
Abstract
Background
The vast amount of natural language clinical notes about patients with cancer presents a challenge for efficient information extraction, standardization, and structuring. Traditional NLP methods require extensive annotation by domain experts for each type of named entity and necessitate model training, highlighting the need for an efficient and accurate extraction method.
Methods
This study introduces a tool based on the Large Language Model (LLM) for zero-shot information extraction from cancer-related clinical notes into structured data aligned with the minimal Common Oncology Data Elements (mCODE™) structure. We utilize the zero-shot learning capabilities of LLMs for information extraction, eliminating the need for data annotated by domain experts for training. Our methodology employs advanced hierarchical prompt engineering strategies to overcome common LLM limitations like token hallucination and accuracy issues. We tested the approach on 1,000 synthetic clinical notes representing various cancer types, comparing its performance to a traditional single-step prompting method.
Results
Our hierarchical prompt engineering strategy (accuracy = 94%, misidentification, and misplacement rate = 5%) outperforms the traditional prompt strategy (accuracy = 87%, misidentification, and misplacement rate = 10%) in information extraction. By unifying staging systems (e.g., TNM, FIGO) and specific stage details (e.g., Stage II) into a standardized framework, our approach achieves improved accuracy in extracting cancer stage information.
Conclusions
Our approach demonstrates that LLMs, when guided by structured prompting, can accurately extract complex clinical information without the need for expert-labeled data. This method has the potential to harness unstructured data for advancing cancer research.
Plain Language Summary
Clinical notes about cancer patients contain a lot of valuable information, but they are often written in free text, making it hard for computers to use them in research. This study develops a new framework that uses large language models (LLMs) to automatically extract important details from these notes without needing manual labeling by experts. We introduce two advanced prompting techniques—BFOP and 2POP—that hierarchically guide the LLMs step-by-step through the information extraction process. We test BFOP and 2POP on 1,000 synthetic cancer notes, achieving high accuracy and low error rates. Our approaches could help researchers better understand cancer and make more informed clinical decision making by turning hard-to-read notes into structured, standardized data for analysis.
Similar content being viewed by others

Introduction
Cancer research has evolved dramatically over the past several years, generating a large amount of data1. The process of diagnosing, formulating treatment plans, conducting medical assessments, and creating genetic profiles generates a vast and diverse volume of information, which presents both opportunities and challenges in organizing and utilizing such data effectively for medical providers and researchers2. The primary challenge, however, is that much of the data generated is in an unstructured data format. Notably, in electronic health records (EHRs), unstructured data accounts for nearly 80% of information3. Many clinical procedures and findings, such as physician notes, radiology reports, and pathology findings, are often kept in the form in which they were first created – in the form of free-text4. Free-text data contains valuable information that can greatly advance cancer research and patient care despite its inherent complexity. These unstructured data sources can provide crucial details about a patient’s medical history, treatment responses, and disease progression that are important for developing personalized treatment plans and conducting research into novel therapies. Currently, however, there are no software tools to efficiently and accurately identify and extract all useful clinical information from such data in a standardized manner5.
Converting unstructured data about cancer into a structured format is a nontrivial challenge, particularly because the medical terminology and concepts are highly specific6. Conventional NLP methodologies often depend on datasets annotated by humans and hand-curated rules. This, in turn, leads to named entity recognition (NER) or information extraction systems that are limited in their generalizability and, by extension, portability7. This is highlighted by the widely recognized issue of out-of-distribution prediction, wherein these systems may exhibit sub-optimal performance when deployed in novel or disparate contexts, a consequence of their substantial dependence on prior training data and labels. In contrast, large language models (LLMs) typically encompass billions of parameters. This scale provides a potential for NER tasks to be performed directly from the text without a need for prior training data. By leveraging the LLM’s zero-shot learning capabilities (the model being able to learn to recognize things that it hasn’t explicitly seen before in training), we can bypass the lengthy and resource-intensive processes of data annotation and model tuning, achieving quicker deployment in clinical applications.
Information extraction has emerged as a promising approach for transforming free-text cancer information into structured data. This process involves a series of NLP techniques, including named entity recognition, term extraction, relationship extraction, and machine learning. NER is a sub-task of information extraction that classifies named entities into predefined categories such as person names, organizations, locations, medical codes, time expressions, diseases, and symptoms. Commonly used tools and libraries for NER tasks include Natural Language Toolkit (NLTK)8, spaCy, and Stanford NLP9. Nonetheless, in the biomedical domain, coding systems, abbreviations, and acronyms present unique challenges that traditional NER techniques often face10,11. Medical text can be long and filled with specialized terminology derived from medical coding systems or ambiguous shorthand (e.g., acronyms) that are often relied upon to represent medical concepts. Different healthcare providers or researchers might describe the same medical condition or procedure in various ways. For example, the medical condition myocardial infarction can be represented by equivalent entity expressions such as Heart attack, MI, Acute myocardial infarction (AMI), ST-segment elevation myocardial infarction (STEMI), Non-ST segment elevation myocardial infarction (NSTEMI), or heart episode, depending on the context. To address this complexity, the Unified Medical Language System (UMLS) has emerged as an effort to integrate and harmonize various biomedical terminologies12.
In recent years, large language models such as GPT, Llama, Bard, and others have shown great promise in tasks such as question answering, coding, and solving problems. Since they are trained on vast corpora, these models are more familiar with diverse linguistic constructs, abbreviations, and entity variations. For example, Monajatipoor et al.13 demonstrated the effectiveness of prompt engineering, where carefully designed prompts and in-context examples improved F1 scores by 15–20% in few-shot clinical NER tasks. Instruction tuning has further enhanced the performance of general-purpose LLMs, enabling them to match specialized architectures like PubMedBERT and PMC-LLaMA on biomedical tasks14. Innovative frameworks such as VANER, introduced by Bian et al.15, have combined LLMs with sequence labeling and external knowledge bases to outperform traditional BioNER systems. Knowledge-enhanced prompting has also proven effective in one-shot biomedical NER scenarios, where data-scarce environments have benefited from the adaptability of LLMs16. Furthermore, specialized models like BioGPT17, BioBERT18, and SciBERT19, pre-trained on domain-specific corpora, have greatly improved NER performance by capturing biomedical semantics more effectively. Hybrid approaches that integrate LLMs with rule-based systems or dictionary-based techniques have further enhanced interpretability and precision in biomedical NER tasks20. Finally, models like OntoGPT have utilized external ontologies and structured knowledge to address challenges posed by rare or novel entity types21. These collective advancements highlight the transformative potential of LLMs in biomedical NER, directly addressing long-standing challenges like terminological ambiguity, limited training data, and annotation complexity. Techniques like prompt engineering, instruction tuning, knowledge integration, and hybrid modeling approaches have enabled LLMs to achieve state-of-the-art results in this domain, offering scalable and effective solutions for extracting critical information from biomedical text.
Initial cancer ontologies were rudimentary and primarily focused on cataloging histological types and anatomical locations of tumors22. However, with the advances in molecular biology and genetics, subsequent cancer ontology studies started incorporating molecular and genetic markers and examining the heterogeneity of tumors and their different pathways23. The National Center for Biomedical Ontology (NCBO) provides a platform BioPortal, including over 270 biomedical ontologies and terminologies. This has substantial implications in ontology studies, especially for enhanced data interpretation. One important development in the field is mCODE (minimal Common Oncology Data Elements), which is an open-source, standardized data model designed to facilitate the exchange of comprehensive cancer patient data24. Developed by the American Society of Clinical Oncology (ASCO) and MITRE, mCODE creates a common language for cancer data across different systems and platforms, thus enabling better interoperability, data sharing, and integration in clinical and research settings. The mCODE ontology includes standardized data elements for patient demographics, clinical status, treatments, outcomes, and genomic information. To realize the full potential of mCODE, these standardized data elements must be integrated with electronic health record (EHR) systems. Retrieving this information from EHRs enables the seamless exchange of cancer patient data, enhancing precision oncology support by providing clinicians with comprehensive and consistent information for making informed treatment decisions, supporting precision oncology, and improving the quality and consistency of cancer data.
OntoGPT is a solution using LLMs to query and extract ontology information from free text21. It creates or uses existing ontologies and knowledge bases, feeds into LLMs for query-answering, and finally converts the outputs into a pre-defined format. However, OntoGPT was developed to support general ontology query-answer tasks, such as food recipes, disease treatment, and gene pathways, and is not specifically designed for handling domains such as cancer ontologies. Consequently, there are two key areas for improvement. First, while OntoGPT works effectively for question-answering prompt structures, for clinical applications, especially when information extraction precision is particularly needed, it lacks certain mechanisms to mitigate erroneous classification. Second, learning and creating a YAML template for an ontology or knowledge-based system is time-consuming. OntoGPT requires representing ontology in YAML language, a data serialization language for programming languages, which has its own syntax and grammar. Moreover, OntoGPT’s reliance on YAML templates presents certain limitations due to the absence of algorithmic support for dynamic template generation and adaptability. Since YAML templates are fixed and predefined, they offer limited flexibility in accommodating a wide variety of potential questions, which can restrict the scope of query-answering tasks. Additionally, the fixed nature of prompts within YAML templates means OntoGPT may not adjust effectively to diverse contexts or user-specific needs. Furthermore, YAML templates do not inherently consider the hierarchical relationships between named entities within ontologies, which can reduce efficiency and accuracy when representing and querying complex domains. These factors strongly suggest the need for a more adaptive approach to ontology processing.
Thus, in this paper, we introduce an advanced hierarchical ontology processing approach that is combined with strategic prompt engineering to support large ontology structures for accurate information extraction and towards an easier ontology representation toolkit. This method helps mitigate erroneous information extractions while using LLMs, making hierarchical ontology processing and strategic prompt engineering essential. The goals of the proposed approach are (1) to use hierarchical prompt generation and result refinement algorithms to mitigate erroneous information extractions, enhancing accuracy, and (2) to automate the ontology template generation process. Specifically, the ontology embeds a hierarchical structure (relationships) among various named entities, such as parent-child relations. This kind of structure can naturally be captured via a graph. Constructing prompts from ontological structures can be automated by representing the ontology as a graph and using a graph traversal algorithm. Moreover, we divide the hierarchical structure into several phases. Unlike OntoGPT, which combines all questions and input text into a single prompt and queries the LLM to perform information extraction, we use two hierarchical prompt generation methods that divide one-shot prompting into multiple phases.
This study shows that our hierarchical prompting methods, BFOP and 2POP, guide LLMs to accurately extract structured cancer data from unstructured notes. Both prompting methods, combined with GPT-4o, consistently outperform the baseline approach by reducing extraction errors and hallucinations. These findings indicate that structured prompting enables zero-shot LLMs to extract complex biomedical information with high precision, paving the way for supporting scalable clinical data structuring.
Methods
A suitable data structure is essential to facilitate data representation and the automated generation of prompts for information extraction to represent named entities and their relations in the ontology effectively. This section presents the data structure designed for ontology representation efficiency. Additionally, two prompt engineering methods are introduced to mitigate hallucination and erroneous extraction outcomes of LLMs.
Ontology representation
An ontology formalizes a shared understanding of concepts, also known as named entities, and their relationships, typically organized in a hierarchical structure from general to specific. To efficiently represent named entities and their relations within the ontology, we leverage a graph structure to generate prompts for information extraction. A graph is a natural data structure that represents ontology. Prompt generation can be automated by leveraging various efficient graph traversing algorithms to visit the nodes (named entities in our application). We represent an ontology using a Directed Acyclic Graph (DAG) G(V,E), where V represents the set of nodes in the graph that represent named entities, and E represents the set of edges between the named entities.
We introduce five attributes for each named entity \({v}_{i}(\in V)\):
where:
Label(\({v}_{i}\)) is the name of the entity, Description(\({v}_{i}\)) is a string that represents the prompt message to be used for extracting the named entity \({v}_{i}\) from the input text.
IsLeaf(\({v}_{i}\)) is a Boolean value that represents if the node is a leaf node (i.e., a node devoid of siblings in the graph).
Level \(\left({v}_{i}\right)\) is an integer that represents the position in the graph the node \({v}_{i}\) is at.
Present \(({v}_{i})\) is a Boolean value that represents if the information associated with \({v}_{i}\) is present in the input text.
Each directed edge \({e}_{{ij}}\in E\) from the node \({v}_{i}\) to the node \({v}_{j}\) represents the relation between the two nodes. In the mCODE context, the majority relations are the patient-child relations, where a named entity \({v}_{i}\) has a named entity \({v}_{j}\) as an attribute, this is the relation our tool is focused on.
Formatting and Prompt Completion
The output of the LLM is also free text. However, specific instructions about output format can be specified in the prompt to constrain the output format (e.g., JSON, XML, or a specific template), ensuring the generated text adheres to the desired structure. For the prompts generated from the graph \(G\), a JSON format is specified,
where for each named entity \({v}_{i}\), a label and a description of the named entity (usually a question) is defined as the output format. The final prompt to be fed into LLM for named entity extraction will be of the following format,
where
Leading-Question denotes a concise task description to instruct the LLM of what specific task it needs to perform, e.g., <Please extract the following information from the text.>.
Formatted-Prompt denotes multiple lines of prompts generated from graph \(G\) in the format of (2).
Background-Info denotes the indication of the beginning of the provided free text, it can be – <Here is the text:>.
Input-Text denotes the provided free text to extract information from.
Prompt Generation Methods
We introduce two advanced prompt generation methods, BFOP and 2POP, for extracting information according to the mCODE ontology.
Breadth-First Ontology Pruner (BFOP)
mCODE is composed of a comprehensive set of data elements for cancer. However, it is crucial to recognize that an individual clinical note may not encapsulate all entities present in a comprehensive ontology. Utilizing an extensive prompt for information retrieval can be counterproductive, as it may induce hallucination, a scenario where large language models erroneously produce or identify non-existent entities within the data. These hallucinations often result from models being overly influenced by a detailed ontology, leading to false identifications that could undermine the accuracy of clinical decision-making. Consequently, careful pruning of ontological entities is imperative to ensure precision in the extraction process. We propose BFOP, a method engineered to pinpoint a relevant subgraph tailored to the designated target text. This approach is inspired by the Chain-of-Thought prompting methodology25, which utilizes a parsing strategy akin to the breadth-first search algorithm, employing a hierarchical level-wise analysis.
BFOP is a layer-wise prompt generation method. It refines the next-level named entity prompts based on whether the information of the named entities of a higher level is present or absent. Initially, entities on the first level (the root entity) of the ontology are parsed and transformed into prompts suitable for querying (Algorithm BFOP lines 1-8). Subsequently, these prompts are fed into the LLM to extract pertinent information from patient notes (Algorithm BFOP line 9).
A unique feature of our approach is its dynamic pruning mechanism. Suppose a particular named entity is absent in the patient’s record. In that case, it is natural to infer that its children will also be devoid of relevant data, which eliminates the need to parse them, as well as all their descendants (Algorithm BFOP lines 10-15). Therefore, in the next level, \(L+1\), based on the previous level (\(L\)) result, named entities whose parents Present(\({v}_{i}\)) = False can be skipped. Supplementary Fig. 1 provides an example prompt for the BFOP algorithm. Here, when the LLM detects an entity human specimen, there is no information in the context. In the subsequent round, the BFOP algorithm can eliminate all named entities that correspond to the next nodes of the entity human specimen.
Algorithm
BFOP
1 set Present\(({v}_{i})\) as true for all \({v}_{i}\in V\)
2 # For named entities on a certain level in the ontology tree graph \(G(V,E)\)
3 for level \(L:\left[\right.0\to\) height of the tree graph \(G(V,E)\left]\right.\)
4 or all \({v}_{i}\) s.t. Level\(\left({v}_{i}\right)==L\) &Present(\({v}_{i}\)) == true
5 if IsLeaf\(({v}_{i})\) == true
6 set Description\(({v}_{i})\) = What is the <Label(\({v}_{i}\))> from the input text?
7 if IsLeaf\(({v}_{i})\) == false
8 set Description\(({v}_{i})\)= Does the text contain any information about <Level\(({v}_{i})\)>? Answer YES or NO.
9 query all LLM and extract information for all named entities only from level \(L\)
10 for all \({v}_{i}\) s.t. Level\(\left({v}_{i}\right)==L\):
11 if information not present for named entity \({v}_{i}\)
12 set Present\(({v}_{i})\) = false
13 if Present\(({v}_{i})\) == false:
14 set Present\(({v}_{i})\) = false
15 set Present\(({v}_{j})\) = false, for all descendants \({v}_{j}\) of \({v}_{i}\)
Two-Phase Ontology Parser (2POP)
The fundamental principle of the 2POP method is that queries about the mere existence of a named entity are simpler to resolve than queries seeking detailed information about the entity, particularly in the context of intricate ontologies such as the mCODE. 2POP aims to isolate a pertinent subgraph from the comprehensive ontology that correlates with the target text. Unlike the incremental, hierarchical extraction process characteristic of BFOP, 2POP adopts a comprehensive approach, extracting the entire pertinent structure in one step. The 2POP algorithm employs a two-pronged strategy: First, it queries all leaf nodes, classifying the outcomes based on binary responses. Then, the second phase utilizes only the entities confirmed by a Yes response to create a prompt. This prompt is then utilized to prompt an LLM to extract information from unstructured text, thereby enabling the retrieval of relevant data (Algorithm 2POP). An example prompt is in Supplementary Fig. 2.
Algorithm
2POP
1 set Present\(({v}_{i})\) = true for all leaf nodes \({v}_{i}\in V\)
2 for all leaf nodes \({v}_{i}\)
3 set Description\(({v}_{i})\) = Does the information of <Label\(\left({v}_{i}\right)\)>(in the context of the named entities from root to \({v}_{i}\)) exist in the text
4 query LLM and extract information for all named entities leaf nodes \({v}_{i}\)
5 set Present\(({v}_{i})\) to true/false based on the LLM result
7 for all leaf nodes \({v}_{i}\)
8 set Description\(({v}_{i})\) = What is the <Label\(\left({v}_{i}\right)\)>(in the context of the named entities from root to \({v}_{i}\))
9 query LLM and extract information for all named entities leaf nodes \({v}_{i}\)
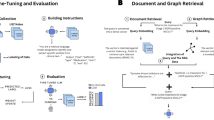
The pipeline is structured as follows. First, an ontology is fed into the graph-building module to generate a graph, which incorporates all the relationship information in the ontology. Each node (named entity) has five features, which are used later by the algorithms. The entire pipeline is shown in Fig. 1.

The mCODE ontology is converted into a directed acyclic graph by the graph builder module, encoding named entities and their relationships. The pipeline then applies one of three prompting strategies – baseline, BFOP, or 2POP – to generate structured prompts for large language models, enabling the extraction of standardized mCODE data fields from unstructured oncology clinical notes.
Baseline method
To demonstrate the advantages of BFOP and 2POP, we provide a baseline method. The baseline’s prompting strategy is based on ontoGPT21, a query-answering tool for extracting information from the text. We leverage the automatic graph builder (Fig. 1) to organize the mCODE ontology into the LLM pipeline, excluding the need to create YAML templates manually in a way like ontoGPT. Unlike BFOP and 2POP, the baseline is a straightforward approach. The prompt structure is one-round and non-hierarchical, directly querying the answers of information extraction across all leaf nodes. An example prompt is described in Supplementary Fig. 3.
Experimental design
Data processing
We evaluate the efficacy of the proposed LLM-based named entity extraction and the effectiveness of each prompt-generating method. Privacy regulations, such as HIPPA, restrict the sharing and processing of sensitive patient information to entities without explicit agreements, especially with third-party tools like OpenAI APIs. To address this privacy concern when evaluating open-source LLMs, our experiments were conducted using synthetic oncology notes, produced by the advanced generative model GPT3.5 16 K using the OpenAI API (Chat Completions API). The model was configured with a temperature setting of 0.8 and a maximum token limit of 16,384 to create a dataset of simulated clinical notes. To incorporate mCODE entity information into each clinical note, we first create a pre-defined set of answers (i.e., values) for each named entity (i.e., keys) formatted in a dictionary. We compile a list of named entities for each patient in our dataset with corresponding answers to form this ground truth. We then produce clinical narratives from these dictionary files, simulating authentic clinical notes. The prompts for generating the clinical notes are shown in Supplementary Note 1. Our dictionaries encompass a diverse range of cancer types, with the subject of each dictionary being randomly selected from a predetermined list of cancer categories. Supplementary Table 1 specifies the cancer types in this experiment. We generate 1,000 cancer reports (clinical notes), each focusing on the characteristics and details specific to the cancer type it represents. For each note, a random cancer type is chosen from Supplementary Table 1 to generate biologically meaningful descriptions. To evaluate the robustness of our proposed approaches on an external dataset, we conducted additional validation experiments using real-world clinical data (see Supplementary Note 6, Supplementary Figs. 5-8, and Supplementary Tables 8-11 for detailed methods and results). The hyperparameter settings and prompting strategies were kept identical to those used in this work to ensure consistency.
In our dataset, the distribution across cancer categories makes diverse representations, with approximately equal proportions of each cancer category. Each note is approximately 350–1000 words long. For the sake of generalizability in analyzing clinical notes, our study considers 49 named entities, covering several major mCODE categories. While implementing the BFOP algorithm, the ontology is structured into three hierarchical levels for conducting the experiments. Level 1 includes 21 queries, with 9 representing next-level queries and 12 as leaf nodes encompassing patient demographics entities. Level 2 includes 29 queries, with 1 serving as a next-level query and 28 as leaf nodes, which include entities related to human specimens, disease details, tumors, tumor marker tests, radiotherapy course summaries, comorbidities, genomic variants, and genomic regions studied. Level 3 includes 9 queries, all of which are leaf nodes related to cancer stage entities. While implementing the baseline and 2POP algorithms, the ontology contains all 49 named entities as leaf nodes.
Open-sourced and OpenAI models
We compared the effectiveness of BFOP and 2POP with various models, including open-source and OpenAI models, as summarized in Supplementary Table 2. The open-source models - Gemma, LLama-3, Phi-3, and Mistral - were collected from HuggingFace and deployed on a local server with 8 H100 GPUs to perform the information extraction task. The OpenAI models consisted of GPT-3.5 4 K and 16 K versions and the GPT-4 8 K and 32 K versions. We also incorporated a baseline that directly queries the LLM to extract the named entities in the ontology.
Evaluation metrics
To assess model performance, we compare extraction outcomes and ground truths. The ground truths correspond to the named entity values in our pre-defined dictionary (Section 4.1, Supplementary Note 2). The comparative analysis is performed through programmatic automation and human validation. We first justify exactly matching results after standardizing case sensitivity and context formats. Next, we apply a fuzzy string-matching algorithm26 to calculate the similarity score (i.e., based on Levenshtein Distance) and use a threshold (>0.5) to identify semantically equivalent results. Lastly, we incorporate post-hoc human evaluation to manually double-check the results with high similarity scores and compare the results with low similarity scores based on their understanding of the content of the original clinical notes.
We categorize extraction outcomes into three types—correct, error, and hallucination—to conduct performance analysis. The details of metrics calculation are provided in Supplementary Note 4. Correct extractions are when the information extraction result is the same as the ground truth or semantically equivalent. For example, the ground truth is Female, but the extracted result is female, or Normal vs. Within the norm range, or 15-Jan-75 vs. Jan 15, 1975. The correct extractions include cases of true presence—where the present information in the notes is identified correctly by the model—and true absence, where the information is not mentioned in the notes and the model states N/A.
Errors occur when the information extraction result is inconsistent with the ground truth. This includes cases of misidentification – where the correct information is available in the notes, but the information extraction result is none (N/A, none, Not mentioned, N/A (not mentioned in the text), etc.)—and misplacement, where the named entity has information in the notes. The information extraction result is not correct, but from the note itself (not hallucinated). Hallucination refers to the generation of text that is factually incorrect, nonsensical, or not based on the input data. Hallucinations are instances where the model generates fabricated information that does not exist in the original notes, presenting a unique challenge in ensuring data integrity (Supplementary Table 3).
Statistics and reproducibility
All experiments were conducted using a dataset of 1,000 synthetic oncology clinical notes, each simulating patient information across 49 named entities based on the mCODE ontology. For each LLM model-prompt method combination, named entity extraction was evaluated once per note, totaling 1,000 replicates per setting. Model performance was assessed using three outcome categories: correct, error, and hallucination. Accuracy, error rate, and hallucination rate were calculated per entity and averaged across the dataset. Statistical comparisons between methods (BFOP, 2POP, and baseline) were performed using independent samples t-tests, with a significance threshold of p < 0.05. Reproducibility was ensured through deterministic prompt construction. Results were verified through both automated matching algorithms and manual validation by human reviewers.
Institutional Review Board (IRB) approval
This study was approved by the Committee for the Protection of Human Subjects at UTHealth under protocol number HSC-SBMI-13-0549. Data access was restricted to BIG-ARC servers, and no individually identifiable information was extracted or used; therefore, informed consent was not needed.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Results
Overall extraction performance
This section evaluates the performance of our tool on named entity extraction tasks from the mCODE ontology using different LLMs as backbones combined with the two prompt generation methods. Additional experiment results are provided in Supplementary Fig. 4, Supplementary Note 5, and Supplementary Tables 4–7.
Table 1 presents the accuracy of each model on the 1000 clinical notes. With respect to the incorrect results, we also identified the incorrect incidence rate and hallucination rate. The table indicates that mCodeGPT generally performed better with the 2POP method, consistently having the highest accuracy. This aligns with the initial design intent of the method, which is to perform a first-round screening (query about presence) before prompting more difficult questions (query about details).
Among all the models, GPT4o performed the best, achieving an accuracy of 0.939 using 2POP. Among the open-source models, Llama 3 achieved the best accuracy with 2POP at 0.899 and was closely followed by Mistral 7B at 0.896. By contrast, the baseline method (simple prompting) tended to achieve the lowest accuracy (0.767 by Gemma-7b-it). This finding aligns well with the nature of the baseline method, which issues queries for all named entities straightforwardly without leveraging hierarchical structuring or an easy-to-difficult design approach.
Hallucinations rarely happened (<2.5%) for open-source and OpenAI models. In general, BFOP and 2POP slightly reduced hallucination compared with baseline, which can be explained by the designed chain-of-thought queries. Overall, the OpenAI models hallucinated less than the open-source models.
Statistical significance was assessed using independent samples T tests to compare performance against the baseline. Across all LLM models, BFOP and 2POP consistently outperformed the baseline in terms of accuracy and error rates within 1,000 individual notes, with p-values frequently meeting the p < 0.05 threshold. Both BFOP and 2POP demonstrated statistically significant reductions in hallucinations for most models. These results suggest the robustness of the two prompt generation methods in achieving superior performance.
Figure 2 illustrates the evaluation of the named entity recognition performance of GPT4o 2POP for the dataset of 1000 documents. Each bar in the graph represents the accuracy, error, and hallucination rate for one named entity. The results indicate a perfect extraction for many named entities, especially for patient demographic information. For medical-related information, the model performs well for most concepts, with an accuracy of over 90%. However, certain types of named entities exhibited lower accuracy rates. For example, entities about genomic data, such as genomic variant code, genomic region studied, gene mutation, and genomic region studied, displayed comparatively higher hallucination or error rates. This occurred because the model frequently confused these entities with similar ones, like the genomic variant studied gene, the studied genomic region, or the genomic variant cytogenetic location. The entity genomic region description achieved suboptimal accuracy as the model tended to provide full-sentence descriptions, whereas the correct response required concise specifications of regions (e.g., Exon 2). The entity human specimen identifier exhibited a higher hallucination rate, as the model sometimes erroneously classified other numeric numbers (e.g., patient zip code or patient phone number) as identifier numbers.

The figure shows the accuracy (orange), error rate (pink), and hallucination rate (yellow) for each of the 49 mCODE named entities extracted by GPT4o using the 2POP method on 1,000 synthetic clinical notes. Higher error and hallucination rates were observed for complex biomedical entities, while demographic information like patient gender and patient birth rate was extracted with near-perfect accuracy.
Analysis of true presence and absence
Next, we break down the accuracy of each model to see the different cases of true presences (TPs) and true absences (TAs). Accurate identification of a named entity comprises true presences (present information identified correctly) and true absences (information not mentioned and model states N/A). Intuitively, it is a much harder task to correctly extract the information if information is present in the notes than to state N/A when information is not available. Therefore, to determine if the high accuracy of the models and methods is attributed to the high occurrence of true absences, we analyzed the TPs and TAs achieved by each named entity in Fig. 3. Except for the patient’s death date, all named entities’ information is present in almost all 1000 notes. The results show that the LLM can correctly find and extract the correct information from the notes, without picking up anything that isn’t there.

The figure shows the True Presence Percentage (blue) and True Absence Percentage (orange) for each of the 49 mCODE named entities extracted by GPT4o using the 2POP method on 1,000 synthetic clinical notes. The sum of the true presence and absence rate equals the accuracy rate, allowing for a granular evaluation of the model’s accuracy in detail.
LLM model comparison by named entity type
The model’s training context greatly impacts its capacity to identify, and extract named items. As a result, the model may perform differently on named entities according to their nature (e.g., demographics and medical information). Thus, we compared the accuracy, hallucination rate, and error rate of several named entities using the model/method with the best performance - GPT4o 2POP. The accuracy of each model-method pair for the named entities is demonstrated in Fig. 4. The accuracy across different models remains consistent for all named entities, with no specific model excelling or underperforming in any area. All models accurately capture demographic information as they are general domain questions. Comparatively, domain-specific named entities achieve relatively lower performance, possibly due to the model having been presented with less such data during training than general domain data.

The figure presents a heatmap of accuracy scores for 49 mCODE named entities across different model-method pairs. Darker shades indicate higher accuracy, with GPT4o combined with the 2POP method showing consistently strong performance.
Additionally, the 2POP method consistently outperforms the other two methods across all models, as evidenced by the darker color in every third column. Similarly, the error and hallucination rates can be found in Fig. 5 and Fig. 6. The patterns in Fig. 5 and Fig. 6 largely overlap, which indicates that the named entities’ lower accuracy is attributed to a higher error rate rather than hallucination. Certain named entities, such as cancer_stage_type, disesase_evidence, and genomic_region_description, have consistently lower performance across all models. Genomic_variation_code has a higher hallucination rate.

The figure shows a heatmap of error rates for 49 mCODE-named entities across various model-method combinations. Higher error rates (darker red) are concentrated among complex clinical entities such as genomic and cancer staging terms, while demographic entities like patient gender and patient name exhibit minimal error.

The figure displays a heatmap of hallucination rates for 49 mCODE-named entities across different model-method pairs. Hallucinations are rare overall but occur more frequently in complex genomic entities, particularly with models using baseline prompting strategies.
Prompt Refinement for Cancer Staging
The model’s performance varied across different named entities within specific information extraction tasks. Among these, the entity’s cancer staging method and cancer stage type are particularly critical for oncology physicians when making informed decisions. However, the model struggled to effectively distinguish between these closely related entities (Figs. 2–5). For instance, when tasked with extracting the entity cancer stage type, the model frequently misinterpreted the prompt, providing overarching staging classifications (e.g., TNM and FIGO) instead of the specific cancer progression levels (e.g., Stage II or Stage A). To improve information extraction for these entities, we provided a refined version of the prompting methods and evaluation process on LLM models. To address ambiguities, we incorporated detailed definitions to clarify the intended scope of the requested information (see Supplementary Note 3 for prompt details). Furthermore, as noted by the National Cancer Institute27, the AJCC staging method is based on the TNM system, and the FIGO and TNM systems share high similarities, enabling straightforward conversion between them. This overlap added an additional layer of complexity for the model in distinguishing between the systems. To address this challenge, we standardized the representation of staging systems by grouping AJCC, TNM, and FIGO under a unified label—FIGO or TNM, thereby simplifying the extraction process.
The impact of these optimizations is reflected in the accuracy improvements shown in Fig. 7. We report the results of the refined prompting methods and evaluation strategies, which greatly improved the model’s ability to extract accurate information for both entities. These enhancements underscore the importance of explicitly defining the scope of information extraction to mitigate confusion and improve performance in complex, domain-specific tasks.

The figure compares the accuracy of extracting two cancer staging-related entities—cancer_staging_method and cancer_stage_type—before (orange bars) and after (blue bars) prompt optimization across various model-method pairs. Optimized prompts consistently improved performance, particularly for models using hierarchical prompting strategies like BFOP and 2POP.
Discussion
This study provides insight into the possibilities and power of LLMs, especially when used with clinical ontologies. Beyond its direct application to cancer ontologies, our methodologies can be extended and applied to various other medical specialties and healthcare domains with ontological frameworks.
The comparative analysis of different prompt engineering algorithms used in our study reveals significant differences in their efficiency in extracting structured data from unstructured texts. The comparison among 2POP, BFOP, and the baseline highlights the advantages of pruning the extraction queries before performing the extraction. Moreover, the 2POP algorithm is more likely to traverse the subgroup correctly than the BFOP. This can be attributed to 2POP’s strategy of verifying the presence of information before advancing to detailed queries, which inherently guides the model through a more accurate path in the ontology. This methodological refinement reduces the occurrence of hallucinations that are common when models are overloaded with extensive but irrelevant data cues.
The 2POP algorithm appears more likely to traverse the correct subgraph than the baseline prompting method. This is likely due to 2POP’s strategy of verifying the presence of leaf nodes before advancing to detailed queries, which inherently guides the model through a more accurate path in the ontology. Additionally, pruning the set of extraction queries improves accuracy. This methodological refinement reduces the occurrence of hallucinations, which are common when models are overloaded with extensive but irrelevant data cues. These findings highlight the advantages of these approaches and suggest that such methods could generalize to other ontologies beyond cancer, enhancing their applicability across various medical specialties and healthcare domains with ontological frameworks. 2POP achieves linear improvements by isolating relevant leaves through binary presence-check queries, with scalability proportional to the number of leaf nodes. Since its benefits are more incremental compared to BFOP, which reduces many downstream queries and optimizes token usage, BFOP is more applicable for extremely large ontologies constrained by the LLM context window.
To leverage these advantages in practical applications, non-commercial LLMs, such as those available through GPT4ALL28 and HuggingFace29, can be assessed freely and easily integrated into existing systems via open-source libraries. Moreover, data privacy is the key consideration for using large language models in healthcare settings. Unlike commercial models that require stricter controls, non-commercial LLMs can ensure better privacy by keeping all data and results local. When using commercial models offered by OpenAI, one must ensure compliance with healthcare regulations. One practical approach is establishing a Business Associate Agreement (BAA) with the service provider, such as Microsoft Azure OpenAI. These measures prevent patient data from being misused and ensure compliance with privacy standards, enabling LLMs’ safe and effective utilization in clinical workflows.
We choose to use synthetic clinical notes instead of real-world data due to stringent privacy regulations and the sensitive nature of patient information. Synthetic data allows us to develop and test our methods in a controlled environment without the ethical and legal complications associated with handling real-world data. To ensure the feasibility of using synthetic data, we generated notes by carefully crafting prompts to mimic the linguistic and structural variability of real-world clinical notes. This enabled us to simulate diverse clinical scenarios, including different cancer categories and varying mCODE entities, while maintaining compliance with privacy laws. Although synthetic data lacks the full complexity and variability of real-world notes, it provides a privacy-preserving and scalable alternative for early-stage testing and development. Furthermore, by comparing performance across different LLMs on synthetic data, we could underscore the advancement of our proposed prompting methods in controlled scenarios. These promising results build a fundamental benchmark for evaluating our methods on real-world clinical notes in the future.
There are several limitations of the paper. Despite achieving high accuracy, there were instances where only some named entities were accurately identified. However, this does not diminish the value of our tool. Human review of the outputs to address missed or misidentified information is much easier and less time-consuming than extracting information from humans from scratch, considering the high baseline accuracy achieved by our system. Thus, we advocate for a human-in-the-loop approach to review the outputs and address missed or misidentified information. Clinical notes in real-world scenarios exhibit substantial variability, often encompassing a wider range of mCODE entities and condition-specific details not represented in our internally structured dataset. While this study’s dataset includes a diverse but manageable subset of mCODE entities that cover all major categories, future research should expand this coverage to ensure applicability across a broader spectrum of clinical contexts. Additionally, the heterogeneity in physicians’ writing styles and the linguistic complexity of clinical notes pose challenges for the current methodologies, which may not capture all possible variations. While our algorithms demonstrate promising results for synthetic clinical notes under controlled environments, further validation and refinement using real-world clinical data are essential to enhance their robustness, adaptability, and generalizability. A limitation of BFOP lies in its reliance on a top-down hierarchy. Real-world clinical notes may describe child entities (e.g., tumor size) without explicitly mentioning their parent nodes, particularly when alternative terms (e.g., neoplasm or polyp for the term tumor) are used to describe parent nodes, leading to missed extractions if the LLM cannot infer these relationships. To address this, we propose to refine prompts to identify implied patient nodes better and fine-tune LLMs for domain-specific applications, such as cancer registries, to handle diverse terminologies more effectively.
Conclusions
In this study, we evaluated the performance of our named entity extraction tool using the mCODE ontology, leveraging various large language models (LLMs) and two distinct prompt generation methods. The 2POP (Two-phase Orderly Prompting) method was designed to enhance accuracy by performing a preliminary screening for the presence of entities before delving into more complex queries. This hierarchical approach was intended to reduce the error and hallucination rates. The models were tested on a dataset of 1000 clinical notes, providing a robust evaluation environment. Multiple LLMs were assessed, including GPT-4 32 K, GPT-3.5, and various open-source models like Llama 3 and Mistral 7B. Performance metrics included accuracy, error rate, and hallucination rate.
The 2POP method generally achieved higher accuracy across models, with GPT-4o achieving the highest accuracy (0.939) and Llama 3 leading among open-source models (0.899). Hallucination rates were low (<2.5%) across all models, with 2POP and BFOP methods slightly reducing hallucinations compared to the baseline. Demographic information was extracted with high accuracy, while domain-specific entities like genomic data showed lower performance, indicating a need for improved training data or model adjustments. Errors and hallucinations were more common in complex entities like genomic variant code, highlighting areas for further refinement. These contributions underscore the potential of the hierarchical prompting method for enhancing named entity extraction in clinical contexts while also identifying specific challenges that require additional attention.
Code availability
We have published the mCodeGPT as a ready-to-use toolkit (https://github.com/anotherkaizhang/mCodeGPT)31, and the experiment codes are found here (https://doi.org/10.5281/zenodo.16888491)30.
References
Ya, R. A., Depinho, M. & Ernst, K. Cancer research: past, present and future. Nat. Rev. Cancer 11, 749–754 (2011).
Chin, L., Andersen, J. N. & Futreal, P. A. Cancer genomics: from discovery science to personalized medicine. Nat. Med. 17, 297–303 (2011).
Li, I. et al. Neural natural language processing for unstructured data in electronic health records: a review. Computer Sci. Rev. 46, 100511 (2022).
Consultant, H. I. T. Why Unstructured Data Holds the Key to Intelligent Healthcare Systems (HIT Consultant, 2015).
Jensen, P. B., Jensen, L. J. & Brunak, S. Mining electronic health records: towards better research applications and clinical care. Nat. Rev. Genet. 13, 395–405 (2012).
Warner, J. L. et al. Development, implementation, and initial evaluation of a foundational open interoperability standard for oncology treatment planning and summarization. J. Am. Med. Inform. Assoc. 22, 577–586 (2015).
Sarawagi, S. Information Extraction. Found. Trends® Databases 1, 261–377 (2008).
Bird, S. NLTK: The natural language toolkit. https://aclanthology.org/P06-4018.pdf (2006).
Manning, C. et al. The Stanford CoreNLP natural language processing toolkit. In Proc. 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations (Association for Computational Linguistics, 2014). https://doi.org/10.3115/v1/p14-5010.
Chang, J. T., Schütze, H. & Altman, R. B. GAPSCORE: finding gene and protein names one word at a time. Bioinformatics 20, 216–225 (2004).
Liu, H., Lussier, Y. A. & Friedman, C. Disambiguating ambiguous biomedical terms in biomedical narrative text: an unsupervised method. J. Biomed. Inform. 34, 249–261 (2001).
Bodenreider, O. The Unified Medical Language System (UMLS): integrating biomedical terminology. Nucleic Acids Res. 32, 267D–270D (2004).
Monajatipoor, M. LLMs in biomedicine: a study on clinical named entity recognition. Preprint at https://arxiv.org/abs/2404.07376 (2024).
Keloth, V. K. et al. Advancing entity recognition in biomedicine via instruction tuning of large language models. Bioinformatics 40, btae163 (2024).
Bian, J. VANER: leveraging large language models for versatile and adaptive biomedical named entity recognition. Preprint at https://arxiv.org/abs/2404.17835 (2024).
Bian, J., Zheng, J., Zhang, Y., Zhou, H. & Zhu, S. One-shot biomedical named entity recognition via knowledge-inspired large language model. In Proc. 15th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics 1–10 (ACM, New York, NY, USA, 2024).
Luo, R. et al. BioGPT: generative pre-trained transformer for biomedical text generation and mining. Brief. Bioinform. 23, bbac409 (2022).
Lee, J. BioBERT: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 36, 1234–1240 (2020).
Beltagy, I., Lo, K. & Cohan, A. SciBERT: a pretrained language model for scientific text. In Proc. 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP) (eds Inui, K., Jiang, J., Ng, V. & Wan, X.) (Association for Computational Linguistics, Hong Kong, China, 2019).
Lou, Y., Zhu, X. & Tan, K. Dictionary-based matching graph network for biomedical named entity recognition. Sci. Rep. 13, 1–9 (2023).
Caufield, J. H. et al. Structured Prompt Interrogation and Recursive Extraction of Semantics (SPIRES): a method for populating knowledge bases using zero-shot learning. Bioinformatics 40, btae104 (2024).
Kleihues, P. & Cavenee, W. K. (eds). Pathology and Genetics of Tumours of the Nervous System (IARC Press, Lyon, 2000).
Stratton, M. R., Campbell, P. J. & Futreal, P. A. The cancer genome. Nature 458, 719–724 (2009).
Osterman, T. J., Terry, M. & Miller, R. S. Improving cancer data interoperability: the promise of the Minimal Common Oncology Data Elements (mCODE) initiative. JCO Clin. Cancer Inform. 4, 993–1001 (2020).
Wei, J. et al. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 35, 24824–24837 (2022).
Левенштейн, В. И. Двоичные коды с исправлением выпадений, вставок и замещений символов [Levenshtein, V. I. et al. Binary codes capable of correcting deletions, insertions, and reversals. Sov. Phys. Dokl. 163, 707–710 (1965).
NCI dictionaries. https://www.cancer.gov/publications/dictionaries (2015).
Anand, Y., Nussbaum, Z., Duderstadt, B., Schmidt, B. & Mulyar, A. GPT4All: Training an Assistant-style Chatbot with Large Scale Data Distillation from GPT-3.5-Turbo (GitHub, 2023).
Wolf, T. et al. Transformers: State-of-the-art natural language processing. In Proc. 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations (Association for Computational Linguistics, Stroudsburg, PA, USA, 2020). https://doi.org/10.18653/v1/2020.emnlp-demos.6.
Huang, T. Tongtong-h/MCodeGPT: Experimental Release for MCodeGPT. Zenodo https://doi.org/10.5281/ZENODO.16888567 (2025)
Zhang, K. Anotherkaizhang/MCodeGPT: Stable. Zenodo https://doi.org/10.5281/ZENODO.16887570 (2025).
Acknowledgements
This project is partially supported by NCI U01CA274576, CPRIT RR180012, and UTHealth Houston’s internal funding. The funder played no role in study design, data collection, analysis, data interpretation, or the writing of this manuscript.
Author information
Authors and Affiliations
Contributions
K.Z. drafted the manuscript, developed and implemented the pipeline, and contributed to the conception of ideas, performed result analysis. T.H. drafted the manuscript, conducted experiments, and evaluated the results. B.A.M., T.O. and Q.L. drafted and revised the manuscript. X.J. drafted the manuscript, proposed and contributed to the pipeline, initiated the conception of ideas, and intensely reviewed and polished the paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Communications Medicine thanks the anonymous reviewers for their contribution to the peer review of this work. A peer review file is available
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhang, K., Huang, T., Malin, B.A. et al. Introducing mCODEGPT as a zero-shot information extraction from clinical free text data tool for cancer research. Commun Med 5, 422 (2025). https://doi.org/10.1038/s43856-025-01116-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s43856-025-01116-x
