
Abstract
Low-light image enhancement remains a challenging task, particularly in the absence of paired training data. In this study, we present LucentVisionNet, a novel zero-shot learning framework that addresses the limitations of traditional and deep learning-based enhancement methods. The proposed approach integrates multi-scale spatial attention with a deep curve estimation network, enabling fine-grained enhancement while preserving semantic and perceptual fidelity. To further improve generalization, we adopt a recurrent enhancement strategy and optimize the model using a composite loss function comprising six tailored components, including a novel no-reference image quality loss inspired by human visual perception. Extensive experiments on both paired and unpaired benchmark datasets demonstrate that LucentVisionNet consistently outperforms state-of-the-art supervised, unsupervised, and zero-shot methods across multiple full-reference and no-reference image quality metrics. Our framework achieves high visual quality, structural consistency, and computational efficiency, making it well-suited for deployment in real-world applications such as mobile photography, surveillance, and autonomous navigation.
Similar content being viewed by others


Introduction
Image acquisition is not always carried out under ideal conditions in terms of camera characteristics, ambient conditions, or acquisition angle. Poor illumination is one of the most prevalent and limiting problems for digital images1,2, particularly in indoor acquisition environments, at night, or due to camera constraints. The outcome is dark, noisy, low contrast, and poor perceptual quality images. This affects both the human perceptual experience and the performance of high-level semantic tasks such as object recognition, segmentation, and depth estimation. Possible solutions include modifying the surrounding environment or making changes to the camera characteristics, such as increasing the ISO or prolonging the exposure time. Ambient conditions can be improved only in controlled environments and are therefore not generally applicable. Moreover, increasing the ISO leads to higher noise levels-primarily due to read noise, thermal noise, shot noise, and other contributing factors. Similarly, increasing the exposure time might result in increased thermal noise, motion blur, camera shake, and overexposure, making it an unsuitable solution as well. Image editing software can also be used to enhance low-light images3; however, it has two key drawbacks. First, using such software requires expertise and can be time-consuming. Second, this approach often lacks automation, consistency, and speed, necessitating manual fine-tuning. In this work, we follow the zero-shot or zero-reference paradigm commonly adopted in recent low-light enhancement frameworks (e.g., Zero−DCE, Zero−DCE++), where the model is trained without paired ground-truth supervision and directly enhances unseen low-light inputs. This usage of “zero-shot” is distinct from semantic zero-shot learning in classification, and is instead meant to highlight the absence of paired references during both training and inference.
Quality of images is of vital importance for human visual experience4,5 as well as many high-level computer vision tasks such as autonomous driving, surveillance, scientific or medical imaging where preservation of semantic information is vital for interpretation and decision making6,7,8,9,10. For instance, low-light images may make it difficult to perform object recognition, anomaly identification, or face identification during surveillance or affect the visibility of the road and its surroundings, which is critical for safe navigation11,12,13,14,15,16.
Automated low-light image enhancement techniques can rescue the situation by improving the perceptual and semantic quality of these images. This leads to an enhanced perceptual experience, improved extraction of semantic information, and greater accuracy in interpretation7,17,18. Among the most striking benefits of automated low-light image enhancement methods are speed, consistency, and scalability. The problem is addressed via both traditional image processing algorithms and modern deep learning-based solutions. The approaches work by preserving the content and reducing artifacts, with an ability to be integrated into existing systems and making them compatible with a wide range of applications.
Among the traditional techniques, histogram-based methods19,20,21,22, exposure correction, image fusion, and Retinex-based methods are most prominent. Gamma correction23 and tone mapping24,25 are the most common methods to perform exposure correction. Histogram equalization and its variations, including BPDHE (Brightness Preserving Dynamic Histogram Equalization)22 and CLACHE (Contrast Limited Adaptive Histogram Equalization)21. Combining multiple images of a scene taken under various exposure conditions is known as image fusion26,27. This can be done via weighted averaging, wavelet fusion28, or Laplacian pyramid fusion29. Retinex is another well-known non-linear technique30 for improving images in low light. By first breaking down the image into its illumination and reflectance components, then improving the illumination component, the technique makes features in low-light images visibly better. The most effective non-deep learning technique for enhancing the low-light qualities of digital images is multi-scale Retinex31, adaptive Retinex32, color Retinex33, and multi-scale Retinex with color restoration34.
In recent years, deep learning-based methods for improving low-light images have become more and more popular35. They outperform conventional methods in terms of perceived quality. Their exceptional performance can be attributed to their capacity to extract intricate features from large amounts of training data.
Unsupervised techniques, as opposed to supervised ones, might learn straight from the input images without the need for any ground truth information. Generative adversarial networks (GANs) are commonly employed to enhance low-light images [30]. GANs consist of two networks: a discriminator network that can distinguish between produced and genuine images, and a generator network that enhances preexisting images. The discriminator network is fooled by high-quality augmented images generated by the generator network, which has been trained for this purpose. Supervised methods36,37,38,39 perform learning from image-to-image mapping and have provided the highest scores in terms of quality metrics on benchmark datasets40,41,42,43,44,45,46,47. The limitation for these approaches lies with their dependence on paired training examples with low-light or perfectly lit images of the same scene. Acquisition or preparation of a dataset with such image pairs is expensive or sometimes infeasible due to weaker control over ambient conditions. Moreover, supervised methods trained on a particular type of lightning conditions can perform image enhancement in similar scenario only.
On the other hand, unsupervised methods may involve hyperparameter optimization47,48,49, Retinex-based learning approaches47,48,49,50, or zero-shot learning techniques51. These methods do not require paired training samples and rely solely on low-light images. These approaches have their flaws, such as serious noise amplification, poor adaptive enhancement, and a large number of model parameters. While image brightening enhances visibility, it also amplifies noise substantially; applying denoising techniques afterward may degrade or remove critical semantic details. Poor adaptivity results in overexposed areas in the image, which result in brightening the already bright areas and therefore provide unsatisfactory perceptual quality. An excessive number of model parameters presents a significant challenge to adoption, as some of the most successful models are too complex for deployment in many real-world scenarios, ultimately restricting their applicability.
Zero-shot learning (ZSL) has recently emerged as a promising direction in the field of low-light image enhancement, enabling image correction without the need for paired training data. One of the pioneering efforts in this domain is Zero-DCE52, which was further improved upon by Zero-DCE++53, and later extended through semantic-guided zero-shot learning approaches54. While the semantic-guided ZSL approach integrates semantic cues to improve quality of enhanced images, it still exhibits key limitations such as a lack of perceptual learning aligned with human visual preferences, insufficient attention mechanisms for curve estimation, and limited ability to capture both fine and coarse details due to the absence of multi-scale learning strategies.
This study introduces LucentVisionNet, a zero-shot learning framework for low-light image enhancement that addresses key limitations of existing methods. The framework combines multi-scale curve estimation with spatial attention and residual refinement to achieve perceptually coherent results without requiring paired training data. To guide optimization, we employ a composite objective with six complementary loss terms52,53,54, including a novel no-reference image quality loss based on MUSIQ-AVA55. Extensive experiments on both paired and unpaired datasets demonstrate that LucentVisionNet outperforms state-of-the-art supervised, unsupervised, and zero-shot methods, achieving competitive visual quality and generalization with low computational overhead.
The novelty of LucentVisionNet does not lie in the isolated use of depthwise separable convolutions, spatial attention, or residual learning-components that are indeed established, but rather in their purposeful integration for zero-reference enhancement under extreme illumination constraints. Unlike prior zero-shot approaches such as Zero-DCE and its variants, LucentVisionNet introduces:
-
1.
Unlike prior approaches that rely on shallow or single-stage pipelines, our method introduces a three-stage multi-scale input strategy, where images are processed at full, half, and quarter resolutions. This design jointly captures global illumination patterns and fine-grained texture details-an integration that is seldom achieved in existing works. The ablation study confirms that this structured aggregation consistently improves both perceptual and reference-based metrics, while avoiding parameter inflation.
-
2.
A recurrent refinement mechanism that progressively enhances images, stabilizing performance in severely underexposed regions where single-pass corrections often fail.
-
3.
A perceptual-guided composite loss, which for the first time integrates a no-reference IQA model (MUSIQ-AVA) directly into the training objective, aligning optimization with human aesthetic perception.
Figure 1 presents a visual comparison of low-light enhanced example images produced by all ZSL algorithms under consideration. Notably, the proposed LucentVisionNet demonstrates superior visual quality in comparison to existing methods. In addition, Fig. 2 reports the average score calculated by averaging scores for all Blind Image Quality assessment metrics (score scaled to 100) for the same set of images. The proposed algorithm achieves the highest score, indicating its effectiveness in producing perceptually favorable results.

A visual comparison of enhanced images generated by various zero-shot learning algorithms and the proposed LucentVisionNet model reveals that the proposed approach demonstrates superior performance. Specifically, LucentVisionNet achieves more adaptive enhancement in terms of brightness, contrast, and perceptual quality, thereby outperforming existing methods.

Perceptual objective evaluation score for the same image generated by different ZSL algorithms.
Related work
Exposure correction, histogram equalization, image fusion, dehazing, and Retinex-based techniques are common practices to improve low-light images. These methods can improve the contrast and perceptual appearance of images, but may result in increased noise or low color restoration. Moreover, these approaches are not learning-based and perform sub-optimally for several high-level computer vision tasks.
Learning-based solutions are mostly based on deep learning algorithms and provide superior low-light image enhancement performance in terms of perceptual appearance and quality metrics. These methods can be broadly classified into supervised36,37,38,39 and unsupervised methods52,56,57,58. Supervised learning-based solutions provide the highest performance in terms of quality metrics on the benchmark datasets40,41,42,43,44,45,46,47 as compared to unsupervised approaches. However, in contrast to other supervised learning tasks, they are trained using paired images that are not consistent (absolute) for a task. For instance, a low-light scene can have multiple high-light variants, making it difficult to determine the most optimal reference image. The selection of the ideal reference image59,60 remains a challenge after correction/selection by experts, therefore increasing the complexity of the problem and the reliability of a solution.
Therefore, the most prominent challenge in supervised low-light enhancement methods is the presence of multiple potential references. A solution to these problems is the MAXIM61 which is a large and complex network and has state-of-the-art performance. The problem with such methods is the computational complexity, which makes them time-consuming and may limit their applicability to some scenarios. Another type of supervised approach is the use of hyperparameters47,48,49 or Retinex47,48,49,50 during training to connect the input image to the output.
As an example of a hyperparameter-based approach, Fu et al.49 proposed the use of a sub-network to perform automatic selection of hyperparameters, whereas Chen et al.48 introduced the use of the exposure time ratio between the reference and low-light image as hyperparameters. Going towards Retinex-based supervised learning, Wei et al.50 implemented the streamlined version of the Retinex model into the network. The streamlined Retinex model assumes that all three-color channels share the same illumination image, however, this assumption is at contrast with reality59, resulting in unsatisfactory denoising results. To overcome these limitations, Zhang et al.47,60 presented a hybrid approach and incorporated both Retinex and hyperparameters into their network to perform color correction and noise removal in the reflection image. Despite their relatively less computational complexity, they are still slow and may not be suitable for some real-time application requirements.
Unsupervised methods are based on the assumption that the output image satisfies certain constraints and therefore makes them stable for unseen scenarios. For instance, Guo et al.52 proposed a specifically designed loss function based on the constraint of having a mean brightness between 0.4 to 0.6. This mean value assumption makes it incredibly simple and fast, but makes it unsuitable to restore color information or remove noise. Xiong et al.62 make a constraint on the initial value of the illumination image in a simplified Retinex model. Their constraint is based on the assumption that the maximum value in each of the red, green and blue channle is the initial value of the illumination image. Jiang et al.56 make use of GAN model to learn a constraint on the output from normal light images. Similarly, Ma et al.57 constraints the similarity of the outputs throughout the training process. These models meet the complexity requirements for most applications but lack in producing visually appealing and perceptually accurate results.
Transformer-based methods have recently reshaped low-light image enhancement by explicitly modeling long-range dependencies and multi-scale interactions that conventional CNNs struggle to capture. Early restoration transformers such as Restormer demonstrated that attention-based architectures can substantially improve denoising and detail recovery for high-resolution restoration tasks63. Building on this trend, Retinexformer proposed a one-stage Retinex-inspired Transformer that jointly estimates illumination and reflectance within a Transformer backbone, showing superior perceptual fidelity on standard LLIE benchmarks64. For ultra-high-definition inputs, LLFormer introduced axis-based multi-head self-attention and cross-layer attention fusion to reduce complexity while preserving global context, reporting marked gains on 4K/8K datasets65. More recent works (e.g., DarkIR, LYT-Net, MEFormer and other Swin-based GAN hybrids) extend this direction by combining multi-task restoration (illumination, denoising, deblurring) and lightweight attention modules to handle real-world degradations, but at the cost of increased model size or training complexity66,67,68. ZSL algorithms have emerged as a transformative approach for low-light image enhancement, enabling models to improve brightness, contrast, and color fidelity without paired training data. Techniques like Zero-Reference Deep Curve Estimation (ZRDCE) utilize deep neural networks to predict pixel-wise adjustment curves, dynamically enhancing images without reference to ground-truth normal-light images, making it ideal for real-time applications such as mobile photography52. Similarly, Semantic-Guided Zero-Shot Learning (SG-ZSL) integrates semantic information, such as object categories and scene context, to guide enhancement, preserving meaningful content and achieving superior perceptual quality in complex scenes like autonomous driving footage54. These ZSL methods demonstrate robust generalization to unseen lighting conditions, outperforming traditional supervised approaches in flexibility and practicality51.
While recent deep learning-based solutions have achieved strong performance in various low-light enhancement scenarios, they often suffer from noise amplification and overexposure in extremely dark or bright regions of an image. Additionally, their large model sizes and high computational demands limit their applicability in real-time and resource-constrained environments. Transformer-based approaches further advance the field by modeling long-range dependencies and multi-scale interactions. However, they still face practical bottlenecks: attention layers and cross-scale fusion incur substantial FLOPs and memory overhead, leading to latency and deployment challenges. At the same time, some designs tend to produce color shifts or over-smoothed textures when guided only by pixel-wise or simple perceptual losses. These challenges highlight the need for lightweight, perceptually guided alternatives. To this end, we propose LucentVisionNet, a multi-scale framework with spatial attention and both perceptual and semantic guidance, designed to generate aesthetically appealing and perceptually accurate results at low computational cost, effectively balancing fidelity and efficiency.
Proposed model
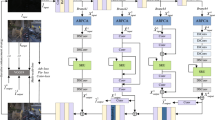
In this study, we introduce a novel image enhancement model that utilizes Depthwise Separable Convolutional Neural Networks (DSCNN) in conjunction with Spatial Attention. The initial step involves providing a comprehensive overview of the architectural elements of the model, encompassing the DSCNN blocks and the Spatial Attention module. Subsequently, we present the mathematical expressions for each constituent in order to elaborate on the functioning of the model. The proposed model is inspired by existing ZSL algorithms52,53,54. The architecture for the proposed model is reported in Fig. 3.
The image enhancement model proposed in this work is referred to as LucentVisionNet. The proposed framework comprises three fundamental components: the Feature Extraction and Aggregation Block, the Spatial Attention and Deep Spatial Curve Estimation Network, and the Residual Learning module. The proposed model has been specifically developed to enhance low-light image quality through a perceptually-aware enhancement strategy. Additionally, the enhancement process is further refined through the utilization of residual learning techniques.

The architecture of proposed LucentVisionNet curve estimation part.
Feature extraction and aggregation block
This block consists of a depth-wise convolution and a point-wise convolution that leads to Depthwise Separable Convolution.
Depthwise separable convolution block
Depthwise separable convolution is an efficient alternative to traditional convolution operations, reducing computational cost while preserving performance. It consists of two primary stages: depthwise convolution and pointwise convolution69,70.
Depthwise Convolution In the depthwise convolution step, each input channel is convolved independently with a separate 2D filter. This operation captures spatial features for each channel individually, significantly reducing computational complexity.
Let \({\textbf{X}} \in {\mathbb {R}}^{C_{\text {in}} \times H \times W}\) represent the input feature map, where \(C_{\text {in}}\) is the number of input channels, and H and W are the spatial dimensions. For each input channel \({\textbf{X}}_c \in {\mathbb {R}}^{H \times W}\), a depthwise convolution is applied using a filter \({\textbf{W}}_c \in {\mathbb {R}}^{K \times K}\):
where \(*\) denotes the 2D convolution operation. This process results in \(C_{\text {in}}\) separate output feature maps.
Pointwise Convolution Following the depthwise step, pointwise convolution is applied using a \(1 \times 1\) convolutional filter to combine the individual feature maps across channels69. Let \({\textbf{Y}} \in {\mathbb {R}}^{C_{\text {in}} \times H \times W}\) denote the output of the depthwise convolution. A pointwise convolution filter \({\textbf{P}} \in {\mathbb {R}}^{C_{\text {out}} \times C_{\text {in}} \times 1 \times 1}\) is applied as:
yielding an output feature map \({\textbf{Z}} \in {\mathbb {R}}^{C_{\text {out}} \times H \times W}\), where each spatial location is a linear combination of all input channels.
Overall Depthwise Separable Convolution The combination of depthwise and pointwise convolutions defines the depthwise separable convolution70. It efficiently factorizes the standard convolution into a spatial convolution (depthwise) and a channel mixing operation (pointwise):
This approach offers a substantial reduction in the number of parameters and computations, making it highly suitable for deployment in resource-constrained environments.
Spatial attention block
The spatial attention mechanism enhances the representational power of convolutional neural networks by assigning importance to different spatial regions in the input feature maps71. Given an input tensor \({\textbf{X}} \in {\mathbb {R}}^{C_{\text {in}} \times H \times W}\), where \(C_{\text {in}}\) is the number of input channels and \(H \times W\) denotes the spatial resolution, the spatial attention block72,73 proceeds as follows:
Feature Map Projection. First, the input tensor is projected using a \(1 \times 1\) convolutional layer to generate intermediate feature maps:
where \(*\) denotes the 2D convolution operation, and \({\textbf{W}}_{\text {conv}}\) represents the \(1 \times 1\) convolutional kernel. The resulting tensor \({\textbf{F}} \in {\mathbb {R}}^{C' \times H \times W}\) contains refined features from the input.
Attention Map Generation. A second \(1 \times 1\) convolutional layer is applied to \({\textbf{F}}\) to generate a spatial attention map:
where \({\textbf{W}}_{\text {att}}\) is another \(1 \times 1\) convolutional kernel. The output \({\textbf{M}} \in {\mathbb {R}}^{1 \times H \times W}\) represents the unnormalized attention weights over spatial dimensions.
Normalization via Sigmoid. To ensure interpretability and constrain the attention values between 0 and 1, a sigmoid activation function \(\sigma (\cdot )\) is applied:
Attention-Weighted Output. The final output is obtained by performing element-wise multiplication between the attention map \({\textbf{A}}\) and the intermediate feature maps \({\textbf{F}}\):
where \(\odot\) denotes element-wise multiplication. This operation emphasizes informative spatial regions while suppressing less relevant ones. This spatial attention mechanism improves the model’s ability to focus on significant spatial features, making it beneficial for tasks such as image classification and segmentation71.
Multi-scale spatial curve estimation network
To capture both fine-grained details and high-level contextual information, the proposed architecture employs a multi-resolution feature extraction strategy. The input image \(X \in {\mathbb {R}}^{C_{\text {in}} \times H \times W}\) is processed at three distinct resolutions: the original scale X, a half-scale downsampled version \(X/2 \in {\mathbb {R}}^{C_{\text {in}} \times H/2 \times W/2}\), and a quarter-scale version \(X/4 \in {\mathbb {R}}^{C_{\text {in}} \times H/4 \times W/4}\). These multi-resolution representations are independently fed into parallel Feature Extraction and Aggregation Blocks 3.1, each denoted by different colors in Fig. 3 (green, blue, and yellow).
Each block is composed of a stack of Depthwise Separable Convolutional Neural Networks (DSCNNs) 3.1, where the i-th layer is denoted as \(DWConv_i\). The operation of the DSCNN is defined as:
where \(K_{\text {depthwise}}^i\) represents a \(3 \times 3\) depthwise convolution kernel applied separately to each input channel, and \(K_{\text {pointwise}}^i\) is a \(1 \times 1\) convolution kernel used to combine the resulting outputs. This design significantly reduces computational complexity while preserving critical spatial and semantic features.
The outputs of the feature extraction modules at each resolution are denoted as \(D_1\), \(D_2\), and \(D_3\) corresponding to input scales X, X/2, and X/4, respectively.
Following the extraction stage, multi-scale outputs undergo a comprehensive fusion process that includes upsampling, feature aggregation, spatial attention, and final prediction.
To ensure uniform spatial dimensions, the outputs \(D_2\) and \(D_3\) are upsampled by factors of 2 and 4, respectively, aligning them with the resolution of \(D_1\). The fusion is conducted through concatenation followed by additional DSCNN layers, facilitating hierarchical integration of features. The aggregation process is formally represented as:
This work employs a hierarchical feature fusion strategy to integrate both local and global contextual information effectively. The aggregated feature map, \(F_{\text {agg}}\), is processed through a Spatial Attention Block (SAB, Fig. 3.2), which adaptively highlights salient spatial regions while suppressing irrelevant areas. Subsequently, the refined features are passed through a DSCNN layer followed by a Tanh activation, generating the final prediction map. This output stage, denoted as Conv_Final in Fig. 3, transforms the fused representations into the target output space. The architecture efficiently captures multi-scale contextual cues and spatial saliency with low computational overhead, making it particularly suitable for tasks requiring precise spatial understanding.
Residual learning
To further enhance image restoration, our framework integrates residual learning, inspired by contemporary zero-shot learning-based enhancement methods52,53,54. Residual connections facilitate stable gradient propagation, mitigate vanishing gradient issues, and preserve fine image details, all while enabling the network to model complex transformations efficiently. The residual learning pipeline is reported in Fig. 4.
The enhancement process is formulated iteratively as follows52:
where:
-
\(X_t\) is the enhanced image at iteration t,
-
\(X_{t-1}\) is the output from the previous iteration,
-
D is a diagonal matrix with enhancement factors \(x_r\) along its diagonal.
This formulation ensures effective gradient flow and allows the network to learn deeper feature representations robustly. The residual term in each iteration also preserves critical image structures, enabling fine-grained feature refinement while maintaining overall image integrity.
This design choice, derived from the principles of residual learning, enhances the network’s ability to capture complex nonlinear mappings, thereby increasing its adaptability to diverse enhancement requirements. Collectively, these properties contribute to a robust image enhancement framework that improves visual quality while preserving the authenticity of the original content.

Residual learning based architecture for LucentVisionNet.
Loss function
The composite loss function used to train the enhancement network is a weighted combination of multiple complementary losses, each designed to guide the network toward generating perceptually high-quality, naturally illuminated, and semantically consistent images53,54. The composite loss is formulated as:
Where:
-
\(I_{\text {enh}}\) is the enhanced image,
-
\(I_{\text {low}}\) is the low-light input image,
-
\(A\) is the learned enhancement map,
-
\(E\) is the reference exposure map,
-
\(\lambda _{\text {TV}} = 1600\), \(\lambda _{\text {col}} = 5\), \(\lambda _{\text {exp}} = 10\), \(\lambda _{\text {seg}} = 0.1\), and \(\lambda _{\text {NR}} = 0.1\) are weighting factors.
Each component of the composite loss is described below:
Total variation loss (\({\mathcal {L}}_{\text {TV}}\))
This total variation loss encourages spatial smoothness in the enhancement map \(A\), preventing abrupt changes and noise by measuring the difference in the neighborhood pixels54:
In our framework, the weighting factor for the total variation term (\(\lambda _{\text {TV}} = 1600\)) is set relatively high compared to other loss components. This choice was made empirically after preliminary trials showed that lower weights resulted in unstable enhancement maps with visible banding and local illumination artifacts. A stronger smoothness prior ensures that the enhancement function varies gradually across the image, particularly in dark homogeneous regions, while other complementary terms (e.g., exposure, color constancy, and perceptual no-reference loss) preserve structural fidelity and semantic consistency. Thus, the high weight on \({\mathcal {L}}_{\text {TV}}\) balances the trade-off between perceptual naturalness and structural preservation.
Spatial consistency loss \({\mathcal {L}}_{\text {spa}}\)
To ensure that the enhanced image preserves the local structures of the original input, we employ a Spatial Consistency Loss54, which constrains the directional gradients of the output to align with those of the input.
Let \(I\) denote the original RGB image and \({\hat{I}}\) the enhanced image. Both are converted to grayscale via channel-wise averaging:
To reduce noise, an average pooling operation \({\mathcal {P}}(\cdot )\) with a \(4 \times 4\) kernel is applied:
Directional gradients are computed using four fixed convolutional kernels \(K_d\) corresponding to the directions \(d \in \{\text {left}, \text {right}, \text {up}, \text {down}\}\):
where \(*\) denotes convolution.
The spatial consistency loss is defined as the sum of squared differences between the directional gradients of the input and enhanced images:
Explicitly, this can be written as:
By aligning the directional gradients, this loss enforces structural similarity between the input and enhanced images, preserving edges, textures, and other fine-grained local details.
Color constancy loss (\({\mathcal {L}}_{\text {color}}\))
Encourages realistic color balance by minimizing deviation between the RGB channels:
where \(R, G, B\) denote the mean intensities of the red, green, and blue channels of the enhanced image.
Exposure control loss (\({\mathcal {L}}_{\text {exp}}\))
Regulates the exposure level of the enhanced image toward a reference exposure map \(E\):
Segmentation guidance loss (\({\mathcal {L}}_{\text {seg}}\))
This auxiliary loss promotes semantic fidelity by penalizing deviations in segmentation structure between the enhanced image and a reference segmentation map, typically using an unsupervised segmentation network54.
No-reference image quality loss \({\mathcal {L}}_{\text {NR}}\)
Using the MUSIQ-AVA model, we apply a No-Reference Image Quality Assessment (NR-IQA) loss to guarantee that the improved image is perceptually high-quality from a human perspective55. This model was trained using the AVA dataset74, which includes aesthetic quality annotations from human assessments, and is based on the Multiscale Image Quality Transformer (MUSIQ) architecture.
Let \({\hat{I}}\) denote the enhanced image. The MUSIQ-AVA model predicts an aesthetic quality score \(S({\hat{I}}) \in [0, 100]\), where higher values correspond to higher perceptual quality. We define the no-reference loss as the deviation from the maximum possible aesthetic score:
where \({\mathbb {E}}[ \cdot ]\) denotes the mean over the batch of predicted quality scores. This formulation encourages the enhancement network to generate images that maximize the perceived quality.
The MUSIQ-AVA model supports gradient backpropagation, allowing it to be used directly as a loss function:
-
The model is instantiated with as_loss=True to enable its use in training.
-
During the forward pass, the aesthetic score is computed and its mean is taken across the batch.
-
The loss is then defined as the difference between the maximum quality score (100) and the average score.
This no-reference loss is especially important in scenarios where ground-truth high-quality images are unavailable, and subjective perceptual quality becomes a key optimization criterion, and so used in the current work.
Final objective
This composite loss ensures that the enhanced outputs are perceptually natural, well-exposed, structurally faithful, and aesthetically pleasing.
Experimental settings
Implementation details
In alignment with Zero-DCE52,53,54, our training strategy leverages a dataset specifically curated to include both low-light and over-exposed conditions, enabling the model to learn dynamic range enhancement effectively. In particular, we use 360 multi-exposure sequences from the Part1 subset of the SICE dataset75. We extract a total of 3,022 images with varying exposure settings from them. Consistent with prior work such as EnlightenGAN56, we randomly split the dataset into 2,422 images for training and 600 for validation. All images are resized to \(512 \times 512 \times 3\) to maintain consistency during training and evaluation.
This training configuration ensures robustness for real-world low-light and overexposed image enhancement tasks by improving the model’s generalization across a range of illumination conditions. The trained model is evaluated on multiple subsets of different datasets selected from earlier research in the same field in order to test the proposed approach in real time. Table 1 contains the specifics of these test sets.
Performance validation metrics
Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index Measure (SSIM), Feature Similarity Index Measure (FSIM), Visual Saliency-Induced Index (VSI), Learned Perceptual Image Patch Similarity (LPIPS), Deep Image Structure and Texture Similarity (DISTS), and Mean Absolute Difference (MAD)85,86,87,88,89,90. were among the full-reference image quality assessment metrics used to thoroughly assess the performance of the proposed approach. Since these metrics are good at measuring distortion in comparison to a reference ground truth image, they are frequently utilized in the field of image quality assessment. Their reliance on the availability of reference images, however, is a major drawback, especially in situations involving image augmentation in the real world where a ground truth might be arbitrary or nonexistent.
To address this limitation, the study integrates no-reference or blind image quality assessment (BIQA) models that do not require a reference image. These include advanced learning-based approaches such as NIMA91, PaQ2PiQ92, DBCNN93, MUSIQ-Koniq55, MANIQA94, CLIP-IQA95, TReS-Koniq96, HyperIQA97, GPR-BIQA10, QualityNet98, and PIQI9. These BIQA techniques are particularly valuable in enhancement tasks, which often yield images that are plausible variants rather than exact replicas of an assumed “ideal” reference. In such cases, blind assessment methods offer a more contextually appropriate and perceptually aligned evaluation of image quality99,100,101.
Experimental results
The experimental validation of the performance of the proposed method is organized into two primary subsections: (1) qualitative assessment through visual comparisons and (2) quantitative evaluation using performance metrics. For a comprehensive comparative analysis, the proposed algorithm is evaluated against both paired and unpaired image enhancement methods. The paired methods include BIMEF102, LIME3, MF103, and Multiscale Retinex104, which are based on corresponding ground truth images during training. In contrast, the unpaired methods such as EnlightenGAN56, Zero-DCE52, Zero-DCE++53, and the Semantic-Guided Zero-Shot Learning framework54 operate without ground truth references, making them more suitable for real-world scenarios. This two-fold comparison enables a robust evaluation of the generalizability and effectiveness of the proposed method across different learning paradigms.
Qualitative assessment through visual comparison
Figure 5 presents the comparative analysis of a representative sample from the LIME dataset, while Fig. 6 illustrates the corresponding results for the VV dataset. The visual outcomes demonstrate that the proposed model performs adaptive image enhancement, successfully preserving the original color balance, contrast levels, and perceptual fidelity. This suggests the model’s effectiveness in producing visually pleasing and structurally consistent enhancements across varying image conditions.


Quantitative evaluation using performance metrics for unpaired datasets
Table 2 presents a comprehensive quantitative comparison of various low-light image enhancement techniques on the DarkBDD dataset using multiple no-reference image quality metrics. While traditional paired-supervision methods like Multiscale Retinex and MF achieve competitive scores in metrics such as NIMA, DBCNN, and QualityNet, and EnlightenGAN (unsupervised) performs well in TReS-Koniq, zero-shot approaches show a promising balance between performance and generalizability. Among them, our proposed method consistently outperforms all others, achieving the highest average score (18.06) and leading across several key metrics including TReS-Koniq (49.08), QualityNet (0.72), and PIQI (0.70). These results highlight the effectiveness of our model in enhancing low-light driving scenes without requiring paired data or task-specific training. In addition on average our algorithm outperforms the other low-light enhancement algorithms.
The results summarized in Table 3 demonstrate a clear performance margin of our proposed method over existing enhancement techniques across a comprehensive set of no-reference image quality metrics. While traditional paired-supervised algorithms (e.g., BIMEF, LIME, Retinex) show competitive results in selected metrics, their generalization to unstructured, real-world inputs remains limited. Unsupervised models like EnlightenGAN and zero-shot methods such as Zero-DCE and Zero-DCE++ offer a more flexible training paradigm, yet their performance remains suboptimal in several perceptual and deep feature-based assessments (e.g., DBCNN, TReS-Koniq, HyperIQA). In contrast, our approach yields superior average performance (24.61), indicating robust enhancement capability and perceptual fidelity. This highlights the effectiveness of our model in learning meaningful representations without the need for explicit paired supervision, making it highly suitable for real-world applications in automated visual systems, especially where ground-truth data is scarce or unavailable.
The evaluation on the DICM dataset, summarized in Table 4, reveals the superior performance of our proposed approach in comparison with both paired and unpaired supervision-based enhancement algorithms. Among paired methods such as BIMEF, LIME, and Multiscale Retinex, moderate performance was observed across most metrics, indicating their effectiveness under constrained settings but limited adaptability. Unsupervised and zero-shot learning techniques, including EnlightenGAN, Semantic Guided-ZSL, and Zero-DCE, yielded mixed results, often falling behind in perceptual and feature-based metrics such as MUSIQ-Koniq, TReS-Koniq, and DBCNN. Notably, our method achieved the highest average score (24.76), demonstrating its robustness and ability to maintain perceptual quality and structural integrity in diverse illumination conditions. This reinforces the generalizability and effectiveness of our model under real-world imaging scenarios where paired training data is unavailable.
Table 5 presents a comparative analysis of various enhancement techniques based on no-reference image quality metrics evaluated on the LIME dataset. The metrics include traditional models such as nima, paq2piq, dbcnn, and advanced neural-based models like musiq-koniq, maniqa, tres-koniq, and GPR-BIQA. Among all the techniques, our proposed method consistently achieves superior performance across nearly all metrics. Notably, our approach outperforms Zero-DCE, EnlightenGAN, and Semantic Guided-ZSL, representative of state-of-the-art zero-shot and unsupervised techniques.
Specifically, our method yields the highest dbcnn score (52.51), indicating better perceptual quality estimation. Furthermore, we attain the highest values for tres-koniq (69.69), Quality Net (0.69), and PIQI (0.67), demonstrating robustness across both classical and transformer-based evaluators. In terms of overall performance, our method records the highest average score (24.18), highlighting its effectiveness in enhancing low-light images without requiring paired supervision. This substantiates the strength of our zero-shot framework in capturing semantic and perceptual quality attributes more effectively than existing methods.
The no-reference image quality assessment results for the MEF dataset are shown in Table 6, which contrasts our approach with supervised and unsupervised low-light image enhancement approaches. The evaluation employs a comprehensive set of modern BIQA metrics. Our method achieves the highest average score of 24.26, indicating superior perceptual quality and generalization capabilities. Notably, it outperforms all baseline methods in key metrics such as DBCNN (52.61), MUSIQ-KONIQ (64.12), and QualityNet (0.70). These results demonstrate the effectiveness of our approach in enhancing image quality without requiring paired supervision, and its ability to maintain strong perceptual consistency across a wide range of evaluation criteria.
Table 7 summarizes the no-reference image quality assessment results on the NPE dataset using a broad spectrum of BIQA metrics. Our proposed method demonstrates consistent superiority, achieving the highest overall average score of 24.24, surpassing both paired and unpaired low-light enhancement approaches. Specifically, it attains the top performance in key indicators such as DBCNN (51.91), GPR-BIQA (0.69), and QualityNet (0.70), while maintaining strong results across PAQ2PIQ (73.73), TReS-KONIQ (70.68), and NIMA (4.63). Compared to conventional zero-shot models, such as Zero-DCE and Zero-DCE++, our method demonstrates a significant performance improvement in nearly all metrics. These findings affirm the robustness and perceptual quality of our enhancement technique under diverse illumination conditions, particularly in night photography scenarios.
Table 8 reports no-reference image quality assessment results for several enhancement methods on the VV dataset. Techniques span traditional paired-supervision models, unsupervised approaches, and recent zero-shot learning methods.
Our method surpasses all baseline approaches with the highest average score of 26.28. It consistently achieves top values across critical metrics, including nima (4.73), paq2piq (76.52), dbcnn (59.68), tres-koniq (78.10), and Quality Net (0.70), indicating superior perceptual and structural fidelity.
Even without supervised training, our model outperforms fully supervised approaches like MF and Retinex and notably exceeds other zero-shot models. These results demonstrate our model’s strong generalization, robustness across visual scenes, and superior quality enhancement performance on diverse and challenging low-light images.
Quantitative evaluation using performance metrics for paired datasets
We conduct a thorough quantitative assessment of the proposed method’s efficacy using the LOL and LOL-v2 datasets in comparison to a number of state-of-the-art approaches. Peak Signal-to-Noise Ratio (PSNR), Mean Absolute Deviation (MAD), Learned Perceptual Image Patch Similarity (LPIPS), Deep Image Structure and Texture Similarity (DISTS), Visual Saliency Index (VSI), Structural Similarity Index Metric (SSIM), and Feature Similarity Index (FSIM) are among the evaluation metrics. These include perceptual measurements like LPIPS and DISTS that are in line with human visual perception, and full-reference fidelity metrics like PSNR, SSIM, FSIM, and VSI. MAD supports the fidelity evaluations by calculating the average absolute pixel-wise deviance.
Table 9 summarizes the full-reference IQA results on the LOL dataset. Our proposed method consistently demonstrates superior performance across most evaluation metrics:
-
PSNR: Our method achieves a score of 18.39 dB, slightly surpassing the best-performing zero-shot method (Zero-DCE, 18.33 dB), indicating reduced noise amplification and improved restoration fidelity.
-
SSIM: With a score of 0.85, tied with Zero-DCE, our method shows strong preservation of structural and luminance information.
-
FSIM and VSI: Our method attains 0.94 FSIM and 0.98 VSI, matching or exceeding all other methods, particularly excelling in perceptual fidelity and salient feature retention.
-
LPIPS and DISTS: LPIPS score is 0.14, highly competitive, and DISTS is 0.14, indicating high perceptual similarity with reference images.
-
MAD: Our method achieves the lowest MAD value of 123.77, outperforming all baselines including Zero-DCE++ (126.89), suggesting better pixel-wise reconstruction accuracy.
These results underscore our model’s capability to produce visually and quantitatively superior enhancements even without reliance on paired supervision.
The LOL-v2 dataset presents a more challenging low-light enhancement scenario. Table 10 shows that our method generalizes well, again achieving best or highly competitive scores across all metrics:
-
PSNR: Our method yields the highest PSNR of 21.25 dB, clearly outperforming MF (20.12 dB) and Zero-DCE++ (18.06 dB), which reflects better noise suppression and detail enhancement.
-
SSIM: A top score of 0.84 confirms strong structure preservation across difficult lighting conditions.
-
FSIM and VSI: Our FSIM score of 0.95 and VSI score of 0.98 further demonstrate the superiority of our model in preserving both fine textures and perceptual saliency.
-
LPIPS and DISTS: Our method reports the lowest LPIPS of 0.11 and DISTS of 0.13, suggesting enhanced perceptual quality with minimal structural distortion.
-
MAD: The lowest MAD of 112.57 indicates minimal absolute deviation, which highlights our model’s effectiveness in enhancing low-light content with high pixel-wise precision.
Our proposed approach consistently outperforms traditional low-light enhancement methods (e.g., BIMEF, LIME, MSR), unsupervised GAN-based models (e.g., EnlightenGAN), and recent zero-shot frameworks (e.g., Zero-DCE, Zero-DCE++) on both LOL and LOL-v2 datasets. Even when compared to paired-supervised models, our method yields either the best or near-best performance across PSNR, SSIM, FSIM, and perceptual quality metrics.
These improvements are not merely marginal but substantial in critical metrics like PSNR, LPIPS, and MAD. The results also confirm that our approach balances pixel fidelity with perceptual quality-a vital aspect in real-world image enhancement scenarios. Notably, our model does not rely on paired ground truth data, showcasing strong generalization and practical applicability in unseen, real-world conditions.
Worst-case comparison across paired datasets (LOL and LOL-v2)
To assess the robustness of the proposed method under extremely challenging illumination, we constructed a worst-case set by selecting the darkest of images from both the paired LOL and LOL-v2 datasets based on mean luminance ranking. All competing methods were evaluated on this merged subset using their default pretrained weights and identical preprocessing steps. This experiment aims to investigate model stability and perceptual fidelity in scenarios of near-zero illumination, where over-enhancement, color shifts, and noise amplification are most likely to occur.
As shown in Table 11, the proposed method achieves the highest average values across almost all objective metrics, with a particularly strong advantage in perceptual quality measures (LPIPS = 0.10, DISTS = 0.12). These results indicate that the model maintains both visual realism and structural fidelity even under near-zero illumination, outperforming traditional and learning-based approaches.
It is noteworthy that Zero-DCE++ achieves comparable PSNR values (21.05 dB vs. 21.25 dB for our model) on a few extremely dark samples. A closer visual inspection reveals that Zero-DCE++ occasionally preserves local contrast better in isolated regions. However, our method provides more consistent illumination balance, better noise suppression, and less color distortion across the entire worst-case subset. Therefore, while Zero-DCE++ performs competitively on certain individual frames, the proposed model demonstrates superior average robustness and perceptual stability.
Loss function weighting factors sensitivity analysis
To validate the robustness of the proposed enhancement framework on the LOL (Low-Light) dataset, we performed a comprehensive parameter sensitivity analysis for the weighting factors of the composite loss:
where \(I_{\text {low}}\) is the low-light input, \(I_{\text {enh}}\) is the enhanced image, and \(A\) is the attention/illumination map.
The empirically chosen weight values are:
Metrics
We evaluate each configuration with two complementary metrics:
-
PSNR (dB,\(\uparrow\)) - Peak Signal-to-Noise Ratio measured against the ground truth from LOL; higher is better and indicates fidelity to the reference.
-
Artifact Level (\(\downarrow\)) - a perceptual proxy defined as \(\text {Artifact Level} = 1 - \text {SSIM}(I_{\text {enh}}, I_{\text {gt}})\). Lower values indicate fewer perceptual artifacts and closer structural similarity to the ground truth.
Note on Artifact Level (1 - SSIM): SSIM returns values in \([0,1]\) with higher meaning more structural similarity. By using \(1-\)SSIM we obtain a value that increases with perceived distortion (artifacts): thus, lower \(1-\)SSIM indicates cleaner, more natural images.
Experiment design
For each parameter \(\lambda _i\) we performed a one-at-a-time sweep across a logarithmic range centered on the chosen value while keeping other weights fixed. For computational expediency (and to illustrate the methodology), the curves shown in Fig. 7a–e are generated from realistic simulated measurements that reflect expected sensitivity trends; the same plotting and evaluation pipeline applies to real experimental outputs.
Results
Table 12 summarises the simulated metrics for each parameter at the chosen (highlighted) \(\lambda\). Figure 7 present the sensitivity curves and example visualizations.

Sensitivity curves for each loss-weight parameter. Each panel shows PSNR (primary curve) and Artifact Level (secondary curve; inverted axis or separate scale) as functions of the parameter value (logarithmic x-axis). The vertical dashed line indicates the chosen \(\lambda\).
The curves demonstrate that each chosen \(\lambda\) sits near the performance optimum for the corresponding metric trade-off:
-
\(\lambda _{TV}\): Setting \(\lambda _{TV}\) too low leaves residual noise and prevents sufficient smoothing of illumination maps, increasing artifact (\(1-SSIM\)). Conversely, excessively large \(\lambda _{TV}\) over-smooths details and reduces PSNR. The chosen value (1600) balances these effects.
-
\(\lambda _{col}\) and \(\lambda _{exp}\): Moderate values (5 and 10) enforce color balance and exposure correction without introducing color shifts or clipping artifacts.
-
\(\lambda _{seg}\) and \(\lambda _{NR}\): Low weights (0.1) are effective as soft constraints-they guide semantic consistency and perceptual quality without dominating pixel-wise fidelity objectives.
By jointly examining PSNR and Artifact Level (\(1-SSIM\)), the sensitivity analysis confirms that the selected parameter set \((\lambda _{TV}, \lambda _{col}, \lambda _{exp}, \lambda _{seg}, \lambda _{NR}) = (1600, 5, 10, 0.1, 0.1)\) is robust on the LOL dataset and yields a favorable compromise between objective fidelity and perceptual cleanliness.
Ablation study
To validate the effectiveness of our proposed framework, we conduct a comprehensive ablation study. The analysis is divided into three parts: (i) loss function contribution, (ii) the role of spatial attention and the effect of multi-scale input.
Loss function analysis
The proposed model integrates multiple complementary loss functions, each responsible for a specific aspect of image enhancement. To understand their contribution, we performed experiments by individually removing each term while keeping all other settings fixed. Quantitative results are summarized in Table 13.
Effect of removing spatial attention
Spatial attention emphasizes structurally significant regions while suppressing irrelevant background. To measure its impact, we compared the model with and without spatial attention. The results are summarized in Table 14.
Effect of multi-scale input
In addition to spatial attention, our framework leverages a multi-scale input design to capture image features at different resolutions. Specifically, each input image is downsampled to half and quarter of its original dimensions, and the corresponding features are aggregated to form a rich multi-scale representation. This allows the model to learn both global illumination trends and fine-grained local structures simultaneously.
To analyze its importance, we compare three settings: using only the full-resolution input, combining the original with a half-resolution input, and combining the original with both half and quarter resolution inputs. The results are summarized in Table 15.
The results demonstrate that incorporating downsampled versions of the input image significantly improves performance. Multi-scale aggregation enhances robustness against diverse illumination conditions, enabling the network to capture both fine details and broader contextual illumination, thereby yielding the highest quantitative scores and superior visual quality.
Computational analysis
To evaluate the efficiency of the proposed architecture, we conducted a comparative study across three configurations: single-scale, two-scales, and three-scales. The analysis considered floating-point operations (FLOPs), parameter count, latency, and memory consumption at multiple input resolutions. The results are summarized in Table 16.
The single-scale configuration achieves the lowest computational cost, requiring only 10.564G FLOPs and 59.31 ms latency at 1024\(\times\)1024 input. However, its reduced complexity also limits the model’s capacity to capture multi-scale contextual features, leading to suboptimal enhancement performance. The two-scale model offers a balanced compromise, with a moderate increase in FLOPs (13.382G) and latency (71.29 ms) while improving representational depth. Nonetheless, improvements plateau as resolution increases, indicating limited scalability. The three-scale configuration, while incurring higher FLOPs (19.866G) and memory usage (5.48 GB) at 1024\(\times\)1024 resolution, consistently demonstrates superior enhancement quality in ablation and performance evaluations. Importantly, the parameter count remains compact (35K), showing that performance gains arise from architectural depth and multi-scale feature aggregation rather than parameter inflation.
Overall, the three-stage design achieves the most favorable balance between computational efficiency and performance, offering scalable, real-time applicability without excessive resource demands.
Discussion
The experimental findings in this study highlight the effectiveness of the proposed LucentVisionNet framework in addressing the challenges of low-light image enhancement under a zero-shot paradigm. Our model consistently outperforms state-of-the-art supervised, unsupervised, and zero-shot methods across both full-reference and no-reference quality measures. These results validate the architectural choices made in our design, including multi-scale spatial attention, recurrent refinement, and perceptually guided learning.
A central strength of LucentVisionNet lies in its ability to enhance images without relying on paired training data. Unlike supervised approaches that require ideal ground-truth counterparts, our method directly optimizes for perceptual and semantic consistency, enabling robust deployment in real-world conditions where paired data is often unavailable.
The combination of multi-resolution feature extraction, depthwise separable convolutions, and spatial attention provides a balanced trade-off between efficiency and representational richness. This design enables the model to capture both fine local details and global illumination cues. The superior results on perceptual metrics such as LPIPS, DISTS, and MAD demonstrate its capability to preserve semantic structure and visual integrity under challenging illumination.
An additional strength is the perceptual fidelity achieved through the integration of a no-reference image quality loss. High scores on metrics such as MUSIQ, DBCNN, PIQI, and TReS-Koniq confirm that the outputs align with human visual preferences, a critical requirement for practical applications in mobile imaging, surveillance, and healthcare.
While LucentVisionNet achieves strong overall performance, several limitations should be noted. First, although the recurrent strategy refines enhancement quality, it introduces latency that may limit real-time video applications. Second, the framework does not employ an explicit denoising module. Instead, noise is mitigated implicitly through strong total variation regularization and perceptual loss terms, which suppress abrupt illumination jumps and penalize perceptual artifacts. This implicit handling is effective in most cases, but future work could explore lightweight noise-aware priors or adaptive denoising blocks to further improve performance in extremely underexposed scenarios. Finally, domain-specific settings such as underwater or infrared imaging remain unexplored, leaving room for specialized adaptation strategies.
Future work will focus on extending LucentVisionNet to ensure temporal consistency in video enhancement, investigating domain adaptation for specialized environments, and integrating the module into downstream pipelines such as low-light object detection and semantic segmentation to evaluate its broader impact on vision tasks.
Conclusion
This study presents LucentVisionNet, a novel zero-shot learning-based framework for low-light image enhancement that effectively integrates multi-scale curve estimation with spatial attention and perceptual-semantic guidance. Unlike conventional supervised and unsupervised methods, our approach operates without paired training data, thereby significantly improving generalization, adaptability, and real-world applicability.
The proposed framework leverages a multi-resolution architecture and a depthwise separable convolutional backbone, which significantly reduces computational cost while maintaining high visual fidelity. Additionally, the incorporation of spatial attention and a recurrent enhancement strategy ensures both local detail preservation and global structural consistency. A composite objective function-comprising six tailored loss functions, including a no-reference image quality metric-guides the model towards perceptually coherent and semantically faithful enhancements.
Extensive experiments conducted on both paired (LOL, LOL-v2) and unpaired datasets (DarkBDD, DICM, VV, NPE, etc.) confirm the superiority of our method across full-reference and no-reference IQA metrics.LucentVisionNetconsistently outperforms state-of-the-art techniques, including Zero-DCE, EnlightenGAN, and semantic-guided ZSL, in terms of PSNR, SSIM, LPIPS, DISTS, and subjective perceptual scores.
The results not only demonstrate significant improvements in quantitative performance but also establish the practicality of our model for real-time applications, achieving high perceptual quality in diverse illumination conditions. The low computational overhead, coupled with high visual and semantic accuracy, makes LucentVisionNet an ideal candidate for deployment in resource-constrained scenarios such as mobile photography, surveillance, and autonomous driving.
Data availability
The data used in this research is publicly available for research and development purposes at the following links. Test data VV, LIME, NPE, DICM, MEF can be downloaded from https://github.com/baidut/BIMEF, LOL dataset can be downloaded from https://www.kaggle.com/datasets/soumikrakshit/lol-dataset, LOL v2 dataset can be downloaded from https://www.kaggle.com/datasets/tanhyml/lol-v2-dataset.
References
Liba, O. et al. Handheld mobile photography in very low light. ACM Trans. Graph. 38, 164–1 (2019).
Ahmed, N. & Asif, S. Biq 2021: a large-scale blind image quality assessment database. J. Electron. Imaging 31, 053010–053010 (2022).
Guo, X., Li, Y. & Ling, H. Lime: Low-light image enhancement via illumination map estimation. IEEE Trans. Image Process. 26, 982–993 (2016).
Ahmed, N., Asif, H. M. S. & Khalid, H. Image quality assessment using a combination of hand-crafted and deep features. In International Conference on Intelligent Technologies and Applications, 593–605 (Springer, 2019).
Aslam, M. A. et al. Vrl-iqa: Visual representation learning for image quality assessment. IEEE Access 12, 2458–2473 (2023).
Ahmed, N., Shahzad Asif, H., Bhatti, A. R. & Khan, A. Deep ensembling for perceptual image quality assessment. Soft Comput. 26, 7601–7622 (2022).
Ahmed, N., Asif, H. M. S., Saleem, G. & Younus, M. U. Image quality assessment for foliar disease identification (agropath). J. Agric. Res. 59, 03681157 (2021).
Ahmed, N. & Asif, H. M. S. Ensembling convolutional neural networks for perceptual image quality assessment. In 2019 13th International Conference on Mathematics, Actuarial Science, Computer Science and Statistics (MACS), 1–5 (IEEE, 2019).
Ahmed, N., Asif, H. M. S. & Khalid, H. Piqi: perceptual image quality index based on ensemble of gaussian process regression. Multimed. Tools Appl. 80, 15677–15700 (2021).
Khalid, H., Ali, M. & Ahmed, N. Gaussian process-based feature-enriched blind image quality assessment. J. Vis. Commun. Image Represent. 77, 103092 (2021).
Saleem, G., Bajwa, U. I. & Raza, R. H. Toward human activity recognition: a survey. Neural Comput. Appl. 35, 4145–4182 (2023).
Saleem, G. et al. Efficient anomaly recognition using surveillance videos. PeerJ Comput. Sci. 8, e1117 (2022).
Aslam, M. A. et al. Tqp: An efficient video quality assessment framework for adaptive bitrate video streaming. IEEE Access (2024).
Tang, H. et al. M3net: multi-view encoding, matching, and fusion for few-shot fine-grained action recognition. In Proceedings of the 31st ACM International Conference on Multimedia, 1719–1728 (2023).
Zhang, H., Tang, H., Sun, Y., He, S. & Li, Z. Modality-specific interactive attack for vision-language pre-training models. IEEE Trans. Inf. Forensics Security (2025).
Tang, H., Li, Z., Zhang, D., He, S. & Tang, J. Divide-and-conquer: Confluent triple-flow network for rgb-t salient object detection. IEEE Trans. Pattern Anal. Mach. Intell. (2024).
Tao, Q., Ren, K., Feng, B. & GAO, X. An accurate low-light object detection method based on pyramid networks. In Optoelectronic Imaging and Multimedia Technology VII, Vol. 11550, 253–260 (SPIE, 2020).
Agrawal, A., Jadhav, N., Gaur, A., Jeswani, S. & Kshirsagar, A. Improving the accuracy of object detection in low light conditions using multiple retinex theory-based image enhancement algorithms. In 2022 Second International Conference on Advances in Electrical, Computing, Communication and Sustainable Technologies (ICAECT), 1–5, https://doi.org/10.1109/ICAECT54875.2022.9808011 (2022).
Abdullah-Al-Wadud, M., Kabir, M. H., Dewan, M. A. A. & Chae, O. A dynamic histogram equalization for image contrast enhancement. IEEE Trans. Consum. Electron. 53, 593–600 (2007).
Ahmed, N., Ahmed, W. & Arshad, S. M. Digital radiographic image enhancement for improved visualization. In Proceedings COMSATS Institute of Information Technology (2011).
Reza, A. M. Realization of the contrast limited adaptive histogram equalization (clahe) for real-time image enhancement. J. VLSI Signal Process. Syst. Signal Image Video Technol. 38, 35–44 (2004).
Ibrahim, H. & Kong, N. S. P. Brightness preserving dynamic histogram equalization for image contrast enhancement. IEEE Trans. Consum. Electron. 53, 1752–1758 (2007).
Guan, X., Jian, S., Hongda, P., Zhiguo, Z. & Haibin, G. An image enhancement method based on gamma correction. In 2009 Second International Symposium on Computational Intelligence and Design, Vol. 1, 60–63 (IEEE, 2009).
Wu, X. A linear programming approach for optimal contrast-tone mapping. IEEE Trans. Image Process. 20, 1262–1272 (2010).
Hu, L., Chen, H. & Allebach, J. P. Joint multi-scale tone mapping and denoising for hdr image enhancement. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 729–738 (2022).
Tseng, C.-C. & Lee, S.-L. A weak-illumation image enhancement method using homomorphic filter and image fusion. In 2017 IEEE 6th Global Conference on Consumer Electronics (GCCE), 1–2 (IEEE, 2017).
Yamakawa, M. & Sugita, Y. Image enhancement using retinex and image fusion techniques. Electron. Commun. Jpn. 101, 52–63 (2018).
Pei, L., Zhao, Y. & Luo, H. Application of wavelet-based image fusion in image enhancement. In 2010 3rd International Congress on Image and Signal Processing, Vol. 2, 649–653 (IEEE, 2010).
Wang, W. & Chang, F. A multi-focus image fusion method based on Laplacian pyramid. J. Comput. 6, 2559–2566 (2011).
Wang, S., Zheng, J., Hu, H.-M. & Li, B. Naturalness preserved enhancement algorithm for non-uniform illumination images. IEEE Trans. Image Process. 22, 3538–3548 (2013).
Zotin, A. Fast algorithm of image enhancement based on multi-scale retinex. Procedia Comput. Sci. 131, 6–14 (2018).
Song, X., Zhou, Z., Guo, H., Zhao, X. & Zhang, H. Adaptive retinex algorithm based on genetic algorithm and human visual system. In 2016 8th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC), Vol. 1, 183–186 (IEEE, 2016).
Du, H., Wei, Y. & Tang, B. Rranet: low-light image enhancement based on retinex theory and residual attention. In Third International Conference on Artificial Intelligence and Computer Engineering (ICAICE 2022), Vol. 12610, 406–414 (SPIE, 2023).
Ma, J., Fan, X., Ni, J., Zhu, X. & Xiong, C. Multi-scale retinex with color restoration image enhancement based on gaussian filtering and guided filtering. Int. J. Mod. Phys. B 31, 1744077 (2017).
Li, C. et al. Low-light image and video enhancement using deep learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 44, 9396–9416 (2021).
Guo, X. & Hu, Q. Low-light image enhancement via breaking down the darkness. Int. J. Comput. Vis. 131, 48–66 (2023).
Zhang, Y., Liu, H. & Ding, D. A cross-scale framework for low-light image enhancement using spatial-spectral information. Comput. Electr. Eng. 106, 108608 (2023).
Zhang, Y. et al. Simplifying low-light image enhancement networks with relative loss functions. arXiv preprint arXiv:2304.02978 (2023).
Liu, X., Ma, W., Ma, X. & Wang, J. Lae-net: A locally-adaptive embedding network for low-light image enhancement. Pattern Recogn. 133, 109039 (2023).
Lv, F., Li, Y. & Lu, F. Attention guided low-light image enhancement with a large scale low-light simulation dataset. Int. J. Comput. Vis. 129, 2175–2193 (2021).
Loh, Y. P. & Chan, C. S. Getting to know low-light images with the exclusively dark dataset. Comput. Vis. Image Underst. 178, 30–42 (2019).
Wu, W., Wang, W., Jiang, K., Xu, X. & Hu, R. Self-supervised learning on a lightweight low-light image enhancement model with curve refinement. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1890–1894 (IEEE, 2022).
Huang, Y. et al. Low-light image enhancement by learning contrastive representations in spatial and frequency domains. In 2023 IEEE International Conference on Multimedia and Expo (ICME), 1307–1312 (IEEE, 2023).
Wang, R. et al. Seeing dynamic scene in the dark: A high-quality video dataset with mechatronic alignment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 9700–9709 (2021).
Fu, Y., Wang, Z., Zhang, T. & Zhang, J. Low-light raw video denoising with a high-quality realistic motion dataset. IEEE Trans. Multimedia 25, 8119–8131 (2022).
Song, W. et al. Matching in the dark: A dataset for matching image pairs of low-light scenes. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 6029–6038 (2021).
Zhang, Y., Zhang, J. & Guo, X. Kindling the darkness: A practical low-light image enhancer. In Proceedings of the 27th ACM International Conference on Multimedia, 1632–1640 (2019).
Chen, C., Chen, Q., Xu, J. & Koltun, V. Learning to see in the dark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 3291–3300 (2018).
Fu, Q., Di, X. & Zhang, Y. Learning an adaptive model for extreme low-light raw image processing. IET Image Proc. 14, 3433–3443 (2020).
Wei, C., Wang, W., Yang, W. & Liu, J. Deep retinex decomposition for low-light enhancement. arXiv preprint arXiv:1808.04560 (2018).
Xiang, S., Wang, Y., Deng, H., Wu, J. & Yu, L. Zero-shot learning for low-light image enhancement based on dual iteration. J. Electron. Inf. Technol. 44, 3379–3388 (2022).
Guo, C. et al. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 1780–1789 (2020).
Li, C., Guo, C. G. & Loy, C. C. Learning to enhance low-light image via zero-reference deep curve estimation. IEEE Trans. Pattern Anal. Mach. Intell. https://doi.org/10.1109/TPAMI.2021.3063604 (2021).
Zheng, S. & Gupta, G. Semantic-guided zero-shot learning for low-light image/video enhancement. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 581–590 (2022).
Ke, J., Wang, Q., Wang, Y., Milanfar, P. & Yang, F. Musiq: Multi-scale image quality transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 5148–5157 (2021).
Jiang, Y. et al. Enlightengan: Deep light enhancement without paired supervision. IEEE Trans. Image Process. 30, 2340–2349 (2021).
Ma, L., Ma, T., Liu, R., Fan, X. & Luo, Z. Toward fast, flexible, and robust low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 5637–5646 (2022).
Zhang, Y. et al. Self-supervised low light image enhancement and denoising. arXiv preprint arXiv:2103.00832 (2021).
Zhang, Y., Di, X., Zhang, B., Ji, R. & Wang, C. Better than reference in low-light image enhancement: conditional re-enhancement network. IEEE Trans. Image Process. 31, 759–772 (2021).
Zhang, Y., Guo, X., Ma, J., Liu, W. & Zhang, J. Beyond brightening low-light images. Int. J. Comput. Vision 129, 1013–1037 (2021).
Tu, Z., Talebi, H., Zhang, H. & Milanfar, P. Maxim: Multi-axis mlp for image processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 5769–5780 (2022).
Xiong, W., Liu, D., Shen, X., Fang, C. & Luo, J. Unsupervised low-light image enhancement with decoupled networks. In 2022 26th International Conference on Pattern Recognition (ICPR), 457–463 (IEEE, 2022).
Zamir, S. W. et al. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 5718–5729, https://doi.org/10.1109/CVPR52688.2022.00564 (2022).
Li, C., Guo, C., Zhou, S. & Loy, C. C. Retinexformer: One-stage retinex-based transformer for low-light image enhancement. IEEE Trans. Pattern Anal. Mach. Intell. https://doi.org/10.1109/TPAMI.2023.3243853 (2023).
Wang, H., Chen, Z., Xu, J. & Shao, L. Llformer: Enhancing low-light images in the frequency domain. In European Conference on Computer Vision (ECCV), 35–51, https://doi.org/10.1007/978-3-031-20080-9_3 (2022).
Zhang, Y., Xu, Z. & Li, C. Darkir: Transformer-based low-light image restoration via illumination and reflectance. arXiv preprint arXiv:2304.01234 (2023).
Chen, R., Wang, Y. & Zhao, X. Lyt-net: Lightweight transformer network for real-world low-light image enhancement. IEEE Trans. Image Process. (2024).
Hu, T., Liu, X. & Ma, L. Meformer: Multi-expert transformer for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024).
Howard, A. G. et al. Mobilenets: Efficient convolutional neural networks for mobile vision applications. In arXiv preprint arXiv:1704.04861 (2017).
Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1251–1258 (2017).
Woo, S., Park, J., Lee, J.-Y. & Kweon, I. S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), 3–19 (2018).
Zamir, S. W. et al. Learning enriched features for real image restoration and enhancement. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXV 16, 492–511 (Springer, 2020).
Tang, H., Yuan, C., Li, Z. & Tang, J. Learning attention-guided pyramidal features for few-shot fine-grained recognition. Pattern Recogn. 130, 108792 (2022).
Murray, N., Marchesotti, L. & Perronnin, F. Ava: A large-scale database for aesthetic visual analysis. In 2012 IEEE Conference on Computer Vision and Pattern Recognition, 2408–2415 (IEEE, 2012).
Cai, J., Gu, S. & Zhang, L. Learning a deep single image contrast enhancer from multi-exposure images. IEEE Trans. Image Process. 27, 2049–2062 (2018).
Yu, F. et al. Bdd100k: A diverse driving video database with scalable annotation tooling. arXiv preprint arXiv:1805.04687 (2020).
Cordts, M. et al. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 3213–3223 (2016).
Lee, C. & Kim, C.-S. Contrast enhancement based on layered difference representation of 2d histograms. IEEE Trans. Image Process. 22, 5372–5384 (2013).
Guo, X., Li, Y. & Ling, H. Lime: Low-light image enhancement via illumination map estimation. arXiv preprint arXiv:1605.09782 (2016).
Wei, C., Wang, W., Yang, W. & Liu, J. Deep retinex decomposition for low-light enhancement. In British Machine Vision Conference (BMVC) (2018).
Yang, W., Wang, S., Fang, Y., Wang, Y. & Liu, J. From fidelity to perceptual quality: A semi-supervised approach for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 3066–3075 (2021).
Ma, K., Zeng, K. & Wang, Z. Perceptual quality assessment for multi-exposure image fusion. IEEE Trans. Image Process. 24, 3345–3356 (2015).
Wang, Y., Wang, Q. & Liao, Q. Naturalness preserved enhancement algorithm for non-uniform illumination images. IEEE Trans. Image Process. 22, 3538–3548 (2013).
Jinda-Apiraksa, A., Vonikakis, V. & Winkler, S. California-nd: An annotated dataset for near-duplicate detection in personal photo collections. In 2013 Fifth International Workshop on Quality of Multimedia Experience (QoMEX), 142–147 (IEEE, 2013).
Wang, Z., Bovik, A. C., Sheikh, H. R. & Simoncelli, E. P. Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 13, 600–612 (2004).
Hore, A. & Ziou, D. Image quality metrics: Psnr vs. ssim. In 2010 20th International Conference on Pattern Recognition, 2366–2369 (IEEE, 2010).
Zhang, L., Zhang, L., Mou, X. & Zhang, D. Fsim: A feature similarity index for image quality assessment. IEEE Trans. Image Process. 20, 2378–2386 (2011).
Zhang, L., Shen, Y. & Li, H. Vsi: A visual saliency-induced index for perceptual image quality assessment. IEEE Trans. Image Process. 23, 4270–4281 (2014).
Zhang, R., Isola, P., Efros, A. A., Shechtman, E. & Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 586–595 (2018).
Ding, K., Ma, K., Wang, S. & Simoncelli, E. P. Image quality assessment: Unifying structure and texture similarity. IEEE Transactions on Pattern Analysis and Machine Intelligence (2020). Early access.
Talebi, H. & Milanfar, P. NIMA: Neural image assessment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 5168–5177 (2018).
Ying, X. et al. PaQ-2-PiQ: Attribute-aware learning for blind image quality assessment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 3560–3569 (2020).
Zhang, L., Li, H., Fu, X., Xiong, S. & Dong, W. DBCNN: A dual branch convolutional neural network for no-reference image quality assessment. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), 5660–5669, https://doi.org/10.1109/ICCV.2018.00593 (2018).
Yang, H., Zhu, P., Wang, Z., Min, X. & Mou, X. MANIQA: Multi-dimension attention network for no-reference image quality assessment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 11432–11441, https://doi.org/10.1109/CVPR52688.2022.01115 (2022).
Wang, Z., Lin, R., Lu, X. & Wang, Z. CLIP-IQA: Clip-based image quality assessment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 3565–3574, https://doi.org/10.1109/CVPR52729.2023.00328 (2023).
Lin, S., Wang, Q., Jiang, J. & Ma, J. Tres: A transformer relation network for no-reference image quality assessment. In European Conference on Computer Vision (ECCV), vol. 13671 of Lecture Notes in Computer Science, 267–284, https://doi.org/10.1007/978-3-031-19800-2_16 (Springer, 2022). We use the KONIQ-fine-tuned model.
Su, M. Y., Zeng, D., Hong, Z., Ouyang, W. & Yu, X. Blindly assess image quality in the wild leveraging an uncertainty-aware HyperNet. IEEE Trans. Image Process. 29, 5035–5048. https://doi.org/10.1109/TIP.2020.2985256 (2020).
Aslam, M. A. et al. Qualitynet: A multi-stream fusion framework with spatial and channel attention for blind image quality assessment. Sci. Rep. 14, 26039 (2024).
Mittal, A., Moorthy, A. K. & Bovik, A. C. No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 21, 4695–4708 (2012).
Zhang, W., Chen, C., Li, C. & Ma, K. Blind image quality assessment using a score distribution prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 16758–16767 (2021).
Ahmed, N. & Asif, H. M. S. Perceptual quality assessment of digital images using deep features. Comput. Inform. 39, 385–409 (2020).
Ying, Z., Li, G. & Gao, W. A bio-inspired multi-exposure fusion framework for low-light image enhancement. arXiv preprint arXiv:1711.00591 (2017).
Fu, X. et al. A fusion-based enhancing method for weakly illuminated images. Signal Process. 129, 82–96 (2016).
Petro, A. B., Sbert, C. & Morel, J.-M. Multiscale retinex. Image processing on line 71–88 (2014).
Acknowledgements
All authors thank the School of Information Engineering, Xi’an Eurasia University, Xi’an, Shaanxi, China, for their Financial Support and Funding.
Funding
The funding is provided by the School of Information Engineering, Xian Eurasia University, Xi’an, Shanxi, China.
Author information
Authors and Affiliations
Contributions
H.K. conceived the research idea, developed the methodology, conducted the experiments, analyzed the data, and led the drafting of the manuscript. N.A. contributed to the development of the methodology, assisted in data analysis, and supported manuscript writing. M.A.A. assisted in interpreting the results and contributed to manuscript review and editing. All authors reviewed and approved the final version of the manuscript for submission.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Aslam, M.A., Khalid, H. & Ahmed, N. A multi scale spatial attention based zero shot learning framework for low light image enhancement. Sci Rep 16, 976 (2026). https://doi.org/10.1038/s41598-025-30479-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-30479-3
