
Abstract
Given the growing global elderly population and the accelerating decrease in grey matter volume (GMV) with age, understanding healthy brain aging is increasingly important. This study investigates whether variations in modifiable traits can account for differences in GMV and whether these traits can inform strategies to mitigate risks of future brain disorders. We identified 66 traits significantly associated with total GMV. Further, we examined the joint contributions of different domain traits to the GMV variance, finding that blood biomarkers and physical measurements accounted for the largest proportion of GMV variance. Some traits mediated the relationship between the genetic risk for brain disorders and GMV. Moreover, the identified traits divided the population into two subgroups, with significant differences in GMV and incidences of brain disorders. Our findings underscore the importance of modifiable traits in supporting healthy brain aging and reducing the risk of brain disorders, suggesting potential targets for intervention.
Similar content being viewed by others
Introduction
Over the past few decades, the global elderly population has grown significantly1,2. A hallmark of aging is the accelerated decrease in GMV, a neuroanatomical alteration that can disrupt brain function and increase the vulnerability to brain disorders3,4. Therefore, interventions that slow GMV decline are essential for maintaining mental and cognitive health and improving quality of life in later life. Even in the context of neurodegenerative diseases, preserving GMV remains critical due to the brain’s compensatory capacity—unaffected regions can partially compensate for dysfunction in damaged areas5,6. Emerging evidence suggests that the brain reserve capacity in patients with neurodegenerative diseases correlates with the severity and progression of the disease7,8,9,10,11, reinforcing the value of strategies aimed at preserving GMV across both healthy and pathological aging.
Magnetic resonance imaging (MRI) has been pivotal in elucidating the neuroanatomical changes that accompany aging4,6,12,13. Structural neuroimaging studies consistently reveal marked heterogeneity in brain aging trajectories across individuals and brain regions, highlighting the inherent heterogeneity of brain aging14,15,16. Modifiable risk traits, including body mass index (BMI)17,18, physical activity19, and sedentary behavior19,20, have been independently linked to GMV loss21. Consequently, the observed variability in brain aging trajectories is likely influenced by a range of lifestyle, environmental, and genetic factors, acting individually, interactively, or in combination22,23,24, suggesting that GMV loss may be amenable to targeted modification25.
Despite these insights, the intricate interplay between these traits, their cumulative impact on GMV, and their interactions with genetic risk factors remain largely unexplored. First, although individual associations between specific risk factors and GMV have been reported26,27,28,29, comprehensive phenome-wide analyses that systematically assess both global and regional GMV associations in midlife and older adults are still lacking. Second, the joint contributions of modifiable traits from different domains—such as early-life factors, dietary habits, environmental exposures, psychosocial factors, and socioeconomic status—to GMV variance have not been quantitatively determined. Third, the interplay between modifiable traits and genetic susceptibility—such as polygenic risk scores (PRS) for brain disorders—has not been systematically explored. Finally, the co-occurrence patterns of health-related factors and their combined impact on brain aging trajectories merit investigation to provide the basis for personalized prevention strategies.
Midlife represents a critical intervention window, as cumulative exposure to biological and environmental factors during this period profoundly shapes subsequent brain health trajectories. Leveraging data from the UK Biobank (UKB)30, a large prospective study involving over 500,000 middle-to-older participants31, we conducted a multi-domain analysis to dissect the relationships among genetic risk, modifiable traits, and GMV: (1) single-trait associations with total and regional GMV to prioritize high-impact targets; (2) multivariate regression modeling to quantify the joint contributions of modifiable trait domains to GMV variance; (3) mediation analysis to evaluate whether specific traits modulate genetic risk effects on GMV; and (4) data-driven subgroups exhibiting distinct modifiable trait profiles, GMV patterns, and disease risk patterns. This integrative approach advances our understanding of how modifiable traits individually and collectively influence brain aging trajectories, while highlighting opportunities for promoting healthy brain aging that account for genetic background and phenotypic complexity.
Results
Population characteristics
In this study, the UKB population was divided into two groups, namely one group with T1-weighted MRI (T1-MRI) and the other without T1-MRI, depending on whether MRI was conducted at the time of the first imaging visit (Fig. 1). The main analysis included 35,195 participants who had undergone T1-MRI. The mean age of this MRI Group was 54.77 years (Standard Deviation [SD] = 7.50) at baseline, and 47.57% were male. The mean interval from baseline to the first imaging visit was 8.95 years. The mean age of the first imaging visit was 63.70 years (SD = 7.66). An additional 458,422 participants, who did not undergo T1-MRI scanning, served as a validation group. This non-MRI Group had a mean age of 56.67 years (SD = 8.13), and 45.43% were males. The non-MRI Group is older and has a higher percentage of females compared to the MRI Group. Comprehensive demographic information for the participants is summarized in Supplementary Table 1.

Analytical procedure to identify modifiable traits associated with GMV in the UK Biobank. The study comprises four parts: PWAS of total and regional GMVs, joint association of modifiable traits with GMVs and brain disorders, mediation analysis of the roles of modifiable traits in the relationship between PRS for brain disorders and GMVs, and clustering analysis of identified modifiable traits. The four dotted boxes represent the following analytical stages: PWAS (red), joint association analysis (blue), mediation analysis (pink), and cluster analysis (brown). Solid blue rectangles indicate analyzed data, green signifies analysis methods, and yellow denotes study outcomes.
Phenome-wide association study of total and regional GMV
After correcting for multiple comparisons, 66 out of 182 modifiable traits showed a significant association with total GMV (p = 2.75 × 10−4), as shown in Fig. 2. Among the top 20 most significantly associated traits, 11 were negatively correlated with total GMV, and 9 showed a positive association.

The x axis shows the category domains, and the y axis represents regression coefficient. The dashed horizontal line marks the minimum absolute coefficient for factors that are statistically significant after multiple comparisons (Bonferroni correction, P < 2.75 × 10−4). A set of top risk traits was annotated. Models were adjusted for age at baseline, sex, ethnicity, assessment site, imaging center, TIV, and the time interval between baseline assessment and imaging visit.
The 11 negative associations included four physical measurements: BMI (β = –0.034 [–0.039, –0.028]; p < 1 × 10−16), whole-body fat mass (β = –0.022 [–0.027, –0.016]; p = 1.55×10−15), arm fat percentage (β = –0.034 [–0.041, –0.027]; p < 1 × 10−16), and leg fat percentage (β = –0.050 [–0.060, –0.039]; p < 1 × 10−16). Seven hematological markers also showed negative associations: neutrophil count (β = –0.035 [–0.040, –0.030]; p < 1×10−16), white blood cell count (β = –0.031 [–0.036, –0.026]; p < 1 × 10−16), C-reactive protein (CRP; β = –0.026 [–0.031, –0.021]; p < 1 × 10−16), urate (β = –0.027 [–0.033, –0.021]; p < 1 × 10⁻16), high light scatter reticulocyte count (HLR-C; β = –0.025 [–0.030, –0.020]; p < 1 × 10−16), systolic blood pressure (β = –0.026 [–0.032, –0.021]; p < 1 × 10−16), and diastolic blood pressure (β = –0.029 [–0.034, –0.024]; p < 1 × 10−16).
The nine positive associations included overall health status (β = 0.059 [0.044, 0.074]; p = 8.22 × 10−15), walking pace (brisk vs. usual; β = 0.050 [0.040, 0.060]; p < 1 × 10−16), forced expiratory volume in one second (β = 0.048 [0.041, 0.055]; p < 1 × 10−16), forced vital capacity (β = 0.046 [0.039, 0.053]; p < 1 × 10−16), arm impedance (β = 0.040 [0.032, 0.047]; p < 1 × 10−16), peak expiratory flow (β = 0.032 [0.025, 0.038]; p < 1×10−16), leg impedance (β = 0.029 [0.023, 0.034]; p < 1 × 10−16), total cholesterol (β = 0.029 [0.024, 0.034]; p < 1×10−16) and low-density lipoprotein (LDL; β = 0.027 [0.022, 0.032]; p < 1 × 10−16).
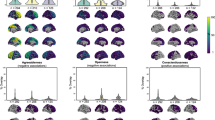
We also examined the relationship between modifiable traits and regional GMV (Fig. 3). Notably, the majority of significant traits showed generally similar patterns across regions, echoing the trends observed in total GMV. However, some physical measurement-related measures, such as basal metabolic rate (cortical GMV: β = −0.020 [−0.030, −0.010]; p = 8.55 × 10−5, subcortical GMV: β = 0.037 [0.026, 0.048]; p = 5.16 × 10−11), whole body fat-free mass (cortical GMV: β = −0.019 [−0.030, −0.008]; p = 1.04 × 10−3, subcortical GMV: β = 0.045 [0.033, 0.057]; p = 9.97 × 10−13), and diastolic blood pressure (cortical GMV: β = -0.032 [−0.038, −0.027]; p < 1 × 10−16, subcortical GMV: β = 0.014 [0.008, 0.021]; p = 1.16 × 10−5), had opposite correlations with cortical and subcortical brain regions.

Models were adjusted for age at baseline, sex, ethnicity, assessment site, imaging center, TIV, and the time interval between baseline assessment and imaging visit. The color of cells indicates the regression coefficient (β) between each modifiable trait and regional GMV (n = 35,195). P values were corrected using Bonferroni correction for multiple tests (* P < 2.75×10−4; ** P < 1.51×10−6; *** P < 8.29×10−9).
Joint associations of modifiable traits and GMVs, as well as brain disorders
To quantify joint contribution to the variance in total and regional GMV by different domain modifiable traits, we employed Partial Least Squares regression (PLS). All these 182 traits accounted for 4.6% of the variance in total GMV. The variance explained by all these 182 traits across regional brain varied widely, ranging from 1.19% to 4.00%, with a standard deviation of 0.62% (Fig. 4a and Supplementary Table 2). Brain regions showing the highest degree of variance explanation included the cerebellum, lateral ventricles, and medial orbitofrontal cortex, while the pericalcarine, cuneus, and pars triangularis showed the lowest.

a The joint explanation of variance with all 182 traits in regional GMV. The detailed results are available in Supplementary Table 2. b The joint explanation of variance in total and regional GMV by different domain modifiable traits. R2 was calculated using PLS after adjusting for age at baseline, sex, ethnicity, assessment site, imaging center, TIV, and the time interval between baseline assessment and imaging visit. The detailed results are available in Supplementary Table 2. c Associations between the composite score of modifiable traits with brain disorders. The unfavorable profile was set as reference in each brain disorder. Dots represent HR horizontal lines indicate corresponding 95% CIs. The detailed results are available in Supplementary Table 4.
Our analysis of domain-specific traits demonstrated that physical measurements, blood biomarkers, and diet were the top three domains in explaining the variance in the GMVs (Fig. 4b). For example, considering the total GMV, blood biomarkers explained 2.21% of the variance, physical measurements 1.42%, diet 0.70%, lifestyle 0.61%, and the remaining five domains each explained less than 0.4%. In the majority of regions, blood biomarkers explained for a greater proportion of the variance compared to physical measurements. However, this was not the case in the inferior parietal, lateral orbitofrontal, medial orbitofrontal, accumbens, caudate, lateral ventricles, and cerebellum. Furthermore, we carried out analogous analyses in line with the categories of blood biomarkers corresponding to various functional systems. Our findings indicate that the blood biomarkers related to immune function, metabolism, liver function, and bone marrow hematopoietic function are the four principal systems in accounting for the variance of GMV observed in the brain (Supplementary Fig. 1 and Supplementary Table 3).
Subsequently, we examined whether the composite score of modifiable traits for total GMV generated by PLS in the MRI Group is also associated with brain disorders in the non-MRI Group. The composite scores were divided into tertiles representing favorable, intermediate, and unfavorable profiles. Compared to the unfavorable profile, both the intermediate and favorable profiles were generally associated with a lower risk of brain disorders (Fig. 4c and Supplementary Table 4). For instance, a favorable profile of composite score was significantly associated with lower risk of all cause dementia (ACD; hazard ratios (HR); HR = 0.48, 95% CI = 0.47–0.50, p < 2×10−308), as was an intermediate profile (HR = 0.63, 95% CI = 0.61–0.64, p = 8.70 × 10−258). The composite score of modifiable traits for cortical and subcortical regions yielded similar results (Supplementary Fig. 2 and Supplementary Table 4). These results suggest that the composite score for protection against small GMV also confers protection against brain disorders.
Mediating roles of modifiable traits in the relationship between PRS for brain disorders and GMVs
Consistent with the pleiotropic nature of many genes32, our analyses identified significant associations among PRS for brain disorders, GMV, and modifiable traits (Supplementary Figs. 3–4, Supplementary Tables 5–6). To investigate the mediating pathways linking PRS to both regional and total GMV through these modifiable traits, we conducted disorder-specific mediation analyses across a spectrum of brain disorders. Key findings for each disorder are summarized below, with detailed effect estimates provided in Table 1 and Supplementary Fig. 5.
Alzheimer’s disease (AD)
For AD, LDL, ApoB, cholesterol, and CRP demonstrated mediation effects on total GMV. In contrast, ApoA1 and HDL exhibited suppression effects on total GMV.
Bipolar disorder (BD)
In the context of BD, educational qualifications and impedance of arm showed a mediation effect on total GMV. Conversely, white blood cell count, smoking status, long-standing illness, Townsend deprivation index and shorter height size at age 10 exhibited suppression effects on total GMV.
Ischemic stroke (ISS)
The relationship between ISS PRS and GMV was mediated by multiple traits, with no observed suppression effects. Key mediators included blood pressure, BMI, arm/leg fat percentage, whole-body fat mass, HLR-C, urate levels, neutrophil count, and white blood cell count.
Major depressive disorder (MDD)
For MDD, the overall state of health mediated 10.34% of the total effects on total GMV.
Parkinson’s disease (PD)
For PD, educational qualifications mediated 7.12% of the total effects on total GMV.
Schizophrenia (SCZ)
In SCZ, smoking status, white blood cell count, Townsend deprivation index, overall state of health, tea intake, getting up in morning, frequency of tiredness, lymphocyte count, and alcohol intake frequency demonstrated mediation effects on total GMV. However, impedance of arm and leg exhibited suppression effects on total GMV.
Identified modifiable traits define two distinct population subgroups
We explored whether the identified traits could cluster the participants into distinct subgroups. The analysis revealed two subgroups (Fig. 5a). Subgroup 1 consisted of 8,455 participants with a mean age of 54.81 years (SD = 7.37), of whom 48.17% were male. Conversely, Subgroup 2 comprised 26,740 participants, with a mean age of 54.75 years (SD = 7.54) and 47.38% male. No significant differences were found in common covariates between the two subgroups (Supplementary Table 7).

a Dendrogram of the hierarchical cluster of patients in MRI group. b The differences in regional GMVs between two subgroups in MRI group. Only ROI with statistically significant corrected P values were visualized in the figures. The full results are available in Supplementary Table 8. c The differences in modifiable traits between subgroups in MRI group. The x axis shows the category domains, and the y axis represents t value of two samples t-test. The dashed horizontal line marks the minimum absolute t value for traits that are statistically significant after multiple comparisons (Bonferroni correction, P < 2.75 × 10−4). A set of top significant traits were annotated. The detailed results are available in Supplementary Table 7.
The phenotypic profiles of the two subgroups differed markedly. Briefly, Subgroup 1 exhibited higher levels of obesity, elevated blood pressure, poorer blood biomarkers, and inferior physical status compared to Subgroup 2 (Fig. 5c, Supplementary Fig. 6 and Supplementary Table 7). Regarding GMV, Subgroup 1 displayed significantly lower GMV within the pallidum and most cortical regions compared with Subgroup 2, particularly in the medial orbitofrontal and middle temporal regions (Fig. 5b and Supplementary Table 8).
We further conducted joint association and mediation analyses within each subgroup. Our findings indicated that, within Subgroup 1, variations in modifiable traits accounted for a greater proportion of both total and regional GMV variance (Supplementary Fig. 7, Supplementary Tables 9 and 10). These results suggest that interventions targeting these traits may yield greater benefits for brain health in Subgroup 1. However, the proportion of the relationship between PRS and GMVs mediated by these traits was comparable between subgroups (Supplementary Fig. 8). This may be due to the fact that PRS for AD, BD, PD, and SCZ were significantly lower in Subgroup 1 compared to Subgroup 2 (Supplementary Table 11). Only the PRS for ISS and MDD was significantly higher in Subgroup 1 than in Subgroup 2. No significant difference was observed in the gene risk scores for MS between the two subgroups.
We trained machine learning models to classify different subgroups based on the 66 significant traits identified in the MRI Group using the Light Gradient Boosting Machine (Light-GBM) algorithm. The model achieved a 10-fold cross-validated area under the receiver operating characteristic curve (AUC) of 0.95 ± 0.004 (Fig. 6a). The top five features were BMI, slow pace, whole-body fat mass, white blood cell count (WBC), and HLR-C (Fig. 6b). We then applied this classifier to the non-MRI Group to predict the corresponding subgroups and investigated the differences in these significant traits among the subgroups. (Supplementary Fig. 6 and Supplementary Table 12). The correlation coefficient from the two-sample t-test for traits between the MRI Group and the non-MRI Group was 0.98, confirming the consistency between these two groups (Fig. 6c).

a Receiver operating characteristic curves showing performance of light-GBM algorithm in a 10-fold cross-validated in MRI group. b The ranked feature importance of the Light-GBM algorithm was determined through SHAP additive explanations for the top 40 predictive features within the model. c Correlation of the t value of modifiable traits in two subgroups between MRI group and non-MRI group. d Kaplan-Meier survival curves between two subgroups across all 8 brain disorders analyzed. The HR, 95% CI, and corresponding p-values for were calculated in Cox proportional hazard regression models. The detailed results are available in Supplementary Table 13.
Next, we investigated the differences in brain disorder risk between the two subgroups, focusing on the non-MRI group to avoid confounding by existing conditions affecting brain structure. Our results revealed Subgroup 1 showed a significantly higher risks across various diseases compared to Subgroup 2 (Fig. 6d): including SCZ (HR = 2.19, 95% CI = 1.84–2.61; p = 5.8×10−19), MDD (HR = 1.78, 95% CI = 1.73–1.83; p < 2×10−308), BD (HR = 1.75, 95% CI = 1.53-2.01; p = 5.01×10−16), MS (HR = 1.54, 95% CI = 1.29–1.84; p = 1.29×10−6), ACD (HR = 1.54, 95% CI = 1.50–1.57; p = 6.62×10−304), all cause stroke (ACS; HR = 1.52, 95% CI = 1.46–1.57; p = 2.00×10−124), anxiety (AXT; HR = 1.48, 95% CI = 1.45–1.52; p = 6.40×10−195), and PD (HR = 1.09, 95% CI = 1.02–1,17; p = 1.55×10−2; Supplementary Table 13).
Discussion
In this prospective, large-scale, population-based biobank cohort study, we comprehensively investigated the complex relationship between modifiable traits, genetic risk scores, and GMV. We demonstrated that total GMV is associated with 66 modifiable traits, encompassing multifaceted behavioral and multiorgan-related traits. Joint domain analysis revealed that, among these domains, blood biomarkers and physical measurements explained the greatest variance in GMV. Some of these modifiable traits mediated the relationship between genetic risk for brain disorders and GMV. Furthermore, the identified modifiable traits divided the population into two distinct subgroups with significant differences in GMV patterns and varying incidences of brain disorders. Our findings provide insights into the modifiable traits that have the potential to help preserving GMV and reduce the risk of brain disorders. This could potentially lead to targeted interventions or preventive measures that support healthy cognitive aging.
We identified significant associations between 66 distinct traits and total GMV. These traits encompassed both previously reported associations with reduced GMV, such as smoking26, obesity17,27, blood pressure28, and inflammation29,33, as well as positive correlations with GMV, including cereal intake34,35 and lung function36. Moreover, our study unveiled potentially novel traits that have received limited attention in the context of preserving GMV thus far, including alkaline phosphatase, aspartate aminotransferase, red cell distribution width, and HLR-C. These biomarkers reflect the function of multiple organs, suggesting that GMV is influenced by the function of various organs13. Notably, the strongest correlation was observed with lung function traits, underscoring the crucial role of oxygen supply in maintaining brain health37,38. This finding is further supported by our observation that blood oxygen-related biomarkers are positively correlated with GMV, and the previous finding that advanced pulmonary age emerged as the most significant predictor of mortality13. Moreover, obesity and blood pressure-related traits exhibited differential relationships with GMV, showing a negative correlation in the cortex and a positive correlation in subcortical regions. Further research is warranted to elucidate the mechanisms underlying these associations.
Although the modifiable traits collectively explained about 4.6% of the observed inter-individual variation in GMV, given that the human brain contains approximately 86 billion neurons39, even 4.6% equates to about 3.96 billion neurons. This number is considerable and holds significant implications for brain function. Across different domains, blood biomarkers, physical measurements, and diet were identified as the top three domains that explain the most variance in GMV across most brain regions. Blood biomarkers and physical measurements are easily monitored and managed, while dietary habits are amenable to intervention. The relatively low percentage of explanations for GMV variance from other lifestyles does not reduce the significance of lifestyle, as it is closely related to blood biomarker profiles. For instance, reducing inflammation can be achieved through dietary modifications40,41,42 and increased physical activity43. Notably, biomarkers related to the immune system were identified as the top domains explaining the variance in GMV across most brain regions, followed by biomarkers related to the liver, kidneys, and lungs. This further emphasizes the significance of healthy dietary and more physical activity. Additionally, we reported the composite score of modifiable traits consistently associated with total GMV and the risk of brain disorders, suggesting that the composite scores provide a generalizable method for risk classification that can be applied in diverse samples from population settings.
Through mediation analysis, we identified distinct modifiable traits that play varying roles in mediating the relationship between genetic risks for different brain disorders and GMV. Specifically, in the case of ISS, we found that the number of traits mediating the genetic effects on total GMV is the largest, followed by SCZ, BD, and AD, with a significant decrease in turn. These findings imply that the effect of PRS for ISS and SCZ on GMV is more likely achieved through changes in these modifiable traits. Additionally, we found that a large number of traits have a suppression effect on the GMV of different brain regions. One possible explanation for these findings is antagonistic pleiotropy, where a genetic locus has a beneficial effect on one trait but a detrimental effect on another32,44,45,46. This further emphasizes the importance of considering the genetic background when identifying individuals who can benefit the most from improvements in modifiable traits32,47. Notably, we discovered that education level mediates the relationship between the genetic effects of ISS, BD, and PD and total GMV. This is in line with previous finding that there is genetic overlap between these disease, educational level, and total GMV48,49,50,51.
Traits related to total GMV divided the participants into two subgroups. Subgroup 1 exhibited smaller GMV across most cortical regions and had a higher risk of incidence across all eight considered brain disorders. The traits that significantly distinguished Subgroup 1 from Subgroup 2, such as higher BMI, higher blood pressure, slower walking pace, and easier to have long-standing illness, were negatively correlated with GMV in the PWAS. This finding suggests a synergistic contribution of these unhealthy modifiable traits to the lower GMV and higher incidences of brain disorders in Subgroup 1, which aligns with previous findings indicating that individuals with multiple unhealthy lifestyle factors are at a higher risk of developing dementia52,53. Notably, the two subgroups did not differ significantly in covariates such as age and gender. Moreover, Subgroup 1 had lower PRS for brain disorders, except for ISS and MS, compared to Subgroup 2. This suggests that the differences in GMV and brain disorder risk were primarily due to differences in modifiable traits. Future public health interventions may need to focus more on individuals in Subgroup 1 to maintain their brain health and reduce their incidences of brain disorders.
The strengths of our study include a large sample size of well-phenotyped and genotyped general individuals with a long follow-up period. However, several limitations should be acknowledged. Firstly, the UKB participants is predominantly composed of individuals of white european ancestry, which may limit the generalizability of our findings to other ethnic groups. To address this limitation, replication studies in more diverse populations would be valuable. Secondly, as this is an observational study, it is important to exercise caution when inferring causality. Nonetheless, the fact that the modifiable traits were measured several years before the brain MRI scans strengthen the temporal precedence of these traits and may indicate that some of them serve as early markers of GMV loss. Thirdly, the reliance on self-reported data and single-time point measurements may introduce inaccuracies and may not fully capture the variability and temporal changes in certain traits over time. Future studies could benefit from incorporating longitudinal assessments and more objective measures to improve the accuracy and precision of the data. Additionally, we did not fully explore potential nonlinear relationships between the modifiable traits and GMVs. Investigating such relationships could provide insights into more complex interactions and potentially identify thresholds or critical periods of change54. Furthermore, while our analysis focused on GMV, future research should expand its scope to include additional brain-related metrics, such as white matter integrity, cortical thickness, and functional connectivity, to gain a more comprehensive understanding of the underlying mechanisms.
In summary, in this large community-based cohort, we identified a range of modifiable traits associated with GMV in middle-aged and older individuals, and certain modifiable traits mediated the relationship between genetic risk for brain disorders and GMV. Importantly, these modifiable traits stratified participants into two distinct subgroups exhibiting differential GMV patterns and brain disorder susceptibility. These findings highlight the potential of modifying these traits in middle-aged and older individuals to promote healthy brain aging and mitigate the risk of brain disorders.
Methods
Study design
A detailed flowchart outlining the study process is provided in Fig. 1. The study design consists of four main components: (1) PWAS of total and regional GMV: This component involves a comprehensive analysis to identify associations between various traits and both total and regional GMV. (2) Joint association of modifiable traits with GMV and brain disorders: This part examines the combined effects of modifiable traits on GMV and the incidence of brain disorders. (3) Mediation analysis of the roles of modifiable traits: This component investigates how modifiable traits mediate the relationship between PRS for brain disorders and GMV. (4) Clustering analysis of identified modifiable traits: This component entails clustering analysis to categorize individuals with comparable modifiable traits into subgroups. The identified clusters are subsequently compared to assess differences in modifiable trait profiles, GMV, and disease risk patterns.
Study participants
The UKB prospectively enrolled over 500,000 individuals, aged 37–73, from 2006 to 2010 (https://www.ukbiobank.ac.uk/). Comprehensive data on lifestyle, physical metrics, biological samples, imaging, genetic profiling, and health status were gathered through interviews, questionnaires, and direct measurements30. This community-based cohort interfaces with national health records, encompassing primary care, hospital records, mortality data, and cancer registries, with ongoing long-term follow-up initiated post-initial evaluation. In our study, participants lacking the common covariates were excluded. Participants were categorized into two groups (MRI Group and non-MRI Group) based on whether T1-MRI was performed at the time of the first imaging visit. To eliminate the impact of disease on the decline in GMV, within the MRI Group, participants with conditions that might confound GMV were further removed (Supplementary Table 14).
The UKB study received central ethical approval from the North West Multi-centre Research Ethics Committee (REC Reference:21/NW/0157), which covers all participating centers in the UK. The study was conducted in accordance with the Declaration of Helsinki. All participants provided written informed consent.
Modifiable traits
Of the initial modifiable variables, we excluded those with more than 15% missing values in the MRI Group and only included baseline data (exploring variables at https://biobank.ndph.ox.ac.uk/showcase/browse.cgi). We identified 182 potential modifiable traits from baseline measurements or derivations. The traits were categorized into nine domains: (1) blood biomarkers (for example, CRP), (2) diet (for example, beef intake), (3) early life factors (for example, maternal smoking around birth), (4) general health (for example, the overall state of health), (5) lifestyles (for example, smoking status), (6) local environment (for example, noise pollution), (7) physical measures (for example, forced vital capacity), (8) psychosocial factors (for example, irritability), and (9) socioeconomic status (SES, for example, household income). The categories of blood biomarker traits are outlined in Supplementary Table 15.
All modifiable traits included in the study were summarized in Supplementary Table 16. From the initial available modifiable traits, we excluded those with missing value > 15% of the full sample and only retained data collected at baseline. We then manually removed obviously unmodifiable exposure variables, which mainly came from the “Genomics” and “Cognitive function” categories. Multiple-choice categorical variables (e.g., types of physical activity attended) were dummy coded into dichotomous variables (i.e., whether participated in one type of activity, assigning NA to those missing on the top-level array variable). Variables with only one level were removed. We have further imposed a stricter limit on the minimum requirement for the number of cases (n > 500) in the analysis. For single-choice categorical variables, we reset the order of levels (following logical ordinal progression) and removed variables with only one level. The above data cleaning and processing steps adhere to the established methods, mirroring the procedures utilized in prior studies53. Continuous variables were loge transformed where appropriate after graphically checking their distributions, before being scaled to the standardized normal distribution to aid interpretation. All meaningless negative values were set as missing (NA).
Some variables were rearranged. For the cooked vegetable intake (Field ID 1289), the value that less than one (coding -10) were reset as 0.5 for our analysis. For the inverse distance to the nearest major road (Field ID 24012), we have calculated the reciprocal to obtain the actual direct distance for our analysis. For the variables of hand grip strength, impedance of leg, impedance of arm, leg fat percentage, and arm fat percentage, which are recorded for both the left and right sides (Field IDs 46/47, 23107/23108, 23109/23110, 23111/23115, and 23119/23123 respectively), we have computed the mean of the corresponding left and right measurements to derive the result for analysis.
Procedure used to select predictors for imputation
We used the ‘quickpred’ function from the ‘mice’ package in R to select predictors for each variable. The function creates a predictor matrix as described by Van Buuren et al. 55 This precaution allows working of this function in large sample sizes56. Missing values of traits were imputed using the multiple imputation by chained equations approach, with 5 imputed datasets and 10 iterations. For each trait, we applied a predictive mean matching model, incorporating predictors with absolute correlations exceeding 0.2.
Structural MRI data
Quality-controlled T1-weighted neuroimaging data (n = 43,101) were measured at the UKB assessment center. The scanner was a standard Siemens Skyra 3 T system with a standard Siemens 32-channel RF receive head coil. The details of image acquisition are provided on the UKB website (https://biobank.ndph.ox.ac.uk/showcase/refer.cgi?id=2367). All T1-MRI scans were processed using FreeSurfer version 6.057 (https://biobank.ndph.ox.ac.uk/showcase/refer.cgi?id=1977). Surface templates were used to extract imaging-derived phenotypes, referred to as atlas regions’ surface volume58. Subcortical regions were extracted via FreeSurfer’s aseg tool59. FreeSurfer DKT (Category ID 196) and ASEG (Category ID 190) atlas corresponding to 62 cortical regions58 and 14 subcortical regions59 were used in this study. By combining left and right hemisphere measures, we obtained 38 regional GMVs.
In addition to regional GMV measures, we included global and compartmental GMV metrics based on available UKB field identifiers. Total GMV (Field ID 26518) was used as a summary measure representing overall GMV in the brain. Separate analyses were also performed for cortical GMV (Field IDs 26552, 26583), subcortical GMV (Field ID 26517), and cerebellar GMV (Field IDs 26557, 26588). It is important to note that while GMV specifically refers to gray matter tissue, total brain volume encompasses both gray and white matter components. In total, this approach provided 42 distinct GMV measures, along with lateral ventricle volume, enabling a comprehensive analysis of both regional and global gray matter morphology.
Polygenic risk score for brain disorders
PRS, frequently derived from genome-wide association studies (GWAS), has emerged as a valuable tool for quantifying an individual’s genetic predisposition. In our research, we utilized Standard PRS for brain disorders—AD, BD, ISS, MS, PD, and SCZ—obtained from the UKB cohort. The PRS for MDD was generated using genotype data and summary statistics from a large-scale GWAS for MDD (which did not include UKB participants) with the PRSice software60. Generally speaking, the PRS were derived using a Bayesian method that leveraged meta-analyzed summary statistics GWAS data, which were exclusively sourced from external GWAS datasets. Where possible, ancestry-specific summary statistics were also incorporated to enhance accuracy. Subsequently, a principal component-based ancestry centering technique, as described by Khera et al. 61 was implemented to align the score distributions approximately to zero across various ancestries. However, it is important to note that some traits still exhibited residual deviations from zero within certain ancestry groups. Additionally, score distributions were standardized within ancestry groups to achieve an approximate unit variance, determined through a geometric inference within PC space. For further details, please refer to the UKB website (https://biobank.ndph.ox.ac.uk/showcase/refer.cgi?id=5202).
Polygenic risk score for MDD
Over 500,000 UKB participants had genotype data available. Genotyping and initial quality control were conducted by the UKB62. Quality control measures included the exclusion of single nucleotide polymorphisms (SNPs) with call rates below 95%, minor allele frequencies under 0.5%, deviations from Hardy-Weinberg equilibrium with p-values less than 1 × 10−8, and imputation information scores below 0.8. Additionally, we selected individuals based on having less than a 5% missingness rate, no heterozygosity outliers, no evidence of sex chromosome aneuploidy, self-reported white British ancestry, and no more than 10 putative third-degree relatives within the kinship matrix. After applying these criteria, we retained a total of 9,921,253 SNPs and 337,138 individuals.
PRS for MDD were constructed using the genotype data and summary statistics derived from a large-scale GWAS of MDD63, which did not include UKB participants, processed with PRSice software. Out of the initial pool, 7,972,486 SNPs were found to be common between the GWAS sample and the UKB cohort. We performed linkage disequilibrium (LD)-based clumping with a threshold of r2 = 0.1within a 250-kilobase window, resulting in 419,393 SNPs being used for PRS calculation. For our analysis, PRS was computed at a representative p-value threshold of 0.05.
Cluster analysis
We investigated whether these traits significantly associated with total GMV could classify participants into different subgroups. Initially, we adjusted for the covariates of these significant traits to remove their confounding effects, except for binary traits. Furthermore, we standardized these traits to avoid the influence of differing unit sizes. To reduce the influence of noise, principal component analysis (PCA) was applied, retaining 31 components that accounted for 75% of the variance. We applied hierarchical clustering, utilizing Ward’s method based on principal components and Euclidean distance. To determine the optimal number of clusters, we employed silhouette, Calinski–Harabasz, and Davies-Bouldin criterion. Three criterions all indicated that the participants were more appropriately divided into two subgroups, as depicted in Supplementary Fig. 9. Two-sample t-tests was employed to compare the differences in traits and GMV between these two subgroups.
Light-GBM64 algorithm was implemented by R v.4.3.2 using the publicly available R libraries; lightgbm (v.4.4.0), SHAPforxgboost (v.0.1.3), pROC65 (v.1.18.5) and caret (v.6.0-94). Light-GBM models were trained with 66 identified traits to predict the cluster results of the MRI Group. The predictive performance of the model was evaluated using a 10-fold cross-validation approach. Subsequently, this classifier was applied to the non-MRI Group. Furthermore, we conducted two-sample t-tests to compare the difference in traits and calculated the correlation between the t-values of the two groups for an evaluation of the model’s accuracy. In the survival analysis, we utilized the ‘lifelines’ package in Python to plot the Kaplan-Meier curve, enabling us to assess and compare the survival outcomes of the groups over the study period. Participants were followed up until the date of first diagnosis, death, loss to follow-up or the last date with available information (April 30, 2024), whichever came first53.
Statistical analyses
To determine traits significantly associated with GMV, we utilized a multivariable linear regression model for each trait, using Z-standardized GMV as the dependent variable and controlling for common covariates including age at baseline, sex, ethnicity, assessment site, imaging center, total intracranial volume (TIV), and the time interval between baseline assessment and imaging visit. After examining their distributions and applying loge transformation where appropriate, the traits were scaled to the standardized normal distribution66. For continuous variables, the results were reported as the β coefficient, representing the expected difference in GMV per 1 SD increase in the trait. For binary variables, the β coefficient indicated the difference in GMV between individuals with and without the trait. To account for multiple hypothesis testing in subsequent analyses, we set a stringent significance threshold using the Bonferroni correction. Traits were considered significantly associated with GMV if they achieved a corrected p-value of less than 2.75 × 10−4.
PLS was utilized with all available modifiable traits to quantify their collective contribution of the variance in GMV. This multivariate approach effectively accounts for multicollinearity among traits while identifying latent components that maximize the covariance between predictors (i.e., modifiable traits) and outcomes (i.e., total and regional GMV). To assess the relative contribution of each trait domain, we performed separate PLS analyses within each domain and compared the variance explained in GMV.
To examine whether the cumulative effects of modifiable traits were associated with disease risk, we derived a composite score based on the β coefficients obtained from the PLS analysis of total GMV in the MRI group. These coefficients were applied to the corresponding traits in the independent non-MRI group to generate an aggregate score reflecting each individual’s overall profile of modifiable risk. Scores were then categorized into tertiles representing favorable, intermediate, and unfavorable modifiable-trait profiles. These categories were then incorporated into Cox proportional hazards regression models to test associations with incident brain disorders, after adjusting for age at baseline, sex, and ethnicity.
Mediation analysis was employed to assess whether specific traits act as mediators in the relationship between the specific genetic risk for brain disorders and GMV across diverse brain regions. Initially, we adjusted the effects of covariates from the continues modifiable traits, such as age, sex, ethnicity, and assessment site. Similarly, we also adjusted for covariates in the GMV, including age at baseline, sex, ethnicity, assessment site, imaging site, TIV and the time interval between the baseline assessment and the imaging visit. After regression out these common covariates, we normalized both traits and GMV. Subsequently, mediation analysis was employed to evaluate whether specific traits mediate the relationship between each individual PRS (for 7 brain disorders: AD, BD, ISS, MDD, PD, MS, SCZ) and GMV across various brain regions, using the bruceR (v.2024.6) R package. Notably, all PRS analyses were conducted separately for each disorder to ensure specificity of effects. In the study, mediation effects refer to the indirect effect of an independent variable on a dependent variable through a mediator variable. Suppression effects describe a phenomenon where the true effect of a variable on the dependent variable is concealed or distorted due to the presence of other variables63. The bootstrapping method with 1000 resamples was used to estimate the effects, and bias-corrected 95% confidence intervals were calculated.
To assess the differences in brain disorder risk between the two subgroups, we used Cox proportional hazard regression models adjusted for the common covariates mentioned above. Missing values of traits were imputed using the multiple imputation by chained equations approach67, with 5 imputed datasets and 10 iterations. For each trait, we applied a predictive mean matching model, incorporating predictors with absolute correlations exceeding 0.256. All P values were two-sided, and analyses were conducted using MATLAB R2021a, R v 4.3.2, Python 3.9.6.
Data availability
Individual-level UKB data (phenotypic, neuroimaging, and genotype) are available via the UKB Research Analysis Platform (RAP). Detailed information on registration and data access can be found at http://www.ukbiobank.ac.uk/register-apply/. Use of UKB data in this study was approved under application number 19542.
Code availability
The codes used in this study are available at GitHub (https://github.com/SnowSunshine-gqp/UKB_PWAS) and archived at Zenodo (https://doi.org/10.5281/zenodo.15554259). Analytical tools include: The SHAPforxgboost R package (https://github.com/liuyanguu/SHAPforxgboost/) for SHAP value calculation; The LightGBM R package (https://lightgbm.readthedocs.io/en/stable/) for gradient-boosted modeling; The lifelines Python package (https://lifelines.readthedocs.io/en/latest/) for Cox proportional hazards regression analysis; PLINK 2.0 (https://www.cog-genomics.org/plink/2.0/) for genome-wide association studies (GWAS); PRSice-2 (https://choishingwan.github.io/PRSice/) for PRS analysis.
References
Livingston, G. et al. Dementia prevention, intervention, and care: 2020 report of the Lancet Commission. Lancet 396, 413–446 (2020).
Partridge, L., Deelen, J. & Slagboom, P. E. Facing up to the global challenges of ageing. Nature 561, 45–56 (2018).
Yang, Y., Wang, D., Hou, W. & Li, H. Cognitive Decline Associated with Aging. Adv. Exp. Med. Biol. 1419, 25–46 (2023).
Bethlehem, R. A. I. et al. Brain charts for the human lifespan. Nature 604, 525–533 (2022).
Johansson, M. E., Toni, I., Kessels, R. P. C., Bloem, B. R. & Helmich, R. C. Clinical severity in Parkinson’s disease is determined by decline in cortical compensation. Brain 147, 871–886 (2024).
Cabeza, R. et al. Maintenance, reserve and compensation: the cognitive neuroscience of healthy ageing. Nat. Rev. Neurosci. 19, 701–710 (2018).
Pan, G. et al. Identification of Parkinson’s disease subtypes with distinct brain atrophy progression and its association with clinical progression. Psychoradiology 4, kkae002 (2024).
Dzialas, V. et al. Structural underpinnings and long-term effects of resilience in Parkinson’s disease. NPJ Parkinsons Dis 10, 94 (2024).
Knights, E., Henson, R. N., Morcom, A. M., Mitchell, D. J. & Tsvetanov, K. A. Neural evidence of functional compensation for fluid intelligence in healthy ageing. Elife 13, RP93327 (2023).
Guo, L., Alexopoulos, P., Wagenpfeil, S., Kurz, A. & Perneczky, R. Brain size and the compensation of Alzheimer’s disease symptoms: a longitudinal cohort study. Alzheimer’s. Dement. 9, 580–586 (2013).
Wang, L. et al. Association of structural measurements of brain reserve with motor progression in patients with Parkinson disease. Neurology 99, e977–e988 (2022).
Lee, J. et al. Deep learning-based brain age prediction in normal aging and dementia. Nat. Aging 2, 412–424 (2022).
Tian, Y. E. et al. Heterogeneous aging across multiple organ systems and prediction of chronic disease and mortality. Nat. Med. 29, 1221–1231 (2023).
Yang, Z. et al. Brain aging patterns in a large and diverse cohort of 49,482 individuals. Nat. Med. 30, 3015–3026 (2024).
Duan, H. et al. Population clustering of structural brain aging and its association with brain development. Elife 13, RP94970 (2024).
Eavani, H. et al. Heterogeneity of structural and functional imaging patterns of advanced brain aging revealed via machine learning methods. Neurobiol. Aging 71, 41–50 (2018).
Hamer, M. & Batty, G. D. Association of body mass index and waist-to-hip ratio with brain structure: UK Biobank study. Neurology 92, e594–e600 (2019).
Lv, H. et al. Association between body mass index and brain health in adults: a 16-year population-based cohort and Mendelian randomization study. Health Data Sci. 4, 0087 (2024).
Sun, Y. et al. The causal relationship between physical activity, sedentary behavior and brain cortical structure: a Mendelian randomization study. Cereb. Cortex 34, bhae119 (2024).
Zhong, Y. et al. Resting heart rate causally affects the brain cortical structure: Mendelian randomization study. Cerebral Cortex 34, bhad536 (2024).
Huang, L. Y. et al. Identifying modifiable factors associated with neuroimaging markers of brain health. CNS Neurosci. Ther. 30, e70057 (2024).
Walhovd, K. B. et al. Timing of lifespan influences on brain and cognition. Trends Cognit. Sci. 27, 901–915 (2023).
Moguilner, S. et al. Brain clocks capture diversity and disparities in aging and dementia across geographically diverse populations. Nat. Med. 30, 3779 (2024).
Li, Y. et al. Healthy lifestyle and life expectancy free of cancer, cardiovascular disease, and type 2 diabetes: Prospective cohort study. BMJ 368, l6669 (2020).
Wrigglesworth, J. et al. Health-related heterogeneity in brain aging and associations with longitudinal change in cognitive function. Front. Aging Neurosci. 14, 1063721 (2023).
Xiang, S. et al. Association between vmPFC gray matter volume and smoking initiation in adolescents. Nat. Commun. 14, 4684 (2023).
Mulugeta, A., Lumsden, A. & Hyppönen, E. Unlocking the causal link of metabolically different adiposity subtypes with brain volumes and the risks of dementia and stroke: A Mendelian randomization study. Neurobiol. Aging 102, 161–169 (2021).
Luo, D. et al. Association between high blood pressure and long term cardiovascular events in young adults: Systematic review and meta-analysis. BMJ 370, m3222 (2020).
Bahorik, A. L., Hoang, T. D., Jacobs, D. R., Levine, D. A. & Yaffe, K. Association of changes in C-reactive protein level trajectories through early adulthood with cognitive function at midlife: the CARDIA study. Neurology 103, e209526 (2024).
Sudlow, C. et al. UK Biobank: an open access resource for identifying the causes of a wide range of complex diseases of middle and old age. PLoS Med. 12, e1001779 (2015).
Dohm-Hansen, S. et al. The ‘middle-aging’ brain. Trends Neurosci. 47, 259–272 (2024).
Benton, M. L. et al. The influence of evolutionary history on human health and disease. Nat. Rev. Genet. 22, 269–283 (2021).
Williams, J. A. et al. Inflammation and brain structure in schizophrenia and other neuropsychiatric disorders. JAMA Psychiatry 79, 498 (2022).
Kang, J. et al. Increased brain volume from higher cereal and lower coffee intake: shared genetic determinants and impacts on cognition and metabolism. Cereb. Cortex 32, 5163–5174 (2022).
Luciano, M. et al. Mediterranean-type diet and brain structural change from 73 to 76 years in a Scottish cohort. Neurology 88, 449–455 (2017).
Petersen, R. C., Joyner, M. J. & Jack, C. R. Cardiorespiratory fitness and brain volumes. Mayo Clin. Proc. 95, 6–8 (2020).
Beinlich, M. F. R. et al. Oxygen Imaging of Hypoxic Pockets in the Mouse Cerebral Cortex. Science 383, 1471–1478 (2024).
Grande, G. et al. Lung function in relation to brain aging and cognitive transitions in older adults: A population-based cohort study. Alzheimers Dement 20, 5662–5673 (2024).
Herculano-Houzel, S. The human brain in numbers: A linearly scaled-up primate brain. Front. Human Neurosci. 3, 31 (2009).
Wang, P. et al. Optimal dietary patterns for prevention of chronic disease. Nat. Med 29, 719–728 (2023).
Duggan, M. R. et al. Plasma proteins related to inflammatory diet predict future cognitive impairment. Mol. Psychiatry 28, 1599–1609 (2023).
Dove, A. et al. Anti-inflammatory diet and dementia in older adults with cardiometabolic diseases. JAMA Netw. Open 7, e2427125 (2024).
De Miguel, Z. et al. Exercise plasma boosts memory and dampens brain inflammation via clusterin. Nature 600, 494–499 (2021).
Long, E. & Zhang, J. Evidence for the role of selection for reproductively advantageous alleles in human aging. Sci Adv. 9, eadh4990 (2023).
Trumble, B. C. et al. Apolipoprotein-ε4 is associated with higher fecundity in a natural fertility population. Sci. Adv. 9, eade9797 (2023).
Nesse, R. M. Evolutionary psychiatry: foundations, progress and challenges. World Psychiatry 22, 177–202 (2023).
Sun, D. et al. Joint impact of polygenic risk score and lifestyles on early- and late-onset cardiovascular diseases. Nat. Hum. Behav. 8, 1810–1818 (2024).
Zhang, J. et al. Genetic overlap between schizophrenia and cognitive performance. Schizophrenia 10, 31 (2024).
Karpinski, R. I., Kinase Kolb, A. M., Tetreault, N. A. & Borowski, T. B. High intelligence: A risk factor for psychological and physiological overexcitabilities. Intelligence 66, 8–23 (2018).
Deary, I. J., Cox, S. R. & Hill, W. D. Genetic variation, brain, and intelligence differences. Mol. Psychiatr. 27, 335–353 (2022).
Shi, J. et al. Intelligence, education level, and risk of Parkinson’s disease in European populations: a Mendelian randomization study. Front. Genet. 13, 963163 (2022).
Hendriks, S. et al. Risk factors for young-onset dementia in the UK biobank. JAMA Neurol. 81, 134–142 (2023).
Zhang, Y. et al. Identifying modifiable factors and their joint effect on dementia risk in the UK Biobank. Nat. Hum. Behav. 7, 1185–1195 (2023).
Zhao, Y. et al. The brain structure, immunometabolic and genetic mechanisms underlying the association between lifestyle and depression. Nat. Mental Health 1, 736–750 (2023).
Van Buuren, S., Boshuizen, H. C. & Knook, D. L. Multiple imputation of missing blood pressure covariates in survival analysis. Stat. Med 18, 681–694 (1999).
Ganna, A. & Ingelsson, E. 5 year mortality predictors in 498 103 UK Biobank participants: a prospective population-based study. Lancet 386, 533–540 (2015).
Dale, A. M., Fischl, B. & Sereno, M. I. Cortical Surface-Based Analysis I. Segmentation and Surface Reconstruction. Neuroimage 9, 179–194 (1999).
Klein, A. & Tourville, J. 101 labeled brain images and a consistent human cortical labeling protocol. Front. Neurosci. 6, 171 (2012).
Fischl, B. et al. Whole brain segmentation. Neuron 33, 341–355 (2002).
Wray, N. R. et al. Genome-wide association analyses identify 44 risk variants and refine the genetic architecture of major depression. Nat. Genet 50, 668–681 (2018).
Khera, A. V. et al. Whole-genome sequencing to characterize monogenic and polygenic contributions in patients hospitalized with early-onset myocardial infarction. Circulation 139, 1593–1602 (2019).
Bycroft, C. et al. The UK Biobank resource with deep phenotyping and genomic data. Nature 562, 203–209 (2018).
Wray, N. R. et al. Genome-wide association analyses identify 44 risk variants and refine the genetic architecture of major depression. Nat. Genet. 50, 668–681 (2018).
Ke, G. et al. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. https://github.com/Microsoft/LightGBM.
Robin, X. et al. pROC: An open-source package for R and S+ to analyze and compare ROC curves. BMC Bioinform 12, 77 (2011).
Bountziouka, V. et al. Modifiable traits, healthy behaviours, and leukocyte telomere length: a population-based study in UK Biobank. Lancet Healthy Longev 3, e321–e331 (2022).
van Buuren, S. & Groothuis-Oudshoorn, K. Mice: multivariate imputation by chained equations in R. J. Stat. Softw. 45, 1–67 (2011).
Acknowledgements
This study was funded by grants from the National Natural Science Foundation of China (82302312, 82071997, 82472055, and 62433008), the Natural Science Foundation of Shanghai (23ZR1406000), Shanghai Science and Technology Commission Program (23JS1410100), Shanghai Rising-Star Program (21QA1408700) and 111 Project (B18015). Further, we would like to thank the support from the Shanghai Center for Brain Science and Brain-Inspired Technology, ZHANGJIANG LAB, and the State Key Laboratory of Neurobiology and Frontiers Center for Brain Science of Ministry of Education. We want to thank all the participants and researchers from the UKB. This paper's language has been polished by Qwen 2.5 to improve its readability and overall linguistic quality. The authors are responsible for the originality, accuracy, and integrity of the work.
Author information
Authors and Affiliations
Contributions
G.Q.P., L.B.W., and W.C. had full access to all study data and take responsibility for the integrity of the data and the accuracy of the data analysis. L.B.W. and W.C. conceived and designed this study. G.Q.P. drafted the initial version of the manuscript. Y.Z., J.J.K., Y.C.J., W.Z., J.-F.F., J.T.Y., W.K.G., X.J.Z., W.C., and L.B.W. critically revised the manuscript for important intellectual content. Statistical analysis was conducted by G.Q.P. and L.B.W. Funding for the project was acquired by L.B.W., W.C., and J.-F.F. All authors were actively engaged in the acquisition, analysis, or interpretation of the data. Additionally, all authors read and gave their approval to the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Pan, G., Zhang, Y., Kang, JJ. et al. Modifiable traits and genetic associations with grey matter volume in mid-to-late adulthood: a population-based study in the UK biobank. npj Aging 11, 67 (2025). https://doi.org/10.1038/s41514-025-00255-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41514-025-00255-8
