
Abstract
Type 2 diabetes (T2D) is a multifaceted disease associated with several factors, including diet, genetics, exercise, sleep and gut microbiome. Current diagnostic and monitoring methods based on episodic assays like glycated hemoglobin (HbA1c) fail to capture its full complexity. Here, in a prospective cohort of 1,137 participants in the United States, we analyzed multimodal data from 347 deeply phenotyped individuals (174 normoglycemic, 79 prediabetic and 94 T2D). We found significant differences in the distribution of glucose spike metrics among different diabetes states, with longer expected time for spike resolution and higher values of nocturnal hypoglycemia in T2D. We identified significant correlations between mean glucose level and gut microbiome diversity, and between expected time for spike resolution and resting heart rate. Our multimodal glycemic risk profiles, validated in 1,955 normoglycemic and 114 prediabetic individuals from an independent cohort, improved risk stratification by highlighting substantial variability among individuals with the same value of HbA1c. Such a multimodal approach provides a detailed phenotype that can potentially improve T2D prevention, diagnosis and treatment, and is more informative than HbA1c.
Similar content being viewed by others

Main
In the United States, 38.4 million people have diabetes, and 97.6 million people aged 18 years or older have prediabetes1. Despite the multiple factors that may influence an individual’s glucose homeostasis, we continue to rely solely on glycated HbA1c and fasting glucose measurements for diagnosis and monitoring2,3,4,5. Previous research indicated a high frequency of postprandial abnormal glucose spikes in healthy individuals6,7,8, but the basis of these spikes is poorly understood. Factors such as age9, diet10, physical activity11, sleep12, gut microbiome constituents13, stress14, comorbidities15,16 and genetics17 are thought to be potential modulators. Taking a holistic approach encompassing multimodal data could greatly enhance understanding of individual variability in glucose spikes. Prior studies established the foundation for multimodal analysis of glucose dynamics, but they are limited in scope as they focused primarily on normoglycemic and prediabetic individuals7,8 and did not place specific emphasis on ensuring adequate representation of all individuals, including those underrepresented in biomedical research (UBR).
We conducted a prospective, site-less clinical trial to collect multimodal data from a diverse group of participants with a range of abnormal glucose homeostasis, from normoglycemia to prediabetes (or intermediate hyperglycemia) to type 2 diabetes (T2D). The PRediction Of Glycemic RESponse Study (PROGRESS) digitally enrolled 1,137 participants in the United States who were asked to provide a unique combination of demographic, anthropometric, clinical, physiological, biological and lifestyle data (Fig. 1) Building on the promising results of previous studies based on continuous monitoring of glucose levels6,7,8,18,19, we remotely collected multimodal data that enabled the development of an advanced model for enhanced risk stratification of prediabetic individuals. The analytical techniques developed in this study were subsequently tested using Human Phenotype Project (HPP) data, including 12,014 deeply phenotyped individuals.

a, Tools for multimodal remote data collection in PROGRESS, including study-provided wearable devices and kits for biosample self-collection. b, Visual representation of the definition of a glucose spike: a rise in glucose level of at least 30 mg dl−1 within 90 min or less. Panels a and b created with BioRender.com.
The aim of this work was to investigate the determinants of abnormal glucose spikes across different diabetes states and to leverage multimodal data to define multimodal glycemic risk profiles that can potentially change our approach to preventing and treating T2D by enhancing early diagnosis and improving monitoring of prediabetes and prediction of T2D.
Results
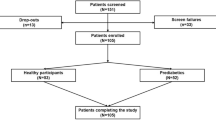
Between 3 November 2021 and 1 September 2023, PROGRESS enrolled 1,137 individuals, of whom 423 (37.2%) were normoglycemic, 316 (27.8%) were prediabetic and 398 (35.0%) had T2D, based on self-reported data. Among enrolled participants, 463 shared their Fitbit data, 445 shared their food logging data and 412 shared their continuous glucose monitoring (CGM) device data during the 10-day period of active tracking; 657 participants shared their electronic health record (EHR) data. For 503 of the enrolled participants, an HbA1c value was available from self-collected blood samples; for 471 participants, probiotic scores and Shannon diversity indices were computed from self-collected stool samples; and, for 506 participants, a polygenic risk score (PRS) for T2D was derived from the analysis of self-collected saliva samples. Of the 1,137 enrolled participants, 73 withdrew from the study. Based on EHR data, we manually excluded 13 participants with type 1 diabetes (T1D) or taking insulin at the time of enrollment.
For this analysis, we considered participants who wore the CGM device for at least 16 h per day and at least 5 days. We excluded participants who did not report their age or sex or whose HbA1c was not available. We included 347 individuals, of whom 174 (50.1%) were normoglycemic, 79 (22.8%) were prediabetic and 94 (27.1%) had T2D (Extended Data Fig. 1).
The average age of the selected population was 49.1 ± 15.6 years (mean ± s.d.), and 66.9% were females. The average body mass index (BMI) was 27.8 ± 7.0 kg m−2. The differences between the participants included in the analysis and those excluded from the analysis were not statistically significant in terms of age (t-test, P = 0.970) and sex (Fisherʼs exact test, P = 0.200).
Participants were considered UBR if they self-identified as any of the following: race and ethnicity other than White; gender identity other than male or female; age > 65 years; less than a high school diploma; or resides in a rural zip code20. By these criteria, 48.1% of the selected participants were UBR, and 23.3% were UBR for race/ethnicity (Table 1).
Glucose spikes
We analyzed the following glucose spike metrics: the mean glucose level, the nocturnal hypoglycemia, the percentage of time spent above 150 mg dl−1, the expected maximum spike value relative to the baseline, the expected daily number of spikes and the spike resolution (average time required to absorb 50% of the glucose spike). Statistically significant differences, while controlling for age, sex and PRS, in all glucose spike metrics were observed between individuals with T2D and normoglycemic individuals (P < 0.001 for all metrics, except for the expected daily number of spikes where P = 0.001). Prediabetic individuals showed statistically significant differences compared to individuals with T2D in terms of expected daily number of spikes (partial eta squared (ηp2) = 0.036, P = 0.019) and expected maximum spike relative value (ηp2 = 0.102, P < 0.001). However, these differences were not observed when comparing prediabetic to normoglycemic individuals (P = 0.727 and P = 0.919, respectively). Furthermore, the differences between prediabetic and T2D were more pronounced compared to the differences between prediabetic and normoglycemic in terms of spike resolution (ηp2 = 0.139, P < 0.001 compared to T2D; ηp2 = 0.068, P < 0.001 compared to normoglycemic), percentage of time spent in hyperglycemia (ηp2 = 0.167, P < 0.001 compared to T2D; ηp2 = 0.091, P < 0.001 compared to normoglycemic), mean glucose level (ηp2 = 0.143, P < 0.001 compared to T2D; ηp2 = 0.110, P < 0.001 compared to normoglycemic) and nocturnal hypoglycemia (ηp2 = 0.068, P = 0.001 compared to T2D; ηp2 = 0.061, P < 0.001 compared to normoglycemic) (Fig. 2).

a–f, Glucose spike metrics box plots: mean glucose level, defined as the average of glucose values over the entire tracking period (a); expected maximum spike relative value, defined as the maximum spike value relative to the baseline, averaged across different days (b); percentage of time spent above 150 mg dl−1 (c); spike resolution, defined as the time required to absorb 50% of the glucose spike, averaged across all glucose spikes (d); expected daily number of spikes, defined as the daily number of glucose spikes, averaged across different days (e); and nocturnal hypoglycemia, defined as the average minimum glucose value occurring between 24:00 and 7:00, averaged across different days (f). The glucose spike metrics are reported by stratifying them based on self-reported diabetes status (normoglycemia, n = 174; prediabetes, n = 79; T2D, n = 94). The boxes represent the interquartile range, the vertical lines are the median values, and the whiskers show the 5th and 95th percentiles.
Reference values of the multimodal variables considered in the analysis and the distributions of glucose spike metrics across diabetes states are reported (Extended Data Table 1 and Extended Data Fig. 2).
By analyzing the drug exposure table from the EHR data, we discovered that, of the 347 participants included in our study, 78 individuals were prescribed antihyperglycemic medications. Among them, 64 had T2D, 12 were prediabetic and 2 were normoglycemic. We did not find statistically significant differences in glucose spike metrics between individuals with T2D who were taking antihyperglycemic medications and those who were not (n = 30).
To investigate the associations between the glucose spike metrics and demographic, anthropometric, biological, physiological and lifestyle factors, we computed the Spearman’s rank correlation coefficient (r) while controlling for age, sex and PRS. The available multimodal factors were divided into three groups (demographic factors, metabolic factors and lifestyle factors) based on their potential for intervention. Age was the only demographic factor that exhibited statistically significant correlations with all glucose spike metrics considered except with the expected daily number of spikes (P = 0.092). Among the metabolic factors, the HbA1c was positively correlated with all the glucose spike metrics; BMI and resting heart rate were found positively correlated with mean glucose level, nocturnal hypoglycemia, percentage of time spent in hyperglycemia and spike resolution; and gut microbiome diversity was negatively correlated with all glucose spike metrics except spike resolution (with which the correlation was found not statistically significant, P = 0.240)—in particular, r = −0.301 (P < 0.001) with mean glucose level and r = −0.288 (P < 0.001) with percentage of time spent in hyperglycemia—indicating that a more diverse gut microbiome is generally associated with healthier glucose spike metrics traditionally used for monitoring purposes. Regarding lifestyle factors, the daily intake of carbohydrates showed statistically significant positive correlations with expected maximum spike relative value and the expected daily number of spikes. Notably, we observed a statistically significant negative correlation between carbohydrate intake and spike resolution, suggesting that a higher daily intake of carbohydrates is associated with a faster absorption of glucose spikes. A negative correlation was observed between activity level and all glucose spike metrics, except for the expected daily number of spikes (with which the correlation was not statistically significant, P = 0.436). This suggests that individuals who engage in higher levels of physical activity tend to exhibit more favorable glucose spike metrics (Fig. 3).

a,b, Spearman’s rank correlation coefficients (dots) between glucose spike metrics representing mean glucose levels (a) and spike resolution—that is, the average time (in minutes) to absorb 50% of the glucose spike (b). Two-sided statistical tests were used. Lines represent 95% confidence intervals. Correlations with statistically significant FDR-corrected P values are marked with the star symbol. Multimodal factors are divided into three groups: demographic factors (top), metabolic factors (middle) and lifestyle factors (bottom). n, sample size.
Correlations with expected daily number of spikes, expected maximum spike relative value, nocturnal hypoglycemia and percentage of time spent above 150 mg dl−1 are reported (Extended Data Fig. 3).
Multimodal glycemic profiles for T2D risk assessment
We designed a multimodal binary classification model, trained to separate normoglycemic individuals and individuals with T2D in the PROGRESS cohort, which had an area under the curve (AUC) of 0.96 and a confidence interval of 0.94–0.98 (Supplementary Fig. 1). This model was tested also in the external, independent validation cohort (HPP), where we obtained AUC = 0.90 (confidence interval: 0.82–0.97) and an area under the precision-recall curve (AUPRC) of 0.60 (confidence interval: 0.40–0.77) (Supplementary Results). The feature importance analysis for this binary classification task is reported (Supplementary Fig. 2).
This model proposes a metric that is complementary to HbA1c, improving the identification of prediabetic individuals at risk of progressing into the pathological stage of the disease. We use this model to get multimodal glycemic risk profiles for T2D risk assessment (Supplementary Fig. 3).
Although we observed that the multimodal glycemic risk profiles are, on average, higher for individuals with higher values of HbA1c, we also observed substantial variability, potentially highlighting that our model is considering all available data and provides a tool to assess an individual’s potential progression to T2D, beyond observing only one value of HbA1c. To validate the model, we used HPP as an external, independent cohort. As of 1 September 2024, 12,014 individuals were present in the HPP dataset. Using the same selection criteria used for PROGRESS participants, 2,069 individuals were included in the external validation dataset, of whom 1,955 (94.5%) were normoglycemic and 114 (5.5%) were prediabetic, based on self-reported data. The average age was 51.6 ± 8.0 years, and 51.9% were females. The average BMI was 26.2 ± 4.2 kg m−2. A demographic comparison between the PROGRESS prediabetic cohort and the HPP prediabetic cohort highlighted a difference in sex (Fisherʼs exact test, P = 0.003) but no statistically significant difference in age (t-test, P = 0.458). We did not have sufficient information to determine the percentage of UBR individuals in the HPP dataset.
Similar to what was observed in the prediabetic cohort in PROGRESS, the multimodal glycemic risk profiles of the prediabetic cohort in HPP showed a pattern consistent with the HbA1c values. More importantly, we observed substantial variability in the risk profile for the same values of HbA1c, potentially confirming in the external validation cohort that our model provides additional information on the progression to T2D with respect to the value of HbA1c alone (Fig. 4).

a,b, HbA1c values and multimodal glycemic risk profiles for prediabetic participants in the PROGRESS cohort (a) and for prediabetic participants in the HPP cohort (b). The multimodal glycemic risk profiles were obtained from a binary classification model trained on PROGRESS with demographics, anthropometrics, CGM, food intake and gut microbiome as input data modalities. The blue horizontal lines represent the multimodal glycemic risk profile median values after binning the HbA1c with intervals of width 0.4. The red vertical dashed lines mark the boundaries of the prediabetic range, spanning from 5.7% to 6.5%. We limited the x axis to values of HbA1c less than 9% to enhance visualization. As a result, one HPP participant with an HbA1c value of 9.5% and a multimodal glycemic risk profile equal to 0.87 was omitted from the graph.
The same considerations apply to the multimodal glycemic risk profiles of the HPP normoglycemic cohort (Extended Data Fig. 4). A comparison between PROGRESS and the external HPP validation dataset is also reported (Extended Data Table 2).
Discussion
T2D and prediabetes are currently diagnosed and monitored using episodic assays of HbA1c or fasting glucose21,22. Prior studies indicated that healthy individuals, as well as those with prediabetes, have frequent, variable postprandial glucose spikes that are not detected by HbA1c or fasting glucose measurements6,7,8. We sought to understand the basis for these spikes in a range of glucose homeostatic conditions using deep phenotyping in a prospective cohort. Research has largely focused on predicting the glycemic response to individual meals. However, there has been limited exploration into effectively integrating multimodal data for monitoring and prevention purposes, and it remains unclear to what extent global glycemic patterns, observed over multiple days, can be used to characterize different diabetes states. What remains unknown are the drivers and weights of each driver for these glucose spikes, such as gut microbiome, exercise, sleep, stress, genomics, age, body habitus and comorbidities. To understand the complex relationship across these variables and their association with glucose metabolism, we collected real-world multimodal data from normoglycemic individuals, prediabetic individuals and individuals with T2D and studied how glucose spikes relate to different diabetes states and to demographic, anthropometric, clinical, biological, physiological and lifestyle factors.
We defined metrics capturing various aspects of glucose spike dynamics and demonstrated that, when considering the three groups of normoglycemic, prediabetic and T2D, there are significant differences in their overall distribution. The intermediate stage of prediabetes showed greater similarities to normoglycemia than T2D. The high variability observed within each diabetes status highlights the remarkable heterogeneity of the disease, indicating the need for individual-level analysis to adequately represent its nuances.
The correlations found between lifestyle factors and glucose spike metrics unveiled that interventions targeting dietary habits, sleep patterns and physical activity might have a measurable impact on glucose regulation. Furthermore, in line with prior studies7,8, our findings provide additional support for the critical importance of maintaining a diverse gut microbiome, which we found associated with improved glucose control. We observed a noteworthy decline in glucose spike metrics as individuals age, which emerged as the sole demographic factor exhibiting statistically significant correlations with these metrics. Interestingly, the association between the PRS for T2D and glucose spikes was not statistically significant, suggesting that a combination of environmental and genetic factors may be necessary for onset of disease.
Considering the heterogeneity of T2D, new models of disease have been proposed, such as McCarthy’s palette model23, which goes beyond hard categorizations that rely on the oversimplistic view provided by routine episodic laboratory measures of hyperglycemia. Identifying these phenotypes would allow us to risk-stratify individuals to enable targeted interventions, from monitoring high-risk prediabetic individuals to promoting education and support for intensive lifestyle changes in high-risk normoglycemic individuals24. To investigate this more deeply, we designed a multimodal machine learning model for T2D risk assessment, incorporating all glucose spike metrics and multimodal factors other than HbA1c, and we applied it to PROGRESS prediabetic participants. The multimodal glycemic risk profiles generated by our model, while globally consistent with HbA1c values, delineated a more detailed phenotype able to effectively discriminate between individuals with the same HbA1c value but different glycemic patterns. We applied our model to normoglycemic and prediabetic participants from an independent cohort (HPP) for external validation. Despite the multimodal glycemic risk profiles having lower values in the HPP cohort compared to the PROGRESS cohort, there was a consistent pattern with HbA1c values and a substantial variability, albeit reduced compared to PROGRESS, in individuals with the same HbA1c. This external validation, conducted on a large dataset and on a population that is markedly different from the PROGRESS cohort in terms of geographical location, dietary habits, demographics and data acquisition methods, demonstrates the wider applicability of our multimodal glycemic risk profiles. Our findings showcase how a multimodal approach can better capture the nuances of T2D, with respect to the narrower perspective of episodic assays. Our multimodal artificial intelligence (AI) model, which includes continuous biosensor data, may be instructive for future analysis of multilayered datasets that include sensors.
This work draws on recent studies exploring the potential of multimodal data, and in particular CGM, for advancing the scientific understanding of T2D and prediabetes. By combining clinical, biological, physiological and lifestyle data, many unknown patterns have been uncovered6,7,18,19,25,26, but it remains challenging to understand how multimodal analytics can change the way we practice and understand diabetes. Notably, the multivariate subphenotyping of the TUEF/TULIP prediabetic cohort (consisting of 899 prediabetic individuals) identified six distinct clusters of subphenotypes, two of which were associated with imminent risk of T2D27. Similarly, in a large cohort of 1,567,636 patients with T2D recruited in Ontario, Canada, adverse outcomes due to diabetes complications were predicted based on physician claims, laboratory results, prescriptions, medication history and other administrative heath data28.
Our study is taking this further by incorporating food intake, CGM, genetics data and gut microbiome data in addition to all the clinical data available from the EHR in both a pathologic and a non-pathologic cohort. Furthermore, digital, decentralized clinical trials, which use mobile technology such as wearable devices and digital platforms to facilitate trial processes, and where all tasks (ranging from enrollment to self-collection of biosamples) can be performed from the comfort of the participant’s home, represent a clear shift from the traditional site-centric paradigm to a remote, participant-centric one29,30,31. The PROGRESS study demonstrates how decentralized digital trials allow for continuous capture of contextualized data in real-world settings while ensuring robust representation with a diverse cohort with 48.1% of participants self-identified as UBR. This exceptional representation of underrepresented individuals enhances the importance and value of our analysis, contributing to a more thorough understanding of glucose spikes across different diabetes states.
Using large studies such as HPP and combining variables from multiple sources, the variability in risk for developing T2D or further complications of the disease can be explored within different subphenotypes. Multivariate subphenotyping has already proved to be effective in predicting disease progression27. However, if based on infrequent and expensive laboratory test results, this approach may not be scalable. The PROGRESS study suggests a potential solution by demonstrating the feasibility of passive collection of physiological data through wearable devices, which allows the continuous remote monitoring of an individual’s health status at finer temporal resolutions. This monitoring strategy could transform the way individuals are screened and diagnosed and ultimately how care is delivered, especially in a clinically asymptomatic cohort. Acknowledging that the appropriate infrastructure and privacy/security controls would have to be addressed, the implementation of personalized risk assessment in clinical practice would allow clinicians to gain a comprehensive understanding of individuals’ health status and the risk of developing T2D, enabling timely interventions and adjustments to treatment plans. The potential impact of this approach on public health is substantial because, after prospective validation, it could effectively assess diabetes risk within primary care settings and deliver crucial information to improve preventive lifestyle programs. Ultimately, this could help reduce the prevalence of T2D and prediabetes.
This study represents the initial step toward the early diagnosis, monitoring and prevention of T2D and prediabetes through the use of multimodal data. We conducted an initial assessment of the correlations between glucose spikes and various demographic, metabolic and lifestyle factors that will inform future interventional studies focused on investigating the causal relationships that underlie these associations. Additionally, our method for multimodal risk assessment of prediabetic individuals, which was validated on an independent cross-sectional cohort, will potentially serve as a foundation for future longitudinal studies that aim to use multimodal data for T2D risk stratification. Our group intends to understand the relevance of these findings on adverse clinical outcomes of diabetes in a longitudinal cohort of a prediabetic and diabetic population. We are actively designing a study to look at the prognostic impact of glucose spike metrics, integrating novel tools such as proteomic organ clocks in our analysis.
Technologies are a key component of remote, real-world data collection in decentralized clinical trials, although they may cause unintentional selection biases due to difficulties for certain groups of individuals to access many of these technologies, resulting in potential discrimination against the low-income socioeconomic class or the elderly. In this study, we attempted to mitigate this bias through study-provisioned devices to all participants. Additionally, the precision of the sensors and the accuracy of self-reported data, such as diabetes status and food intake logging, may introduce limitations in the findings. In particular, accurate reporting of food intake for participants in real-world conditions as part of a decentralized clinical trial proved challenging (in adherence and accuracy) for many. Further studies are needed to develop a more user-friendly application for collecting food intake focused on participant preferences. Additionally, the use of different CGM devices in PROGRESS and HPP might lead to biases in the analysis of the multimodal glycemic risk profiles. In future studies, it would be valuable to investigate potential biases arising from the use of different devices and methodologies for data collection. Raw data from wearable devices, EHRs, self-reported food intake, genomics and gut microbiome were aggregated to derive summary metrics for each participant. The chosen data aggregation methods could potentially impact the multimodal analysis and the assessment of significance for each data modality. Moreover, the use of antihyperglycemic therapies, which are common for individuals with diabetes, might potentially result in underestimated differences in glucose spike metrics between diabetics and non-diabetics. Additionally, before it can be applied clinically, our model should be validated in clinical settings with standardized equipment on larger-scale, collaborative, multi-institutional prospective studies.
The PROGRESS study demonstrated the feasibility of continuous multimodal data collection in a remotely monitored cohort, encompassing a range of glucose homeostatic conditions and with unparalleled representation of individuals historically underrepresented in biomedical research. Our investigation identified the underlying factors associated with abnormal glucose spikes, shedding light on the potential of interventions targeting lifestyle factors such as dietary habits, sleep and physical activity, as well as gut microbiome diversity, to improve glucose regulation and metabolic health. Although the analysis of glucose spikes revealed significant differences among normoglycemic individuals, prediabetic individuals and individuals with T2D, in particular in the expected time for spike resolution (longer for T2D) and in the value of the nocturnal hypoglycemia (higher for T2D), it also highlighted substantial heterogeneity. Most notably, within the prediabetic state, we showed that a multimodal risk profile can vary substantially for participants with the same value of HbA1c. We showed that the collected multimodal data can be incorporated into a comprehensive multimodal risk profile that can stratify the prediabetic population to a finer resolution compared to the unimodal analysis of HbA1c. The inclusion of additional data modalities, such as environmental exposure, into future AI models could further enhance the precision of T2D risk assessment. These findings lay the foundation for alternative approaches that could potentially revolutionize the way complex diseases such as T2D are prevented, diagnosed and treated.
Methods
Ethical considerations
The protocol for this study was reviewed and approved by the Scripps Office for the Protection of Research Subjects (IRB-20-7635). All individuals participating in the PROGRESS study provided informed consent electronically. The HPP study was approved by the institutional review board of the Weizmann Institute of Science.
Study population (PROGRESS)
The PROGRESS study is a digital clinical trial aimed at enrolling a total of 1,000 adults—half with and half without T2D—to monitor their continuous glucose levels, dietary intake, resting heart rate, sleep and activity levels over a period of 10 days. In addition, participants were asked to self-administer biosample collection kits that were used to assay blood for HbA1c, saliva for genomics and stool samples for gut microbiome. Participants were required to connect and share their EHR data for the duration of the study, which is 3 years. All study participants were recruited in the United States. Exclusion criteria included the following: T1D mellitus; inability to participate in or comply with any of the testing modules asked during the study; currently pregnant; prior bariatric surgery; chemotherapy or radiation treatment for cancer in the past year; inflammatory bowel disease; known skin allergy to adhesives and nickel (or other contraindications to the CGM device); currently taking any oral steroids; currently taking insulin (injected, inhaled or via insulin pump); antibiotic use in the last 3 months prior to the start of the study or planned use during the duration of the study; non-dietary supplemental probiotic use either daily or weekly; hospice or palliative care; and end-stage renal disease. The ClinicalTrials.gov registration identifier is NCT04881019.
Study population (external validation dataset, HPP)
The HPP (https://humanphenotypeproject.org/) is a large-scale prospective study that was used as an external validation dataset for our multimodal model. The study enrolled 27,916 participants to date, of whom 12,014 individuals were deeply phenotyped, aged 40–70 years, with the goal of following them longitudinally for 25 years. The collected data span a wide range of data modalities, including blood tests, retinal fundus images, carotid ultrasound, liver ultrasound, gut microbiome, human genetics, glucose levels monitored for 2 weeks with CGM devices and continuous sleep data collected over three nights with home sleep apnea test devices. All participants were recruited in Israel. Major exclusion criteria included pregnancy or currently undergoing fertility treatments, cardiovascular diseases, chronic metabolic diseases, chronic gastrointestinal diseases, chronic kidney diseases and weight loss more than 5% in the recent year without deliberate diet32.
Outreach and recruitment (PROGRESS)
Study recruitment was initiated in February 2021 via social media outreach and partnerships with healthcare provider systems. Paid advertisements on the website Nextdoor in the greater San Diego area drove interested individuals to a study web page (https://progress.scripps.edu/) where they indicated a desire to join the study as well as a brief capture of their diabetes status. Over 1,000 interested individuals from that campaign were then invited to screen for the study beginning in July 2021. Additional social media channels such as Facebook campaigns were used to generate interest nationally. In addition, outreach to patients from our healthcare partners was done via identification of eligible participants based on criteria (for example, diabetes status) via EHR. Individuals who appeared to meet the inclusion and exclusion criteria were sent an electronic notification through the EHR with an invitation to participate in the study. All recruitment campaigns directed interested individuals to the study website with an overview of the study and a call to action to either join the waiting list or enroll to screen. Lastly, an email-based campaign leveraging a third-party organization, Research Match, was used where notifications were sent to participants who had registered in the Research Match database and reported having prediabetes or T2D. By focusing on digital campaigns and emphasizing that participants did not need to attend any in-person site visits to fully participate, we were able to recruit a diverse patient population in terms of age, socioeconomic status and geographic location.
Data collection and preprocessing (PROGRESS)
A study-specific smartphone app (MyDataHelps; CareEvolution) was developed to facilitate participants in their self-guided completion of the required tasks. Specifically, the PROGRESS app allowed participants to order their BioKit (for the self-collection of blood, saliva and stool samples) and GlucoKit (including a continuous glucose monitor, a wrist-worn fitness tracker and instructions on how to download and use a food logging app) and provided self-guided modules with tips, videos and instructions to facilitate the self-collection and shipment of the biosamples. In addition, the PROGRESS app included a customized data visualization tool that combined real-time CGM data with logged food intake data. From the raw data, we derived summary metrics that are representative of the participant’s overall health status and lifestyle as well as other physiological and biological parameters that are thought, based on existing literature, to be associated with T2D.
BMI was computed from self-reported weight and height. To minimize the impact of outliers on our analyses, we considered a participant’s BMI of 121.6 kg m−2 as abnormally high and treated it as a missing value. Diabetes status (normoglycemic, prediabetic or T2D) was self-reported. Based on the HbA1c test result, an individual is defined as normoglycemic if their HbA1c value is less than 5.7%, prediabetic if it falls within the range 5.7–6.4% and diabetic if it is equal to or exceeds 6.5% (ref. 33).
Interstitial glucose levels were measured by Dexcom G6 (Dexcom) devices that were self-applied and activated by the participants. Readings collected in the first 12 h after device activation were discarded to maximize data accuracy. The raw CGM signals were collected with a nominal 5-min sampling period, but we observed slight fluctuations in the sampling intervals, resulting in non-uniform sampling. To address this, we used linear interpolation between consecutive 5-min data points to derive 1-min epochs. This approach also provided finer temporal resolution for the analysis of glucose dynamics, which is useful for capturing short-term variations. Missing values were imputed for no longer than 10 min from a valid measurement. We employed peak detection techniques on the CGM signal to identify glucose spikes, which we defined as peaks with a minimum relative amplitude of 30 mg dl−1 within a time window of 90 min or less (Fig. 1).
We then computed six glycemic measures, capturing different aspects of the glucose spike dynamics: the mean glucose level; nocturnal hypoglycemia, defined as the average (across different days) minimum glucose value occurring between 24:00 and 7:00; time spent in hyperglycemia, defined as the percentage of time spent above 150 mg dl−1; the expected maximum spike relative value, defined as the average (across different days) of the maximum daily spike value relative to the baseline; the expected daily number of spikes, defined as the average (across different days) of the number of glucose spikes in a day; and the spike resolution, defined as the average time (across all glucose spikes) required to absorb 50% of the glucose spike. The choice of using a 150 mg dl−1 threshold for the time spent in hyperglycemia was motivated by clinical considerations; because, in this study, we measure glucose levels continuously, we selected a cutoff value that lies between the fasting hyperglycemia threshold (125 mg dl−1) and the 2-h postprandial hyperglycemia threshold (180 mg dl−1)34. The assessment and definition of a glucose spike in the era of CGM is an evolving field. We used metrics provided by other studies in the field coupled with additional exploratory metrics with physiologic relevance18,35.
During the 10-day active tracking period, participants logged their dietary intake through the food diary app Bitesnap (Bite AI). To model participants’ dietary habits, we summed up the composition of meals logged on the same day and computed the average value of carbohydrates, fat and protein daily intake over the 10 days of active tracking.
Study-provided fitness trackers (Fitbit Charge 4 or 5; Fitbit), or personal Fitbit devices compatible with the study, allowed for the passive collection of daily resting heart rate, sleep duration and physical activity (based on daily step counts). All Fitbit metrics were averaged over the 10 days of active tracking. For participants who did not meet the minimum wear time (16 h per day for at least 5 days), the Fitbit metrics were not used in our analyses. We observed statistically significant correlations between Fitbit wear time and age (r = 0.186, P = 0.003) and between Fitbit wear time and BMI (r = −0.192, P = 0.003), which might impact the generalizability of findings pertaining to the Fitbit metrics. However, the impact might be limited because the magnitudes of the correlations are relatively small.
Blood samples were self-collected by participants through study-provided Tasso-M20 kits (Tasso). At the time of its use in the study, the Tasso-M20 had received FDA 510(k) Class II Medical Device clearance. The device was internally validated by the manufacturer with comparisons to whole blood control samples, showing strong alignment. The device also met all criteria for intraday precision, interday precision, linearity and specificity, with values within acceptable ranges, even if it has not been validated in peer-reviewed studies. The collected samples were sent to a Clinical Laboratory Improvement Amendments (CLIA)-certified laboratory and run on AU680 analyzers (Beckman Coulter) to get HbA1c values.
Saliva samples were self-collected by participants through study-provided Oragene 600 devices (DNA Genotek) and processed with low-pass sequencing at Gencove. The PRSs for T2D were computed using a standard weighted allele-counting approach, under the assumption that loci effects are independent, as defined by the formula: \({\rm{PRS}}_{i}={\varSigma }_{j=1}^{n}{x}_{{ij}}{\beta }_{j}\), where the PRS for each individual is calculated as the sum of the effect allele dosages (\(0\le {x}_{{ij}}\le 2\)) for each variant (j) in the score, multiplied by its respective marginal effect size (\({\beta }_{j}\)), represented as the log odds ratio per effect allele dosage. We specifically constructed a PRS comprising 558 single nucleotide polymorphisms (SNPs) based on a recent study that identified robust T2D risk loci36, with weights derived from the latest large-scale T2D meta-genome-wide association studies, incorporating data from the Million Veteran Program, DIAMANTE and Biobank Japan, among other sources. To adjust the PRS percentile by ancestry, we first estimated genetic ancestry using a pruned set of SNPs selected by linkage disequilibrium pruning with PLINK version 1.9 (parameters: ‘–indep-pairwise 100 10 0.05’)37. We then computed the proportional ancestry for each individual across the five continental superpopulations from the 1000 Genomes Project (1000G) dataset38 using ADMIXTURE version 1.3.0 in supervised mode (‘–supervised 5’)39. The raw PRS was then transformed into a percentile score based on a simulated reference population, which was generated by sampling the 1000G dataset in proportion to each person’s ancestry composition. For each individual, we conducted 1,000,000 sampling iterations across the five 1000G superpopulations, ensuring that ancestry-specific adjustments to the PRS percentile remained robust and minimizing fluctuations due to sampling variability. Additionally, we performed principal component analysis on genotype data for the participants selected for the analysis and incorporated the first 10 principal components as input features for the multimodal glycemic risk profile model.
Stool samples were self-collected by participants through study-provided gut health tests (Thorne) and processed using whole-genome shotgun sequencing by Thorne. We performed adapter trimming and low-quality reads filtering with fastp version 0.23.4 using default parameters and sliding window from front to tail (that is, ‘cut-right’ parameter enabled)40. Host reads were detected with Bowtie 2 version 2.5.2 based on the alignment with the human genome (human reference genome assembly GRCh38) and then removed41. Paired-end reads were merged with fast length adjustment of short reads (FLASH version 1.2.11) using default parameters except for the maximum overlap length, set to 200 base pairs42. Relative abundances were obtained with metagenomic phylogenetic analysis (MetaPh1An version 4.0.6) with default parameters43. The Shannon diversity index was used as a measure of alpha diversity and computed as \(\mathop{\sum}\nolimits_{i=1}^{{n}_{\rm{g}}}{p}_{i} \times \log ({p}_{i})\), where pi denotes the relative abundance of the ith genus and ng denotes the total number of genera. Probiotic scores were obtained by adding up the relative abundances of the following genera: Faecalibacterium, Lactobacillus, Bifidobacterium, Enterococcus, Lactococcus, Pediococcus and Leuconostoc.
Medical conditions documented up to 10 years prior to the enrollment date were extracted from the participants’ EHR data. We grouped the medical conditions into eight higher-level categories based on the Systematized Nomenclature of Medicine Clinical Terms (SNOMED CT) hierarchy: disorders of the cardiovascular system (SNOMED CT concept ID ‘134057’); disorders of the digestive system (‘4201745’); disorders of the respiratory system (‘320136’); disorders of the musculoskeletal system (‘4244662’); disorders of the nervous system (‘376337’); disorders of the genitourinary system (‘4171379’); disorders of the auditory system (‘4176644’); and disorders of the visual system (‘4134440’). Medical conditions marked as resolved were excluded. We determined the number of comorbidities by considering the count of high-level categories that contained at least one recorded medical condition. We used the drug exposure table in the EHR data to extract information on the usage of antihyperglycemic medication. Specifically, we identified entries that included the names of commonly prescribed medications for improving glycemic control in individuals with T2D: metformin, alogliptin, linagliptin, saxagliptin, sitagliptin, dulaglutide, exenatide, liraglutide, lixisenatide, semaglutide, bexagliflozin, canagliflozin, dapagliflozin, empagliflozin, glimepiride, glipizide, glyburide, rosiglitazone and pioglitazone44. We classified a participant as someone using antihyperglycemic medications if they had at least one recorded entry within 1 year prior to the start of CGM monitoring and throughout the monitoring period.
Data collected and preprocessing (external validation cohort, HPP)
From the external validation dataset, we included the data modalities that were also available in PROGRESS—namely, CGM, food intake and gut microbiome, in addition to age, sex, BMI and HbA1c. The diabetes status was self-reported by the participants. Participants without any recorded diabetes or prediabetes condition were considered as normoglycemic. Participants with T1D or with diabetes of unspecified type (as determined by self-report) were excluded from the analysis.
To obtain the HbA1c values, we identified the HbA1c test from the EHR data that was closest in time to the start date of CGM, within a 180-day time window (ranging from 90 days before the monitoring start date to 90 days after). The potential time mismatch between the HbA1c test and the CGM is limited to a maximum of 90 days, but we note that it can potentially cause inaccuracies in the analysis.
Interstitial glucose levels were measured by FreeStyle Libre Pro Flash (Abbott) devices. The raw CGM signals were collected with a 15-min sampling period. Linear interpolation between consecutive 15-min data points was used to derive 1-min epochs. Missing values were imputed for no longer than 15 min from a valid measurement. The glucose spike metrics were calculated by using the same procedure employed for PROGRESS data.
Following the approach used for PROGRESS, we determined the average daily food intake for carbohydrates, fat and protein by summing up the composition of meals logged (through a mobile phone app) in the same day. Stool samples for the analysis of gut microbiome were collected in the clinic and analyzed via shotgun metagenomic sequencing. The Shannon diversity index and the probiotic score were computed from the relative abundances (at the genus level) with the same methods used for PROGRESS data.
Adopting the same criteria used for PROGRESS, we selected participants who had sufficient CGM data (at least 16 h per day and at least 5 days), an HbA1c test result and demographic information. It is important to acknowledge that different CGM devices were used for data collection in the two cohorts. Furthermore, some specific data processing steps, particularly regarding the processing of microbiome data, were different in the two studies. These differences can introduce potential confounding factors in the joint analysis of PROGRESS and HPP data.
Statistical analysis
We conducted ANCOVA tests controlled for age, sex and PRS to compare glucose spike metrics across self-reported diabetes statuses, and we evaluated the effect size with computed partial eta squared (ηp2), which measures the proportion of variance accounted for by the independent variable while controlling for covariates. Furthermore, we investigated the correlations between the glucose spikes and the available anthropometric, biological, physiological and lifestyle variables. We employed Spearman’s rank correlation coefficient (r) to assess the strength and direction of the associations while controlling for age, sex and PRS. We used a bootstrap percentile-based method with 10,000 iterations to estimate confidence intervals for correlations (with a confidence level of 95%) and determined the statistical significance by evaluating P values using a two-sided paired bootstrap test. False discovery rate (FDR) Benjamini–Hochberg correction was used to account for multiple testing.
Multimodal machine learning model for T2D risk assessment
We developed a multimodal machine-learning-based model to compute glycemic profiles for T2D risk assessment of PROGRESS prediabetic participants and normoglycemic and prediabetic participants from the HPP external cohort32. We used the collected demographic, anthropometric, clinical, biological, physiological and lifestyle data as input for the multimodal model. We trained binary classifiers based on gradient boosting decision trees (XGBoost) to distinguish between individuals with T2D and normoglycemic individuals. We chose the XGBoost model to capture potentially nonlinear relationships among the variables. XGBoost was selected among other nonlinear models as it is less complex and requires less data for training. We considered different configurations of input features, including age, sex and BMI (‘Base’ features), glucose spike variables (‘Spikes’), food intake variables (‘Food’), microbiome variables (‘Microbiome’), genomic variables (‘Genomics’), Fitbit variables (‘Fitbit’) and EHR condition variables (‘EHR’). The model’s hyperparameters were tuned separately for each input configuration using a preliminary grid search cross-validation loop with five splits. To assess the model’s performance, we used a leave-one-person-out scheme, where the data of each participant were excluded from training and used solely for testing. We assessed the models using the receiver operating characteristic curve and the corresponding AUC. We used a bootstrap percentile-based method with 10,000 iterations to estimate confidence intervals with a confidence level of 95%. We determined the statistical significance of the improvements relative to the base model by evaluating P values using a two-sided paired bootstrap test. We acknowledge that this approach does not eliminate the risk of potential residual confounding. Furthermore, to assess the contribution of each feature to the binary classification task, we computed the Shapley additive explanations (SHAP) for each test data point45. We considered the normalized absolute SHAP value and computed the median value over the entire test set to get a global feature importance score.
Next, we trained a multimodal classification model on all T2D and normoglycemic participants of the PROGRESS cohort using demographics, anthropometrics, CGM, food intake and gut microbiome as input data modalities. The multimodal model was then applied to the prediabetic group of the PROGRESS cohort and to the normoglycemic and prediabetic groups of the HPP cohort, which were not used for training the model. The objective was to evaluate the glycemic risk profile associated with the individuals being tested and compare it with the HbA1c value. To accomplish this, the model calculated the probabilities of being classified as part of the T2D group, based on the patterns learned from the training data. We considered this probability of belonging to the T2D group as a glycemic risk profile and compared it with the HbA1c value.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
Participant data with known identifiers removed are available for academic research purposes upon reasonable request and within established restrictions—that is, not for commercial purposes or for the benefit of for-profit entities. Access to the PROGRESS data is subject to approval by the study sponsor (Tempus AI) and the study principal investigator to ensure alignment with the original study objectives and ethical guidelines. Approved researchers will be granted secure access through a designated data environment; direct downloads or transfer of individual-level raw data are not permitted. Requests for data access should include a summary of the proposed research objectives, analytic plan and institutional affiliation. For further information or to submit a data access request, please contact the corresponding authors. Responses will be processed within 6 weeks. Reference data from the HPP study are available at https://github.com/ayya-keshet/CGMap. Access to this dataset, for universities and other research institutions, can be requested at https://humanphenotypeproject.org/. The 1000 Genomes Project dataset was sourced from https://www.internationalgenome.org/. The GRCh38 human reference genome dataset was sourced from the UCSC Genome Browser (https://genome.ucsc.edu).
Code availability
Python libraries used in the analysis include Python version 3.11.5 for code development; NumPy version 1.26.0, pandas version 2.1.1 and SciPy version 1.11.2 for data manipulation and processing; pingouin version 0.5.3 for statistical tests; XGBoost version 2.0.3 for machine learning model training; and seaborn version 0.13.2 and Matplotlib version 3.8.0 for visualization. The code used for the analyses is accessible at https://github.com/scripps-research/progress_nat_med.
References
National Diabetes Statistics Report (Centers for Disease Control and Prevention, 2024); https://www.cdc.gov/diabetes/php/data-research/index.html
Holst, J. J., Gasbjerg, L. S. & Rosenkilde, M. M. The role of incretins on insulin function and glucose homeostasis. Endocrinology 162, bqab065 (2021).
Myers, M. G. Jr, Affinati, A. H., Richardson, N. & Schwartz, M. W. Central nervous system regulation of organismal energy and glucose homeostasis. Nat. Metab. 3, 737–750 (2021).
Carrasco-Zanini, J. et al. Proteomic signatures for identification of impaired glucose tolerance. Nat. Med. 28, 2293–2300 (2022).
Hou, J. et al. Associations of residing greenness and long-term exposure to air pollution with glucose homeostasis markers. Sci. Total Environ. 776, 145834 (2021).
Hall, H. et al. Glucotypes reveal new patterns of glucose dysregulation. PLoS Biol. 16, e2005143 (2018).
Berry, S. E. et al. Human postprandial responses to food and potential for precision nutrition. Nat. Med. 26, 964–973 (2020).
Zeevi, D. et al. Personalized nutrition by prediction of glycemic responses. Cell 163, 1079–1094 (2015).
Lartey, A. H., Li, X., Li, Z., Zhang, Q. & Wang, J. Age-and sex-specific profiles of temporal fasting plasma glucose variability in a population undergoing routine health screening. BMC Public Health 21, 320 (2021).
Fechner, E., Op’t Eyndt, C., Mulder, T. & Mensink, R. P. Diet-induced differences in estimated plasma glucose concentrations in healthy, non-diabetic adults are detected by continuous glucose monitoring—a randomized crossover trial. Nutr. Res. 80, 36–43 (2020).
Munan, M. et al. Acute and chronic effects of exercise on continuous glucose monitoring outcomes in type 2 diabetes: a meta-analysis. Front. Endocrinol. 11, 495 (2020).
Zhu, B. et al. Associations between sleep variability and cardiometabolic health: a systematic review. Sleep. Med. Rev. 66, 101688 (2022).
Simon, M. C., Sina, C., Ferrario, P. G., Daniel, H. & Working Group ‘Personalized Nutrition’ of the German Nutrition Society. Gut microbiome analysis for personalized nutrition: the state of science. Mol. Nutr. Food Res. 67, 2200476 (2023).
Muijs, L. T. et al. Glucose variability and mood in adults with diabetes: a systematic review. Endocrinol. Diabetes Metab. 4, e00152 (2021).
Ceriello, A., Monnier, L. & Owens, D. Glycaemic variability in diabetes: clinical and therapeutic implications. Lancet Diabetes Endocrinol. 7, 221–230 (2019).
Spanakis, E. K. et al. Association of glucose variability at the last day of hospitalization with 30-day readmission in adults with diabetes. BMJ Open Diabetes Res. Care 8, e000990 (2020).
Lagou, V. et al. Sex-dimorphic genetic effects and novel loci for fasting glucose and insulin variability. Nat. Commun. 12, 24 (2021).
Keshet, A. et al. CGMap: characterizing continuous glucose monitor data in thousands of non-diabetic individuals. Cell Metab. 35, 758–769 (2023).
Shilo, S. et al. Continuous glucose monitoring and intrapersonal variability in fasting glucose. Nat. Med. 30, 1424–1431 (2024).
Mapes, B. M. et al. Diversity and inclusion for the All of Us research program: a scoping review. PLoS ONE 15, e0234962 (2020).
Lundholm, M. D., Emanuele, M. A., Ashraf, A. & Nadeem, S. Applications and pitfalls of hemoglobin A1C and alternative methods of glycemic monitoring. J. Diabetes Complications 34, 107585 (2020).
Ceriello, A. et al. Glycaemic management in diabetes: old and new approaches. Lancet Diabetes Endocrinol. 10, 75–84 (2022).
McCarthy, M. I. Painting a new picture of personalised medicine for diabetes. Diabetologia 60, 793–799 (2017).
Tobias, D. K. et al. Second international consensus report on gaps and opportunities for the clinical translation of precision diabetes medicine. Nat. Med. 29, 2438–2457 (2023).
Li, L. et al. Identification of type 2 diabetes subgroups through topological analysis of patient similarity. Sci. Transl. Med. 7, 311ra174 (2015).
Tsereteli, N. et al. Impact of insufficient sleep on dysregulated blood glucose control under standardised meal conditions. Diabetologia 65, 356–365 (2022).
Wagner, R. et al. Pathophysiology-based subphenotyping of individuals at elevated risk for type 2 diabetes. Nat. Med. 27, 49–57 (2021).
Ravaut, M. et al. Predicting adverse outcomes due to diabetes complications with machine learning using administrative health data. NPJ Digit. Med. 4, 24 (2021).
Steinhubl, S. R., Muse, E. D. & Topol, E. J. The emerging field of mobile health. Sci. Transl. Med. 7, 283rv283 (2015).
Inan, O. T. et al. Digitizing clinical trials. NPJ Digit. Med. 3, 101 (2020).
Quer, G. et al. Feasibility of wearable sensor signals and self-reported symptoms to prompt at-home testing for acute respiratory viruses in the USA (DETECT-AHEAD): a decentralised, randomised controlled trial. Lancet Digit. Health 6, e546–e554 (2024).
Shilo, S. et al. 10K: a large‐scale prospective longitudinal study in Israel. Eur. J. Epidemiol. 36, 1187–1194 (2021).
ElSayed, N. A. et al. 2. Classification and diagnosis of diabetes: Standards of Care in Diabetes—2023. Diabetes Care 46, S19–S40 (2023).
Mouri, M. & Badireddy, M. Hyperglycemia. In StatPearls (StatPearls Publishing, 2023).
Battelino, T. et al. Continuous glucose monitoring and metrics for clinical trials: an international consensus statement. Lancet Diabetes Endocrinol. 11, 42–57 (2023).
Vujkovic, M. et al. Discovery of 318 new risk loci for type 2 diabetes and related vascular outcomes among 1.4 million participants in a multi-ancestry meta-analysis. Nat. Genet. 52, 680–691 (2020).
Chang, C. C. et al. Second-generation PLINK: rising to the challenge of larger and richer datasets. Gigascience 4, 7 (2015).
Consortium, G. P. A global reference for human genetic variation. Nature 526, 68 (2015).
Alexander, D. H., Novembre, J. & Lange, K. Fast model-based estimation of ancestry in unrelated individuals. Genome Res. 19, 1655–1664 (2009).
Chen, S., Zhou, Y., Chen, Y. & Gu, J. fastp: an ultra-fast all-in-one FASTQ preprocessor. Bioinformatics 34, i884–i890 (2018).
Langmead, B. & Salzberg, S. L. Fast gapped-read alignment with Bowtie 2. Nat. Methods 9, 357–359 (2012).
Magoč, T. & Salzberg, S. L. FLASH: fast length adjustment of short reads to improve genome assemblies. Bioinformatics 27, 2957–2963 (2011).
Segata, N. et al. Metagenomic microbial community profiling using unique clade-specific marker genes. Nat. Methods 9, 811–814 (2012).
Oral & Injectable Medications for Type 2 Diabetes (American Diabetes Association, 2025); https://diabetes.org/health-wellness/medication/oral-other-injectable-diabetes-medications
Lundberg, S. M. & Lee, S.-I. A unified approach to interpreting model predictions. In Proc. 31st International Conference on Neural Information Processing Systems (eds Von Luxburg, U. et al.) 4768–4777 (Curran Associates, 2017).
Acknowledgements
Funding for this research was provided, in part, by the study sponsor, Tempus AI. The clinical trial infrastructure was also supported by the National Center for Advancing Translational Sciences at the National Institutes of Health (UM1TR004407). We thank former and/or current Tempus employees for their support of the PROGRESS study: W. Zhou, J. Dudley, N. Shamsi, S. B. Khatau and J. De Freitas. We are grateful to A. Khattab, S.-F. Chen and J. Kueper for their help during the review process.
Author information
Authors and Affiliations
Contributions
E.J.T. conceived of the project. E.R. served as principal investigator of the PROGRESS study. K.B.-M., V.K. and E.R. made substantial contributions to the study design. M.G., D.C., F.D., K.Q., R.M., B.B., K.B.-M., V.K., E.R. and G.Q. made substantial contributions to the acquisition of data. M.C., M.G. and G.Q. processed the multimodal data, conducted statistical analysis, and directly accessed and verified the underlying data. B.F., J.A.R.G. and A.T. processed microbiome and genomics data. M.C., H.R., E.S. and G.Q. processed and analyzed the HPP data. M.C., J.P., M.G., E.R. and G.Q. made substantial contributions to the interpretation of data. M.C. and G.Q. drafted the first version of the paper. All authors had access to the data presented in the study, contributed to critical revisions and approved the final version of the manuscript. All authors take responsibility for the integrity of the work and were responsible for the decision to submit for publication.
Corresponding authors
Ethics declarations
Competing interests
R.M. is employed by Tempus AI. B.B., V.K. and E.R. are employed by CareEvolution. H.R. is employed by Pheno.AI. K.B.-M. is a consultant for CareEvolution and was on the Heartline Study Executive Committee. E.J.T. is on the Dexcom Board of Directors and on the Science Advisory Boards of Tempus AI and Pheno.AI. E.S. and H.R. have equity interest in Pheno.AI. The other authors declare no competing interests.
Peer review
Peer review information
Nature Medicine thanks Jan Verbakel and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Primary Handling Editor: Lorenzo Righetto, in collaboration with the Nature Medicine team.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data
Extended Data Fig. 1 PROGRESS participants selected for the analysis.
Participants selection process from the PROGRESS cohort. T1D, type 1 diabetes.
Extended Data Fig. 2 Distribution of glucose spike metrics in the PROGRESS cohort.
Distribution of glucose spike metrics: mean glucose level, defined as the average of glucose values over the entire tracking period (a); expected maximum spike relative value, defined as the maximum spike value relative to the baseline, averaged across different days (b); percentage of time spent above 150 mg dl−1 (c); spike resolution, defined as the time required to absorb 50% of the glucose spike, averaged across all glucose spikes (d); expected daily number of spikes, defined as the daily number of glucose spikes, averaged across different days (e); nocturnal hypoglycemia, defined as the average minimum glucose value occurring between 24:00 and 7:00, averaged across different days (f). Continuous distributions were obtained through kernel density estimation with Gaussian kernels, Scott’s bandwidth estimation method and bandwidth scaling factor equal to 0.75.
Extended Data Fig. 3 Correlations between additional glucose spike metrics and multimodal factors in the PROGRESS cohort.
Spearman’s rank correlation coefficients (dots) between glucose spike metrics representing the expected daily number of spikes, defined as the daily number of glucose spikes, averaged across different days (a); the expected maximum spike relative value, defined as the maximum spike value relative to the baseline, averaged across different days (b); the nocturnal hypoglycemia, defined as the average minimum glucose value occurring between 24:00 and 7:00, averaged across different days (c); the percentage of time spent above 150 mg dl−1 (d). Two-sided statistical tests were used. Lines represent 95% confidence intervals. Correlations with statistically significant FDR-corrected p-values are marked with the star symbol. Multimodal factors are divided into three groups: demographic factors (top), metabolic factors (middle), and lifestyle factors (bottom). FDR, false discovery rate; P, p-value; n, sample size.
Extended Data Fig. 4 Multimodal glycemic risk profiles for HPP normoglycemic participants.
HbA1c values and multimodal glycemic risk profiles for normoglycemic participants in the HPP cohort. The multimodal glycemic risk profiles were obtained from a binary classification model trained on PROGRESS with demographics, anthropometrics, CGM, food intake, and gut microbiome as input data modalities. The blue horizontal lines represent the multimodal glycemic risk profiles median values after binning the HbA1c with intervals of width 0.4. The red vertical dashed lines mark the boundaries of the prediabetic range, spanning from 5.7% to 6.5%.
Supplementary information
Supplementary Information
Supplementary Results and Figs. 1–3.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Carletti, M., Pandit, J., Gadaleta, M. et al. Multimodal AI correlates of glucose spikes in people with normal glucose regulation, pre-diabetes and type 2 diabetes. Nat Med 31, 3121–3127 (2025). https://doi.org/10.1038/s41591-025-03849-7
Received:
Accepted:
Published:
Version of record:
Issue date:
DOI: https://doi.org/10.1038/s41591-025-03849-7
