
Abstract
In this study, we model a solution surface using an ensemble machine learning approach to simultaneously predict and optimise rock fragmentation and ground vibration during blasting operations at the Jwaneng Diamond Mine in Botswana. Using 120 production blasts and ten input parameters, we trained several models: ANN, RF, ANN–RF and other hybrid baselines PSO–ANN, PSO–ELM, ANN–SVR, PSO–XGBoost and GA–ANN . The ANN-RF ensemble achieved the best test performance (R2 = 0.956, RMSE = 0.315, MAE = 0.250, and VAF = 95.5 for fragmentation; R2 = 0.930, RMSE = 0.380, MAE = 0.302, VAF = 92.5 for PPV). Tree-SHAP analysis identified powder factor and burden as dominant fragmentation drivers, and burden, charge per delay, and distance as key vibration controls. A projected gradient-descent search on the learned solution surface produced feasible blast settings that increase fragmentation toward approximately 84% while reducing PPV to nearly 0.12 mm/s. This approach allows blasting engineers to interactively vary input parameters within defined constraints to obtain optimal environmental and operational outcomes. The input parameters include spacing, charge per delay, burden, stemming length, powder factor, hole depth, hole diameter, rock factor, distance from the blast point to the monitoring point and blastability index, offering a comprehensive AI-driven framework for precision blast design in open-pit mining.
Similar content being viewed by others
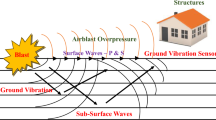
Introduction
The prevalent method employed in mining, quarrying, and civil engineering projects to break down rocks is blasting. Only around 20–30% of the energy produced is utilised for the desired rock fragmentation, while the remaining energy is wasted on ground vibration, airblast, noise, flyrock, and backbreak1,2,3,4,5,6. The severity of these undesirable effects results in human discomfort, endangers human safety, and destroys nearby structures and equipment within the blast zone7,8,9. Achieving an appropriate rock size is advantageous for reducing costs associated with loading, hauling, crushing, and grinding operations10,11,12,13,14. Consequently, accurate forecasting of rock fragmentation and ground vibration plays a vital role in the mining industry. This enables the optimisation of the particle size distribution of the blasted rock and minimises the environmental impact caused by ground vibration.
Blast fragmentation measurements can be grouped into three broad categories: (i) laboratory sieving, which is the accuracy benchmark on representative samples but is labour-intensive and prone to sampling bias at production scale; (ii) 2D/3D image based methods (e.g., Split Desktop and stereo photogrammetry), which require metric scale calibration and careful segmentation and may undercount oversize fragments in occluded muckpiles; and (iii) active 3D scanning (laser), which captures point clouds over full muckpiles or benches, mitigating occlusion but imposing line-of-sight requirements and higher cost. In routine operations, image analysis is often preferred for coverage and speed, with periodic validation against sieving. Strain waves from a blast propagating as elastic waves at ground level are known as ground vibrations. Ground vibration is evaluated based on its frequency, acceleration, displacement, and peak particle velocity (PPV)15.
Blast impacts are typically influenced by two factors: controllable and uncontrollable parameters. Controllable parameters can be adjusted, such as blast design and explosive parameters. On the other hand, uncontrollable parameters cannot be modified, such as the geological and geotechnical properties of the rock16,17,18. Researchers have developed various empirical methods to estimate rock fragmentation and ground vibration19,20,21,22,23,24. These models, however, face limitations due to their inability to incorporate the effects of additional parameters comprehensively. Typically, empirical methods rely on a limited set of input variables and produce a single output, resulting in reduced accuracy. This approach makes it challenging to simultaneously consider all the relevant parameters, especially given the complex and non-linear interrelationships among them.
Classical vibration and fragmentation models aggregate physics into a few site constants, so they struggle with interaction effects and contextual variables: timing, explosive energy density, confinement (burden,spacing,stemming interplay), geology (RQD, joint spacing/orientation, weathering, moisture), bench geometry and face condition, and source-receiver path (near-field vs. far-field, attenuation and impedance contrasts). Many of these have clear physical meanings for example, higher powder factor increases specific energy up to an optimum before energy is wasted as fines; larger burden increases confinement but can damp energy release into the face; charge per delay and inter-hole timing shape wave superposition and PPV.
As a result, various artificial intelligence methodologies have been adopted in numerous engineering studies, including blasting, to address the shortcomings associated with traditional empirical approaches25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45. Zhou et al.46 estimated the particle size distribution resulting from blasting operations by analysing 88 blasting datasets from two quarries located in Iran. They utilised several computational techniques, namely an adaptive neuro-fuzzy inference system (ANFIS) optimised with the firefly algorithm (FFA), genetic algorithm (GA), support vector regression (SVR), and artificial neural network (ANN). Among these models, the ANFIS-GA demonstrated superior predictive capabilities, achieving the highest coefficient of determination (\(R^2\)) value of 0.989 and the lowest root mean square error (RMSE) value of 0.974. Furthermore, Fang et al.47 proposed an approach for predicting rock fragmentation outcomes by combining the boosted generalised additive model (BGAM) with the firefly algorithm (FFA). This integrated FFA-BGAM framework was benchmarked against other soft computing approaches, including FFA-ANN, FFA-ANFIS, support vector machine (SVM), Gaussian process regression (GPR), and k-nearest neighbors (k-NN). The comparative analysis indicated that the FFA-BGAM method provided superior performance in forecasting rock fragmentation compared to the alternative models.
Huang et al48 predicted rock fragmentation using auto-tuning model, called cat swarm optimisation (CSO) and particle swarm optimisation (PSO) algorithm. The input parameters considered for the study were spacing, burden, stemming, maximum charge per delay, rock mass rating, and specific charge. The CSO algorithm outperformed the PSO algorithm in estimating rock fragmentation with a RMSE of 0.847. Sensitivity analysis from the same study revealed that stemming had the most influence on fragmentation.
Amiri et al49 introduced an integrated approach combining artificial neural network (ANN) and k-nearest neighbours (k-NN) algorithms for the simultaneous prediction of blast-induced ground vibrations and air overpressure. They evaluated the performance of this combined ANN-kNN framework against an individual ANN model and two conventional empirical formulas established by the United States Bureau of Mines (USBM). Their findings revealed that the proposed ANN-kNN hybrid model delivered enhanced predictive accuracy for both ground vibration and airblast, outperforming the other tested approaches. Zhou et al50 employed Bayesian network (BN) and random forest (RF) methodologies to estimate ground vibrations induced by blasting, utilising data from 102 blasting operations. To enhance predictive accuracy by reducing the dataset dimensionality, a feature selection (FS) method was implemented, initially comprising eleven parameters. Subsequently, the FS approach identified five critical parameters, power factor, hole depth, maximum charge per delay, stemming, and distance from the blast face, as essential for accurate ground vibration predictions. Comparative analysis indicated that the RF model exhibited greater precision in forecasting ground vibrations than the BN model.
Yang et al51 employed an adaptive neuro-fuzzy inference system (ANFIS) optimised by genetic algorithm (GA) and particle swarm optimisation (PSO) for predicting ground vibration. Their findings indicated that the ANFIS-GA variant achieved superior predictive performance, resulting in a significant 61% reduction in root mean square error (RMSE) and a 10% improvement in the coefficient of determination (\(R^2\)), compared to the conventional ANFIS approach.
Chandrahas et al.52 simultaneously predicted rock fragmentation and blast-induced ground vibrations utilising a dataset comprising 152 blast instances from Opencast mine I located at Ramagundam III Area of Singareni Collieries Company Limited, Telangana, India. They implemented several machine learning algorithms, including extreme gradient boosting (XGBoost), k-nearest neighbors (k-NN), and random forest (RF). Their study indicated that XGBoost outperformed the other models, demonstrating optimal values of mean absolute percentage error (MAPE) (22.5), RMSE (3.873), and \(R^2\) (0.9125) for fragmentation prediction, as well as MAPE (18.4), RMSE (2.8890), and \(R^2\) (0.9125) for ground vibration estimation. The inputs they analysed included spacing to burden ratio, maximum charge per delay, total explosive quantity, firing pattern, and joint angle degree. Taken together, the above studies indicate that modern data-driven methods (ANNs, tree ensembles, neuro-fuzzy systems and their evolutionary hybrids) can provide accurate site-specific prediction of either blast-induced fragmentation or ground vibration when they are calibrated on historical data. However, three important shortcomings remain clear from the literature. First, most existing work treats each impact in isolation and develops separate single-output models for fragmentation or PPV, so the coupled behaviour of these responses under a given blast design is not captured explicitly. Second, many models rely on a restricted subset of inputs (often only design or only path variables) and do not simultaneously incorporate explosive design, geometric and rock-mass indices, which limits their ability to generalise across operating conditions. Third, only a few studies link prediction to explicit optimisation, and these typically focus on tuning one response at a time rather than providing a multi-objective tool that can support trade-offs between improved fragmentation and controlled vibration. Even the simultaneous study by Chandrahas et al52, focuses on predictive accuracy for the two targets and does not provide a unified optimisation framework or systematic sensitivity analysis. In view of these gaps, our objective is to develop and interpret a simultaneous, multi-output modelling and optimisation framework for blast-induced fragmentation and ground vibration at Jwaneng Diamond Mine. To the best of our knowledge, Chandrahas et al52 is the only researcher who has made a simultaneous prediction of rock fragmentation and ground vibration. This work is closely compared with his, as it also considers the simultaneous prediction of blast-induced rock fragmentation and ground vibration. Therefore the main contributions of this paper are the following:
-
The research gathered a dataset comprising 120 blasting events, sourced from the blast records of the Jwaneng Diamond Mine in Botswana.
-
This work takes into account ten input variables, which include parameters related to blast design, explosive properties, and rock mass characteristics.
-
Several machine learning models are proposed for the simultaneous prediction of blast-induced rock fragmentation and ground vibration. These models are ANN, RF, ANN–RF and the hybrid baselines PSO–ANN, PSO–ELM, ANN–SVR, PSO–XGBoost and GA–ANN.
-
Feature importance analysis is performed using the Tree SHAP method and the results are confirmed from the created solution space.
-
Optimisation of input parameters to maximise fragmentation and minimise ground vibration is conducted using the gradient descent method from the created solution surface. The solution surface can be used for prediction, optimisation and finding the inverse solution by setting the desired value of fragmentation and ground vibration and searching in the solution space for the values of the corresponding input parameters.
Materials and methods
This section explores the materials and methodologies employed in this study, focusing on the datasets collected from the Jwaneng Diamond Mine, the machine learning techniques applied, the feature importance analysis conducted, and the optimisation processes implemented.
Materials
A compilation of 120 blast datasets sourced from the mining records in Jwaneng has been used to train and test the models proposed in this research. Figure 1 shows data collected from fragmentation images and seismographs. For each blast, multiple muckpile images were acquired with a camera from a safe stand-off distance at oblique angles to reduce overlap and occlusion. A rigid scale object was placed in-scene for metric calibration, and images with severe occlusion, glare, motion blur, or deep shadows were excluded. Processing in Split-Desktop comprised: (i) metric scale calibration using the in-scene target; (ii) semi-automatic edge-based segmentation with limited manual edits to correct merge/split errors; (iii) oversize correction by boulder add-back (counting fragments above a top-size threshold and appending them to the coarse tail of the PSD); and (iv) export of characteristic sizes (P\(_{20}\), P\(_{50}\), P\(_{80}\)). Quality assurance/quality control (QA/QC) involved periodic spot-checks of image-based PSDs against sieve analyses of grab/bucket samples, with acceptance tolerances of \(\pm 10\%\) relative difference for P\(_{80}\) and P\(_{50}\) and \(\pm 25\%\) for P\(_{20}\); datasets exceeding these thresholds were reprocessed (verifying scale placement and segmentation parameters) or re-acquired. Split-Desktop was then used to generate the particle size distribution (PSD) curve from the camera images (see Fig. 1a). The \(P_{80}\) is the primary KPI due to its link to crusher throughput and downstream performance.
Ground vibration was monitored using portable digital triaxial seismographs (Mini Supergraph II, Nomis Seismographs Inc., USA) deployed at up to five locations from the blast source (Fig. 1c). Each instrument is equipped with a triaxial velocity transducer and an air overpressure microphone and records radial, transverse and vertical particle velocities together with dominant frequency and airblast levels at a sampling rate of 1024 Hz (i.e., \(\sim 1000\) samples/s per component). Data are stored for post-processing in the SuperGraphics software; a representative event summary is shown in Fig. 1e. According to the manufacturer’s specifications, the units provide a flat velocity response over the blasting-frequency range with amplitude and timing accuracy within the tolerances required for blast-vibration monitoring, and all seismographs were factory-calibrated within the recommended interval. In accordance with widely used field practice, the seismographs were configured to record the full time-history waveform (rather than only summary peaks), with a ground-vibration trigger set near 1.3 mm/s to avoid missed events and a record length exceeding the expected blast duration by a small buffer (at least 2 s, plus \(\sim\)1 s per 335 m of distance) to prevent truncation. For each blast, the instruments were installed on firm, compacted ground or rock outcrop, with the geophone spikes driven into the ground to ensure good coupling; the sensor was levelled and oriented so that the radial channel pointed towards the blast centre. Distances from the blast to each instrument were obtained from mine survey data. This combination of instrumentation, configuration and installation minimises measurement error and ensures that the recorded PPV values are reliable for subsequent modelling. The data used in the study span the period from 2017 to 2024, covering all blasting conditions and potential biases in these 7 years. The parameters under consideration, along with their respective ranges, are outlined in Tables 1, 2. The data was preprocessed which included data cleaning and normalisation. To characterise linear associations among variables prior to model training, we computed an input-output correlation matrix. The dataset was then divided into a training set (80%) and a testing set (20%).
Blastability index (BI)
Blastability index (BI) was used as an input parameter to account for the influence of the rock mass condition on blast performance. At Jwaneng Mine, BI is routinely computed from geotechnical logging using the empirical system proposed by Lilly53. The BI is obtained from Eqs. (2)–(3), where the ratings for individual components are assigned according to Table 1.
where BI is the blastability index, RMD is the rock mass description rating, JPS is the joint plane spacing rating, JPO is the joint plane orientation rating, RDI is the rock density influence rating, \(S_{r}\) is the rock strength influence rating, UCS is the uniaxial compressive strength (MPa), and \(\rho _r\) is the rock density (t/m\(^{3}\)). The BI values used in this study were extracted from the mine’s standard blast design and geotechnical records for each blast.

Data collected from muckpile images and seismographs with their deployment on-site.
Data preprocessing
Prior to model training, we applied a leakage-safe pipeline to the numeric inputs. Units were harmonised, the dataset was screened after quality assurance and checks (no missing values remained), and obvious acquisition errors were not observed within the physical ranges. To prevent information leakage, all features were standardised to zero mean and unit variance using statistics fitted on the training folds only and then applied to validation/test data; no categorical fields required encoding. The full dataset (n = 120 blasts) was partitioned 80/20 into train/test, and model selection used 5-fold cross-validation with 3 repeats on the training portion, with folds stratified by coarse bins of PPV (Gv) and \(P_{80}\) to stabilise variance across target ranges. We explored Yeo–Johnson and \(\log (x{+}c)\) transformations during diagnostics but report main results on the original scale because residual symmetry and scale–location checks showed no material benefit. Experiments were run with fixed random seeds (seed = 42) and locked library versions to ensure reproducibility.
The Spearman rank-correlation analysis in Fig. 2 revealed patterns consistent with blasting physics. Ground vibration (PPV) showed a strong negative association with distance to the monitoring point and a positive association with charge per delay, with burden also positively related to PPV; this aligns with the expectation that larger instantaneous charge amplifies wave energy while greater source–receiver distance attenuates it. Fragmentation exhibited a positive correlation with powder factor and stemming, but a negative correlation with burden, reflecting that higher specific energy and sufficient confinement generally enhance breakage, whereas excessive burden can dampen energy release into the face. Inter-input relationships indicated moderate coupling between charge per delay, powder factor, and design variables (e.g., burden), mirroring practical constraints in blast design. By contrast, hole diameter and the rock/BI indices displayed weaker monotonic links, suggesting interaction-dependent effects that are better captured by the non-linear models presented later. In particular, rock factor and blastability index showed a weak but positive correlation, which is consistent with their theoretical definitions: in the Lilly53 formulation adopted here (2), higher BI values correspond to more competent, massive and unfavourably jointed rock masses that are harder to blast, and the Kuz–Ram rock factor is an empirical function of the same descriptors; thus, higher BI generally coincides with higher rock factor, both indicating increased rock-mass resistance to explosive breakage rather than opposite trends. Overall, these diagnostics cohere with the feature-importance analysis in Section and the solution surface results in Section reinforcing the physical plausibility of the learned relationships.

Spearman rank-correlation heatmap showing monotonic non-linear associations among blasting inputs and outputs (Fr and PPV).
Methods
According to the literature, there is a consensus among researchers that ANNs are effective for predicting blast-induced impacts. However, Yan et al54 highlighted their prolonged training times, while Jadav et al55 emphasised their susceptibility to local minima. To address these challenges and enhance prediction accuracy, this study proposes an ensemble ANN-RF model. Additionally, standalone ANN and RF models are utilised for comparison purposes. The model assessment was conducted using RMSE and R2 as performance indices. Sensitivity analysis was performed using the Tree SHAP method. The projected gradient descent method was used to optimise the outputs, and the Monte Carlo method was applied to find the optimal architecture of the best-performing model.
ANN
We tuned a fully connected artificial neural network (ANN) using Grid Search CV on the training split only to avoid information leakage. Candidate hyperparameters included learning rate \(\eta \in \{0.001,\,0.01,\,0.1\}\); hidden-layer configurations \(\in \{20,\,32,\,64,\,100,\,(50,50),\,(65,100),\,(25,75)\}\); activation \(\in \{\textrm{ReLU},\,\tanh ,\,\textrm{sigmoid}\}\); batch size \(\in \{32,\,64\}\); optimiser \(\in \{\textrm{Adam},\,\textrm{SGD}\}\); and epochs \(\in \{100,\,200,\,300\}\). A dynamic model–builder function instantiated architectures consistent with each hyperparameter combination. Data were split by blast into \(80\%\) training and \(20\%\) held-out test sets. Model selection used repeated 5-fold cross-validation (3 repeats) on the training set, with folds stratified by coarse PPV and P80 bins to stabilise target coverage. The primary scoring metric was negative RMSE (tie-break by MAE); random seeds were fixed (42) and library versions pinned. The final ANN was refit on the full training set using the best hyperparameters from the grid search (see Table 3), and evaluated once on the untouched test set. To monitor optimisation stability we recorded training and validation losses across epochs; the loss trajectory for the selected ANN is shown in Fig. 3. This protocol ensures that hyperparameter tuning, model selection, and generalisation assessment are cleanly separated (CV on training; single final report on test), improving robustness and reproducibility.

The loss curve for the optimum ANN model.
RF
We tuned a random forest (RF) regressor using Randomized Search CV on the training split only to prevent information leakage. The search drew 100 random hyperparameter samples from: \(n_{\text {est}}\!\in \!\{50,100,200,300\}\); \(\text {max\_depth}\!\in \!\{10,20,30,\text {None}\}\); \(\text {min\_samples\_split}\!\in \!\{2,5,10\}\); \(\text {min\_samples\_leaf}\!\in \!\{1,2,4\}\); \(\text {bootstrap}\!\in \!\{\text {True},\text {False}\}\). This strategy provides broad coverage at lower computational cost than exhaustive grids. Data were split by blast into \(80\%\) training and \(20\%\) held-out test sets. Model selection used repeated 5-fold cross-validation (3 repeats) on the training set, with folds stratified by coarse PPV and P80 bins to stabilise target coverage. The primary scoring metric was negative RMSE (tie-break by MAE); random seeds were fixed (42) and library versions pinned. After selection, the RF was refit on the full training set using the best hyperparameters (Table 3) and evaluated once on the untouched test set. To assess learning behaviour, we report training/validation learning curves for the selected RF (Fig. 4); additional diagnostics are provided in the Supplement. This protocol cleanly separates tuning (CV on training) from final generalisation assessment (single report on test), improving robustness, efficiency, and reproducibility.

The learning curve for the optimum RF model.
ANN–RF
We constructed an ensemble by combining the independently tuned ANN and RF models (Sections and) using a VotingRegressor. Each base learner was first selected via cross-validated model selection on the training split only and then refit on the full training set using its best hyperparameters (summarised in Table 3). The ensemble prediction is the average of the two member predictions; unless stated otherwise, equal weights \((0.5,\,0.5)\) were used (We also verified that small weight grids, e.g., \(w_{\textrm{ANN}}\in \{0.25,0.5,0.75\}\) with \(w_{\textrm{RF}}=1-w_{\textrm{ANN}}\), did not improve held-out performance materially.). Note that the ensemble has no additional “architecture” beyond its members and the voting rule. Evaluation followed the same protocol as for the base learners: after refitting the selected ANN and RF on the full training set, the ensemble was evaluated once on the untouched \(20\%\) test set. Performance was summarised using RMSE, \(R^{2}\) (and MAE for completeness), with metrics reported on the held-out test set. This approach leverages the complementary strengths of the ANN (smooth interaction learning) and the RF (robust, split-based generalisation) while preserving a clean separation between tuning and final assessment. A flowchart of the overall research workflow is provided in Fig. 5.
PSO–ANN
For comparison with the proposed ANN–RF ensemble, we also implemented a particle swarm optimisation-tuned artificial neural network (PSO–ANN). The PSO algorithm was used to search over a reduced ANN hyperparameter space comprising the learning rate, number of hidden units, and number of hidden layers. Each particle encoded a candidate vector \((\eta , h_1, h_2)\), where \(\eta\) is the learning rate and \(h_1,h_2\) denote the sizes of up to two hidden layers (a value of zero for \(h_2\) corresponds to a single–hidden–layer network). The swarm size was drawn from \(\{20,40,60\}\), inertia weight \(w \in [0.4,0.9]\), and cognitive and social coefficients \(c_1,c_2 \in [1.0,2.5]\), with a maximum of 100 iterations per run. For each particle position, an ANN was trained on the training split using early stopping and evaluated by RMSE on the validation folds of the repeated 5-fold CV scheme described earlier. The best particle (lowest validation RMSE, tie-broken by MAE) defined the final PSO–ANN configuration, which was then refit on the complete training set and evaluated once on the held-out test set.
PSO–ELM
The PSO–ELM model combines particle swarm optimisation with an extreme learning machine (ELM) regressor. In an ELM, the input-to-hidden weights are randomly initialised and fixed, while the output weights are obtained by a single least-squares solve. The PSO was used to tune the number of hidden neurons (\(h \in \{20,40,60,80,100\}\)), the activation function (ReLU, sigmoid, or tanh), and an \(\ell _2\) regularisation coefficient \(\lambda \in [10^{-5},10^{-1}]\) on the output weights. Particles encoded \((h,\lambda ,\text {activation})\) and were evolved under the same swarm settings as for PSO–ANN. At each iteration, candidate ELMs were trained on the training folds only and scored by validation RMSE. The best configuration per target (fragmentation and PPV) was refit on the full training data and assessed on the test set.
ANN–SVR
The ANN–SVR hybrid uses a shallow ANN as a non-linear feature extractor followed by a support vector regression (SVR) output layer. The ANN part maps the original 10-dimensional input to a compact latent representation, which is then passed to an SVR with radial basis function (RBF) kernel. GridSearchCV was used to tune the size of the hidden layer (\(h \in \{16,32,64\}\)), the SVR penalty parameter \(C \in \{10,100,1000\}\), the RBF kernel width \(\gamma \in \{10^{-3},10^{-2},10^{-1}\}\), and the \(\varepsilon\)-tube radius \(\varepsilon \in \{0.001,0.01,0.1\}\). The same repeated 5-fold CV protocol (stratified by PPV/P80 bins) and negative RMSE scoring were used. The selected ANN–SVR model was refit on the complete training set and evaluated once on the test set.
PSO–XGBoost
The PSO–XGBoost model employs particle swarm optimisation to tune an extreme gradient boosting regressor (XGBoost). Each particle encoded the tuple \((n_{\text {est}}, \text {max\_depth}, \eta , \text {subsample}, \text {colsample\_bytree})\), where \(n_{\text {est}}\) is the number of trees, \(\eta\) the learning rate, and the last two terms control row and column subsampling. Search ranges were \(n_{\text {est}} \in [100,500]\), \(\text {max\_depth} \in \{3,4,5,6\}\), \(\eta \in [0.01,0.3]\), \(\text {subsample} \in [0.6,1.0]\), and \(\text {colsample\_bytree} \in [0.6,1.0]\). Swarm dynamics matched those used for PSO–ANN. Candidate XGBoost models were trained on the training folds and scored by validation RMSE; the best particle per target was refit on the full training split and evaluated on the test set.
GA–ANN
Finally, a genetic algorithm–tuned ANN (GA–ANN) was implemented as a second evolutionary baseline. Chromosomes encoded discrete ANN architectures and optimisation hyperparameters: \((n_L,h_1,h_2,\eta )\), where \(n_L \in \{1,2\}\) is the number of hidden layers, \(h_\ell \in \{32,64,100\}\) the units per layer, and \(\eta \in \{0.001,0.01,0.05\}\) the learning rate. A GA with population size 30, tournament selection, simulated binary crossover (rate \(p_c = 0.8\)), and bit-flip mutation (rate \(p_m = 0.1\)) was run for 50 generations, using validation RMSE under the repeated 5-fold CV scheme as fitness. The fittest individual per target defined the final GA–ANN configuration, which was retrained on the full training set and evaluated once on the held-out test set.

Research workflow: data acquisition (fragmentation imaging and seismographs), preprocessing and split, ANN/RF tuning via repeated CV, ensemble construction, test evaluation, Tree-SHAP sensitivity, solution-surface generation, and projected gradient-descent multi-objective optimisation.
Hyperparameter optimisation and cross-validation
We tuned models using scikit-learn’s model selection utilities on the training split only. For the ANN we employed Grid Search CV; for the RF we used Randomized Search CV (100 samples). All searches used repeated 5-fold cross-validation (3 repeats) with folds stratified by coarse PPV and P80 bins to stabilise coverage across target ranges. The primary selection metric was negative RMSE on the validation folds. Random seeds were fixed to 42 for reproducibility, and library versions were pinned. A concise summary of search spaces and selected best hyperparameters (per target) is reported in Table 3.
Feature importance
In this study, we quantify the contribution of each input variable to the model outputs (ground vibration and rock fragmentation) using Tree SHAP, an efficient, axiomatic attribution method for decision-tree ensembles. Let \(f(\textbf{x})\) denote the trained model (here, the Random Forest used in the final ensemble), and let \(\phi _j(\textbf{x})\) be the SHAP value that attributes to feature \(f_j\) its local contribution to the prediction at sample \(\textbf{x}\). Tree SHAP satisfies local additivity, i.e.,
where \(\mathbb {E}[\,f(\textbf{X})\,]\) is the reference (baseline) prediction under the empirical feature distribution and K is the number of input features. Thus, \(\phi _j(\textbf{x})\) measures how much feature \(f_j\) moves the prediction away from the baseline for that specific \(\textbf{x}\).
Formally, the SHAP value for feature \(f_j\) is the Shapley value of a cooperative game where features are players and the model prediction is the payoff. It is defined as the weighted average marginal contribution of \(f_j\) across all subsets \(S\subseteq \{1,\dots ,K\}\setminus \{j\}\):
where \(\mathscr {F}\) is the full feature set and \(f_{S}\) denotes the model expectation when only features in S are known (others are marginalised). For tree models, Tree SHAP computes (5) exactly in polynomial time by propagating path probabilities down each tree and aggregating the expected marginal contributions at leaves, without retraining or brute-force enumeration.
To obtain a global ranking of feature influence, local attributions are aggregated across a dataset \(\mathscr {D}\) (here, the held-out test set). Following common practice, we use the mean absolute SHAP value:
which reflects the average magnitude of \(f_j\)’s effect on predictions irrespective of sign. For interpretability, we normalise these global importances to percentages so they sum to 100:
Compared to impurity-based scores, Tree SHAP provides (i) local explanations at the sample level via \(\phi _j(\textbf{x})\) and (ii) global rankings via (6), while satisfying desirable axioms (local accuracy, missingness, and consistency). We report the SHAP plot that visualise, for each feature, the distribution of \(\phi _j(\textbf{x})\) across test samples (as illustrated in Fig. 7).
Bi-objective optimisation via projected gradient descent
We seek blast designs that maximise fragmentation and minimise ground vibration. Let \(\textbf{p}\in \mathbb {R}^N\) denote the vector of design variables (e.g., burden B, spacing S, stemming T, charge per delay C, powder factor PF, distance DI, hole depth H, diameter D, etc.). Let \(\widehat{Fr}(\textbf{p})\) and \(\widehat{Gv}(\textbf{p})\) be the ensemble predictions of Fragmentation (defined as percentage passing the 150 mm threshold, in %) and PPV (in mm/s), respectively, obtained from the ANN–RF model.
We scalarise the bi-objective into a single smooth objective
where \(\alpha ,\beta >0\) weight operational priorities (default \(\alpha =\beta =1\); weight sensitivity is reported in the Supplement), and \(\Phi (\textbf{p})\ge 0\) is a soft penalty for any feasibility violations (e.g., minimum explosive column length, stemming/burden proportionality, maximum charge per delay, and regulatory PPV compliance). When all constraints are satisfied, \(\Phi (\textbf{p})=0\).
Design space and constraints
The search space is restricted to the empirical ranges in Table 2, expanded by \(\pm 10\%\) per variable:
with \(\Delta _i = p_i^{\max }-p_i^{\min }\). Additionally, we enforce practical feasibility through \(\Phi (\textbf{p})\) and by projecting onto \(\Omega\) every iteration.
Gradient estimation
Because the ensemble includes a non-differentiable RF component, we estimate the gradient of J numerically by a stable central-difference scheme:
where \(\textbf{e}_i\) is the i-th coordinate vector. This yields \(\nabla J(\textbf{p}) = \big (g_1(\textbf{p}),\ldots ,g_N(\textbf{p})\big )^\top\).
Projected gradient descent with backtracking
Starting from an initial feasible \(\textbf{p}^{(0)}\) (best of \(M{=}50\) Latin hypercube seeds in \(\Omega\)), we iterate
where \(\Pi _{\Omega }\) denotes Euclidean projection onto the box \(\Omega\) in (9). We use an initial learning rate \(\eta ^{(0)}=0.05\) with backtracking line search (\(\eta ^{(k)} \leftarrow \rho \,\eta ^{(k)}\), \(\rho =0.5\)) until
(Armijo-like decrease). This keeps steps stable near steep or curved regions of the solution surface.
Stopping criteria and output
We terminate when any of the following holds:
The reported “optimal” design is the best feasible iterate encountered (smallest J), together with its predicted outcomes \(\widehat{Fr}\) and \(\widehat{Gv}\) and a practicality checklist (stemming, maximum charge/delay, PPV margin to regulatory limit).
Implementation notes
The ensemble predictor used in (8) is a VotingRegressor that averages independently tuned ANN and RF models. Default weights \(\alpha =\beta =1\) reflect equal importance of fragmentation and PPV; alternative priorities are explored in sensitivity analyses. Penalty weight \(\gamma\) was set to \(10^3\) so that any constraint violation dominates the objective until feasibility is restored.
Results and discussion
To check the performance of all the predictive models, RMSE, MAE, \(R^{2}\) and VAF were utilised as performance indices. These are expressed by Eqs. (14)-(17):
where \(y_i\) and \(y_i^{\prime }\) are the measured and predicted values, respectively; \(\bar{y}\) is the mean of the measured values; N is the number of samples; and \(\textrm{Var}(\cdot )\) denotes the variance operator.
Results from the chosen models (ANN, RF, ANN–RF and the benchmark hybrid approaches PSO–ANN, PSO–ELM, ANN–SVR, PSO–XGBoost, and GA–ANN) for estimating fragmentation and ground vibration, along with their performance indices, are outlined in Tables 4 and 5 for the training and testing sets, respectively. The high \(R^{2}\) and VAF values, together with the low RMSE and MAE values reported in Table 4, show that the models have learned the training data well. Among the single models, the ANN and RF provide a solid baseline, with RF slightly better at capturing local, non-linear responses of the outputs to individual input variables, and ANN better at learning smooth global trends in the multi-dimensional input space.
When the hybrid and metaheuristic-based approaches are considered, a clear performance hierarchy emerges. The PSO–ELM model generally ranks toward the lower end of the hybrids, with \(R^{2}\) and VAF values comparable to, or only marginally higher than, those of the standalone ANN and RF. This behaviour is consistent with the fact that ELM relies on randomly assigned hidden-layer weights; even though PSO tunes the number of neurons and regularisation strength, the representational capacity is still constrained by the fixed random basis. PSO–ANN improves on these results by optimising the ANN architecture and learning rate through PSO, which yields networks with better-calibrated capacity and, in turn, lower RMSE and MAE values; however, its performance remains sensitive to local minima and the specific training initialisation.
The ANN–SVR and GA–ANN models further reduce the prediction error. ANN–SVR benefits from using the ANN as a non-linear feature extractor and the SVR output layer as a margin-based regressor, which tends to be more robust to outliers and yields smoother residuals, particularly for PPV. GA–ANN achieves similar gains by exploring a richer space of ANN architectures using genetic operators; this allows the algorithm to discover architectures that balance depth and width more effectively than manual or grid-based tuning. Both methods therefore exhibit higher \(R^{2}\) and VAF, and lower RMSE and MAE than the PSO-based models, especially on the fragmentation task.
Among the benchmark hybrids, PSO–XGBoost provides the closest competitor to the proposed ANN–RF ensemble. The boosted-tree framework naturally handles interaction effects and piecewise non-linearities in the blasting parameters, and the PSO-tuned hyperparameters control tree depth, learning rate, and subsampling in a way that limits overfitting. As a result, PSO–XGBoost attains consistently high \(R^{2}\) and VAF values and relatively small errors on both outputs, with only a modest gap to the ANN–RF ensemble on the test set.
The proposed ANN–RF model nevertheless remains the best-performing approach overall. Its superior performance can be attributed to the complementary strengths of its two base learners: the ANN captures smooth, high-order non-linear relationships among the blast-design and rock-mass variables, while RF captures localised interactions and handles irregularities or outliers in the data. The VotingRegressor combination averages these two perspectives, reducing variance without introducing substantial bias and thereby producing predictions that are both accurate and stable across the input domain. This is reflected in the testing metrics in Table 5, where ANN–RF attains the highest \(R^{2}\) and VAF and the lowest RMSE and MAE among all models. Specifically, the ANN–RF model demonstrates superior performance on the testing set as indicated by the following \(R^{2}\) values: 0.956 for fragmentation and 0.930 for ground vibration. Additionally, the RMSE values are 0.315 for fragmentation and 0.380 for ground vibration, with correspondingly low MAE and high VAF values. The close agreement between training and testing metrics further indicates limited overfitting. Taken together, these results suggest that the ANN–RF ensemble achieves the lowest overall system error and the highest accuracy in simultaneously modelling fragmentation and ground vibration, outperforming all other implemented models.
Figure 6a–f depict the predicted versus actual values of fragmentation and ground vibration for the models used in this study within the testing datasets. Generally, all the models demonstrate a high predictive accuracy, but Fig. 6f and e for ANN-RF model shows that the predicted values closely match the measured ones, following the ideal y:x line, which shows a strong correlation compared to other models. This confirms the effectiveness of the ANN-RF model in accurately predicting these outcomes. The superior performance of the ANN-RF hybrid model can be attributed to the complementary strengths of its components. The ANN (see Fig. 6a and b) outperformed the RF (see Fig. 6c and d) due to their ability to capture non-linear relationships and extract complex features through their layered architecture, which is particularly effective for datasets with intricate variable interactions like the dataset considered in this study. However, ANNs are prone to overfitting and lack interpretability, while RF excels in generalisation by handling structured patterns and mitigating overfitting through ensemble learning. The hybrid model leverages these advantages by using the ANN for feature extraction and the RF for robust decision-making, resulting in improved predictive accuracy. This enables the hybrid approach to address the limitations of each standalone model and achieve superior performance and robustness.
Random forests (RF) tend to excel when inputs include structured design variables (e.g., spacing, burden, and stemming) that create useful splits, yielding competitive accuracy for PPV; artificial neural networks (ANN) capture smooth multi-way interactions such as PF\(\times\)B\(\times\)T that govern fragmentation (P\(_{80}\)).The PPV variance is dominated by distance (DI) and maximum charge per delay (C), favouring tree-based partitioning; for fragmentation, interaction effects benefit from ANN’s representation capacity. The RF-ANN ensemble leverages both behaviours, ANN’s energy-confinement curvature for fragmentation and RF’s robustness where DI and C dominate PPV, producing the best overall generalisation.

Predicted versus measured values on the held-out test set. (a,c,e) Fragmentation (\(P_{80}\)) for ANN, RF, and the ANN–RF ensemble; (b,d,f) PPV for the same models. The 1:1 line aids calibration assessment. The ensemble combines ANN’s ability to learn smooth multi-way interactions with RF’s robustness on split-friendly variables, yielding the tightest scatter about the identity line and the lowest error.
To situate our results within the literature, Table 6 summarises representative studies by targets (fragmentation indices and/or PPV), methods, inputs, dataset size, and best reported test metrics. This consolidated view enables a like-for-like reading of how different modelling choices and input sets affect accuracy and generalisation. Three patterns are consistent across prior work: (i) most studies optimise a single target (either PPV or fragmentation), while truly simultaneous multi-target prediction is uncommon; (ii) design and path variables (spacing, burden, stemming, charge per delay, distance) are core inputs, whereas rock-mass descriptors are included inconsistently; and (iii) modern ML (RF, ANN, XGBoost and hybrids) generally outperforms fixed-form empirical equations when evaluated out-of-sample.
Relative to the ranges reported in Table 6, our ANN-RF ensemble achieved state-of-the-art out-of-sample accuracy on both targets within a unified train/validation protocol. In particular:
-
For fragmentation (P80), the ensemble captured non-linear PF\(\times\)B\(\times\)T interactions that single models often miss, yielding tighter calibration and lower error.
-
For PPV, tree-based structure provided robustness where DI and maximum charge per delay dominate variance; the ensemble combined this with ANN’s smooth interaction learning.
-
Unlike most prior studies, we trained and evaluated both targets on the same operational dataset under identical preprocessing and cross-validation, allowing a direct read of cross-target trade-offs.
Taken together, the comparative evidence and our results suggest that, firstly, ensembles reduce target-specific weaknesses of single learners; secondly, including both design and path variables is necessary but not sufficient interaction learning matters; and thirdly, reporting unified protocols for multi-target prediction helps practitioners reason about design trade-offs in real operations.
Feature importance analysis
Figure 7 illustrates the results of the sensitivity analysis conducted for both fragmentation and ground vibration. For fragmentation, powder factor (17%) emerges as the most influential input parameter. This finding underscores its critical role in determining the energy applied per unit volume of rock, which directly impacts the extent of breakage during blasting. Burden (15%) follows closely, reaffirming its importance in controlling the confinement and direction of explosive energy, both of which influence fragmentation outcomes. Other notably contributing factors include stemming and rock factor, indicating that both explosive confinement and rock mass characteristics significantly affect fragmentation. On the contrary, the blastability index, with a contribution of only 6%, was found to be the least influential parameter for fragmentation. This suggests that, within the context of this dataset, rock breakability characteristics play a secondary role compared to design-driven variables.
For ground vibration, the analysis identifies burden (15%) as the most impactful parameter. This highlights the burden’s key function in moderating explosive energy dissipation, where larger burdens can absorb more energy, thereby reducing the intensity of vibrations transmitted through the ground. Hole diameter (6%) is observed to have the least effect on ground vibration, indicating that either its variation is limited across the blast designs, or that its contribution is indirect and less significant compared to other parameters. Parameters such as maximum charge per delay, powder factor, and stemming also demonstrated moderate influence, suggesting their relevance across both performance metrics.
These results demonstrate that certain parameters, particularly powder factor and burden are critically influential in controlling both fragmentation and ground vibration, making them essential targets in blast design optimisation. In contrast, parameters such as blastability index and hole diameter may be of lesser priority, particularly under consistent geological conditions. These observations are consistent with findings from previous studies50,56,57,58,59,60, which similarly report the dominant effects of explosive energy distribution and confinement on blast-induced outcomes.

Relative input influence for each target. Bars show model-derived importance aggregated over the test folds. For fragmentation (\(P_{80}\)), energy-confinement drivers (PF, S, B, T) dominate; for PPV, source terms (B and Rf) contribute most variance. Lower influence for D and BI in this dataset reflects their narrower operating ranges.
Analysis of the optimisation results
Figure 8a and c display the results of the optimisation procedure. In each figure, the red dots represent the randomly selected initial points, with seven such points chosen. Applying the gradient descent method to each initial point led to convergence at the optimal solution, depicted by the blue dot. The optimised values for fragmentation and ground vibration are approximately 84% and 0.12 mm/s, respectively. Table 7 shows the optimised input parameters. The solution surface can be used for prediction, optimisation and finding the inverse solution by setting the desired value of fragmentation and ground vibration and searching in the solution space for the values of the corresponding input parameters. Variations in optimised parameters are influenced by the model’s complexity, random initialisation, and interpolation errors. The model’s inherent complexity, with numerous interdependent variables and non-linear relationships, makes it sensitive to initial conditions, causing fluctuations in outcomes. Additionally, the random initialisation of network weights results in different starting points for each training run, leading to varied convergence paths and optimised parameters. Furthermore, interpolation errors arise from the grid resolution used to identify optimal points; the grid is not sufficiently fine, hence it misses more precise locations, resulting in inaccuracies in the final parameters.

Solution surfaces and 2D slices showing the relationship between outputs and selected input parameters. Inputs were chosen based on sensitivity analysis, highlighting the most and least influential parameters affecting the outputs: (a)–(b) fragmentation and (c)–(d) ground vibration.
From the sensitivity analysis, blastability index and hole diameter are the least influential input parameters on fragmentation and ground vibration, respectively. Because of this, we compare these parameters versus all the other input parameters kept constant, to observe the variations in the values of the output parameter in a two dimensional plot. We assign blastability index and hole diameter to be the x-axis, while ground vibration is assigned as the y-axis.
In Fig. 8a, when the powder factor increases while the blastability index is fixed, rock fragmentation value increases towards an optimal value then decreases with fluctuations. Fragmentation rises with specific energy (PF) until an optimum; beyond that, extra energy partitions into fines without improving \(P_{80}\), consistent with energy-per-volume arguments. For a fixed BI (rock breakability), the confinement and energy balance control the curvature. In Fig. 8c, increasing the hole diameter while keeping the burden fixed results in ground vibrations initially increasing then decreases to an optimal value before increasing again. The PPV reflects scaled distance and confinement: very small B promotes violent face breakout (higher PPV); increasing B initially raises transmitted energy as confinement increases, then attenuation dominates and PPV declines before rising again when D (and thus charge geometry/decoupling) shifts the source strength. Non-monotonicity is expected from superposition and geometric spreading effects.
The solution space also confirms the results of the feature importance analysis. As can be seen in Fig. 8b, generated by varying blastability index which is the least influential input parameter on fragmentation and fixing all the other parameters, and taking a slice through the lowest, optimised point in the solution space. Powder factor is the most influential input parameter on fragmentation, and exhibits significant fluctuations over the blastability index range compared to other parameters. Figure 8d, shows that burden has the most significant variations compared to other parameters, suggesting a higher sensitivity to ground vibration.
This multi-output optimisation of fragmentation and ground vibration has significant practical applications. It allows for the simultaneous consideration of these critical factors, enabling a balanced approach to blasting that enhances operational efficiency while minimising environmental impacts. By optimising fragmentation, mining operations can achieve the desired material size, which improves the efficiency of downstream processes like loading, hauling, and milling. At the same time, controlling ground vibration helps to reduce the risk of damage to nearby structures, ensures compliance with regulatory standards, and mitigates the environmental impact of blasting activities. This approach leads to more efficient and safer mining operations, ultimately contributing to cost savings, improved productivity, and reduced environmental footprint.
Need for future research
Although the present study demonstrates that the ANN-RF ensemble can simultaneously predict and optimise blast-induced fragmentation and ground vibration with high accuracy, several avenues for future research remain. First, the optimised blast designs obtained from the solution surface and projected gradient-descent procedure are model-derived recommendations that have not yet been validated through controlled field trials. Carefully designed production experiments at Jwaneng Diamond Mine are therefore needed to confirm that the predicted improvements in fragmentation (towards finer size distributions) and reductions in PPV can be realised under operational conditions, and to quantify the economic and environmental benefits of adopting the proposed framework in routine practice.
Second, the input space in this work was constrained by the availability of routinely recorded operational and rock-mass indices, namely rock factor and blastability index. While these indices compactly summarise key geotechnical attributes, they inevitably mask some of the spatial and directional variability present in the rock mass. Future studies should aim to incorporate richer, blast-aligned geotechnical descriptors such as detailed structural mapping, geotechnical logging parameters, rock-mass classification schemes and in situ stress information. Doing so would allow the models to resolve more subtle interactions between geology and blast design, potentially improving both predictive performance and the physical interpretability of the learned relationships.
Third, the current multi-output framework focuses on two primary blast-induced impacts (fragmentation and ground vibration). In practice, engineers must often balance additional responses such as airblast, flyrock, backbreak and slope damage. Extending the present approach to a truly multi-impact setting for example, by jointly modelling and optimising fragmentation, PPV, air overpressure, back break and flyrock risk would move closer to holistic blast design and provide a more comprehensive decision-support tool. Such extensions could be naturally combined with uncertainty-aware or probabilistic variants of the ANN-RF framework, enabling blast designs that explicitly account for prediction intervals and risk tolerances rather than relying solely on point estimates.
Finally, while the methodology developed here is transferable in principle, its deployment at other operations will require site-specific adaptation and retraining. Future research should therefore investigate transfer-learning and multi-site modelling strategies that leverage data from several mines while preserving local calibration, as well as the integration of real-time monitoring data (e.g., vibration, fragmentation and slope-response streams) for online model updating. Addressing these topics will help transform the proposed site-specific prototype into a robust, generalisable and continuously improving AI-based framework for precision blast design in open-pit mining.
Conclusions
This work presents an integrated machine-learning framework for simultaneous prediction and optimisation of two key blast outcomes in open-pit mining: rock fragmentation and ground vibration. Using production data from the Jwaneng Diamond Mine, the study shows that combining ANN and RF in an ANN–RF ensemble provides reliable dual-target generalisation, outperforming the standalone models for both outputs and hybrid baselines PSO–ANN, PSO–ELM, ANN–SVR, PSO–XGBoost and GA–ANN. This indicates that hybridising smooth non-linear learning (ANN) with robust tree-based structure (RF) is a practical strategy for blast systems where variables interact in complex and partly monotonic ways. Beyond accuracy, the framework contributes operational insight. Tree-SHAP interpretation confirms that energy distribution and confinement geometry are central to blast performance: powder factor and burden dominate fragmentation behaviour, while burden, charge per delay, and distance govern ground-vibration response. These dominance patterns are consistent with blasting physics, and they provide a defensible basis for prioritising controllable parameters during design. The solution-surface and gradient-descent search further demonstrate how the trained model can be used inversely to obtain feasible blast settings that improve fragmentation while reducing vibration within the historical design space. This turns the model from a predictive tool into a practical decision aid for daily blast planning, with the potential to enhance downstream productivity, reduce secondary breakage and re-handling costs, and maintain compliance with vibration limits.The study has limitations. The optimisation results are model-derived recommendations and were not validated through controlled field trials during this work. In addition, detailed geotechnical variables were not available in a blast-aligned form for all events; therefore, rock factor and blastability index were used as composite descriptors. While the pipeline is transferable, site-specific retraining remains essential before deployment elsewhere due to differences in geology, monitoring layouts, and regulatory thresholds. Future research will focus firstly on, field validation of the recommended designs at Jwaneng, secondly, expanding the input space to include explicit geotechnical measurements where consistently logged, thirdly, testing additional multi-target hybrid optimisers under the same protocol, and finally, incorporating uncertainty-aware optimisation to provide confidence bounds on suggested blast designs.
Data availability
The datasets analysed during the current study are not publicly available due to a non-disclosure agreement with Debswana Mining Company.
Abbreviations
- ANN:
-
Artificial neural network
- RF:
-
Random forest
- PSO:
-
Particle swarm optimisation
- ELM:
-
Extreme learning machine
- SVR:
-
Support vector regressor
- XGBoost:
-
Extreme gradient boosting
- GA:
-
Genetic algorithm
- PPV (Gv):
-
Peak particle velocity / ground vibration (mm/s)
- Fr:
-
Fragmentation (\(X_{80}\))
- B:
-
Burden (m)
- S:
-
Spacing (m)
- T:
-
Stemming length (m)
- L:
-
Hole depth (m)
- D:
-
Hole diameter (mm)
- DI:
-
Distance from blast face to monitoring point (m)
- C:
-
Maximum charge per delay (kg)
- Pf:
-
Powder factor (kg/m\(^3\))
- Rf:
-
Rock factor
- BI:
-
Blastability index
- RMD:
-
Rock mass description
- JPS:
-
Joint plane spacing (m)
- JPO:
-
Joint plane orientation
- RDI:
-
Rock density influence (\(t/m^{3}\))
- \(S_{r}\) :
-
Rock strength influence (MPa)
- SHAP:
-
SHapley Additive exPlanations
- CV:
-
Cross-validation
- R2:
-
Coefficient of determination
- RMSE:
-
Root mean square error
- MAE:
-
Mean absolute error
- VAF:
-
Variance accounted for
References
An, H., Song, Y., Liu, H. & Han, H. Combined finite-discrete element modelling of dynamic rock fracture and fragmentation during mining production process by blast. Shock Vib. 2021, 1–18 (2021).
Yu, Z., Shi, X., Zhou, J., Chen, X. & Qiu, X. Effective assessment of blast-induced ground vibration using an optimized random forest model based on a harris hawks optimization algorithm. Appl. Sci. 10, 1403 (2020).
Keshtegar, B., Hasanipanah, M., Bakhshayeshi, I. & Sarafraz, M. E. A novel nonlinear modeling for the prediction of blast-induced airblast using a modified conjugate fr method. Measurement 131, 35–41 (2019).
Temeng, V. A., Ziggah, Y. Y. & Arthur, C. K. Blast-induced noise level prediction model based on brain inspired emotional neural network. J. Sustain. Mining 20, 1 (2021).
Trivedi, R., Singh, T. & Gupta, N. Prediction of blast-induced flyrock in opencast mines using ann and anfis. Geotech. Geol. Eng. 33, 875–891 (2015).
Shirani Faradonbeh, R., Monjezi, M. & Jahed Armaghani, D. Genetic programing and non-linear multiple regression techniques to predict backbreak in blasting operation. Eng. Comput. 32, 123–133 (2016).
Khandelwal, M. & Singh, T. Evaluation of blast-induced ground vibration predictors. Soil Dyn. Earthq. Eng. 27, 116–125 (2007).
Nateghi, R., Kiany, M. & Gholipouri, O. Control negative effects of blasting waves on concrete of the structures by analyzing of parameters of ground vibration. Tunn. Undergr. Space Technol. 24, 608–616 (2009).
Hajihassani, M., Armaghani, D. J., Sohaei, H., Mohamad, E. T. & Marto, A. Prediction of airblast-overpressure induced by blasting using a hybrid artificial neural network and particle swarm optimization. Appl. Acoust. 80, 57–67 (2014).
Jahed Armaghani, D., Hasanipanah, M. & Tonnizam Mohamad, E. A combination of the ica-ann model to predict air-overpressure resulting from blasting. Eng. Comput. 32, 155–171 (2016).
Monjezi, M., Rezaei, M. & Varjani, A. Y. Prediction of rock fragmentation due to blasting in gol-e-gohar iron mine using fuzzy logic. Int. J. Rock Mech. Min. Sci. 46, 1273–1280 (2009).
Karami, A. & Afiuni-Zadeh, S. Sizing of rock fragmentation modeling due to bench blasting using adaptive neuro-fuzzy inference system and radial basis function. Int. J. Min. Sci. Technol. 22, 459–463 (2012).
Shams, S., Monjezi, M., Majd, V. J. & Armaghani, D. J. Application of fuzzy inference system for prediction of rock fragmentation induced by blasting. Arab. J. Geosci. 8, 10819–10832 (2015).
Bahrami, A., Monjezi, M., Goshtasbi, K. & Ghazvinian, A. Prediction of rock fragmentation due to blasting using artificial neural network. Eng. Comput. 27, 177–181 (2011).
Dumakor-Dupey, N. K., Arya, S. & Jha, A. Advances in blast-induced impact prediction—a review of machine learning applications. Minerals 11, 601 (2021).
Khandelwal, M. & Kankar, P. Prediction of blast-induced air overpressure using support vector machine. Arab. J. Geosci. 4, 427 (2011).
Singh, T., Dontha, L. & Bhardwaj, V. Study into blast vibration and frequency using anfis and mvra. Min. Technol. 117, 116–121 (2008).
Khandelwal, M. & Singh, T. Application of an expert system to predict maximum explosive charge used per delay in surface mining. Rock Mech. Rock Eng. 46, 1551–1558 (2013).
Persson, P.-A., Holmberg, R. & Lee, J. Rock Blasting and Explosives Engineering (CRC Press, 2018).
Mishnaevsky, L. & Schmauder, S. Analysis of rock fragmentation with the use of the theory of fuzzy sets. In ISRM International Symposium-EUROCK 96 (OnePetro, 1996).
Ragam, P. & Nimaje, D. Assessment of blast-induced ground vibration using different predictor approaches-a comparison. Chem. Eng. Trans. 66, 487–492 (2018).
Hustrulid, W. A. Blasting Principles for Open Pit Mining, Volume 1: General Design Concepts (A.A. Balkema, 1999).
Ghosh, A. & Daemen, J. J. A simple new blast vibration predictor (based on wave propagation laws). In ARMA US Rock Mechanics/Geomechanics Symposium, ARMA–83 (ARMA, 1983).
Langefors, U. & Kihlström, B. The Modern Technique of Rock Blasting (Wiley, 1963).
Kaklis, K., Saubi, O., Jamisola, R. & Agioutantis, Z. Machine learning prediction of the load evolution in three-point bending tests of marble. Mining Metall. Explor. 39, 2037–2045 (2022).
Kaklis, K., Saubi, O., Jamisola, R. & Agioutantis, Z. A preliminary application of a machine learning model for the prediction of the load variation in three-point bending tests based on acoustic emission signals. Procedia Struct. Integr. 33, 251–258 (2021).
Saubi, O., Gaopale, K., Jamisola, R. S., Suglo, R. S. & Matsebe, O. Enhancing blast design efficiency for rock fragmentation with gradient descent and artificial neural networks: An optimization study. In 2023 4th International Conference on Computers and Artificial Intelligence Technology (CAIT) 1–5 (IEEE, 2023).
Saubi, O., Jamisola, R. S. Jr., Gaopale, K., Suglo, R. S. & Matsebe, O. A solution surface in nine-dimensional space to optimise ground vibration effects through artificial intelligence in open-pit mine blasting. Mining 5, 40 (2025).
Petso, T., Jamisola, R. S. Jr., Mpoeleng, D., Bennitt, E. & Mmereki, W. Automatic animal identification from drone camera based on point pattern analysis of herd behaviour. Eco. Inform. 66, 101485 (2021).
Xue, X., Yang, X. & Li, P. Evaluation of ground vibration due to blasting using fuzzy logic. Geotech. Geol. Eng. 35, 1231–1237 (2017).
Bamford, T., Esmaeili, K. & Schoellig, A. P. A deep learning approach for rock fragmentation analysis. Int. J. Rock Mech. Min. Sci. 145, 104839 (2021).
Monjezi, M., Bahrami, A. & Varjani, A. Y. Simultaneous prediction of fragmentation and flyrock in blasting operation using artificial neural networks. Int. J. Rock Mech. Min. Sci. 47, 476–480 (2010).
Sayadi, A., Monjezi, M., Talebi, N. & Khandelwal, M. A comparative study on the application of various artificial neural networks to simultaneous prediction of rock fragmentation and backbreak. J. Rock Mech. Geotech. Eng. 5, 318–324 (2013).
Zihan, Z., Xiaosheng, L., Lijun, W. & Guangqiu, H. Prediction of blast-induced ground vibration using eight new intelligent models. IAENG Int. J. Comput. Sci. 51, 1 (2024).
Hosseini, S. et al. Assessment of the ground vibration during blasting in mining projects using different computational approaches. Sci. Rep. 13, 5. https://doi.org/10.1038/s41598-023-46064-5 (2023).
Rabbani, A. et al. Optimization of an artificial neural network using four novel metaheuristic algorithms for the prediction of rock fragmentation in mine blasting. J. Inst. Eng. Ser. D 106, 1261–1280. https://doi.org/10.1007/s40033-024-00781-x (2025).
Chandrahas, N. S., Choudhary, B. S., Venkataramayya, M. S. & Fissha, Y. An inventive approach for simultaneous prediction of mean fragmentation size and peak particle velocity using futuristic datasets through improved techniques of genetic xg boost algorithm. Mining Metall. Explor. 41, 2391–2405. https://doi.org/10.1007/s42461-024-01045-8 (2024).
Rabbani, A. et al. A comprehensive study on the application of soft computing methods in predicting and evaluating rock fragmentation in an opencast mining. Earth Sci. Inf. 17, 6019–6034. https://doi.org/10.1007/s12145-024-01488-z (2024).
Chen, L. et al. Accurate prediction of blast induced ground vibration intensity using optimised machine learning models. Defence Technol. 52, 32–46. https://doi.org/10.1016/j.dt.2025.06.019 (2025).
Chen, L. et al. Swarm based metaheuristic and reptile search algorithm for downstream operation dependent fragmentation size prediction. Neural Comput. Appl. 37, 25033–25059. https://doi.org/10.1007/s00521-025-11321-3 (2025).
Fissha, Y. et al. Data-driven machine learning approaches for simultaneous prediction of peak particle velocity and frequency induced by rock blasting in mining. Rock Mech. Bull. 4, 166. https://doi.org/10.1016/j.rockmb.2024.100166 (2024).
Bisoyi, S. K. et al. Optimizing blast-induced vibration predictions using hybrid ann: A study in dongri-buzurg mine. J. Appl. Geophys. 241, 105867. https://doi.org/10.1016/j.jappgeo.2025.105867 (2025).
Fissha, Y. et al. Predicting ground vibration during rock blasting using optimised relevance vector machine models. Sci. Rep. 14, 1. https://doi.org/10.1038/s41598-024-70939-w (2024).
Gebretsadik, A. et al. Enhancing rock fragmentation assessment in mine blasting through machine learning algorithms: A practical approach. Discov. Appl. Sci. 6, 1. https://doi.org/10.1007/s42452-024-05888-0 (2024).
Ullah, S. et al. Machine learning based prediction of blast induced ground vibration in open pit mining. J. Vib. Eng. Technol. 13, 1. https://doi.org/10.1007/s42417-025-01855-0 (2025).
Zhou, J., Li, C., Arslan, C. A., Hasanipanah, M. & Bakhshandeh Amnieh, H. Performance evaluation of hybrid ffa-anfis and ga-anfis models to predict particle size distribution of a muck-pile after blasting. Eng. Comput. 37, 265–274 (2021).
Fang, Q., Nguyen, H., Bui, X.-N., Nguyen-Thoi, T. & Zhou, J. Modeling of rock fragmentation by firefly optimization algorithm and boosted generalized additive model. Neural Comput. Appl. 33, 3503–3519 (2021).
Huang, J. et al. A new auto-tuning model for predicting the rock fragmentation: a cat swarm optimization algorithm. Eng. Comput. 1, 1–12 (2020).
Amiri, M., Bakhshandeh Amnieh, H., Hasanipanah, M. & Mohammad Khanli, L. A new combination of artificial neural network and k-nearest neighbors models to predict blast-induced ground vibration and air-overpressure. Eng. Comput. 32, 631–644 (2016).
Zhou, J., Asteris, P. G., Armaghani, D. J. & Pham, B. T. Prediction of ground vibration induced by blasting operations through the use of the bayesian network and random forest models. Soil Dyn. Earthq. Eng. 139, 106390 (2020).
Yang, H., Hasanipanah, M., Tahir, M. & Bui, D. T. Intelligent prediction of blasting-induced ground vibration using anfis optimized by ga and pso. Nat. Resour. Res. 29, 739–750 (2020).
Chandrahas, N. S., Choudhary, B. S., Teja, M. V., Venkataramayya, M. & Prasad, N. K. Xg boost algorithm to simultaneous prediction of rock fragmentation and induced ground vibration using unique blast data. Appl. Sci. 12, 5269 (2022).
Lilly, P. A. An empirical method of assessing rock mass blastability. In Proceedings of the Large Open Pit Mining Conference 89–92 (Newman, 1986).
Yan, Y., Hou, X. & Fei, H. Review of predicting the blast-induced ground vibrations to reduce impacts on ambient urban communities. J. Clean. Prod. 260, 121135 (2020).
Jadav, K. & Panchal, M. Optimizing weights of artificial neural networks using genetic algorithms. Int. J. Adv. Res. Comput. Sci. Electron. Eng. 1, 47–51 (2012).
Qiu, Y. et al. Performance evaluation of hybrid woa-xgboost, gwo-xgboost and bo-xgboost models to predict blast-induced ground vibration. Eng. Comput. 1, 1–18 (2021).
Tiile, R. N. Artificial Neural Network Approach to Predict Blast-Induced Ground Vibration, Airblast and Rock Fragmentation. Master’s thesis, Missouri University of Science and Technology, Rolla, Missouri (2016).
Monjezi, M., Amiri, H., Farrokhi, A. & Goshtasbi, K. Prediction of rock fragmentation due to blasting in sarcheshmeh copper mine using artificial neural networks. Geotech. Geol. Eng. 28, 423–430 (2010).
Monjezi, M., Mohamadi, H. A., Barati, B. & Khandelwal, M. Application of soft computing in predicting rock fragmentation to reduce environmental blasting side effects. Arab. J. Geosci. 7, 505–511 (2014).
Huang, J. et al. A new auto-tuning model for predicting the rock fragmentation: a cat swarm optimization algorithm. Eng. Comput. 1, 1–12 (2022).
Acknowledgements
We thank Jwaneng Diamond Mine for supplying data. We acknowledge contributions by Thuso Mogotsi, Chite Joe Matenga and Ethna Kasitiko. Funding: Debswana Diamond Company (P00064).
Funding
This research was funded by Debswana Diamond Company with grant number P00064. The APC was funded by Debswana.
Author information
Authors and Affiliations
Contributions
Conceptualization, O.S., and R.S.J.J.; methodology, O.S. and R.S.J.J.; software, O.S.; validation, O.S. and R.S.J.J.; formal analysis, O.S. and R.S.J.J.; writing—original draft preparation, O.S.; writing—review and editing, O.S., R.S.S., R.S.J.J., and O.M.; supervision, R.S.S., R.S.J.J., and O.M.; project administration, R.S.J.J.; funding acquisition, R.S.J.J. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Saubi, O., Jamisola, R.S., Suglo, R.S. et al. Simultaneous prediction and optimisation of rock fragmentation and ground vibration using an ANN–RF ensemble in open-pit blasting. Sci Rep 16, 3825 (2026). https://doi.org/10.1038/s41598-025-33871-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-33871-1
