
Abstract
When detecting small objects in drone aerial imagery, the traditional YOLOv8 detection algorithm suffers from low accuracy, strong background interference, and model redundancy. Meanwhile, the hardware constraints of drones impose strict requirements on model size and computational complexity. To address these issues, this paper proposes an improved lightweight detection model named LPAE-YOLOv8, with the following modifications to the YOLOv8 architecture. First, an innovative detection head, LSE-Head, is introduced to balance the model’s parameter count and bounding box prediction accuracy. Second, the large-object detection layer is removed, and a new small-object detection layer is added to optimize the network structure and retain richer feature information. Third, an improved EfficiCIoU loss function is adopted to enhance the model’s bounding box regression capability. Finally, an improved convolutional module, ACMConv, which integrates the CMUNeXtBlock and Adaptive Attention (AA) mechanism, is designed to strengthen small-object perception. Experiments conducted on the VisDrone2019 and TinyPerson datasets demonstrate that LPAE-YOLOv8 achieves a lightweight design while maintaining high detection accuracy. On the VisDrone2019 dataset, mAP@0.5 increases by 16.9% compared with the baseline model, mAP@0.5:0.95 improves to 21.3%, and the number of parameters is reduced to 1.97 M, representing a 34.5% decrease from the original model. On the TinyPerson dataset, mAP@0.5 is enhanced from 14.4% to 18.7%. Ablation experiments verify the individual effectiveness of each improved module, while comparative experiments with mainstream algorithms demonstrate that the proposed model achieves an excellent balance among accuracy, complexity, and inference efficiency, fully proving its effectiveness and practical value for small object detection in drone aerial imagery.
Similar content being viewed by others
Introduction
With the rapid advancement of modern technology, unmanned aerial vehicles (UAVs) have emerged as a vital branch of contemporary aviation. Owing to their high flexibility, wide coverage, and relatively low cost, UAVs have become indispensable tools for aerial operations, among which object detection represents a key enabling technology. Compared with fixed cameras, UAVs provide greater maneuverability and broader fields of view. According to relevant studies, aerial imagery has been widely applied across numerous domains1,2,3. For instance, aerial imagery can assist in accomplishing tasks in harsh environments, at high altitudes, or in hazardous conditions. In the event of natural or man-made disasters, UAV-captured images enable rescuers to rapidly assess the situation, guide rescue activities, and improve operational efficiency4,5. In the military field, aerial imagery can be employed for intelligence collection to support the formulation of optimal command strategies6,7. Additionally, UAV imagery has found applications in traffic monitoring, the detection of abnormal human activities, and agricultural data collection8. Beyond these, UAV-based aerial imaging also facilitates the automated acquisition and analysis of ground information, providing valuable data support for a wide range of industries and disciplines9,10. Consequently, UAV-based aerial object detection technology holds substantial research significance.
Object detection represents a crucial branch of computer vision and has been widely applied, particularly in the domain of UAV-based object detection. By employing object detection techniques, substantial human labor can be conserved. Since aerial images are captured from high altitudes, they typically contain a large number of small objects. However, several challenges persist, including complex backgrounds and severe object occlusions11,12. Moreover, aerial images are often acquired under varying weather and illumination conditions, which may cause significant variations in object appearance and lighting, thereby increasing the difficulty of detection. Small objects in particular are sparsely distributed within images and may be easily confused with the background, making them more difficult to distinguish and localize. Therefore, models capable of effectively handling the contrast and feature discrepancies between objects and complex backgrounds are essential to addressing these challenges13. The study and development of small-object detection algorithms contribute to advancing object detection technologies in complex scenarios. Furthermore, aerial imagery encompasses a diverse range of object categories, including vehicles, buildings, human activities, and natural environments, which requires detection models to demonstrate strong generalization ability and adaptability.This study proposes a lightweight detection algorithm that achieves significant performance improvements through multi-dimensional structural innovations. The proposed model is capable of accurately detecting small objects in complex scenarios, thereby achieving a favorable balance between detection accuracy and model size. Such enhanced detection capability not only improves recognition precision but also better meets the demands of diverse real-world applications. The main contributions of this work are as follows:
-
Innovative detection head design: An efficient detection head is proposed by introducing a lightweight feature enhancement module based on ShuffleNetV214. This design improves small-object detection accuracy while reducing computational complexity. By leveraging the channel-shuffling mechanism and lightweight depthwise separable convolutions (DWConv) of ShuffleNetV2, the approach enhances cross-channel feature interaction, thereby improving bounding box prediction precision with lower computational costs.
-
Integration of a small-object detection layer (P2): To improve the detection of small objects in UAV aerial imagery, an additional detection layer, P215, is incorporated into the YOLOv8 architecture. By reducing the number of downsampling operations and exploiting abundant low-level feature information, this layer effectively enhances the detection of small-scale objects.
-
Adoption of the EfficiCIoU loss function: The proposed model employs EfficiCIoU16, which integrates the advantages of CIOU and EIOU. By jointly considering overlap area, center-point distance, and aspect ratio, this loss function accelerates model convergence and improves localization accuracy.
-
Backbone enhancement with CMUNeXtBlock and adaptive attention: To address the limitations of YOLOv8 in small-object detection, the backbone is enhanced with CMUNeXtBlock17, which combines large-kernel depthwise convolutions with inverted residual structures. Furthermore, an Adaptive Attention (AA) module18 is fused at the output stage. This integration strengthens the model’s capability to perceive small objects and achieves superior detection accuracy.
Related work
In the field of deep learning, the development of object detection algorithms has shifted from traditional methods that rely on handcrafted feature extraction to deep learning approaches capable of automatically learning image representations. At present, deep learning-based object detection algorithms can be broadly categorized into two types: single-stage detectors and two-stage detectors. Single-stage detectors, such as the YOLO series19, are favored for their fast and efficient detection capabilities. They directly predict bounding boxes and class probabilities on the input image without generating region proposals, thereby significantly improving detection speed and efficiency. In contrast, two-stage detectors, such as Faster R-CNN20,21,22, utilize a region proposal network (RPN) to generate candidate regions, followed by classification and bounding box regression on these proposals. Although two-stage detectors generally achieve higher detection accuracy, they suffer from slower inference speed and higher computational cost, making them less suitable for real-time UAV-based object detection.
Although the YOLO series of algorithms was introduced relatively late in the field of object detection, it has rapidly become a research focus due to its simple architecture and efficient detection performance. By achieving a favorable balance between detection accuracy and speed, the YOLO series has become one of the key technologies for UAV-based aerial object detection. For example, Zhao et al.23 incorporated MobileNetV3 into YOLOv5, designed a depthwise separable information module, employed CARAFE for upsampling to enhance feature extraction capability, and adopted a dynamic head to achieve model lightweighting. However, these modifications led to a decline in mAP performance. Xu et al.24 developed the YOLOv5s-pp model, which integrates a channel attention (CA) module to mitigate interference from complex backgrounds and negative samples, thereby improving small-object detection performance in low-resolution images. Zhao et al.25 employed XIoU as the bounding box loss function and introduced the CoordAtt attention mechanism, enabling the model to better focus on critical feature information and thereby improving detection accuracy. Wang et al.26 integrated a small-target detection structure (STG) into the network to enhance the collection of semantic information for small objects and introduced a Global Attention Module (GAM) to fuse multi-dimensional feature information, resulting in improved detection performance. Zhong et al.27 proposed the SPD-YOLOv8 algorithm for small-object detection in complex scenarios. In this approach, traditional convolution and pooling layers were replaced with SPD-Conv modules, and the MPDIoU loss function was utilized to optimize bounding box regression, thus enhancing small-object detection accuracy. Cao et al.28 presented a lightweight GCL-YOLO network, which requires fewer parameters and lower computational complexity. By incorporating GhostConv modules, a novel prediction head, and the Focal-EIoU loss function, this method achieved accurate localization of densely distributed small objects. Zhang et al.29 extended YOLOv8 with the CBAM module and applied WIoU to improve adaptability to multi-scale object variations. However, this approach increased model parameters and reduced processing speed.
These deep learning models demonstrate relatively strong performance across various tasks and are capable of producing satisfactory results. Nevertheless, certain limitations remain. In relatively simple scenarios, the potential of these models is not fully exploited; when dealing with large numbers of objects, their effectiveness may be constrained. Such factors can diminish model robustness in practical applications, particularly in cases involving complex backgrounds or small objects, where performance may fall short of expectations. Therefore, further research and improvements are required to overcome these limitations.
Methods
YOLOv8 network architecture
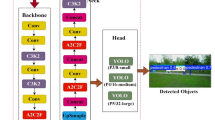
YOLOv8, released by Ultralytics on January 10, 2023, represents an improved version of the previous YOLO series of algorithms. The YOLOv8 architecture is composed of three main components: the backbone for feature extraction, the neck for feature fusion, and the head for generating detection results. As illustrated in Figure. 1, the backbone adopts the C2f structure, which provides richer feature representations compared to the C3 structure used in YOLOv5, with channel dimensions adjusted according to different model scales. The neck incorporates the E-ELAN module, first introduced in YOLOv7, to enhance feature fusion capability across different layers. The detection head consists of three standard convolutional detectors with a decoupled head design, enabling simultaneous detection, classification, and segmentation tasks. Depending on the model’s depth and width, YOLOv8 is available in five variants: YOLOv8n, YOLOv8s, YOLOv8m, YOLOv8l, and YOLOv8x. Among these, YOLOv8n has the smallest number of parameters and computational complexity but achieves the lowest accuracy, while YOLOv8x possesses the largest parameter count and computational cost, delivering the highest accuracy. Considering both model size and accuracy trade-offs, YOLOv8n is selected as the baseline model in this study.

YOLOv8 network structure.
LPAE-YOLOv8 network architecture
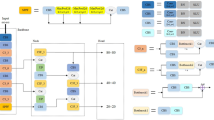
YOLOv8 builds upon the strengths of previous YOLO versions, incorporating their advantages to achieve higher object detection accuracy. Nevertheless, the detection accuracy of YOLOv8 still leaves room for improvement. To address this limitation, we propose a small-object detection model named LPAE-YOLOv8. The overall architecture of LPAE-YOLOv8 is illustrated in Fig. 2.

LPAE-YOLOv8 network structure.
Innovative detection head design LSE-Head (lightweight shuffle-enhanced head)
Considering the characteristics of the VisDrone2019 dataset, where small objects occupy a high proportion, backgrounds are complex, and targets are easily confused, this study introduces lightweight feature enhancement modules into both the regression and classification branches of the YOLOv8 detection head to improve small object detection accuracy while reducing computational complexity. In the original YOLOv8 detection head, the regression and classification branches consist of two standard convolutional layers followed by a 1 × 1 convolution. Although this structure possesses strong feature extraction capability, it suffers from insufficient feature interaction and parameter redundancy, which can result in imprecise bounding box localization and less distinctive classification features, espceially in small object detection scenarios.
In the regression branch (REG), this study adopts a ‘convolution + ShuffleNetV2 module’ structure to replace the original double-convolution stack. The ShuffleNetV2 module internally incorporates channel splitting, channel shuffle, and lightweight depthwise separable convolution (DWConv), which enhances cross-channel feature interaction while reducing computational cost. This enables the network to better capture the spatial and textural details of small objects and improves the accuracy of bounding box prediction. The input feature is first processed by a 3 × 3 convolution for preliminary feature extraction, followed by the ShuffleNetV2 module for channel-wise information fusion, and finally integrated through an additional convolution before being mapped to a 4×reg_max dimensional regression prediction via a 1 × 1 convolution.
In the classification branch (CLS), the first standard convolution is replaced by a depthwise separable convolution (DWConv) to reduce parameter count and computational cost while mitigating the smoothing effect on small object discriminative features. DWConv preserves spatial feature structures while minimizing redundant computations, making it suitable for fine-grained texture preservation in small object classification tasks. The output of the classification branch is mapped to nc-dimensional category predictions through a 1 × 1 convolution.
The two branches remain fully decoupled, and after separately extracting regression and classification features, they are concatenated along the channel dimension and fed into the Distribution Focal Loss (DFL) module for discrete distribution decoding to obtain the final bounding box coordinates and class probabilities. Through structural lightweight design and enhanced feature interaction, the proposed detection head achieves a balance between computational efficiency and detection accuracy, demonstrating superior performance on small-object-dense aerial datasets such as VisDrone2019.
As illustrated in Fig. 3, compared with the original YOLOv8 detection head, the proposed LSE-Head demonstrates several advantages: the channel shuffle mechanism of ShuffleNetV2 enhances feature fusion and improves small object localization accuracy; the incorporation of DWConv reduces parameter count and computational cost; and the branch-decoupled design combined with lightweight architecture enhances small object detection performance while maintaining inference speed.

Comparison of the YOLOv8Detect and LSE-Head structures.
Small object detection layer
The YOLOv8 detection model outputs predictions from three detection layers: P3, P4, and P5. The P3 detection layer has a feature map size of 80 × 80 and is responsible for detecting objects of 8 × 8 pixels or larger. The P4 layer has a feature map size of 40 × 40, suitable for objects of 16 × 16 pixels or larger. Finally, the P5 layer has a feature map size of 20 × 20, targeting objects of 32 × 32 pixels or larger. In aerial imagery, a substantial proportion of objects are small, and due to the deep sampling depth of YOLOv8, accurately detecting these small objects is challenging. Successive deep convolutions and multiple pooling operations lead to significant loss of critical feature information. This can result in the features of large objects overshadowing those of small objects, causing misdetections and missed detections. Consequently, the original three-scale feature maps are insufficient for effectively detecting small objects in UAV imagery.
To address this limitation, a P2 detection layer (feature map size: 160 × 160) was introduced to detect objects of 4 × 4 pixels or larger. In this design, the input image undergoes only two downsampling operations in the backbone before being directly fed into the small detection head, thereby preserving rich low-level feature information. Although the addition of this detection head increases the model’s computational complexity and inference time, it significantly enhances small object detection performance.
In the head section, the large-object detection head was removed and replaced with a micro detection head, as the large head is redundant for small objects with pixel dimensions less than 32. Compressing feature maps to 20 × 20 for primarily small-object detection would result in substantial loss of object feature information. Therefore, the large-object detection layer in YOLOv8 was eliminated, and an additional high-resolution P2 detection layer (160 × 160), rich in feature information, was introduced. Multi-scale feature fusion in the enhanced network improves the extraction of shallow semantic features, enabling the model to capture finer details and improving small object detection accuracy.In the improved LPAE-YOLOv8 detection head, only the P2, P3, and P4 layers are retained. This modification substantially reduces the number of model parameters, increases inference speed, and minimally affects detection accuracy in UAV-based small object detection tasks.
EfficiCIoU loss
In the optimization process of deep learning-based object detection models, the regression loss function plays a critical role in determining localization accuracy. Among various metrics, the Intersection over Union (IoU) is the most widely used criterion for measuring the similarity between predicted bounding boxes and ground truth boxes by selecting positive and negative samples. However, the IoU metric fails to provide meaningful gradients when the predicted and ground truth boxes do not overlap, which limits its effectiveness in bounding box regression.To address this limitation, several improvements have been proposed based on the original IoU loss. Notably, the Complete Intersection over Union (CIoU) loss has been developed to accelerate model convergence and improve regression performance.
CIoU is currently the most effective bounding box regression loss function, as it incorporates three critical geometric factors: overlapping area, center point distance, and aspect ratio. CIoU measures the overlapping area between the predicted bounding box and the ground truth box using IoU, Euclidean distance, corresponding aspect ratio, and angle. The principle of CIoU is illustrated by the following formulas (1), (2), and (3).
Here, \(R_{{CI{\text{o}}U}}\) denotes the penalty term corresponding to the distance between the center of the predicted bounding box and the ground truth bounding box. b represents the predicted bounding box, which is defined by four elements: the top-left xcoordinate, the top-left y coordinate, the width w, and the height h. \(b^{{gt}}\) corresponds to the ground truth bounding box, which is characterized by four elements: the top-left x coordinate, the top-left y coordinate, the width \(w^{{gt}}\), and the height \(h^{{gt}}\). \(\rho ^{2} \left( {b,b^{{gt}} } \right)\) denotes the Euclidean distance between the centers of the predicted and ground truth bounding boxes, i.e., the straight-line distance between the two centers in the plane. c refers to the diagonal length of the target bounding box. \(\alpha\) denotes the weighting parameter, while \(\nu\) is used to measure the similarity of the aspect ratios.
During regression, the width and height of the predicted box cannot increase or decrease simultaneously because \(\alpha \nu\) does not represent the true width-height difference along with its confidence. Therefore, once it converges to the linear ratio between the width and height of the predicted and ground truth boxes, it may sometimes prevent the model from effectively optimizing the similarity. The EIoU (Efficient Intersection over Union) loss function, based on the CIoU loss, decouples the aspect ratio influence factor \(\alpha \nu\) and calculates the width and height of the predicted and ground truth boxes, thereby addressing the limitations of the CIoU loss.
When there are extremely long edges, only the EIoU Loss exhibits slow calculation without early convergence. This study proposes a novel enhanced loss function, ECIOU (Enhanced Intersection over Union, EIoU), which can increase the adjustment of predicted bounding boxes and accelerate the bounding box regression rate. The combination of the two loss functions, CIOU and EIoU, serves as the foundation of ECIOU. Specifically, the aspect ratio of the predicted bounding box is first adjusted by CIOU until it converges to an appropriate range, and then each edge is finely adjusted by EIoU until it converges to the correct value. This loss function is termed EfficiCIoU Loss. The specific formula of EfficiCIoU Loss is presented as follows:
Here, \({\text{c}}_{{\text{w}}}\) denotes the height of the target bounding box, representing the distance along the vertical direction, which is typically measured in pixels. \({\text{c}}_{{\text{h}}}\) represents the width of the target bounding box, corresponding to the distance along the horizontal direction, also measured in pixels.\(\:\rho ^{{\text{2}}} {\text{(h,h}}^{{{\text{gt}}}} {\text{),}}\rho ^{{\text{2}}} {\text{(w,w}}^{{{\text{gt}}}} )\:\)are the square of the height difference and the square of the width difference between the predicted box and the ground truth box (i.e., \(\:{\text{|h}} - {\text{h}}^{{{\text{gt}}}} {\text{|}}^{{\text{2}}} {\text{,|w}} - {\text{w}}^{{{\text{gt}}}} {\text{|}}^{{\text{2}}}\)), which are used to directly constrain the size deviation in the height and width dimensions.
Improved module based on CMUNeXt block and adaptive attention (AA)
Although YOLOv8 demonstrates remarkable performance in object detection, it still exhibits certain limitations in scenarios involving small object detection, particularly under complex backgrounds and multi-scale conditions. YOLOv8 relies primarily on conventional convolutions within the backbone, where the receptive field is restricted, making it difficult to effectively capture long-range global contextual information. Moreover, during multiple downsampling operations, the feature information of small objects is gradually lost, leading to a noticeable decline in detection accuracy. In addition, YOLOv8 lacks an efficient attention mechanism tailored to the characteristics of small object detection, which prevents it from adaptively highlighting salient target regions.
To address these issues, this study introduces a CMUNeXtBlock—based on large-kernel depthwise convolution and inverted residual structures—into YOLOv8, while incorporating an Adaptive Attention (AA) module at the output stage, as illustrated in Fig. 4. The ACMConv effectively expands the receptive field while maintaining a lightweight structure, thereby enhancing the capacity to model global contextual information. Furthermore, the integration of the AA module during the channel reduction phase enables the network to adaptively learn the importance distribution across different channels, assigning higher weights to small-object regions. This design significantly strengthens the model’s capability to perceive small objects in complex and densely populated scenes. By effectively combining both components, the proposed approach improves small-object detection accuracy on small-scale datasets while retaining the lightweight advantage of the model.

ACMConv: innovative convolutional module architecture.
The CMUNeXtBlock serves as the fundamental structural unit of the CMUNeXt network. Its design philosophy is to enhance the global contextual modeling capability of the network through the use of large-kernel depthwise convolutions (Depthwise Conv) and an inverted bottleneck structure, while simultaneously maintaining model lightweight characteristics by reducing both the number of parameters and computational overhead. The implementation process consists of three main steps:
Depthwise separable convolution: In conventional convolution operations, convolution is simultaneously performed across both the spatial and channel dimensions, which leads to high computational cost. Depthwise separable convolution decomposes this process into two operations: depthwise convolution and pointwise convolution (1 × 1 convolution).
Depthwise convolution: Each input channel is convolved independently with a single kernel, avoiding inter-channel mixing. Within the CMUNeXtBlock, large-kernel depthwise convolutions (e.g., 7 × 7 or 9 × 9) are adopted to capture global contextual information, thereby improving the discriminability of small objects. This design significantly reduces both computational complexity and the number of parameters.
Pointwise convolution (1 × 1): A 1 × 1 convolution is employed to linearly combine information across the channel dimension, thereby enabling inter-channel feature interaction.
Inverted bottleneck structure: The core concept of the inverted bottleneck is the opposite of the conventional bottleneck design. Instead of first compressing the number of channels and then expanding them, the structure initially expands the channel dimension to four times its original size via a 1 × 1 convolution to enhance feature representation capacity. This is followed by a large-kernel depthwise convolution to perform spatial feature modeling. Finally, another 1 × 1 convolution is applied to restore the channel dimension to its original size, thereby achieving lightweight design while preserving rich contextual information. In addition, the incorporation of residual connections effectively mitigates the loss of small-object features during multi-layer propagation, enhancing the model’s ability to represent small targets, while maintaining a low computational overhead.
Here, \(J_{{l - 1}}\) denotes the input feature map of the \(l - 1\) layer, while \(\sigma\) represents the GELU activation function.
BN refers to batch normalization, and DepthwiseConv and PointwiseConv correspond to depthwise convolution and pointwise convolution, respectively.
In the CMUNeXtBlock module, the adaptive attention (AA) mechanism is introduced to the output feature map \(J_{l}\) and multiplied with it element-wise, thereby enhancing the representation of critical features. The AA module is a lightweight channel-wise attention mechanism, whose core concept is to enable the network to automatically focus on feature channels associated with small objects while suppressing irrelevant or redundant channel features, thus improving the model’s responsiveness to small object detection.
The input feature map \(J_{l}\) is first processed through a 1 × 1 convolution layer, which captures inter-channel relationships without altering the spatial dimensions. The mathematical formulation is expressed as follows:
Here, A denotes the feature map obtained after convolution. The attention feature map is normalized to the range [0, 1] using the Sigmoid activation function, resulting in the normalized attention map\(\:\widehat{\text{A}}\):
Here, \(\sigma\) denotes the Sigmoid function.
The normalized attention map is multiplied element-wise with the original input feature map \(J_{l}\), resulting in the weighted feature map Y:
Here, ⊙ denotes the element-wise multiplication operation.
Experimental design and result analysis
Datasets
To verify the effectiveness and generalization ability of the proposed model, two datasets were used. Both datasets consist of aerial images captured by drones or remote sensing, containing a large number of small objects caused by factors such as distance and altitude: the VisDrone 2019 dataset30 (developed by the AISKYEYE team of Tianjin University, official access link: https://github.com/VisDrone) and the TinyPerson dataset31 (released by the University of Chinese Academy of Sciences in 2019, official access link: https://github.com/TinyPerson). Typical samples are shown in Figs. 5 and 6, respectively. Among them, VisDrone 2019 includes 10,209 aerial images and 288 video clips, covering 10 target categories, and is divided into a training set (6471 samples), a validation set (548 samples), and a test set (1610 samples) according to the challenge division; TinyPerson contains 1610 annotated images (794 for training and 816 for validation), focusing on the detection of tiny individuals smaller than 20 pixels, with a total of 72,651 annotated instances.

Example images from the VisDrone2019 dataset.

Example images from the TinyPerson dataset.
Experimental environment
To achieve a balance between accuracy and real-time performance, the sample images in the datasets were resized to 640 × 640 pixels. All experiments were conducted under the same software and hardware environment. On the software side, Ubuntu 22.04 served as the operating system, with Python 3.10, PyTorch 2.1.2, and CUDA 11.8 utilized for desktop computing. The hardware employed for these experiments included an RTX 4090D GPU.Training was performed for 100 epochs using the stochastic gradient descent (SGD) optimization algorithm, with the initial learning rate set to 0.01 and gradually decayed to a final learning rate of 0.0001. To maintain the integrity and authenticity of model performance, each model was trained from scratch without the use of pre-trained weights to ensure a fair comparison.YOLOv8n was adopted as the baseline model. Its architecture follows the same principles as all models in the YOLOv8 series, with the only difference being the network width and depth. The specific experimental environment and parameter settings are summarized in Table 1.
Evaluation metrics
The proposed model was evaluated in terms of both detection performance and model size. Precision (P), recall (R), average precision (AP), and mean average precision (mAP) were employed to assess the accuracy across all object categories. Additionally, the network’s computational complexity was evaluated using the metric of giga floating-point operations per second (GFLOPs). Model size was determined by the total number of parameters.
-
(1)
Precision (P) represents the accuracy of the detected objects and reflects the effectiveness of the algorithm. It is calculated as follows:
TP denotes the number of true positive instances that are correctly identified as belonging to the positive class. FP denotes the number of false positive instances that are incorrectly identified as the positive class.
-
(2)
Recall (R) represents the proportion of correctly detected positive objects, i.e., the probability of predicting positive samples. FN denotes the number of positive instances that were not detected. It is calculated as follows:
-
(3)
Average Precision (AP) is used to measure the performance of the model for a single class. It corresponds to the area under the Precision-Recall curve. The calculation is expressed as follows :
Mean Average Precision (mAP) is a commonly used evaluation metric in object detection, which combines precision and recall across different categories. Specifically, for each category, the area under the Precision-Recall curve (AP, Average Precision) is first calculated, and then the mean of AP values across all categories is computed to obtain mAP. The calculation is expressed as follows (Eq. 14):
-
(4)
Parameters denote the total number of learnable parameters in the network.
-
(5)
GFLOPs represent the number of floating-point operations, expressed in giga operations.
Experimental results and analysis
Backbone network comparison
To evaluate the impact of inserting the ACMConv module at different positions within the backbone on model performance, detection results for various insertion configurations are presented in Table 2. In the YOLOv8-A variant, the ACMConv modules were inserted at layers 3, 5, and 7, resulting in an improvement of 3.9% in mAP@0.5 and 3.4% in mAP@0.5:0.95, with a total parameter count of 3.19 × 106.For YOLOv8-B, the original convolutions at layers 1, 3, and 5 were replaced with ACMConv modules, yielding increases of 6.2% in mAP@0.5 and 7.3% in mAP@0.5:0.95. YOLOv8-C incorporated ACMConv modules at layers 0, 1, and 3. Compared with the baseline model, YOLOv8-C achieved improvements of 7.2% in mAP@0.5 and 8.5% in mAP@0.5:0.95, while maintaining the lowest parameter count among the three variants.Based on the comparative results, the YOLOv8-C configuration, which demonstrated the best overall performance, was selected for subsequent experiments.
To further enhance the performance of the ACMConv module, four attention mechanisms—AA (Adaptive Attention), GC (Global Context Attention), SA (Spatial Attention), and CA (Channel Attention)—were selected for comparative experiments. As shown in the results presented in Table 3, the performance improvements in terms of mAP@0.5 and mAP@0.5:0.95 achieved by CA, SA, and GC were all inferior to those obtained using AA.
Comparison of loss functions
In this section, several commonly used loss functions—Inner-IoU, XIoU, MPDIoU, and EfficiCIoU—were compared to evaluate their impact on the algorithm. The experimental results are summarized in Table 4. Compared with the baseline model, the EfficiCIoU loss function demonstrated superior performance in terms of mAP@0.5, precision (P), and recall (R). Moreover, EfficiCIoU achieved a better balance between precision and recall. Overall, EfficiCIoU outperformed the other loss functions, enhancing model performance and demonstrating greater practical applicability.
Ablation study
To verify the effectiveness of the improvements incorporated in the LPAE-YOLOv8 network, an ablation study was conducted based on the YOLOv8n model, with modifications added sequentially. The enhancements—P2, LSE-Head, ACMConv (AA), and EfficiCIoU—were introduced in order and labeled as A, B, C, and D, respectively. The results are summarized in Table 5, where a checkmark (√) indicates that the corresponding module has been added.To more intuitively present the improvement effects of each module on Precision (P) and Recall (R), Fig. 7, Comparison of Precision and Recall of Models under Different Module Combinations, is plotted.

Comparison of precision and recall of models under different module combinations.
In Experiment A (P2), by removing the 20 × 20 detection layer and adding a new detection layer to detect 160 × 160 small objects, all indicators show improvement. mAP@0.5 and mAP@0.5:0.95 increase by 12.7% and 15.8% respectively. In Experiment B (LSE-Head), through innovative detection head design, compared with the baseline model, the recall rate increases by 3.6%. This indicates that replacing the original detection head with LSE-Head can not only greatly reduce the number of GFLOPs and parameters, but also improve the accuracy. When adding module C (ACMConv(AA)), the model precision (P) increases by 5.5%, and mAP@0.5 increases by 9.4%. In Experiment D (EfficiCIoU), by replacing the original CIoU, the number of model parameters and calculation amount remain unchanged, but the precision increases by 1.7%, which reflects the ability of EfficiCIoU to locate small targets more accurately. When multiple modules work together, although the FPS decreases, the effects on precision (P), recall rate (R), mAP@0.5 and mAP@0.5:0.95 are more significant, increasing by 8.5%, 17.3%, 16.9% and 20.3% respectively. The number of parameters and the size of the weight file decrease by 34.5% and 22.6% respectively. Compared with the baseline, the model achieves a better balance between precision and computational efficiency, proving the lightweight and effectiveness of the LPAE-YOLOv8 network model.
Figure 8 illustrates the precision, recall, mAP@0.5, and mAP@0.95 curves for the YOLOv8n model after incorporating each improvement module (P2, LSE-Head, ACMConv with AA, and EfficiCIoU) and compares them systematically with the baseline YOLOv8n model. It can be observed that all four improvement modules outperform the baseline across different metrics, effectively enhancing the model’s detection precision, recall, and other key performance indicators.

Visualization comparison of precision, recall, mAP@0.5, and mAP@0.95 for the four improvement modules.
Figures 9 and 10 present the Precision-Recall curves for different object categories, comparing the YOLOv8 and YOLOv8 + LSE-Head models. It can be observed that after incorporating the innovative LSE-Head detection head, the model exhibits higher precision across most categories, particularly in regions of lower recall. For instance, at a recall of 0.3, the precision of the LSE-Head-enhanced model is noticeably higher than that of the original YOLOv8 detection head. Moreover, as recall increases, the precision of the model decreases at a slower rate, indicating improved stability in high-recall predictions. These results demonstrate that LSE-Head contributes to enhanced performance in object detection tasks.

Precision-Recall (PR) curves of the original YOLOv8 detection head.

Precision-Recall (PR) curves of the YOLOv8 model with the LSE-Head detection head.
To more intuitively demonstrate the superiority of LPAE-YOLOv8, the evaluation metrics of the baseline model were compared with those of LPAE-YOLOv8. The comparison results are presented in Fig. 11. It can be clearly observed that LPAE-YOLOv8 outperforms YOLOv8 across all evaluation metrics, exhibiting superior overall performance.

Visualization comparison of precision, recall, mAP@0.5, and mAP@0.95 between the original and improved algorithms.
Comparison with other models
To validate the effectiveness of the proposed algorithm, comparative experiments were conducted on the VisDrone 2019 dataset against several mainstream object detection algorithms. The comparison included classical one-stage YOLO series, the two-stage detection algorithm Faster R-CNN, as well as other widely used detection methods. The experimental results are presented in Table 6. The results indicate that the proposed improved algorithm outperforms existing popular state-of-the-art (SOTA) models in terms of detection accuracy.
Through comparison, it can be observed that the proposed LPAE-YOLOv8 object detection algorithm outperforms other detection algorithms across various evaluation metrics. Specifically, compared with YOLOv3, YOLOv5, YOLOv6, and YOLOv10, the proposed algorithm achieves improvements of 60.5%, 21.3%, 29.7%, and 21.8% in mAP@0.5, respectively. These results demonstrate that the proposed algorithm can detect and recognize small objects in UAV aerial images more accurately, exhibiting significant advantages.
To further validate the generalization capability of the proposed model, comparative experiments were also conducted on the TinyPerson dataset against the original model and other detection algorithms. The experimental results are presented in Table 7. On the TinyPerson dataset, our model achieved an mAP@0.5 of 18.7%, compared with 14.4% for YOLOv8n. In addition, in terms of precision (P) and recall (R), the LPAE-YOLOv8n model also outperforms the original YOLOv8 model. Compared with other YOLO variants, our model shows a clear advantage in mAP, further demonstrating its effectiveness in small object detection.
Visualization of detection results
To demonstrate the detection performance of LPAE-YOLOv8, this study presents confusion matrices for both LPAE-YOLOv8 and the baseline model. In the confusion matrices, the rows represent the predicted classes, while the columns correspond to the ground-truth classes. Values along the diagonal indicate correctly predicted instances, whereas off-diagonal values represent misclassifications. Observations from the confusion matrices in Figs. 12 and 13 indicate that, compared with the YOLOv8n model, the last row in the LPAE-YOLOv8 confusion matrix exhibits lighter shading, suggesting a reduction in instances misclassified as background. A comparison of the diagonal values further demonstrates that LPAE-YOLOv8 achieves significantly better detection performance across all classes compared with YOLOv8.

Confusion matrix of the YOLOv8 model.

Confusion matrix of the LPAE-YOLOv8 model.
To visually illustrate detection performance, four UAV-acquired images with different complex backgrounds were selected, as shown in Fig. 14. Comparative analysis clearly indicates that the proposed model not only exhibits significantly fewer false positives and false negatives but also achieves higher recognition accuracy. The detection results in the figure demonstrate that the improved LPAE-YOLOv8 model performs markedly better in handling these complex scenarios. Compared with the baseline model, the enhanced model is capable of detecting smaller and more distant objects, substantially reducing false positives and false negatives for occluded and densely packed small targets, thereby effectively improving detection accuracy and reliability. This comparison highlights that the improved model can more effectively capture fine-grained details of small objects while managing complex backgrounds.

Visualization of detection results: (a) Original images, (b) Detection results of YOLOv8n, and (c) Detection results of LPAE-YOLOv8n.
Conclusions
In this study, we proposed the LPAE-YOLOv8 model to address the challenges of small object detection in UAV-captured images. By integrating multiple technical innovations, the model significantly optimizes the original YOLOv8 framework, enhancing both detection accuracy and computational efficiency. Experimental results on the VisDrone2019 and TinyPerson datasets demonstrate that LPAE-YOLOv8 achieves higher detection performance across all scales compared to YOLOv8, while maintaining a reduced number of parameters. Moreover, the model’s parameter count at each scale is lower than that of the baseline network. Compared with other mainstream detection algorithms, LPAE-YOLOv8 exhibits notable improvements in key metrics such as mean Average Precision (mAP), precision, and recall, while simultaneously reducing parameter quantity and computational complexity, thereby demonstrating both lightweight design and effectiveness. Despite these improvements, detection performance under highly complex backgrounds or extensive occlusions remains a limitation. Future research may focus on further optimizing the network architecture to enhance robustness, exploring multimodal data fusion to improve detection performance, and investigating more advanced attention mechanisms and loss functions to accelerate convergence and improve stability.
Data availability
The VisDrone2019 dataset used in this study is publicly available in the VisDrone-Dataset repository on GitHub (https://github.com/VisDrone/VisDrone-Dataset). This dataset comprises abundant image data captured by diverse unmanned aerial vehicle (UAV) platforms, encompassing images of various cities, environmental scenarios, and target objects. It is applicable to multiple computer vision tasks, particularly UAV-based object detection. The TinyPerson dataset employed in the experiments can be accessed via its official GitHub repository (https://github.com/TinyPerson). All data supporting the findings of this study are openly available in these public repositories, ensuring reproducibility of the research.
References
Lau, W. J., Lim, J. M., Chong, C. Y., Ho, N. S. & Ooi, T. W. M. General outage probability model for UAV-to-UAV links in multiuav networks. Comput. Netw. 229, 109752. https://doi.org/10.1016/j.comnet.2023.109752 (2023).
Rudys, S. et al. Hostile UAV detection and neutralization using a UAV system. Drones 6, 250. https://doi.org/10.3390/drones6090250 (2022).
Liao, Y. H., Juang, J. G. & Real-Time, U. A. V. Trash monitoring system. Appl. Sci. 12, 1838. https://doi.org/10.3390/app12041838 (2022).
Alladi, T., Naren, Bansal, G., Vinay, C. & Mohsen, G. SecAuthUAV: A novel authentication scheme for UAV-Ground station and UAV-UAV communication. IEEE Trans. Veh. Technol. 69, 15068–15077. https://doi.org/10.1109/TVT.2020.3033060 (2020).
Hadiwardoyo, S. A. et al. Three dimensional UAV positioning for dynamic UAV-to-Car communications. Sensors 20, 356. https://doi.org/10.3390/s20020356 (2020).
Kim, K. et al. UAV chasing based on YOLOv3 and object tracker for counter UAV system. IEEE Access. 11, 34659–34673. https://doi.org/10.1109/ACCESS.2023.3264603 (2023).
Ye, J., Zhang, C., Lei, H. J., Pan, G. F. & Ding, Z. G. Secure UAV-to-UAV systems with spatially random UAVs. IEEE Wirel. Commun. Le. 8, 564–567. https://doi.org/10.1109/LWC.2018.2879842 (2018).
Li, F., Luo, J., Qiao, Y. & Li, Y. Joint UAV deployment and task offloading scheme for Multi-UAV-Assisted edge computing. Drones 7 (284). https://doi.org/10.3390/drones7050284 (2023).
Ye, Z., Hu, H., Li, F. Y. & Huang, K. Z. Disentangling semantic-to-visual confusion for zero-shot learning. IEEE Trans. Multimed. 24, 2828–2840. https://doi.org/10.1109/TMM.2021.3089017 (2021).
Ye, Z. H. et al. SR-GAN: semantic rectifying generative adversarial network for zero-shot learning. IEEE ICME. 85–90. https://doi.org/10.1109/ICME.2019.00023 (2019).
Liao, L. et al. Eagle-YOLO: an eagle-inspired YOLO for object detection in unmanned aerial vehicles scenarios. Mathematics 11, 2093. https://doi.org/10.3390/math11092093 (2023).
Li, J., Ye, D. H., Kolsch, M., Wachs, J. P. & Bouman, C. A. Fast and robust UAV to UAV detection and tracking from video. IEEE Trans. Emerg. Top. Commun. 10, 1519–1531. https://doi.org/10.1109/TETC.2021.3104555 (2021).
Ye, Z. H., Yang, G. Y., Jin, X. B., Liu, Y. F. & Huang, K. Z. Rebalanced zero-shot learning. IEEE Trans. Image Process. https://doi.org/10.1109/TIP.2023.3295738 (2023).
Zhang, X. et al. ShuffleNet: an extremely efficient convolutional neural network for mobile devices. In 2018 IEEE/CVF Conference on Computer Vision and (CVPR). https://doi.org/10.1109/CVPR.2018.00716 (IEEE, 2018).
Qin, J., Yu, W., Feng, X., Meng, Z. & Tan, C. A UAV aerial image target detection algorithm based on YOLOv7 improved model. Electronics 13, 3277. https://doi.org/10.3390/electronics13163277 (2024).
Shen, Q. Research on fault diagnosis method of wind turbine blades based on improved YOLO algorithm. Master’s Thesis, Shenyang Institute of Engineering, Shenyang, China. https://doi.org/10.27845/d.cnki.gsygc.2023.000077 (2023).
Tang, F. et al. Cmunext: An efficient medical image segmentation network based on large kernel and skip fusion. In 2024 IEEE International Symposium on Biomedical Imaging (ISBI), 1–5. https://doi.org/10.48550/arXiv.2308.01239 (IEEE, 2024).
Luo, J. & Hu, D. An image classification method based on adaptive attention mechanism and feature extraction network. Comput. Intell. Neurosci. 2023, 4305594. https://doi.org/10.1155/2023/4305594 (2023).
Redmon, J., Divvala, S., Girshick, R., Farhadi, A. & Recognition, P. IEEE Conference on Computer Vision and You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the (CVPR), Seattle, WA, USA, 27–30 June 2016, 779–788. https://doi.org/10.48550/arXiv.1506.02640 (IEEE, 2016).
Girshick, R. et al. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 580–587. https://doi.org/10.1109/CVPR.2014.81.
Ren, S., He, K., Girshick, R., Sun, J. & Faster, R-C-N-N. Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 39, 1137–1149. https://doi.org/10.1109/TPAMI.2016.2577031 (2017).
Girshick, R. & Fast, R-C-N-N. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13, 1440–1448. https://doi.org/10.1109/ICCV.2015.169 (2015).
Zhao, X. & Song, Y. Improved ship detection with YOLOv8 enhanced with mobilevit and GSConv. Electronics 12, 4666. https://doi.org/10.3390/electronics12224666 (2023).
Xu, H., Zheng, W., Liu, F., Li, P. & Wang, R. Unmanned aerial vehicle perspective small target recognition algorithm based on improved YOLOv5. Remote Sens. 15, 3583. https://doi.org/10.3390/rs15143583 (2023).
Zhao, X. et al. ITD-YOLOv8: an infrared target detection model based on YOLOv8 for unmanned aerial vehicles[J]. Drones 8 (4), 161. https://doi.org/10.3390/drones8040161 (2024).
Wang, F. et al. UAV target detection algorithm based on improved YOLOv8. IEEE Access. https://doi.org/10.1109/ACCESS.2023.3325677 (2023).
Zhong, R. et al. SPD-YOLOv8: an small-size object detection model of UAV imagery in complex scene. J. Supercomput. 80 (12), 17021–17041. https://doi.org/10.1007/s11227-024-06121-w (2024).
Cao, J., Bao, W., Shang, H., Yuan, M. & Cheng, Q. GCL-YOLO: a GhostConv-based lightweight YOLO network for uav small object detection. Remote Sens. 15 (20), 4932. https://doi.org/10.3390/rs15204932 (2023).
Zhang, W., Li, Y. & Liu, A. RCDAM-Net: A foreign object detection algorithm for transmission tower lines based on RevCol network. Appl. Sci. 14, 1152. https://doi.org/10.3390/app14031152 (2024).
Du, D., Zhu, P. & Wen, L. Visdrone-sot2019: the vision meets drone single object tracking challenge results. In 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), 199–212. https://doi.org/10.1109/ICCVW.2019.00029 (2019).
Yu, X., Gong, Y., Jiang, N., Ye, Q. & Han Z. Scale match for tiny person detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 1257–1265. https://doi.org/10.48550/arXiv.1912.10664 (2020).
Sun, J. et al. Optimized YOLOv8 algorithm for UAV aerial view object detection. Comput. Eng. Appl. 61, 109–120 (2025).
Funding
This study was funded by the Capable Craftsman Technology & Guizhou Normal University Joint Project on AI Technology Innovation R&D Center (No: 2024053).
Author information
Authors and Affiliations
Contributions
Conceptualization, Y.Z. and G.C.; methodology, Y.Z.; software, Y.Z.; validation, Y.Z.; formal analysis, Y.Z. and G.C.; investigation, Y.Z.; resources, Y.Z. and G.C.; data curation, Y.Z. ; writing—original draft preparation, Y.Z.; writing—review and editing, Y.Z. , G.C. ; visualization, Y.Z.; supervision, Y.Z. and G.C.; project administration Y.Z and G.C.; funding acquisition, G.C. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhao, Y., Chen, G. LPAE-YOLOv8: lightweight aerial small object detection via LSE-Head and adaptive attention. Sci Rep 15, 44780 (2025). https://doi.org/10.1038/s41598-025-28741-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-28741-9
