
Abstract
Chronic Kidney Disease (CKD) is a progressive condition primarily caused by diabetes and hypertension, affecting millions worldwide. Early diagnosis remains a clinical challenge since traditional approaches, such as Glomerular Filtration Rate (GFR) estimation and kidney damage indicators, often fail to detect CKD in its initial stages. This study aims to enhance early CKD prediction by developing a deep neural network optimized with a novel hybrid metaheuristic that combines the Waterwheel Plant Algorithm (WWPA) with Grey Wolf Optimization (GWO). Using the UCI CKD dataset, rigorous preprocessing techniques-including data imputation, normalization, and synthetic oversampling-were employed to enhance data quality and mitigate class imbalance. A multilayer perceptron (MLP) regression model was trained and optimized through the WWPA-GWO framework and benchmarked against other optimization algorithms, including PSO, GA, and WOA. Results demonstrated that the standard MLP achieved moderate performance (MSE = 0.00177, RMSE = 0.0420, MAE = 0.0100, \(R^2\) = 0.8793), whereas the optimized model achieved significant improvements (MSE = \(3.06 \times 10^{-6}\), RMSE = 0.00175, \(R^2\) = 0.9730) with reduced computational time (0.0999 s). Statistical validation using ANOVA (\(p < 0.0001\)) and Wilcoxon signed-rank testing (\(p = 0.002\)) confirmed the robustness of the approach. These findings highlight the effectiveness of the WWPA-GWO hybrid optimization strategy for deep neural networks, offering a reliable and efficient pathway for early CKD detection. Future work will explore the integration of advanced imputation methods, multi-modal data sources, and federated learning frameworks to enhance the model’s generalizability and clinical utility in diverse healthcare settings.
Similar content being viewed by others

Introduction
Chronic kidney disease (CKD) affects approximately 9% of the global population, representing over 674 million individuals, and is increasingly recognized as a leading cause of premature mortality worldwide. Recent estimates project that CKD will become the fifth leading cause of years of life lost (YLL) by 2040, surpassing diseases such as cancer and diabetes. In 2021 alone, CKD was associated with 1.5 million deaths globally, with mortality expected to rise to over 2.2 million by 2040 under current progression trends.
The health system burden of CKD is particularly severe due to the high costs associated with end-stage treatments. Hemodialysis and peritoneal dialysis remain financially burdensome, with annual costs per patient exceeding $50,000 in high-income countries and rapidly rising in middle-income economies. Global kidney replacement therapy (KRT) expenditures are projected to increase from $169.6 billion in 2022 to over $186.6 billion by 2027. This economic impact, compounded by limited access to treatment in resource-poor settings, underscores the need for improved early detection strategies.
The progressive decline in kidney function characterizes CKD over time. It is a growing and emerging cause of death globally, ranking number five by 20401. In high-income countries, the annual increase in healthcare costs due to transplantation and dialysis is 2–3%2. Dialysis or kidney transplantation in poor and middle-income countries remains difficult as most patients with renal failure live there3. New economies, such as China and India, can be expected to record more renal failure cases than previously observed4. More fluids in the blood cannot be easily expelled from the body when the kidneys’ function is gradually impaired, leading to complications such as hypertension, anemia, osteoporosis, and nerve damage. Glomerular filtration rate (GFR) remains the gold standard for measuring kidney health5.
Furthermore, the GFR helps doctors in determining the presence of renal disease. Both chronic kidney damage lasting three months and a GFR of less than 60 mL/min/1.73 m2 over the same period are needed to diagnose CKD. Five stages are recognized for CKD, and at each stage, the GFR worsens; it can be determined using the GFR6, which is the most accurate estimator of renal activity. If the GFR levels are less than 15 mL/min, the patient is in renal failure6. Diagnosing CKD is not easy since there are many causes of the disease, and physicians’ experience plays a key role7. With the growing complexity of healthcare data and the introduction of new diagnostic techniques, machine learning (ML) offers a reliable and automated way to assist in early detection8,9.
ML has emerged as a transformative approach for enhancing disease diagnostics by uncovering complex, non-linear patterns within large and heterogeneous medical datasets. In the context of chronic diseases, ML-based models offer significant advantages in automating diagnostic workflows, reducing reliance on subjective clinical judgment, and increasing early detection accuracy. Recent studies have illustrated the effectiveness of ML algorithms in predicting various disorders, including polycystic ovary syndrome (PCOS), heart disease, thyroid dysfunction, and arrhythmias10,11,12,13. For example, Kumar et al.10 demonstrated that a hybrid logistic regression model enhanced with particle swarm optimization achieved an accuracy of 96.3% in PCOS diagnosis, highlighting the value of optimization-enhanced classifiers. Similarly, Lai et al.14 showed that integrating improved Grey Wolf Optimization with artificial neural networks can substantially enhance diagnostic accuracy in skin cancer detection, while Ghafariasl et al.15 fine-tuned pre-trained deep networks for superior breast cancer classification performance. These studies further emphasize the importance of hybrid and optimization-based deep learning strategies for improving medical prediction tasks.
Despite these advancements, traditional ML techniques often treat feature selection and hyperparameter tuning as independent processes, leading to suboptimal diagnostic performance, especially in high-dimensional biomedical data. A recent systematic review emphasized that integrating these two processes through hybrid optimization frameworks can substantially improve diagnostic accuracy, computational efficiency, and model interpretability16. These frameworks employ metaheuristic algorithms in combination with classifiers like Support Vector Machines (SVM), Decision Trees (DT), and Random Forests (RF), yielding 12–15% gains in classification accuracy across diseases such as cardiovascular conditions, diabetes, and various cancers. The review also highlighted the growing importance of cross-validation, federated learning, and explainable AI (XAI) in building clinically actionable and generalizable models.
In the specific case of CKD, ML techniques such as Random Forest17, Fuzzy C-Means18, Naive Bayes19, and SVMs20,21 have been widely applied. However, these models are frequently limited by their inability to handle the intricate, high-dimensional nature of clinical data without significant feature engineering or tuning. Moreover, they often face issues of overfitting, convergence to local optima, and high computational costs. Consequently, there is an emerging research need to develop hybrid optimization frameworks that can jointly optimize feature subsets and classifier hyperparameters, thereby producing more robust and efficient diagnostic models tailored for early CKD detection.
Artificial Neural Networks (ANNs), or more specifically, deep neural networks (DNNs), are increasingly preferred for medical diagnostics because they can directly learn non-linear relationships within datasets and automatically extract relevant features. Nevertheless, their performance is highly sensitive to hyperparameter settings, which can be enhanced through sophisticated optimization strategies. Common optimization methods often suffer from premature convergence and entrapment in local optima, which limits their capacity to generalize.
To overcome these challenges, this study proposes a hybrid Waterwheel Plant Algorithm–Grey Wolf Optimization (WWPA–GWO) framework that leverages the complementary strengths of both methods. The WWPA contributes robust exploration by dynamically diversifying the search space and preventing early stagnation, while GWO offers efficient exploitation by refining solutions around promising regions through its hierarchical leadership mechanism. This synergistic combination ensures a more balanced and adaptive optimization process, enhancing the convergence speed, stability, and predictive performance of the DNN for early CKD prediction.
In this study, the primary computational problem addressed is the inefficient and suboptimal hyperparameter optimization of DNNs for early CKD prediction. Conventional techniques such as grid search, and random search incur high computational costs or converge prematurely to local optima, resulting in limited model performance. The proposed WWPA–GWO hybrid algorithm effectively integrates biological inspiration and swarm intelligence to optimize DNN hyperparameters, yielding higher diagnostic accuracy, lower computational cost, and improved robustness.
Literature review
Predictive modeling for osteoporosis in patients with CKD has shown promising results using machine learning approaches. Research by22 demonstrated that Random Forest algorithms achieved exceptional predictive capabilities, especially among female patients who exhibited a 17.57% disease prevalence. The female-specific model identified critical predictors, including body weight, hormone replacement therapy usage, patient age, ethnic background, and erythrocyte counts, culminating in a clinically validated predictive instrument.
The absence of reliable diagnostic markers for CKD presents a significant challenge in contemporary healthcare. Research findings from23 revealed that sophisticated bioinformatics methodologies successfully identified four key tubular damage biomarkers-DUSP1, GADD45A, TSC22D3, and ZFAND5-which demonstrate crucial roles in immune regulation and inflammatory cascades, showing strong correlations with established parameters such as Glomerular Filtration Rate and creatinine levels.
With approximately 697.5 million individuals affected globally, CKD represents a substantial health burden. The investigation by24 suggests that conventional analytical approaches may inadequately capture the intricate, non-linear connections between environmental exposures and CKD development. Advanced interpretable machine learning techniques revealed meaningful correlations, particularly identifying urinary volatile organic compound metabolites, such as N-Acetyl-S-(3,4-dihydroxybutyl)-L-cysteine (DHBMA), as crucial disease predictors, potentially informing targeted preventive interventions.
Patients diagnosed with CKD experience elevated risks for medication-related complications due to multiple comorbidities and complex pharmaceutical regimens. The study by25 successfully employed machine learning methodology, particularly random forest algorithms, to identify high-risk CKD patients for medication therapy problems within primary care environments, utilizing standard clinical parameters including diabetic status, glycated hemoglobin levels, and blood pressure measurements.
The global burden of CKD is compounded by its frequent association with dilated cardiomyopathy, substantially elevating cardiovascular risk profiles. Research conducted by26 addressed the diagnostic challenges in detecting dilated cardiomyopathy among CKD patients, building upon established evidence linking renal impairment to subsequent cardiac pathology.
Multiple patient characteristics, including age, hemoglobin levels, educational background, and social engagement, have been identified as important determinants of cognitive decline in populations with CKD. The research by27 demonstrated that neural network models achieved superior predictive capabilities for this complication, with subsequent feature analysis revealing age, educational attainment, and hemoglobin concentration as primary influential variables.
Coronary artery disease prevalence among CKD patients substantially elevates their cardiovascular morbidity and mortality risks. The investigation by28 established that inflammatory pathways play central roles in CAD development within CKD populations, leading to the identification of promising biomarkers, including glutamate cysteine ligase modifier subunit (GCLM) and nuclear protein 1 (NUPR1), for enhanced diagnostic and therapeutic applications.
Contemporary machine learning approaches are increasingly incorporating multi-biomarker strategies for disease detection, although the economic implications are often inadequately considered. The analysis by29 revealed that expanding model features can increase procedural expenses by nearly threefold while providing minimal accuracy improvements, demonstrating substantial disparities between classifier effectiveness and associated costs. These findings suggest that minor performance enhancements may not justify significantly higher expenditures, underscoring the need for cost-benefit analyses in the selection of clinical models.
Social determinants have a significant influence on the development and progression of CKD. The study by30 demonstrated that incorporating social determinants into machine learning frameworks, particularly random forest models, substantially improved the accuracy of CKD risk prediction among Type 2 diabetic patients, achieving an impressive area under the receiver operating characteristic curve of 0.89.
Calcification prevalence remains elevated in CKD populations, with abdominal aortic calcification serving as a powerful predictor of cardiac complications. The research by31 utilized machine learning models to identify key determinants of calcification across both CKD and non-CKD cohorts. Results indicated that age, smoking history, and estimated glomerular filtration rate consistently emerged as primary influential factors in both groups. Additionally, while glucose levels and albumin-to-creatinine ratios represented shared risk elements, specific inflammatory markers, including monocyte-to-lymphocyte and neutrophil-to-lymphocyte ratios, demonstrated particular importance for calcification progression in CKD patients.
Early-stage CKD detection in diabetic populations remains challenging due to subtle clinical presentations. The study by32 addressed these diagnostic difficulties through attention-based deep learning architectures that demonstrated exceptional accuracy in CKD stage classification, highlighting serum creatinine and cystatin C as pivotal classification parameters.
Risk stratification for one-year CKD progression in patients with type 2 diabetes mellitus has been investigated using diverse machine learning methodologies. The analysis by33 encompassed ten different algorithmic approaches applied to extensive patient datasets, with XGBoost demonstrating optimal predictive performance for kidney function deterioration and subsequent integration into a clinician-friendly web-based platform.
CKD mineral bone disorder commonly complicates advanced and end-stage kidney disease, significantly increasing fracture and osteoporosis susceptibility. The research by34 developed machine learning predictive models, with artificial neural networks showing exceptional accuracy in osteoporosis risk identification among these patient populations, demonstrating substantial clinical screening potential.
Sarcopenia represents a frequent complication in CKD patients, adversely affecting clinical outcomes. The findings by35 established that machine learning-based predictive models identified advanced age, waist circumference, low-density lipoprotein cholesterol, high-density lipoprotein cholesterol, triglyceride levels, and diastolic blood pressure as significant determinants of sarcopenia risk in this population.
CKD patients constitute the primary at-risk population for post-contrast acute kidney injury, yet specialized predictive instruments remain limited. The study by36 demonstrated that explainable deep neural network models represent valuable tools for predicting this complication in patients undergoing coronary procedures, exhibiting superior performance compared to conventional scoring systems while enabling essential clinical risk assessment.
Feline CKD ranks among the most prevalent veterinary conditions and represents a leading cause of death in cats exceeding five years of age. The investigation by37 employed metabolomics methodologies to identify early disease indicators through comparisons between healthy cats and those with early-stage disease. Research identified the serum-to-urine 3-hydroxykynurenine ratio as a significant individual biomarker, while machine learning models incorporating metabolites such as creatinine, symmetric dimethylarginine, and aconitic acid improved diagnostic precision. This sophisticated modeling approach enabled diagnosis approximately six months earlier than conventional techniques, demonstrating pathways toward enhanced diagnostics and timelier disease intervention.
CKD represents a widespread health condition requiring individualized treatment approaches across its five progressive stages. The work by38 demonstrated that machine learning and generative artificial intelligence technologies show significant promise for forecasting disease progression using patient information. However, current predictive models encounter constraints regarding generalizability, interpretability, and computational requirements.
Significant correlations have been documented between CKD and exposure to principal xenoestrogens, encompassing phthalates, parabens, and phenolic compounds. The findings by39 utilized interpretable machine learning models to demonstrate the substantial predictive value of specific urinary xenoestrogen metabolites, particularly methyl paraben, mono-(carboxynonyl) phthalate, and triclosan, for identifying individuals at risk.
CKD represents a worldwide health challenge that frequently remains undiagnosed due to its initially subtle clinical manifestations, contributing to rising morbidity and mortality rates. The analysis by40 implemented an optimized machine learning framework across more than 39,000 research abstracts to identify 68 comorbidities spanning 15 disease categories that influence the development or progression of CKD, thereby advancing the comprehension of prognostic factors.
Patients with concurrent diabetes mellitus and CKD experience elevated cardiovascular event risks, with conventional prediction methodologies demonstrating inadequate performance. The research by41 showed that machine learning techniques, particularly Light Gradient Boosting Machine models, can achieve satisfactory predictive capabilities by leveraging key variables including estimated glomerular filtration rate, patient age, and triglyceride glucose index. The methodology and key findings of all the literature reviewed are summarized in Table 1.
Based on these limitations, this study presents a hybrid deep learning framework that combines the Waterwheel Plant Algorithm (WWPA) and Grey Wolf Optimization (GWO) to optimize deep neural network parameters. Our model aims to fill the gap by enhancing prediction accuracy, reducing computational time, and statistically validating the model’s superiority over traditional methods.
From the reviewed literature, it is evident that while machine learning techniques such as Random Forest, SVM, Naive Bayes, and hybrid models have been applied to CKD prediction and related conditions, several critical gaps remain unaddressed. First, most existing studies focus primarily on conventional ML classifiers without integrating advanced deep learning architectures capable of capturing complex, non-linear patterns in high-dimensional clinical data. Second, even when metaheuristic optimization methods are employed, they are often applied in isolation to either feature selection or hyperparameter tuning, rather than jointly optimizing model parameters in a unified framework. Third, few studies systematically evaluate the trade-off between predictive performance and computational efficiency, and even fewer validate their findings with rigorous statistical tests such as Analysis of Variance (ANOVA) or Wilcoxon signed-rank tests. This study addresses these gaps by proposing a hybrid deep learning model optimized using a novel WWPA-GWO algorithm designed to improve predictive accuracy, reduce computational cost, and ensure robust statistical validation for early CKD prediction.
Materials and methods
Data collection
Chronic kidney disease data were culled from the UCI Repository at the University of California, Irvine. The data collection contains 400 patient records, some of which are incomplete. One class feature represents the projected occurrence of chronic renal failure, while the other 24 clinical traits are associated with the prognosis of chronic kidney disease. In the diagnostic for anticipated features, you’ll see the values “ckd” and “notckd.” There are 250 “ckd” values (62.5% of the total) and 150 “notckd” values (37.5%) in the dataset.
The dataset utilized in this study contains 24 features that encompass demographic, clinical, and laboratory attributes relevant to the diagnosis of CKD. These features collectively capture patient-specific indicators, including vital signs, urinary and blood biomarkers, and comorbid conditions, making the dataset rich in multidimensional patterns essential for reliable prediction.
The target variable is the class label, which categorizes patients as either ckd (positive diagnosis) or notckd (negative diagnosis). The remaining 23 attributes serve as input variables for the classification models. These features, summarized in Table 2, include both numerical and categorical variables such as blood pressure, blood glucose levels, red blood cell counts, and presence of comorbidities like diabetes or hypertension. This comprehensive feature space enables the practical training of machine learning models to capture the complex, non-linear relationships underlying CKD pathology.
To ensure a balanced distribution of classes, data augmentation techniques, such as Synthetic Minority Over-sampling Technique (SMOTE), were applied to the minority class, “notckd.” This was done to avoid the issue of class imbalance that could impact the performance of the predictive model.
Figure 1 displays the Histogram of numerical variables from a CKD dataset. For “age,” “hemoglobin,” and “pcv,” key observations indicate a normal distribution. Histograms are crucial in understanding the distribution of each feature in the dataset, helping to identify potential outliers, skewness, or patterns that could affect the performance of machine learning models. Additionally, these visualizations can offer insights into the feature scaling requirements for the data.

Histograms of numerical variables in the CKD dataset.
Data preprocessing
The data was normalized and validated, missing values were estimated, and outliers were removed during preparation. It is possible for an incomplete or incorrect set of measures to be used in a patient’s evaluation. Additionally, the dataset is incomplete, as it lacks information for all but 158 instances. Ignoring records is the easiest method for dealing with missing values; however, this is impractical except for very tiny data sets. During data preparation, the dataset is checked for missing attribute values. Mean imputation was used to provide an educated estimate for the missing numeric attributes. The mode approach was employed to impute missing nominal feature values. Category values must be encoded into numbers to feed the dataset into a machine-learning model. Categories such as “no” and “yes” are represented by the binary numbers “0” and “1,” respectively.
The selected method of imputation, such as mean and mode imputation, is crucial in preserving the integrity of the dataset. Other developmental imputation methods, such as K-Nearest Neighbors imputation or multiple imputation, could be further explored in future work to enhance data accuracy.
On the other hand, data transformation is applied to ensure that no single variable has an outsized impact on the final results. If the unit of measure is not specified, then learning algorithms always interpret greater values as higher and smaller ones as lower. Its values are often transformed to prepare a dataset for subsequent analysis42. To enhance the precision of machine learning models, this study employs a normalization method to refine the underlying data. From a negative one to a positive one, it transforms data. The transformed information has a mean of zero and a standard deviation of one. The formula for standardization is applied as follows:
where, the observed value is denoted by x, the standard deviation is denoted by \(\sigma\), the standardized score is denoted by w, and the mean is denoted by \(\hat{x}\).
Apart from normalization, scaling methods (such as Min-Max Scaling) of the features could be investigated to reduce convergence times for specific ML models, especially for deep learning models. Scaling ensures an equal contribution of all features to the model’s predictions, eliminating feature dominance due to its extensive range.
Points in the data that don’t fit in with the rest are called outliers. An outlier result may be due to a measurement error or random chance. An outlier can skew the results of a machine learning algorithm’s training phase. The outcomes include longer training times, decreased model accuracy, and worse performance. When cleaning data for a learning system, the authors of this study employ an IQR-based technique42.
It is here that methods such as the Z-score or IQR method become crucial in improving model accuracy. It is also beneficial for future researchers to consider more advanced techniques, such as isolation forests or one-class SVMs, to identify and manage outliers more efficiently, particularly in high-dimensional medical data.
Although the primary goal of this research is to classify patients into either ckd or notckd, the underlying predictive task was approached through a regression framework. This design enables the neural network to generate a continuous output score that reflects the likelihood of CKD presence. Such a probabilistic interpretation offers greater flexibility, especially in medical contexts where decision thresholds may vary depending on the patient’s risk profile. After the regression model generates a score between 0 and 1, a threshold (commonly 0.5) is applied to convert the output into a binary classification. This strategy not only enables the use of traditional classification metrics, such as accuracy, Sensitivity, and F1-Score, but also supports evaluation using regression-based metrics, including MSE, RMSE, and R-squared, providing a more comprehensive assessment of model performance.
Despite its advantages, applying SMOTE introduces the potential risk of overfitting, as it synthetically generates new samples that may closely resemble existing minority class instances. Overfitting occurs when the model memorizes training data-including the synthetic examples-instead of learning generalizable patterns. To mitigate this issue, this study incorporates multiple regularization strategies, including dropout layers within the neural network, early stopping during training, and rigorous cross-validation. These mechanisms collectively reduce the risk of overfitting and ensure that the model maintains robust generalization capability when evaluated on unseen test data.
Feature selection
Recursive structure elimination (RFE) is a recursive process that recursively removes features, constructing a model based on eliminating other features43. It employs a greedy search algorithm to identify the subset of features that is most effective in achieving its goals. Utilize the model’s accuracy to ascertain which features best predict a feature. It generates models iteratively, evaluating each feature at each stage of development to determine if it is an improvement or a regression. Afterward, the features are organized into categories according to the order in which they were eliminated. If the data set comprises N functions, recursive feature elimination will eagerly seek a combination of 2N features in the worst-case scenario. This is because N is the number of functions in the data set.
In addition to RFE, alternative feature selection methods include L1 regularization (Lasso) and tree-based methods, such as Random Forest feature importance, which can enhance the robustness of the feature selection process. These approaches may provide new insights into the importance of distinguishing the most predictive features.
Regression model
The regression model adopted for predicting CKD is a deep neural network. The suggested model comprises 12 layers: an input layer, followed by five dense layers, five dropout layers, and an output dense classifier layer. Each thick layer is directly connected within this design using a feed-forward mechanism. The layer is constructed so that the outputs of its activation maps are passed on as input to all subsequent layers. This model’s dropout layer is situated between two thick layers, with drop rates of 0.5, 0.4, 0.3, 0.2, and 0.1, respectively. The CNN model has several hyperparameters that require optimization to function correctly. Selecting the ideal hyperparameters involves experimentation; nonetheless, it is a laborious, time-consuming, and complex process. During the training phase, the Adam44 optimizer implements hyperparameters with reduced parameter sizes. Adam determines individual learning rates for various hyperparameter grades via adaptive assessment. These grades range from first to second-order gradients. Adam is a more time and resource-effective algorithm than stochastic gradient optimization (SGD)45. It requires a small amount of both learning time and memory to master. The proper activation function of a CNN contributes to an improvement in classification performance. Sigmoid, tan, Rectified Linear Unit (ReLU)46, Exponential Linear Unit (ELU)47, and Self-Normalized Linear Unit (SELU)48 are the typical activation functions for neural networks. In this study, many activation functions were applied to the CKD data set, and the results were compared to see which performed best across all models. Apart from DNN, other regression models, such as Support Vector Regression (SVR) or Random Forest Regression, can be applied to evaluate their performance in comparison to DNN. A possible contribution to the prediction accuracy of CKD by hybrid models using these regression techniques with ensemble learning techniques may also be promising.
Waterwheel optimization algorithm
The Waterwheel plant (Aldrovanda vesiculosa) features fascinating carnivorous traps positioned on broad petioles, resembling miniature, translucent versions of Venus flytraps, measuring approximately 1/12 inch. These remarkable structures are protected by a ring of bristle-like hairs that prevent accidental damage from contact with other aquatic vegetation. Each trap’s perimeter contains multiple hook-shaped teeth that interlace securely when capturing prey, similar to the mechanism found in Venus flytraps. The interior houses approximately forty sensitive trigger hairs-significantly more than the 6-8 found in Venus flytraps, which activate the rapid closure mechanism upon single or multiple stimulations. Beyond these trigger structures, the plant possesses specialized acid-secreting glands that facilitate the digestion of its prey. Once captured, victims become trapped by the interlocking teeth and mucus sealant, which creates a watertight enclosure that forces the prey toward the trap’s base, near the hinge joint. The digestive process expels most of the water content while breaking down the trapped organism. Each Aldrovanda trap maintains functionality for two to four capture cycles before requiring replacement, paralleling the lifecycle of Venus flytrap mechanisms49.
These aquatic traps rank among nature’s most rapid and efficient carnivorous mechanisms, achieving closure within milliseconds after the activation of their trigger hairs. This lightning-fast response represents a crucial evolutionary adaptation, enabling the plant to capture swift-moving aquatic prey before it can escape. The closure mechanism relies on hydraulic pressure dynamics combined with rapid cellular expansion, achieved through precise manipulation of turgor pressure within the trap’s cellular walls.
The Waterwheel Optimization Algorithm (WWPA) draws inspiration from these highly effective, rapid, and selective capturing strategies, translating them into computational optimization techniques. By emulating the plant’s ability to identify and secure high-value targets while discarding less promising alternatives, WWPA offers a novel and powerful approach to solving complex optimization challenges, particularly excelling in high-dimensional problems with noisy objective functions.
Initialization
WWPA operates as a population-based metaheuristic that iteratively improves solutions through the collective search capabilities of its population members within the solution space. Each waterwheel within the WWPA population represents a potential solution characterized by its position in the search space, with parameter values corresponding to problem variables. Mathematically, each waterwheel can be expressed as a solution vector, with the entire population forming the complete solution set represented by Eq. 2. The algorithm initializes waterwheel positions randomly throughout the search space using Eq. 3.
Denoting the number of water wheels, and the number of variables by N and m, respectively, \(r_{i,j}\) is a random number[0, 1],\(lb_j\) and \(ub_j\) are the lower bound and upper bound of the j-th problem variable, and P are populations of locations of water wheel. Pi – i- th waterwheel (candidate solution), \(p_{i,j}\)- its j-th dimension (problem variable).
Since each waterwheel corresponds to a unique solution, we can evaluate the objective function for every individual in the population. The objective function values can be efficiently represented using the vector format shown in Eq. 4.
The vector F contains all objective function evaluations, with \(F_i\) representing the fitness value for the i-th waterwheel. These objective function evaluations serve as the primary criterion for solution ranking, where the optimal candidate solution corresponds to the highest objective function value. In contrast, the poorest solution exhibits the lowest value. The best solution evolves dynamically as waterwheels navigate the search space with varying velocities across different iterations.
Phase 1: Prey Detection and Hunting Behavior (Exploration)
Waterwheels demonstrate exceptional predatory capabilities through their acute sensory mechanisms, enabling them to detect and track potential prey with excellent efficiency. Upon detecting nearby insects, the waterwheel initiates an aggressive pursuit sequence, systematically locating, attacking, and capturing the target. WWPA models this behavioral pattern in its initial population update phase, simulating the waterwheel’s attack strategy against insect colonies and the subsequent positional adjustments within the search space. This modeling approach enhances WWPA’s exploratory capabilities, improving its ability to identify promising regions while avoiding local optima traps. The algorithm calculates new waterwheel positions during prey approach using the following equations, where position updates are accepted only if they result in improved objective function values.
When solutions fail to improve over three consecutive iterations, the algorithm applies the following position update mechanism to maintain search diversity:
where \(\overrightarrow{r}_1\) and \(\overrightarrow{r}_1\) are random variables with values in the range [0, 2] and [0, 1], respectively. In addition, K is an exponential variable with values in the range [0, 1], \(\overrightarrow{W}\) is a vector that indicates the circle’s diameter in which the waterwheel plant will search for the promising areas.
Phase 2: Prey transport to digestive chamber (Exploitation)
Following successful prey capture, the waterwheel transports the captured insect into its specialized digestive tube through a tightly controlled process. WWPA’s second phase emulates this behavior, focusing on intensifying the search around promising areas that have already been discovered. This exploitation mechanism enhances local search capabilities by attracting solutions toward the neighborhood of high-quality candidates, creating refined positional adjustments within the search space. The algorithm generates new random positions representing optimal feeding locations for each waterwheel, implementing position updates only when improvements to the objective function are achieved.
where \(\overrightarrow{r}_3\) is a random variable with values in the range [0, 2], \(\overrightarrow{P}(t)\) is the current solution at iteration t, and \(\overrightarrow{P}_{best}\) is the best solution.
Similar to the exploration phase, the algorithm applies mutation when solutions stagnate for three iterations, preventing local minima entrapment:
The variables F and C are random parameters within \([-5, 5]\). The parameter K decreases exponentially throughout the optimization process according to:
Grey wolf optimization algorithm
The gray wolf optimizer recreates the behaviors of wolves as they hunt for their prey by simulating their motions. Wolves are social animals that live in groups called packs, which can range in size from five to twelve members. Four distinct types of wolves comprise a single pack: alpha, beta, delta, and omega. The choices that are made in each pack are made by the alpha wolf. The beta wolves provide assistance to the alpha wolves in decision-making. The wolves of the delta pack are submissive to the alpha and beta packs. The omega wolves are the most submissive of the pack. The alpha (\(\overrightarrow{L}_\alpha\)) solution is considered to be the optimal one according to mathematical standards; the beta (\(\overrightarrow{L}_\beta\)) and delta (\(\overrightarrow{L}_\delta\)) solutions, on the other hand, take second and third place, respectively. Other potential solutions are denoted with the omega symbol (\(\overrightarrow{L}_\omega\)). As seen in Eqs. 12, 13, 14, and 15, the alpha, beta, and delta wolves serve as guides for the other wolves as they pursue and ultimately capture their prey.
If t is the current iteration, \(\overrightarrow{A}\) and \(\overrightarrow{C}\) are vectors representing the coefficients, \(\overrightarrow{L}_p\) is the location of the prey, and G stands for the position of the wolf. The \(\overrightarrow{A}\) and \(\overrightarrow{C}\) vectors may be calculated as follows:
Where the components of \(\overrightarrow{a}\) are decreasing linearly from 2 to 0 during the iterations, and the values of vectors \(\overrightarrow{r}_1\) and \(\overrightarrow{r}_2\) are random in the range [0, 1]. The value of the parameter \(\overrightarrow{a}\) is adjusted, and it is used to maintain a healthy equilibrium between the exploration and exploitation processes50. The values of \(\overrightarrow{a}\) are found by computing them according to the following equation:
Where \(M_t\) refers to the total number of possible iterations that the optimizer has access to.
As \(\overrightarrow{a}\) decreases over time, the optimizer shifts from an exploration phase (at the beginning of the iterations) to an exploitation phase (as it gets closer to an optimal solution). This shift ensures that the optimization process is both robust and adaptive, enabling it to avoid premature convergence.
The top three solutions, \(\overrightarrow{L}_\alpha\), \(\overrightarrow{L}_\beta\), and \(\overrightarrow{L}_\delta\), direct other individuals to modify their locations so that they are closer to the predicted location of the prey. Equations 17 and 18 show the process of updating the wolves’ positions.
Where \(\overrightarrow{A}_1\), \(\overrightarrow{A}_2\), and \(\overrightarrow{A}_3\) are determined using the Eq. from Eq. 15, and \(\overrightarrow{C}_1\), \(\overrightarrow{C}_2\), and \(\overrightarrow{C}_3\) are determined using the Eq. from Eq. 15. The current locations of the population, denoted by \(\overrightarrow{L}(t + 1)\), may be stated as an average of the three solutions denoted by \(\overrightarrow{L}_1\), \(\overrightarrow{L}_2\), and \(\overrightarrow{L}_3\) derived from Eq. 17. This expression can be written as follows:
This averaging process ensures that the algorithm continues to improve its search for the optimal solution by leveraging the collective strength of the three best solutions at each iteration. This approach not only accelerates convergence but also enhances the robustness of the algorithm by reducing the likelihood of being trapped in local minima.
Moreover, the algorithm’s flexibility can be further enhanced through the use of advanced strategies, such as multi-dimensional adaptation and hybrid approaches, which combine the strengths of GWO with other optimization techniques, thereby enabling better handling of more complex or multi-modal optimization landscapes.
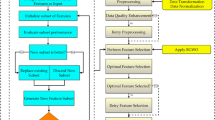
The basic structure of the model is illustrated in Fig. 2. The proposed optimization algorithm comprises three stages: preprocessing, model hyper-tuning, and classification. The preparation stage is critical since the data set may contain noise and redundant values. During this phase, various methodologies were employed, including those for handling missing values, encoding categorical data, data transformation, removing outliers and extreme values, and feature selection. Following the completion of the preprocessing step, the CKD dataset is partitioned into a training dataset and a testing dataset.

The architecture of the proposed methodology.
The proposed hybrid WWPA-GWO optimization algorithm
The procedure of the proposed optimization algorithm is presented in Algorithm 1. The proposed optimization algorithm relies on a highly balanced exploration-exploitation strategy, a desirable characteristic of contemporary metaheuristic optimization algorithms. In WWPA-GWO, exploration is conducted to discover new and potentially superior solutions. Simultaneously, the rest is done by narrowing down on the best solutions and optimising them.

WWPA-GWO algorithm.
Comparative metaheuristic algorithms
To evaluate the effectiveness of the proposed hybrid optimization framework for enhancing DNN training in early CKD prediction, a set of state-of-the-art metaheuristic algorithms was employed. These algorithms span multiple computational paradigms, including swarm intelligence, evolutionary computation, and bio-inspired stochastic search, and were utilized solely for optimizing the internal parameters (weights and biases) of the DNN, without applying any feature selection strategies.
The following optimization algorithms were utilized and benchmarked:
-
Waterwheel Plant Algorithm (WWPA): Inspired by the energy dynamics of waterwheels, this algorithm simulates torque and energy flow to guide search trajectories through complex solution spaces, promoting balanced exploration and exploitation51.
-
Grey Wolf Optimizer (GWO): Models the leadership hierarchy and collective hunting strategy of grey wolves, effectively balancing diversification and intensification through the guidance of alpha, beta, and delta wolves52.
-
Particle Swarm Optimization (PSO): Simulates the movement of particles influenced by their own and neighbors’ previous best positions, facilitating fast convergence in continuous and discrete optimization problems53.
-
Whale Optimization Algorithm (WOA): Emulates the bubble-net feeding mechanism of humpback whales, combining encircling and spiral movements for adaptive local and global search54.
-
Genetic Algorithm (GA): Based on evolutionary biology, GA applies natural selection, crossover, and mutation to iteratively evolve better solutions, fostering robustness and diversity in the search process55.
-
Firefly Algorithm (FA): Inspired by firefly bioluminescence and attraction behavior, FA explores the search space based on light intensity and spatial distance, enabling multiple optima discovery56.
-
Harris Hawks Optimization (HHO): Mimics the cooperative and intelligent hunting style of Harris hawks, dynamically switching between exploratory and exploitative phases based on the prey’s energy57.
-
Fast Evolutionary Programming (FEP): An improved evolutionary programming variant using Gaussian mutation and competitive selection to speed up convergence while maintaining solution quality58.
-
Stochastic Fractal Search (SFS): Employs a diffusion and local intensification mechanism modeled on fractal growth, which enhances the exploration of high-dimensional and non-linear search spaces59.
By applying these algorithms to the same DNN structure, the study establishes a fair and comprehensive evaluation of their comparative performance, demonstrating the superiority of the proposed hybrid model in terms of accuracy, convergence speed, and robustness for CKD prediction.
Evaluation metrics
To comprehensively assess the predictive accuracy and statistical robustness of the proposed hybrid optimization model for early CKD detection, a suite of standard regression-based performance metrics was employed. These metrics quantify various aspects of prediction quality, including error magnitude, variance explanation, correlation strength, and model agreement with actual observations. Their integration provides a multidimensional view of model performance, enabling fair comparison with existing approaches.
Table 3 summarizes the mathematical expressions and interpretative roles of each metric used in this study. These include both traditional measures-such as Mean Squared Error (MSE), Root Mean Squared Error (RMSE), and Mean Absolute Error (MAE)-and advanced statistical indicators like Nash–Sutcliffe Efficiency (NSE) and Willmott’s Index of Agreement (WI), which are particularly useful in model validation for medical forecasting applications.
The collective use of these evaluation metrics enables a nuanced understanding of the model’s generalization capability, robustness, and practical applicability for clinical decision-making.
Experimental results
In this section, the results obtained using the proposed methodology are discussed. The adopted dataset is first preprocessed, and the proposed optimization algorithm is then trained, and its parameters are optimized using the proposed algorithm. Then, a promising model is selected and used for further experimentation. The adopted model is optimized using the suggested optimization algorithm, and the results of the chronic disease prediction for this model are presented and discussed in this section.
Experimental setup
In this study, all algorithms were evaluated under identical experimental conditions to ensure the fairness of comparison. The details of the parameter configurations are provided in Table 4. Each optimizer was executed with its respective parameter ranges, ensuring consistency across the evaluation process. The population size and number of iterations were kept constant for all methods. In contrast, algorithm-specific parameters such as random numbers, learning factors, and mutation or crossover probabilities were set according to their typical configurations. This uniform setup guarantees that performance differences arise from the inherent characteristics of the algorithms rather than unequal parameter tuning.
To further enhance reproducibility and transparency, Table 5 summarizes the key hyperparameters of the DNN used in this study. These include the architecture configuration, activation functions, learning rate, dropout strategy, batch size, and optimization algorithm. Such detailed reporting ensures that other researchers can accurately reproduce the model setup.
By providing this summary, the experimental design becomes fully transparent, enabling reproducibility and allowing future studies to benchmark or extend the proposed WWPA–GWO-optimized DNN under comparable configurations.
Regression models evaluation
The results tabulated in Table 6 give an exhaustive overview of the effectiveness of various regression models in predicting CKD. Such an exploration provides valuable insights into the suitability of these models for medical diagnosis and prognosis. Firstly, it is essential to assess the predicted accuracy, and measures such as MSE, RMSE, and MAE are helpful for this task. Lower ones represent better prediction performance for all criteria. The Multilayer Perceptron model achieved better performance compared to other models under consideration, with the lowest values of MSE=0.00177, RMSE=0.04202, and MAE=0.01002, validating the fact that the MLP model’s output is most comparable to the actual values.
The distributions of MSE, RMSE, and MAE appear in the first three subplots of Fig. 3. The fourth subplot in this analysis displays MBE values, indicating systematic prediction biases present in the models.

Mixed plot (Density + KDE) for the distribution of performance metrics: MSE, RMSE, MAE, MBE, r, \(R^2\), RRMSE, NSE, and WI.
The simultaneous display of evaluation metric behavior across multiple regression models is illustrated in Fig. 4 using a parallel coordinates plot. A set of evaluation metrics that includes MSE, RMSE, MAE, MBE, r, \(R^2\), RRMSE, NSE and WI appears in this figure.

Parallel coordinates plot showing the performance of baseline regression models across various evaluation metrics.
MSE distributions appear with RMSE and MAE in the first row of Fig. 5. The second row includes MBE, r, and \(R^2\). The third row provides density distributions of RRMSE, NSE, and WI. The graphical representations offer viewers with a clearer understanding of how each metric behaves and varies across models.

Density and Kernel Density Estimation (KDE) plots of the performance metrics: MSE, RMSE, MAE, MBE, r, \(R^2\), RRMSE, NSE, and WI.
Optimization algorithm results
The findings presented in Table 7 provide a comprehensive perspective on the predictive performance of various optimization methods when applied to the goal of improving the prediction of CKD. The proposed optimization algorithm is shown to outperform the other nine optimization methods. These models have been thoroughly examined using a variety of important performance measures, which have shed light on their efficacy in producing accurate predictions and assisting medical diagnosis. Let’s start by concentrating on MSE and RMSE. These metrics provide an essential measure for predicting accuracy, with lower values indicating better performance. The WWPA-GWO model stands out from its competitors because it has the lowest mean squared error (MSE) \(3.06 \times 10^{-6}\) and root mean squared error (RMSE) of 0.00175.
MSE optimization trends become visible through cubic spline interpolation in Fig. 6. The precise examination of performance differences between models becomes possible due to MSE values, which smoothly advance throughout the tested models. The displays enable users to observe which optimization methods yield the lowest error rates, facilitating easier comparison of predictive outcomes.

Spline interpolation of the MSE trend across the optimization algorithms.
The performance assessment of the optimization algorithms is presented in Fig. 7, which utilizes bar charts to facilitate easy comparison of multiple metrics. The different subplots in this figure display the quantitative performance results for MSE, RMSE, MAE, MBE, r, \(R^2\), RRMSE, NSE, and WI. The facet grid design enables direct performance comparison of algorithms by placing them side by side, allowing users to easily see predictive variations.

Facet grid of bar charts illustrating the performance of the optimization algorithms across multiple evaluation metrics.
When applied to the problem of CKD prediction, the findings of the given ANOVA test, presented in Table 8, provide valuable insights into the statistical significance of the suggested optimized deep network. ANOVA is a robust technique that enables us to compare the means of various groups. This allows us to determine whether there are significant differences between these groups. In this case, the “Treatment” group refers to the ten different optimization algorithms applied to the proposed optimization algorithm, whereas the “Residual” group is responsible for accounting for the variability within each of these models. The “Total” numbers represent the entire range of variation that may be found in the dataset.
When applied to predicting CKD using an optimized deep network, the findings of the Wilcoxon signed-rank test reported in Table 9 provide valuable insights into the efficacy of various optimization algorithms. This non-parametric statistical test is invaluable for comparing the paired observations of various algorithms, as it helps determine whether there are significant variations in the performance of each algorithm. The number for each algorithm’s “Theoretical median” is set to 0, suggesting that, in theory, there should be no substantial difference between the algorithms’ performances. This value is set to be the same for all algorithms.
Figure 8 shows how performance metrics from optimization algorithms are distributed through the usage of a histogram plot. This chart makes it easy to see how different evaluated methods perform because it shows the distribution of metric values. Identifying regular performance behavior becomes possible through this type of analysis, along with detecting algorithms that successfully reach target range values.

Histogram illustrating the distribution of performance metric values across the optimization algorithms.
Figure 9 reveals three subplots that show residual distributions as (1) residuals versus fitted values and (2) standardized residuals versus fitted values, along with (3) residuals versus leverage for detecting heteroscedasticity and non-linearity, and extreme points. The fourth display evaluates the normality of residuals using a Q-Q plot, which compares the actual quantiles of the residuals to theoretical distributions.

Regression diagnostic plots including residual analysis, Q-Q plot, and residual heatmap for evaluating model assumptions and fit quality.
The comparison of performance variability between optimization algorithms is presented in Fig. 10, which utilizes error bars with individual markers for each model. The visualization approach effectively represents both location information about performance metrics and their spread statistics, enabling users to better understand model stability.

Scatter plot with error bars and distinct markers for the optimization algorithms, representing mean performance and variability across models.
The findings of the statistical analysis of the prediction of chronic renal disease using the proposed optimization algorithm give significant insights into the performance and features of various optimization techniques as presented in Table 10. These results shed light on various statistical features and metrics that help evaluate the models’ dependability and stability. When we first look at the column labeled “Number of values,” we see that each method was tested using the same dataset with ten different examples. Because of this consistency, it is possible to compare their respective performances accurately. The various measures of central tendency, including “Minimum,” “25% Percentile,” “Median,” “75% Percentile,” and “Maximum,” provide a comprehensive perspective on the distribution of prediction errors produced by the different algorithms.
Conclusion
Chronic Kidney Disease represents a growing global health challenge, primarily driven by diabetes and hypertension. Traditional diagnostic approaches rely heavily on Glomerular Filtration Rate measurements and other indicators of kidney dysfunction, yet early detection remains problematic in clinical practice. Since CKD involves progressive renal function deterioration and significantly increases mortality risk, timely diagnosis becomes crucial for improving patient outcomes and reducing disease-related deaths.
This research addresses the diagnostic challenge by introducing an innovative early prediction framework based on an optimized deep neural network. Our approach leverages a novel hybrid optimization algorithm that combines the strengths of the waterwheel plant algorithm with grey wolf optimization techniques, creating a powerful synergy for enhanced predictive performance.
We conducted comprehensive evaluations using multiple prediction models to validate the effectiveness of our proposed method. To demonstrate the superiority of our hybrid optimization approach, we benchmarked it against ten established optimization algorithms applied to identical deep network architectures. The comparative analysis revealed significant improvements in prediction accuracy, computational efficiency, and overall model performance.
Our multilayer perceptron model exhibited a remarkable transformation following optimization, with the mean squared error decreasing from 0.00177 to \(3.06 \times 10^{-6}\), and computational time reducing to just 0.0999 seconds. These substantial improvements demonstrate both enhanced accuracy and operational efficiency.
Statistical validation through rigorous testing frameworks, including ANOVA and Wilcoxon signed-rank tests, confirmed the statistical significance of our improvements. The ANOVA results yielded a highly significant P-value of <0.0001, while the Wilcoxon signed-rank test produced a P-value of 0.002, both of which strongly support the superiority of our method over conventional approaches.
This work contributes a promising solution for early CKD detection, potentially enabling healthcare providers to intervene earlier in disease progression and ultimately improve patient outcomes in clinical practice.
Despite the promising results, this study has several limitations. First, the dataset used may not fully represent the heterogeneity of broader clinical populations, which may affect generalizability. Second, while the hybrid WWPA-GWO algorithm demonstrated superior performance, it is computationally intensive and has yet to be validated in real-time or clinical settings. Third, the model’s interpretability remains limited-a crucial factor for clinical adoption. Future work should explore the integration of explainable AI tools, larger and more diverse datasets, and real-world clinical deployment to overcome these limitations.
Data availability
The dataset used in this study can be found in https://archive.ics.uci.edu/dataset/336/chronic+kidney+disease
References
Foreman, K. J., Marquez, N., Dolgert, A. & Fukutaki, K. Fullman: Forecasting life expectancy, years of life lost, and all-cause and cause-specific mortality for 250 causes of death: Reference and alternative scenarios for 2016–40 for 195 countries and territories. Lancet (London, England) 392(10159), 2052–2090. https://doi.org/10.1016/S0140-6736(18)31694-5 (2018).
Vanholder, R., Annemans, L. & Brown, E. Gansevoort: Reducing the costs of chronic kidney disease while delivering quality health care: A call to action. Nat. Rev. Nephrol. 13(7), 393–409. https://doi.org/10.1038/nrneph.2017.63 (2017).
2020 WKD Theme - World Kidney Day. (2019). https://www.worldkidneyday.org/2020-campaign/2020-wkd-theme/, Accessed 2023-10-08
Jha, V. et al. Chronic kidney disease: Global dimension and perspectives. The Lancet 382(9888), 260–272. https://doi.org/10.1016/S0140-6736(13)60687-X (2013).
Kidney Disease. https://www.kidney.org/kidneydisease/global-facts-about-kidneydisease Accessed 2023-10-08
Chapter 1: Definition and classification of CKD. Kidney International Supplements 3(1), 19–62 (2013) https://doi.org/10.1038/kisup.2012.64
Chen, T. K., Knicely, D. H. & Grams, M. E. Chronic kidney disease diagnosis and management: A review. JAMA 322(13), 1294. https://doi.org/10.1001/jama.2019.14745 (2019).
Gürbüz, E. & Kılıç, E. A new adaptive support vector machine for diagnosis of diseases. Expert. Syst. 31(5), 389–397. https://doi.org/10.1111/exsy.12051 (2014).
Mahyoub, M., Randles, M., Baker, T., Yang, P.: Comparison Analysis of Machine Learning Algorithms to Rank Alzheimer’s Disease Risk Factors by Importance. In: 2018 11th International Conference on Developments in eSystems Engineering (DeSE), pp. 1–11. IEEE, Cambridge, United Kingdom (2018). https://doi.org/10.1109/DeSE.2018.00008
Kumar, A., Singh, J. & Khan, A. A. A comprehensive machine learning framework with particle swarm optimization for improved polycystic ovary syndrome (pcos) diagnosis. Eng. Res. Expr. 6(3), 035233. https://doi.org/10.1088/2631-8695/ad76f9 (2024).
Sharma, A. et al. A systematic review on machine learning intelligent systems for heart disease diagnosis. Arch. Computat. Meth. Eng. https://doi.org/10.1007/s11831-025-10271-2 (2025).
Dhanka, S. et al. Advances in machine learning and deep learning for hormonal disorder diagnosis: An exhaustive review on PCOS, thyroid, and optimization techniques. Arch. Comput. Meth. Eng. https://doi.org/10.1007/s11831-025-10380-y (2025).
Kumar, A., Singh, J., Khan, A.A.: Arrhythmia detection using machine learning: A study with uci arrhythmia dataset. In: Bhateja, V., Patel, P., Tang, J. (eds.) Evolution in Computational Intelligence, pp. 217–226. Springer (2025). https://doi.org/10.1007/978-981-96-2124-8_16
Lai, W. et al. Skin cancer diagnosis (scd) using artificial neural network (ann) and improved gray wolf optimization (igwo). Sci. Rep. 13(1), 19377. https://doi.org/10.1038/s41598-023-45039-w (2023).
Ghafariasl, P., Zeinalnezhad, M. & Chang, S. Fine-tuning pre-trained networks with emphasis on image segmentation: A multi-network approach for enhanced breast cancer detection. Eng. Appl. Artif. Intell. 139, 109666. https://doi.org/10.1016/j.engappai.2024.109666 (2025).
Dhanka, S., Sharma, A., Kumar, A., Maini, S. & Vundavilli, H. Advancements in hybrid machine learning models for biomedical disease classification using integration of hyperparameter-tuning and feature selection methodologies: A comprehensive review. Arch. Computat. Meth. Eng. https://doi.org/10.1007/s11831-025-10309-5 (2025).
Ilyas, H. et al. Chronic kidney disease diagnosis using decision tree algorithms. BMC Nephrol. 22(1), 273. https://doi.org/10.1186/s12882-021-02474-z (2021).
AhmedK, A., Aljahdali, S. & Naimatullah Hussain, S. Comparative prediction performance with support vector machine and random forest classification techniques. Int. J. Comput. Appl. 69(11), 12–16. https://doi.org/10.5120/11885-7922 (2013).
Yan, Z. et al. China National Survey of Chronic Kidney Disease Working Group: Hypertension control in adults with CKD in China: Baseline Results From the Chinese Cohort Study of Chronic Kidney Disease (C-STRIDE). Am. J. Hypertens. 31(4), 486–494. https://doi.org/10.1093/ajh/hpx222 (2018).
B.V, R., Sriraam, N., Geetha, M. (2017) Classification of non-chronic and chronic kidney disease using SVM neural networks. Int. J. Eng. Technol., 7(13), 191 https://doi.org/10.14419/ijet.v7i1.3.10669
Elhoseny, M., Shankar, K. & Uthayakumar, J. Intelligent diagnostic prediction and classification system for chronic kidney disease. Sci. Rep. 9(1), 9583. https://doi.org/10.1038/s41598-019-46074-2 (2019).
Li, H., Zhang, Y. & Zhang, C. Development and validation of machine learning models for osteoporosis prediction in chronic kidney disease patients: Data from national health and nutrition examination survey. Digital health https://doi.org/10.1177/20552076251357758 (2025).
Sun, F. et al. Machine learning and transcriptomic analysis identify tubular injury biomarkers in patients with chronic kidney disease. Int. Urol. Nephrol. https://doi.org/10.1007/s11255-025-04636-6 (2025).
Jiang, L., Wang, H., Xiao, Y., Xu, L. & Chen, H. Exploring the association between volatile organic compound exposure and chronic kidney disease: Evidence from explainable machine learning methods. Ren. Fail. https://doi.org/10.1080/0886022X.2025.2520906 (2025).
Alghwiri, A. A. et al. Using machine learning to predict medication therapy problems among patients with chronic kidney disease. Am. J. Nephrol. https://doi.org/10.1159/000546540 (2025).
Liu, Y., Wang, Y., Nie, W. & Wang, Z. Identification of biomarkers for the diagnosis of chronic kidney disease (ckd) with dilated cardiomyopathy (dcm) by bioinformatics analysis and machine learning. Front. Genet. https://doi.org/10.3389/fgene.2025.1562891 (2025).
Cao, M., Tang, B., Yang, L. & Zeng, J. Machine learning-based prediction model for cognitive impairment risk in patients with chronic kidney disease. PLoS ONE https://doi.org/10.1371/journal.pone.0324632 (2025).
Yang, B. et al. Identification and validation of inflammatory response genes linking chronic kidney disease with coronary artery disease based on bioinformatics and machine learning. Sci. Rep. https://doi.org/10.1038/s41598-025-03622-3 (2025).
Bialonczyk, U. et al. Balancing accuracy and cost in machine learning models for detecting medial vascular calcification in chronic kidney disease: Apilot study. Sci. Rep. https://doi.org/10.1038/s41598-025-02457-2 (2025).
Islam, M. M., Poly, T. N., Okere, A. N. & Wang, Y.-C. Explainable machine learning model incorporating social determinants of health to predict chronic kidney disease in type 2 diabetes patients. J. Diabetes Metab. Disord. https://doi.org/10.1007/s40200-025-01621-9 (2025).
Lin, H. et al. Exploring the influencing factors of abdominal aortic calcification events in chronic kidney disease (ckd) and non-ckd patients based on interpretable machine learning methods. Int. Urol. Nephrol. https://doi.org/10.1007/s11255-025-04564-5 (2025).
Chowdhury, M. N. H. et al. Deep learning for early detection of chronic kidney disease stages in diabetes patients: A tabnet approach. Artif. Intell. Med. https://doi.org/10.1016/j.artmed.2025.103153 (2025).
Wu, J. et al. Explainable machine learning prediction of 1-year kidney function progression among patients with type 2 diabetes mellitus and chronic kidney disease: A retrospective study. QJM: monthly journal of the Association of Physicians https://doi.org/10.1093/qjmed/hcaf101 (2025).
Hsu, C.-T. et al. Machine learning models to predict osteoporosis in patients with chronic kidney disease stage 3–5 and end-stage kidney disease. Sci. Rep. https://doi.org/10.1038/s41598-025-95928-5 (2025).
Lu, R. et al. Predictive model for sarcopenia in chronic kidney disease: A nomogram and machine learning approach using charls data. Front. Med. https://doi.org/10.3389/fmed.2025.1546988 (2025).
Tang, Y. et al. Deep learning for the prediction of acute kidney injury after coronary angiography and intervention in patients with chronic kidney disease: A model development and validation study. Ren. Fail. https://doi.org/10.1080/0886022X.2025.2474206 (2025).
Broecke, E. V. et al. Early detection of feline chronic kidney disease via 3-hydroxykynurenine and machine learning. Sci. Rep. https://doi.org/10.1038/s41598-025-90019-x (2025).
Chandralekha, E., Saravanan, T. R. & Vijayaraj, N. Clinical decision system for chronic kidney disease staging using machine learning. Technol. Health Care: Off. J. Eur. Soci. Eng. Med. https://doi.org/10.1177/09287329251316447 (2025).
Zhang, B., Chen, L. & Li, T. Unveiling the effect of urinary xenoestrogens on chronic kidney disease in adults: A machine learning model. Ecotoxicol. Environ. Saf. https://doi.org/10.1016/j.ecoenv.2025.117945 (2025).
Sághy, E. et al. A novel machine learning methodology for the systematic extraction of chronic kidney disease comorbidities from abstracts. Front. Digit. Health https://doi.org/10.3389/fdgth.2025.1495879 (2025).
Kwiendacz, H. et al. Predicting major adverse cardiac events in diabetes and chronic kidney disease: A machine learning study from the silesia diabetes-heart project. Cardiovasc. Diabetol. https://doi.org/10.1186/s12933-025-02615-w (2025).
Han, J. & Kamber, M. Data mining: Concepts and techniques 3rd edn. (Elsevier, 2012).
Saeys, Y., Inza, I. & Larrañaga, P. A review of feature selection techniques in bioinformatics. Bioinformatics 23(19), 2507–2517. https://doi.org/10.1093/bioinformatics/btm344 (2007).
Brantner, B.: Generalizing Adam To Manifolds For Efficiently Training Transformers. arXiv:2305.16901 [cs, math] (2023).
Lu, J.: Gradient Descent, Stochastic Optimization, and Other Tales. arXiv:2205.00832 [cs, math] (2022).
Jahan, I., Ahmed, M. F., Ali, M. O. & Jang, Y. M. Self-gated rectified linear unit for performance improvement of deep neural networks. ICT Express 9(3), 320–325. https://doi.org/10.1016/j.icte.2021.12.012 (2023).
Catalbas, B. & Morgul, O. Deep learning with ExtendeD Exponential Linear Unit (DELU). Neural Comput. Appl. 35(30), 22705–22724. https://doi.org/10.1007/s00521-023-08932-z (2023).
Klambauer, G., Unterthiner, T., Mayr, A., Hochreiter, S.: Self-Normalizing Neural Networks. arXiv:1706.02515 [cs, stat] (2017).
Abdelhamid, A. A. et al. Waterwheel Plant Algorithm: A Novel Metaheuristic Optimization Method. Processes 11(5), 1502. https://doi.org/10.3390/pr11051502 (2023).
El-Kenawy, E.-S.M., Eid, M. M., Saber, M. & Ibrahim, A. MbGWO-SFS: Modified binary grey wolf optimizer based on stochastic fractal search for feature selection. IEEE Access 8, 107635–107649. https://doi.org/10.1109/ACCESS.2020.3001151 (2020).
Abdelhamid, A. A. et al. Waterwheel plant algorithm: A novel metaheuristic optimization method. Processes 11(5), 5. https://doi.org/10.3390/pr11051502 (2023).
Mirjalili, S., Mirjalili, S. & Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 69, 46–61. https://doi.org/10.1016/j.advengsoft.2013.12.007 (2014).
Kennedy, J., Eberhart, R.: Particle swarm optimization. In: Proceedings of ICNN’95 - International Conference on Neural Networks, vol. 4, pp. 1942–1948 (1995). https://doi.org/10.1109/ICNN.1995.488968.
Mirjalili, S. & Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 95, 51–67. https://doi.org/10.1016/j.advengsoft.2016.01.008 (2016).
Reeves, C.: Genetic algorithms. In: Handbook of Metaheuristics. International Series in Operations Research & Management Science, vol. 146, pp. 109–139. Springer (2010). https://doi.org/10.1007/978-1-4419-1665-5_5 .
Johari, N., Zain, A., Mustaffa, N. & Udin, A. Firefly algorithm for optimization problem. Appl. Mech. Mater. 421, 512–517. https://doi.org/10.4028/www.scientific.net/AMM.421.512 (2013).
Heidari, A. A. et al. Harris hawks optimization: Algorithm and applications. Futur. Gener. Comput. Syst. 97, 849–872. https://doi.org/10.1016/j.future.2019.02.028 (2019).
Yao, X., Liu, Y. & Lin, G. Evolutionary programming made faster. IEEE Trans. Evol. Comput. 3(2), 82–102. https://doi.org/10.1109/4235.771163 (1999).
Salimi, H. Stochastic fractal search: A powerful metaheuristic algorithm. Knowl.-Based Syst. 75, 1–18. https://doi.org/10.1016/j.knosys.2014.07.025 (2014).
Acknowledgements
Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2025R754), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Author information
Authors and Affiliations
Contributions
D.K: Writing-original draft, Visualization, Software, Methodology, Formal analysis, Conceptualization. N.K: Writing-review & editing, Supervision, Project administration. E.K: Writing-review & editing and Visualization,A.A: Writing-review & editing, Validation.,M.E: Writing-review & editing, Validation S.K: Writing-original draft, Data curation.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Khafaga, D.S., Khodadadi, N., Khodadadi, E. et al. Enhanced early chronic kidney disease prediction using hybrid waterwheel plant algorithm for deep neural network optimization. Sci Rep 15, 42584 (2025). https://doi.org/10.1038/s41598-025-26382-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-26382-6
