
Abstract
The identification of unknown parameters for proton exchange memberane fuel cells (PEMFCs) using nature-inspired optimization algorithms has emerged as a significant field of research in recent years. In the present study, a novel approach is presented, namely the hybrid Gray Particle Cuckoo (GPC) algorithm based on the hybrid properties of the grey wolf optimizer (GWO), particle swarm optimization (PSO), and cuckoo search (CS) to address the identification problem associated with PEMFCs. The effectiveness of the proposed GPC algorithm is evaluated on four commercially available PEMFCs (BCS500-W, Ballard Mark V, Temasek, as well as NedStack PS6). The fitness function has been expressed as the sum of the squared errors (SSE) that occurred between the estimated voltage and the data that corresponded to it. To further validate the model of the PEMFC, it is contrasted with other complex algorithms. The GPC algorithm showed the lowest SSE across all cases, resulting in SSE values of 0.011699, 0.813912, 2.267687, and 0.123276775 for the BCS500-W, Ballard Mark V, NedStack PS6 and Temasek PEMFC stack, respectively. Also, the PEMFC stacks are evaluated using different partial temperature and pressure conditions. In addition to real-world challenges, the GPC algorithm has been assessed on 100-digit CEC 2019 benchmarks and contrasted to other MH algorithms. Furthermore, both the parametric and non-parametric statistical tests are conducted to evaluate the efficacy of the GPC algorithm. The results in terms of mean square error (MSE), individual absolute error (IAE), mean bias error (MBE), mean absolute error (MAE), and root-mean-square error (RMSE) demonstrate that the GPC algorithm is the optimal choice contrasted to other algorithms due to its better solution quality and faster convergence time.
Similar content being viewed by others
Introduction
The depletion of fossil fuels, caused by the increasing consumption of energy, as well as increased awareness of environmental conservation, has led individuals and governments to focus on alternative energy sources. As a result, researchers have presented significant interest in exploring other energy sources that are more environmentally friendly, such as wind, solar and wave energy1,2. These sources have gained considerable attention because of their potential to mitigate the negative impacts of traditional energy production methods on the environment. Therefore, various studies and investigations have been conducted to assess the feasibility and efficiency of these greener energy sources. The main obstacles associated with the sources mentioned are their unpredictable characteristics and dependence on climatic factors. However, these constraints have clearly highlighted the crucial need for energy storage. Hydrogen, a topic of current interest, has the potential to serve as an energy storage medium to effectively store renewable energy until it can be converted to electricity by an energy conversion device3. A fuel cell (FC) is a very important technology for converting energy, usually generating electricity, by employing a chemical reaction between hydrogen as well as oxygen. The PEMFC has become popular in many fields, including automotive, on-site generation, as well as portable electronic devices, because of its advantages, which include high power density, low operating temperature, and solid electrolyte4.
Enhancing the efficiency as well as performance of PEMFCs has become an important area of study. The mechanical model incorporates the internal dynamics of cells through mass and heat conservation laws, alongside chemical reaction equations, whereas the empirical model represents the external properties of cells using empirical formulas derived from experimentation, which are less complex than those of the mechanical model. The precise identification of the model’s parameters remains to be a considerable challenge5,6. This paper utilises a semi-empirical model that integrates a mechanism model with empirical components, presenting a voltage model that thoroughly addresses active polarisation loss, ohmic polarisation loss, and concentration polarisation loss7,8. A precise mathematical model is essential to accurately represent the actual behavior of the system under various operating scenarios9,10. Identifying the optimal values of the unknown parameters results in a mathematical model that exhibits a high level of precision11. As a result of the related non-linearity of the FC, the modeling procedure becomes complex due to the presence of certain unknown parameters in the manufacturer’s datasheet12.
In recent decades, extensive research has been done on estimating unknown parameters in the literature, categorising studies into two primary areas, such as MH as well as deterministic optimization techniques. Deterministic optimization methods, including derivative-based optimization as well as linear programming, depend on precise mathematical principles. MH and deterministic methods offer unique advantages that depend on the specific characteristics of the problem at hand13,14. Deterministic techniques provide efficient and accurate solutions for small-scale and linear problems, ensuring optimal results. These methods may be insufficient for complex problems characterised by multiple variables and non-linear relationships, as they are prone to convergence on suboptimal solutions. The MH optimization algorithms have gained significant popularity for addressing various optimisation problems due to their flexibility, derivation-free approach, and simplicity15,16,17. The complicated nature of the PEMFC parameter identification challenge has resulted in the inadequate performance of conventional search strategies in accurately determining the best possible solutions18,19. In addition, various other MHA have been implemented to improve both the accuracy and the effectiveness of the model, including Dimension Learning-based Modified Grey Wolf Optimizer (DLHMGWO)5, Improved Heap-based optimizer (IHBO)20, Lightning Search Algorithm (LSA)21, Artificial Hummingbird Algorithm (AHA)22, Repairable Grey Wolf Optimization (RGWO)23, Shark Smell Optimizer (ShSO)24, Manta Rays Foraging Optimizer (MRFO)25, Flower Grey INFO Naked (FGIN)26, Hybrid Vortex Search Differential Evolution (VSDE)27, Honey Badger Optimization Algorithm (HBA)28, Improved Artificial Bee Colony (IABC)29, Imperialist Competitive Algorithm (ICA)30, Flower Pollination Algorithm (FPA)31, Pathfinder Algorithm (PFA)32, Transient Search Optimization (TSO)33, Dandelion Optimize (DO)34, Hunger Games Search Marine Predator Algorithm (HGS-MPA)35, Aquila Optimizer Arithmetic Algorithm Optimization (AOAAO)36, Parrot Optimizer (PO)37, Hybrid Artificial Bee Colony Differential Evolution Optimizer (ABC-DE)38, Chaotically based-bonobo optimizer (CBO)39, Enhanced Salp Swarm Algorithm (ESSA)40, Honey Badger Optimizer (HBO)9, Autonomous Groups Particle Swarm Optimization (AGPSO)8, Gorilla Troops Optimizer (GTO)41, Enhanced Walrus Optimization (EWO)42, Improved Artificial Ecosystem Optimizer (IAEO)43, Combined Owl Search Algorithm (COSA)44, War Strategy Optimization (WSO)45, Improved Fish Migration Optimizer (IFMO)46, Ali Baba and forty thieves (ABFT)47, Puma Optimizer (PuO)48, Kepler Red Meerkat Grey (KRMG)49 and so on. Also, a comparative literature table has been included in order to clarify existing research on PEMFC parameter estimation, summarizing essential elements such as optimization algorithm, PEMFC stack utilization, objective functions, and the use of statistical analysis is given in Table 1.
Now, there is the shortage of a dependable and efficient method for getting an accurate estimating procedure that can serve as a unique reference for research objectives. In addition, the no-free lunch (NLF) theorem motivates researchers to create novel optimization techniques or enhance/hybrid existing ones to address the real-world challenges across several domains50. Thus, a research gap needs to be addressed by determining the most appropriate algorithm for PEMFC and exploring other algorithms that have not been utilized in the PEMFC area. These MHAs provide several approaches to optimize the parameters of PEMFC systems and enhance their performance. However, it is possible for them to get trapped in local minima while performing the search, resulting in a gradual decline in their efficiency with every repetition. This paper presents a novel hybrid optimization (GPC) algorithm to optimally estimate the unknown parameters of PEMFC. Furthermore, Eleven MH optimization algorithms consisting of the Zebra Optimization Algorithm (ZOA)51, sinh cosh optimizer (SCHO)52, Propagation Search Algorithm (PSA)53, SABO54, Young’s Double-Slit Experiment (YDSE)55, exponential distribution optimizer (EDO)56, RIME57, Chernobyl Disaster Optimizer (CDO)58, Coati Optimization Algorithm (COA)59, Harris Hawks Optimizer (HHO)60, and GWO61,62, and the results obtained through these eleven algorithms are also compared with GPC algorithm. To further validate the GPC algorithm, it has been tested on CEC 2019 benchmark challenges63,64 and compared to some of the well-known and recently presented algorithms including, BWOA65, CDO58, COA59, flower pollination algorithm (FPA)66, HHO60, YDSE55, ZOA51, ARNMRA67, FROBLGJO68, as well as jDE10069.

Graphical outline of the article.
This paper’s main contributions can be summarized as follows.
-
To precisely estimate the parameters of the PEMFC, a hybridized algorithm known as the Grey Particle Cuckoo (GPC) algorithm has been presented and validated.
-
The GPC algorithm has been tested with CEC 2019 challenges and compared to BWOA65, CDO58, COA59, FPA66, HHO60, YDSE55, ZOA51, ARNMRA67, FROBLGJO68, and jDE10069. Also, non-parametric test (Friedman and Wilcoxon signed rank test) analysis, as well as the box plot, have been conducted to verify the precision as well as reliability of the GPC algorithm in comparison to existing MH algorithms.
-
Four different commercial FC stacks (NedStack PS6, Ballard Mark V, Temasek, as well as the BCS 500 W PEMFC model) have been evaluated to assess the accuracy as well as reliability of the GPC algorithm.
-
Comparing the PEMFC results obtained from the proposed GPC algorithm with other MH algorithms (ZOA51, SCHO52, PSA53, SABO54, YDSE55, EDO56, RIME57, CDO58, COA59, HHO60, and GWO61), it was evident that the GPC algorithm performed significantly.
-
In addition, the GPC algorithm is applied for an optimal analysis of the PEMFC stacks with changing pressure (\(P_{H2}\) / \(P_{O2}\)) and temperature levels.
-
Statistical studies such as SSE, IAE, MBE, MAE, MSE and RMSE, as well as nonparametric test (Friedman and Wilcoxon signed rank test) have been performed to demonstrate the superiority of the GPC algorithm compared to the other eleven MH optimization algorithms.
The structure of the paper is as follows. Section II outlines the mathematical concept of a PEMFC and the optimization challenge of identifying the unknown parameters of a PEMFC. The details of the proposed approach are presented in Section III. Section IV presents the experimental results as well as a related discussion. The conclusion and future scope of the presented work are given in Section V. The graphical outline of the article is given in Fig. 1.
Mathematical modeling of PEMFC
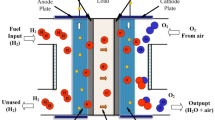
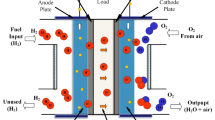
A PEMFC is made up of two electrodes, an anode as well as a cathode, with a thin solid membrane that conducts protons placed between them70,71, as illustrated in Fig. 2. In addition, Fig. 2 illustrates the reactions that take place at two electrodes. In the catalyst layer of the cathode, the oxygen reacts with the electrons and protons, resulting in the production of water and electricity. The overall reaction is given below:
The electrochemical model is utilized to mathematically show the behaviour of the electrolyzer. Also, the PEMFC equivalent circuit diagram is presented in Fig. 3. The mathematical representation for the output voltage (\(V_{STAC}\)) of the stack, as shown in Equation 2, consists of many cells connected in series (\(N_{num}\))72,73.
Where, reversible open circuit voltage (\({E}_{NERS}\)), activation voltage loss (\({V}_{ACTI}\)) due to the activation of both the anode and cathode, concentration over-potential (\({V}_{CONCENT}\)), and ohmic voltage loss (\({V}_{OHM}\)). The \({E}_{NERS}\) is determined using the Nernst equation, as shown in Eq. (3)29.
where the cell operating temperature (\({T_{ot}}\)), partial pressure (atm) of hydrogen and oxygen (\(P_{H2}\) as well as \(P_{O2}\)), can be calculated using Eq. (4), as well as (5)74,75.
Where, the inlet pressure of the cathode as well as the anode (\(P^c\) and \(P^a\)), saturation pressure of water vapor (\(P_{{H_2}O}\)), operating current (\(I_{oc}\)), and PEM area (A).
The \(V_{ACTI}\), which is the \(2^{nd}\) term on the right side of Eq. (2), can be computed utilizing the Eq. (6)71.
Where, semi-empirical coefficients (\(\xi _a\), \(\xi _b\), \(\xi _c\), and \(\xi _d\)), the concentration of oxygen (\(C_{O2}\)) and is defined as Eq. (7)40,76.
The \(V_{OHM}\), which is the term \(3^{rd}\) on the right side of Eq. (2), can be mathematically represented in Eq. (8)77,78.
Where, the resistance of the connections (\(R_{con}\)), as well as the membrane resistance (\(R_{memb}\)), that can be obtained by utilizing Eq. (9).

PEMFC model.

PEMFC equivalent circuit.
where, the thickness of the membrane (\(l_{thic}\)), as well as the specific resistivity of the membrane (\(\rho _{memb}\)), can be calculated using Eq. (10).
Where, actual current density (J), and parameter \(\lambda\) are adjustable and are associated with the water content of the membrane.
The drop in concentration voltage (\(V_{CONCENT}\)) is caused by changes in the concentration of reactants on the electrode surface and can be mathematically expressed in Eq. (11):
Where, the symbol \(\beta\) serves to represent the semi-empirical coefficient.
The main objective of our investigation is to determine the most optimal values for the parameters (\(\xi _a\), \(\xi _b\), \(\xi _c\), \(\xi _d\), \(R_{con}\), \(\lambda\) and \(\beta\)) through the application of the GPC algorithm. This helps ensure that the output voltage of the model aligns with the experimental data.
Objective Function
The Eqs. (2–11), present a set of equations where the operation parameters \(T_{ot}\), \(RH_c\), \(P^c\), \(RH_a\), \(P_{H2}\), \(P^a\), as well as \(P_{O2}\) are measurable and their values depend on the specific operating conditions. Additionally, the physical parameters (\(\xi _a\), \(\xi _b\), \(\xi _c\), \(\xi _d\), \(R_{con}\), \(\lambda\), and \(\beta\)) are unknown. Due to the significant impact of the unknown parameter on the model outcomes, it is essential to extract them with the greatest accuracy to be precisely matched with the actual voltage-current (V-I) characteristic of the PEMFC.
Before determining the unknown parameter (\(\xi _a\), \(\xi _b\), \(\xi _c\), \(\xi _d\), \(R_{con}\), \(\lambda\), and \(\beta\)), it is imperative to determine an objective function. In order to compare with previous literature, the objective of optimization in this study is to determine a set of parameter values that will reduce the SSE between the experimental voltage (\(V_{exper}\)) as well as the model-estimated voltage (\(V_{estimat}\)) as determined by Eq. (12).
Where, the number of voltage data samples (\(N_{volt}\)), and the proposed constraints are presented as.
In the next section, we present the basics of nature-inspired algorithms and proposed methodology used to optimize the objective function discussed above.
Basics of nature-inspired algorithms
This section presents the fundamental principles underlying the algorithms utilized to develop a novel GPC optimization algorithm. This is an outline of the recently employed algorithms, including GWO, PSO, and CS optimization algorithms:
Grey Wolf Optimizer
In 2014, Mirjalili et al. proposed the GWO algorithm, inspired by the social behaviour as well as hunting strategies of wild grey wolves, scientifically known as Canis lupus61. These wolves reveal social behaviour and maintain a rigid social hierarchy, categorised into four distinct ranks: alpha (\(\alpha\)), beta (\(\beta\)), delta (\(\delta\)), as well as omega (\(\omega\)). The mathematical framework of GWO depends on the social structure and hunting techniques of grey wolves. The fundamental aspects of hunting involve tracking, encircling, and subsequently attacking the prey79.
Social hierarchy
In the development of the GWO, the social hierarchy of wolves is mathematically expressed by identifying the optimal solution as the \(\alpha\). Therefore, the \(2^{nd}\) and \(3^{rd}\) most efficient solutions are designated as \(\beta\) as well as \(\delta\) accordingly. The remaining candidate solutions have been assumed to be \(\omega\). The optimization process of the GWO algorithm is governed by \(\alpha\), \(\beta\), and \(\delta\). The \(\omega\) wolves follow the group of 3 wolves (\(\alpha\), \(\beta\), and \(\delta\)).
Encircling prey
Grey wolves encircle their prey while hunting, as mentioned earlier. In order to represent encirclement behaviour numerically, the following equations are given.
where variables \(\overset{\rightarrow }{\mathop {T}}\,(t+1)\), t, and \(\overset{\rightarrow }{\mathop {T}}\,_{p}(t)\) denote the position of the \(i^{th}\) grey wolf, the current iteration, and the location of the prey, respectively. The vectors \(\overset{\rightarrow }{\mathop {Q}}\) and \(\overset{\rightarrow }{\mathop {E}}\) acting as control parameters are computed using Eqs. (16) and (17).
where components \(\overset{\rightarrow }{\mathop {b}}\) are linearly decreased from 2 to 0 throughout the iterations, while \(\overset{\rightarrow }{\mathop {{{r}_{1}}}}\) and \(\overset{\rightarrow }{\mathop {{{r}_{2}}}}\) are random vectors within the interval [0, 1].
Hunting
Grey wolves identify the location of prey and encircle it, with direction from the \(\alpha\). The \(\beta\) and \(\delta\) may also engage in the hunt. The optimum location (prey) remains unknown. To model wolf hunting behaviour, it is assumed that the \(\alpha\), \(\beta\), and \(\delta\) possess superior knowledge regarding potential prey locations. Retain the three best solutions and adjust the positions of other search agents based on the positions of the top-performing agents.
Attacking the prey
Grey wolves finalise the hunt by focussing on the prey once it becomes stationary. To build a mathematical model of the hunter advancing towards its prey, decrease the value of \(\overset{\rightarrow }{\mathop {b}}\). The range of \(\overset{\rightarrow }{\mathop {{{Q}}}}\) decreases by the effect of \(\overset{\rightarrow }{\mathop {b}}\). \(\overset{\rightarrow }{\mathop {{{Q}}}}\) is a randomly chosen value within the interval of -2b to 2b, where \(\overset{\rightarrow }{\mathop {b}}\) is progressively decreased from 2 to 0 during the repetitions. When random values of \(\overset{\rightarrow }{\mathop {{{Q}}}}\) range from [-1,1], the subsequent location of a search agent may lie anywhere between its current location and the location of the prey. The coefficient\(\overset{\rightarrow }{\mathop {T}}\) additionally regulates the exploratory phase of the algorithm. This component allocates arbitrary weights to prey to avoid stagnation at local optima, enabling the algorithm to incorporate randomization during the optimization process. In doing so, grey wolves engage in a hunting process characterized by repetitive behaviors of encircling and pursuing, as mentioned above.
Particle Swarm Optimization
The PSO is a stochastic optimization method based on population dynamics. It was \(I^{st}\) proposed by Kennedy and Eberhart in 1995, drawing inspiration from the social behaviours exhibited in bird flocking and fish schooling80.
Mathematical formulation
In PSO, a particle is characterised by its location as well as velocity within a d-dimensional search space. Let \(T_i(t)= (T_{i1 },T_{i2}..........T_{id})\) be the location of particle i at iteration (t), and velocity \(U_i(t)= (u_{i1 },u_{i2}..........u_{id})\). The individual optimal location of the particle is \(k_i(t)= (k_{i1 },k_{i2}..........k_{id})\), while the global best location identified by the entire swarm is \(k_g(t)= (k_{g1 },k_{g2}..........k_{gd})\). The Eqs. (21), and (22) determine the updates for velocity as well as location:
The formulation of a new velocity update equation follows from the addition of inertia weight (S) to the velocity update formula.
where, t and \(T_{max}\) are the current iteration as well as maximum iteration. The \(S_{max}\) and \(S_{min}\) indicate the maximum as well as lower limits of the range of inertia weight (S(t)) parameter.
Cuckoo search algorithm
The CS algorithm has been motivated by the obligatory brood behavior of cuckoos as well as relies on three fundamental principles such as.
-
Each cuckoo lays one egg at a time, depositing it in a randomly selected nest.
-
The nests with the best quality eggs (i.e., best fitness solutions) are carried over to the next generation.
-
There are a fixed number of host nests, and there is a probability that the worst nests will be replaced by new ones, representing the discovery of alien eggs by host birds.
The CS algorithm primarily focuses on exploration as well as exploitation of cuckoo species, as outlined by these three principles. The process is divided into two main stages: a local search stage that addresses exploitation and a global search stage that deals withexploration. Another parameter functions as the governing element of the CS algorithm. The parameter selected randomly from a uniform distribution is referred to as the switch probability, denoted as p. The subsequent subsections provide an expanded discussion of each of the previously covered stages.
Global search phase
The cuckoo search has been executed in accordance with the three rules. A Lévy flight is executed to provide a new solution Y for the ith cuckoo. This process is referred to as a global random walk and is outlined in Eq. (25)
where as \(T_i^p\) denotes the previous solution, while \(T_{i}^{p+1}\) is current soloution. This step follows the newly generated solutions using Lévy flights (\(L(\lambda )\)). The main reason for using such this mechanism is the longer tail and better flight trajectory of the Lévy flight mechanism, which helps to provide better search capabilities to the algorithm. Apart from that, the Lévy flight mechanism is given in Eq. (26).
where \(\hspace{5pt} s=\frac{U}{|V|^1/\lambda }\hspace{10pt} U\sim N(0,\sigma ^2), \hspace{10pt}V\sim N(0,1)\) and \(\sigma ^2=\bigg \{\frac{\Gamma (1+\lambda )}{\lambda \Gamma [(1+\lambda )/2]}. \frac{\sin (\pi \lambda /2)}{2^{(\lambda -1)/2}}\). Also, \(\Gamma (\lambda )\) is a gamma function and the value of \(\lambda\) is equal to 1.5. During this exploration phase, the parameter N is sampled from a standard Gaussian distribution with a mean of 0 and a variance of \(\sigma ^2\). This process is designed to explore the solution space effectively. To generate a new solution, the current best solution (\(T_{best}\)) is utilised in conjunction with the sample parameter.
Local search phase
The \(2^{nd}\) phase of CS algorithm is the local random-walk mechanism, which aligns with the exploitation process. This phase involves the generation of a new solution (\(T_i^{p+1}\)) through a local search using two randomly selected solutions from the search pool.The local random walk is presented in Eq. (27).
where \(T_j^p\) and \(T_k^p\) correspond to two random solutions, \(\epsilon \in [0, 1]\) is a uniformly distributed random number.
The proposed approach
This section deals with the proposal of the GPC algorithm, starting with the motivation behind the proposal, the details of the proposal and finally the computational complexity of the proposed approach.
Motivation behind the proposal
In optimization, the trade-off between searching for new, potentially better solutions (exploration) and refining known good solutions (exploitation) is a critical determinant of algorithmic success. Exploration enables coverage of diverse and unexplored regions in the search space, increasing the likelihood of escaping local optima, while exploitation ensures refinement of promising solutions for accelerated convergence81. Striking an effective balance between these two processes is essential, as overemphasis on either may lead to an inefficient search or premature convergence. Addressing this, the proposed GPC algorithm adopts a modular, phase-wise hybridization strategy to enforce a temporal and spatial balance between exploration and exploitation.
The algorithm utilizes CS-based L’evy flight updates in the early stages to ensure a wide exploratory radius, leveraging the heavy-tailed distribution to traverse far-reaching regions of the search space. As the algorithm progresses, the leadership-driven model of GWO is introduced to promote guided, yet diverse, exploitation through hierarchical decision-making. To further intensify convergence in later iterations, PSO-based velocity updates are incorporated with adaptively tuned inertia weights. This phase-wise hybridization is not a simple combination, but a role-specific assignment, where each component algorithm governs a particular aspect of the search. Unlike traditional hybrids that apply all components uniformly or in a static blend, GPC dynamically partitions the population and allocates algorithms temporally, allowing each strategy to dominate in its optimal phase. This role-based hybridization not only enhances search efficiency, but also reduces algorithmic bias. The adaptability of the framework ensures resilience in diverse problem landscapes, in accordance with the No Free Lunch Theorem50. Thus, the novelty of GPC lies in the structured orchestration and transition of exploration–exploitation roles, rather than merely the selection of constituent algorithms.
The Grey Particle Cuckoo Algorithm
Although individual metaheuristic algorithms such as PSO80, GWO61 and CS82 have demonstrated merit in solving complex optimization problems, each suffers from specific limitations. PSO is prone to premature convergence due to loss of diversity and stagnation in local optima. GWO lacks exploratory capabilities in the early stages and tends to focus narrowly on leader-driven search. CS, despite its exploratory strength through Lévy flights, exhibits instability in convergence and often fails to fine-tune solutions effectively. An inherent limitation of these basic algorithms lies in their suboptimal exploration capability, given their tendency to follow smaller step sizes. This behavior leads to the clustering of new solutions, impeding the exploration process. Consequently, the algorithm tends to confine its search to specific regions within the search space, resulting in an inefficient approach to exploration and an overall sub-par operational performance. Although there are problems with basic algorithms, the organizational structure of CS has been found to be very efficient and can be used as a benchmark to propose new algorithms81.
To counter these deficiencies, GPC proposes a layered hybridization model that restructures both global and local search dynamics. The global search capability is enhanced by embedding new movement equations that encourage distant but purposeful solution updates. Gleichzeitig, the local exploitation phase is improved through mechanisms that capitalize on the proximity of current best solutions, continuously benchmarking new candidates against elite ones, and accelerating convergence toward global optima. The GPC architecture is designed to preserve the useful traits of its constituents (GWO, PSO, and CS) while mitigating their drawbacks. Retain the organizational efficiency of CS, refine the hierarchical strategy of GWO for better guidance, and incorporate the adaptive velocity control of PSO for convergence tightening. These elements are integrated without disrupting the structural integrity of the parent algorithms, making GPC an inherently robust and versatile optimization framework. We now formally define the algorithmic steps, population management, and GPC control parameters.
The algorithm begins by setting N within a constrained search space, as defined by (29)
for the \(i^{th}\) member of the search space, j is the D dimensional problem, \(a \in [0, 1]\) \(y_{min}\) and \(y_{max}\) are the lower bound and upper bounds of the \(D^{th}\) problem. After initialization, we divide the population into two iterative halves.
Stage I : \(p = 1: \frac{p_{maximum}}{2}\)
In the first step, we follow the basic search equations of CS algorithm. This step follows the newly generated solutions using Lévy flights. The main reason for utilizing this mechanism is the longer tail and better flight trajectory of the Lévy flight mechanism, which helps to provide better search capabilities to the algorithm. The general equation for this stage is given by
where
Apart from that, the Lévy flight mechanism is given by
The local search phase is the local random-walk mechanism, which aligns with the exploitation process. This phase involves the generation of a new solution (\(z_i^{p+1}\)) through a local search using two randomly selected solutions from the search pool. The overarching equation for the local search phase is provided as follows:
where \(z_j^p\) and \(z_k^p\) correspond to two random solutions, \(\epsilon \in [0, 1]\) is a uniformly distributed random number.
The local search phase is activated only for a certain fraction of iterations and depends on the probability switch parameter (sp). In the current scenario, this parameter is adjusted using an exponential decreasing inertia weight operator. This phase helps to decide the extent of exploration and exploitation. The general equation is thus given by
where \(\eta _{max}\) as well as \(\eta _{min}\) are maximum and minimum random values [0,1].
Stage II : \(p = \frac{p_{maximum}}{2}+ 1: p_{maximum}\)
In this phase, the main concern is to have lower exploration and more exploitation. During this phase, the global search phase is divided into two parts, and here also the first half of the population follows a similar approach as used in the generalized algorithm. This is done to make the algorithm perform intensive exploration along with some exploitation operation. For the second half of the population, GWO based equations are used. These equations are meant for the initialization of new solutions within the search space, are generally generated using three new solutions, and are formulated as
During this phase, the local search equation is further categorized into two distinct population segments. For the \(I^{st}\) half of the population, again CS based local search is followed, but for the second half of the population, a more rigorous approach is used. Here we are using a PSO-based equation as given by
where \(g_{best}\) is the personal best solution, \(z_{best}\) is the current best solution, \(F = c_1.r_1\) is a random number initialized using simulated annealing inertia weight and is given by
where, the variables T, \(r_1\) \(\eta _{max}\), and \(\eta _{min}\) are uniformly distributed in the range [0,1]. Furthermore, the value of a is set to 0.95.
\(I = c_2.r_2\) is another random number initialized using the sigmoid inertia weight operation as given by
where, \(\eta _{max}=0.9, \eta _{min}=0.5\), \(gen=51\), \(r_2\) and \(h, k \in [0, 1].\)
Population adaptation
To address a reduction in population size, a strategy outlined in82 is followed. The proposed approach involves modifying the population size during algorithm iterations, emphasizing greater exploration initially and transitioning towards adaptive exploitation later. The reduction in population size as iterations progress aims to optimize the algorithm by efficiently utilizing search agents. In simpler terms, the algorithm employs a larger population during exploration to thoroughly cover the search space, while exploitation, focused on specific areas, is achieved with a smaller population. This adaptive population adjustment ensures effective exploration in the early stages and targeted exploitation in the later stages, striking a balance between resource utilization and optimization.
In this study, a proportional population reduction phenomenon is employed, inspired by the ideas presented in82. This method involves reducing the population size in proportion to the increase in fitness. The rationale behind adopting this approach lies in its suitability for addressing multimodal problems, where solutions need to explore extensive areas. When confronted with a large initial population size, it becomes possible for new solutions to explore the entire search space. As the iterations progress, these solutions may converge toward the global best solution, which lies in a specific direction. Consequently, the size of the population can decrease. This reduction in population size facilitates improved genetic drift, allowing the discovery of new solutions without compromising the retention of the best solution. Toward the conclusion of the process, each member of the population is given an equal opportunity to potentially become the best global solution. In a more general context, the equation governing population reduction is expressed as
Where, \(Q_{p+1}\) represents the population at generation p, \(\sigma f_p^{best}\) is stated by \((\frac{f_{p-1}^{best}-f_{p-2}^{best}}{|f_{p-2}^{best}|})\) indicates the change in the best fitness, and \(\sigma f_{max}^{best}\) presents the threshold value.
Selection operation
In the last phase, it is important to carefully select the individuals who are the most appropriate from both the candidates generated in the current iteration and those from previous iterations. The selection technique is determined by comparing the fitness of the new solution, indicated as \(f(z_{new})\), with the fitness of the previously known solution, represented as \(f(z_i^p)\).If the fitness of the new solution, denoted as (\(f(z_{new}\))), is found to be superior to the fitness of the previous known solution, denoted as (\(f(z_i^p)\)), then the new solution replaces the original solution as the one selected. However, if the previous solution (\(z_i\)) has a higher level of fitness, it will be retained as the selected solution for the subsequent stages of the process.
This selection mechanism ensures that the most suitable individuals remain in the population, encouraging improved fitness and ultimately leading to a more optimal and efficient solution for the problems under consideration. The pseudocode of the GPC algorithm is presented in Algorithm 1. The pseudocode of the proposed algorithm is shown in Fig. 4.

Pseudocode of proposed GPC algorithm.

Flowchart of GPC algorithm.
Complexity of the proposed GPC algorithm
The computational complexity of the proposed GPC algorithm is governed by the operations performed during initialization and across each iteration of the main loop. Let N be the population size, D be the dimensionality of the optimization problem, and \(t_{\text {max}}\) be the maximum number of iterations.
-
Initialization: Each of the N individuals is initialized in a D-dimensional space. This step requires \(\mathscr {O}(N \cdot D)\) operations.
-
Stage I (\(t = 1\) to \(t_{\text {max}}/2\)): Each individual undergoes a global update based on Lévy flights and, with some probability, a local search using two random solutions. Both operations are \(\mathscr {O}(D)\) per individual per iteration, resulting in \(\mathscr {O}(N \cdot D)\) per iteration.
-
Stage II (\(t = t_{\text {max}}/2 + 1\) to \(t_{\text {max}}\)): The population is divided into two segments. One-half uses GWO-based updates (involving three directional updates and averaging), while the other-half uses a PSO-based update with adaptive inertia weights. Each of these update mechanisms requires \(\mathscr {O}(D)\) operations per individual per iteration.
Combining all stages, the total computational complexity of the GPC algorithm is as follows.
Comparison with baseline algorithms
To contextualize the computational efficiency of the proposed GPC algorithm, we compare its complexity with those of the canonical CS, PSO and GWO, as
-
CS involves Lévy flight-based position updates and optional random walk-based local search, both operating in D dimensions. The total complexity is:
$$\begin{aligned} \mathscr {O}(t_{\text {max}} \cdot N \cdot D) \end{aligned}$$(47) -
PSO updates each particle’s velocity and position based on personal and global best positions. Each update involves D-dimensional operations:
$$\begin{aligned} \mathscr {O}(t_{\text {max}} \cdot N \cdot D) \end{aligned}$$(48) -
GWO updates the position of each individual based on three leading solutions (\(\alpha\), \(\beta\), \(\delta\)), requiring three vector operations per update:
$$\begin{aligned} \mathscr {O}(t_{\text {max}} \cdot N \cdot D) \end{aligned}$$(49)
Although all four algorithms share the same asymptotic complexity of \(\mathscr {O}(t_{\text {max}} \cdot N \cdot D)\), the proposed GPC algorithm incurs higher constant factors due to its dual-phase architecture and hybridization strategy. Specifically, GPC integrates the Lévy flight exploration of CS, the leader-based exploitation of GWO, and the adaptive velocity-driven convergence of PSO. This structured combination leads to increased per-iteration operations, but significantly improves the algorithm’s ability to balance exploration and exploitation. Therefore, despite similar theoretical complexity, GPC achieves superior performance in diverse and complex optimization scenarios leveraging richer update dynamics.
Results and discussion
This section demonstrates the experimental results to show the effectiveness of the hybrid algorithm (GPC) proposed in this paper. This section is divided into three subsections. In the \(I^{st}\) subsection, details of the test suite and parameter settings of all MH algorithms used for comparative analysis are discussed. In the next subsection, the performance of the GPC algorithm is determined by performing experiments on the numerical optimization challenges of CEC 2019. The results of the GPC optimization algorithm are compared with the other MH optimization such as BWOA65, CDO58, COA59, FPA66, HHO60, YDSE55, ZOA51, ARNMRA67, FROBLGJO68, and jDE10069. In the third subsection, GPC is applied for parameter extraction of PEMFC models (Temasek, NedStack PS6, Ballard MarkV, and BCS 500W PEMFC model). The effectiveness of the GPC algorithm is compared with various well-recognized MH algorithms, including ZOA51, SCHO52, PSA53, SABO54, YDSE55, EDO56, RIME57, CDO58, COA59, HHO60, and GWO61.
Test suite and parameter settings
The implemented Algorithm (GPC) has been executed using the MATLAB R2023b software environment. The computational experiments have been conducted on a laptop equipped with an Intel\(\text{\textregistered}\) Core (TM) i5-12500H operating system at a clock speed of 2.50 GHz, x64-based processor, 64-bit operating system, along with 16 GB of RAM with the Windows 11 operating system. In this subsection, the effectiveness of the proposed GPC algorithm in relation to the benchmark challenges of CEC 2019, and real-world challenge (Parameter Extraction of PEMFC models) is evaluated. The present study tests the effectiveness of the proposed GPC algorithm compared to several MH algorithms such as BWOA65, CDO58, COA59, FPA66, HHO60, YDSE55, and ZOA51 on benchmark challenges (CEC 2019). For real-world challenges (parameter extraction of PEMFC models), the GPC algorithm is tested and compared with several MH algorithms, including ZOA51, SCHO52, PSA53, SABO54, YDSE55, EDO56, RIME57, CDO58, COA59, HHO60, and GWO61. The parameter settings for all algorithms were obtained from their respective papers and are displayed in Table 2.
The CEC 2019 benchmark challenges
The effectiveness and efficiency of the proposed GPC optimization algorithm are tested on CEC 2019 benchmark challenges by statistically measuring the mean values, as well as standard deviation (Std), and comparing them with those obtained with other MH algorithms. Seven MH optimization algorithms such as CDO58, COA59, BWOA65, FPA66, HHO60, YDSE55 and ZOA51 were utilized to evaluate and compare the outcomes achieved by the proposed GPC optimization algorithm. To ensure a fair comparison between GPC and other algorithms, all are subjected to population size of 50 as well as the maximum number of iterations = 500 with 51 runs.
The results presented in Table 3 show that, for challenge \(GPC_{1}\), the FROBLGJO algorithm exhibits outstanding results compared to other MH algorithms. The results for challenges \(GPC_{2}\), \(GPC_{3}\), \(GPC_{4}\), \(GPC_{5}\), \(GPC_{7}\), and \(GPC_{9}\), the outcomes obtained from the GPC algorithm demonstrate superior results compared to other MH techniques in terms of mean as well as Std values. The outcomes obtained for challenges \(GPC_{6}\), \(GPC_{8}\), and \(GPC_{10}\), the ZOA algorithm shows outstanding performance compared to the other MH methods. Therefore, based on the results obtained from the experimentation, it can be observed that of the 10 numerical test challenges, the GPC algorithm shows effectiveness in solving 6 challenges. The ZOA algorithm has shown competence in addressing three challenges, but the FROBLGJO method has been successful in addressing only one challenge. The analysis indicates that the GPC algorithm has superior performance in addressing the numerical challenges of CEC 2019. Therefore, it can be concluded that the GPC optimization algorithm is generally the most effective algorithm to address these challenges.
Statistical testing:
Furthermore, two statistical tests, the Friedman rank test and the Wilcoxon rank sum test, have been employed in statistical analysis. The statistical results for each test challenge are presented as loss(l), win(w), or tie(t). Here, “win” (w) is used to represent a scenario in which the test algorithm outperforms the GPC algorithm and is denoted by the symbol “+”. On the other hand,, the term “loss” (l) refers to a scenario in which the test algorithm performs worse than the GPC algorithm and is denoted by the symbol “-”. The symbol “=” is used to indicate a tie (t), indicating that both algorithms are statistically similar in relation to each other. The ranking of all algorithms is shown in the third row of Table 3 for every challenge, denoted by w/l/t. Furthermore, the f-rank is determined for every function, and subsequently, the mean of all rankings is given. Every algorithm has received a distinct ranking according to its performance. The mean rank of each algorithm is shown in the \(2^{nd}\) last row of Table 3. In addition, an overall f-rank has been computed based on the outcomes of all challenges, displayed in Table 3. The table indicates that the GPC technique has been the most effective, achieving the highest rank (\(1^{st}\)) among all tested MH algorithms.
Convergence profile, Boxplot and Radar profile Analysis: This subsection displays the convergence, boxplot, and radar profiles of eight MH optimization algorithms such as ZOA, CDO, COA, FPA, BWOA, HHO, YDSE, and GPC. Figures 5, 6, and 7 demonstrate graphic representations. The GPC algorithm exhibits faster convergence for challenges, \(GPC_{2}\), \(GPC_{3}\), \(GPC_{4}\), \(GPC_{5}\), \(GPC_{7}\), and \(GPC_{9}\), and are shown in Fig. 5a–i, as well as 5j, respectively. Figure 6 shows the box plot that represents the fitness values of the COA, YDSE, CDO, HHO, ZOA, FPA, BWOA, and GPC optimization algorithms. The findings indicate that the proposed GPC algorithm is economically efficient regarding fitness values, shown by its significantly low median fitness value. This can be observed from the box plots presented in Fig. 6a–j, respectively. Furthermore, the radar plot in Fig. 7 shows the ranking of the 12 MH optimization algorithms on the CEC2019 test function. The GPC exhibits a smaller darkening area in comparison to the other MH optimization algorithms. This is visible from the radar charts Fig. 7a–k, respectively. The above outcomes demonstrate the performance of the GPC algorithm.

Convergence profiles for the CEC 2019 numerical challenges of FPA, ZOA, COA, BWOA, YDSE, HHO, CDO, and GPC MH algorithms.

Boxplot profiles for the CEC 2019 numerical challenges for FPA, ZOA, COA, BWOA, YDSE, HHO, CDO, and GPC MH algorithms.

Radar plot for the CEC 2019 numerical challenges of FPA, ZOA, COA, BWOA, YDSE, HHO, CDO, and GPC MH optimization algorithms.
Quantative analysis of GPC algorithm
In this section, we perform a qualitative and quantitative analysis of the GPC algorithm. We are using a set of seven classical benchmark problems62, as given in Table 4.
The evaluation of the proposed algorithm uses a set of informative visualization graphs that collectively provide a comprehensive understanding of its search behavior and performance. The exploration–exploitation balance plot tracks how the algorithm transitions from global exploration to local exploitation over the course of iterations. The convergence graph (on a logarithmic fitness scale) illustrates how quickly and effectively the algorithm minimizes the objective function, offering insight into its optimization speed and stability. The fitness distribution plot captures the spread and concentration of fitness values throughout the population, revealing how diversity evolves during the search. Principal Component Analysis (PCA) trajectories visualize the movement of the population in the reduced-dimensional solution space, highlighting patterns in search directionality and convergence. Lastly, the agent-wise fitness plot shows the performance of the individual agents in iterations, indicating how the population collectively approaches optimal solutions.
From the results in Fig. 8, the proposed GPC algorithm shows robust and adaptive performance. The exploration–exploitation plots confirm that GPC maintains diversity early on and shifts to focused search later, preventing premature convergence. The convergence curves show a consistent reduction in fitness values, suggesting effective optimization over time. The fitness distribution plots reveal that GPC encourages both competition and refinement within the population, with the spread narrowing as better solutions dominate. The PCA trajectories exhibit structured movement toward specific regions in the search space, reflecting guided and non-random exploration. Finally, agent-wise fitness trends indicate population-level improvement and strong convergence toward high-quality solutions. Together, these observations affirm that GPC is well-equipped to handle complex, high-dimensional optimization problems with both efficiency and stability.

Quantitative analysis of GPC.
Results on parameter extraction of PEMFC models
In this section, we address the parameter extraction challenges of four distinct PEMFC models utilizing the GPC algorithm to perform a comprehensive performance analysis of the proposed GPC algorithm. The decision to integrate these three algorithms was driven by their complementary strengths in addressing the two-fold challenge inherent in PEMFC parameter estimation: (1) Navigating a complex, high-dimensional and multimodal error surface and (2) achieving precise convergence to the true parameters while avoiding premature stagnation. The parameters that require extraction in the model mentioned above have been listed in Table 5 74li2020accurate84,85. In addition, this table clearly represents the upper as well as lower limits for each parameter. The traditional Ballard Mark V, NedStack PS6 PEMFC model, Temasek, and the BCS 500 W PEMFC model, with their datasheets shown in Table 625,83,84,85. The other Statistical error tests such as SSE (Minimum , mean, and standard deviation (Std)), IAE, MBE, MAE, MSE, and RMSE values for all four PEMFC stacks are presented in Table 7.
To evaluate the performance of the GPC algorithm, several well-recognized MHA are compared, including ZOA51, SCHO52, PSA53, SABO54, YDSE55, EDO56, RIME57, CDO58, COA59, HHO60, and GWO61. To ensure a fair comparison between GPC and other algorithms, all are subjected to the population size (P= 50) and the maximum number of iterations (T = 400) with 30 runs.
NedStack PS6 PEMFC model
The effectiveness of the GPC algorithm is demonstrated using a commonly highlighted PEMFC (NedSstack PS6) in existing literature, with a rated power of 6kW. The data specifications and upper and lower limits are presented in Tables 6 and 5. The experimental Power (\(P_{exper}\)), experimental voltage (\(V_{exper}\)), estimated voltage (\(V_{estimat}\)), model-estimated power (\(P_{estimat}\)), and IAE values obtained by the GPC algorithm for NedStack PS6 PEMFC 8. The optimal parameter outcomes determined by different algorithms for the NedSstack PS6 stack are presented in Table 9. Table 9 show that when considering the same function evaluations, certain methods, such as ZOA51, SCHO52, PSA53, SABO54, YDSE55, EDO56, RIME57, CDO58, COA59, HHO60, and GWO61, achieve a range of optimal SSE values. However, the GPC algorithm obtains the lowest SSE value (2.26768E + 00) for the NedSstack PS6 PEMFC stacks. This gives further confirmation that the parameter values obtained by the proposed GPC algorithm are very precise and reliable. Figure 9a clearly shows that the model curves (IV) closely align with the experimental data for NedStack PS6, and there is little variation between them.
Furthermore, the curves of the PEMFC model (PI) are shown in Fig. 9b, which provides additional evidence that the GPC algorithm is accurate in analyzing the parameters of the NedStack PS6 PEMFC. Temperature variations are simulated at four different temperatures: 303, 323, 343, and 353K are presented in Fig. 10a and b for the I-P and I-V curves, respectively. These simulations are carried out under constant partial pressures (that is, \(P_{H2}\) / \(P_{O2}\) = 1.000 / 1.000 (bar)). It has been observed that as the temperature rises, there is an increase in the output voltage of the stack. Figure 11a and b illustrate the model curves stated in terms of the I-P and I-V curves. Initially, the I-P and I-V curves are graphed at pressures (\(P_{H2}\)/ \(P_{O2}\)) of 1.000/1.000, 2.000/1.500, 3.000/2.000 and 4.000/2.500 bar, respectively. These measurements were taken at a constant stack temperature of 343 K and are shown in Figure 11a and b respectively. When the supply pressures of the (\(P_{H2}\)/ \(P_{O2}\)) increase, there is an observed enhancement in the output voltage of the stack. Using a similar simulation environment, Figure 12, illustrates the average convergence curves of 400 iterations of the proposed GPC, ZOA, SCHO, PSA, SABO, YDSE, EDO, RIME, CDO, COA, HHO, and GWO for the NedStack PS6 PEMFCs stack. Figure 13 shows the ranges of the final objective function values after 30 runs of the GPC, ZOA, SCHO, PSA, SABO, YDSE, EDO, RIME, CDO, COA, HHO, and GWO algorithms for the extraction of parameters from the NedStack PS6 PEMFCs stack. Based on the size of the box and the number of outliers, it is evident from Fig. 13 that the proposed GPC algorithm outperforms the other 11 algorithms. The results of the Friedman ranking test are given in Table 10. The Friedman test assesses algorithms based on their overall performance, with GPC achieving the highest average rank of 2.103926. Table 10, clearly indicates that the GPC algorithm has achieved the highest ranking (\(I^{st}\) rank). The Wilcoxon ranking test results indicate that GPC significantly outperforms the others, evidenced by 465 winner, no losses, and minimal p-values ranging from 2.03E–07 to 3.02E–11. The Friedman and Wilcoxon ranking test clearly demonstrates that the GPC algorithm is superior in terms of precision as well as accuracy compared to the MH algorithms.

Model curves of NedStack PS6 PEMFC stack.

NedStack PS6 stack performance plots based on GPC algorithm parameters extraction under different operating conditions.

NedStack PS6 stack performance plots based on GPC algorithm parameters extraction under different operating conditions.

The convergence curves obtained from 400 iterations and 30 runs of 12 algorithms utilized to NedStackPS6 PEMFC stack parameter extraction.

The boxplot curves obtained 30 runs of 12 algorithms utilized to NedStackPS6 PEMFC stack parameter extraction.
Ballard Mark V
The Ballard mark V PEMFC stack comprises 35 individual cells that are connected in series with a membrane thickness of 178 \(\mu\)m. The upper and lower limits and data specifications and are presented in Tables 5 and 6. The experimental Power (\(P_{exper}\)), experimental voltage (\(V_{exper}\)), estimated voltage (\(V_{estimat}\)), model-estimated power (\(P_{estimat}\)), and IAE values obtained by the GPC algorithm for Ballard Mark V PEMFC 11. The GPC, ZOA, SCHO, PSA, SABO, YDSE, EDO, RIME, CDO, COA, HHO, and GWO, MH optimization algorithms have been utilized in order to achieve optimal parameter extraction for this model. The resulting values, which have been found to be the best according to the SSE objective, have been organized and presented in Table 15. From this table, the GPC shows superior performance along with the lowest objective function (SSE) value of 0.813912 compared to other MH algorithms. Figure 14a and b clearly demonstrate that the model curves (I-V as well as I-P curves) closely align with the experimental data for the Ballard Mark V PEMFC stack and there is little variation between them. This gives further confirmation that the parameter values obtained by the proposed GPC algorithm are very precise and reliable.
Furthermore, the temperature variations are simulated at four different temperatures: 303, 323, 343, and 353K with constant partial pressures (that is, \(P_{H2}\) / \(P_{O2}\) = 1.000 / 1.000 (bar)) are shown in Fig. 15a and b for the I-P and I-V curves, respectively Table 12. It has been observed that as the temperature rises, there is an increase in the output voltage of the stack. The pressure variations are then simulated at four different temperatures: (\(P_{H2}\)/ \(P_{O2}\)) of 1.000/1.000, 2.000/1.500, 3.000/2.000 and 4.000/2.500 bar with constant temperature (ie 343K) are shown in Fig. 16 (16a and b) for I-P and I-V curves, respectively. When the supply pressures of the (\(P_{H2}\)/ \(P_{O2}\)) increase, an enhancement is observed in the output voltage of the stack. Using the same simulation environment, Fig. 17, shows the convergence curves obtained from 400 iterations and 30 runs of 12 algorithms (GPC, ZOA, SCHO, PSA, SABO, YDSE, EDO, RIME, CDO, COA, HHO and GWO) used to extract the parameters of the Ballard Mark V PEMFC stack. Figure 18 illustrates the box plot curves obtained from 30 runs of the GPC, ZOA, SCHO, PSA, SABO, YDSE, EDO, RIME, CDO, COA, HHO and GWO algorithms utilized to extract the parameters from the Ballard Mark V PEMFC stack. Based on the size of the box and the number of outliers, it is evident from Fig. 18 that the proposed GPC algorithm outperforms the other 11 algorithms. Table 13 presents the Friedman and Wilcoxon rank test of various MH algorithms for the Ballard Mark V PEMFC stack. The Friedman test assesses algorithms based on their overall performance, with GPC achieving the highest average rank of 1.856791. From Table 13, it is clearly observed that the GPC algorithm has achieved the highest rank (\(I^{st}\)). The Wilcoxon ranking test results indicate that GPC significantly outperforms the others, evidenced by 465 winner, no losses, and minimal p-values 3.02E–11. The Friedman and Wilcoxon ranking test clearly demonstrates that the GPC algorithm is superior in terms of precision and accuracy compared to the MH algorithms.

Model curves of Ballard Mark V PEMFC stack.

Ballard Mark V stack performance plots based on GPC algorithm parameters extraction under different operating conditions.

Ballard Mark V stack performance plots based on GPC algorithm parameters extraction under different operating conditions.

The convergence curves obtained from 400 iterations and 30 runs of 12 algorithms utilized to Ballard Mark V PEMFC stack parameter extraction.

The boxplot curves obtained from 30 runs of 12 algorithms utilized to Ballard Mark V PEMFC stack parameter extraction.
BCS 500 W
The BCS 500-W PEMFC stack operates at a power output of 500 watts as well as current of 30 amperes. The specifications of the BCS 500-W PEMFC stack are presented in Table 6 and can be found in90,91. The experimental Power (\(P_{exper}\)), experimental voltage (\(V_{exper}\)), the estimated voltage (\(V_{estimat}\)), model-estimated power (\(P_{estimat}\)), and IAE values obtained by the GPC algorithm for the BCS500-W PEMFC 14. In addition, Table ?? presents the optimal values of the unknown parameters of the BCS 500-W PEMFC stack obtained by the GPC algorithm and compared to the other MH optimization algorithm. Also, the GPC algorithm obtained the lowest objective function (SSE) value (0.011699). This clearly shows its significant superiority compared to the other MH optimization algorithms reported in the literature. This illustrates that an accurate representation of the BCS 500-W PEMFC stack has been achieved. Figure 19a and b clearly illustrate that the model curves (I-V and I-P curves) closely align with the experimental data for the BCS500-W PEMFC stack, and there is little variation between them. The convergence curves have been obtained from 400 iterations and 30 runs of 12 algorithms utilized to extract parameter values from the BCS500-W PEMFC stack. Figure 22 illustrates the convergence curve of the objective function. Here, it is clear that the convergence curve is continuous and rapidly reaches its final value.
Furthermore, the simulation results of the GPC algorithm-based PEMFC model have been obtained in varying temperature and pressure scenarios. Figure 20a and b display the I-P and I-V characteristics of this PEMFC model at different temperatures (303, 323, 333, and 353 K). The pressures \(P_{H2}\)/ \(P_{O2}\) have been kept constant (1.000/0.2075 (bar)). It is clear that the voltage as well as the power of the PEMFC increase as the temperature of the PEMFC increases. Furthermore, Fig. 21a and b show the PI and PI characteristics of this PEMFC model at different pressures (1.000 / 0.21075, 1.5 / 1, and 2.5 / 1.000 bar) and maintained constant temperature (333K). It is significant to note that an increase in the \(P_{H2}\) / \(P_{O2}\), results in an increase in the voltage and power output of the PEMFC. As a result, these pressures can be precisely adjusted to achieve the desired output power from the PEMFC according to particular environmental conditions. Friedman and Wilcoxon rank tests of various MH algorithms for BCS500-W PEMFC are given in Table 16. From Table 16 and box plots in Fig. 23, it is clearly seen that the GPC algorithm obtained the lowest Friedman rank (1.970593), and based on the Friedman rank, the GPC algorithm achieved \(\hbox {I}^{st}\) rank. The Wilcoxon ranking test results indicate that GPC significantly outperforms the others, evidenced by 465 winner, no losses, and minimal p-values ranging from 3.02E–11 to 4.50E–11. The Friedman and Wilcoxon ranking test clearly demonstrates that the GPC algorithm is superior in terms of precision and accuracy compared to the MH algorithms.

Model curves of BCS500-W PEMFC stack.

BCS 500 W stack performance plots based on GPC algorithm parameters extraction under different operating conditions.

BCS 500 W stack performance plots based on GPC algorithm parameters extraction under different operating conditions.

The convergence curves corresponding to BCS500-W PEMFC stack parameter extraction.

The boxplot curves obtained from 30 runs of 12 algorithms utilized to BCS500-W PEMFC stack parameter extraction.
Temasek Stack
The Temasek Stack PEMFC stack comprises 20 individual cells that are connected in series with a membrane thickness of 51 \(\mu\)m85. The upper and lower limits and data specifications and are given in Tables 5 and 6. The experimental Power (\(P_{exper}\)), experimental voltage (\(V_{exper}\)), estimated voltage (\(V_{estimat}\)), model-estimated power (\(P_{estimat}\)), and IAE values obtained by the GPC algorithm for Temasek PEMFC are displayed in Table 17. The GPC, ZOA, SCHO, PSA, SABO, YDSE, EDO, RIME, CDO, COA, HHO, and GWO, MH optimization algorithms have been used in order to achieve optimal parameter extraction for this model. The resulting values, which have been found to be the best according to the SSE objective, have been organized and displayed in Table 18. From this table, the GPC shows superior performance along with the lowest objective function (SSE) value of 0.12327677 compared to other MH algorithms. Figure 24a and b clearly illustrate that the model curves (I-V as well as I-P curves) closely align with the experimental data for the Temasek Stack PEMFC stack and there is little variation between them. This gives further confirmation that the parameter values obtained by the proposed GPC algorithm are very precise and reliable.
Furthermore, temperature variations are simulated at four different temperatures: 303, 323, 333, and 353K are shown in Fig. 25a and b for I-P and I-V curves, respectively. These simulations are carried out under constant partial pressures (that is, \(P_{H2}\) / \(P_{O2}\) = 0.5 / 0.5 (bar)). It has been observed that as the temperature rises, there is an increase in the output voltage of the stack. Initially, the I-P and I-V curves are graphed at pressures (\(P_{H2}\)/ \(P_{O2}\)) of 1.000/0.2075, 1.5/1.000, and 2.500/1.500 bar, respectively. These measurements were taken at a constant stack temperature of 323 K and are presented in Fig. 26a and b respectively. When the supply pressures of the (\(P_{H2}\)/ \(P_{O2}\)) increase, there is an observed increase in the output voltage of the stack. Using the same simulation environment, Fig. 27, shows the convergence curves obtained from 400 iterations and 30 runs of 12 algorithms (GPC, ZOA, SCHO, PSA, SABO, YDSE, EDO, RIME, CDO, COA, HHO and GWO) used to extract the parameters of the Temasek PEMFC stack.

Model curves of Temasek PEMFC stack.

Temasek PEMFC stack performance plots based on GPC algorithm parameters extraction under different operating conditions.

Temasek PEMFC stack performance plots based on GPC algorithm parameters extraction under different operating conditions.

The convergence curves obtained from 400 iterations and 30 runs of 12 algorithms utilized to Temasek PEMFC stack parameter extraction.
Figure 28 shows the box plot curves obtained from 30 runs of the GPC, ZOA, SCHO, PSA, SABO, YDSE, EDO, RIME, CDO, COA, HHO and GWO algorithms used to extract the parameters from the Temasek PEMFC stack. Based on the size of the box and the number of outliers, it is clear from Fig. 28 that the proposed GPC algorithm outperforms the other 11 algorithms. Table 19 presents the Friedman and Wilcoxon rank test of various MH algorithms for the Temasek PEMFC stack. From Table 16 it is clearly seen that the GPC algorithm obtained the lowest Friedman rank (2.503926), and based on the Friedman rank, the GPC algorithm achieved \(\hbox {I}^{st}\) rank. The Wilcoxon ranking test results indicate that GPC significantly outperforms the others, evidenced by 465 winner, no losses, and minimal p-values < 0.05 in all cases. The Friedman and Wilcoxon ranking test clearly demonstrates that the GPC algorithm is superior in terms of precision and accuracy compared to the MH algorithms.

The boxplot curves obtained from 30 runs of 12 algorithms utilized to Temasek PEMFC stack parameter extraction.
Conclusions
This paper presents a novel multi-hybrid optimization algorithm, known as the hybrid Gray Particle Cuckoo (GPC) algorithm, to identify unknown parameters of the PEMFC stack. Determining the values of the unknown model parameters (\(\xi _a\), \(\xi _b\), \(\xi _c\), \(\xi _d\), \(R_{con}\), \(\lambda\), and \(\beta\)) is a crucial subject in the discipline of PEMFC research. However, the complex nature of the PEMFC system makes it a very difficult challenge. Four different commercial PEMFCs (BCS500-W, Ballard Mark V, NedStack PS6, and Temasek Stack) were examined to determine their unknown parameters utilizing the GPC algorithm. The precision of the GPC algorithm was validated by the precise correlation between the results derived from the estimated and experimentally observed results. Statistical analysis, such as SSE (minimum, mean, and std.), IAE, MBE, MAE, MSE, and RMSE has been performed to demonstrate the superiority of the GPC algorithm compared to the other 11 MH optimization algorithms (ZOA, SCHO, PSA, SABO, YDSE, EDO, RIME, CDO, COA, HHO, and GWO). The objective function has been implemented as the SSE between the estimated and experimental voltage values, and the fitness values for the four PEMFC stacks (BCS500-W, Ballard Mark V, NedStack PS6 and Temasek) are 0.011699, 0.813912, 2.267687, and 0.123276775, respectively, using the GPC algorithm. In addition, all test cases undergo a thorough evaluation of the effects of altering the input operating parameters of the PEMFCs, such as temperature and supply pressures. In addition to the PEMFC extraction challenges, the performance of the proposed algorithm has been tested using the CEC 2019 challenges, and the results achieved by the GPC algorithm have been compared with other MH optimization algorithms (FPA, BWOA, FROBLGJO, CDO, COA, HHO, ZOA, ARNMRA, YDSE, as well as jDE100) to demonstrate its superiority. Additionally, a nonparametric test analysis (Friedman and Wilcoxon signed rank test), as well as the box plot, has been performed to verify the precision and reliability of the GPC algorithm compared to existing algorithms, and it is clear that the GPC algorithm is superior.
The performance variability of GPC in different benchmarks and PEMFC datasets can be attributed to the interaction between the internal dynamics of the algorithm and the inherent characteristics of the datasets themselves. In cases where the landscape of the underlying parameters is highly multimodal, with numerous local optima, GPC tends to outperform standalone algorithms due to its phase-wise integration of exploration and exploitation strategies. Early stage Lévy flights from CS help escape deceptive basins, while the guided search of GWO and the convergence strength of PSO allow for effective refinement. This layered adaptability is particularly effective in data sets with non-linear interdependencies and irregular error surfaces. However, in scenarios where the optimization landscape is relatively smooth or low-dimensional, simpler algorithms with fewer control parameters, such as standard PSO or GWO, may yield comparable or better results due to their lower overhead and faster convergence. Thus, the advantage of GPC becomes more pronounced in complex, noisy, or ill-conditioned datasets, while its performance may converge to baseline methods in well-behaved or low-complexity data sets. This suggests a potential avenue for future work, adapting the degree of hybridization dynamically based on landscape analysis or preliminary fitness landscape sampling.
Future studies should prioritize the validation of the proposed GPC algorithm for different fuel cell technologies, solar photovoltaic parameter extraction, smart grids, and other real-world applications. The GPC algorithm can also be improved for better solution quality by using new equations for exploration and exploitation operations. Other important factors can be the introduction of population size reduction, a memory bank to store previous solutions, and the reduction of computational time for better performance of the proposed GPC algorithm.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request. Funding Statement: We gratefully acknowledge the funding support by program “Excellence initiative—research university” for the AGH University of Kraków, Poland as well as the ARTIQ project: UMO-2021/01/2/ST6/00004 and ARTIQ/0004/2021.
Abbreviations
- FC:
-
Fuel Cell
- PEMFC:
-
Proton Exchange Memberane Fuel Cells
- GWO:
-
Grey wolf optimizer
- PSO:
-
Particle Swarm Optimization
- CS:
-
Cuckoo Search
- SABO:
-
Subtraction Average based Optimizer
- YDSE:
-
Young Double Slit Experiment
- EDO:
-
Exponential Distribution Optimizer
- BWOA:
-
Black Widow Optimization Algorithm
- FROBLGJO:
-
Fast Random Opposition-based Learning Golden jackal optimization
- jDE100:
-
Self-adaptive DE
- ARNMRA:
-
Attraction and Repulsion-based Naked Mole Rat Algorithm
- IHBO:
-
Improved Heap-based Optimizer
- LSA:
-
Lightning Search Algorithm
- STLBO:
-
Simplified Teaching Learning Based Optimization
- AHA:
-
Artificial Hummingbird Algorithm
- RGWO:
-
Repairable Grey Wolf Optimization
- ShSO:
-
Shark Smell Optimize
- MRFO:
-
Manta Rays Foraging Optimizer
- VSDE:
-
Hybrid Vortex Search Differential Evolution
- HBOA:
-
Honey Badger Optimization Algorithm
- IABC:
-
Improved Artificial Bee Colony
- ICA:
-
Imperialist Competitive Algorithm
- FPA:
-
Flower Pollination Algorithm
- TSA:
-
Transient Search Optimization
- DO:
-
Dandelion Optimize
- IFMO:
-
Improved Fish Migration Optimizer
- ABC-DE:
-
Artificial Bee Colony Differential Evolution
- CBO:
-
Chaotically based bonobo optimize
- FOA:
-
Firefly Optimization Algorithm
- SMBOA:
-
Slime Mould based Optimization Algorithm
- ESSA:
-
Enhanced Salp Swarm Algorithm
- HBO:
-
Honey Badger Optimizer
- AGPSO:
-
Autonomous Groups Particle Swarm Optimization
- GTO:
-
Gorilla Troops Optimizer
- EWO:
-
Enhanced Walrus Optimization
- SSO:
-
Salp Swarm Optimizer
- IAEO:
-
Improved Artificial Ecosystem Optimizer
- OOA:
-
Osprey Optimization Algorithm
- NNO:
-
Neural Network Optimizer
- WSO:
-
War Strategy Optimization
- IFMO:
-
Improved Fish Migration Optimizer
- ZOA:
-
Zebra Optimization Algorithm
- PSA:
-
Propagation Search Algorithm
- CDO:
-
Chernobyl Disaster Optimizer
- COA:
-
Coati Optimization Algorithm
- NFLT:
-
No Free-Lunch Theorem
- MH:
-
Meta-heuristic
- CEC:
-
Congress on Evolutionary Computation
- MAE:
-
Mean Absolute Error
- IAE:
-
Individual Absolute Error
- MBE:
-
Mean Bias Error
- MSE:
-
Mean Square Error
- RMSE:
-
Root-Mean Square Error
- TSEs:
-
Total Squared Errors
- SQEs:
-
Sum of Quadratic Errors
- SSE:
-
Sum of Square Error
References
Bakır, H. et al. Forecasting of future greenhouse gas emission trajectory for India using energy and economic indexes with various metaheuristic algorithms. J. Clean. Prod. 360, 131946 (2022).
Rathod, A. A. & Subramanian, B. Scrutiny of hybrid renewable energy systems for control, power management, optimization and sizing: Challenges and future possibilities. Sustainability 14, 16814 (2022).
Mitra, U., Arya, A. & Gupta, S. A comprehensive and comparative review on parameter estimation methods for modelling proton exchange membrane fuel cell. Fuel 335, 127080 (2023).
Yang, B. et al. A critical survey on proton exchange membrane fuel cell parameter estimation using meta-heuristic algorithms. J. Clean. Prod. 265, 121660 (2020).
Saidi, S. et al. Fast and accurate estimation of pemfcs model parameters using a dimension learning-based modified grey wolf metaheuristic algorithm. Measurement 2025, 116917 (2025).
Rathod, A. A., Sharma, P., Choudhary, A., Raju, S. & Subramanian, B. An efficient framework for proton exchange membrane fuel cell parameter estimation using numerous mh algorithms. Renew. Sustain. Energy Rev. 216, 115603 (2025).
Aljaidi, M. et al. Enhanced pemfc parameter estimation using a hybrid gorilla troops optimizer and honey badger algorithm. Comput. Chem. Eng. 2025, 109216 (2025).
Elfar, M. H. et al. Optimal parameters identification for pemfc using autonomous groups particle swarm optimization algorithm. Int. J. Hydrogen Energy 69, 1113–1128 (2024).
Ashraf, H., Abdellatif, S. O., Elkholy, M. M. & El-Fergany, A. A. Honey badger optimizer for extracting the ungiven parameters of pemfc model: Steady-state assessment. Energy Convers. Manage. 258, 115521 (2022).
Bao, S. et al. A new method for optimal parameters identification of a pemfc using an improved version of monarch butterfly optimization algorithm. Int. J. Hydrogen Energy 45, 17882–17892 (2020).
Sultan, H. M., Menesy, A. S., Kamel, S., Selim, A. & Jurado, F. Parameter identification of proton exchange membrane fuel cells using an improved salp swarm algorithm. Energy Convers. Manage. 224, 113341 (2020).
Aljaidi, M. et al. A hybrid snow ablation optimized multi-strategy particle swarm optimizer for parameter estimation of proton exchange membrane fuel cell. Ionics 2025, 1–28 (2025).
Bakır, H. Enhanced artificial hummingbird algorithm for global optimization and engineering design problems. Adv. Eng. Softw. 194, 103671 (2024).
Bakır, H. A novel artificial hummingbird algorithm improved by natural survivor method. Neural Comput. Appl. 36, 16873–16897 (2024).
Bakir, H., Guvenc, U., Kahraman, H. T. & Duman, S. Improved lévy flight distribution algorithm with fdb-based guiding mechanism for avr system optimal design. Comput. Ind. Eng. 168, 108032 (2022).
Bakır, H. Dynamic fitness-distance balance-based artificial rabbits optimization algorithm to solve optimal power flow problem. Expert Syst. Appl. 240, 122460 (2024).
Bakır, H., Duman, S., Guvenc, U. & Kahraman, H. T. Improved adaptive gaining-sharing knowledge algorithm with fdb-based guiding mechanism for optimization of optimal reactive power flow problem. Electr. Eng. 105, 3121–3160 (2023).
Lekouaghet, B., Haddad, M., Benghanem, M. & Khelifa, M. A. Identifying the unknown parameters of pem fuel cells based on a human-inspired optimization algorithm. Int. J. Hydrogen Energy 129, 222–235 (2025).
Yuan, Y. et al. Attack-defense strategy assisted osprey optimization algorithm for pemfc parameters identification. Renew. Energy 225, 120211 (2024).
Abdel-Basset, M., Mohamed, R., Elhoseny, M., Chakrabortty, R. K. & Ryan, M. J. An efficient heap-based optimization algorithm for parameters identification of proton exchange membrane fuel cells model: Analysis and case studies. Int. J. Hydrogen Energy 46, 11908–11925 (2021).
Mohanty, B. et al. Parameters identification of proton exchange membrane fuel cell model based on the lightning search algorithm. Energies 15, 1452. https://doi.org/10.3390/en15217893 (2022).
Abdel-Basset, M., Mohamed, R. & Abouhawwash, M. On the facile and accurate determination of the highly accurate recent methods to optimize the parameters of different fuel cells: Simulations and analysis. Energy 272, 127083 (2023).
Ebrahimi, S. M., Hasanzadeh, S. & Khatibi, S. Parameter identification of fuel cell using repairable grey wolf optimization algorithm. Appl. Soft Comput. 147, 110791 (2023).
Rao, Y., Shao, Z., Ahangarnejad, A. H., Gholamalizadeh, E. & Sobhani, B. Shark smell optimizer applied to identify the optimal parameters of the proton exchange membrane fuel cell model. Energy Convers. Manage. 182, 1–8 (2019).
Selem, S. I., Hasanien, H. M. & El-Fergany, A. A. Parameters extraction of pemfc’s model using manta rays foraging optimizer. Int. J. Energy Res. 44, 4629–4640 (2020).
Sharma, P., Raju, S. & Salgotra, R. An evolutionary multi-algorithm based framework for the parametric estimation of proton exchange membrane fuel cell. Knowl.-Based Syst. 283, 111134 (2024).
Fathy, A., Abd Elaziz, M. & Alharbi, A. G. A novel approach based on hybrid vortex search algorithm and differential evolution for identifying the optimal parameters of pem fuel cell. Renew. Energy 146, 1833–1845 (2020).
Almodfer, R. et al. Improving parameter estimation of fuel cell using honey badger optimization algorithm. Front. Energy Res. 10, 875332 (2022).
Zhang, B. et al. Parameter identification of proton exchange membrane fuel cell based on swarm intelligence algorithm. Energy 283, 128935 (2023).
Kandidayeni, M., Macias, A., Khalatbarisoltani, A., Boulon, L. & Kelouwani, S. Benchmark of proton exchange membrane fuel cell parameters extraction with metaheuristic optimization algorithms. Energy 183, 912–925 (2019).
Priya, K. & Rajasekar, N. Application of flower pollination algorithm for enhanced proton exchange membrane fuel cell modelling. Int. J. Hydrogen Energy 44, 18438–18449 (2019).
Gouda, E. A., Kotb, M. F. & El-Fergany, A. A. Investigating dynamic performances of fuel cells using pathfinder algorithm. Energy Convers. Manage. 237, 114099 (2021).
Hasanien, H. M. et al. Precise modeling of pem fuel cell using a novel enhanced transient search optimization algorithm. Energy 247, 123530 (2022).
Mujeer, S. A., Chandrasekhar, Y., Kumari, M. S. & Salkuti, S. R. An accurate method for parameter estimation of proton exchange membrane fuel cell using dandelion optimizer. Int. J. Emerg. Electr. Power Syst. 2023, 2563 (2023).
Issa, M., Elaziz, M. A. & Selem, S. I. Enhanced hunger games search algorithm that incorporates the marine predator optimization algorithm for optimal extraction of parameters in pem fuel cells. Sci. Rep. 15, 4474 (2025).
Singla, M. K. et al. Revolutionizing proton exchange membrane fuel cell modeling through hybrid aquila optimizer and arithmetic algorithm optimization. Sci. Rep. 15, 5122 (2025).
Aljaidi, M. et al. A novel parrot optimizer for robust and scalable pemfc parameter optimization. Sci. Rep. 15, 11625 (2025).
Hachana, O. & El-Fergany, A. A. Efficient pem fuel cells parameters identification using hybrid artificial bee colony differential evolution optimizer. Energy 250, 123830 (2022).
Fathy, A., Rezk, H., Alharbi, A. G. & Yousri, D. Proton exchange membrane fuel cell model parameters identification using chaotically based-bonobo optimizer. Energy 268, 126705 (2023).
Saidi, S. et al. Precise parameter identification of a pemfc model using a robust enhanced salp swarm algorithm. Int. J. Hydrogen Energy 71, 937–951 (2024).
Abd Elaziz, M., Abualigah, L., Issa, M. & Abd El-Latif, A. A. Optimal parameters extracting of fuel cell based on gorilla troops optimizer. Fuel 332, 126162 (2023).
Alqahtani, A. H., Hasanien, H. M., Alharbi, M. & Chuanyu, S. Parameters estimation of proton exchange membrane fuel cell model based on an improved walrus optimization algorithm. IEEE Access 2024, 562 (2024).
Rizk-Allah, R. M. et al. Artificial ecosystem optimizer for parameters identification of proton exchange membrane fuel cells model. Int. J. Hydrogen Energy 46, 37612–37627 (2021).
Yuan, K., Ma, Y., Zhang, H., Razmjooy, N. & Ghadimi, N. Optimal parameters estimation of the proton exchange membrane fuel cell stacks using a combined owl search algorithm. Energy Sourc. Part A: Recov. Utiliz. Environ. Effects 45, 11712–11732 (2023).
Ayyarao, T. L., Polumahanthi, N. & Khan, B. An accurate parameter estimation of pem fuel cell using war strategy optimization. Energy 2024, 130235 (2024).
Zhou, J. et al. Improved fish migration optimization method to identify pemfc parameters. Int. J. Hydrogen Energy 48, 20028–20040 (2023).
Khajuria, R., Sharma, P., Kumar, R., Lamba, R. & Raju, S. Efficient parameter extraction for accurate modeling of pem fuel cell using ali-baba and forty thieves algorithm. Multiscale Multidiscipl. Model. Exp. Design 8, 1–26 (2025).
Liu, E.-J. & Cheng, J.-C. Parameter identification and sensitivity analysis of pem fuel cell systems via puma optimizer. Energy Rep. 13, 6328–6348 (2025).
Salgotra, R., Sharma, P. & Raju, S. A multi-hybrid algorithm with shrinking population adaptation for constraint engineering design problems. Comput. Methods Appl. Mech. Eng. 421, 116781 (2024).
Wolpert, D. H. & Macready, W. G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1, 67–82 (1997).
Trojovská, E., Dehghani, M. & Trojovskỳ, P. Zebra optimization algorithm: a new bio-inspired optimization algorithm for solving optimization algorithm. IEEE Access 10, 49445–49473 (2022).
Bai, J. et al. A sinh cosh optimizer. Knowl.-Based Syst. 282, 111081 (2023).
Qais, M. H., Hasanien, H. M., Alghuwainem, S. & Loo, K. H. Propagation search algorithm: a physics-based optimizer for engineering applications. Mathematics 11, 4224 (2023).
Trojovskỳ, P. & Dehghani, M. Subtraction-average-based optimizer: a new swarm-inspired metaheuristic algorithm for solving optimization problems. Biomimetics 8, 149 (2023).
Abdel-Basset, M., El-Shahat, D., Jameel, M. & Abouhawwash, M. Young’s double-slit experiment optimizer: a novel metaheuristic optimization algorithm for global and constraint optimization problems. Comput. Methods Appl. Mech. Eng. 403, 115652 (2023).
Abdel-Basset, M., El-Shahat, D., Jameel, M. & Abouhawwash, M. Exponential distribution optimizer (edo): a novel math-inspired algorithm for global optimization and engineering problems. Artif. Intell. Rev. 2023, 1–72 (2023).
Su, H. et al. Rime: A physics-based optimization. Neurocomputing 532, 183–214 (2023).
Shehadeh, H. A. Chernobyl disaster optimizer (cdo): a novel meta-heuristic method for global optimization. Neural Comput. Appl. 35, 10733–10749 (2023).
Dehghani, M., Montazeri, Z., Trojovská, E. & Trojovskỳ, P. Coati optimization algorithm: a new bio-inspired metaheuristic algorithm for solving optimization problems. Knowl.-Based Syst. 259, 110011 (2023).
Heidari, A. A. et al. Harris hawks optimization: algorithm and applications. Futur. Gener. Comput. Syst. 97, 849–872 (2019).
Mirjalili, S., Mirjalili, S. M. & Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 69, 46–61 (2014).
Salgotra, R., Sharma, P., Raju, S. & Gandomi, A. H. A contemporary systematic review on meta-heuristic optimization algorithms with their matlab and python code reference. Arch. Comput. Methods Eng. 2023, 1–74 (2023).
Price, K., Awad, N., Ali, M. & Suganthan, P. The 2019 100-digit challenge on real-parameter, single-objective optimization: analysis of results. nanyang technological university. Tech. Rep., Singapore, Technical Report. http://www. ntu. edu. sg/home/epnsugan (2019).
Sharma, P. & Raju, S. Metaheuristic optimization algorithms: a comprehensive overview and classification of benchmark test functions. Soft. Comput. 28, 3123–3186 (2024).
Hayyolalam, V. & Kazem, A. A. P. Black widow optimization algorithm: a novel meta-heuristic approach for solving engineering optimization problems. Eng. Appl. Artif. Intell. 87, 103249 (2020).
Yang, X.-S. Flower pollination algorithm for global optimization. In International conference on unconventional computing and natural computation 240–249 (Springer, 2012).
Singh, S., Singh, U., Mittal, N. & Gared, F. A self-adaptive attraction and repulsion-based naked mole-rat algorithm for energy-efficient mobile wireless sensor networks. Sci. Rep. 14, 1040 (2024).
Mohapatra, S. & Mohapatra, P. Fast random opposition-based learning golden jackal optimization algorithm. Knowl.-Based Syst. 275, 110679 (2023).
Brest, J., Maučec, M. S. & Bošković, B. The 100-digit challenge: Algorithm jde100. In 2019 IEEE congress on evolutionary computation (CEC) 19–26 (IEEE, 2019).
Fathy, A. & Rezk, H. Multi-verse optimizer for identifying the optimal parameters of pemfc model. Energy 143, 634–644 (2018).
Xu, S., Wang, Y. & Wang, Z. Parameter estimation of proton exchange membrane fuel cells using eagle strategy based on jaya algorithm and nelder-mead simplex method. Energy 173, 457–467 (2019).
Khajuria, R., Yelisetti, S., Lamba, R. & Kumar, R. Optimal model parameter estimation and performance analysis of pem electrolyzer using modified honey badger algorithm. Int. J. Hydrogen Energy 49, 238–259 (2024).
Zhang, Z. et al. A novel generalized prognostic method of proton exchange membrane fuel cell using multi-point estimation under various operating conditions. Appl. Energy 357, 122519 (2024).
Korkmaz, S. A. et al. Comparison of various metaheuristic algorithms to extract the optimal pemfc modeling parameters. Int. J. Hydrogen Energy 51, 1402–1420 (2024).
Yang, B. et al. Parameter identification of pemfc via feedforward neural network-pelican optimization algorithm. Appl. Energy 361, 122857 (2024).
Diab, A. A. Z., Abdul-Ghaffar, H. I., Ahmed, A. A. & Ramadan, H. A. An effective model parameter estimation of pemfcs using gwo algorithm and its variants. IET Renew. Power Gener. 16, 1380–1400 (2022).
Sultan, H. M. et al. Optimal values of unknown parameters of polymer electrolyte membrane fuel cells using improved chaotic electromagnetic field optimization. IEEE Trans. Ind. Appl. 57, 6669–6687 (2021).
Gouda, E. A., Kotb, M. F. & El-Fergany, A. A. Jellyfish search algorithm for extracting unknown parameters of pem fuel cell models: Steady-state performance and analysis. Energy 221, 119836 (2021).
Al-Tashi, Q., Rais, H., Abdulkadir, S. J., Mirjalili, S. & Alhussian, H. A review of grey wolf optimizer-based feature selection methods for classification. Evol. Mach. Learn. Techn. Algor. Appl. 2020, 273–286 (2020).
Kennedy, J. & Eberhart, R. Particle swarm optimization. In Proceedings of ICNN’95-international conference on neural networks, vol. 4, 1942–1948 (IEEE, 1995).
Salgotra, R., Singh, U. & Saha, S. New cuckoo search algorithms with enhanced exploration and exploitation properties. Expert Syst. Appl. 95, 384–420 (2018).
Salgotra, R., Singh, U., Saha, S. & Gandomi, A. H. Self adaptive cuckoo search: analysis and experimentation. Swarm Evol. Comput. 60, 100751 (2021).
Li, J. et al. Accurate, efficient and reliable parameter extraction of pem fuel cells using shuffled multi-simplexes search algorithm. Energy Convers. Manage. 206, 112501 (2020).
Singla, M. K. et al. An enhanced efficient optimization algorithm (einfo) for accurate extraction of proton exchange membrane fuel cell parameters. Soft. Comput. 27, 9619–9638 (2023).
Priya, K., Selvaraj, V., Ramachandra, N. & Rajasekar, N. Modelling of pem fuel cell for parameter estimation utilizing clan co-operative based spotted hyena optimizer. Energy Convers. Manage. 309, 118371 (2024).
Rezk, H., Olabi, A., Ferahtia, S. & Sayed, E. T. Accurate parameter estimation methodology applied to model proton exchange membrane fuel cell. Energy 255, 124454 (2022).
Li, N., Zhou, G., Zhou, Y., Deng, W. & Luo, Q. Extracting unknown parameters of proton exchange membrane fuel cells using quantum encoded pathfinder algorithm. Front. Energy Res. 10, 964042 (2022).
El-Fergany, A. A. Electrical characterisation of proton exchange membrane fuel cells stack using grasshopper optimiser. IET Renew. Power Gener. 12, 9–17 (2018).
Fawzi, M., El-Fergany, A. A. & Hasanien, H. M. Effective methodology based on neural network optimizer for extracting model parameters of pem fuel cells. Int. J. Energy Res. 43, 8136–8147 (2019).
El-Fergany, A. A. Extracting optimal parameters of pem fuel cells using salp swarm optimizer. Renew. Energy 119, 641–648 (2018).
Miao, D., Chen, W., Zhao, W. & Demsas, T. Parameter estimation of pem fuel cells employing the hybrid grey wolf optimization method. Energy 193, 116616 (2020).
Chen, Y. & Wang, N. Cuckoo search algorithm with explosion operator for modeling proton exchange membrane fuel cells. Int. J. Hydrogen Energy 44, 3075–3087 (2019).
Funding
Open access funding provided by Óbuda University.
Author information
Authors and Affiliations
Contributions
CrediT Roles: P.S.: Data curation, Writing- Original draft , Software, Validation, Result and Discussion, Real-world Application. R.S.: Conceptualization, Methodology, Formal Analysis, Data curation, Writing- Original draft, Real-world Application, Reviewing and Editing. S. R., S.L., A.H.G.: Supervision, Project administration, Resources, Reviewing and Editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sharma, P., Salgotra, R., Raju, S. et al. Efficient estimation of proton exchange membrane fuel cells parameters using a hybrid swarm intelligent algorithm. Sci Rep 16, 1116 (2026). https://doi.org/10.1038/s41598-025-14297-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-14297-1
