
Abstract
Lung diseases remain one of the major causes of mortality worldwide. Medical experts usually require information from multiple sources, including clinical symptoms, laboratory and pathological tests, in combination with chest X-rays, to confirm a lung disease diagnosis. However, the manual interpretation of information collected from various sources is time-consuming and may lead to misdiagnosis of lung disease due to structural overlap and similar symptoms. An automated classification framework that integrates information from multiple sources, such as clinical notes, disease symptoms, and chest X-ray images, could enhance diagnostic precision and optimize clinical workflow efficiency. Therefore, this study proposed a multimodal approach based on the Graph Attention Network that integrates the pre-trained Clinical ModernBERT and RAD-DINO models, allowing for granular cross-modal interactions and providing robust multimodal representation learning to advance lung disease classification. The experiments are conducted using a publicly available lung disease dataset, which consists of chest X-ray images and their corresponding clinical text. For multiclass lung disease classification, the proposed multimodal approach achieved an accuracy of 95.73%, precision of 95.75%, recall of 95.72%, and F1-score of 95.70%, along with an expected calibration error of 0.0124. The proposed graph attention network-based multimodal framework outperformed existing state-of-the-art methods and effectively integrated imaging and textual information at the token level, offering an accurate and reliable automated alternative for lung disease diagnosis.
Similar content being viewed by others
Introduction
Lung diseases remain one of the most common causes of morbidity and mortality around the world. It is well known that millions of individuals worldwide are affected by various lung diseases. Some of these conditions can be effectively treated if the disease is identified in its early stages, before it becomes life-threatening1,2,3. The early and accurate detection is crucial for effective treatment and optimal patient outcomes. The traditional methods of diagnosing thoracic diseases predominantly depend on medical imaging techniques (such as X-rays and CT scans) or clinical findings (such as medical history, symptoms, and signs)4,5,6. However, the overlapping and intricate symptoms of various lung diseases make lung disease diagnosis challenging. To accomplish this task effectively and accurately, highly qualified and experienced medical professionals are required. The lack of competent and experienced radiologists, coupled with manual interpretation, often leads to misdiagnoses1,5,7. Additionally, observations and information gathered from a single modality are usually inadequate and may not provide sufficient information to accurately and efficiently diagnose lung diseases8,9. It is crucial to merge information from multiple data sources to ensure an accurate, comprehensive, and effective diagnosis of lung diseases. These sources include laboratory tests, clinical notes, disease manifestations, and additional relevant information. To automate and improve lung disease detection, a deep learning approach is required that leverages and consolidates multimodal data from multiple sources4,7,10.
Recently, deep learning strategies, particularly multimodal learning that incorporates visual and textual data, have gained considerable attention and impact in the medical domain, where datasets typically consist of paired images and related clinical text11,12. Therefore, multimodal learning has emerged as a dominant strategy for acquiring extensive and detailed medical knowledge by integrating data from multiple modalities to improve the effectiveness of subsequent multimodal tasks13,14. However, multimodal fusion techniques still face numerous challenges. It remains a considerable challenge to align and merge heterogeneous data from diverse modalities, such as imagery and textual information. Simple concatenation or cross-modal attention techniques are often incapable of capturing the complex relationships among various modalities, leading to the loss of fine-grained semantic information. Furthermore, end-to-end training is challenging due to high computational costs and unstable training dynamics, particularly when employing large backbone models. Additionally, the fine-tuning of pre-trained backbones may result in the loss of valuable pre-trained knowledge4,13,15. To preserve pre-trained knowledge and reduce training costs, the benefits of partially freezing components, such as language models or vision backbones, within multimodal pre-training frameworks are explored13,15,16, but not both components simultaneously.
Deep learning approaches based on graph learning technology have been extensively applied in various medical-related tasks, including segmentation17, multimodal fusion18, and disease classification19,20. Therefore, this study proposes a novel multimodal approach based on graph structure, specifically the Graph Attention Network (GAT), that leverages chest X-ray (CXR) images and clinical text to classify lung diseases. The proposed approach integrates domain-specific pre-trained models: RAD-DINO is used to extract high-quality visual features, while Clinical ModernBERT is utilised to derive semantically rich textual embeddings. Keeping both components in an entirely frozen state simultaneously, the study presents a robust and efficient multimodal approach that retains domain-specific knowledge and eliminates the high computational demands usually associated with fine-tuning and training. The high-dimensional textual and visual embeddings are projected into a common latent space and subsequently transformed into a cosine-similarity-based multimodal Top-K graph, enabling effective multimodal fusion and enhancing the comprehension of the complex relationships between the various modalities. A multimodal graph structure is created by defining relationships among the visual and textual Top-K most semantically similar features based on cosine similarity, enabling the model to capture meaningful cross-modal relationships at the token level. The GAT module allows feature interactions within and across modalities and retains attention weights information for neighbourhood nodes. A public dataset consisting of CXR images and their associated clinical texts is used to evaluate the proposed approach. The empirical findings show that the suggested GATMM framework outperformed other multimodal frameworks. The study presents several key contributions:
-
1.
Developed a multimodal framework using a multimodal graph and GAT module to improve the interaction between imaging features and clinical text embeddings. By combining complementary information from visual and textual sources, the proposed multimodal framework is designed to improve lung disease classification accuracy.
-
2.
The proposed approach extracts rich embeddings from both image and text modalities using pre-trained, domain-specific encoders (RAD-DINO and Clinical ModernBERT), which are frozen simultaneously throughout training. Therefore, the proposed strategy is more efficient and robust because it eliminates the need for domain-specific knowledge and reduces computational overhead.
-
3.
The suggested approach uses a cosine-similarity-based bipartite Top-K graph construction mechanism to capture fine-grained interactions across modalities. This technique optimally integrates the most relevant features of both modalities, reducing information loss and lowering computing complexity.
-
4.
The proposed multimodal approach is validated through extensive experiments on a public benchmark dataset that includes CXR images and clinical text. Compared with existing methods, the presented framework achieved state-of-the-art performance, demonstrating the effectiveness of the developed multimodal fusion strategy for lung disease classification.
The article is structured as follows: Sect. “Related work” offers a comprehensive analysis of related work, highlighting key developments and identifying research gaps that motivate our study. Extensive descriptions of the proposed methodology are provided in Sect. “Methodology”, including the datasets, data preprocessing, overall framework design, the feature extraction processes, graph-based fusion mechanisms, and evaluation metrics. In Sect. “Experimental setup and results analysis”, the experimental setup and implementation details are described, followed by an exhaustive analysis of experimental results. Section “Discussion” describes the implications, strengths, and comparisons with other related methods. Section “Limitations and challenges” highlights the limitations and challenges of the proposed framework, whereas Sect. “Conclusion” concludes the study and outlines future research directions.
Related work
The lung disease classification and detection are crucial and widely researched areas of medical research. Recently, multimodal learning has captured the interest of researchers and emerged as an effective tool for improving disease diagnosis accuracy and reliability through the use of diverse, complementary clinical data from various sources. CXR is one of the most widely used imaging modalities for evaluating lung diseases, attributed to its low cost, ease of use, and wide range of clinical applicability. The combination of CXR images with computed tomography (CT) images, clinical texts, and lung sounds has been extensively explored by researchers to enhance the diagnostic reliability and accuracy of lung-related abnormalities. In the published literature, numerous studies have investigated the classification of lung diseases using multimodal techniques. However, this section discusses the most relevant studies. The study elucidates the strengths and weaknesses of related studies and explains the need to develop a more reliable, efficient, and robust multimodal framework for interpreting lung diseases using CXR and clinical text data.
Research studies21,22,23,24 have combined the CXR images with other imaging modalities, such as CT scans, to improve the classification reliability and accuracy of lung diseases. Farhan et al.21 used the CT scans in combination with CXR images to develop a multimodal framework for the identification and classification of lung diseases. For chest radiograph feature extraction, the convolutional neural networks (CNNs) were used. The features derived from CXR and CT images were passed to Decision Tree, SVM, and LSTM models to classify lung diseases. The proposed model gained an accuracy of 98.78% accuracy, 98.99% precision, 95.89% recall, and 97.41% F1-score. The research study22 combined multiple imaging modalities (CXR, CT, and PET) to design a multimodal approach for lung disease classification. The feature maps from multiple modalities were collected through modality-specific feature extraction and fusion strategies. The authors employed CNN and pooling layers to extract high-level abstractions, subsequently using the fully connected layers for the classification of lung diseases. Varunkumar et al.23 introduced a multimodal method that combined the CT scans and histopathological images to enhance the screening of lung diseases. The features of CT scans were extracted using a SimSiam-based self-supervised learning method, while histopathological features were obtained with the MIXTURE model. The collected features of both modalities were then passed to a Random Forest classifier to predict lung diseases. The study24 proposed a novel multimodal framework, VisCapsNet, that combines a Vision Transformer with a Capsule Network for optimal feature extraction from CT and CXR images. Multimodal features were fused using a soft attentive dense weighted fusion mechanism, followed by a SoftMax classifier. However, the multimodal approaches based on imaging modalities have demonstrated improved performance in analyzing lung diseases, but due to the reliance on visual data, these approaches lack semantic richness to contextualize visual findings.
The research studies25,26,27,28 explored multimodal learning approaches that combine chest radiographs with lung or cough sounds to improve the analysis of lung diseases. Issahaku et al.25 presented a multimodal deep learning framework to detect lung diseases using CXR images and cough sounds. Modified VGG16 networks were used to extract features from both CXR images and cough sound spectrograms. To fuse the multimodal features, an attention mechanism is applied, while a modified Faster R-CNN is used for disease detection. The study26 presented a multimodal technique for early detection of COVID-19 employing breathing sounds and CXR images. The CXR images were processed using Anisotropic Diffusion, Fast Guided Filter, U-shaped Dual Swin Attention Transformer, and Deep Graph Regularized Nonnegative Matrix Factorization. In parallel, tri-gaussian filters with mel frequency cepstral coefficient features were employed for sound signal processing. The progressive split deformable field fusion module integrates visual and audio features, which are then classified using a dual sampling residual attention CNN. The proposed framework achieved accuracy, precision, recall, F-score, and AUC values of about 98%. In the study27, an innovative approach named FuzzyGuard was introduced, which utilized CT scans and audio signals (such as cough and lung sounds) for the early identification of chronic obstructive pulmonary disease. A Neuro-fuzzy Random Vector Functional Link network was used to extract features across all modalities, and a weighted sum-fusion technique was utilized to fuse these features. Malik et al.28 developed a multimodal framework based on CNNs for the classification of nine lung diseases. The proposed model comprises batch normalization layers, Max-pooling, rank-based average pooling, dropout, and the multiple-way data generation module. For lung disease classification, the proposed method achieved 99.01% accuracy, 98.98% precision, 98.30% recall, 98.12% F1-score, and 93.7% AUC. While image-sound-based multimodal frameworks typically integrate heterogeneous features through the implementation of fusion layers or attention mechanisms, the availability of large and well-labeled lung sound datasets poses a significant challenge to these approaches. In addition to taking chest radiographs and recording lung or cough sounds at different times, matching up the times between them is a challenging task.
The research studies29,30,31 examined multimodal learning approaches that integrated chest radiographs with tabular patient metadata to enhance lung disease analysis. Shimbre et al.29 introduced ChestXFusionNet, an efficient multimodal deep learning framework that combined CXR images with patient metadata for the accurate prediction of lung diseases. The model applied 2D CNNs to extract visual features from CXR images, whereas a parallel dense deep learning branch encoded auxiliary patient information, including age, gender, and view position. After extracting features from both modalities, the extracted features were combined to predict lung disease. In addition, a blended map of Image activation was employed as an additional step for further optimization. For binary lung disease classification, the presented approach obtained an accuracy of 92.4%, a precision of 92.2%, a recall of 93.5%, and an F1-score of 92.3%. The study30 proposed a novel transformer-based multimodal framework to improve the classification of lung disease, leveraging CXR images and patient metadata. In the proposed model, visual features are extracted using a vision transformer, and non-imaginary clinical data is incorporated using a cross-attention mechanism. The transformer encoders were used to merge information across modalities, followed by multilayer perceptrons to predict disease. Althenayan et al.31 developed a novel multimodal framework for the classification of lung diseases by integrating CXR images with tabular medical information. After extracting features using both ResNet-like and VGG-like architectures, early fusion was performed in order to combine both modalities. Synthetic samples were generated using Generative Adversarial Networks fr balancing the dataset. For multiclass lung disease classification, the proposed approach gained an accuracy of 95.97%, a precision of 96.01%, a recall of 95.97%, an F1-score of 95.98%, and an AUC of 95%. For lung disease classification, methods based on CXR and patient metadata showed the best results. However, using metadata may be inappropriate or suboptimal in certain scenarios, particularly if it is not specific to radiographic findings. Furthermore, the diagnosis of most lung diseases is not based on demographics or general patient information.
Research studies32,33,34,35 investigated the most promising and rapidly advancing research direction that combines chest radiographs and clinical textual data to enhance the lung disease classification. Kumar et al.32 proposed an innovative multimodal fusion architecture that integrates CXR images and clinical data to detect lung disease. To extract image features, three modified CNN architectures were employed (DenseNet121, DenseNet169, and ResNet50), while clinical information was processed using an LSTM with a self-attention mechanism. Using the SVM model, feature vectors from both modalities are aligned and concatenated. For classification, the fused features are passed through ReLU and Softmax layers. The presented framework achieved 93.85% accuracy, 93.80% precision, and 94.74% F1-score. In the study33, a transformer-based multimodal approach was introduced, which incorporated CXR images and clinical data to enable accurate diagnosis of lung diseases. To extract CXR features, a CNN model was used, whereas to extract clinical data features, a denoising autoencoder model was utilized. The proposed method merged features from diverse modalities for disease classification by using a cross-attention transformer module. Yang et al.34 implemented a multimodal approach named MCX-Net, which integrates CXR with clinical texts to aid in the diagnosis of multi-label lung diseases. The MCX-Net used pretrained BERT as a text encoder, BEIT-v2 as an image encoder, and as a cross-modal image-text transformer module. The study35 introduced a multimodal approach based on early and late fusion techniques to enhance lung disease classification, integrating clinical text and CXR images. The LLaMA-2 model is used for text data, while the 2D CNN is used for images. Both modalities were fused using cross layers (consisting of attention blocks). For multiclass lung disease classification, the proposed early fusion-based multimodal approach achieved an AUC of 97.10%. The image-text fusion methods have shown promising results. Nevertheless, these methods often overlook interactions at the token and region levels, potentially missing crucial semantic information. Furthermore, employing large backbone models requires substantial computational resources, which could hinder efficient training, fine-tuning, and deployment in clinical environments.
Recent multimodal learning methods for lung disease classification have demonstrated the benefits of integrating chest radiographs with additional data sources, including lung sounds, metadata, and clinical text. However, these methodologies usually used simple fusion procedures that may fail to capture cross-modal dependencies. Furthermore, training or fine-tuning complex, large deep learning architectures on limited medical datasets considerably increases the risk of overfitting, particularly for models with a massive number of parameters. This gap underscores the urgent need for an advanced, robust multimodal approach. Therefore, this study introduced a GAT-based multimodal (GATMM) strategy that explicitly captures interactions between the visual features of CXR images and the textual embeddings of clinical text at the token or pitch level. The semantically sparse Top-K multimodal graph and the GAT module enable fine-grained, interpretable interactions between visual and textual modalities. By leveraging pre-trained domain-specific models, such as RAD-DINO for visual feature extraction and Clinical ModernBERT for textual embeddings, the proposed multimodal approach not only enhances classification performance but also reduces the high computational burden. The proposed GATMM method offers a viable, scalable alternative with superior performance for the classification of multiclass lung-related diseases.
Methodology
This study introduced a multimodal deep learning framework that used pre-trained domain-specific vision and language models, a multimodal cosine-similarity-based Top-K graph, and two GAT layers to integrate CXR images and clinical text for lung disease analysis. The developed multimodal framework benefits from the complementary strengths of domain-specific pre-trained models and the diverse nature of visual and textual information derived from CXR images and clinical text. The subsequent subsections provide a comprehensive description of the proposed GATMM framework.
Dataset
This research work used a public dataset “Lung X-Ray Image + Clinical Text Dataset”36, which consists of about 80,000 CXR images and clinical texts. The dataset has eight subfolders, such as Obstructive Pulmonary Diseases, Higher Density, Lower Density, Chest Changes, Encapsulated Lesions, Degenerative Infectious Diseases, Mediastinal Changes, and Normal. Each subfolder originally contains 10,000 images related to a particular lung condition. The CXR images were obtained from the dataset “X-ray Lung Diseases Images”37, which has CXR images without patient information, deidentified by radiologists, and made publicly available for researchers. The clinical texts are collected from public datasets and medical literature sources, which include the symptoms related to each lung condition. All CXR images are pre-processed, normalized, and resized to 224 × 224 pixels before being fed to the model. The clinical texts are cleaned and pre-processed using regular expressions, and for tokenization, the Clinical ModernBERT model tokenizer is used. The study used stratified sampling by class label, with a fixed random seed (42) to split the data into three subsets (training, validation, and test), which helps to maintain class balance across splits and ensure reproducibility. A 60:20:20 ratio is used for the initial dataset splitting.
In public datasets, clinical text may show partial reuse or templating across its samples. As mentioned, the study uses a public dataset, so this issue is addressed by implementing a multi-stage leakage-control technique to ensure rigorous separation across the training, validation, and test data. Initially, to identify exact reuse or duplication across the splits, three basic filtering techniques (normalized image identifiers, normalized clinical text, and joint image-text identifiers) are used. The result of pairwise overlap comparison between splits such as training-validation, training-test, and validation-test is 0 for all three techniques, indicating that no exact instances are shared across the three subsets of the dataset. To further reduce hidden textual redundancy or templating, the normalized clinical texts are encoded using term frequency-inverse document frequency representations with a maximum of 50,000 features and a minimum document frequency of 2. Encoding is only applied to the training set to avoid the contamination of evaluation data. Cosine similarity is computed between each validation and test sample and all training samples. The validation and test samples with a similarity greater than or equal to 0.95 are excluded. In addition, the test samples having a similarity of 0.95 or higher to the filtered validation set are removed to preserve rigorous distinction between splits and eliminate near-duplicate textual redundancy among all splits of the dataset. Most importantly, only the validation and test sets are filtered, but the training set remains unchanged. After the extensive filtering operations, the final filtered dataset contains the training instances of 48,000, the validation instances of 7619, and the test instances of 5688. The subsequent consistency analysis verified that there are no exact or near-duplicate samples across all subsets. Table 1 shows the distribution of the final cleaned and filtered dataset across classes and splits.
Proposed GAT-based multimodal approach
The lung disease classification task based on a multimodal approach is formulated as a multiclass classification problem. The goal of this study is to leverage both textual reports (T) and medical images (V) associated with lung disease samples (N) to predict their diagnostic categories accurately. The GATMM framework is developed to address the underlying challenges related to heterogeneous modalities and learn robust joint representations. The framework processes multimodal input in four distinct stages: Feature Encoding from text and image data, multimodal space projection and multimodal graph construction, graph attention network module, graph-level pooling, and classification head. Each component of the GATMM approach is discussed in the following sections. Figure 1 shows the proposed GATMM approach based on pre-trained domain-specific encoders, multimodal graph structure, and a GAT layer for the classification of multiclass lung diseases.

Proposed GATMM approach for lung disease classification.
Visual and textual feature encoders
Visual feature encoder
For the visual modality, the input CXR image V = {p1, p2, …, pn }, representing the entire image at the pixel or pitch level, is processed to extract feature embeddings. For this task, the study utilized a domain-specific pre-trained model, RAD-DINO38, as a Vision Encoder Model (VEM). The RAD-DINO is a pre-trained self-supervised learning based vision transformer model, DINOv239, which has been trained and fine-tuned to encode CXR images. The last hidden state represents the output of the vision model, which is a sequence of embeddings that represents the visual semantics of the image. Mathematically, the visual encoder output can be expressed as follows:
where vi denotes the sequence of pitch-level visual embeddings {v1, v2, …, vn} for the ith input sample obtained from the RAD-DINO encoder, these embeddings contain both semantic and spatial information captured from various regions of CXR images and serve as the foundation for subsequent multimodal graph generation. For visual tokens, these raw embeddings derived from CXR images have a dimension of 768, using the RAD-DINO model.
Textual feature encoder
For the textual modality, the clinical text is interpreted as a sequence of tokens or words, T = {w1, w2, …, wl }, related to the lung disease instance. The pre-trained domain-specific language model, Clinical ModernBERT40, is utilized as a Language Encoder Model (LEM) to capture rich semantic and syntactic representations. Clinical ModernBERT is a state-of-the-art encoder-based transformer model, particularly designed to handle clinical and biomedical texts. It is based on ModernBERT41 and incorporates domain-specific knowledge to generate a semantically rich representation of biomedical literature and clinical descriptions. As an output, the study extracted token-wise embeddings of the last hidden state of the textual encoder. Mathematically, the textual encoder output can be expressed as follows:
where tj denotes the sequence of token-level textual embeddings, {t1, t2, …, tl} for the jth input sample extracted from the Clinical ModernBERT encoder model, these embeddings capture both semantic and contextual information from the clinical text. These raw textual embeddings have a dimension of 768 for textual tokens. Based on these processed textual features, the set of textual nodes for graph construction can be established for subsequent multimodal graph construction.
Multimodal space projection and multimodal graph construction
Multimodal space projection
To achieve optimal multimodal representation learning, it is crucial to address the heterogeneity gap that arises due to the distinct modalities and their specialized encoders. To bridge this gap and enable semantically meaningful unified joint learning, the study project high-dimensional features from the visual and textual encoders into a 512-dimensional embedding space using modality-specific linear layers. Mathematically, it can be presented as follows:
where \(PN_{i}^{v}\) and \(PN_{j}^{t}\) indicate the projected visual and textual feature representations, respectively. The projection layers transform the heterogeneous output distributions of pre-trained encoders into a unified space. It also enables seamless and effective joint representation learning, addresses the heterogeneity gap, and serves as a base for efficient multimodal Top-K graph generation.
Multimodal graph construction
To capture semantically rich relationships between visual and textual projected embeddings, a semantically sparse cross-modal Top-K multimodal graph, GMM = (NMM, EMM), is constructed. In the Top-K multimodal graph, the nodes NMM are created by concatenating the projected textual and visual token embeddings for each input sample. Mathematically, it can be represented as follows:
Each node NMM in the constructed graph represents a token-level embedding from either the image or the text modality. The nodes in the graph encode local, token-level contextual and semantic information from their respective modalities, enabling the graph to model fine-grained cross-modal interactions.
To determine the edges EMM, the study initially computed cosine similarity between the projected and normalized feature vectors of the visual and textual nodes. The cross-modal cosine similarity for the feature vectors of the ith visual node and the jth textual node can be expressed mathematically as follows:
where \(PN_{i}^{v} .\;PN_{j}^{t}\) represents the inner dot product of feature vectors, and \(\left\| {PN_{i}^{v} } \right\|2 \cdot \left\| {PN_{j}^{t} } \right\|2\) is the ℓ2-normalization.
The cosine similarity is computed exclusively across modalities, resulting in a bipartite similarity matrix Svt (i, j). In the bipartite similarity matrix Svt, each entry represents the cosine similarity between the ith visual node and the jth textual node, effectively determining their cross-modal semantic relationship. The edges are induced using the reciprocal Top-K neighbors selection strategy. For each image node \({\text{i}} \in \left\{ {{\text{1,}} \ldots {\text{,n}}} \right\}\), directed edges are formed toward its Top-K most similar text nodes, and reciprocally, for each text node \({\text{j}} \in \left\{ {1,{\text{ }} \ldots ,{\text{ }}l} \right\}\), edges are created toward its Top-K most similar image nodes. This bidirectional Top-K graph construction ensures balanced cross-modal interactions while avoiding intra-modal connections and domination by a single modality. The reciprocal Top-K selection process helps to determine cross-modal semantically similar relations, ensuring balanced bidirectional interaction while maintaining sparsity and robust graph construction, even when either modality contains fewer tokens than the K parameter. To accommodate variable token lengths across samples, the effective neighbor counts that adapt to token availability can be mathematically defined as follows:
Here, kv and kt indicate the optimal numbers of neighbors selected by the Top-K operations, which are adapted according to the availability of tokens. The hyperparameter K is the sparsity parameter that controls the total number of neighbors, which is set to 12 in the experiments of this study. To construct a sparse yet semantically meaningful graph, edges are created only among visual and textual nodes (bipartite topology) after determining the Top-K most semantically similar neighbors. For each image token i, directed edges are formed toward its Top-K most similar text tokens. In contrast, each text token j independently selects its Top-K most similar image tokens, which can be defined mathematically as follows:
where n is corresponding to visual tokens and the indices n, …, n + ℓ-1 represent text tokens in the shared multimodal node space. The final cross-modal edge set can be represented mathematically as follows:
This reciprocal graph construction process naturally introduced bidirectional connectivity among cross-modal semantically most similar neighbor nodes, enabling balanced cross-modal information sharing while maintaining graph sparsity and enhancing computational efficiency. Self-loops are added to all nodes in the graph to ensure robust, stable message passing across the GAT layers. Mathematically, this can be defined as follows:
The final edge set of multimodal used is the union of the cross-modal edges and the self-loop edges, which can be demonstrated mathematically as follows:
The multimodal graph construction topology used detached token embeddings to avoid unstable gradients caused by Top-K discrete operations. However, message-passing operations still use the original (non-detached) node features. This graph construction method enables end-to-end training with a stable graph topology while maintaining the differentiability of feature representations. The cosine-similarity-based cross-modal Top-K graph enables semantically aligned connections, retains the most meaningful Top-K multimodal relationships, supports directed message passing, and ensures the stability of self-loops in the GAT layers. The cross-modal graph constructed with this strategy is a sparse, semantically meaningful graph that captures fine-grained cross-modal token interactions while maintaining computational efficiency for multi-head attention GAT layers.
For optimal computation, the above graph-construction approach is applied to each sample in the mini-batch, generating a list of individual graphs [G1, G2, …, GB], where B denotes the batch size. Using the dgl batching operation, the per-sample single graphs are converted into a batched graph, which facilitates efficient parallel computation across all samples within the batch using the proposed GAT framework. In the constructed multimodal graph, nodes represent text tokens and image regions, while edges encode the most salient adaptive cross-modal relationships, which offer a semantically aligned and computationally efficient graph structure for downstream multimodal learning.
Graph attention network
A two-layer Graph Attention Network (GAT) module42 is applied to the developed cosine-similarity-based Top-K multimodal graph GMM = (NMM, EMM) to generate graph-level embeddings and learn rich multimodal representations. The GAT layers utilize the self-attention mechanism to compute the hidden features of each node by aggregating neighbourhood information. The GAT layer improves the representation of a node by adjusting its features and collecting the most relevant neighborhood information. A GAT layer takes a set of node features h as input and generates a refined set of features h′ as output. The attention weight eij between node i and node j is computed with a learnable linear transformation weight matrix W, which is applied across all nodes. The attention coefficients represent the significance of node j to node i, which is determined as follows:
where hi and hj refer to the feature vectors of nodes i and j, respectively, ∥ refers to the concatenation operation, and W is a learnable weight matrix. The a represents the attention coefficient between nodes i and j. The GAT layer enables each node to attend to every other node, computing eij for nodes j ∈ Ni, where Ni refers to the most semantically similar neighbors of node i. To reduce the risk of overfitting during model training, after computing the eij, it is activated employing the nonlinear LeakyReLU function and normalized by using the SoftMax function. Mathematically, it can be expressed as follows:
To improve the learning stability of the GAT, the multi-head attention mechanism of the GAT layer is extended and formulated as follows:
where \(a_{ij}^{k}\) represents the attention coefficient between nodes i and j for head Kth, the Wk is a learnable weight matrix, σ is the activation function Elu, and ∥ refers to concatenation across heads. Using multi-head attention mechanisms, the output features generated by each attention head are concatenated and passed to the subsequent layers. After propagating through the stacked GAT layers, when the multi-head attention mechanism operates in the final layer, the concatenation operation is substituted by an average operation. Mathematically, it can be represented as follows:
The multi-head attention mechanism could be used to explore diverse strength-factor alternatives and enhance training stability. Employing multi-head attention mechanisms, the model can capture complex multimodal interactions by integrating data from multiple, diverse sources. This study used two GAT layers, each with eight heads, to classify lung diseases. The first layer uses concatenation, whereas the second layer averages information from multiple heads. Hence, the output of the first GAT layer is concatenated from K = 8 attention heads, each with 64-dimensional embedding nodes. The second GAT layer outputs from the K = 8 attention heads are averaged along with the head dimensions, yielding a 256-dimensional embedding per node.
Graph-level pooling and classification head
Graph-level pooling operation
Following the acquisition of updated node-level features via the GAT multi-head attention module, the study applied global max node pooling operations for graph-level representation, which can be represented mathematically as follows:
where \(h_{i}^{\prime }\) is the output feature vector of node i, N is the total number of nodes in the graph, and hGMM is the global max-pooled graph embedding. This graph-level max pooling over all node embeddings captures the most salient cross-modal features across the graph, generating a highly effective and discriminantive graph-level representation for the downstream classification.
Classification head
As the final stage of the proposed GATMM architecture, the study employs a fully connected classification head for the classification of lung diseases. The learned multimodal graph-level representation hGMM, which encapsulates semantic information derived from both text and image modalities, is used as input to this module. The classification head consists of two linear layers. For generalization and training stability, the first linear layer maps the input features to a 128-dimensional latent space, followed by a ReLU activation, a Dropout layer, and Layer Normalization. In the second linear layer, the intermediate representation is projected into the output space with dimensions equal to the number of target classes (in our case, eight classes are used for classifying multiclass lung diseases). A SoftMax function is used on raw logits to transform them into class probabilities.
where z refers to the raw logits predicted by the method for the ith instance, C represents the total number of classes, and pi is the predicted probabilities after computing the SoftMax method.
During training, the proposed multimodal architecture is trained by reducing the standard multiclass cross-entropy loss. For a single sample, the multiclass cross-entropy loss can be formulated mathematically as follows:
where C refers to the number of classes, yi represents the one-hot encoded of the true label, and pi denotes the predicted probability for class i calculated from the SoftMax activation function applied to the raw logits z of the model.
In multimodal representation learning, modelling complex inter-modal relationships remains a significant challenge. This study proposes a cosine-similarity-based Top-K multimodal graph and a GAT multi-head attention framework that selectively preserves the top-most semantically meaningful edges between visual and textual nodes, thus reducing noise and redundancy associated with fully connected or static-threshold graphs. The Top-K sparsity of the graph reduces the number of parameters and mitigates human bias by eliminating manual coding and arbitrary graph construction. The GAT multi-head attention module efficiently weights the contributions of neighboring nodes in the semantically reciprocal Top-K sparse multimodal graph. The proposed method aims to learn robust and semantically rich multimodal representations to improve the performance of lung disease diagnosis.
Evaluation metrics
The performance evaluation metrics, such as AUROC, Area Under the Precision-Recall Curve (AUPRC), accuracy, loss, precision, recall, and F1-score, are used to assess the effectiveness of the proposed approach. By considering these performance evaluation indicators, it is possible to determine the model’s potential to identify and classify lung diseases. These evaluation metrics assess the classification performance of a model across all classes. The TN illustrates true negatives, TP indicates true positives, FN denotes false negatives, and FP represents false positives.
Experimental setup and results analysis
This section presents a comprehensive description of the experimental setup and the analysis of results obtained from various experiments conducted in this research for the multiclass lung disease classification task.
Experimental setup
The effectiveness of the developed GATMM method is assessed using a publicly available image-text dataset named “Lung X-Ray Image + Clinical Text Dataset,” which is one of the most frequently downloaded multimodal datasets for the classification of lung diseases. The data is split into three distinct subsets to conduct experiments: the training set is used for training the model, the validation set for validation, and the test set is kept unseen during training and validation and used for testing the model. The hyperparameters of the proposed multimodal approach are adjusted based on the average loss. Cross-entropy loss is employed as a loss function in the experiments performed in this study. The AdamW is applied as an optimizer with weight decay and a multiplicative factor of the learning rate. To minimize the risk of overfitting, the proposed approach is implemented with an early stop and L2 regularization. Pre-trained RAD-DINO is used as a vision encoder, and pre-trained Clinical ModernBERT is used as a textual encoder. The multimodal graph is constructed and passed to the GAT module to enhance cross-modal interaction. For development and experimental purposes, Python 3.9, PyTorch 2.2, DGL graph library, Anaconda 3, TensorFlow 2.10, and CUDA 12.6 are installed on a Windows 11 computer with an Intel(R) Core (TM) i7-10700 K 3.8 GHz processor, NVIDIA RTX 2080 Ti GPU 11 GB, and 32 GB of RAM. All model implementations are carried out using the PyTorch library. The Concatenation-based Multimodal (CMM) fusion approach contains approximately 224.0164 million parameters, the Cross-model Multi-head Attention-based Multimodal (CMAMM) has about 225.067 million parameters, the Graph Convolution Network-based Multimodal (GCNMM) contains approximately 224.378 million parameters, and the proposed GATMM has about 226.384 million parameters. The inference time during testing for all 12,000 test instances is approximately 350–460 s for all models. Table 2 presents the hyperparameter settings used for experiments and model training in this study.
Experimental results analysis
Detailed descriptions of the experimental results for the proposed approach are provided in the following subsections. As performance evaluation metrics, the confusion matrix, loss, accuracy, precision, recall, F1-score, AUROC, and AUPRC are considered. Each evaluation metric is described in detail, accompanied by a visual representation, in the following sections.
Confusion matrix
In this subsection, the study provides a comparative analysis of the main multimodal fusion strategies using confusion matrices to evaluate their performance on the test dataset. For the classification of eight lung disease classes, each fusion approach reveals distinctive characteristics in terms of accuracy and error rates. Among 5688 test instances, 5303 are correctly classified by the CMM fusion approach, whereas 385 are incorrectly classified. The CMAMM fusion approach correctly classified 5383 samples and incorrectly classified 305 samples out of the total 5688 test samples. The GCNMM fusion method correctly identified 5394 cases while misclassifying 294 samples from 5688 test samples. On the other hand, out of 5688 test instances, the proposed GATMM method correctly classified 5445 instances while misclassifying only 243 instances. The proposed strategy reduces false negative and false positive rates and outperforms other competing multimodal strategies, indicating its reliability and robustness. The confusion matrices show that classes (0, 5, and 6) are classified with high confidence, while classes (4 and 7) exhibit a high misclassification rate due to confusion with classes (2 and 3). Figure 2 shows the comparison of the confusion matrix for the developed GATMM strategy with other comparative multimodal fusion strategies employed for the classification of multiclass lung diseases in this research study.

The comparison of the confusion matrices of all multimodal strategies.
Training and validation loss, accuracy curve
Training and validation curves for all multimodal fusion strategies are discussed in this subsection. These curves represent the learning and generalization power of a method. The research evaluates various multimodal fusion strategies, including CMM, CMAMM, GCNMM, and GATMM, for the classification of lung diseases. The CMM approach achieved training and validation accuracies of 0.9116 and 0.9313, respectively, with training and validation losses of 0.3745 and 0.2684. The CMAMM method got a training accuracy of 0.9243 and a validation accuracy of 0.9442, along with a training loss of 0.3276 and a validation loss of 0.2355. For the GCNMM method, the training accuracy is 0.9264, and the loss is 0.3220, whereas the validation accuracy is 0.9474, and the loss is 0.2282. In contrast, the proposed GATMM framework achieved a training accuracy of 0.9403 and a loss of 0.2227, as well as a validation accuracy of 0.9553 and a loss of 0.1373.
The evaluation findings indicate that the GATMM approach performed much better during training and validation. It illustrates the effectiveness of the proposed strategy for representing the complicated inter- and intra-modal interactions. The closely aligned and minimal variation between the training and validation curves of the GATMM demonstrate its generalization potential. Furthermore, the training and validation loss curves of the proposed approach remain constant and decrease gradually in both phases, demonstrating that no overfitting has occurred. According to this comparison of training and validation curves, the GATMM strategy outperformed the other methods and retained excellent generalization to unseen instances. Figure 3 shows the training and validation curves for loss and accuracy of all multimodal strategies evaluated in this research study.

The training and validation loss and accuracy curves for all multimodal strategies.
Prediction accuracy, precision, recall, and F1-score
The evaluation of experimental results and comparative performance analyses is presented in Table 3. According to Table 3, the experimental findings demonstrate impressive improvements in prediction performance and efficiency for different multimodal fusion approaches for lung disease classification. It also shows the implications of architectural design choices on multimodal efficiency and performance. The CMM architecture achieved an accuracy of 93.23 ± 0.65%, a precision of 93.44 ± 0.64%, a recall of 93.21 ± 0.65%, and an F1-score of 93.23 ± 0.65%. The CMAMM framework obtained an accuracy of 94.64 ± 0.59%, a precision of 94.65 ± 0.58%, a recall of 94.2 ± 0.59%, and an F1-score of 94.62 ± 0.59%. The GCNMM method gained 94.83 ± 0.58% accuracy, 94.81 ± 0.58% precision, 94.81 ± 0.58% recall, and 94.79 ± 0.58% F1 score. The proposed GATMM method outperformed other traditional techniques for the classification of lung diseases, with an accuracy of 95.73 ± 0.53%, a precision of 95.75 ± 0.52%, a recall of 95.72 ± 0.53%, and an F1 score of 95.70 ± 0.53%. The superior performance of the GATMM model could lead to a considerable reduction in misdiagnosis. The proposed automated multimodal approach could serve as a robust and reliable alternative clinical tool for the diagnosis of lung diseases. In the clinical setting, high precision is required because false negatives have a detrimental impact on patient outcomes and can cause delays in the treatment process.
Receiver operating characteristic curve and precision–recall curve analysis
The AUROC and AUPRC are used to evaluate the performance of the proposed multimodal approach. The AUROC graph describes the correlation between the True Positive Rate (TPR) and the False Positive Rate (FPR), while the AUPRC curve summarizes the trade-offs between precision and recall. These metrics provide the most meaningful insights for the performance evaluation of a classification method43. The AUROC and AUPRC for the multimodal approaches used in this study are shown in Figure 4. The multimodal frameworks, such as CMM, CMAMM, and GCNMM, obtained AUROCs of 99.56 ± 0.17%, 99.64 ± 0.16%, and 99.70 ± 0.14%, while the AUPRCs of 98.03 ± 0.36%, 98.53 ± 0.31%, and 98.73 ± 0.29%, respectively. Conversely, the GATMM approach achieved the highest AUROC of 99.79 ± 0.12% and AUPRC of 99.06 ± 0.25%, indicating its reliability in distinguishing among various lung conditions.

Comparison of AUROC (left) and AUPRC (right) for all multimodal architectures.
Additionally, the study calculated per-class AUROC and AUPRC for the GATMM approach. Per-class AUROC and AUPRC provide a more comprehensive and clinically significant assessment of the prediction model, revealing how well it distinguishes each disease category from all others. Figure 5 shows the proposed GATMM approach per-class AUROC and AUPRC. Class 6 achieved the highest AUROC of 100.00 ± 0.01%, whereas class 7 had the lowest AUROC of 99.35 ± 0.21%. Furthermore, class 6 also achieved the highest AUPRC of 99.98 ± 0.04%, and class 7 recorded the lowest AUPRC of 97.40 ± 0.41% for the proposed GATMM approach. According to the findings, the GATMM approach achieved optimal AUROC and AUPRC for each class, indicating its reliability in distinguishing among different classes.

Proposed GATMM framework per-class AUROCs (left) and AUPRCs (right) visualization.
The interpretability and error analysis
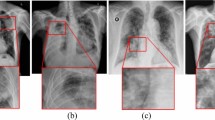
For the predictive transparency of the proposed GATMM framework, the study employed gradient-based feature attribution on projected image and text embeddings to examine the influence of each feature on predictions. To highlight regions and influential clinical terms involved in the prediction, pitch-level heatmaps for the CXR image and ranked saliency scores for the clinical text are generated. This highlighting approach for image regions and influential terms in clinical text provides reliable, consistent representations for qualitative error analysis. Figure 6 illustrates the visual attributions, salient clinical tokens, and both ground-truth and predicted labels for the example test instances.

Representative qualitative examples with visual and textual explanations.
Probabilistic calibration and predictive uncertainty analysis
The reliability and uncertainty characteristics of the proposed GATMM model are evaluated on the test dataset. The probabilistic calibration of the proposed model is evaluated using the Expected Calibration Error (ECE), the Negative Log-Likelihood (NLL), and the multiclass Brier score. According to Table 4, the proposed multimodal approach achieved an ECE of 0.0124, an NLL of 0.1431, and a Brier score of 0.0656, which indicates meaningful probability estimates with minimal calibration error. In addition, the epistemic uncertainty is determined by applying the Monte Carlo Dropout with 20 forward iterations. The proposed model achieved a mean predictive entropy of 0.4612, an epistemic variance of 0.0025, and a mean mutual information of 0.0540. The mutual information for misclassified cases is often higher than for correctly classified cases (0.2009 vs. 0.0481). These empirical findings show that the proposed approach effectively identifies error-prone predictions while producing robust and ambiguity-aware outputs.
In addition, Fig. 7 shows the visual representations of reliability, predictive entropy, epistemic variance, and mutual information for the proposed approach. The reliability curve shows a close correlation between the predicted confidence and the empirical accuracy across the confidence interval. On the other hand, the distributions of predictive entropy, epistemic variance, and mutual information highlight cases that are uncertain or misclassified. These results jointly show that the proposed model provides more reliable probability estimates and clinically useful uncertainty measures that could help to enhance transparency in confidence analysis and improve the reliability of automatic clinical decision-making systems.

The probabilistic calibration and uncertainty analysis for the proposed GATMM model (a) Reliability diagram. (b) Predictive entropy. (c) Epistemic variance. (d) Mutual information.
Ablation study
It is crucial to perform an ablation study to evaluate the impacts of different components on the performance of the proposed approach. In this study, a series of ablation experiments is conducted to validate the effectiveness of the proposed GATMM architecture. The experiments for the ablation study are performed across multiple variants of the proposed approach, including the number of GAT layers, graph-level global pooling techniques, graph creation strategies (cosine-similarity-based and Top-K), and the Top-K values. Initially, the proposed GATMM backbone is evaluated using varying numbers of GAT layers. Next, the performance of the proposed approach is evaluated using different graph-level global pooling techniques (attention pooling, mean pooling, and max pooling). Afterward, the performance of GATMM is evaluated for graph construction topologies, including the cosine-similarity-based graph and the Top-K graph. Finally, the proposed framework is evaluated for various Top-K values. The findings demonstrate that the proposed GATMM architecture, which employs two layers of GAT (each with 8 heads), global max-pooling at the graph-level, and a cosine-similarity-based Top-K graph with K = 12, improved classification performance. These findings confirm that the number of GAT layers, the Top-K value, the global pooling strategy at the graph level, and cosine-similarity-based Top-K graph construction are critical factors for improving the performance of the proposed GATMM framework in the analysis of lung diseases. Table 5 presents the ablation study results conducted for the proposed approach.
Proposed model generalization test
To evaluate the generalization and robustness of the proposed approach, the study performed generalization test experiments using a single-label ten-class lung-related subset collected from the most frequently downloaded publicly accessible MIMIC-CXR-JPG dataset44. The collected subset comprises 45,358 CXR images and corresponding findings sections from clinical reports for single-label lung diseases, with an imbalanced class distribution, various CXR image views, and diverse disease classes, which makes it different from the primary public dataset used in this study. These sorts of variations usually impose considerable generalization challenges for a medical image classification model. The experiments are conducted on the subset dataset, using the same preprocessing, training, validation, and evaluation procedures as the primary dataset. However, the dataset is split on the patient-based approach and uses a weighted cross-entropy loss. The diseases included in the subset are Atelectasis, Consolidation, Edema, Lung Lesion, Lung Opacity, Pleural Effusion, Pleural Other, Pneumonia, Pneumothorax, and No Finding. The down-sampling technique, which uses random state 42, is employed to randomly select No Finding cases from all No Finding samples. Table 6 shows the dataset distribution, splits, and number of instances for each class.
The proposed method achieved an accuracy of 80.52%, precision of 80.19%, recall of 80.13%, and F1-score of 80.52%. Also, the GATMM framework achieved an average AUROC of 95.88% and an AUPRC of 86.67%, with ECE of 0.0763, NLL of 0.6675, and Brier score of 0.3109 for the subset. The decrease in performance is expected because accuracy is heavily influenced by class imbalance and differences in disease prevalence across the dataset. However, the higher AUROC and AUPRC scores indicate that the proposed GATMM approach retains strong discriminative power even when distributions shift and class imbalance is present. The higher values of AUROC and AUPRC suggest that the model maintains the high predictive performance across diseases, which is crucial for disease screening. The performance of the GATMM approach on the external Mimic subset is lower compared to the primary dataset, but it exhibits excellent and clinically useful generalization, with high AUROC and AUPRC values despite significant distribution change and class imbalance. Figure 8 shows a visual representation of the GATMM model performance achieved on the single-label subset of the MIMIC-CXR-JPG dataset.

GATMM performance achieved on the single-label subset dataset.
Discussion
The proposed study leverages the complementary strengths of pre-trained domain-specific models, such as RAD-DINO and Clinical ModernBERT, to extract visual and textual features from CXR images and clinical texts, respectively. In the proposed approach for capturing the inter-modal interactions at the token level and aligning textual and visual features, semantically sparse Top-K multimodal graphs and the GAT layers are used. A comprehensive comparison of various fusion techniques and performance metrics demonstrated the effectiveness of the suggested multimodal approach. Experimental results reveal that the proposed GATMM framework performed remarkably well for multiclass lung disease classification. The developed GATMM method achieved the highest prediction accuracy of 95.73 ± 0.53%, precision of 95.75 ± 0.52%, recall of 95.72 ± 0.53%, F1 score of 95.70 ± 0.53%, AUROC of 99.79 ± 0.12%, and AUPRC of 99.06 ± 0.25% for the classification of multiclass lung diseases. On the other hand, the traditional multimodal methods, such as CMM, CMAMM, and GCNMM, achieved performance ranging from 93.23 ± 0.65% to 94.83 ± 0.58% across all evaluation metrics. The GATMM approach achieved optimal performance as compared to the other methods, indicating its robustness and effective generalization.
Furthermore, compared with conventional fusion methods, the GATMM approach leverages multimodal graph structures and multi-head node-wise attention mechanisms to capture complex relationships between visual and textual modalities, enabling important inter-modal representations. Thus, multimodal features are better aligned, represented, and classified. The proposed method ensures the smooth and effective integration of heterogeneous data sources, providing a multimodal framework that serves as a powerful tool for automating the analysis of lung diseases. Figure 9 compares the proposed GATMM approach with other fusion approaches used in this research study.

Comparison of the proposed GATMM approach with other fusion approaches used in this study.
A comparative analysis of the proposed multimodal approach with other related state-of-the-art approaches is presented in Table 7. According to Table 7, the previous research reported average accuracy, precision, recall, and F1-score values ranging from 77 to 95.59%. However, the proposed GATMM approach outperforms these traditional multimodal integration techniques, achieving a classification performance of about 95.73 ± 0.53% for multiclass lung diseases. Furthermore, the integration of frozen-pretrained domain-specific RAD-DINO for visual feature extraction and Clinical ModernBERT for textual feature representation provides substantial benefits by leveraging rich semantic representations while reducing the computational resources required for model fine-tuning and training from scratch. The proposed approach could also help to minimize the risk of overfitting when training large models from scratch on limited medical datasets. The empirical findings of the proposed approach validate the effectiveness of the GATMM framework in the medical domain. Combined with the advantages of transfer learning and graph learning, the developed framework presents a promising solution to advance automated lung disease diagnosis and other multimodal healthcare AI challenges by representing complex cross-modal relationships between heterogeneous data sources.
Limitations and challenges
The GATMM framework is presented in this study, which obtained competitive performance on the image-text dataset, making significant contributions to the automated classification of lung diseases and establishing a solid foundation for future research in this area. However, the model is evaluated on public and curated datasets that may not reflect the true complexity and variation of medical data. The clinical texts in the main dataset are disease-related symptoms collected from public datasets and the literature, and may not reflect the actual complexity of clinical reports. So, the generalizability analysis of the framework requires further validation through cross-institutional studies and prospective clinical trials. It is also necessary to optimize the computational complexity of the model to adapt it for real-time use. As part of the proposed framework, future work will focus on expanding its application to additional modalities as well as on improving its interpretability to enhance clinical trust.
Conclusion
The study presented a GATMM framework that integrates pre-trained domain-specific RAD-DINO and Clinical ModernBERT models with the GAT module for the classification of lung diseases. A publicly available multimodal CXR and clinical text dataset is used to evaluate the efficiency of the developed framework. The proposed approach addresses the limitations of previous approaches, such as the heterogeneity gap in multimodal medical data and existing solutions that used complex fusion techniques to integrate the different modalities, thereby increasing the risk of overfitting. Unlike previous approaches, our approach represents multimodal data in the form of a graph, with image and clinical features represented as nodes and edges, allowing fine-grained inter-modal interactions. For eight classes of lung diseases, the proposed GATMM approach achieved 95.73 ± 0.53% accuracy and 99.79 ± 0.12% AUROC. The results show that the proposed GATMM outperformed the traditional fusion methods across various performance evaluation metrics. The proposed architecture offers an efficient multimodal solution for automating the diagnosis of lung diseases, potentially leading to enhanced patient outcomes and reduced missed diagnoses.
In future research, the capabilities and clinical relevance of the GATMM approach will be examined and enhanced. The proposed approach will be evaluated on the most famous and clinically relevant CXR and clinical text datasets, such as MIMIC-CXR-JPG and CheXpert Plus, to rigorously validate and establish its robustness and generalizability. Furthermore, the proposed method will be improved to integrate multimodal data sources, including laboratory results, audio data, and temporal clinical information, which is crucial for capturing a wide range of patient diagnostic information. Future research should integrate advanced explainable AI tools to improve the reliability and explainability of the proposed approach.
Data availability
The data supporting the findings of this research are publicly available, and the code will be released on GitHub upon acceptance and publication of the article.
References
Shao, J. et al. A multimodal integration pipeline for accurate diagnosis, pathogen identification, and prognosis prediction of pulmonary infections. Innovation https://doi.org/10.1016/J.XINN.2024.100648 (2024).
Labaki, W. W. & Han, M. L. K. Chronic respiratory diseases: a global view. Lancet Respir. Med. 8(6), 531–533. https://doi.org/10.1016/S2213-2600(20)30157-0 (2020).
Reddy, K. D. & Patil, A. CXR-MultiTaskNet a unified deep learning framework for joint disease localization and classification in chest radiographs. Sci. Rep. 15(1), 32022. https://doi.org/10.1038/s41598-025-16669-z (2025).
Liu, X. et al. MDFormer: Transformer-based multimodal fusion for robust chest disease diagnosis. Electronics 14(10), 1926. https://doi.org/10.3390/ELECTRONICS14101926 (2025).
Leslie, A., Jones, A. J. & Goddard, P. R. The influence of clinical information on the reporting of CT by radiologists.. Br. J. Radiol. 73(874), 1052–1055. https://doi.org/10.1259/BJR.73.874.11271897 (2000).
Cohen, M. D. Accuracy of information on imaging requisitions: Does it matter?. J. Am. Coll. Radiol. 4(9), 617–621. https://doi.org/10.1016/J.JACR.2007.02.003 (2007).
Shetty, S., S, A. V. & Mahale, A. Multimodal medical tensor fusion network-based DL framework for abnormality prediction from the radiology CXRs and clinical text reports. Multimed. Tools Appl. 82(28), 44431–44478. https://doi.org/10.1007/S11042-023-14940-X/TABLES/1 (2023).
Xie, W., Fang, Y., Yang, G., Yu, K. & Li, W. Transformer-based multi-modal data fusion method for COPD classification and physiological and biochemical indicators identification. Biomolecules 13(9), 1391. https://doi.org/10.3390/BIOM13091391 (2023).
Yao, J., Wang, J., Xiao, Z., Hao, X. & Jiang, X. Intelligent analysis of chest x-ray based on multi-modal instruction tuning. Meta-Radiol 3(3), 100172. https://doi.org/10.1016/J.METRAD.2025.100172 (2025).
Baltrusaitis, T., Ahuja, C. & Morency, L. P. Multimodal machine learning: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 41(2), 423–443. https://doi.org/10.1109/TPAMI.2018.2798607 (2019).
Guo, Y. & Wan Z. Performance evaluation of multimodal large language models (LLaVA and GPT-4-based ChatGPT) in medical image classification tasks. In Proceedings - 2024 IEEE 12th International Conference on Healthcare Informatics, ICHI 2024, 541–543 (2024). https://doi.org/10.1109/ICHI61247.2024.00080.
Wu, Q., Qi, J., Zhang, D., Zhang, H. & Tang, J. Fine-tuning for few-shot image classification by multimodal prototype regularization. IEEE Trans. Multimedia 26, 8543–8556. https://doi.org/10.1109/TMM.2024.3379896 (2024).
Qin, J., Liu, C., Cheng, S., Guo, Y. & Arcucci, R. Freeze the backbones: A parameter-efficient contrastive approach to robust medical vision-language pre-training. In ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing - Proceedings, 1686–1690 (2024). https://doi.org/10.1109/ICASSP48485.2024.10447326.
Chen, T., Kornblith, S., Norouzi, M. & HintonG. A simple framework for contrastive learning of visual representations. In 37th International Conference on Machine Learning, ICML 2020, 1575–1585, Vol. PartF168147–3, accessed 03 July 2025; [Online]. Available: https://arxiv.org/pdf/2002.05709 (2020).
Qin, Z., Yi, H., Lao, Q. & Li, K. Medical image understanding with pretrained vision language models: A comprehensive study. In 11th International Conference on Learning Representations, ICLR 2023, accessed 03 July 2025; [Online]. Available: https://arxiv.org/pdf/2209.15517 (2022).
Liu, C. et al. M-FLAG: Medical vision-language pre-training with frozen language models and latent space geometry optimization. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 637–647, Vol. 14220 LNCS, (2023). https://doi.org/10.1007/978-3-031-43907-0_61.
Wang, X., Zhang, L., Roth, H., Xu, D. & Xu Z. Interactive 3D Segmentation Editing and Refinement via Gated Graph Neural Networks. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 9–17, Vol. 11849 LNCS, (2019). https://doi.org/10.1007/978-3-030-35817-4_2/FIGURES/4.
Yang, H. et al. Interpretable multimodality embedding of cerebral cortex using attention graph network for identifying bipolar disorder. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 799–807, Vol. 11766 LNCS, (2019). https://doi.org/10.1007/978-3-030-32248-9_89/FIGURES/2.
Parisot, S. et al. Disease prediction using graph convolutional networks: Application to Autism Spectrum Disorder and Alzheimer’s disease. Med. Image Anal. 48, 117–130. https://doi.org/10.1016/J.MEDIA.2018.06.001 (2018).
Kazi, A. et al. InceptionGCN: Receptive field aware graph convolutional network for disease prediction. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 73–85, Vol. 11492 LNCS, (2019). https://doi.org/10.1007/978-3-030-20351-1_6/TABLES/3.
Farhan, A. M. Q., Yang, S., Al-Malahi, A. Q. S. & Al-antari, M. A. MCLSG:Multi-modal classification of lung disease and severity grading framework using consolidated feature engineering mechanisms. Biomed. Signal Process. Control 85, 104916. https://doi.org/10.1016/J.BSPC.2023.104916 (2023).
Shingan, G. & Ranjan, P. VisCapsNet: Multimodality-based lung disease classification using deep features of integrated vision transformer with capsule network. Learn. Anal. in Intell. Syst. 45, 101–110. https://doi.org/10.1007/978-3-031-82706-8_11/TABLES/3 (2025).
Varunkumar, K. A., Zymbler, M. & Kumar, S. Multimodal deep dilated convolutional learning for lung disease diagnosis. Braz. Arch. Biol. Technol. 67, e24231088. https://doi.org/10.1590/1678-4324-2024231088 (2024).
Lami, K. et al. Enhancing interstitial lung disease diagnoses through multimodal AI integration of histopathological and CT image data. Respirology 0, 1–10. https://doi.org/10.1111/RESP.70036 (2025).
Issahaku, FlahY. et al. Multimodal deep learning model for Covid-19 detection. Biomed. Signal Process. Control 91, 105906. https://doi.org/10.1016/J.BSPC.2023.105906 (2024).
Thandu, A. L. & Gera, P. Privacy-centric multi-class detection of COVID 19 through breathing sounds and chest X-ray images: Blockchain and optimized neural networks. IEEE Access 12, 89968–89985. https://doi.org/10.1109/ACCESS.2024.3418202 (2024).
Kumar, S., Shvetsov, A. V. & Alsamhi, S. H. FuzzyGuard: A novel multimodal neuro-fuzzy framework for COPD early diagnosis. IEEE Internet Things J. https://doi.org/10.1109/JIOT.2024.3467176 (2024).
Malik, H. & Anees, T. Multi-modal deep learning methods for classification of chest diseases using different medical imaging and cough sounds. PLoS ONE 19(3), e0296352. https://doi.org/10.1371/JOURNAL.PONE.0296352 (2024).
Shimbre, N. & Solanki, R. K. ChestXFusionNet: A multimodal deep learning framework for predicting chest diseases from X-ray images and clinical data. EPJ Web Conf. 328, 01059. https://doi.org/10.1051/EPJCONF/202532801059 (2025).
Khader, F. et al. Multimodal deep learning for integrating chest radiographs and clinical parameters: A case for transformers. Radiology https://doi.org/10.1148/RADIOL.230806 (2023).
Althenayan, A. S. et al. COVID-19 hierarchical classification using a deep learning multi-modal. Sensors (Basel) 24(8), 2641. https://doi.org/10.3390/S24082641 (2024).
Kumar, S., Ivanova, O., Melyokhin, A. & Tiwari, P. Deep-learning-enabled multimodal data fusion for lung disease classification. Inform. Med. Unlocked 42, 101367. https://doi.org/10.1016/J.IMU.2023.101367 (2023).
Kumar, S. & Sharma, S. An improved deep learning framework for multimodal medical data analysis. Big Data Cogn. Comput. 8(10), 125. https://doi.org/10.3390/BDCC8100125 (2024).
Yang, L., Wan, Y. & Pan, F. Enhancing chest x-ray diagnosis with a multimodal deep learning network by integrating clinical history to refine attention. J. Imaging Inform. Med. https://doi.org/10.1007/S10278-025-01446-1/TABLES/4 (2025).
Gapp, C., Tappeiner, E., Welk, M. & Schubert R. Multimodal medical disease classification with LLaMA II, accessed 03 July 2025; [Online]. Available: https://arxiv.org/pdf/2412.01306 (2024).
Lung x-ray image+clinical text dataset, accessed 25 September 2025; [Online]. Available: https://www.kaggle.com/datasets/ghostbat101/lung-x-ray-image-clinical-text-dataset.
X-ray Lung Diseases Images (9 classes), accessed 17 November 2025; [Online]. Available: https://www.kaggle.com/datasets/fernando2rad/x-ray-lung-diseases-images-9-classes.
Pérez-García, F. et al. Exploring scalable medical image encoders beyond text supervision. Nat. Mach. Intell. 7(1), 119–130. https://doi.org/10.1038/S42256-024-00965-W (2025).
Oquab, M. et al. DINOv2: Learning robust visual features without supervision. In Transactions on Machine Learning Research, Vol. 2024, accessed 09 July 2025; [Online]. Available: https://arxiv.org/pdf/2304.07193 (2023).
Lee, S. A., Wu, A. & Chiang, J. N. Clinical ModernBERT: An efficient and long context encoder for biomedical text, accessed 03 July 2025; [Online]. Available: https://arxiv.org/pdf/2504.03964v1 (2025).
Warner, B. et al. Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference, accessed 09 July 2025; [Online]. Available: https://arxiv.org/pdf/2412.13663 (2024).
Veličković, P., Casanova, A., Liò, P., Cucurull, G., Romero, A. & Bengio, Y. Graph attention networks. In 6th International Conference on Learning Representations, ICLR 2018 - Conference Track Proceedings (2017). https://doi.org/10.1007/978-3-031-01587-8_7.
Rahman, M., Cao, Y., Sun, X., Li, B. & Hao, Y. Deep pre-trained networks as a feature extractor with XGBoost to detect tuberculosis from chest X-ray. Comput. Electr. Eng. 93(June), 107252. https://doi.org/10.1016/j.compeleceng.2021.107252 (2021).
Johnson, A. E. W. et al. MIMIC-CXR-JPG, a large publicly available database of labeled chest radiographs, accessed 01 December 2025; [Online]. Available: http://arxiv.org/abs/1901.07042 (2019).
Hamdi, A., Aboeleneen, A. & Shaban, K. MARL: multimodal attentional representation learning for disease prediction. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 14–27, Vol. 12899 LNCS, 2021. https://doi.org/10.1007/978-3-030-87156-7_2/TABLES/4.
Acknowledgements
The authors of this article express their honest gratitude for the useful feedback and constructive comments provided by the editors and reviewers. Their perceptive recommendations extensively enhanced the transparency, clarity, and quality of our article. Furthermore, the authors are grateful to the providers of the chest X-ray dataset used in this study for making their data publicly available, which significantly helped the research.
Funding
This research is currently not supported or funded by an external organization.
Author information
Authors and Affiliations
Contributions
Muhammad Rahman engaged in brainstorming, data collection, formal analysis, model development, conducting experiments, writing the original manuscript, responding to reviews, enhancing the content, and editing as needed. Cao Yongzhong assisted with co-supervision, review, data curation, and support for hardware and software. Li Bin contributed with supervision, validation, review, provided suggestions, acquired funding, and managed the project.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Rahman, M., YongZhong, C. & Bin, L. Graph attention network-based multimodal approach for lung diseases classification. Sci Rep 16, 10914 (2026). https://doi.org/10.1038/s41598-026-44282-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-026-44282-1
