microscopy (TEM). The diameter distribution of EVs isolated from the four clinical sample groups ranged from 40 to 200 nm (Fig. 2b). WB results showed the enrichment of EV markers (CD9, CD81, and TSG101) and the absence of non-EV markers (Calnexin) (Fig. 2c). These results verified the high purity of urinary EVs in four groups. Under TEM, the isolated EVs appeared as disc or teat-like vesicle structures (Fig. 2d–g). These results attest to the high quality of the isolated urinary EVs, suitable for downstream analysis.

a Characteristics of participants in the discovery cohort, encompassing identified N-glycans number, sex, age, BMI, hematuria, urinary tract infection status, TNM staging, and histologic grading. b NTA results revealed that the diameter range of isolated EVs spanned 40–200 nm across all four sample groups. c WB results demonstrated the presence of characteristic EV markers (CD9, CD81, TSG101) with Calnexin as the negative control in urinary EVs. d–g TEM images depicted urinary EVs in the BC, UB, UM, and HC groups, respectively. h Distributions of pair-wise Pearson’s r within QC samples and non-QC samples. The inner boxplots denote the minimum values, 25th percentiles, medians, 75th percentiles, and maximum values, respectively from bottom to top. i Comparative distribution of CVs among QC and biological samples in discovery cohorts. Images shown are representative of three independent experiments. Source data are provided as a Source Data file.
Before the differential analysis of urinary EV N-glycome, the quality of the experimenting procedures was assessed on the QC samples. Quality control analysis showed a strong correlation among QC samples, with all Pearson’s correlation coefficients (r) exceeding 0.80. The median r value of QC samples achieved 0.93 (Fig. 2h), indicating the mass spectrometry instrument’s high stability throughout the workflow. Moreover, the intensity distributions of these QC samples revealed robust stability across the entire experiment (Supplementary Fig. 1a). In the discovery cohort, QC samples revealed a median coefficient of variation (CV) of 17.1% for N-glycans (Supplementary Fig. 1b, Fig. 2i). These results indicate the high stability of our instruments and the reliability of our experimenting procedures. The biological inter-sample CVs were marginally higher, showing a median of 57.6% (Supplementary Fig. 1b, Fig. 2i). These results also indicate the stability of the procedure and suggest that technical variability was much lower than biological variability, thus proving the variance induced by experiments was trivial for meaningful biological patterns to emerge.
A comprehensive landscape of the N-Glycome profiles in urinary EVs
A total of 252 N-glycans were identified in urinary EVs across four sample groups (n = 132). The average number of N-glycans identified were 114 in the BC group, 133 in the UB group, 140 in the UM group, and 143 in the HC group (Fig. 3a). Significantly more N-glycans were identified in HC group than in the BC group (p = 5.15 × 10−8). Similarly, the average number of N-glycan identifications for BC was significantly lower compared to the other two groups (p = 7.60 × 10−4, 9.55 × 10−6 for UB and UM group, respectively). Moreover, no significant difference was observed in the average number of N-glycans identified between the HC group and the UB and UM groups (p = 0.29, 0.50 for UB and UM group, respectively). In total, 219, 226, 219, and 226 N-glycans were respectively identified in the BC, UB, UM, and HC groups. Of all identified, 194 N-glycans (77.0%) were present in all four groups, and over 90% N-glycans were found in two or more subgroups (Fig. 3b). A comprehensive landscape of the N-Glycome profiles in urinary EVs was generated.

a The boxplot illustrates N-glycan identifications in BC (n = 45), UB (n = 31), UM (n = 25), and HC (n = 31) samples. P-values from two-sided Wilcoxon rank-sum test (Benjamini-Hochberg adjusted) are annotated. b The venn diagrams illustrates the overlap of N-glycan identification among the four groups. 194 N-glycans were identified in all 4 groups. c The sankey diagram demonstrates the number of different types of N-glycans identified in urinary EVs N-glycome. Distinct N-glycan characteristics include N-glycan branching numbers, the presence or absence of fucose, sialic acid, and the N-glycosylation types. The thickness of the lines represents the number of N-glycans in each category. d The heatmap demonstrates the differential expression of various types of glycans across the four groups. Source data are provided as a Source Data file.
The characterization of the N-glycome of urinary EVs was further analyzed, focusing on the diversity of identified N-glycan types. Of the 252 identified N-glycans, 70.2% exhibited high branching structures (HexNAc >4). Of those with high branching structures, 59.3% contained sialic acids, while only 37.3% of the low branching N-glycans were sialylated. Additionally, 133 glycans were sialylated, slightly surpassing those asialylated. More than 70.0% of the N-glycans exhibited fucosylation. Furthermore, regarding N-glycan glycosylation types, 97.6% were of the hybrid or complex types, with a minor fraction being high-mannose type (Fig. 3c).
Next, we performed further comparative analysis for urinary EV N-glycome. For a more robust statistical implication, we removed N-glycans with a missing value rate above 50% across samples. After that, a total of 130 N-glycans was retained for subsequent quantitative analysis (Supplementary Fig. 2). Detailed information, including the N-glycans composition, mass-to-charge ratios, is shown in Supplementary Data 2. The N-glycome characteristics of the four groups (BC, UB, UM, and HC) were further analyzed separately. We aggregated N-glycans with similar structures and categorized them into 26 categories to explore more global changes in urinary EV N-glycome (Categorical features are defined in Supplementary Table 1). It is worth noting that only five categories (low-branching and asialylated N-glycans, low-branching and fucosylated N-glycans, high-branching and afucosylated N-glycans, mono-sialylated and tri-sialylated N-glycans) showed no significant differences across the four groups, whereas the remaining 21 categories exhibited significant variations (Supplementary Fig. 3). Regarding N-glycosylation types, high-mannose type N-glycans distributed similarly across the four groups, with percentages of 5.7%, 6.7%, 7.1%, and 6.9%, respectively. Complex or hybrid N-glycans dominated the majority in urinary EVs, representing more than 90% of the N-glycome in all four groups (Fig. 3d, Supplementary Fig. 4a). For branching composition in the HC group, high-branching and low-branching structural N-glycans were nearly equal in proportion, each accounting for about 50%. In BC group, the branching composition distribution significantly differs from that in the HC group. High-branching glycan structures account for only 32.0%, whereas low-branching structures constitute 68.0%. Low-branching N-glycan levels in BC groups were significantly higher than those in the other three groups (p = 2.72 × 10−5, 1.24 × 10−8, 2.86 × 10−13 for UB, UM and HC group, respectively). Similarly, levels of low-branching and afucosylated and low-branching and sialylated N-glycans were elevated in the BC group compared to the other three groups (Fig. 3d). This change may be linked to the inhibition of some glycosyltransferases, which are responsible for the formation of β-1,4 or β-1,6 branching. Similarly, the UB group exhibited characteristics similar to the BC group, with increased low-branching and decreased high-branching structural N-glycans, though the differences were less pronounced (Fig. 3d, Supplementary Fig. 4b). In terms of fucose expression, the content of afucosylated and mono-fucosylated N-glycans was similar in HC group, which was around 40%, while the content of multi-fucosylated N-glycans was 16.6%. Conversely, in the BC group, afucosylated N-glycans increased to 60.2%, indicating a reduced fucose content in bladder cancer patients. The UB and UM groups also demonstrated similar characteristics to BC group, with down-regulated fucosylation, albeit to a lesser extent (Fig. 3d, Supplementary Fig. 4c). Finally, the analysis of sialylation in N-glycans of urinary EVs was conducted. In the HC group, sialylated N-glycans accounted for 63.4%. Bi-sialylated N-glycans represented the largest portion of sialylated N-glycans, at 31.6% of the total content. Conversely, in the BC group, sialylated N-glycans increased to 73.2%. This indicates an elevation in sialylation level in bladder cancer patients compared to healthy individuals. Notably, among the sialylated N-glycans, only bi-sialylated N-glycans showed a significant increase, comprising nearly 40% of the total N-glycan content. Mono-sialylated and tri-sialylated N-glycans did not show significant changes in any of the four groups, with negligible inter-group variations. Moreover, the content of tetra-sialylated N-glycans was somewhat reduced compared to healthy individuals (Fig. 3d, Supplementary Fig. 4d). This phenomenon may align with the decrease in the proportion of high branching N-glycans in the BC group. Abnormal expression of sialic acids has been linked to the development and metastasis of various cancers28. Altered sialylation on cancer cell surfaces may facilitate evasion from immune surveillance29. Therefore, elevated sialic acid levels in the urinary EVs of bladder cancer patients could be associated with the disease’s development and progression, necessitating further investigation.
Screening of candidate N-glycan diagnosis biomarkers for bladder cancer
To further investigate the N-glycan alteration in patients with urological diseases compared to the healthy population, we conducted an ANOVA analysis to analyze the differences in N-glycans across the four sample groups. Initially, potential confounders including age, sex, and BMI were proved to have minimal impact on N-glycan profile variations (p > 0.05, Supplementary Fig. 5). Of the 130 N-glycans, 83 demonstrated significant inter-group differences (p < 0.05). The most pronounced differences were noted between the BC and HC groups. Within this subset, 71 N-glycans were significantly altered, comprising 39 up regulated and 32 down regulated N-glycans (Fig. 4a). Beyond these groups, expression differences were found in 49 N-glycans between the BC and UM groups, including 28 up regulated and 21 down regulated N-glycans. The differences between BC and UB groups were relatively minor, with only 22 N-glycans showing significant differences in abundance. Furthermore, the comparative analysis identified 33 significant N-glycans between UB and HC, 11 N-glycans between UM and HC, and 3 N-glycans between UB and UM. (Fig. 4a). This aligns with the current clinical understanding that benign urological conditions can confound the diagnosis of other malignant tumors.

a The Nightingale rose diagram illustrates the quantity of differential N-glycans among BC, UB, UM, and HC groups. b The heatmap depicts the intensity distribution of 21 differential N-glycans across urology-related diseases and healthy individuals. c The volcano plot represents differentially expressed N-glycans in three pairwise comparisons, including BC versus HC, BC versus UB, and BC versus UM (log2(FC) > 1, p < 0.05). P-values were calculated from Tucky’s HSD post-hoc test (two-sided), adjusted by the Benjamini-Hochberg method. d The strategy for screening candidate N-glycans biomarkers. e Intensity distribution of candidate N-glycan biomarkers in the N-glycome of urinary EVs. f Performance benchmark of 10 machine learning classifiers based on three evaluation metrics: accuracy, F1 score and ROC AUC.Source data are provided as a Source Data file.
To delineate the characteristic N-glycan profile of bladder cancer, we integrated the differentially expressed N-glycans identified between BC and the other three non-BC groups (p < 0.05). 21 N-glycans were screened out based on this strategy (Fig. 4b). Subsequently, to ensure the reliability and robustness of biomarkers, 10 N-glycans were selected from the 21 characteristic N-glycans identified between BC and non-BC groups, applying the selection criterion of p < 0.05 and log2FC > 1 (Fig. 4c). Two N-glycans were then excluded due to a detection rate less than 95% (Supplementary Fig. 6). Ultimately, eight N-glycans—H6N5S3, H5N5F1S2, H5N5S1, H4N3S1, H5N4S2, H4N4F1, H5N3S1, and H5N4F1—were selected as candidate diagnostic markers (Fig. 4d, Supplementary Fig. 7). These 8 N-glycans exhibited high intensities among all N-glycans, ranking in the top 50% (Fig. 4e). Tandem mass spectrometry analysis was conducted manually to ascertain the structure of these 8 glycans (Supplementary Figs. 8–15). More importantly, all 8 candidate N-glycan markers are complex or hybrid types. And 75% of these eight glycans contain sialic acids, underscoring the significance of sialylation capping in the pathology of bladder cancer.
Development and assessment of the bladder cancer diagnostic model
Machine learning techniques were leveraged to build the diagnostic model based on the 8 candidate biomarkers above. We compared the classification capabilities of nine different machine learning algorithms on the discovery cohort’s N-glycome using 10-fold cross-validation against a baseline model (random guessing based on a priori probability). During this evaluation, models such as logistic regression, random forests, support vector machines (SVM), and K-nearest neighbor algorithms (KNN) were assessed across three metrics: accuracy, F1 score, and ROC AUC value. The results indicate that the performance of these models was similar (Fig. 4f), demonstrating that the selected candidate N-glycan markers inherently possess strong discriminative power, enabling linear models such as logistic regression to achieve decent classification performance. Due to the logistic regression model’s simplicity and interpretability, it was ultimately selected for constructing the final diagnostic model.
Then, we evaluate the performance of the diagnostic model by analyzing the N-glycans in the validation cohort 1, which comprised 36 healthy individuals and 47 BC patients (Fig. 5a). Quality control metrics, including inter-sample correlation and CV values distribution, confirmed the high stability of mass spectrometry instrumentation, robust EV isolation, and reliable quantitative analysis of the N-glycome (Supplementary Fig. 16). Subsequently, the classification performance of this diagnostic model was evaluated. The model demonstrated a ROC AUC of 0.88, with accuracy of 79.5%, sensitivity of 85.1%, and specificity of 72.2% (Supplementary Fig. 17, Fig. 5c), indicating its effective discrimination between bladder cancer and healthy individuals. Furthermore, according to the depth of invasion into the bladder wall, BC can be classified into two principal subtypes including NMIBC and MIBC. We subsequently assessed whether this diagnostic model could distinguish healthy individuals from these two BC subtypes. The results demonstrate that both NMIBC and MIBC patients can be distinctly differentiated from healthy individuals, with AUC values of 0.83 and 0.89, respectively (Supplementary Fig. 18). We then named the probability scores given by the logistic regression model EV Glycan Scores (EVGScores). With an EVGScore greater than 0.5, the individual is considered likely to have bladder cancer. In the validation cohort 1, the EVGScore for each sample further confirmed the model’s robust discriminatory ability for BC patients (Fig. 5d). In addition, we evaluated the feature importance of the eight N-glycan candidate biomarkers (Supplementary Fig. 19), discovering that their importance was not directly related to the abundance of the N-glycans themselves. Notably, those with higher importance rankings did not necessarily have top abundance rankings.

a Characteristics of participants in the validation cohort 1, encompassing identified N-glycans number, sex, age, BMI, hematuria, urinary tract infection status, TNM staging, and histologic grading. b Characteristics of participants in the validation cohort 2, encompassing identified N-glycans number, sex, age, BMI, hematuria, urinary tract infection status, TNM staging, and histologic grading. c The receiver operating characteristic (ROC) curve evaluates the model’s capacity to distinguish between bladder cancer patients and healthy individuals. d EVGScores for each sample in BC (n = 47) and HC (n = 36) groups within the validation cohort 1, showcasing the model’s discriminatory capacity. P-value was derived from Wilcoxon rank-sum test (two-sided). The boxplots denote the minimum values, 25th percentiles, medians, 75th percentiles, and maximum values, respectively from bottom to top. e Same as (d) but for validation cohort 2 (BC: n = 29, HC: n = 30). Source data are provided as a Source Data file.
We further assessed the N-glycans diagnostic model on the validation cohort 2. Compared with validation cohort 1, validation cohort 2 further includes the UB and UM groups to evaluate the model’s diagnostic capability. The cohort 2 includes 118 individuals from 29 BC patients, 30 UB patients, 29 UM patients, and 30 HC individuals (Fig. 5b). Despite the cohort change, the model maintained its diagnostic capability with an AUC value of 0.86, with accuracy of 83.1%, sensitivity of 75.9%, and specificity of 90.0% (Fig. 5c). The EVGScore values for each participant in the validation cohort 2 further demonstrated the diagnostic model’s excellent capacity to distinguish between BC patients and healthy controls (Fig. 5e). The diagnostic performance of this model in distinguishing BC from UB and UM is moderate, with AUC values of 0.72 and 0.69, respectively (Supplementary Fig. 20).
A comprehensive characterization of EV glycoproteins carrying cancer-associated N-glycan signatures
To further understand the functions and potential roles of urinary EVs, we conducted N-glycoproteomic analyses of urinary EVs from the BC, UB, UM, and HC groups to explore the nature of glycoproteins carrying cancer-associated N-glycan signatures in EVs. In total, we identified 7787 glycoforms, which constitutes of 1286 glycopeptides, 1336 glycosylation sites, and 285 glycan compositions. Among the glycopeptides, 1236 had one glycosylation site, and only 50 had two glycosylation sites. Of the identified glycoforms, 3553 were consistently quantified across all samples. We further explore EV glycoproteins carrying cancer-associated N-glycan signatures (EVcans). We named the glycosylation sites with the EVcans as “EVcans sites”, and the proteins with the EVcans as “EVcans proteins”. There were 549 EVcans sites and 206 EVcans proteins. Most EVcans sites had only one glycan, while only less than 10% had more than three glycans. Similarly, nearly a half of the EVcans proteins had only one N-glycan, with only 15% having more than three N-glycans (Fig. 6a). We then checked the co-occurrence of glycan compositions on the same protein or the same glycosylation site. Interestingly, H5N4S2 were more likely to co-occur with H6N5S3 and H4N3S1 both on the protein and the site level (Fig. 6b). All three glycans were sialylated, afucosylated glycans. When performing motif analysis, no obvious difference was observed between the EVcans and global glyco-sites.

a Pie charts show distribution of EVcans sites and EVcans proteins. b The co-occurrence probability of EVcans on the same protein or the same glycosylation site. c The heatmap demonstrates the differential expression of various glycoforms across the four groups. d Most dysregulated EVcans glycoforms were up-regulated in BC groups. e Hematoxylin and eosin (H&E) staining of the formalin-fixed, paraffin-embedded (FFPE) section used for MALDI-MSI. Scale bar: 2.5 mm. f Spatial clustering of N-glycans in formalin-fixed, paraffin-embedded (FFPE) sections based on MALDI-MSI outcomes. g The intensity distribution of differentially expressed N-glycans in tissues and EVs (Benjamini-Hochberg-adjusted ANOVA p < 0.05, log2 | FC | > 1). H&E staining data shown are from a single experimental replicate. Source data are provided as a Source Data file.
For a more robust statistical implication, we kept glycoforms with no missing values across all samples. This procedure resulted in 485 glycoforms with EVcans. Nearly half of the glycoforms were obviously more abundant in BC samples than in other samples (Fig. 6c). Then, we performed PCA on the quantification data (Supplementary Fig. 21). Four distinct clusters were observed, corresponding to the four sample types. HC, UB, and UM samples showed a clear separation from BC samples on the first principal component (PC1), while separated with each other on the second component (PC2). As PC1 contains most variance in PCA, this implies a unique glycosylation pattern in BC samples.
Next, we performed further comparative analysis for urinary EV N-glycoproteome. There are 273, 273, and 270 significantly dysregulated glycoforms (p < 0.05, log2 | FC | > 1) between BC and HC, BC and UM, and BC and UB samples, respectively. Furthermore, the expression of these EVcans on glycoproteins was investigated. The findings indicated consistency with performances observed in the clinical cohort. The majority of dysregulated EVcans on glycoproteins were upregulated in BC groups (Fig. 6d). As these 8 biomarker N-glycans were up-regulated according to the N-glycome analysis, we focused on the up-regulated glycoforms for further analysis. Of all 260 up-regulated glycoforms, 158 glycoforms were consistently up-regulated in all three comparisons, covering 63 proteins. KEGG and GO enrichment analysis were performed for the proteins with consistently up-regulated glycoforms (Supplementary Fig. 22). GO results indicate that these proteins are involved in immune activity, complement activation, and wound healing pathways, particularly in their negative regulation. This association may stem from the abnormal vascular structure of tumors and their propensity for rupture. KEGG analysis indicates that these proteins are significantly involved in the complement and coagulation cascades. This pathway plays a crucial role in maintaining immune health. These EVcans proteins may activate the complement system, potentially inhibiting the cytotoxic effects of immune cells, and may also promote tumor cell invasion and metastasis through activation of the coagulation cascade. Overall, these EVcans proteins are intimately linked to internal immune functions and play a pivotal role in the development and progression of bladder cancer. This also underscores the significance of the cancer-associated N-glycan features identified through our analysis.
Pairwise comparative analysis of urinary EVs and tissue N-glycome
To further compare the glycosylation profiles in bladder cancer patients, we collected tumors, paired normal adjacent tissues (NATs), and urinary EVs from three BC patients for N-glycome analysis. A total of 153 N-glycans were identified in both tumors and NATs. On average, 107 N-glycans were identified in each tumor sample, and 88 N-glycans were identified in each NAT sample (Supplementary Fig. 23a). Considering only the N-glycans consistently identified across all three technical replicates of a sample, 114 N-glycans were consistently identified. Of these, 105 N-glycans were consistently identified in the tumor sample and 68 glycans were identified in the NAT sample (Supplementary Fig. 23b). A total of 59 N-glycans were identified in both the tumor and NAT samples.
We presented the expression of relatively high intensity N-glycans in three pairs of tumors and NATs using bar charts. This analysis demonstrated consistent expression trends of these N-glycans across different samples (Supplementary Fig. 24). Next, we utilized N-glycans identified in all three technical replicates for further differential analysis. Among these, 21 N-glycans showed significant difference (p < 0.05). High-mannose glycans were significantly enriched in tumor samples (Supplementary Fig. 25). We performed spatial profiling of N-glycans from formalin-fixed, paraffin-embedded (FFPE) sections of bladder cancer tissues using matrix-assisted laser desorption/ionization-mass spectrometry imaging (MALDI-MSI). N-glycans exhibited varied spatial distributions corresponding to tissue alterations. Notably, high mannose-type N-glycans, specifically H6N2, H7N2, and H8N2, were significantly upregulated in the cancerous regions (Supplementary Fig. 26). Additionally, we conducted detailed histological analysis using hematoxylin and eosin (H&E) staining, annotated by expert clinical surgical pathologists (Fig. 6e). The spatial clustering of N-glycans closely matched the H&E staining results across various histological features including tumor tissues, normal uroepithelial cells, mesenchyme, collagen fibers, muscle, blood vessels, and lymphatic vessels (Fig. 6f). This indicates that N-glycan characteristics are intricately associated with different tissue types, and that various N-glycans perform distinct functions within the organism.
Next, we conducted a paired analysis comparing the N-glycan profiles of tissue and urinary EVs. A total of 29 N-glycans were identified in both tissue and EV samples. Among them, 7 N-glycans showed significant differences between EVs and tumors, and 10 N-glycans differed between EVs and NATs (p < 0.05, log2 | FC | > 1) (Fig. 6g). We observed a significant increase in sialylation levels in EVs compared to cancer tissues. This increase may be attributed to the more active transport mechanisms within cancer tissues.
Analysis of N-glycome differences between bladder cancer cell lines and their derived EVs
To investigate the glycosylation characteristics of EVs and their source cells, we cultured five distinct bladder cell lines and isolated EVs using ultracentrifugation for N-glycomics analysis. The five cell lines include the immortalized normal urothelial cell line SVHUC, the non-muscle invasive cell lines RT112 and SW780, and the muscle invasive cell lines T24 and J82. In these five cell lines, the average numbers of identified N-glycans were 61, 69, 124, 87, and 108 (SVHUC, SW780, RT112, T24 and J82, respectively). Correspondingly, the numbers of N-glycans identified in the derived EVs were 95 for SVHUC, 62 for SW780, 97 for RT112, 57 for T24, and 76 for J82 (Fig. 7a). A total of 47 N-glycans were commonly identified across all cell lines, while 56 common N-glycans were detected in all derived EVs (Fig. 7b). Compared with four bladder cancer cell lines, the SVHUC cell line exhibited the most distinct characteristics, with the highest number of N-glycans identified exclusively in the EVs. Additionally, the proportion of N-glycans identified in both EVs and cell lines was consistent across all cell lines, averaging approximately 50% (Supplementary Fig. 27). This suggests a notable degree of similarity in the N-glycome profiles between EVs and their source cells.

a The average numbers of identified N-glycans in the five cell lines and their derived EVs. Error bars denote standard errors (SDs) among three biological replicates. b The Venn diagrams illustrate the overlap of N-glycan identification in the five cell lines and their derived EVs. c The abundance distribution of top ten N-glycans identified in five cell lines and their EVs. d The abundance characteristics of N-glycome in five cell lines and their EVs. e The heatmap demonstrates the differential expression of 27 N-glycans in the five cell-derived EVs. Source data are provided as a Source Data file.
Subsequently, we conducted a joint analysis of the N-glycome features of EVs and their source cells. We compared the top ten N-glycans by content in both the EVs and their source cells. It is observed that the discrepancies between cell lines and EV samples are significantly larger than those among cell lines. Specifically, EV samples predominantly contained large, multi-sialylated, and afucosylated species, whereas cell lines predominantly featured high-mannose, hybrid, or small complex species. This trend was consistent across all cell lines (Fig. 7c).
We then aggregated N-glycans with similar structures and categorized them into 4 categories (including high-mannose, high-branching, sialylated, and fucosylated) to explore more global change. Regarding N-glycosylation types, high-mannose type N-glycans accounted for over 50% in all five cell lines, whereas less than 10% in derived EVs. This indicated an increase in the proportion of complex or hybrid N-glycans in EVs. Besides, high-branching glycans accounted for approximately 60% in EVs across all five cell lines. In terms of fucosylation, the degree was relatively consistent among the five cell lines, being approximately 30%. The analysis of sialylation levels revealed that the proportion of sialylated N-glycans was below 30% for cell lines. The proportion of sialylated N-glycans in EVs approached 80%, indicating significantly higher sialylation levels (Fig. 7d). Across all cell lines, sialylated glycans were significantly more prevalent in EV samples, while high-mannose glycans were significantly lower. Overall, while there is some overlap in the N-glycans identified from EVs and their source cells, significant differences exist in the specific features of their N-glycome profiles. The observed discrepancies in N-glycosylation patterns between EVs and source cells could arise from multiple factors. These include, but are not limited to: (i) selective incorporation of glycans during EV biogenesis30; or (ii) technical biases introduced by differential glycoprotein solubility during ultracentrifugation.
Finally, we performed differential analysis on the N-glycome of EVs. Within the 36 glycans stably identified in EV samples, 27 glycans were significantly different (Fig. 7e). The fucose content in bladder cancer cell EVs is notably lower than in SVHUC. This correlation aligned with the trends observed in our clinical cohort study regarding fucosylation N-glycan levels in urinary EVs from BC patients.
To further investigate the underlying factors contributing to changes in the glycan characterization of EVs, we isolated cellular subfractions for subsequent N-glycomics experiments of the five bladder cell lines (Supplementary Fig. 28). It is evident that, for all five cell lines, the number of N-glycans identified in the cytoplasm was significantly lower than those identified in the plasma membrane (PM), with nearly all cytoplasmic N-glycans being identified in the PM (Supplementary Fig. 29a). Additionally, nearly 50% of the N-glycans identified in the cellular PM were also identified in the corresponding cell-derived EVs, indicating a degree of correlation between these two. We further performed a difference analysis of N-glycome to assess the changes in N-glycosylation modifications of bladder cancer cells. Interestingly, although nearly half of the N-glycans were identified in both the PM and EVs, they did not exhibit a consistent trend of change (Supplementary Fig. 29b). The correlation between the multiplicity of changes in these N-glycans in the PM and EVs was consistently less than 0.3, indicating a weak correlation between them. The weak correlation between PM and EV glycan changes suggests that EV glycosylation profiles are not merely passive reflections of parental cell membrane composition. While selective glycan sorting during EV formation30 could contribute to this phenomenon, methodological limitations (e.g., incomplete PM glycoprotein extraction or EV subtype heterogeneity) must also be considered.
Discussion
Bladder cancer ranks among the top ten tumors globally, significantly impacting individuals’ health and daily lives31. Clinically used diagnostic tools, often highly invasive or prone to high false positive rates, fail to meet the frequent testing needs of bladder cancer patients. Therefore, there is an urgent need for non-invasive diagnostic markers. Tumor-derived EVs have increasingly received attention due to high stability, rich molecular cargos and critical roles in various cellular functions. However, current EV-based liquid biopsy studies are predominantly focused on proteins and RNAs, while the research on glycosylation is still rare. As an important post-translational modification, glycosylation affects tumor growth, invasion and metastasis, and is closely related to the disease progression21. Meanwhile, urinary EVs, originating from kidney, bladder, and genitourinary tract cells, could directly mirror the health status of the bladder and other urinary system organs. Therefore, urinary EV glycans can be considered as a new hallmark of bladder cancer, showing great potential for non-invasive cancer detection, monitoring and prognosis. In this work, we explored the glycosylation changes of urinary EVs to develop diagnostic markers.
This study explores the development of a bladder cancer diagnostic biomarker from the EV N-glycomics perspective. Over 300 clinical samples were enrolled in the study, comprising the largest clinical cohort for such studies in urinary EVs to date. Throughout the workflow, we used a self-developed high-throughput glycomics sample pretreatment method based on 96-well plates. N-glycans enrichment and derivatization can be completed within 12 h. Moreover, we only need 1 mL urine to complete the comprehensive N-glycomics analysis of urinary EVs, significantly reducing sample demand. Furthermore, we employed MALDI-TOF-MS instead of LC-MS/MS for N-glycan analysis, significantly reducing the detection time and facilitating high-volume processing, thus enhancing its suitability for clinical diagnosis.
We reported the most comprehensive N-glycome profile of human urinary EVs to date. In the BC group, the average number of N-glycan identifications per sample is relatively low. This suggests complex physiopathologic changes in cancer patients, leading to significant alterations in the N-glycome of urinary EVs. Characterization of N-glycome across the four groups revealed decreased levels of high-branching and fucosylated N-glycans, alongside increased sialic acid levels in bladder cancer patients. N-glycosylation is a complex, multistep process, and the whole process requires the involvement of about 200 glycosyltransferases32. We analyzed the mRNA expression levels of bladder carcinomas and adjacent normal tissues from the Cancer Genome Atlas Urothelial Bladder Carcinoma (TCGA-BLCA) database. Of these, nine glyco-genes showed significant differences between tumors and NATs ( | log2 FC | > 1, p < 0.05), which involves the N-glycans synthesis (Supplementary Fig. 30). These glyco-genes are associated with diverse glycans including mannose, N-acetylgalactosamine, N-acetylglucosamine and sialic acid. Among the 9 glyco-genes, both MGAT4B and MGAT5B experienced significant down-regulation, consistent with the observed decrease in high branching N-glycan levels. The glycosyltransferase Alpha-1,3-Mannosyl-Glycoprotein 4-Beta-N-Acetylglucosaminyltransferase B (MGAT4B), product of the MGAT4B gene can specifically add GlcNAc to mannose residues, forming a β-1,4 bond crucial for glycan chain extension and complexation. Likely, Alpha-1,6-Mannosylglycoprotein 6-Beta-N-Acetylglucosaminyltransferase B (MGAT5B, product of the MGAT5B gene) facilitates the addition of GlcNAc to mannose residues in the glycan chain, forming β-1,6 bonds, thereby promoting the formation of multi-antennary complex N-glycans. The decrease in high branching N-glycans content affects cell-cell or cell-matrix adhesion, subsequently influencing tumor cell invasiveness21. Subsequently, the changes in the content of poly-antennal glycans in NMIBC and MIBC can be monitored to further explore their relationship with bladder cancer progression. Additionally, B4GALNT2 (beta 1,4-N-acetylgalactosaminyltransferae 2) is involved in the synthesis of the carbohydrate antigen Sd(a), and also significantly down regulated in bladder cancer. More importantly, the biosynthesis of antigens sialyl Lewis and Sd(a) are mutually exclusive, most likely due to steric hindrance. Abnormal up-regulated expression of Lewis antigens is often highly correlated with tumor metastasis33. Furthermore, the aberrant expression of the B4GALNT2 gene is closely associated with various cancers, including colorectal, lung, gastric, and breast cancers34. We also observe a significant rise in sialic acid content in the urinary EV N-glycome of bladder cancer. Research also shows an increase in sialic acid content in plasma EVs from bladder cancer, highlighting a key role of sialic acid in EV uptake35. Furthermore, we observed a decrease in fucosylation levels in the urinary EV N-glycome of bladder cancer. Fucose, a six-carbon sugar, is primarily regulated by fucosyltransferases in organisms36. It plays a pivotal role in intercellular communication, immune system regulation, and the development of various diseases37. The down-regulation of fucose levels could impact intercellular communication and signaling, potentially altering cellular interactions within the tumor microenvironment and contributing to tumor progression or immune evasion38. Fucosylation also plays a critical role in the recognition and response mechanisms of the immune system37. Alterations in the fucosylation patterns on EVs may affect how immune cells recognize and respond to these vesicles, potentially enabling tumor cells to evade immune detection. The above observations not only deepen our understanding of the dynamic changes in bladder cancer but also aid in the development of potential diagnostic markers based on investigating the glycosylation changes during cancer development.
After analyzing the variations in N-glycan profiles among four groups, a total of 21 N-glycans differed between bladder cancer patients and the other three groups were discovered. Finally, eight N-glycans were identified as candidate diagnostic markers based on the selection criteria. In the validation phase, a logistic regression-based machine learning model was constructed, enabling the direct calculation of the predictive probability-EVGScore, effectively distinguishing bladder cancer patients from healthy individuals. The model demonstrated strong performance in both validation cohorts, achieving ROC AUC values of 0.88 and 0.86, respectively. Furthermore, this diagnostic model successfully differentiated both NMIBC and MIBC from healthy individuals, underscoring the model’s superiority. Currently, the model’s limitation lies in its performance in differentiating BC patients from UB and UM patients is less satisfactory. It may be possible to enhance its predictive capability by integrating clinical features or other existing diagnostic methods.
Beyond diagnostic modeling, we further investigated the characteristic composition of EVs and the glycoproteins carrying cancer-associated N-glycan signatures. Compared to the other three groups, these glycoproteins were significantly upregulated in bladder cancer. Additionally, PCA plot revealed that these four groups exhibit distinct glycoproteomic profiles, suggesting that dynamic changes in bladder cancer in vivo could be further explored from a glycoproteomic perspective to deepen our understanding of this disease. GO and KEGG analyses demonstrated that these glycoproteins are intimately associated with immune activities within the organism, offering insights into disease mechanisms and potentially identifying novel therapeutic targets. These findings not only deepen our understanding of the molecular mechanisms of bladder cancer but also highlight the potential applications of glycoproteomics in cancer research.
We also investigated the N-glycome changes in tumors and paired NATs of bladder cancer patients. Significant differences were observed between the N-glycome of cancerous and adjacent non-cancerous tissues. Increase in high mannose-type N-glycans was detected in tumor tissues compared to adjacent non-cancerous regions. Furthermore, we conducted in situ analysis of N-glycans in bladder cancer FFPE tissue sections using MALDI-MSI for visualization of the spatial distribution of the glycans in tissue sections. The results demonstrate that N-glycans exhibited varied spatial distributions corresponding to tissue alterations. Moreover, the N-glycans spatial clustering analysis results align closely with the spatial distribution of different tissue types, as confirmed by annotated H&E staining. This not only underscores the potential of identifying diagnostic markers for bladder cancer through N-glycan profiling but also enhances our understanding of the underlying mechanisms of disease progression.
We also examined the glycosylation profiles of various bladder cell lines and their derived EVs. Collectively, our data demonstrate that EV N-glycome exhibit both shared and unique features compared to their source cells. Whether these differences reflect biologically meaningful sorting mechanisms during EV biogenesis requires systematic validation. Nevertheless, the identification of EV-enriched glycoforms (e.g., multi-sialylated species) highlights their potential as invasive biomarkers, independent of bulk cellular glycosylation states.
In conclusion, we have successfully developed a diagnostic model for bladder cancer based on the N-glycome analysis of EVs isolated from 1 mL urine. This study establishes a foundation for developing EV-based glycan assays for clinical BC screening and offers insights into glycosylation studies for other cancers.
Methods
The human urine and tissue samples used in this study were obtained from Shanghai Changhai Hospital, affiliated with the Naval Medical University. This procedure was approved by the Shanghai Changhai Hospital Ethics Committee under ethical approval number CHEC2023-069.
Materials
Dimethyl sulfoxide (DMSO) was purchased from Sinopharm Chemical Reagent Co., Ltd. (Shanghai, China). Trifluoroacetic acid (TFA), triethylammonium bicarbonate (TEAB), formic acid (FA), protease inhibitors (Complete tablets) were purchased from Roche (Basel, Switzerland). Acetonitrile was obtained from Merck (Darmstadt, Germany). Trypsin was purchased from Beijing Shengxia Proteins Scientific Ltd. (Beijing, China). Bicinchoninic acid (BCA) protein assay kit was obtained from Pierce (Thermo, U.S.A.). Peptide N-glycosidase F (PNGase F) was purchased from New England Biolabs (MA, U.S.A.). Distilled water was purified by a Milli-Q system (MA, U.S.A.). Sterilized cotton was purchased from Shanghai Honglong Medical Equipment Co., Ltd. (Shanghai, China). The other chemical reagents unless specified otherwise noted were from Sigma-Aldrich (St. Louis, U.S.A.).
Participants
All participants provided written informed consent. A total of 333 participants were recruited from December 2022 to August 2024 for this study. All urine samples were provided by the Department of Urology, Shanghai Changhai Hospital, Naval Medical University, Shanghai, China. All patients were diagnosed by at least two experienced physicians specializing in clinical urology and excluded from patients with co-occurring other tumors of the urinary system. For discovery cohort, a total of 132 individuals were divided into 4 groups, including bladder cancer patients (n = 45), urologic-associated Benign patients (n = 31), patients with other urologic malignancies (n = 25) and healthy controls (n = 31). The validation cohort 1 was set up with 2 groups totaling 83 individuals, including bladder cancer patients (n = 45), healthy controls (n = 36). This validation cohort 2 includes 118 individuals from 29 BC patients, 30 UB patients, 29 UM patients, and 30 HC individuals. Specific clinical information is presented in Supplementary Data 1, including age, sex, body mass index (BMI), pathological stage, pathological grade, urine cytology results (whether hematuria), and urinary tract infection (UTI) results. Among them, the UB group encompasses a variety of disease types, including cystitis, ureteral stones, prostatitis, and urethral stricture. The UM group primarily consists of various cancer types, such as prostate cancer, renal clear cell carcinoma, and papillary renal cell carcinoma. And the inclusion criteria for healthy individuals were (1) no benign or malignant tumors, (2) no vital organ dysfunction after passing the physical examination, and (3) no renal and urinary system-related diseases.
In addition, to verify the stability and feasibility of the whole experimental process, 45 individuals were randomly selected from all participants. One mL urine from each sample was mixed together to serve as quality control (QC) samples in subsequent experimental process.
Urine collection
All participants collected the mid-portion of their first morning urine, ranging from 10 to 40 mL. The collected urine samples were centrifuged three times at 2500 × g for 10 min each to remove cells and cellular debris. The supernatant was then stored at −80 °C until used for subsequent EV extraction.
Tissue procurement
The human tissue samples were procured from patients diagnosed with bladder cancer who underwent radical cystectomy. Following excision, the bladder was opened along the anterior wall, and tumor tissue was carefully dissected from the core of the tumor, ensuring the exclusion of necrotic areas. Approximately 300 mg of tumor tissue was collected. In addition, a comparable weight (300 mg) of normal urothelial tissue was harvested from a region approximately 3 cm away from the tumor. The specimens were subsequently divided into two portions: one was cryopreserved in liquid nitrogen, while the other was fixed in formalin and embedded in paraffin. Tissue sections were prepared and subjected to hematoxylin and eosin (H&E) staining. Pathological evaluation was conducted by at least two qualified pathologists to confirm the identity of the tissue as either malignant tumor tissue or normal urothelial tissue.
We homogenized approximately 50 mg pieces of frozen tissues in 0.5 ml of 4% SDS, 0.1 M Tris/HCl, pH 8.0 using a high-throughput tissue grinding machine (BiHeng Biotechnology Inc, China) at 60 Hz for 120 s. The crude extract was centrifuged at 16,000 × g for 15 min and the supernatant was extracted. Protein concentration was determined by BCA method. The 100 μg protein was precipitated using chloroform-methanol precipitation and redissolved in 25 mM ammonium bicarbonate (ABC) containing 0.015%SDS for N-glycomics analysis.
Cell culture
Human bladder cancer cell lines (SW780, RT-112, T24, J82) and human benign bladder epithelial cell line SVHUC were obtained from American Type Culture Collection (ATCC, USA). SW780 and T24 cells were cultured in DMEM (Gibco, C11995500BT) medium at 37 °C. J82 cells were cultured in MEM (Gibco, C11095500BT) at 37 °C with 5% CO2. RT-112 cells were cultured in RPMI-1640(Gibco, C11875500BT) medium at 37 °C with 5% CO2. SVHUC cells were cultured in F12K(Gibco,21127-022) medium at 37 °C with 5% CO2. All medium were supplemented with 10% FBS (Umobio, UR50202) and 1% penicillin/streptomycin (Gibco, 15070063).
EV isolation from urine
In this study, EV isolation was performed using the EVTrap isolation kit27. Urine stored at −80 °C was thawed in a 37 °C water bath. To 1 mL urine, 20 μL EVtrap magnetic beads were added and incubated by end-over-end rotation for 1 h. After removing the supernatant by a magnetic separator rack, the beads were washed with 1 mL 0.01% Triton X100/0.01% NP40, followed by two PBS washes (0.5 and 0.1 mL, respectively). Finally, the EVs were eluted with 50 μL 100 mM fresh triethylamine (TEA) by 10 min vortexing incubation, repeated twice. Then the combined supernatant (100 μL in total) was collected and dried for subsequent analysis.
EV isolation by ultracentrifugation
For cell line EV isolation, cells were cultured to reach a confluency of 80% prior to EV isolation. The collected media (80 mL) were centrifuged at 300 × g for 10 min then centrifuged at 2000 × g for 10 min to remove cells and large debris. The resulting supernatant was filtered through a 0.22 μm Millipore filter. The supernatant was centrifuged at 5000 × g for 40 min using an ultrafiltration tube (Millipore, UFC910096), and then transferred to an ultracentrifuge tube (Beckman, Z20621SCA) to centrifuge at 100,000 × g for 70 min. The EVs were obtained by suspending the pellet in 100 μL of 1× PBS (Servicebio, G4202). The collected cell line EVs were stored at −80 °C before use.
Lysis of cells and their derived EVs
Cell pellets were resuspended in lysis buffer containing 4% SDS, 1% (v/v) protease inhibitor cocktail (EDTA-free, Roche Diagnostics) in 0.1 M Tris/HCl and sonicated for 3 min and centrifuged at 18,000 × g for 10 min at 4 °C to collect the supernatant. The concentration of proteins was determined using BCA assay. The 100 μg protein was precipitated using chloroform-methanol precipitation and redissolved in 25 mM ammonium bicarbonate (ABC) containing 0.015%SDS for N-glycomics analysis.
EVs isolated from cell lines were quantified after repeated freeze–thaw cycle using the BCA kit. The 100 μg protein was precipitated using chloroform-methanol precipitation and redissolved in 25 mM ammonium bicarbonate (ABC) containing 0.015%SDS for N-glycomics analysis.
Transmission electron microscopy (TEM)
EVs were resuspended in 200 μL 2% formaldehyde and placed on Formvar-carbon covered copper mesh for fixation. Following a wash with 100 μL PBS, the samples were fixed using 50 μL 1% glutaraldehyde reaction for 5 min. Then the samples were washed repeatedly eight times for 2 min each using 100 μL ddH2O. Subsequently, the samples were subjected to contrast staining with dicumyl oxalate solution (pH 7.0) for 5 min. Further fixation and protection were performed by treating with methylcellulose for 10 min on ice. Throughout the process, excess liquid was blotted with filter paper, ensuring the Formvar film side of the copper mesh remained moist and the opposite side dry. Finally, the samples were dried in air for 5–10 min, then observed and imaged using the transmission electron microscope HT7800 (HITACHI, Japan) at 80 kV.
Nanoparticle tracking analysis (NTA)
The Nanocoulter G instrument (RESUNTECH, China) was used to determine the size distribution and concentration of EVs. EVs were diluted using PBS for backup. Prior to measuring samples, the cuvette was cleaned with ddH2O. Subsequently, the dilutions were measured to confirm that the instruments and components were functioning properly. Finally, the diluted EV samples were measured, and the test concluded once the particle count reached 100 or more.
Western blot (WB)
For western blot, EVs were redissolved in loading buffer and heated at 100 °C for 10 min. Size separation was performed using SDS-PAGE. The samples were then transferred to PVDF membrane. The PVDF membrane was blocked with 5% milk for 1 h at room temperature. The blocked PVDF membrane was incubated overnight at 4 °C with anti-CD81 antibody (1:5000, Rabbit mAb, A4863, ABclonal), anti-CD9 antibody (1:5000, Rabbit mAb, A19027, ABclonal), anti-TSG101(1:1000, Rabbit mAb, A5789, ABclonal), anti-Calnexin antibody (1:5000, Rabbit mAb, ab133615, abcam), anti-Na+/K+-ATPase antibody (1:50,000, Rabbit mAb, A11683, ABclonal) and anti-GAPDH antibody (1:10,000, Rabbit mAb, ET1601-4, HUABIO), followed by washing three times for 5 min using TBST buffer. The PVDF membrane was subsequently incubated with HRP-conjugated anti-rabbit IgG (1:5000, #7074, Cell Signaling Technology) at room temperature for 1 h. Blots were washed three times for 5 min using TBST buffer and visualized using ECL (GE Healthcare) scanned by ImageQuant ECL Imager (GE Healthcare Life Sciences).
Release and enrichment of N-glycans
EVs isolated from urine were resuspended in 40 μL 25 mM ammonium bicarbonate (ABC) solution (pH 7.8), snap-frozen in liquid nitrogen, and briefly thawed in a water bath at 25 °C. This freeze–thaw cycle was repeated three times. The samples were then heated at 100 °C for 5 min. After cooling to room temperature, 0.5 μL PNGase F was added, and the mixture was incubated at 37 °C and 1200 rpm for overnight reaction. The reaction was terminated by heating in a 100 °C water bath for 10 min.
The high-throughput sample pretreatment method developed by our group was utilized for the enrichment of N-glycans. First, the cotton (3.75–4.25 mg) was packed into a 10 μL pipet tip to serve as a separation device. The tip was then placed in a PCR plate with the bottom removed and these two were transferred together to a 96-deep well plate for centrifugation. Prior to loading samples, the tip was washed twice by 80 μL ddH2O and equilibrated with 80 μL 80%(v/v) ACN/H2O containing 0.1% TFA. In addition, all samples were adjusted to 80%(v/v) ACN/H2O solution. Subsequently, samples were loaded into tip twice, followed by six washes with 80 μL 80%(v/v) ACN/H2O containing 0.1% TFA. Finally, N-glycans on the cotton were eluted with 0.1% TFA 3 times, each with 50 μL. All elutions were then combined and lyophilized. Additionally, a one-minute interval was set between adding solution and centrifugation (3000 × g, 1 min) to allow efficient soaking of cotton wool during every operation.
Methylamidation of sialylated N-glycans
Methylamidation of N-glycans was performed according to the previous report with appropriate adjustments39. Following lyophilization, 10 μL 5 M methylamine hydrochloride solution (dissolved in DMSO) and 10 μL 250 mM (7-azabenzotria zol-1-yloxy) trispyrrolidinophosphonium hexafluorophosphate (PyAOP) solution (dissolved in N-methylmorpholine (NMM): DMSO = 3:7) were added to the purified N-glycans. The mixture was incubated for 1 h at 37 °C. At the end of the reaction, 180 μL 80%(v/v) ACN/H2O containing 0.1% TFA was added to quench the reaction, and then the solution was lyophilized after purification through the tip of a sterilized cotton tip.
Protein digestion
1 ml of urine from 10 individuals from each of the 4 groups was randomly sampled for mixing and separated using the EVTrap for the ensuing glycoproteomics experiments. The protein digestion of EVs is based on previously published literature with appropriate adjustments40. EVs were resuspended in EV lysis, reduction and alkylation buffer (12 mM sodium deoxycholate (SDC), 12 mM N-lauroylsarcosine sodium salt, 10 mM TCEP-HCl, 40 mM CAA in 100 mM Tris/HCl, pH 8.5). The samples were then heated at 95 °C for 5 min. After cooling to room temperature, 400 μL of 50 mM triethylammonium bicarbonate (TEAB) was added. Trypsin was added to a final enzyme-to-substrate ratio of 1:50 and incubated overnight at 37 °C. Acidify the digested peptides by adding TFA to a final concentration of 0.5% (vol/vol) and add 500 μL of ethyl acetate to 500 μL of digested solution.Vortex the solution for 2 min, and then centrifuge at 20,000 g for 2 min at RT to obtain aqueous and organic phases. Discard the top organic layer. Add 500 ul of ethyl acetate to the solution again and repeat to collect the aqueous phase and dry it in a vacuum centrifuge. After digestion, peptides were desalted using a C18 SPE cartridge. The desalted samples were then dried by vacuum centrifugation and stored at −20 °C for further use.
Enrichment of glycopeptides
The enrichment of glycopeptides was performed described previously24. Briefly, the desalted peptides were redissolved in the loading buffer consisting of 80% (v/v) acetonitrile and 1% TFA, and then the N-glycopeptides were enriched using an in-house zwitterioic hydrophilic interaction liquid chromatography (ZIC-HILIC) micro-column containing 15 mg of ZIC-HILIC particles (Merck Millipore).After the ZIC-HILIC column was equilibrated by the loading buffer for three times, the peptides were loaded into ZIC-HILIC micro-column, and then the column was washed with 200 μL loading buffer for three times. Then, enriched N-glycopeptides were eluted with 100 μL 0.1% TFA for three times. Finally, the N-glycopeptides were dried by vacuum centrifugation for LC-MS/MS analysis.
Subcellular fractionation
Cell fractionation was performed following previous publications41,42. The cells were first resuspended into AS buffer (30 mM HEPES, 15 mM NaCl, 350 mM sucrose, 1 tablet/10 mL EDTA-free protease inhibitor (Roche), pH=7.4) containing 0.015% digitonin (Sigma-Aldrich) and 0.5% Tween-20 (Sigma-Aldrich). The cell suspension was gently triturated 5 times, incubated on ice for 35 min, and centrifuged at 500 × g for 3 min. The supernatant was recovered and transferred to a clean tube labeled as Fraction 1. Then cell pellets were washed with 1 mL of AS buffer and resuspended in AG buffer (30 mM HEPES, 15 mM NaCl, 20% glycerol, 1 tablet/10 mL EDTA-free protease inhibitor, pH=7.4) containing 1% dodecyl maltoside. The operation is the same as above. The supernatant was recovered as Fraction 2. All collected fractions were centrifuged at 16,000 × g for 10 min, and the supernatant was subsequently collected as the cytoplasmic and plasma membrane fractions, respectively. Samples were stored at −20 °C for further analysis.
MALDI-TOF-MS analysis
Samples dissolved in 10 μL ddH2O were spotted on a MALDI target plate and naturally air-drying. Subsequently, 2 μL DHB matrix (10 mg/mL, solubilized in 80%(v/v) ACN/H2O containing 0.1% TFA) was added at the same position and naturally air-drying. All mass spectra were collected using a MALDI-TOF/TOF-MS-rapifleX analyzer (Bruker Daltonics, USA). Data were collected in positive ion mode, and a total of 20,000 laser shots in the mass range of 1000–4000 m/z were accumulated for each spectrum. For MS2, the MS/MS method was selected in positive ion mode after choosing the target precursor ion. The N-glycan structure was subsequently determined through manual matching using GlycoWorkbench (v2.1).
Data preprocessing
The MALDI-TOF spectra were first processed in flexAnalysis 4.0, where the mass lists were exported to XLSX files after baseline subtraction. The Peak Detection Algorithm was set to Snap, Signal to Noise Threshold was set to 3, and the isotope peaks were merged. All peak areas and signal-to-noise ratios were extracted from the mass lists, and quantitative information was obtained from the peak areas provided in the mass lists. The annotation of the mass list files was performed using an in-house tool GlyHunter (https://github.com/FudanLuLab/glyhunter) with the retrosynthetic glycan library developed previously43.
Data analysis was performed on R (v4.3.2) and RStudio (v2023.12.1 + 402). Glycan identification counts were used to find sample outliers. Samples in which the number of glycans identified was less than the median minus 1.5 times the interquartile range were regarded as outliers, and were removed from further analysis. Glycans with missing value proportions larger than 50% were also ruled out. Missing values were imputed using the minimum abundance of each glycan across samples. Finally, total abundance normalization (TAN) and Median Quotient Normalization (MQN) were performed sequentially on the imputed abundance table.
LC-MS/MS analysis for glycoproteomic analysis
LC-MS/MS analysis were performed on an EASY-NanoLC 1200 system (Thermo Fisher Scientific) connected to Thermo Scientific™ Orbitrap Eclipse™ Tribrid™ mass spectrometer (Thermo Fisher Scientific) equipped with an online nanoelectrospray ion source with custom spray potential. A total of 1 μg glycopeptides dissolved in solvent A (0.1% formic acid) was loaded onto the analytical column (75 μm × 25 cm) and subsequently separated with a linear gradient. Solvent B was 80 % acetonitrile with 0.1 % formic acid. The gradient was 180 min in total for the glycopeptides: 5–35% B from 0 to 167.5 min, 35–45% B from 167.5 to 172.5 min, 45 - 90% B from 172.5 to 173 min, 90% B from 173 to 177.5 min, 90 - 2% B from 177.5 to 177.7 min, and held for 2% B for the last 4.3 min. The flow rate was maintained at 300 nL/min.
The parameters used for glycopeptide analysis were set as follows: for MS1, the scan range was set from 350 to 2000 m/z, with a resolution of 60,000, a Normalized AGC Target of 125 %, a maximum injection time of 50 ms, and included charge states of 2–7. For MS2, Collision Energy Type = Normalized; Isolation Mode = Quadrupole; Enable Intelligent Product Acquisition for MS Isolation = False; Isolation Window = 2; Scan Range Mode = Define m/z range; Activation Type = HCD; Collision Energy Mode = Stepped; Collision Energy (%) = 20,30,40; Detector Type = Orbitrap; Orbitrap Resolution = 30 K; Scan Range (m/z) = 120–2000; Maximum Injection Time (ms) = 250; AGC Target = 400,000; Normalized AGC Target = 800 %.
Glycopeptide identification and quantification
The raw data was imported into pGlyco3 for the identification of N-glycopeptide analysis44. The search was performed using the following parameters: (1) Trypsin was selected as enzyme; (2) fixed modification, carbamidomethylamidation ( + 57.021 Da) of C; (3) dynamic modifications, oxidation of M ( + 15.995 Da), acetylation of ProteinN-term ( + 42.011 Da) (4) maximum missed cleavages, 3; (4) precursor ion mass tolerance 10 ppm; (5) fragment ion mass tolerance 20 ppm. (6) glycan database, pGlyco-N-Human.gdb. (7) Swiss-human protein databases, downloaded on July 26, 2022, containing 20,381 protein sequence entries. Quantification was performed on pGlycoQuant45. Both MS raw files and peptide identification files obtained from the pGlyco3 search results in the form of “pGlycoDB-GP-FDR-Pro.txt” files were imported. The search was performed using the following parameters: (1) TYPE_QUANT, DDA LabelFree; (2) FLAG_MIR_GLYCO, No; (3) DDALF_RT_WIN_IN_MIN, 2.00 min; (4) DDALF_PPM_HALF_WIN_ACCURACY_PEAK, 20.00 ppm; (5) DDALF_FLAG_DECOY, No.
Formalin-fixed paraffin-embedded (FFPE) slide preparation for MALDI-MSI
Formalin-fixed paraffin-embedded (FFPE) slide preparation for MALDI-MSI was performed according to the previous report with appropriate adjustments46. The FFPE slide was immersed in xylene for 5 min and rehydrated through a graded ethanol series (80% ethanol - 60% ethanol - 50% ethanol - water). The slide was incubated in a 10 mM ammonium bicarbonate solution, followed by a 10 mM sodium citrate solution (pH 6.0) at 90 °C for 1 hour. After incubation, the slide was rinsed in ultrapure water and washed twice with ammonium bicarbonate solution.
N-glycan MALDI imaging mass spectrometry of FFPE tissue slides
PNGase F (10 µL) was diluted with 140 µL of H2O and evenly sprayed onto the tissue surface using an HTX matrix sprayer (Bruker Daltonics, USA). The sections were then incubated at 37 °C overnight. After PNGaseF digestion, desiccated tissue sections were sprayed using an HTX TM sprayer with 10 mg/mL CHCA (α-Cyano-4-hydroxycinnamic acid), dissolved in acetonitrile-water (7:3, v/v). The sprayer temperature was set to 75 °C, with a flow rate of 0.1 mL/min, pressure of 10 psi. Four passes of the matrix were applied to slides with 10 s of drying time between each pass.
MALDI-MSI experiments were performed on the prototype Bruker timsTOF flex MS system (Bruker Daltonics, USA) equipped with a 10 kHz smart beam 3D laser. Laser power was set to 70% and then fixed throughout the whole experiment. The mass spectra were acquired in positive mode. The mass spectra data were acquired over a mass range from m/z 700 to 4000 Da. The imaging spatial resolution was set to 40 μm for the tissue, and each spectrum consisted of 400 laser shots. MALDI mass spectra were normalized with the Root Mean Square, and the signal intensity in each image was shown as the normalized intensity.
Statistical analysis
Statistical analysis was performed using rstatix package (v0.7.2). Glycan abundances were log2-transformed before further analysis. First, the relationship between potential confounders including sex, age, and BMI with glycan abundances was checked through t-test (sex) and Pearson’s correlation analysis (age and BMI). For the discovery cohort, one-way ANOVA and Tukey post-hoc test was performed to find significantly differential glycans among groups, with p values adjusted for multiple comparison using Benjamini-Hochberg method. Fold changes were also calculated.
Machine learning
Machine learning was performed using mlr3verse package (v0.2.8). 10 algorithms were trained on the discovery cohort data, including decision tree, logistic regression, linear discriminant analysis, quadratic discriminant analysis, support vector machine, Naïve Bayes, k-neighbor nearest, random forest, XGBoost, and one dummy baseline model. Model selection was done using 10-fold stratified cross-validation on the discovery cohort, using accuracy, f1-score, and ROC AUC as metrics. Logistic regression was chosen as the final diagnostic model. The model was trained on all data in the discovery cohort, and evaluated on the validation cohort, by accuracy, f1-score, ROC AUC, sensitivity, and specificity. Feature importance was acquired using DALEX (v2.4.3) and DALEXtra (v2.3.0) packages.
TCGA glyco-gene expression analysis
Gene expression data of TCGA-BLCA project was downloaded and analyzed using TCGAbiolinks package (v2.30.0) from the TCGA GDC portal. Downloaded data was prepared using the “GDCprepare” function, and preprocessed using the “TCGAanalyze_Preprocessing” function. The preprocessed data was normalized using the “TCGAanalyze_Filtering” function. Outlier samples were removed by the “TCGAanalyze_Filtering” function with method setting to “quantile” and cut threshold to 0.25. Differential expression analysis (DEA) was performed by the “TCGAanalyze_DEA” function, with method setting to “glmLRT” and p to 0.05.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The N-glycomics raw data generated in this study have been deposited in GlycoPOST (https://glycopost.glycosmos.org) under the accession numbers GPST000437. It can be accessed with the following information (https://glycopost.glycosmos.org/entry/GPST000437). The N-glycoproteomics data have been deposited to the ProteomeXchange Consortium via iProx with the dataset identifier PXD057882. All other data generated in this study are provided in the Supplementary Information. Source data are provided with this paper.
Code availability
The Python code used for N-glycans annotation are deposited to GitHub repository at https://github.com/FudanLuLab/glyhunter.
References
Flaig, T. W. et al. Bladder cancer, version 3.2020, NCCN clinical practice guidelines in oncology. J. Natl Compr. Canc Netw. 18, 329–354 (2020).
Bray, F. et al. Global cancer statistics 2022: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 74, 229–263 (2024).
Ritch, C. R. et al. Use and validation of the AUA/SUO risk grouping for nonmuscle invasive bladder cancer in a contemporary cohort. J. Urol. 203, 505–511 (2020).
Kamoun, A. et al. A consensus molecular classification of muscle-invasive bladder cancer. Eur. Urol. 77, 420–433 (2020).
Witjes, J. A. et al. European association of urology guidelines on muscle-invasive and metastatic bladder cancer: summary of the 2020 guidelines. Eur. Urol. 79, 82–104 (2021).
Zhu, C. Z., Ting, H. N., Ng, K. H. & Ong, T. A. A review on the accuracy of bladder cancer detection methods. J. Cancer 10, 4038–4044 (2019).
Lenis, A. T., Lec, P. M., Chamie, K. & Mshs, M. D. Bladder cancer: A review. Jama 324, 1980–1991 (2020).
Compérat, E. et al. Current best practice for bladder cancer: a narrative review of diagnostics and treatments. Lancet 400, 1712–1721 (2022).
Ng, K., Stenzl, A., Sharma, A. & Vasdev, N. Urinary biomarkers in bladder cancer: a review of the current landscape and future directions. Urol. Oncol. 39, 41–51 (2021).
Ahn, J. H., Kang, C. K., Kim, E. M., Kim, A. R. & Kim, A. Proteomics for early detection of non-muscle-invasive bladder cancer: clinically useful urine protein biomarkers. Life (Basel) 12, 395 (2022).
Oliveira, M. C. et al. Urinary biomarkers in bladder cancer: where do we stand and potential role of extracellular vesicles. Cancers (Basel) 12, 1400 (2020).
Crocetto, F. et al. Liquid biopsy in bladder cancer: state of the art and future perspectives. Crit. Rev. Oncol. Hematol. 170, 103577 (2022).
Jeong, S. H. & Ku, J. H. Urinary markers for bladder cancer diagnosis and monitoring. Front Cell Dev. Biol. 10, 892067 (2022).
Li, Y., Wang, J., Chen, W., Lu, H. & Zhang, Y. Comprehensive review of MS-based studies on N-glycoproteome and N-glycome of extracellular vesicles. Proteomics 24, e2300065 (2023).
Tkach, M. & Théry, C. Communication by extracellular vesicles: where we are and where we need to go. Cell 164, 1226–1232 (2016).
Li, Y. et al. Thermophoretic glycan profiling of extracellular vesicles for triple-negative breast cancer management. Nat. Commun. 15, 2292 (2024).
Shin, H. et al. Single test-based diagnosis of multiple cancer types using Exosome-SERS-AI for early stage cancers. Nat. Commun. 14, 1644 (2023).
Braun, F. et al. The proteomic landscape of small urinary extracellular vesicles during kidney transplantation. J. Extracell. Vesicles 10, e12026 (2020).
Xu, K. et al. Elevated extracellular matrix protein 1 in circulating extracellular vesicles supports breast cancer progression under obesity conditions. Nat. Commun. 15, 1685 (2024).
Erdbrügger, U. et al. Urinary extracellular vesicles: a position paper by the urine task force of the international society for extracellular vesicles. J. Extracell. Vesicles 10, e12093 (2021).
Thomas, D., Rathinavel, A. K. & Radhakrishnan, P. Altered glycosylation in cancer: a promising target for biomarkers and therapeutics. Biochim Biophys. Acta Rev. Cancer 1875, 188464 (2021).
Wilczak, M., Surman, M. & Przybyło, M. Altered glycosylation in progression and management of bladder cancer. Molecules 28, 3436 (2023).
Jian, Y. et al. The roles of glycans in bladder cancer. Front Oncol. 10, 957 (2020).
Liu, X. et al. High-throughput intact glycopeptide quantification strategy with targeted-MS (HTiGQs-target) reveals site-specific IgG N-glycopeptides as biomarkers for hepatic disorder diagnosis and staging. Carbohydr. Polym. 325, 121499 (2024).
Sun, Z. et al. High-throughput site-specific N-glycoproteomics reveals glyco-signatures for liver disease diagnosis. Natl Sci. Rev. 10, nwac059 (2023).
Rodriguez, E. et al. Sialic acids in pancreatic cancer cells drive tumour-associated macrophage differentiation via the Siglec receptors Siglec-7 and Siglec-9. Nat. Commun. 12, 1270 (2021).
Wu, X., Li, L., Iliuk, A. & Tao, W. A. Highly efficient phosphoproteome capture and analysis from urinary extracellular vesicles. J. Proteome Res 17, 3308–3316 (2018).
Reily, C., Stewart, T. J., Renfrow, M. B. & Novak, J. Glycosylation in health and disease. Nat. Rev. Nephrol. 15, 346–366 (2019).
Munkley, J. Aberrant sialylation in cancer: therapeutic opportunities. Cancers (Basel) 14, 4248 (2022).
Pendiuk Goncalves, J. et al. High-throughput analysis of glycan sorting into extracellular vesicles. Biochim Biophys. Acta Mol. Cell Res. 1871, 119641 (2024).
Jubber, I. et al. Epidemiology of bladder cancer in 2023: a systematic review of risk factors. Eur. Urol. 84, 176–190 (2023).
Joshi, H. J. et al. Glycosyltransferase genes that cause monogenic congenital disorders of glycosylation are distinct from glycosyltransferase genes associated with complex diseases. Glycobiology 28, 284–294 (2018).
Schjoldager, K. T., Narimatsu, Y., Joshi, H. J. & Clausen, H. Global view of human protein glycosylation pathways and functions. Nat. Rev. Mol. Cell Biol. 21, 729–749 (2020).
Dall’Olio, F., Pucci, M. & Malagolini, N. The cancer-associated antigens Sialyl Lewis(a/x) and Sd(a): two opposite faces of terminal Glycosylation. Cancers (Basel) 13, 5273 (2021).
Lin, M. et al. Sialylation on vesicular integrin β1 determined endocytic entry of small extracellular vesicles into recipient cells. Cell Mol. Biol. Lett. 29, 46 (2024).
Schneider, M., Al-Shareffi, E. & Haltiwanger, R. S. Biological functions of fucose in mammals. Glycobiology 27, 601–618 (2017).
Adhikari, E. et al. L-fucose, a sugary regulator of antitumor immunity and immunotherapies. Mol. Carcinog. 61, 439–453 (2022).
Lin, Y. & Lubman, D. M. The role of N-glycosylation in cancer. Acta Pharm. Sin. B 14, 1098–1110 (2024).
Peng, Y. et al. A streamlined strategy for rapid and selective analysis of serum N-glycome. Anal. Chim. Acta 1050, 80–87 (2019).
Andaluz Aguilar, H., Iliuk, A. B., Chen, I. H. & Tao, W. A. Sequential phosphoproteomics and N-glycoproteomics of plasma-derived extracellular vesicles. Nat. Protoc. 15, 161–180 (2020).
Xiong, Y. et al. Rapid and large-scale glycopeptide enrichment strategy based on chemical ligation. Natl Sci. Rev. 11, nwae341 (2024).
Martinez-Val, A. et al. Spatial-proteomics reveals phospho-signaling dynamics at subcellular resolution. Nat. Commun. 12, 7113 (2021).
Kronewitter, S. R. et al. The development of retrosynthetic glycan libraries to profile and classify the human serum N-linked glycome. Proteomics 9, 2986–2994 (2009).
Zeng, W. F., Cao, W. Q., Liu, M. Q., He, S. M. & Yang, P. Y. Precise, fast and comprehensive analysis of intact glycopeptides and modified glycans with pGlyco3. Nat. Methods 18, 1515–1523 (2021).
Kong, S. et al. pGlycoQuant with a deep residual network for quantitative glycoproteomics at intact glycopeptide level. Nat. Commun. 13, 7539 (2022).
Wallace, E. N. et al. An N-glycome tissue atlas of 15 human normal and cancer tissue types determined by MALDI-imaging mass spectrometry. Sci. Rep. 14, 489 (2024).
Acknowledgements
The work was supported by the National Key Research and Development Program of China (2021YFA1301602 to Y.Z.), the National Natural Science Foundation of China (22174021 and 22474024 to Y. Z., 22434001 to H. L.). Thanks to the technology platform provided by Core Facility of Shanghai Medical College, Fudan University.
Author information
Authors and Affiliations
Contributions
Y.L. (Yang Li): acquisition of data, interpretation of data, statistical analysis and drafting of the manuscript; B.F.: statistical analysis and drafting of the manuscript; M.W.: sample collection and acquisition of data; W.C., J.F.: acquisition of data; Y.L. (Yueyue Li), X.L. and J.W.: data analysis; Z.Z.: sample collection and study design; H.L., Y.Z.: study design and supervision. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks the anonymous reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Source data
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Li, Y., Fu, B., Wang, M. et al. Urinary extracellular vesicle N-glycomics identifies diagnostic glycosignatures for bladder cancer. Nat Commun 16, 2292 (2025). https://doi.org/10.1038/s41467-025-57633-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41467-025-57633-9
This article is cited by
-
Machine learning for extracellular vesicles enables diagnostic and therapeutic nanobiotechnology
Journal of Nanobiotechnology (2026)
-
A Review of Microfluidic Chip-Based Strategies for Extracellular Vesicle Isolation: Bridging Traditional Methods and Clinical Translation
BioChip Journal (2026)
-
Comparative evaluation of methods for isolating extracellular vesicles from ICC cell culture supernatants: Insights into proteomic and glycomic analysis
Cell Communication and Signaling (2025)
-
Identification of a free-N-glycan with difucosylated type-1 lactosamine in cancerous tissue and its validation for cancer diagnosis by urinary testing
Scientific Reports (2025)
-
A functionally tunable magnetic nanochains platform for N-glycoproteomic analysis of extracellular vesicles from ultratrace biofluids
Nature Communications (2025)
