
Abstract
Objective: Cross-subject generalization in EEG-based seizure detection remains a significant challenge due to diverse physiological differences among patients, which can degrade model performance across individuals. This work aims to develop a robust, lightweight, and fast-deployable model for cross-subject seizure detection that achieves high accuracy while enabling real-time, low-latency inference on resource-constrained devices. Methods: We propose PSD-LW-DCN, a novel lightweight deep convolutional network that leverages power spectral density (PSD) features extracted via multitaper spectral estimation. Raw EEG signals are preprocessed through bandpass filtering, segmentation, and class balancing. PSD features are computed across multiple frequency bands (\(\delta\),\(\theta\),\(\alpha\),\(\beta\),\(\gamma\)), averaged across channels to enhance generalizability, and concatenated as input to the network. The model was trained and evaluated separately on the CHB-MIT and TUSZ datasets, with no data mixing between them. Results: With only 61,218 parameters, PSD-LW-DCN achieves state-of-the-art efficiency, reducing inference time to 1.9 ms/sample on CHB-MIT and 2.1 ms/sample on TUSZ, demonstrating its suitability for real-time applications. It attains 85.84% accuracy on CHB-MIT and 83.21% on TUSZ, representing improvements of 5% and 3%, respectively, over previous approaches. Notably, the model shows strong cross-subject generalization and robustness across diverse patient populations. In clinically meaningful event-based evaluation, it achieves a low false alarm rate of 0.33 false alarms per hour (FA/h) on CHB-MIT and 1.09 FA/h on TUSZ, indicating high operational reliability in long-term monitoring scenarios. Conclusions: PSD-LW-DCN offers an optimal balance between accuracy, speed, and model size, making it highly suitable for real-time, edge-based clinical diagnosis of epilepsy. Its efficiency and low false alarm burden confirm its potential for deployment in low-power wearable and point-of-care systems. Future work will focus on further reducing the false alarm rate, particularly in more heterogeneous datasets like TUSZ, to enhance clinical usability.
Similar content being viewed by others

Introduction
Electroencephalography (EEG) is essential for diagnosing neurological disease1, capturing dynamic brain electrical activity. It plays a crucial role in identifying epilepsy types, diagnosing syndromes, and assessing recurrence risks2. However, traditional manual EEG analysis is manual, subjective, and highly dependent on specific datasets, making it less generalizable and prone to inter-expert variability, which leads to inefficient and inconsistent resource utilization3. Given the complexity and variability of EEG patterns during seizures, there is a growing need for automated EEG processing systems to improve detection accuracy, consistency, and efficiency4. Existing approaches typically involve segmenting raw EEG signals, extracting features, and using neural networks or machine learning for classification, aiming to reduce clinician burden and enhance diagnostic precision5,6.
Feature extraction is essential for identifying epileptic activities, traditionally relying on manual methods in time, frequency, and nonlinear domains, which are labor-intensive and impact model performance7. To address these limitations, various improvements have been proposed, such as optimization algorithms for SVM8, Kernel Sparse Representation Classification (KSRC)9, and AdaBoost LS-SVM frameworks10. However, feature extraction remains a bottleneck. Deep learning techniques, including CNNs, RNNs, and BiLSTMs, have been widely adopted to automate feature extraction11,12,13. Recent studies have further explored their potential, such as transformer-based algorithms14, 1D-CNN with data augmentation15, EEGWaveNet16, adversarial neural networks17, dynamic EEG channel selection18, multi-head self-attention mechanisms19, LDA-LASSO framework for selecting minimal EEG channels and features to achieve seizure detection20. Despite these advancements, challenges in feature extraction and model generalization persist.
EEG signals are easily affected by physiological noise, making the extraction of epileptic features challenging. Traditional methods such as power spectral density (PSD) have been widely used for EEG classification. For example, PSD parameterization was employed to separate periodic and aperiodic components of EEG signals and validated on two public datasets for epilepsy detection21. Similarly, a hypergraph network framework combined PSD with Conv-LSTM to capture temporal-spatial and frequency domain features22. Additionally, a CNN model (AlexNet) was trained using PSD-encoded images constructed from all channels at different time periods23. However, these methods often suffer from high computational complexity, limited robustness to inter-subject variability, and suboptimal representation of spectral dynamics.
To address these limitations, recent studies have introduced adaptive channel selection strategies and deep learning models. For example, an adaptive channel selection module was proposed to identify seizure-relevant channels using EEG power spectral features24. Empirical Mode Decomposition (EMD) combined with PSD was also used as input to CNNs for improved feature extraction25. Cross-subject seizure detection remains challenging due to the non-stationarity of EEG signals. Recent approaches include leveraging weak labels to train Dense-CNN models26, multi-view feature fusion based on adversarial learning27, and Self-Organizing Fuzzy Logic (SOF) classifiers for both cross-patient and patient-specific detection28. Other methods combine CNN and LSTM for distinguishing seizure types29 and use frameworks like SeizureNet to classify seizure types by integrating information from different frequency bands30.
Building on the challenges of detecting different patient states and the need for efficient deployment in resource-constrained environments, we propose a highly automated, PSD-based lightweight deep convolutional neural network. By directly learning discriminative spectral patterns from aggregated per-channel PSD features, without explicit spatial modeling, the proposed model achieves accurate seizure detection with a lightweight design ideal for real-world clinical deployment.
The main contributions of this paper are as follows.
-
We propose PSD-LW-DCN, a unified framework that synergizes PSD analysis with a lightweight Deep Convolutional Network. This integration explicitly bridges the gap between spectral feature extraction and deep representation learning to tackle the challenge of cross-subject seizure detection.
-
Motivated by the practical need for edge deployment, we developed a lightweight framework where signal preprocessing simplifies the downstream neural workload. This co-optimized approach allows for robust seizure detection on resource-constrained devices without sacrificing accuracy.
-
We validate the co-design rationale through a systematic analysis of EEG energy variations across seizure states. This confirms that coupling explicit energy-based features with learnable convolutional features captures the intrinsic dynamics of seizures better than either approach in isolation.
Methodology
Seizure detection
Seizure detection involves the automatic identification of epileptic seizure events from continuous EEG recordings, aiming to distinguish ictal periods from interictal states with high accuracy and low false detection rates. This task is challenging due to the complex, non-stationary, and patient-specific nature of EEG signals. Effective seizure detection models are crucial for assisting clinicians in epilepsy diagnosis, reducing the manual burden of EEG review, and enabling real-time monitoring in clinical and home settings.
Description of the dataset
The experiments were conducted separately on two benchmark datasets: the CHB-MIT dataset from Boston Children’s Hospital and the Massachusetts Institute of Technology (CHB-MIT)31, and the Temple University Hospital Seizure(TUSZ) dataset32.
The CHB-MIT database contains 940 hours of long-term, continuous, multi-channel EEG recordings from 23 epilepsy subjects aged between 1.5 and 22 years. Data on CHB01 and CHB21 were collected from the same patient, 1.5 years apart. The EEG signals were sampled at a frequency of 256 Hz, with at least 19 channels recorded according to the international 10–20 system. The dataset includes 198 seizures, with the onset and offset of each seizure precisely annotated by clinicians with expertise in neuroscience.
The TUH EEG dataset is currently the largest publicly available EEG dataset. The TUSZ dataset is a subset of TUH dataset. The EEG signals were sampled at 250 Hz with a 16-bit resolution, and the recordings were acquired using 20 to 128 channels. The TUSZ dataset contains manually annotated EEG seizure event data, including start time, stop time, channels, and seizure types. It comprises 1,643 sessions, 675 patients, and 3,971 seizure events, with a total seizure duration of 1,474 hours.
Since the TUSZ dataset contains many subjects but with varying total seizure durations, we selected the 20 subjects with the longest seizure durations under the same montage configuration, in order to ensure consistency in channels and montage.
Preprocessing
During EEG signal collection, noise such as power line interference (50–60 Hz) and eye movement artifacts can be introduced. To remove ocular and muscular artifacts, we first applied Independent Component Analysis (ICA) as part of the preprocessing pipeline. Then, to retain seizure-related information while suppressing high-frequency noise and power line interference, a 0.5–50 Hz FIR band-pass filter was applied. The long-duration signals were then segmented into 4-second intervals to simplify analysis and enhance computational efficiency while capturing meaningful EEG patterns33,34,35. On the CHB-MIT dataset, we used the commonly adopted 18 EEG channels, while on the TUSZ dataset, we used the standard 20-channel36,37. All data were strictly partitioned according to the labels provided by the datasets. Boundary segments overlapping seizure intervals were preserved and labeled as ictal if any part of the segment fell within the clinically annotated seizure period. As shown in Table 1, the original sample sizes were presented. Next, interictal samples were downsampled to achieve class balance, ensuring that result biases caused by sample imbalance were avoided. Ultimately, 59,346 samples (29,673 ictal and 29,673 interictal) were obtained from the CHB-MIT dataset, and 108,976 samples (54,488 ictal and 54,488 interictal) were obtained from the TUSZ dataset. Subsequently, Z-score normalization was applied using statistics computed from the training dataset in each leave-one-out cross-validation fold, ensuring consistency and enhancing the convergence efficiency of the deep learning models.
Lightweight high-performance deep convolutional neural network

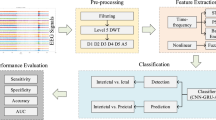
The overall framework of our proposed method.
As illustrated in Fig. 1, the EEG signal is processed through a series of steps. Initially, bandpass filtering is applied to the signal, followed by segmentation into 4-second intervals. After preprocessing, PSD features are extracted and concatenated. These fused features are then processed through the Conv 1 module to extract high-dimensional features, and further processed through the Conv 2 module to extract low-dimensional features. Finally, the features are flattened and passed through two fully connected layers for classification of ictal and interictal states.
Feature fusion
(1) Frequency band division
The EEG signals were decomposed into five canonical physiological frequency bands: \(\delta\)(0.5–4.5 Hz), \(\theta\)(4–8 Hz), \(\alpha\)(8–13 Hz), \(\beta\)(13–30 Hz), and \(\gamma\)(30–50 Hz). For each channel, bandpass filtering was applied to extract the corresponding band-limited components, resulting in five filtered versions of the original multi-channel signal, each representing neural activity within a specific frequency range. Subsequently, power spectral density (PSD) features for each band were computed from the segmented raw data using the multitaper method (MTM), a robust spectral estimation technique that reduces variance through orthogonal tapers.
(2) Calculation of Power Spectral Density
The MTM is a sophisticated technique for estimating PSD38, involving three essential steps: selection of orthogonal windows, individual PSD estimation, and averaging.
Selection of Orthogonal Windows
A set of \(K\) data windows, which are mutually orthogonal, are chosen from the Slepian function set or Discrete Prolate Spheroidal Sequences (DPSS). For a given time series length \(N\) and bandwidth parameter \(W\), one can find a set of \(K\) mutually orthogonal tapers \(\{v_k(n)\}_{k=0}^{K-1}\), where \(n = 0, 1, ..., N-1\).
Individual PSD Estimation
For each taper, the original time series is multiplied by that taper to produce a new time series, which is then Fourier transformed to obtain the corresponding PSD estimate. Assuming we have a time series \(x(n)\), the PSD estimate using the \(k\)th taper \(v_k(n)\) is calculated as follows:
Here, \(f\) denotes frequency, \(j\) is the imaginary unit, and \(e^{-j2\pi fn}\) is the complex exponential function used to transform the time-domain signal into the frequency domain.
Averaging Process
All \(K\) individual PSD estimates produced by the tapers are summed to compute the average PSD:
The PSD values were averaged across the channel dimension and then combined across the five frequency bands. After averaging, the resulting PSD representation is one-dimensional (1D) with respect to time and frequency band, which preserves spectral characteristics while reducing spatial variability. This 1D feature vector is then used as the input to the PSD-LW-DCN model. This design is pivotal for our lightweight framework. it minimizes spatial variability, and thus model complexity, while retaining comprehensive spectral information.
Model classification
The PSD-LW-DCN model is designed for cross-subject seizure detection, incorporating two feature extraction modules, Conv Module 1 and Conv Module 2, which process reconstructed PSD features sequentially.
The use of two convolutional modules enables the network to learn progressively more complex spectral patterns while maintaining a lightweight architecture, which is crucial for efficient deployment in resource-constrained clinical environments. During preliminary experiments, we observed that adding a third convolutional module did not yield significant performance improvements but substantially increased model size and computational cost. In contrast, a single-layer design was insufficient to capture the hierarchical spectral dynamics required for robust seizure detection. Therefore, two modules were selected as an optimal trade-off between representational capacity, model compactness, and inference efficiency within the PSD-LW-DCN framework.
Conv Module 1 consists of two convolutional blocks: the first includes a convolutional layer (32 kernels, size 3, stride 1), a batch normalization layer, and a max-pooling layer (kernel size 2, stride 1); the second block includes a convolutional layer (32 kernels, size 3, stride 1), a max-pooling layer (kernel size 2, stride 1), and a batch normalization layer.
Conv Module 2 mirrors this structure but omits the max-pooling layer in the second block. The high-level representations from Module 2 are concatenated and passed through two fully connected layers for final classification.
Experiments
In this section, the experimental setup is detailed, encompassing data evaluation metrics and implementation details. These components are critical for ensuring the rigor and reproducibility of the experiments.
Evaluation metrics
The performance of the proposed model was evaluated using accuracy, sensitivity, specificity, F1 score, AUC, and false alarms per hour.
Accuracy measures the overall proportion of correct predictions:
where TP (True Positive) and TN (True Negative) are correctly classified seizure and non-seizure samples, FP (False Positive) are incorrect seizure predictions, and FN (False Negative) are missed seizures.
Sensitivity (recall) measures the model’s ability to detect actual seizures:
Specificity measures the proportion of non-seizure events correctly identified:
The F1 score is the harmonic mean of precision and recall, providing a balanced measure for imbalanced data:
AUC (Area Under the ROC Curve) evaluates the model’s overall discriminative ability between seizure and non-seizure classes.
A predicted seizure is considered a true positive if it occurs within 30 seconds before or 60 seconds after a true seizure onset; otherwise, it is counted as a false alarm. This asymmetric event-based matching protocol—allowing for early detection and delayed response—follows the standardized evaluation framework defined in SzCORE39, ensuring clinically meaningful and comparable assessment across studies.
Building on this event-based evaluation, the false alarm rate per hour is reported to assess the model’s clinical reliability in long-term monitoring. It is computed for each subject as:
where a false alarm event is any predicted seizure that does not align with a true seizure within the \(-30\) to \(+60\) seconds tolerance window. This metric provides a practical measure of system usability, helping to quantify the risk of alarm fatigue in real-world clinical environments.
Together, these metrics provide a comprehensive evaluation of both performance and real-world applicability.
Experimental setup
To ensure the robustness and validity of the proposed model, leave-one-out cross-validation (LOOCV) was employed for evaluation. This method iteratively selects N-1 subjects for training and one subject for testing, ensuring reliable model assessment. The overall accuracy is computed as the average precision across all iterations.
The model was trained and validated on two publicly available datasets, CHB-MIT and TUSZ, using the cross-entropy loss function and optimized with the Adam optimizer. The best model weights were selected based on the minimum validation loss achieved during training, using an early stopping mechanism with a patience of 10 epochs to prevent overfitting. All implementations utilized PyTorch, an open-source deep learning framework.
Experimental results and discussion
Performance evaluation In CHB-MIT
As shown in Table 2, the proposed model achieves an average accuracy of 85.84% ± 10.13%, sensitivity of 79.57% ± 15.64%, specificity of 92.12% ± 14.78%, AUC of 0.94 ± 0.09, F1 score of 0.84 ± 0.11, and a low false alarm rate of 0.33 ± 0.37 per hour. High performance is observed in subjects like chb01, chb02, and chb22 (accuracy >96%, F1 \(\ge\) 0.96, <0.1 false alarms/h), while chb02 and chb09 achieve near-perfect sensitivity (100.00% and 99.21%), and chb01/chb04 show high specificity (>99.3%). Most subjects (chb17/chb23) have fewer than 0.5 false alarms per hour, indicating strong clinical feasibility. However, performance declines in subjects with atypical physiology, chb14 exhibits low accuracy (61.50%) and sensitivity (39.56%), chb06 has poor specificity (51.99%), and chb05 suffers from high false alarms (1.64/h), suggesting limited generalizability for some individuals. Overall, the model demonstrates robust seizure detection with high specificity and low false alarms across most subjects, highlighting its potential for real-world epilepsy diagnosis.
Performance evaluation In TUSZ
As shown in Table 3, the proposed model achieves competitive performance on the TUSZ dataset with an average accuracy of 83.21% ± 6.57%, sensitivity of 78.02% ± 10.32%, specificity of 88.39% ± 7.48%, AUC of 0.91 ± 0.07, F1 score of 0.81 ± 0.08, and a false alarm rate of 1.09 ± 0.75 per hour. High-performing subjects such as PN19 (accuracy: 97.52%, F1: 0.97, false alarms: 0.02/h) and PN20 (92.92%, F1: 0.92, 0.50/h) demonstrate strong detection reliability, while PN09 and PN19 achieve high sensitivities (96.91% and 95.22%) and PN19 attains near-perfect specificity (99.79%). The majority of subjects show balanced F1 scores (mean 0.81) and moderate false alarm rates, though some exhibit higher alerts (e.g., PN17: 2.98/h) or lower sensitivity (e.g., PN04: 62.38%), indicating variability across individuals. Overall, the model shows good generalization capability in cross-subject seizure detection with consistent accuracy, acceptable F1 scores, and manageable false alarms, highlighting its potential for clinical application in epilepsy monitoring.
Interpretability analysis

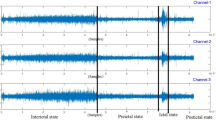
Interpretability analysis in the CHB-MIT dataset and the TUSZ dataset.
For interpretability analysis, subjects with varying classification performance (good, moderate, and poor) were selected from the CHB-MIT and TUSZ datasets. Their EEG signals were annotated by experts for epilepsy diagnosis. As shown in Fig. 2, subjects with good classification performance (e.g., chb01 and PN19) exhibited significant increases in PSD values during seizure periods across most frequency bands. In contrast, subjects with moderate or poor performance (e.g., chb14 and PN04) showed higher PSD values during interictal periods in certain frequency bands. This suggests that the lack of a clear energy difference between interictal and seizure periods in specific frequency bands may contribute to reduced classification accuracy. These findings highlight the importance of considering individual variability in EEG signal characteristics when interpreting model performance.
Ablation study
Ablation experiments systematically evaluated the contribution of individual and combined frequency bands (\(\alpha\), \(\beta\), \(\gamma\), \(\delta\) and \(\theta\)) to cross-subject seizure detection on CHB-MIT and TUH datasets, with detailed results presented in Tables 4 and 5.
Among the single-frequency inputs, the \(\theta\) band consistently delivered the most pronounced improvements. On CHB-MIT, \(\theta\) exceeded the average of the remaining four bands by 5.53 percentage points in accuracy, 3.81 percentage points in sensitivity, 6.22 percentage points in specificity, and approximately 0.05 in AUC. Parallel gains were observed on TUH: 4.25, 7.36, 7.29 percentage points and approximately 0.05, respectively. These enhancements confirm that \(\theta\)-band inputs most effectively boost sensitivity and specificity for cross-subject seizure detection, aligning with prior findings that link \(\theta\)-band activity to seizure onset40,41,42.
Among all dual-band inputs, the (\(\beta\), \(\theta\)) combination consistently outperforms the others. On CHB-MIT it achieves 80.43% accuracy, 73.21% sensitivity, 87.65% specificity and 0.89 AUC, surpassing every alternative pairing. A parallel pattern is observed on TUH, where (\(\beta\), \(\theta\)) attains 79.63% accuracy, 72.15% sensitivity, 86.25% specificity and 0.88 AUC, again exceeding all competing dual-band inputs. These findings establish (\(\beta\), \(\theta\)) fusion as the most effective two-band configuration for cross-subject seizure detection, corroborating prior evidence of strong (\(\beta\), \(\theta\)) coupling43,44 and highlighting the complementary roles of \(\beta\) oscillations in seizure onset, particularly in focal epilepsy45,46.
Tri-band ((\(\beta\), \(\gamma\), \(\delta\)), (\(\beta\), \(\gamma\), \(\theta\)), (\(\alpha\), \(\gamma\), \(\delta\)),) and quad-band ((\(\alpha\), \(\beta\), \(\gamma\), \(\delta\)), (\(\alpha\), \(\gamma\), \(\delta\), \(\theta\)), (\(\beta\), \(\gamma\), \(\delta\), \(\theta\))) ensembles achieve robust performance, confirming complementarity across high-, mid- and low-frequency components. Despite these gains, all multi-band combinations still trail the full five-band baseline in overall accuracy and AUC. Notably, on CHB-MIT the (\(\beta\), \(\gamma\), \(\delta\), \(\theta\)) quartet surpasses the full-band setup by 0.46 in sensitivity, likely because the \(\alpha\) band carries predominantly interictal information and attenuates ictal-related sensitivity47.
Overall, these ablation studies demonstrate that multi-band feature fusion significantly outperforms single-band input for cross-subject seizure detection. The complementary nature of different frequency bands enhances both sensitivity and generalizability. The model effectively leverages full-spectrum EEG information to achieve robust and accurate seizure detection across various subjects and datasets. These findings validate the necessity of incorporating multi-band EEG information into seizure detection frameworks and highlight the potential for further performance improvements through the optimization of band selection and fusion strategies. Future work will investigate patient-specific band selection to further optimize detection for individual seizure profiles.
Parameter tuning
As illustrated in Fig. 3, the impact of hyperparameters on model performance reveals clear trends. The highest F1-score of 0.84 was achieved with a learning rate of 0.001, batch size of 64, kernel size of 3, and 32 filters—marked as the peak in the visualization. This configuration significantly outperformed most settings with a higher learning rate (0.01), confirming that slower, more stable training leads to better generalization. The plot further shows that lower learning rates consistently yield higher scores across different batch sizes and kernel configurations, especially when combined with moderate filter counts.
The visualization highlights that small kernel sizes (3) and medium filter counts (32) achieve optimal performance, while larger kernels (5 or 7) and excessive filters (64) lead to performance drops, particularly at higher learning rates. Increasing filters from 16 to 32 generally improves results, but further expansion offers diminishing returns. Similarly, batch sizes of 64 and 128 perform comparably, with 64 slightly favored under optimal conditions. Overall, the parameter landscape peaks at a well-balanced configuration, emphasizing the importance of coordinated tuning for maximizing model effectiveness.

Hyperparameter impact on F1-score. The blue line highlights the optimal configuration.
Comparisons with advanced models
The proposed PSD-LW-DCN model was evaluated on the CHB-MIT and TUSZ datasets against state-of-the-art baselines, including CNN-Self-Attention19, DCN36, DeepCNN37, ResNet-LSTM18, PANN17, StackedCNN15, EEGWaveNet16, and Transformer14, using metrics such as accuracy, sensitivity, specificity, AUC, and F1 score. The experimental results are presented in Table 6. On CHB-MIT, PSD-LW-DCN achieved the highest accuracy (85.84%), sensitivity (79.57%), AUC (0.94), and F1 score (0.84), outperforming the best prior method (ResNet-LSTM) by 2.10% in accuracy and significantly surpassing Transformer in AUC (+0.05) and F1 (+0.06). It also showed competitive specificity (92.12%). On TUSZ, the model attained the best accuracy (83.21%) and specificity (88.39%), with a high sensitivity of 78.02%, close to the best, and achieved the highest AUC (0.91) and F1 score (0.81), surpassing Transformer in both. These results demonstrate that PSD-LW-DCN consistently outperforms existing methods, offering superior overall performance and robustness in epileptic seizure detection.
Lightweight and deployability analysis
In clinical applications and edge-device deployment of electroencephalogram (EEG)-based epilepsy detection systems, model computational efficiency, parameter size, and inference speed are critical factors determining practical usability. This section presents a comparative analysis of the proposed PSD-LW-DCN method against mainstream deep learning models in terms of training overhead, model complexity, and inference performance, demonstrating its significant advantages in lightweight design and deployability while maintaining high accuracy.
To evaluate the practicality of these models in resource-constrained environments, we tested their inference efficiency on low-power devices. The results are shown in Table 7. The test platform was a laptop equipped with a GeForce GTX 960M GPU (2GB VRAM), an i7-4700MQ CPU, 4GB RAM, and running Ubuntu 14.04, simulating a typical edge computing scenario. The evaluation metric is the average inference time per EEG sample in milliseconds (ms/sample), where lower values indicate better real-time performance.
Contemporary research frequently pursues performance through increasing model complexity, resulting in architectures like ResNet-LSTM and HybridCNN that suffer from significant parameter bloat (e.g., reaching 24.61 million parameters) and sluggish inference (>5ms/sample). Challenging this paradigm, PSD-LW-DCN is built upon the principle of minimalism for generalization. Instead of relying on brute-force depth, we employ holistic lightweight strategies to distill the architecture down to its essentials (61,218 parameters), achieving a 99.7% reduction compared to ResNet-LSTM. This shift in philosophy translates directly to operational efficiency: our model attains superior inference speeds of 1.9 ms/sample on the CHB dataset. While advanced methods like QFF-MLNet and PANN offer strong representational power, their latency renders them impractical for edge scenarios. In contrast, PSD-LW-DCN proves that high efficiency and robust generalization are not mutually exclusive, offering a viable solution for real-time deployment on resource-constrained devices.
In summary, the PSD-LW-DCN distinguishes itself not only by its compact model size and rapid inference speed but also by its significant clinical translational value. Its lightweight architecture directly addresses the real-world constraint of limited computational resources in edge devices, while its robust generalization capability ensures consistent performance across heterogeneous patient data. These attributes position PSD-LW-DCN as an ideal candidate for integration into mobile healthcare devices and wearable systems. Although large-scale deployment in clinical settings remains a direction for future work, our findings confirm that the model effectively bridges the gap between theoretical efficiency and practical, bedside utility.
Conclusion
The PSD-LW-DCN model has been proposed to enhance cross-subject seizure detection performance. By integrating PSD feature reconstruction, data augmentation, and balancing techniques, the model significantly improves detection accuracy. Interpretability analysis of PSD features provides insights into the model’s decision-making process. Extensive experiments on the CHB-MIT and TUSZ datasets demonstrate its effectiveness, achieving accuracies of 85.84% and 83.21%, respectively, with improvements of 5% and 3% over existing methods. The lightweight design ensures computational efficiency, making it suitable for real-time applications. Future work may focus on optimizing the architecture, exploring additional feature extraction techniques, and validating performance on larger datasets to further enhance robustness and applicability.
Data availability
Data availability: This study of the use of CHB-MIT data sets and TUSZ data set is available at https://physionet.org/content/ chbmit/1.0.0/ and https://isip.piconepress.com/projects/nedc/html/tuh_eeg.
References
Fisher, R. S. et al. Instruction manual for the ILAE 2017 operational classification of seizure types. Epilepsia 58, 531–542 (2017).
Van Mierlo, P., Höller, Y., Focke, N. K. & Vulliemoz, S. Network perspectives on epilepsy using EEG/MEG source connectivity. Front. Neurol. 10, 721 (2019).
Kerr, W. T., McFarlane, K. N. & Figueiredo Pucci, G. The present and future of seizure detection, prediction, and forecasting with machine learning, including the future impact on clinical trials. Front. Neurol. 15, 1425490 (2024).
Rasheed, K. et al. Machine learning for predicting epileptic seizures using eeg signals: A review. IEEE reviews in biomedical engineering 14, 139–155 (2020).
Aggarwal, S. & Chugh, N. Review of machine learning techniques for EEG based brain computer interface. Arch. Comput. Methods Eng. 29, 3001–3020 (2022).
Kode, H., Elleithy, K. & Almazaydeh, L. Epileptic seizure detection in EEG signals using machine learning and deep learning techniques. IEEE Access 12, 80657–80668 (2024).
Ahmad, I. et al. An efficient feature selection and explainable classification method for EEG-based epileptic seizure detection. J. Inf. Secur. Appl. 80, 103654 (2024).
Divya, P. & Devi, B. A. Hybrid metaheuristic algorithm enhanced support vector machine for epileptic seizure detection. Biomed. Signal Process. Control. 78, 103841 (2022).
Wang, Q. et al. A hybrid SVM and kernel function-based sparse representation classification for automated epilepsy detection in EEG signals. Neurocomputing 562, 126874 (2023).
Al-Hadeethi, H., Abdulla, S., Diykh, M., Deo, R. C. & Green, J. H. Adaptive boost LS-SVM classification approach for time-series signal classification in epileptic seizure diagnosis applications. Expert Syst. Appl. 161, 113676 (2020).
Chen, W. et al. An automated detection of epileptic seizures EEG using CNN classifier based on feature fusion with high accuracy. BMC Med. Inform. Decis. Mak. 23, 96 (2023).
Zhu, R., Pan, W.-X., Liu, J.-X. & Shang, J.-L. Epileptic seizure prediction via multidimensional transformer and recurrent neural network fusion. J. Transl. Med. 22895. (2024).
Tang, Y., Wu, Q., Mao, H. & Guo, L. Epileptic seizure detection based on path signature and Bi-LSTM network with attention mechanism. IEEE Trans. Neural Syst. Rehabil. Eng. 32, 304–313 (2024).
Sun, Y. et al. Continuous seizure detection based on transformer and long-term iEEG. IEEE J. Biomed. Health Inform. 26, 5418–5427 (2022).
Wang, X. et al. One dimensional convolutional neural networks for seizure onset detection using long-term scalp and intracranial EEG. Neurocomputing 459, 212–222 (2021).
Thuwajit, P. et al. Eegwavenet: Multiscale cnn-based spatiotemporal feature extraction for eeg seizure detection. IEEE Transactions on Industrial Informatics 18, 5547–5557 (2021).
Zhang, Z. et al. Cross-patient automatic epileptic seizure detection using patient-adversarial neural networks with spatio-temporal EEG augmentation. Biomed. Signal Process. Control 89, 105664 (2024).
Song, Y., Fan, C. & Mao, X. Optimization of epilepsy detection method based on dynamic EEG channel screening. Neural Netw. 172, 106119 (2024).
Ru, Y., An, G., Wei, Z. & Chen, H. Epilepsy detection based on multi-head self-attention mechanism. PLoS One 19, e0305166 (2024).
Peng, G., Nourani, M., Harvey, J. & Dave, H. Personalized EEG feature selection for low-complexity seizure monitoring. Int. J. Neural Syst. 31, 2150018 (2021).
Liu, S., Wang, J., Li, S. & Cai, L. Epileptic seizure detection and prediction in EEGs using power spectra density parameterization. IEEE Trans Neural Syst Rehabil Eng 31, 3884–3894 (2023).
Liu, J., Yang, Y., Li, F. & Luo, J. An epilepsy detection method based on multi-dimensional feature extraction and dual-branch hypergraph convolutional network. Front. Physiol. 15, 1364880 (2024).
Majzoub, S., Fahmy, A., Sibai, F., Diab, M. & Mahmoud, S. Epilepsy detection with multi-channel EEG signals utilizing AlexNet. Circuits Syst. Signal Process. 42, 6780–6797 (2023).
Li, H., Liao, J., Wang, H., Chang’an, A. Z. & Yang, F. EEG power spectra parameterization and adaptive channel selection towards semi-supervised seizure prediction. Comput. Biol. Med. 175, 108510 (2024).
Pan, Y., Dong, F., Yao, W., Meng, X. & Xu, Y. Empirical mode decomposition for deep learning-based epileptic seizure detection in few-shot scenario. IEEE Access 12, 86583–86595 (2024).
Saab, K., Dunnmon, J., Ré, C., Rubin, D. & Lee-Messer, C. Weak supervision as an efficient approach for automated seizure detection in electroencephalography. npj Digit. Med. 3, 59 (2020).
Zhao, Y. et al. Multi-view cross-subject seizure detection with information bottleneck attribution. J. Neural Eng. 19, 046011 (2022).
Zhou, J. et al. Both cross-patient and patient-specific seizure detection based on self-organizing fuzzy logic. Int. J. Neural Syst. 32, 2250017 (2022).
Einizade, A., Mozafari, M., Sardouie, S. H., Nasiri, S. & Clifford, G. A deep learning-based method for automatic detection of epileptic seizure in a dataset with both generalized and focal seizure types. In 2020 IEEE Signal Processing in Medicine and Biology Symposium (SPMB), 1–6 (IEEE, 2020).
Asif, U., Roy, S., Tang, J. & Harrer, S. Seizurenet: Multi-spectral deep feature learning for seizure type classification. In Machine Learning in Clinical Neuroimaging and Radiogenomics in Neuro-oncology: Third International Workshop, MLCN 2020, and Second International Workshop, RNO-AI 2020, Held in Conjunction with MICCAI 2020, Lima, Peru, October 4–8, 2020, Proceedings 3, 77–87 (Springer, 2020).
Guttag, J. CHB-MIT Scalp EEG Database, https://doi.org/10.13026/C2K01R (2010).
Harati, A. et al. The tuh eeg corpus: A big data resource for automated eeg interpretation. In 2014 IEEE signal processing in medicine and biology symposium (SPMB), 1–5 (IEEE, 2014).
Shyu, K.-K., Huang, S.-C., Lee, L.-H. & Lee, P.-L. Less parameterization inception-based end to end CNN model for EEG seizure detection. IEEE Access 11, 49172–49182 (2023).
Dong, X. et al. Deep learning based automatic seizure prediction with EEG time-frequency representation. Biomed. Signal Process. Control 95, 106447 (2024).
Dong, C., Sun, D., Zhang, Z. & Luo, B. EEG-based patient-specific seizure prediction based on spatial-temporal hypergraph attention transformer. Biomed. Signal Process. Control 100, 107075 (2025).
Schirrmeister, R. T. et al. Deep learning with convolutional neural networks for EEG decoding and visualization. Hum. Brain Mapp. 38, 5391–5420 (2017).
Acharya, U. R., Oh, S. L., Hagiwara, Y., Tan, J. H. & Adeli, H. Deep convolutional neural network for the automated detection and diagnosis of seizure using EEG signals. Comput. Biol. Med. 100, 270–278 (2018).
Prieto, G. A. The multitaper spectrum analysis package in Python. Seismol. Res. Lett. 93, 1922–1929 (2022).
Dan, J. et al. Szcore: Seizure community open-source research evaluation framework for the validation of electroencephalography-based automated seizure detection algorithms. Epilepsia https://doi.org/10.1111/epi.18113 (2024).
Baumgartner, C. et al. Role of specific interictal and ictal EEG onset patterns. Epilepsy Behav. 164, 110298 (2025).
Latreille, V. et al. Oscillatory and nonoscillatory sleep electroencephalographic biomarkers of the epileptic network. Epilepsia 65, 3038–3051 (2024).
Qiu, C. et al. Differences and potential mechanisms of theta oscillation and temporoparietal and temporal-central networks in temporal lobe epilepsy patients with unilateral hippocampal sclerosis. Acta Epileptol. 6, 26 (2024).
Liu, X., Han, F., Fu, R., Wang, Q. & Luan, G. Epileptogenic zone location of temporal lobe epilepsy by cross-frequency coupling analysis. Front. Neurol. 12, 764821 (2021).
Tenney, J. R., Williamson, B. J. & Kadis, D. S. Cross-frequency coupling in childhood absence epilepsy. Brain Connect. 12, 489–496 (2022).
Villa, A. E. & Tetko, I. V. Cross-frequency coupling in mesiotemporal EEG recordings of epileptic patients. J. Physiol. Paris 104, 197–202 (2010).
Zhang, J. et al. Resting-state MEG source space network metrics associated with the duration of temporal lobe epilepsy. Brain Topogr. 34, 731–744 (2021).
Pyrzowski, J., Siemiński, M., Sarnowska, A., Jedrzejczak, J. & Nyka, W. M. Interval analysis of interictal EEG: Pathology of the alpha rhythm in focal epilepsy. Sci. Rep. 5, 16230 (2015).
Esmaeilpour, A., Tabarestani, S. S. & Niazi, A. Deep learning-based seizure prediction using EEG signals: A comparative analysis of classification methods on the CHB-MIT dataset. Eng. Rep. 6, e12918 (2024).
Jayanthi, V. & Sivakumar, S. Quantum inspired wavelet and Fourier feature fusion for EEG based epilepsy and seizure detection. Sci. Rep. https://doi.org/10.1038/s41598-025-31219-3 (2026).
Funding
This work was supported by the National Natural Science Funds of China (62006100) and the Foundation and Cutting-Edge Technologies Research Program of Henan Province (CN) (262102210163).
Author information
Authors and Affiliations
Contributions
Peipei Gu and Ming Zhang: Conceptualization, Methodology, Formal analysis, Writing–original draft. Duo Chen and Naian Xiao: Supervision, editing, Writing–review & editing, Funding acquisition. Meiyan Xu, Jibin Shou and Jiayang Guo: Investigation, Data curation, Validation. All authors reviewed and approved the final version of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Gu, P., Zhang, M., Xu, M. et al. PSD-LW-DCN: a generalizable power spectral density based lightweight deep convolutional neural network for seizure detection. Sci Rep 16, 14073 (2026). https://doi.org/10.1038/s41598-026-44536-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-026-44536-y
