
Abstract
The accurate prediction of blood glucose is critical for the effective management of diabetes. Modern continuous glucose monitoring (CGM) technology enables real-time acquisition of interstitial glucose concentrations, which can be calibrated against blood glucose measurements. However, a key challenge in the effective management of type 2 diabetes lies in forecasting critical events driven by glucose variability. While recent advances in deep learning enable modeling of temporal patterns in glucose fluctuations, most of the existing methods rely on unimodal inputs and fail to account for individual physiological differences that influence interstitial glucose dynamics. These limitations highlight the need for multimodal approaches that integrate additional personalized physiological information. One of the primary reasons for multimodal approaches not being widely studied in this field is the bottleneck associated with the availability of subjects’ health records. In this paper, we propose a multimodal approach trained on sequences of CGM values and enriched with physiological context derived from health records of 40 individuals with type 2 diabetes. The CGM time series were processed using a stacked Convolutional Neural Network (CNN) and a Bidirectional Long Short-Term Memory (BiLSTM) network followed by an attention mechanism. The BiLSTM learned long-term temporal dependencies, while the CNN captured local sequential features. Physiological heterogeneity was incorporated through a separate pipeline of neural networks that processed baseline health records and was later fused with the CGM modeling stream. To validate our model, we utilized CGM values of 30 min sampled with a moving window of 5 min to predict the CGM values with a prediction horizon of (a) 15 min, (b) 30 min, and (c) 60 min. We achieved the multimodal architecture prediction results with Mean Absolute Point Error (MAPE) between 14 and 24 mg/dL, 19–22 mg/dL, 25–26 mg/dL in case of Menarini sensor and 6–11 mg/dL, 9–14 mg/dL, 12–18 mg/dL in case of Abbot sensor for 15, 30 and 60 min prediction horizon respectively. The results suggested that the proposed multimodal model achieved higher prediction accuracy compared to unimodal approaches; with upto 96.7% prediction accuracy; supporting its potential as a generalizable solution for interstitial glucose prediction and personalized management in the type 2 diabetes population.
Similar content being viewed by others
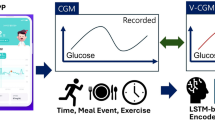

Introduction
Type 2 Diabetes Mellitus (T2DM) is characterized by insulin resistance, leading to elevated blood glucose levels, and it accounts for approximately 90% of all diagnosed cases of diabetes1. Individuals with T2DM are at 15% higher risk of mortality2 as the International Diabetes Federation estimated 537 million people were affected, causing 6.7 million deaths in 20213 and projected to rise up to 783 million by 2045. This not only impacts population health but also imposes a heavy financial strain on both individuals and the global healthcare system, as the American Diabetes Association reported that the total cost of diagnosed diabetes in the United States was 412.9 billion USD in 20224, with a 35% increase in medical costs over the past decade5. Efforts to mitigate these costs focus on early detection, effective management strategies, and preventive measures to reduce the incidence and severity of diabetes complications5.
Multiple studies have shown that self-monitoring of blood glucose is effective in supporting diabetes management6. With the advent of modern wearables and technologies, one study identified high compliance with regular monitoring of blood glucose and other T2DM variables (e.g. diet, physical activity) among individuals using smartphones compared to those using paper diaries7. The regular self-monitoring of blood glucose can promote adherence to clinical guidelines for diet and physical activity, resulting in improvements in hemoglobin A1c (HbA1c) levels8. Traditionally, regular blood glucose monitoring requires a finger prick test, which is invasive and cumbersome9. In contrast, Continuous Glucose Monitoring (CGM) measures the concentration of glucose in the interstitial fluid at regular intervals10. While CGM is well established in type 1 diabetes care, its use in T2D is expanding. The ADA Standards of Care in Diabetes 2025 recommend CGM for adults with T2D on glucose-lowering therapies, reflecting its growing role in managing glycemic variability11. CGM use in T2D has been associated with reduced risk of severe hypoglycemia, diabetic ketoacidosis, and hospitalizations. Developing accurate glucose predictive models for this population is therefore timely and clinically relevant.
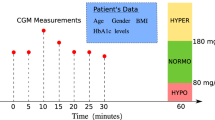
Regular acquisition of blood glucose data holds significant potential for predicting future glucose levels and improving glycaemic control12. It also enables the estimation of critical glycaemic events, such as hypoglycaemia (defined as blood glucose levels below 70 mg/dL) and hyperglycaemia (above 180 mg/dL)13. However, there are certain challenges associated with predicting blood glucose via CGM values only. Firstly, there is a proven 10-min sensor delay between interstitial fluid glucose and actual blood glucose as measured by CGM14. Secondly, CGM systems are susceptible to occasional sensor failure or signal loss, and therefore require reliable strategies to ensure continuity of glucose monitoring during these periods15,16.
Advances in artificial intelligence (AI), including traditional machine learning and deep learning techniques, have enabled the development of models that predict interstitial glucose levels 15 to 60 min in advance based on historical CGM-derived glucose readings17,18. However, clinical studies suggest the patient-specific differences in glycaemic variability are possible due to underlying conditions (e.g., demographics, comorbidities, or diet plans)19 and currently, predictive models do not inform CGM variations based on these underlying conditions.
To address the aforementioned challenge, in this study, glucose levels were monitored using a continuous glucose monitoring (CGM) device, which measures glucose concentration in the interstitial fluid via the subcutaneous tissue. We investigated a multimodal deep learning approach to estimate short-term interstitial glucose levels in individuals with T2D in real-life conditions by informing continuous glucose monitoring (CGM) data with baseline health conditions. The multimodal learning approach involves a sequential deep learning pipeline trained on CGM sequences and context information, while baseline health data serve as auxiliary knowledge to inform CGM variations, which are then combined via a multimodal fusion function. The overall workflow of our architecture has been presented in Fig. 1. The details are presented in the upcoming sections according to the TRIPOD statement as tabulated in Supplementary Table 1.

Overall architecture of predicting the continuous interstitial glucose via multimodal architecture.
Results
Participants
Table 1 presents the set of input variables along with the characteristics examined in the present predictive modelling study for the 40 subjects. In particular, 15 out of 40 patients used the GlucoMen Day CGM Menarini® sensor (we call Sensor 1) for a monitoring period of 10–19 days, and the remaining 25 patients used the Libre Abbott® system (we call Sensor 2) for a monitoring period of 8–28 days. This has served as initial step for Ambulatory Glucose Profile (AGP) analysis.
Based on AGP analysis, the time spent in clinically defined glucose ranges varied across participants. On average, participants spent approximately 2.68% of the time in low range (glucose < 70 mg/dL) and 0.64% in very low range (glucose < 54 mg/dL), as shown in Fig. 2. Time spent in the high range (glucose > 180 mg/dL) was approximately 20%, and time spent in the very high range (glucose > 250 mg/dL) was approximately 5%. The mean interstitial glucose across the cohort was 146.1 ± 22.98 mg/dL (see Table 2). The results were extracted prior to data curation and preprocessing. Also, the Augmented Dickey-Fuller (ADF) confirmed that the CGM time series for each patient was stationary over the observation period.

The time in ranges based on AGP report.
CGM prediction
Table 3 reports the performance of the unimodal prediction pipeline for a 15-min prediction horizon, evaluated using Mean Absolute Percentage Error (MAPE)20. The results indicate that emphasizing local CGM features, via weighting mechanisms informed by high CGM contextual variability, enhances prediction accuracy. The Convolutional Neural Network (CNN) driven Long Short Term Memory (LSTM) i.e. CNN-LSTM model with attention achieved the lowest MAPE across both sensors, demonstrating the benefit of incorporating temporal dynamics and adaptive focus on high-variability regions in glucose trends. The statistical significance among difference in MAPE among different architectures of CGM pipeline has been performed via T test21 and has been presented in Table 4. The results show significant improvement towards adding LSTM and attention mechanism. However, our experiments also suggest that adding more complex layers (e.g. adding multilayer convolutional layers) will add further complexity in the architecture; resulting in decreased performance of the model.
Comparison between multimodal and unimodal architectures
After the CGM pipeline development, we then developed the multimodal architecture by performing additive concatenation between the CGM pipeline and baseline pipeline trained via fully connected dense architecture. The reason for opting for simpler architecture is because the performance of the complex multimodal architecture was constrained by the availability of baseline variables. Including more baseline variables reduced the number of subjects available for training, which in turn impacted model performance. Through our experiments, we have achieved 7 sets of baseline variables which are present with respective number of patient numbers acquired through both Menarini and Abbot sensors. The results have been presented in Table 5.
The comparison between unimodal and multimodal architectures has been presented in terms of MAPE as shown in Figs. 3 and 4. We have also tabulated these results not only in terms of overall MAPE, but also in terms of Hyperglycaemic MAPE (where acquired interstitial glucose was greater than 180 mg/dL) as well as Hypoglycaemic MAPE (where acquired interstitial glucose was less than 70 mg/dL). The results have been presented in Table 6. Due to low number of Hypoglycaemic events in Type 2 diabetic subjects acquired from Abbot sensors, the Hypoglycaemic MAPE for these subjects have not been calculated. Besides, due to smaller number of participants for set 5 and onwards, their MAPE results were not stable and therefore not included in the results.

Comparing violin plot of absolute point error for multimodal and unimodal architectures developed for Menarini sensor across different variable sets at three prediction horizon. The violin plot shows the distribution of absolute point error 25%, 50% and 75% quartile via dashed line.

Comparing violin plot of absolute point error for multimodal and unimodal architectures developed for Abbot sensor across different variable sets at three prediction horizon. The violin plot shows the distribution of absolute point error 25%, 50% and 75% quartile via dashed line.
The results reveals that increasing the prediction horizon negatively impacted cross-validation accuracy. As expected, MAPE increased with longer prediction horizons, with wider APE distributions observed at the 60-min horizon. Despite of constrained availability of baseline variables, the multimodal architecture significantly outperformed the unimodal model for the first four baseline variable sets at both 30-min and 60-min horizons. For the 15-min horizon, the difference in cross-validated MAPE between architectures was not statistically significant for the Menarini sensor (Sensor 1) with baseline sets 3 and 4 due to a smaller sample size (see Table 5), but was significant for the Abbott sensor (Sensor 2), where more subjects were available. In summary, while the unimodal and multimodal models performed comparably at the 15-min horizon, the multimodal architecture showed significantly better performance at 30 and 60 min, likely due to the incorporation of baseline variables that helped inform CGM trends over longer horizons.
Clinical explainability of prediction performance
We further evaluated the prediction performance of the multimodal architecture in a clinical context using Parkes Error Grid analysis22. The Parkes Grid Error was developed to present performance zones for blood/interstitial glucose prediction performance for type 2 diabetic subjects. It has 5 zones ranging from zone A – E with zone A defines “clinically accurate measurements with no impact on clinical actions” and zone B as “altered clinical action, little or no effect on clinical outcome”. The results are tabulated in Table 7 as well as shown in Figs. 5 and 6 for some baseline variable sets. For each prediction horizon visualization, we selected the variable set where the multimodal architecture significantly outperformed the unimodal model (as shown in Figs. 3,4). The results demonstrate that, in all significant cases, multimodal predictions had a higher concentration of values within Zone A of Parkes’ Error Grid for earlier baseline variable sets, across all horizons and for both sensors, indicating greater clinical accuracy. The variable sets with low number of patients do present better performance of unimodal architecture. Moreover, the multimodal models demonstrated improved performance in clinically critical ranges, accurately predicting glucose values as low as 70 mg/dL (hypoglycemia) and as high as 180 mg/dL (hyperglycemia). These findings suggest that incorporating personalized baseline information not only enhances statistical performance, but also improves the clinical reliability of CGM prediction models.

Parkes’ Grid error comparison between multimodal and unimodal architectures at selected variable set for prediction horizon of 15 min, 30 min and 60 min for Menarini sensor.

Parkes Grid error comparison between multimodal and unimodal architectures at selected variable set for prediction horizon of 15 min, 30 min and 60 min for Abbot sensor.
Discussion
Interpretation
In this study, we presented a novel multimodal architecture for predicting interstitial glucose with prediction horizon of 15, 30 and 60 min based on 30-min CGM variation sampled at 5 min along with baseline information of Type 2 subjects representing physiological status. Our novel multimodal architecture addresses several key questions, and, to the best of our knowledge, this is the first study to develop a multimodal architecture for predicting interstitial glucose of Type 2 diabetic subjects with personalized prior information. This study has the potential to estimate the chronic events such as hyperglycaemia and hypoglycaemia in real time based on personalized information with high clinical reliability. The technique was tested on a specific dataset of CGM values collected via two different sensors (Menarini sensor 1 with 1-min sampling downsampled to 5 min and Abbot sensor 2 with 15-min sampling which were upsampled to 5 min for consistency) from an elderly population with Type 2 diabetes whose baseline information representing their physiological status was also provided. The use of this original dataset highlights the robustness of the method in handling the complexities and challenges inherent in cohort interstitial glucose prediction and its accuracy at the personalized level.
Initially, we developed the unimodal architecture in which we developed the training pipeline based solely on CGM values. We first utilized basic deep learning blocks (such as convolutional neural networks (CNN), and long short-term memory (LSTM)) which was followed by adding the attention mechanism in order to train CGM sequential features while highlighting them based on temporal context. This improved the interstitial glucose prediction performance at a prediction horizon of 15 min in terms of Mean Absolute Percentage Error (MAPE) as separate architectures were developed for CGM values acquired from two different sensors; thus compared separately.
The CGM training pipeline was then concatenated with the personalized baseline information pipeline to inform variations in the CGM training through additive concatenation, leading towards multimodal information. The multimodal architecture performance was compared with the unimodal architecture which involved a CGM pipeline only for predicting with prediction horizon of 15, 30 and 60 min. The leave-day cross validation protocol was introduced in which a day was kept out for testing purposes whereas the rest of days were used as training set with day-window sliding after every cycle. The prediction performance was also compared in terms of clinical significance using Parkes’ Grid error, a graphical tool used to evaluate both accuracy and clinical relevance of glucose predictions in Type 2 diabetes subjects. The results show that informing the CGM variations based on personalized baseline information improves the prediction performance at the cohort level.
The multimodal model architecture significantly outperformed the unimodal architecture in terms of MAPE for first four baseline variable sets. For a prediction horizon of (i) 15 min, (ii) 30 min and (iii) 60 min, the MAPE was between (i) 14–16 mg/dL, (ii) 19–21 mg/dL and (iii) 25–26 mg/dL respectively compared to unimodal architectures with MAPE between (i) 14–16 mg/dL, (ii) 21–23 mg/dL and (iii) 26–27 mg/dL respectively. Besides, there has been higher concentration in zone A of Parkes’ Grid error for multimodal architecture of these variable sets which shows high clinical significance. Of course the increase of prediction horizon reduced the prediction performance in terms of both MAPE and Parkes’ Grid error. Nevertheless, the performance drop for multimodal architecture while moving from a prediction horizon of 15 min to 60 min was lower compared to unimodal architectures as shown in APE distribution in Figs. 3 and 4.
In this study, we also observed the MAPE in terms of chronic events such as Hyperglycaemia and Hypoglycaemia. We observed that the performance of predicting high interstitial glucose values (Hyperglycaemia) was even better within 15 min and 30 min prediction horizon. This results in significance of our multimodal architecture in the case of Type 2 diabetes as there had been high number of hyperglycaemic events in Type 2 diabetes. On the other hand, our multimodal architecture performance was relatively poor in predicting blood glucose in hypoglycaemic range. This is because there had been low number of hypoglycaemic events occurred in Type 2 diabetes; resulting in data imbalance problem.
Limitations
This study had some limitations. Firstly the bottleneck associated with multimodal architecture performance for large baseline variable set was their availability. The variable sets were defined based on their availability with respect to the individual patients. As shown in Table 5, increase in number of baseline variables reduced the number of patients as there were only few patients with every baseline information. The low number of patients actually impacted the multimodal architecture performance as it worked better for a higher number of patients. Secondly, the CGM values collected for individual subjects were not consistent as data acquisition varied from total number from 4 to 10 days. Our upcoming studies may incorporate augmenting the dataset based on probabilistic distribution at the individualized physiology. Thirdly, the dataset size was relatively small (n = 40) and unevenly split across the two CGM devices (Sensor 1 and Sensor 2). Although population models were trained separately for each sensor to account for device-specific variation, domain adaptation techniques were not applied in this study. Future work will explore such approaches to enhance model generalizability across CGM systems and broader T2D populations.
In this study, we opt for additive concatenation approach due to the limitation of size of the dataset. This is because adding model complexity (such as transformer mechanism) resulted in prediction performance. As a part of our future studies, we aim to develop the advanced Graphical Neural Networks which can train the CGM variations based on counterfactual analysis of underline comorbidities. Besides, due to limitations in terms of dataset size, the performance depreciation was observed while increasing the underline comorbidities due to their availability with limited patients.
Methods
Study protocol
This study is part of the GATEKEEPER strategy for the Multinational Large-Scale Piloting of an eHealth Platform23. The data were collected in the frame of the Central Greece High Complexity Phase I pilot study: a non-interventional, prospective observational study. The applied eligibility criteria encompass elderly patients with T2D and comorbidities, aged 60 years and older. These patients belonged to the intermediate and poor health groups according to clinical guidelines mentioned in24. These groups had 3 or more non-diabetic chronic illnesses with mild to severe cognitive impairment. Specifically, people with T2D participated in Phase I, using either the GlucoMen Day Menarini® Continuous Glucose Monitoring (CGM) system (15-min sampling interval) or the Libre Abbot® system (5-min sampling interval) for a monitoring period of up to 4 weeks.
Calibration is the key difference among both sensors. Abbott’s FreeStyle Libre is factory calibrated and remains stable throughout its lifespan, while Menarini’s GlucoMen Day requires periodic user calibration, which can introduce variability. Sensor placement also differs: Abbott sensors are worn on the back of the arm, and Menarini sensors may be placed elsewhere, affecting accuracy due to variations in skin thickness, blood flow, and fat. Additionally, Abbott’s sensor measures every 15 min, while Menarini’s system measures every minute, which can impact data quality, especially during rapid glucose changes. Both sensors can be influenced by environmental factors like temperature, sweating, and physical activity, with Menarini’s sensor being more sensitive to skin perspiration. These factors, along with individual physiological differences, contribute to discrepancies between the two devices.
Patients with severe hearing or vision problems or any other acute or chronic condition that would limit the ability of the user to participate in the study were excluded25. All the data collection methods were performed in accordance with the relevant guidelines of the Institutional Review Board of Larisa University Hospital, which are aligned with the Declaration of Helsinki26. The names of all participants and other HIPAA identifiers27 have been removed prior to data sharing. Furthermore, informed consent has been obtained from all participants and/or their legal guardians. The timeline for the study protocol (incl. ethical approval, study design, data acquisition and integration into GATEKEEPER high performance big data platform) has been presented in Supplementary Fig. 1. For more information about study participants, please check clinical trials.gov ID NCT05461716.
Data curation and preprocessing
We applied exploratory techniques to visualize each patient’s CGM data, including histograms, autocorrelation plots, partial autocorrelation plots, and the Augmented Dickey-Fuller (ADF) test. We also checked for duplicates and outliers in each time series. To handle missing values in the glucose sensor data, linear interpolation was applied to ensure continuity in the time series. Specifically, missing values in the glucose sensor readings were imputed using linear interpolation. Additionally, for patients using the Abbott sensor, the data was kept at its original sampling frequency of 15 min, as provided by the sensor. However, for patients using the Menarini sensor, the data was resampled to a 5-min interval. Patients were excluded from the analysis if more than 50% of their CGM data was missing, either due to sensor dropouts or user non-compliance. This threshold was set to ensure that the remaining data was sufficiently complete to maintain the integrity and reliability of the analysis. Each type of data was processed separately before merging. Min–Max scaling was applied to normalize the CGM data to a range of [0, 1], while no normalization techniques were applied to the baseline variables.
Outcome and predictors definition
The output of the predictive model describes the concentration of glucose concentration in the interstitial fluid at time t + PH for a prediction horizon (PH) equal to 15, 30 or 60 min. The univariate models’ input comprises the history of interstitial glucose concentration values, as recorded by the CGM system. In the case of multimodal models, the input includes additionally specific EHR variables. T2D participated in this study used either the GlucoMen Day Menarini® Continuous Glucose Monitoring (CGM) system with sampling interval of 15 min; or the Libre Abbot® system with sampling interval of 5 min; for a monitoring period of up to 4 weeks. Besides, for informing interstitial glucose variation with underline comorbidities, we have also included baseline variables representing these comorbidities as predictors.
Multimodal architecture for CGM prediction
We developed multimodal architectures built upon deep neural networks which have the capability to model real-time CGM variations while informing these variations via appropriate information fusion methods. The CGM variations have been informed by patient electronic health records (e.g. demographics, or anthropometrics, as shown in Table 1). CGM data had been acquired from T2DM patients under real-time conditions. We compiled and compared the results by performing cross validation using the first 30 min of CGM data for training and predicting the CGM values after prediction horizon of (i) 15 min, (ii) 30 min and (iii) 60 min. The training and test sets were derived based on setting the interval length of test set of one day which were sliding from beginning till end of the dataset.
At the first instance, we derived the CGM-only trained population model to find optimal deep neural network architecture; we call it unimodal architecture.
At the second instance, we derived the deep neural networks pipeline which was trained on the T2D patient baseline information. First, we involved two baseline variables which were present in most of the subjects using Abbot and Menarini CGM devices. The inclusion of more baseline variables led to a reduction in the number of available subjects. At the end, there were only 6 subjects who had 14 baseline variables. The list has been presented in Table 5. This enabled us to develop 7 multimodal architectures due to 7 baseline variables subsets. The output of the baseline deep neural network was then fused into the CGM-only training pipeline (unimodal architecture) via additive fusion methods followed by the deep neural network training on CGM variation features informed by the baseline network.
We trained and compared unimodal and multimodal architectures across 7 variable sets for predicting CGM values for the aforementioned prediction horizons of 15, 30 and 60 min. The comparison for both sensors was performed separately using violin plot, showing the distribution of absolute point errors between predicted CGM values and real CGM values, along with quartile markings at 25%, 50% and 75%. Due to instability in the model performance for baseline variable set 5 and onwards, we included the performance comparison from variable set 0 to variable set 4 only.
Clinical explainability of prediction performance
We further assessed the multimodal architecture prediction performance under clinical settings based on Parkes grid error22. The Parkes ‘grid error classifies the scatter plot of predicted interstitial glucose and reference interstitial glucose for type 2 diabetic subjects in five different zones: A, B, C, D and E. The estimation in zone A would be considered as ideal, whereas estimation in zone B would be considered as clinically acceptable.
Model development
The block diagram of architecture has been presented in Fig. 7. The architecture has been designed to predict the interstitial glucose at defined time horizon based on (i) time series historical values from continuous glucose monitoring (CGM) and (ii) static baseline health record information. Let CGM is represented as \(X\) has the dimension of \(n\) x T; where \(n\) is number of users and T is the length of temporal dimension of the CGM input. The CGM values had been acquired from multiple users across different number of days. Each user had been provided one out of two types of CGM devices. One type of device had sampling frequency of 5 min whereas other type of device had sampling frequency of 15 min. For users with a 15-min sampling interval (i.e., Abbot Sensor 2), CGM time series were upsampled to 5 min intervals using linear interpolation. Similarly, Menarini sensor with sampling interval of 1-min was downsampled to 5 min to ensure consistent temporal resolution with Abbot Sensor 2. Considering data acquisition spanning around a couple of days, we performed the data window scheme acquiring \({t}_{0}-{t}_{5}\), \({t}_{1}-{t}_{6}\), \({t}_{{T}^{n}-5}-{t}_{{T}^{n}}\); where \({T}^{n}\) is total number of samples for user \(n\). We used 30-min sample to predict interstitial glucose with time horizon of (i) 15 min, (ii) 30 min and (iii) 60 min.

Multimodal Architecture for predicting blood glucose.
As mentioned in Figs. 1 and 7, the local and temporal features of CGM have been acquired by 1D BiLSTM network with attention layer followed by staked 1D CNN layer. The model initially prepares the CGM values based on the aforementioned window scheme. Concurrently, the baseline data is treated as separate input which is preprocessed and learned separately using a set of dense layers to extract representative deep features. After acquisition of local and temporal features from CGM and representative deep features from baseline data, we added a fusion layer concatenating both types of features followed by a dense layer with sigmoid activation for regressing the CGM values.
To model the temporal context of the CGM data, we first deployed BiLSTM layers; allowing temporal patterns from CGM to be extracted. The core structure of the LSTM cell is the use of three gates i.e. the input gate (\({i}_{{t}_{T}}\)), the forget gate (\({f}_{{t}_{T}}\)), and the output gate (\({o}_{{t}_{T}}\)). These gates control the update, maintenance, and deletion of information contained in a cell state \({C}_{{t}_{T}}\); \({C}_{{t}_{T-1}}\), and \({\widetilde{C}}_{{t}_{T}}\) respectively whereas \({h}_{{t}_{T}}\) is the value of the hidden layer at time \({t}_{T}\). \(\theta\) s represent set of weight matrices and \(b\) s represent set of biases vectors which are updated following backpropagation algorithm with each temporal iteration. Besides, \(\theta\) s and the \(b\) s are the set of weight matrices and biases vectors, respectively, updated following the backpropagation through time algorithm. In addition, \(\otimes\) represents the Hadamard product; \(\sigma\) is the standard logistic sigmoid function; \(\oplus\) is the concatenation operator; and \(\varphi\) the output activation function. Equations (1)–(7) give the transmission of information in the memory cell at each step.
In order to take the advantage of temporal context in both directions, we deployed BiLSTM which combines input from two separate hidden LSTM layers in opposite direction to the same output. Let’s consider \({X}^{1}({t}_{0:5})\)=( \({X}^{1}({t}_{0}\)), \({X}^{1}({t}_{1}\)), \({X}^{1}({t}_{2}\)), \({X}^{1}({t}_{3}\)), \({X}^{1}({t}_{4}\)), \({X}^{1}({t}_{5}\)) ); for which LSTM hidden layer becomes \({\overrightarrow{h}}_{t}^{n}=\left({\overrightarrow{h}}_{{t}_{0}}^{n},{\overrightarrow{h}}_{{t}_{1}}^{n},{\overrightarrow{h}}_{{t}_{2}}^{n},{\overrightarrow{h}}_{{t}_{3}}^{n},{\overrightarrow{h}}_{{t}_{4}}^{n},{\overrightarrow{h}}_{{t}_{5}}^{n}\right)\) towards forward hidden sequence and \({\overleftarrow{h}}_{t}^{1}=\left({\overleftarrow{h}}_{{t}_{0}}^{1},{\overleftarrow{h}}_{{t}_{1}}^{1},{\overleftarrow{h}}_{{t}_{2}}^{1},{\overleftarrow{h}}_{{t}_{3}}^{1},{\overleftarrow{h}}_{{t}_{4}}^{1},{\overleftarrow{h}}_{{t}_{5}}^{1}\right)\) towards backward hidden sequence. Thus, Eq. (7) is now driven as:
The output \({y}_{t}^{n}\) is used as an input to the self-attention layer which had been deployed to highlight the local CGM features under consideration based on the temporal context. This can be represented by \({\sigma }^{a}{\left({q}^{a},{v}^{a}\right)}_{t,{t}{\prime}}\) which is the softmax function between query (context) of the attention layer \({q}^{a}\) and value of attention layer \({v}^{a}\) at time \(t\) and \({t}{\prime}\).
where \({l}_{f}\)=6 is the number of output units of the BiLSTM later. Since it is the self-attention mechanism, the input to both is \({y}_{t}^{n}\).
The 1D Convolutional Neural Network (CNN) blocks had been deployed to model the local features provided by self-attention layer based on temporal context of the CGM. 1D CNN can learn attention driven temporal context time series univariate data where convolution is done separately along the time dimension for every input vector. Formally if input \({\sigma }^{a}{\left({q}^{a},{v}^{a}\right)}_{t,{t}{\prime}}\in {\mathbb{R}}^{{l}_{f}\times 1}\) and kernel \(K\) is \(m\times 1\) then convolutional output in new feature space would be \({\sigma }^{{\prime}a}{\left({q}^{a},{v}^{a}\right)}_{t,{t}{\prime}}\in {\mathbb{R}}^{[\frac{{l}_{f}-m}{d+1},1]}\), where \(d\) is the step size. Based on number of filters, the CNN expands the attention output to more abstract and informative features, called feature maps. Each value \({p}_{i}\) of the feature map \(p\) is then fed into activation function, \(\varnothing\), to calculate \({p}_{i}=\varnothing \left({K}^{T}\times {\sigma }^{a\left(i:i+j-1\right)}+b\right)\), where activation function \(\varnothing\) is non-linear activation function \(RELU\left(x\right)=\text{max}(o,x)\), \(b\) is the bias and \({\sigma }^{a\left(i:i+j-1\right)}\) is the \(j\) observation from \({\sigma }^{a}.\) The CNN networks have been followed by 20% dropout to avoid overfitting. The kernel in the convolutional layer had been initialized by Glorot Uniform which initializes the convolutional weights based on uniform distribution within range [-limit, limit] where limit = \(\sqrt{\frac{6}{{f}_{in}+{f}_{out}}}\) where \({f}_{in}\) is number of input units and \({f}_{out}\) is number of output units.
As empirical experimentation, we put size of kernel K as 3 for CNN with number of filters as 100. The CNN network was then followed by 10% dropout.
The multimodal fusion network allows to fuse the representations learned from the CGM values and the baseline data. Considering that the learned representation from CGM values (i.e. CNN output) is \({Z}^{1}\) and the learned representations from fully connected neural networks trained on baseline data is \({Z}^{2}\). The fusion of both representations are learned by multi-layer fully connected neural network. This can be represented as:
where \(\oplus\) is the fusion operator, \({W}_{3}\) is the matrix of trainable weights and \(G\) is the multilayer fully connected neural network. Following the multimodal fusion, we deployed dense layer regressor to predict the interstitial glucose with specified prediction horizon. The regressor is a fully connected neural network followed by sigmoid function. The final results of the regressor and classifier are represented as \({\widehat{Y}}_{{T}^{n}}^{n}\in {T}^{n}\times 1\) where \({T}^{n}\) is total number of time samples for the subject \(n\).
The objective loss function of estimating interstitial glucose is log likelihood function represented as:
where \({t}_{i}\) is the prediction horizon for estimating interstitial glucose of the subject \(k\). Noting that loss function is the summation of predicting interstitial glucose for every subject \(k\) with their respective samples \({T}_{k}\).
Model evaluation
Mean Absolute Point Error (MAPE) has been selected to evaluate the model which measures average magnitude of error produced by a model with the advantage of scale-independency and interpretability20. It can be calculated as:
where \(CG{M}_{t}^{A}\) is actual CGM value and \(CG{M}_{t}^{P}\) is the predicted CGM value.
Τo evaluate model performance, we employed a leave-one-day-out cross-validation approach. In this method, each day’s data was sequentially designated as the test set while the remaining data was used for training. This sliding window technique ensured that each data point was tested at least once while maximizing the amount of training data available for each iteration. For each iteration, data preceding the test day and data following the test day were combined to form the training set, while the designated day was held out as the test set. This data partitioning strategy is commonly used in time-series forecasting studies where temporal dependencies are critical.
The multimodal architecture training and validation had been implemented on GATEKEEPER Big Data platform where all the data from the pilot has been hosted and deep learning packages have been trained and tested in the platform. The total training time was 1 min to run 50 iterations in each cross-validation cycle.
Related work
Deep learning has emerged as a leading approach in interstitial glucose predictions, with a primary focus on applications in Type 1 Diabetes Mellitus (T1DM)28. Initial work using LSTM-based models on the OhioT1DM dataset29,30 showed limited gains over feature-engineered traditional Machine Learning (ML) methods. More sophisticated architectures, including attention-based Gated Recurrent Units (GRU)s31 and CNNs32, have since demonstrated improved performance across T1D, T2D, and gestational diabetes datasets.
A growing number of studies aim to improve individual-level prediction accuracy while ensuring generalizability across diverse populations and data sources. In the context of T1D, Zhu et al.33 utilised meta-learning and evidential deep learning (i.e., including an attention-based bidirectional Recurrent Neural Networks (RNN) and evidential regression) to quantify uncertainty and personalize glucose forecasting. Daniels et al.34 introduced a multitask learning architecture that jointly models shared and individual-specific representations of glucose dynamics in T1D patients. Regarding T2D, Deng et al.35 employed deep transfer learning with data augmentation to improve robustness under limited data conditions. Sun et al.36 developed a Bayesian structural time series model that incorporates clinical data priors (i.e., anthropometric and biochemical characteristics) to address inter-individual variability in T2D. Similarly, Yang et al.37 proposed a clustering-based domain adaptation approach, enabling more personalized modelling by aligning latent representations across patient subgroups.
Complementary to models based solely on CGM, Montaser et al.38 proposed a seasonal stochastic local modelling framework that explicitly incorporates variable-length, time-stamped events such as meals and physical activity. This work underscores the relevance of irregular but clinically significant behavioural factors in interstitial glucose prediction. Other contributions have emphasized model interpretability in multivariate glucose predictive modelling; a graph-attentive RNN (GARNN) framework39 captures detailed interactions among CGM and self-reported event data, enhancing both prediction accuracy and transparency.
Conclusion
In this paper, we designed and developed a novel generalized multimodal architecture based on 30-min CGM values informed by baseline physiological information of Type 2 diabetic patients for predicting CGM values with prediction horizon of 15, 30 and 60 min. To the best of our knowledge, this is the first study of predicting interstitial glucose values where CGM variation were informed by individual physiology. Compared to unimodal architecture, we achieved the mean absolute point error of (i) 14–16 mg/dL, (ii) 19–21 mg/dL and (iii) 25–26 mg/dL for predicting CGM values with prediction horizon of 15, 30 and 60 min respectively while addressing the clinical trustworthiness of our model. Besides, the multimodal architectures had lower MAPE for predicting interstitial glucose compared to unimodal architectures in hypoglycaemic as well as in hyperglycaemic range. The model had limitations due to the non-availability of baseline physiological information for every patient along with the lower number of participants in the study. Therefore, as our planned future work, we aim to develop the methodologies to augment missing information based on probabilistic distribution of the dataset. Nevertheless, this model managed to predict the interstitial glucose for prediction horizon of up to 60 min with adequate prediction accuracy which can serve as a first step for generalized interstitial glucose prediction model. Besides, we also aim to conduct the studies based on impact of meal and exercises on interstitial glucose variation.
Data availability
The data that support the findings of this study are available upon reasonable request to the pilot managers from University Hospital of Larisa such as Alexandra Bargiota (abargio@med.uth.gr) and University of Thessaly such as George E Dafoulas (gdafoulas@uth.gr).
Code availability
The code used in this study is available upon request to the corresponding author Dr. Muhammad Salman Haleem salman.haleem@warwick.ac.uk via University of Warwick license.
Change history
20 August 2025
A Correction to this paper has been published: https://doi.org/10.1038/s41598-025-16371-0
References
Zimmet, P., Alberti, K. G., Magliano, D. J. & Bennett, P. H. Diabetes mellitus statistics on prevalence and mortality: Facts and fallacies. Nat. Rev. Endocrinol. 12(10), 616–622 (2016).
Galicia-Garcia, U. et al. Pathophysiology of type 2 diabetes mellitus. Int. J. Mol. Sci. 21(17), 6275 (2020).
Sun, H. et al. IDF Diabetes Atlas: Global, regional and country-level diabetes prevalence estimates for 2021 and projections for 2045. Diabetes Res. Clin. Pract. 183, 109119 (2022).
Parker, E. D. et al. Economic costs of diabetes in the US in 2022. Diabetes Care 47(1), 26–43 (2024).
Bellary, S., Kyrou, I., Brown, J. E. & Bailey, C. J. Type 2 diabetes mellitus in older adults: clinical considerations and management. Nat. Rev. Endocrinol. 17(9), 534–548 (2021).
Kaufman, J. M., Thommandram, A. & Fossat, Y. Acoustic analysis and prediction of type 2 diabetes mellitus using smartphone-recorded voice segments. Mayo Clinic Proceedings: Digital Health 1(4), 534–544 (2023).
N. S. Padhye, J. Wang, Pattern of active and inactive sequences of diabetes self-monitoring in mobile phone and paper diary users, in 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), 2015: IEEE, pp. 7630–7633.
Ernawati, U., Wihastuti, T. A. & Utami, Y. W. Effectiveness of diabetes self-management education (DSME) in type 2 diabetes mellitus (T2DM) patients: Systematic literature review. J. Public Health Res. 10(2), jphr-2021 (2021).
Wagner, J., Malchoff, C. & Abbott, G. Invasiveness as a barrier to self-monitoring of blood glucose in diabetes. Diabetes Technol. Ther. 7(4), 612–619 (2005).
Bailey, T., Bode, B. W., Christiansen, M. P., Klaff, L. J. & Alva, S. The performance and usability of a factory-calibrated flash glucose monitoring system. Diabetes Technol. Ther. 17(11), 787–794 (2015).
A. D. Association. The American Diabetes Association Releases Standards of Care in Diabetes—2025. https://www.diabesrelief.online/newsroom/press-releases/american-diabetes-association-releases-standards-care-diabetes-2025 (accessed 02–05, 2025).
Kebede, M. M., Zeeb, H., Peters, M., Heise, T. L. & Pischke, C. R. Effectiveness of digital interventions for improving glycemic control in persons with poorly controlled type 2 diabetes: A systematic review, meta-analysis, and meta-regression analysis. Diabetes Technol. Ther. 20(11), 767–782 (2018).
Sobel, S. I., Chomentowski, P. J., Vyas, N., Andre, D. & Toledo, F. G. Accuracy of a novel noninvasive multisensor technology to estimate glucose in diabetic subjects during dynamic conditions. J. Diabetes Sci. Technol. 8(1), 54–63 (2014).
Andellini, M. et al. Artificial intelligence for non-invasive glycaemic-events detection via ECG in a paediatric population: Study protocol. Heal. Technol. 13(1), 145–154 (2023).
Cisuelo, O. et al. Development of an artificial intelligence system to identify hypoglycaemia via ECG in adults with type 1 diabetes: Protocol for data collection under controlled and free-living conditions. BMJ Open 13(4), e067899 (2023).
Fokkert, M. et al. Performance of the FreeStyle Libre Flash glucose monitoring system in patients with type 1 and 2 diabetes mellitus. BMJ Open Diabetes Res. Care 5(1), e000320 (2017).
van Doorn, W. P. et al. Machine learning-based glucose prediction with use of continuous glucose and physical activity monitoring data: The Maastricht Study. PLoS ONE 16(6), e0253125 (2021).
Liu, K. et al. Machine learning models for blood glucose level prediction in patients with diabetes mellitus: Systematic review and network meta-analysis. JMIR Med. Inform. 11(1), e47833 (2023).
Service, F. J. Glucose variability. Diabetes 62(5), 1398–1404 (2013).
Kim, S. & Kim, H. A new metric of absolute percentage error for intermittent demand forecasts. Int. J. Forecast. 32(3), 669–679. https://doi.org/10.1016/j.ijforecast.2015.12.003 (2016).
Kim, T. K. T test as a parametric statistic. Korean J. Anesthesiol. 68(6), 540–546 (2015).
Pfützner, A., Klonoff, D. C., Pardo, S. & Parkes, J. L. Technical aspects of the Parkes error grid. J. Diabetes Sci. Technol. 7(5), 1275–1281 (2013).
de Batlle, J. et al. GATEKEEPER’s strategy for the multinational large-scale piloting of an eHealth platform: tutorial on how to identify relevant settings and use cases. J. Med. Internet Res. 25, e42187. https://doi.org/10.2196/42187 (2023).
LeRoith, D. et al. Treatment of diabetes in older adults: An endocrine society* clinical practice guideline. J. Clin. Endocrinol. Metab. 104(5), 1520–1574. https://doi.org/10.1210/jc.2019-00198 (2019).
G. E. Dafoulas. Incidence of Hypoglycaemia Events in Patients With Stable Insulin-treated Type 2 Diabetes Mellitus Based on Continuous Glucose Monitoring. https://clinicaltrials.gov/study/NCT05461716?term=George%20Dafoulasrank=1#participation-criteria (accessed 02-05, 2025).
W. M. Association, WMA Declaration of Helsinki–ethical principles for medical research involving human participants, 2013, ed.
Portability, I. & Act, A. Guidance regarding methods for de-identification of protected health information in accordance with the health insurance portability and accountability act (HIPAA) privacy rule (Human Health Services, 2012).
Felizardo, V., Garcia, N. M., Pombo, N. & Megdiche, I. Data-based algorithms and models using diabetics real data for blood glucose and hypoglycaemia prediction–a systematic literature review. Artif. Intell. Med. 118, 102120 (2021).
Martinsson, J., Schliep, A., Eliasson, B. & Mogren, O. Blood glucose prediction with variance estimation using recurrent neural networks. J. Healthc. Inform. Res. 4, 1–18 (2020).
C. Marling, R. Bunescu, The OhioT1DM dataset for blood glucose level prediction: Update 2020, in CEUR workshop proceedings, 2020, vol. 2675: NIH Public Access, p. 71.
Koca, Ö. A., Kabak, H. Ö. & Kılıç, V. Attention-based multilayer GRU decoder for on-site glucose prediction on smartphone. J. Supercomput. 80(17), 25616–25639 (2024).
Seo, W., Park, S.-W., Kim, N., Jin, S.-M. & Park, S.-M. A personalized blood glucose level prediction model with a fine-tuning strategy: A proof-of-concept study. Comput. Methods Programs Biomed. 211, 106424 (2021).
Zhu, T., Li, K., Herrero, P. & Georgiou, P. Personalized blood glucose prediction for type 1 diabetes using evidential deep learning and meta-learning. IEEE Trans. Biomed. Eng. 70(1), 193–204 (2022).
Daniels, J., Herrero, P. & Georgiou, P. A multitask learning approach to personalized blood glucose prediction. IEEE J. Biomed. Health Inform. 26(1), 436–445 (2021).
Deng, Y. et al. Deep transfer learning and data augmentation improve glucose levels prediction in type 2 diabetes patients. NPJ Digital Med. 4(1), 109 (2021).
Y. Sun, P. Kosmas, Integrating bayesian approaches and expert knowledge for forecasting continuous glucose monitoring values in type 2 diabetes mellitus, IEEE Journal of Biomedical and Health Informatics 2024.
Yang, T., Yu, X., Tao, R., Li, H. & Zhou, J. Blood glucose prediction for type 2 diabetes using clustering-based domain adaptation. Biomed. Signal Process. Control 105, 107629 (2025).
Montaser, E., Díez, J.-L. & Bondia, J. Glucose prediction under variable-length time-stamped daily events: A seasonal stochastic local modeling framework. Sensors 21(9), 3188 (2021).
Piao, C. et al. GARNN: an interpretable graph attentive recurrent neural network for predicting blood glucose levels via multivariate time series. Neural Netw. 185, 107229 (2025).
Acknowledgements
The authors would like to express their sincerest gratitude to all the partners and participants of the GATEKEEPER project. This project has received funding from the European Union’s Horizon 2020 research and innovation program (under grant 857223), cofounded by the European Regional Development Fund (ERDF), “A way to make Europe.” The funder played no role in study design, data collection, analysis and interpretation of data, or the writing of this manuscript.
Author information
Authors and Affiliations
Consortia
Contributions
MSH: Conceptualisation, Methodology, Software, Formal analysis, Investigation, Data Processing, Writing—Original Draft, Review and Editing, Visualisation; DK: Conceptualisation, Methodology, Formal analysis, Investigation, Data Processing, Writing—Original Draft, Review and Editing; EG: Conceptualisation, Investigation, Data Processing, Writing—Original Draft, Review and Editing; GD: Domain Expert, Data Collection, Clinical Study Lead and Clinical Interpretation of Results; AB: Domain Expert, Clinical Study Definition, Data Collection; LLP: Review, Editing and Writing; MR: Review, Editing and Writing; GF: Funding Acquisition, Review, Editing and Writing; LP: Funding Acquisition, Review, Editing and Writing; DF: Funding Acquisition, Review, Editing and Writing. The authors read and approved the final manuscript and are accountable for ensuring accuracy and integrity of any part of the work.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval
The ethical approval of this study has been obtained through Institutional Review Board of Larisa University Hospital prior to commencement of data collection. The study protocol has been registered in clinicaltrials.gov (NCT05461716). All the methods were performed in accordance with the relevant guidelines of the Institutional Review Board of Larisa University Hospital which are aligned with the Declaration of Helsinki. The names of all participants and other HIPAA identifiers have also been removed prior to data sharing. Besides, informed consent has been obtained from all participants and/or their legal guardians.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this Article was revised: The original version of this Article contained an error in the keywords, in which “Times series modelling” was omitted. The keywords now read: “Multimodal AI, Deep Learning, Interstitial glucose prediction, Time series modelling”. Additionally, in the original Figure 3 and Figure 4, the information given did not align with the set variables mentioned in Table 5. The original article has been corrected.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Haleem, M.S., Katsarou, D., Georga, E.I. et al. A multimodal deep learning architecture for predicting interstitial glucose for effective type 2 diabetes management. Sci Rep 15, 27625 (2025). https://doi.org/10.1038/s41598-025-07272-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-07272-3
