
Abstract
This paper provides a novel approach to estimating CO₂ emissions with high precision using machine learning based on DPRNNs with NiOA. The data preparation used in the present methodology involves sophisticated stages such as Principal Component Analysis (PCA) as well as Blind Source Separation (BSS) to reduce noise as well as to improve feature selection. This purified input dataset is used in the DPRNNs model, where both short and long-term temporal dependencies in the data are captured well. NiOA is utilized to tune those parameters; as a result, the prediction accuracy is quite spectacular. Experimental results also demonstrate that the proposed NiOA-DPRNNs framework gets the highest value of R2 (0.9736), lowest error rates and fitness values than other existing models and optimization methods. From the Wilcoxon and ANOVA analyses, one can approve the specificity and consistency of the findings. Liebert and Ruple firmly rethink this rather simple output as a robust theoretic and empirical framework for evaluating and projecting CO2 emissions; they also view it as a helpful guide for policymakers fighting global warming. Further study can build up this theory to include other greenhouse gases and create methods enabling instantaneous tracking for sophisticated and responsive approaches.
Similar content being viewed by others
Introduction
Concerns about the increasing intensity of carbon dioxide (CO2) emissions have increased in recent decades because emissions have been associated with global warming and climate change1,2. Carbon dioxide, generated by human actions in factories, cars, buses, and power generation from thermal stations through fossil fuel combustion, has resulted in the buildup of an atmospheric blanket of greenhouse gases3,4,5. This accumulation puts a cover, which is heat, and this has resulted in global warming. The impact of these additional emissions is devastating, resulting in the melting of polar ice caps, rising levels of the sea, alterations in ecosystems, and extreme weather, including but not limited to floods, droughts, and hurricanes. Reduction of CO2 emissions is no longer a question of environmentalism; it is a social, economic, and global health question requiring practical solutions6,7,8.
Figure 1 depicts the critical issue at the heart of this study: industrial activities release vast amounts of CO2 into the atmosphere. The figure showcases a large industrial complex with multiple smokestacks emitting thick clouds of smoke, symbolizing the ongoing contributions of industry to global CO2 levels9. This visual representation emphasizes the urgent need for accurate predictions of CO2 emissions, as it highlights the scale of emissions from industrial sources and their role in accelerating climate change. So, this figure serves as a backdrop to the methodology and study proposed in this study, reinforcing the importance of developing accurate tools and models to mitigate the environmental impacts of these emissions.

Industrial emissions contributing to global CO2 levels.
CO2 emission forecasting is, therefore, an essential part of environmental control and climate change policy measurement. Such concrete predictions allow governments, certain industries, and environmental agencies to have predictions on what may happen in the coming years, formulate their future policies on how to approach the issue of climate change, and decide on how to reduce the impact of climate change in the world10. In other words, if the trends of future CO2 emissions can be forecasted, policymakers can fashion and implement emission control policies in areas thought to have the propensity to expand, such as energy production or transport. In the same way, industries can redesign themselves to meet environmental standards for sustainability and the economic bottom line11,12,13.
The whopping CO2 emissions raise the need to employ modern techniques in predicting CO2 emissions since the traditional statistical methods fail to capture nature and the source of variation in emission levels. Consequently, the adoption of machine learning (ML) methodologies has garnered attention in recent years due to their ability to analyze big and complicated data and employ historical data to make predictions14,15. It is noted that machine learning models for time series data are preferable when it comes to forecasting CO2 emissions because they can reflect both short-term and long-term dynamics of the emissions’ fluctuations16,17,18.
Metaheuristic optimization is pivotal in enhancing the performance and efficiency of complex stochastic machine learning models, especially when working with large, dynamic datasets like those used in this study to predict CO₂ emissions. These algorithms are designed to approximate optimal solutions for difficult optimization problems characterized by expansive search spaces and numerous local optima. Traditional optimization methods often struggle to navigate such nonlinear landscapes effectively, making methods of mathematics a critical alternative19,20.
By incorporating stochastic techniques, metaheuristic algorithms offer the flexibility to explore diverse regions of the search space while mitigating the risk of premature convergence to suboptimal solutions. This adaptability ensures robust and efficient optimization, allowing these algorithms to identify near-optimal solutions even in highly complex and fluctuating problem domains21.
Further, as opposed to conventional optimization techniques, metaheuristics are more general and can work with extensive search spaces and are capable of coming out of the local optimum via stochastic methods22,23. Furthermore, applying metaheuristic optimization to machine learning models for environmental prediction, such as CO2 emission, enhances flexibility and reliability. They are flexible in that they may be used on any environmental data set and adapt in real time to changes in the problem domain24,25,26.
Feature selection is one of the most important procedures in the data preprocessing phase in the construction of ML models, specifically when used with large-volume data that can include extraneous or merely duplicate information27,28,29. In feature selection, the various correlations that are relevant to the prediction outcome of a model are considered while eliminating the rest that is more noise. In choosing the most important variables, the model will be able to concentrate on the significant variables of the given dataset, which in turn helps to enhance its accuracies, prevent overtraining and decrease the costs of the algorithm computation30,31,32.
When it comes to the process of CO2 emissions prediction, feature selection is also a crucial step that defines what factors should be considered for the prediction, including industrial production, energy usage, transportation, and legislation. Some of the attributes include these, and the overall successful CO2 emissions prediction is strongly determined by the correct selection of features in the model33,34. Moreover, feature selection serves to decrease the noise level, which can help the ML algorithm detect the significant patterns associated with the features35. The feature selection methods used in this study, metaheuristic approaches, make certain that the key features are captured while at the same time minimizing the number of features captured. Furthermore, by applying feature selection, this study optimizes the dataset given to the Dual-Path Recurrent Neural Networks (DPRNNs) model such that the model only processes crucial information. This step is relevant, especially in environments where there are many features to analyze, and many of them may not be helpful in solving a given problem. Moreover, with skilled feature selection, all machine-generated predictions can be more interpretable by studyers and policymakers, indicating which factors have the greatest impact on CO2 emissions and how they can be addressed by certain policies36.
This approach, which teaches information preprocessing, noise filtering, machine learning, and numerous optimization strategies, is explained to create solid approaches to gauge CO2 emissions. This study is of great importance for climate change mitigation efforts on the international level because accurate forecasts contribute to the development of political, industrial, and economic strategies in response to greenhouse gas emissions. The correct projection of CO2 emissions is not only important for enhancing environmental performance but also can be a strong stimulus for economic growth due to potential investment in the effective use of resources and the creation of energy-saving technologies. This framework is designed as an approach that would help close the gap between Prediction and Action.
To this end, the Ninja Optimizer (NiOA) is used within this study study as the metaheuristic optimization algorithm to adjust the DPRNNs’ parameters. This means that NiOA is always equipped to harmonize between the efficiency of exploration and exploitation so that it does not stagnate on a local optimum, as this kind of model usually has a chance to end at the global optimum. NiOA, therefore, comes in handy in reducing such errors by allowing dynamic control of the model parameters. Slackness or oversights, as well as the level of accuracy of the model in its predictions. Metaheuristic algorithms such as NiOA are most beneficial when the optimization problem is characterized by many local optima, or is non-convex, so deterministic methods cannot provide the best solution. Thus, the multi-modal functions and the application of adaptive methods for the regulation of the search in NiOA make it an important factor that can contribute to the improvement of the DPRNNs in the task of CO2 emissions forecasting.
This study introduces a novel approach of combining the Dual-Path Recurrent Neural Networks (DPRNNs) with the Ninja Metaheuristic Optimization Algorithm (NiOA) to predict CO₂ emissions with less error. Unlike prior models, this technique integrates short and long-temporal function identification with a high-level optimization, so they do not get stuck at local optima. Key contributions include:
-
Novel integration: This paper integrates DPRNNs, with a novel method, NiOA, for the first time to increase the reliability of emissions forecasting.
-
Advanced optimization: NiOA shows better exploration and exploitation than JAYA, HHO, and SCA in avoiding the local optima traps.
-
Comprehensive preprocessing: Reduces noise with PCA and BSS and selects proper features with bNiOA that improve data quality and model performance.
-
Application-specific focus: Focuses on cement production emissions for which the global lowering of CO2 emissions can potentially create a significant impact: Uses improved datasets and new methods by employing static modeling for improvement.
-
Empirical validation: Sits atop the podium of robust models with the lowest error metrics as indicated by ANOVA and Wilcoxon tests.
-
Real-world adaptability: It has the feature of real-time CO2 monitoring, and its technique can be easily applied to other greenhouse gases crucial to global climate change policies.
This study is organized into several key sections that follow a logical flow, starting with an introduction to the global issue of CO2 emissions and the importance of developing accurate predictive models. The subsequent section provides an overview of prior work in CO2 emissions prediction, the use of machine learning, and optimization in the forecast. This literature review forms the background for the novel strategies applied in this study. In the present article, the materials and methods section explain the dataset used in the study, the selected deep learning models, and the metaheuristic optimization techniques incorporated.
In the proposed methodology section, the study explains the critical steps of data preprocessing, noise reduction using Blind Source Separation (BSS), and how the DPRNNs model is used for time-series forecasting of CO2 emissions. The integration of NiOA is also highlighted as an essential tool for fine-tuning the model’s parameters and improving performance. The subsequent section of experimental results then describes the results of feature selection and optimized DPRNNs, showing the effectiveness of the presented framework. Lastly, the conclusion and future direction section gives a summary of the study findings, as well as identifying areas for further studies.
Related studies
Carbon dioxide (CO2) is among the leading greenhouse gases comprising the largest warming and climate change percentage. CO2 is a greenhouse gas that is released by using fossil fuels for industrial uses or for transportation, burning forests, or as a result of many activities performed by human beings and because of all these, it remains in the atmosphere to emit heat back to the earth. Especially in the past few decades, the rapid increase in CO2 concentration in the atmosphere has attracted much attention in the scientific community regarding sources, effects and potential control options. To implement effective environmental policies, create efficient power systems and address COP agreements, including the Paris Agreement, timely and accurate CO2 emissions forecasting remains paramount. These studies illustrate the further development of analytical tools and optimization methodologies, such as machine learning and optimization, to address a complex system problem, which is CO2 emission reduction on a global scale.
In the study37, the authors address the critical problem of air pollution and environmental degradation through the emission of greenhouse gas (GHG) by presenting a mixed approach of machine learning and a mathematical model for prediction. This study acquires energy data and links Iran’s GHG emissions from 1990 up to 2018, including CO2, N2O, CH4, and Fluorinated gases. Using emissions estimation, nine algorithms are used, including ANN, AR, ARIMA, SARIMA, RF, and LSTM; the performance of the algorithms is tested using performance metrics. The values predict emissions up to 2028, and they also reveal higher efficiency when metaheuristic algorithms such as PSO and GWO are implemented in combination with the output of machine learning. The incorporation of PSO and GWO in the proposed machine learning framework increases the prediction accuracy by 31.7% and 12.8% compared to the individual machine learning methods. The study concludes that Iran’s GHG emissions targets will be over 1096 Mt/year by 2028, which supports the finding of the hybrid model.
In another study38, the authors consider an interesting approach towards reducing the role of fossil fuels and using renewable resources at the same time—the captured CO2 emissions are used for plant growth in the nearest greenhouses. This study aims to design a combination of a greenhouse system, an absorption chiller, and an Organic Rankine Cycle using high-temperature exhaust gases from the micro power plant. Exhaust in the system splits the generated CO2, which is then utilized to provide the right measure of CO2 necessary for the growth of plants inside the greenhouse as dictated by the standardized greenhouse CO2 norms. The system’s performance is studied in detail from energy, exergy, economic and environmental points of view. An artificial neural network integrated with the depth of the network is used to predict system response for two seasons, summer and winter, using climate data of 10 years. Following optimization, there was a 56% reduction in CO2 generation and the overall specific energy and exergy efficiencies of 47.3% and 36.6%, respectively. Also, the increase in the greenhouse harvest led to generating more than $23 4 million in net interest annually.
According to39, the construction industry has significant sustainability problems, especially related to concrete and its aggregates and additives; cement making is a major polluter, a waste generator, a destroyer of biodiversity, and a threat to human health. One of the solutions for these problems is using sustainable concrete that will utilize construction and demolition waste (CDW) as a replacement for natural resources. However, the amendment of new solid wastes, including supplementary cementitious materials, recycled aggregates and geopolymers, creates concrete design complications that could not be addressed by traditional linear regression models when evaluating multi-level material systems. I systematically review the application of artificial intelligence (AI) in evaluating sustainable concrete, particularly mixture ratio, static performance and durability. The result remains consistent with the need to establish an elaborate database that covers the material composition and curing conditions crucial for defining the generalizability of the predictive equations. Machine learning (ML) models, which account for multicollinearity, can optimize concrete mixtures and predict performance, while feature importance analysis helps to uncover the influence of input variables and address the “black box” issue inherent in AI models. Further, the article presents the weaknesses of the existing study and the ideas for their improvement. Algorithmic and performance-based details and evaluation of sustainable concrete structures.
In the study40, an integrated model based on mixed-integer linear programming is proposed and applied to economize water and energy in buildings and estimate economic and environmental performances. It uses twelve machine learning algorithms to predict both the cost optimization and the reduction of carbon emission, with an accuracy of between 0.8 and 0.96 for cost optimization and between 0.79 and 0.91 for carbon emission reduction. The Extra Tree algorithm comes closer to the Light Gradient Boosting Machine, which displays the highest accuracy. Data dimensions were reduced using Principal Component Analysis (PCA), which slightly decreased prediction accuracy. Stepwise Regression determined the parameters influencing performance, and the overall model generally achieved low prediction errors for many geographical areas essential for sustainable resource utilization. Another study41 proposes a novel LSTM and MVO-based intelligent hybrid model to forecast and investigate air pollution due to the Combined Cycle Power Plants with special reference to NO2 and SO2 emission concentrations. Specifically, the LSTM acts as a reconnaissance model, whereas the MVO improves the LSTM fundamental parameters to yield reduced forecast mistakes. The plain real data set was from a Combined Cycle Power Plant in Kerman, Iran, including wind speed, air temperature, and NO2/SO2 emissions for five months. The examination of two input parameters forms the following hypotheses. The current study examined two input parameter types and showed that the proposed LSTM-MVO outperformed benchmark models ENN-PSO, ENN-MVO, and LSTM-PSO and had higher accuracy in various inputs.
This study42 focuses on carbon dioxide (CO2) emissions, a major source of atmospheric pollution and global warming, by investigating the solution of carbon geological sequestration (CGS) in saline aquifers. It shows that reliable identification of critical trapping efficiency indexes – residual-trapping index (RTI) and solubility-trapping index (STI)–is very problematic when relying on standard simulations. To improve prediction accuracy, the study develops six hybrid machine-learning models (HML) that integrate least-squares support vector machines (LSSVM) and radial basis function neural net study (RBFNN) with three optimization algorithms: other optimization techniques which are similar to the proposed model include genetic algorithm (GA), cuckoo optimization (COA), and particle swarm optimization (PSO). The current study, using 6810 records of geological formation simulation datasets, suggests that HML models greatly surpass standalone machine learning models, with the LSSVM-COA model having the lowest root mean square errors of 0.00421 for RTI and 0.00067 for STI. The analysis also shows that residual gas saturation and permeability are among the most sensitive variables in the model. In conclusion, the HML-based approaches for prediction achieve even higher accuracy, which can significantly diminish the level of uncertainty that CGS projects face.
As pointed out by the authors in the study43, conducted energy has high implications in hospitals due to high operational costs, technologies, advanced equipment, sanitation standards and compliance with environmental conditions in both weather conditions. In the course of the conducted study done on two different climate zones of Turkey, Aksaray and Bursa, 1440 different scenarios were formulated and developed using building elements available in Revit BIM software. Such scenarios included differences in the thermal transmittance coefficient values, solar heat gain coefficient values, and building orientation angles. The study used machine learning models for the prediction of energy consumption, carbon dioxide (CO2) emissions, total expenditure, and the life cycle cost of the building. Thus, despite the great variety of options for using various types of building materials in the Revit BIM library, the practical testing of such materials during construction is carried out only with a narrowly selected list of options. The purpose of this study is as follows: to minimize the use of computer drafting or energy calculating programs and to reduce an estimation time for energy consumption and CO2 emissions as well as the overall lifecycle costs in such similar architectural settings under such same climatic conditions. When it comes to all the tested machine learning algorithms, the one that was characterized by relatively high proximity between the algorithms’ output and actual values was the artificial neural net study. The R-squared (R2) values, a critical metric for evaluation, yielded promising results: In this study, energy R2 values of 0.95, total cost achieved values of 0.93 and 0.97, CO2 emissions of 0.94 and 0.97, and life cycle costs of 0.95 and 0.94 for validation and test datasets, respectively were identified. These results suggest that the success obtained can be applied to data from all the regions in the country. In addition, the applied model angular dependency is used to identify energy consumption, costs, and CO2 emissions based on the TH values determined according to TS 825 in Turkish and building orientation angles.
The study described in44 aims to analyze the use of ML models to investigate committed environmental processes marked by high relative temporal and spatial dynamics. The current study aims to examine the performance of three categories of ML regression models, namely classical regression models, models of shallow learning and models of deep learning in estimating soil GHG emissions from an agricultural field. We used a five-year record of Enterprise survey mean weekly CO2 and N2O emissions and environmental, agronomic, and soil characteristics in a study conducted in Quebec, Canada. By comparing the statistical significance and cross-validation for predicting both CO2 and N2O flux, it was demonstrated that the Long Short-Term Memory (LSTM) model provided the highest R coefficient and the minimum RMSE compared to other loglinear considered ML models. Importantly, the accuracy of the LSTM model was higher than that of the biophysical-based Root Zone Water Quality Model used in prior study. Cyclical and seasonal characteristics of CO2 and N2O fluxes were well described by the classical regression models such as Random Forest, SVM, and LASSO, with the determination coefficient, R = 0.75 for CO2 and R < 0.25 for N2O peak; however, the peak N2O flux values were not predicted well. The shallow ML models showed fairly poor performance in predicting the GHG fluxes compared to other categories of ML algorithms, whereby the CO2 flux (R < 0.7) and N2O flux (R < 0.3). More broadly, this piece of study, which presents a comparison between the LSTM model and previous study, indicates that the LSTM model proposed in this study can also be applied to simulate agricultural soil GHG emissions within a certain accuracy range, which provides a new idea for the application of machine learning methods in GHG emissions prediction.
In the study45, the authors discuss the environmental problem of decreasing CO2 emissions from fossil fuel-fired power plants, wherein solvent-based post-combustion capture (PCC) technology is highlighted as critical to solving these emissions. The study presents the development of various machine learning models, including a fine tree, Matérn Gaussian process regression, rational quadratic, and squared exponential, which are compared against a feed-forward artificial neural net study model. Interestingly, the models demonstrated quite high accuracy in approximating the output of the PCC unit, which ranged from 98%. Additionally, machine learning models were employed to identify optimal operating conditions for the process, utilizing sequential quadratic programming and genetic algorithm (GA) optimization techniques. To this respect, the authors point out the benefits that can be gained in terms of machine learning while, at the same time, the complete mechanistic model is too cumbersome and time-consuming for asking for and receiving efficient optimal solutions. Some input variable parameters included reboiler duty, condenser duty, reboiler pressure, flow rate, temperature and flue gas pressure. The performance of all the models in predicting critical process outputs, including SER, CR, and PU of the condenser outlet stream, was an indication that the application of machine learning can greatly improve the efficiency of the PCC processes.
In the study identified as46, the authors present a multi-stage methodology aimed at efficiently predicting carbon dioxide emissions, focusing on two critical factors: energy use, on the one hand, and economic development, on the other hand. Data classification is done using self-organizing map clustering methodology, establishing individual cluster prediction models using adaptive neuro-fuzzy inference systems (ANFIS) and artificial neural net study (ANN). The approach is based on the several input variables associated with economic development and energy utilization in Group 20 countries. To improve the model, singular value decomposition is employed to condensation dimensions and predict the zero values in the data set. The findings also show that the chosen indicators allow for accurate prediction of carbon dioxide emissions using the multi-stage methodology offered by the authors. By comparing the result with that of other studies, it has been identified that the interconnection of ANFIS with ANN using the self-organizing map and singular value decomposition results in an MAE accuracy of 0.065. Notably, when comparing the SVD-self-organizing map-ANFIS with the SVD-self-organizing map-ANN method, it results in a better accuracy of 0.104 in the CO2 emissions prediction. Additionally, the low accuracy of MLR was obtained (accuracy is 0.522) compared to the improved machine learning methods used in this study. Thus, the results pointing at the need for increased awareness of the relationship between economic development, CO2 emissions, and energy consumption gain the special emphasis that is necessary for formulating the energy and, in fact, economic policy for the countries that are members of Group 20 that are mostly aimed at the formation of the global economic governance.
As described in the study47, the authors examine the highly significant percentage that the building sector makes up within the global CO2 emissions in relation to energy use, with figures indicating that the sector used to take up to 50% of the emissions. This context shows why the sector is rather critical in the fight against decarbonization worldwide. This study discusses and compares different methods of ML techniques to forecast the CO2 emissions from buildings through 2050. The analyzed methods are linear regression, ARIMA, shallow neural net studies, and deep neural net studies; both univariate and multivariate modeling were used. Further, we identify that various extract features are used in this case, including lagged values and polynomial transformation. The analysis covers a broad range of regions of the world, including Brazil, India, China, South Africa, the United States, Great Britain, the world average, and the European Union. Several assessments are performed to assess and analyze the accuracy of these ML methodologies and to make useful recommendations on how CO2 emission forecasting in the building sector can be optimized.
The study presented in48 analyses the critical problem of carbon emissions in the Yellow River Basin, which is an essential ecological and economic area in China. Considering this basin is important for achieving the country’s peak carbon goals, the studyers use the quadratic assignment procedure-regression analysis to analyze carbon emissions and pay a special focus on the disparities in regions. To improve forecasting precision, a new machine learning model with LSTM associated with the sparrow search algorithm for carbon emission prediction has been developed. The study helps expose an alarming increase in carbon dioxide emissions within the Yellow River Basin accompanied by distinct provincial disparity. Most importantly, the carbon emission intensity was reduced, showing a gradual decline. Also, carbon emissions are said to be below one-tenth of those of Shandong, which is the highest emitter in the country. The study shows how GDP per capita emerged as the key determinant for carbon emissions between 2000 and 2010, while the population level became predominant after 2010. Most notably, the present proposed LSTM model greatly improves the predictability ratio by a mean absolute percentage error of 44.38% less than that of the normal LSTM study. This study is relevant in income as it unveils crucial information on formulating proper emission reduction policies given the Specifications of the Yellow River Basin.
Based on the study done in49, the authors focus on the challenges inherent in the enhancement of thermal efficiency of hydrogen production processes to reduce the emission of carbon dioxide (CO2). At the present time, the most preferred method in hydrogen production is steam methane reforming, which is famous for its CO2 emissions. This study focuses on the second problem of low-carbon hydrogen production, considering both overall thermal efficiency and CO2 emissions. To this end, a novel deep neural network is proposed, which is integrated with the optimization algorithm to improve its stability. This model is linked to a multi-objective particle swarm optimization algorithm that employs dominated solutions. Optimized solutions, obtained by experimental results, are Pareto optimal, with thermal efficiency between 77.5% and 87.0% and CO2 emissions varying between 577.9 and 597.6 tons per year. Also, the Pareto-optimal front’s analysis gives decision-makers multiple proportional solutions that consider various operations’ characteristics. The results obtained in this study can be beneficial for further development of recommendations aimed at increasing the efficiency and flexibility of processes of hydrogen production.
In the study discussed in50, the authors focus on the problem of global economic growth as an activity that causes more and more degradation of long-term planetary sustainability, providing examples of the relationship between increased levels of economic development and the concentration of anthropogenic greenhouse gases, CO2 in particular, that lead to a growth of the planetary heat load and are damaging to both the natural environment and society. That is why classic methods of predicting economic indicators and CO2 emissions using a neural network often encounter drawbacks such as gradient disappearance or explosion, which can result in forecasts being inaccurate. In order to compensate for these challenges, this study presents a new prediction model that will incorporate RESNET, a residual neural network that has been developed to improve the energy structures of a country or region in the entire world. The RESNET adapts incorporation of skip connections within its inner residual blocks since deeper neural networks cause vanishing gradient issues, hence assisting the model in retaining the input data by passing a few of them directly. It leads to higher predictive precision in this optimization. The basic economic model of the study employs information on 24 different countries or regions’ demand for natural gas, hydroelectricity, oil, coal, nuclear energy and renewable energy from 2009 to 2020. In this frame study, the undesired output is CO2 emission, whereas the desired output is the per capita GDP of the country. Experimental results show that the proposed RESNET has better accuracy and function performance than traditional CNN, RBF, ELM, and BP approaches. Moreover, the model presented can be utilized as a reference and development pattern for areas with low rates of energy efficiency, promising to improve energy performance, contribute to economic progress and provide more efficient regulation of CO2 emissions.
In the analysis made in51, the authors stress that the growth of humanity is currently a global problem, although pollution of the environment and the dispersion of haze hinder its development. Past studies have established vehicle emission fumes as one of the main causes of environmental pollution and haze, as well as population growth resulting in a heightened number of vehicles with high energy demands. The study examines the viability of intelligent routing technology that draws from data to reduce the total carbon footprints of vehicles within a road network. Towards this urgently needed objective, the authors design a traffic flow prediction model based on a combination of a genetic algorithm and support vector regression improved by particle swarm optimization. This approach helps develop a model with the objective of estimating the amount of exhaust emission from vehicles while considering anticipated road conditions as well as fuel consumption. Next, a low-carbon-emission-oriented navigation algorithm was proposed based on a spatially optimized dynamic path planning algorithm. Detailed findings of the present study reveal that this proposed navigation strategy can notably minimize the total vehicular carbon emissions and can thus seek the establishment of low carbon emission ITS and towards the progress of the smart city.
The level of air pollution in India, in general, has been on the increase, as determined by the study done in52 on the climate and health impacts of air pollution. A major factor contributing to degraded indoor air quality in urban settings is carbon dioxide (CO2), which is generated in part by human activities. CO2 measurements and verification using conventional approaches can be expensive and cumbersome, oftentimes involving the use of complicated measurement instruments. To overcome these limitations, this study uses ML to predict the concentration of CO2 in offices. Measurements used in this study were real-time measurements, including CO2 Levels of the indoor environment, number of occupants, area per person, outside temperature, wind velocity, relative humidity, and Air Quality Index. A set of 10 algorithms, including artificial neural networks (ANN), support vector machines (SVM), decision trees (DT), Gaussian process regression (GPR), linear regression (LR), ensemble learning (EL) and their optimized counterparts, were used to forecast CO2 levels. The results demonstrated that the optimized GPR model outperformed the other models in terms of prediction accuracy, achieving impressive metrics with R, RMSE, MAE, NS, and a20-index values of 0.98874, 4.20068 ppm, 3.35098 ppm, 0.9817, and 1, respectively. This study provides valuable insights for designers, studyers, healthcare professionals, and smart city developers, enabling them to assess indoor air quality effectively and design appropriate air ventilation systems to monitor CO2 levels in buildings.
As lauded in the study conducted in53, the construction sector ranks among industries responsible for the emission of carbon dioxide (CO2), which has a vital effect on global warming. The reduction of the use of CO2 is very important, and incorporating new technologies can complement this cause. Therefore, this study aims to provide a critical analysis of the role of AI and ML in CO2 emission reduction in construction. An overview of practice approaches outlined in the literature is provided; the study seeks to offer meaningful information enhancing the development and coordination of construction enterprises. The study uses a systematic review approach and derives a dataset with 78 studies from the relevant literature search. The study approach applied both content analysis of information sources and simultaneous necessary analytical mapping of co-occurrence terms, co-authorship networks, and publication origins. The reviewed studies were categorized into five conceptual clusters: These subcategories are (1) sustainable materials and components design/production, renewable vehicles and equipment, (2) energy and life cycle assessment, (3) optimization, decision support, and solution platforms, and (4) field monitoring. Possible deficits in the current state of literature were determined in each cluster, which resulted in the presentation of directions for future study. This study fills the gap in the literature by providing suggestions about intelligent techniques that can help reduce CO2 emissions in the construction sector.
According to the study in54, the prediction of CO2 emissions is very significant in the promotion of China’s carbon peak and carbon neutralization strategy. This study proposes a new two-stage forecasting method with SVR, RF, Ridge, and ANN models as a way of conducting an empirical investigation. The approach is compared with a single-step forecasting method with a dataset of nine independent variables for the years 1985 to 2020. The results show that while “h” ranges between 1 and 8, the average RMSE and MAE of two-stage models, including SVR–SVR, SVR–RF, SVR–Ridge and SVR–ANN, are closer to zero and less than those of the single-stage models. Notably, the SVR–ANN model achieved the lowest forecast errors, while the SVR–RF model exhibited the highest errors. Specifically, the mean percentage reductions in forecast errors for RMSE between the two-stage and single-stage models are 36.06 for SVR–SVR vs. SVR, 5.98 for SVR–RF vs. RF, 43.05 for SVR–Ridge vs. Ridge, and 14.81 for SVR–ANN vs. ANN. For MAE, the reductions are similarly substantial, indicating the effectiveness of the two-stage procedure. In addition, this methodology is considered suitable for forecasting other variables like the consumption of fossils and renewable energy sources, making it useful in a variety of energy and environmental analyses.
According to the study conducted in55, the authors argue that the transportation sector has a bad impact on emission levels and the economic growth of developing countries. Today, the transportation sector continues to depend on fossil fuels for over 99% of its energy supplies; this leads to about six and a half million deaths per year from the effects of air pollution diseases worldwide. There is a need for more knowledge concerning the energy demand and additionally CO2 emissions in a particular country to alter future energy investments and policies. In this regard, three machine learning techniques, deep learning (DL), support vector machine (SVM), and artificial neural network (ANN), are used to predict transportation-based CO2 emissions and energy demand in Turkey. The independent variables that have been used for the analysis are GDP per capita, population, vehicle kilometers and year. The results reveal a highly positive relationship between the year of investigation, economic factors, population, vehicle kilometers traveled, transportation energy consumption, and CO2 emissions. For a comprehensive comparison, the results from these algorithms are evaluated using six commonly used statistical metrics: R2, RMSE, MAPE, MBE, rRMSE, and MABE. The R2 values for all machine learning algorithms range from 0.8639 to 0.9235, with RMSE values remaining below 5 × 106 tons for CO2 emissions and 2 Mtoe for energy demand. According to established classifications, the forecasting results are generally deemed “excellent” for the rRMSE metric (less than 10%) and exhibit “high prediction accuracy” for the MAPE metric (also less than 10%). Furthermore, two mathematical models are utilized to project future energy demand and CO2 emissions from the transportation sector in Turkey up to the year 2050. The results suggest an annual growth rate of 3.7% for transportation-related energy demand and 3.65% for CO2 emissions. By 2050, both energy demand and CO2 emissions from the transportation sector in Turkey are expected to be nearly 3.4 times higher than current levels. This study underscores the necessity for policymakers to adjust the next energy commitments and develop different policies, regulations, and measures regarding energy consumption and emission reduction in the transportation sector.
The study in56 addresses the issue of CO2 emission prediction with reference to climate change, industries, and the COVID-19 impact. The authors use four Seasonal Autoregressive of Integrated Moving Average (SARIMA) models to provide estimates of global total CO2 emissions for one or more periods from the year 2022 to 2072, particularly in the post-COVID-19 era. Evaluating the data by the mean absolute percentage error (MAPE) to measure accuracy, the post-COVID model got the lowest figure of 0.09, thus confirming the application of the model in emissions forecasting. The forecast of CO2 emissions over 2022–2027 amounts to 36,218.59 million tons to 37,921.47 million tons. The results align well with the Intergovernmental Panel on Climate Change model, suggesting that these forecasts could inform policies aimed at CO2 reduction. The study also suggests the direction in which other inflation determinants could be included in future study to improve prediction results.
As highlighted by the authors in57, the transport sector plays a central role in the growth of many countries’ economies, though the emission of pollutants in the atmosphere, especially in developing countries, is well known. Persistent reliance on fossil fuels and excessive emission of greenhouse gasses, particularly carbon dioxide (CO2) emissions caused by the combustion of fossil-fueled vehicles, requires countries to acquire detailed knowledge of these emissions in order to aid their future energy policies and investment plans. Using three machine learning methods, namely ordinary least squares regression, support vector machine, and gradient boosting regression, this study estimates transport-related CO2 emissions while utilizing socio-transport features. There are 30 countries selected for the analysis: the first emission tier, including the five highest emission countries, which are responsible for 61% of global CO2 emissions, and the second emission tier, including the 25 next countries, which are responsible for 35% of total emissions. Employing four-fold cross-validation, a number of statistical measures of model performances such as R2, MAE, rRMSE, and MAPE are estimated. The results reveal that the GBR model, which integrates socioeconomic and transportation features (GBR_ALL), demonstrates the best performance, achieving an R2 of 0.9943, rRMSE of 0.1165, and MAPE of 0.1408.
Table 1 presents an overview of previous studies in the domain of employing ML, optimization algorithms, and the integration of both sides to predict and forecast/suppress GHG discharge across various segments. The studies address issues related to environmental concerns, including air pollution, green construction, energy utilization, and CO2 capture using techniques like ANN, SVM, and LSTM. Climate change help improve modern prediction models and thus supports the development of strategies for emission reductions by increasing the efficiency of emission forecasts, increasing the effectiveness of energy use, and offering the most suitable solutions in terms of the specific requirements of the sectors, including energy and construction sectors, the transportation sector and so on.
CO2 is a significant contributor to global greenhouse gas emissions and is widely recognized as a key driver of climate change. Its emissions primarily result from human activities such as burning fossil fuels for energy, industrial processes, and deforestation. As illustrated in the table, many studies focus on developing advanced machine learning models and optimization techniques to predict, monitor, and reduce CO2 emissions across various sectors, including energy production, construction, and transportation. Accurate prediction models, such as those using neural networks and hybrid approaches, are essential for informing policy decisions and enhancing the efficiency of carbon mitigation strategies. These models help identify the most critical factors influencing CO2 emissions, allowing for more targeted interventions to reduce atmospheric concentrations of this harmful gas. The integration of renewable energy, sustainable materials, and optimized energy systems plays a crucial role in the global effort to curtail CO2 emissions, ensuring a more sustainable and climate-resilient future.
Materials and methods
In this section, the following aspects of study are explained: the dataset used for the analysis in order to predict CO2 emissions, the deep learning models used to perform this analysis, and the meta-heuristic optimization techniques used to optimize the models used in the studies.
Dataset
The data set utilized in this study focuses on cement production data as an essential driver of CO2 emissions, given the high carbon footprint of cement industries. Most of the data was extracted from the United States Geological Survey (USGS), and some historical data was collected from the Carbon Dioxide Information Analysis Center (CDIAC). The basic data were received with the help of the CDIAC database of the year 2019. More input records were sharpened for Soviet states before the dissolution of the Soviet Union. By using the USGS data, a control point was established as to what was from 1990 onwards; minor adjustments had to be made, though, due to slight inconsistencies. Whenever the cement production data of the recent past were not available, a simple interpolation method was used to maintain a filled dataset. By using this approach, the studyers were able to develop a sound continuous data set that was vital in the emissions prediction. The obtained dataset was collected from Kaggle, an open-source platform, which serves to increase its relevance for environmental studies.
Cement is one of the most important sources of direct CO2 emissions since the process of cement-making involves the use of limestone (calcium carbonate) to generate clinker with the emission of large volumes of carbon dioxide. Therefore, the dataset acts as a mirror image of industrial activity while providing an estimate of national emissions in countries where other emission data might be scarce. The method of back-calculating and adjustment of the dataset provides a comparison of historical data and the current levels of production, thus providing a good picture of trends in emissions across various parts of the world. The dataset is sourced from an online repository available at https://www.kaggle.com/datasets/nooteboom/global-CO2-cement-emissions.
Metaheuristic optimization
In fact, the performance of the developed machine learning models, including time series forecasting, depends on the choice of appropriate temporal parameters. For optimal tuning of these parameters, the study used several metaheuristic algorithms. The metaheuristic optimization methods are especially favored for large and multidimensional tasks where the use of simple optimization approaches is either unadvisable or leads to excessive computation time. In this study, the main optimization technique used is the Ninja Optimizer Algorithm (NiOA). NiOA balances exploration and exploitation phases in the search process to avoid local optima. on the one hand, for new solutions across a range of options and, on the other, for better solutions, taking it from an explored region of the solution space. This balance is important in order to prevent getting locked into local optima—solutions that, on the surface, look like the best ones but are, in fact, suboptimal at the global scale.
Several sample metaheuristic algorithms were used for testing purposes to compare the performance of NiOA. The financial nature of the problem means that it needs a mathematical method to guide the optimizer in the solution space; the SCA, which is based on trigonometric functions, sin/cosines, enables the optimizer to find new areas in the solution space as well as refine the areas that have been revisited. Harris Hawks Optimization Algorithm (HHO), which relies upon the hunting behavior of Harris Hawks, incorporates new strategies for converging towards optimal solutions. This behavior replicates natural conditions where certain animals catch others more effectively within certain conditions that are met to get a better result that will benefit the survival of the hawk. Finally, the JAYA algorithm is a basic but quite efficient optimization algorithm whose objective is to improve solutions that are near the more efficient candidates and, conversely, to move away from the inefficient ones. The optimality of such an approach derives from the fact that it eliminates the need for complex calculations, ensuring that it is computationally inexpensive and highly efficient. These optimization methods, as different in their functionality, aim to fine-tune the machine learning models employed in the study58.
Deep learning models
In this work, the task of emission estimation using cement production data consisted of models that would reflect temporal aspects and complexity of the data. Several deep learning architectures were used each due to their different characteristics in handling sequential data and thus capturing short term changes as well as long term trends.
The primary model was Dual-Path Recurrent Neural Networks (DPRNNs) since it can directly handle both short and long-term relativities of time series data. DPRNNs incorporate two distinct pathways: one that captures local patterns and another that captures broader trends, to give the model the ability to capture brief specific changes in emissions, such as diurnal or seasonal fluctuations, while also enabling the model to track large-scale industrial changes over the long term as well as policy changes. This double method of modeling supplies a better explanation of the input factors affecting CO2 emissions as well as enhanced temporal forecast59.
However, the authors also experimented with Traditional Recurrent Neural Networks (RNNs) in their endeavors. RNNs are built to keep a record of passed values because they are used in sequential or time series data. However, because of the vanished gradient problem, which hinders their memorization abilities over long sequences, their ability to capture long trends tends to be negatively affected. In order to overcome these constraints, Gated Recurrent Units (GRUs) were incorporated into the current analysis. In GRUs, we add gating mechanisms that assist the model in the decision of which messages to remember and which ones to forget, enhancing long-term memory but, at the same time, ensuring computational effectiveness. GRUs are especially significant for those cases when the model must work with both recent and older data while not implementing more complicated models60.
LSTM Networks was also used because of its capability of handling long-term dependencies on sequential data, as widely documented in previous studies. LSTMs utilize a system of gates to regulate the flow of information, thereby capturing important patterns in the data for the long term. This makes them suitable for processes such as CO2 emissions, where past industrial experience and policy continue to affect future emissions for longer periods. The use of these models enables this study to cover a cross-sectional of time-series forecasting methods, with DPRNN having the best performance. Favorable outcomes because of its complex design and its capacity to address both unit and cumulative evidence in the shortest possible timeframe61,62.
Combined, the dataset, optimization approaches, and deep learning models generate a paradigm enabling them to achieve successful predictions of CO2 emissions that can prove valuable for policy and industrial decision-makers interested in decreasing their negative influence on the environment.
Proposed methodology
The proposed methodology presents a systematic approach for accurately predicting CO2 emissions by leveraging advanced data processing and machine learning techniques. As shown in Fig. 2, the structure starts with the collection and preparation of the raw and unstructured Global CO2 Emissions Dataset from several sources from all around the world. It may contain missing values or noise, which will affect the effectiveness of the models because the current dataset can be noisy. Thus, the strategy for the treatment of results starts with intensive data preparation, which is the first section of the methodology. This phase helps keep the data unadulterated and of a high standard, which is more helpful for further preparation. Some of the common tasks carried out under data preprocessing are as follows: dealing with missing values, scaling of values, dealing with outliers, and making sure that data values of all input features are consistent. This is important in shaping the input dataset to the type that is appropriate for the other parts of the framework.

Framework for CO2 emissions prediction using NiOA-DPRNNs model.
After the dataset gets preprocessed, several additional processing steps are exercised in order to proceed with the final and necessary noise reduction steps to increase the quality and credibility of the dataset. These techniques include Copula, PCA, BSS, and a second PCA, which is applied after the BSS. The Copula method used in this study is helpful in modeling the dependency relations among the variables, while the PCA, on the other hand, is useful in data dimensionality reduction. BSS is then used to isolate the independent sources from the mixture of signals in the dataset so as to get the best and cleanest source possible. The second extraction of the PCA carried out after BSS aims to purify the dataset further from any unwanted information. These measures act together to help mitigate interference and noise and regularize the input data set in general, therefore making it better suited for machine learning.
Subsequent to the data pre-processing and noise reduction, the cleaned data is used to train the NiOA-DPRNNs model, which is a dual-path recurrent neural network fine-tuned using NiOA. This particular type of machine learning model is selected because it can recursively look for short-term and long-term temporal patterns that would be helpful in time-series forecasts, such as the prediction of CO2 emission over time. In the NiOA-DPRNNs model, DPRNNs provide two parallel pathways, which include modeling two disparate temporal scales to boost the forecast performance. Ninja Optimization adds to the model in that it optimizes the parameters of the model so that it will be operating at an optimal capacity. Ninja Optimization, as a metaheuristic algorithm, updates the search distribution to search for the best parameter set, avoiding getting stuck at local optima and improving the model’s robustness across different datasets.
The last stage in the development of the presented methodology is using statistical analysis to confirm the effectiveness of the proposed model. After having computed the NiOA-DPRNNs model to predict future CO2 emissions, such prediction is statistically tested and validated in order to minimize any potential error. The statistical analysis involves things like mean squared error (MSE), root mean squared error (RMSE), and other forms of measurement that help determine the efficiency of the model predicted. By applying this stringent analysis, one is able to pinpoint the possible deviations as well as the possible sources of error within the predictions, hence improving the results given by the model.
Data preprocessing
Data preprocessing of the raw data is the first identified activity within the proposed framework. The raw and unstructured data, in this case, is in the Global CO2 Emissions Dataset, where all messy data has to undergo a thorough process of cleaning to reformat it to an analysis-ready state. This includes processing missing values, dealing with outliers, scaling and transforming values, and checking for data consistency. All these are crucial in the pre-processing of the data before feeding it to the noise reduction stage, as well as the machine learning algorithm. Data preprocessing helps the model not to make errors and uncertainties that will, in one way or another, affect its outcome. Therefore, this phase allows the input data to be not only accurate but also relevant to the occurrence of the trends, which ultimately improves the accuracy of the predicted CO2 emissions.
In the data preprocessing phase, Principal Component Analysis (PCA) and Blind Source Separation (BSS) were utilized for noise reduction and feature optimization. PCA was configured to retain components that captured at least 95% of the dataset’s variance, resulting in the selection of 15 principal components out of the original feature set. This threshold was chosen to ensure a balance between dimensionality reduction and information retention. Following PCA, BSS was applied to extract independent signals, with its parameters tuned to maintain a mutual information score below 0.01, ensuring minimal overlap among the separated components. These steps ensured a refined and reproducible feature set for downstream analysis.
This building block, as shown in Fig. 3, depicts and compares the trend in CO2 emissions from the ten largest emitters in the world. The figure also displays differences in emissions between the countries and whether the emissions have risen, sank, or remained constant. This analysis is useful in determining specific sectors and countries that have the greatest responsibility for contributing to the global level of CO2 emissions and also in creating more specific approaches for making concrete efforts to lessen emissions in high-emitting zones. The figure achieves this by capturing the trends and patterns in the map, enabling a determination of past and future emission trends for the world’s biggest emitter based on the policies formulated.

CO2 emissions for top 10 emitters over time (cumulative data).

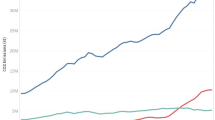
Global CO2 emissions over time.
Figure 4 presents the time series analysis of global cooperative carbon dioxide emissions in GCP, providing a general view of the emissions growth or shrinkage at the macro level around the world. This figure is important to examine the extent of climate change that is influenced by human interactions as well as the interacting consequences of emissions coming from different areas. This figure allows studyers to identify historical trends in emissions, determine the progress towards reaching global climate objectives (e.g., the Paris Agreement), and use trends as a basis for estimating future global emissions. Knowledge of emissions distribution is crucial to developing successful local and international strategies meant to address climate change.
Blind source separation (BSS)
Blind Source Separation (BSS) is one of the major approaches utilized in the improvement path in the proposed methodology to unpack combined signals or data inputs with no original signal information. Specifically, for the predictive analysis of CO2 emissions, BSS is used for the extraction of latent coherent features from the given set of data that may be contaminated with noise or overlapping. This technique can prove especially powerful when the data is not clear and observable, contradictory, or contains masked relations.

Comparison of original data, PCA components, ICA components, and BSS components for signal separation.
When using BSS, the sources of the emissions data are differentiated clearly, which is very important in enhancing the accuracy of the next employed machine learning models. BSS improves the general data set by filtering out the noise and isolating separate sets of attributes that are unique and capture different causes of CO2 emissions. In cooperation with other methods, like PCA and Copula, BSS contributes to the prediction model inherently after providing clean and safe data.
Finally, comparable data for the Core dataset before the application of different methods and after the application of the Dimensionality Reduction and Separation techniques, namely PCA, ICA, and BSS, have been shown in Fig. 5. The figure shows how each of the techniques is useful in extracting desired elements from the dataset. To be precise, while PCA aims at reducing dimensionality and considering only the important features, and ICA tries to provide the statistically independent components, BSS is aimed at providing a clearer view of the original sources of the mixed signals. This comparison shows how BSS outperforms in decoupling separate signals as an important step in data preparation for enhancing the prediction of CO2 emissions.
Dual-path recurrent neural networks (DPRNNs)
Dual-Path Recurrent Neural Networks (DPRNNs), the Mean of using predictors to achieve high accuracy of predicted CO2 emissions, is considered one of the strategic advancements of the proposed methodology. This highly developed architecture is designed to address these challenges inherent in the time series datasets: data containing oscillations in the short term and trends in the long term, for example, the dataset of CO2 emissions across different countries. Unlike traditional Recurrent Neural Networks (RNNs) that struggle with retaining long-term dependencies due to issues like vanishing gradients, DPRNNs address these challenges by employing two distinct pathways. Specifically, the current design consists of two RNNs that process the dependencies of short and long durations, respectively. Such a structure enables the model to function well in handling temporal relations concerning different time scales.
The short-term pathway of the DPRNN highlights the fact that it abstracts from modeling the smallest integer data values plus fewer ones. This is particularly important when estimating CO2 emission rates since day-to-day activities, which elicit industrial activity, seasons, or energy consumption hikes, may lead to regularly oscillating figures. Thus, long short-term memory is capable of representing such short temporal dependencies, which describe immediate changes in the system irrelevant to those that occurred in the past and will take place in the future but specify a profound effect on emissions in a short range.
On the other hand, the long-term signal pathway of the DPRNN is aimed at obtaining trend and pattern information that changes on a large time scale. These remain fixed long-term factors that determine the levels of emissions by affecting the economic development of the countries, changes in laws and policies, switching over to renewable sources of energy, and gradual fluctuations in industrial activity. However, by processing this type of long-term data, the DPRNN guarantees that the model takes into account such trends and is relevant to making long-term forecasts. This way, it became possible to maintain and shape the long-term dependencies, which is otherwise difficult in most RNNs used in practice.
The strength of the DPRNN is that it combines both kinds of dependencies in one model, offering the best view of data. This dual-path structure means that the model can take advantage of the immediacies and localized patterns at the same time as the broader, more general trends, which makes for better and more accurate predictions. For instance, the DPRNN can successfully detect short-term bursts of emissions triggered by temporary factors such as fluctuating energy demand in the winter and segregate it from long-term trends, including a progressive decline in emissions arising from the application of improved technologies or compliance with environmental legislation.
However, DPRNNs are most suitable where temporal data is important, like in the modeling of climate or the forecasting of CO2 emissions. In this study, the cleaned and noise-reduced data set is applied to DPRNN architecture to make predictions that retain short-term fluctuations and long-term trends. This is critical for accurate forecasting of future CO2 emission rates because it enables the model to evaluate not only the macro-level effects of recent changes but also the slow movements that define the emissions trajectory.
On balance, this framework of employing DPRNNs improves the overall point forecast capability of the model, which is valuable for providing effective and timely insights. In other words, DPRNNs allow the model to capture short and long dependencies of the data to ensure that the model can effectively depict the complexity of CO2 emissions and provide a precise short term and long-term prediction. However, it increases the role of DPRNNs in the identified methodology for effective CO2 emission forecasting.
Ninja optimizer (NiOA)
The Ninja Optimizer (NiOA) is a high-performance meta-heuristic optimization algorithm used in the framework to improve the performance of the Dual-Path Recurrent Neural Networks (DPRNNs). NiOA functions by adjusting the network parameters in a profitable manner in that they can both exploit the search space while also avoiding local optima while moving more towards the global optima. The primary components of NiOA are established by the displacement of the agents (potential solutions), their interactions with other agents, external random values, positions in prior time, and mathematical functions like cosine wave and exponential functions.
NiOA relies on a set of control parameters to regulate the exploration and exploitation processes. These parameters include \(\:a\), a random integer between 6 and 10, as well as factors like \(\:{v}_{1}\), \(\:{r}_{2}\), \(\:{r}_{3}\), \(\:{J}_{1}\), \(\:{J}_{2}\), and \(\:n\), Each of these operates within a defined range to influence different aspects of optimization. For example, \(\:{r}_{2}\) and \(\:{r}_{3}\)control random exploration movements while \(\:{J}_{1}\) and \(\:{J}_{2}\) are responsible for tuning the exploitation phase. The choice of these parameters provides the necessary adaptability and means that NiOA can be useful for a wide range of optimization tasks.
Exploration phase
In the exploration phase, the location of the agent \(\:{L}_{s}\) is updated based on the current and past positions, along with random factors that drive the search, as shown in Eq. (1). The position update equation incorporates a random factor \(\:{r}_{1}\), which allows the algorithm to explore new regions of the search space by calculating the difference between two positions at different times, \(\:{t}_{1}\) and \(\:{t}_{2}\). If the conditions are not met, the algorithm introduces randomness by selecting a new location from a predefined, allowing the exploration process to continue broadly. This mechanism ensures that the search covers a wide range of potential solutions, increasing the likelihood of finding the global optimum.
where \(\:{F}_{S}\) represents the fitness solution, ensuring the agent explores new positions effectively.
The position of another agent, \(\:{D}_{s}\), is updated through an equation that introduces periodic fluctuations using a cosine wave function, along with a random factor \(\:{r}_{2}\). This continuity enables the maintenance of variability in the agent substituting fixed value with γ, thus avoiding cases where the search is trapped within local optima. The cosine wave brings the cyclical behavior which allows the algorithm to go to new regions in a controlled manner which is like some biological systems, as detailed in Eq. (2):
The search process further integrates the updated locations of \(\:{L}_{s}\) and \(\:{D}_{s}\), enabling a composite search approach, as described in Eq. (3):
Exploitation phase
During the exploitation phase, the focus shifts from exploration to refining the solutions that have already been discovered. The algorithm uses a non-linear equation involving parameters. \(\:{J}_{1}\) and \(\:{J}_{2}\) to control the extent of exploitation, allowing for incremental improvements in the agent’s position. This phase is ideal for refining the solutions that are discovered in the exploration phase given the fact that algorithm fine tunes the result at this stage. The exploitation equation introduces non linearity that directs the optimizer to find local optima within the search space while driving the process towards the global optimum, due to small incremental steps.
The movement around the best solution is controlled by a non-linear equation, as shown in Eq. (4):
NiOA incorporates a resource or reward update mechanism to further refine the optimization process. This update is based on an exponential growth model that is influenced by a cosine function, introducing periodic growth in the resource or reward state. This periodic effect ensures that the optimization process remains adaptive and can respond to changing conditions during the search. The use of \(\:{J}_{2}\) as a control parameter allows for fine-tuning of the reward updates, adding another layer of precision to the algorithm, as represented in Eq. (5):
If the best solution has not changed for several iterations (usually 3), the NiOA applies an update equation that incorporates multiple terms, including the difference between the locations of agents \(\:{L}_{s}\) and \(\:{D}_{s}\), and the contributions from \(\:{M}_{s}\) and \(\:{R}_{s}\). This helps to ensure that the optimizer does not stagnate, as it forces updates to occur even when progress has slowed. The use of scaling factors \(\:i\) and \(\:n\), along with the contribution of parameter, adds flexibility to this update mechanism, allowing the algorithm to adjust its approach based on the current state of the optimization process. The updated search around the solution combines the refined values of \(\:{M}_{s}\) and \(\:{R}_{s}\) for better exploitation, as indicated in Eq. (6):
The optimization algorithm is fast and highly adaptive, known as the Ninja Optimizer (NiOA), and is designed to fine-tune the DPRNNs within this framework. Through a combination of random walks and fixed oscillations, as well as through non-linear adaptations and reward-based modifications, NiOA prevents the model from getting stuck and helps it manage a clearly divided search space. Such features as mutation strategies used, cosine functions, and dynamic parameter updates introduce certain levels of randomness and make the model resistant to local optima, ensure its fast transition to global optimum and predict the emissions of CO2 with very high degrees of accuracy.
Mutation
With NiOA, the author presents a mutation strategy to add an even greater level of diversification to the process. This entails a summation equation where signs change to form a type of non-linear mutation to the agent’s motion. Evidently, for this reason, the mutation parameter a is randomly taken within a range while its sign is preserved so that the magnitude of constructed mutations in two iterations is different. This strategy avoids the risk of making optimization too deterministic and gives the algorithm a chance to ‘break free’ from local optima and potentially find more promising regions of the search space.
So if the solution does not improve for three iterations, a mutation strategy introduces diversity by modifying the current solution based on multiple factors, as illustrated in Eq. (7):
Finally, the parameters governing the exploration and exploitation phases ensure the algorithm’s adaptability and efficiency, as outlined in Eq. (8):
Experimental results
The experimental results section thoroughly compares various optimization techniques and predictive models for estimating CO₂ emissions. The models’ performance was assessed using error rates, fitness values, and statistical analyses, underscoring their effectiveness and precision. An 80/20 training-validation split was adopted across all experiments, allocating 80% of the data for training to identify patterns and relationships. In contrast, the remaining 20% was reserved for validating performance on previously unseen data.
Before feature selection and model training, meticulous data cleaning and preprocessing were done to ensure the dataset’s integrity and reliability. Missing values were addressed through statistical imputation techniques, such as mean or median substitution, depending on the distribution of the variables. Outliers were identified using interquartile range (IQR) analysis and either capped or removed to prevent them from skewing model results. Numerical features were scaled and normalized to standardize input ranges, promoting stability during model training.
Feature selection results
In this study, the feature selection process utilized binary-based methods, with a strong emphasis on the binary Ninja Optimizer Algorithm (bNiOA) to streamline the input dataset. The primary objective was to isolate the most critical and consistently influential features for enhancing predictive accuracy while discarding redundant or irrelevant ones. The bNiOA algorithm excelled in this task by minimizing errors and optimizing fitness values, effectively identifying a concise yet highly informative subset of features.
The feature selection problem was modeled as a binary vector, where each element represented the inclusion (1) or exclusion (0) of a feature. This binary framework allowed for efficient feature selection by toggling vector elements based on probabilistic values. Continuous values were transformed into binary form using a sigmoid function, defined as follows:
At each iteration \(\:t\), the binary output was determined by the best feature value (\(\:{X}_{Best}\)) using the rule:
This method effectively converted continuous values into binary decisions, enabling the selection of an optimal subset of features that balanced minimal redundancy with maximum predictive relevance.
Table 2 shows the performance metrics for feature selection results, comparing nine different feature selection algorithms: bNiOA, bSCA, bHHO, bJAYA, bSSA, bPSO, bGA, bGWO, and bWAO. The following parameters are used to demonstrate the results obtained by the methods: average error, the size of the selection, average fitness, the best fitness, the worst fitness, and the standard deviation of the obtained fitness values. Specifically, for feature selection reliability, bNiOA shows the lowest mean of average error = 0.4829, meaning it provides the highest accuracy. However, bNiOA presents the smallest selection size of 0.4508 as well as a low standard deviation of fitness of 0.3835, which confirms its efficiency in contrast with the other approaches. These outcomes indicate that bNiOA is the most effective algorithm for addressing feature selection in this experiment.

Average error plot of feature selection results.
Figure 6 exhibits the average of the error percent for the feature selection results of the various algorithms. The graph also highlights how well the proposed bNiOA performs when compared to the other techniques as it has the least average error. This is also useful in visually analyzing the correctness of the algorithms used, and highlight that indeed, bNiOA > bPSO and bWAO as they demonstrate higher error rates than bNiOA.
Table 3 gives details of the ANOVA table on the performance metrics of the feature selection methods. The table also shows that there is a statistically significant difference in the results of different feature selection methods based on the F-statistic of 399.1 and p < 0.0001. From this, it can be inferred that the kind of algorithm used heavily influences the feature selection, and the most successful one has been bNiOA in the analysis of the variance. The residual values in the ANOVA table are also small enough, thus indicating a good fit for the model to the data.
Wilcoxon Signed Rank test results of feature selection performance metrics are presented in Table 4 below. The P-value from using the Wilcoxon test, a non-parametric test, is 0.002 for all the methods of feature selection, making the result statistically significant. The sum of signed ranks for bNiOA is higher than those for the other methods, which means that bNiOA is superior to the other analyzed methods in terms of error reduction and feature selection precisions.
The results of the feature selection methods in terms of performance metrics for the dataset are provided in Table 5 in terms of minimum, maximum, and median values. The dispersion of results for bNiOA is small, their variation ranging from 0.0036, and the median value of bNiOA is also close to the minimum and maximum values, which also suggests uniformity. The mean error for bNiOA, 0.4829, is still smaller than all methods, hence affirming its effectiveness. The standard deviation for bNiOA is also very small (0.0009), which further supports that the method is accurate and reliable in the selection of features with minimal error.
Figure 7 shows the residuals, homoscedasticity, QQ plots and the heat map of the feature selection models. The residuals are approximately equally dispersed. Thus, the models do not have the heteroscedasticity issue. By observing the QQ plot, it is clear that the estimated results are normally distributed, thus making the results credible.

Residual, homoscedasticity, and QQ plots and heat map for the feature selection models.
In terms of the performance analysis, a heat map is used to show all the basic statistics and orientation to the real performance of bNiOA in contrast to the other algorithms. The above figure also shows why bNiOA is the best feature selection method for future studies of aggressive behavior in children.
Optimized DPRNNs results
Table 6 contains the information about several deep learning structures such as DPRNNs, RNN, GRUs, LSTM, and MLPRegressor. The table also shows the Mean Squared Error (MSE), Root Mean Squared Error (RMSE), Mean Absolute Error (MAE) and correlation coefficient (r). DPRNNs give the lowest MSE of 0.0385 and the lowest RMSE of 0.0910, outcompeting all other models. The correlation coefficient, or r value for DPRNNs, is 0.9406, which, on any scale, can be classified as an excellent means of prediction. Besides, the current study has shown that DPRNNs have better computational efficiency, where the model has been fitted within a shorter time compared to the LSTM and GRU models, which are the most commonly used models.
Table 7 highlights the performance metrics results for the optimized DPRNNs using different optimization techniques: NiOA, SC, HHO, and JAYA. The NiOA-DPRNNs provide the greatest predictability with the overall lowest MSE = 0.0018, the minimal RMSE = 0.0294, and the maximal) r (= 0.9845. It clearly shows that the NiOA has greatly improved the DPRNNs over the other optimizers for achieving a higher level of accuracy in the models and, therefore, decreasing the overall prediction errors.
The RMSE graph related to optimized DPRNNs is shown in Fig. 8. From the figure, it can also be clear that the NiOA-DPRNNs always produce the least error rate, which supports the finding that the Ninja Optimizer is the best optimization technique for improving the DPRNNs model. This figure, to some extent, illustrates the amount of error reduction that can be accrued from NiOA optimization.

RMSE plot of optimized DPRNNs results.
Figure 9 describes the analysis of RMSE size when various optimization techniques are used on the DPRNNs model. NiOA is seen to be far better than other methods in terms of the RMSE values obtained. This figure demonstrates the superiority of NiOA over other optimization techniques, such as HHO and JAYA, in achieving higher model parameter tuning precision and, subsequently, higher accuracy of the predictions made on weather patterns.

Radar plot of performance metrics of optimized DPRNNs results.
Figure 10 provides a detailed breakdown of the optimized DPRNNs model across various configurations. The NiOA-optimized DPRNNs remain to indicate the lowest RMSE, hence proving that it is the best optimization algorithm without comparatives. This figure shows how parameters have to be tuned in an optimum way in order to reduce the inaccuracies in the predictions for the model.

Average error plot of feature selection results.
Table 8 shows the ANOVA of the optimized DPRNNs models for wind speed forecasts. The obtained F-statistic of 205.4 and a very low p-value of less than 0.0001, evidences towards a significant influence of the optimization methods on model performance. This indicates that NiOA elaborates a relatively significant enhancement over other optimization techniques and the ANOVA substantiated the statistical significance of the outcomes. A slight residual variance also speaks to the appropriateness of the fitted NiOA-optimized DPRNNs model.
In Table 9, the results from the Wilcoxon Signed Rank test for the optimized DPRNNs models are presented. This non-parametric test shows significant evidence that NiOA-DPRNNs outperform the other models at p = 0.002 across all configurations. The enhancement of signed ranks and other statistical measures summarizes how the effectiveness of NiOA can enhance the accuracy and reliability of DPRNN, thereby strengthening the existing proof against other optimization strategies.
Table 10 provides the original performance metrics of the chosen features and the optimized DPRNNs models in detail. As is seen from above, the range and standard deviation of NiOA-DPRNNs are the smallest of all, which can also prove that our method has been stable and precise in lowering the number of errors. The supplied and the expected nice values for NiOA-DPRNN are quite comparable. This depicts how accurate NiOA-DPRNN is in bringing out minimal prediction errors. The comparison of different kinds of confidence intervals and other statistical measures strengthens the claim about the effectiveness of NiOA in this regard.
Figure 11 illustrates the residuals, homoscedasticity, and QQ plots, as well as a heat map for the optimized DPRNNs models. The plots show a normal distribution of residuals, with no signs of heteroscedasticity, validating the statistical assumptions. The QQ plot confirms the normality of the data, while the heat map provides a clear summary of the performance metrics, highlighting the strong performance of NiOA-optimized DPRNNs in comparison to other optimization techniques. This visual analysis further supports the conclusion that NiOA is the most effective method for optimizing DPRNNs.

Residual, homoscedasticity, and QQ plots and heat map for the optimized models.
Figure 12 depicts the Kernel Density Estimate (KDE) plot for the Mean Squared Error (MSE) of the optimized models, offering a detailed view of the error distribution across various optimization methods. The KDE curve represents the density of MSE values, showing how frequently specific error ranges occur within the dataset. This visualization is instrumental in evaluating the consistency and reliability of the model’s performance by highlighting the spread and central tendency of error metrics across all trials. The peak of the KDE curve marks the most frequent MSE values, while the tails indicate areas of higher variability or potential outliers.

KDE plot of mean squared error (MSE) for the optimized models.
Figure 13 illustrates the density distribution of algorithm performance across different optimization techniques, providing a comparative analysis of their effectiveness. The curves represent performance metrics for JAYA-DPRNNs, HHO-DPRNNs, SC-DPRNNs, and NiOA-DPRNNs, with each curve’s shape and spread shedding light on the consistency and variability of the respective algorithms. Sharper peaks suggest more consistent performance, whereas broader distributions reflect greater variability. This comparative evaluation helps identify which optimization approach delivers the most stable and reliable results, guiding the selection of the most effective algorithm for predictive modeling tasks.

Density distribution of algorithm performance.
This study focuses on the improvement of CO2 emissions prediction by using advanced feature selection and optimization methodologies, and experimental results substantiate them. In regard to the reduction of error and enhancement of model accuracy, the NiOA performed better than other algorithms on average. To do this, the methodology merges NiOA with Dual-Path Recurrent Neural Networks, which strikes an optimal short-term/long-term trade-off, making the approach perform highly in time-series forecasting tasks. The performance of the models has also been further validated by employing the ANOVA test and the Wilcoxon Signed Ranks Test, which shows that the results are indeed statistically significant and greatly underlines the reliability of the optimized models. All in all, the proposed framework results in a precise way of estimating the total CO2 emissions and may become a useful tool for policy-making activities fabricating climate change critically.
Conclusion and future direction
This study effectively presents an enhanced approach integrating DPRNNs with NiOA for accurate CO₂ emissions prediction. With sound preprocessing methodologies such as PCA and BSS, the input data is preprocessed and filtered so that only the most helpful information for the model’s implementation is fed to the algorithm to model short- and long-term dependencies inherent in the emissions data. The experimental results show that the predictability of the model is very high (R² = 0.9736) and is more efficient than a conventional model. The ANOVA and Wilcoxon tests established the efficacy and accuracy of the proposed method, where intra-annual volatility and trends in future inflation rates and oil price scatter plots ultimately demonstrate the usefulness of the proposed technique for supporting climate policy and industrial goals of reducing the environmental burden.
Potential topics for extended studies involve further developing the proposed framework for other climatically active gases, including methane and nitrous oxide. Real-time data integration can add even more value to its application since emissions patterns can be monitored continually, and adjustments can be made as necessary. The model can also be fine-tuned, for example, in sectors like transport, agriculture and energy, to provide sector solutions. Also, linking the predictive framework with policy simulation models will enable a policy impact assessment in the long run. Studying the integration of NiOA with other metaheuristic algorithms will open up a way of increasing the NiOA efficiency and effectiveness of the model.
Data availability
A publicly available dataset was analyzed in this study. This data can be found here: https://www.kaggle.com/datasets/nooteboom/global-CO2-cement-emissions.
References
Yang, Z., Zhang, M., Liu, L. & Zhou, D. Can renewable energy investment reduce carbon dioxide emissions? Evidence from scale and structure. Energy Econ. 112, 106181. https://doi.org/10.1016/j.eneco.2022.106181 (2022).
An, S. I. et al. Intensity changes of Indian ocean dipole mode in a carbon dioxide removal scenario. NPJ Clim. Atmos. Sci. 5 (1), 1–8. https://doi.org/10.1038/s41612-022-00246-6 (2022).
Montoya-Vallejo, C., Guzmán, F. L., Duque, J. C., Quintero & Díaz Biomass and lipid production by the native green microalgae chlorella sorokiniana in response to nutrients, light intensity, and carbon dioxide: experimental and modeling approach. Front. Bioeng. Biotechnol. 11 https://doi.org/10.3389/fbioe.2023.1149762 (2023).
Lv, K., Cheng, Y. & Wang, Y. Does regional innovation system efficiency facilitate energy-related carbon dioxide intensity reduction in China? Environ. Dev. Sustain. 23 (1), 789–813. https://doi.org/10.1007/s10668-020-00609-0 (2021).
Rahman, M. M., Sultana, N. & Velayutham, E. Renewable energy, energy intensity and carbon reduction: experience of large emerging economies. Renew. Energy. 184, 252–265. https://doi.org/10.1016/j.renene.2021.11.068 (2022).
Sarkodie, S. A., Owusu, P. A. & Leirvik, T. Global effect of urban sprawl, industrialization, trade and economic development on carbon dioxide emissions. Environ. Study Lett. 15 (3), 034049. https://doi.org/10.1088/1748-9326/ab7640 (2020).
Cheekatamarla, P. Performance analysis of hybrid power configurations: impact on primary energy intensity, carbon dioxide emissions, and life cycle costs. Int. J. Hydrog. Energy. 45, 34089–34098. https://doi.org/10.1016/j.ijhydene.2020.09.269 (2020).
Xu, X., Wang, C. & Zhou, P. GVRP considered oil-gas recovery in refined oil distribution: from an environmental perspective. Int. J. Prod. Econ. 235, 108078 (2021).
Chen, Y., Li, Q. & Liu, J. Innovating sustainability: VQA-based AI for carbon neutrality challenges. JOEUC 36, 1–22 (2024).
Qader, M. R., Khan, S., Kamal, M., Usman, M. & Haseeb, M. Forecasting carbon emissions due to electricity power generation in Bahrain. Environ. Sci. Pollut. Study. 29 (12), 17346–17357. https://doi.org/10.1007/s11356-021-16960-2 (2022).
Karakurt, I. & Aydin, G. Development of regression models to forecast the CO2 emissions from fossil fuels in the brics and mint countries. Energy 263, 125650. https://doi.org/10.1016/j.energy.2022.125650 (2023).
Adebayo, T. S. et al. Economic performance of Indonesia amidst CO2 emissions and agriculture: a time series analysis. Environ. Sci. Pollut. Study. 28 (35), 47942–47956. https://doi.org/10.1007/s11356-021-13992-6 (2021).
Li, T. et al. Carbon emissions of 5G mobile networks in China. Nat. Sustain. 6, 1620–1631 (2023).
Zaki, A. M., Gaber, K. S., Rizk, F. H. & Mohamed, M. E. Machine learning approaches for malaria risk prediction and detection: Trends and insights. Metaheur. Optim. Rev. (1), 55–65. https://doi.org/10.54216/MOR.010105 (2024).
Tian, Y. et al. A deep-learning ensemble method to detect atmospheric rivers and its application to projected changes in precipitation regime. J. Geophys. Res. Atmos. 128, e2022JD037041 (2023)..
Ye, L., Xie, N. & Hu, A. A novel time-delay multivariate grey model for impact analysis of CO2 emissions from China’s transportation sectors. Appl. Math. Model. 91, 493–507. https://doi.org/10.1016/j.apm.2020.09.045 (2021).
Bakır, H. et al. Forecasting of future greenhouse gas emission trajectory for India using energy and economic indexes with various metaheuristic algorithms. J. Clean. Prod. 360, 131946. https://doi.org/10.1016/j.jclepro.2022.131946 (2022).
Javed, S. A., Zhu, B. & Liu, S. Forecast of biofuel production and consumption in top CO2 emitting countries using a novel grey model. J. Clean. Prod. 276, 123997. https://doi.org/10.1016/j.jclepro.2020.123997 (2020).
Khajavi, H. & Rastgoo, A. Predicting the carbon dioxide emission caused by road transport using a random forest (rf) model combined by meta-heuristic algorithms. Sustain. Cities Soc. 93, 104503. https://doi.org/10.1016/j.scs.2023.104503 (2023).
Sapnken, F. E., Hong, K. R., Chopkap Noume, H. & Tamba, J. G. A grey prediction model optimized by meta-heuristic algorithms and its application in forecasting carbon emissions from road fuel combustion. Energy 302, 131922. https://doi.org/10.1016/j.energy.2024.131922 (2024).
El-kenawy, E. S. M. et al. Greylag goose optimization: nature-inspired optimization algorithm. Expert Syst. Appl. 238, 122147. https://doi.org/10.1016/j.eswa.2023.122147 (2024).
Moayedi, H. et al. Forecasting of energy-related carbon dioxide emission using ann combined with hybrid metaheuristic optimization algorithms. Eng. Appl. Comput. Fluid Mech. 18(1), 2322509. https://doi.org/10.1080/19942060.2024.2322509 (2024).
Meng, S. et al. A robust infrared small target detection method jointing multiple information and noise prediction: algorithm and benchmark. IEEE Trans. Geosci. Remote Sens. 61, 1–17 (2023).
Abdollahzadeh, B. et al. Puma optimizer (po): a novel metaheuristic optimization algorithm and its application in machine learning. Cluster Comput. 27 (4), 5235–5283. https://doi.org/10.1007/s10586-023-04221-5 (2024).
Farag, A. A. et al. Exploring optimization algorithms: a review of methods and applications. J. Artif. Intell. Metaheuristics. 2, 08–17. https://doi.org/10.54216/JAIM.070201 (2024).
Aydın, Y. et al. Neural network predictive models for alkali-activated concrete carbon emission using metaheuristic optimization algorithms. Sustainability 16(1), Art. no. 1. https://doi.org/10.3390/su16010142 (2024).
Kong, F., Song, J. & Yang, Z. A daily carbon emission prediction model combining two-stage feature selection and optimized extreme learning machine. Environ. Sci. Pollut. Study. 29 (58), 87983–87997. https://doi.org/10.1007/s11356-022-21277-9 (2022).
Vu, H. T. T. & Ko, J. Effective modeling of CO2 emissions for light-duty vehicles: linear and non-linear models with feature selection. Energies 17(7), Art. no. 7. https://doi.org/10.3390/en17071655 (2024).
Akin, P. & Çemrek, F. A new experimental design to predict carbon dioxide emissions using boruta feature selection and hybrid support vector regression techniques. Int. J. Glob. Warm.. 32 (3), 296–308. https://doi.org/10.1504/IJGW.2024.136513 (2024).
Rizk, F. H., Elshabrawy, M., Sameh, B., Mohamed, K. & Zaki, A. M. Optimizing student performance prediction using binary waterwheel plant algorithm for feature selection and machine learning. J. Artif. Intell. Metaheuristics. 1, 19–37. https://doi.org/10.54216/JAIM.070102 (2024).
Naseri, H., Waygood, E. O. D., Wang, B., Patterson, Z. & Daziano, R. A. A novel feature selection technique to better predict climate change stage of change. Sustainability. 14(1), Art. no. 1. https://doi.org/10.3390/su14010040 (2022).
Ali, M. Z. et al. Advances and challenges in feature selection methods: a comprehensive review. J. Artif. Intell. Metaheuristics. 1, 67–77. https://doi.org/10.54216/JAIM.070105 (2024).
Zhou, J. et al. Cooperative prediction method of gas emission from mining face based on feature selection and machine learning. Int. J. Coal Sci. Technol. 9 (1), 51. https://doi.org/10.1007/s40789-022-00519-8 (2022).
Cesar de Lima Nogueira, S. et al. Prediction of the nox and CO2 emissions from an experimental dual fuel engine using optimized random forest combined with feature engineering. Energy 280, 128066. https://doi.org/10.1016/j.energy.2023.128066 (2023).
Aras, S. & Hanifi Van, M. An interpretable forecasting framework for energy consumption and CO2 emissions. Appl. Energy. 328, 120163. https://doi.org/10.1016/j.apenergy.2022.120163 (2022).
Artificial intelligence for. Reducing the carbon emissions of 5G networks in China. Nat. Sustain. 6, 1522–1523 (2023).
Emami Javanmard, M. & Ghaderi, S. F. A hybrid model with applying machine learning algorithms and optimization model to forecast greenhouse gas emissions with energy market data. Sustainable Cities Soc. 82, 103886. https://doi.org/10.1016/j.scs.2022.103886 (2022).
Nasrabadi, A. M., Malaie, O., Moghimi, M., Sadeghi, S. & Hosseinalipour, S. M. Deep learning optimization of a combined CCHP and greenhouse for CO2 capturing; case study of Tehran. Energy Convers. Manag. 267, 115946. https://doi.org/10.1016/j.enconman.2022.115946 (2022).
Wang, S. et al. Prediction and optimization model of sustainable concrete properties using machine learning, deep learning and swarm intelligence: a review. J. Build. Eng. 80, 108065. https://doi.org/10.1016/j.jobe.2023.108065 (2023).
Emami Javanmard, M., Ghaderi, S. F. & Hoseinzadeh, M. Data mining with 12 machine learning algorithms for predict costs and carbon dioxide emission in integrated energy-water optimization model in buildings. Energy. Convers. Manag. 238, 114153. https://doi.org/10.1016/j.enconman.2021.114153 (2021).
Heydari, A., Majidi Nezhad, M., Astiaso Garcia, D., Keynia, F. & De Santoli, L. Air pollution forecasting application based on deep learning model and optimization algorithm. Clean Technol. Environ. Policy 24(2), 607–621. https://doi.org/10.1007/s10098-021-02080-5 (2022).
Davoodi, S., Vo Thanh, H., Wood, D. A., Mehrad, M. & Rukavishnikov, V. S. Combined machine-learning and optimization models for predicting carbon dioxide trapping indexes in deep geological formations. Appl. Soft Comput. 143, 110408. https://doi.org/10.1016/j.asoc.2023.110408 (2023).
As, M. & Bilir, T. Machine learning algorithms for energy efficiency: mitigating carbon dioxide emissions and optimizing costs in a hospital infrastructure. Energy Build. 318, 114494. https://doi.org/10.1016/j.enbuild.2024.114494 (2024).
Hamrani, A., Akbarzadeh, A. & Madramootoo, C. A. Machine learning for predicting greenhouse gas emissions from agricultural soils. Sci. Total Environ. 741, 140338. https://doi.org/10.1016/j.scitotenv.2020.140338 (2020).
Shalaby, A., Elkamel, A., Douglas, P. L., Zhu, Q. & Zheng, Q. P. A machine learning approach for modeling and optimization of a CO2 post-combustion capture unit. Energy 215, 119113. https://doi.org/10.1016/j.energy.2020.119113 (2021).
Mardani, A., Liao, H., Nilashi, M., Alrasheedi, M. & Cavallaro, F. A multi-stage method to predict carbon dioxide emissions using dimensionality reduction, clustering, and machine learning techniques. J. Clean. Prod. 275, 122942. https://doi.org/10.1016/j.jclepro.2020.122942 (2020).
Giannelos, S., Bellizio, F., Strbac, G. & Zhang, T. Machine learning approaches for predictions of CO2 emissions in the building sector. Electr. Power Syst. Study. 235, 110735. https://doi.org/10.1016/j.epsr.2024.110735 (2024).
Zhao, J. et al. Carbon emission prediction model and analysis in the Yellow River Basin based on a machine learning method. Sustainability. 14(10), Art. no. 10. https://doi.org/10.3390/su14106153 (2022).
Hong, S. et al. Multi-objective optimization of CO2 emission and thermal efficiency for on-site steam methane reforming hydrogen production process using machine learning. J. Clean. Prod. 359, 132133. https://doi.org/10.1016/j.jclepro.2022.132133 (2022).
Han, Y. et al. Feb., Novel economy and carbon emissions prediction model of different countries or regions in the world for energy optimization using improved residual neural network. Sci. Total Environ. 860, 160410. https://doi.org/10.1016/j.scitotenv.2022.160410 (2023).
Peng, T., Yang, X., Xu, Z. & Liang, Y. Constructing an environmental friendly low-carbon-emission intelligent transportation system based on big data and machine learning methods. Sustainability. 12(19), Art. no. 19. https://doi.org/10.3390/su12198118 (2020).
Kapoor, N. R. et al. Machine learning-based CO2 prediction for office room: a pilot study. Wirel. Commun. Mob. Comput. 1, 9404807. https://doi.org/10.1155/2022/9404807 (2022).
Farahzadi, L. & Kioumarsi, M. Application of machine learning initiatives and intelligent perspectives for CO2 emissions reduction in construction. J. Clean. Prod. 384, 135504. https://doi.org/10.1016/j.jclepro.2022.135504 (2023).
Wang, C., Li, M. & Yan, J. Forecasting carbon dioxide emissions: application of a novel two-stage procedure based on machine learning models. J. Water Clim. Change 14(2), 477–493. https://doi.org/10.2166/wcc.2023.331 (2023).
Ağbulut, Ü. Forecasting of transportation-related energy demand and CO2 emissions in Turkey with different machine learning algorithms. Sustain. Prod. Consum. 29, 141–157. https://doi.org/10.1016/j.spc.2021.10.001 (2022).
Meng, Y. & Noman, H. Predicting CO2 emission footprint using ai through machine learning. Atmosphere. 13(11), Art. no. 11. https://doi.org/10.3390/atmos13111871 (2022).
Li, X., Ren, A. & Li, Q. Exploring patterns of transportation-related CO2 emissions using machine learning methods. Sustainability 14(8), Art. 8. https://doi.org/10.3390/su14084588 (2022).
El-Kenawy, E. S. M. et al. NiOA: a novel metaheuristic algorithm modeled on the stealth and precision of Japanese Ninjas. J. Artif. Intell. Eng. Pract. 1, 17–35. https://doi.org/10.21608/jaiep.2024.386693 (2024).
Luo, Y., Chen, Z. & Yoshioka, T. Dual-path rnn: efficient long sequence modeling for time-domain single-channel speech separation. In ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), May 2020, 46–50. https://doi.org/10.1109/ICASSP40776.2020.9054266
Shan, F., He, X., Jahed Armaghani, D., Zhang, P. & Sheng, D. Success and challenges in predicting tbm penetration rate using recurrent neural networks. Tunn. Undergr. Space Technol. 130, 104728. https://doi.org/10.1016/j.tust.2022.104728 (2022).
El-Kenawy, E. S. M. et al. Time series forecasting of cryptocurrency prices with long short-term memory networks. Financial Technol. Innov.. 2, 18–26. https://doi.org/10.54216/FinTech-I.020202 (2023).
Abdelmgeed, A., Zaki, A. M. & Soliman, M. A. An evaluation of ARIMA and persistence models in IoT-driven smart homes. J. Artif. Intell. Metaheuristics. 6(2), 08–15. https://doi.org/10.54216/JAIM.060201 (2023).
Acknowledgements
This project was funded by the National Plan for Science, Technology and Innovation (MAARIFAH)—King Abdulaziz City for Science and Technology—the Kingdom of Saudi Arabia—award number (13-MAT377-08). The authors thank the Science and Technology Unit, King Abdulaziz University.
Author information
Authors and Affiliations
Contributions
Conceptualization, E.-S.M.E.; methodology, A.G. and E.-S.M.E; software, E.M.A. and I.E.; validation, M.M.E. and E.M.A.; formal analysis, A.B.G., A.G. and E.-S.M.E.; investigation, E.-S.M.E. and A.B.G.; writing—original draft, E.-S.M.E. and M.M.E.; writing—review and editing, I.E., E.M.A., and E.-S.M.E.; visualization, M.M.E., A.B.G., and A.G.; project administration, A.B.G.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Ghorbal, A.B., Grine, A., Elbatal, I. et al. Predicting carbon dioxide emissions using deep learning and Ninja metaheuristic optimization algorithm. Sci Rep 15, 4021 (2025). https://doi.org/10.1038/s41598-025-86251-0
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-86251-0
Keywords
This article is cited by
-
Intelligent low carbon reinforced concrete beam design optimization via deep reinforcement learning
Scientific Reports (2025)
-
Air Quality Forecasting Using Machine Learning: Comparative Analysis and Ensemble Strategies for Enhanced Prediction
Water, Air, & Soil Pollution (2025)
-
Leveraging artificial intelligence in management information systems for sustainable supply chain optimization and environmental impact analysis
Discover Artificial Intelligence (2025)
-
Improvement of ANFIS with a snake optimizer for capturing CO2 emissions: a model for predicting future emissions for India
Theoretical and Applied Climatology (2025)
