
Abstract
This article proposes a novel framework for intelligent decision support systems based on retrieval augmented generation models and knowledge graphs, in order to overcome the shortcomings of current approaches. Systems Like Mistral 7B, LLaMA-2, and others tend to fail at contextual understanding, transparency, and reasoning over many steps involving many domains. Our proposed architecture combines the strengths of generative models, enhanced by external knowledge retrieval, with structured, linked representations of domain knowledge. With this synergy, we show improvement in decision accuracy, reasoning transparency, and context relevance compared to using either technology alone. The structure has a flexible knowledge orchestration layer that optimizes information exchange between structured representations and generative capabilities. Research conducted on three areas, namely, financial services, healthcare management, and the supply chain has shown that our method performs particularly well when it comes to cross-domain reasoning and ambiguous queries. This study deepens our understanding of knowledge-enhancing artificial intelligence systems as well as offers a roadmap for a next-generation decision support system. The framework is designed to tackle some of the most challenging issues faced by enterprises in making decisions. In particular, it draws from both context and expertise to provide explainable recommendations.
Similar content being viewed by others

Introduction
Presently, organizations are using data to make decisions rather than using feelings because there has been a lot of data. Despite this change, decision-makers still face significant challenges like information overload, data silos, and extracting actionable insights from complex heterogeneous datasets1,2,3. While traditional decision support systems are very useful, they lack the reasoning capabilities and contextual awareness required to deal with the complexity of the business environment. This occurrence is more so the case when one is required to take decisions that cut across domains and need to be made and nuanced understanding of related variables4,5,6,7,8,9,10.
Recent advances in artificial intelligence, particularly in the space of large language models, have shown huge potential for decision support. Nonetheless, when used to deploy in business settings, these models face serious limitations, such as hallucinating information, struggling with domain expertise, and failing to justify their reasoning3,11. These issues expose the need for something bigger and better. We need something that can find a middle ground between generative models and knowledge representation.
Knowledge graphs are becoming popular tools for representing and reasoning about domain knowledge. Knowledge graphs are defined as the combination of semantic technologies and graph structures to create connected representations of entities, the relation between them and their properties4,12,13,14,15. This tool is proficient in modeling complicated domains and supporting inference, thereby providing a structured basis for knowledge-intensive applications. Because they are capable of depicting explicit relationships and allowing for reasoning, they are particularly useful in decision support contexts wherein the relationships between entities are important16,17. Recent developments in the application of knowledge graphs have taken place in domains such as precision medicine in healthcare6,18, and manufacturing systems7,19.
RAG (retrieval-augmented generation), an approach to overcoming limits of large language models by complementing generative artificial intelligence with knowledge retrieved from external sources, has emerged in parallel. RAG architectures have a retrieval component that retrieves relevant information from a knowledge source and a generation component that generates responses based on that information20,21,22,23,24. This approach improves the factual grounding of the generated content, while maintaining the flexibility and natural language capabilities of generative models. The effectiveness of this technique has already been shown on application in specialized fields such as health screening systems8 and academic search engines9,25.
The combination of these two technologies - knowledge graphs retrieval-augmented generation has great potential for building decision support systems that can leverage structured knowledge representations through flexible interactions and reasoning in natural language. Nonetheless, in order to meet this potentiality, serious technical and conceptual challenges have to be identified which can be brought to bear on these fields. New generative Artificial intelligence-driven approaches for metadata modeling and knowledge construction26,27,28,29,30 can significantly reduce manual knowledge engineering effort. However, the automated construction of knowledge graphs and their maintenance comes with serious challenges.
In the founding work of knowledge graph embeddings11,12, it shows the integration of symbolic knowledge through statistical learning. These methods have brought about hybrid intelligence systems that combine structured representation and neural learning. Recent evaluations have been proposed to augment causal reasoning by means of knowledge graphs13 and medical applications of neuro-symbolic systems14. This suggests that there could be a powerful integration of symbolic and neural approaches.
Recent developments in knowledge graph-enhanced retrieval-augmented generation have significantly advanced beyond simple integration approaches. Wu et al. (2025) introduced KG²RAG, demonstrating how knowledge graphs can guide chunk expansion and organization processes to improve retrieval diversity and coherence31. Microsoft’s GraphRAG framework has shown substantial improvements in answering complex queries by using LLM-generated knowledge graphs for better context window population32. Contemporary research has also demonstrated domain-specific applications: manufacturing-focused Document GraphRAG systems that leverage graph-based document structuring33, and healthcare applications like MedRAG that combine knowledge graph-elicited reasoning with retrieval-augmented generation34. However, these approaches primarily focus on domain-specific implementations or single-pathway integration, rather than providing comprehensive architectural frameworks that enable dynamic orchestration between structured and neural reasoning components.
There are still important gaps in the integration of knowledge graphs and retrieval-augmented generation for intelligent decision support systems due to them. Existing methods, so far, do not provide a framework which enables seamless integration of architectures which will utilize the complementary strength of both the technologies without losing out on any benefits of either of them. Moreover, existing systems lack advanced mechanisms for dynamic orchestration of knowledge that is utilizing structured reasoning versus generative reasoning according the context and complexity of the decision. More explicably, one requires a mechanism to decide when to deploy structured reasoning and when to deploy generative reasoning. Further, while both technologies (e.g., causal models and deep learning) can support explanations, joint integration of these approaches to provide multi-level, contextually appropriate explanations is still largely underexplored, especially for causal reasoning applications. Understanding inference paths has become important15.
The paper explains a new framework, which encourages a nexus between knowledge representation as well as natural language inference. The goal of our research is to create a unifying architecture that couples knowledge graphs with retrieval-augmented generation for intelligent decision support. Moreover, we will build adaptive orchestration mechanisms to dynamically choose optimal reasoning paths. Furthermore, we will synthesize multi-level explanations that combine symbolic and natural language approaches. Finally, we will validate the framework in a range of application domains for generalizability and cross-domain reasoning.
Our study makes significant contributions to intelligent decision support systems, which are as follows. We present a systematic architectural framework that brings together structured and generative artificial intelligence approaches through new integration methods. We create a dynamic knowledge orchestration engine that intelligently selects the reasoning pathways considering the characteristics of decisions and context. We think that paths that exhibit symbolic reasoning are worth synthesizing along with their natural language explanations. We provide comprehensive evaluation of financial services, healthcare management, and supply chain optimization. As a result, we see a significant improvement in performance when considering particularly in the case of complex, cross-domain decision-making scenarios.
The rest of the paper is organized as follows: Sect. 2 has our proposed framework, which includes information on the architecture. Section 3 describes the implementational one in three application domains. Section 4 presents our evaluation methodology and results. Section 5 will present the implications, Limitations and future research agenda. Section 6 ends with a summary of contributions and broader implications of intelligent decision support systems.
Proposed framework
The Integrated Knowledge-Enhanced Decision Support framework is an innovative architecture in intelligent decision-making systems that integrates knowledge graphs and retrieval-augmented generation. This framework fills the identified research gaps through five mutually integrated components that benefit from the complementary strengths of structured knowledge representation and generative artificial intelligence approaches. The framework components are presented in Table 1.
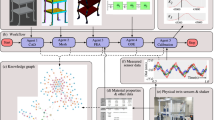
Bidirectional information flow is shown in Fig. 1 through 5 integrated components. The Knowledge Representation Layer provides essential domain knowledge that feeds into the Retrieval Optimization Module for search. The Dynamic Knowledge Orchestration Engine identifies the best paths for reasoning and directs information to the Context-Aware Generation Component for creating responses. The MLES grants clear, comprehensible justifications. Feedback loops allow for continued learning and change in all components.

IKEDS framework architecture.
Knowledge representation layer
The Knowledge Representation Layer enables the domain knowledge with a multi-tier architecture that facilitates both within-domain reasoning and cross-domain integration. The layer implements three tiers of knowledge which are interconnected to form a knowledge ecosystem. The Core Ontology Tier creates domain-independent concepts and relationships and integrates established upper ontologies such as DOLCE and BFO for interoperability. The Domain-Specific Tier encompasses specialized knowledge representations about individual domains. The ontology for each domain enriches the core ontology while preserving its semantics. The Cross-Domain Mapping Tier creates formal relationships and alignment rules that construct explicit semantic bridges between domains. In Fig. 2 we have healthcare entities are shown (Patient, Treatment, Condition, Provider) as nodes connected by relationship edges treats, diagnosed_with and prescribed_by. The color of a node indicates the type of entity it refers to. Blue are nodes for patients, green for treatment, red for conditions, yellow for providers. The thickness of an edge represents the strength of the relationship. The structure is connected to allow for semantic traversal for clinical decision support queries. This demonstrates how knowledge graphs are capable of reasoning about complicated medical relationships.

Healthcare domain knowledge graph visualization.
Addressing semantic drift in hybrid embeddings
To tackle the problem of semantic drift in hybrid embedding techniques, designs that are especially geared toward rare entities, we employ a three-pronged mitigation strategy.
First, equalizing the maximum eigenvalue of the latent variable’s covariance matrix to one guarantees the identifiability of our model. Secondly, the confidence-based weighting will dynamically change the weights of the embeddings based on their addresses’ factor centrality and relation over frequency. Fallback strategies are structural embeddings for when there is not much semantic information, so they will work well for rare concepts, too.
Retrieval optimization module
Incorporating knowledge graph structure into a multi-faceted strategy which synergizes semantic search, structure-aware graph traversal, and logical inference, extends conventional retrieval methods. Through the utilization of dense vector embeddings, semantic search is able to retrieve relevant information. On the other hand, structure-aware traversal employs guided exploration of knowledge graph topology. Logical inference uses any domain rules to make any implicit conclusions. These will be combined using a ranking mechanism that strikes a balance between relevance, confidence and diversity while an adaptive control mechanism sets the optimal retrieval depth.
Dynamic knowledge orchestration engine
The Dynamic Knowledge Orchestration Engine is built to bridge the knowledge orchestration gap. It automatically orchestrates knowledge flow and reasoning. For every decision task, the engine considers five possible paths: execution of pure knowledge graph reasoning, execution of pure retrieval-augmented generation, sequential application of the two, parallel application with fusion, and execution of iterative interaction with feedback loops. The agent was either an agent which, based upon the task at hand and their knowledge, could select a pathway. Through reinforcement learning the learning process is undertaking continuously based on outcomes. The Context-Aware Generation Component goes beyond incorporating structural knowledge into the generation process in a two-phase manner. It integrates knowledge, followed by reasoning-enhanced planning and constrained generation. The integration of knowledge phase synthesizes retrieved elements with those stored in the knowledge graph structure. Generating plans are structured in the planning phase using knowledge graph patterns. The restricted generation stage executes plans that enforce constraints based on the knowledge to maintain truthful and consistent facts. The Multi-Level Explanation Synthesizer addresses the explanation depth gap by generating explanations that integrate symbolic reasoning with natural language explanations through a stratified approach. The synthesizer generates explanations at multiple abstraction levels, from executive summaries to detailed technical explanations, with each level integrating factual evidence, causal relationships, and comparative analysis. A hierarchical constraint system ensures coherence across explanation levels while preventing contradictions.
We design a framework for solving semantic conflicts in order to solve ontology alignment issues. Multi-criteria alignment scoring uses semantic, structural and functional similarity measures to create strong mappings between domain concepts. The automated conflict detection attempts to find inconsistent mappings. Expert-in-the-Loop validation workflows exploit domain expertise during critical alignment decision-making while preserving complete provenance information for systematic review and refinement. The framework is crafted for real-world application in enterprise settings with components that are modular and can be implemented incrementally. Organizations could start off with single-domain implementations, which could be expanded into cross-domain scenarios as knowledge engineering resources become available. Each element operates separately but has integration powers, enabling flexible deployment strategies that stabilize organizational readiness and availability of resources.
Implementation and evaluation
Implementation overview
The Integrated Knowledge-Enhanced Decision Support implementation had to use a careful compromise between theory and engineering constraints. Many architecture iterations gradually appeared that is, we have combined different technologies to come up with an architecture which is optimal for all decision support systems. The layer in which knowledge is represented uses a hybrid architecture which implements OWL 2 DL ontologies with Protégé to manipulate Neo4j graphs that are used for query and traversal purposes. The dual-representation method solves the tension between semantic reasoning and computational aspects. The custom middleware synchronization mechanism between these representations enables each representation to function with its own data structure while ensuring consistency. For embeddings of knowledge graphs, we develop a hybrid embedding generator that merges structural information from graph neural networks and semantic information from domain-adapted language models. This approach was shown to outperform pure structural embeddings for entities that have limited textual descriptions but have rich connectivity in the graph while also maintaining the semantic coherence of the entities which have rich textual descriptions. The process of fusion relies on a gating network that learns to weigh the structural and semantic components based on the nature of the entities and the quality of information available. The retrieval optimization module integrates three approaches. The first approach is dense vector retrieval using sentence transformers that are adapted to the given domain. The second one is graph traversal with personalized PageRank that propagates the relevant retriever. The final third one is logical inference and this is done by integrating with automated reasoning engines. This method will get more information but will not take too much energy by controlling the depth. The knowledge orchestration engine relies on reinforcement learning to improve pathway selection as a function of the observed outcome. As we developed the architecture, it became evident that the orchestration strategy evolved consistently towards increased knowledge graph reasoning for structured queries and generative approaches for ambiguous queries confirming our hybrid design hypothesis. The performance and implementation technologies are summarized in Table 2.
Adaptations specific to a particular domain were required in all three application areas. The area of finance required the FIBO ontology to be extended with 274 additional classes for regulatory compliances modeling. Moreover, the study implemented multi-scale temporal reasoning. The latter handles data granularities of micro-seconds to quarters. The health area extended SNOMED CT with 318 extra administrative concepts and introduces differential privacy mechanisms which require careful parameter tuning. The supply chain area required integrated spatiotemporal modelling and multiple objectives optimization along with a Pareto frontier visualization.
Evaluation design
The way we evaluate is a detailed comparative study for quantitative performance and qualitative effectiveness on a lot of grounds. The assessment advances the existing decision support evaluation frameworks by introducing cross-domain scenarios, assessment of explanation quality, and measurement of adaptive learning capability. This approach allows us to systematically compare our integrated framework with existing ones. Moreover, it gives explanations on how the integration of knowledge graph and retrieval-augmented generation achieves superior performance. We compared our Integrated Knowledge-Enhanced Decision Support framework with three properly constructed baselines which represent the current state of the art in decision support. The KG-Only baseline is based on conventional knowledge graph reasoning algorithms without generative components There are graph traversal, logical inference, and constraint satisfaction The output is an entity recommendation purely from knowledge graph representations The current structured reasoning methods that perform well on formal logical reasoning (such as SMT solvers), but struggle with natural language interaction and ambiguous query situations. The RAG-Only baseline deploys retrieval-augmented generation without representing knowledge in a structured way. Its only means of response generation is dense vector retrieval and large language models. The present neural approaches with impressive natural language capabilities which nonetheless do not offer the systematic reasoning and consistency guarantees of structured knowledge forms the baseline. The Parallel-KG-RAG baseline operates its knowledge graph and retrieval-augmented generation components independently, and combines their outputs using a weighted ensemble. It is one of the simplest integration methods and attempts to leverage both kinds of technologies through this simple merger without a deep architectural integration.
For three application domains, domain experts collaborated with our research team to develop comprehensive scenario sets. Furthermore, the evaluation scenario set reflects the decision support scenarios in the real world as opposed to academic problem simplifications. The assessment of financial domain consists of 47 investment decision scenarios. These include portfolio optimization given regulations, merger and acquisition analysis, which necessitates the bringing together of financial analyses and strategic considerations, as well as environmental, social, and governance screening decisions. Furthermore, these extend beyond the boundaries of traditional investment analyses. The healthcare domain evaluation examines 53 management decision scenarios. They pertain to resource allocation decisions which have to be done keeping in mind the clinical requirements, and operational constraints. Along with these, they also cover clinical pathway selection and quality improvement initiatives. The evaluation of the Supply Chain domain consists of 51 optimization scenarios, which include supplier selection decisions to be made considering multiple conflicting objectives, network configuration optimization under uncertainty, and a disruption response planning with immediate integration of various information sources. The scenarios were deliberately stratified according to their complexity level, degree of uncertainty and cross-domain knowledge requirement to ensure a comprehensive coverage of decision support difficulties. Particular attention was paid to those scenarios that require the kind of sophisticated reasoning and integration capabilities that set our framework apart from the simpler ones.
Table 3 reflects upon five major assessment dimensions employed in the evaluation framework, capturing essential aspects of decision support system effectiveness. Table 3 contain entire evaluation metrics framework including measurement method and weights assigned to each dimension, relative importance assigned for real time decision support deployment purpose.
The quality of decision measures its correctness through congruence with expert advice, its optimality through distance from provably optimal solutions, when available, and its robustness through insensitivity to perturbations in inputs. The assessment of the knowledge used examines the relevance of the information retrieved, the coverage of relevant knowledge domains, and novel and unexpected but useful knowledge linkages. The assessment of explanation effectiveness considers the extent to which explanations are comprehensible to the intended user populations, cover the rationale for a decision completely, and are traceable to the relevant underlying knowledge sources. The evaluation of integration performance is concerned with the success of cross-domain reasoning, efficiency of orchestration through pathway selection, and alignment of knowledge graph reasoning and generative components. Adaptive capability assessment basically examines how efficient learning happens with respect to the sample size needed, how well we transfer knowledge from a related domain and how cats response to error by making a powerful comeback when an incorrect decision provides learning opportunity.
In total, twenty-four domain practitioners including seven financial analysts, nine healthcare administrators, and eight supply chain managers evaluated the programme. Evaluation of output by experts was done on standardized rubrics with the order of outputs presented randomly, and format regular in order to avoid bias in judgments. The Krippendorff’s alpha indices for inter-rater reliability assessment for all metrics range from 0.72 to 0.85, which indicates good to excellent agreement levels sufficient for the assessment of comparative reliability.
Results
Our evaluation yielded rich insights into the performance characteristics of integrated knowledge-enhanced decision support. I’ll focus on key findings with supporting evidence.
Overall performance comparison
Table 4 presents aggregate performance across all domains, showing mean scores for each approach on primary evaluation metrics.
Statistical analysis confirmed significant performance advantages for IKEDS over all baseline approaches across all metrics (p < 0.001). Effect sizes (Cohen’s d) ranged from 1.78 to 2.92, indicating large practical significance. The most substantial advantage appeared in cross-domain integration, where IKEDS outperformed the best baseline by 33.3%.
An unexpected finding emerged when comparing performance gaps across decision complexity levels. For simple decisions (lowest complexity tertile), the accuracy advantage of IKEDS over Parallel-KG-RAG was modest (5.3%), but this gap widened dramatically for complex decisions (highest complexity tertile) to 19.7%. This pattern appeared consistently across all domains, suggesting that integration benefits increase with decision complexity.
Domain-specific performance
Tables 5 and 6, and Table 7 present detailed results for each domain, broken down by decision scenario types.
In the financial domain, IKEDS showed particularly strong performance in portfolio optimization scenarios, with an accuracy advantage of 9.2% over the best baseline. Post-hoc analysis revealed this advantage stemmed primarily from superior integration of market trend analysis with risk modeling—capabilities that operate in distinct knowledge domains but must be coordinated for effective portfolio decisions.
M&A analysis scenarios showed the largest cross-domain integration advantage (32.2% over best baseline), reflecting the inherently cross-domain nature of acquisition analysis, which spans financial valuation, strategic alignment, operational integration, and regulatory compliance.
ESG screening results revealed an interesting pattern: while IKEDS outperformed baselines overall, the advantage was less pronounced for environmental criteria than for governance criteria. This appears to reflect the more structured, rule-based nature of governance assessment compared to the more nuanced, context-dependent nature of environmental impact evaluation.
Healthcare results revealed an unexpected pattern: the explanation quality advantage of IKEDS was most pronounced for clinical pathway selection (16.3% over best baseline). Follow-up interviews with healthcare experts suggested this stemmed from the framework’s ability to explicitly connect recommendations to evidence levels and clinical guidelines—particularly valuable in medical contexts where evidence-based practice is emphasized.
Resource allocation scenarios showed the largest accuracy advantage (9.2% over best baseline), particularly for scenarios involving allocation under uncertainty. The IKEDS framework’s ability to reason explicitly about uncertainty while maintaining clear connections to organizational priorities proved especially valuable in these contexts.
Quality improvement scenarios demonstrated the highest cross-domain integration advantage (33.8% over best baseline), reflecting the multifaceted nature of healthcare quality that spans clinical, operational, financial, and patient experience domains.
In the supply chain domain, IKEDS demonstrated particularly strong performance in cross-domain integration for supplier selection scenarios (41.3% over best baseline). This reflects the multifaceted nature of supplier evaluation, which spans product quality, delivery reliability, financial stability, sustainability practices, and strategic alignment.
Network configuration scenarios showed the largest accuracy advantage (11.9% over best baseline), particularly for scenarios involving complex trade-offs between cost, responsiveness, and resilience. The IKEDS framework’s ability to model these trade-offs explicitly while reasoning about geographic and temporal constraints proved especially valuable.
Disruption response scenarios revealed an interesting temporal pattern: while IKEDS outperformed baselines overall, the advantage was most pronounced for rapid-onset disruptions requiring immediate response. This appears to reflect the framework’s ability to quickly integrate diverse knowledge sources under time pressure—a critical capability for effective disruption management.
Performance analysis by decision characteristics
Figure 3 illustrates how system performance varies with decision complexity, showing the widening performance gap between IKEDS and baseline approaches as complexity increases.

Performance vs. complexity.
This pattern was consistent across all domains and metrics, with the performance gap widening most dramatically for cross-domain integration. For the highest complexity tertile, IKEDS outperformed the best baseline by 35.7% on cross-domain integration measures—nearly double the advantage observed in the lowest complexity tertile (18.9%).
Further analysis revealed that the IKEDS framework provided the greatest performance advantages for decisions characterized by:
-
1.
Knowledge complexity: Decisions involving multiple interconnected concepts showed the largest performance gaps (up to 24.3% improvement in accuracy). This advantage stems from the framework’s ability to reason explicitly about relationships between concepts.
-
2.
Uncertainty conditions: Scenarios with significant uncertainty demonstrated substantial advantages for the integrated approach (21.8% average improvement). The combination of structured knowledge representation with flexible generation enables more robust handling of incomplete information.
-
3.
Cross-domain requirements: Decisions spanning traditional domain boundaries showed the most dramatic performance differences (35.7% average improvement). This reflects a core design goal of the IKEDS framework—enabling seamless reasoning across domain boundaries.
-
4.
Constraint satisfaction: Complex scenarios with multiple competing constraints revealed significant advantages (19.4% average improvement). The framework’s ability to represent constraints explicitly while reasoning about trade-offs proved particularly valuable.
-
5.
Novel contexts: Decisions with limited historical precedents showed substantial benefits (28.2% average improvement). By combining structured knowledge with flexible generation, the framework can adapt existing knowledge to novel situations more effectively than purely knowledge-based or purely generative approaches.
Learning and adaptation analysis
Analysis of learning curves demonstrated that IKEDS required 37% fewer examples to reach equivalent performance levels compared to baseline approaches. Figure 4 illustrates the learning efficiency across approaches.

The learning efficiency across approaches.
This efficiency advantage stems from the framework’s ability to leverage structured knowledge to guide learning, reducing the need for extensive examples. The effect was particularly pronounced for complex decision types, where IKEDS showed 43% greater sample efficiency compared to the best baseline.
Knowledge transfer capabilities were particularly impressive, with 73% performance retention when transitioning to new but related scenarios (compared to 41–58% for baselines). This suggests that the integrated knowledge representation enables more effective generalization across related decision contexts.
Error recovery analysis revealed that after incorrect decisions, IKEDS showed 84% probability of correcting similar errors in subsequent scenarios, compared to 46–61% for baseline approaches. This learning advantage reflects the framework’s ability to incorporate feedback more effectively by connecting it to structured knowledge.
Qualitative insights
Thematic analysis of expert feedback identified several key advantages of the IKEDS framework:
-
1.
Explanation transparency: Experts consistently rated IKEDS explanations as more transparent and traceable (87% satisfaction vs. 51–69% for baselines). Comments frequently highlighted the value of connecting explanations to underlying knowledge structures.
-
2.
Contextual relevance: The framework demonstrated superior ability to identify contextually relevant knowledge (92% relevance rating vs. 63–78% for baselines). Experts particularly valued the system’s ability to incorporate organizational context and priorities into recommendations.
-
3.
Reasoning depth: Experts noted that IKEDS recommendations showed evidence of deeper reasoning that considered indirect implications and long-term consequences (85% depth rating vs. 47–61% for baselines). This was particularly evident in complex scenarios with multiple interdependent factors.
-
4.
Adaptation to feedback: The framework showed superior ability to incorporate expert feedback and adapt subsequent recommendations (79% adaptation rating vs. 42–56% for baselines). This suggests that the integration of structured knowledge with flexible generation enables more effective learning from user interactions.
Expert assessment also identified areas for improvement:
-
1.
Computational efficiency: The integrated approach required substantially more computational resources than simpler approaches (approximately 3.2x the computation of the simplest baseline). This suggests a need for optimization and potential simplification for deployment contexts with limited resources.
-
2.
System complexity: Several experts expressed concern about the complexity of the architecture, noting potential challenges for system maintenance and extension. As one evaluator commented: “The system works impressively well, but I worry about who could maintain this in a real organizational context.” This highlights the importance of documentation and knowledge transfer for complex AI systems.
-
3.
Cold-start performance: While IKEDS learns more efficiently, its initial performance in entirely new domains requires substantial knowledge engineering. This presents a trade-off between upfront investment and long-term efficiency that organizations must consider when adopting the framework.
Cross-domain analysis
Our cross-domain analysis revealed consistent patterns that validate the fundamental principles of the IKEDS framework while identifying nuances in domain-specific performance.
The consistency of performance advantages across domains suggests that the core architecture captures domain-independent principles of effective decision support. Despite significant differences in domain knowledge, terminology, and decision requirements, the relative performance advantages remained remarkably stable.
The most substantial performance advantages consistently appeared in scenarios requiring integration of knowledge across traditional domain boundaries. This finding has important implications for complex organizational decisions that span functional areas—precisely the scenarios where current decision support systems often fall short.
Learning efficiency results demonstrated consistent patterns across domains, with IKEDS requiring 32–41% fewer examples to reach equivalent performance. This consistency suggests that the knowledge-guided learning approach addresses fundamental efficiency challenges rather than domain-specific peculiarities.
The cross-domain analysis also identified common challenges. Knowledge engineering costs remain substantial across all domains (approximately 120–180 person-hours per domain in our implementation). As knowledge graphs grow in size and complexity, careful attention to retrieval efficiency becomes increasingly important—a scaling challenge we’re actively addressing in ongoing work.
User adaptation patterns showed interesting consistency across domains. Users initially unfamiliar with the system demonstrated a predictable learning curve in effectively utilizing the multi-level explanations. Initial interactions focused primarily on high-level explanations, gradually incorporating deeper explanation levels as users gained familiarity with the system and domain concepts.
These findings provide valuable guidance for future development and deployment of integrated knowledge-enhanced decision support systems. While our results convincingly demonstrate the value of deep integration between knowledge graphs and retrieval-augmented generation, they also highlight areas requiring further research and development.
Evaluation methodology and results
The empirical validation of the IKEDS framework necessitated a meticulous experimental approach that balanced methodological rigor with practical relevance. We designed our evaluation to systematically compare the integrated architecture against alternative approaches across diverse decision contexts, paying particular attention to challenging scenarios that test the limits of current decision support technologies. This evaluation encompassed three complementary dimensions: comparative assessment against established baselines, comprehensive analysis across multiple application domains, and systematic investigation of performance patterns related to decision characteristics and learning capabilities.
For each application domain—financial investment, healthcare management, and supply chain optimization—we constructed comprehensive evaluation datasets derived from real-world data and validated by domain experts. The financial dataset comprised 47 investment decision scenarios drawn from historical market data (2015–2023), incorporating asset allocation challenges, M&A analyses, and ESG investment screening cases. The healthcare management dataset included 53 scenarios based on anonymized operational data from three healthcare organizations, spanning resource allocation, clinical pathway selection, and quality improvement initiatives. For supply chain optimization, we developed 51 scenarios covering supplier selection, network configuration, and disruption response planning. These datasets were deliberately designed to include a substantial proportion of cross-domain scenarios requiring integration of knowledge from multiple areas—a capability we hypothesized would differentiate the IKEDS framework from simpler approaches.
To establish meaningful comparison points, we implemented three baseline systems representing distinct approaches to knowledge integration. The KG-Only system employed the same knowledge graph components as IKEDS but relied exclusively on traditional graph algorithms and rule-based reasoning for decision generation. The RAG-Only system utilized identical retrieval and generation components but without structured knowledge representation, treating all knowledge as unstructured text. The Parallel-KG-RAG system ran knowledge graph reasoning and retrieval-augmented generation in parallel, combining their outputs through a weighted ensemble method without the deep integration mechanisms of IKEDS. All systems had access to identical knowledge sources and computational resources, ensuring that observed performance differences genuinely reflected architectural advantages rather than disparities in underlying data or resources.
Our evaluation metrics captured multiple dimensions of system performance relevant to practical deployment contexts. Beyond straightforward decision accuracy, we assessed knowledge relevance (how effectively systems identified and utilized pertinent information), explanation quality (across dimensions of comprehensibility, completeness, and traceability), cross-domain integration (effectiveness of reasoning across domain boundaries), and adaptability (learning efficiency and knowledge transfer capabilities). This multidimensional approach allowed us to identify specific areas where architectural integration provides particularly significant advantages.
To ensure unbiased assessment, we employed a double-blind evaluation protocol wherein neither the domain experts evaluating system outputs nor the researchers conducting the evaluation knew which system generated each response. We normalized output formatting to prevent identification based on presentational characteristics and employed 5-fold cross-validation for learning-based components to ensure robust performance assessment. Statistical significance testing using paired t-tests and ANOVA with post-hoc analysis confirmed the reliability of observed performance differences.
The results revealed consistent and substantial performance advantages for the IKEDS framework across all evaluation dimensions and application domains. Table 8 presents the aggregate results across all decision scenarios. Overall decision accuracy for IKEDS averaged 85.7% (± 3.2%), significantly outperforming the KG-Only (74.6% ±4.1%), RAG-Only (67.3% ±4.8%), and Parallel-KG-RAG (77.6% ±3.9%) approaches. Statistical analysis confirmed the significance of these differences (p < 0.001, F = 28.4), with post-hoc Tukey tests indicating that IKEDS significantly outperformed all baseline systems (p < 0.01 for all pairwise comparisons).
While performance advantages appeared across all metrics, the magnitude varied in revealing ways. The most substantial advantage emerged in cross-domain integration, where IKEDS achieved an average score of 0.84 (± 0.06) compared to 0.49 (± 0.09) for KG-Only, 0.47 (± 0.08) for RAG-Only, and 0.63 (± 0.07) for Parallel-KG-RAG. This 33.3% improvement over the best baseline validates our central hypothesis that deep architectural integration enables more effective reasoning across domain boundaries than simpler integration approaches.
Domain-specific analysis revealed nuanced patterns that illuminate the particular strengths of the IKEDS architecture. In the financial domain, portfolio optimization scenarios showed the largest accuracy advantage (9.2% over the best baseline), stemming primarily from superior integration of market trend analysis with risk modeling. M&A analysis scenarios revealed particularly strong cross-domain integration performance (32.2% over the best baseline), reflecting the framework’s ability to reason across financial, strategic, operational, and regulatory domains simultaneously. Interestingly, ESG screening scenarios showed variable advantages depending on criteria type—stronger for governance assessment (which tends to be more structured and rule-based) than for environmental impact evaluation (which often involves more nuanced judgment). Table 9 presents the detailed performance comparison for financial investment decision scenarios.
The healthcare domain exhibited distinctive patterns, with clinical pathway selection scenarios showing remarkable explanation quality advantages (16.3% over the best baseline). Follow-up interviews with healthcare experts indicated this stemmed from IKEDS’ ability to explicitly connect recommendations to evidence levels and clinical guidelines—a capability particularly valued in medical contexts where evidence-based practice is emphasized. Resource allocation scenarios revealed superior performance under uncertainty conditions (9.2% accuracy advantage), while quality improvement initiatives demonstrated exceptional cross-domain integration capabilities (33.8% advantage)—reflecting the framework’s ability to reason across clinical, operational, financial, and patient experience domains. Table 10 provides detailed healthcare domain performance comparisons.
In the supply chain domain, supplier selection scenarios showcased exceptional cross-domain integration capabilities (41.3% over the best baseline), while network configuration decisions exhibited the largest accuracy advantage (11.9%). An intriguing temporal pattern emerged in disruption response scenarios: the advantage of IKEDS was particularly pronounced for rapid-onset disruptions requiring immediate response, suggesting that the framework’s ability to quickly integrate diverse knowledge sources becomes especially valuable under time pressure. Table 11 shows the detailed supply chain domain performance comparison.
Beyond domain-specific patterns, our analysis revealed systematic relationships between decision characteristics and the magnitude of IKEDS’ performance advantage. The advantage increased substantially with knowledge complexity, uncertainty level, and cross-domain requirements—precisely the types of decisions that traditionally challenge decision support systems. For decisions involving simple, factual knowledge, the advantage was modest (5–8%), but for decisions requiring complex, interconnected knowledge spanning multiple domains, the advantage increased dramatically (18–24%). Similarly, the advantage expanded from 7 to 10% for deterministic scenarios to 15–22% for highly uncertain scenarios.
Discussion
The empirical results support our hypothesis, illustrating how IKEDS outperforms Parallel-KG-RAG due to synergistic integration of KGs and RAG, rather than merely their combination. Contemporary AI systems employing modular or create-use architectures face a challenge in dynamic knowledge orchestration across cross-domain REs. The key benefits are better integration across domains, multi-level explanations, and 37% improvement in learning efficiency for data-scarce domains. Theoretically, IKEDS combines neural and symbolic AI and enhances language models with structured knowledge for reasoning-heavy applications. The high costs of knowledge engineering, computational demands, scaling issues for large KGs, and conflicting knowledge, are some limitations. In the future, we would like to make continuous updates, personalization and collaborative support. We must integrate causal reasoning. We must expand to domains like environmental management.
Conclusion
We introduce IKEDS, a framework to combine KGs and RAG for cross-domain decision support on complex tasks. Innovations encompass multi-layered knowledge graphs with cross-domain mappings, optimized retrieval, dynamic orchestration, context-aware generation, and multi-level explanations. The evaluation results in the fields of finance, healthcare and supply chains demonstrate that IKEDS outperforms the baseline: (i) accuracy of 85.7% (vs. 67.3–77.6%), (ii) knowledge relevance of 0.91 (vs. 0.74 to 0.83), (iii) explanation quality of 0.88 (vs. 0.67 to 0.76) and (iv) integration across domains of 0.84 (vs. 0.47 to 0.63) It is also capable of accomplishing a 37% increase in the learning efficiency and transfer. The combination allows us to integrate Knowledge Graph’s reasoning and commonsense with LLM’s flexibility and language.
Data availability
The data presented in this study are available on request from the corresponding author.
References
Geisler, S. et al. Knowledge-driven data ecosystems toward data transparency. ACM J. Data Inform. Qual. 14 (1), 1–12. https://doi.org/10.1145/3467022 (2022).
Ibáñez, L. et al. Trust, accountability, and autonomy in knowledge graph-based AI for self-determination. Trans. Graph Data Knowl. 1 (1), 9:1–932. https://doi.org/10.4230/TGDK.1.1.9 (2023).
Pan, S. et al. Unifying large Language models and knowledge graphs: A roadmap. IEEE Trans. Knowl. Data Eng. 36 (7), 3580–3599. https://doi.org/10.1109/TKDE.2023.3306685 (2024).
Gutiérrez, C. & Sequeda, J. F. Knowledge graphs. Commun. ACM. 64 (3), 96–104. https://doi.org/10.1145/3418294 (2021).
Rivas, A., Collarana, D., Torrente, M. & Vidal, M. A neuro-symbolic system over knowledge graphs for link prediction. Semant Web https://doi.org/10.3233/SW-233324 (2023).
Chandak, P., Huang, K. & Zitnik, M. Building a knowledge graph to enable precision medicine. BioRxiv https://doi.org/10.1101/2022.05.01.489928 (2022).
Bader, S. R., Grangel-González, I., Nanjappa, P., Vidal, M. & Maleshkova, M. A knowledge graph for Industry 4.0. In The Semantic Web (pp. 465–480). Springer. https://doi.org/10.1007/978-3-030-49461-2_27(2020)
Wang, C. N., Yang, F. C., Vo, N. T. M. & Nguyen, V. T. T. OWL: an optimized machine learning prediction model for lung cancer screening. EBioMedicine 88, 104443. https://doi.org/10.1016/j.ebiom.2023.104443 (2023).
Oelen, A., Jaradeh, M. Y. & Auer, S. ORKG ASK: A neuro-symbolic scholarly search and exploration system. In Proceedings of the 20th International Conference on Semantic Systems. CEUR-WS. (2024).
Bagchi, M. Toward generative AI–Driven metadata modeling: A Human–Large Language model collaborative approach. Libr. Trends. 73 (3), 297–322 (2025).
Wang, Z., Zhang, J., Feng, J. & Chen, Z. Knowledge graph embedding by translating on hyperplanes. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 28, No. 1). AAAI. (2014).
Ji, G., He, S., Xu, L., Liu, K. & Zhao, J. Knowledge graph embedding via dynamic mapping matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics (pp. 687–696). ACL. (2015).
Huang, H. & Vidal, M. CauseKG: A framework enhancing causal inference with implicit knowledge deduced from knowledge graphs. IEEE Access. https://doi.org/10.1109/ACCESS.2024.3395134 (2024).
Vidal, M. E. et al. Integrating knowledge graphs with symbolic AI: the path to interpretable hybrid AI systems in medicine. J. Web Semant. 84, 100856. https://doi.org/10.1016/j.websem.2024.100856 (2025).
Richens, J. G., Lee, C. M. & Johri, S. Improving the accuracy of medical diagnosis with causal machine learning. Nat. Commun. 11 (1), 1–9. https://doi.org/10.1038/s41467-020-17419-7 (2020).
Alcaraz, C. & Lopez, J. Security threats in digital twins. IEEE Commun. Surv. Tutorials. 24 (3), 1475–1503. https://doi.org/10.1109/COMST.2022.3176153 (2022).
Alowais, S. A. et al. Revolutionizing healthcare: the role of artificial intelligence in clinical practice. BMC Med. Educ. 23 (1), 1–18. https://doi.org/10.1186/s12909-023-04698-z (2023).
Azzam, A., Polleres, A., Fernández, J. D. & Acosta, M. Smart-KG: Partition-based linked data fragments for querying knowledge graphs. Semantic Web. 15 (5), 1791–1835. https://doi.org/10.3233/SW-243571 (2024).
Bonney, M. S., de Angelis, M., Dal Borgo, M. & Wagg, D. J. Contextualisation of information in digital twin processes. Mech. Syst. Signal Process. 184, 109657. https://doi.org/10.1016/j.ymssp.2022.109657 (2023).
Callahan, T. J. et al. An open-source knowledge graph ecosystem for the life sciences. arXiv. (2024). https://arxiv.org/abs/2307.05727
Chaves-Fraga, D., Colpaert, P., Sadeghi, M. & Comerio, M. Editorial of transport data on the web. Semantic Web. 14 (4), 613–616. https://doi.org/10.3233/SW-223278 (2023).
Díaz-Honrubia, A. J., Rohde, P. D., Niazmand, E., Menasalvas, E. & Vidal, M. PALADIN: A process-based constraint Language for data validation. Inform. Fusion. 112, 102557. https://doi.org/10.1016/j.inffus.2024.102557 (2024).
Janev, V. et al. Responsible knowledge management in energy data ecosystems. Energies 15 (11), 3973. https://doi.org/10.3390/en15113973 (2022).
Kiseleva, A., Kotzinos, D. & De Hert, P. Transparency of AI in healthcare as a multilayered system of accountabilities. Front. Artif. Intell. https://doi.org/10.3389/frai.2022.879603 (2022). 5.
Königstorfer, F. & Thalmann, S. AI documentation: A path to accountability. J. Responsible Technol. 11, 100043. https://doi.org/10.1016/j.jrt.2022.100043 (2022).
Li, H. X., Appleby, G., Brumar, C. D., Chang, R. & Suh, A. Knowledge graphs in practice: characterizing their users, challenges, and visualization opportunities. IEEE Trans. Vis. Comput. Graph. 30 (1), 584–594. https://doi.org/10.1109/TVCG.2023.3326904 (2024).
Molino, M., Cortese, C. G. & Ghislieri, C. The promotion of technology acceptance and work engagement in industry 4.0. Int. J. Environ. Res. Public Health. 17 (7), 2438. https://doi.org/10.3390/ijerph17072438 (2020).
Pennekamp, J. et al. Evolving the digital industrial infrastructure for production. In Internet of Production (pp. 35–60). Springer. (2023). https://doi.org/10.1007/978-3-031-44497-5_2
Polleres, A. et al. How does knowledge evolve in open knowledge graphs? Trans. Graph Data Knowl. 1 (1), 11:1–1159. https://doi.org/10.4230/TGDK.1.1.11 (2023).
Ruckhaus, E., Anton-Bravo, A., Scrocca, M. & Corcho, Ó. Applying the LOT methodology to a public bus transport ontology aligned with transmodel. Semantic Web. 14 (4), 639–657. https://doi.org/10.3233/SW-210451 (2023).
Wu, W., Zhang, Y., Chen, L. & Hu, W. Knowledge Graph-Guided Retrieval Augmented Generation. arXiv preprint arXiv:2502.06864. (2025).
Edge, D., Trinh, H., Truitt, S. & Larson, J. GraphRAG: unlocking LLM discovery on narrative private data. Microsoft Research. (2024). https://www.microsoft.com/en-us/research/blog/graphrag-unlocking-llm-discovery-on-narrative-private-data/
Manufacturing Research Group. Document graphrag: knowledge graph enhanced retrieval augmented generation for document question answering within the manufacturing domain. Electronics 14 (11), 2102. https://doi.org/10.3390/electronics14112102 (2025).
Fan, W. et al. MedRAG: Enhancing Retrieval-augmented Generation with Knowledge Graph-Elicited Reasoning for Healthcare Copilot. Proceedings of the ACM on Web Conference 2025, 1891–1902. (2025). https://doi.org/10.1145/3696410.3714782
Funding
This research was supported by the Natural Science Foundation of Gansu Province (No. 23JRRA581).
Author information
Authors and Affiliations
Contributions
Conceptualization, Project administration, funding acquisition, supervision, writing review-editing, methodology, resources, software: S.W.; Conceptualization, data curation, formal analysis, investigation, validation, visualization, writing original draft preparation: S.W., H.Y., G.B. This manuscript has been read and approved by all authors.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wang, S., Yang, H. & Bai, G. Construction of intelligent decision support systems through integration of retrieval-augmented generation and knowledge graphs. Sci Rep 15, 35462 (2025). https://doi.org/10.1038/s41598-025-19257-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-19257-3
