
Abstract
RNA capped with dinucleoside polyphosphates has been discovered in bacteria and eukaryotes only recently. The likely mechanism of this specific capping involves direct incorporation of dinucleoside polyphosphates by RNA polymerase as noncanonical initiating nucleotides. However, how these compounds bind into the active site of RNA polymerase during transcription initiation is unknown. Here, we explored transcription initiation in vitro, using a series of DNA templates in combination with dinucleoside polyphosphates and model RNA polymerase from Thermus thermophilus. We observed that the transcription start site can vary on the basis of the compatibility of the specific template and dinucleoside polyphosphate. Cryo-electron microscopy structures of transcription initiation complexes with dinucleoside polyphosphates revealed that both nucleobase moieties can pair with the DNA template. The first encoded nucleotide pairs in a canonical Watson–Crick manner, whereas the second nucleobase pairs noncanonically in a reverse Watson–Crick manner. Our work provides a structural explanation of how dinucleoside polyphosphates initiate RNA transcription.

Similar content being viewed by others
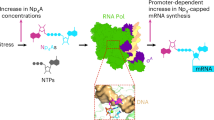

Main
RNA modifications have important roles in the life of RNA, including its stabilization, localization and specific recognition of its interacting partners. More than 170 RNA modifications are known1 in all types of organisms. Their roles are understood and well described in the most abundant types of RNA such as transfer RNA and ribosomal RNA. However, their function in other types of RNA, like mRNA or long noncoding RNA, is still under investigation. Some of the best-described RNA modifications are canonical 5′ m7G caps, which are known to have an important role in eukaryotic mRNAs. The discovery of 5′ noncanonical capping of RNA, namely the capping of RNA with nicotinamide adenine dinucleotide (NAD)2,3,4,5 and coenzyme A (CoA)6, triggered a search for other alternative RNA caps. Lately, flavin adenine dinucleotide (FAD)7,8, sugar conjugate9 and dinucleoside polyphosphate (NpnNs)10,11,12 RNA caps have been discovered in a variety of organisms13.
The most widely accepted hypothesis concerning the biosynthesis of noncanonically capped RNA is that RNA polymerases (RNAPs) directly use these molecules as noncanonical initiating nucleotides (NCINs). This is analogous to noncanonical transcription initiation by 5′-end hydroxyl dinucleotide primers14,15, which are used instead of regular nucleoside triphosphates (NTPs). The ability of bacterial or bacteriophage RNAP to initiate transcription with NAD, CoA or FAD cofactor molecules was first described in vitro16,17. Later on, cofactor incorporation by bacterial and eukaryotic RNAP II was confirmed in vivo, as well18. X-ray structures of Thermus thermophilus (Tt) RNAP visualized these cofactors as NCINs18.
Various types of NpnNs serving as RNA caps have been detected in Escherichia coli by using liquid chromatography–mass spectrometry (LC–MS) analysis11. We and others have demonstrated that NpnNs can be incorporated into RNA directly by bacteriophage and bacterial RNAPs as NCINs11,19 in a similar manner as cofactors.
In our previous study, we focused on the direct incorporation of NpnNs by RNAP during the initiation phase of transcription20. We observed that the addition of NpnNs, such as Ap3G, into an in vitro transcription (IVT) reaction with T7 RNAP led to a several times greater production of 2-mer or 3-mer RNAs. It is important to note that because NpnNs are linked 5′ to 5′ (Fig. 1a and Extended Data Fig. 1), they have two free 3′ hydroxyl groups and can be incorporated into a nascent RNA chain in two alternative orientations. Molecular dynamics simulations predicted that both nucleosides from the Ap3G NCIN pair with the template DNA strand. Whereas G paired in the RNAP i site with the template transcription start site (TSS) +1C in a Watson–Crick (WC) manner, A paired in the i − 1 site with the template −1T in a noncanonical manner. In comparison, the 5′-end hydroxyl dinucleotide primers, where the direction of incorporation of the dinucleotides is governed by the canonical 5′-to-3′ linkage, pair in the regular WC manner in both i and i − 1 sites15.

a, Chemical structure of NpnNs. b, Schemes of IVT experiments where NTPs or NpnNs bind to the template TC (with a premelted bubble from position −11 to +2) during transcription initiation with different base-pairing combinations between NpnNs and the −1 and +1 template strand positions. T, template; NT, nontemplate. c, Sequences of color-coded RNA products with and without the addition of NpnNs. Uncapped 15-mer referred to as (+1)TSS-RNA is indicated by a blue dot, uncapped 16-mer referred to as (−1)TSS-RNA is indicated by a brown dot, capped 15-mers referred to as cap(+1)TSS-RNA are indicated by green and yellow dots and capped 16-mers referred to as cap(−1)TSS-RNA are indicated by purple and pink dots. d, PAGE analysis with acryloylaminophenyl boronic acid (APB) showing RNA products obtained from IVT reactions with the template TC and NTPs or their combination with various NpnNs radiolabeled with α-[32P]CTP. Each control (CTRL AG, CTRL GG, CTRL AA) was designed according to Supplementary Table 2; it shows the migration of the uncapped RNA 15-mer (blue dots) and 16-mer (brown dots) and serves as a molecular weight marker (e). The capped products are marked with colored dots according to c. The IVT was performed in ten independent experiments; one representative gel is shown. Nonadjacent lanes from the same experiment were rearranged and are separated by delineating black lines. Each lane originates from the same gel. e, PAGE (without APB) analysis showing the migration patterns of a 16-mer and 15-mer monophosphate marker along with the triphosphate RNA (ppp-CTRL) and the monophosphate RNA (p-CTRL) generated using template TC and regular NTPs. The markers have the same sequence as the RNA transcript expected from the template TC (Extended Data Table 1), starting at position −1 (p-MARKER(16)) and +1 (p-MARKER(15)). This experiment was performed in triplicate; one representative gel is shown. Created in BioRender. Serianni, V. (2025) https://BioRender.com/p388ku2.
To further investigate the details of the initiation phase of transcription with NCINs in bacteria, we focused on Tt RNAP as a robust structural model of bacterial transcription and on purine-containing NpnNs, which are the most studied examples of NpnNs in bacteria21,22,23. Moreover, Tt σA belongs to the same family of sigma factors24 as housekeeping E. coli σ70, which has been reported to initiate transcription primarily with ATP or GTP25. We designed experiments where various NpnNs (Ap3-4A, Ap3-4G and Gp3-4G) were probed as NCINs by IVT assays with templates having combinations of T and/or C at positions −1 and +1 of the template strand with respect to the TSS. Following on these experiments, we visualized, using cryogenic electron microscopy (cryo-EM), a set of Tt RNAP transcription initiation complexes with various ApnNs bound as NCINs to templates in the RNAP active site (AS). The structural analysis confirmed that both nucleosides of ApnNs can base pair with the template DNA strand and provided a structural basis for understanding their role as NCINs.
Results
Two possible ways of transcription initiation with NpnNs
To explore the role of NpnNs in the transcription initiation process, we designed a series of templates with artificial transcription bubbles for use in an IVT assay using the Tt RNAP-σA holoenzyme26. The templates were designed on the basis of previous work27,28 (Fig. 1, Extended Data Table 1, Supplementary Table 1 and Supplementary Fig. 1), having combinations of C and/or T at positions −1 and +1 of the template strand with respect to the TSS. We then performed radioactively labeled IVT reactions using these templates with four regular NTPs in combination with NpnNs (Ap3-4A, Ap3-4G and Gp3-4G; Fig. 1b,c). We prepared control experiments where the concentration of NpnNs was replaced by the two respective NTPs (ATP or GTP). Each control contained the same total final concentration of initiating nucleotides (Supplementary Table 2).
The control reactions using the template TC and regular NTPs resulted in the production of the expected 15-mer product ((+1)TSS-RNA), initiating at the putative +1C TSS (Fig. 1c,d). We also observed formation of a 1-nt-longer product potentially starting at the −1T TSS ((−1)TSS-RNA) and other shorter aberrant products (Fig. 1c,d), which might be abortive products, as previously reported for IVTs using E. coli RNAP29,30. When we used the template TC and added NpnNs into the IVT mixture, we observed the formation of capped RNA of two different lengths, depending on the type of NpnN (Fig. 1c,d). The addition of Ap3-4G and Gp3-4G in the reaction mixture led to the formation of a dominant RNA product migrating slower in PAGE than the control RNA without NpnNs (15-mer). The size of this RNA corresponds to a capped 15-mer transcription product starting with the G nucleoside of NpnG at position +1C of the template (cap(+1)TSS-RNA). This potentially allows the A nucleoside of Ap3-4G to interact with the −1T base of the template (Fig. 1b). In experiments with added Ap3-4G, we also observed traces of a capped 16-mer RNA product (cap(−1)TSS-RNA). This suggests that Ap3-4G can initiate transcription with the A moiety at the template −1T position. However, this would require a shift of the template strand by one nucleotide with respect to the RNAP AS for the −1 template position to serve as the TSS. Variability in TSS selection has been already described and involves DNA scrunching and antiscrunching31,32,33. Lastly, when we added Ap3-4A to the IVT reactions, we observed the formation of the capped 16-mer transcription product (cap(−1)TSS-RNA; Fig. 1d). This suggests that initiation by Ap3-4A leads to the production of capped RNA encoded from the −1T position rather than from the putative +1C position of the DNA template.
To confirm the results of the IVT PAGE experiments and, thus, verify that we observed NpnN-capped RNA products initiating at the +1 and −1 template positions as the TSSs, we established a very sensitive LC–MS method capable of detecting the full-length products of IVT with Tt RNAP. We were able to identify all expected IVT products, encoded from both the +1 TSS and the −1 TSS (Fig. 1c), in the reaction mixtures containing NpnNs or in the control mixtures (Supplementary Table 3 and Extended Data Fig. 2). Surprisingly, we also detected unexpected products with an extra C added at the 3′ end (Supplementary Table 3, Extended Data Fig. 2 and Supplementary Fig. 2), indicating that, for example, the IVT PAGE band corresponding to a 16-mer (Fig. 1d) contains, in addition to the (−1)TSS-RNA, a (+1)TSS-RNA with an extra 3′ C. Similar nontemplated addition of C at the 3′ end of RNA has been already reported for mitochondrial RNAP of the protist Physarum polycephalum34,35.
To understand whether capped RNA is also formed by Tt RNAP in the context of native-like DNA promoter, we developed another transcription assay using a circular supercoiled plasmid (plasmid TC)36 Supplementary Table 1) containing a fully complementary promoter with the −35 and −10 elements used in this study and with a T at the −1 position and a C at the +1 position, resembling the TC template. Using this assay, we observed the formation of all NpnN-capped RNAs through PAGE and LC–MS analysis combined with RNase A treatment (Extended Data Fig. 3 and Supplementary Table 4).
Furthermore, we performed the same IVT and LC–MS experiments as for template TC also on additional templates containing combinations of C and/or T at positions −1 and +1 of the template strand (templates gTT and CT) (Extended Data Table 1, Extended Data Figs. 4–7 and Supplementary Tables 5 and 6). Indeed, we confirmed that the Tt RNAP holoenzyme in combination with the DNA templates used in this study allow the NpnNs to initiate transcription from both the +1 and −1 template positions as TSSs. Additionally, when using NAD as NCIN in the IVT, we confirmed that it has a much lower incorporation efficiency19 than NTPs and NpnNs (Supplementary Fig. 3).
Structural insights into transcription initiation by NpnNs
During transcription initiation, RNAP catalyzes the synthesis of the first phosphodiester bond between the initiating nucleotide bound in the i site (+1 with respect to the canonical TSS of the template) and the extending nucleotide bound in the i + 1 site (+2 with respect to the canonical TSS of the template) of the catalytic site. Previous structural studies defined NCINs to be able to react de novo in the catalytic site of bacterial RNAP18. However, the binding of NCINs into the i site and the i − 1 site (−1 with respect to the canonical TSS of the template) to react with an extending nucleotide was never captured. This is because the NCINs were allowed to react with the extending nucleotide and the AS was visualized in a posttranslocated state. Here, we aimed to visualize the state just before the very first step of the initial nucleotidyl transfer, where NCINs align to react with the first extending nucleotide (Supplementary Fig. 4), but before the reaction occurs—in the precatalytic state. For this purpose, we reconstituted an artificial Tt holoenzyme complex with an opened transcription bubble with defined mixtures of substrates and nonhydrolyzable analogs.
We first visualized, using cryo-EM, the canonical de novo transcription initiation complex with template TC together with GTP and the nonhydrolyzable CTP analog cytidine-5′-[(α,β)-methyleno]triphosphate (CMPcPP). The cryo-EM analysis (Supplementary Figs. 5 and 6 and Supplementary Tables 7 and 8) revealed two relevant structures, one with an unoccupied AS, hereafter referred to as TC-empty, and one with the AS occupied by GTP and CMPcPP, hereafter referred to as TC-GTP. The TC-GTP structure (Extended Data Fig. 8a,b, Supplementary Figs. 4a and 7a and Supplementary Table 7) is similar to crystallographic structures of analogous complexes (PDB 4Q4Z (ref. 37) and PDB 4OIO (ref. 38)). The initiating GTP is bound in the i site and the extending CMPcPP in the i + 1 site, both canonically base pairing with the TSS +1C and +2G base, respectively. MgA is coordinated by the catalytic aspartate triad, whereas MgB is only partially coordinated by β′/D739. Notably, there is interpretable density for Mg2+ (hereafter MgC), which is coordinated by phosphates of the GTP in a tridentate manner. The GTP α and γ phosphates canonically interact with conserved residues37 β/K838 and K846, and β/Q567 and H999, respectively. Additionally, residue β/Y998 adopts two alternative conformations, one pointing away and one pointing toward the γ phosphate.
In the TC-empty structure (Supplementary Fig. 4a and Extended Data Fig. 8c), we observed that the template strand is antiscrunched31,33,39 by one nucleotide, placing the template −2G base in line with the i − 1 site, the template −1T base in line with the i site and the template +1C base in line with the i + 1 site, while the +2G base is shifted over the bridge helix toward the downstream DNA duplex (Extended Data Fig. 8c and Supplementary Fig. 8a–c). The nontemplate strand is not shifted in register, which is highlighted by the +2G base of the nontemplate strand bound in the core recognition element (CRE)-specific binding pocket of RNAP27 (Supplementary Fig. 8a–c). As the AS is unoccupied, the antiscrunching of the template by one nucleotide and the concomitant TSS shift happens without any stabilization by nucleotides pairing with the antiscrunched template. This template oscillation32 then allows the use of both +1 and −1 TSS in the IVT reactions in our in vitro system. Altogether, the TC-GTP and TC-empty structures set a basis for structural comparison of complexes with various bound NpnNs visualized in this study.
Distal base binds template in a reverse WC (rWC) manner
Next, we visualized the same template TC holoenzyme complex with Ap3G and CMPcPP, hereafter referred to as TC-Ap3G (Fig. 2a,b, Supplementary Figs. 4b and 7b and Supplementary Table 7). Like in the TC-GTP structure, the CMPcPP in the i + 1 site base pairs with the +2G base in a preinsertion position. The guanosine of Ap3G in the i site base pairs canonically with the +1C TSS (hereafter, we call the nucleoside of NpnN in the i site proximal; Fig. 2b). The guanosine is, thus, aligned for the first nucleotidyl transfer reaction. The α phosphate (counted from the proximal nucleoside) is positioned by β/K838 and β/K846 in a similar way to GTP in the TC-GTP structure. The β phosphate (instead of the γ phosphate in TC-GTP) is positioned by β/H999 and the γ phosphate is positioned by β/Q567; β/Y998 points away from Ap3G. There is an interpretable density for MgC coordinated by the α and γ phosphates of Ap3G. The torsion angles between the γ phosphate and the adjacent ribose moiety direct the adenosine into the i − 1 position to base pair with the template −1T (hereafter, we call the nucleoside of NpnN in the i − 1 site distal). The glycosidic bond of the distal adenosine is in the trans orientation and the adenine base pairs with the −1T base in an rWC manner (Extended Data Fig. 9a). This is in contrast to the cis orientation in regular RNA–DNA27 or 5′-end hydroxyl dinucleotide primer–DNA duplexes15 (Extended Data Fig. 9b). The cryo-EM density (Fig. 2b and Supplementary Fig. 7b) does not support other potential noncanonical base-pairing options such as the Hoogsteen mode. The base pair in the i − 1 site is further stabilized by stacking interactions with the base pair in the i site from one side and from the other with the template purine base −2G in line with the i − 2 site, which overlaps with both the template −1T and the distal adenine base of Ap3G. Such stacking stabilization by a purine template base in line with the i − 2 site was previously observed for nascent dinucleotide RNA27 and 5′-end hydroxyl dinucleotide primers15.

a, AS structure of de novo transcription initiation, where Ap3G guanine binds canonically in the i site and adenine binds noncanonically in the i − 1 site. CMPcPP is bound in a preinsertion position in the i + 1 site, stabilized by partially closed trigger loop. The DNA template strand is marked with respect to the putative +1 TSS site. The aspartate triad of the AS coordinates MgA. Conserved residues β/K838 and K846 reach toward the Ap3G α phosphate, β/H999 reaches toward the Ap3G β phosphate, β/Q567 reaches toward the Ap3G γ phosphate and β/Y998 points away from Ap3G. The distal adenine base pair with −1T is sandwiched between the i site base pair and −2G. Color coding as in Fig. 1. b, Cryo-EM density for Ap3G (gray) and template (blue). The proximal guanine base in the i site WC base pairs with template +1C. The distal adenine base in the i − 1 site rWC base pairs with template −1T. c, AS structure of de novo transcription initiation, where Ap4G guanine binds canonically in the i site and adenine binds noncanonically in the i − 1 site. The depiction is analogous to a. β′/D739 coordinates both MgA and MgB. Conserved residues β/K838 and K846 reach toward the Ap4G α phosphate, whereas conserved residues β/Q567 and β/H999 reach toward the Ap4G γ and δ phosphates; β/Y998 points toward the Ap4G δ phosphate. d, Cryo-EM density for Ap4G (gray) and template (blue). The proximal guanine base in the i site WC base pairs with template +1C. The cryo-EM density for the distal part of Ap4G is less well defined. The adenine base in the i − 1 site rWC base pairs with template −1T.
In summary, the proximal guanosine in the i site binds canonically in the RNAP AS to enable the initial nucleotidyl transfer. The 5′-to-5′ triphosphate linker towards the distal adenosine does not allow for the regular cis orientation of the ribose that would enable canonical base pairing with the template; instead, the ribose adopts a trans conformation and the distal adenosine base pairs in a rWC manner.
Ap4G tetraphosphate linker allows distal base rWC pairing
In the next step, we aimed to structurally visualize the effect of the tetraphosphate linker of Ap4G on binding to the RNAP AS. We reconstituted the template TC holoenzyme complex with Ap4G and CMPcPP and obtained a reconstruction hereafter referred to as TC-Ap4G (Fig. 2c,d, Supplementary Figs. 4c and 7c and Supplementary Table 7). The CMPcPP and the proximal guanosine of Ap4G are canonically bound, aligned for the first nucleotidyl transfer reaction. The α phosphate is canonically positioned by β/K838 and β/K846 and the γ and δ phosphates are in close proximity to β/H999 and β/Q567. Additionally, in contrast to TC-Ap3G, residue β/Y998 points toward the δ phosphate group of the Ap4G tetraphosphate linker, although a weak map for the alternative conformation pointing away from Ap4G is also present. However, the cryo-EM density for the δ phosphate, the distal ribose and the adenine base is less well defined (Fig. 2d and Supplementary Fig. 7c). Nevertheless, the distal ribose clearly adopts the trans orientation relative to the template −1T and the distal adenine base pairs in the rWC manner with the −1T base of the template, stabilized further by stacking with the −2G base (Fig. 2c).
Taken together, the results confirm that the proximal moiety of Ap4G is aligned for the transcription initiation reaction but the effect of the tetraphosphate linker on the binding of the distal part of the Ap4G could not be resolved in detail in the TC-Ap4G structure. We, therefore, set out to visualize the tetraphosphate linker and the distal nucleoside binding using Ap4A.
Distal base of Ap4A does not require base pairing
The transcription reaction initiating with Ap4A on the TC template yielded a capped product (Fig. 1c,d) starting from the −1T template position as the TSS, instead of the putative +1C TSS position, confirmed by LC–MS (Extended Data Fig. 2 and Supplementary Table 3). Reconstitution of the TC template holoenzyme complex with Ap4A and GMPcPP yielded a reconstruction hereafter referred to as TC-Ap4A (Fig. 3a,b, Supplementary Figs. 4d and 7d and Supplementary Table 7). In this structure, indeed, the template strand is antiscrunched31,32,33,39 by one nucleotide, like in the TC-empty structure (Extended Data Fig. 8c), placing the template −2G base in line with the i − 1 site, the template −1T base in line with the i site and the template +1C base in line with the i + 1 site (Supplementary Fig. 8d,e). The GMPcPP and the proximal adenosine of Ap4A are canonically paired in the i + 1 site with the +1C base and in the i site with the −1T base, respectively (Fig. 3a and Supplementary Fig. 7d). The distal adenosine of Ap4A does not base pair with the bulky −2G purine residue in the i − 1 site and is, therefore, flanking into the void of the AS cavity toward σA region 3.2. There is only a blurred density for the distal ribose (Fig. 3b) and no defined density for the distal base, suggesting that there is no contact with σA region 3.2. The base pair in the i site is stabilized by a stacking interaction with the −2G base in line with the i − 1 site. This type of stacking has already been reported to occur during stabilization of the first initiation NTP (iNTP) binding in the initiation complex37. Similarly, the interaction of the Ap4A proximal base is sufficient to retain it in the AS, even without additional stabilization from pairing of the distal nucleoside base of Ap4A at the i − 1 site. The tetraphosphate linker is stabilized by the canonical interaction of α and γ phosphates with conserved residues β/K838 and K846, and β/H999 and Q567, respectively. The mutual orientation of the phosphates is also stabilized by the coordination of MgC, engaging all four phosphates.

a, AS structure of de novo transcription initiation, where Ap4A proximal adenine binds canonically in the i site. GMPcPP is bound in a preinsertion position in the i + 1 site. The DNA template strand is antiscrunched by one nucleotide relative to the AS and to the nontemplate strand. The aspartate triad of the AS coordinates MgA and β′/D739 coordinates MgB. Conserved residues β/K838 and K846 reach toward the Ap4A α phosphate and β/H999 and Q567 reach towards the Ap4A γ phosphate; β/Y998 points away from Ap4A. The distal adenine does not base pair with the −2G base of the template in the i − 1 site and flanks. Color coding as in Fig. 1. b, Cryo-EM density for Ap4A (gray) and template (blue). The proximal adenine base in the i site WC base pairs with template −1T. The distal adenine base flanks. c, AS structure of de novo transcription initiation, where Ap4A proximal adenine binds canonically in the i site and the distal adenine binds noncanonically in the i − 1 site. The depiction is analogous to a. Conserved residues β/K838 and K846 reach toward the Ap4A α phosphate, H999 reaches toward the Ap4A γ phosphate and β/Q567 reaches toward both γ and δ phosphates of the Ap4A; β/Y998 points away from Ap4A. d, Cryo-EM density for Ap4A (gray) and template (blue). The proximal adenine base in the i site WC base pairs with template +1T. The distal adenine base in the i − 1 site rWC base pairs with template −1T. e, Comparison of triphosphate and tetraphosphate linkers in TC-Ap3G (green) and aTT-Ap4A (gray) structures. Phosphorus atoms are highlighted as orange spheres. Nonbridging oxygen atoms of phosphates are omitted for clarity.
In summary, the inherent capability of the TC template strand to antiscrunch in the AS by one nucleotide enabled the Ap4A to canonically bind in the i site. The purine incompatibility at the i − 1 site, however, forces the distal base of Ap4A to flank. Nevertheless, such an Ap4A initiation complex is stable enough for the transcription reaction to proceed.
Ap4A can base pair using both proximal and distal nucleosides
To visualize the pairing of Ap4A nucleosides in both i and i − 1 sites, we attempted to reconstruct the holoenzyme complex with Ap4A, GMPcPP and a modified template tTC (Extended Data Table 1) that would place the T base in line with the i − 1 site after template antiscrunching. However, even though the template was positioned as expected, we could only visualize blurred contours of Ap4A and GMPcPP in the AS. We, therefore, created the aTT template (Extended Data Table 1 and Supplementary Fig. 4e), which featured a transcription bubble shortened by one base to prevent antiscrunching and was still compatible with IVT reactions (Supplementary Fig. 9). We expected that this template would position the +1T and −1T bases in line with the i and i − 1 sites, respectively, to achieve full base pairing with Ap4A; the +2G base would be in line with the i + 1 site to base pair with CMPcPP. The resulting structure, hereafter referred to as aTT-Ap4A (Fig. 3c,d, Supplementary Fig. 7e and Supplementary Table 7), indeed visualized CMPcPP and the proximal adenosine of Ap4A canonically bound in the i + 1 and i sites, respectively (Fig. 3c). The cryo-EM density was clearly defined for the tetraphosphate linker and for the distal adenosine base pairing with the −1T base of the template in the i − 1 site (Fig. 3d and Supplementary Fig. 7e). The α phosphate is canonically positioned by β/K838 and β/K846. Residue β/H999 reaches toward the γ phosphate, which itself interacts with β/Q567. The cryo-EM map for residue β/Y998 indicates two alternative conformations, pointing away and toward Ap4A; however, the conformation pointing away from Ap4A prevails. Concomitantly, the δ phosphate of Ap4A in aTT-Ap4A adopts a different position in comparison to Ap4G in TC-Ap4G. The β and α phosphates together coordinate MgC. The relatively loosely defined distal ribose adopts a trans orientation relative to the −1T template base, with the distal adenine forming an rWC pair with −1T, as supported by the cryo-EM map (Fig. 3d and Supplementary Fig. 7e). The distal adenine base is also stabilized in the base pair with −1T by stacking interactions with the −2A purine base of the template in line with the i − 2 site. The distal adenine binds similarly to the −1T template base in both TC-Ap3G and aTT-Ap4A (Fig. 3e; root mean square deviation of the distal base = 0.421 Å). Intriguingly, it appears that the binding conformations of the two bases in NpnNs are constant and that it is the conformation of the triphosphate or tetraphosphate linker that needs to adjust in between proximal and distal nucleosides.
In all our structures, when base pairing, the distal adenosine in the i − 1 site features ribose in the trans orientation relative to the template in line with the i − 1 site, which forces the distal adenosine to rWC base pair with the template base in line with the i − 1 site. We, therefore, conclude that the rWC mode is the preferred binding mode of the distal adenosine, induced by the spatial constrains of the 5′-to-5′ triphosphate or tetraphosphate linker between the ribose of the proximal nucleoside and that of the distal nucleoside.
Discussion
In this article, we describe the molecular details of 5′ RNA capping with NpnNs by bacterial RNAP. We confirm previous observations11,19 that NpnNs are used as NCINs in IVT reactions using bacterial RNAP (in our case, Tt RNAP). As anticipated, NpnNs readily initiate with the proximal base at the putative +1 TSS of a DNA promoter when canonical base pairing is available. In our in vitro system, using artificial promoters with preformed transcription bubbles (Fig. 1b and Extended Data Table 1), the template strand TSS can oscillate between the +1 and −1 positions (Supplementary Fig. 4a, Extended Data Fig. 8 and Supplementary Fig. 8). When the putative +1 TSS is not compatible with canonical base pairing with the proximal base of NpnNs, the −1 position, where canonical base pairing is possible, is readily used as the TSS instead. This leads to the formation of capped RNA longer by one nucleotide. We observe this TSS shift, for example, with Ap3-4A initiating at the −1T position of the TC template (Fig. 1d) as confirmed by the detection of the cap(−1)TSS-RNA product in our LC–MS analyses (Extended Data Fig. 2 and Supplementary Table 3). Furthermore, we observed the TSS shift for other combinations of NpnNs and templates (Extended Data Figs. 4–7 and Supplementary Tables 5 and 6), demonstrating that this is a general behavior of this particular set of artificial DNA promoters with preformed transcription bubbles. As only limited information19 is available on natural RNA sequences capped by NpnNs, it is difficult to study this behavior in the context of native DNA promoters. To assess NpnN capping under more native-like conditions, we developed an IVT assay using a supercoiled plasmid with a fully complementary DNA promoter. PAGE and LC–MS analyses combined with RNase A treatment confirmed that Tt RNAP generates all NpnN-capped RNAs from this standard template, initiating transcription from both +1 and −1 positions as TSSs (Extended Data Fig. 3 and Supplementary Table 4).
Next, to characterize NpnNs as NCINs, we visualized the initial binding of NpnNs into the RNAP AS just before the first nucleotidyl transfer reaction. In a series of cryo-EM structures, we captured the RNAP AS, where NCINs align to react with the first extending nucleotide. The structures reveal how NpnNs bind to the i and i − 1 sites of the RNAP AS and how they base pair with the promoter template strand. Expectedly, the proximal G or A of either ApnG or ApnA base pairs with the template in line with the i site in a canonical WC manner to align with the RNAP AS to react with the extending nucleotide. The distal nucleoside either base pairs in line with the i − 1 site or flanks into the AS cavity. Importantly, the base pairing of the distal base is not canonical because of the presence of the 5′-to-5′ triphosphate or tetraphosphate linker between the two nucleosides, instead of a 5′-to-3′ single phosphate in a regular RNA product15 (Extended Data Figs. 1 and 9). The orientation of the distal and proximal ribose of the NpnNs resulting from the 5′-to-5′ linkage does not allow the canonical cis conformation of the distal ribose aligned with the i − 1 site but instead dictates a trans conformation. The trans conformation is then compatible with the rWC base pairing of the distal nucleoside. The rWC-pairing distal bases in both TC-Ap3G and aTT-Ap4A adopt similar binding poses (Fig. 3e), likely facilitated by conformational adjustment of the flexible triphosphate or tetraphosphate linker between the proximal and distal nucleosides. In addition, we also conclude that, when there is a bulky purine template base in line with the i − 1 site, such as the −2G base in the antiscrunched template TC, the distal purine nucleoside of Np4N does not form any noncanonical purine–purine base pair because of steric hindrance and is forced to flank. In other words, two bulky purines cannot be accommodated opposite each other.
One of the best known noncanonical RNA caps is NAD, which has also been detected in various bacterial RNAs3,18,40,41. However, the incorporation efficiency of NAD as an NCIN is only about one seventh of that of ATP19. Nevertheless, we wanted to compare the incorporation efficiency of NAD by Tt RNAP with NpnNs. Expectedly, our efforts to use NAD as NCIN produced only traces of NAD-RNA (Supplementary Fig. 3) and these experiments confirmed that NAD is indeed a much less potent NCIN than NTPs and NpnNs. Our attempts to visualize NAD binding to the i and i − 1 sites of the RNAP AS by cryo-EM have failed. Therefore, we can only compare NpnN binding at the i and i − 1 sites to NAD binding at the i − 1 and i − 2 sites, as visualized in the RNAP complex with NAD-pC trinucleotide (PDB 5D4D; Extended Data Fig. 9d).
The Tt RNAP is a well-established representative of the RNAP AS, conserved across all cellular RNAPs37,42; therefore, it can be used as a model to study interactions of NpnNs with the RNAP itself. However, apart from the conserved residues β/K838, K846, H999 and Q567, which contact the phosphate groups of both the canonical iNTPs and NpnNs as NCINs, we only identified β/Y998 as a potential additional interacting residue (Fig. 2c and Extended Data Fig. 8a). The alternative conformation of β/Y998 pointing toward the NCIN might potentially interact with the δ phosphate group in the case of the tetraphosphate linker, as observed in the TC-Ap4G structure. However, given the low occupancy of this β/Y998 conformer in the structures with Ap4A, it does not seem to be critical for tetraphosphate linker binding into the RNAP AS. Surprisingly, we observed an MgC cation coordinated by the triphosphate or tetraphosphate of iNTPs or NpnNs. MgC does not specifically interact with the RNAP protein and we propose that it serves as a countercharge to the phosphate groups.
The only determinant of how NpnNs bind in the RNAP AS seems to be the DNA promoter sequence at the +1 and −1 template positions aligned in the i and i − 1 sites, respectively. A strict requirement is canonical WC compatibility in the i site. In our in vitro system, we observe that the template strand can be antiscrunched, thereby shifting the TSS by one position (Extended Data Fig. 8c and Supplementary Figs. 4a and 8). Intriguingly, in the case of the TC-Ap4A structure (Supplementary Fig. 4d), the base identity of Ap4A favored the antiscrunched TSS template strand position to canonically bind in the i site. As NpnNs have two 3′ hydroxyl groups available for initiation on both termini of the molecule, ApnGs use both termini in our IVT reactions. The selection of the proximal base (A or G) in the i site follows the base identity requirements in the TSS.
The incorporation of NpnNs as NCINs increases the efficiency of transcription initiation in comparison to regular iNTPs19,20. Furthermore, template pyrimidine bases at the i − 1 site increase the efficiency of NpnNs noncanonical transcription initiation, one of the explanations being potential WC base pairing19. Our structure analysis revealed rWC base pairing of the T pyrimidine base at the i − 1 site. Nevertheless, transcription initiation with template TC and Ap4A is efficient (Fig. 1d) despite the lack of base pairing at the i − 1 site with the bulky purine −2G (Fig. 3a,b). On the other hand, −2G stabilizes the proximal base pair by a stacking interaction. Our structural data on the very first step of transcription initiation, thus, do not provide any clear mechanistic explanation of the observed19 increase in transcription initiation efficiency caused by pyrimidine bases aligned with the i − 1 site. Future structural studies of subsequent transcription steps might provide a deeper understanding.
In summary, we present molecular details of how NpnNs bind into the AS of RNAP at the very beginning of transcription, which demonstrate how NpnNs function as versatile and efficient NCIN. Given the conservation of the NpnN-binding region in the RNAP AS, we presume that the here-described modes of NpnNs binding will be found to be universal for other cellular RNAPs, including eukaryotic polymerase II.
Methods
Unless mentioned otherwise in the text, the chemicals used were purchased from Merck chemicals. If available, the chemicals were of molecular biology grade. Oligonucleotides were purchased from Generi Biotech. DNA scaffolds were prepared using two oligonucleotides (template strand and nontemplate strand) and annealed in a total volume of 240 μl containing 33 μM each oligonucleotide, 10 mM Tris pH 7.8, 50 mM NaCl and 1 mM EDTA. Samples were heated to 90 °C for 5 min, after which the temperature gradually decreased to 20 °C in 2 h. All templates are listed in Supplementary Table 1.
Tt RNAP holoenzyme expression and purification
As previously described26, purification of the RNAP holoenzyme poses difficulties caused by its unstable σA subunit that is susceptible to proteolysis. To prevent sample heterogeneity, we isolated the native RNAP core from T. thermophilus and complexed it with a recombinantly expressed σA subunit to obtain a homogeneous preparation of the RNAP holoenzyme.
For isolation of the RNAP core, Tt HB8 (DSM579, German Collection of Microorganisms and Cell Cultures) cells were grown at 75 °C in a medium containing 4 g l−1 yeast extract, 8 g l−1 proteose peptone no. 3 and 2 g l−1 NaCl at pH 7.0. Cells were harvested after 20 h of cultivation, resuspended in lysis buffer (20 mM Tris-HCl pH 8.7, 50 mM NaCl, 10 mM EDTA, 10 mM β-mercaptoethanol and 0.1 mM PMSF), disrupted using an EmulsiFlex-C3 cell disrupter (Avestin) and centrifuged at 20,000g. The resulting cell lysate was applied to a Q-Sepharose high-performance column (Cytiva) equilibrated in lysis buffer. The column was washed with lysis buffer and eluted with a seven-step gradient of sodium chloride (0.15–1 M). Fractions containing the RNAP core were collected and concentrated using Amicon Ultra centrifugal units (30-kDa molecular weight cutoff (MWCO); Merck Life Sciences). This step is crucial because it facilitates the removal of most of the DNA from the sample, allowing it to efficiently bind to the Mono-Q column in the next step. Each sample was then dialyzed into buffer A (20 mM Tris-HCl pH 8.7, 50 mM NaCl, 5 mM β-mercaptoethanol and 1 mM EDTA) and loaded onto a Mono-Q 5/50 GL column (Cytiva) equilibrated in buffer A. The column was washed with buffer A and eluted with a linear gradient of sodium chloride (0.05–1 M). Each sample was subsequently concentrated and loaded onto a Superdex 200 10/300 GL column (Cytiva) with a running buffer containing 25 mM Tris-HCl pH 8.7, 200 mM NaCl and 5% glycerol. Fractions containing the RNAP core were concentrated to 1 mg ml−1 and stored at −80 °C.
The σA subunit synthetic gene was subcloned into the pMCSG7 vector (T7 promoter-driven, originally designed for ligation-independent cloning43). The vector was first modified by a sequence coding for the N-terminal His6 tag, followed by a sequence coding for the tobacco etch virus protease cleavage site with additional amino acid residues (SNAAS). The σA subunit coding sequence was cloned as an NHeI–EcoRI insert into this modified vector. The protein was overexpressed in the E. coli strain BL21 (DE3) (New England Biolabs (NEB)) at 37 °C in LB medium supplemented with 0.8% glycerol and 100 μg ml−1 ampicillin. Subsequently, σA expression was induced at an optical density at 600 nm of 0.6 by addition of ETG to the final concentration of 1 mM and cells were further cultivated for 3 h before they were harvested by centrifugation. Cells were resuspended in ten volumes of lysis buffer (50 mM Tris-HCl pH 7.9, 200 mM NaCl, 10 mM β-mercaptoethanol and 5% glycerol) containing protease inhibitors (cOmplete EDTA-free, Roche) and lysed using an EmulsiFlex-C3 cell disrupter (Avestin). The cell lysate was clarified by centrifugation at 20,000g and loaded onto a 5-ml HisTrap Ni-NTA column equilibrated in lysis buffer. The column was washed with lysis buffer supplemented with 10 mM imidazole and the protein was eluted in three steps with lysis buffer containing 50, 250 and 500 mM imidazole. Fractions containing the σA subunit were collected and concentrated using Amicon Ultra centrifugal units (30-kDa MWCO; Merck Life Sciences). The last purification step involved gel filtration on a Superdex 200 10/300 GL column (Cytiva) in a running buffer containing 50 mM Tris-HCl pH 7.9, 200 mM NaCl, 10 mM β-mercaptoethanol and 5% glycerol. The purified σA protein was concentrated to 13 mg ml−1 and stored at −80 °C. The purification yield was 7.8 mg of protein from 1 l of bacterial culture with the purity assessed by silver-stained SDS–PAGE to be greater than 95%.
To prepare the holoenzyme complex, the σA subunit was transferred into a buffer containing 20 mM Tris-HCl pH 8.7, 100 mM NaCl and 5% β-mercaptoethanol, mixed with the RNAP core in a 4:1 molar ratio and incubated overnight at 4 °C. The mixture was then applied to a Superdex 200 10/300 GL column (Cytiva) equilibrated in 20 mM Tris-HCl pH 8.7, 100 mM NaCl and 1% glycerol. In this step, the excess of the σA subunit was separated from the RNAP holoenzyme, as verified by SDS–PAGE analysis (Supplementary Fig. 10). Fractions containing the RNAP holoenzyme were pooled, concentrated to a final concentration of 1 mg ml−1 using Amicon Ultra centrifugal units (30-kDa MWCO, Merck Life Sciences) and stored at −80 °C.
IVT with Tt RNAP
IVT was performed in a reaction volume of 25 μl containing 2 μM template DNA (Supplementary Table 1), 0.6 mM ATP, 0.6 mM GTP, 0.6 mM UTP, 0.4 mM CTP and 0.2 μl of α-[32P]CTP (activity: 9.25 MBq in 25 μl), 1.6 mM NpnNs (Ap3A, Ap4A, Ap3G, Ap4G, Gp3G and Gp4G; Jena Bioscience) or NAD in different concentrations (0.6 mM, 1.6 mM, 3.2 mM and 6.4 mM), 50 mM Tris-HCl pH 7.9, 100 mM KCl, 10 mM MgCl2, 1 mM DTT, 5 μg ml−1 BSA, 5% glycerol and 96 nM Tt RNAP. In negative controls, NpnNs were replaced with appropriate regular NTPs ATP and/or GTP (Supplementary Table 2). The concentration of ATP was 2.2 mM in the negative controls for the samples containing ApnA as starting nucleotides. The concentration of GTP was 2.2 mM in the negative controls for the samples containing GpnG as starting nucleotides. The concentration of ATP and GTP was 1.4 mM each in the negative controls for the samples containing ApnG as starting nucleotides (Supplementary Table 2). The IVT mixture was incubated for 2 h at 65 °C.
DNAse treatment of in vitro transcripts
To obtain pure RNA, the DNA template was removed by DNase I digestion. A total of 25 μl of the transcription mixture was mixed with 3 μl of 10× reaction buffer for DNase I (10 mM Tris-HCl pH 7.6 at 25 °C, 2.5 mM MgCl2 and 0.5 mM CaCl2, supplied with the enzyme) and 4 U of DNase I (NEB) and incubated at 37 °C for 60 min. The enzyme was heat-deactivated at 75 °C for 10 min and then immediately cooled on ice. All samples were purified using size-exclusion columns (Micro Bio-Spin P-6 gel columns, Biorad).
RNA 5′-polyphosphatase treatment of uncapped RNA transcripts
To obtain monophosphate RNA, uncapped RNA was treated with 20 U of 5′-polyphosphatase (Lucigen) in a solution of 1× buffer (supplied with the enzyme) in a total volume of 25 μl for 1 h at 37 °C. Samples were purified using size-exclusion columns (Micro Bio-Spin P-6 gel columns, Biorad).
Radiolabeling of RNA markers
The RNA markers having a sequence complementary to that of template TC and template CT (starting at the −1 and +1 position) and gTT (starting at the +1 position) were purchased from Eurofins genomics. The radiolabeling was performed in a volume of 20 μl using 0.6 μl of T4 polynucleotide kinase (NEB), 2 μl of T4 polynucleotide kinase reaction buffer (70 mM Tris-HCl pH 7.6 at 25 °C, 10 mM MgCl2 and 5 mM DTT, supplied with the enzyme), 4.55 μl α-[32P]ATP (activity: 9.25 MBq in 25 μl) and 0.75 μM RNA. The reaction mixture was incubated at 30 °C for 30 min and the enzyme was heat-deactivated at 65 °C for 20 min. The samples were purified using size-exclusion columns (Micro Bio-Spin P-6 gel columns, Biorad).
PAGE analysis of in vitro transcripts
Samples (10 μl) were mixed with 10 μl of 2× RNA loading dye (NEB), incubated at 75 °C for 5 min and then cooled on ice. Samples were loaded onto 12.5% polyacrylamide gels (with or without the addition of acryloylaminophenyl boronic acid (APB)) and electrophoretic separation was performed under denaturing conditions at 600 V for 3 h using 1× TBE as a running buffer. Denaturing PAGE gels were visualized by a Typhoon FLA 9500 imaging system and analyzed with ImageJ 1.53e software.
IVT for LC–MS analysis
IVT was performed in a volume of 25 μl containing 2 μM template DNA (Supplementary Table 1), 0.6 mM ATP, 0.6 mM GTP, 0.6 mM CTP, 1.6 mM NpnNs, 5 mM Tris-HCl pH 7.9, 10 mM KCl, 1 mM MgCl2, 0.1 mM DTT and 96 nM Tt RNAP. The mixture was incubated for 2 h at 65 °C. All samples were purified using MWCO filters (Sartorius, Vivacon 500, 10-kDa MWCO HY). The filters were prewashed once with 50 µl of the reaction buffer and then the samples diluted with 20 µl of molecular-biology-grade water were added and centrifuged at 13,000g for 15 min at room temperature. Samples were then analyzed by hydrophilic interaction liquid chromatography (HILIC) with MS detection.
LC–MS analysis of IVT products
RNA products were diluted tenfold with 50 mM ammonium acetate (pH 7.0). For the analysis, a high-performance LC instrument (Acquity H-class, Waters) equipped with an Xbridge Premier BEH amide column (2.5 µm and 4.6 mm × 150 mm; Waters) was used. The column temperature was 35 °C. Mobile phase A contained 20 mM ammonium acetate (Fisher) in a 90:10 v/v mixture of acetonitrile (Optima, Fisher) with ultrapure water (18.2 MΩ cm; Purelab Chorus system, Elga). Mobile phase B contained 20 mM ammonium acetate in ultrapure water. The autosampler was kept at 10 °C. The injection volume was 5 µl. The gradient of separation is shown in Supplementary Table 9. MS detection was performed on a Xevo G2-XS quadrupole time-of-flight (Q-TOF) MS instrument (Waters) equipped with an electrospray ionization source with parameters detailed in Supplementary Table 10. Fragmentation spectra of mass selected ions were generated with increased collision energy (30 eV). LC–MS data were acquired and analyzed with MassLynx version 4.2 software and graphs were prepared with GraphPad Prism 10.
TC plasmid preparation
The plasmid pRLG7558 containing p770 promoter driving the veg RNA expression and ribosomal RNA B (rrnB) under the P1 promoter36 was a gift from the L. Krasny laboratory. In this plasmid, we substituted the veg promoter with our TC promoter sequence below using the EcoRI and HindIII restriction sites. The inserts were generated by annealing the following 5′-monophosphorylated oligonucleotides: forward: (5′-AATTCTCTTGACATAATCCATATGGTTGGGTATAATGGGAGAG-3′); reverse: (5′-AGCTCTCTCCCATTATACCCAACCATATGGATTATGTCAAGAG-3′)
The −1 and +1 positions in both strands are in bold.
The resulting constructs were verified by DNA sequencing. Plasmid DNA was purified using the PureLink HiPure plasmid midiprep kit (ThermoFisher Scientific), further extracted using phenol–chloroform purification and dissolved in pure water.
IVT with the TC plasmid
IVT was performed in a reaction volume of 25 μl containing 10 ng μl−1 TC plasmid (Supplementary Table 1), 1.6 mM NpnNs (Ap3A, Ap4A, Ap3G, Ap4G, Gp3G and Gp4G; Jena Bioscience) and 1 μl of RNase Inhibitor (NEB), in the presence of reaction buffer containing 50 mM Tris-HCl (pH 7.9), 100 mM KCl, 10 mM MgCl2, 1 mM DTT, 5 μg ml−1 BSA and 5% (v/v) glycerol. For reactions with Tt RNAP, 0.15 μM σA subunit and 0.05 μM Tt RNAP were added. For the reaction with E. coli RNAP, the supplied 1× reaction buffer (NEB) and 1 μl of E. coli RNAP holoenzyme (NEB) were used instead. A separated nucleotide mixture was prepared containing 0.6 mM ATP, 0.6 mM GTP, 0.6 mM UTP, 0.4 mM CTP and 0.3 μl of α-[32P]CTP (activity: 9.25 MBq in 25 μl). Reaction mixtures without NTPs were preincubated for 10 min at 65 °C (Tt RNAP) or at 37 °C (E. coli RNAP), followed by addition of the NTP mix. Complete IVT reactions were then incubated for 2 h at 65 °C (Tt RNAP) or at 37 °C (E. coli RNAP). In negative control reactions, NpnNs were replaced with GTP to observe only the +1 starting uncapped RNA. Following incubation, the samples were purified using size-exclusion columns (Micro Bio-Spin P-6 gel columns, Biorad).
PAGE analysis of IVT products from the TC plasmid
Samples (10 μl) were mixed with 10 μl of 2× RNA loading dye (NEB) and incubated at 90 °C for 5 min and then cooled on ice. Samples were loaded onto 8% polyacrylamide gels (with the addition of APB) and electrophoretic separation was performed under denaturing conditions at 600 V for 4 h using 1× TBE as a running buffer. Denaturing PAGE gels were visualized by a Typhoon FLA 9500 imaging system.
IVT with the TC plasmid for LC–MS analysis
IVT was performed as described above, with modified enzyme concentrations. Specifically, 0.3 μM σA subunit and 0.1 μM Tt RNAP were used in each 25-µl reaction. Following incubation, RNA samples were purified using RNA mini Quick Spin columns (Merck), eluting in 15 µl before LC–MS analysis.
Digestion of IVT products from the TC plasmid by RNase A
The RNA samples (15 µl) were mixed with 2.5 µl of ammonium acetate (500 mM, pH 7.5), 2.5 µl of EDTA (1 mM) and 5 µl of RNase A (200 ng µl−1, NEB). RNase A specifically degrades single-stranded RNA after C and U residues leaving a phosphate at the 3′ end. The reaction was kept for 30 min at 37 °C. Right after, the reaction was transferred to an HPLC vial and directly measured by ion-pairing reverse-phase chromatography with MS detection.
LC–MS analysis of IVT products from the TC plasmid
Digested RNA products were separated on Acquity I-class (Waters) equipped with Acquity Premier oligonucleotide BEH C18 column (1.7 µm, 2.1 mm × 50 mm; Waters). The column temperature was 35 °C. Mobile phase A contained 15 mM triethylamine (Fisher) and 400 mM 1,1,1,3,3,3-hexafluoro-2-propanol (HFIP) in ultrapure water (18.2 MΩ cm; Purelab Chorus system, Elga). Mobile phase B contained 15 mM triethylamine and 400 mM HFIP in methanol (Optima, Fisher). The autosampler was kept at 10 °C. The injection volume was 10 µl. The gradient of separation is shown in Supplementary Table 11. MS detection was performed with the same Xevo G2-XS Q-TOF MS instrument. Ionization parameters are detailed in Supplementary Table 12.
Ap4G purification for the cryo-EM study
To prevent contamination of the Ap4G standard by pppApG, we treated Ap4G and pppApG standard (used as a control, Jena Bioscience) with 1 U of nuclease P1 (NEB) in 1× buffer (50 mM ammonium acetate, pH 5.3) for 30 min at 37 °C followed by treatment with 0.03 U of shrimp alkaline phosphatase (NEB) in 1× rCutSmart buffer (50 mM potassium acetate, 20 mM Tris acetate, 10 mM magnesium acetate and 100 µg ml−1 recombinant albumin, pH 7.9 at 25 °C) and incubated for 10 min at 37 °C. The samples were purified using MWCO filters (Sartorius, Vivacon 500, 10-kDa MWCO HY). The filters were washed once with 50 µl of the reaction buffer and then samples, diluted with 20 µl of molecular-biology-grade water, were added and centrifuged at 10,000g for 10 min at room temperature. The samples were dried on a Speedvac system and dissolved in 50 μl of 50 mM ammonium acetate, pH 7.0. The filtrate was analyzed by LC–MS using the same method described above.
Cryo-EM grid preparation
In vitro reconstitution was performed in 30 μl of 50 mM Tris-HCl pH 7.9, 100 mM KCl, 10 mM MgCl2, 1 mM DTT, 2.6 μM DNA template, 3.3 mM GTP or 1.6 mM NpnNs, 1.6 mM CMPcPP or GMPcPP (Jena Bioscience), 1.3 μM Tt RNAP σA holoenzyme and an additional 1.5 μM σA. Each sample was incubated for ~10 min at 4 °C. Sample aliquots of 3 μl were applied to glow-discharged Quantifoil R2/1 Au 300-mesh grids, immediately blotted for 2 s and plunged into liquid ethane using a Thermo Fisher Scientific Vitrobot Mark IV (4 °C, 100% humidity).
Cryo-EM data collection
The grids were loaded into a 300-kV Titan Krios (FEI) electron microscope equipped with a Gatan K3 (model 1025) direct electron detector mounted on a Gatan BioQuantum (model 1967) energy filter. Data were collected using Serial EM software44 in image shift acquisition mode (3 × 3 holes; 7–8 exposures per hole) at a nominal magnification of ×105,000 with a pixel size of 0.8336 Å per pixel. Videos were collected for 2–2.7 s at a flux of 15–20 electrons per Å2 per s, giving a total exposure of around 40–50 electrons per Å2. The defocus values ranged from −0.5 to −3.0 μm. In total, 40 frames of each video were saved, except aTT-Ap4A, for which 46 frames were saved.
Cryo-EM image processing
All data processing (Supplementary Figs. 5 and 6 and Supplementary Tables 7 and 8) was performed using the RELION 4.0 software package45. Motion correction was performed using the RELION implementation of MotionCor2 (ref. 46). Videos were aligned using 7 × 5 patches with dose weighting. Contrast transfer function (CTF) was estimated using CTFFIND4.1 (ref. 47) from summed power spectra48 for every four electrons per Å2. From each dataset, 25 micrographs were randomly selected and a representative set of particles was picked manually. These particles, along with their coordinates, were pooled for the training of a consensus Topaz picking model49. Particles were subsequently picked from individual datasets by Topaz using this consensus-trained model.
After initial binning, particles underwent three rounds of two-dimensional classification. In each round, the particles were sorted into 200 classes with an E-step of 8 Å and a mask diameter of 240 Å. Only classes with well-defined structural features were retained and subjected to three-dimensional (3D) classification using a reference from the Tt RNAP crystal structure (PDB 4Q4Z)37. The first 3D classification sorted particles into ten classes with the regularization parameter set to T = 4 and an E-step of 5 Å. Quantitative analysis of the individual class types is summarized in Supplementary Table 8. Selected classes were aligned into a global 3D refinement. A subsequent 3D classification, using the result of the previous 3D refinement as input along with the corresponding mask, was performed using local searches from 3.7° to 1.8° with the regularization parameter increased to T = 8. Particles with poorly defined structural features were removed and the remaining particles were reextracted to native pixel size. Particles were refined globally again and corrected for aberrations, Bayesian-polished and 3D refined. The result of the refinement was used as input for focused 3D classification with masks around the broad core of the RNAP, performed at a local search interval of 0.5°, and the regularization parameter was increased to T = 200. Particles with poorly defined structural features for bound DNA were removed and the remaining particles were pooled and 3D refined. For TC-Ap4G and aTT-Ap4A, another round of focused 3D classification with masks around the RNAP AS was performed without angular searches. Classes were selected on the basis of features of the RNAP AS and pooled for the final 3D refinement. The final cryo-EM density maps were generated by the postprocessing feature in RELION and sharpened or blurred into MTZ format using CCP-EM50. The final set consisted of sharpened or blurred MTZ maps with B = −200, −100, −50, 0, 50, 100 and 200 Å2. The resolution of the cryo-EM density maps (Supplementary Table 7 and Supplementary Fig. 6d) was estimated with the gold-standard Fourier shell correlation cutoff value of 0.143. Reference-based local amplitude scaling was performed by LocScale51. The angular orientation distribution of the 3D reconstruction was calculated by cryoEF (version 1.1.0)52. Local resolution was calculated within RELION 4.0.
Cryo-EM model building and refinement
The TC-Ap3G model was built as follows. The X-ray structure of the Tt RNAP transcription initiation complex (PDB 4Q4Z)37 was used as a starting model and docked into the cryo-EM map by Molrep53. The model was rebuilt manually in Coot (version 0.9.8.92)54 against a blurred MTZ map (B = 50 Å2) generated in CCP-EM55. Model self-restraints were used, as well as base pairing and parallelity restraints for DNA, Ap3G and CMPcPP, which were automatically generated by the program libG56 running under Refmac (version 5.8.0405)57 within the CCP4 Interface (version 8.0.010)58 and curated manually. The model was refined in real space59 against a postprocessed MRC map in PHENIX (version 1.21-5207)60, using self-restraints with the strict rotamer matching option enabled, as well as secondary-structure restraints, including base pairing and parallelity restraints for DNA, Ap3G and CMPcPP. The restraints were generated automatically in PHENIX (version 1.21-5207)60 and edited manually. In general, parallelity was maintained among adjacent bases of the NpnNs, the extending nucleotide analogs and the nonpairing template base adjacent to the distal pairing NpnN base. Distances and weights for the base-pairing hydrogen bonds were inferred from values used by libG56 for canonical DNA base pairing. Ligand geometry restraints for NpnNs and nucleotide analogs were generated using the Grade web server (version 2.0.14; Global Phasing). The final refinement round in PHENIX included one cycle of ADP refinement only. The refined models were validated using MolProbity61 and the wwPDB database62 validation server. The final TC-Ap3G model was used as the starting model for the TC-GTP, TC-Ap4G, TC-Ap4A and aTT-Ap4A models, which were built and refined analogously to the above description. In the case of TC-GTP, parallelity was also maintained between the GTP base and the adjacent nonpairing template base. The TC-empty structure was built and refined analogously, using the TC-Ap4A template-shifted structure as the starting model.
Because of disorder, residues β′/217–339 from the β′ nonconserved domain were not included in any of the models. Additionally, residues σ/346–414, template-strand nucleotides 37–51 and nontemplate-strand nucleotides 3–17 were excluded from the TC-GTP, TC-Ap4G, TC-Ap4A, aTT-Ap4A and TC-empty models.
The CMPcPP molecule in the TC-Ap3G, TC-GTP, TC-Ap4G and aTT-Ap4A models was present in two conformations, one coordinating a magnesium cation (MgB) and one free of magnesium. The magnesium-coordinated conformation of CMPcPP was accompanied by a nearly closed conformation of the trigger loop, whereas the magnesium-free conformation of CMPcPP was associated with an alternative, unstructured conformation of the trigger loop. We describe the MgB-coordinated conformation with a nearly closed trigger loop in the Results. The TC-Ap4A model, in which the template is antiscrunched by one nucleotide, comprises a GMPcPP in a single, MgB-coordinated conformation and the trigger loop is unstructured. In the TC-empty structure, the trigger loop is unstructured.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
LC–MS data are available from Zenodo (https://doi.org/10.5281/zenodo.14215049)63. Coordinates and maps for Tt RNAP de novo transcription initiation complexes were deposited to the Protein Data Bank (PDB) and Electron Microscopy Data Bank (EMDB) under the following accession numbers: TC-Ap3G, PDB 9FOG and EMD-50622; TC-Ap4G, PDB 9FOK and EMD-50625; TC-Ap4A, PDB 9FP3 and EMD-50634; TC-GTP, PDB 9FO6 and EMD-50618; aTT-Ap4A, PDB 9FRJ and EMD-50715; TC-empty, PDB 9R75 and EMD-53711. Source data are provided with this paper.
References
Cappannini, A. et al. MODOMICS: a database of RNA modifications and related information. 2023 update. Nucleic Acids Res. 52, D239–D244 (2024).
Chen, Y. G., Kowtoniuk, W. E., Agarwal, I., Shen, Y. & Liu, D. R. LC/MS analysis of cellular RNA reveals NAD-linked RNA. Nat. Chem. Biol. 5, 879–881 (2009).
Cahova, H., Winz, M.-L., Hoefer, K., Nuebel, G. & Jaeschke, A. NAD captureSeq indicates NAD as a bacterial cap for a subset of regulatory RNAs. Nature 519, 374–377 (2015).
Winz, M.-L. et al. Capture and sequencing of NAD-capped RNA sequences with NAD captureSeq. Nat. Protoc. 12, 122 (2016).
Jiao, X. et al. 5′ end nicotinamide adenine dinucleotide cap in human cells promotes RNA decay through DXO-mediated deNADding. Cell 168, 1015–1027 (2017).
Kowtoniuk, W. E., Shen, Y., Heemstra, J. M., Agarwal, I. & Liu, D. R. A chemical screen for biological small molecule–RNA conjugates reveals CoA-linked RNA. Proc. Natl Acad. Sci. USA 106, 7768–7773 (2009).
Sherwood, A. V. et al. Hepatitis C virus RNA is 5′-capped with flavin adenine dinucleotide. Nature 619, 811–818 (2023).
Wang, J. et al. Quantifying the RNA cap epitranscriptome reveals novel caps in cellular and viral RNA. Nucleic Acids Res. 47, e130 (2019).
Julius, C. & Yuzenkova, Y. Bacterial RNA polymerase caps RNA with various cofactors and cell wall precursors. Nucleic Acids Res. 45, 8282–8290 (2017).
Luciano, D. J., Levenson-Palmer, R. & Belasco, J. G. Stresses that raise Np4A levels induce protective nucleoside tetraphosphate capping of bacterial RNA. Mol. Cell 75, 957–966 (2019).
Hudeček, O. et al. Dinucleoside polyphosphates act as 5′-RNA caps in bacteria. Nat. Commun. 11, 1052 (2020).
František Potužník, J. et al. Diadenosine tetraphosphate (Ap4A) serves as a 5′ RNA cap in mammalian cells. Angew. Chem. Int. Ed. Engl. 63, e202314951 (2024).
Potužník, J. F. & Cahova, H. If the 5′ cap fits (wear it)—non-canonical RNA capping. RNA Biol. 21, 1–13 (2024).
Vvedenskaya, I. O. et al. Growth phase-dependent control of transcription start site selection and gene expression by nanoRNAs. Genes Dev. 26, 1498–1507 (2012).
Skalenko, K. S. et al. Promoter-sequence determinants and structural basis of primer-dependent transcription initiation in Escherichia coli. Proc. Natl Acad. Sci. USA 118, e2106388118 (2021).
Malygin, A. G. & Shemyakin, M. F. Adenosine, NAD and FAD can initiate template-dependent RNA a synthesis catalyzed by Escherichia coli RNA polymerase. FEBS Lett. 102, 51–54 (1979).
Huang, F. Efficient incorporation of CoA, NAD and FAD into RNA by in vitro transcription. Nucleic Acids Res. 31, e8 (2003).
Bird, J. G. et al. The mechanism of RNA 5′ capping with NAD+, NADH and desphospho-CoA. Nature 535, 444–447 (2016).
Luciano, D. J. & Belasco, J. G. Np(4)A alarmones function in bacteria as precursors to RNA caps. Proc. Natl Acad. Sci. USA 117, 3560–3567 (2020).
Benoni, R., Culka, M., Hudeček, O., Gahurova, L. & Cahová, H. Dinucleoside polyphosphates as RNA building blocks with pairing ability in transcription initiation. ACS Chem. Biol. 15, 1765–1772 (2020).
Despotović, D. et al. Diadenosine tetraphosphate (Ap4A)—an E. coli alarmone or a damage metabolite? FEBS J. 284, 2194–2215 (2017).
Ji, X. et al. Alarmone Ap4A is elevated by aminoglycoside antibiotics and enhances their bactericidal activity. Proc. Natl Acad. Sci. USA 116, 9578–9585 (2019).
Kimura, Y., Tanaka, C., Sasaki, K. & Sasaki, M. High concentrations of intracellular Ap4A and/or Ap5A in developing Myxococcus xanthus cells inhibit sporulation. Microbiology (Reading) 163, 86–93 (2017).
Paget, M. S. B. & Helmann, J. D. The σ70 family of sigma factors. Genome Biol. 4, 203 (2003).
Saecker, R. M., Record, M. T. Jr. & Dehaseth, P. L. Mechanism of bacterial transcription initiation: RNA polymerase–promoter binding, isomerization to initiation-competent open complexes, and initiation of RNA synthesis. J. Mol. Biol. 412, 754–771 (2011).
Zhang, G. et al. Crystal structure of Thermus aquaticus core RNA polymerase at 3.3 Å resolution. Cell 98, 811–824 (1999).
Zhang, Y. et al. Structural basis of transcription initiation. Science 338, 1076–1080 (2012).
Shi, J. et al. Structural basis of Mfd-dependent transcription termination. Nucleic Acids Res. 48, 11762–11772 (2020).
Triana-Alonso, F. J., Dabrowski, M., Wadzack, J. & Nierhaus, K. H. Self-coded 3′-extension of run-off transcripts produces aberrant products during in vitro transcription with T7 RNA polymerase. J. Biol. Chem. 270, 6298–6307 (1995).
Goldman, S. R., Ebright, R. H. & Nickels, B. E. Direct detection of abortive RNA transcripts in vivo. Science 324, 927–928 (2009).
Winkelman, J. T. et al. Multiplexed protein-DNA cross-linking: scrunching in transcription start site selection. Science 351, 1090–1093 (2016).
Yu, L. et al. The mechanism of variability in transcription start site selection. eLife 6, e32038 (2017).
Robb, N. C. et al. The transcription bubble of the RNA polymerase-promoter open complex exhibits conformational heterogeneity and millisecond-scale dynamics: implications for transcription start-site selection. J. Mol. Biol. 425, 875–885 (2013).
Miller, M. L. & Miller, D. L. Non-DNA-templated addition of nucleotides to the 3′ end of RNAs by the mitochondrial RNA polymerase of Physarum polycephalum. Mol. Cell. Biol. 28, 5795–5802 (2008).
Cheng, Y. W., Visomirski-Robic, L. M. & Gott, J. M. Non-templated addition of nucleotides to the 3′ end of nascent RNA during RNA editing in Physarum. EMBO J. 20, 1405–1414 (2001).
Krásný, L. & Gourse, R. L. An alternative strategy for bacterial ribosome synthesis: Bacillus subtilis rRNA transcription regulation. EMBO J. 23, 4473–4483 (2004).
Basu, R. S. et al. Structural basis of transcription initiation by bacterial RNA polymerase holoenzyme. J. Biol. Chem. 289, 24549–24559 (2014).
Zhang, Y. et al. GE23077 binds to the RNA polymerase ‘i’ and ‘i+1’ sites and prevents the binding of initiating nucleotides. eLife 3, e02450 (2014).
Vvedenskaya, I. O. et al. Massively systematic transcript end readout, ‘MASTER’: transcription start site selection, transcriptional slippage, and transcript yields. Mol. Cell 60, 953–965 (2015).
Morales-Filloy, H. G. et al. The 5′-NAD cap of RNAIII modulates toxin production in Staphylococcus aureus isolates. J. Bacteriol. 202, e00591-19 (2019).
Frindert, J. et al. Identification, biosynthesis, and decapping of NAD-capped RNAs in B. subtilis. Cell Rep. 24, 1890–1901 (2018).
Ebright, R. H. RNA polymerase: structural similarities between bacterial RNA polymerase and eukaryotic RNA polymerase II. J. Mol. Biol. 304, 687–698 (2000).
Stols, L. et al. A new vector for high-throughput, ligation-independent cloning encoding a tobacco etch virus protease cleavage site. Protein Expr. Purif. 25, 8–15 (2002).
Mastronarde, D. N. Automated electron microscope tomography using robust prediction of specimen movements. J. Struct. Biol. 152, 36–51 (2005).
Kimanius, D., Dong, L., Sharov, G., Nakane, T. & Scheres, S. H. W. New tools for automated cryo-EM single-particle analysis in RELION-4.0. Biochem. J. 478, 4169–4185 (2021).
Zheng, S. Q. et al. MotionCor2: anisotropic correction of beam-induced motion for improved cryo-electron microscopy. Nat. Methods 14, 331–332 (2017).
Rohou, A. & Grigorieff, N. CTFFIND4: fast and accurate defocus estimation from electron micrographs. J. Struct. Biol. 192, 216–221 (2015).
McMullan, G., Vinothkumar, K. R. & Henderson, R. Thon rings from amorphous ice and implications of beam-induced Brownian motion in single particle electron cryo-microscopy. Ultramicroscopy 158, 26–32 (2015).
Bepler, T. et al. Positive-unlabeled convolutional neural networks for particle picking in cryo-electron micrographs. Res. Comput. Mol. Biol. 10812, 245–247 (2018).
Burnley, T., Palmer, C. M. & Winn, M. Recent developments in the CCP-EM software suite. Acta Crystallogr. D 73, 469–477 (2017).
Jakobi, A. J., Wilmanns, M. & Sachse, C. Model-based local density sharpening of cryo-EM maps. eLife 6, e27131 (2017).
Naydenova, K. & Russo, C. J. Measuring the effects of particle orientation to improve the efficiency of electron cryomicroscopy. Nat. Commun. 8, 629 (2017).
Vagin, A. & Teplyakov, A. Molecular replacement with MOLREP. Acta Crystallogr. D 66, 22–25 (2010).
Emsley, P. & Cowtan, K. Coot: model-building tools for molecular graphics. Acta Crystallogr. D 60, 2126–2132 (2004).
Wood, C. et al. Collaborative computational project for electron cryo-microscopy. Acta Crystallogr. D 71, 123–126 (2015).
Brown, A. et al. Tools for macromolecular model building and refinement into electron cryo-microscopy reconstructions. Acta Crystallogr. D 71, 136–153 (2015).
Kovalevskiy, O., Nicholls, R. A., Long, F., Carlon, A. & Murshudov, G. N. Overview of refinement procedures within REFMAC5: utilizing data from different sources. Acta Crystallogr. D 74, 215–227 (2018).
Winn, M. D. et al. Overview of the CCP4 suite and current developments. Acta Crystallogr. D 67, 235–242 (2011).
Afonine, P. V. et al. Real-space refinement in PHENIX for cryo-EM and crystallography. Acta Crystallogr. D 74, 531–544 (2018).
Liebschner, D. et al. Macromolecular structure determination using X-rays, neutrons and electrons: recent developments in PHENIX. Acta Crystallogr. D 75, 861–877 (2019).
Williams, C. J. et al. MolProbity: more and better reference data for improved all-atom structure validation. Protein Sci. 27, 293–315 (2018).
Berman, H., Henrick, K. & Nakamura, H. Announcing the worldwide Protein Data Bank. Nat. Struct. Biol. 10, 980 (2003).
Molecular insight into 5′ RNA capping with dinucleoside polyphosphates by bacterial RNA polymerase. Zenodo https://doi.org/10.5281/zenodo.14215049 (2025).
Acknowledgements
We are grateful to all members of the H.C. group for their help and advice; to L. Gahurová for help with the design of the template; and to M. Lepšík, H. Martinez-Seara Monne and K. K. Telukunta from the High-Performance Computing Core Facility of the Institute of Organic Chemistry and Biochemistry of the Czech Academy of Sciences (IOCB Prague) for support. We thank M. Klíma and P. Pachl from IOCB Prague for advice on the definition of restraints. We thank the staff of the CEITEC facility, especially J. Nováček and Z. Hlavenková, for access to the Krios microscope and the Czech Infrastructure for Integrative Structural Biology (CIISB) Instruct-CZ Center, supported by the Ministry of Education, Youth and Sports of the Czech Republic (LM2023042), the European Regional Development Fund-Project ‘UP CIISB’ (no. CZ.02.1.01/0.0/0.0/18_046/0015974) and the European Regional Development Fund-Project ‘Innovation of Czech Infrastructure for Integrative Structural Biology’ (no. CZ.02.01.01/00/23_015/0008175). We acknowledge funding from the European Research Council Executive Agency under the European Union’s Horizon Europe Framework Program for Research and Innovation (grant no. 101041374, StressRNaction, to H.C.) and the Operational Program Johannes Amos Comenius project ‘RNA for Therapy’ (CZ.02.01.01/00/22_008/0004575, to H.C. and P.Ř.), cofinanced by the EU. The schematic in the graphical abstract (online) was created in BioRender. Serianni, V. (2025) https://BioRender.com/qdn74rj.
Author information
Authors and Affiliations
Contributions
H.C., T.K. and P.Ř. conceptualized and supervised the project. V.M.S., A.Š., T.K. and H.C. designed the experiments. M.F. carried out the cloning. T.V. expressed and purified proteins for biochemistry experiments and cryo-EM. V.M.S. performed the transcription experiments and prepared cryo-EM samples. A.Š. carried out the LC–MS analyses. A.F. prepared the cryo-EM grids. A.F. and T.K. collected the cryo-EM data. A.K.D. and H.Š. performed the cryo-EM image processing and 3D reconstruction. J.Š. built the initial models together with H.Š. and T.K. J.Š. refined the final atomic models. H.C., T.K., V.M.S. and J.Š. wrote the manuscript with input from all coauthors. V.M.S., T.K., J.Š., A.K.D. and H.Š. prepared the figures. All authors discussed the manuscript and contributed to the interpretation of the data.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Chemical Biology thanks Richard Ebright and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data
Extended Data Fig. 1 Distinct phosphodiester linkages in NpnNs and canonical RNA.
Chemical structures of NpnNs (a), pppNpN nascent RNA dinucleotide (b) and NpN 5′-end hydroxyl dinucleotide primer (c). Created in BioRender. Serianni, V. (2025) https://BioRender.com/qasouxb.
Extended Data Fig. 2 LC-MS analysis of IVT products with template TC.
Extracted ion chromatograms of IVT products with and without addition of NpnNs. IVT products encoded from the +1 TSS are marked blue, IVT products encoded from the +1 TSS with an extra C added at the 3′ end are marked dashed blue. IVT products encoded from the −1 TSS are marked red, IVT products encoded from the −1 TSS with an extra C added at the 3′ end are marked dashed red. The sequences of the formed products with exact masses are shown in Supplementary Table 3. The PAGE gel from Fig. 1d is reproduced here for clarity (see Fig. 1c-e legend). Created in BioRender. Serianni, V. (2025) https://BioRender.com/55wowug.
Extended Data Fig. 3 PAGE analysis and LC-MS analysis of IVT products generated from plasmid TC.
PAGE analysis (with APB) shows RNA products obtained from IVT reactions using the TC plasmid and NTPs or their combination with NpnNs radiolabeled with α-[32P]CTP. The IVT reaction was performed in five independent experiments. The controls (CTRL E. coli and CTRL) show the migration of the uncapped RNA (150 nt) produced by E. coli RNAP and Tt RNAP, respectively, and serve as molecular weight markers. Moreover, the formation of the known RNAI encoded in the plasmid (109 nt) and produced by E. coli RNAP was observed. Non-radiolabeled RNA was used for digestion with RNase A (cleaving after pyrimidines) and further analyzed by LC-MS. Extracted ion chromatograms show RNA fragments generated from IVT with or without NpnNs. Uncapped RNA (CTRL) is indicated in gray: solid gray lines represent transcripts initiating at the +1 TSS (defined as uncapped(+1)TSS-RNA), while dashed gray lines represent transcripts initiating at the −1 TSS (defined as uncapped(−1)TSS-RNA). Capped IVT products encoded from the +1 TSS (cap(+1)TSS-RNA) are shown in blue and products encoded from the −1 TSS (cap(−1)TSS-RNA) are shown in red. The sequences and exact masses of the corresponding products are listed in Supplementary Table 4. Created in BioRender. Serianni, V. (2025) https://BioRender.com/pbscak2.
Extended Data Fig. 4 IVT reactions with NpnNs and the template gTT.
a, Schemes of IVT experiments showing NTPs or NpnNs binding to the template gTT (with a pre-melted bubble from position −11 to +2) during transcription initiation with different base pairing at the −1 and +1 positions. b, Sequences of color-coded RNA products with and without the addition of NpnNs. Uncapped 15-mer referred to as (+1)TSS-RNA is indicated by a blue dot, uncapped 16-mer referred to as (−1)TSS-RNA is indicated by a brown dot, capped 15-mers referred to as cap(+1)TSS-RNA are indicated by violet and yellow dots. c, PAGE (with APB) showing RNA products obtained from IVT reactions with the template gTT and NTPs or their combination with NpnNs radiolabeled with α-[32P]CTP. Each control (CTRL AG, CTRL GG, CTRL AA), designed according to Supplementary Table 2, shows the migration of the uncapped RNA 15-mer and 16-mer and serves as a molecular weight marker (panel e). The capped products are marked with colored dots according to panel b. We observed also the formation of uncapped 17-mer with an extra C added at the 3′ end. The label ‘+ 3′C’ indicates RNA transcripts with an extra 3′ C, as determined by LC-MS (see Extended Data Figure 5). The IVT was performed in ten independent experiments; one representative gel is shown. d, PAGE (without APB) was used to analyze RNA products obtained from IVT reactions. The reactions were performed as in panel c and it shows that, without APB, there is no difference in migration between capped and uncapped RNA. The controls/markers are analogous to panel c. e, PAGE (without APB) shows the migration of 15-mer monophosphate marker (p-MARKER(15)) along with the monophosphate RNA (p-CTRL) and triphosphate RNA (ppp-CTRL) generated using template gTT and regular NTPs. The experiment was performed in triplicate. Created in BioRender. Serianni, V. (2025) https://BioRender.com/fggd152.
Extended Data Fig. 5 LC-MS analysis of IVT products with template gTT.
The PAGE gel from Extended Data Fig. 4c is reproduced here for clarity. Extracted ion chromatograms of IVT products with and without addition of NpnNs. IVT products encoded from the +1 TSS are marked blue, IVT products encoded from the +1 TSS with an extra C added at the 3′ end are marked dashed blue. IVT products encoded from the −1 TSS are marked red, IVT products encoded from the −1 TSS with an extra C added at the 3′ end are marked dashed red. The sequences of the formed products with exact masses are shown in Supplementary Table 5. We confirmed the 16-mer product encoded from the −1 TSS and we detected a 17-mer RNA product corresponding with its mass also to the (−1)TSS-RNA but with an extra C added at the 3′ end. Only trace amounts of the 15-mer RNA encoded from the +1 TSS were detected by PAGE and LC-MS. The PAGE analysis of IVT reactions with Ap3-4A and the template gTT showed the formation of two capped products. LC-MS analysis confirmed the production of capped RNA encoded from the +1 TSS, but contrary to the control IVT, we did not detect capped RNA encoded from the −1 TSS. The second observed product has the mass of cap(+1)TSS-RNA with the 3′ extra C. These observations indicate that Ap3-4A initiate transcription only from the +1 TSS of the gTT template. The experiment with Ap3-4G led to the formation of similar products as in the case of Ap3-4A. As expected, Gp3-4G cannot base pair with the gTT template and did not produce capped RNA. N/D = not detected. Created in BioRender. Serianni, V. (2025) https://BioRender.com/jj7ixi3.
Extended Data Fig. 6 IVT with NpnNs and template CT.
a, Schemes of IVT experiments showing NTPs or NpnNs binding to the template CT (with a pre-melted bubble from position −11 to +2) during transcription initiation with different base pairing at the −1 and +1 positions. b, Sequences of color-coded RNA products with and without the addition of NpnNs. Uncapped 15-mer referred to as (+1)TSS-RNA is indicated by a blue dot, uncapped 16-mer referred to as (−1)TSS-RNA is indicated by a brown dot, capped 15-mer referred to as cap(+1)TSS-RNA is indicated by a green dot, and capped 16-mers referred to as cap(−1)TSS-RNA are indicated by red and yellow dots. c, PAGE (with APB) showing RNA products from IVT using the template CT with NTPs or various NpnNs, radiolabeled with α-[32P]CTP. Each control (CTRL AG, CTRL GG, CTRL AA, Supplementary Table 2) shows the migration of the uncapped RNA 15-mer and 16-mer and serves as size marker (panel d). IVT reaction (Extended Data Table 1) without NpnNs led to the production of mainly 16-mer and also 15-mer uncapped products. The RNA products are marked according to panel b. We observed formation of capped 15-mer RNA encoded from the +1 T position when Ap3-4A were added to IVT. When Ap3-4G and Gp3-4G were added, we observed mainly capped 16-mer RNA encoded from the −1 C position of the template. This indicates that the transcription was initiated by the G nucleoside of GpnNs bound at the −1 C position of the template. The IVT was performed in ten independent experiments; one representative gel is shown. d, PAGE (without APB) shows migration of 15-mer (p-MARKER(15)) and 16-mer (p-MARKER(16)) monophosphate marker along with the monophosphate RNA (p-CTRL) and triphosphate RNA (ppp-CTRL) generated using template CT and regular NTPs. The experiment was performed in triplicate. Created in BioRender. Serianni, V. (2025) https://BioRender.com/opxr6fh.
Extended Data Fig. 7 LC-MS analysis of IVT products with template CT.
The PAGE gel from Extended Data Fig. 6c is reproduced here for clarity. Extracted ion chromatograms of IVT products with and without addition of NpnNs. IVT products encoded from the +1 TSS are marked blue, IVT products encoded from the +1 TSS with an extra C added at the 3′ end are marked dashed blue. IVT products encoded from the −1 TSS are marked red, IVT products encoded from the −1 TSS with an extra C added at the 3′ end are marked dashed red. The sequences of the formed products with exact masses are shown in Supplementary Table 6. Majority of our observations from the PAGE analysis were also confirmed by the LC-MS analysis. The only exception was the reaction with Ap3G, which led to the formation of capped RNA encoded from the +1 TSS as the main product. We also observed the formation of products with an extra C added at the 3′ end. Created in BioRender. Serianni, V. (2025) https://BioRender.com/xnjca7i.
Extended Data Fig. 8 GTP bound in de novo transcription initiation complex; anti-scrunched template strand in the TC-empty complex.
a, AS structure of de novo transcription initiation, where GTP binds canonically in the i site and CMPcPP is bound in a pre-insertion position in the i + 1 site, consistent with the trigger loop being only partially closed towards the AS. The DNA template strand is marked with respect to the +1 TSS site. The aspartate triad of the AS coordinates MgA and partially also MgB. Conserved residues are positioning the GTP phosphates, which themselves coordinate an additional MgC ion. b, Cryo-EM density for the GTP in the i site (transparent gray), base pairing with the template +1 C (transparent blue). c, When the AS is unoccupied, the template strand is antiscrunched by one nucleotide in respect to when the AS is occupied by GTP and CMPcPP (panel a). The template −2 G base is in line with the i − 1 site, the template −1 T base is in line with the i site and the template +1 C base is in line with the i + 1 site. The +2 G base is shifted over the bridge helix towards the downstream DNA duplex.
Extended Data Fig. 9 Comparison of WC and rWC base pairing, and NAD binding to RNAP AS.
a, In TC-Ap3G, the glycosidic bond of the distal Ap3G adenosine and the glycosidic bond of the template −1 T are in mutual trans orientation, which results in their reverse WC base pairing. b, In a regular RNA/DNA duplex, here represented by a 5′-end hydroxyl dinucleotide primer/DNA complex (PDB 7EH1), the glycosidic bond of the distal adenosine in ApG (featuring regular 5′ to 3′ monophosphate linker) and the glycosidic bond of the template −1 T are in mutual cis orientation, which favors canonical WC base pairing. The original CC template and GpG dinucleotide in PDB ID 7EH1 were mutated to TC and ApG for the sake of direct comparison of A-T base pairing in the i − 1 site. c, In TC-Ap4A, the distal Ap4A adenosine flanks due to purine-purine base-pairing incompatibility at the i − 1 site. d, NAD as NCIN visualized after incorporation into nascent product and translocation (PDB 5D4D). The proximal adenosine of NAD base pairs in the i − 1 site, while the distal nicotinamide moiety does not base pair with the template strand adenine purine base in line with the i − 2 site. A direct comparation of NAD and Np4N binding at the i and i − 1 site of the AS during the very initial step of transcription awaits the determination of a structure with NAD bound in the respective sites.
Supplementary information
Supplementary Information (download PDF )
Supplementary Tables 1–12, Supplementary Figs. 1–10, Supplementary References and Source Data for Supplementary Information.
Source data
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Serianni, V.M., Škerlová, J., Dubánková, A.K. et al. Molecular insight into 5′ RNA capping with NpnNs by bacterial RNA polymerase. Nat Chem Biol (2026). https://doi.org/10.1038/s41589-025-02134-5
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41589-025-02134-5
