
Abstract
The timely and accurate detection of unidentified drones is crucial for public safety. However, challenges arise due to background noise in complex environments and limited feature representation of small, distant targets. Additionally, deep learning algorithms often demand substantial computational resources, limiting their use on low-capacity platforms. To address these issues, we propose LMWP-YOLO, a lightweight drone detection method that incorporates a multidimensional collaborative attention mechanism and multi-scale fusion. Inspired by ARM CPU efficiency optimizations, the model uses depthwise separable convolutions and efficient activation functions to reduce parameter size. The neck structure is enhanced with a collaborative attention mechanism and multi-scale fusion, improving feature representation. An optimized loss function refines bounding box matching for small targets, while a pruning strategy removes redundant filters, boosting computational efficiency. Experimental results show that LMWP-YOLO outperforms YOLO11n, with a 22.07% increase in mAP and a 52.51% reduction in parameters. The model demonstrates strong cross-dataset generalization, balancing accuracy and efficiency. These findings contribute to advancements in small drone target detection.
Similar content being viewed by others

Introduction
In recent years, the development and widespread adoption of drone technology have enabled their extensive application in fields such as environmental monitoring, infrastructure inspection, and agriculture1,2,3,4,5,6,7,8 . Drones have significantly enhanced productivity across various industries due to their flexibility and efficiency. Muksimova et al.8 proposed an innovative UAV-based fire detection system that is capable of detecting and locating fires in various backgrounds. However, despite their advantages, drones also present significant challenges, particularly regarding public safety and personal privacy, which are increasingly at risk of violation. The detection and tracking of unauthorized or unintended drone intrusions have thus become critical. A study by Nick Tepylo et al.9 revealed that most respondents expressed concerns about the safety risks posed by drones. Consequently, there is an urgent need for the development of high-precision and efficient technologies to detect unidentified drones, addressing both public and personal security concerns.
Previous drone detection methods can be broadly divided into traditional detection techniques and computer vision-based approaches10. Traditional methods primarily include radar-based detection systems11,12,13,14,15,16,17. For example, Yang et al.18 presented a Transformer-based drone detection architecture that frames the detection task as a binary classification problem for each range cell. This architecture utilizes radar echo features to combine training with different CPI echoes, enabling the simultaneous extraction of Doppler shift and micro-Doppler features. Similarly, Cai et al.19 developed a reliable drone identification framework based on radio frequency (RF) fingerprints. By collecting, analyzing, and recording RF signals from telemetry links of various drones under different flight modes and distances, they created a comprehensive drone signal dataset. They further designed intelligent algorithms and an anti-drone system, achieving a monitoring and identification accuracy exceeding 95% when the signal-to-noise ratio (SNR) was at least 5 dB. Despite these advances, radar-based methods face limitations. Factors such as frequency and wavelength restrict their ability to detect small drone targets effectively. Additionally, environmental factors like terrain, weather conditions, and electromagnetic interference significantly impact radar performance. In contrast, computer vision-based approaches have gained popularity due to their robust feature extraction capabilities and strong resilience in complex environments, making them a preferred choice for drone detection tasks.
Computer vision research methods are generally divided into machine learning and deep learning approaches. Machine learning relies on handcrafted features extracted from input images, such as edges, textures, shapes, and colors. These features are then fed into classifiers, including support vector machines (SVMs), decision trees, and k-nearest neighbors, for training and classification. For example, Anwar et al.20 developed a machine learning framework to distinguish amateur drone (ADr) sounds in noisy environments. Their approach, utilizing an SVM with a cubic kernel, achieved an ADr detection accuracy of approximately 96.7%. Similarly, Ma et al.21 introduced a machine learning-based technique for detecting loosened bolts, with a random forest model achieving 90.07% accuracy. Pan et al.22 employed machine learning algorithms, including SVMs, artificial neural networks, and random forests, to classify normal and damaged road surfaces. Likewise, Kyle et al.23 proposed an automated blade collision detection system for wind turbines using machine learning methods, offering an innovative solution to identify collisions. Despite their utility, machine learning approaches are limited by their dependence on handcrafted features, which fail to capture complex and abstract high-dimensional patterns. This constraint often results in reduced detection accuracy. In contrast, deep learning leverages automatic feature learning and multi-layer networks, enabling the modeling of intricate patterns. Consequently, deep learning has gained widespread application in object detection tasks, surpassing the capabilities of traditional machine learning methods.
Object detection in deep learning is categorized into two-stage and one-stage algorithms. Two-stage methods, such as Faster R-CNN, Mask R-CNN, and Cascade R-CNN, first generate region proposals before classifying and refining them. Koyun et al.24 proposed a two-stage detection network called “Focus-Detect,” specifically designed for detecting small objects in aerial images, achieving an AP score of 42.06 on the VisDrone dataset. Similarly, Peng et al.25 enhanced two-stage detectors by introducing top-down signal importance, which provides high-level contextual information to complement low-level features, resulting in consistent performance improvements on the MS-COCO dataset. Wang et al.26 developed a two-stage detection network using an anchor-free, sliding window-free deconvolutional region proposal approach. Experiments on the NWPU VHR-10 dataset showed that this network achieved near state-of-the-art performance. Despite their effectiveness, two-stage methods have notable limitations, particularly in computational cost. The need to generate region proposals followed by classification and regression makes these methods slower and less efficient, especially for real-time detection tasks. Consequently, one-stage methods, which follow an end-to-end detection approach, have gained widespread adoption in object detection due to their higher efficiency and speed.
One-stage deep learning methods include the YOLO series27,28,29,30,31,32, the SSD series33, and RetinaNet34. Huang et al.35 proposed EDGS-YOLOv8, a lightweight, real-time anti-drone detection model that achieved a 0.971 AP on the DUT Anti-UAV dataset, surpassing YOLOv8n by 3.1% mAP with a compact size of 4.23 MB. Similarly, Wang et al.36 developed a lightweight drone swarm detection method based on YOLOX, optimized with depthwise separable convolutions to reduce parameters. Experimental results showed an mAP of 82.32%, approximately 2% higher than the baseline model, with a model size of just 3.85 MB. Bo et al.37 proposed YOLOv7-GS, which improves small drone detection in complex backgrounds by refining prior box sizes and integrating InceptionNeXt, SPPFCSPC-SR, and Get-and-Send modules. The final model achieved strong performance on the DUT Anti-UAV datasets. Despite these advancements, limitations persist. YOLOX’s anchor-free detection framework improves adaptability across various scales but struggles with feature representation for dense targets. YOLOv7 enhances its feature extraction network yet shows minor shortcomings in small object detection. YOLOv8 incorporates attention mechanisms to improve feature channel learning but sacrifices inference speed. YOLOv10 improves multi-scale detection using adaptive convolutions and refined anchor optimization, but its performance gains for low-resolution images and small objects remain limited. To address these challenges, YOLO1138 employs a deeper network architecture, integrating an efficient feature pyramid network and adaptive attention mechanisms. By refining cross-scale information integration, YOLO11 significantly enhances small object detection accuracy, particularly for small targets and low-resolution images.
In summary, while existing object detection algorithms have made significant advancements across various application domains, they continue to face critical challenges in detecting small objects and handling complex background scenarios. Small objects, occupying only a limited number of pixels and often blending with the background, make it difficult for traditional algorithms to extract their features effectively. Additionally, factors such as noise, dynamic variations, occlusion, and lighting changes in complex backgrounds further complicate the differentiation between targets and the background. Furthermore, the high computational complexity of many algorithms hinders the ability to achieve a balance between efficiency and accuracy. Although some algorithms perform well under specific conditions, their limitations in real-time detection and highly complex environments restrict their broader applicability.
Although YOLO11 achieves good performance in object detection, it still has some limitations in the task of small drone target detection. First, the Neck layer uses P4 and P5 layers to process high-level features, but these high-level features may lose detailed information when handling small targets, as small targets typically contain more detail in low-level features. Additionally, the traditional structure of YOLO11 does not fully utilize convolutions of different sizes to extract fine-grained information during multi-scale object detection, resulting in missed detections of small targets. Finally, the loss function of YOLO11 does not adequately account for the size differences of targets, leading to insufficient sensitivity in detecting small targets.
To address these challenges, this paper introduces LMWP-YOLO, a lightweight object detection model based on the YOLO11 architecture. The model integrates a multidimensional collaborative attention mechanism and a multi-scale fusion module to enhance small target detection accuracy and robustness in complex backgrounds. The main contributions of this study are as follows:
-
1.
To improve the real-time performance of drone detection, a lightweight feature extraction backbone network is proposed. This module reduces the model size and parameter count through depthwise separable convolutions and efficient activation functions. In hardware-constrained environments, residual blocks are combined with depthwise separable convolutions to reduce computational costs.
-
2.
To mitigate the loss of small target details during feature extraction, a multidimensional collaborative attention mechanism and a multi-scale feature fusion module are incorporated into the Neck layer. By combining dynamic convolutions, group convolutions, and residual connections, the model adaptively adjusts feature representations, enhancing its ability to detect small drone targets at long distances and in complex background regions.
-
3.
To address the excessive sensitivity of the loss function to slight boundary box shifts in small target detection, the normalized Wasserstein distance and a dynamic weighting mechanism are introduced. These mechanisms, combined with dynamic target area-based weighting, improve boundary box matching accuracy and enhance sensitivity to small target detection.
-
4.
To tackle the challenges of model lightweight design and real-time performance, pruning techniques are applied to optimize redundant filters in the Backbone and Neck layers, significantly reducing model parameters and inference time while preserving detection accuracy.
Section “Introduction” reviews the current status of traditional handcrafted feature extraction algorithms and deep learning detection methods, followed by an introduction to the proposed algorithm. Section “Proposed methods” provides a detailed description of the LMWP-YOLO network. Section “Experimental results and analysis” analyzes the experimental setup and results, comparing them with existing literature. Finally, section “Discussion” discusses the experimental findings and draws conclusions.
Proposed methods
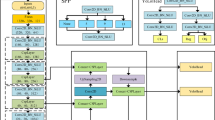
YOLO11 is a highly efficient object detection algorithm that significantly improves feature extraction compared to YOLOv7 and YOLOv8, especially for small object detection and complex background scenarios. Using CSPDarknet as its backbone network, YOLO11 enhances the model’s ability to capture detailed and robust features. Compared to its predecessors, YOLO11 employs a more advanced feature fusion strategy. By integrating improved FPN and PAN structures, it achieves more effective multi-scale feature aggregation. Additionally, an optimized non-maximum suppression (NMS) strategy enhances the suppression of redundant bounding boxes, resulting in greater detection accuracy. To meet the requirements of real-time detection, this study utilizes the lightweight YOLO11n as the baseline model, introducing further optimizations. The YOLO11n architecture is composed of four key components: the input layer, backbone layer, neck layer, and output layer. The overall structure is shown in Fig. 1.

The structure of YOLO11.
The input layer handles image preprocessing tasks, such as resizing and normalization, to ensure consistency in the input data. The backbone layer is responsible for extracting deep semantic features from the image. It consists of multiple convolutional layers, pooling layers, and activation functions, enabling the capture of image features ranging from low-level elements, such as edges and textures, to high-level structures, such as shapes. The neck layer, located between the backbone and output layers, performs feature fusion and enhancement. It employs PANet to strengthen the connections between features from different levels, thereby improving the network’s ability to detect objects of varying scales through multi-scale feature learning. The output layer translates the features extracted and processed by the backbone and neck layers into the final detection results. This includes the localization of object bounding boxes, the prediction of class labels, and the computation of confidence scores.
As shown in Fig. 2, this paper optimizes and improves the YOLO11 network to develop a lightweight and efficient network with the following enhancements:
-
1.
To reduce model parameters and computational cost, a lightweight network is implemented using depthwise separable convolutions and an optimized activation function, forming a new backbone.
-
2.
The newly designed MAFR is introduced into the neck layer of the network, improving the feature representation ability and efficiency for small object detection in drones.
-
3.
A more effective loss function is adopted, incorporating the normalized Wasserstein distance and a dynamic weighting mechanism to enhance the robustness of bounding box similarity measurements
-
4.
A pruning-based optimization strategy is applied to the network structure, removing redundant filters and their corresponding feature maps that contribute minimally to feature extraction, significantly reducing the model’s computational cost and parameter count.

Optimization techniques in LMWP-YOLO include the development of a novel feature extraction network utilizing PP-LCNet as a replacement for the original backbone. Furthermore, the multidimensional collaborative attention incorporates the multi-scale feature fusion module to create an enhanced feature fusion network, which replaces the original neck layer.
Lightweight feature extraction network module
System latency in drone detection can delay the timely identification of unidentified drones, jeopardizing detection success and safety. As a result, achieving efficient real-time drone detection has become a critical objective. The YOLO11 backbone layer performs essential feature extraction tasks, including local feature extraction, spatial dimensionality reduction, and channel fusion. Within this backbone, the C3K2 module optimizes gradient flow based on the CSP structure, while capturing multi-scale features through 3 × 3 and 2 × 2 convolutions. This optimization improves gradient flow, reduces computational redundancy, and enhances feature representation. The CSP module, consisting of convolution, batch normalization, and the SiLU activation function, efficiently extracts local features, stabilizes training, and enhances the model’s ability to fit nonlinearly. However, conventional convolutions and the C3K2 module rely on numerous computationally intensive fully connected convolution operations, which significantly reduce inference efficiency and adversely affect the real-time performance of drone detection. To address these challenges, this study introduces an improved backbone design, LCbackbone39. The LCbackbone reduces computational complexity by employing a lightweight design that integrates depthwise separable convolutions and optimized activation functions. Furthermore, it incorporates SE modules40 and large convolutional kernels to enhance feature representation and contextual modeling. This design achieves efficient inference while maintaining an optimal balance between speed and accuracy.
As illustrated in Fig. 3, the LCbackbone module begins by leveraging depthwise separable convolutions to break down convolution operations into two steps: first, depthwise convolutions independently extract spatial features from each channel; second, pointwise convolutions using a 1 × 1 kernel enable cross-channel feature fusion. To further optimize performance, the module employs the H-Swish activation function, as defined in Eqs. (1) and (2), which replaces complex exponential operations with a combination of a hard sigmoid and linear transformations, improving computational efficiency. An SE module is integrated at the end of the network to capture global information for each channel through global average pooling. The SE module generates adaptive channel weights via activation functions and fully connected layers, enhancing feature reweighting and representation. Additionally, a 5 × 5 convolutional kernel is incorporated in the deeper layers of the network to expand the receptive field, enabling the capture of broader contextual information. Finally, a 1×1 convolutional layer with 1280 dimensions is added after the global average pooling layer to strengthen the model’s global feature fitting capability.

Improvement scheme at the backbone combined with the PP-LCNet.
The improved neck incorporates a multidimensional collaborative attention mechanism alongside multi-scale fusion and residual connections to enhance performance
In small object detection tasks for drones, small objects occupy minimal space in feature maps, leading to poor feature representation. In YOLO11, the neck layer’s convolutions and C3K2 module enhance perception through multi-scale fusion, but small object features are often lost or diluted. To address this, we propose the MAFR-neck layer, incorporating multidimensional collaborative attention41 to capture relationships between features. A lightweight multi-scale fusion module, combined with the SE module and residual connections42, optimizes feature extraction. Micro residual blocks improve gradient propagation, and adjustments to the neck layer enhance high-resolution feature representation.
As shown in Fig. 4, MAFR models the collaborative relationships among the channel, width, and height dimensions of input features by capturing attention weights for each dimension. It processes a feature tensor \(F\in R^{C\times H\times W}\), using global average and standard deviation pooling to extract statistical features along the channel dimension, as described in Eqs. (3) and (4).
After concatenating the mean and standard deviation, channel attention weights are generated through a fully connected layer, as shown in Eq. (5).
Here, \(W_1\) and \(W_2\) are learnable weights, \(\delta\) represents the ReLU activation function, \(\sigma\) denotes the Sigmoid activation function, and \(\left[ , \right]\) indicates concatenation. The feature map is aggregated along the width dimension to produce descriptors for the height dimension, with a similar process used to generate height attention weights.
Similarly, the feature map is globally aggregated along the height dimension to generate feature descriptors for the width dimension.
The attention weights from the three dimensions are then individually applied to the input features.
Here, \(\odot\) represents element-wise multiplication. The three calibrated feature sets are then fused to generate multidimensional calibrated features.

Enhanced contextual information capture.
Multi-scale features are crucial for small object detection. To address this, as illustrated in Fig. 5, a lightweight multi-scale fusion module uses grouped convolutions for feature extraction and 1 × 1 convolutions for integration, reducing parameter complexity. An SE module captures inter-channel relationships, while residual connections improve feature retention and gradient propagation. A micro residual block is added after the multi-scale fusion module to enhance feature extraction. It uses two 3 × 3 convolutions and batch normalization to extract fine-grained features, with residual connections preserving original information and detailed small object features.

Multi-scale feature fusion and residual connect module.
Traditional neck layers like FPN and PANet rely on P4 and P5 layers to capture large object features, limiting small object detection. To address this limitation, this study modifies the neck structure by decreasing the P4 and P5 layers and introducing a P2 layer, designed for small object features. The P2 layer processes higher-resolution feature maps, enhancing small object detail capture while reducing computational complexity. The full MAFR-Neck structure is shown in Fig. 6.

The structure of improved MAFR network.
Improved loss function based on area-weighted Wasserstein loss
In drone small object detection tasks, challenges arise due to the small size of targets, complex backgrounds, and dense distributions. Consequently, the robustness and accuracy of bounding box similarity measures are crucial for detection performance. However, YOLO11’s loss function, which relies on an IoU-based bounding box regression mechanism, has notable limitations. It is highly sensitive to small positional shifts in targets and encounters gradient vanishing issues when bounding boxes have no overlap or are fully enclosed. To overcome these limitations, this study introduces a novel loss function. The key idea is to model the similarity between bounding boxes as a two-dimensional Gaussian distribution43 and use the Wasserstein distance to compute the distributional difference between predicted and ground-truth boxes. A dynamic weighting mechanism based on target area prioritizes the optimization of small objects, while the inclusion of a scale difference term improves the loss function’s adaptability to multi-scale scenarios.
The horizontal bounding box \(R=\left( c_x,c_y,w,h \right)\) is represented as a two-dimensional Gaussian distribution. In this representation, \(\left( c_x,c_y \right)\) denotes the center point coordinates, while w and h indicate the width and height of the box, respectively. The Gaussian distribution corresponding to this representation is defined as:
Here, \(\mu =\left[ \begin{array}{c} c_x\\ c_y\\ \end{array} \right] , \varSigma =\left[ \begin{array}{ll} \frac{w^2}{4}& \quad 0\\ 0& \quad \frac{h^2}{4}\\ \end{array} \right]\). \(\mu\) represents the center of the Gaussian distribution, corresponding to the center point of the bounding box. \(\varSigma\) is the covariance matrix, which defines the width and height of the box. Using this model concept, the predicted bounding box A and the ground truth bounding box B can be represented as \(N_A\left( \mu _A,\varSigma _A \right)\) and \(N_B\left( \mu _B,\varSigma _B \right)\), respectively. The 2D Wasserstein distance is defined as:
This can be simplified as:
Coupled with bounding boxes \(R_A\) and \(R_B\), the equation can be formulated as:
To constrain the 2D Wasserstein distance within the range (0, 1), the typical 2D Wasserstein distance can be expressed as:
C is the normalization constant, determined based on the statistical information of the dataset. The schematic diagram of the predicted box and ground truth box is shown in Fig. 7. The box loss function can be expressed as:

The scheme of area-weighted Wasserstein loss function.
The classification loss function can be expressed as:
In this context, \(S^2\) represents the total number of grid cells in the image, B denotes the number of bounding boxes, \(N_C\) refers to the number of object categories, and \(p_i\) represents the confidence score of bounding box i for class C. The object confidence loss function is defined as:
Here, \(1_{ij}^{obj}\) represents the object located in cell i, selected by the j-th bounding box. \(C_i\) and \(\hat{C}_i\) denote the predicted and actual confidence levels, respectively. The loss function for iterative computation is defined as the sum of the three previously described functions, formulated as:
In this case, \(\lambda _{box}\), \(\lambda _{cls}\), and \(\lambda _{obj}\) denote the respective weights assigned to each loss function. In the approach described, the bounding box is modeled as a two-dimensional Gaussian distribution. The normalized Wasserstein distance is employed to precisely quantify differences in the position and size of the bounding boxes, ensuring smooth gradient calculations even in scenarios without overlap or containment relationships.
This paper subsequently introduces a dynamic weighting mechanism based on target area. A sigmoid mapping is applied to the target area, allowing the optimization weights for bounding box regression to be dynamically adjusted according to target size. Smaller targets are assigned higher weights, increasing their priority during optimization and significantly enhancing the model’s sensitivity to detecting small objects. Finally, a relative scale difference term is added to the loss function to explicitly quantify the width and height differences between predicted and ground truth boxes. This encourages more precise predictions of target dimensions, thereby improving detection performance across multi-scale scenarios.
Pruning method for the drone detection network
Efficiently extracting and utilizing small object features under limited computational resources is a critical challenge in drone-based small object detection tasks. YOLO11 improves feature extraction and object perception through multi-scale feature fusion in the backbone’s convolutional layers and the neck layer. However, many unpruned filters in the convolutional layers introduce redundancy, as small object features occupy only a tiny portion of the convolutional feature maps. This results in weak feature activation for some filters, rendering them ineffective and wasting computational resources. To address this issue, this paper introduces a pruning-based optimization strategy into the YOLO11 network structure44. The strategy involves evaluating the importance of each filter in the convolutional neural network and removing redundant filters, along with their associated feature maps, that contribute minimally to the network’s output. This approach reduces both computational cost and the number of network parameters, enhancing the model’s efficiency.
Specifically, the importance of each filter in a convolutional layer is evaluated using the L1-norm. For the j-th filter Fi in the i-th layer, represented by the weight tensor \(F_{i,j}\in R^{n_i\times k\times k}\), the L1-norm is defined as:
Here, \(n_i\) represents the number of input channels, k × k denotes the kernel size, and \(K_{l,m,n}\) indicates the weight value of the j-th filter in the i-th layer at channel l and position (m,n). Filters in each convolutional layer are ranked by their L1-norm, and those with the lowest values are selected for removal. As shown in Fig. 8, the pruned filters correspond to feature maps that are also removed, subsequently affecting the convolutional kernels in the following layers.

Schematic diagram of channel pruning method.
Experimental results and analysis
This section evaluates the proposed model’s detection performance on datasets and compares it with current object detection algorithms to demonstrate its superiority.
Dataset and training
With the increasing adoption of civilian drones, their applications in daily life are expanding rapidly. Publicly available datasets offer a variety of drone images captured under diverse environmental conditions. However, many of these datasets lack sufficient small-object feature information, which can compromise the accuracy of models in detecting small drone targets. To address this limitation, this study utilizes the publicly available TIB-Net small drone target dataset45, which consists of a total of 2850 images of various types of drones, including multi-rotor and fixed-wing drones, with an approximate distance of 500 m. The dataset covers scenes ranging from daytime to nighttime under various lighting conditions. In this study, 2565 images are selected as the training set, and 285 images are used as the validation set. The dataset annotates small drone targets using text files containing five columns: class label, center coordinates of the bounding box (x and y), width, and height. Figure 9 presents the data distribution of drone classes and the bounding box specifications within the training set. To ensure consistency in controlled experiments, all models use the same hyperparameters, with an input image size fixed at 640 × 640. The model was trained for 100 epochs on 2565 images from the training set using an A100, with a batch size of 48 and the AdamW optimizer.
The experimental environment in this paper is based on the Ubuntu 20.04 operating system, with an Tensor Core A100 GPU, 40GB of memory. The programming language used is Python 3.9.11, and the deep learning model is built using PyTorch 1.10.0, cudnn 8.2.0, and torchvision 0.12.0. The computational library used is numpy 1.23.3, and parallel computing is supported by the NVIDIA CUDA Toolkit 11.3.0. The code is available at https://github.com/Surprise-Zhou/LMWP-YOLO.

Label volume and distribution for drones detection.
Accuracy evaluation
Drone small object detection models are evaluated using four metrics: precision (P), recall (R), F1-score, and mean average precision (mAP), with their calculation formulas provided.
TP represents correctly detected small drones, FP are non-existent targets wrongly identified, and FN are missed actual targets. Precision (P) indicates the proportion of correct detections, while recall (R) measures the ratio of actual targets detected. The F1-score, the harmonic mean of P and R, balances these metrics. Mean average precision (mAP) averages AP across all classes to assess overall performance. Model size and parameters are also analyzed to evaluate complexity and computational demands. FPS (Frames Per Second) represents the number of image frames the system can process per second, reflecting the system’s computational efficiency. A higher FPS indicates that the system can process input data more quickly and provide more timely feedback.
Evaluation of model lightweighting and detection accuracy
To comprehensively evaluate the effectiveness of LMWP-YOLO, the improved YOLO model was compared to the baseline model using the same training dataset. The results, presented in Table 1, indicate that LMWP-YOLO outperforms the baseline model across all performance metrics. Specifically, it achieved improvements of 9.72% in average precision, 29.48% in recall, 19.61% in F1-score, 22.07% in mAP@0.5, and 29.31% in mAP@0.95.
The observed improvements are primarily attributed to the newly designed MAFR module integrated into the neck layer. This module minimizes the influence of background noise and irrelevant regions through dynamic weight allocation while preserving detailed information in target regions using local feature extraction and gradient optimization mechanisms. Furthermore, the enhanced loss function, with its robust design and effective scale difference modeling, significantly improves the accuracy of bounding box predictions for small targets.
Additionally, LMWP-YOLO achieves a compact model size of 2.71 MB and a parameter count of 1.23M. Compared to the original YOLO11n baseline, this represents reductions of 47.88% and 52.51%, respectively. These improvements are primarily due to the integration of the LCbackbone module, which utilizes depthwise separable convolutions as its fundamental building blocks. Moreover, the pruning strategy further reduces computational overhead by eliminating redundant filters.
The experimental results confirm the effectiveness of the proposed lightweight approach, demonstrating that LMWP-YOLO is particularly well-suited for micro-embedded systems. To provide a more precise evaluation of the model’s performance, PR curves before and after the improvements were generated during testing using an IoU threshold of 0.5, as illustrated in Fig. 10.

The PR diagram between YOLO11n and LMWP-YOLO.
The precision-recall area under the curve (AUC-PR) is a standard metric for evaluating model performance. A higher AUC-PR reflects superior performance across different precision-recall trade-offs. The improved model demonstrates a significantly higher AUC-PR. Additionally, the confusion matrix obtained by LMWP-YOLO and the baseline model is shown in Fig. 11, which visualizes the classification of object categories. In Fig. 11, each row represents a predicted category, and each column represents a true category. The value on the diagonal represents the proportion of correctly classified instances for that category. As shown in Fig. 11, compared to the baseline model, LMWP-YOLO significantly reduces the false negative (FN) rate and increases the proportion of correctly classified instances, indicating that LMWP-YOLO effectively improves detection accuracy.

The confusion matrix between YOLO11n and LMWP-YOLO.
Ablation experiments
To assess the detection performance of the proposed innovations, including “LCbackbone,” “MAFR,” “AWLoss,” and “Pruning,” ablation experiments were conducted. These experiments evaluated the contribution of each algorithmic improvement, focusing on model simplification, attention mechanisms, and multi-level feature integration. The performance metrics included mean average precision(mAP) and model size. Table 2 and Fig. 12 summarize the results of LMWP-YOLO on the dataset across various optimization strategies.

Comparison of mAP and model size with different methods.
As shown in Table 2 and Fig. 12, method (1) reduces the model size by 0.47 MB compared to the baseline model while improving mAP. This improvement is primarily attributed to the incorporation of depthwise separable convolutions and the H-Swish activation function in the enhanced backbone module, which effectively reduce computational complexity. Furthermore, the SE module enhances backbone performance by optimizing feature interactions between channels.
Method(2) demonstrates that the newly designed MAFR reduces the model size by 1.47 MB compared to the original neck layer, primarily due to structural optimizations, particularly in the P4 and P5 layers. Additionally, mAP@0.5 improves by 15.85% compared to the baseline model. This improvement is attributed to MAFR’s ability to model attention across both channel and spatial dimensions, thereby enhancing the focus on critical regional features. The multi-scale fusion module further increases adaptability to varying object scales by employing grouped convolutions for multi-scale feature extraction and efficiently integrating these features with 1 × 1 convolutions. Furthermore, the micro residual module enhances feature representation through local feature extraction and gradient optimization.
Method(3) demonstrates that the newly designed loss function improves mAP@0.5 by 4.18% compared to the baseline model. This improvement is attributed to the incorporation of the normalized Wasserstein distance, which enhances bounding box regression performance, and the dynamic weighting mechanism, which prioritizes small targets by assigning them higher optimization weights.
Method(4) builds upon method(1), achieving an additional 6.85% improvement in mAP while further reducing the model size by 1.46 MB. This demonstrates that combining the LCbackbone and MAFR modules enables synergistic optimization of backbone feature extraction and multi-scale feature fusion. Similarly, methods(5), (6), and (7), which combine the techniques from methods(1), (2), and (3), emphasize the advantages of the proposed “LCbackbone,” “MAFR,” and “AWLoss” across three key dimensions: model lightweighting, feature fusion efficiency, and bounding box regression performance.
Method(8), built upon method(7), achieves an additional reduction of 0.56 MB in model size while further improving mAP. This improvement is primarily attributed to pruning optimization, which eliminates redundant parameters using L1-norm importance filtering while retaining critical computational paths. This strategy effectively reduces model size without compromising performance. These findings highlight that the combination of “LCbackbone,” “MAFR,” “AWLoss,” and “Pruning” successfully balances small target feature extraction, feature fusion, bounding box regression optimization, and model lightweighting. Consequently, the LMWP-YOLO model adopts the structure of Method(8) to ensure optimal performance.
This paper conducted an interpretability analysis of the model improvement strategies using Grad-CAM46. Figure 13 illustrates the Grad-CAM-generated heatmaps for YOLO11n and LMWP-YOLO on the drone dataset. Compared to YOLO11n, LMWP-YOLO demonstrates a stronger ability to focus on target locations while reducing attention to irrelevant environmental information. For small targets, the LMWP-YOLO algorithm more effectively concentrates on positive sample regions, minimizing distractions from unrelated environmental details. This analysis highlights the effectiveness of the multidimensional collaborative attention mechanism in enhancing feature dependencies across dimensions. Additionally, the multi-scale feature fusion module efficiently extracts multi-scale features, while the improved loss function enhances the robustness of bounding box regression in modeling the shape and position of small targets.

Heat maps of YOLO11n and LMWP-YOLO for drones obtained by Grad-CAM. (a) Heat maps generated by YOLO11n for drones on the TIB-Net dataset. (b) Heat maps generated by LMWP-YOLO for drones on the TIB-Net dataset.
Comparison with state-of-the-art methods
This study evaluates the proposed LMWP-YOLO method against several existing single-stage and two-stage object detection algorithms, including Faster-RCNN, RT-DETR, SSD, EfficientDet, YOLOv6, YOLOv8, YOLOv9-Tiny, and YOLOv10. The performance metrics include mean average precision (mAP) per class, recall, F1-score, and precision. Precision and mAP were calculated using the PASCAL VOC 2007 benchmark with an intersection over union (IoU) threshold of 0.5. Table 3 and Fig. 14 summarize the results on the TIB-Net dataset.

Comparative experiments with different models on TIB-Net dataset.
The results indicate that our method achieved a mAP of 95.7%, representing a moderate improvement in detection accuracy over the YOLO11 baseline network. Additionally, LMWP-YOLO outperformed the comparable YOLOv10 algorithm with a 32.5% higher mAP. When compared to the lightweight YOLOv9-Tiny algorithm, our method achieved a 46.1% increase in mAP while reducing the model size by 35.7%.
Compared to SSD-MobilenetV2, Centernet-Resnet50, DETR-Resnet18, YOLOv6, and YOLOv8, LMWP-YOLO achieved overall performance improvements, with mAP increases of 73.1%, 47.1%, 14.1%, 57.0%, and 25.2%, respectively. Additionally, the model size of LMWP-YOLO is significantly smaller than that of the aforementioned algorithms.
As shown in Table 3, compared to LMWP-YOLO, other YOLO-based algorithms exhibit significantly higher precision than recall. This difference is mainly due to the fact that, in drone small target detection, other YOLO models employ higher confidence thresholds or more conservative detection strategies to minimize false positives, thereby reducing false alarms. However, this approach also leads to the omission of some true targets, particularly small ones, which results in decreased recall. In contrast, this study introduces the MCA module and lightweight multi-scale feature fusion, along with NWD and a dynamic weight mechanism based on target area. These innovations improve sensitivity to small targets, increase recall, and maintain high precision.
As shown in Fig. 15, this study compares the detection results of LMWP-YOLO with other advanced algorithms using the TIB-Net dataset. The results reveal that the compared algorithms exhibit varying confidence levels in detecting small targets. Models such as YOLOv6n, YOLOv8n, YOLOv9t, YOLOv10n, and the baseline YOLO11n all demonstrate varying degrees of missed and false detections. Missed detections(False negative) are primarily due to these models’ inability to fully integrate shallow fine-grained features when extracting small target details, causing small targets to be blurred through downsampling in high-level feature maps. Additionally, anchor boxes may significantly differ in size compared to small targets, leading to low IoU values and undetected targets. False detections(Flase positive) occur when models, facing complex backgrounds or small targets with low contrast, misidentify background noise as a target, reducing detection accuracy. In contrast, LMWP-YOLO significantly improves confidence and detection accuracy. This enhancement is mainly attributed to the integration of channel and spatial dimension modeling attention mechanisms and an improved multi-scale feature extraction module. These innovations strengthen feature extraction and information transfer for small targets, enhancing the model’s ability to detect them. Furthermore, LMWP-YOLO reduces false positives from background noise by dynamically adjusting weights and utilizing a refined loss function design. These strategies effectively improve the multi-dimensional representation of small target features.

Visual comparison of detection results between LMWP-YOLO and other state-of-the-art methods on TIB-Net dataset.
Discussion
In drone detection, existing object detection models face significant challenges, including limited target recognition in complex backgrounds and inadequate feature extraction for high-resolution tasks. The baseline model, YOLO11, demonstrates strong performance in single-stage object detection but is constrained by the inefficiencies of its original convolutional modules, particularly in computational efficiency, multi-scale feature extraction, and handling feature redundancy. These limitations reduce the accuracy of small drone target detection and compromise the real-time performance of detection systems. To overcome these challenges, this study introduces LMWP-YOLO, a lightweight object detection model specifically designed for detecting small, multi-scale, and low-latency drone targets over long distances.
This study enhances YOLO11n’s backbone network by integrating the LCbackbone architecture, which employs depthwise separable convolutions and the H-Swish activation function. These improvements optimize computational efficiency and feature extraction, enabling the model to perform effectively on resource-constrained devices. Furthermore, a novel MAFR module is introduced in the neck layer. This module incorporates a multidimensional collaborative attention mechanism to strengthen feature dependencies across dimensions and efficiently extract multi-scale features. Additionally, the SE module and residual connections refine feature representation and enhance gradient propagation. The loss function is also improved by incorporating the normalized Wasserstein distance, which mitigates IoU’s sensitivity to positional and shape deviations in small targets. Finally, a pruning strategy is implemented to eliminate low-importance network channels and convolutional kernels, effectively reducing model redundancy.
Compared to traditional machine learning methods for object detection, deep learning algorithms offer superior feature representation capabilities and excel at processing large-scale data. These algorithms are broadly categorized into two types: one-stage and two-stage models. Single-stage detection algorithms typically provide faster inference speeds and require fewer computational resources than two-stage models. This study introduces the one-stage LMWP-YOLO model and evaluates its performance against traditional two-stage detection methods, such as Faster-RCNN and SSD, as well as lightweight one-stage methods, including YOLOv6, YOLOv8, YOLOv9-Tiny, and YOLOv10. The results in Table 3 indicate that LMWP-YOLO outperforms all compared algorithms in the evaluation.
Faster-RCNN relies on a complex structure to extract global image features, leading to slow inference speeds that fail to meet real-time requirements. Additionally, SSD’s reliance on predefined anchor boxes restricts its ability to capture the range and variability of small drone targets. Furthermore, both Faster-RCNN and RT-DETR did not converge when applied to the dataset.
In contrast, YOLOv6 integrates CSPNet, which employs a cross-stage branching structure to reduce gradient redundancy, thereby enhancing the network’s feature learning capabilities and training efficiency. Despite these improvements, it exhibits limited performance in small object detection and lacks sufficient optimization of the feature pyramid. YOLOv8 eliminates the anchor box design and refines the positive and negative sample assignment process through dynamic label assignment. However, this approach proves unstable when dealing with small objects. YOLOv9-Tiny incorporates deformable convolutions to improve adaptability to variations in object shape and position. Nevertheless, it still demonstrates weak representation and detection performance for small objects. YOLOv10 introduces an improved prediction head, enabling more independent learning for classification and regression tasks. However, it lacks a dynamic weighting mechanism and fails to fully model the scale-specific characteristics of targets. In comparison, LMWP-YOLO achieves a lightweight design, enhances detection efficiency, and significantly improves recognition capabilities for small drone targets. This advancement offers an innovative and effective solution for the detection of small drone targets.
However, this study has several limitations. First, the dataset used does not include complex weather conditions such as strong winds, heavy fog, and snow, leaving the model’s performance in adverse environments unverified. Second, although a multi-scale feature fusion module was introduced to enhance the feature representation of small targets, in high-density scenarios of small drone target detection, issues such as target occlusion and feature blurring may lead to missed detections. Lastly, while the loss function improves the robustness of target detection through a dynamic weighting mechanism, in scenarios involving small target swarms, the loss signal may be weakened due to the high-density target distribution, thereby affecting the model’s accuracy in detecting small targets.
Future research should expand the dataset to include complex extreme weather conditions and diverse scenarios, thereby improving the model’s generalization ability across various environments. Additionally, specialized detection modules for high-density drone swarms should be developed. For example, incorporating Transformer-based global feature modeling can enhance the model’s capacity to capture complex relationships among multiple targets. In high-density target scenarios, dynamic multi-target distribution modeling mechanisms can be employed to group and separate swarm features, effectively mitigating the impact of occlusion on detection outcomes. Moreover, designing a jointly optimized loss function for extreme weather and swarm scenarios would enable dynamic adjustment of loss weights across targets, thereby improving the precision of single-target detection within dense swarms. These advancements will further enhance the model’s adaptability to extreme environments, offering a more comprehensive and robust solution for detecting small drone swarms.
To address this, we designed a new C3TR module, based on a Transformer encoder47, following the MAFR in the neck layer to validate the effectiveness of global feature modeling by Transformers. As shown in Fig. 16, this module uses a self-attention mechanism to capture long-range dependencies in the image, overcoming the limitations of the C3K2 module in modeling such dependencies. Additionally, it explicitly captures the contextual information of occluded targets, helping to accurately distinguish these targets and reduce the likelihood of missed detections due to occlusion.

The structure of C3TR module.
Additionally, we introduce an occlusion-aware factor in the loss function, which estimates local density by calculating the Intersection over Union (IoU) between predicted boxes, enabling effective detection of drone swarms. We also incorporate illumination invariance adjustments through simple brightness consistency constraints to enhance the model’s robustness. Finally, we add a relative scale difference term to the loss function to explicitly measure the relative width and height differences between predicted and ground truth boxes. This term, combined with dynamic weights, the occlusion factor, and temperature coefficients, optimizes the stability and adaptability of the loss function.
To evaluate the detection performance of our innovative designs “LCbackbone,” “MAFR,” “AWLoss,” and “C3TR” in drone swarm detection, we conducted comparison experiments with the baseline model using the drone swarm dataset. The drone swarm dataset is derived from the publicly available UAVSwarm dataset48. These experiments assessed the impact of the algorithmic improvements, focusing primarily on the global information modeling capability of the C3TR module. The evaluation metrics include mean average precision (mAP) and model parameters. The results on the drone swarm dataset are presented in Table 4.
The results in Table 4 show that our method outperforms the baseline model in key performance metrics, with mAP@0.5 and mAP@0.95 increasing by 3.3% and 19.0%, respectively. These improvements are largely attributed to the newly designed C3TR module in the neck layer. The module effectively captures global contextual information through the self-attention mechanism of the Transformer. This enables the model to better understand the relationships between different regions, particularly in the context of drone swarm detection, where multiple dispersed swarm individuals are involved, and enhances the modeling of long-range dependencies.
Additionally, To evaluate the detection performance of our innovative designs under extreme weather conditions, we created a custom dataset featuring extreme weather scenarios, including heavy snow and fog. We then conducted comparative experiments with the baseline model. These experiments assessed the impact of the algorithmic improvements, with a particular focus on the effect of the enhanced loss function in extreme weather detection. The evaluation metrics included mean average precision (mAP) and model parameters. The results on the extreme weather dataset are presented in Table 5.
The results in Table 5 demonstrate that our method outperforms the baseline model in key performance metrics, with mAP@0.5 and mAP@0.95 increasing by 4.4% and 3.8%, respectively. The observed improvements are largely attributed to the newly designed AWLoss function. This loss function enhances detection stability under extreme weather conditions by incorporating illumination invariance adjustments and dynamic weighting based on the target area ratio.
Conclusion
To address the challenges of low accuracy in detecting small drone targets within complex backgrounds, limited feature extraction capabilities, and the trade-off between real-time performance and computational efficiency, this study presents LMWP-YOLO, an enhanced lightweight detection framework. Designed for long-distance small drone target detection, the framework integrates lightweight network components, multi-scale feature fusion modules, and dynamically optimized loss functions, making it highly suitable for deployment in complex environments. The key contributions are as follows: 1. Depthwise separable convolutions and efficient activation functions are designed in the backbone layer, significantly reducing model parameters and achieving lightweight optimization. 2. The neck structure integrates a multi-dimensional collaborative attention mechanism and a multi-scale fusion module, enhancing small target detection capability. 3. The improved loss function further improves the boundary box matching ability for distant small targets. 4. Pruning strategies, by eliminating redundant filters in the backbone and neck, significantly enhance computational efficiency. Experimental results demonstrate that LMWP-YOLO significantly enhances small target detection performance in complex backgrounds, achieving a 9.72% increase in accuracy, a 29.48% improvement in recall, and a 22.07% increase in mAP compared to the baseline model. Additionally, pruning techniques contribute to a lightweight design and real-time performance, reducing model parameters by 52.51%. However, the model’s generalization capability on the dataset remains limited, and further improvements are needed for drone target detection under extreme weather conditions. Additionally, the model still struggles with adapting to densely distributed targets or high-similarity scenarios, and further advancements in drone swarm detection are required. Future research will focus on expanding the dataset, optimizing drone swarm detection scenarios, and addressing issues related to target occlusion and complex distributions. We will also enhance algorithms based on Transformer global dependency modeling to further improve the model’s detection capability for drone swarms.
Data availability
The datasets used and analysed during the current study are available from the corresponding author on reasonable request.
References
Saadaoui, F. Z., Cheggaga, N. & Djabri, N. Multi-sensory system for UAVs detection using Bayesian inference. Appl. Intell. 53, 29818–29844. https://doi.org/10.1007/s10489-023-05027-z (2023).
Zhang, J., Campbell, J. F. & Sweeney, D. C. II. A continuous approximation approach to integrated truck and drone delivery systems. Omega Int. J. Manag. Sci. 126, 103067. https://doi.org/10.1016/j.omega.2024.103067 (2024).
Estevez, J., Nunez, E., Lopez-Guede, J. M. & Garate, G. A low-cost vision system for online reciprocal collision avoidance with UAVs. Aerosp. Sci. Technol. 150, 109190. https://doi.org/10.1016/j.ast.2024.109190 (2024).
Nwaogu, J. M., Yang, Y., Chan, A. & Chi, H.-L. Application of drones in the architecture, engineering, and construction (AEC) industry. Autom. Constr. 150, 104827. https://doi.org/10.1016/j.autcon.2023.104827 (2023).
Meng, Z., Zhou, Y., Li, E. Y., Peng, X. & Qiu, R. Environmental and economic impacts of drone-assisted truck delivery under the carbon market price. J. Clean. Prod. 401, 136758. https://doi.org/10.1016/j.jclepro.2023.136758 (2023).
Lee, S., Hong, D., Kim, J., Baek, D. & Chang, N. Congestion-aware multi-drone delivery routing framework. IEEE Trans. Veh. Technol. 71, 9384–9396. https://doi.org/10.1109/TVT.2022.3179732 (2022).
DroneCells: Improving 5G spectral efficiency using drone-mounted flying base stations [arXiv]-all databases. https://www.webofscience.com/wos/alldb/full-record/INSPEC:17152813.
Muksimova, S., Umirzakova, S., Mardieva, S., Abdullaev, M. & Cho, Y. I. Revolutionizing wildfire detection through UAV-driven fire monitoring with a transformer-based approach. Fire 7, 443. https://doi.org/10.3390/fire7120443 (2024).
Tepylo, N., Debelle, L. & Laliberte, J. Public perception of remotely piloted aircraft systems in Canada. Technol. Soc. 73, 102242. https://doi.org/10.1016/j.techsoc.2023.102242 (2023).
Al-lQubaydhi, N. et al. Deep learning for unmanned aerial vehicles detection: A review. Comput. Sci. Rev. 51, 100614. https://doi.org/10.1016/j.cosrev.2023.100614 (2024).
Oh, B.-S. & Lin, Z. Extraction of global and local micro-doppler signature features from FMCW radar returns for UAV detection. IEEE Trans. Aerosp. Electron. Syst. 57, 1351–1360. https://doi.org/10.1109/TAES.2020.3034020 (2021).
Rudys, S. et al. Investigation of UAV detection by different solid-state marine radars. Electronics 11, 2502. https://doi.org/10.3390/electronics11162502 (2022).
Alvarez Lopez, Y., Garcia Fernandez, M. & Las-Heras Andres, F. Comment on the article “a lightweight and low-power UAV-borne ground penetrating radar design for landmine detection’’. Sensors 20, 3002. https://doi.org/10.3390/s20103002 (2020).
Zheng, J. et al. An efficient strategy for accurate detection and localization of UAV swarms. IEEE Internet Things J. 8, 15372–15381. https://doi.org/10.1109/JIOT.2021.3064376 (2021).
Hu, N. et al. Geometric distribution of UAV detection performance by bistatic radar. IEEE Trans. Aerosp. Electron. Syst. 60, 2445–2452. https://doi.org/10.1109/TAES.2023.3347685 (2024).
Wang, Q. et al. A low-slow-small UAV detection method based on fusion of range-doppler map and satellite map. IEEE Trans. Aerosp. Electron. Syst. 60, 4767–4783. https://doi.org/10.1109/TAES.2024.3381086 (2024).
Sipos, D. & Gleich, D. A lightweight and low-power UAV-borne ground penetrating radar design for landmine detection. Sensors 20, 2234. https://doi.org/10.3390/s20082234 (2020).
Yang, Y., Yang, F., Sun, L., Xiang, T. & Lv, P. Echoformer: Transformer architecture based on radar echo characteristics for UAV detection. IEEE Sens. J. 23, 8639–8653. https://doi.org/10.1109/JSEN.2023.3254525 (2023).
Cai, Z., Liu, Z. & Kou, L. Reliable UAV monitoring system using deep learning approaches. IEEE Trans. Reliab. 71, 973–983. https://doi.org/10.1109/TR.2021.3119068 (2022).
Anwar, M. Z., Kaleem, Z. & Jamalipour, A. Machine learning inspired sound-based amateur drone detection for public safety applications. IEEE Trans. Veh. Technol. 68, 2526–2534. https://doi.org/10.1109/TVT.2019.2893615 (2019).
Ma, Y., Mustapha, F., Ishak, M. R., Abdul Rahim, S. & Mustapha, M. Machine learning methods for multi-rotor UAV structural damage detection based on MEMS sensor. Int. J. Aeroacoust. 22, 656–674. https://doi.org/10.1177/1475472X231206495 (2023).
Pan, Y., Zhang, X., Cervone, G. & Yang, L. Detection of asphalt pavement potholes and cracks based on the unmanned aerial vehicle multispectral imagery. IEEE J. Select. Top. Appl. Earth Observ. Remote Sens. 11, 3701–3712. https://doi.org/10.1109/JSTARS.2018.2865528 (2018).
Clocker, K., Hu, C., Roadman, J., Albertani, R. & Johnston, M. L. Autonomous sensor system for wind turbine blade collision detection. IEEE Sens. J. 22, 11382–11392. https://doi.org/10.1109/JSEN.2021.3081533 (2022).
Koyun, O. C., Keser, R. K., Akkaya, I. B. & Toreyin, B. U. Focus-and-detect: A small object detection framework for aerial images. Signal Process. Image Commun. 104, 116675. https://doi.org/10.1016/j.image.2022.116675 (2022).
Peng, J., Wang, H., Yue, S. & Zhang, Z. Context-aware co-supervision for accurate object detection. Pattern Recogn. 121, 108199. https://doi.org/10.1016/j.patcog.2021.108199 (2022).
Wang, C. et al. Geospatial object detection via deconvolutional region proposal network. IEEE J. Select. Top. Appl. Earth Observ. Remote Sens. 12, 3014–3027. https://doi.org/10.1109/JSTARS.2019.2919382 (2019).
Redmon, J., Divvala, S., Girshick, R. & Farhadi, A. You only look once: Unified, real-time object detection. In 2016 IEEE Conference on Computer vision and Pattern Recognition (CVPR), 779–788, (IEEE, New York, 2016). https://doi.org/10.1109/CVPR.2016.91.
YOLO9000: Better, faster, stronger [arXiv]-all databases. https://www.webofscience.com/wos/alldb/full-record/INSPEC:16848896.
YOLOv4: Optimal speed and accuracy of object detection [arXiv]-all databases. https://www.webofscience.com/wos/alldb/full-record/INSPEC:19672657.
Wang, C.-Y., Bochkovskiy, A. & Liao, H.-Y. M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 7464–7475, (IEEE, Vancouver, BC, Canada, 2023). https://doi.org/10.1109/CVPR52729.2023.00721.
YOLOv9: Learning what you want to learn using programmable gradient information [arXiv]-all databases. https://www.webofscience.com/wos/alldb/full-record/INSPEC:24758387.
Wang, A. et al. YOLOv10: Real-time end-to-end object detection, arXiv:2405.14458 (2024).
Liu, W., et al. SSD: Single shot MultiBox detector, https://doi.org/10.48550/arXiv.1512.02325 (2016).
Lin, T.-Y., Goyal, P., Girshick, R., He, K. & Dollar, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 42, 318–327. https://doi.org/10.1109/TPAMI.2018.2858826 (2020).
Huang, M., Mi, W. & Wang, Y. EDGS-YOLOv8: An improved YOLOv8 lightweight UAV detection model. Drones 8, 337. https://doi.org/10.3390/drones8070337 (2024).
Wang, C. et al. A lightweight UAV swarm detection method integrated attention mechanism. Drones 7, 13. https://doi.org/10.3390/drones7010013 (2023).
Bo, C., Wei, Y., Wang, X., Shi, Z. & Xiao, Y. Vision-based anti-UAV detection based on YOLOv7-GS in complex backgrounds. Drones 8, 331. https://doi.org/10.3390/drones8070331 (2024).
Khanam, R. & Hussain, M. YOLOv11: An overview of the key architectural enhancements, https://doi.org/10.48550/arXiv.2410.17725 (2024).
Cui, C. et al. PP-LCNet: A lightweight CPU convolutional neural network, https://doi.org/10.48550/arXiv.2109.15099 (2021).
Hu, J., Shen, L. & Sun, G. Squeeze-and-excitation networks. In 2018 IEEE/CVF Conference On Computer Vision and Pattern Recognition (CVPR), 7132–7141 (IEEE, New York, 2018). https://doi.org/10.1109/CVPR.2018.00745.
Yu, Y., Zhang, Y., Cheng, Z., Song, Z. & Tang, C. MCA: Multidimensional collaborative attention in deep convolutional neural networks for image recognition. Eng. Appl. Artif. Intell. 126, 107079. https://doi.org/10.1016/j.engappai.2023.107079 (2023).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770–778 (IEEE, New York, 2016). arXiv:1512.03385, https://doi.org/10.1109/CVPR.2016.90.
Wang, J., Xu, C., Yang, W. & Yu, L. A normalized gaussian wasserstein distance for tiny object detection, https://doi.org/10.48550/arXiv.2110.13389 (2022).
Li, H., Kadav, A., Durdanovic, I., Samet, H. & Graf, H. P. Pruning filters for efficient ConvNets, https://doi.org/10.48550/arXiv.1608.08710 (2017).
Sun, H. et al. TIB-net: Drone detection network with tiny iterative backbone. IEEE Access 8, 130697–130707. https://doi.org/10.1109/ACCESS.2020.3009518 (2020).
Selvaraju, R. R. et al. Grad-CAM: Visual explanations from deep networks via gradient-based localization. Int. J. Comput. Vis. 128, 336–359. https://doi.org/10.1007/s11263-019-01228-7 (2020).
Dosovitskiy, A. et al. An image is worth 16x16 words: Transformers for image recognition at scale [arxiv]. arXiv 21 pp. (2020).
Wang, C., Su, Y., Wang, J., Wang, T. & Gao, Q. UAVSwarm dataset: An unmanned aerial vehicle swarm dataset for multiple object tracking. Remote Sens. 14, 2601. https://doi.org/10.3390/rs14112601 (2022).
Acknowledgements
The authors appreciate the editors and anonymous reviewers for their valuable recommendations.
Funding
This research was supported by Students’ Innovation and Entrepreneurship Foundation of USTC(CY2024X008B), National Natural Science Foundation of China(61935008), the China Postdoctoral Science Foundation (2024M753120), the joint funding from National Synchrotron Radiation Laboratory(NO.KY2090000080).
Author information
Authors and Affiliations
Contributions
Conceptualization: Sicheng Zhou, Shuai Zhao; Methodology: Sicheng Zhou, Shuai Zhao; Software: Sicheng Zhou and Lei Yang; Validation: Huiting Liu, Chongqin Zhou and Jiacheng Liu; Formal analysis: Yang Wang; Writing—original draft preparation: Sicheng Zhou; Writing—review and editing: Sicheng Zhou; Supervision: Keyi Wang. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhou, S., Yang, L., Liu, H. et al. Improved YOLO for long range detection of small drones. Sci Rep 15, 12280 (2025). https://doi.org/10.1038/s41598-025-95580-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-95580-z
Keywords
This article is cited by
-
FDU-YOLO: efficient surface floating debris detection model for UAV perspectives detection
Journal of Real-Time Image Processing (2026)
-
Vehicle detection in drone aerial views based on lightweight OSD-YOLOv10
Scientific Reports (2025)
