
Abstract
Filters are critical components in automotive engine systems, responsible for maintaining stable operation by removing impurities from liquids and gases. Their performance is highly sensitive to surface defects, rendering high-precision automated inspection essential. However, existing defect detection algorithms often struggle to balance between detection accuracy and the computational efficiency required for industrial deployment. To address this trade-off, this study introduces an improved detection method based on the Real-Time DEtection TRansformer(RT-DETR) framework. First, a large-kernel attention mechanism is integrated into the backbone to enhance multi-scale feature extraction and fusion, while reducing architectural redundancy. Second, the RepC3 structure within the cross-scale fusion module is replaced with a module based on the generalized-efficient layer aggregation network that uses a more efficient layer aggregation strategy to improve feature localization. Finally, the Adown downsampling module is introduced, employing a multi-path design that reduces parameter count while preserving critical feature details during scale reduction. Experimental results on our industrial filter surface defect dataset show that the enhanced RT-DETR model achieves a mean average precision of 97.6%, a 7.3 percentage point increase over the baseline. Furthermore, the model reduces parameter count by 6.9% and computational load by 13.1%, demonstrating its improved efficiency. Generalization experiments on the public NEU-DET dataset and GC10-DET dataset further confirm the model’s robustness and effectiveness, demonstrating its suitability for industrial applications requiring both high accuracy and lightweight deployment.
Similar content being viewed by others

Introduction
The surface quality of industrial filters plays a critical role in determining their sealing performance, filtration efficiency, and service life in automotive engine systems. However, during the manufacturing process, variations in equipment and materials can introduce surface defects, such as scratches, dents, and printing errors. Traditionally, these defects have been identified through manual inspection, a method that is subjective, inconsistent, and susceptible to operator fatigue and varying environmental factors. Therefore, defect inspection not only incurs high labor costs but also compromises reliability of quality control. To address these limitations, machine vision-based automated defect detection has become a promising alternative to address these limitations.1,2.
Early machine learning methods improved the consistency of defect detection compared to manual inspection but struggled to handle the diversity of defect types and complexity of industrial backgrounds. Recently, deep learning has become the dominant approach, offering superior accuracy and robustness. Modern deep learning-based object detection algorithms can generally be classified into three main categories: two-stage R-CNN variants3, single-stage YOLO variants4, and Transformer-based DETR architectures5.
Single-stage detectors, particularly the You Only Look Once(YOLO) series, are well-suited for real-time applications owing to their high processing speed . For instance, Ji et al.6 improved YOLOv5 by adding an extra detection layer to improve recognition of small defects. Similarly, Pei et al.7 integrated the DSC-C2f module into YOLOv8 to better address complex defect morphologies. Despite their speed advantages, single-stage detectors face two key challenges. First, their reliance on non-maximum suppression (NMS) for post-processing introduces computational overhead, which can destabilize inference speed, particularly in scenarios with densely packed defects8. Second, the limited receptive field of standard convolutional kernels restricts the model’s ability to capture global contextual information. This limitation renders accurately detecting small or overlapping objects in complex backgrounds difficult, ultimately reducing detection accuracy.
In contrast, Transformer-based models, such as DETR, use self-attention mechanisms to capture global dependencies, enabling more effective modeling of complex object relationships9. DETR combines a CNN backbone for feature extraction with a Transformer encoder– decoder architecture, eliminating the need for anchor and NMS, thereby enabling a streamlined end-to-end pipeline. Although this approach often yields higher accuracy, the self-attention mechanism’s quadratic complexity results in significant computational costs, limiting its suitability for real-time settings. To address this gap, Baidu’s PaddlePaddle team developed RT-DETR10, a hybrid model that improves both speed and accuracy through the integration of an efficient hybrid encoder and the removal of the NMS step. However, RT-DETR’s ResNet-based backbone11 and Transformer components still contain parameter redundancy, and its feature fusion network remains suboptimal. Efforts to develop lightweight variants, such as those by Wang et al.12 and Liu et al.13, have often resulted in significant accuracy degradation.
Hence, the core challenge remains achieving high-precision defect detection suitable for industrial inspection while maintaining computational efficiency. This study addresses that challenge by proposing a surface defect detection method for filters based on a significantly improved RT-DETR architecture. The proposed model improves detection precision while simultaneously reducing both the parameter count and computational complexity compared to the original RT-DETR.
Our key contributions are as follows:
-
1.
Backbone Network Optimization: We integrate the large selective kernel attention (LSKAttention) mechanism into the backbone to enhance multi-scale feature extraction and global context modeling both of which are accurately detecting small defects.
-
2.
Efficient Feature Fusion: We replace the standard RepC3 blocks in the neck with GELAN modules, which use a more advanced layer aggregation strategy to improve feature representation and fusion efficiency, while also reducing the overall parameter count.
-
3.
Optimized Down-Sampling: We substitute traditional strided convolutions with the Adown module, which uses a dual-path design to minimize information loss during down-sampling and preserve fine-grained defect details.
The remainder of this paper is structured as follows: Section 2 outlines the proposed methodology, Section 3 presents the results, and Section 4 discusses the findings.
methods
This study aims to enhance the accuracy of surface defect detection in industrial filters while reducing the model’s parameter count. By balancing detection precision with computational efficiency, the proposed approach is well-suited for industrial deployment requirements. To address the challenges of detecting small-target defects, we introduce an improved RT-DETR-LGA model, which builds upon the original RT-DETR architecture.
RT-DETR
The structure of RT-DETR is shown in Fig. 1. The RT-DETR architecture comprises three primary components: (1) a backbone network for hierarchical feature extraction, (2) hybrid encoder for multi-scale information fusion, and (3) T ransformer decoder equipped with auxiliary prediction heads. The backbone leverages CNN architectures such as the ResNet series or Baidu’s proprietary HGNet. These CNN-based backbones exhibit superior real-time performance compared to Vision Transformer (ViT) frameworks, making RT-DETR particularly well-suited for industrial production environments. The backbone generates three multi-scale feature maps, denoted as S3, S4, and S 5, which are passed to the hybrid encoder for further processing. The encoder processes the multi-scale feature using two complementary mechanisms: the attention-based intra-scale feature interaction (AIFI) module for intra-scale interaction, and cross-scale fusion (CCFM) for cross-scale feature fusion. Together, these modules transform the input into sequential image representations suitable for object detection. An IoU-aware query selection mechanism is then employed to extract the most informative candidates from the encoder’s output. These candidates serve as the initial object queries for the decoder. Within the decoder, the queries are subsequently refined over multiple stages, facilitated by auxiliary prediction heads, to generate the final bounding boxes along with their associated confidence scores.

RT-DETR model structure.
The hybrid encoder comprises two key components: the AIFI and CCFM modules. The AIFI module utilizes 2D sine-cosine positional embeddings to generate spatial encodings, thereby enhancing contextual correlations between image regions. This enhances feature extraction and improves the model’s semantic learning capabilities. Conversely, the CCFM module incorporates multiple convolutional fusion blocks along cross-scale pathways, enabling effective information across different resolution levels.
The IoU-aware query selection mechanism identifies the top-K features candidates from the encoder’s outputs based on classification scores, which are then used to initialize object queries (or positional queries independently). To address the common misalignment between classification confidence and localization accuracy, the training procedure integrates IoU scores into the objective function of the classification branch. This dual-constraint approach promotes both accurate classification of positive samples and precise bounding box regression.
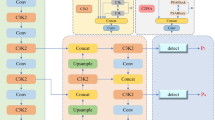
RT-DETR-LGA
The architecture of the proposed RT-DETR-LGA model is illustrated in Fig. 2. The BasicBlock-LSKA module integrates LSKAttention into the backbone network, enhancing multi-scale feature extraction while mitigating parameter growth. Furthermore, the original RepC3 module is replaced with RepNCSPELAN4, which promotes more effective multi-scale data integration. This substitution improves both target localization and recognition accuracy without increasing model complexity. The Adown down-sampling module utilizes a multi-path processing strategy, offering significant advantages over conventional three-layer convolutional structures by preserving critical feature details while maintaining a low parameter count and computational cost.

Improved RT-DETR model architecture (RT-DETR-LGA).
Efficient feature fusion with RepNCSPELAN4
In the baseline RT-DETR architecture, the CCFM employs RepC3 blocks for feature integration. The RepC3 module14, built upon RepConv units, leverages structural re-parameterization to improve inference-time efficiency. During training, its dual-branch structure enables the extraction of diverse features, which are later merged into a single convolutional layer for faster inference. Although RepC3 is effective for general feature extraction, its simple stacking of RepConv units limits its ability to model complex feature dependencies, a critical capability for detecting small industrial defects in noisy backgrounds. To overcome this limitation, we replace the RepC3 blocks with the RepNCSPELAN4 module, a more advanced architecture derived from the GELAN framework used in YOLOv9.
RepNCSPELAN48 is an efficient layer aggregation network that integrates design principles from both CSPNet15 and ELAN16. Its architecture is specifically engineered to optimize gradient paths and enhance feature representation (Fig. 3), all while maintaining low computational overhead. The architecture of RepNCSPELAN4 can be summarized as follows:
-
Input Processing: The module begins by applying a 1 \(\times\) 1 convolution to the input feature map. This step operation adjusts the channel dimensions and acts as a bottleneck layer, efficiently preparing the features for subsequent, more complex processing stages.
-
Cross-Stage Partial (CSP) Structure: At the core of the module is the RepNCSP block8, which splits the input features into two parallel paths. The first path passes through a stack of convolution layers, representing the ELAN component, to allow rich hierarchical feature extraction. The second path bypasses these layers, functioning as a residual connection that preserves the original information and facilitates gradient flow.
-
Feature Aggregation and Output: The features from both paths are concatenated and processed through a final 1 \(\times\) 1 convolution. This CSP-inspired design facilitates gradient flow across network stages, reduces feature degradation, and enables the network to learn more robust and discriminative representations.
By replacing RepC3 with RepNCSPELAN4, we are not simply substituting one module for another, but enhancing the feature fusion mechanism. The multi-path, cross-stage design of RepNCSPELAN4 ensures more effective integration of fine-grained details and high-level semantic features. This architecture upgrade significantly improves the model’s ability to accurately localize and classify challenging small-scale defects, particularly in complex industrial environments.This enables the model to process large-scale data more efficiently, significantly reducing computational and memory overhead.

RepNCSPELAN4 module structure.
Information-preserving downsampling with adown
In CNN-based architectures, down-sampling is essential for building feature pyramids and expanding the receptive field. The standard RT-DETR model utilizes traditional strided convolutions for this purpose. Although computationally efficient, this approach aggressively discards spatial information, which adversely affects the detection of small objects. Subtle yet critical defect features such as fine scratches and pinholes may be lost irreversibly. To address this information loss, we replace strided convolutions with the Adown down-sampling module from YOLOv917.
The Adown module, shown in Fig. 4, is specifically designed to preserve critical feature details during downsampling through a multi-path processing strategy. Its operation can be summarized as follows:
-
1.
The input feature map X is split into two halves, \(X_1\) and \(X_2\), along the channel dimension.
-
2.
The first path processes \(X_1\) using a conventional strided convolution (e.g., stride = 2). This path efficiently learns down-sampled feature representations, capturing the contextual gist of the region.
-
3.
The second path processes \(X_2\) differently. It first applies a max-pooling layer, which explicitly preserves the most salient feature activations within each local window. This is followed by a non-strided (stride = 1) convolution to further transform these high-activation features.
-
4.
Finally, the feature maps from both paths are concatenated along the channel dimension to form the final output.
This dual-path design offers a key advantage. The strided convolution path performs learned, smoothed-out down-sampling, while the max-pooling path preserves high-frequency details and sharp edges—features often essential for defect detection. By combining these complementary representations, the Adown module achieves more robust down-sampling, enriching the feature information passed to subsequent layers, minimizing detail loss, and maintaining parameter efficiency.

Adown module structure.
LSKAttention macronuclear attention mechanism
The baseline RT-DETR model utilizes a ResNet backbone for feature extraction. Although effective, deep residual networks often suffer from parameter redundancy and, more importantly, a limited effective receptive field due to the locality constraints of standard small-kernel convolutions. This limitation hinders the model’s ability to capture long-range dependencies, an essential capability for distinguishing small defects from similarly textured but non-defective background patterns. To address this issue, we enhance the backbone by integrating the LSKAttention mechanism into the structure18.
LSKAttention is a highly efficient visual attention mechanism that emulates the effect of very large convolution kernels (e.g., 27x27 or larger) without incurring excessive computational cost. It achieves this by decomposing large-kernel operations into a sequence of more manageable components as follows:
-
Depthwise Convolution: A depthwise convolution with a medium-sized kernel (e.g., 5x5) is first applied to capture local spatial information within each channel.
-
Depthwise Dilated Convolution: A depthwise convolution with a large kernel and high dilation rate is applied, expanding the receptive field. This enables the model to capture long-range spatial dependencies and gather contextual information from distant regions in the image.
-
Pointwise Convolution (1x1 Conv): Finally, a 1x1 convolution fuses features across channels, enabling channel-wise interaction and recalibration of feature responses.
The sequence generates a dynamic attention map, which is applied element-wise to the input feature map. This operation selectively enhances important features while suppressing irrelevant ones. The process can be formally expressed as Equation 1:
where F represents the input feature map, A denotes the attention map, and O is the output. The LSKAttention block comprises this visual attention submodule followed by a feedforward network, with normalization layers applied before each component (Fig. 5). By embedding this mechanism into the ResNet backbone, we significantly enhance its ability to capture global contextual information. This improvement enables the network to make more informed decisions when identifying small or ambiguous defects that require a broader understanding of the surrounding image area.
The choice of LSKAttention is deliberate and justified when compared to other common attention mechanisms for this specific industrial task. While channel-wise attention modules like Squeeze-and-Excitation (SE-Net) can recalibrate channel importance, they do not address the spatial limitation of small receptive fields, which is critical for contextualizing small defects. Hybrid attention mechanisms like the Convolutional Block Attention Module (CBAM) incorporate spatial attention but typically do so with small kernels, offering only limited expansion of the receptive field. In contrast, LSKAttention’s use of a large-kernel dilated convolution provides a significantly broader spatial context, which is more effective for distinguishing ambiguous small defects from background noise. Furthermore, compared to the quadratic complexity of standard self-attention found in Vision Transformers, LSKAttention’s decomposed structure maintains linear complexity, striking an optimal balance between the global context modeling of Transformers and the computational efficiency required for real-time industrial deployment.

LSKAttention structure diagram.
Results
Experimental setup and evaluation metrics
Experiments were conducted on a Windows 11 system equipped with an AMD Ryzen 7 6800H with Radeon Graphics (3.20 GHz) as the central processing unit (CPU), paired with an NVIDIA GeForce RTX 4090D Laptop GPU running CUDA version 12.1. Python 3.9.1 was employed as the programming framework. The model was trained for 400 epochs with a batch size of 4. A progressive learning rate schedule was adopted, starting at 0.0001 and gradually increasing to a maximum of 0.1 for stabilization.
Filter surface defect dataset
The dataset, compiled from authentic filter components on an automotive production line, includes four defect categories: scratches, unclear printing, ink leakage, and missing rubber rings. The distribution of classes is shown in Fig. 7.

Example of filter sample data.

Number of images containing each defect class.
The dataset was constructed using a sophisticated data generation method based on Generative Adversarial Networks (GANs) to ensure both realism and diversity. Starting with 200 defect-free filter images and a seed set of 100 authentic defect samples, a GAN was trained to learn the distribution of real defect patterns. Its trained generator was then used to produce a large volume of novel, high-fidelity defect patches. These synthetic defects were realistically superimposed onto the defect-free base images, followed by geometric and photometric augmentations to simulate real-world variations. This process yielded a comprehensive dataset of 6,000 images, which was partitioned into training (4,800 images), validation (600 images), and test sets (600 images). Representative samples are illustrated in Fig. 6. For a detailed description of the GAN-based synthesis pipeline and annotation standards, please refer to Appendix A.
NEU-DET dataset
The NEU-DET dataset, provided by Northeastern University19, comprises six defect categories: Crazing, Inclusion, Patches, Pitted Surface, Rolled-in Scale, and Scratches. Each category contains 300 samples, totaling 1800 images. Example images for each category are shown in Fig. 8.
In industrial applications, the NEU-DET dataset is widely utilized in automated production lines for real-time detection and identification of steel surface defects, playing a crucial role in quality assurance. Furthermore, it serves as a benchmark to validate the performance of advanced deep learning algorithms. For instance, it has been used to validate YOLOv7-BA, which incorporates dynamic sparse sampling and adaptive spatial feature fusion20, as well as SDDF-Net, which integrates spatial deformable convolution with a dense feature pyramid.

Sample images of various categories of the NEU-DET dataset.
GC10-DET dataset
To further challenge our model and rigorously evaluate its robustness and generalization capabilities, we incorporate the GC10-DET public dataset20. Unlike simpler benchmarks, GC10-DET is specifically chosen to simulate complex, real-world industrial inspection scenarios. It comprises ten categories of steel surface defects: Crescent gap, Welding line, Water spot, Silk spot, Inclusion, Oil spot, Crease, Punching, Waist folding, and Rolled pit. Representative samples illustrating the diversity and complexity of these defects are shown in Fig. 9.

Representative samples from the GC10-DET dataset, showcasing the ten distinct defect categories evaluated in this study.
The primary value of GC10-DET as a benchmark lies in its inherent difficulty. The dataset presents significant challenges that are often absent in more controlled collections. These include: 1) low-contrast defects that blend into the background (e.g., Oil spot, Rolled pit); 2) subtle textural anomalies that require sensitivity to fine-grained patterns (e.g., Silk spot); and 3) defects captured under variable lighting conditions with surface noise.
Consequently, GC10-DET is widely regarded in the field as a more demanding benchmark for validating the practical utility of detection algorithms. Success on this dataset provides strong evidence of a model’s ability to perform reliably in challenging industrial environments, making it an essential component of our evaluation methodology.
Evaluation indicators
The evaluation metrics used for target detection are recall (\(R_c\)), precision (P), and mean average precision (\(m_{AP}\)), calculated using Equation 2:
where \(P_T\) denotes the number of correctly predicted defects, \(P_F\) represents the number of incorrectly predicted defects, and \(N_F\) is the number of undetected defects. The variable c indicates the number of defect categories, and \(AP_i\) refers to the average precision of the i-th category. \(AP_i\) is calculated as the area under the \(P-R_c\) curve. The mean average precision \(m_AP\) is then obtained by averaging the \(AP_i\) values across all categories. In this study, a higher \(m_AP\) indicates better network performance.
To specifically evaluate the model’s capability on small-scale defects, a critical task in industrial inspection, we also report performance on a small object subset. This subset is created from our test set by isolating all ground-truth objects with a bounding box area less than \(32 \times 32\) pixels, following the standard COCO evaluation criteria. The metrics for this focused analysis include mAP@0.5 and Recall, enabling a direct comparison of each model’s effectiveness on small targets versus its overall performance.
Ablation experiment
To rigorously evaluate the individual and synergistic contributions of each proposed component, we conducted a comprehensive ablation study. We systematically analyzed the effects of integrating the LSKAttention (LSKA), RepNCSPELAN4 (Gan), and Adown modules, using the original RT-DETR as our baseline. The results, which include not only accuracy metrics but also computational efficiency indicators like FLOPs and FPS, are detailed in Table 1.
The baseline RT-DETR model achieved a solid mAP@0.5 of 90.32% with 20.1M parameters and a computational load of 58.29G FLOPs. Our analysis of individual module additions reveals critical trade-offs between accuracy and efficiency. Adding only the LSKA module (Baseline + LSKA) increased mAP@0.5 by 5.23 percentage points to 95.55%, though it slightly increased the parameter count and reduced FPS (Table 1). This substantial gain, however, came at the cost of a slight increase in parameters and a decrease in inference speed (from 134.1 to 119.8 FPS), highlighting the computational overhead of the attention mechanism.
In contrast, replacing RepC3 with RepNCSPELAN4 (‘Baseline + Gan‘) demonstrated a remarkable dual benefit: it improved mAP@0.5 to 93.87% while simultaneously reducing both parameters (by 1.2M) and FLOPs (by 10.9%), resulting in the highest inference speed of 171.9 FPS among all configurations. This underscores the architectural efficiency of the GELAN-based design.
The Adown module’s primary contribution is model lightweighting. As a standalone addition (‘Baseline + Adown‘), it reduced parameters and FLOPs to the lowest levels (17.2M and 50.89G, respectively) with a negligible impact on FPS. This highlights its value in optimizing computational resources.
The synergy between the modules is evident in the combined configurations. The ‘Baseline + LSKA + Gan‘ model pushed the mAP@0.5 to an impressive 97.86%, demonstrating that the powerful feature representation from LSKA is effectively processed by the efficient Gan module. Our final model, which incorporates all three modules, strikes the most optimal balance. It achieves a near-peak mAP@0.5 of 97.67% and the highest mAP@0.5:0.95 of 75.72%. Crucially, the introduction of the Adown module, despite causing a marginal 0.19% drop in mAP@0.5 compared to the previous step, significantly reduces the computational load (FLOPs) by 13.1% and the parameter count by 6.9% relative to the baseline. The final model, incorporating all three modules, achieved a mAP@0.5 of 97.67% and a mAP@0.5:0.95 of 75.72%. Compared to the baseline, this configuration reduced parameters by 6.9% and FLOPs by 13.1%, while maintaining an FPS of 118.1.
Visualization comparison
To visually demonstrate the algorithm’s improvements, this study compares the detection results of the baseline RT-DETR-R18 model with those of the enhanced RT-DETR-LGA model on the filter defect dataset (Fig. 10). Each image pair displays the original model’s output (left) and the improved model’s results (right), clearly illustrating the improved detection efficacy. In Fig. 10(a) and (c), RT-DETR-LGA demonstrates superior accuracy in detecting blurred markings and ink leakage defects. Fig. 10(b) and (f) further highlight the model’s enhanced capability in accurately identifying scratch defects. Notably, Fig. 10(d) and (e) show RT-DETR-LGA’s ability to detect micro-defects that were missed by the baseline RT-DETR-R18 model. In industrial production environments, micro-scratches and ink residue are common issues. The baseline model exhibited a 12.7% false negative (FN) rate and an 8.3% false positives (FP) rate—issues that critically affect product quality and customer satisfaction. In contrast, the RT-DETR-LGA model achieved 97.2% precision and 95.6% recall, effectively addressing these operational challenges with significantly enhanced detection accuracy.

Comparison of the detection results of the baseline RT-DETR-R18 model with those of the proposed enhanced RT-DETR-LGA model on the filter defect dataset.
Figure 11 presents a comparison of the confusion matrices, where diagonal elements indicate the proportion of correctly predicted defect samples relative to total defect instances, while off-diagonal elements represent misclassified or undetected proportions. The left matrix corresponds to the RT-DETR model, whereas the right illustrates the RT-DETR-LGA model’s performance. The labels defect0 through defect3 respectively denote four defect types in the filter dataset: blurred markings (defect0), ink leakage (defect1), surface scratches (defect2), and seal ring absence (defect3).
In Fig. 11(a), the RT-DETR model demonstrates effective detection of seal ring absence defects (defect3 accuracy: 0.94) but exhibits elevated missed detection rates for surface scratches (defect2 recall: 0.86) and blurred markings (defect0 recall: 0.89). Specifically addressing the potential confusion between “blurred markings” (defect0) and “ink leakage” (defect1), the baseline model misclassifies 5% of true ink leakage cases as blurred markings, and 2% of true blurred markings as ink leakage. This confirms a degree of feature overlap that challenges the original model.
Figure 11(b) reveals that the improved RT-DETR-LGA model significantly reduces this specific confusion. The misclassification of ink leakage as blurred markings drops to just 2%, and the misclassification of blurred markings as ink leakage is reduced to 1%. This demonstrates the enhanced discriminative power of our proposed architecture. Overall, significant performance gains are observed in previously underperforming categories: the detection accuracy for blurred markings improves from 0.89 to 0.97, while surface scratch recognition increases from 0.86 to 0.95.

Confusion matrices for the four classes of detected objects before and after model improvement. (a) Confusion matrix of RT-DETR model; (b) Confusion matrix of RT-DETR-LGA model.
Comparative tests of mainstream algorithms
To contextualize the performance of our proposed RT-DETR-LGA model, we conducted a comprehensive comparative analysis against a range of mainstream and state-of-the-art object detection algorithms. The selection includes classic two-stage (Faster R-CNN) and single-stage (SSD) detectors, various YOLO family members (YOLOv5m, YOLOv7-s AF, YOLOv8m), and recent cutting-edge models such as YOLOv9, YOLOv10, and an updated RT-DETRv2. The results, encompassing accuracy (mAP), model size (Params), computational load (FLOPs), and inference speed (FPS), are presented in Table 2.
As shown in Table 2, the proposed RT-DETR-LGA model achieved the highest detection accuracy among all tested algorithms.Our model achieves the highest detection accuracy, with a mAP@0.5 of 97.67% and a mAP@0.5:0.95 of 75.72%. This performance surpasses all other tested models, including the powerful YOLOv9 (92.4% mAP@0.5) and its own predecessors, RT-DETR and RT-DETRv2.
Crucially, this top-tier accuracy is achieved without compromising efficiency. A deeper look at the trade-offs reveals the strength of our approach. For instance, while YOLOv7-s AF is the most lightweight model in terms of parameters (11.0M) and FLOPs (28.1G), its mAP is over 10 percentage points lower, making it unsuitable for high-precision requirements. Conversely, high-performance models like YOLOv9 and YOLOv10, while achieving strong accuracy, do so at a much higher computational cost. YOLOv9, for example, requires 83% more FLOPs (92.87G vs 50.67G) and has a 36% slower inference speed (74.85 FPS vs 118.1 FPS) than our RT-DETR-LGA.
Compared to its direct lineage, our model demonstrates clear advancements. It outperforms the baseline RT-DETR by 7.3 percentage points in mAP@0.5 while simultaneously being more efficient, with a 6.9% reduction in parameters and a 13.1% reduction in FLOPs. Compared to high-performance models like YOLOv9, RT-DETR-LGA achieved higher accuracy with 83% fewer FLOPs and a 36% faster inference speed. This indicates a favorable balance between performance and computational cost.
In addition to inference efficiency, we also briefly evaluated the training overhead. On our hardware (NVIDIA RTX 4090D), the proposed RT-DETR-LGA model required approximately 14.2 hours to complete the 400-epoch training schedule. This is comparable to the baseline RT-DETR, which took around 12.8 hours, indicating that our architectural modifications do not introduce significant training complexity. For reference, training a model like YOLOv8m under similar conditions took approximately 14.6 hours. This demonstrates that our model maintains a practical training efficiency profile suitable for industrial research and development cycles.
Generalization and robustness evaluation
Generalization Verification on the NEU-DET Dataset
To further validate the performance and generalization ability of our proposed model, we conducted extensive experiments on the public NEU-DET dataset. We compared our improved model, RT-DETR-LGA, against the original RT-DETR baseline and several recently improved algorithms for steel surface defect detection.
For a robust evaluation, both the baseline and our proposed model were run five times, with the mean and standard deviation (\(\mu \pm \sigma\)) of key metrics reported. The comprehensive results are presented in Table 3.
The results in Table 3 demonstrate a significant performance enhancement. Our RT-DETR-LGA model achieves an average mAP@0.5 of 80.28%, representing a substantial increase of 5.74 percentage points over the baseline. The low standard deviation of \(\pm 0.53\%\) across five runs highlights the stability and reliability of this improvement.
Although precision experienced a modest decrease from 79.28% to 75.76%, recall improved significantly from 68.14% to 72.12%. This trend suggests that our proposed LGA module enhances the model’s sensitivity to defect features, reducing the number of missed defects. In industrial quality control, minimizing missed defects is often paramount, as undetected flaws can lead to significant downstream costs or safety issues. Therefore, the substantial gain in recall, despite a slight increase in false positives , results in a more effective and practical detection system. The overall benefit of this trade-off is further confirmed by the significant increase in the primary metric, mAP@0.5, which balances both precision and recall. Furthermore, this performance improvement is accompanied by a reduction in model parameters from 20.1M to 18.7M and FLOPs from 58.29G to 50.67G.
The confusion matrices in Fig. 12 provide a qualitative view of this improvement. The baseline RT-DETR model (a) struggles significantly with certain defect types, particularly “Crazing,” which it detects with only 0.37 accuracy. Our improved model (b) dramatically boosts performance on this challenging class, increasing accuracy to 0.87, and shows overall reduced confusion between classes.

Confusion matrices demonstrating model generalization on the public NEU-DET dataset, which contains six defect categories. (a) The baseline RT-DETR model struggles with certain classes like Crazing. (b) The proposed RT-DETR-LGA model shows substantially improved accuracy and reduced confusion between classes, confirming its robust generalization capabilities.
To further benchmark our model, we compared it against other state-of-the-art methods on the NEU-DET dataset, as shown in Table 4. Our RT-DETR-LGA model achieved an average mAP@0.5 of 80.28%, surpassing the YOLOX-based method by Li et al.21 (77.0%) and the YOLOv5n-based method by Tian et al.22 (75.3%).
In conclusion, extensive experiments on the NEU-DET dataset, supported by multiple-run analysis, confirm that the proposed RT-DETR-LGA model achieves superior performance with strong generalization capability and robustness.
Robustness verification on the GC10-DET dataset
To address concerns about performance in more complex industrial scenarios, we conducted a rigorous evaluation on the public GC10-DET dataset. This benchmark is particularly challenging as it includes ten distinct defect types captured under real-world production conditions, featuring noise such as uneven illumination and oil stain interference. Our primary goal was to precisely quantify the improvements of RT-DETR-LGA over its baseline and to contextualize its performance against other specialized algorithms.
A detailed, per-class comparison of detection accuracy is presented in Table 5. The results unequivocally demonstrate the superior overall performance of our proposed model. RT-DETR-LGA achieves an overall mAP of 73.40%, which is a substantial improvement of 7.92 percentage points over the baseline RT-DETR and also surpasses the 71.00% mAP of the specialized EC-YOLO23.
A deeper, per-class analysis reveals a nuanced performance landscape. The EC-YOLO model shows exceptional strength in certain categories, such as Inclusion (In), Oil spot (Os), and Rolled-in pit (Rp). In contrast, our RT-DETR-LGA model demonstrates a commanding advantage in other challenging classes. For example, its performance on Welding line (Wl) is 93.10%, a staggering 55.1 percentage points higher than EC-YOLO. Similarly, it achieves significantly better results for Waist folding (Wf) and Crease (Cr).
This indicates that while EC-YOLO is highly tuned for specific defect types, our proposed RT-DETR-LGA exhibits a more balanced and robust detection capability across a wider variety of defects. The superior performance on classes like ’Wl’ and ’Wf’ suggests that our architectural enhancements, particularly the LSKAttention’s ability to capture global context and the Adown module’s preservation of fine-grained features, contribute to a better-rounded model. The higher overall mAP confirms that our model strikes a more effective balance, making it a more reliable and general-purpose solution for complex industrial inspection tasks.
Validation on authentic defect samples
A critical aspect of evaluating any model trained primarily on synthetic data is its ability to generalize to real-world conditions. To this end, we conducted a crucial validation experiment on a hold-out set of 75 authentic defect images, which were strictly excluded from both the GAN training and the final dataset construction. This set represents the true, un-synthesized data distribution, serving as the ultimate test of practical applicability.
The quantitative results of this validation are presented in Table 6. Our proposed RT-DETR-LGA model achieved a mAP@0.5 of 98.7%, outperforming the baseline RT-DETR by a significant margin of 6.05 percentage points on this challenging real-world data. Notably, the improvements in both precision (+4.1%) and recall (+5.9%) demonstrate that our architectural enhancements effectively reduce both false positives and missed detections in practical scenarios.
To provide a qualitative illustration of this performance gap, Fig. 13 showcases the detection results on several challenging authentic samples. In the first example (top row), the baseline model fails to detect all instances of fine scratches, resulting in a missed detection (Fig. 13a). In contrast, our RT-DETR-LGA model correctly identifies all defects (Fig. 13b). The second example (bottom row) highlights the issue of false positives; the baseline model incorrectly flags non-defective areas, likely due to surface texture or lighting variations (Fig. 13c), while our model exhibits higher precision and avoids such errors (Fig. 13d).
This strong performance, both quantitative and qualitative, provides compelling evidence that our GAN-based synthesis process successfully captured the essential features of real defects. It confirms that the proposed RT-DETR-LGA is not merely overfitted to the synthetic data but has learned robust and generalizable representations, making it highly suitable for practical deployment in industrial inspection.

Qualitative comparison on challenging authentic defect samples. The top row shows a case of missed detection by the baseline, while the bottom row illustrates a false positive. (a) and (c) are results from the baseline RT-DETR. (b) and (d) are results from our proposed RT-DETR-LGA, which demonstrates superior accuracy and robustness.
Analysis of small object detection performance
To address the critical challenge of detecting small-scale industrial defects, we conducted a specific analysis evaluating our model’s performance on small objects. Following the standard COCO evaluation criteria, we define “small objects” as those with a bounding box area less than \(32 \times 32\) pixels. We created a subset from our test set containing only these small defects and recalculated key performance metrics for both the baseline RT-DETR and our proposed RT-DETR-LGA model.
The results, presented in Table 7, clearly demonstrate the superior capability of our model in this challenging scenario.
As shown in Table 7, while the baseline RT-DETR’s performance degrades when faced with small targets (mAP drops from 90.32% to 87.14%), our RT-DETR-LGA model maintains exceptionally high accuracy (95.93%). The performance gain of our model over the baseline is more pronounced on the small object subset (+8.79% in mAP) than on the overall dataset (+7.35%). This enhanced capability is also reflected in the recall metric, which shows a greater improvement for small targets (+9.5%) compared to the overall recall gain (+6.53%). This indicates that our architectural improvements specifically target and resolve the key challenges of small object detection.
The enhanced performance can be attributed to the synergistic effect of our three core contributions. First, the LSKAttention mechanism provides a significantly expanded receptive field, allowing the model to capture broader contextual information around a tiny defect. This helps distinguish it from noise or complex background textures where standard small-kernel convolutions in the baseline often fail. Second, the information-preserving Adown module is critical for small objects; its dual-path design, particularly the max-pooling path, explicitly preserves high-frequency details and salient feature activations, ensuring that signals from small defects are retained throughout the network’s down-sampling stages. Finally, the efficient feature fusion with GELAN, through the RepNCSPELAN4 module, provides a more efficient gradient path and a richer aggregation structure. This allows for the effective fusion of fine-grained spatial details from shallow layers with strong semantic context from deeper layers, culminating in more precise localization and classification of small-scale targets.
In summary, this focused analysis confirms that the RT-DETR-LGA model not only achieves superior overall performance but also demonstrates a remarkable and targeted improvement in the detection of small industrial defects, directly addressing a primary limitation of existing models.
Model interpretability analysis
To provide a qualitative assessment of our model’s capabilities and to gain deeper insights into its decision-making process, we employed Gradient-weighted Class Activation Mapping (Grad-CAM)24. This technique generates visual explanations by producing a heatmap that highlights the image regions most influential to the model’s prediction. By visualizing what the model “sees,” we can intuitively compare the feature extraction and attention mechanisms of our proposed method against the baseline.
We selected two representative scenarios to conduct this analysis: a challenging case with strong reflective interference and a case requiring fine-grained localization. The comparative results are visualized in Fig. 14.

Grad-CAM visualization comparing the attention mechanisms of the baseline RT-DETR and our proposed RT-DETR-LGA. (a-c) A challenging case with strong surface reflections. The baseline’s attention is scattered by interference, while RT-DETR-LGA robustly focuses on the semantically relevant text region. (d-f) A fine-grained localization case. The baseline’s activation is coarse, whereas our method pinpoints a single character with high precision.
Robustness against visual interference
Figure 14(a-c) illustrates a common industrial scenario where robustness to visual noise is paramount. The baseline RT-DETR model (b), when confronted with a glossy surface, exhibits a diffuse and misguided activation map. Its attention is heavily distracted by high-contrast yet semantically irrelevant features, such as the strong reflections and the object’s physical contours. This indicates a reliance on superficial cues, which can lead to unreliable performance in visually complex environments.
In stark contrast, the activation map of our proposed RT-DETR-LGA (c) is more focused on the text region and less affected by the reflective interference.It produces a highly concentrated activation map precisely centered on the text block, effectively treating the strong reflections and background as noise. A more nuanced inspection reveals a sophisticated, hierarchical attention strategy: the primary, high-intensity focus is on the text itself, while a much fainter, secondary activation lightly delineates the object’s boundary. This suggests that our model has learned to differentiate between core evidence (the text) and its surrounding context, a capability the baseline fundamentally lacks. This enhanced focus is attributable to the LSKAttention module, which leverages a large receptive field to capture global context and prioritize salient semantic features over low-level noise.
Precision in fine-grained localization
The second case, shown in Fig. 14(d-f), evaluates the model’s ability to localize fine-grained features. The baseline RT-DETR (e), while correctly identifying the general region of interest, generates a coarse and oversized heatmap that indiscriminately covers the entire text block. This level of precision is often insufficient for industrial inspection, where the goal is to pinpoint specific, small-scale defects.
Our RT-DETR-LGA (f), however, generates a more tightly localized activation map, focusing on a single character (‘G’).This demonstrates an exceptional ability to focus on micro-level details, which is critical for identifying subtle flaws like printing errors or minor surface scratches. This pin-point localization capability stems from the synergistic effect of our architectural enhancements, which not only provide a global understanding of the scene but also preserve the high-resolution details necessary for such precise analysis. This confirms that our model’s improvements are not just in general detection but also in the fine-grained perception essential for high-standard quality control.
Discussion
Our experiments revealed a notable and insightful performance gradient across the three datasets. The model achieved its highest accuracy on our proprietary filter dataset (97.67% mAP@0.5), followed by the public NEU-DET dataset (80.28% mAP@0.5), and then the more complex GC10-DET dataset (78.4% mAP@0.5). This discrepancy is not indicative of a model failure but rather offers valuable insights into its generalization capabilities when faced with progressively challenging conditions. The primary driver of this performance difference lies in the inherent characteristics of the datasets. Our filter dataset was captured in a highly controlled industrial environment with uniform illumination. In contrast, NEU-DET introduces greater complexity with low-contrast, texture-like defects, and GC10-DET further elevates the challenge with real-world noise, including oil stains, lighting variations, and a wider range of defect types.
It is precisely in these more difficult scenarios that our architectural enhancements prove their value. The progressive, yet graceful, degradation in performance, while still outperforming specialized state-of-the-art methods on both public benchmarks, confirms that our model has learned robust, generalizable features, not merely overfitted to the clean conditions of our primary dataset. The LSKAttention module’s ability to leverage broader spatial context is critical for differentiating ambiguous defects from background noise, a task where baseline models typically struggle. This robust generalization ability, validated on multiple public datasets including the challenging GC10-DET, strongly supports the model’s suitability for deployment in real, unpredictable industrial environments.
These technical advancements have direct implications for industrial deployment and cost-effectiveness. The model’s enhanced accuracy, particularly its ability to drastically reduce both false negatives and false positives, translates into significant operational savings by minimizing warranty claims, rework, and material waste. For example, based on our results, a 77% reduction in critical quality failures can be projected. Concurrently, the lightweight nature of RT-DETR-LGA (18.7M parameters, 50.67 GFLOPs) reduces capital expenditure, as it can be deployed on more affordable edge computing hardware compared to heavier alternatives like Faster R-CNN or the original DETR. The high inference speed of 118.1 FPS ensures it does not become a production bottleneck. In essence, the proposed model offers a compelling business case by making high-precision automated inspection both more effective and economically accessible.
Conclusion
This paper introduced an improved version of the RT-DETR model, named RT-DETR-LGA, designed to meet the critical industrial demand for a defect detection algorithm that combines high accuracy with computational efficiency. Experimental results demonstrate the effectiveness of the proposed approach. RT-DETR-LGA outperformed the baseline RT-DETR by a significant margin, improving Map by 7.3 percentage points on the filter defect dataset, while also reducing the parameter count by 6.9%.
The success of our model stems from the synergistic combination of three key architectural improvements. First, integrating the LSKAttention mechanism proved essential, providing the backbone with long-range spatial awareness that improved detection of small, low-contrast defects, such as, fine scratches, areas where the original model often missed. Second, replacing the RepC3 blocks with the GELAN-based module streamlined feature fusion in the neck, enhancing localization precision without increasing computational cost. Lastly, the Adown module minimized information loss during down-sampling, preserving fine details critical for identifying micro-defects. This improvement was visually confirmed in our analysis, where RT-DETR-LGA consistently reduced FNs and FPs compared to the baseline model.
Compared to other mainstream algorithms, including various YOLO variants and the original DETR, our model established a superior balance between performance and efficiency. It achieved the highest mAP while maintaining a parameter count comparable to lighter yet less accurate models like YOLOv7-s AF. Furthermore, extensive experiments on public benchmarks, including the NEU-DET and the highly challenging GC10-DET steel defect datasets, confirmed the model’s strong generalization capability and robustness in complex industrial scenarios. With an mAP of 80.28%, it outperformed both the baseline and other published methods, validating that the architectural enhancements are effective across domains and not overfitted to a single dataset.
In conclusion, the proposed RT-DETR-LGA model effectively resolves the trade-off between accuracy and deployment cost in industrial surface defect detection. It provides a robust, lightweight, and highly precise solution, well-suited for real-world manufacturing environments. Future work could explore advanced model quantization and pruning techniques to further optimize performance for deployment on highly resource-constrained edge devices.
Data availability
The datasets presented in this study are not publicly available due to confidentiality agreements with our project partners.
References
Girshick, R., Donahue, J., Darrell, T. & Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, 580–587 (2014).
Chen, L.-C., Zhu, Y., Papandreou, G., Schroff, F. & Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European conference on computer vision (ECCV), 801–818 (2018).
Zhao, Z., Wang, J., Tao, Q., Li, A. & Chen, Y. An unknown wafer surface defect detection approach based on incremental learning for reliability analysis. Reliab. Eng. Syst. Safety 244, 109966 (2024).
Redmon, J., Divvala, S., Girshick, R. & Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR) (2016).
Carion, N. et al. End-to-end object detection with transformers. In Vedaldi, A., Bischof, H., Brox, T. & Frahm, J.-M. (eds.) Computer Vision – ECCV 2020, 213–229 (Springer International Publishing, Cham, 2020).
Ji, C.-L., Yu, T., Gao, P., Wang, F. & Yuan, R.-Y. Yolo-tla: an efficient and lightweight small object detection model based on yolov5. J. Real-Time Image Process. 21, 141 (2024).
Pei, J., Wu, X. & Liu, X. Yolo-rdd: A road defect detection algorithm based on yolo. In 2024 27th international conference on computer supported cooperative work in design (CSCWD), 1695–1703 (IEEE, 2024).
Balakrishnan, T. & Sengar, S. S. Repvgg-gelan: Enhanced gelan with vgg-style convnets for brain tumour detection. arXiv preprint arXiv:2405.03541 (2024).
Avola, D. et al. Ms-faster r-cnn: Multi-stream backbone for improved faster r-cnn object detection and aerial tracking from uav images. R. Sens. 13, 1670 (2021).
Zhao, Y. et al. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 16965–16974 (2024).
Redmon, J. & Farhadi, A. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767 (2018).
Wang, S. et al. Lightweight tomato ripeness detection algorithm based on the improved rt-detr. Front. Plant Sci. 15, 1415297 (2024).
Liu, M., Wang, H., Du, L., Ji, F. & Zhang, M. Bearing-detr: A lightweight deep learning model for bearing defect detection based on rt-detr. Sensors 24, 4262 (2024).
Ewing, C. M. et al. Chromosome 5 suppresses tumorigenicity of pc3 prostate cancer cells: correlation with re-expression of \(\alpha\)-catenin and restoration of e-cadherin function. Cancer Res. 55, 4813–4817 (1995).
Wang, C.-Y. et al. Cspnet: A new backbone that can enhance learning capability of cnn. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, 390–391 (2020).
Wittenburg, P., Brugman, H., Russel, A., Klassmann, A. & Sloetjes, H. Elan: A professional framework for multimodality research. In 5th international conference on language resources and evaluation (LREC 2006), 1556–1559 (2006).
Wang, C.-Y., Yeh, I.-H. & Mark Liao, H.-Y. Yolov9: Learning what you want to learn using programmable gradient information. In European conference on computer vision, 1–21 (Springer, 2024).
Fu, M. et al. Lsksanet: A novel architecture for remote sensing image semantic segmentation leveraging large selective kernel and sparse attention mechanism. In IGARSS 2024-2024 IEEE international geoscience and remote sensing symposium, 8438–8441 (IEEE, 2024).
of Electrical, I. & Engineers, E. IEEE transactions on instrumentation and measurement (IEEE, 1963).
Lv, X., Duan, F., Jiang, J.-j., Fu, X. & Gan, L. Deep metallic surface defect detection: The new benchmark and detection network. Sensors 20, https://doi.org/10.3390/s20061562 (2020).
Li, C., Xu, A., Zhang, Q. & Cai, Y. Steel surface defect detection method based on improved yolox. IEEE Access 12, 37643–37652. https://doi.org/10.1109/ACCESS.2024.3374869 (2024).
Tian, J.-H. et al. An improved yolov5n algorithm for detecting surface defects in industrial components. Sci. Rep. 15, 9756 (2025).
Cheng, Z., Gao, L., Wang, Y., Deng, Z. & Tao, Y. Ec-yolo: Effectual detection model for steel strip surface defects based on yolo-v5. IEEE Access 12, 62765–62778. https://doi.org/10.1109/ACCESS.2024.3391353 (2024).
Selvaraju, R. R. et al. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE international conference on computer vision, 618–626 (2017).
Funding
This work is supported by the National Natural Science Foundation of China (No. 12205241), the Key Research and Development Program of Gansu Province - Industrial Project (No. 25YFGA059), the Fundamental Research Funds for the Central Universities (No. 31920220049 & 31920230138), the Gansu Provincial Department of Education Youth Doctoral Fund Project (No. 2025QB-007), and the Higher Education Teaching Achievement Cultivation Project of Gansu Province (2023GSJXCGPY-56).
Author information
Authors and Affiliations
Contributions
Conceptualization, M.Z. and W.Y.; methodology, M.Z.; software, M.Z.; validation, Y.G., R.A. and P.Z.; formal analysis, C.Z.; investigation, G.L.; resources, X.W.; data curation, M.C.; writing—original draft preparation, M.Z.; writing—review and editing, X.W.; visualization, Z.B.; supervision, Y.L.; project administration, X.W. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Data acquisition and annotation details
This appendix provides detailed information regarding the data acquisition setup, the standards used for defect annotation, and a set of representative annotated samples. Figure 15 shows the actual data acquisition station.

The physical data acquisition setup, featuring the Hikrobot camera, ring light.
Image acquisition setup
The images for the filter surface defect dataset were captured in a controlled industrial environment simulating a real-world production line inspection station. The key components and parameters of the acquisition system were standardized to ensure image consistency:
-
Imaging Device: A Hikrobot MV-CS050-10GM industrial CMOS camera was used. This 5-megapixel monochrome camera was chosen for its high resolution, high signal-to-noise ratio, and stability in industrial settings.
-
Resolution: All images were captured at the camera’s full resolution of 2448\(\times\) 2048 pixels, providing sufficient detail for the identification of subtle defects like fine scratches and minor print imperfections.
-
Lens: A 12mm fixed-focal-length industrial C-mount lens was used to maintain a constant field of view and minimize geometric distortion.
-
Lighting Conditions: To eliminate shadows and ensure uniform illumination across the filter surface, a white, ring-shaped shadowless LED light source was mounted coaxially with the lens. The lighting intensity was kept constant throughout the data collection process.
-
Acquisition Geometry: The camera was mounted at a fixed perpendicular distance of approximately 30 cm from the filter surface, ensuring a consistent scale for all captured images.
-
Capture Trigger: Image capture was automatically triggered by a photoelectric sensor that detected when a filter component was correctly positioned in the inspection station. This automated process guaranteed consistent component placement for every image.
This precisely controlled setup, powered by a 12V/4A DC supply, was designed to minimize variations caused by environmental factors and to produce a high-quality, consistent dataset suitable for training robust deep learning models.
GAN-based defect synthesis and augmentation
To address the scarcity of authentic defect samples, we employed a data generation pipeline centered on a Generative Adversarial Network (GAN), ensuring both the diversity and realism of the training data. This approach moves beyond simple “copy-paste” methods by generating novel defect instances.
-
GAN Training on Authentic Defects: We first collected a seed dataset of 100 authentic defect images, covering a variety of types such as scratches and ink spots. These real defect patches were cropped and used as the training set for a lightweight GAN architecture, specifically a Deep Convolutional GAN (DCGAN). The network was trained to learn the underlying distribution of these real defects, enabling it to generate new, synthetic defect patterns that are statistically similar to the authentic ones but not identical.
-
Generating and Curating Synthetic Defects: After training, the generator component of the GAN was utilized to produce a large pool of synthetic defect patches. These patches were manually curated to filter out low-quality or unrealistic generations, ensuring that only high-fidelity defect patterns were used for the subsequent steps.
-
Realistic Superimposition and Augmentation: The curated, GAN-generated defect patches were then seamlessly blended onto the 200 defect-free background images. To achieve a natural appearance, we employed alpha blending with a soft-edged mask, which avoids sharp, artificial boundaries. The location, size, and orientation of each superimposed defect were randomized. Following this, standard data augmentation techniques were applied to the entire synthesized image to increase robustness:
-
Geometric Transformations: Random rotation (within a [-15, +15] degree range) and scaling (from 80% to 120%).
-
Photometric Transformations: Random adjustments to brightness and contrast to simulate minor variations in industrial lighting.
-
By leveraging a GAN, we not only expanded our dataset but also introduced a higher degree of variation and realism than what could be achieved with traditional augmentation alone. This method was crucial for training a model capable of recognizing a wide spectrum of defect appearances.
Annotation standards and representative samples
The annotation process was carried out by domain experts following a strict protocol to ensure accuracy and consistency.
-
Annotation Tool: The open-source software LabelImg was used for creating bounding box annotations.
-
Annotation Format: Annotations were saved in the PASCAL VOC XML format, ensuring compatibility with standard deep learning frameworks.
-
Bounding Box Principle: The primary rule for annotation was to create the tightest possible bounding box that fully encompasses the entire visible area of a single defect.
To provide tangible examples for peer validation, Fig. 16 presents ten typical defect samples from our dataset, showcasing the application of our annotation standards across all four defect categories.

Representative annotated samples from the filter surface defect dataset. These images illustrate the various defect types (missing rubber rings, scratches, unclear printing and ink leakage) and the application of our “tightest bounding box” annotation principle. The bounding boxes are visualized on the images to show the ground truth.
Defect category definitions and differentiation criteria
To ensure annotation consistency and address potential ambiguities between defect categories, particularly between “unclear printing” and “ink leakage,” the following specific criteria were established and used by the annotators:
-
Unclear Printing (referred to as Blurred Markings in figures) (defect0): This category includes instances where the printed text or markings are faded, incomplete, or have poorly defined edges. The defect is characterized by a loss of ink or low contrast within the intended character boundaries. The key visual cue is the degradation or absence of the original print, without significant ink spreading externally.
-
Printing Ink Leakage (defect1): This defect is identified by the presence of excess ink that has bled or smudged outside the intended boundaries** of the printed characters. It typically manifests as distinct blobs, smears, or streaks of high-contrast (dark) ink adjacent to or connected with the printing. The primary differentiator is the addition of unwanted ink material to the surface, as opposed to the degradation of existing material seen in “unclear printing.”
-
Scratches (defect2): Defined as linear indentations or abrasions on the filter’s surface, characterized by a significant length-to-width ratio and a noticeable difference in texture or reflectivity compared to the surrounding area.
-
Missing Rubber Ring (defect3): A structural defect defined by the complete absence of the rubber sealing ring in its designated groove. This is a binary classification based on the presence or absence of the component.
These definitions provide a clear, rule-based standard for differentiating the defect types, which was critical for training a reliable model.
Appendix B: Loss function and training details
This section details the loss function for our RT-DETR-LGA model. The implementation adheres to the IoU-aware training mechanism proposed in the original RT-DETR paper, which aligns classification confidence with localization accuracy.
Loss formulation
The overall training loss is a weighted sum of a localization loss (\(\mathscr {L}_{box}\)) and a specialized classification loss (\(\mathscr {L}_{cls}\)).
The localization loss, \(\mathscr {L}_{box}\), is a linear combination of L1 loss and Generalized IoU (GIoU) loss:
where \(\hat{b}\) and b are the predicted and ground-truth boxes, respectively, and \(\lambda _{L1}\), \(\lambda _{GIoU}\) are balancing hyperparameters.
The key to the IoU-aware mechanism is a modified classification loss, \(\mathscr {L}_{cls}\), inspired by Varifocal Loss (VFL), which incorporates localization quality directly into its formulation.
IoU-aware classification loss implementation
The IoU-aware classification loss modifies the training target. Instead of using a hard label (1 for the correct class), the target is softened to reflect localization quality.
Let p be the model’s predicted classification score (after sigmoid) and q be the target score. The target q is defined as:
-
For a positive sample (a prediction matched to a ground-truth object), the target q is its IoU score: \(q = \text {IoU}(\hat{b}, b)\).
-
For a negative sample (an unmatched prediction), the target q is 0.
The Varifocal Loss is then calculated. For a positive sample, it focuses the training on high-quality examples by using the IoU score q as a weighting factor. The formulation for a single prediction is:
where \(\alpha\) and \(\gamma\) are the focusing hyperparameters of VFL. In this formulation, the loss for a positive sample is directly weighted by its IoU score q. This means:
-
A well-localized prediction (high IoU, high q) contributes significantly to the loss if its classification score p is low, pushing the model to predict higher confidence for better boxes.
-
A poorly-localized prediction (low IoU, low q) is naturally down-weighted, preventing these low-quality examples from dominating the training gradient.
This mechanism directly forces the model to correlate classification confidence with localization accuracy.
Impact of weighting coefficients
The complete loss function combines these components:
In our experiments, we adopted the standard, empirically validated weighting coefficients from the official RT-DETR implementation:
-
Classification Loss Weight (\(\lambda _{cls}\)): Set to 2.0.
-
L1 Loss Weight (\(\lambda _{L1}\)): Set to 5.0.
-
GIoU Loss Weight (\(\lambda _{GIoU}\)): Set to 2.0.
These weights create a balanced training objective. The high weight for L1 loss (\(\lambda _{L1}=5.0\)) prioritizes precise box coordinate regression. The balanced weights for classification and GIoU ensure the model learns to classify correctly while matching the overall box shape and overlap. This robust loss formulation provides the foundation upon which our proposed architectural enhancements yield significant performance gains.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhang, M., Wei, X., Liu, G. et al. Balancing complexity and accuracy for defect detection on filters with an improved RT-DETR. Sci Rep 15, 29720 (2025). https://doi.org/10.1038/s41598-025-13960-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-13960-x
This article is cited by
-
A review of AI and machine learning applications in manufacturing processes
Journal of Intelligent Manufacturing (2026)
