
Abstract
Intensive care units (ICU) produce numerous progress notes that may contain stigmatizing language that perpetuate negative biases and punitive approaches against patients. Patients with substance use disorders are particularly vulnerable to stigma. This study examined the performance of Large Language Models (LLMs) in the identification of stigmatizing language. We annotated a dataset with over 77,000 stigmatizing and non-stigmatizing notes from the MIMIC-III database. We utilized Meta’s Llama-3 8B Instruct LLM to run the following experiments for stigma detection: zero-shot; in-context learning; in-context learning with a selective retrieval; supervised fine-tuning (SFT); and keyword search. All approaches were evaluated on a held-out test set and external validation (University of Wisconsin Health System). SFT had the best performance with 97.2% accuracy, followed by in-context learning. The LLMs with in-context learning and SFT provided appropriate reasoning for false positives during human review. Both approaches identified clinical notes with stigmatizing language that were missed during annotation. SFT achieved 97.9% accuracy on external validation dataset. LLMs, particularly SFT and in-context learning, effectively identify stigmatizing language in ICU notes with high accuracy while explaining their reasoning in an asynchronous fashion and demonstrated the ability to identify novel stigmatizing language, not explicitly in training data nor existing guidelines.
Similar content being viewed by others

Introduction
Stigmatizing language in electronic health records (EHRs) can hinder effective communication between patients and healthcare providers, influencing clinical decision-making and potentially reinforcing health disparities. The 21st Century Cures Act requires that EHR notes be made available to patients in real-time, online, and at no cost through Open Notes, dramatically increasing the visibility of clinical documentation to both patients and providers1. This transparency has heightened the impact of language choice, as terms like “substance abuser” have been shown to provoke more negative provider attitudes and reduce the likelihood of appropriate treatment, compared to more clinically accurate, person-centered alternatives like “substance use disorder”2. With the rapid integration of large language models (LLMs) in healthcare settings, the risk of amplifying these biases at scale has become a pressing concern. AI-generated notes and clinical summaries, trained on existing human-authored texts, inherently reflect the biases of their underlying data, potentially perpetuating harmful language if left unchecked3. As major EHR vendors are now capable of incorporating LLMs to streamline documentation4, proactive strategies are essential to prevent the unchecked spread of stigmatizing language in clinical practice2. LLMs offer a unique opportunity to drive positive change, serving as tools to reduce stigma, educate providers about the impact of language, and promote documentation practices that build trust and support patient-centered care.
This work explores automated methods for detecting stigmatizing language with respect to addiction within clinical text using LLMs. Our study utilizes the publicly available Medical Information Mart for Intensive Care (MIMIC-III) dataset, which comprises over 2 million intensive care unit (ICU) notes5. We hypothesize that LLM-based approaches will outperform simple keyword searches to detect stigmatizing language in accordance with National Institute on Drug Abuse (NIDA) best practices, offering a more accurate and scalable solution for identifying bias in clinical documentation for patients with Addiction Disease. Identification of bias would prompt the clinician to be more aware of the impact of stigma on patient care.
To date, relatively few studies have designed a natural language processing (NLP)-based tool that can classify clinical notes containing stigmatizing language related to substance use. A recent study by Weiner et al.6 developed a rule-based, closed-source NLP system to detect substance use–related stigmatizing language in clinical notes. Their approach combined a curated list of stigmatizing terms, inspired by the NIDA guidelines5, with regular expressions and rule-based contextual checks to classify sentences as stigmatizing or non-stigmatizing.
Other studies have focused on detecting stigmatizing language in clinical documentation from various domains, including obstetrics and gynecology notes7,8,9. These approaches typically used traditional machine learning methods—including decision trees, logistic regression, and support vector machines—combined with features such as term frequency-inverse document frequency (TF-IDF) vectorization of clinical text and patient demographics.
A complementary line of work has investigated sentence-level analysis of stigmatizing language using transformer-based models such as bidirectional encoder representations from transformers (BERT)10,11. These methods first extract potentially stigmatizing sentences using predefined term lists and regular expressions, then classify the contextual use of those terms at the sentence level using transformer models.
An additional study investigated the use of prompt engineering to reduce generation of substance use-related stigmatizing language by 14 different LLMs in response to 60 clinical questions12. The authors demonstrated engineering prompts with NIDA5 guidelines reduced stigmatizing language generation by almost 30%.
In contrast to these prior approaches, our study leverages generative decoder-only LLMs to perform context-aware classification of entire clinical notes. This enables the model to capture both explicit and subtle forms of stigmatizing language without relying solely on predefined term lists or sentence-level parsing.
Our study differs from prior work in several important ways. First, the methods we evaluate are capable of processing entire clinical notes holistically, without requiring any feature engineering, parsing, or pre-selection of potentially stigmatizing sentences. Prior approaches typically rely on keyword-based extraction steps that can miss semantically equivalent but lexically distinct expressions of stigma. Second, unlike sentence-by-sentence evaluation pipelines, which require many independent executions of transformer models, our decoder-only LLM-based approaches can process full clinical notes in a single model execution, leveraging more global context and more efficient computation. Our LLM-based approaches were also found to explain its reasoning behind label predictions, unlike prior approaches.
Additionally, our work investigates detection of stigmatizing language from existing clinical notes using various context engineering and fine-tuning approaches, unlike12, which evaluates the occurrence of stigmatizing language in LLM responses to clinical questions.
Results
To create our training and internal testing, we employed a semi-manual approach to identify and label 38,552 clinical notes (from MIMIC-III) containing stigmatizing language and randomly sampled an equivalent number of clinical notes without stigmatizing language. A breakdown of the demographics of all the MIMC-III data that was split into training, validation, and test sets, provided in Table 1. Table 2 outlines the most frequent stigmatizing terms.
To create the external validation dataset, we used a data corpus of 288,130 ICU patient clinical notes from UW. This patient data spanned the period from 2009 to 2020, encompassing patients aged 18–86. We also down-sampled the full external validation dataset to select a random convenience sample of 4144 notes that were evenly split between “yes” and “no” predictions with similar baseline characteristics as the full cohort (Table 1). The approaches were evaluated on both the entire external validation dataset and down-sampled dataset. Tables 3 and 4 outline the external validations most frequent stigmatizing terms respectively.
This study was reviewed by the University of Wisconsin-Madison Institutional Review Board (IRB; 2023-1252) and determined to be exempt from human subjects research. The IRB approved the study with a waiver of informed consent.
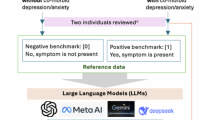
Here we summarize our experiments. Several approaches were experimented with, including a baseline keyword method and several LLM-based strategies for detecting stigmatizing language in addiction care. The baseline method relied on keyword searches using a custom dictionary of stigmatizing language-related terms, compiled from established guidelines on reducing bias in clinical communication for addiction care5,12. For the LLM-based approaches, we employed open models such as the Meta-Llama-3-8B-Instruct model13 using the HuggingFace transformers library14 and PyTorch15,16. We explored multiple configurations: simple zero-shot prompting, in-context generation and retrieval-augmented generation (RAG) using additional context from stigmatizing language guidelines, and supervised fine-tuning (SFT) to adapt the model specifically to our task. These configurations were designed to capture both explicit and context-dependent instances of stigmatizing language, offering a more flexible and context-aware approach than traditional keyword matching. A summary of these methods is provided in Supplementary Fig. 1.
We evaluated our models on a fully held-out test set, as well as on a more challenging subset of the test set. Every note in this challenging subset contains terms in a list of terms inspired by NIDA guidelines5. Upon manual review of the surrounding context around the flagged term, some of these notes were labeled as non-stigmatizing despite their potential for misinterpretation. This latter evaluation was designed to test the models’ ability to distinguish stigmatizing language from contextually appropriate use (i.e., patient has a ‘junky’ cough), reflecting the nuanced nature of real-world clinical documentation. To evaluate model performance, we employed accuracy and F1 scores for the automated identification of stigmatizing language with 1000-iteration bootstrapped 95% Confidence Intervals (95% CI). Detailed manual error analysis was also performed on cases missed by the LLM. To assess the generalizability of the approaches tested, we also evaluated the approaches on an external validation dataset from UW. The external validation dataset was utilized in both native prevalence and down-sampled balanced prevalence of stigmatizing labels. This was to evaluate the approaches on unseen data with true prevalence of stigmatizing labels (entire dataset) and the down-sampled version to mimic the same distribution labels utilized on the MIMIC-based test set.
Findings
The results of the performance evaluation on the full held-out test set are presented in Fig. 1. The SFT approach achieved the highest performance for identifying substance use-related stigmatizing language, with a bootstrapped macro-averaged F1 score of 0.970 (95% CI: 0.970–0.973), followed by the in-context model, which achieved a score of 0.890 (95% CI: 0.889–0.895) (Fig. 1). In contrast, the baseline keyword search approach performed worse, with a macro-averaged F1 score of 0.680 (95% CI: 0.678–0.687). Notably, the in-context learning approach, which leveraged task-specific context during inference, approached the performance of the SFT model despite requiring significantly less task-specific training data, highlighting its potential as an alternative, more parsimonious model.

Bootstrapped (n = 1000) performance on the complete held-out test set (11,586 clinical notes). Each approach reflects a distinct prompting or fine-tuning strategy for identifying stigmatizing language. Results are reported as mean macro F1 score with 95% bootstrapped confidence intervals.
Additionally, RAG performed similarly to the In-Context approach on the full test set (Fig. 1), whereas Zero-shot lagged with an approximately 0.05 drop in F1 score (Fig. 1). However, all these approaches outperformed the baseline keyword approach with gains of at least 0.17 F1 score (Fig. 1).
The performance evaluation on the challenging subset of the test set is summarized in Fig. 2. The SFT approach achieved the highest macro-averaged F1 score of 0.896 (95% CI: 0.890–0.902), outperforming the in-context learning approach, which reached 0.690 (95% CI: 0.683–0.698). Notably, the SFT approach exhibited less performance degradation when transitioning from the full test set to this more challenging subset, with its F1 score decreasing by just 0.078, compared to a 0.202 decrease for the in-context approach. In contrast, the baseline keyword search method, which lacks the capacity to interpret context, performed worse, with a macro-averaged F1 score of 0.340 (95% CI: 0.337–0.344), compared to the SFT model. These results highlight the advantage of context-aware LLM-based methods in distinguishing between stigmatizing language in contextually appropriate use, even in challenging scenarios.

This challenging subset contains stigmatizing terms which could make the clinical note stigmatizing or non-stigmatizing depending on the context it’s surrounded with. Bootstrapped (n = 1000) performance on a subset of 6889 clinical notes from the held-out test set, each containing one or more stigmatizing terms. Labels were assigned based on manual review of contextual usage by addiction care expert (ESA), reflecting whether the term was used in a genuinely stigmatizing or non-stigmatizing manner. Results are reported as mean macro F1 score with 95% bootstrapped confidence intervals.
The best-performing approach (SFT) and the baseline keyword method were externally validated on the EHR cohort from UW. We evaluated both approaches on the external dataset at its native label prevalence, which comprised 288,130 notes, of which only 2072 (0.72%) were labeled as stigmatizing by our semi-manual annotation pipeline. As expected, performance declined in this more imbalanced, real-world scenario. The SFT model achieved a macro F1 score of 0.759 (95% CI: 0.747–0.772), while the keyword baseline continued to have lower performance at 0.699 (95% CI: 0.682–0.715) (Fig. 3). Despite this drop, the SFT model maintained superior performance over the baseline, demonstrating its ability to generalize beyond the training distribution and handle low-prevalence settings more effectively. We also evaluated both approaches on a balanced subset of the full external dataset. This balanced dataset contained 4144 clinical notes, evenly split between stigmatizing and non-stigmatizing labels to mirror the data distribution used during model training. On this balanced set, the SFT model demonstrated robust generalization, achieving a macro F1 score of 0.978 (95% CI: 0.974-0.983) and outperforming the keyword baseline, which achieved a macro F1 score of 0.849 (95% CI: 0.838–0.860) (Fig. 4).

Bootstrapped (n = 1000) performance on the complete external dataset (288,130 clinical notes), in which stigmatizing language was present in 2072 notes (0.72%). Results reflect model performance in a real-world, highly imbalanced setting without artificial rebalancing of label distribution.

Bootstrapped (n = 1000) performance on a down-sampled subset of 4144 clinical notes from the external dataset, evenly balanced between notes labeled as containing stigmatizing language and those labeled as non-stigmatizing (2072 each). This evaluation mirrors the balanced distribution used during model training and enables direct comparison of model performance across approaches.
Error analysis
To further assess the robustness of LLM-based approaches in identifying stigmatizing language, we conducted an LLM-assisted human-in-the-loop error analysis, focusing on false positive instances—clinical notes that the models labeled as stigmatizing but were annotated as non-stigmatizing. Both the SFT and in-context models were included in this analysis. For each false positive, the models were prompted a second time to explain their reasoning, with the in-context approach receiving the same context used during the initial classification. These explanations were then manually reviewed by an addiction care expert (ESA) to determine whether the original human annotations might have missed genuinely stigmatizing language. The SFT approach correctly identified 10 clinical notes as genuinely stigmatizing upon this second review, while the in-context approach identified 22 such instances (Table 5). A comparative analysis of the specific phrases identified by each model, including terms detected in isolation and conjunction, is presented in Fig. 5. Notably, many of these terms were not explicitly included in the NIDA guidelines5, highlighting the potential for LLMs to detect contextually stigmatizing language that extends beyond their original training data.

These are examples of substance use-related stigmatizing language from clinical notes that were labeled originally as non-stigmatizing. These examples are isolated from false positives made by SFT and in-context approaches. These false positives were reviewed by an addiction care specialist (ESA) to determine whether the approaches were correct to label these phrases as stigmatizing. Of note, these examples are ones that were not present in the training set nor mentioned in the NIDA guidelines for substance use-related stigmatizing language. The segments in the middle are language identified by both approaches, while the flanking segments are those identified solely by the approach under which they appear. Abbreviations from the examples above: Intravenous Drug Abuse (IVDA), ethanol/alcohol (EtOH), h/o (history of), hx (history). Stigmatizing terms are surrounded by ‘*’.
Another noteworthy finding from the error analysis was the frequency with which the models revised their initial classifications when prompted to provide reasoning. The SFT approach demonstrated significantly more decision switching, with approximately 50% of its original classifications being adjusted upon second review, compared to less than 1% for the in-context approach (Table 5). However, expert review revealed that roughly 90% of these false positive instances were indeed genuinely non-stigmatizing, suggesting that the greater consistency observed in the in-context model often reflected a rigidity in its decision-making rather than superior accuracy. This finding underscores a key advantage of the SFT approach: despite being fine-tuned for the specific task of identifying stigmatizing language, it retains flexibility in responding to varied prompts, potentially allowing for more contextually accurate classifications when reconsidering ambiguous cases.
Here we outline the computational considerations for our experiments. In terms of processing efficiency, the RAG approach had the longest average inference time, requiring 46.46 s per note. This extended latency reflects the overhead associated with first identifying the most relevant context entries before generating a response. In contrast, the baseline keyword approach was the fastest, with an average inference time of less than 0.001 s per note, owing to its straightforward text-matching design. The SFT approach, while significantly faster than RAG, required a substantial up-front training investment, including approximately 6 h of fine-tuning on 8 parallel NVIDIA A6000 Graphical Processing Units (GPUs), with an effective batch size of 64 for 3 epochs. Detailed inference speed comparisons for each approach are provided in Table 6.
Discussion
This study demonstrates that the LLM-based approaches consistently yielded superior performance in detecting stigmatizing language within substance use-related clinical notes compared to keyword search methods. The SFT model performed the best, achieving the highest precision and context sensitivity, and a critical requirement for this task. However, the in-context learning approach, despite lacking the task-specific training of the SFT model, achieved competitive performance, highlighting its potential as a more resource-efficient alternative.
RAG and zero-shot approaches served as additional approaches that did not require fine-tuning, similar to the in-context approach. These approaches outperformed the baseline approach, demonstrating the advantage of utilizing LLMs over simple keyword search algorithms for stigmatizing language. However, in-context performed the best from these approaches on the challenging test subset and warranted further comparisons with the SFT approach to investigate the benefits of additional fine-tuning on this task.
Both the SFT and in-context approaches demonstrated the ability to identify novel, contextually stigmatizing language that was not explicitly included in their training data or predefined guidelines. For instance, the SFT model accurately flagged terms like “drug-seeking behavior” and “alcoholic cirrhosis,” which were not part of the NIDA guidelines5 used to annotate the training dataset. This suggests that these models can extend beyond the specific terms they were trained on, potentially identifying emerging stigmatizing language as clinical documentation evolves, unlike simple baseline keyword searches.
Results from external validation demonstrated that the SFT approach generalized well to unseen data. As expected, the SFT model exhibited a performance decline in external validation when evaluated on the external dataset at its native prevalence of stigmatizing language, where non-stigmatizing notes vastly outnumbered stigmatizing ones. This drop was likely attributable to the model’s heightened sensitivity, which was calibrated during training on a balanced dataset, potentially leading to increased false positives in a highly imbalanced real-world setting. However, the SFT model continued to outperform the baseline keyword approach in this scenario. Importantly, this performance drop could likely be mitigated in practice with domain adaptation on data reflecting the native label distribution (though we did not perform this experiment here due to computational constraints associated with training on a much larger, imbalanced dataset and lack of training appropriate representation for stigmatizing terms in the imbalanced set). Notably, the SFT model retained excellent performance on the balanced subset of the external dataset, mirroring the distribution used during training, further validating the robustness of the fine-tuning strategy.
Despite this advantage, the SFT model also demonstrated a notable trade-off in flexibility. During error analysis, the SFT model was more responsive to varied prompts, effectively reconsidering its classifications upon second review. However, this adaptability came at the cost of consistency, with the SFT model reversing its initial decisions more often than the in-context approach. Given that most of these reversals were ultimately found to be unnecessary upon expert review, this finding suggests that the SFT model’s flexibility might increase the risk of false-positive identification, particularly in ambiguous cases.
In contrast, the in-context learning approach, which relies on prompting without additional task-specific training, maintained more consistent decision-making during the error analysis phase, revising fewer initial classifications. This consistency may be advantageous in clinical applications where reliability is critical, although further evaluation across a broader range of clinical contexts is necessary to confirm this finding. Additionally, the in-context learning approach achieved competitive results without the resource-intensive requirements of custom training, highlighting its potential for rapid deployment in evolving clinical settings.
Nevertheless, the SFT model demonstrated a superior ability to account for context, as evidenced by its more stable performance on a challenging subset of test notes. This subset, which included terms that may or may not be stigmatizing depending on the context, revealed a sharper decline in performance for the in-context approach, reinforcing the SFT model’s robustness in distinguishing genuinely stigmatizing language from contextually appropriate use.
Overall, while the in-context learning approach offers a promising, low-cost alternative for rapidly aligning LLMs to evolving guidelines, the SFT approach was the more precise and context-aware option, particularly in high-stakes medical applications.
In a clinical setting, the approaches evaluated in this study could be deployed as real-time tools that alert clinicians when stigmatizing language appears in a draft note and, when possible, localize the specific text. Such functionality could reduce the risk of negatively influencing care delivery or eroding patient trust. Given their stronger performance, full-context and SFT approaches are best for this prospective use case. Full context provides more flexibility for documentation guidelines to change without the need for retraining. However, SFT provides the advantage of higher accuracy with periodic retraining on guideline shifts.
Here we outline limitations of this study. All experiments were performed utilizing LLMs with 8B parameters or less due to memory constraints. Furthermore, a few clinical notes exceeding the input token restrictions prevent accurate predictions for those notes. Finally, although our dataset contained over 70,000 examples for training and evaluation, only around 4000 of those examples were clinical notes that contained stigmatizing terms and were considered non-stigmatizing. Despite its high performance in internal and external validation, the SFT model trained could have benefited from more such examples.
Future work should explore hybrid strategies that combine the contextual strength of fine-tuning with the consistency of in-context methods, potentially improving both accuracy and interpretability in real-world deployments. Naturally, the next step involves building on findings from the identification of stigmatizing language and designing a system for correcting such language without modifying the meaning of the original text.
Methods
We used the MIMIC-III, a publicly available, de-identified database comprising over 2 million clinical notes from ICU stays at Beth Israel Deaconess Medical Center between 2001 and 201217. MIMIC-III is widely utilized in medical informatics research due to its scale, granularity, and real-world clinical context.
To identify candidate records for our analysis, we leveraged a set of substance use–related stigmatizing terms defined by NIDA5. Using this term list, we performed a keyword search across 2,083,180 progress notes within MIMIC-III17, extracting 42,641 notes that contained at least one potentially stigmatizing term (e.g., “addict,” “drunk”). 4089 of these notes are considered non-stigmatizing despite containing terms that are potentially stigmatizing. 34,463 notes were sampled from the progress notes no containing any potentially stigmatizing terms to create an evenly balanced dataset of both labels.
In the MIMIC-III17 corpus, clinical notes often exist in clusters corresponding to a single patient encounter (e.g., iterative modifications to the same note). To prevent data leakage across training, validation, and test sets, we first grouped notes by encounter ID, patient ID, and caregiver ID. These groups were then assigned to splits using a stratified 70-15-15 (train-validation-test) strategy, ensuring that no encounter was represented in more than one split and limit data leakage. Breakdown of the dataset in Tables 7 and 8.
To create the external validation dataset, we used a data corpus of 288,130 patient clinical notes from UW. This patient data spanned 2009–2020 from patient ages 18–86, and the external validation dataset only included notes that were from patients in the ICU. Since this dataset included PHI, all analyses with the external validation dataset took place in a HIPAA-secure computing environment. For the balanced external validation dataset, we down-sampled the full external validation dataset to 4144 notes that were evenly split between “yes” and “no” labels. Approaches were evaluated on both the full and balanced external validation datasets. Breakdown of the dataset in Table 8.
Hyperparameters explored for approaches investigated. RAG similarity metric was the metric utilized to determine the similarity between a clinical note and guideline entry and is only relevant for the RAG approach. Number of context entries is how many guideline entries are included in the prompt of the RAG approach. Context source is what resource the guideline entries are extracted from and relevant for RAG and In-context approaches. Finally, chunking segments of clinical notes. Hyperparameters for chunking include the size of the chunks and overlap between each chunk.
The primary outcome of this study was the automated identification of stigmatizing language in clinical documentation as a classification task. Reference labels were generated through a semi-manual annotation process designed to distinguish stigmatizing language from non-stigmatizing or contextually appropriate usage.
From the initial subset of 42,641 notes containing stigmatizing terms, each note was semi-manually reviewed and labeled as either stigmatizing or non-stigmatizing based on a set of predefined, context-aware criteria inspired by NIDA5. These criteria accounted for the presence of quotation marks, speaker attribution, and linguistic context. For example, the phrase “he feels ‘stinking drunk’ after…” includes the term “drunk,” but was not labeled as stigmatizing because the language was attributed to the patient language, not the provider. There was some manual review involved for inputs that did not meet all criteria outlined in Supplementary Fig. 2. This review was performed by an addiction specialist (ESA) who also provides training to clinicians on appropriate use of language and stigma.
This review process resulted in 38,552 notes labeled stigmatizing and 4089 notes labeled non-stigmatizing from manual review. To ensure class balance and enable more robust model training, we randomly sampled an additional 34,478 notes from the remainder of the MIMIC-III17 dataset that did not contain any stigmatizing terms or language. These notes were labeled as non-stigmatizing. Breakdown on the notes is summarized in Table 7.
The final dataset comprised three distinct categories: (1) stigmatizing, i.e., notes containing stigmatizing terms used in a stigmatizing context; (2) contextually non-stigmatizing, i.e., notes containing stigmatizing terms not used in a stigmatizing context; (3) non-stigmatizing, i.e., notes without any stigmatizing terms or language.
To ensure balanced representation across all stages of model development, we maintained consistent distributions of these categories across the training, validation, and test sets (70-15-15). An overview of the dataset development process is outlined in Supplementary Fig. 2. We followed the transparent reporting of a multi-variable model for individual prognosis or diagnosis (TRIPOD)-LLM guidelines, and the accompanying checklist is available in the Tripod LLM Checklist file.
The same pipeline for labeling the MIMIC-based dataset was applied to the external validation dataset for labeling (minus dataset splits as external validation was treated as a test set).
To evaluate the effectiveness of various strategies for detecting stigmatizing language in clinical text, we implemented and compared five approaches: a keyword-based baseline and four configurations leveraging an LLM (Supplementary Fig. 1). All LLM-based methods utilized the Meta-Llama-3-8B-Instruct model14, an open-source, instruction-tuned LLM released by Meta. This model supports a range of inference paradigms, including zero-shot prompting, RAG, in-context learning, and SFT.
Keyword-based baseline
The keyword-based method served as a baseline. Clinical notes were tokenized using whitespace, and each token was compared to a predefined list of stigmatizing terms derived from the NIDA Guidelines5. If a note contained any matching term (regardless of context), it was labeled as stigmatizing. This approach does not account for quotation usage or speaker attribution; therefore, it cannot differentiate between stigmatizing intent and neutral or patient-attributed mentions.
Zero-shot prompting
The zero-shot approach involved prompting the LLM with a direct question: “Does this note contain stigmatizing language in a substance use context?” The prompt was designed to elicit binary (“yes” or “no”) responses and was optimized using the validation set. This configuration provided no additional context or examples. Model outputs were converted to binary labels to facilitate evaluation. The sample prompt format is shown in Fig. 6.

When applying this prompt to the RAG approach, there are n context entries. When applying the in-context approach, all available context entries are provided. Finally, when applying to the Zero-Shot or SFT approach, there is no context subfield in the user portion of the prompt. System prompts prime the LLM to answer user prompts following certain directions. Hence the system prompt gives the LLM a scenario and an output format.
Retrieval-augmented generation (RAG)
The RAG configuration enhanced the base prompt with relevant contextual information drawn from external guideline sources. These sources included structured examples and definitions of stigmatizing language5,13. Each guideline entry was encoded into an embedding using the Meta-Llama-3-8B-Instruct model14. Input clinical notes were similarly embedded, and cosine similarity was computed to identify the top-n most relevant entries. These were appended to the prompt as contextual guidance. The number of retrieved entries, n, was treated as a hyperparameter and optimized using the validation set. This approach aimed to strike a balance between contextual specificity and prompt length. Prompt formatting is illustrated in Fig. 6.
In-context learning
This configuration provided the full set of guideline-derived context entries alongside the clinical note, without filtering based on similarity in the RAG approach. While less selective than RAG, this approach ensured comprehensive access to guidance examples. The same source materials were used as in the RAG setup.
Supervised fine-tuning (SFT)
In the SFT configuration, the Meta-Llama-3-8B-Instruct14 model was fine-tuned on the labeled dataset to specialize it for the task of stigmatizing language detection. The input format during inference matched that of the zero-shot configuration. Fine-tuning was performed using the LLaMA Factory18 implementation of Parameter-Efficient Fine-Tuning (PEFT) via Low-Rank Adaptation (LoRA).
Additionally, the DeepSpeed integration within LLaMA Factory18 was employed to accelerate training and optimize memory usage.
This section outlines key low-level design choices and optimization strategies implemented across our LLM-based methods, including the selection and structuring of external guidelines for prompt augmentation, input chunking for handling long notes, and the hyperparameter tuning process used to optimize each configuration. Meta-Llama-3-8B-Instruct14 was implemented for all LLM-based approaches. The final use for inference and training on 03/2025.
For both the RAG and In-Context approaches, we incorporated external clinical communication guidelines to provide the model with explicit definitions and examples of stigmatizing language. These guidelines were presented as structured tables in the source literature, with each entry describing a category of stigmatizing language alongside representative examples. Two distinct resources were used for context:
-
1.
NIDA Stigmatizing Language Guidelines5, which provide substance use–specific recommendations and include 14 table entries.
-
2.
A Systematic Review of Stigmatizing Language in Healthcare13, which offers broader guidance encompassing both substance use–related and general stigmatizing language. This resource contains 30 entries.
Each entry was processed into an embedding vector using the Meta-Llama-3-8B-Instruct14 model via Hugging Face’s feature-extraction pipeline15. These embeddings were stored and used to compute similarity scores with input clinical notes for the RAG method. For both RAG and In-Context prompting, the source of guideline entries (either5 or13) and the number of entries used were treated as tunable hyperparameters.
Due to token limitations inherent in transformer-based LLMs and the potentially long length of clinical progress notes, we implemented a chunking strategy for the Zero-Shot, RAG, and Full-Context configurations. Each note was divided into overlapping segments of length N tokens, with an overlap of M tokens between adjacent chunks. Each chunk was processed independently using the standard prompting schema (as shown in Fig. 6). If any chunk was classified as containing stigmatizing language, the entire note was labeled as stigmatizing. Both the chunk size, N, and overlap, M, were treated as hyperparameters. Chunking was evaluated against non-chunked versions of each method to assess performance trade-offs, particularly in the context of long clinical notes.
Hyperparameter tuning was performed using the validation set for each model configuration. The following hyperparameters were explored:
Not all hyperparameters were applicable to all methods; a full breakdown is provided in Table 9. For each approach, every combination of valid hyperparameters was evaluated on the validation set, and the best-performing configuration was selected and used for final model testing. The final selected hyperparameters are defined in Table 10. Hyperparameters used for fine-tuning are provided in Table 11.
All LLM-based approaches were designed to output a binary response (“yes” or “no”). Model outputs were parsed and mapped to integer labels: 1 for “yes” (stigmatizing), and 0 for “no” (non-stigmatizing). These labels were then used to compute evaluation metrics across the test dataset. Sample prompt shown in Fig. 6.
We assessed performance using scikit-learn19 accuracy and macro-averaged F1 score implementation, which accounts for performance across both classes irrespective of class imbalance. To estimate the variability of our metrics, we computed 95% confidence intervals via bootstrapping with 1000 resamples. Two sample student t-test were performed on bootstrapped F1 macro scores to establish significant differences in scores.
Evaluation was conducted on four subsets of the test data:
-
1.
Full Test Set – All clinical notes included in the held-out test split.
-
2.
Subset with Potentially Stigmatizing Terms – Only notes that contained one or more stigmatizing terms as defined by the NIDA Guidelines5.
-
3.
External Validation Full from UW
-
4.
External Validation Down-Sampled from UW
This second evaluation subset was included to assess model performance on the most challenging examples - those where potentially stigmatizing terms are present, but their contextual use may or may not be stigmatizing. This distinction is critical, as it tests the model’s ability to move beyond keyword detection to understand context and nuance in language.
The third and fourth subsets were datasets curated by UW and contained unseen progress notes by the approaches in training and/or hyperparameter selection phases. This was utilized to assess the generalizability of the approaches for the task of stigmatizing language detection. The full external validation set was utilized to assess how the approaches perform on detecting stigmatizing language at the native prevalence of such language. We also assessed the model on the down-sampled balanced subset to create a fair comparison between the MIMIC-derived dataset and external validation dataset, as this would allow us to understand if performance differences are solely due to the unseen nature of the external dataset.
Error analysis
To further characterize model behavior, we conducted a qualitative error analysis on the best-performing fine-tuned and best-performing non-fine-tuned models, as determined by validation set performance. Specifically, we focused on false positives: cases where the model incorrectly labeled non-stigmatizing notes as stigmatizing.
For each false positive instance, the model was prompted to explain its classification decision using a separate, explanatory prompt designed to elicit a natural language justification. This analysis served two purposes: (1) to evaluate the fluency and coherence of the model’s explanations, and (2) to determine whether the model’s errors reflected plausible misinterpretations or spurious correlations.
To maintain consistency with their original inference settings, the in-context learning configuration received the same contextual guidelines during explanation generation. The explanatory prompt used in this analysis is shown in Fig. 7.

When applying the in-context approach, all available context entries are provided. Finally, when applying to the Zero-Shot or SFT approach, there is no context subfield in the user portion of the prompt. System prompts prime the LLM to answer user prompts following certain directions. Hence the system prompt gives the LLM a scenario and an output format.
This analysis provided insight into the types of linguistic cues the models considered stigmatizing and highlighted potential areas in which fine-tuning improved contextual understanding or exacerbated overfitting. The error analyses were evaluated and verified by a board-certified Addiction Medicine specialist and trainer on how to avoid stigmatizing language in addiction care (ESA).
Data availability
The data that support the findings of this study are available from MIMIC17 but restrictions apply to the availability of these data, which were used under license for the current study, and so are not publicly available. Data are, however, available from the authors upon reasonable request and with permission of MIMIC17. Data will be distributed through PhysioNet after the paper is accepted. The underlying code for this study can be accessed via this link: https://github.com/rsethi21/clinicallyStigmatizingLanguage.
Code availability
The data that support the findings of this study are available from MIMIC17 but restrictions apply to the availability of these data, which were used under license for the current study, and so are not publicly available. Data are, however, available from the authors upon reasonable request and with permission of MIMIC17. Data will be distributed through PhysioNet after the paper is accepted. The underlying code for this study can be accessed via this link: https://github.com/rsethi21/clinicallyStigmatizingLanguage.
References
US Senate Committee on Health, Education, Labor, and Pensions. Implementing the 21st Century Cures Act: Making electronic health information available to patients and providers. US Government Publishing Office, Washington, DC (2021).
Kelly, J. F. & Westerhoff, C. M. Does it matter how we refer to individuals with substance-related conditions? A randomized study of two commonly used terms. Int. J. Drug Policy 21, 202–207 (2010).
Yang, Y. et al. Unmasking and quantifying racial bias of large language models in medical report generation. Commun. Med. 4, 176, https://doi.org/10.1038/s43856-024-00601-z (2024).
Afshar, M. et al. A novel playbook for pragmatic trial operations to monitor and evaluate ambient artificial intelligence in clinical practice. Preprint at https://doi.org/10.1101/2025.03.12.243154 (2025).
National Institutes of Health. Words matter – terms to use and avoid when talking about addiction. https://nida.nih.gov/nidamed-medical-health-professionals/health-professions-education/words-matter-terms-to-use-avoid-when-talking-about-addiction (Accessed 27 May 2025).
Weiner, S. G. et al. The incidence and disparities in use of stigmatizing language in clinical notes for patients with substance use disorder. J. Addict. Med. 17, 424–430 (2023).
Alley, D. E., Asomugha, C. I., Conway, P. H. & Sanghavi, D. M. Evaluating strategies for reducing health disparities by addressing the social determinants of health. Health Aff. 35, 1416–1423 (2016).
Barcelona, V. et al. Using natural language processing to identify stigmatizing language in labor and birth clinical notes. Matern. Child Health J. 28, 578–586, https://doi.org/10.1007/s10995-023-03772-2 (2023).
Himmelstein, G., Bates, D. & Zhou, L. Examination of stigmatizing language in the electronic health record. JAMA Netw. Open 5, e2144967 (2022).
Scroggins et al. Identifying stigmatizing and positive/preferred language in obstetric clinical notes using natural language processing. J. Am. Med. Inf. Assoc. 32, 308–317 (2025).
Harrigian, K. et al. Characterization of stigmatizing language in medical records. In Proc. 61st Annu Meet Assoc Comput Linguist (Vol. 2: Short Papers), 312–329 (Association for Computational Linguistics, 2023).
Wang, Y. et al. Stigmatizing language in large language models for alcohol and substance use disorders: a multimodel evaluation and prompt engineering approach. J. Addict. Med. (2025). |https://doi.org/10.1097/ADM.0000000000001536.
Healy, M. et al. How to reduce stigma and bias in clinical communication: a narrative review. J. Gen. Intern. Med. (2022). https://doi.org/10.1007/s11606-022-07830-0 (Accessed 27 May 2025).
AI@Meta. LLaMA 3 model card. https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md (Accessed 27 May 2025).
Wolf, T. et al. Transformers: State-of-the-art natural language processing. In: Proc 2020 Conf Empir Methods Nat Lang Process: Syst Demonstrations, 38–45. Association for Computational Linguistics (2020).
Paszke, A. et al. PyTorch: an imperative style, high-performance deep learning library. Adv. Neural. Inf. Process. Syst. 32, (2019).
Johnson, A., Pollard, T. & Mark, R. MIMIC-III clinical database (version 1.4). https://physionet.org/content/mimiciii/1.4/ (Accessed 27 May 2025).
Zheng, Y. et al. LLaMAFactory: Unified efficient fine-tuning of 100+ language models. In Proc 62nd Annu Meet Assoc Comput Linguist (Association for Computational Linguistics, 2024).
Pedregosa, F. et al. Scikit-learn: machine learning in Python. J. Mach. Learn Res. 12, 2825–2830 (2011).
Acknowledgements
This work was funded by National Institutes of Health (NIH) R01LM012973, R01DA051464. This funder played no role in study design, data collection, analysis and interpretation of data, or the writing of this manuscript. This work was also funded by PCORI ME-2024C2-37484. All statements in this report, including its findings and conclusions, are solely those of the authors and do not necessarily represent the view of the Patient-Centered Outcomes Research Institute (PCORI), its Board of Governors or Methodology Committee.
Author information
Authors and Affiliations
Contributions
R Sethi preprocessed train, validation, and test datasets. R Sethi performed LLM training and inference, LLM approach engineering, prompt/context engineering, LLM evaluation (performance and error analysis). R Sethi drafted the manuscript. J Caskey engineered dataset labeling process and labeled train, validation, test, and external validation datasets. J Caskey and A Mayampurath ran external validation. ES Afshar analyzed false positives for error analysis. D D Dligach and M Afshar provided feedback on LLM approach engineering, evaluation, and manuscript editing. All authors (R Sethi, J Caskey, Y Gao, Mm Churpek, TA Miller, A Mayampurath, ES Afshar, M Afshar, D Dligach) read and reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sethi, R., Caskey, J., Gao, Y. et al. Detecting stigmatizing language in clinical notes with large language models for addiction care. npj Health Syst. 3, 15 (2026). https://doi.org/10.1038/s44401-026-00069-0
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s44401-026-00069-0
