
Abstract
This paper proposes a novel UWB/INS integration framework that utilizes attention-based Long Short-Term Memory (LSTM) neural networks to address challenges related to UWB signal degradation during non-line-of-sight (NLOS) propagation. The network is adopted to generate pseudo measurements to maintain Kalman filter measurement update during NLOS. LSTM networks are well-suited for modeling sequential data due to their ability to capture long-term dependencies, making them particularly effective in handling the temporal aspects of navigation data. By leveraging attention mechanisms, the proposed approach enhances temporal feature extraction and improves the accuracy of pseudo-UWB observations generation. Extensive experiments demonstrate that the attention-LSTM model significantly reduces positioning errors under both loosely and tightly coupled configurations in NLOS scenarios. This hybrid fusion of model-based and learning-based techniques ensures robust and precise UWB/INS localization.
Similar content being viewed by others

Introduction
The demand for high-precision positioning services in urban environments has surged exponentially with the rise of autonomous vehicles, drone navigation, the Internet of Things and intelligent transportation systems. Among the various positioning technologies, ultra-wideband (UWB) has been widely adopted for indoor and outdoor applications due to its high accuracy and strong resistance to interference1,2. However, the performance of UWB positioning deteriorates significantly in complex environments, where non-line-of-sight (NLOS) conditions introduce severe ranging errors3,4,5,6,7. In contrast, inertial navigation systems (INS) offer continuous position estimation but are prone to sensor drift, leading to cumulative errors over time8,9,10,11,12. Therefore, integrating the complementary strengths of UWB and INS to achieve robust, high-precision positioning has emerged as a critical research focus for navigation in challenging scenarios13,14. By combining these two technologies, systems can leverage the high accuracy of UWB and the continuous estimation capabilities of INS, offering a promising approach for advanced positioning solutions.
Traditional approaches to state estimation in UWB/INS fusion systems predominantly rely on extended Kalman filters (EKF) or particle filters (PF)13,15,16,17. While these methods improve positioning accuracy to some extent, they struggle to effectively manage the cumulative and unevenly distributed errors introduced by UWB signals under NLOS conditions18,19,20. Additionally, their limited adaptability to dynamic environments constrains their practical application. With the rapid advancement of machine learning, deep learning-based pseudo-observation prediction methods have been introduced to UWB/INS fusion systems. For instance, recurrent neural networks (RNNs) and long short-term memory networks (LSTMs) have demonstrated strong performance in processing time-series data, making them effective for predicting missing or corrupted UWB measurements and mitigating the impact of NLOS conditions21,22,23,24,25. Furthermore, attention mechanisms, which dynamically assign weights to time-series features, have recently gained prominence for their ability to capture long-range dependencies and support parallel processing26. These innovations significantly enhance the potential of UWB/INS systems, offering improved robustness and accuracy in challenging scenarios.
Despite these advancements, significant gaps remain in current research. First, most deep learning methods exhibit limited adaptability to highly dynamic and complex environments, struggling to accurately capture rapidly changing motion patterns23. Second, existing studies on multi-modal sensor data fusion often emphasize simplistic feature extraction, failing to fully exploit the spatiotemporal correlations between UWB and INS data27. Furthermore, sequence-based models such as LSTMs are inherently sequential in their processing, resulting in low computational efficiency that hinders their suitability for real-time applications8,22,24. The robustness of current approaches under severe NLOS conditions and highly dynamic scenarios remains insufficient, necessitating further investigation.
Building on the aforementioned analysis, this study proposes a deep learning framework leveraging an attention mechanism to address the limitations of existing UWB/INS fusion systems. The attention mechanism is employed to dynamically extract and emphasize critical features from sensor data, enabling adaptive weight allocation that enhances the prediction accuracy of pseudo-observations. These pseudo-observations serve as robust substitutes for UWB measurements degraded under NLOS conditions. By integrating pseudo-observations with a Kalman filter, the proposed framework significantly improves the positioning accuracy and robustness of UWB/INS fusion systems in complex environments. Through theoretical modeling and experimental validation, this research aims to tackle the challenges posed by UWB signal degradation and INS cumulative errors in dynamic and obstructed scenarios. The proposed framework offers a novel solution for achieving high-precision positioning and provides a valuable technical reference for advancing multisensor fusion methodologies in challenging operational environments.
Problem statement
INS error model
The INS is a fundamental component of integrated navigation, delivering critical information about attitude, velocity, and position. However, errors in the IMU can lead to rapid performance degradation. By introducing perturbations into the INS update equations, an error model for the INS can be derived.
The attitude error model of the INS is given by:
where the superscript n indicates the navigation frame, defined as the east-north-up (ENU) geographic coordinate system. \({{\varvec{\omega }}}_{in}\) and \({{\varvec{\delta }}{\varvec{\omega }}}_{in}\) denote the angular velocity of the e-frame relative to the i-frame and its error, respectively. Similarly, \({\delta {\varvec{\omega }}}_{ib}\) represents the angular velocity error of the b-frame relative to the i-frame, and \({{\varvec{\theta }}}\) is the attitude angle error.
The velocity error model is expressed as:
where \({\varvec{\omega }} _{ie}\) and \({\delta {\varvec{\omega }}}_{ie}\) denote the angular velocity of the e-frame relative to the i-frame and its error, respectively. \(\textbf{a}\) represents acceleration, while \(\textbf{v}\) and \({\delta \textbf{v}}\) refer to velocity and its error. Additionally, \({\delta {\varvec{g}}}_p\) accounts for the gravitational acceleration error.
The position error model is described by:
where \(\varphi\), \(\lambda\), and h are the latitude, longitude, and height, respectively. The errors in these parameters are denoted as \(\delta \varphi\), \(\delta \lambda\), and \(\delta h\). \({R_M}\) and \({R_N}\) represent the local radii of the meridian and prime vertical, respectively.
Kalman filter
UWB technology provides high-precision distance measurements, while INS offer continuous position estimates using inertial sensors. However, UWB can suffer from signal blockage and multipath effects, and INS is prone to drift over time due to sensor errors. Integrating UWB and INS data using a Kalman filter can leverage the strengths of both systems, resulting in improved positioning accuracy and reliability.
Kalman Filter is a recursive least-squares estimator based on the state-space model, widely used in signal processing, navigation systems, control systems, and other fields. The Kalman filter reduces uncertainty by estimating system states and combining measurement data, focusing on prediction and update. Suppose the system can be described by a linear state-space model, with the state transition equation given as:
where \(\textbf{x}_k\) represents the state vector at time k, \(\textbf{F}_{k-1}\) is the state transition matrix, and \(\textbf{w}_{k-1}\) is the process noise, which follows a zero-mean Gaussian distribution, \(\textbf{w}_{k-1} \sim {\mathscr {N}}(0, \textbf{Q}_{k-1})\). The measurement equation is given as:
where \(\textbf{z}_k\) is the measurement vector, \(\textbf{H}_k\) is the measurement matrix, and \(\textbf{v}_k\) is the measurement noise, which follows a zero-mean Gaussian distribution, \(\textbf{v}_k \sim {\mathscr {N}}(0, \textbf{R}_k).\)
The Kalman filter operates in two main steps: the prediction step and the update step. In the prediction step, the state estimate is given by:
where \(\hat{\textbf{x}}_{k|k-1}\) represents the predicted state at time k based on the estimate at time \(k-1\). The covariance of the prediction error is given by:
In the update step, the Kalman gain is calculated as:
which balances the predicted error covariance and the measurement noise to update the state estimate. The updated state estimate is given by:
where \(\textbf{z}_k - \textbf{H}_k \hat{\textbf{x}}_{k|k-1}\) is the measurement residual, i.e., the difference between the current measurement and the prediction. The updated error covariance matrix is:
Kalman filter based UWB/INS system
Integrating UWB and INS data using a Kalman Filter enhances positioning accuracy by leveraging the complementary strengths of both systems. UWB technology provides high-precision distance measurements but can be affected by signal blockage and multipath effects. Conversely, INS offers continuous position estimates using inertial sensors but is prone to drift over time due to sensor errors. By employing a Kalman Filter with an error state vector, the integration can effectively reduce the impact of sensor errors and improve overall navigation performance. This integration can be implemented in two architectures: loosely-coupled and tightly-coupled systems.
In the loosely-coupled UWB/INS integration, the INS and UWB systems operate independently, and their outputs are fused at a higher level using a Kalman Filter based on the error state vector. The INS provides estimates of position, velocity, and attitude by integrating accelerations and angular rates. The UWB system offers position estimates based on ranging measurements to fixed anchors. The error state vector for the loosely-coupled system is defined as:
where \(\delta \textbf{p}_k\), \(\delta \textbf{v}_k\), and \({\varvec{\theta }}_k\) represent the position, velocity, and attitude errors at time k, respectively. The terms \(\delta \textbf{b}_a\) and \(\delta \textbf{b}_g\) denote the accelerometer and gyroscope bias errors. The state transition equation for the error state vector is derived from the linearized INS error dynamics:
where \(\textbf{F}_{k-1}\) is the state transition matrix derived from the INS error model, and \(\textbf{w}_{k-1}\) represents the process noise. The measurement equation utilizes the difference between the UWB position estimates and the INS position estimates:
where \(\textbf{H}_k\) is the measurement matrix that maps the error state vector to the measurement domain, and \(\textbf{v}_k\) is the measurement noise. The Kalman Filter uses these equations to recursively update the error state estimate, which is then used to correct the INS estimates, effectively reducing drift and improving accuracy.
In contrast, the tightly-coupled UWB/INS integration directly incorporates raw UWB ranging measurements with INS data within the Kalman Filter framework using the error state vector. This method allows the system to maintain accurate positioning even when fewer UWB anchors are available, as it does not require a complete position solution from the UWB system alone. The error state vector is extended to include UWB-related errors, such as range measurement biases:
where \(\delta \textbf{b}_r\) represents the biases in the UWB range measurements. The measurement model incorporates the raw range measurements to multiple UWB anchors, comparing the predicted ranges based on INS estimates with the actual measurements:
where \(z_k^i\) is the innovation for anchor i, \(\hat{\textbf{p}}_k\) is the estimated position from the INS, \(\textbf{p}_a^i\) is the known position of anchor i, \(\delta b_r^i\) is the range bias error, and \(v_k^i\) is the measurement noise. The measurement equation for the error state vector is obtained by linearizing the nonlinear measurement model around the current estimates:
where \(\textbf{h}_k^i\) is the Jacobian of the measurement function with respect to the error state vector. The Kalman Filter updates the error state estimates using these measurements, enhancing robustness against UWB signal degradation and allowing for continued operation in challenging environments.
UWB NLOS challenge
NLOS propagation introduces significant errors in UWB distance measurements due to signal blockage and multipath effects. These errors can be both biased and have increased variance compared to LOS conditions. Here, we rigorously examine how NLOS propagation impacts the UWB/INS integrated navigation system and provide mathematical formulations to illustrate these effects.
Under LOS conditions, the UWB measurement noise \(\textbf{v}\) is typically modeled as zero-mean Gaussian white noise with covariance \(\textbf{R}\). However, under NLOS conditions, the measurement equation under NLOS conditions becomes:
where \(\textbf{b}\) represents the bias introduced by NLOS propagation, which is generally non-zero and unknown. Substituting the measurement residual into the state update equation and rearranging terms, we get:
where \(\tilde{\textbf{x}}_{k|k} = \textbf{x}_k - \hat{\textbf{x}}_{k|k}\) is the estimation error. Taking the expectation on both sides, we obtain:
The term \(-\textbf{K}_k \textbf{b}_k\) introduces a non-zero mean in the estimation error, leading to biased state estimates. Moreover, the recursive nature of the Kalman filter means that this bias can accumulate over time. The estimation error mean evolves according to:
The cumulative effect of the biases \(\textbf{b}_j\) will lead to a non-zero estimation error mean. Therefore, the error introduced by NLOS propagation can significantly degrade the positioning accuracy of the UWB/INS integrated system.
Innovation-based NLOS detection
Innovation-based NLOS detection for UWB is an effective method to differentiate between NLOS and NLOS measurements. In Kalman filtering, the innovation sequence represents the difference between the predicted and measured values, denoted as:
where \(\textbf{z}_k\) is the current measurement, \(\hat{\textbf{x}}_{k|k-1}\) is the predicted state, and \(\textbf{H}_k\) is the measurement matrix. The innovation covariance matrix \(\textbf{S}_k\) is given by:
A standardized innovation test statistic, \(d_k\), is computed as:
which follows a chi-square distribution. By comparing \(d_k\) with a threshold, the system can detect whether the current measurement is affected by NLOS conditions. If \(d_k\) exceeds the threshold, the measurement is identified as potentially NLOS, allowing the system to either exclude or down-weight the unreliable measurement, thereby improving positioning accuracy.
Proposed method
System overview
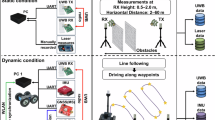
We designed a deep learning-based UWB/INS adaptive positioning system for accurate localization in complex environments with obstructions. The Figure 1 shows the proposed system. When UWB signals are accurately received via LOS propagation, the system enters training mode. In this mode, a neural network based on an attention mechanism utilizes IMU data, calculated attitude angles, velocity, position, and raw UWB measurements from previous time steps to predict the current UWB position increment (loosely-coupled) or UWB ranges increment (tightly-coupled). The predicted value is compared with the true value to compute the loss, which is then used to update the neural network’s parameters through backpropagation. When innovation based detection determines that the current UWB signal is subject to NLOS propagation, the system switches to prediction mode. The neural network uses information from the previous time steps to predict the current UWB position increment. This predicted value is used in the next Kalman filter step, achieving good positioning accuracy even in NLOS conditions.

The overview of the proposed method.
Attention mechanism
Attention mechanism is the most important part of the Transformer. Essentially, the attention mechanism is a neural network module that can achieve parallel signal weighting functions. The architecture of the attention mechanism is delineated in Fig. 2. To realize the attention mechanism, the normalized attention matrix is introduced to characterize different degrees of attention to the input. More important input INS data is assigned with larger weights and the final output is obtained by weighting the input based on the attention weights in the attention matrix.

The structure of the attention mechanism.
For the input data sequence \(\mathbf{{X}} = \left[ {\begin{array}{*{20}{c}}{{\varvec{x}_1}}&{{\varvec{x}_2}}&\cdots&{{\varvec{x}_n}} \end{array}} \right] \in {\mathbb {R}}^{m\times n}\), where n refers to the sequence length and m refers to the feature dimension. We apply three linear transformations to the input sequence as follows:
where \(\mathbf{{K}}=\left[ {\begin{array}{*{20}{c}}{{\varvec{k}_1}}&{{\varvec{k}_2}}&\cdots&{{\varvec{k}_n}}\end{array}} \right] \in {\mathbb {R}}^{d\times n}\), \(\mathbf{{Q}}=\left[ {\begin{array}{*{20}{c}}{{\varvec{q}_1}}&{{\varvec{q}_2}}&\cdots&{{\varvec{q}_n}}\end{array}} \right] \in {\mathbb {R}}^{d\times n}\), and \(\mathbf{{V}}=\left[ {\begin{array}{*{20}{c}}{{\varvec{v}_1}}&{{\varvec{v}_2}}&\cdots&{{\varvec{v}_n}}\end{array}} \right] \in {\mathbb {R}}^{m\times n}\) are the key matrix, the query matrix, and the value matrix, respectively, \({\mathbf{{W}}^k} \in {\mathbb {R}}^{d\times m}\), \({\mathbf{{W}}^q} \in {\mathbb {R}}^{d\times m}\) and \({\mathbf{{W}}^v} \in {\mathbb {R}}^{m\times m}\) refer to the corresponding trainable linear transformations. Key matrix \(\mathbf{{K}}\) is aimed at being matched or queried the importance by other components. Query matrix \(\mathbf{{Q}}\) is aimed at matching or querying the importance of other components. Value matrix \(\mathbf{{V}}\) is aimed at extracting or keeping the feature of the input.
From key matrix \(\mathbf{{K}}\) and query matrix \(\mathbf{{Q}}\), the attention weight matrix \({\mathbf{{E}}} \in {\mathbb {R}}^{n\times n}\) can be obtained as follows:
As the product of \(\mathbf{{K}}\) and \(\mathbf{{Q}}\) increase as feature dimension d, the attention weight matrix is adjusted by multiplying \(1/\sqrt{d}\). Then the Softmax operation \(\textrm{Softmax}\left( {{x_i}} \right) = \frac{{\exp \left( {{x_i}} \right) }}{{\sum {\exp \left( {{x_i}} \right) } }}\) is applied to normalize each column of the matrix.
Finally the output matrix \({\mathbf{{O}}} \in {\mathbb {R}}^{m\times n}\) can be obtained by multiplying value matrix \(\mathbf{{V}}\) and attention weight matrix \(\mathbf{{E}}\):
Long short-term memory networks
LSTMs extend the capabilities of RNNs by addressing the vanishing gradient problem and enabling efficient learning of long-term dependencies. They achieve this through a structured design that includes a cell state and three gates—forget, input, and output gates—each regulating the flow of information, as shown in the Fig. 3. The forget gate determines which information from the previous cell state \(C_{t-1}\) is retained or discarded:
Here, \(W_f\) and \(b_f\) represent weights and biases, while \(\sigma\) is the sigmoid function, constraining values between 0 and 1. The input gate adds new information to the cell state, involving a gate activation and a candidate value \({\tilde{C}}_t\):
The updated cell state combines the retained old state with the new candidate information:
The output gate determines the hidden state based on the current cell state:
By coordinating these mechanisms, LSTMs effectively capture both short-term and long-term dependencies in time-series data. In scenarios with NLOS conditions, LSTMs leverage their temporal modeling capabilities to generate accurate pseudo-UWB observations from INS data. The gating mechanisms and memory units mitigate noise and drift, adapting to dynamic motion patterns. Incorporating multi-modal inputs like acceleration and attitude angles further enhances precision and stability. Compared to conventional methods, LSTMs reduce error accumulation from INS drift, making them highly effective in complex environments with dense obstacles or severe signal blockage. This ensures reliable pseudo-UWB observations, maintaining high positioning accuracy in fusion-based systems.

Architecture of Long Short-Term Memory networks (LSTMs).
Network training strategy
When the UWB signal can be accurately received through LOS propagation, the system enters a training mode. In this mode, attention mechanism-based neural networks are employed to predict UWB measurements, utilizing data collected over a unified time window T. The input data include IMU readings, calculated attitude angles, velocity, position, and UWB measurements, all sampled at different frequencies. The system can operate in either a loosely-coupled or a tightly-coupled configuration, each having its own data fusion strategy and corresponding neural network.
In the loosely-coupled system, the goal is to predict the UWB position increment \(\Delta \textbf{p}_k\) at the current time step k, based on data from the previous time window T. The neural network used in the loosely-coupled system is denoted as \(f_{\text {NN,LC}}\). The input sequence includes:
-
\(\{\textbf{a}_{i}\}_{i=1}^{T/n_1}\): IMU linear acceleration sampled at a high frequency \(n_1\).
-
\(\{\varvec{\omega }_{i}\}_{i=1}^{T/n_1}\): IMU angular velocity sampled at the same frequency as \(\textbf{a}\).
-
\(\{\varvec{\theta }_{j}\}_{j=1}^{T/n_2}\): INS calculated attitude angles proposed at a half frequency of \(n_2 = \frac{1}{2} n_1\) due to the double-sample algorithm for inertial navigation.
-
\(\{\textbf{v}_{j}\}_{j=1}^{T/n_2}\): INS calculated velocity with the frequency \(n_2\).
-
\(\{\textbf{p}_{j}\}_{j=1}^{T/n_2}\): INS calculated position with the frequency \(n_2\).
-
\(\{\Delta \textbf{p}_{k}\}_{k=1}^{T/n_3}\): UWB raw position increments sampled at a lowest frequency \({n_3}\).
The neural network \(f_{\text {NN,LC}}\) learns to map these inputs to the current UWB position increment:
Using a unified time window T ensures that the model can effectively leverage both high-resolution dynamic information from IMU (acceleration and angular velocity) and broader contextual information from the lower-resolution measurements (attitude, velocity, and position). The attention mechanism within the neural network helps the model to focus on the most relevant features from different time steps, enhancing prediction accuracy.
In the tightly-coupled system, the goal is to predict the UWB raw measurement distances \(\Delta \textbf{r}_k\) at the current time step k, which directly reflect the distances to multiple base stations. Another neural network, denoted as \(f_{\text {NN,TC}}\), is used for this task. The input data sequence includes:
-
\(\{\textbf{a}_{i}\}_{i=1}^{T/n_1}\): IMU linear acceleration sampled at a high frequency \(n_1\).
-
\(\{\varvec{\omega }_{i}\}_{i=1}^{T/n_1}\): IMU angular velocity sampled at the same frequency as \(\textbf{a}\).
-
\(\{\varvec{\theta }_{j}\}_{j=1}^{T/n_2}\): INS calculated attitude angles proposed at a half frequency of \(n_2 = \frac{1}{2} n_1\) due to the double-sample algorithm for inertial navigation.
-
\(\{\textbf{v}_{j}\}_{j=1}^{T/n_2}\): INS calculated velocity with the frequency \(n_2\).
-
\(\{\textbf{p}_{j}\}_{j=1}^{T/n_2}\): INS calculated position with the frequency \(n_2\).
-
\(\{\Delta \textbf{r}\}_{k=1}^{T/n_3}\): UWB raw measurement distances from the previous time steps.
The neural network \(f_{\text {NN,TC}}\) takes these inputs and predicts the current UWB raw measurement distances:
In the tightly-coupled system, the UWB raw measurement distances are directly incorporated as observations, which allows the model to leverage base station distance information to more accurately reflect the spatial relationships during navigation. The attention mechanism enables the network to weigh each input differently, capturing the significance of each measurement in estimating the true UWB distance for the current time step.
For both loosely and tightly-coupled systems, the predicted values (\(\Delta \hat{\textbf{p}}_k\) for the loosely-coupled system using \(f_{\text {NN,LC}}\) and \(\Delta \hat{\textbf{r}}_k\) for the tightly-coupled system using \(f_{\text {NN,TC}}\)) are compared to the true values, and a loss function is computed:
where \(\Delta \textbf{y}_k\) can represent either the UWB position increment or the raw measurement distances, depending on the configuration. This loss is minimized through backpropagation, allowing each network to learn effective representations from both high-frequency dynamic data and lower-frequency spatial context.
The loosely-coupled system uses a neural network \(f_{\text {NN,LC}}\) to predict UWB position increments, while the tightly-coupled system uses a different neural network \(f_{\text {NN,TC}}\) to predict raw UWB distances, directly utilizing the relationships between the tag and multiple base stations. By leveraging different data frequencies within a unified time window and using an attention mechanism, both systems are designed to achieve high accuracy in predicting UWB-related measurements, ultimately enhancing navigation robustness under LOS and challenging NLOS conditions.
NLOS positioning with Pseudo-observations
The trained neural network will be used for accurate positioning under NLOS conditions. Due to extensive training, the network has learned an accurate mapping from the input data to the UWB position increment or the UWB raw measurement distances, depending on the system configuration (loosely- or tightly-coupled). When the innovation test detects that the current UWB measurement is affected by NLOS conditions, the corresponding input data and the trained neural network are used to generate a pseudo-observation. This pseudo-observation represents an estimate of what the UWB measurement would be under normal LOS conditions and is then used in the subsequent Kalman filter update process.
The pseudo-observation \({\Delta \hat{\textbf{p}}}_k\) (in the loosely-coupled system) or \({\Delta \hat{ \textbf{r}}}_k\) (in the tightly-coupled system) serves as a substitute for the unreliable UWB measurement. This pseudo-observation is then incorporated into the Kalman filter measurement update equation, allowing the filter to proceed with state estimation even when direct UWB measurements are unreliable or unavailable. By utilizing the pseudo-observation, the system can maintain a high level of positioning accuracy under NLOS conditions.
The Kalman filter update in NLOS conditions thus relies on the pseudo-observation generated by the neural network. The process can be described as follows:
-
When an NLOS condition is detected via the innovation test, the neural network \(f_{\text {NN}}\) (either \(f_{\text {NN,LC}}\) or \(f_{\text {NN,TC}}\) depending on the configuration) generates the pseudo-observation \({\Delta \hat{\textbf{y}}}_k\).
-
This pseudo-observation replaces the actual UWB measurement in the Kalman filter measurement update step.
-
The updated state estimate \(\hat{\textbf{x}}_k\) is obtained using this pseudo-observation, allowing the system to continue operating accurately even in challenging NLOS environments.
This approach ensures robustness in positioning by making the system less reliant on direct UWB measurements, which are often degraded in NLOS scenarios. The neural network effectively uses the correlations between different sensor inputs and the history of the motion, thereby improving the resilience and adaptability of the positioning system.
By incorporating a pseudo-observation in the Kalman filter, the proposed system leverages both model-based and data-driven methods: the Kalman filter provides an optimal estimator based on the system dynamics and noise characteristics, while the neural network provides a learned model capable of generating reliable estimates under degraded conditions. This hybrid approach helps to achieve consistent positioning accuracy in environments where UWB measurements alone would be insufficient.

Training and prediction process for deep-learning based UWB/INS integration
Complexity analysis
To evaluate the scalability and real-time feasibility of our proposed framework, we analyze the theoretical time complexity of its main components.
Let T denote the input sequence length, D the input feature dimension, and H the hidden state dimension. The LSTM module involves four gating operations per time step, each consisting of matrix multiplications between the input and hidden states. This yields a time complexity of \({\mathscr {O}}(T \cdot H \cdot (H + D))\), which scales linearly with the sequence length. The attention module, implemented using scaled dot-product attention with A heads, requires computing attention weights over all time steps. This results in a time complexity of \({\mathscr {O}}(T^2 \cdot H)\), dominated by the pairwise dot-product and softmax operations across the \(T \times T\) attention matrix for each head. For the UWB/INS fusion layer, assuming the concatenated input feature size is F and the hidden size of the fully connected layer is K, the computational cost is \({\mathscr {O}}(T \cdot F \cdot K)\), which is again linear in the sequence length.
While the attention module introduces a quadratic dependency on T, in practice, we constrain T to a manageable range and employ moderate values for H and A to ensure that the entire framework operates efficiently in real-time applications. This balance between expressiveness and efficiency makes the model suitable for deployment on embedded or resource-constrained platforms.
Experiment results and analysis
Experiment settings
To verify the effectiveness of our proposed method, we conducted comprehensive tests in both simulation and real-world environments. In the simulation phase, 10,000 sets of IMU and UWB data were generated, capturing various motion types such as straight-line movement, turns, acceleration, and deceleration. The error characteristics of the IMU and UWB are presented in the Table 1. This diverse dataset was designed to enhance the network’s generalization ability across different dynamic scenarios. The data incorporated both LOS and NLOS conditions, with noise characteristics modeled to reflect realistic environments. IMU data included acceleration and angular velocity, while UWB data simulated signal propagation with varying environmental effects. The dataset was split into training and testing subsets with no overlap to rigorously evaluate the algorithm’s performance. Training was performed using a combination of LOS and NLOS data, while the testing set introduced more complex and diverse NLOS scenarios.
Real-world experiments were conducted in an office building setting, including stairwells, corridors, and offices, as shown in Fig. 10. UWB anchors were strategically placed in different areas to ensure comprehensive coverage and simulate transitions between LOS and NLOS conditions. During the tests, a person carrying a UWB tag and smartphone moved through various parts of the environment, replicating realistic indoor navigation scenarios with dynamic and obstructed signal propagation.
To ensure a robust evaluation, our proposed method was compared against a wide range of algorithms, including traditional Kalman Filter (KF) and its variant with zero-velocity updates (KF-ZUPT)28, as well as machine learning models such as DNN, recurrent structures (RNN, GRU, LSTM), transformer-based methods, and attention-enhanced recurrent networks (Attention-RNN, Attention-GRU). This comprehensive comparison framework enabled us to thoroughly assess the advantages of our attention-based LSTM model in handling both simulated and real-world challenges, demonstrating its capability to adapt to complex indoor environments and signal conditions effectively.
Model convergence analysis
Here, we compared the performance of different models in generating pseudo-UWB measurements from INS in loosely-coupled and tightly-coupled UWB/INS systems. The purpose of these experiments was to assess the effectiveness of various deep learning models, including their ability to capture temporal dependencies and improve positioning accuracy, in both integration scenarios. The training was conducted over 100 epochs, and the loss values were recorded to evaluate each model’s convergence behavior and prediction accuracy. The results are shown in the Figs. 4 and 5.

Training curves of the proposed methods in the loosely coupled system.

Training curves of the proposed methods in the tightly coupled system.
In both experiments, the DNN model consistently exhibited the highest loss, with little change in the loss curve throughout training. This indicates that the DNN model struggles to capture the temporal dependencies inherent in sequential data, making it inadequate for accurately predicting pseudo-UWB measurements. In comparison, the RNN model showed initial improvement, with a gradual reduction in loss, but demonstrated variability, particularly in the loosely-coupled system, indicating issues with stability and difficulty in handling long-term dependencies effectively. The GRU and LSTM models significantly outperformed both the DNN and RNN, exhibiting smoother loss reduction curves and achieving lower final losses. In both experiments, the LSTM model showed slightly better performance compared to the GRU, achieving lower loss values, which indicates a slight advantage in capturing complex temporal dependencies.
Models incorporating attention mechanisms further enhanced performance. The Attention-RNN model showed improvement over the basic RNN, but it still did not perform as well as the LSTM and GRU models. Both Attention-GRU and Attention-LSTM demonstrated the best performance in the two experiments, achieving faster convergence and lower final losses. Among them, the Attention-LSTM achieved the lowest loss in both loosely and tightly-coupled systems, highlighting the effectiveness of combining LSTM’s long-term dependency capturing ability with the attention mechanism’s focus on key features, leading to improved accuracy in predicting pseudo-UWB measurements.
The Transformer model was also included in the comparison to evaluate its effectiveness. While the Transformer demonstrated its strength in modeling long-range dependencies in other domains, its performance in these experiments was suboptimal. The loss reduction was slower compared to recurrent models, and the final loss values remained higher. This may be attributed to the Transformer’s reliance on global attention mechanisms, which might overlook the strong local temporal dependencies inherent in sequential data of this specific task. Additionally, the computational overhead of the Transformer was higher, making it less practical for real-time applications in UWB/INS systems.
In conclusion, in both loosely-coupled and tightly-coupled systems, attention-enhanced recurrent models, particularly Attention-LSTM, showed significant advantages. The Attention-LSTM model combines the LSTM’s capability to capture long-term dependencies with the attention mechanism’s ability to focus on important features, resulting in better handling of complex temporal patterns and improving the accuracy of pseudo-UWB measurement generation in UWB/INS systems.
NLOS detection based on innovation sequence
The experimental results demonstrate that both the innovation norm and the Mahalanobis distance are highly effective in distinguishing NLOS conditions. In the Fig. 6, peaks in the innovation norm clearly indicate actual NLOS states (red points), where most NLOS points exhibit significantly higher innovation values compared to normal points. This aligns with the theoretical expectation that NLOS introduces larger measurement errors. However, there are a few non-NLOS points with high innovation values, likely caused by noise disturbances or other errors, which may lead to false positives. Additionally, some NLOS points show relatively low innovation values, which could result in missed detections.

Innovation Sequence with True NLOS Points Highlighted.

Mahalanobis distance with detection results.
The Mahalanobis distance sequence in the Fig. 7, further validates the effectiveness of the detection model. By setting a 95% confidence threshold based on the chi-squared distribution, most NLOS points can be clearly distinguished from normal points. The proportion of correctly detected NLOS points (red points) reaches a high 80.49%, indicating that the detection model accurately identifies the majority of NLOS conditions. However, there are some missed detections (purple points), where actual NLOS points fail to exceed the threshold, possibly due to low noise levels or measurement characteristics resembling normal values. Moreover, a small number of normal points are incorrectly marked as NLOS points (black points), reflecting the presence of some false positives during detection.
Overall, the detection model achieves a high true positive rate with a low false positive rate, though missed detections remain an area for improvement. Adjusting the detection threshold dynamically to adapt to varying noise conditions or incorporating additional features (such as measurement residual distributions) for auxiliary detection may further enhance the accuracy and robustness of NLOS detection. While there is still room for performance improvement, the current detection model effectively distinguishes most NLOS conditions, providing critical support for the reliability and stability of the system.

Position trajectories of the proposed methods based on the loosely-coupled system.

Position trajectories of the proposed methods based on the tightly-coupled system.
Performance on the loosely coupled system
From Table 2, the numerical results reveal that the traditional Kalman filter (KF) exhibits significantly higher positioning errors across all scenarios compared to deep learning-based methods. This is particularly evident in complex scenarios, such as Scenes 2 and 3, where errors accumulate prominently. This indicates the KF method struggles to handle cumulative error problems effectively in challenging environments (e.g., with signal obstruction or high dynamic changes). The KF-ZUPT algorithm28, which incorporates zero-velocity updates, significantly improves performance but still does not achieve the optimal results seen with deep learning methods.
Among deep learning methods, the classic DNN achieves relatively good results in most scenarios. However, it falls short compared to sequential models like RNN, GRU, and LSTM, which better capture temporal dependencies. For instance, GRU outperforms both RNN and LSTM in Scene 3, achieving the lowest positioning error of 0.35 m. Furthermore, models incorporating attention mechanisms, such as Att-RNN, Att-GRU, and Att-LSTM, further enhance accuracy. Specifically, Att-LSTM demonstrates superior performance, achieving the lowest errors in multiple scenarios (e.g., 0.45 m in Scene 1 and 0.37 m in Scene 6). This highlights its capability to capture critical temporal dependencies and emphasize essential features effectively.
From the trajectory comparisons in Fig. 8, the limitations of traditional KF are visually apparent, with significant deviations, especially in curved paths or over extended periods where cumulative errors dominate. KF-ZUPT corrects these deviations in most scenarios, but its trajectories still do not fully align with the ground truth. In contrast, deep learning-based methods clearly demonstrate closer adherence to the ground truth, with trajectories that are smoother and exhibit minimal deviations. Attention-enhanced models, particularly Att-LSTM, show the best alignment with the ground truth, with smooth and precise trajectories that closely match the real paths.
Performance on the tightly coupled system
From Table 3, it is evident that the tightly-coupled system delivers a significant improvement in positioning accuracy across all scenarios when compared to the loosely-coupled system. Traditional KF, while providing a baseline for state estimation, exhibits larger errors, particularly in complex scenarios such as Scene 1 and Scene 4, where non-linear dynamics and signal obstructions exacerbate cumulative drift. Although the KF-ZUPT algorithm reduces errors by incorporating zero-velocity updates, its performance remains constrained by its reliance on fixed model assumptions and limited adaptability to dynamic environments.
Deep learning methods exhibit notable advancements in positioning accuracy, with LSTM achieving the error of 0.08 m in Scene 3. This highlights LSTM’s strength in capturing sequential patterns and mitigating cumulative errors over time. Furthermore, attention-enhanced models, such as Att-RNN, Att-GRU, and Att-LSTM, further elevate performance by effectively weighting critical temporal features. Among these, Att-LSTM achieves the lowest errors in most scenarios, underscoring its ability to integrate long-term dependencies with dynamic feature prioritization for precise positioning.
The trajectory comparisons in Fig. 9 reinforce these findings. Traditional KF trajectories exhibit significant deviations from the ground truth, especially in curved and high-dynamic paths, indicating its limitations in handling rapid motion changes. While KF-ZUPT trajectories show improved alignment due to better drift correction, residual errors remain noticeable. By contrast, deep learning models demonstrate superior tracking fidelity, with smoother and more stable trajectories that closely adhere to the ground truth. Notably, Att-LSTM achieves the most accurate and smooth trajectories, maintaining precise alignment across varying scenarios, thereby validating its robustness and adaptability in dynamic environments.
Real-world experiment
The experiments were conducted to evaluate the proposed attention-based tightly-coupled UWB/INS integration system in real-world environments. The testing scenarios were set up in a complex office building, including stairwells, corridors, and offices, as shown in Fig. 10. UWB anchors were strategically placed in various locations to ensure adequate coverage and simulate transitions between LOS and NLOS conditions. During the tests, a person carrying a UWB tag and a smartphone moved through different rooms and pathways, providing realistic and diverse data for performance evaluation.
Figures 11 and 12 present the position trajectories of the tested methods in two distinct scenes. The black curve represents the ground truth, while the trajectories estimated by various algorithms are compared against it. In both scenes, the attention-based methods, particularly Att-GRU and Att-LSTM, show trajectories that closely follow the ground truth, demonstrating higher accuracy than other approaches. Conventional methods such as the KF and KF-ZUPT exhibit notable deviations, especially in areas with sharp turns and under NLOS conditions. Deep learning-based models (DNN, Transformer) and recurrent structures (RNN, GRU, LSTM) achieve moderate accuracy but still show visible errors compared to the attention-enhanced models.
Table 4 provides a quantitative comparison of the position errors across different methods in the two scenarios. The proposed Att-LSTM achieves the lowest average errors of 0.092 m in Scene 1 and 0.083 m in Scene 2, outperforming all other methods. Att-GRU also performs competitively, with slightly higher errors but maintaining significant accuracy improvements over the baseline methods. Traditional algorithms such as KF and KF-ZUPT exhibit higher errors, underscoring the challenges they face in dynamic and obstructed environments. The results validate the superior performance of the attention-based models in effectively handling complex environments and transitions between LOS and NLOS conditions.
These findings highlight the robustness and accuracy of the proposed algorithm in real-world scenarios, demonstrating its potential for deployment in diverse indoor environments with varying levels of complexity.

Experimental environment.

Position trajectories (scene1) of the proposed methods based on the tightly-coupled system.

Position trajectories (scene2) of the proposed methods based on the tightly-coupled system.
Real-time capability analysis
To evaluate whether the proposed method supports real-time training and prediction, we conducted a series of experiments to measure the inference time of various models. The experiment was performed on a computer equipped with an Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz, 16GB of RAM, and an NVIDIA GeForce RTX 1660 Ti graphics card. The results are presented in Table 5.
The results indicate that all models achieve inference times within the millisecond range, demonstrating that the proposed method is well-suited for real-time prediction. Specifically, the DNN model exhibits the shortest inference time of 0.16 ms, while the Transformer model shows the longest time of 0.63 ms due to its higher complexity. Models incorporating attention mechanisms (e.g., Att-GRU, Att-RNN, Atn-LSTM) have slightly higher inference times compared to their base versions but remain within acceptable limits for real-time applications.
However, it is important to note that real-time training presents certain challenges due to the computational complexity involved, particularly for models with attention mechanisms that require extensive processing of historical data during parameter updates. As training is typically performed offline, real-time constraints are less critical during this phase. Once the models are trained, they fully support real-time prediction, making them highly suitable for applications requiring rapid response times.
Effect of network parameters on performance
The Fig. 13 illustrates the impact of varying network parameters on the performance of Attention-LSTM, including hidden layer size (h), number of layers (l), and learning rate (\(\alpha\)). The results indicate that these parameters significantly influence both the convergence rate and the final loss.
The configuration with \(h = 64\), \(l = 2\), and \(\alpha = 0.005\) (red line) achieves the fastest convergence and the lowest final loss, demonstrating that a larger hidden size and deeper network structure, combined with a higher learning rate, can effectively improve learning performance. The larger hidden size allows the network to capture more complex relationships, while the additional layer provides a deeper representation of the data, contributing to better accuracy.
On the other hand, configurations with smaller hidden sizes (\(h = 32\)) or fewer layers (\(l = 1\)) generally exhibit slower convergence and higher final losses. For example, the configuration with \(h = 32\), \(l = 1\), and \(\alpha = 0.001\) (blue line) shows the slowest convergence and the highest loss, indicating a lack of model capacity to adequately fit the data.
Furthermore, the results show the importance of matching learning rate with model complexity. While a higher learning rate can accelerate convergence, it may also cause instability if the model lacks sufficient capacity. This is evident in the configuration with \(h = 32\), \(l = 1\), and \(\alpha = 0.005\) (orange line), where the loss fluctuates significantly, suggesting that the network is not complex enough to handle the fast learning rate.
In summary, the optimal performance for Attention-LSTM is achieved with \(h = 64\), \(l = 2\), and \(\alpha = 0.005\), highlighting the importance of selecting appropriate network parameters to ensure efficient learning. Larger hidden sizes, more layers, and a balanced learning rate help achieve lower final loss and more stable convergence, thereby enhancing model performance in complex scenarios.

Training curves of the proposed methods.
Discussion
The paper introduces a deep learning approach to generate pseudo-observations for UWB/INS integrated navigation systems, aiming to enhance positioning accuracy under NLOS conditions. During NLOS, UWB signals often face high noise or signal loss, leading to degraded performance. To address this, the proposed Attention-LSTM model effectively generates pseudo-observations that compensate for missing or noisy measurements. The attention mechanism helps the model focus on the most relevant features, reducing the impact of error propagation common in sequential data processing, while LSTM efficiently captures temporal dependencies. The study applies the proposed method to both loosely-coupled and tightly-coupled UWB/INS systems, showing improved performance in both. The results demonstrate that Attention-LSTM significantly enhances positioning accuracy in both architectures by providing reliable pseudo-observations during challenging NLOS scenarios, effectively reducing estimation errors and improving overall system robustness. Future work will focus on further enhancing the adaptability of the proposed system, particularly by incorporating dynamic modeling of both process and measurement noise covariance matrices to make the Kalman filter more responsive to varying signal conditions. Additionally, exploring alternative deep learning architectures, could further improve the model’s ability to manage long-term dependencies in complex environments. The integration of reinforcement learning for adaptive adjustment of model parameters in real time is also a promising direction for improving performance in highly dynamic scenarios.
Data availability
Some of the data or codes presented in this study are available on request from the corresponding authors.
References
Xianjia, Y., Qingqing, L., Queralta, J. P., Heikkonen, J. & Westerlund, T. Cooperative uwb-based localization for outdoors positioning and navigation of uavs aided by ground robots. In 2021 IEEE International Conference on Autonomous Systems (ICAS) 1–5 (IEEE, 2021).
Queralta, J. P., Almansa, C. M., Schiano, F., Floreano, D. & Westerlund, T. Uwb-based system for uav localization in gnss-denied environments: Characterization and dataset. In 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 4521–4528 (IEEE, 2020).
Stahlke, M., Kram, S., Mutschler, C. & Mahr, T. Nlos detection using uwb channel impulse responses and convolutional neural networks. In 2020 International Conference on Localization and GNSS (ICL-GNSS) 1–6 (IEEE, 2020).
Barral, V., Escudero, C. J., García-Naya, J. A. & Maneiro-Catoira, R. Nlos identification and mitigation using low-cost uwb devices. Sensors 19, 3464 (2019).
Muqaibel, A. H., Landolsi, M. A. & Mahmood, M. N. Practical evaluation of nlos/los parametric classification in uwb channels. In 2013 1st International Conference on Communications, Signal Processing, and their Applications (ICCSPA) 1–6 (IEEE, 2013).
Guvenc, I., Chong, C.-C. & Watanabe, F. Nlos identification and mitigation for uwb localization systems. In 2007 IEEE Wireless Communications and Networking Conference 1571–1576 (IEEE, 2007).
Chan, Y.-T., Tsui, W.-Y., So, H.-C. & Ching, P.-C. Time-of-arrival based localization under nlos conditions. IEEE Trans. Veh. Technol. 55, 17–24 (2006).
Taghizadeh, S. & Safabakhsh, R. An integrated ins/gnss system with an attention-based hierarchical lstm during gnss outage. GPS Sol. 27, 71 (2023).
Li, B. et al. Gnss/ins integration based on machine learning lightgbm model for vehicle navigation. Appl. Sci. 12, 5565 (2022).
Wen, W., Pfeifer, T., Bai, X. & Hsu, L. T. Factor graph optimization for gnss/ins integration: a comparison with the extended kalman filter. NAVIGATION J. Inst. Navig. 68, 315–331 (2021).
Bestmann, U. & Hecker, P. Turntable calibration of an optimal gyro-free-imu and its application in a full state integrated ins-gnss system. In Proceedings of the 22nd International Technical Meeting of the Satellite Division of The Institute of Navigation (ION GNSS 2009) 987–994 (2009).
Lichtenstern, M., Angermann, M. & Frassl, M. Imu-and gnss-assisted single-user control of a mav-swarm for multiple perspective observation of outdoor activities. In Proceedings of the 2011 International Technical Meeting of The Institute of Navigation 1062–1069 (2011).
Ochoa-de Eribe-Landaberea, A., Zamora-Cadenas, L., Peñagaricano-Muñoa, O. & Velez, I. Uwb and imu-based uav’s assistance system for autonomous landing on a platform. Sensors 22, 2347 (2022).
Liu, R. et al. Cooperative positioning for emergency responders using self imu and peer-to-peer radios measurements. Inf. Fusion 56, 93–102 (2020).
Al Bitar, N. & Gavrilov, A. A novel approach for aiding unscented kalman filter for bridging gnss outages in integrated navigation systems. Navigation 68, 521–539 (2021).
Meng, Q. & Hsu, L.-T. Integrity monitoring for all-source navigation enhanced by kalman filter-based solution separation. IEEE Sens. J. 21, 15469–15484 (2020).
Davari, N. & Gholami, A. Variational bayesian adaptive kalman filter for asynchronous multirate multi-sensor integrated navigation system. Ocean Eng. 174, 108–116 (2019).
Djosic, S., Stojanovic, I., Jovanovic, M. & Djordjevic, G. L. Multi-algorithm uwb-based localization method for mixed los/nlos environments. Comput. Commun. 181, 365–373 (2022).
Liu, M. et al. Nlos identification for localization based on the application of uwb. Wireless Pers. Commun. 119, 3651–3670 (2021).
Jiang, C. et al. Uwb nlos/los classification using deep learning method. IEEE Commun. Lett. 24, 2226–2230 (2020).
Gao, W., Li, Z., Chen, Q., Jiang, W. & Feng, Y. Modelling and prediction of gnss time series using gbdt, lstm and svm machine learning approaches. J. Geodesy 96, 71 (2022).
Wang, J., Jiang, W., Li, Z. & Lu, Y. A new multi-scale sliding window lstm framework (mssw-lstm): a case study for gnss time-series prediction. Remote Sens. 13, 3328 (2021).
Aziez, S. A., Al-Hemeary, N., Reja, A. H., Zsedrovits, T. & Cserey, G. Using knn algorithm predictor for data synchronization of ultra-tight gnss/ins integration. Electronics 10, 1513 (2021).
Fang, W. et al. A lstm algorithm estimating pseudo measurements for aiding ins during gnss signal outages. Remote Sens. 12, 256 (2020).
Guo, K., Wang, N., Liu, D. & Peng, X. Uncertainty-aware lstm based dynamic flight fault detection for uav actuator. IEEE Trans. Instrum. Meas. 72, 1–13 (2022).
Xu, Y. et al. Motion-constrained gnss/ins integrated navigation method based on bp neural network. Remote Sens. 15, 154 (2022).
Wang, Y., Zhao, B., Zhang, W. & Li, K. Simulation experiment and analysis of gnss/ins/leo/5g integrated navigation based on federated filtering algorithm. Sensors 22, 550 (2022).
Zhang, Y., Tan, X. & Zhao, C. Uwb/ins integrated pedestrian positioning for robust indoor environments. IEEE Sens. J. 20, 14401–14409 (2020).
Acknowledgements
This research is financially supported by the National Natural Science Youth Foundation of China under Grant No. 62201598.
Author information
Authors and Affiliations
Contributions
M.R. conceived the experiment(s), M.R. and J.Q. conducted the experiment(s), J.W. and X.G. analysed the results. H.W. and S.L. revised and suggested the paper, and helped with the formatting review and editing of the paper. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Ren, M., Wei, J., Qin, J. et al. Attention based LSTM framework for robust UWB and INS integration in NLOS environments. Sci Rep 15, 21637 (2025). https://doi.org/10.1038/s41598-025-05501-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-05501-3
