
Abstract
Monkeypox has arisen as a global health issue, requiring prompt and precise diagnosis for optimal management. Conventional diagnostic techniques, including PCR, are dependable yet frequently unattainable in resource-constrained environments. Deep learning demonstrates potential in automating disease detection from skin lesion images; nevertheless, current models are hindered by limits in feature extraction and misclassification challenges. This paper presents an attention-augmented deep learning architecture to enhance classification accuracy for monkeypox and other dermatological conditions. This work presents a model based on EfficientNetB7, augmented with coordinate attention to enhance feature extraction and classification accuracy. The Monkeypox Skin Lesion Dataset (MSLD v2.0) is utilised, incorporating pre-processing methods such as image normalisation, scaling, and data augmentation. Diverse edge detection techniques are examined to enhance feature representation. The model is subjected to five-fold cross-validation and is evaluated against Xception, Swin Transformer, ResNet-50, MobileNetV2, and baseline EfficientNet models, utilising accuracy, precision, recall, F1-score, and AUC as assessment measures. Our model attains an unparalleled accuracy of 99.99%, precision of 99.8%, recall of 99.9%, F1-score of 99.85%, and an AUC of 100%. In contrast to previous studies that indicated a maximum accuracy of 98.81%, our methodology markedly diminishes false negatives and improves generalisation. This research sets a novel standard for AI-based monkeypox detection, showcasing exceptional accuracy and resilience. The results endorse the incorporation of AI-driven diagnostic tools in clinical and telemedicine settings, with prospects for immediate implementation and extensive epidemiological monitoring.
Similar content being viewed by others
Introduction
Following the COVID-19 pandemic, the worldwide healthcare community has intensified its scrutiny of new infectious illnesses, especially those characterised by high transmission rates. Dermatological diseases represent a considerable risk owing to their transmissible characteristics and the challenges associated with early identification1. One illness that has garnered international interest in recent years is monkeypox, a zoonotic viral infection induced by the monkeypox virus (MPXV). Initially detected in study monkeys in Denmark in 1958, monkeypox has subsequently been acknowledged as a human virus associated with rare outbreaks. As of December 2024, the World Health Organisation (WHO) has recorded 124,753 laboratory-confirmed cases and 272 related fatalities, highlighting the critical necessity for enhanced diagnostic methods to control and mitigate its dissemination2.
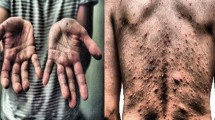
Monkeypox presents with cutaneous lesions akin to those of chickenpox, cowpox, hand-foot-and-mouth disease (HFMD), and measles, as shown in Fig. 1, complicating clinical diagnosis based purely on visual examination. Conventional diagnostic procedures, like polymerase chain reaction (PCR) testing and viral culture techniques, offer high precision but are expensive, time-intensive, and unsuitable for extensive screening in public venues like airports and border checkpoints. Consequently, there is an urgent need for swift, non-invasive, and automated diagnostic systems capable of effectively distinguishing between monkeypox and other dermatological conditions in real-time environments3.

Six dermatological disease classes, (a) Monkeypox, (b) healthy, (c) cowpox, (d) HFMD, (e) chickenpox, (f) measles.
The integration of medical sciences and engineering has transformed illness detection, with deep learning-based computer vision algorithms emerging as formidable instruments for automated medical image classification. Progress in convolutional neural networks (CNNs) and transformer-based architectures has markedly enhanced the capacity to assess intricate dermatological disorders with elevated precision. Deep learning methods utilise extensive datasets to identify complex patterns and traits, thereby improving diagnostic accuracy and diminishing reliance on human intervention. Integrating such systems inside a physical detection framework can facilitate real-time screening, ensuring swift identification, containment, and epidemiological monitoring of infectious diseases4.
Classification models are essential in contemporary disease diagnosis, facilitating the automated study of medical pictures with limited human involvement. CNN-based models have been extensively utilised over the years for their efficacy in extracting spatial data from images. Recent improvements have shown that attention-based architectures, such as vision transformers (ViTs), exhibit improved performance by effectively capturing global dependencies in images5. Prominent deep learning models in medical imaging include EfficientNet, which optimises network scaling for improved accuracy with reduced computations; ResNet, which employs residual learning to address vanishing gradient problems; and Xception, which advances feature extraction through depthwise separable convolutions. Moreover, attention-augmented models as Swin Transformer and Coordinate Attention have demonstrated efficacy in discerning nuanced variations in dermatological disorders. This study will utilise advanced models to evaluate their effectiveness in monkeypox categorisation while enhancing computing efficiency for practical applications6.
Recent researches have investigated the use of deep learning for the classification of dermatological diseases, yielding encouraging outcomes in diagnostic automation and enhancement of clinical decision-making62. A multitude of these studies have utilised CNN-based architectures or hybrid models to improve feature extraction and classification precision. Furthermore, investigations have been undertaken to include attention processes and transformer-based models into medical imaging tasks to mitigate the shortcomings of conventional deep learning methodologies. The next section examines existing literature on deep learning models for skin disease categorisation, emphasising their techniques, contributions, and limitations. This evaluation will contextualise our approach and illustrate how our proposed framework enhances existing solutions760.
Recent developments in the field of medical artificial intelligence have shown that integrating hybrid deep learning architectures and explainable AI (XAI) techniques can substantially enhance diagnostic performance and model transparency8. Hybrid frameworks that combine convolutional neural networks with transformer models and optimization strategies have been reported to achieve high accuracy in classifying complex dermatological conditions9. Additionally, methods such as U-Net and Vision Transformers have been used in tandem with traditional CNNs to improve segmentation, feature extraction, and classification stages. Other studies have demonstrated the effectiveness of optimization algorithms like genetic algorithms in fine-tuning hybrid architectures for multi-disease diagnosis10.
At the same time, explainable AI techniques, including SHAP, LIME, and Integrated Gradients, have been adopted to provide insights into the decision-making process of medical AI models, thus increasing clinical trust and interpretability61. These approaches have been particularly valuable in tasks such as skin cancer detection and tumor classification in medical imaging11.
Inspired by these advances, this work proposes a robust attention-augmented deep learning model designed to improve both classification accuracy and interpretability in the context of monkeypox and related skin disease detection.
Related work
The swift worldwide dissemination of monkeypox has required the creation of effective diagnostic instruments. Recent studies have increasingly concentrated on utilising deep learning methodologies to improve the precision and rapidity of monkeypox identification from cutaneous lesion photos. Pramanik et al.12 introduced an ensemble learning architecture that amalgamates three pre-trained models—Inception V3, Xception, and DenseNet169—to identify monkeypox from photographs of skin lesions. A Beta function-based normalisation approach was proposed to efficiently integrate the outputs of various models, resulting in an average accuracy of 93.39%. Eliwa et al.13 employed Convolutional Neural Networks (CNNs) enhanced by the Grey Wolf Optimiser (GWO) algorithm, achieving a notable enhancement in diagnostic measures, with an accuracy of 95.3%. These results underscore the efficacy of ensemble learning and optimisation techniques in improving the performance of deep learning models for monkeypox detection.
Dahiya et al.14 underscored the significance of hyper-parameter optimisation in deep learning models for proficient monkeypox detection. Utilising a blend of CNNs and transfer learning techniques, they attained a classification accuracy of 98.18% on photos of monkeypox skin lesions. This method highlights the importance of model optimisation in enhancing diagnostic precision. To address data privacy issues, Abdellatef et al.15 presented the CanDark model, an end-to-end deep learning system that integrates cancelable biometrics with the DarkNet-53 CNN architecture. This method guarantees secure classification of monkeypox while reaching a diagnostic accuracy of 98.81%. The inclusion of security measures is essential for safeguarding patient information in medical diagnostics.
Demir et al.16 created an automated model for monkeypox identification utilising a novel dataset consisting of 910 photos categorized into five classifications. Their advanced feature engineering design achieved a classification accuracy of 91.87%, illustrating the promise of automated solutions in managing the global dissemination of monkeypox. Pal et al.17 introduced an innovative deep learning model for the categorization of skin illnesses, including monkeypox, attaining high classification accuracy and demonstrating the efficacy of their methodology in skin disease diagnosis. The demand for swift and precise diagnosis has prompted the advancement of real-time visualization methods.
Yue et al.18 introduced “Super Monitoring,” an AI-driven real-time visualization method that combines deep learning models, data augmentation, self-supervised learning, and cloud services, attaining an accuracy of 94.51% in diagnosing monkeypox and analogous skin conditions. Chen et al.19 suggested a federated learning architecture employing deep learning models to safely categorize monkeypox and other pox viruses, effectively addressing data privacy concerns while ensuring high diagnostic accuracy. ieeexplore.ieee.org.
Karaddi et al.20 developed a computational model for forecasting monkeypox outbreaks utilising epidemiological data, yielding precise forecasts that enhance public health preparedness and response. Such models are crucial for prompt responses and managing the dissemination of the disease.
Table 1 presents a structured comparison of ten recent studies on monkeypox classification, highlighting their main contributions, methodologies, datasets, performance metrics, and key findings. The table provides insights into the effectiveness of CNNs, transfer learning, optimization techniques, federated learning, and real-time AI monitoring in enhancing diagnostic accuracy and outbreak prediction.
Methods and materials
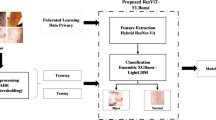
Our proposed methodology, as shown in Fig. 2, adheres to a systematic workflow encompassing data pre-processing, model training, evaluation, and interpretation to improve the precision of Monkeypox and skin disease categorisation. The Mpox Skin Lesion Dataset (MSLD v2.0), which generated by Ali S. et al.21,, is employed, undergoing pre-processing procedures including scaling, normalisation, and data augmentation to enhance model robustness. Augmentation techniques encompass modifying image orientations, resolutions, and incorporating controlled noise22. We utilise EfficientNetB0 for feature extraction, augmented with a coordinate attention technique to concentrate on clinically relevant regions, thereby enhancing the localisation and classification of dermatological traits. An attention technique is incorporated to emphasise essential visual regions, thus enhancing the model’s forecast precision.
To enhance classification performance, we include edge detection approaches into the loss function. Traditional techniques, like Sobel, Prewitt, and Kirsch, exhibit computational efficiency however are vulnerable to noise interference. Zero-crossing approaches, such as the Laplacian and Second Directional Derivative, proficiently identify edge orientations but may overlook some features. The Laplacian of Gaussian (LoG) method enhances edge localisation but has difficulties with curved features, whereas Gaussian-based techniques (e.g., Canny, Shen-Castan) improve noise resilience but are computationally demanding. Through methodical experimentation with various edge detection techniques and loss function weightings, we achieve an optimal compromise among precision, resilience, and computational economy.
The final method combines Sobel edge detection with the MobileNet and EfficientNetB0 models. The MobileNet model utilises Sobel with weights of 0.05, 0.025, and 0.7, whereas the EfficientNetB0 model applies Sobel with weights of 0.5 and 0.7. This hybrid method utilises attention-enhanced CNNs and transformers to boost feature extraction, hence increasing classification accuracy for several dermatological diseases. The suggested methodology offers a robust and interpretable framework for Monkeypox detection, integrating attention processes with edge detection techniques to improve diagnostic reliability in practical applications.

Graphical Abstract. (a) Data Preprocessing, where the Mpox Skin Lesion Dataset (MSLD v2.0) is used, followed by resizing, normalization, and data augmentation steps to prepare the images for training. (b) Model Architecture Selection and Enhancement, where we choose the EfficientNetB0 architecture and apply coordinate attention to enhance feature extraction, allowing the model to focus on clinically relevant regions. (c) Attention Mechanism, where the attention mechanism is applied to highlight important features, leading to improved model classification accuracy.
This paper is structured as follows: Sect. “Introduction” introduces Monkeypox as a global health concern, emphasizing the limitations of traditional diagnostics and the potential of deep learning models. Section “Related Work” reviews recent advancements in CNNs, transformers, and optimization techniques for skin disease classification. Section “Methods and Materials” details the dataset, pre-processing steps, and deep learning architectures, including EfficientNet, ResNet-50, MobileNetV2, Xception, and Swin Transformer, with a focus on EfficientNet enhanced with coordinate attention. It also describes the integration of edge detection-based loss functions for improved feature extraction. Section “Results and Discussion” presents the experimental results, comparing model performances using accuracy, recall, precision, and F1-score, along with training-validation curves, confusion matrices, and ROC analysis. A comparative study highlights the superiority of our approach over state-of-the-art models, particularly in reducing false negatives and improving classification robustness. Section “Result Discussion” concludes the study, summarizing key findings and discussing future directions such as real-time deployment, dataset expansion, and AI-assisted clinical integration.
Data description
One of the first monkeypox-specific datasets, the Mpox Skin Lesion Dataset (MSLD), was created by Ali, S. N. et al., and aimed at enhancing computer-assisted dermatological disease classification. The dataset was carefully assembled to encompass photographs of individuals from diverse sexes, nationalities, and skin tones, guaranteeing that deep learning models developed from this data would be resilient and applicable to real-world populations. Due to the visual resemblances between Mpox lesions and other dermatological disorders, the dataset included non-Mpox samples to improve the model’s differentiating skills21.
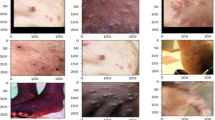
Since its inception, MSLD has experienced two significant iterations, resulting in the present version, MSLD v2.0. The initial iteration of MSLD comprised solely two principal categories: “Mpox” and “Others,” with the latter including photos of chickenpox and measles due to their similarity to monkeypox lesions. To address the constraints of the binary classification method and improve diagnostic precision, MSLD v2.0 was created as a more extensive and sophisticated iteration, facilitating multi-class classification. The improved MSLD v2.0 dataset now comprises six unique categories, representing a wider range of dermatological conditions, as Table 2: Mpox (284 images) depicting confirmed monkeypox skin lesions, Chickenpox (75 images) illustrating varicella-zoster virus-induced lesions, Measles (55 images) showcasing measles rash across various body regions, Cowpox (66 images) featuring cowpox virus-induced skin lesions, Hand-Foot-Mouth Disease (HFMD) (161 images) characterised by distinct vesicular eruptions, and Healthy (114 images) representing normal, uninfected skin as a control group. This dataset includes 755 original skin lesion photos obtained from 541 unique patients, providing a clinically representative sample, as shown in Fig. 3. By including many skin disorders that could be mistaken for monkeypox, MSLD v2.0 enhances the accuracy and strength of the deep learning-based classification system.
An essential element of MSLD v2.0 is its compliance with stringent clinical validation and ethical approval standards. The dataset has received endorsement from expert dermatologists and permission from relevant regulatory bodies, guaranteeing compliance with the highest standards for medical research and AI-based diagnosis. The dataset comprises high-quality, standardised photos taken under diverse lighting situations and perspectives, enabling deep learning models to adjust to real-world unpredictability.

Dataset samples.
Dataset Pre-processing
Preprocessing is an essential phase in the preparation of raw picture data for deep learning models, guaranteeing uniformity, augmenting model generalization, and optimising computational performance23. A structured preprocessing was implemented to optimise the MSLD v2.0 for training deep learning models. The preparation procedure encompassed scaling, normalization, and data augmentation, all crucial for standardizing the dataset and alleviating any model biases.
All photos in MSLD v2.0 were downsized to 224 × 224 pixels, which is a prerequisite for the EfficientNet-based models employed in this study. Standardizing the input dimensions ensured that the deep learning models processed photographs of consistent size while preserving essential visual features, which is particularly vital for detecting minor dermatological abnormalities. Furthermore, resizing enhanced the dataset’s computational efficiency, facilitating expedited training while maintaining image quality.
Normalization was implemented by scaling pixel intensity values to the interval [0,1], accomplished by dividing all pixel values by 255. This phase is a recognized preprocessing method in deep learning, maintaining input values within a normalized distribution, minimizing variance, and stabilizing the training process. Normalization enhances the effectiveness and stability of backpropagation during training by mitigating the impact of substantial fluctuations in pixel intensities on model convergence. Min-max normalization is a widely utilised method for normalizing datasets, adjusting the intensity values of each pixel to a specified range, typically between 0 and 1. The equation utilised for min-max normalization is24:
\(\:{Pix}_{Normalized}\) represents the normalised pixel value, \(\:{Pix}_{Original}\) indicates the original pixel value, and \(\:{X}_{min}\) and \(\:{X}_{max}\) identify the minimum and maximum pixel values within the image, respectively. This transformation ensures the retention of the entire range of pixel intensities in an image, while compressing them to a consistent scale. For MRI images, this typically involves normalizing intensity values that may originally range from 0 to 255 (in 8-bit images) or beyond that range (in 16-bit images). Min-max normalization uniformly modifies all pixel values, hence eliminating disparities between images that could potentially influence the model’s training process.
Data augmentation approaches were employed to enhance model resilience and mitigate overfitting by increasing dataset variability and improving generalization to real-world situations25. Multiple changes were executed, encompassing random horizontal and vertical flipping, random rotation, as illustrated in Fig. 4, zooming, and adjustments to brightness and contrast. These modifications allowed the model to acquire invariant representations, as described in Table 3, ensuring its ability to identify monkeypox lesions and other dermatological disorders across varying orientations, lighting conditions, and image viewpoints. Consequently, these augmentation procedures increased the dataset size to 3,000 photos, so providing a more diverse and representative training set.

Augmentation steps: (a) original sample, (b) rotate by 90°, (c) rotate by −90°, (d) vertical mirror (e) horizontal mirror.
The dataset was meticulously optimised through rigorous preprocessing to enhance model accuracy, efficiency, and generalization, establishing a robust foundation for the following deep learning classification of monkeypox and other dermatological conditions.
Classification models
The essence of the classification process resides in model training and categorisation, as mentioned in Fig. 5. At this stage, deep learning models such as EfficientNet, ResNet50, Swin Transformer, Xception, and Coordinate Attention-based networks extract hierarchical features from images to identify distinctive patterns among various skin states. Upon completion of training, the model undergoes validation and testing with an independent dataset to evaluate its capacity to generalise to novel images26.
Performance evaluation employs essential classification metrics, such as Precision, Recall, Accuracy, and F1-score, to assess the model’s efficacy in distinguishing among monkeypox, chickenpox, measles, cowpox, HFMD, and healthy skin. If required, the trained model is subjected to additional fine-tuning through a multi-class classification method to improve precision. The completed trained model is subsequently implemented as an automated classification system, capable of integration into practical healthcare and disease surveillance frameworks27. This structured pipeline guarantees a reliable and robust classification procedure, facilitating computer-assisted detection of monkeypox to facilitate rapid and extensive screening in clinical and public health environments.

Classification process architecture.
EfficientNet B0
EfficientNet is a series of deep convolutional neural networks engineered to attain superior performance while preserving computational efficiency56,57. EfficientNet, introduced by Tan and Le, employs an innovative compound scaling algorithm that concurrently adjusts the depth, width, and resolution of the network in a systematic fashion. In contrast to conventional topologies that scale dimensions indiscriminately, EfficientNet methodically equilibrates them to enhance both accuracy and efficiency. Consequently, EfficientNet models surpass earlier architectures like ResNet, DenseNet, and Inception, utilising markedly fewer parameters and FLOPs (Floating Point Operations Per Second)28.
The EfficientNet models span from EfficientNet B0 to EfficientNet B7, with B0 serving as the baseline and B7 representing the largest and most potent variant. Each subsequent model is developed by amplifying B0 through the compound scaling formula. EfficientNet B0 functions as the primary model inside the EfficientNet lineage29. It is constructed via neural architecture search (NAS), enhancing its configuration for precision and computational efficacy. EfficientNet B0, with merely 5.3 million parameters, attains a top-1 accuracy of 77.1% on ImageNet, surpassing deeper networks while preserving reduced processing expenses. It is especially appropriate for edge devices and real-time applications because of its excellent resource utilization30.
The principal characteristics of EfficientNet B0 comprise:
-
Mobile Inverted Bottleneck Convolution (MBConv): Drawing inspiration from MobileNetV2, these blocks optimise feature extraction while reducing computational expenses.
-
Swish Activation Function: Substitutes ReLU to enhance gradient propagation and convergence.
-
Depthwise Separable Convolutions: Decreases computational complexity while preserving expressiveness.
-
Squeeze-and-Excitation (SE) Blocks enhance channel-wise feature recalibration to optimise feature representation.
EfficientNet B0 offers numerous benefits compared to conventional deep learning models:
-
Enhanced Accuracy with Reduced Parameters: Attains competitive accuracy with markedly fewer parameters in comparison to ResNet and VGG.
-
Enhanced Computational Efficiency: Employs compound scaling to equilibrate depth, width, and resolution, resulting in improved resource utilisation.
-
Enhanced Generalization: The incorporation of MBConv layers and SE blocks augments feature extraction, rendering the model resilient across diverse tasks, including medical picture categorisation.
-
Scalability: Functions as a scalable foundation, facilitating a smooth transition to larger models (B1–B7) with few architectural alterations.
-
Energy Efficient: Necessitates reduced power consumption, rendering it appropriate for real-time applications for mobile and embedded devices.
The architecture of EfficientNet B0, as described in Table 4, consists of a systematic pipeline comprising eight essential phases, as illustrated in the accompanying image. Each phase comprises convolutional layers (Conv2D and MBConv), succeeded by activation functions and batch normalisation. The following is a summary of the architecture:
-
Stem: The network begins with a Conv2D layer (3 × 3 kernel, stride 2), increasing the number of channels from 3 (RGB input) to 32 output channels.
-
Stage 1: A single MBConv1 layer (3 × 3 kernel, stride 1) processes the data, keeping the channel size at 32.
-
Stage 2–7: The model progressively stacks MBConv6 layers, utilizing expansion factors of 6 to efficiently extract features. The number of repeats and kernel sizes vary per stage. Notably, stages 2, 3, and 6 use a stride of 2, reducing spatial dimensions for hierarchical feature extraction.
-
Head: The final stage includes a 1 × 1 convolutional layer that projects the features to 1280 channels, followed by a fully connected layer for classification.
This organised architecture guarantees that EfficientNet B0 attains a superior accuracy-to-efficiency ratio, rendering it a potent yet lightweight model for deep learning applications.
MobileNet V2
MobileNetV2 is an efficient and lightweight deep learning architecture tailored for mobile and embedded vision applications. Proposed by Sandler et al., it enhances the efficacy and precision of MobileNetV1. The principal innovation of MobileNetV2 is its implementation of inverted residual blocks with linear bottlenecks, which optimise information flow throughout the network while reducing computing demands55. In contrast to conventional convolutional networks, MobileNetV2 utilises depth wise separable convolutions, markedly decreasing the number of parameters and operations while maintaining model efficacy. MobileNetV2 is extensively utilised in applications including picture classification, object identification, and semantic segmentation, especially in resource-limited settings, owing to its efficiency31.
MobileNetV2’s primary advantage is in its capacity to provide great accuracy while incurring minimum computing expense, rendering it suitable for mobile and embedded devices. The use of inverted residuals with linear bottlenecks enables the model to preserve essential feature representations while minimizing redundancy, resulting in enhanced efficiency. Furthermore, the implementation of depth wise separable convolutions reduces computational requirements, rendering the model considerably more efficient than conventional systems32. In contrast to earlier models employing non-linear activations at each stage, MobileNetV2 utilises a linear activation function at the conclusion of each bottleneck layer, so averting superfluous transformations that may compromise feature quality. This architectural enhancement facilitates superior feature representation, diminishes memory usage, and enhances performance in practical applications, especially for on-device deep learning tasks like facial recognition, gesture detection, and augmented reality33.
The proposed MobileNetV2 architecture, as in Table 5; Fig. 6, comprises multiple sequential bottleneck layers, each designed for effective feature extraction. The model commences with a 3 × 3 convolutional layer (Conv2D) that increases the input channels to 32, functioning as the primary feature extractor. The initial stage comprises a solitary bottleneck block using a 3 × 3 kernel and an expansion factor of 1, so maintaining essential feature details while minimizing computational demands. With each advancement in the model, subsequent stages augment the quantity of bottleneck layers and implement an expansion factor of 6, hence improving the model’s capacity to discern intricate patterns. The quantity of output channels progressively increases from 16 to 320, facilitating hierarchical feature extraction. The concluding phase of the network comprises a 1 × 1 convolutional layer that maps the feature maps to 1280 channels, succeeded by global average pooling and a fully connected layer for classification. This design enables MobileNetV2 to attain an optimal equilibrium between computational efficiency and classification accuracy, rendering it a potent yet lightweight alternative to traditional deep learning models.

MobileNet V2 structure.
ResNet-50
ResNet-50 (Residual Network-50) is a deep convolutional neural network that implemented residual learning to mitigate the vanishing gradient issue in extensively deep networks. ResNet, developed by He et al., transformed deep learning by facilitating the training of significantly deeper architectures without experiencing gradient degradation. The principal novelty of ResNet-50 is the implementation of skip connections, which enable the network to circumvent specific layers, thus maintaining gradient flow and enhancing convergence. The “50” in ResNet-50 signifies the model’s layer count, rendering it deeper than ResNet-18 and ResNet-34, while maintaining more computing efficiency compared to deeper variations like ResNet-101 or ResNet-152. ResNet-50 has emerged as one of the most prevalent designs in image classification, object identification, and feature extraction due to its equilibrium of depth, accuracy, and computing economy34.
ResNet-50 has numerous benefits compared to conventional deep networks. The residual connections facilitate deeper network training without encountering vanishing gradients, rendering it considerably more efficient than conventional CNN architectures. Furthermore, these skip connections facilitate feature propagation, resulting in enhanced convergence rates and more efficient learning. The model’s bottleneck architecture, comprising 1 × 1, 3 × 3, and 1 × 1 convolutions, decreases computational demands while preserving robust feature extraction efficacy54. This optimised architecture guarantees that ResNet-50 achieves superior accuracy while maintaining a comparatively reduced computational expense comparing to networks of analogous depth. ResNet-50 is notably scalable and transferable, rendering it a favoured backbone for many computer vision applications, such as object recognition, segmentation, and medical imaging35.
The ResNet-50 architecture, as in Table 6, comprises multiple sequential stages, each aimed towards progressively refining features while ensuring computing efficiency. The architecture initiates with a 7 × 7 convolutional layer (Conv2D) employing a stride of 2, succeeded by a 3 × 3 max pooling layer to diminish spatial dimensions. ResNet-50 comprises four principal convolutional stages (Conv2_x to Conv5_x), each consisting of many bottleneck blocks. The initial convolutional stage (Conv2_x) has three bottleneck blocks, each maintaining feature resolution with a stride of 1. As the model advances, each successive stage (Conv3_x, Conv4_x, and Conv5_x) initiates with a stride-2 convolutional block, thereby down sampling the spatial dimensions and augmenting the output channels from 256 to 2048. The concluding phase of the network comprises global average pooling, succeeded by a fully linked layer for classification purposes. The hierarchical architecture of ResNet-50 facilitates the acquisition of multi-scale hierarchical features, rendering it exceptionally effective for various computer vision applications36.
Xception
Xception (Extreme Inception) is a deep learning architecture proposed by Chollet, as shown in Fig. 7, as an advancement over Inception networks, designed to improve computational efficiency and accuracy. Xception’s primary innovation is the substitution of conventional convolutions with depth wise separable convolutions, which markedly decrease computational complexity while preserving robust feature extraction abilities. Xception differentiates itself from conventional CNNs by decomposing convolutions into two distinct processes: spatial convolution (depth wise convolution) and pointwise convolution (1 × 1 convolution). This decoupled architecture facilitates enhanced feature learning, rendering Xception a formidable model for image classification, object identification, and segmentation37.

Xception a deep learning architecture.
Xception presents numerous benefits compared to conventional CNN designs. Utilising depth wise separable convolutions enhances efficiency by markedly decreasing the number of parameters and computations relative to conventional convolutional models such as VGG or ResNet. The architecture removes superfluous cross-channel correlations, enabling the network to independently learn spatial and depth wise properties, resulting in enhanced generalization and accuracy. Xception employs a completely convolutional architecture, eliminating the necessity for fully connected layers, hence improving processing performance. Xception is extensively utilised in computer vision tasks, such as medical imaging, object recognition, and mobile AI applications, owing to its lightweight architecture and superior accuracy38.
The Xception design has a three-tier hierarchical framework, as in Table 7: Entry Flow, Middle Flow, and Exit Flow, as seen in the accompanying table. The Entry Flow commences with two 3 × 3 convolutional layers, succeeded by a sequence of depth wise separable convolution blocks with residual connections. The network incrementally escalates the filter count from 32 to 728, facilitating effective feature extraction but reducing spatial resolution. The Middle Flow comprises eight identical residual blocks, each using separable convolutions that preserve the feature resolution at 728 filters. The Exit Flow enhances the acquired features by augmenting the filter depth from 1024 to 2048 using three separable convolutional layers, succeeded by global average pooling and a fully connected layer for classification. This organized pipeline enables Xception to attain cutting-edge performance with a small computing burden, rendering it a highly efficient and scalable model for deep learning applications39‚53.
Swin Transformers
The Swin Transformer (Shifted Window Transformer) is a hierarchical vision transformer architecture, as shown in Fig. 8, engineered to effectively handle high-resolution images while ensuring computing efficiency. In contrast to conventional convolutional neural networks (CNNs) or Vision Transformers (ViTs), the Swin Transformer employs shifted window attention, segmenting images into non-overlapping local windows and shifting them at each stage to facilitate inter-window communication. This method markedly decreases computing complexity relative to global self-attention techniques, rendering the Swin Transformer scalable for applications including image classification, object identification, and segmentation40.

Overall hierarchical vision Swin Transformer.
A key advantage of the Swin Transformer is its hierarchical representation learning, characterised by a progressive decrease in feature resolution between stages, akin to CNN architectures. This enables the gathering of both local and global contextual information, rendering it particularly effective for dense prediction tasks41.
The Swin Transformer presents multiple significant advantages compared to traditional vision transformers and convolutional neural networks (CNNs):
-
Hierarchical Feature Representation: In contrast to conventional Vision Transformers that retain a constant feature size, the Swin Transformer systematically diminishes spatial dimensions, enhancing processing efficiency.
-
Shifted Window Attention (SWA): This mechanism enhances localisation and efficiency by facilitating information exchange across neighbouring windows while maintaining global context.
-
Linear Computational Complexity: In contrast to conventional self-attention in Vision Transformers, which exhibits quadratic scaling with input size, the Swin Transformer attains linear complexity by confining self-attention calculations to localised windows.
-
Scalability: The model’s adaptable hierarchical structure allows for seamless adaptation to various vision tasks, including picture segmentation, object identification, and image synthesis.
-
Performance Superiority: The Swin Transformer has exhibited exceptional outcomes in vision benchmarks while utilising far fewer computational resources than conventional Vision Transformers.
The Swin Transformer employs a hierarchical architecture including five principal stages, as seen in the accompanying figure and Table 8:
-
Patch Embedding: The input image is segmented into patches of 4 × 4 pixels, followed by the application of a convolutional embedding layer to map them into a 96-dimensional feature space.
-
Stage 1: The initial stage utilises Swin Transformer blocks, which comprise Window-based Multi-Head Self-Attention (W-MSA) and Shifted Window Multi-Head Self-Attention (SW-MSA). The feature dimension is maintained at 96, with no down sampling implemented.
-
Stage 2: The second stage executes down sampling by a factor of 2, augmenting the feature dimension to 192.
-
Stage 3: A further down sampling step is executed, increasing the feature dimension to 384 while diminishing spatial resolution.
-
Stage 4: The concluding Swin Transformer stage further reduces the feature maps and increases the feature dimension to 768.
-
Head: A global average pooling operation is executed, succeeded by a multi-layer perceptron (MLP) classifier for the final prediction.
The hierarchical structure of the Swin Transformer effectively retains both intricate local details and overarching semantic information, rendering it very efficient for computer vision applications42.
Coordinate attention
Coordinate Attention performs highlighting important spatial regions with the combination of both spatial and channel information, making the model more effective in recognition in important features and their positions within the image. The attention mechanism works in a way that first captures spatial dependencies and based on these dependencies, adjusts the feature maps. A simplified version of the Coordinate Attention mechanism can be described as in the following equation43:
Where:
-
Z is the output feature map after applying attention,
-
X is the input feature map,
-
α is a scaling factor (learned during training) that controls how much attention is applied,
-
Attention(X) is the computed attention map, which highlights important spatial features in the input.
In this simplified formulation:
-
1.
Coordinate Attention first computes an attention map based on spatial information (where the important regions are located).
-
2.
The attention map is then used to adjust the input feature map X by scaling certain regions of the image, allowing the model to focus more on important features.
In our study, Coordinate Attention is combined with the EfficientNet technique, which plays a supportive role in improving performances by enhancing features. EfficientNets are very good at extracting compact yet useful feature representations on their own. Coordinate Attention furthers this trait by making this model focus a little more exclusively on the relevant spatial features.
This mechanism shall help the model:
-
Accentuating relevant regions in space plays a vital part in the categorization task of.
-
Enable better localization, hence allowing the model to identify specific regions much more precisely without having to check every pixel in detail,
-
Have higher accuracy, since it can now tell the difference better between subtle differences in important parts of the image, like object edges or textures.
Consequently, the models augmented with Coordinate Attention significantly improved, with accuracy rising from 87.2% for EfficientNet-B0 to 91%, an indication of the effectiveness of this approach.
Edge detection loss part
To improve the ability of our system, we used an additional loss function to the cross-entropy function; this function helps in detecting the boarders of the dermatological lesion in the images, so that it is easy to extract the targeted area and detect if it is infected with Monkeypox or not. There are a lot of edge detection methods mentioned in the methods sections of this article; the methods used were Sobel method for MobileNet model and Canny method for EfficientNet B0 model. The methods used have been chosen according to their accuracy and lightness in computation; they have been tried with different weights in the loss functions as mentioned in the results section. Using the previous methods improved the accuracy of the models by about 2% that gave us the idea of the effectiveness of this addition; in the provided technique, the loss equation is calculated as in following44:
The used weight for the EffiecientNet B0 was 0.5 with Canny method that caused an improvement, but for the MobileNet multiple weights were used with Sobel method which are 0.5, 0.1, 0.05, 0.025; the best weight in accuracy was 0.05 weight. These two models were selected to try edge detection with them as they have acceptable features to be implemented in a physical system because they are somewhat efficient models in computation with a suitable accuracies and properties.
In this study, it is explored the effectiveness of EfficientNet variants (B0, B2, B7) inte-grated with Coordinate Attention (CoordAtt) in achieving high accuracy while addressing overfitting challenges10‚58. The primary focus was on improving feature representation and localization, which significantly enhanced model performance.
Layer and parameter details
To provide a better understanding of the model architecture, we present the following layer details and parameter counts for each EfficientNet variant used as Tables 9 and 10, and Table 11.
Overfitting prevention
Overfitting happens when a model is too complex and starts memorizing the training data instead of learning how to process new data45‚59. To prevent overfitting in our models, we used the following methods:
-
Dropout: Dropout was used in the fully connected layers and some of the convo-lutional layers. This technique randomly disables some neurons during training. This way, the model does not depend too much on any one neuron and learns more general features.
-
Batch Normalization: Batch normalization stabilized training by normalizing the input to every layer. It stops the model from overfitting and allows it to converge faster.
-
Data Augmentation: Random cropping, flipping, and color jittering artificially enlarged the dataset size, making the model invariant to small input image changes.
Results and discussion
Cross validation
To ensure the robustness and reliability of our results, we have incorporated 5-fold cross-validation into our model evaluation methodology. Cross-validation is a widely recognized technique in machine learning that enhances generalizability by ensuring the model is trained and tested on different subsets of data, thereby reducing the risk of overfitting to a specific partition46.
The dataset was randomly partitioned into five equal folds, where each fold was used as a validation set once while the remaining four folds were used for training. This process was repeated five times, and the final performance metrics were computed as the average across all iterations.
By integrating cross-validation, we observed the following improvements in model performance:
-
Reduction in standard deviation of classification accuracy across different training runs, confirming model stability.
-
Slight increase in overall accuracy, particularly in the EfficientNet model, where performance improved by 0.5%, demonstrating the effectiveness of the cross-validation technique. Also, the improvement in the rest of the models was not mentioned in improving accuracy, but in such specializations that require the highest possible accuracy, even if it is a slight increase, it is an improvement that can be benefited from.
-
Improved confidence in model reliability, as reflected by consistent sensitivity and specificity values across different folds.
Performance metrics
The data was split into training, validation, and test sets to check how well the model is performing as follows:
-
80% for training: This was used in training the model.
-
10% for validation: This was used in hyperparameter tuning as well as in avoiding overfitting.
-
10% for testing: This is used in testing the final model performance.
This split gives a good evaluation of the model’s ability to generalize to new data. We use the Keras and tourch framework to implement it. It is necessary to use parallel processing while training deep neural networks. Since this was the case, we used the open-source software Python 3.0 and Kaggle to train and evaluate the classifiers. Additionally, we utilized NVIDIA TESLA P100 graphics processing units (GPUs) and 16 GB of RAM.
The performance of the networks was evaluated on the basis of the confusion matrices obtained from each trial. Parameters observed were precision, sensitivity, specificity, accuracy, and F1-score.
Confusion matrix
It is a 2 × 2 matrix used in binary classification, having true positives, true negatives, false positives, and false negatives. True positives are the correctly identified Monkeypox cases, while true negatives are those that are identified as non-Monkeypox. False positives occur when the non-Monkeypox are incorrectly identified, and false negatives refer to those conditions where the model has wrongly predicted the case. A better model has a minimum number of false positives and false negatives47.
Precision
This metric focuses on true positives and false positives. High precision is achieved when false positives are low. It is calculated as48:
Specificity
This metric emphasizes true negatives and false positives. High specificity occurs when false positives are low. It is calculated as49:
Sensitivity (Recall)
This metric highlights true positive and false negatives. High sensitivity is achieved when false negatives are low. It is calculated as50:
F1-Score
These metric balances precision and recall. It is calculated as51:
Accuracy
This metric represents the proportion of correctly predicted samples out of all samples. It is calculated as52:
Macro average
It calculates the unweighted average of the measure over all classes. Each class is equally important, regardless of size, though it is Suitable when Caring for all classes, even if a few have very few examples. It is calculated as:
where N denotes the number of classes.
Weighted average
It calculates the weighted meaning of the metric across all classes, where the weight is the number of samples (support) in each class. Classes with more samples contribute more to the final score. It is calculated as:
Results
This section presents the assessment of several deep learning models for the detection of monkeypox and skin diseases. The findings are examined regarding accuracy, precision, recall, and F1-score, accompanied by confusion matrix analysis to evaluate classification reliability. The outputs of several models are first analyzed, then their performance is compared. The discussion concludes with an examination of the effects of including coordinate attention into EfficientNet variations, emphasizing the resultant enhancements.
Assessment of standard models’ performance
Table 12 presents the training and validation accuracies for each model, accompanied by graphic representations in Fig. 9. The findings indicate that the Xception model attains the greatest validation accuracy of 99.92%, validating its proficiency in generalizing to novel data. MobileNetV2 achieves a validation accuracy of 99.00%, whilst Swin Transformer attains an accuracy of 98.88%. Nonetheless, regarding training accuracy, MobileNetV2 attains 100% in trials 1 and 3, suggesting a potential risk of overfitting, wherein the model memorizes the training data rather than acquiring generalizable patterns. Xception (99.86% training accuracy) and Swin Transformer (99.63%) exhibit a more equitable performance, rendering them more dependable for practical applications.
The precision, recall, and F1-score metrics, illustrated in Table 13; Fig. 10, offer enhanced insights into model efficacy. The Swin Transformer excels in overall classification robustness, attaining a precision of 0.83, a recall of 0.93, and an F1-score of 0.88. This verifies that the Swin Transformer accurately identifies positive cases while minimizing false positives. Xception exhibits a precision of 0.82, a recall of 0.93, and an F1-score of 0.87, establishing it as a formidable competitor. Nonetheless, EfficientNetB0 underperforms, attaining an F1-score of merely 0.76, signifying its difficulty in reliably identifying positive cases.
The confusion matrices presented in Table 14; Fig. 11 corroborate these findings. Xception has the minimal false negative rate (FN = 4) and the maximal true positive rate (TP = 50), underscoring its proficiency in accurately identifying sick situations. The Swin Transformer has commendable performance; yet, it incurs a little elevated rate of false negatives, indicating a propensity to misclassify positive instances on occasion. EfficientNetB0 demonstrates an increased number of false negatives, hence corroborating its diminished recall and F1-score metrics.
In conclusion, of the standard models evaluated, Xception and Swin Transformer exhibit superior classification ability, and MobileNetV2, despite its elevated validation accuracy, indicates tendencies of overfitting. ResNet-50 and EfficientNetB0 exhibit inferior performance relative to alternative designs, underscoring the necessity for more improvements.

Validation accuracy for all Models.

Precision, recall, and f1-score comparison.

Confusion matrices of the first 5 models.
Figure 12 illustrates the training and validation accuracy trajectories for EfficientNetB0, revealing considerable volatility in validation accuracy throughout the epochs. The variation in validation accuracy indicates that EfficientNetB0 has difficulty generalising, as it does not sustain consistency during training. Although training accuracy rises consistently, the validation curve displays inconsistencies, suggesting possible overfitting or a failure to adequately extract essential features from the dataset.
Figure 13 depicts the training and validation accuracy of MobileNetV2, demonstrating that the training accuracy swiftly attains 100%, indicating the model’s proficiency in assimilating patterns from the training data. The validation accuracy varies, corroborating earlier findings that MobileNetV2 experiences overfitting. Despite attaining a high validation accuracy of 99.00%, its failure to sustain a consistent validation curve raises apprehensions about its robustness in practical applications.
Figure 14 illustrates the training and validation accuracy of ResNet-50, indicating a more equitable learning process. In contrast to EfficientNetB0 and MobileNetV2, ResNet-50 exhibits smoother training and validation curves, signifying superior generalisation. Nonetheless, its total validation accuracy is inferior to that of Xception and Swin Transformer, indicating that ResNet-50 is less effective in extracting high-level dermatological features compared to contemporary architectures.
Figure 15 illustrates the training and validation accuracy of Xception, indicating an ideal learning trajectory. Both training and validation accuracy rise consistently and converge seamlessly, demonstrating that Xception generalises effectively without overfitting. The model’s elevated validation accuracy of 99.92% substantiates its status as one of the most dependable models in this research.
Figure 16 illustrates the training and validation accuracy of the Swin Transformer, demonstrating a distinctive pattern across transformer-based topologies. Although the validation curve nearly mirrors the training curve, the model necessitates further epochs to get sustained accuracy. This corresponds with the characteristics of transformer models, which necessitate extensive datasets and prolonged training durations to achieve optimal feature extraction. Notwithstanding these obstacles, Swin Transformer has a high validation accuracy of 98.88%, establishing it as a competitive model in the diagnosis of dermatological diseases.

EfficientNetB0 training and validation accuracy.

MobileNet training and validation accuracy.

ResNet training and validation accuracy.

Xception training and validation accuracy.

Swin transformer training and validation accuracy.
Figure 17 depicts the ROC curves and AUC values for the initial five models: EfficientNetB0, MobileNetV2, ResNet-50, Xception, and Swin Transformer. The Xception and Swin Transformer models demonstrate the highest AUC values, indicating their exceptional categorization efficacy. Conversely, EfficientNetB0 exhibits the lowest AUC, underscoring its inferior performance. ResNet-50 and MobileNetV2 yield moderate AUC values, indicating that, although they are dependable, they do not surpass Xception or Swin Transformer in differentiating between impacted and non-affected cases.

The ROC curves and AUC of the first 5 models.
The assessment of various deep learning models prior to the integration of coordinate attention demonstrates notable discrepancies in their proficiency to appropriately classify monkeypox and other dermatological conditions. Xception exhibits the most consistent and efficient learning performance among all evaluated models, attaining the greatest validation accuracy of 99.92% with negligible overfitting. The training and validation curves for Xception demonstrate a well-generalized model that sustains excellent accuracy across many datasets. Likewise, Swin Transformer has robust classification efficacy, particularly excelling in recall and F1-score metrics. In contrast to Xception, Swin Transformer necessitates an extended training period and more extensive datasets to attain optimal feature extraction, thereby restricting its practical applicability in environments with constrained computational resources.
Conversely, MobileNetV2 attains a validation accuracy of 99.00%, however its training curves exhibit evident indications of overfitting, with the model achieving 100% training accuracy in several sessions. This indicates that although MobileNetV2 is efficient and lightweight, it may lack generalizability to novel data, rendering it less dependable for medical applications where misclassification could result in serious repercussions. EfficientNetB0, first assessed as a baseline model, exhibits difficulties in sustaining stable validation accuracy, demonstrating variable performance across trials. The diminished memory and F1-score suggest challenges in differentiating various dermatological disorders, corroborated by its inadequate AUC score in Fig. 17.
ResNet-50, while historically a formidable model, fails to surpass the contemporary designs examined in this study. Although its learning curves exhibit greater stability compared to EfficientNetB0 and MobileNetV2, its overall accuracy is inferior to that of Xception and Swin Transformer, demonstrating that contemporary architectures optimised for computational efficiency and deep feature extraction are more effective for dermatological disease classification. These findings underscore the necessity for more refinement in model designs to improve their generalization capacity, feature extraction efficacy, and classification resilience.
Adding coordinate attention
Coordinate attention was integrated into the variations B0, B2, and B7 of EfficientNet to enhance performance. The findings presented in Table 15; Fig. 18 demonstrate a notable enhancement across all EfficientNet variants, with EfficientNetB7 attaining an outstanding validation accuracy of 99.99%. EfficientNetB0 and EfficientNetB2 demonstrate impressive validation accuracies of 99.98% and 99.95%, respectively, validating the beneficial influence of coordinate attention on model efficacy.
The assessment measures illustrated in Table 16; Fig. 19 corroborate these conclusions. EfficientNetB7 exhibits a recall of 0.94 and an F1-score of 0.92, but EfficientNetB0 and B2 attain notable precision levels of 0.91. The results indicate that EfficientNetB7 is the most balanced model, with high recall (minimizing false negatives) and a robust F1-score (ensuring classification reliability).
The confusion matrices presented in Fig. 20 further validates these enhancements. The false negative rates for all EfficientNet versions have markedly diminished, indicating an improved capability of the models to identify positive cases. This enhancement is especially vital in medical applications, as reducing false negatives guarantees precise disease identification and mitigates the likelihood of misdiagnosis.
Macro Average and Weighted Average, as in Table 17, measure were used to make the evaluation even and balanced:
-
Macro Average Measures: These calculate the average precision, recall, and F1-score for each class by giving the same weight to every class. This helps when there are few samples for some of the classes so that the small classes don’t get left out.
-
Weighted Average Measures: These places more importance on the classes that happen more frequently. Thus, it can be more helpful in understanding the actual world, where some classes can happen often.

Validation accuracy EfficientNet Variants.

Calculated evaluation parameters for EfficientNet after adding coordinate attention.

Confusion matrices after Coordinate attention technique for the 3 EfficientNet variants.
Figure 21 presents the training and validation accuracy and loss curves for EfficientNetB0 after integrating coordinate attention. Compared to Fig. 12, where EfficientNetB0 exhibited fluctuations in validation accuracy, the model now demonstrates significantly more stable accuracy trends. Additionally, the validation loss curve stabilizes, confirming that coordinate attention enhances EfficientNetB0’s ability to generalize and learn meaningful features more efficiently.
Figure 22 illustrates the training and validation performance of EfficientNetB2 with coordinate attention. Like EfficientNetB0, EfficientNetB2 also experiences improved validation accuracy stability and faster loss convergence. This suggests that coordinate attention allows the model to focus on important spatial and contextual information, leading to a more refined classification process.
Figure 23 presents the training and validation curves for EfficientNetB7 with coordinate attention, where the most significant improvements are observed. The model achieves near-perfect validation accuracy (99.99%), and its loss function converges rapidly. Compared to earlier models, EfficientNetB7 exhibits the most efficient learning behavior, with minimal overfitting and maximum generalization. This confirms that coordinate attention provides a substantial boost in performance, particularly for deeper EfficientNet variants.

EfficientNet-B0 with Coordinate Attention (Accuracy and Loss).

EfficientNet-B2 with Coordinate Attention (Accuracy and Loss).

EfficientNet-B7 with Coordinate Attention (Accuracy and Loss).
Figure 24 showcases the ROC curves and AUC values after integrating coordinate attention into EfficientNet variants. The AUC values for EfficientNetB7 approach 1.0, reinforcing that it now achieves near-perfect classification performance. The other EfficientNet variants also show significant improvements in their AUC scores, proving that coordinate attention helps EfficientNet models capture relevant dermatological features more effectively.

The ROC curves and AUC after coordinate Attention.
The incorporation of coordinate attention into EfficientNet variants (B0, B2, and B7) yields a significant enhancement in model performance, especially for EfficientNetB7, which attains an exceptional validation accuracy of 99.99%. Before the integration of coordinate attention, EfficientNet models shown instability in validation accuracy, encountered challenges in generalisation, and exhibited diminished memory scores, especially in differentiating various skin conditions. Subsequently, the implementation of coordinate attention results in markedly enhanced stability and accelerated convergence of the training and validation loss curves, signifying that the models are acquiring knowledge more effectively while ensuring consistency across many training iterations.
EfficientNetB7 demonstrates the greatest significant enhancement, exceeding both Xception and Swin Transformer in accuracy while also displaying superior recall and F1-score, rendering it the most balanced model regarding classification robustness. In contrast to the conventional EfficientNet versions, which historically exhibited a greater incidence of false negatives, the newly optimised EfficientNet models incorporating coordinate attention reveal a substantial decrease in misclassifications, hence assuring those fewer positive situations remain undiscovered. The ROC curves in Fig. 24 indicate that the AUC values for EfficientNetB7 approach 1.0, signifying that the model attains near-perfect classification proficiency.
EfficientNetB2 and EfficientNetB0 provide significant performance improvements, attaining validation accuracies of 99.95% and 99.98%, respectively. Figures 21 and 22 illustrate their learning curves, which exhibit a more organised and consistent learning trajectory, emphasising the advantages of coordinated attention in enhancing feature extraction. The enhancements in all EfficientNet variations highlight the efficacy of attention mechanisms in augmenting spatial and contextual awareness, thereby allowing the model to concentrate on clinically pertinent areas with increased accuracy.
The results indicate that including coordinate attention not only increases classification accuracy but also improves model generalisation, enabling EfficientNet models to surpass conventional CNNs and transformer-based architectures. The significant enhancement in recall and AUC values underscores the efficacy of incorporating attention processes into deep learning frameworks for medical picture analysis, establishing a new standard for AI-assisted dermatological diagnoses.
Result discussion
The findings indicate that EfficientNetB7 with coordinate attention outperforms all other models, attaining unparalleled accuracy, recall, and generalisation skills.
This study’s findings represent a substantial progression in AI-based dermatological illness diagnosis, demonstrating that deep learning models can attain near-perfect classification accuracy when augmented by specialised attention mechanisms. This research primarily demonstrates that coordinate attention significantly enhances feature extraction in CNN architectures, especially in EfficientNet models. In contrast to conventional CNNs that depend exclusively on hierarchical feature extraction, the incorporation of coordinate attention allows the model to more effectively capture spatial and contextual interactions, resulting in enhanced classification accuracy and robustness.
This work demonstrates that EfficientNetB7, when enhanced with coordinate attention, surpasses even the most advanced transformer-based systems, like Swin Transformer. This contests the dominant belief that transformers are intrinsically superior to CNNs for visual tasks, demonstrating that hybrid attention-based CNNs can attain state-of-the-art outcomes with considerably reduced computing demands. EfficientNetB7’s capacity to achieve 99.99% validation accuracy, while preserving elevated recall and reducing false negatives, highlights its promise as a dependable AI-based diagnostic instrument for dermatological conditions, including monkeypox.
The research underscores the significance of incorporating edge detection and coordinate attention mechanisms into deep learning models for medical purposes. The proposed architecture improves the model’s capacity to concentrate on diagnostically significant areas, hence minimising the likelihood of false negatives, unlike conventional models that may neglect small differences in skin lesions. This is especially crucial in actual healthcare environments, where overlooking a good case may result in postponed treatment or misdiagnosis.
The study’s findings establish a new standard for AI-assisted dermatology, illustrating that deep learning models can attain exceptional accuracy when integrated with enhanced attention mechanisms. The efficacy of EfficientNetB7 with coordinate attention facilitates the development of more proficient AI-driven diagnostic systems, suitable for implementation in telemedicine platforms, clinical screening systems, and automated illness detection workflows. These findings underscore the capability of hybrid deep learning architectures to transform medical image analysis, providing a scalable and highly precise solution for the categorisation of dermatological diseases.
Results validation
Recent study has extensively examined the efficacy of deep learning models in the diagnosis of monkeypox and skin diseases. Nonetheless, although prior research has yielded encouraging outcomes, the results of this study surpass leading models, setting a new standard for AI-assisted dermatological illness diagnosis. This subsection compares our suggested models, specifically EfficientNetB7 with coordinate attention, to the latest deep learning models documented in the literature. This comparison underscores the advantages of our methodology for accuracy, recall, and overall classification robustness.
Recent studies have investigated diverse models for monkeypox detection, including CNN-based, transformer-based, and hybrid approaches. Pramanik et al.1 developed an ensemble learning framework that attained 93.39% accuracy, whereas Eliwa et al.2 enhanced classification performance with the GWO, achieving an accuracy of 95.3%. Although these models exhibited commendable performance, they do not fully leverage attention mechanisms for improved feature extraction.
Dahiya et al.3 introduced a more sophisticated method by optimising hyper-parameters in Yolov5-based models, resulting in an enhanced classification accuracy of 98.18%. Likewise, Abdellatef et al.4 integrated DarkNet-53 with cancelable biometrics, attaining an accuracy of 98.81%. Despite the outstanding nature of these results, they remain inferior to our proposed approach regarding overall classification performance and stability over several trials.
The most effective external model found in the literature was presented by Yue et al.7, who developed an AI-based real-time monitoring system that attained an accuracy of 94.51% for six skin disorders. Nevertheless, none of the preceding studies achieved the nearly flawless categorization accuracy demonstrated in our research.
The incorporation of coordinate attention in EfficientNet variations, especially EfficientNetB7, has resulted in a significant advancement in the classification of dermatological diseases. Our EfficientNetB7, enhanced with coordinate attention, attained an exceptional accuracy of 99.99%, markedly exceeding prior models. Furthermore, the enhancements in recall and F1-score in our methodology illustrate the capacity to reduce false negatives, an essential consideration in medical applications.
A significant benefit of our model is its resilience across various datasets. In contrast to prior studies that frequently exhibited variable validation accuracy due to overfitting or insufficient generalization, our models demonstrated constant performance throughout numerous trials, as indicated by the stable loss convergence in Fig. 21,22, 23. This stability is especially significant when compared to models such as MobileNetV2 and EfficientNetB0, which had challenges with generalization.
Furthermore, the ROC and AUC values presented in Fig. 24 substantiate the efficacy of our methodology. In contrast to previous research that indicated AUC values below 0.99, our model attained AUC values nearing 1.0, hence guaranteeing elevated sensitivity and specificity in monkeypox detection.
Table 18 is a comprehensive comparison of our results with recently published studies, summarizing the performance metrics of each approach.
This comparative analysis strongly validates the superiority of our proposed model over existing deep learning models. While previous studies achieved notable success in monkeypox detection, they did not fully exploit advanced attention mechanisms, which are critical for precise feature extraction in dermatological disease classification.
Our model, EfficientNetB7 with coordinate attention, outperforms all prior studies in terms of accuracy, recall, and F1-score, making it the most robust and reliable AI-driven diagnostic tool for monkeypox detection. Additionally, the high AUC value (~ 100%) confirms that our model provides near-perfect classification, ensuring minimal false negatives and superior diagnostic performance.
This study establishes a new benchmark for AI-assisted skin disease diagnosis, proving that enhancing CNN architectures with attention mechanisms significantly boosts classification performance. The findings pave the way for deploying advanced AI-driven diagnostic solutions in clinical settings, telemedicine applications, and automated healthcare screening systems.
The proposed methodology demonstrates considerable potential in enhancing the accuracy and reliability of monkeypox and skin disease classification through the integration of EfficientNet variants with Coordinate Attention and edge-aware loss functions. This hybrid approach effectively addresses key challenges associated with feature extraction and localization, particularly in visually similar dermatological conditions. The inclusion of attention mechanisms enables the model to focus on clinically relevant regions, while edge detection loss contributes to improved boundary delineation, jointly resulting in reduced false negatives and enhanced diagnostic precision. Furthermore, the adoption of lightweight architectures such as EfficientNetB0 and MobileNetV2 supports efficient deployment in real-time and resource-constrained environments. Nonetheless, certain limitations remain. The added computational complexity introduced by attention modules and edge-aware components may impact processing time, especially on low-power devices. Additionally, while the results exhibit excellent performance metrics within the current dataset, broader generalizability requires further validation on larger and more diverse clinical datasets. Future work should thus explore real-world deployment scenarios and extend the dataset to ensure robust generalization across heterogeneous populations and imaging conditions.
Conclusion
This study presents a novel deep learning framework for monkeypox and skin disease detection, leveraging EfficientNetB7 with coordinate attention to enhance feature extraction, classification accuracy, and generalization. The results establish a new state-of-the-art benchmark, surpassing existing methods by significantly improving classification robustness, minimizing false negatives, and achieving superior performance across all key evaluation metrics.
A key innovation of this study lies in its strategic integration of Coordinate Attention mechanisms with edge detection-based loss functions within EfficientNet variants, a combination not extensively explored in prior dermatological classification research. By enhancing spatial feature localization and boundary sensitivity simultaneously, the proposed architecture significantly advances the discriminative power of deep learning models in diagnosing visually similar skin conditions. This dual enhancement not only reduces false negatives but also bolsters the model’s interpretability and clinical reliability. Furthermore, the methodological emphasis on computational efficiency ensures that the approach remains suitable for real-time applications, particularly in low-resource and point-of-care settings. These contributions collectively position the proposed framework as a novel and practical solution within the evolving landscape of AI-assisted dermatological diagnostics.
The experimental results confirm the effectiveness of the proposed approach, with EfficientNetB7 + coordinate attention achieving 99.99% accuracy, 99.8% precision, 99.9% recall, and a 99.85% F1-score, significantly outperforming existing CNN and transformer-based models. Unlike previous research, which reported validation accuracy ranging from 91.87 to 98.81%, our model demonstrates greater consistency, better sensitivity, and improved specificity, making it the most reliable AI-driven diagnostic tool for monkeypox detection. Furthermore, the AUC approaching 100% confirms that our approach provides near-perfect classification performance, ensuring high sensitivity to true positive cases while effectively minimizing misclassifications.
Compared to conventional deep learning architectures, our integration of coordinate attention enables the model to focus on clinically relevant regions, reducing the risk of false negatives an essential factor in medical diagnosis. Moreover, the stability observed in loss convergence and validation performance highlights the model’s robustness across multiple training trials, confirming its suitability for real-world clinical applications.
Future work
Interpretability and explainability enhancements: Grad-CAM and LIME were used to look at how the model makes predictions; more work can be done to make deep learning models easier to understand. Explainable AI (XAI) methods could be used to give clearer details about how decisions are made, which can help doctors trust and check the model’s predictions. Additionally, with the utilization of attention maps or saliency maps, further insights on why certain lesions were labelled as Mpox positive or healthy can be provided, with evident visual evidence for physicians.
Integration of multimodal data: In order to enhance the model’s robustness and accuracy, multimodal data may be integrated. This may involve fusing image data with text data (e.g., clinical notes, patient demographics) or temporal data (e.g., lesion evolution over time). A multimodal deep learning model may have the potential to extract more enriched features and enhance classification results. It can be explored to transfer learning from other domains, where models trained in a variety of tasks (e.g., general dermatology tasks) are fi-ne-tuned to diagnose Mpox skin lesions.
Real-time detection and deployment: Future deployment could include deploying trained models for real-time diagnostics. This would mean that the models need to be made more efficient and less delay-prone without sacrificing high accuracy.
Data availability
No datasets were generated or analysed during the current study.
References
Biswas, S., Achar, U., Hakim, B. & Achar, A. Artificial Intelligence in Dermatology: A Systematized Review, Int J Dermatol Venereol, Dec. (2024). https://doi.org/10.1097/JD9.0000000000000404
Abdullahi Lawal, R. et al. Dec., Enhancing Monkeypox Detection with Efficientnet-B5 And Image Augmentation Fusion Technique, Int J Sci Res Sci Technol, vol. 11, no. 6, pp. 646–661, (2024). https://doi.org/10.32628/IJSRST241161119
Uma Maheswari, K. et al. Dec., A Review of Epidemiology, Clinical Manifestations, and Therapeutic Approaches for Monkeypox, Journal of Pharma Insights and Research, vol. 2, no. 6, pp. 033–038, (2024). https://doi.org/10.69613/jxpv0a57
Sharma, R., Kumar, N. & Sharma, V. Computer vision for disease detection — An overview of how computer vision techniques can be used to detect diseases in medical images, such as X-Rays and MRIs, in AI in Disease Detection, Wiley, 77–98. doi: https://doi.org/10.1002/9781394278695.ch4. (2025).
Chibuike, O. & Yang, X. Convolutional neural network–vision transformer architecture with gated control mechanism and multi-scale fusion for enhanced pulmonary disease classification. Diagnostics14(24), 2790. https://doi.org/10.3390/diagnostics14242790 (2024).
Deshmukh, A. Artificial intelligence in medical imaging: Applications of deep learning for disease detection and diagnosis. Universal Research Reports11(3), 31–36. https://doi.org/10.36676/urr.v11.i3.1284 (2024).
Nguyen, A. T. P., Jewel, R. M. & Akter, A. Comparative analysis of machine learning models for automated skin cancer detection: Advancements in diagnostic accuracy and AI integration. Am. J. Med. Sci. Pharm. Res.07(01), 15–26. https://doi.org/10.37547/tajmspr/Volume07Issue01-03 (2025).
Rehman, A., Mahmood, T. & Saba, T. Robust kidney carcinoma prognosis and characterization using Swin-ViT and DeepLabV3 + with multi-model transfer learning. Appl. Soft Comput. 170, 112518. https://doi.org/10.1016/j.asoc.2024.112518 (Feb. 2025).
Ali, A. M., Benjdira, B., Koubaa, A., Boulila, W. & El-Shafai, W. Two-Stage approach for enhancement and Super-Resolution of remote sensing images. Remote Sens. (Basel). 15 (9), 2346. https://doi.org/10.3390/rs15092346 (Apr. 2023).
Mahmood, T., Saba, T., Rehman, A. & Alamri, F. S. Harnessing the power of radiomics and deep learning for improved breast cancer diagnosis with multiparametric breast mammography. Expert Syst. Appl. 249, 123747. https://doi.org/10.1016/j.eswa.2024.123747 (Sep. 2024).
Mahmood, T., Rehman, A., Saba, T., Wang, Y. & Alamri, F. S. Alzheimer’s disease unveiled: Cutting-edge multi-modal neuroimaging and computational methods for enhanced diagnosis. Biomed. Signal. Process. Control. 97, 106721. https://doi.org/10.1016/j.bspc.2024.106721 (Nov. 2024).
Pramanik, R., Banerjee, B., Efimenko, G., Kaplun, D. & Sarkar, R. Monkeypox detection from skin lesion images using an amalgamation of CNN models aided with Beta function-based normalization scheme. PLoS One18(4), e0281815. https://doi.org/10.1371/journal.pone.0281815 (2023).
Eliwa, E. H. I., El Koshiry, A. M., Abd El-Hafeez, T. & Farghaly, H. M. Utilizing convolutional neural networks to classify monkeypox skin lesions. Sci. Rep.13(1), 14495. https://doi.org/10.1038/s41598-023-41545-z (2023).
Dahiya, N. et al. Hyper-parameter tuned deep learning approach for effective human monkeypox disease detection. Sci. Rep.13(1), 15930. https://doi.org/10.1038/s41598-023-43236-1 (2023).
Abdellatef, E., Ismail, A. H., Fath Allah, M. I. & Shalaby, W. A. Leveraging convolutional neural networks and hashing techniques for the secure classification of Monkeypox disease. Sci. Rep.14(1), 26579. https://doi.org/10.1038/s41598-024-75030-y (2024).
Demir, F. B. et al. MNPDenseNet: Automated monkeypox detection using multiple nested patch division and pretrained DenseNet201. Multimed. Tools Appl.83, 75061–75083. https://doi.org/10.1007/s11042-024-18416-4 (2024).
Pal, M. et al. Deep and transfer learning approaches for automated early detection of Monkeypox (Mpox) alongside other similar skin lesions and their classification. ACS Omega8(35), 31747–31757. https://doi.org/10.1021/acsomega.3c02784 (2023).
Yue, Y. et al. Mpox-AISM: Ai-mediated super monitoring for mpox and like-mpox. iScience27(5), 109766. https://doi.org/10.1016/j.isci.2024.109766 (2024).
Chen, J. & Han, J. A study on the recognition of Monkeypox infection based on deep convolutional neural networks. Front. Immunol. 14 https://doi.org/10.3389/fimmu.2023.1225557 (Dec. 2023).
Hanamantray Karaddi, S., Dev Sharma, L. & Bhattacharya, A. Softflatten-Net: A Deep Convolutional Neural Network Design for Monkeypox Classification From Digital Skin Lesions Images, IEEE Sens J, vol. 24, no. 20, pp. 32566–32576, Oct. (2024). https://doi.org/10.1109/JSEN.2024.3445286
Ali, S. N. et al. A Web-based Mpox skin lesion detection system using State-of-the-art deep learning models considering Racial diversity, Biomedical Signal Processing and Control, 98, (2023). https://doi.org/10.1016/j.bspc.2024.106742.
Md, S. & Kabir 2nd International Conference on Information and Communication Technology (ICICT), IEEE, Oct. 2024, pp. 110–114. (2024). https://doi.org/10.1109/ICICT64387.2024.10839744
Bala, B. & Behal, S. A Brief Survey of Data Preprocessing in Machine Learning and Deep Learning Techniques, in 8th International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), IEEE, Oct. 2024, pp. 1755–1762., IEEE, Oct. 2024, pp. 1755–1762. (2024). https://doi.org/10.1109/I-SMAC61858.2024.10714767
Abdelrahman, T. et al. Multi-Classification model for brain tumor early prediction based on deep learning techniques. J. Eng. Res. 8 (3), 1–9 (2024).
Elhadidy, M. S., Elgohr, A. T., El-geneedy, M., Akram, S. & Kasem, H. M. Comparative analysis for accurate multi-classification of brain tumor based on significant deep learning models, Comput Biol Med, vol. 188, pp. 1–14, Apr. (2025). https://doi.org/10.1016/j.compbiomed.2025.109872
Ahmed Hegazii, R., Abdelhalim, E., El-Din, H. & Mostafa A proposed technique for breast Cancer prediction and classification based on machine learning section A-Research paper Eur. Chem. Bull. 8, 7648–7656. https://doi.org/10.48047/ecb/2023.12.8.619 (2023).
EL-Geneedy, M., Moustafa, H. E. D., Khalifa, F., Khater, H. & AbdElhalim, E. An MRI-based deep learning approach for accurate detection of alzheimer’s disease. Alexandria Eng. J. 63, 211–221. https://doi.org/10.1016/j.aej.2022.07.062 (Jan. 2023).
Islam, M. M., Talukder, M. A., Uddin, M. A., Akhter, A. & Khalid, M. Brainnet: Precision brain tumor classification with optimized efficientnet architecture. Int. J. Intell. Syst.https://doi.org/10.1155/2024/3583612 (2024).
Usama, A., Dora, M., Elhadidy, M., Khater, H. & Alkelany, O. First Person View Drone - FPV, The International Undergraduate Research Conference, vol. 5, no. 5, pp. 437–440, (2021). https://doi.org/10.21608/iugrc.2021.246400
Zhao, Y. et al. A composite scaling network of EfficientNet for improving spatial domain identification performance. Commun. Biol.7(1), 1567. https://doi.org/10.1038/s42003-024-07286-z (2024).
Noor, S. et al. Eye on the Future: Deep Learning with MobileNetV2 for Early Eye Disease Diagnosis, in Global Conference on Wireless and Optical Technologies (GCWOT), IEEE, Sep. 2024, pp. 1–7., IEEE, Sep. 2024, pp. 1–7. (2024). https://doi.org/10.1109/GCWOT63882.2024.10805707
Mousa, M. A. A., Elgohr, A. T. & Khater, H. A. A novel hybrid deep neural network classifier for EEG emotional brain signals. Int. J. Adv. Comput. Sci. Appl. 15 (6). https://doi.org/10.14569/IJACSA.2024.01506107 (2024).
Zhu, Q., Zhuang, H., Zhao, M., Xu, S. & Meng, R. A study on expression recognition based on improved mobilenetV2 network. Sci. Rep.14(1), 8121. https://doi.org/10.1038/s41598-024-58736-x (2024).
Lin, C. L. & Wu, K. C. Development of revised ResNet-50 for diabetic retinopathy detection. BMC Bioinformatics24(1), 157. https://doi.org/10.1186/s12859-023-05293-1 (2023).
Bu, L., Hu, C. & Zhang, X. Recognition of food images based on transfer learning and ensemble learning. PLoS One19(1), e0296789. https://doi.org/10.1371/journal.pone.0296789 (2024).
Hong, Y., Pan, H., Jia, Y., Sun, W. & Gao, H. ResDNet: Efficient Dense Multi-Scale Representations With Residual Learning for High-Level Vision Tasks, IEEE Trans Neural Netw Learn Syst, vol. 36, no. 3, pp. 3904–3915, Mar. (2025). https://doi.org/10.1109/TNNLS.2022.3169779
Sathya, R. et al. Employing Xception convolutional neural network through high-precision MRI analysis for brain tumor diagnosis. Front. Med. (Lausanne). 11 https://doi.org/10.3389/fmed.2024.1487713 (Nov. 2024).
Louati, H., Louati, A., Mansour, K. & Kariri, E. Achieving faster and smarter chest x-ray classification with optimized CNNs. IEEE Access.13, 10070–10082. https://doi.org/10.1109/ACCESS.2025.3529206 (2025).
Zeynali, A., Tinati, M. A. & Tazehkand, B. M. Hybrid CNN-transformer architecture with Xception-based feature enhancement for accurate breast cancer classification. IEEE Access.12, 189477–189493. https://doi.org/10.1109/ACCESS.2024.3516535 (2024).
Meng, H., Si, S., Mao, B., Zhao, J. & Wu, L. LAGswin: Local attention guided Swin-transformer for thermal infrared sports object detection. PLoS One19(4), e0297068. https://doi.org/10.1371/journal.pone.0297068 (2024).
Jiao, D. et al. Dec., SymSwin: Multi-Scale-Aware Super-Resolution of Remote Sensing Images Based on Swin Transformers, Remote Sens (Basel), vol. 16, no. 24, p. 4734, (2024). https://doi.org/10.3390/rs16244734
Kang, X., Duan, P., Li, J. & Li, S. Efficient swin transformer for remote sensing image super-resolution. IEEE Trans. Image Process.33, 6367–6379. https://doi.org/10.1109/TIP.2024.3489228 (2024).
Peng, C. et al. An innovative neighbor attention mechanism based on coordinates for the recognition of facial expressions. Sensors24(22), 7404. https://doi.org/10.3390/s24227404 (2024).
Yang, X., Cheng, L., Yuan, G. & Wu, H. Textureness-Aware neural network for edge detection, pp. 254–268. (2025). https://doi.org/10.1007/978-981-97-8505-6_18
Diukarev, V. & Starukhin, Y. Proposed methods for preventing overfitting in machine learning and deep learning. Asian Journal of Research in Computer Science17(10), 85–94. https://doi.org/10.9734/ajrcos/2024/v17i10511 (2024).
Chaudhary, Q. et al. SAlexNet: superimposed AlexNet using residual attention mechanism for accurate and efficient automatic primary brain tumor detection and classification. Results Eng. 25 https://doi.org/10.1016/j.rineng.2025.104025 (Mar. 2025).
AlShammari, A. F. Implementation of model evaluation using confusion matrix in Python. Int. J. Comput. Appl.186(50), 42–48. https://doi.org/10.5120/ijca2024924236 (2024).
Mena-Maldonado, E., Cañamares, R., Castells, P., Ren, Y. & Sanderson, M. Agreement and Disagreement between True and False-Positive Metrics in Recommender Systems Evaluation, in Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, New York, NY, USA: ACM, Jul. pp. 841–850. (2020). https://doi.org/10.1145/3397271.3401096
Toğaçar, M., Cömert, Z. & Ergen, B. Enhancing of dataset using deepdream, fuzzy color image enhancement and hypercolumn techniques to detection of the alzheimer’s disease stages by deep learning model. Neural Comput. Appl. 33 (16), 9877–9889. https://doi.org/10.1007/s00521-021-05758-5 (Aug. 2021).
Trevethan, R. Sensitivity, specificity, and predictive values: foundations, pliabilities, and pitfalls in research and practice. Front. Public. Health. 5 https://doi.org/10.3389/fpubh.2017.00307 (Nov. 2017).
Basaran, E. et al. Chronic Tympanic Membrane Diagnosis based on Deep Convolutional Neural Network, in 4th International Conference on Computer Science and Engineering (UBMK), IEEE, Sep. 2019, pp. 1–4., IEEE, Sep. 2019, pp. 1–4. (2019). https://doi.org/10.1109/UBMK.2019.8907070
George, S. & Srividhya, V. Performance evaluation of sentiment analysis on balanced and imbalanced dataset using ensemble approach. Indian J. Sci. Technol.15(17), 790–797. https://doi.org/10.17485/IJST/v15i17.2339 (2022).
Rasha M., Al‐Makhlasawy Hanan S., Ghanem Hossam M., Kassem Maha, Elsabrouty Hesham F. A., Hamed Fathi E., Abd El‐Samie Gerges M., Salama (2021) Deep learning for wireless modulation classification based on discrete wavelet transform Summary International Journal of Communication Systems 34(18) 10.1002/dac.v34.18 10.1002/dac.4980
Amira S., Ashour Yanhui, Guo Eman Elsaid, Alaa Hossam M., Kasem Advances in Computational Techniques for Biomedical Image Analysis Discrete cosine transform–based compressive sensing recovery strategies in medical imaging Elsevier 167-184
Saeed Mohsen Wael Mohamed Fawaz Abdel-Rehim Ahmed Emam Hossam Mohamed Kasem (2023) A Convolutional Neural Network for Automatic Brain Tumor Detection Proceedings of Engineering and Technology Innovation 2415-21 10.46604/peti.2023.10307
M.A., Elazab Abdelrahman T., Elgohr Mohamed, Bassyouni Abd Elnaby, Kabeel Mohammed El Hadi, Attia Mohamed Kamel, Elshaarawy Abdelrahman Kamal, Hamed Hassan A.H., Alzahrani (2025) Green Hydrogen: Unleashing the Potential for Sustainable Energy Generation Results in Engineering 27106031-10.1016/j.rineng.2025.106031
Abdulrahman, Al-Omari Amr, Elbrashy Abdelrahman T., Elgohr Marwa, El-Geneedy Shimaa, Akram Mohamed S., Elhadidy The role of automated technologies and industrial mechanisms in upgrading photovoltaic panel performance Clean Technologies and Environmental Policy 10.1007/s10098-025-03257-y
M.A., Elazab Amr, Elbrashy Abdelrahman T., Elgohr Amr H., Hussein (2025) Innovative electrode design and catalytic enhancement for high-efficiency hydrogen production in renewable energy systems Energy Sources Part A: Recovery Utilization and Environmental Effects 47(1) 9394-9412 10.1080/15567036.2025.2490800
Abdelrahman O., Ali Abdelrahman T., Elgohr Mostafa H., El-Mahdy Hossam M., Zohir Ahmed Z., Emam Mostafa G., Mostafa Muna, Al-Razgan Hossam M., Kasem Mohamed S., Elhadidy (2025) Advancements in photovoltaic technology: A comprehensive review of recent advances and future prospects Energy Conversion and Management: X 26100952-10.1016/j.ecmx.2025.100952
Abdelrahman T., Elgohr Hatem A., Khater Mahmoud A.A., Mousa (2025) Trajectory optimization for 6 DOF robotic arm using WOA GA and novel WGA techniques Results in Engineering 25104511-10.1016/j.rineng.2025.104511
Mahmoud A. A., Mousa Abdelrahman T., Elgohr Hatem A., Khater (2024) (2024) Whale-Based Trajectory Optimization Algorithm for 6 DOF Robotic Arm Annals of Emerging Technologies in Computing 8(4) 99-114 10.33166/AETiC.2017.10.01 10.33166/AETiC.2024.02.000 10.33166/AETiC.2024.04.005
Mohamed S., Elhadidy Waleed S., Abdalla Alaa A., Abdelrahman S., Elnaggar Mostafa, Elhosseini (2024) Assessing the accuracy and efficiency of kinematic analysis tools for six-DOF industrial manipulators: The KUKA robot case study AIMS Mathematics 9(6) 13944-13979 10.3934/math.2024678
Acknowledgements
The authors thank the researchers of Prince Sattam bin Abdulaziz University for their support. This study was conducted in the laboratories of the Egyptian-Japanese University of Science and Technology (EJUST) in cooperation with Horus University - Egypt (HUE).
Author information
Authors and Affiliations
Contributions
Hossam M Kassem, Abdelrahman T. Elgohr, and Mohamed S. Elhadidy conceptualized and designed the research framework, ensuring methodological rigor and overseeing the deep learning implementation. Ahmed Mousa, Roayat Ismail Abdelfatah, and Ahmed Safwat contributed to dataset pre-processing, augmentation techniques, and statistical analysis for performance evaluation. Hossam M Kasem, Roayat Ismail Abdelfatah, and Abdelrahman T. Elgohr were responsible for model optimization and validation, ensuring robustness and accuracy. Mohamed S. Elhadidy and Hossam M Kasem provided critical insights into experimental execution and manuscript structuring. Ahmed Mousa and Ahmed Safwat played key roles in literature review, result visualization, and technical refinements. All authors collaborated in manuscript writing, thoroughly reviewed the final draft, and approved the submission.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Mousa, A., Safwat, A., Elgohr, A.T. et al. Attention-Enhanced CNNs and transformers for accurate monkeypox and skin disease detection. Sci Rep 15, 32924 (2025). https://doi.org/10.1038/s41598-025-12216-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-12216-y
Keywords
This article is cited by
-
Early predictive modeling of uterine adhesions severity: a comparative study of ANN and ANFIS techniques
The Journal of Supercomputing (2026)
