
Abstract
Silent speech interfaces decode speech intent without audible sound, enabling communication in settings where voice is inaccessible, or for individuals with speech impairments. Here we examine how sensing technologies shape the capabilities of silent speech interfaces. We compare off-, on- and in-body sensing modalities, identifying how proximity, coupling stability and invasiveness govern signal fidelity, robustness and user comfort. We highlight key trends, including the rise of flexible bioelectronics, multimodal sensor fusion for artefact resilience, and the growing role of edge artificial intelligence in real-time, low-power decoding. We show that on-body systems currently offer the best balance between accuracy and deployability, whereas in-body approaches provide unmatched neural access for individuals with complete loss of articulation. Looking ahead, advances in multimodal sensing, embedded intelligence and closed-loop architectures are poised to expand silent communication across rehabilitation, daily interaction and human–machine interfaces.
Similar content being viewed by others

Main
Silent speech interfaces (SSIs) aim to unlock a new dimension of human communication by decoding speech-related intent without relying on vocalized sound1,2. Rather than viewing speech solely as an audible output, these systems conceptualize it as a complex neuromotor process that originates in the brain, propagates through articulatory musculature and can be sensed and reconstructed through a variety of physiological pathways3. This transformative class of technologies redefines how individuals interact with machines and with each other, offering fundamentally new modes of expression in contexts where acoustic speech is inaccessible, impractical or undesired. From enabling silent interaction in noise-sensitive or privacy-critical environments to restoring communication for individuals affected by stroke, neurodegenerative disease or laryngectomy, SSIs address both everyday and medically underserved needs across society2,4.
At the core of any SSI lies the sensing interface, which governs which signal can be accessed, how reliably it can be recorded and under which constraints it can be deployed. Sensing strategies fall into three major categories—off body, on body and in body—defined not solely by physical placement, but also by the nature and stability of coupling between the sensor and the physiological source of speech-related information (Fig. 1a). Off-body interfaces, such as optical and acoustic sensors, prioritize user comfort and deployability through non-contact or loosely coupled approaches, but are limited by indirect or distal coupling to the articulatory system5,6. On-body sensors, including electromyography (EMG), strain and inertial modules, offer a closer and more stable connection to neuromuscular activity through tight skin contact, but introduce wearability considerations7,8,9. In-body neural interfaces, such as electrocorticography (ECoG) or intracortical microelectrodes, provide direct access to the brain’s speech-generating regions and enable decoding even in the complete absence of peripheral muscle control. However, this advantage comes at the cost of invasiveness and a need for custom-designed solutions or intervention procedures due to patient diversity in their anatomical structure, pathological conditions, biological responses and functional goals, alongside ethical constraints10,11.

a, Sensor modalities in SSIs can be categorized, by the proximity of signal acquisition to the human body, as either off-body device interfaces (for example, optical cameras or ultrasound probes), on-body sensor interfaces (for example, surface EMG, strain sensors, EEG and IMUs) or in-body neural interfaces (for example, ECoG, sEEG or MEAs). These categories represent a continuum between user comfort and signal specificity, ranging from general-purpose wearable devices to highly personalized clinical systems. b, Representative deployment examples for each category, aligned with the same taxonomy: off body (smartphones, earbuds and smart glasses), on body (facial patch/tattoo, choker/throat patch, mask and EEG hat) and in body (ECoG, sEEG and MEA implants). The asterisks denote technologies with clinical validation.
These sensing modalities present diverse form factors tailored to different user contexts (Fig. 1b). Off-body sensing has been integrated into earbuds, mobile phones and smart glasses, offering non-contact solutions with high comfort but lower signal specificity. On-body approaches, leveraging biomechanical and bioelectrical sensors, are implemented in smart chokers, facial patches, masks and head-mounted wearables, balancing wearability with stable neuromuscular access. In-body strategies are represented by invasive brain–computer interfaces, such as ECoG grids and intracortical electrodes, some of which have already been applied in clinical speech decoding trials.
Overall, these categories delineate trade-offs among comfort, invasiveness and system complexity. Signal fidelity introduces a further dimension: while not dictated by proximity alone, it depends on modality, device properties (for example, impedance and bandwidth), placement stability and downstream processing. Yet, a broad trend remains—closer interfaces to articulatory or neural sources generally yield higher fidelity, manifested as greater information throughput and error resilience under realistic use. These gradients also map onto application domains: off-body sensors support general-purpose interaction (such as silent command input or privacy-preserving communication); on-body sensors enable early-stage restoration of speech in patients with residual motor function; and in-body systems remain the only current method for decoding continuous, near-real-time speech in completely locked-in individuals.
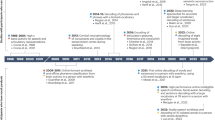
The timeline of the development of SSI technologies mirrors this stratification (Fig. 2). Early studies explored both camera-based lipreading and surface EMG12,13, with intracortical recording of speech-related brain activity also beginning to show feasibility in the late 1990s14. Since 2020, the field has witnessed the proliferation of flexible sensing materials, integration with consumer electronics, and initial clinical deployments of wearable and implanted systems. Across modalities, advances in spatial and temporal resolution, signal robustness and integration with learning algorithms are reshaping what is feasible (Table 1).

Presented is a timeline of SSI innovations, from the earliest to the latest: EMG-based vowel recognition (1985)12, camera-based lipreading (1985)13, EEG word decoding (1997)14, intracortical microelectrodes (1998)81, ECoG speech decoding (2004)52, ultrasound imaging (2004)82, depth cameras (2012)83, ultra-wideband (UWB) radar (2016)84, camera SSIs for mobile devices (2018)85, full-sentence decoding via ECoG (2019)86, flexible EMG sensors (2020)7, wearable strain sensors (2021)87, TENG-based lipreading (2022)33, flexible strain sensors (2022)8, IMU-based decoding (2023)30 and magnetoelastic silent speech sensors (2024)88. Each milestone is categorized as off body (red), on body (yellow) or in body (blue) based on the specific sensing implementation used in the corresponding silent speech study, rather than the full spectrum of technological variants. The asterisks denote technologies with clinical validation.
As silent speech technologies approach a translational inflection point, a sensing-led perspective becomes essential to reframe system capability, usability and societal reach. The field is rapidly expanding with the introduction of novel sensor modalities, advances in flexible bioelectronics, and early-stage clinical studies. However, it still lacks a comprehensive framework that integrates these developments through the lens of sensing. By positioning sensing as both a constraint and a catalyst, this Review redefines the foundations of silent speech systems. Trade-offs in comfort, fidelity and invasiveness are not just technical considerations but strategic levers that shape adoption and impact.
We classify existing approaches into off-, on- and in-body sensing strategies, each presenting distinct trade-offs in signal fidelity, comfort and clinical relevance. We compare sensor modalities across spatial and temporal resolution, invasiveness and integration potential and trace their development from early vision-based systems to recent advances in flexible bioelectronics and neural interfaces. Finally, we outline emerging directions in sensor–artificial intelligence (AI) integration, real-time decoding and closed-loop systems that are poised to transform communication, rehabilitation and human–machine interaction at scale.
SSIs using off-body sensors
Off-body sensors enable non-intrusive SSIs by capturing articulatory and physiological signals without direct skin contact. These systems typically rely on optical and acoustic modalities integrated into external devices such as cameras, smartphones, glasses or headsets. Their appeal lies in high user comfort, ease of deployment and compatibility with commodity hardware, making them attractive for scalable and low-burden interaction. However, signal quality in off-body sensing is often susceptible to environmental conditions, such as lighting variation or acoustic interference, and may suffer from indirect coupling to the user’s intent.
Recent advances have broadened the landscape of off-body silent speech systems, transitioning from laboratory-grade setups to increasingly wearable and context-aware platforms. For instance, optical systems have evolved from static RGB cameras to mobile and multi-angle vision modules, whereas acoustic approaches have moved beyond medical ultrasound towards integrated earbud and headphone solutions that leverage subtle biomechanical cues. These innovations mark an important step towards accessible, privacy-preserving and device-integrated SSIs, but challenges remain in achieving consistent performance across diverse real-world settings and user profiles.
Optical sensing
Optical sensing enables silent speech input by visually capturing articulatory movements, including lip and facial dynamics, through off-body modalities. The most straightforward approach involves RGB cameras, which offer high-resolution visual data for articulator tracking5,15,16. However, this method is inherently sensitive to occlusion, head pose variation and lighting conditions and typically requires a fixed setup, limiting portability and real-world applicability.
To improve deployment flexibility, optical sensing has been integrated into mobile platforms. Front-facing smartphone cameras enable real-time interaction without auxiliary hardware (Fig. 3a)17,18,19, whereas depth-sensing modules enhance robustness against environmental variation by capturing three-dimensional motion profiles, achieving 91.3% within-user accuracy and 74.9% cross-user accuracy on a 30-command vocabulary20. Nevertheless, both solutions remain constrained by frontal positioning and the instability of handheld use.

a–i, Schematics illustrating key sensing technologies enabling silent speech decoding, categorized by sensing principle: optical sensing (a; a smartphone-based front camera detects articulatory motion, such as lip and jaw movements); ultrasonic sensing (b; an ultrasound imaging probe beneath the jaw visualizes tongue motion in real time); IMU sensing (c; IMUs distributed at the head, lip and chin track multi-point facial kinematics during articulation); triboelectric sensing (d; self-powered wearable sensors detect facial motion through contact electrification); EMG (e; tattoo-like epidermal electrodes acquire facial myopotentials associated with silent articulation); strain sensing (f; textile strain sensors embedded in a smart choker capture throat deformation patterns); EEG (g; in-ear conformal bioelectronics measure brain activity associated with speech imagery); ECoG (h; implanted cortical arrays decode neural activity from speech-generating regions in patients with brainstem injury); and MEA (i; intracortical electrodes implanted in the motor cortex record neural activity associated with fine motor intention, enabling high-resolution decoding of attempted handwriting and speech imagery). PI, polyimmide; PVC, polyvinyl chloride. Panels adapted from: d, ref. 33, CC BY 4.0; e, ref. 36, CC BY 4.0; f, ref. 42, CC BY 4.0; g, ref. 47, CC BY 4.0.
To overcome these limitations, alternative camera placements have been explored. Side-21 and chin-mounted22 optical systems provide more stable tracking and allow for more natural user movements during interaction, with reported performance exceeding 90% accuracy on vocabularies of approximately 50 words. Although challenges remain in ensuring consistent performance across diverse usage scenarios, optical sensing remains a user-friendly and hardware-light strategy that is particularly suited for applications prioritizing convenience and accessibility.
Acoustic sensing
Acoustic sensing has gained marked traction in SSIs due to its off-body implementation, strong resilience to occlusion and poor lighting, and inherent advantages for preserving user privacy. Although conventional speech decoding relies on external microphones to capture audible voice signals, such methods fall outside the scope of SSIs, which aim to decode speech intent in the absence of vocalized sound. One early-studied silent approach utilizes ultrasound imaging, wherein probes placed beneath the jaw capture fine-grained tongue kinematics with high spatial fidelity (Fig. 3b)23. This approach achieves a 3.6-s decoding speed with ~33% word error rate (WER) on vocabularies of several dozen commands, but its dependence on specialized imaging hardware restricts its practicality for daily use.
To circumvent such hardware constraints, several strategies have turned to commodity devices. Smartphone-based methods, for instance, emit inaudible acoustic signals via built-in speakers and analyse their reflections using onboard microphones24,25,26. The reflected echoes encode articulatory movements of the lips and tongue, allowing the systems to reach >90% word-level accuracy and <10% sentence-level WER across vocabularies spanning from simple commands to short conversational sentences. These systems offer a hardware-light solution, yet often face performance degradation in noisy or dynamic environments.
To enhance robustness and integrate seamlessly into everyday settings, researchers have embedded acoustic sensors into wearable devices. Glasses-mounted systems detect perioral skin deformation27, earbuds capture air-pressure variations within the ear canal6,28 and headphones monitor temporomandibular joint motion29. Each configuration taps into distinct biomechanical cues, collectively enabling silent command recognition with minimal user effort and improved tolerance to ambient noise. Reported implementations have repeatedly achieved >90% accuracy on vocabularies of more than 100 words, delivering performance comparable to smartphone-based methods while offering substantially greater portability. Together, these diverse implementations underscore the versatility of acoustic sensing and highlight its growing relevance as a scalable, non-intrusive pathway for silent speech decoding.
Developmental trends and outlook
Off-body sensing has evolved from static, laboratory-bound cameras and ultrasound probes to wearable and device-integrated platforms such as smartphones, glasses and earbuds. Reported accuracies above 90% demonstrate feasibility, yet performance remains fragile under real-world lighting, acoustic noise and inter-user variability. Future progress hinges on environmental robustness, cross-user adaptation and edge AI integration, and socially acceptable and privacy-preserving form factors are likely to define scalability. Together, these directions frame off-body systems as the most accessible entry point for widespread SSI adoption.
SSIs using on-body sensors
Although off-body sensors offer high user comfort and ease of integration, their indirect coupling to physiological signals and sensitivity to environmental noise often limit decoding accuracy in unconstrained scenarios. To address these limitations, on-body sensing has emerged as a compelling alternative, providing closer physical proximity to the articulatory system and enabling more direct access to neuromuscular or biomechanical activity. By attaching directly to the body surface through either flexible materials or compact rigid modules, on-body sensors can achieve motion-resolved and often higher-fidelity capture of speech-related signals, even under motion, occlusion or low-light conditions.
This improvement in signal quality comes with trade-offs. Compared with off-body methods, on-body systems require physical contact, which introduces considerations around comfort, attachment stability and long-term usability. Nevertheless, these challenges are often outweighed by the benefits in scenarios that demand precision and robustness. On-body sensors have therefore gained traction not only in silent communication for daily use but also in clinical contexts, where they assist individuals with impaired speech. These systems have been explored in the decoding of residual muscle activity in patients with dysarthria, laryngectomy or neurodegenerative diseases, offering an accessible and responsive interface where conventional acoustic speech is unavailable. The enhanced signal access and application versatility position on-body sensing as a critical component in the development of both consumer and healthcare-grade SSIs.
Inertial measurement unit sensing
Inertial measurement units (IMUs), long used in gait and gesture recognition, have only recently gained traction for SSIs due to difficulty resolving fine-scale articulatory kinematics amid head motion. Early systems used facial accelerometer arrays to detect speech-induced vibrations, achieving high accuracy (94.65 ± 2.54% in classifying 40 English words) but suffering from head-motion artefacts that constrained real-world use30. Differential sensing paradigms were developed to tackle this challenge, where signals from articulator-mounted IMUs are fused with reference sensors on stable regions such as the forehead or ears to isolate speech-specific motion (Fig. 3c), achieving an average accuracy of 92% across seven users for actual continuous lip-speech recognition on 93 English sentences9. The method offers strong environmental robustness, with immunity to lighting, occlusion and noise, and supports ultra-low-power, consumer-ready form factors. Despite sacrificing spatial specificity compared with bioelectric methods, their motion resilience and wearability position IMUs as scalable solutions for mobile SSI deployment.
Triboelectric nanogenerator sensing
Triboelectric nanogenerators (TENGs) convert mechanical deformation into electrical signals via contact electrification and electrostatic induction. Their self-powered, low-cost and flexible design makes them attractive for wearable sensing31,32. In SSIs, TENGs enable energy-autonomous detection of articulatory motion. Recent studies have shown that soft, skin-mounted TENG arrays can capture lip dynamics and decode phrases using machine learning (Fig. 3d), yielding an accuracy of 94.5% on 20 words33. Compared with optical methods, which depend on ambient illumination, TENGs provide greater privacy and robustness in variable environments. They can also be seamlessly embedded into daily wear, such as face masks or patches, making them unobtrusive for long-term use. However, their outputs depend on tribo-charge state and contact regime and are sensitive to humidity, sweat and material ageing. Combined with the ultra-high source impedance and load-dependent readout, this leads to non-stationarity and session-to-session gain drift that often requires charge management, high-impedance front ends and periodic calibration.
EMG sensing
Surface EMG provides non-invasive direct access to muscle activation underlying articulation, enabling robust decoding of speech intent in silent contexts. Compared with inertial or force-based methods, EMG captures signals at the neuromuscular source, offering higher specificity but requiring stable skin contact and being susceptible to motion artefacts34,35. Early systems used rigid electrodes and benchtop acquisition setups, limiting usability. Recent advances in conformal bioelectronics have addressed this. Tattoo-like EMG sensors affixed to facial muscles enabled high-accuracy word-level decoding under dynamic, real-world conditions, recognizing up to 110 daily-use words with an average accuracy of 92.6% (Fig. 3e)36. Additionally, textile-based EMG electrodes integrated into headphone earmuffs captured neuromuscular activity from periauricular and jaw-adjacent muscles and leveraged a multi-channel adaptive decoding network to dynamically weight signal quality. This setup demonstrated high usability and robustness in mobile contexts, achieving 96% accuracy on ten commonly used voice-free control words37. Together, these studies exemplify a convergence of high-fidelity sensing with ergonomic form factors.
Strain sensing
Strain sensors capture subtle deformations of facial and laryngeal tissue during articulation, providing a direct mechanical interface between user intent and silent speech decoding. Foundational work in wearable strain sensors established the feasibility of stretchable, skin-conformal materials for physiological monitoring across dynamic body surfaces38,39. Translating this concept to SSI, researchers have explored a range of material strategies to balance comfort, signal stability and deployment readiness.
Early demonstrations using ultrathin silicon gauges achieved high sensitivity and fast relaxation times, enabling robust word-level decoding under skin strain (87.53% accuracy among 100 words)8. Building on bioinspired mechanisms, ionic hydrogel sensors mimicked mechanoreceptor transduction to detect throat vibrations without requiring electrical contact, achieving an average accuracy of 95% in the 26-instruction test40. Hybrid systems integrating facial deformation and subcutaneous vibration cues revealed that combined motion signatures carry rich, decodable linguistic information even in noisy settings, demonstrating an average accuracy of 99.05% in classifying basic speech elements (phonemes, tones and words)41.
Textile-based strain sensors further advanced the field by embedding high-resolution sensing into wearable form factors optimized for daily use (Fig. 3f), achieving 95.25% accuracy on 20 frequently used English words42. These systems have evolved from controlled experiments to real-world trials in patients who have suffered strokes, where strain signals were leveraged not only for word decoding but also for capturing emotional context, achieving a 4.2% WER and improving daily communication satisfaction by 55% in five patients recovering from strokes43. Across these developments, strain sensing highlights how material and structural innovations can directly shape the usability and expressiveness of silent speech technologies.
Electroencephalography sensing
Electroencephalography (EEG) enables non-invasive access to cortical activity via scalp or ear-adjacent electrodes, offering a wearable, surface-based approach to capture neural correlates of speech intent upstream of articulation. However, EEG signals are inherently noisy and spatially diffuse, posing major challenges for speech decoding. Foundational studies demonstrated that event-related potentials44 and modulated sensorimotor rhythms45 can support basic intent detection, laying the groundwork for EEG-based communication.
Recent efforts have redefined the role of EEG in silent speech decoding by innovating at the sensor and system levels. Ear-centred46 and in-ear EEG devices (Fig. 3g)47 have matched traditional scalp setups in decoding accuracy while enhancing comfort and form factor. Meanwhile, to mitigate physiological and motion artefact limitations48, recent studies have explored integrated multimodal platforms combining EEG with additional modalities49,50. By providing complementary spatial and physiological signals (for example, inertial, haemodynamic or muscular activity), these systems enable artefact identification and weighting in decoding pipelines, thereby improving robustness. Moving beyond command classification, large-scale studies now leverage contrastive learning to align EEG signals with deep speech representations51, enabling zero-shot decoding of perceived sentences without retraining on specific vocabularies, with an average accuracy of ~41% (up to 80% in some individuals) over more than 1,000 candidate segments.
Although EEG is constrained by low signal fidelity and high intersubject variability, its distinct advantage lies in the ability to access pre-articulatory neural activity, offering a uniquely scalable non-invasive modality for early-stage intent decoding. Although current accuracies remain modest compared with peripheral sensing methods, ongoing advances in sensor design and learning architectures highlight the potential of EEG to enable predictive and generalized SSI systems.
Developmental trends and outlook
On-body sensors have evolved from rigid electrodes to soft, skin-conformal bioelectronics and energy-harvesting textiles, aiming to balance signal fidelity with everyday wearability. However, this proximity introduces vulnerability to motion artefacts, skin impedance drift and long-term comfort challenges. Recent progress increasingly hinges on functionally complementary multimodal fusion. For example, EMG signals capture neuromuscular intent but are motion sensitive, whereas strain sensors track tissue deformation and sensor displacement. Fusing the two allows decoding models to contextualize signal quality, improving robustness under movement.
This shift reframes sensor fusion not as redundancy, but as a deliberate strategy to resolve the fidelity–stability trade-off inherent in wearable decoding. Combined with advances in stretchable substrates and low-power design, on-body platforms are positioned as the most deployable SSI solution, balancing accuracy with resilience in real-world conditions.
SSIs using in-body sensors
In-body sensing offers the most direct access to the neural substrates of speech, capturing activity from cortical regions responsible for planning and articulation. By implanting electrodes either onto the brain surface or within its depths, these systems bypass peripheral musculature and enable speech decoding in individuals who have lost all voluntary motor output. They are uniquely positioned to support communication in cases of locked-in syndrome or advanced neurodegeneration, where no other interface is viable.
Although in-body approaches provide exceptional signal fidelity and decoding precision, they require invasive procedures, patient-specific adaptation and long-term clinical support. As such, their application remains limited to research settings and highly selected clinical scenarios. Nevertheless, recent progress in electrode miniaturization, signal processing and neurosurgical techniques has expanded the scope of implanted speech interfaces. These systems not only advance assistive communication but also serve as platforms for probing the neural basis of language and developing future brain-centred interaction technologies.
ECoG sensing
ECoG acquires high-fidelity local field potentials via subdural electrode grids placed over cortical speech regions. Compared with non-invasive EEG, ECoG offers superior spatial resolution and bandwidth with reduced signal attenuation, enabling direct access to the neural substrates of articulation52,53. Its semi-invasive nature positions it between scalp-based and intracortical approaches, making it a clinically viable modality for patients with severe motor speech impairments.
Over the past decade, ECoG-based silent speech systems have progressed from decoding isolated phonemes to reconstructing full sentences in real time54,55. Further evolution reflects a broader shift from offline, trial-based studies to continuous, streaming paradigms that prioritize naturalistic communication (Fig. 3h), achieving large-vocabulary decoding at up to 78 words per minute with ~25% WER56 and enabling online fluent synthesis in 80-ms increments57. Recent efforts emphasize low-latency, high-intelligibility speech synthesis directly from neural activity, marking a transition towards closed-loop brain-to-speech systems. In parallel, the development of high-density micro-electrocorticography arrays has enabled finer spatial resolution and improved signal fidelity, reinforcing a device-level trend towards more precise, information-rich neural interfaces58. As decoding architectures mature and deployment barriers narrow, ECoG stands as the most clinically advanced in-body interface for restoring communication in individuals with profound speech loss.
Stereo-EEG sensing
Stereo-EEG (sEEG) records intracranial neural activity via depth electrodes implanted in cortical and subcortical regions, offering three-dimensional spatial coverage. Compared with ECoG, which requires craniotomy to place grid or strip electrodes directly on the cortical surface, sEEG electrodes are introduced through stereotactically guided burr holes. This minimally invasive surgical approach generally carries lower perioperative morbidity, despite the deeper implantation sites59,60. This accessibility to deeper structures makes sEEG particularly valuable for capturing both cortical and subcortical elements of speech planning and tone modulation.
Recent advances have enhanced sEEG as a sensing modality by improving both stimulation and recording strategies. Intermediate-frequency protocols increase mapping sensitivity while reducing afterdischarges, enabling more stable and spatially specific probing of language circuits61. Complementing these protocol-level refinements, the release of structured sEEG datasets capturing vocalized, mimed and imagined speech provides a richer basis for modelling the sensor-to-signal relationship in diverse linguistic contexts62. Together, these developments position sEEG as a minimally invasive and increasingly optimized sensing platform for speech decoding.
Microelectrode array sensing
Intracortical microelectrode arrays (MEAs) offer direct access to the spiking activity of neurons, providing unparalleled temporal resolution and spatial specificity for speech decoding63,64. By penetrating cortical tissue, these sensors can capture fine-scale dynamics of speech motor planning that are not accessible through surface-level recordings.
Initial demonstrations showed that MEAs could support phoneme-level decoding in open-loop paradigms, laying the groundwork for intracortical speech interfaces65. More recently, their integration into closed-loop systems has enabled real-time synthesis of intelligible words and phrases in individuals with severe speech loss (Fig. 3i)66. These advances mark a shift from offline analysis to continuous decoding pipelines aimed at restoring functional communication.
Despite their exceptional signal fidelity, MEAs face practical limitations including surgical invasiveness, long-term biocompatibility and signal degradation over time. Nevertheless, they remain the benchmark for understanding the upper bounds of neural resolution in brain-to-speech interfaces.
Developmental trends and outlook
In-body interfaces represent the frontier of SSI potential, offering direct access to cortical speech networks and enabling decoding capabilities that are fundamentally beyond the reach of peripheral sensing. Although current systems have yet to match the real-time accuracy of advanced on-body solutions, particularly in healthy users, their unique strength lies in restoring communication when peripheral musculature is no longer viable. This transformative promise, however, is inseparable from profound biological and ethical tensions. Biologically, craniotomy, long-term biocompatibility challenges and foreign-body responses threaten signal stability, and the absence of fully implantable wireless systems increases infection risk and hinders long-term deployment. Ethically, these interfaces engage directly with the neural substrates of language, raising unprecedented concerns around mental privacy, data ownership and informed consent for the continuous decoding of inner speech. Far from ancillary, these risks will fundamentally shape the pace, scope and social acceptability of in-body SSI technologies.
Looking ahead, progress in minimally invasive electrodes, fully sealed wireless closed-loop platforms and adaptive learning architectures may help to reconcile the demands of high decoding fidelity with the requirements of long-term biological safety. At the same time, robust governance frameworks addressing privacy, data rights and user agency will be essential to uphold ethical standards and ensure responsible deployment. Taken together, these technological and ethical developments may allow in-body systems to serve not only as clinical tools for individuals with severe impairments, but also as scientific instruments for exploring and interacting with the neural mechanisms underlying human language.
Conclusions
SSIs are reshaping the landscape of human communication by enabling speech decoding without audible output. This Review examines the field through the lens of sensing technologies, revealing how sensing configurations fundamentally shape system fidelity, comfort and usability. By categorizing SSIs into off-, on- and in-body modalities, we have highlighted the trade-offs that govern their deployment—from ambient, non-contact interaction to implantable neuroprosthetics.
These sensing choices are not merely technical parameters but strategic levers that determine who can benefit, where systems can operate and how effectively silent speech can be translated into actionable outputs. With the convergence of flexible electronics, neuromuscular decoding and intelligent feedback, SSIs are emerging not only as assistive tools for individuals with speech impairments but also as scalable platforms for future human–machine interaction.
Yet, sensing alone does not determine system capability. As SSIs transition towards real-world deployment, the co-evolution of sensing, embedded hardware and learning algorithms is becoming increasingly central. In this context, sensing acts not only as an input modality, but as the foundation of tightly coupled signal processing pipelines that enable responsive, low-latency interaction.
Signals acquired from off-, on- or in-body sensors must be routed through analogue front ends, microcontrollers and wireless modules. Modern SSI systems increasingly incorporate edge AI processors that support real-time, low-power inference directly on wearable or mobile platforms, minimizing latency and safeguarding privacy67. This hardware–algorithm co-design paradigm underpins recent advances, including throat-mounted acoustic and biomechanical sensors that drive robotic control via silent commands68.
Figure 4 provides a conceptual overview of this integrated pipeline—from acquisition to decoding to feedback. The captured signals span optical, acoustic, biomechanical and bioelectrical domains, each offering distinct trade-offs between fidelity and comfort. For instance, wearable ultrasonic sensors and strain gauges have demonstrated strong signal-to-noise ratios and resilience to ambient interference8,24, in some cases outperforming surface EMG in specificity7. These signals are standardized through pre-processing pipelines and increasingly fused across modalities to improve robustness across users and settings.

SSIs follow a multi-stage pipeline beginning with the acquisition of articulatory or neural signals via off-, on- or in-body sensors. These signals are first conditioned by hardware circuits comprising analogue front ends (AFEs), microcontrollers (MCUs), wireless modules (such as Bluetooth or WiFi) and power and memory units. Although most systems transmit pre-processed data to external devices for inference, a subset integrates edge AI processors to enable local, low-latency decoding. The captured signals span optical, acoustic, biomechanical and bioelectrical domains, each reflecting distinct aspects of speech-related activity. Decoding is achieved through algorithmic frameworks, including deep learning, transfer learning and contrastive learning, enabling context-aware interpretation across users and settings. The outputs are translated into feedback modalities, such as synthesized speech, robotic actions or haptic cues, forming a closed-loop interface for assistive and interactive applications.
The decoding stage is primarily driven by lightweight deep learning models—convolutional and transformer-based architectures that support near-real-time performance on embedded systems42,69. Transfer learning and few-shot personalization enable rapid adaptation to new vocabularies or users11,70, whereas contrastive and cross-modal learning increasingly bridge silent and vocal speech domains using large-scale audio datasets17,51. These algorithmic advances substantially reduce data requirements and enhance generalization.
The final outputs of SSIs range from text and synthesized speech to direct robotic or digital commands43,68. Real-time feedback, such as haptic cues or voice synthesis, is crucial for enabling closed-loop, interactive communication. Although challenges remain in generalization, energy efficiency and vocabulary breadth, the synergistic development of sensing hardware, embedded inference and learning architectures is rapidly moving SSIs towards widespread real-world application.
Looking ahead, the next wave of hardware advances will centre on sensor evolution, miniaturization and integration. Flexible and stretchable materials will continue to transform sensors into conformal, skin-like interfaces capable of robust acquisition under motion and daily wear71,72,73. The emergence of hybrid systems, merging bioelectrical, biomechanical and acoustic domains, will offer richer signal streams and redundancy to counteract artefacts and variability74. Real-time decoding will be increasingly enabled by edge AI processors embedded in wearable circuits, unlocking low-latency inference and feedback without cloud reliance75. These developments are complemented by ultra-low-power design and energy-autonomous sensors such as TENGs, paving the way for continuous, passive sensing ecosystems. As sensing hardware becomes more discreet, adaptive and multimodal, it will not only reshape how silent speech is captured, but enlarge where and by whom it can be used.
Beyond hardware, the software layer of SSIs is entering a new era driven by embodied intelligence and large-scale models. Algorithmically, we anticipate a shift from task-specific neural networks towards multimodal foundation models that integrate audio, EMG, strain and even neural data through shared embeddings and attention mechanisms76. This will enable cross-modal learning, few-shot personalization and generalization across vocabularies and users. Embedded inference will increasingly adopt neuromorphic or event-driven architectures, optimizing latency and energy consumption for real-world use77,78. Furthermore, SSIs are positioned to serve as a key interface for human body digital twins, where physiological signals are continuously mapped onto real-time avatars for speech, emotion and motor intent, enabling closed-loop interaction across healthcare, social robotics and communication prosthetics79. As algorithms evolve to reflect not just learned data but the embodied dynamics of human expression, the boundary between input and interface will blur.
In the broader societal context, the future of SSIs extends far beyond clinical assistive technology. As silent interfaces become embedded in daily life, supporting unobtrusive interaction in public spaces, privacy-preserving commands in shared environments and silent collaboration in noisy or sensitive contexts, they will extend the boundary of human–human and human–machine communication. More importantly, for individuals with profound speech or motor disabilities, SSIs might offer not just a tool but a restoration of agency and identity, helping to alleviate psychological distress and foster more effective rehabilitation80. By grounding these technologies in inclusive design and responsible innovation, we can ensure that silent speech systems contribute not only to technical progress but also to human dignity, empowerment and equitable access to communication.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
References
Denby, B. et al. Silent speech interfaces. Speech Commun. 52, 270–287 (2010). This comprehensive review formalizes SSIs as a research field.
Gonzalez-Lopez, J. A. et al. Silent speech interfaces for speech restoration: a review. IEEE Access 8, 177995–178021 (2020).
Guenther, F. H. et al. in Speech Motor Control in Normal and Disordered Speech 29–49 (Oxford Univ. Press, 2004).
Silva, A. B. et al. The speech neuroprosthesis. Nat. Rev. Neurosci. 25, 473–492 (2024).
Afouras, T. et al. Deep audio-visual speech recognition. IEEE Trans. Pattern Anal. Mach. Intell. 44, 8717–8727 (2022).
Jin, Y. et al. EarCommand: “hearing” your silent speech commands in ear. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 6, 1–28 (2022).
Liu, H. et al. An epidermal sEMG tattoo-like patch as a new human–machine interface for patients with loss of voice. Microsyst. Nanoeng. 6, 16 (2020). This study introduces flexible surface EMG sensors to silent-speech-related human–machine interfaces.
Kim, T. et al. Ultrathin crystalline-silicon-based strain gauges with deep learning algorithms for silent speech interfaces. Nat. Commun. 13, 5815 (2022).
Liu, S. et al. A data-efficient and easy-to-use lip language interface based on wearable motion capture and speech movement reconstruction. Sci. Adv. 10, eado9576 (2024).
Card, N. S. et al. An accurate and rapidly calibrating speech neuroprosthesis. N. Engl. J. Med. 391, 609–618 (2024).
Willett, F. R. et al. A high-performance speech neuroprosthesis. Nature 620, 1031–1036 (2023).
Sugie, N. & Tsunoda, K. A speech prosthesis employing a speech synthesizer: vowel discrimination from perioral muscle activities. IEEE Trans. Biomed. Eng. 32, 485–490 (1985).
Petajan, E. D. Automatic lipreading to enhance speech recognition. In Proc. IEEE Conference on Computer Vision and Pattern Recognition 40–47 (IEEE, 1985). This conference paper describes an off-body silent speech decoding system using camera-based automatic lipreading.
Suppes, P., Lu, Z.-L. & Han, B. Brain wave recognition of words. Proc. Natl Acad. Sci. USA 94, 14965–14969 (1997).
Assael, Y. M., Shillingford, B., Whiteson, S. & de Freitas, N. LipNet: end-to-end sentence-level lipreading. Preprint at https://doi.org/10.48550/arXiv.1611.01599 (2016).
Wand, M., Koutník, J. & Schmidhuber, J. Lipreading with long short-term memory. In Proc. 2016 IEEE International Conference on Acoustics, Speech and Signal Processing 6115–6119 (IEEE, 2016).
Su, Z., Fang, S. & Rekimoto, J. LipLearner: customizable silent speech interactions on mobile devices. In Proc. 2023 CHI Conference on Human Factors in Computing Systems 1–21 (ACM, 2023).
Pandey, L. & Arif, A. S. LipType: a silent speech recognizer augmented with an independent repair model. In Proc. 2021 CHI Conference on Human Factors in Computing Systems 1–19 (ACM, 2021).
Pandey, L. & Arif, A. S. MELDER: the design and evaluation of a real-time silent speech recognizer for mobile devices. In Proc. CHI Conference on Human Factors in Computing Systems 1–23 (ACM, 2024).
Wang, X., Su, Z., Rekimoto, J. & Zhang, Y. Watch your mouth: silent speech recognition with depth sensing. In Proc. CHI Conference on Human Factors in Computing Systems 1–15 (ACM, 2024).
Chen, T. et al. C-Face: continuously reconstructing facial expressions by deep learning contours of the face with ear-mounted miniature cameras. In Proc. 33rd Annual ACM Symposium on User Interface Software and Technology 112–125 (ACM, 2020).
Zhang, R. et al. SpeeChin: a smart necklace for silent speech recognition. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 5, 1–23 (2021).
Kimura, N., Kono, M. & Rekimoto, J. SottoVoce: an ultrasound imaging-based silent speech interaction using deep neural networks. In Proc. 2019 CHI Conference on Human Factors in Computing Systems 1–11 (ACM, 2019).
Tan, J., Nguyen, C.-T. & Wang, X. SilentTalk: lip reading through ultrasonic sensing on mobile phones. In Proc. IEEE INFOCOM 2017—IEEE Conference on Computer Communications 1–9 (IEEE, 2017).
Gao, Y. et al. EchoWhisper: exploring an acoustic-based silent speech interface for smartphone. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 4, 1–27 (2020).
Zhang, Q. et al. SoundLip: enabling word and sentence-level lip interaction for smart devices. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 5, 1–28 (2021).
Zhang, R. et al. EchoSpeech: continuous silent speech recognition on minimally-obtrusive eyewear powered by acoustic sensing. In Proc. 2023 CHI Conference on Human Factors in Computing Systems 1–18 (ACM, 2023).
Dong, X. et al. ReHEarSSE: recognizing hidden-in-the-ear silently spelled expressions. In Proc. CHI Conference on Human Factors in Computing Systems 1–16 (ACM, 2024).
Zhang, R. et al. HPSpeech: silent speech interface for commodity headphones. In Proc. 2023 International Symposium on Wearable Computers 60–65 (ACM, 2023).
Kwon, J. et al. Novel three-axis accelerometer-based silent speech interface using deep neural network. Eng. Appl. Artif. Intell. 120, 105909 (2023).
Zhou, Q. et al. Triboelectric nanogenerator-based sensor systems for chemical or biological detection. Adv. Mater. 33, 2008276 (2021).
Wang, Z. L. On Maxwell’s displacement current for energy and sensors: the origin of nanogenerators. Mater. Today 20, 74–82 (2017).
Lu, Y. et al. Decoding lip language using triboelectric sensors with deep learning. Nat. Commun. 13, 1401 (2022). This paper reports on a triboelectric-sensor-based silent speech decoding system.
De Luca, C. J. The use of surface electromyography in biomechanics. J. Appl. Biomech. 13, 135–163 (1997).
Phinyomark, A. et al. Feature extraction and selection for myoelectric control based on wearable EMG sensors. Sensors 18, 1615 (2013).
Wang, Y. et al. All-weather, natural silent speech recognition via machine-learning-assisted tattoo-like electronics. npj Flex.Electron. 5, 20 (2021).
Tang, C. et al. Wireless silent speech interface using multi-channel textile EMG sensors integrated into headphones. IEEE Trans. Instrum. Meas. 74, 1–10 (2025).
Lipomi, D. J. et al. Skin-like pressure and strain sensors based on transparent elastic films of carbon nanotubes. Nat. Nanotechnol. 6, 788–792 (2011).
Amjadi, M. et al. Stretchable, skin-mountable, and wearable strain sensors and their potential applications: a review. Adv. Funct. Mater. 26, 1678–1698 (2016).
Xu, S. et al. Force-induced ion generation in zwitterionic hydrogels for a sensitive silent-speech sensor. Nat. Commun. 14, 219 (2023).
Yang, Q. et al. Mixed-modality speech recognition and interaction using a wearable artificial throat. Nat. Mach. Intell. 5, 169–180 (2023).
Tang, C. et al. Ultrasensitive textile strain sensors redefine wearable silent speech interfaces with high machine learning efficiency. npj Flex. Electron. 8, 27 (2024).
Tang, C. et al. Wearable intelligent throat enables natural speech in stroke patients with dysarthria. Preprint at https://doi.org/10.48550/arXiv.2411.18266 (2024). This on-body sensing study demonstrates generalized silent speech decoding directly in patients with speech impairment.
Farwell, L. A. & Donchin, E. Talking off the top of your head: toward a mental prosthesis utilizing event-related brain potentials. Electroencephalogr. Clin. Neurophysiol. 70, 510–523 (1988).
Wolpaw, J. R. & McFarland, D. J. Control of a two-dimensional movement signal by a noninvasive brain–computer interface in humans. Proc. Natl Acad. Sci. USA 101, 17849–17854 (2004).
Kaongoen, N., Choi, J. & Jo, S. Speech-imagery-based brain–computer interface system using ear-EEG. J. Neural Eng. 18, 016023 (2021).
Wang, Z. et al. Conformal in-ear bioelectronics for visual and auditory brain–computer interfaces. Nat. Commun. 14, 4213 (2023).
Occhipinti, E., Davies, H. J., Hammour, G. & Mandic, D. P. Hearables: artefact removal in ear-EEG for continuous 24/7 monitoring. In Proc. 2022 International Joint Conference on Neural Networks 1–6 (IEEE, 2022).
Mandic, D. P. et al. In your ear: a multimodal hearables device for the assessment of the state of body and mind. IEEE Pulse 14, 17–23 (2023).
Cooney, C. et al. A bimodal deep learning architecture for EEG-fNIRS decoding of overt and imagined speech. IEEE Trans. Biomed. Eng. 69, 1983–1994 (2021).
Défossez, A. et al. Decoding speech perception from non-invasive brain recordings. Nat. Mach. Intell. 5, 1097–1107 (2023).
Leuthardt, E. C. et al. A brain–computer interface using electrocorticographic signals in humans. J. Neural Eng. 1, 63–71 (2004).
Schalk, G. & Leuthardt, E. C. Brain–computer interfaces using electrocorticographic signals. IEEE Rev. Biomed. Eng. 4, 140–154 (2011).
Angrick, M. et al. Speech synthesis from ECoG using densely connected 3D convolutional neural networks. J. Neural Eng. 16, 036019 (2019).
Moses, D. A. et al. Neuroprosthesis for decoding speech in a paralyzed person with anarthria. N. Engl. J. Med. 385, 217–227 (2021).
Metzger, S. L. et al. A high-performance neuroprosthesis for speech decoding and avatar control. Nature 620, 1037–1046 (2023).
Littlejohn, K. T. et al. A streaming brain-to-voice neuroprosthesis to restore naturalistic communication. Nat. Neurosci. 28, 1–11 (2025).
Duraivel, S. et al. High-resolution neural recordings improve the accuracy of speech decoding. Nat. Commun. 14, 6938 (2023).
Munari, C. et al. Stereo-electroencephalography methodology: advantages and limits. Acta Neurol. Scand. 89, 56–67 (1994).
Mullin, J. P. et al. Is SEEG safe? A systematic review and meta-analysis of stereo-electroencephalography-related complications. Epilepsia 57, 386–401 (2016).
Abarrategui, B. et al. New stimulation procedures for language mapping in stereo-EEG. Epilepsia 65, 1720–1729 (2024).
He, T. et al. VocalMind: a stereotactic EEG dataset for vocalized, mimed, and imagined speech in tonal language. Sci. Data 12, 657 (2025).
Schwartz, A. B. et al. Brain-controlled interfaces: movement restoration with neural prosthetics. Neuron 52, 205–220 (2006).
Flint, R. D. et al. Accurate decoding of reaching movements from field potentials in the human motor cortex. J. Neural Eng. 9, 046006 (2012).
Mugler, E. M. et al. Direct classification of all American English phonemes using signals from functional speech motor cortex. J. Neural Eng. 11, 035015 (2014).
Willett, F. R. et al. High-performance brain-to-text communication via handwriting decoding. Nature 593, 249–254 (2021).
Matsumura, G. et al. Real-time personal healthcare data analysis using edge computing for multimodal wearable sensors. Device 3, 100597 (2025).
Liu, T. et al. Machine learning-assisted wearable sensing systems for speech recognition and interaction. Nat. Commun. 16, 2363 (2025).
Cai, D. et al. SILENCE: protecting privacy in offloaded speech understanding on resource-constrained devices. Adv. Neural Inform. Proc. Syst. 37, 105928–105948 (2024).
Deng, Z. et al. Silent speech recognition based on surface electromyography using a few electrode sites under the guidance from high-density electrode arrays. IEEE Trans. Instrum. Meas. 72, 1–11 (2023).
Pang, C. et al. A flexible and highly sensitive strain-gauge sensor using reversible interlocking of nanofibres. Nat. Mater. 11, 795–801 (2012).
Tang, C. et al. A deep learning-enabled smart garment for accurate and versatile monitoring of sleep conditions in daily life. Proc. Natl Acad. Sci. USA 122, e2420498122 (2025).
Xu, M. et al. Simultaneous isotropic omnidirectional hypersensitive strain sensing and deep learning-assisted direction recognition in a biomimetic stretchable device. Adv. Mater. 37, 2420322 (2025).
Gong, S. et al. Hierarchically resistive skins as specific and multimetric on-throat wearable biosensors. Nat. Neurosci. 18, 889–897 (2023).
Xue, C. et al. A CMOS-integrated compute-in-memory macro based on resistive random-access memory for AI edge devices. Nat. Electron. 4, 81–90 (2021).
Fei, N. et al. Towards artificial general intelligence via a multimodal foundation model. Nat. Commun. 13, 3094 (2022).
Roy, K. et al. Towards spike-based machine intelligence with neuromorphic computing. Nature 575, 607–617 (2019).
Wang, S. et al. Memristor-based adaptive neuromorphic perception in unstructured environments. Nat. Commun. 15, 4671 (2024).
Tang, C. et al. A roadmap for the development of human body digital twins. Nat. Rev. Elect. Eng. 1, 199–207 (2024).
Zinn, S. et al. The effect of poststroke cognitive impairment on rehabilitation process and functional outcome. Arch. Phys. Med. Rehab. 85, 1084–1090 (2004).
Kennedy, P. R. & Bakay, R. A. E. Restoration of neural output from a paralyzed patient by a direct brain connection. Neuroreport 9, 1707–1711 (1998). This paper reports on a patient-level in-body neural interface demonstrating direct brain-connected communication in a paralysed individual.
Denby, B. & Stone, M. Speech synthesis from real-time ultrasound images of the tongue. In Proc. 2004 IEEE International Conference on Acoustics, Speech, and Signal Processing 685–688 (IEEE, 2004). This conference paper demonstrates silent speech synthesis using real-time ultrasound imaging of the tongue.
Galatas, G., Potamianos, G. & Makedon, F. Audio-visual speech recognition incorporating facial depth information captured by the Kinect. In Proc. 20th European Signal Processing Conference 2714–2717 (IEEE, 2012).
Shin, Y. H. & Seo, J. Towards contactless silent speech recognition based on detection of active and visible articulators using IR-UWB radar. Sensors 16, 1812 (2016).
Sun, K. et al. Lip-Interact: improving mobile device interaction with silent speech commands. In Proc. 31st Annual ACM Symposium on User Interface Software and Technology 581–593 (ACM, 2018).
Anumanchipalli, G. K., Chartier, J. & Chang, E. F. Speech synthesis from neural decoding of spoken sentences. Nature 568, 493–498 (2019). This paper reports a neural decoder that synthesizes full spoken sentences from ECoG recordings.
Ravenscroft, D. et al. Machine learning methods for automatic silent speech recognition using a wearable graphene strain gauge sensor. Sensors 22, 299 (2022).
Che, Z. et al. Speaking without vocal folds using a machine-learning-assisted wearable sensing-actuation system. Nat. Commun. 15, 1873 (2024).
Acknowledgements
C.T. acknowledges funding from Endoenergy (grant G119004). S.G. acknowledges funding from the National Natural Science Foundation of China (grant 62171014). W.Y. acknowledges funding from Pragmatic Semiconductor (grant G125298). E.O. is partially funded by the Chan Zuckerberg Initiative DAF (grant 2022-316777), an advised fund of the Silicon Valley Community Foundation. L.G.O. acknowledges funding from the British Council (UK–India Education and Research Initiative grant 45371261), UK Research and Innovation (grants EP/W024284/1 and EP/P027628/1), Endoenergy (grant G119004) and Pragmatic Semiconductor (grant G125298).
Author information
Authors and Affiliations
Contributions
C.T., S.G. and L.G.O. discussed and conceived of the idea for the paper. C.T., L.Q. and S.G. drafted the manuscript. C.T. and Z.Z. visualized the figures. S.G. and L.G.O. supervised the work. C.T., S.G., W.Y., M.X., E.O., Y.P. and L.G.O. contributed to discussing, writing and revising the article.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Sensors thanks Jun Chen and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Tang, C., Qi, L., Gao, S. et al. Sensing technologies for silent speech interfaces. Nat. Sens. 1, 16–26 (2026). https://doi.org/10.1038/s44460-025-00010-2
Received:
Accepted:
Published:
Version of record:
Issue date:
DOI: https://doi.org/10.1038/s44460-025-00010-2
