
Abstract
In tuberculosis (TB), chest radiography (CXR) patterns are highly variable, mimicking pneumonia and many other diseases. This study aims to evaluate the efficacy of Google teachable machine, a deep neural network-based image classification tool, to develop algorithm for predicting TB probability of CXRs. The training dataset included 348 TB CXRs and 3806 normal CXRs for training TB detection. We also collected 1150 abnormal CXRs and 627 normal CXRs for training abnormality detection. For external validation, we collected 250 CXRs from our hospital. We also compared the accuracy of the algorithm to five pulmonologists and radiological reports. In external validation, the AI algorithm showed areas under the curve (AUC) of 0.951 and 0.975 in validation dataset 1 and 2. The accuracy of the pulmonologists on validation dataset 2 showed AUC range of 0.936–0.995. When abnormal CXRs other than TB were added, AUC decreased in both human readers (0.843–0.888) and AI algorithm (0.828). When combine human readers with AI algorithm, the AUC further increased to 0.862–0.885. The TB CXR AI algorithm developed by using Google teachable machine in this study is effective, with the accuracy close to experienced clinical physicians, and may be helpful for detecting tuberculosis by CXR.
Similar content being viewed by others
Introduction
Tuberculosis (TB) is one of the most important infectious diseases worldwide and causes millions of illnesses and deaths annually1. Chest radiography is an essential first-line diagnostic tool for TB because of its low cost and speed. However, the characteristics of TB chest X-ray (CXR) are highly variable, mimicking pneumonia and many other diseases. The atypical pattern is particularly common in elderly patients, immunocompromised, and those with multiple comorbidities2,3. Consequently, the early diagnosis of TB using CXRs can be challenging. Moreover, CXR reports often cannot be completed in a timely manner, this also increases the difficulty of early TB detection for the frontline clinicians.
The application of artificial intelligence (AI) to CXR for TB is a field with tremendous potential. The deep neural network-based image interpretation has achieved remarkable results in the field of medical imaging. Recent research has developed numerous medical image recognition algorithms for CXR patterns4,5,6 and various pulmonary diseases (pneumonia, lung cancer, TB, pneumothorax, COVID-19, etc.)7,8,9,10,11,12,13,14,15, in some of them the accuracy can match or even outperform that of radiologists. Some of them had external validation confirmed accuracy7,8,9,10,12,14,16,17. In a study evaluation CXR algorithms for pulmonary diseases classification, the combination of algorithm with physicians successfully improve accuracy than physicians alone. And the benefit is observed in both radiologists and non-radiology physicians8. In another study evaluating CXR algorithm for TB detection, a similar accuracy benefit is found in physicians with algorithm assistance7. Five commercial TB AI algorithms had been carefully validated, and the specificity ranged from 61 to 74% when sensitivity was fixed at 90%13,14.
In 2019, Google Teachable Machine (GoogleTM) launched its second version18. This tool allows users to train deep neural networks for image recognition using a graphical user interface on a Chrome browser with almost no coding required. Its highly lightweight design, along with its use of transfer learning techniques, significantly reduces the computational requirements and amount of data required for training. This implies that AI training can be simply performed using a desktop or laptop computer. Therefore, the purpose of this study is to assess the feasibility and accuracy of GoogleTM, for the detection of CXR images in patients with TB. To see its utility in clinical practice, we also plan to compare the accuracy of this simple AI tool to the frontline physicians.
Materials and methods
This study was designed to use freely available open TB CXR datasets as training data for our AI algorithm. Subsequent accuracy analyses were performed using independent CXR datasets and actual TB cases from our hospital. All image data were de-identified to ensure privacy. This study was reviewed and approved by institutional review board (IRB) of Kaohsiung Veterans General Hospital, which waived the requirement for informed consent (IRB no.: KSVGH23-CT4-13). This study adheres to the principles of the Declaration of Helsinki.
Training datasets
The flowchart of the study design is shown in Fig. 1. Due to a high prevalence of TB and varied imaging presentation, TB cannot be entirely excluded in case of CXR presenting with pneumonia or other entities. Our preliminary research indicated that training a model solely on TB vs. normal resulted in bimodally distributed predictive values. Therefore, CXRs that were abnormal but not indicative of TB usually had predictive value too high or too low, and failed to effectively differentiate abnormal cases from normal or TB. For common CXR abnormalities such as pneumonia and pleural effusion, the TB risk is lower, but not zero. Thus, we trained two models using 2 different training datasets, one for TB detection and another for abnormality detection. Then the output predictive values were averaged.
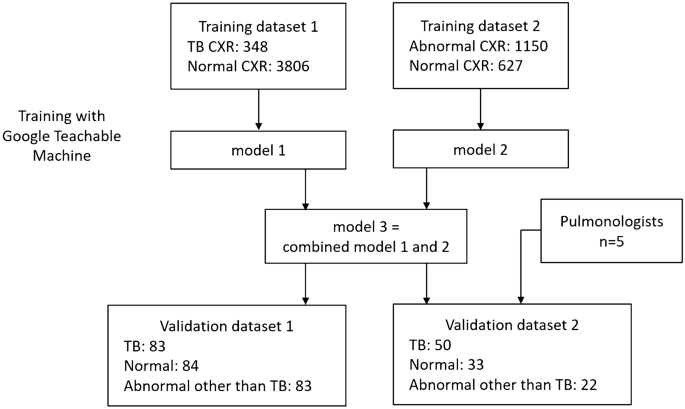
Flow chart of model training and validations.
The features of the CXR datasets for training is summarized in Table 1. The inclusion criteria are CXR of TB, other abnormality, or normal. Both posteroanterior view and anteroposterior view CXRs are included. The exclusion criteria are CXR with poor quality, lateral view CXR, children CXR, and those with lesions too small to detect at 224 × 224 pixels size). All the CXR images were confirmed by C.F.C. to ensure both image quality and correctness.
Training dataset 1 is used for training algorithms to detect typical TB pattern on CXR. 348 TB CXRs and 3806 normal CXRs were collected from various open datasets for training, including the Shenzhen dataset from Shenzhen No. 3 People’s Hospital, the Montgomery dataset19,20, and Kaggle's RSNA Pneumonia Detection Challenge21,22.
Training dataset 2 is used for training algorithms to detect CXR abnormalities. A total of 1150 abnormal CXRs and 627 normal CXRs were collected from the ChestX-ray14 dataset23. The abnormal CXRs consisted of consolidation: 185, cardiomegaly: 235, pulmonary edema 139, pleural effusion: 230, pulmonary fibrosis 106, and mass: 255.
Algorithm: Google teachable machine
In this study, we employed GoogleTM18, a free online AI software dedicated to image classification. GoogleTM provides a user-friendly web-based graphical interface that allows users to execute deep neural network computations and train image classification models with minimal coding requirements. By utilizing the power of transfer learning, GoogleTM significantly reduces the computational time and data amount required for deep neural network training. Within GoogleTM, the base model for transfer learning was MobileNet, a model pretrained by Google on the ImageNet dataset featuring 14 million images and capable of recognizing 1,000 classes of images. Transfer learning is achieved by modifying the last 2 layers of the pre-trained MobileNet, and then keep subsequent specific image recognition training18,24. In GoogleTM , all images are adjusted and cropped to 224 × 224 pixels for training. 85% of the image is automatically divided into training dataset, and the remaining 15% into validation dataset to calculate the accuracy.
The hardware employed in this study included a 12th-generation Intel Core i9-12900K CPU with 16 cores, operating at 3.2–5.2 GHz, an NVIDIA RTX A5000 GPU equipped with 24GB of error-correction code (ECC) graphics memory, 128 GB of random-access memory (RAM), and a 4TB solid-state disk (SSD).
Dataset for external validation
To evaluate the accuracy of the algorithms, we collected clinical CXR data for TB, normal cases, and pneumonia/other disease from our hospital.
Validation dataset 1 included 250 de-identified CXRs retrospectively collected from VGHKS. The CXRs dates were between January 1, 2010 and February 27, 2023. This dataset included 83 TB (81 confirmed by microbiology, and 2 confirmed by pathology), 84 normal, and 83 abnormal other than TB cases (73 pneumonia, 14 pleural effusion, 10 heart failure, and 4 fibrosis. Some cases had combined features). The image size of these CXRs ranged from width: 1760–4280 pixels and height: 1931–4280 pixels.
Validation dataset 2 is a smaller dataset derived from validation dataset 1, for comparison of algorithm and physician’s performance, and included 50 TB, 33 normal and 22 abnormal other than TB cases (22 pneumonia, 5 pleural effusion, 1 heart failure, and 1 fibrosis) CXRs. The features of the two validation datasets are provided in Table 1.
Data collected from clinical CXR cases included demographic data (such as age and sex), radiology reports, clinical diagnoses, microbiological reports, and pathology reports. All clinical TB cases included in the study had their diagnosis confirmed by microbiology or pathology. Their CXR was performed within 1 month of TB diagnosis. Normal CXRs were also reviewed by C.F.C. and radiology reports were considered. Pneumonia/other disease cases were identified by reviewing medical records and examinations, with diagnoses made by clinical physicians’ judgement, and without evidence of TB detected within three months period.
Physician’s performance test
We employed validation dataset 2 to evaluate the accuracy of TB detection of 5 clinical physicians (five board-certified pulmonologists, average experience 10 years, range 5–16 years). Each physician performed the test without additional clinical information, and was asked to estimate the probability of TB in each CXR, consider whether sputum TB examinations were needed, and make a classification from three categories: typical TB pattern, normal pattern, or abnormal pattern (less like TB).
We also collected radiology reports from validation dataset 2 to evaluate their sensitivity for detecting TB. Reports mentioning suspicion of TB or mycobacterial infection were classified as typical TB pattern. Reports indicating abnormal patterns such as infiltration, opacity, pneumonia, effusion, edema, mass, or tumor (but without mentioning “tuberculosis”, “TB”, or “mycobacterial infection”) were classified as abnormal pattern (less like TB). Reports demonstrating no evident abnormalities were classified as normal pattern. Furthermore, by analyzing the pulmonologists’ decisions regarding sputum TB examinations, we estimate the sensitivity of TB detection in pulmonologist’s actual clinical practice.
Statistical analysis
Continuous variables are represented as mean ± standard deviation (SD) or median (interquartile range [IQR]), while categorical variables are represented as number (percentage). For accuracy analysis, the receiver operating characteristic (ROC) curve was used to compute the area under the curve (AUC). Sensitivity, specificity, positive predictive value (PPV), negative predictive value (NPV), likelihood ratio (LR), overall accuracy, and F1 score were calculated. A confusion matrix was used to illustrate the accuracy of each AI model. Boxplots were used to evaluate the distribution of the predicted values of the AI models for each etiology subgroup.
The formulas for each accuracy calculation are as follows:
(TP is true positives, TN is true negatives, FP is false positives, FN is false negatives, P is all positives, and N is all negatives.)
Results
In this study, model 1 was trained by training dataset 1 (TB vs. normal), with the purpose to detect typical TB pattern on CXR. Model 2 was trained by training dataset 2 (abnormal vs. normal), with the purpose to detect CXR abnormalities. Each training dataset was trained at least 10 times, and the algorithm with the best overall accuracy was chosen. In model 2, twofold data augmentation was performed by zoom in method. Model 3 was a combination of model 1 and model 2, by averaging the predictive values of the two models. It was developed to detect both TB and other CXR abnormalities.
Internal validation
The internal validation results calculated during training showed excellent accuracy: model 1 showed a sensitivity of 0.96, specificity of 0.98, and overall accuracy of 0.97. Model 2 exhibited a sensitivity of 0.92, specificity of 0.92, and an overall accuracy of 0.92. A detailed analysis of the accuracy is provided in Table 2, and the confusion matrix is provided in Table S1. The hyperparameters in training GoogleTM, and the accuracy curve and loss function were shown in Figure S1 and S2.
External validation
The accuracy analysis for external validation is shown in Table 3 and Fig. 2a–d. For the analysis of TB vs. normal, model 1 showed AUC of 0.8 and 0.795 in validation dataset 1 and 2, respectively. Model 2 showed AUC of 0.902 and 0.917. Model 3 demonstrated better accuracy, with AUC of 0.951 and 0.975, respectively. For the analysis of TB vs. normal and abnormal other than TB, model 1 showed AUC of 0.72 and 0.752 in validation dataset 1 and 2, respectively. Model 2 showed AUC of 0.656 and 0.718. Model 3 showed AUC of 0.758 and 0.828.

Receiver operating characteristic curves of AI models in external validations. (a) Validation dataset 1: TB vs. normal, (b) validation dataset 1: TB vs. normal and abnormal other than TB, (c) validation dataset 2: TB vs normal, (d) validation dataset 2: TB vs. normal and abnormal other than TB. TB tuberculosis, AI artificial intelligence.
Both datasets revealed that model 3 outperformed model 1 and 2, with the best AUC, overall accuracy and F1 score. The distribution of predictive values of model 1 to model 3 in each disease subgroup were provided in Figure S3.
Physicians’ performance
Five pulmonologists independently assessed validation dataset 2. The detailed results of the accuracy analysis are presented in Table 4 and Fig. 3a, b. For the analysis of TB vs. normal, the AUC ranged from 0.936 to 0.995. For TB vs. normal and abnormal other than TB, the AUC ranged from 0.843 to 0.888. The AUC of model 3 is close but mild inferior to the five pulmonologists. The overall accuracy and F1 score of Model 3 are similar or even better than pulmonologist. Model 3 has a higher sensitivity than pulmonologists (0.86 vs. 0.34–0.76), while the specificity is lower (0.65–1.0 vs. 0.85–1.0). When combining pulmonologists with model 3 by averaging predictive values, 4 of 5 pulmonologists showed improving of AUC (0.862–0.885, Table 4 and Fig. 4). The radiographic report for validation dataset 2 revealed an even lower sensitivity for TB (0.3), and a good specificity (0.98–1.0).

Receiver operating characteristic curves of model 3 and 5 pulmonologists evaluating validation dataset 2. (a) TB vs normal, (b) TB vs. normal and abnormal other than TB. TB tuberculosis. V1–V5 represents the 5 pulmonologists.

Receiver operating characteristic curves of the 5 pulmonologists that combined with model 3, evaluating validation dataset 2 (TB vs. normal and abnormal other than TB). TB tuberculosis. V1–V5 represents the 5 pulmonologists.
Table S2 showed the decisions of pulmonologists on TB sputum exams in each subgroup. The average TB sputum exam rate is 97% in CXR typical TB pattern, 62% in those with abnormal pattern (less like TB). The average TB sputum coverage rate of TB cases is 87%, abnormal other than TB cases is 56%, and normal cases is 2%.
CXR image patterns and cutoff value evaluation
According to the average result of the five pulmonologists’ interpretation, the CXR image patterns are classified as three categories: typical TB pattern, abnormal pattern (less like TB), and normal pattern. The summary of predictive values of AI models and pulmonologists in each CXR image pattern are provided in Table 5. For model 3, the median predictive value is 0.97 (IQR: 0.64–0.99) in typical TB pattern, 0.5 (IQR: 0.5–0.9) in abnormal pattern (less like TB), and 0.03 (IQR: 0.005–0.13) in normal pattern. The boxplot for distribution of predictive values of model 3 and pulmonologists was shown in Figure S4. A cross table analyzing CXR patterns and disease groups of validation dataset 2 is provided in Table S3, showing that only 26 of 50 TB cases (52%) had typical TB pattern. Meaning while, 4 of 22 of abnormal other than TB cases (18%) presented with CXR pattern mimicking TB. Figure S5 compared the predictive value of model 3 between each disease group and image pattern subgroup. Model 3 had higher predictive values in CXR with typical TB pattern than abnormal pattern (both for TB group and abnormal other than TB group).
Cutoff value evaluation for model 3 is shown in Table S4. At cutoff value of 0.4, the sensitivity approached 0.92 and 0.94 in validation dataset 1 and 2, respectively. While at cutoff value of 0.8, the specificity is 0.81 and 0.89. When setting sensitivity at 0.90, the specificity is 0.48 and 0.60 in validation dataset 1 and 2, respectively.
Deployment of the TB CXR AI
Based on the results of this study, we deployed model 3, which had the best accuracy performance, as a readily accessible web application (utilizing JavaScript and TensorFlow.js). This TB CXR AI algorithm can run on a web browser and process data on your device, without sending image to the server. The AI algorithm can be accessed via the following URL: https://www.cxrai-prediction.net/, and the CXR interpretation examples were shown in Figs. S6 and S7. We also provided some examples of TB cases detected by AI algorithm but miss diagnosed by physicians in Fig. S8, and some examples that AI algorithm failed to detect TB in Fig. S9.
Discussion
In this study, the TB CXR AI algorithm training via Google Teachable Machine with a relatively small number of images, has achieved an acceptable accuracy close to that of professional pulmonologists, and it has a higher sensitivity in TB detection, showing a potential to aid both specialist and non-specialist physicians in enhancing their TB screening sensitivity.
The TB cases collected in this study had relatively high percentage (48%) of atypical CXR pattern. This may be due to older age of our patient group (average 72.7 years old in TB patients). Literature also showed that the percentage of typical TB CXR pattern (upper lung predominant) is significantly influenced by patient’s performance status (PS)25. For TB patients with good physical activity (PS of 0), a typical CXR pattern was observed in 71% of cases. As the patient’s physical activity got worse, the proportion of typical CXR patterns drops dramatically (PS = 1: 44%, PS = 2: 19%, PS = 3: 16%, PS = 4: 0%)25.
Among the AI models established in this study, model 1 had good specificity but lower sensitivity for TB. However, we found this model was not effective to detect TB with atypical CXR patterns. As for model 2, it is effective to differentiate abnormal CXR from normal cases. Model 3 is the combination of model 1 and 2, and give the average predictive values of the 2 models. This ensemble method can balance the detection of typical and atypical TB, and compensate the occasional false positives and false negatives from model 1 and 2. In theory, typical TB cases would have predictive values near 1 for both model 1 and model 2, averaging around 1. For abnormal cases without a typical TB pattern, model 1 might predict values close to 0, while model 2 would remain near 1, with an average of 0.5. In normal cases, both models would predict values close to 0, resulting in an average also near 0. As evidenced by validation datasets 1 and 2, model 3 successfully achieved the best AUC, which is close to clinical experts.
Both model 3 and the pulmonologists demonstrate excellent accuracy when evaluating TB vs normal. However, when adding abnormal other than TB (mostly pneumonia), the accuracy decreased remarkably in both model 3 (AUC: 0.975 decrease to 0.828) and pulmonologists (AUC: 0.936–0.995 decrease to 0.843–0.888). Pneumonia and other diseases (e.g. pulmonary fibrosis) may also mimic TB. As pneumonia cases increase, the false positives also increase, and we suggest this is the limitation of CXR TB detection, both for human and AI models. However, our study showed that the integration of AI model with physicians’ clinical judgment could potentially improve the overall accuracy of TB detection.
In terms of the performance of pulmonologists and radiology reports, direct comparisons between them maybe not feasible. Because the pulmonologists are already aware that the study is evaluating TB CXRs, and during the exam, the judgment is made under heightened awareness. Therefore, the sensitivity for TB is better than in real-world clinical practice. In contrast, radiology reports are collected retrospectively, reflecting the radiologists’ daily practice at that time. Awareness of TB in these reports is likely lower. On the other hand, the accuracy difference between the radiology reports (sensitivity: 0.3, overall accuracy: 0.65) and the pulmonologists (sensitivity: 0.34–0.76, overall accuracy: 0.65–0.80) also indicates that increasing physicians' awareness of TB may enhance the accuracy of TB CXR evaluations. In this study, pulmonologists tended to perform more extensive TB sputum examinations (even without clinical information), which reflect the experts’ alertness to improve TB detection (70%-98% exam rate in TB cases). Besides, we suggest TB CXR AI may well potentially improve TB awareness for both specialist and non-specialist physicians.
Although in this study, our model showed a lower accuracy than the 5 commercial TB AI algorithms (specificity 48–60% vs. 61–74%, when sensitivity was fixed at 90%)14. However, the TB patients in our study are much older (median age 74 vs. 37 years), and the percentage of typical TB image pattern is lower (52%). This difference may decrease the accuracy of AI model in our study. In fact, previous literature also showed decreased accuracy performance of the 5 commercial TB AI algorithms in older age group (> 60 years, AUC range: 0.805–0.864)14. This result is getting close to the accuracy of our model (AUC = 0.828) and the pulmonologists (AUC range: 0.843–0.888) in validation dataset 2.
Recent literature has also discussed the problems about TB CXR AI26, including the heterogeneity of accuracy across different populations, determination of prediction value thresholds and their variability, and misjudgments in non-TB patients. Therefore, this study used actual clinical CXRs for external validation to confirm accuracy in clinical situation. The determination of thresholds is both a strength and limitation of AI models. Therefore, this study also conducted a cutoff value evaluation to help determine the relationship of predictive value and accuracy.
The limitations of this study were as follows. First, the image recognition of GoogleTM operates on a relatively small resolution (224 × 224 pixels). Therefore, this AI algorithm can only identify large and obvious image features, and small lung lesions may be missed. Second, the AI model used in this study could not locate lesions. Third, this is a single center retrospective study, and the size of the validation dataset is relatively small. The accuracy result may not be generalizable to different CXR machine and settings. Fourth, this AI model is not optimal for detect TB cases without a typical TB pattern. However, physicians also have the similar limitation. Fifth, we did not evaluate the accuracy of radiologists. However, the retrospectively collected radiology reports may reflect the accuracy of daily clinical practice of radiologists. Finally, we did not evaluate the accuracy of frontline medical staffs such as junior residents and nurse practitioners. However, we can expect their accuracy for TB detection would be lower than expert physicians. And AI algorithm may be more helpful for them.
In conclusion, this study developed an open and free AI algorithm, which is effective in detection of typical TB features on CXR. The accuracy is acceptable and may be close to the clinical experts. We suggest a predictive value > 0.9 for high TB probability. For predictive value 0.5–0.9, abnormal pattern is favored, and TB may be considered. For predictive value < 0.4, TB is unlikely. Further research with larger scale validation to evaluate the generalizability of the algorithm, and compare the performance in different population, is required.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
World Health Organization. Global Tuberculosis Report 2021. https://www.who.int/publications/i/item/9789240037021 (World Health Organization, 2021).
Perez-Guzman, C., Torres-Cruz, A., Villarreal-Velarde, H. & Vargas, M. H. Progressive age-related changes in pulmonary tuberculosis images and the effect of diabetes. Am. J. Respir. Crit. Care Med. 162(5), 1738–1740. https://doi.org/10.1164/ajrccm.162.5.2001040 (2000).
Mathur, M., Badhan, R. K., Kumari, S., Kaur, N. & Gupta, S. Radiological manifestations of pulmonary tuberculosis—A comparative study between immunocompromised and immunocompetent patients. J. Clin. Diagn. Res. 11(9), TC06–TC09. https://doi.org/10.7860/JCDR/2017/28183.10535 (2017).
Rajpurkar, P. et al. Deep learning for chest radiograph diagnosis: A retrospective comparison of the CheXNeXt algorithm to practicing radiologists. PLoS Med. 15(11), e1002686. https://doi.org/10.1371/journal.pmed.1002686 (2018).
Cohen, J. P., Bertin, P., & Frappier, V. Chester: A Web Delivered Locally Computed Chest X-Ray Disease Prediction System. arXiv: https://arxiv.org/abs/1901.11210 (2020).
Al-Antari, M. A., Hua, C. H., Bang, J. & Lee, S. Fast deep learning computer-aided diagnosis of COVID-19 based on digital chest x-ray images. Appl. Intell. (Dordr). 51(5), 2890–2907 (2021).
Hwang, E. J. et al. Development and validation of a deep learning-based automatic detection algorithm for active pulmonary tuberculosis on chest radiographs. Clin. Infect. Dis. 69(5), 739–747. https://doi.org/10.1093/cid/ciy967 (2019).
Wang, C. et al. Development and validation of an abnormality-derived deep-learning diagnostic system for major respiratory diseases. NPJ Digit. Med. 5(1), 124 (2022).
Hwang, E. J. et al. Development and validation of a deep learning-based automated detection algorithm for major thoracic diseases on chest radiographs. JAMA Netw. Open 2(3), e191095 (2019).
Nam, J. G. et al. Development and validation of deep learning-based automatic detection algorithm for malignant pulmonary nodules on chest radiographs. Radiology 290(1), 218–228 (2019).
Sze-To, A., Riasatian, A. & Tizhoosh, H. R. Searching for pneumothorax in X-ray images using autoencoded deep features. Sci. Rep. 11(1), 9817 (2021).
Murphy, K. et al. Computer aided detection of tuberculosis on chest radiographs: An evaluation of the CAD4TB v6 system. Sci. Rep. 10(1), 5492 (2020).
Singh, M. et al. Evolution of machine learning in tuberculosis diagnosis: A review of deep learning-based medical applications. Electronics 11(17), 2634 (2022).
Qin, Z. Z. et al. Tuberculosis detection from chest X-rays for triaging in a high tuberculosis-burden setting: An evaluation of five artificial intelligence algorithms. Lancet Digit. Health 3(9), e543–e554 (2021).
Akhter, Y., Singh, R. & Vatsa, M. AI-based radiodiagnosis using chest X-rays: A review. Front. Big Data 6, 1120989 (2023).
Miyazaki, A. et al. Computer-aided diagnosis of chest X-ray for COVID-19 diagnosis in external validation study by radiologists with and without deep learning system. Sci. Rep. 13(1), 17533. https://doi.org/10.1038/s41598-023-44818-9 (2023).
Abad, M., Casas-Roma, J. & Prados, F. Generalizable disease detection using model ensemble on chest X-ray images. Sci. Rep. 14(1), 5890. https://doi.org/10.1038/s41598-024-56171-6 (2024).
Teachable Machine: Train a Computer to Recognize Your Own Images, Sounds, & Poses. https://teachablemachine.withgoogle.com/
Jaeger, S. et al. Automatic tuberculosis screening using chest radiographs. IEEE Trans. Med. Imaging. 33(2), 233–245. https://doi.org/10.1109/TMI.2013.2284099 (2014).
Candemir, S. et al. Lung segmentation in chest radiographs using anatomical atlases with nonrigid registration. IEEE Trans. Med. Imaging 33(2), 577–590. https://doi.org/10.1109/TMI.2013.2290491 (2014).
Kaggle. RSNA Pneumonia Detection Challenge [Online]. https://www.kaggle.com/c/rsna-pneumonia-detection-challenge/data. Accessed 14 June 2021 (2021).
Rahman, T. et al. Reliable tuberculosis detection using chest X-ray with deep learning, segmentation and visualization. IEEE Access 8, 191586–191601. https://doi.org/10.1109/ACCESS.2020.3031384 (2020).
Wang, X., Peng, Y., Lu, L., Lu, Z., Bagheri, M. & Summers, R.M. ChestX-ray8: Hospital-scale chest X-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 3462–3471 (IEEE, 2017).
Carney, M. et al. Teachable machine: Approachable web-based tool for exploring machine learning classification. In Extended Abstracts of the 2020 CHI Conference on Human Factors in Computing Systems (CHI EA '20). https://doi.org/10.1145/3334480.3382839 (Association for Computing Machinery, 2020).
Goto, A. et al. Factors associated with atypical radiological findings of pulmonary tuberculosis. PLoS One. 14(7), e0220346. https://doi.org/10.1371/journal.pone.0220346 (2019).
Geric, C. et al. The rise of artificial intelligence reading of chest X-rays for enhanced TB diagnosis and elimination. Int. J. Tuberc. Lung Dis. 27(5), 367–372. https://doi.org/10.5588/ijtld.22.0687 (2023).
Acknowledgements
We thank Mrs. Yu-Jung Chang for assisting literature search.
Author information
Authors and Affiliations
Contributions
C.F.C.: Conceptualization, Methodology, Investigation, Formal analysis, Data Curation, Writing—original draft, Writing—review & editing; P.F.C: Conceptualization, Supervision, Software, Investigation, Resources, Writing—review & editing. C.H.H., Y.C.J., W.R.L., W.C.H., I.Y.C.: Validation, Investigation. C.H.L.: Methodology, Investigation, Formal analysis. M.H.L., K.A.C., D.L.L.: Investigation, Resources. All of the authors contributed to and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chen, CF., Hsu, CH., Jiang, YC. et al. A deep learning-based algorithm for pulmonary tuberculosis detection in chest radiography. Sci Rep 14, 14917 (2024). https://doi.org/10.1038/s41598-024-65703-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-65703-z
Keywords
This article is cited by
-
SAM-LCA: a computationally efficient SAM-based model for tuberculosis detection in chest X-rays
Multimedia Systems (2025)
-
Advancing Pulmonary Infection Diagnosis: A Comprehensive Review of Deep Learning Approaches in Radiological Data Analysis
Archives of Computational Methods in Engineering (2025)
-
Bayesian calibration and sensitivity analysis of ordinary differential equation models for Tuberculosis spread in the Russian Federation
Computational Mathematics and Modeling (2025)
-
Detection of tuberculosis using cough audio analysis: a deep learning approach with capsule networks
Discover Artificial Intelligence (2024)
