
Abstract
This research article introduces a hybrid optimization algorithm, referred to as Grey Wolf Optimizer-Teaching Learning Based Optimization (GWO-TLBO), which extends the Grey Wolf Optimizer (GWO) by integrating it with Teaching-Learning-Based Optimization (TLBO). The benefit of GWO is that it explores potential solutions in a way similar to how grey wolves hunt, but the challenge with this approach comes during fine-tuning, where the algorithm settles too early on suboptimal results. This weakness can be compensated by integrating TLBO method into the algorithm to improve its search power of solutions as in teaches students how to learn and teachers are knowledge felicitator. GWO-TLBO algorithm was applied for several benchmark optimization problems to evaluate its effectiveness in simple to complex scenarios. It is also faster, more accurate and reliable when compare to other existing optimization algorithms. This novel approach achieves a balance between exploration and exploitation, demonstrating adaptability in identifying new solutions but also quickly zoom in on (near) global optima: this renders it a reliable choice for challenging optimization problems according to the analysis and results.
Similar content being viewed by others

Introduction
Optimization is a prevalent mathematical challenge across numerous real-world domains ranging from economics1, manufacturing process2, carriage3, engineering design4, systems5, machine learning6 to resource management. Several metaheuristic algorithms6 have been discovered, in recent years, as efficient solvers for such challenging optimization problems with a parameter space characterized by significant non-linearity, multidimensionality and non-differentiability. Although the performance of traditional deterministic techniques performances very well for continuous and differentiable optimization problems, this same method has some intrinsic limitations: On one hand owing to getting stuck in smaller optimum solutions (at local optima) and in contrast with when performing global searches in extremely high dimensional spaces. Consequently, stochastic7,8,9 and population-based metaheuristic algorithms possess reasonable the equilibrium between exploration (wide-ranging global search) and exploitation (targeted local search) to deliver feasible solutions within acceptable computation time10.
Recently, several populations based metaheuristic algorithms have been created and the hybrid Grey Wolf algorithm and Teaching-Learning Optimization method are among best of them because of its simplicity, robustness, flexibility. GWO is an algorithm which is constructed upon the behaviour of grey wolves especially for social hunting strategy of the said wolves, which being a good exploration has ability to guide search agents toward very favorable domain of the solution space. In contrast, GWO suffers from ‘premature convergence’ in terms of exploration when solving complex and high-dimensional problems. TLBO, inspired by the pedagogical principle of a master-teacher and apprentice-class learning strategy, utilizes exploitation to improve candidate solutions iteratively on the counterparts. While TLBO is good on local search, it may not work well when it comes to global search process of vast multimodal landscapes.
To combat these issues, a hybrid optimization algorithm which efficiently utilizes the exploration features capability of GWO11 and exploitation competences of TLBO which has been introduced in this research. The proposed hybrid GWO-TLBO algorithm uses an active, social behaviour of grey wolves to navigate the parameter space in conjugation with the learning and teaching phases of TLBO that facilitate in refining solutions for escaping from local optima. This combination of methods is hoped to result a well-balanced optimization process capable of more effectively solve complex, multimodal and high dimensional problems than each algorithm separately.
Advantages of Hybrid Algorithms:
-
a.
By combining strengths, these algorithms often deliver faster, more accurate, and reliable outcomes than single methods.
-
b.
They work well for all kinds of problems, from everyday tasks to highly complex challenges in areas like AI and machine learning.
-
c.
Hybrid algorithms can dig deeper to find better answers, sometimes getting close to the perfect solution.
-
d.
They adapt better to unexpected changes or noisy data, making them dependable in unpredictable situations.
-
e.
You can tweak them to fit specific needs, making them a perfect match for unique problems.
-
f.
They scale up well for tackling massive datasets or problems with many variables.
-
g.
These algorithms can explore new ideas while still focusing on refining good solutions, avoiding the trap of getting stuck in one spot.
Disadvantages of Hybrid Algorithms:
-
a.
Mixing different methods isn’t easy—it requires time, expertise, and careful planning.
-
b.
They often need more computing power and time to run, which might not be practical for all scenarios.
-
c.
Getting all the settings right for each part of the hybrid algorithm can be tricky and take a lot of trial and error.
-
d.
It can be hard to figure out how all the pieces interact, making these algorithms harder to understand or explain.
-
e.
They shine in certain situations but might not work as well for more general or straightforward tasks.
-
f.
Bringing together different techniques can lead to technical hiccups or inefficiencies during development.
-
g.
Sometimes, combining too many methods can make the algorithm bloated, with parts that don’t add much value.
-
h.
Hybrid algorithms can sometimes become too tailored to a specific problem, making them less effective for other situations.
Literature review
Research in optimization methods has been advancing at an impressive pace, evolving from stochastic and heuristic techniques to more sophisticated metaheuristic12 and hybrid tactics. These methods aim to discover the greatest optimal solutions by integrating various advantageous features of optimization. This paper reviews the latest studies, focusing on different types of metaheuristic approaches13. Generally, populations-based metaheuristics can be categorized as either population-based or single-solution categories, with population-oriented further classified into four groups based upon their inspiration sources which is presented in the following Fig. 1.

Classification of population-based meta heuristics (PMH) optimization techniques.
-
1.
Swarm-based population-based metaheuristics (PMH): PMH mimic such collective behaviour in nature as that of swarms14,15,16,17 flocks and herds18,19. Particle Swarm Optimization (PSO)20,21,22 is a well-known method inspired upon the coordinated movement23 of birds or fishes in school. Similarly, there are many swarm intelligence techniques24 including DGCO25, LFD26, LCBO27, HHO28,29,30,31,32,33,34,35,36,37,38,39, GWO11,40,41,42, MFO algorithm43,44, CS45, ALO46 and ABC47,48 etc.49.
-
2.
Physics-based population-based metaheuristics (PMH): These methods draw on physical laws50,51,52 and phenomena53,54,55,56,57 to guide the interactions of search agents. Simulated Annealing58,59, for example, leverages thermodynamic principles to simulate the process of heating and cooling materials. Additional examples include Electromagnetic Field Optimization (EFO)36, Multi-Verse Optimization (MVO)60, the Gravitational Search Algorithm (GSA)61,62, Sine–Cosine Algorithm63,64,65,66, Charged System Search67, Photon Search Algorithm68, Harmony Search69,70, Billiards Inspired Optimization (BOA)71, Henry Gas Solubility Optimization (HGSO)72, Central Force Optimization (CFO)73, Transient Search Optimization (TSO)74, and Electro Search Optimizer (ESO)75.
-
3.
Evolution-based population-based metaheuristics (PMH): These methods borrow their behaviour from nature7,76,77,78,79,80,81,82,83,84,85,86,87, and in particular they engage the process of biological evolution88,89 to change a set of possible solutions (populations) and come up with a best result90,91,92. GA (Genetic Algorithms)93 are the most popular one, with this we will mix some kind of crossover to create off-springs, and mutation to make more space for optimal solutions94,95. Meaning, there are also some diverse evolutionary algorithms such as Particle Swarm Optimization (PSO), Genetic Programming96,97, Ant Colony Optimization (ACO)98, Evolutionary Programming (EP)99, Dung Beetle Optimizer100, Biogeography-Based Optimization (BBO)101, Differential Evolution (DE)102, and Evolutionary Strategy (ES)103,104.
-
4.
Human-based population-based metaheuristics (PMH): These algorithms are developed based on human behaviour and learning processes. Some popular ones include, Teaching Learning Based Optimization (TLBO)105,106, Human Evolutionary Algorithm (HEA), Group Search Optimizer (GSO)107, Cultural Algorithm (CA), Human memory optimization108 and Tabu Search (TS)109,110
Hybrid approaches111,112,113 where combining two or more algorithms113,114,115,116 results in enhancing performance and free from local optima, are also taking increasingly his place. Recently Proposed Hybrid Methods: Differences between Nonlinear or Linear Hybrid Optimization Techniques117,118 and Some Recent Work Follows119. The most recent hybrid methods120 include the following; Polished Selfish Herd Optimizer (RSHO)121, Simplified Salp Swarm Algorithm (SSSA)122,123, Enhanced GWO124, Self-Adapted Differential ABC (SADABC)125,126, Hybrid Crossover Orienter PSO and GWO (HCPSOGWO)127, Multi-objective Heat Transfer Search Algorithm (MHTSA)128, Multi-Strategy Enhanced SCA (MSESCA)129 Historical, Ant Colony Optimization based on Equilibrium, Dynamic Hunting Leadership Algorithm130, Cat Swarm Optimization with Dynamic Pinhole Imaging and Golden Sine Algorithm131, artificial electric field employing cuckoo search algorithm132 with refraction learning133, MSAO134, Improved Gorilla Troops Optimizer135 and IHAOAVOA136,137. Table 1 summarizes the literature review of the similar recent algorithms and optimizers.
Mathematical modeling of proposed algorithm
Grey wolf optimizer (GWO)
The Grey Wolf Optimizer (GWO) is an innovative optimization algorithm inspired by the social structure and hunting techniques of grey wolves in the wild. By emulating how these animals organize themselves into hierarchies and collaborate during hunts, GWO effectively navigates complex optimization landscapes. This document presents a comprehensive overview of the GWO algorithm, detailing its fundamental principles and mechanisms. The mathematical equations and formulas that underpin this optimization method is explored, illustrating how they contribute to its ability to find optimal solutions across various problem domains. Through this in-depth examination, a deeper understanding of GWO’s functionality and its applications in addressing real-world optimization challenges is gained.
Pack structure
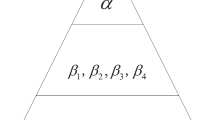
In the GWO algorithm11, the pack structure of the wolves (as shown in Fig. 2) is modeled by categorizing the best solutions as:
-
i.
Alpha (α): Represents the optimal solution and guides the pack.
-
ii.
Beta (β): Offers the alternate-best solution.
-
iii.
Delta (δ): Contributes the tertiary-best solution.
-
iv.
Omega (ω): Encompasses all other remaining solutions.

Social hierarchy in grey wolves.
The wolves exhibit a dynamic positional adjustment in response to the directives of the alpha, beta, and delta wolves, while the omega wolves dutifully follow their lead. This intricate interplay among the ranks exemplifies the nuanced leadership dynamics that characterize the social structure of a wolf pack.
Encircling the prey
In the predatory tactics employed by grey wolves, they engage in a coordinated maneuver to encircle their prey during the hunting phase as illustrates in Fig. 3. This intricate behavior can be articulated mathematically as follows:
where X⃗p(t) denotes the location of the prey, which is synonymous with the optimal best solution, X⃗(t) signifies the position of the grey wolf and A⃗ and C⃗ are defined as the coefficient vectors that play a crucial role in the optimization process.

Hunting strategy of grey wolves to hunt the prey (2D and 3D view).
The evaluation of the vector coefficients is conducted as follows:
where a⃗ over the iterations decreases on or after 2 to 0 linearly and r₁, r₂ are the vectors randomized in the range of zero to one.
Hunting (Optimization)
The wolves navigate towards the prey, representing the optimal solution, drawing upon the intelligence and strategic insights of the alpha, beta, and delta wolves. This behavioral pattern can be mathematically articulated as follows:
The new positions are updated as:
Final position of the wolf with best optimum is updated and can be expressed as:
Exploitation phase
To replicate the culminating (Exploiting) phase of the hunt, wherein the wolves engage in an assault on their prey, the value of A⃗ is diminished. When the magnitude of | A⃗ | falls below 1, the wolves are motivated to launch their attack on the prey, thereby converging towards the optimal solution.
Exploration (search for prey)
When |A|> 1, wolves are compelled to wander the parameter space more extensively, distancing themselves from the prey’s location. This behavioral pattern enables the algorithm to circumvent local minima, thereby facilitating a more thorough quest for a global optimum.
Throughout number of iterations, a⃗ decreases from 2 to 0, which balances exploration and exploitation. When |A⃗|< 1, wolves focus more on exploitation, while |A⃗|> 1 emphasizes exploration.
Convergence
Throughout the iterations, a⃗ decreases from it is initial value of 2–0, which balances exploration as well as exploitation. When ∣A⃗∣ < 1, wolves focus more on exploitation, while ∣A⃗∣ > 1 emphasizes exploration.
The Grey Wolf Optimizer guarantees that the wolves can extensively traverse the parameter space in the initial stages of the optimization process. As the progression unfolds, they gradually shift their focus to exploiting the most promising solutions, ultimately converging toward the global optimum.
Teaching–learning-based optimization (TLBO)
In 2011, Rao et al. introduced the Teaching–Learning-Based Optimization (TLBO) algorithm, a population-centric optimization method designed to mimic the educational process of teaching and learning. The said algorithm is stimulated from natural process based on learning and knowledge transfer as done within a classroom setting, where an instructor/supervisor/teacher conveys knowledge to students/learners with a goal of improving their understanding and performance. TLBO has gained significant attention for its simplicity, effectiveness, and the fact that it does not require specific algorithmic parameters such as crossover rates or mutation probabilities, facilitating its implementation across a diverse array of optimization challenges.
Working principle of TLBO
TLBO operates on the fundamental concept that learners (candidate solutions) improve their knowledge (solution quality) through interaction with a teacher and through peer-to-peer learning. The optimization process is classified into two discrete phases: exploration, referred to as teaching, and learning, known as exploitation:
Teacher phase (global exploration)
During the teacher phase, the individual representing the best solution within the population imparts knowledge to the learners, aiming to enhance the overall quality of the population’s mean. The idea is that the teacher tries to bring the learners closer to an optimal solution by adjusting their knowledge. The said process is mathematically expressed as follows:
where Xnew is the updated solution, Xold is the present solution, Xbest is the optimal solution (teacher), Xmean is the mean solution of the population, TF is the teaching factor, which controls the influence of the teacher, and r is a number randomized between 0 and 1.
This phase focuses on global exploration by allowing learners to discover the parameter space guided by the optimal solution (teacher), thus increasing the probability of finding optimal or near-optimal solutions.
Learner phase (local exploitation)
In the learner phase, the students, or learners, acquire knowledge through their interactions and collaborations with their peers. Pairs of learners are randomly selected, and the better-performing learner attempts to improve the other’s performance. This phase is represented mathematically as:
or
where Xi and Xj represent two learners selected at random, and r denotes a randomly generated number. If the newly discovered solution surpasses the prior one in quality, it will replace the existing solution. This phase emphasizes local exploitation by refining solutions through peer-to-peer learning.
Advantages of TLBO
TLBO stands out from other optimization algorithms due to several key advantages:
-
a.
Parameter-free Optimization: In contrast to numerous population-based algorithms, including Teaching–Learning-Based Optimization, Particle Swarm Optimization (PSO) and Genetic Algorithms (GA) does not depend on parameters that are tailored to the algorithm including mutation rates, crossover probabilities, or inertia weights. The only parameters in TLBO are the pop size (size of the population) and the iteration count, making it simpler to implement as well as tune.
-
b.
Balanced Exploration and Exploitation: The two diverse phases in TLBO, the teacher phase (also known as exploration phase) and learner phase (also known as exploitation), provide a balanced approach to searching the solution space. The teacher phase ensures the population is guided towards promising regions, while the learner phase allows for local refinement, helping the algorithm avoid premature convergence to suboptimal solutions.
-
c.
Fast Convergence: TLBO has been shown to converge more rapidly compared to other metaheuristic algorithms because of its dual-phase learning mechanism. The ongoing enhancement of solutions during both the teacher phase (exploration) and the learner phase (exploitation) serves to expedite the search process, making it particularly suitable for problems where computational efficiency is critical.
-
d.
Wide Applicability: Owing to its simplicity and effectiveness, the application of Teaching–Learning-Based Optimization (TLBO) has achieved notable success across a range of disciplines, particularly in engineering design, scheduling, machine learning, and many more. Its parameter-less nature reduces the complexity of adaptation to different problem types, ensuring that a broad variety of optimization difficulties are handled.
TLBO in hybrid optimization
When used in conjunction with Grey Wolf Optimizer (GWO), TLBO’s strengths in local exploitation complement GWO’s exploration abilities. GWO, being an exploration-heavy algorithm, efficiently navigates large, complex parameter spaces, but can sometimes fall short in fine-tuning solutions, especially in later stages when the population begins to converge. This is where TLBO’s learner phase shines by providing a mechanism for refining solutions without requiring additional parameters or tuning. The teaching phase of TLBO further supports the search by guiding the population towards the best-known solution, maintaining diversity in the search process.
By combining GWO and TLBO, the resulting hybrid algorithm benefits from GWO’s effective exploration of the parameter space and TLBO’s efficient exploitation, ensuring a well-rounded and robust optimization process. This hybrid approach is particularly advantageous for solving multimodal, high-dimensional problems where balancing the phase of exploration and the phase of exploitation is an important factor for finding a global optima (global optimum). Furthermore, the simplicity that TLBO offers ensures that the computational overhead introduced by the hybridization remains minimal, making it an efficient and influential instrument for resolving composite optimization problems.
GWO excels in exploration due to its mechanisms like encircling and hunting but can suffer from premature convergence and weak exploitation. TLBO, on the other hand, is parameter-free and effective in exploitation through its teacher and learner phases but may lack robust exploration. The hybrid GWO-TLBO leverages their complementary strengths—GWO’s dynamic exploration and TLBO’s refined exploitation—while addressing their respective weaknesses, such as improving convergence reliability and balancing search efficiency.
The Grey Wolf Optimizer (GWO) emulates the innate leadership pack structure and hunting tactics of grey wolves, whereas Teaching–Learning-Based Optimization (TLBO) leverages a teacher-student framework to improve learning within a population-based context. In this hybrid algorithm, we combine GWO’s exploration/exploitation phases with the TLBO’s teaching and learning mechanisms to maintain an equilibrium for global as well as local search. The pseudocode for hybrid GWO and TLBO is shown in Fig. 4.

Psuedo code for the proposed algorithm (Hybrid GWO-TLBO).
Explanation
-
I.
Initialization
-
a.
Input Parameters:
-
i.
N: This is the pop size (population) wolves the (number of wolves).
-
ii.
Max_iter: This is the termination conditions or maximum iteration limit.
-
i.
-
b.
Initialize random population of wolves:
-
i.
Each wolf Xj acts as a potential to the optimization challenge, represented in a vector form in the searching space.
-
ii.
j = 1, 2…,Nj, where N represents the population size or wolves (number of wolves).
-
i.
-
c.
Initialize the alpha, beta, and delta wolves:
-
i.
Xα: Signifies the wolf with optimal fitness (best resolution so far).
-
ii.
Xβ: Signifies the alternate best wolf.
-
iii.
Xδ: Signifies the tertiary best wolf.
These three wolves guide the rest of the wolves toward the optimal solution.
-
i.
-
a.
-
II.
While the stopping condition is not met
This iterative process will persist until a specified termination criterion is met, such as achieving the maximum allowable iterations, denoted as Max_iter, or attaining a predefined level of solution accuracy.
-
III.
Phase 1: GWO Phase
The GWO phase encompasses both exploration and exploitation: it involves seeking out new regions within the parameter space while also focusing on refining and optimizing the current best solutions.
For each wolf Xj:
-
a.
Calculate the fitness:
-
1.
Each wolf’s position represents a potential solution, and its quality being estimated using a fitness function (specific to problem being optimized). Higher fitness (for maximization problems) or lower fitness (for minimization problems) indicates a better solution.
-
1.
-
b.
Update alpha, beta, delta based on fitness:
-
1.
If a wolf’s fitness is improved than the present alpha (optimal solution), update Xα.
-
2.
Similarly, update Xβ and Xδ with the alternate and tertiary best wolves.
-
1.
-
c.
Calculate exploration/exploitation coefficients A and C:
-
1.
Coefficient A: Controls the wolf’s exploration/exploitation balance. If ∣A∣ ≥ 1, the algorithm emphasizes exploration (searching new regions of the parameter space). If ∣A∣ < 1, it emphasizes exploitation (refining the current best solutions).
-
2.
Coefficient C: A randomly generated number that regulates the extent of influence exerted by the alpha, beta, and delta wolves on the movement patterns of the other wolves.
-
1.
-
d.
Update the position of each wolf using exploration/exploitation equations:
-
1.
Exploration (∣A∣ ≥ 1):
Wolves are updated to move randomly away from the alpha, beta, or delta positions. This helps them explore new regions.
The wolf’s new position is influenced by a random direction, which encourages divergence and exploration of the parameter space.
-
2.
Exploitation (∣A∣ < 1):
Wolves are updated to move towards the alpha, beta, or delta wolves (best solutions so far), encouraging convergence towards the optimal solution.
This is done using equations that reduce the distance between the wolves and the best solutions.
-
1.
-
a.
-
IV.
Phase 2: TLBO Phase
The TLBO phase helps further refine the population using Teaching and Learning mechanisms.
-
a.
Teaching Phase:
-
1.
The teacher is defined as the wolf with the optimal solution, Xα.
-
2.
For each wolf Xj, adjust its location in accordance with the position of the teacher:
-
a.
The underlying concept is that the teacher has the capacity to enhance the performance of the wolves, who are regarded as students.
-
b.
The new position of Xj is calculated as:
$${X}_{j}={X}_{j}+rand\left(\right)\times {(X}_{{\alpha }}-{T}_{f}\times {X}_{mean}$$where rand() represents a random value within the range of 0 to 1, Tf is the teaching factor, which take on the values of 1 or 2, controlling how much the teacher influences the wolf, Xmean represents the average of all wolves’ positions (mean solution).
This equation encourages wolves to move closer to the teacher, improving their fitness.
-
a.
-
b.
Learning Phase:
-
1.
In the learning phase, each wolf learns by interacting with another randomly selected wolf Xj from the population.
-
2.
For each wolf Xi:
-
i.
If Xi is worse (has a lower fitness) than Xj, it learns from Xj and moves towards it. This encourages weak wolves to move toward better solutions.
-
ii.
Otherwise, Xi moves away from Xj to travel other regions of the parameter space, maintaining diversity within the population.
-
i.
-
1.
-
1.
-
a.
-
V.
Update the positions of alpha, beta, delta as per the new fitness values
-
1.
After completing the GWO and TLBO phases, re-evaluate the fitness of the wolves that have been updated.
-
2.
Update the Xα, Xβ, and Xδ positions based on the new best, second-best (alternate-best), and third-best (tertiary-best) wolves.
-
1.
-
VI.
Increment iteration counter
Update the iteration count t=t+1.
-
VII.
Return the best solution found, Xα
Upon fulfilling the termination criterion, either by reaching the maximum iteration count, denoted as Max_iter, or by discovering an acceptable solution, the algorithm returns Xα, signifying the most optimal solution identified throughout the search process
Analysis and testing of standard benchmark functions (CEC 2014, CEC 2017 and CEC 2022)
CEC-2014
The proposed hybrid GWO-TLBO algorithm is introduced and evaluated using standard benchmark functions99,176 for performance comparison. The functions are classified into three primary groups: unimodal (UM), which includes functions F1 through F7; multimodal (MM), covering functions F8 to F13; and fixed-dimensional (FD), consisting of functions F14 to F23Mathematical expression of the above said functions, are detailed in the following tables (as shown in Tables 2, 3, and 4) for unimodal, multimodal, and fixed-dimensional functions, respectively. Three-dimensional representations of the functions (F1 to F23) are illustrated respectively (as illustrated in Figs. 5, 6, and 7) for unimodal, multimodal, and fixed-dimensional functions.

Uni Modal functions-3D view curves.

Multi modal functions-3D view curves.

Fixed dimension functions-3D view curves.
CEC-2017
The proposed hybrid GWO-TLBO algorithm is introduced and evaluated using standard benchmark functions177 for performance comparison. The example functions are illustrated in Fig. 8 and the details for the CEC 2017 benchmark functions are presented in Table 5.

Test functions for CEC 2017.
CEC-2022
The proposed hybrid GWO-TLBO algorithm is introduced and evaluated using standard benchmark functions178 for performance comparison. The functions are illustrated in Fig. 9 and the details for the CEC 2022 benchmark functions are presented in Table 6.

Test functions for CEC 2022.
Results and discussion
CEC 2014: The hybrid GWO-TLBO algorithm was verified to a variety of benchmark functions to assess its performance. This included seven unimodal (UM) which are functions ranging from F1 to F7, five multimodal (MM) which are functions ranging from F8 to F13, and the rest ten fixed-dimension (FD) which are functions ranging from F14 to F23, across different dimensions. The tests were conducted with a maximum iteration of value 500 and trial runs of 30. The results for the UM functions are reported, including the quartile-based results for these functions across various dimensions are presented in Tables 7, 8 and 9. Figures 10, 11, 12, 13, 14, 15, 16, 17, 18, and 19 displays the parameter space, position history, trajectory, average fitness and convergence curve, for the Unimodal (UM) functions and Multimodal (MM) functions (CEC 2014) for different dimensions (30, 50, 100), highlighting the fast convergence of the GWO-TLBO. The UM functions were particularly useful for evaluating the capability of the proposed GWO-TLBO algorithm in finding the global optima, and outcomes indicate the usefulness of GWO-TLBO consistently outperformed many classical methods. Further, Figs. 20 and 21 shows the parameter space, position history, trajectory, average fitness and convergence curve for the fixed dimension standard benchmark functions (CEC 2014).

Parameter space, position history, trajectory, average fitness and convergence curve for Standard benchmark functions (F1–F2) for 30 dimensions (d = 30).

Parameter space, position history, trajectory, average fitness and convergence curve for Standard benchmark functions (F3–F7) for 30 dimensions (d = 30).

Parameter space, position history, trajectory, average fitness and convergence curve for Standard benchmark functions (F8–F11) for 30 dimensions (d = 30).

Parameter space, position history, trajectory, average fitness and convergence curve for Standard benchmark functions (F12–F13) for 30 dimensions (d = 30).

Parameter space, position history, trajectory, average fitness and convergence curve for Standard benchmark functions (F1–F5) for 50 dimensions (d = 50).

Parameter space, position history, trajectory, average fitness and convergence curve for Standard benchmark functions (F6–F10) for 50 dimensions (d = 50).

Parameter space, position history, trajectory, average fitness and convergence curve for Standard benchmark functions (F1–F13) for 50 dimensions (d = 50).

Parameter space, position history, trajectory, average fitness and convergence curve for Standard benchmark functions (F1–F5) for 100 dimensions (d = 100).

Parameter space, position history, trajectory, average fitness and convergence curve for Standard benchmark functions (F6–F10) for 100 dimensions (d = 100).

Parameter space, position history, trajectory, average fitness and convergence curve for Standard benchmark functions (F11–F13) for 100 dimensions (d = 100).

Parameter space, position history, trajectory, average fitness and convergence curve for Standard benchmark functions (F14–F18).

Parameter space, position history, trajectory, average fitness and convergence curve for Standard benchmark functions (F19–F23).
For 30 dimensions: Table 7 represents the best score, mean score and standard deviation score for the Unimodal and Multimodal Standard Benchmark Functions (CEC 2014) for the dimension count of 30 (d = 30).
For 50 dimensions: Table 8 represents the best score, mean score and standard deviation score for the Unimodal and Multimodal Standard Benchmark Functions (CEC 2014) for 50 dimensions (d = 50).
For 100 dimensions: Table 9 represents the best score, mean score and standard deviation score for the Unimodal and Multimodal Benchmark Functions (CEC 2014) for the dimension count of 100 (d = 100).
Fixed Dimension Standard Benchmark Function Analysis: Table 10 represents the best score, mean score and standard deviation score for the fixed dimension of the standard benchmark functions (CEC 2014).
Further, the proposed algorithm is tested and compared against tvarious algorithms including LSHADE_EpSin138, EBOwithCMAR139, JSO140, LSHADE_SPACMA141 and the analysis is presented in Table 11.
CEC 2017: The algorithms compared in Table 12 provide a comprehensive overview of their respective performances across key metrics. Table 12 compares the performance of five algorithms: LSHADE_EpSin138, EBOwithCMAR139, JSO140, LSHADE_SPACMA141, and GWO-TLBO. The table highlights their effectiveness across various optimization metrics, providing a detailed benchmark to evaluate their relative strengths and weaknesses.
Figures 22, 23, 24, 25, 26, 27 present an in-depth analysis of the GWO-TLBO (Grey Wolf Optimizer—Teaching Learning-Based Optimization) hybrid approach. These figures showcase its performance across various scenarios, focusing on aspects such as convergence behavior, optimization accuracy, and robustness. The visual representation emphasizes the effectiveness of the GWO-TLBO method in addressing complex optimization challenges.

Search history, trajectory, average fitness and convergence curve for CEC 2017 on GWO-TLBO.

Search history, trajectory, average fitness and convergence curve for CEC 2017 on GWO-TLBO.

Search history, trajectory, average fitness and convergence curve for CEC 2017 on GWO-TLBO.

Search history, trajectory, average fitness and convergence curve for CEC 2017 on GWO-TLBO.

Search history, trajectory, average fitness and convergence curve for CEC 2017 on GWO-TLBO.

Search history, trajectory, average fitness and convergence curve for CEC 2017 on GWO-TLBO.
CEC 2022: The comparison in Table 13 provides a comparative analysis of five algorithms— LSHADE_EpSin138, EBOwithCMAR139, JSO140, LSHADE_SPACMA141, and GWO-TLBO—based on the benchmark functions of the CEC 2022 competition. This evaluation highlights the algorithms’ performance in addressing the complex optimization problems defined by the competition standards.
Figures 28, 29, 30 illustrate the performance of the GWO-TLBO algorithm on the benchmark functions of the CEC 2022 competition. These figures provide a visual analysis of the algorithm’s convergence trends, accuracy, and stability, demonstrating its effectiveness in solving challenging optimization problems.

Search history, trajectory, average fitness and convergence curve for CEC 2022 on GWO-TLBO.

Search history, trajectory, average fitness and convergence curve for CEC 2022 on GWO-TLBO.

Search history, trajectory, average fitness and convergence curve for CEC 2022 on GWO-TLBO.
Experimental study on engineering design challenges
In real-world design challenges179, it’s often difficult to achieve optimal results due to the complexity involved. This complexity usually comes from various constraints, such as equality and inequality conditions, which need to be considered during the optimization process. Solutions generated by optimization algorithms are typically classified as either feasible or infeasible, depending on how well they satisfy these constraints. To discover the finest possible solutions efficiently and with minimal computational effort, many approaches may utilize the combination of strengths of diverse algorithms. In this study, eleven constrained engineering design challenges are selected and the proposed hybrid GWO-TLBO algorithm was evaluated on these said challenges along with different algorithms including LSHADE_EpSin138, EBOwithCMAR139, JSO140, LSHADE_SPACMA141. The details of these challenges are depicted in Table 14, with solution and computational times shown in Tables 15 and 16.
Solution and computational times shown in Tables 15 and 16 for the Engineering design challenges
Engineering challenge—three bar truss (special 1)
To assess the effectiveness of the proposed hybrid GWO-TLBO algorithm in solving engineering design challenges, it was applied to the optimization of a Three-Bar Truss system configuration, as seen in Fig. 31180,181. When comparing the outcomes, as represented in Table 17, the hybrid GWO-TLBO algorithm surpasses its performance in contrast with existing metaheuristic solutions, demonstrating its clear advantages. The Convergence curve for grey wolf optimization and hybrid GWO-TLBO is present in Fig. 32. The three-bar truss challenge is outlined mathematically as follows:


Engineering design challenge for a three-bar truss (Special 1).

Convergence curve comparison for three bar truss challenge.
Let us consider,
Minimize,
Subject to,
Range of variables = 0 \(\le\) \({t}_{1}\), \({t}_{2}\le l\)
Here, l = 100 cm, P = 2 KN/\({\text{cm}}^{2}\), \(\sigma\) = 2 KN/\({\text{cm}}^{2}\)
Engineering design challenge—speed reducer (special 2)
The design challenge for speed reducers stands out as one of the most demanding tasks in optimization. It encompasses seven design variables, six of which are continuous, and is subject to eleven constraints. The key aim here is the minimization of the speed reducer weight, i.e. as minimum as could be obtained, while keeping factors like internal stress, shaft deflection, and the twisting and stress on the surface of the gear teeth should be within acceptable limits. Figure 33 illustrates the seven design variables (t1–t7). The Convergence curve for grey wolf optimization and hybrid GWO-TLBO is present in Fig. 34. The mathematical setup for the problem is described below, and the outcomes of the proposed hybrid algorithm of GWO-TLBO, in disparity to other metaheuristic algorithms, are shown in Table 18.


Engineering design challenge- Speed Reducer (Special 2).

Convergence curve Comparison for speed reducer challenge.
Subject to,
Here,
Engineering design challenge—pressure vessel (PV) (special 3)
The optimization challenge for the pressure vessel (PV) design had initially being investigated by Kramer and Kannan in 1994182, focuses on minimizing overall costs, including those for welding, forming, and materials. The vessel has a cylindrical shape with hemispherical ends on both sides, and the design involves four key parameters, as represented in Fig. 35. The Convergence curve for grey wolf optimization and hybrid GWO-TLBO is present in Fig. 36. The mathematical expression for this particular is challenge provided in below. Table 19 presents a comparison of the hybrid GWO-TLBO algorithm’s performance with other existing metaheuristic algorithms.
Subject to,


Pressure vessel (PV) optimal design (Special 3).

Convergence curve Comparison for the challenge of pressure vessel design.
Adjustable ranges are,
Engineering design challenge—compression/tension spring (special 4)
The primary goal of this problem is to reduce the weight of the spring while adhering to essential constraints, including shear stress limits, allowable deflection, geometric specifications, and surge frequency requirements. Achieving this balance is crucial to ensure the spring performs efficiently and safely under operational conditions. This design challenge considers three continuous variables and four nonlinear inequality restrictions. Figure 37 illustrates the design challenge variables, while Eqs. (29)–(31) describe the mathematical formulation. The Convergence curve for grey wolf optimization and hybrid GWO-TLBO is present in Fig. 38. A comparison of the hybrid GWO-TLBO algorithm’s performance with other existing metaheuristic methods is presented in Table 20.


Compression/tension spring challenge (special 4).

Convergence curve Comparison for spring design challenge.
Subject to,
Variable ranges, 0.005 \(\le\) \({s}_{1}\le\) 2.00, 0.25 \(\le\) \({t}_{2}\le\) 1.30, 2.00 \(\le\) \({s}_{3}\le\) 15.0.
Engineering design challenge—welded beam (WB) (special 5)
The main aim of this design challenge is to lower the construction costs associated with a welded beam. This must be accomplished while meeting seven specific constraints and considering four distinct design variables, as illustrated in Fig. 39. Successfully navigating these parameters is essential to optimize both cost-effectiveness and structural integrity. The mathematical expression of the design has been laid out in equations below. The Convergence curve for grey wolf optimization and hybrid GWO-TLBO is present in Fig. 40. Table 21 provides a comparison of the hybrid GWO-TLBO algorithm’s performance against other existing metaheuristic methods.


Design challenge for welded beam (Special 5).

Convergence curve Comparison for welded beam design challenge.
Let us consider,
Minimize,
Subject to,
Range of Variables = 0.1 \(\le\) \({t}_{1}\le\) 2; 0.1 \(\le\) \({t}_{2}\le\) 1; 0.1 \(\le\) \({t}_{3}\le\) 10; 0.1 \(\le\) \({t}_{4}\le\) 2.
Here,
Engineering design challenge—rolling element bearing (special 6)
The key aim of optimizing the design of rolling element bearings is to enhance their dynamic load capacity. By focusing on this improvement, the goal is to ensure that the bearings can withstand greater loads while maintaining performance and reliability. Achieving a higher dynamic load capacity is crucial for extending the lifespan of the bearings and improving the overall efficiency of the machinery they support. The design details, involving 10 decision variables, are depicted in Fig. 41. Important factors include the ball diameter (DIMB) the number of balls (Nb) and pitch diameter (DIMP), along with the coefficients for the curvature of the inner and outer channels. The Convergence curve for grey wolf optimization and hybrid GWO-TLBO is present in Fig. 42. A comparison of the proposed hybrid GWO-TLBO algorithm in contrast with existing metaheuristic algorithms is depicted in Table 22. The design optimization can be expressed mathematically as follows:


Challenge for Rolling element bearing design (Special 6).

Convergence curve Comparison for rolling element bearing challenge.
Maximize,
If, \(DIM\le 25.4mm\)
If, \(DIM\ge 25.4mm\)
Subject to,
Engineering design challenge—multi disk clutch break Special 7
The main goal of the design optimization challenge for the Multi-Disc Clutch Brake (MDCB) is to decrease its weight while maintaining functionality. By achieving a lighter design, the aim is to enhance overall system performance and efficiency, allowing for better handling and reduced energy consumption. This weight reduction is essential for applications where space and weight constraints are critical, ensuring that the MDCB can operate effectively without compromising its braking capabilities. The design details are illustrated in Fig. 43, and Table 23 provides an evaluation of the hybrid GWO-TLBO algorithm’s performance in contrast with existing metaheuristic method. Five important design variables has been considered, which includes the disc thickness (Th), friction surface (Sf), inner radius (Rin), outer radius (Ro), and actuating force (Fac). The Convergence curve for grey wolf optimization and hybrid GWO-TLBO is present in Fig. 44. The mathematical formulation for the optimization can be expressed as follows:


Challenge for Multi disk clutch break design.

Convergence curve Comparison for multi disk clutch brake challenge.
Minimize,
Subject to;
Here,
Engineering design challenge—gear train (special 8)
In this hybrid approach combining Grey Wolf Optimization (GWO) and Teaching–Learning-Based Optimization (TLBO), the objective is to minimize both the gear teeth ratio and its associated scalar value. By effectively reducing these parameters, the method aims to enhance the efficiency and performance of the gear system. Achieving a lower gear teeth ratio can lead to smoother operation and improved torque transmission, while the scalar value reduction contributes to optimization, potentially resulting in weight savings and better mechanical efficiency. The choice of explicit variables is based upon how many teeth each gear has. Figure 45 highlights the optimal design strategies for this problem, while the performance difference presented in Table 24 compares hybrid GWO-TLBO algorithm in contrast to existing metaheuristic optimization techniques. The Convergence curve for grey wolf optimization and hybrid GWO-TLBO is present in Fig. 46. The optimization can be mathematically modeled and expressed as:


Challenge for gear train design.

Convergence curve Comparison for gear train challenge.
Let’s consider,
Minimize,
Subject to; \(12\le {t}_{1},{t}_{2},{t}_{3},{t}_{4}\le 60\)
Engineering design challenge—belleville spring (Special 9)
The goal of the Belleville spring design, as depicted in Fig. 47, aims at lessening the overall mass of the said Belleville spring, which involves both a discrete variable, which represents the spring thickness, and numerous continuous variable quantity. The model needs to satisfy constraints such as, deflection, the height-to-deflection ratio, compressive tension, as well as limits on external and internal diameters, the spring’s slope and the height-to-maximum height ratio. Table 25 offers an evaluation to the hybrid GWO-TLBO algorithm’s performance in contrast with optimization methods. The Convergence curve for grey wolf optimization and hybrid GWO-TLBO is present in Fig. 48. The optimization challenge could be mathematically modelled and expressed as follows:


Engineering design challenge-Belleville spring (Special 9).

Convergence curve Comparison for belleville spring challenge.
Minimize,
Subject to;
Here, \(d=\frac{6}{p\times \mathit{ln}J}\left(\frac{J-1}{\mathit{ln}J}-1\right)\); \(\alpha =\frac{6}{\pi \times \mathit{ln}J}\times {\left(\frac{J-1}{J}\right)}^{2}\); \(\mu =\frac{6}{\pi \times \mathit{ln}J}\times \left(\frac{J-1}{2}\right)\)
Engineering design challenge—cantilever beam (CB) (Special 10)
The beam design model for Cantilever beam (CB), shown in Fig. 49, is focused on reducing the beam’s weight to its lowest possible value. In this case, five structural variables are considered, while keeping the beam’s thickness fixed. Table 26 shows a comparison that validates the effectiveness along with advantages of the hybrid GWO-TLBO tactic when compared to other popular optimization techniques. The Convergence curve for grey wolf optimization and hybrid GWO-TLBO is present in Fig. 50. The optimization challenge could be mathematically expressed for the model of this design challenge as follows:


Challenge for cantilever beam design (Special 10).

Convergence curve Comparison for cantilever beam challenge.
Variable ranges are, \(0.01\le {t}_{1},{t}_{2},{t}_{3},{t}_{4},{t}_{5}\le 100\)
Engineering design challenge—I beam (special 11)
This nonlinear design optimization challenge, shown in Fig. 51, involves four key variables: bs1 (flange thickness), bs2 (web thickness), bs3 (flange width), and bs4 (beam thickness). The design is constrained by the beam’s cross-sectional dimensions and dynamic deflection under the prearranged force. Table 27 compares the hybrid GWO-TLBO algorithm with other existing methods, showing how it performs. The Convergence curve for grey wolf optimization and hybrid GWO-TLBO is present in Fig. 52. The optimization challenge could be mathematically expressed for this problem, as described by Coello and Christiansen183, is as follows:


I-Beam engineering design challenge (Special 11).

Convergence curve Comparison for I-beam problem.
Firstly minimize,
Subject to,
The Computational Analysis for all the Engineering problem designs has been conducted under Section “Experimental study on engineering design challenge” and all the experimental studies has been carried in Lenovo Legion 5 Pro Gen 8, AMD Ryzen 7 7745HX 8 core 16 threads 3.2 GHz, 32 GB DDR5 Ram 5200 MHz.
Sensitivity analysis
In optimization studies under benchmarking functions such as CEC 2014, CEC 2017, and CEC 2022, diversity analysis as depicted in Tables 28, 29 and 30 for CEC 2014, 2017 and 2022 respectively, evaluates the population’s spatial distribution over the search space, highlighting the algorithm’s ability to maintain a balance between convergence and exploration. Exploration/exploitation analysis as depicted in Tables 31, 32, and 33 for CEC 2014, 2017 and 2022 respectively, investigates the algorithm’s dynamic behavior in exploring new regions and intensifying the search in promising areas, crucial for navigating complex multimodal landscapes. Sensitivity analysis as depicted in Tables 34, 35 and 36 for CEC 2014, 2017 and 2022 respectively, examines the impact of algorithmic parameters on performance, identifying critical parameters that significantly influence convergence speed and solution quality. Together, these analyses provide comprehensive insights into the algorithm’s robustness and adaptability across diverse problem landscapes.
Analysis data of GWO-TLBO for CEC-2014
Diversity analysis
Exploration/exploitation analysis
Sensitivity analysis
Analysis data of GWO-TLBO for CEC-2017
Diversity analysis
Exploration/exploitation analysis
Sensitivity analysis
Analysis data of GWO-TLBO for CEC-2022
Diversity analysis
Exploration/exploitation analysis
Sensitivity analysis
Future work
An objective function for optimizing the threshold voltage of the supercapacitor bank’s switching mechanism has been modelled, we need to consider several parameters that influence the system’s performance. The primary goal of this optimization is to maximize the power delivery efficiency and extend the supercapacitor discharge period, while maintaining a stable output voltage.
Let’s define the objective function f(Vth1,Vth2) as a weighted sum of the key parameters to be maximized or minimized:
where Vth1 is the First Threshold Voltage, Vth2 is the Second Threshold Voltage, Td is the discharge time, Eu is the Energy Utilization, Pout is the Power Output, Vs is the Voltage Stability, L is the Load Demands, Td(Vth1,Vth2) is the discharge time as a function of the threshold voltages, Eu(Vth1,Vth2) is the energy utilization efficiency as a function of the threshold voltages, Vs(Vth1,Vth2) is the voltage stability as a function of the threshold voltages, Pout(Vth1,Vth2) is the power output at different voltages, L is the required load demand, and ∣L − Pout(Vth1,Vth2)∣ minimizes the deviation between load demand and power output, and α1,α2,α3,α4,α5 are weighting factors that reflect the importance of each parameter.
Further, the system has physical and operational constraints, which must be respected.
Conclusions
This article presents a novel optimization algorithm called hybrid GWO-TLBO, which has been designed for confront an extensive range of optimization problems (including Standard Benchmark Functions and Engineering challenges). The algorithm combines the strategic behavior of grey wolves while hunting their prey from the Grey Wolf Optimizer (GWO) with the structured learning process based on Teaching-Learning-Based Optimization (TLBO). This blend of natural behaviors provides an enhancement to the capability of the algorithm’s ability to both explore the parameter space as well as exploit new resolutions. GWO-TLBO is appraised on twenty three standard benchmarks and an array of real-world engineering problems, focusing on its ability to find the best solutions, how quickly it converges, and how well it handles different problems with different dimensions. The algorithm was evaluated for its capacity to avoid common pitfalls like premature convergence, ensuring it explores and exploits parameter spaces effectively. Computational tests further confirmed that GWO-TLBO consistently outperforms GWO algorithm. In summary, the findings indicate that the GWO-TLBO method demonstrates exceptional effectiveness, delivering solutions that are both quicker and more precise. This is particularly evident in intricate engineering problems, showcasing its capability as a powerful optimization tool. Its robust performance suggests that GWO-TLBO could significantly enhance decision-making processes in various engineering applications, making it a valuable asset for tackling complex design challenges. The proposed method is however is tested for standard benchmark function and various standard engineering problems, but it cannot be denied that the algo has the potential to perform well when it comes to solving electrical engineering problems for example, it could be the optimal location of the STATCOM in IEEE bus systems, optimization of various parameters of electric vehicle, etc. Author is currently working prolonging the delivery output of supercapacitors in electric vehicles and hopes the proposed algorithm will perform better for this application as well.
Data availability
All data generated or analyzed during this study are included directly in the text of this submitted manuscript. There are no restrictions on data availability.
References
Lin, W.-Y. A novel 3D fruit fly optimization algorithm and its applications in economics. Neural Comput. Appl. 27(5), 1391–1413. https://doi.org/10.1007/s00521-015-1942-8 (2016).
Cheng, Y. et al. Modeling and optimization for collaborative business process towards IoT applications. Mob. Inf. Syst. 2018, 1–17. https://doi.org/10.1155/2018/9174568 (2018).
Wang, X., Choi, T.-M., Liu, H. & Yue, X. A novel hybrid ant colony optimization algorithm for emergency transportation problems during post-disaster scenarios. IEEE Trans. Syst. Man Cybern. Syst. 48(4), 545–556. https://doi.org/10.1109/TSMC.2016.2606440 (2018).
I. E. Grossmann (ed.), Global optimization in engineering design, vol. 9. In Nonconvex optimization and its applications (Springer, 1996). https://doi.org/10.1007/978-1-4757-5331-8.
Rao, R. V. & Waghmare, G. G. A new optimization algorithm for solving complex constrained design optimization problems. Eng. Optim. 49(1), 60–83. https://doi.org/10.1080/0305215X.2016.1164855 (2017).
Mirjalili, S. Dragonfly algorithm: A new meta-heuristic optimization technique for solving single-objective, discrete, and multi-objective problems. Neural Comput. Appl. 27(4), 1053–1073. https://doi.org/10.1007/s00521-015-1920-1 (2016).
Li, S., Chen, H., Wang, M., Heidari, A. A. & Mirjalili, S. Slime mould algorithm: A new method for stochastic optimization. Future Gener. Comput. Syst. 111, 300–323. https://doi.org/10.1016/j.future.2020.03.055 (2020).
Quan, H., Srinivasan, D. & Khosravi, A. Integration of renewable generation uncertainties into stochastic unit commitment considering reserve and risk: A comparative study. Energy 103, 735–745. https://doi.org/10.1016/j.energy.2016.03.007 (2016).
Kamboj, V. K., Bath, S. K. & Dhillon, J. S. Hybrid HS–random search algorithm considering ensemble and pitch violation for unit commitment problem. Neural Comput. Appl. 28(5), 1123–1148. https://doi.org/10.1007/s00521-015-2114-6 (2017).
Maghsudlu, S. & Mohammadi, S. Optimal scheduled unit commitment considering suitable power of electric vehicle and photovoltaic uncertainty. J. Renew. Sustain. Energy 10(4), 043705. https://doi.org/10.1063/1.5009247 (2018).
Mirjalili, S., Mirjalili, S. M. & Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 69, 46–61. https://doi.org/10.1016/j.advengsoft.2013.12.007 (2014).
Tomar, V., Bansal, M. & Singh, P. Metaheuristic algorithms for optimization: A brief review. In RAiSE-2023, MDPI, p 238 (2024). https://doi.org/10.3390/engproc2023059238.
Rezk, H., Olabi, A. G., Wilberforce, T. & Sayed, E. T. A comprehensive review and application of metaheuristics in solving the optimal parameter identification problems. Sustainability 15(7), 5732. https://doi.org/10.3390/su15075732 (2023).
Xu, Z. et al. Orthogonally-designed adapted grasshopper optimization: A comprehensive analysis. Expert Syst. Appl. 150, 113282. https://doi.org/10.1016/j.eswa.2020.113282 (2020).
Saremi, S., Mirjalili, S. & Lewis, A. Grasshopper optimisation algorithm: Theory and application. Adv. Eng. Softw. 105, 30–47. https://doi.org/10.1016/j.advengsoft.2017.01.004 (2017).
Nakamura, R. Y. M., Pereira, L. A. M., Costa, K. A., Rodrigues, D., Papa, J. P. & Yang, X.-S. BBA: A binary bat algorithm for feature selection. In 2012 25th SIBGRAPI Conference on Graphics, Patterns and Images, Ouro Preto, Brazil: IEEE, 291–297 (2012). https://doi.org/10.1109/SIBGRAPI.2012.47
Xu, M., Cao, L., Lu, D., Hu, Z. & Yue, Y. Application of swarm intelligence optimization algorithms in image processing: A comprehensive review of analysis, synthesis, and optimization. Biomimetics 8(2), 235. https://doi.org/10.3390/biomimetics8020235 (2023).
Gandomi, A. H. & Alavi, A. H. Krill herd: A new bio-inspired optimization algorithm. Commun. Nonlinear Sci. Numer. Simul. 17(12), 4831–4845. https://doi.org/10.1016/j.cnsns.2012.05.010 (2012).
Wang, G.-G., Deb, S. & Coelho, L. D. S. Elephant herding optimization. In 2015 3rd International Symposium on Computational and Business Intelligence (ISCBI), Bali, Indonesia: IEEE, 1–5 (2015). https://doi.org/10.1109/ISCBI.2015.8
Nouiri, M., Bekrar, A., Jemai, A., Niar, S. & Ammari, A. C. An effective and distributed particle swarm optimization algorithm for flexible job-shop scheduling problem. J. Intell. Manuf. 29(3), 603–615. https://doi.org/10.1007/s10845-015-1039-3 (2018).
Kennedy, J. & Eberhart, R. Particle swarm optimization. In Proceedings of ICNN’95—International Conference on Neural Networks, Perth, WA, Australia: IEEE, 1942–1948 (1995). https://doi.org/10.1109/ICNN.1995.488968
Cagnina, L. C., Esquivel, S. C. & Coello, C. A. C. Solving engineering optimization problems with the simple constrained particle swarm optimizer. Informatica (Slovenia) 32(2008), 319–326 (2008).
Li, Y., Wang, J., Zhao, D., Li, G. & Chen, C. A two-stage approach for combined heat and power economic emission dispatch: Combining multi-objective optimization with integrated decision making. Energy 162, 237–254. https://doi.org/10.1016/j.energy.2018.07.200 (2018).
Bohre, A. K., Agnihotri, G. & Dubey, M. The butterfly-particle swarm optimization (butterfly-PSO/BF-PSO) technique and its variables. SSRN Electron. J. https://doi.org/10.2139/ssrn.3529113 (2015).
Fouad, M. M., El-Desouky, A. I., Al-Hajj, R. & El-Kenawy, E.-S.M. Dynamic group-based cooperative optimization algorithm. IEEE Access 8, 148378–148403. https://doi.org/10.1109/ACCESS.2020.3015892 (2020).
Houssein, E. H., Saad, M. R., Hashim, F. A., Shaban, H. & Hassaballah, M. Lévy flight distribution: A new metaheuristic algorithm for solving engineering optimization problems. Eng. Appl. Artif. Intell. 94, 103731. https://doi.org/10.1016/j.engappai.2020.103731 (2020).
Khatri, A., Gaba, A., Rana, K. P. S. & Kumar, V. A novel life choice-based optimizer. Soft Comput. 24(12), 9121–9141. https://doi.org/10.1007/s00500-019-04443-z (2020).
Yousri, D., Babu, T. S. & Fathy, A. Recent methodology based Harris Hawks optimizer for designing load frequency control incorporated in multi-interconnected renewable energy plants. Sustain. Energy Grids Netw. 22, 100352. https://doi.org/10.1016/j.segan.2020.100352 (2020).
Heidari, A. A. et al. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 97, 849–872. https://doi.org/10.1016/j.future.2019.02.028 (2019).
Hans, R., Kaur, H. & Kaur, N. Opposition-based Harris Hawks optimization algorithm for feature selection in breast mass classification. J. Interdiscip. Math. 23(1), 97–106. https://doi.org/10.1080/09720502.2020.1721670 (2020).
Bui, D. T. et al. A novel swarm intelligence—Harris Hawks optimization for spatial assessment of landslide susceptibility. Sensors 19(16), 3590. https://doi.org/10.3390/s19163590 (2019).
Attiya, I., Abd Elaziz, M. & Xiong, S. Job scheduling in cloud computing using a modified Harris Hawks optimization and simulated annealing algorithm. Comput. Intell. Neurosci. 2020, 1–17. https://doi.org/10.1155/2020/3504642 (2020).
Chen, H. et al. Multi-population differential evolution-assisted Harris hawks optimization: Framework and case studies. Future Gener. Comput. Syst. 111, 175–198. https://doi.org/10.1016/j.future.2020.04.008 (2020).
Jia, H., Lang, C., Oliva, D., Song, W. & Peng, X. Dynamic Harris Hawks optimization with mutation mechanism for satellite image segmentation. Remote Sens. 11(12), 1421. https://doi.org/10.3390/rs11121421 (2019).
Yıldız, A. R., Yıldız, B. S., Sait, S. M., Bureerat, S. & Pholdee, N. A new hybrid Harris hawks-Nelder-Mead optimization algorithm for solving design and manufacturing problems. Mater. Test. 61(8), 735–743. https://doi.org/10.3139/120.111378 (2019).
Yu, Z., Shi, X., Zhou, J., Chen, X. & Qiu, X. Effective assessment of blast-induced ground vibration using an optimized random forest model based on a Harris Hawks optimization algorithm. Appl. Sci. 10(4), 1403. https://doi.org/10.3390/app10041403 (2020).
Chen, H., Jiao, S., Wang, M., Heidari, A. A. & Zhao, X. Parameters identification of photovoltaic cells and modules using diversification-enriched Harris hawks optimization with chaotic drifts. J. Clean. Prod. 244, 118778. https://doi.org/10.1016/j.jclepro.2019.118778 (2020).
Houssein, E. H. et al. Hybrid Harris hawks optimization with cuckoo search for drug design and discovery in chemoinformatics. Sci. Rep. 10(1), 14439. https://doi.org/10.1038/s41598-020-71502-z (2020).
Dhawale, D., Kamboj, V. K. & Anand, P. An improved chaotic Harris Hawks optimizer for solving numerical and engineering optimization problems. Eng. Comput. 39(2), 1183–1228. https://doi.org/10.1007/s00366-021-01487-4 (2023).
Mohanty, S., Subudhi, B. & Ray, P. K. A new mppt design using grey wolf optimization technique for photovoltaic system under partial shading conditions. IEEE Trans. Sustain. Energy 7(1), 181–188. https://doi.org/10.1109/TSTE.2015.2482120 (2016).
Hameed, I. A., Bye, R. T. & Osen, O. L. Grey wolf optimizer (GWO) for automated offshore crane design. In 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece: IEEE, 1–6 (2016). https://doi.org/10.1109/SSCI.2016.7849998
Akyol, S. New chaos-integrated improved grey wolf optimization based models for automatic detection of depression in online social media and networks. PeerJ Comput. Sci. 9, e1661. https://doi.org/10.7717/peerj-cs.1661 (2023).
Mirjalili, S. Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm. Knowl. Based Syst. 89, 228–249. https://doi.org/10.1016/j.knosys.2015.07.006 (2015).
Pelusi, D. et al. An improved moth-flame optimization algorithm with hybrid search phase. Knowl. Based Syst. 191, 105277. https://doi.org/10.1016/j.knosys.2019.105277 (2020).
Gandomi, A. H., Yang, X.-S. & Alavi, A. H. Cuckoo search algorithm: A metaheuristic approach to solve structural optimization problems. Eng. Comput. 29(1), 17–35. https://doi.org/10.1007/s00366-011-0241-y (2013).
Mirjalili, S. The ant lion optimizer. Adv. Eng. Softw. 83, 80–98. https://doi.org/10.1016/j.advengsoft.2015.01.010 (2015).
Karaboga, D. & Basturk, B. Artificial bee colony (ABC) optimization algorithm for solving constrained optimization problems. In Foundations of fuzzy logic and soft computing, P. Melin, O. Castillo, L. T. Aguilar, J. Kacprzyk, and W. Pedrycz, (eds.) Lecture Notes in Computer Science, vol. 4529, 789–798 (Springer, 2007). https://doi.org/10.1007/978-3-540-72950-1_77
Karaboga, D., Gorkemli, B., Ozturk, C. & Karaboga, N. A comprehensive survey: artificial bee colony (ABC) algorithm and applications. Artif. Intell. Rev. 42(1), 21–57. https://doi.org/10.1007/s10462-012-9328-0 (2014).
Dhiman, G. & Kumar, V. Spotted hyena optimizer: A novel bio-inspired based metaheuristic technique for engineering applications. Adv. Eng. Softw. 114, 48–70. https://doi.org/10.1016/j.advengsoft.2017.05.014 (2017).
Kaveh, A. & Ilchi Ghazaan, M. Enhanced colliding bodies optimization for design problems with continuous and discrete variables. Adv. Eng. Softw. 77, 66–75. https://doi.org/10.1016/j.advengsoft.2014.08.003 (2014).
Fathy, A., Alharbi, A. G., Alshammari, S. & Hasanien, H. M. Archimedes optimization algorithm based maximum power point tracker for wind energy generation system. Ain Shams Eng. J. 13(2), 101548. https://doi.org/10.1016/j.asej.2021.06.032 (2022).
Virmani, S., Adrian, E. C., Imhof, K. & Mukherjee, S. Implementation of a Lagrangian relaxation based unit commitment problem. IEEE Trans. Power Syst. 4(4), 1373–1380. https://doi.org/10.1109/59.41687 (1989).
Heidari, A. A., Ali Abbaspour, R. & Rezaee Jordehi, A. An efficient chaotic water cycle algorithm for optimization tasks. Neural Comput. Appl. 28(1), 57–85. https://doi.org/10.1007/s00521-015-2037-2 (2017).
Mostafa Bozorgi, S. & Yazdani, S. IWOA: An improved whale optimization algorithm for optimization problems. J. Comput. Des. Eng. 6(3), 243–259. https://doi.org/10.1016/j.jcde.2019.02.002 (2019).
Mirjalili, S. & Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 95, 51–67. https://doi.org/10.1016/j.advengsoft.2016.01.008 (2016).
Dhawale, P. G., Kamboj, V. K. & Bath, S. K. A levy flight based strategy to improve the exploitation capability of arithmetic optimization algorithm for engineering global optimization problems. Trans. Emerg. Telecommun. Technol. 34(4), e4739. https://doi.org/10.1002/ett.4739 (2023).
Hussien, A. G., Hassanien, A. E., Houssein, E. H., Amin, M. & Azar, A. T. New binary whale optimization algorithm for discrete optimization problems. Eng. Optim. 52(6), 945–959. https://doi.org/10.1080/0305215X.2019.1624740 (2020).
Kirkpatrick, S., Gelatt, C. D. & Vecchi, M. P. Optimization by simulated annealing. Science 220(4598), 671–680. https://doi.org/10.1126/science.220.4598.671 (1983).
Pooja, A. & Sood, S. K. Scientometric analysis of quantum-inspired metaheuristic algorithms. Artif. Intell. Rev. 57(2), 22. https://doi.org/10.1007/s10462-023-10659-1 (2024).
Mirjalili, S., Mirjalili, S. M. & Hatamlou, A. Multi-verse optimizer: A nature-inspired algorithm for global optimization. Neural Comput. Appl. 27(2), 495–513. https://doi.org/10.1007/s00521-015-1870-7 (2016).
Rashedi, E., Nezamabadi-pour, H. & Saryazdi, S. GSA: A gravitational search algorithm. Inf. Sci. 179(13), 2232–2248. https://doi.org/10.1016/j.ins.2009.03.004 (2009).
Mirjalili, S. & Lewis, A. Adaptive gbest-guided gravitational search algorithm. Neural Comput. Appl. 25(7–8), 1569–1584. https://doi.org/10.1007/s00521-014-1640-y (2014).
Mirjalili, S. SCA: A sine cosine algorithm for solving optimization problems. Knowl. Based Syst. 96, 120–133. https://doi.org/10.1016/j.knosys.2015.12.022 (2016).
Chen, H., Wang, M. & Zhao, X. A multi-strategy enhanced sine cosine algorithm for global optimization and constrained practical engineering problems. Appl. Math. Comput. 369, 124872. https://doi.org/10.1016/j.amc.2019.124872 (2020).
Zhou, W. et al. Multi-core sine cosine optimization: Methods and inclusive analysis. Expert Syst. Appl. 164, 113974. https://doi.org/10.1016/j.eswa.2020.113974 (2021).
Abd Elaziz, M., Oliva, D. & Xiong, S. An improved opposition-based sine cosine algorithm for global optimization. Expert Syst. Appl. 90, 484–500. https://doi.org/10.1016/j.eswa.2017.07.043 (2017).
Kaveh, A. & Talatahari, S. A novel heuristic optimization method: charged system search. Acta Mech. 213(3–4), 267–289. https://doi.org/10.1007/s00707-009-0270-4 (2010).
Liu, Y. & Li, R. PSA: A photon search algorithm. J. Inf. Process. Syst. 16(2), 478–493. https://doi.org/10.3745/JIPS.04.0168 (2020).
Geem, Z. W., Kim, J. H. & Loganathan, G. V. A new heuristic optimization algorithm: Harmony Search. Simulation 76(2), 60–68. https://doi.org/10.1177/003754970107600201 (2001).
Lee, K. S. & Geem, Z. W. A new meta-heuristic algorithm for continuous engineering optimization: Harmony search theory and practice. Comput. Methods Appl. Mech. Eng. 194(36–38), 3902–3933. https://doi.org/10.1016/j.cma.2004.09.007 (2005).
Kaveh, A., Khanzadi, M. & Rastegar Moghaddam, M. Billiards-inspired optimization algorithm; A new meta-heuristic method. Structures 27, 1722–1739. https://doi.org/10.1016/j.istruc.2020.07.058 (2020).
Hashim, F. A., Houssein, E. H., Mabrouk, M. S., Al-Atabany, W. & Mirjalili, S. Henry gas solubility optimization: A novel physics-based algorithm. Future Gener. Comput. Syst. 101, 646–667. https://doi.org/10.1016/j.future.2019.07.015 (2019).
Formato, R. A. Central force optimization: A new metaheuristic with applications in applied electromagnetics. Prog. Electromagn. Res. 77, 425–491. https://doi.org/10.2528/PIER07082403 (2007).
Qais, M. H., Hasanien, H. M. & Alghuwainem, S. Transient search optimization: a new meta-heuristic optimization algorithm. Appl. Intell. 50(11), 3926–3941. https://doi.org/10.1007/s10489-020-01727-y (2020).
Tabari, A. & Ahmad, A. A new optimization method: Electro-Search algorithm. Comput. Chem. Eng. 103, 1–11. https://doi.org/10.1016/j.compchemeng.2017.01.046 (2017).
Yang, X.-S. Flower pollination algorithm for global optimization. In Unconventional computation and natural computation, J. Durand-Lose and N. Jonoska, (eds.) in Lecture Notes in Computer Science, vol. 7445, 240–249 (Springer, 2012). https://doi.org/10.1007/978-3-642-32894-7_27
Sadollah, A., Eskandar, H., Bahreininejad, A. & Kim, J. H. Water cycle algorithm with evaporation rate for solving constrained and unconstrained optimization problems. Appl. Soft Comput. 30, 58–71. https://doi.org/10.1016/j.asoc.2015.01.050 (2015).
Zhao, J., Gao, Z.-M. & Sun, W. The improved slime mould algorithm with Levy flight. J. Phys. Conf. Ser. 1617(1), 012033. https://doi.org/10.1088/1742-6596/1617/1/012033 (2020).
Zubaidi, S. L. et al. Hybridised artificial neural network model with slime mould algorithm: A novel methodology for prediction of urban stochastic water demand. Water 12(10), 2692. https://doi.org/10.3390/w12102692 (2020).
Kumar, C., Raj, T. D., Premkumar, M. & Raj, T. D. A new stochastic slime mould optimization algorithm for the estimation of solar photovoltaic cell parameters. Optik 223, 165277. https://doi.org/10.1016/j.ijleo.2020.165277 (2020).
Liu, M. et al. A two-way parallel slime mold algorithm by flow and distance for the travelling salesman problem. Appl. Sci. 10(18), 6180. https://doi.org/10.3390/app10186180 (2020).
Durmus, A. The optimal synthesis of thinned concentric circular antenna arrays ussing slime mold algorithm. Electromagnetics 40(8), 541–553. https://doi.org/10.1080/02726343.2020.1838044 (2020).
Howard, F. L. The life history of Physarum polycephalum. Am. J. Bot. 18(2), 116–133. https://doi.org/10.1002/j.1537-2197.1931.tb09577.x (1931).
Eskandar, H., Sadollah, A., Bahreininejad, A. & Hamdi, M. Water cycle algorithm—A novel metaheuristic optimization method for solving constrained engineering optimization problems. Comput. Struct. 110–111, 151–166. https://doi.org/10.1016/j.compstruc.2012.07.010 (2012).
Zolghadr-Asli, B., Bozorg-Haddad, O. & Chu, X. Crow search algorithm (CSA). In Advanced optimization by nature-inspired algorithms, O. Bozorg-Haddad, (ed.), in Studies in Computational Intelligence, vol. 720, 143–149 (Springer, 2018). https://doi.org/10.1007/978-981-10-5221-7_14
Gandomi, A. H. Interior search algorithm (ISA): A novel approach for global optimization. ISA Trans. 53(4), 1168–1183. https://doi.org/10.1016/j.isatra.2014.03.018 (2014).
Darwish, A. Bio-inspired computing: Algorithms review, deep analysis, and the scope of applications. Future Comput. Inform. J. 3(2), 231–246. https://doi.org/10.1016/j.fcij.2018.06.001 (2018).
Yang, X.-S. A new metaheuristic bat-inspired algorithm. In Nature inspired cooperative strategies for optimization (NICSO 2010), J. R. González, D. A. Pelta, C. Cruz, G. Terrazas, and N. Krasnogor (eds.) in Studies in Computational Intelligence, vol. 284, 65–74 (Springer, 2010). https://doi.org/10.1007/978-3-642-12538-6_6
Xie, J., Zhou, Y. & Chen, H. A bat algorithm based on Lévy flights trajectory. Pattern Recognit. Artif. Intell. 26(9), 829–837 (2013).
Mafarja, M. et al. Evolutionary population dynamics and grasshopper optimization approaches for feature selection problems. Knowl.-Based Syst. 145, 25–45. https://doi.org/10.1016/j.knosys.2017.12.037 (2018).
Sulaiman, M. H., Mustaffa, Z., Saari, M. M., Daniyal, H., Musirin, I. & Daud, M. R. Barnacles mating optimizer: An evolutionary algorithm for solving optimization. In 2018 IEEE International Conference on Automatic Control and Intelligent Systems (I2CACIS), Shah Alam: IEEE, pp. 99–104 (2018). https://doi.org/10.1109/I2CACIS.2018.8603703
Raglend, I. J., Kumar, R., Karthikeyan, S. P., Palanisamy, K. & Kothari, D. P. Profit based unit commitment problem under deregulated environment. In 2009 Australasian Universities Power Engineering Conference, pp. 1–6 (2009).
Holland, J. H. Genetic algorithms. Sci. Am. 267(1), 66–72. https://doi.org/10.1038/scientificamerican0792-66 (1992).
Al-Hajj, R., Assi, A. & Batch, F. An evolutionary computing approach for estimating global solar radiation. In 2016 IEEE International Conference on Renewable Energy Research and Applications (ICRERA) 285–290 (IEEE, 2016). https://doi.org/10.1109/ICRERA.2016.7884553
Cheng, M.-Y. & Prayogo, D. Symbiotic organisms search: A new metaheuristic optimization algorithm. Comput. Struct. 139, 98–112. https://doi.org/10.1016/j.compstruc.2014.03.007 (2014).
Al-Hajj, R. & Assi, A. 1 Department of Math and Statistics for Engineering, American University of the Middle East, Egaila, Kuwait, and 2 Department of Electrical and Electronics Engineering, International University of Beirut, Lebanon, “Estimating solar irradiance using genetic programming technique and meteorological records”. AIMS Energy 5(5), 798–813. https://doi.org/10.3934/energy.2017.5.798 (2017).
Koza, J. R. Genetic programming as a means for programming computers by natural selection. Stat. Comput. 4, 2. https://doi.org/10.1007/BF00175355 (1994).
Dorigo, M., Birattari, M. & Stutzle, T. Ant colony optimization. IEEE Comput. Intell. Mag. 1(4), 28–39. https://doi.org/10.1109/MCI.2006.329691 (2006).
Yao, X., Liu, Y. & Lin, G. Evolutionary programming made faster. IEEE Trans. Evol. Comput. 3(2), 82–102. https://doi.org/10.1109/4235.771163 (1999).
Xue, J. & Shen, B. Dung beetle optimizer: A new meta-heuristic algorithm for global optimization. J. Supercomput. 79(7), 7305–7336. https://doi.org/10.1007/s11227-022-04959-6 (2023).
Simon, D. Biogeography-based optimization. IEEE Trans. Evol. Comput. 12(6), 702–713. https://doi.org/10.1109/TEVC.2008.919004 (2008).
Storn, R. & Price, K. Differential evolution—a simple and efficient heuristic for global optimization over continuous spaces. J. Glob. Optim. 11(4), 341–359. https://doi.org/10.1023/A:1008202821328 (1997).
Hansen, N., Müller, S. D. & Koumoutsakos, P. Reducing the time complexity of the derandomized evolution strategy with covariance matrix adaptation (CMA-ES). Evol. Comput. 11(1), 1–18. https://doi.org/10.1162/106365603321828970 (2003).
Whitley, D. & Rowe, J. Focused no free lunch theorems. In Proceedings of the 10th Annual Conference on Genetic and Evolutionary Computation 811–818 (ACM, 2008). https://doi.org/10.1145/1389095.1389254
Rao, R. V., Savsani, V. J. & Vakharia, D. P. Teaching–learning-based optimization: An optimization method for continuous non-linear large scale problems. Inf. Sci. 183(1), 1–15. https://doi.org/10.1016/j.ins.2011.08.006 (2012).
Satapathy, S. C., Naik, A. & Parvathi, K. A teaching learning based optimization based on orthogonal design for solving global optimization problems. SpringerPlus 2(1), 130. https://doi.org/10.1186/2193-1801-2-130 (2013).
He, S., Wu, Q. H. & Saunders, J. R. Group search optimizer: An optimization algorithm inspired by animal searching behavior. IEEE Trans. Evol. Comput. 13(5), 973–990. https://doi.org/10.1109/TEVC.2009.2011992 (2009).
Zhu, D., Wang, S., Zhou, C., Yan, S. & Xue, J. Human memory optimization algorithm: A memory-inspired optimizer for global optimization problems. Expert Syst. Appl. 237, 121597. https://doi.org/10.1016/j.eswa.2023.121597 (2024).
Glover, F. & Laguna, M. Tabu search. In Handbook of combinatorial optimization, D.-Z. Du and P. M. Pardalos, (Eds.) 2093–2229 (Springer, 1998). https://doi.org/10.1007/978-1-4613-0303-9_33
Lim, W. L., Wibowo, A., Desa, M. I. & Haron, H. A biogeography-based optimization algorithm hybridized with Tabu search for the quadratic assignment problem. Comput. Intell. Neurosci. 2016, 1–12. https://doi.org/10.1155/2016/5803893 (2016).
Muhammed, D. A., Saeed, S. A. M. & Rashid, T. A. Improved fitness-dependent optimizer algorithm. IEEE Access 8, 19074–19088. https://doi.org/10.1109/ACCESS.2020.2968064 (2020).
Anand, P., Rizwan, M., Bath, S. K., Perveen, G. & Kamboj, V. K. Optimal sizing of hybrid renewable energy system for electricity production for remote areas. Iran. J. Sci. Technol. Trans. Electr. Eng. 46(4), 1149–1174. https://doi.org/10.1007/s40998-022-00524-2 (2022).
Zhao, J. & Gao, Z.-M. The chaotic slime mould algorithm with Chebyshev Map. J. Phys. Conf. Ser. 1631(1), 012071. https://doi.org/10.1088/1742-6596/1631/1/012071 (2020).
Wei, Y. et al. Predicting entrepreneurial intention of students: An extreme learning machine with Gaussian Barebone Harris Hawks optimizer. IEEE Access 8, 76841–76855. https://doi.org/10.1109/ACCESS.2020.2982796 (2020).
Abdel-Basset, M., Chang, V. & Mohamed, R. HSMA_WOA: A hybrid novel Slime mould algorithm with whale optimization algorithm for tackling the image segmentation problem of chest X-ray images. Appl. Soft Comput. 95, 106642. https://doi.org/10.1016/j.asoc.2020.106642 (2020).
Gao, Z.-M., Zhao, J. & Li, S.-R. The improved slime mould algorithm with cosine controlling parameters. J. Phys. Conf. Ser. 1631, 012083. https://doi.org/10.1088/1742-6596/1631/1/012083 (2020).
Gao, Z.-M., Zhao, J., Yang, Y. & Tian, X.-J. The hybrid grey wolf optimization-slime mould algorithm. J. Phys. Conf. Ser. 1617(1), 012034. https://doi.org/10.1088/1742-6596/1617/1/012034 (2020).
Cohen, A. & Yoshimura, M. A branch-and-bound algorithm for unit commitment. IEEE Trans. Power Appar. Syst. PAS-102(2), 444–451. https://doi.org/10.1109/TPAS.1983.317714 (1983).
Wehrens, R. & Buydens, L. M. C. Classical and nonclassical optimization methods. (2006). https://api.semanticscholar.org/CorpusID:11952912
Steffan, N. & Heydt, G. T. Quadratic programming and related techniques for the calculation of locational marginal prices in distribution systems. In 2012 North American Power Symposium (NAPS), pp. 1–6 (IEEE, 2012). https://doi.org/10.1109/NAPS.2012.6336310
Yimit, A., Iigura, K. & Hagihara, Y. Refined selfish herd optimizer for global optimization problems. Expert Syst. Appl. 139, 112838. https://doi.org/10.1016/j.eswa.2019.112838 (2020).
Xiao, B., Wang, R., Xu, Y., Wang, J., Song, W. & Deng, Y. Simplified salp swarm algorithm. In 2019 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA) 226–230 (IEEE, 2019). https://doi.org/10.1109/ICAICA.2019.8873515
Yildiz, A. R. & Mehta, P. Manta ray foraging optimization algorithm and hybrid Taguchi salp swarm-Nelder–Mead algorithm for the structural design of engineering components. Mater. Test. 64(5), 706–713. https://doi.org/10.1515/mt-2022-0012 (2022).
Seyyedabbasi, A. & Kiani, F. I-GWO and Ex-GWO: Improved algorithms of the Grey Wolf Optimizer to solve global optimization problems. Eng. Comput. 37(1), 509–532. https://doi.org/10.1007/s00366-019-00837-7 (2021).
Chen, X., Tianfield, H. & Li, K. Self-adaptive differential artificial bee colony algorithm for global optimization problems. Swarm Evol. Comput. 45, 70–91. https://doi.org/10.1016/j.swevo.2019.01.003 (2019).
Karaboga, D. & Akay, B. A comparative study of Artificial Bee Colony algorithm. Appl. Math. Comput. 214(1), 108–132. https://doi.org/10.1016/j.amc.2009.03.090 (2009).
Banerjee, N. & Mukhopadhyay, S. HC-PSOGWO: Hybrid crossover oriented PSO and GWO based co-evolution for global optimization. In 2019 IEEE Region 10 Symposium (TENSYMP) 162–167 (IEEE, 2019). https://doi.org/10.1109/TENSYMP46218.2019.8971231
Tejani, G. G., Kumar, S. & Gandomi, A. H. Multi-objective heat transfer search algorithm for truss optimization. Eng. Comput. 37(1), 641–662. https://doi.org/10.1007/s00366-019-00846-6 (2021).
Abualigah, L., Diabat, A., Sumari, P. & Gandomi, A. H. A novel evolutionary arithmetic optimization algorithm for multilevel thresholding segmentation of COVID-19 CT images. Processes 9(7), 1155. https://doi.org/10.3390/pr9071155 (2021).
Rereloluwa Adegboye, O. et al. Refinement of dynamic hunting leadership algorithm for enhanced numerical optimization. IEEE Access 12, 103271–103298. https://doi.org/10.1109/ACCESS.2024.3427812 (2024).
Adegboye, O. R. et al. DGS-SCSO: Enhancing sand cat swarm optimization with dynamic pinhole imaging and golden sine algorithm for improved numerical optimization performance. Sci. Rep. 14(1), 1491. https://doi.org/10.1038/s41598-023-50910-x (2024).
Yang, X.-S. & Suash Deb. Cuckoo Search via Lévy flights. In 2009 World Congress on Nature & Biologically Inspired Computing (NaBIC) 210–214 (IEEE, 2009). https://doi.org/10.1109/NABIC.2009.5393690
Adegboye, O. R. & Deniz Ülker, E. Hybrid artificial electric field employing cuckoo search algorithm with refraction learning for engineering optimization problems. Sci. Rep. 13(1), 4098. https://doi.org/10.1038/s41598-023-31081-1 (2023).
Xiao, Y., Cui, H., Hussien, A. G. & Hashim, F. A. MSAO: A multi-strategy boosted snow ablation optimizer for global optimization and real-world engineering applications. Adv. Eng. Inform. 61, 102464. https://doi.org/10.1016/j.aei.2024.102464 (2024).
Xiao, Y. et al. An improved gorilla troops optimizer based on lens opposition-based learning and adaptive β-hill climbing for global optimization. Comput. Model. Eng. Sci. 131(2), 815–850. https://doi.org/10.32604/cmes.2022.019198 (2022).
Abualigah, L., Diabat, A., Mirjalili, S., Abd Elaziz, M. & Gandomi, A. H. The arithmetic optimization algorithm. Comput. Methods Appl. Mech. Eng. 376, 113609. https://doi.org/10.1016/j.cma.2020.113609 (2021).
Xiao, Y. et al. IHAOAVOA: An improved hybrid aquila optimizer and African vultures optimization algorithm for global optimization problems. Math. Biosci. Eng. 19(11), 10963–11017. https://doi.org/10.3934/mbe.2022512 (2022).
Awad, N. H., Ali, M. Z., Suganthan, P. N. & Reynolds, R. G. An ensemble sinusoidal parameter adaptation incorporated with L-SHADE for solving CEC2014 benchmark problems. In 2016 IEEE Congress on Evolutionary Computation (CEC), 2958–2965 (IEEE, 2016). https://doi.org/10.1109/CEC.2016.7744163
Kumar, A., Misra, R. K. & Singh, D. Improving the local search capability of effective butterfly optimizer using covariance matrix adapted retreat phase. In 2017 IEEE Congress on Evolutionary Computation (CEC), 1835–1842 (IEEE, 2017). https://doi.org/10.1109/CEC.2017.7969524
Brest, J., Maucec, M. S. & Boskovic, B. Single objective real-parameter optimization: Algorithm jSO. In 2017 IEEE Congress on Evolutionary Computation (CEC), 1311–1318 (IEEE, 2017). https://doi.org/10.1109/CEC.2017.7969456
Mohamed, A. W., Hadi, A. A., Fattouh, A. M. & Jambi, K. M. LSHADE with semi-parameter adaptation hybrid with CMA-ES for solving CEC 2017 benchmark problems. In 2017 IEEE Congress on Evolutionary Computation (CEC), 145–152 (IEEE, 2017). https://doi.org/10.1109/CEC.2017.7969307
Rahkar Farshi, T. Battle royale optimization algorithm. Neural Comput. Appl. 33(4), 1139–1157. https://doi.org/10.1007/s00521-020-05004-4 (2021).
Nandi, A. & Kamboj, V. K. A Canis lupus inspired upgraded Harris hawks optimizer for nonlinear, constrained, continuous, and discrete engineering design problem. Int. J. Numer. Methods Eng. 122(4), 1051–1088. https://doi.org/10.1002/nme.6573 (2021).
Askari, Q., Younas, I. & Saeed, M. Political optimizer: A novel socio-inspired meta-heuristic for global optimization. Knowl.-Based Syst. 195, 105709. https://doi.org/10.1016/j.knosys.2020.105709 (2020).
Chou, J.-S. & Nguyen, N.-M. FBI inspired meta-optimization. Appl. Soft Comput. 93, 106339. https://doi.org/10.1016/j.asoc.2020.106339 (2020).
Kaur, S., Awasthi, L. K., Sangal, A. L. & Dhiman, G. Tunicate Swarm Algorithm: A new bio-inspired based metaheuristic paradigm for global optimization. Eng. Appl. Artif. Intell. 90, 103541. https://doi.org/10.1016/j.engappai.2020.103541 (2020).
Abualigah, L. RETRACTED ARTICLE: Group search optimizer: A nature-inspired meta-heuristic optimization algorithm with its results, variants, and applications. Neural Comput. Appl. 33(7), 2949–2972. https://doi.org/10.1007/s00521-020-05107-y (2021).
Faramarzi, A., Heidarinejad, M., Mirjalili, S. & Gandomi, A. H. Marine predators algorithm: A nature-inspired metaheuristic. Expert Syst. Appl. 152, 113377. https://doi.org/10.1016/j.eswa.2020.113377 (2020).
Shahrouzi, M. & Salehi, A. Imperialist competitive learner-based optimization: A hybrid method to solve engineering problems. Intl. J. Optim. Civil Eng. 10(1), 155–180 (2020).
Kaveh, A. & Dadras Eslamlou, A. Water strider algorithm: A new metaheuristic and applications. Structures 25, 520–541. https://doi.org/10.1016/j.istruc.2020.03.033 (2020).
Harifi, S., Mohammadzadeh, J., Khalilian, M. & Ebrahimnejad, S. Giza Pyramids Construction: An ancient-inspired metaheuristic algorithm for optimization. Evol. Intell. 14(4), 1743–1761. https://doi.org/10.1007/s12065-020-00451-3 (2021).
Dhiman, G., Garg, M., Nagar, A., Kumar, V. & Dehghani, M. A novel algorithm for global optimization: Rat Swarm Optimizer. J. Ambient Intell. Humaniz. Comput. 12(8), 8457–8482. https://doi.org/10.1007/s12652-020-02580-0 (2021).
Debnath, S., Arif, W. & Baishya, S. Buyer inspired meta-heuristic optimization algorithm. Open Comput. Sci. 10(1), 194–219. https://doi.org/10.1515/comp-2020-0101 (2020).
Ahmadianfar, I., Bozorg-Haddad, O. & Chu, X. Gradient-based optimizer: A new metaheuristic optimization algorithm. Inf. Sci. 540, 131–159. https://doi.org/10.1016/j.ins.2020.06.037 (2020).
Faramarzi, A., Heidarinejad, M., Stephens, B. & Mirjalili, S. Equilibrium optimizer: A novel optimization algorithm. Knowl.-Based Syst. 191, 105190. https://doi.org/10.1016/j.knosys.2019.105190 (2020).
Talatahari, S. & Azizi, M. Chaos game optimization: A novel metaheuristic algorithm. Artif. Intell. Rev. 54(2), 917–1004. https://doi.org/10.1007/s10462-020-09867-w (2021).
Chen, Z. et al. An enhanced teaching-learning-based optimization algorithm with self-adaptive and learning operators and its search bias towards origin. Swarm Evol. Comput. 60, 100766. https://doi.org/10.1016/j.swevo.2020.100766 (2021).
Zheng, R. et al. An improved wild horse optimizer for solving optimization problems. Mathematics 10(8), 1311. https://doi.org/10.3390/math10081311 (2022).
Mahajan, S. et al. Fusion of modern meta-heuristic optimization methods using arithmetic optimization algorithm for global optimization tasks. Soft Comput. 26(14), 6749–6763. https://doi.org/10.1007/s00500-022-07079-8 (2022).
Kaveh, A. & Zaerreza, A. Shuffled shepherd optimization method: A new Meta-heuristic algorithm. Eng. Comput. 37(7), 2357–2389. https://doi.org/10.1108/EC-10-2019-0481 (2020).
Zolf, K. Gold rush optimizer: A new population-based metaheuristic algorithm. Oper. Res. Decis. 33(1), 113–150 (2023).
Al-Baik, O. et al. Pufferfish optimization algorithm: A new bio-inspired metaheuristic algorithm for solving optimization problems. Biomimetics 9(2), 65. https://doi.org/10.3390/biomimetics9020065 (2024).
Dehghani, M. et al. Lyrebird optimization algorithm: A new bio-inspired metaheuristic algorithm for solving optimization problems. Biomimetics 8(6), 507. https://doi.org/10.3390/biomimetics8060507 (2023).
Ou, Y. et al. An improved grey wolf optimizer with multi-strategies coverage in wireless sensor networks. Symmetry 16(3), 286. https://doi.org/10.3390/sym16030286 (2024).
Rajwar, K., Deep, K. & Das, S. An exhaustive review of the metaheuristic algorithms for search and optimization: taxonomy, applications, and open challenges. Artif. Intell. Rev. 56(11), 13187–13257. https://doi.org/10.1007/s10462-023-10470-y (2023).
Ahmad, I., Qayum, F., Rahman, S. U. & Srivastava, G. Using improved hybrid grey wolf algorithm based on artificial bee colony algorithm onlooker and scout bee operators for solving optimization problems. Int. J. Comput. Intell. Syst. 17(1), 111. https://doi.org/10.1007/s44196-024-00497-6 (2024).
Tsai, H.-C. & Shi, J.-Y. Potential corrections to grey wolf optimizer. Appl. Soft Comput. 161, 111776. https://doi.org/10.1016/j.asoc.2024.111776 (2024).
Li, H. et al. An improved grey wolf optimizer with weighting functions and its application to unmanned aerial vehicles path planning. Comput. Electr. Eng. 111, 108893. https://doi.org/10.1016/j.compeleceng.2023.108893 (2023).
Pal, S., Kalita, K. & Haldar, S. Grey wolf optimizer based-natural frequency optimization of laminated composite shells carrying distributed mass. Mech. Based Des. Struct. Mach. 52(11), 8509–8543. https://doi.org/10.1080/15397734.2024.2321971 (2024).
Yang, J. & Gu, W. A multi-stage time-backtracking grey wolf optimizer introducing a new hierarchy mechanism (2024), In Review. https://doi.org/10.21203/rs.3.rs-4126903/v1
Ramana, R. et al. An improved chaotic grey wolf optimization algorithm (CGWO). Int. J. Recent Innov. Trends Comput. Commun. 11(11s), 341–348. https://doi.org/10.17762/ijritcc.v11i11s.8161 (2023).
Department of Electrical and Electronics Engineering, SV College of Engineering, Tirupati, 517507, India et al. Grey wolf optimizer algorithm for multi-objective optimal power flow. J. Intell. Syst. Internet Things 12 (1), 20–32 (2024). https://doi.org/10.54216/JISIoT.120102
Zhang, J., Dai, Y. & Shi, Q. An improved grey wolf optimization algorithm based on scale-free network topology. Heliyon 10(16), e35958. https://doi.org/10.1016/j.heliyon.2024.e35958 (2024).
Chandran, V. & Mohapatra, P. Enhanced opposition-based grey wolf optimizer for global optimization and engineering design problems. Alex. Eng. J. 76, 429–467. https://doi.org/10.1016/j.aej.2023.06.048 (2023).
Ye, Z., et al., Hybrid rice optimization algorithm inspired grey wolf optimizer for high-dimensional feature selection. (2024) In Review. https://doi.org/10.21203/rs.3.rs-4598290/v1
Digalakis, J. G. & Margaritis, K. G. On benchmarking functions for genetic algorithms. Int. J. Comput. Math. 77(4), 481–506. https://doi.org/10.1080/00207160108805080 (2001).
Wu, G., Mallipeddi, R. & Suganthan, P. N. Problem definitions and evaluation criteria for the CEC 2017 competition on constrained real-parameter optimization. Natl. Univ. Def. Technol. Chang. Hunan PR China Kyungpook Natl. Univ. Daegu South Korea Nanyang Technol. Univ. Singap. Tech. Rep. (2017).
Luo, W., Lin, X., Li, C., Yang, S. & Shi, Y. Benchmark functions for CEC 2022 competition on seeking multiple optima in dynamic environments (2022). https://doi.org/10.48550/ARXIV.2201.00523
Kumar, A. et al. A test-suite of non-convex constrained optimization problems from the real-world and some baseline results. Swarm Evol. Comput. 56, 100693. https://doi.org/10.1016/j.swevo.2020.100693 (2020).
Kamboj, V. K., Nandi, A., Bhadoria, A. & Sehgal, S. An intensify Harris Hawks optimizer for numerical and engineering optimization problems. Appl. Soft Comput. 89, 106018. https://doi.org/10.1016/j.asoc.2019.106018 (2020).
Sadollah, A., Bahreininejad, A., Eskandar, H. & Hamdi, M. Mine blast algorithm: A new population based algorithm for solving constrained engineering optimization problems. Appl. Soft Comput. 13(5), 2592–2612. https://doi.org/10.1016/j.asoc.2012.11.026 (2013).
Kannan, B. K. & Kramer, S. N. An augmented lagrange multiplier based method for mixed integer discrete continuous optimization and its applications to mechanical design. J. Mech. Des. 116(2), 405–411. https://doi.org/10.1115/1.2919393 (1994).
Coello Coello, C. A. & Christiansen, A. D. MOSES: A multiobjective optimization tool for engineering design. Eng. Optim. 31(3), 337–368. https://doi.org/10.1080/03052159908941377 (1999).
Author information
Authors and Affiliations
Contributions
HS: Conceptualization, Formal analysis, Writing-original draft SS: Investigation, Software, Visualization HS: Resources, Investigation, Software VKK: Data Curation, Formal analysis, Resources KA: Methodology, Validation, project administration GPJ: Validation, supervision, writing-review & editing WC: Funding acquisition, project administration, Supervision.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Singh, H., Saxena, S., Sharma, H. et al. An integrative TLBO-driven hybrid grey wolf optimizer for the efficient resolution of multi-dimensional, nonlinear engineering problems. Sci Rep 15, 11205 (2025). https://doi.org/10.1038/s41598-025-89458-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-89458-3
Keywords
This article is cited by
-
Performance evaluation and multi-objective optimization of EDM parameters for Ti6Al4V using different tool electrodes
Scientific Reports (2025)
-
Dialectic optimization algorithm (DOA): a novel metaheuristic inspired by dialectical philosophy
The Journal of Supercomputing (2025)
