
Abstract
Images captured from a drone’s perspective are significantly impacted in terms of target detection algorithm performance due to the notable differences in target scales and the presence of numerous small target objects lacking detailed information. This paper proposes a Remote Sensing Small Target Detector (CF-YOLO) based on the YOLOv11 model to address the challenges of small target detection. Firstly, addressing the issue of small target information loss that may arise from hierarchical convolutional structures, we conduct in-depth research on the Path Aggregation Network (PAN) and innovatively propose a Cross-Scale Feature Pyramid Network (CS-FPN). Secondly, to overcome the problems of positional information deviation and feature redundancy during multi-scale feature fusion, we design a Feature Recalibration Module (FRM) and a Sandwich Fusion Module. We advocate for initial feature fusion through the FRM module, followed by feature enhancement using the Sandwich module. Finally, we optimize and reconstruct the model using the RFAConv module and LSDECD detection head. Experiments show that on the public VisDrone dataset, TinyPerson dataset, and HIT-UAV dataset, CF-YOLO improves the mAP50 by 12.7%, 10.1%, and 3.5%, respectively, compared to the baseline model. Compared to other methods, CF-YOLO demonstrates superior performance.
Similar content being viewed by others

Introduction
The rapid advancement of drone technology is profoundly transforming the traditional paradigm of remote sensing monitoring. With its advantages of flexibility, low cost, and immunity to cloud interference, drone aerial imagery has been widely applied in fields such as security surveillance1, intelligent transportation2, and agricultural management3,4, becoming an important complement to satellite remote sensing. In the field of computer vision, although deep learning-driven remote sensing object detection techniques have achieved significant progress in applications such as traffic monitoring5, disaster response6, and military operations7, object detection in drone-based aerial imagery still presents numerous challenges. Firstly, due to typical imaging altitudes ranging from 100 to 500 meters, approximately 60%-80% of objects in the images are smaller than 32\(\times \)32 pixels8. These small objects often exhibit limited feature information, low contrast, and a sparse number of effective feature points-approximately 70% of small objects contain only 10-20 valid feature points9,10. Secondly, the imaging conditions are both complex and highly variable. Factors such as platform movements, lighting changes, and intricate backgrounds can cause object-background aliasing, which complicates the distinction of small objects. Lastly, as camera bandwidth and resolution continue to advance, managing and processing the large volumes of data transmitted from drones to the ground presents a significant challenge.
Therefore, achieving fast and accurate small object detection while maintaining detection speed is of significant theoretical importance and practical value. In recent years, various solutions have been proposed to address the challenges of small object detection. Crowd-SAM11, an enhanced framework built upon the Segment Anything Model (SAM), improves object detection performance in crowded scenes by refining prompt generation and optimizing mask selection. GAN-STD12 leverages generative adversarial networks (GANs) to enhance the similar representations of small and large objects during feature extraction, making small objects as easily detectable as larger ones. MENet13 introduced a center-based label assignment strategy, providing more positive samples for tiny objects. Li et al.14 employed transformers to capture long-range global dependencies related to objects, thereby improving the model’s global perception capabilities. YOLOv8-QSD15 improves small object performance from a multi-scale fusion perspective. While these approaches have made notable progress in small object detection, they still face issues such as the loss of small object information and the untapped potential of multi-scale information.
Unlike the aforementioned studies, this research focuses on addressing the issue of feature information loss in small object detection and systematically explores the optimization potential of multi-scale feature fusion. To this end, we propose CF-YOLO, a high-resolution remote sensing object detection method designed to construct an efficient and accurate detector. The main innovations of this approach are reflected in the following four aspects: First, to mitigate the issue of information attenuation that frequently occurs in the transmission of small object features in remote sensing imagery, we introduce a Cross-Scale Feature Pyramid Network (CS-FPN). This structure establishes cross-resolution feature interaction pathways, preserving fine-grained object features at high-resolution levels while ensuring detection accuracy through a multi-scale deep architecture. Second, to enhance the efficiency of multi-scale feature fusion, we propose a dual-module collaborative mechanism. The Feature Recalibration Module (FRM) extracts and integrates boundary-sensitive and texture features to achieve precise spatial alignment, while the Sandwich Fusion Module adopts an adaptive weighting strategy to effectively resolve the trade-off between insufficient semantics in shallow networks and detail loss in deep networks.Third, considering the challenges posed by severe background interference and sparse small object features in drone imagery, we integrate Receptive Field Attention Convolution (RFAConv) into the backbone network. This module dynamically allocates receptive field weights, enabling the model to maintain stable performance under complex lighting conditions and varying scene environments. Finally, to overcome the limitations of insufficient information interaction in the YOLOv11 detection head, we introduce the Lightweight Spatial-Depth Enhanced Cross-Detection (LSDECD) . By employing a cross-hierarchical feature aggregation mechanism, this structure simultaneously optimizes spatial localization precision and semantic representation capabilities. The main contributions of this study are as follows:
-
We propose CS-FPN to effectively mitigate the issue of feature attenuation in deep networks, preserving essential information for small object detection.
-
To enhance the model’s global perception capability and emphasize the importance of different features within the receptive field, this study introduces the Receptive Field Attention Convolution (RFAConv) module to reconstruct the backbone network.
-
By incorporating Receptive Field Attention Convolution (RFAConv) into the backbone network, we enhance the model’s global perceptual capacity while effectively highlighting the importance of different features within the receptive field.
-
Through the introduction of the LSDECD head, which aggregates cross-hierarchical spatial and semantic features, we mitigate the limitation of insufficient information exchange in the YOLOv11 detection head, thereby enhancing detection accuracy.
Related work
Object detection
Deep learning-based object detection algorithms can be broadly categorized into Transformer-based and CNN-based detectors. Detection Transformer (DETR)16 integrates Transformer and CNN architectures to directly predict bounding boxes and object categories in an end-to-end manner, thereby simplifying the object detection pipeline. However, due to its high training costs, Real-Time Detection Transformer (RT-DETR)17 improves detection performance by incorporating intra-scale interactions and cross-scale fusion to process multi-scale features, effectively mitigating inference delays caused by non-maximum suppression (NMS). Despite its strong performance on large-scale datasets such as MS-COCO, RT-DETR’s computational cost and parameter complexity constrain its overall efficiency.
Unlike these approaches, CNN-based detectors are classified into two-stage and one-stage methods. Two-stage object detection methods18,19,20 first generate region proposals, followed by classification and bounding box regression, making them less suitable for real-time applications. In contrast, one-stage object detection methods directly predict object categories and bounding box locations within the network, simplifying the detection process and enhancing inference speed. The YOLO series21,22,23,24,25,26,27 represents a typical one-stage detection framework, offering advantages in memory efficiency and processing speed but at the expense of small object detection accuracy.
Overall, deep learning-based object detection networks must balance speed and accuracy28. Enhancing the detection precision of small objects remains the primary focus of this study.
Small object detection
Object detection in drone aerial imagery is a typical small object detection task, characterized by a high proportion of small objects and dense distribution. The YOLO framework is widely used due to its ability to effectively balance accuracy and efficiency in real-time applications. Some researchers29,30,31 have combined Transformer with YOLO, aiming to enhance the network’s ability to capture a wider range of informative and diverse features. Compared to the original baseline, these methods improve the model’s capacity to establish long-range dependency information, showing advantages in terms of accuracy. FFCA-YOLO32 proposed a novel context-aware detector for remote sensing image detection, which enhances the model’s ability to perceive contextual information. SFFEF-YOLO33 introduced a fine-grained information extraction module to replace standard convolutions, reducing information loss during the sampling process. Li et al.34 addressed the common issues of false positives and false negatives in small objects in aerial images by introducing the Bi-PAN-FPN concept to improve the neck structure of YOLOv8-s, achieving more advanced feature fusion. FENet35 embeds high-resolution blocks in FPN to preserve the detail features of small objects, and YOLO-SSFS36 improves BiFPN to integrate more shallow-level information. DSP-YOLO37 proposes a lightweight and detail-sensitive PAN (DsPAN) for small object detection. SOD-YOLO38 introduces a pyramid network (BSSI-FPN) that balances the fusion of spatial and semantic information, while EL-YOLO39 proposes a sparse connection asymptotic feature pyramid network (SCAFPN) to eliminate inter-layer interference during feature fusion and improve model performance. Although these methods have achieved notable results in small object detection, they do not further explore multi-scale information. When faced with feature maps containing complex backgrounds, these methods may still suffer from issues of accuracy and robustness.
Feature pyramid network
For object detection tasks, truly valuable information must encompass both semantic information pertinent to the object and detailed information. However, rich semantic information can only be extracted through deeply layered networks. During this extraction process, repeated convolutional and downsampling operations often result in the loss or degradation of detailed information. To address this challenge, numerous researchers have conducted extensive investigations. FPN40 devised a top-down and bottom-up lateral connection architecture to process multiscale information, ensuring that feature maps contain both high-level semantic information and low-level detailed information. However, because of the absence of multiscale feature fusion, the fusion efficiency remains suboptimal. RetinaNet41 integrated the FPN structure with Focal Loss to address class imbalance issues and achieved significant results in small object detection. AugFPN42 ensured that feature maps after lateral connections maintained similar semantic information while minimizing information loss in high-level features. PANet43 introduced an additional bottom-up path augmentation to transmit low-level feature information to high-level feature maps, thereby enhancing the representation capabilities of the feature pyramid. This structure aids in capturing more hierarchical context information and improving object detection accuracy. NAS-FPN44 leveraged Neural Architecture Search (NAS) technology to automatically design the structure of the feature pyramid network. By searching for optimal cross-scale connection patterns in a vast search space, NAS-FPN discovered more efficient feature pyramid structures than those traditionally designed manually. CF-PN45 proposed cross-layer fusion to enhance the fusion effect between different layers. BiFPN46 further refined the cross-scale connection strategy of FPN by introducing bidirectional connections and weighted feature fusion, enabling each layer in the feature pyramid to receive information from all other layers, thereby bolstering the feature representation capabilities. HRNet47 achieved efficient feature fusion and multi-scale representation by connecting subnets of varying resolutions in parallel and exchanging features among them. Although these methods have expanded the scale and scope of object detection, they are not specifically designed for remote sensing scenarios. For small object detection, they still have limitations, as they do not consider the extraction of low-level positional information or the detailed interaction between contextual elements.
Method
The overview of YOLOv11 model
The YOLOv11 object detection model, proposed by the Ultralytics team, adopts a typical three-stage architecture, consisting of the backbone network, neck network, and detection head as its foundational components. This model introduces several innovative features: the C3k2 convolution module, the Spatial Pyramid Pooling (SPPF) structure, and the C2PSA module with a parallel spatial attention mechanism, significantly enhancing feature extraction performance. To meet the demands of various application scenarios, YOLOv11 has released multiple versions, including YOLOv11n, YOLOv11s, YOLOv11m, YOLOv11l, and YOLOv11x, each with a gradient configuration in terms of model depth and channel dimensions.
The overview of CF-YOLO model
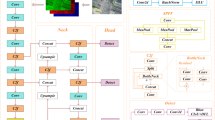
To address the issues of feature information loss and insufficient multi-scale fusion in YOLOv11 for remote sensing small object detection, this study proposes CF-YOLO, an enhanced small object detection algorithm for remote sensing imagery based on YOLOv11n architecture. The overall structure of CF-YOLO is shown in Fig. 1. CF-YOLO is primarily composed of the following three modules: (1) a backbone network with a receptive field adaptive attention mechanism, responsible for multi-level feature extraction; (2) a cross-scale feature pyramid (CS-FPN) and a dual-module collaborative feature fusion strategy to achieve feature fusion and enhancement; (3) a lightweight detection head (LSDECD) for final object prediction.
Specifically, the backbone network of CF-YOLO adopts a hierarchical feature extraction architecture. Initially, the input image of 640\(\times \)640 is downsampled in multiple stages using receptive field attention convolution (RFA Conv), generating feature maps with decreasing resolution and increasing channel dimensions. Subsequently, the C3K2 module extracts features progressively through parallel convolution layers, which capture local details in the image. The deep feature maps are then processed by the SPPF module for serial multi-scale pooling and fused with global context information through the C2PSA dual attention mechanism. Finally, the network outputs feature maps at four different scales, which are passed to the CS-FPN for cross-scale feature fusion.
Next, the four feature maps of different scales output from the backbone network enter the CS-FPN, where a bidirectional (bottom-up + top-down) cross-scale collaborative fusion strategy is employed. Initially, spatial position calibration is performed via the Feature Recalibration Module (FRM), followed by a sandwich fusion operation to achieve adaptive integration of semantic information and fine-grained details. Ultimately, the multi-stage fused feature maps are fed into the LSDECD detection head, where the feature representation is collaboratively optimized across spatial and channel dimensions, resulting in precise object detection outputs.

CS-FPN
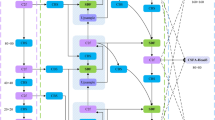
Research Motivation: As shown in Fig. 2a), the traditional PANet adopts a stepwise fusion strategy to combine deep semantic features from the FPN with shallow detailed features. However, this architecture leads to significant fine-grained information loss during multiple upsampling and downsampling processes, which is particularly critical for small object detection. We believe that effective information must meet two fundamental conditions: (1) it must contain high-level semantic information to ensure classification accuracy; (2) it must preserve sufficient spatial details to guarantee localization precision. Existing studies indicate that while deep networks can extract rich semantic features, they inevitably suffer from a loss of spatial resolution. To address this issue, inspired by dense nested attention mechanisms, this study introduces the Cross-Scale Feature Pyramid Network (CS-FPN), as shown in Fig. 2b).
We upsample the deep features and progressively fuse them into the shallow features to enhance the target localization capability of the shallow features. Then, considering that the PAN network frequently uses convolution and upsampling/downsampling operations in the top-down and bottom-up feature extraction processes, this inevitably leads to the loss or degradation of information at different scales. According to the Nyquist-Shannon sampling theorem48,49, when the signal frequency exceeds the Nyquist frequency (i.e., half of the sampling rate), these high-frequency information will be permanently lost during the downsampling process.As shown in Fig. 3b, to mitigate the information decay and loss in the feature layers (\(O_i\)) after multiple convolutions, we downsample the features output by the backbone network (stage1 to stage3) and fuse them with the semantically rich features into \(O_i\). In this process, \(O_i\) not only retains its own features but also incorporates cross-scale features from adjacent layers. However, since different input features contribute differently to the network, we use a sandwich fusion module to weight and fuse each feature branch, allowing the model to autonomously select based on the importance of the features and effectively integrate contextual information. Moreover, considering that the larger the feature map, the richer the small object information it contains, we specifically add a small object detection head, expanding the original 3 detection heads to 4, to further improve detection performance.
Specifically, for a given input feature \(X_i\) with dimensions \(R_{C\times H\times W}\); input feature \(X_{i+1}\) with dimensions \(R_{C'\times H/r\times W/r}\), and intermediate layer feature \(P_i\) with dimensions \(R_{C\times H\times W}\). Here, C represents the number of channels in the shallow feature, \(C'\) represents the number of channels in the deep feature, H and W represent the width and height of the feature map, and r is the downsampling factor.First, we use the Feature Recalibration Fusion Module (FRM) to replace the traditional concat module to effectively fuse high-resolution features with low-resolution features and output the recalibrated intermediate layer feature \(P_i\), as shown in formula 2.
Then, we upsample and downsample the two adjacent layer features \(X_{i+1}\) and \(X_{i-1}\) to \(X_i\), and use the sandwich fusion module to weight and fuse them with \(P_i\) to enhance the feature representation of \(P_i\), which is reflected in formula 3, where the weighted fusion calculation formula is formula 1. It should be particularly noted that in the part close to the detection head, where information loss is more severe, this area is crucial for the overall accuracy of the overall model . Therefore, to reduce computational complexity, we only use the downsampling branch to enhance the feature layers close to the detection head.
where \(X_c\) represents the fused feature, O represents weighted fusion, \(w_i \ge 0\) is ensured by applying the ReLU activation function after each \(w_i\), Ii represents the input feature, and a small learning rate (\(\epsilon \) = 0.0001) is set to avoid numerical instability.

Structural diagrams of PANet and CS-FPN. (a) illustrates the structure of PANet, while (b) presents the structure of CS-FPN. CS-FPN primarily consists of a multi-scale fusion pathway and efficient feature fusion modules, which includes the FRM module and the Sandwich module. Detailed information on the FRM module can be found in Section “FRM”, while the Sandwich module will be introduced in this section.
FRM
Compared to traditional feature fusion structures, the FRM module innovatively introduces a bidirectional fusion mechanism between high-resolution and low-resolution features, greatly promoting information exchange between features and significantly improving the performance of multi-scale feature fusion. Through an adaptive attention mechanism, the module can adjust feature weights according to differences in feature map resolution and content, thereby more accurately capturing the multi-scale characteristics of targets.The specific structure is shown in Fig. 3.
For a given shallow feature Xi with dimensions \(R_{C\times H \times W}\) and a deep feature \(X_{i+1}\) with dimensions \(R_{C'\times H/r\times W/r}\), where C represents the number of channels in the shallow feature, \(C' \)represents the number of channels in the deep feature, H and W represent the width and height of the feature map, and r is the downsampling factor. First, we preprocess \(X_i\) and \( X_{i+1}\) using a 1\(\times \)1 convolution operation to ensure consistency in the number of channels.Then, we perform channel reduction on the feature maps \(X_i\) and its subsequent layer \( X_{i+1}\), halving their dimensions to obtain the reduced feature maps \(X_{\frac{i}{2}}\) and \( X_{\frac{i+1}{2}}\). Subsequently, by introducing the sigmoid nonlinear activation function, these channel-halved feature maps are activated to generate \(g\_L\_feature\) and \(g\_H\_feature\), following the mathematical expressions in formulas 4 to 7 .
Next, we further reduce the feature channels of \(X_{\frac{i}{2}}\) and \(X_{\frac{i+1}{2}}\) to \(X_{\frac{i}{4}}\) and \(X_{\frac{i+1}{4}}\), and employ a feature weighting strategy. Using \(g\_L\_feature\) and \(g\_H\_feature\), we enhance the reduced feature maps to highlight high-frequency details in the image.To alleviate the problem of feature information decay, we introduce a residual connection mechanism. The reduced feature maps \(X_{\frac{i}{4}}\) and \(X_{\frac{i+1}{4}}\) are element-wise summed with the weighted features to obtain the fused feature maps \(C_i\) and \(C_{i+1}\). In the feature fusion strategy, we recognize that shallow features are rich in texture and detail information, suitable for enhancing edge detection and small object recognition; while deep features contain abundant semantic information, applicable for target localization and position calibration.Low-frequency features, such as small object information and edge details, typically have lower weights in the activation mapping, while high-frequency features like large object information have higher activation weights. Therefore, we perform an inversion operation on the shallow features to increase the weight proportion of edge and small object features, thereby deeply fusing them with deep features to draw finer object contours, as described in formula 8. Similarly, we perform an inversion operation on the deep features to enhance the weight of fine-grained information, and fuse it with shallow features to achieve precise target position calibration, as shown in formula 9.Finally, through channel concatenation, the two sets of finely adjusted feature maps are fused in the channel dimension to obtain a composite feature map that integrates clear fine-grained information and rich semantic information, expressed mathematically in formula 10.

Structure of the FRM network. To enhance the interaction between deep and shallow features, we recalibrate them and propose the FRM module. It selectively aggregates boundary and semantic information to depict finer object contours and recalibrate object positions.
RFAConv
Existing convolutional block attention modules (CBAM)50 and coordinate attention (CA)51 are unable to effectively emphasize the importance of each feature within the receptive field and fail to address the parameter sharing issue. To overcome these limitations, this study introduces the Receptive Field Attention Convolutional Block (RFAConv)52. RFAConv utilizes a spatial attention mechanism to share convolution kernel parameters while considering the importance of each feature in the receptive field, generating receptive field features from the original feature map. As shown in the black dashed box in Fig. 1, the module dynamically shares convolution kernel parameters through the spatial attention mechanism, dividing the feature processing into two stages: the spatial feature domain (the original input feature map) and the receptive field feature domain (a set of non-overlapping feature blocks generated by a sliding window with stride = 3). Each 3\(\times \)3 window corresponds to a receptive field unit. RFAConv enables the network to model the relationships between the target region and its surrounding environment early in the feature extraction process.
To optimize computational efficiency, RFAConv adopts a three-level processing strategy: first, average pooling is applied to compress the receptive field feature dimensions; next, a 1\(\times \)1 convolution is used to establish cross-receptive field associations; finally, the softmax function is applied to perform adaptive feature selection. The specific computation process can be expressed by Formula 11. This design significantly enhances feature representation capabilities while maintaining the lightweight nature of the model.
Here, \( g^{i \times i }\) represents a grouped convolution of size \( i \times i \), \( k \) denotes the size of the convolution kernel, Norm refers to normalization, \( X \) is the input feature map, and \( F \) is obtained by multiplying the attention map \( A_{rf} \) with the transformed receptive field spatial features \( F_{rf} \).
LSDECD
In YOLOv11, each detection head has its own independent feature input. This design lacks information interaction between detection heads, which can lead to a decrease in detection performance. To address this issue, we introduce a lightweight and efficient detection head-LSDECD-to enhance detection efficiency.The structure of LSDECD is shown in the Fig. 4.

Structure of the detailed LSDECD network.It aggregates cross-level spatial and semantic information from the P2 to P4 layers using DEConv, thereby enhancing information interaction.
It inputs features from layers \(P_2\) to \(P_5\) into the detection head. First, the number of channels is adjusted through 1\(\times \)1 convolutions based on Group Normalization (GN). Then, Group Normalization-based Detail Enhancement Convolutions (DEConv) are used to aggregate cross-level spatial and semantic information. DEConv53 incorporates traditional local descriptors into the convolutional layer through central difference convolution, angular difference convolution, horizontal difference convolution, and vertical difference convolution, thereby enhancing representation and generalization capabilities and ensuring accurate detection. Finally, the information extracted by shared convolutions is fed into the classification and regression heads. To handle inconsistent target sizes between detection heads and prevent the loss of small object feature information, we employ a scaling layer that includes learnable scaling factors. This layer adjusts the features in the regression head, thereby enhancing the retention of multi-scale features.
Experiment and result
Dataset
The VisDrone dataset54 is a high-quality dataset specifically designed for object detection from the perspective of drones. It consists of 6,471 images in the training set, 3,190 images in the test set, and 548 images in the validation set. The data distribution across various categories is shown in Fig. 5a, which includes 10 categories such as pedestrians, cars, bicycles, and tricycles. Figure 5b illustrates the distribution of object sizes in the dataset, with approximately 60% of objects being smaller than 20\(\times \)20 pixels, and nearly 90% of the objects being classified as small (\(<32 \times 32\) pixels). Due to its diversity and focus on small object detection, this dataset is an ideal choice for research on object detection in complex scenarios.

Target attribute statistics of the VisDrone dataset. (a) Proportion of sample counts across 10 object categories; (b) Distribution of objects across different scales (Small refers to sizes smaller than 20\(\times \)20 pixels, medium refers to sizes between 20 and 32 pixels, and large refers to sizes larger than 32\(\times \)32 pixels.); (c) The width-height distribution of objects in the TinyPerson dataset; (d) The width-height distribution of objects in the HIT-UAV dataset.
The TinyPerson dataset55 is the first benchmark for pedestrian detection in long-distance and large-background scenarios, opening a new direction for ultra-small object detection. This dataset consists of 1610 images, with 794 images in the training set and 816 images in the test set, the latter being used for model performance evaluation. Each image contains over 200 pedestrians, with a total of 72,651 manually annotated ultra-small objects, categorized into five classes: “sea,” “ground,” “ignore,” “uncertain,” and “dense.” For convenience, we consider all the labeled small pedestrians as part of the category of a “person.”As shown in Fig. 5c, extremely small objects dominate this dataset, with the vast majority having both width and height smaller than 0.05 (smaller than 5% of the image size). This extreme scale distribution characteristic makes the dataset an ideal choice for studying tiny object detection.
HIT-UAV is a high-quality benchmark dataset specifically designed for infrared small object detection tasks. It consists of 2898 rigorously selected infrared images captured by UAVs, derived from 43,470 frames of real-world video footage. The dataset is partitioned into training (2030 images), validation (579 images), and test (289 images) sets in a 7:2:1 ratio. It encompasses a diverse range of complex environments, including schools and highways, and features various object types, ranging from individual pedestrians to different types of vehicles. Notably, HIT-UAV exhibits a strong small-object characteristic. As illustrated in Fig. 5d, the majority of objects have both width and height smaller than 0.2, while larger objects (width or height > 0.5) are exceedingly rare. This scale distribution poses significant challenges for object detection models, necessitating robust multi-scale feature extraction capabilities.
Environment and training parameter settings
The experiments were conducted on a remote server, utilizing an NVIDIA 4090 graphics card within a deep learning environment set up based on Python 3.10, PyTorch 2.2.1, and Cuda 11.5. We employed YOLOv11 as the baseline model and conducted training and testing on the VisDrone dataset, HIT-UAV dataset, and TinyPerson dataset, respectively. The experimental parameters used are as follows: the input image size was 640640 pixels, Stochastic Gradient Descent (SGD) was adopted as the optimizer, with an initial learning rate (Lr0) of 0.01 and a final learning rate (Lrf) also set to 0.01, the batch size was 8, and the models were trained for 300 epochs.
Expriment evaluation
In our experiments, we employed a variety of evaluation metrics to comprehensively assess the model’s performance. These metrics include precision, recall, F1 score, mAP50, mAP50:95, Floating Point Operations Per Second (FLOPs), and the number of model parameters. A higher detection precision of the model indicates stronger accuracy; an improvement in recall suggests a decrease in the likelihood of missed detections.F1 score serves as the harmonic average of Precision and Recall, providing a comprehensive evaluation of algorithmic performance. Mean Average Precision (mAP) is obtained by calculating the Average Precision (AP) for each category, while AP reflects the precision and robustness of the model in recognizing targets of a specific category. It is typically determined by plotting a Precision-Recall curve (PR curve) and calculating the Area Under Curve (AUC). FLOPs measure the number of floating-point operations performed by the model per second, serving as a key indicator for evaluating the running speed and computational efficiency of neural network models. The specific expressions are as follows:
Among them, TP represents the number of true positives (correctly identified as true), FP represents the number of false positives (incorrectly identified as true), and FN represents the number of false negatives (incorrectly identified as false).
Ablation expriment
Ablation experiments conducted on the VisDrone-DET dataset
In this section, we employ YOLOv11n as the baseline model and conduct ablation experiments on the VisDrone2019 dataset to validate the effectiveness of the innovative modules in CF-YOLO. As shown in Table 1, the progressive integration of these modules leads to significant performance improvements.
First, replacing the original feature pyramid structure with CS-FPN effectively enhances multi-scale feature fusion, resulting in a 7.7% and 5.7% increase in mAP50 and mAP95, respectively. Next, to address the spatial misalignment in feature fusion, the introduction of the FRM module, which employs a spatial position recalibration mechanism, further boosts mAP50 to 40.2%. Experimental results demonstrate that this module is particularly beneficial for improving the localization accuracy of dense small targets. To further mitigate small-target information degradation in deep features, we design the Sandwich Fusion module. By integrating multi-branch features through an adaptive weighting strategy, this module achieves comprehensive improvements in precision (+4.2%), recall (+2.7%), mAP50 (+3.2%), and mAP95 (+2%) while adding only 0.3M parameters. Regarding backbone network optimization, the RFAConv module enhances feature representation through a parameter-sharing receptive field attention mechanism, leading to a 1% and 0.7% improvement in mAP50 and mAP95, respectively. Notably, the use of a parameter-sharing strategy also reduces the model’s parameter count by 0.4M. Finally, we introduce the lightweight shared convolution detection head (LSDECD) to further optimize the detection head. LSDECD enhances cross-spatial and cross-hierarchical information interaction via shared convolution while significantly reducing computational overhead. Despite the substantial reduction in model parameters and computational complexity, CF-YOLO achieves mAP50 and mAP95 scores of 44.9% and 27.5%, respectively.
Ablation experiments of feature fusion modules
As shown in Table2, a systematic ablation study was conducted to explore the optimal feature fusion strategy within the CS-FPN structure. The experimental results indicate that using the standard feature fusion method yields an mAP50 of 39.5% and an mAP50:95 of 24%. While the Sandwich Fusion module reduces model complexity, it leads to a decline in accuracy. In contrast, applying the FRM module alone improves mAP50 to 40.2% through spatial recalibration. The optimal two-stage fusion strategy-first applying FRM for calibration followed by Sandwich Fusion-achieves significant overall performance gains, enhancing precision, recall, mAP50, and mAP95 by 4.2%, 2.7%, 3.2%, and 2%, respectively.
A visualization analysis (Fig. 6) further reveals that both standard fusion (a) and Sandwich Fusion (b) exhibit notable shortcomings in detecting small targets at long distances. FRM calibration (c) substantially improves localization accuracy for distant small vehicles, while the two-stage fusion strategy (d) successfully detects vehicles as small as 4\(\times \)4 pixels at a 70-meter distance. This approach achieves a 4.5-point accuracy gain at the cost of a 23% increase in computational overhead, making it particularly well-suited for UAV vision tasks. The “calibration-enhancement” cascaded design offers a novel technical perspective for feature fusion in small-target detection.

Visualization of Feature Fusion Methods. (a) Visualization using the standard feature fusion method. (b) Visualization using the Sandwich feature fusion method. (c) Visualization using the FRM fusion method. (d) Visualization using the FRM + Sandwich fusion method.
Compration expriment
Comparison of CS-FPN and other FPNs on the VisDrone dataset
Table 3 presents a comparison between the proposed CS-FPN and classical FPN models. To ensure experimental fairness, a P2 small-object detection head was incorporated in all experiments. The results indicate that CS-FPN outperforms PANet, BiFPN, and AFPN in detection accuracy. Specifically, compared to the state-of-the-art AFPN, CS-FPN achieves overall performance improvements with lower computational cost, yielding a 1.2% increase in mAP50 while enhancing computational efficiency (mAP50/GFLOPs) by 32%. In comparison with BiFPN, CS-FPN attains a 1.6% mAP50 improvement with only an 8.6% increase in parameters. These results validate the effectiveness of CS-FPN’s innovative cross-scale feature interaction mechanism. Its excellent balance between accuracy and efficiency makes it an ideal choice for UAV-based visual detection tasks.
Comparison experiments of mAP50 for different categories on the VisDrone dataset
To further validate the effectiveness of the proposed CF-YOLO, Table4 presents a comparison of per-class mAP50 accuracy across different models on the VisDrone test set. The experimental results demonstrate that CF-YOLO achieves significant improvements over the baseline model YOLOv11n across all 10 target categories. Notably, for small target classes-pedestrians, people, and bicycles-mAP50 increases by 12.2%, 9.7%, and 8.6%, respectively. Compared to state-of-the-art models, CF-YOLO exhibits clear advantages: it outperforms YOLOv8m in six categories and surpasses RT-DETR in small object detection accuracy by an average margin of 15.3%. Particularly noteworthy is CF-YOLO’s outstanding performance in detecting extremely small objects, achieving a pedestrian detection accuracy of 34.1% and a bicycle detection accuracy exceeding 10.9%. These findings strongly validate CF-YOLO’s effectiveness in small object detection tasks from a UAV perspective.
Comparative experiments of different models on the VisDrone dataset
We propose CF-YOLO, a high-resolution remote sensing object detection method based on YOLOv11n. To highlight the superiority of our model, we compare CF-YOLO with state-of-the-art general object detection methods and advanced small object detection approaches. The results, as shown in Table 5, demonstrate that our proposed CF-YOLO achieved the best performance on the VisDrone2019 DET validation set, with the highest detection accuracy, significantly surpassing the mAP values of many models with size m. CF-YOLO achieved a detection accuracy of 52.8%, a recall rate of 43.4%, and an mAP50 of 44.9%, which is about a 12.7% improvement over the baseline model’s mAP50. It is particularly noteworthy that, compared to other lightweight models with size of n, our model surpasses many advanced methods in terms of detection accuracy, recall rate, and average detection accuracy, fully proving the excellent performance of our method in the field of object detection in drone images. Compared to many detection methods with model sizes of m and L, CF-YOLO not only achieves higher accuracy but also maintains a significantly smaller parameter count and computational cost. Specifically, CF-YOLO achieves the highest mAP50 and mAP95 among YOLOv8m, YOLOv10m, and YOLOv11m.Compared to YOLOv5l, CF-YOLO improves mAP50 by 3.5% and mAP95 by 2.9%, while requiring only one-fifth of its parameters and computation. Furthermore, Compared to the Transformer-based RT-DETR, CF-YOLO improves mAP50 and mAP95 by 3.5% and 2.4%, respectively. Notably, compared to many specialized remote sensing detection methods, CF-YOLO demonstrates exceptional accuracy. Specifically, compared to El-YOLO, CF-YOLO improves precision, recall, F1 score, mAP50, and mAP95 by 4%, 3.1%, 4.7%, 2%, and 2.7%, respectively. When compared with high-accuracy models such as EdgeYOLO and EBC-YOLO, CF-YOLO achieves an optimal balance between accuracy and computational cost. These results further validate the outstanding performance of our approach in UAV-based object detection tasks. To visually compare the performance of CF-YOLO with other models, we plotted precision comparison curves for CF-YOLO and each model on the mAP50 metric, as shown in Fig. 7. The orange asterisk curve represents CF-YOLO, and it is clearly evident that CF-YOLO is significantly higher than other models on mAP50, showing the most outstanding performance. These data clearly demonstrate the advantages of CF-YOLO in handling complex scenes and small target detection issues, and in terms of detection accuracy, CF-YOLO has consistently shown its superiority.

Comparison of the precision curves of CF-YOLO with different models at mAP50.
Comparative experiments of different models on the TinyPerson dataset
This study evaluates the performance of CF-YOLO on the highly challenging TinyPerson dataset, which is renowned for its extremely small object sizes and complex backgrounds. As shown in Table 6, CF-YOLO demonstrates a significant performance improvement over the baseline model YOLOv11n, achieving an 8.4% increase in precision , a 9.5% increase in recall , a 9.7% improvement in the F1-score, a 10.1% increase in mAP50, and a 3.6% improvement in mAP50:95. Compared to many models that size of s , CF-YOLO maintains a lower parameter (only 3.77M) while achieving the highest detection accuracy on the TinyPerson dataset, with a precision of 46.8%, a recall of 31.8%, an mAP50 of 29.7%, and an mAP95 of 9.81%. Furthermore, compared to many micro models that size of n, CF-YOLO achieves an optimal balance between accuracy and computational efficiency. These results indicate that CF-YOLO exhibits outstanding detection performance in the TinyPerson data set, further demonstrating its superiority and efficiency in small object detection tasks.
Comparative experiments of different models on the HIT-UAV dataset
The HIT-UAV dataset, with its significant scene diversity and complex background interference, provides a highly challenging test platform for evaluating model robustness. This study uses the dataset to systematically assess the generalization capability of the model in complex environments. As shown in Table 7, compared to the baseline model YOLOv11n, CF-YOLO achieves significant performance improvements while only increasing the parameter count by 0.79M (a 7.2% increase in model complexity). Specifically, CF-YOLO achieves a 7.9 percentage-point increase in F1-score, a 3.5 percentage-point improvement in mAP50, and a 3 percentage-point increase in mAP50:95. Notably, compared to YOLOv6n, CF-YOLO reduces the parameter count by 0.78M (a 6.9% reduction in model complexity) while achieving relative improvements of 4.7% in mAP50 and 5.2% in mAP95. Even when compared to the high-performance YOLOv8n, CF-YOLO maintains a competitive advantage, with mAP50 and mAP95 surpassing YOLOv8n by 1.4% and 1.9%, respectively. These comparative results indicate that CF-YOLO demonstrates stronger feature extraction capabilities in infrared small object detection tasks. Its exceptional generalization performance makes it particularly well-suited for small object detection applications in complex scenarios. This finding provides a new solution for efficient object detection in resource-constrained environments.
Visualization of detection results
Visualization of VisDrone detection results
To comprehensively assess model performance under challenging real-world conditions, this study selected four representative test samples from the VisDrone dataset, encompassing varying illumination conditions and background complexities. A standardized annotation scheme was employed for comparing detection results among YOLOv5, YOLOv8, YOLOv11, and CF-YOLO: red circles indicate true positive detections, while yellow circles denote false negative instances. As illustrated in Fig. 8, CF-YOLO demonstrates remarkable multi-scale object detection capabilities: For long-range small object detection (red markers (a)-1, (b)-1/2, (c)-2):CF-YOLO successfully identified targets with average dimensions below 20\(\times \)20 pixels, whereas comparative models exhibited missed detections (corresponding yellow markers). For partial occlusion handling ((a)-2 / 3): CF-YOLO accurately detected both tree-occluded motorcycles and truncated trucks, demonstrating superior occlusion robustness. In challenging low-light dense scenes (samples (b)-3, (c)-1/3, (d)-1), CF-YOLO demonstrates outstanding small object detection capabilities. Quantitative analysis indicates that for densely packed pedestrian and vehicle targets with an average size smaller than 20\(\times \)20 pixels, CF-YOLO achieves a higher localization accuracy, significantly outperforming the average detection performance of the comparative models.

Visualization of detection results for YOLOV11 and CF-YOLO on the VisDrone dataset. (a) detection results on a suburban highway under bright lighting conditions; (b) and (d) detection results of urban traffic under low-light conditions; (c) detection results of a school entrance scene under dark lighting conditions.
Visualization of tinyperson detection results
As illustrated in Fig. 9, this study conducts a systematic visual comparative analysis between CF-YOLO and mainstream detection models (YOLOv5/YOLOv8/YOLOv11) using the TinyPerson dataset. A standardized annotation scheme is adopted, where red dashed boxes indicate true positive detections and yellow dashed boxes denote false negative instances. The experimental evaluation encompasses four representative scenarios: In the first group (Fig. (a)), featuring medium-range detection of swimmers at sea, CF-YOLO successfully identifies multiple swimming targets with an average size of merely 8-16 pixels, while comparative models exhibit varying degrees of missed detections. The second group (Fig. (b)) presents a long-range beach setting, where CF-YOLO accurately captures sunbathers in diverse postures, demonstrating significantly superior detection completeness compared to baseline models. The third group (Fig. (c)) focuses on medium-range dense crowds, with CF-YOLO maintaining stable detection performance despite substantial target occlusion. The fourth group (Fig. (d)) examines long-range coastal activities, where CF-YOLO achieves reliable detection performance under challenging long-range conditions, in stark contrast to the high miss rates observed in comparative models. Comprehensive analysis reveals CF-YOLO’s notable advantages in three key aspects: (1) consistent detection capability for extremely small targets (<16 pixels); (2) remarkable adaptability to multi-scale scenarios; and (3) exceptional discriminative ability for high-density targets. Particularly in scenarios with extreme target scales, CF-YOLO demonstrates a substantial reduction in miss rate compared to baseline models. These visual results provide compelling validation of the model’s outstanding performance in tiny object detection tasks.

Visualization of detection results for YOLOV11 and CF-YOLO on the TinyPerson dataset. (a) represents the detection scenario of swimmers at sea, (b) and (c) depict scenes of people playing on the beach, and (d) illustrates the scene of people playing by the seaside.
Discussion
The CF-YOLO model proposed in this study demonstrates significant advantages in the target detection task for drone imagery, particularly in small object detection and interference resistance under complex backgrounds, outperforming existing methods. Ablation experiments validate the effectiveness of the proposed improvements. By incorporating the CS-FPN, FRM fusion module, and Sandwich fusion module, CF-YOLO effectively addresses the challenges of object size variability and the loss of small object information in deep networks, while enhancing feature extraction and information fusion capabilities. Furthermore, the model integrates the RFAConv and LSDECD modules, which reduce computational burden while enhancing the network’s global perception ability and facilitating cross-layer information interaction. Fig. 10 presents the confusion matrix of CF-YOLO and the baseline model YOLOv11n on the VisDrone dataset. Quantitative analysis indicates that CF-YOLO exhibits significant advantages in class discrimination ability, with notable improvements in classification accuracy across all object categories. This advantage is further validated by the comparison of PR curves in Fig. 11, where CF-YOLO’s detection accuracy surpasses that of the YOLOv11n model by 11.2%, providing strong evidence of the effectiveness of the model improvements. Notably, for the small object categories that dominate the dataset, such as people, bicycle, and motor, CF-YOLO’s PR curve demonstrates a more pronounced advantage, which strongly confirms the effectiveness of our approach in small object detection.
However, this study still has some limitations. As shown in Table 4, although CF-YOLO outperforms existing models in detection accuracy, its computational complexity is approximately four times that of the baseline model YOLOv11n. This performance degradation primarily arises from two key design factors: the introduction of additional hierarchical structures in the feature pyramid network and the use of advanced feature fusion modules. While these improvements significantly enhance small object detection capabilities, they inevitably increase the computational burden.
Future research will be centered on three key areas. Firstly, optimizing network topology through innovative architecture design and feature fusion strategies; secondly, developing lightweight functional modules with reduced computational complexity; and finally, establishing a dynamic balance mechanism between detection accuracy and computational efficiency. These concerted efforts are expected to substantially improve the model’s operational performance without compromising its detection efficacy.
Overall, we conducted a comprehensive evaluation of CF-YOLO using three datasets and multiple performance metrics. The experimental results demonstrate that CF-YOLO achieves high accuracy in small object detection and excels in addressing challenges such as object occlusion, low visibility, and complex backgrounds. This model offers a novel solution for small object detection in complex environments from a drone’s perspective.

Confusion Matrix for YOLOV11 and CF-YOLO on the VisDrone dataset.

Comparison chart of PR curves between CF-YOLO and YOLOv11.
Conclusions
In recent years, with the rapid advancement of drone technology, how to efficiently and accurately detect and recognize tiny objects in drone images has become an interesting and challenging research topic. This paper introduces a small object detection algorithm based on an improved YOLOv11-CF-YOLO. We comprehensively evaluated the model using the VisDrone2019 dataset, the TinyPerson dataset, and the HIT-UAV dataset, aiming to significantly improve the detection accuracy of small objects.Firstly, in response to the issues of complex backgrounds, significant scale differences, and the susceptibility of small object information to loss in drone images, we innovatively proposed a Cross-Scale Feature Pyramid Network (CS-FPN). Secondly, to overcome the challenges of position offset and feature redundancy, we meticulously designed a Position Recalibration Module (FRM) to process and fuse high-frequency and low-frequency features, as well as a sandwich fusion structure to efficiently extract multi-scale features. Lastly, to enhance the network’s perception of various feature differences, we reconstructed the backbone network by introducing RFAConv; in addition, we improved the detection head by adopting a lightweight shared convolutional detection head, LSDECD, reducing the model’s complexity without sacrificing accuracy. The experimental results significantly indicate that, compared to the original baseline model, the CF-YOLO algorithm has demonstrated remarkable performance improvements across multiple datasets. On the VisDrone dataset, the mAP50 and mAP50:95 metrics have increased by 12.7% and 8.9% respectively; on the TinyPerson dataset, these two metrics have been enhanced by 10.1% and 3.6% respectively; and on the HIT-UAV dataset, mAP50 and mAP50:95 have also seen growth of 3.5% and 3% respectively. The CF-YOLO proposed by us has effectively enhanced the network’s representational capability by absorbing the essence of advanced technologies, thereby achieving significant improvements in the precision of small target detection. In future work, we will be dedicated to exploring a more efficient and accurate target detection architecture for application in the field of drone imagery target detection.
Data availability
All data generated or analysed during this study are included in this published article.
References
Laghari, A. A. et al. Unmanned aerial vehicles advances in object detection and communication security review. Cogn. Robot. 4, 128–141 (2024).
Outay, F., Mengash, H. A. & Adnan, M. Applications of unmanned aerial vehicle (UAV) in road safety, traffic and highway infrastructure management: Recent advances and challenges. Transp. Res. Part A Policy Practice 141, 116–129 (2020).
Kim, J., Kim, S., Ju, C. & Son, H. I. Unmanned aerial vehicles in agriculture: A review of perspective of platform, control, and applications. IEEE Access 7, 105100–105115 (2019).
Istiak, M. A. et al. Adoption of unmanned aerial vehicle (UAV) imagery in agricultural management: A systematic literature review. Ecol. Inf. 78, 102305 (2023).
Lian, R., Wang, W., Mustafa, N. & Huang, L. Road extraction methods in high-resolution remote sensing images: A comprehensive review. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 13, 5489–5507 (2020).
Xu, J. et al. Yoloow: A spatial scale adaptive real-time object detection neural network for open water search and rescue from UAV aerial imagery. IEEE Trans. Geosci. Remote Sens. 622, 1–15 (2024).
Chen, X. et al. DET-YOLO: An innovative high-performance model for detecting military aircraft in remote sensing images. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 17, 17753–17771 (2024).
Liu, C. et al. YOLC: You only look clusters for tiny object detection in aerial images. IEEE Trans. Intell. Transp. Syst. 25, 13863–13875 (2024).
Ding, J. et al. Object detection in aerial images: A large-scale benchmark and challenges. IEEE Trans. Pattern Anal. Mach. Intell. 44, 7778–7796 (2021).
Wang, J., Yang, W., Guo, H., Zhang, R. & Xia, G.-S. Tiny object detection in aerial images. In 2020 25th International Conference on Pattern Recognition (ICPR), 3791–3798 (IEEE, 2021).
Cai, Z., Gao, Y., Zheng, Y., Zhou, N. & Huang, D. Crowd-sam: Sam as a smart annotator for object detection in crowded scenes. In European Conference on Computer Vision, 334–351 (Springer, 2024).
Wang, H., Qian, H. & Feng, S. GAN-STD: Small target detection based on generative adversarial network. J. Real-Time Image Proc. 21, 65 (2024).
Zhang, T. et al. Multistage enhancement network for tiny object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 62, 1–12 (2024).
Li, Z. et al. Local to global: A sparse transformer-based small object detector for remote sensing images. IEEE Trans. Geosci. Remote Sens. 63, 1–16 (2025).
Wang, H., Liu, C., Cai, Y., Chen, L. & Li, Y. Yolov8-qsd: An improved small object detection algorithm for autonomous vehicles based on yolov8. IEEE Trans. Instrum. Meas. 73, 1–16 (2024).
Carion, N. et al. End-to-end object detection with transformers. In European Conference on Computer Vision, 213–229 (Springer, 2020).
Zhao, Y. et al. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 16965–16974 (2024).
Girshick, R. Fast r-CNN. In proceedings of the IEEE International Conference on Computer Vision 1440–1448. Piscataway, NJ: IEEE.[Google Scholar]2 (2015).
Ren, S., He, K., Girshick, R. & Sun, J. Faster r-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 39, 1137–1149 (2016).
He, K., Gkioxari, G., Dollár, P. & Girshick, R. Mask r-CNN. In Proceedings of the IEEE International Conference on Computer Vision, 2961–2969 (2017).
Redmon, J., Divvala, S., Girshick, R. & Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 779–788 (2016).
Redmon, J. & Farhadi, A. Yolo9000: better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 7263–7271 (2017).
Redmon, J. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767 (2018).
Bochkovskiy, A., Wang, C.-Y. & Liao, H.-Y. M. Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934 (2020).
Jocher, G. et al. ultralytics/yolov5: v7. 0-yolov5 sota realtime instance segmentation. Zenodo (2022).
Li, C. et al. Yolov6: A single-stage object detection framework for industrial applications. arXiv preprint arXiv:2209.02976 (2022).
Wang, C.-Y., Bochkovskiy, A. & Liao, H.-Y. M. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 7464–7475 (2023).
Huang, J. et al. Speed/accuracy trade-offs for modern convolutional object detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 7310–7311 (2017).
Zhu, X., Lyu, S., Wang, X. & Zhao, Q. Tph-yolov5: Improved yolov5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2778–2788 (2021).
Feng, Y., Xu, H., Jiang, J., Liu, H. & Zheng, J. ICIF-NET: Intra-scale cross-interaction and inter-scale feature fusion network for bitemporal remote sensing images change detection. IEEE Trans. Geosci. Remote Sens. 60, 1–13 (2022).
Li, M., Chen, Y., Zhang, T. & Huang, W. TA-YOLO: a lightweight small object detection model based on multi-dimensional trans-attention module for remote sensing images. Complex Intell. Syst. 10, 5459–5473 (2024).
Zhang, Y. et al. FFCA-YOLO for small object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 62, 1–15 (2024).
Bai, C. et al. SFFEF-YOLO: Small object detection network based on fine-grained feature extraction and fusion for unmanned aerial images. Image Vis. Comput. 156, 105469 (2025).
Li, Y., Fan, Q., Huang, H., Han, Z. & Gu, Q. A modified YOLOv8 detection network for UAV aerial image recognition. Drones 7, 304 (2023).
Zhang, H. et al. Construction of a feature enhancement network for small object detection. Pattern Recogn. 143, 109801 (2023).
Gu, Z., Zhu, K. & You, S. Yolo-ssfs: A method combining spd-conv/stdl/im-fpn/siou for outdoor small target vehicle detection. Electronics 12, 3744 (2023).
Zhang, Y., Zhang, H., Huang, Q., Han, Y. & Zhao, M. DSP-YOLO: An anchor-free network with dspan for small object detection of multiscale defects. Expert Syst. Appl. 241, 122669 (2024).
Li, Y. et al. SOD-YOLO: Small-object-detection algorithm based on improved yolov8 for UAV images. Remote Sens. 16, 3057 (2024).
Xue, C. et al. El-yolo: An efficient and lightweight low-altitude aerial objects detector for onboard applications. Expert Syst. Appl. 256, 124848 (2024).
Lin, T.-Y. et al. Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2117–2125 (2017).
Lin, T. Focal loss for dense object detection. arXiv preprint arXiv:1708.02002 (2017).
Guo, C., Fan, B., Zhang, Q., Xiang, S. & Pan, C. Augfpn: Improving multi-scale feature learning for object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 12595–12604 (2020).
Liu, S., Qi, L., Qin, H., Shi, J. & Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, 8759–8768 (2018).
Ghiasi, G., Lin, T.-Y. & Le, Q. V. Nas-fpn: Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 7036–7045 (2019).
Li, Z. et al. Cross-layer feature pyramid network for salient object detection. IEEE Trans. Image Process. 30, 4587–4598 (2021).
Tan, M., Pang, R. & Le, Q. V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 10781–10790 (2020).
Wang, J. et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 43, 3349–3364 (2020).
Fu, Y., Hong, Y., Chen, L. & You, S. LE-GAN: Unsupervised low-light image enhancement network using attention module and identity invariant loss. Knowl. Based Syst. 240, 108010 (2022).
Zhang, T., Fu, Y. & Zhang, J. Guided hyperspectral image denoising with realistic data. Int. J. Comput. Vis. 130, 2885–2901 (2022).
Woo, S., Park, J., Lee, J. & Kweon, I. S. Cbam: convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV): 3–19 (2018).
Hou, Q., Zhou, D. & Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 13713–13722 (2021).
Zhang, X. et al. Rfaconv: Innovating spatial attention and standard convolutional operation. arXiv preprint arXiv:2304.03198 (2023).
Noh, H., Hong, S. & Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE international conference on computer vision, 1520–1528 (2015).
Zhu, P. et al. Detection and tracking meet drones challenge. IEEE Trans. Pattern Anal. Mach. Intell. 44, 7380–7399 (2021).
Jiang, N., Yu, X., Peng, X., Gong, Y. & Han, Z. Sm+: Refined scale match for tiny person detection. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1815–1819 (organizationIEEE, 2021).
Luo, H. et al. Ebc-yolo: A remote sensing target recognition model adapted for complex environments. Earth Sci. Inf. 18, 282 (2025).
Liu, S., Zha, J., Sun, J., Li, Z. & Wang, G. Edgeyolo: An edge-real-time object detector. In 2023 42nd Chinese Control Conference (CCC), 7507–7512 (organization IEEE, 2023).
Zhang, Z. Drone-yolo: An efficient neural network method for target detection in drone images. Drones 7, 526 (2023).
Acknowledgements
This work is partly supported by the Key Project of Yunnan Basic Research Program under Grant 202401AS070034, and the Yunnan Provincial Forestry and Grass Science and Technology Innovation Joint Project under Grant 202404CB090002.
Author information
Authors and Affiliations
Contributions
Conceptualization, C.W. and L.Y.; methodology, Y.H.; software, C.W.; validation, C.Y., and M.W.; formal analysis, C.W.; investigation, Z.C.; resources, X.J. and L.Y.; data curation, C.W. and C.Y.; writing-original draft preparation, C.W.; writing-review and editing, C.W.; visualization, C.W.; supervision, M.W.; funding acquisition, L.Y. All authors have read and agreed to the published version of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The author(s) declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wang, C., Han, Y., Yang, C. et al. CF-YOLO for small target detection in drone imagery based on YOLOv11 algorithm. Sci Rep 15, 16741 (2025). https://doi.org/10.1038/s41598-025-99634-0
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-99634-0
Keywords
This article is cited by
-
A Time-Synchronized Multi-Sensor drone dataset acquired from multiple radars and RF receiver
Scientific Data (2026)
-
Enhanced YOLOv11n for small object detection in UAV imagery: higher accuracy with fewer parameters
Scientific Reports (2026)
-
Real-time multi-object detection and tracking in UAV systems: improved YOLOv11-EFAC and optimized tracking algorithms
Journal of Real-Time Image Processing (2025)
-
Agricultural machinery navigation coordinate extraction driven by YOLOv8-MCS-based potato seedling recognition
Precision Agriculture (2025)
